



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于异构注意力网络的图像超分辨率重建方法
[诸宇杰1  , 赵建伟
, 赵建伟1 , 刘婕雨1 , 周正华2 ]
, 赵建伟, 刘婕雨, 周正华]
|
|



作者简介:

诸宇杰,硕士研究生,主要研究方向为深度学习、图像处理等.E-mail:zyj7021@163.com.

刘婕雨,硕士研究生,主要研究方向为深度学习、图像处理等.E-mail:15256345419@163.com.

周正华,博士,副教授,主要研究方向为深度学习、图像处理等.E-mail:zzh2023@zufe.edu.cn.
基于Transformer的图像超分辨率重建方法由于传统的多头设计和稠密的自注意力机制,存在大量冗余计算.针对此问题,文中提出基于异构注意力网络的图像超分辨率重建方法,包括异构多头自注意力模块和部分深度卷积前馈网络模块.异构多头自注意力模块采取三分支结构,即为了减少冗余计算,保留单个密集自注意力分支用于传递完整信息,引入稀疏自注意力分支过滤噪声,引入通道融合分支补充高频信息.同时,部分深度卷积前馈网络模块利用中间层特征图中的相似性进行部分深度卷积运算,降低现有卷积前馈网络的计算代价.实验表明,文中方法具有较优的重建性能和较低的计算成本.
About Author:
ZHU Yujie, Master student. His research interests include deep learning and image processing.
LIU Jieyu, Master student. Her research interests include deep learning and image processing.
ZHOU Zhenghua, Ph.D., associate professor. His research interests include deep learning and image processing.
Existing Transformer-based image super-resolution reconstruction methods suffer from excessive computational redundancy due to their traditional multi-head design and dense self-attention mechanisms. To address this issue, an image super-resolution reconstruction method based on heterogeneous attention network is proposed in this paper. A heterogeneous multi-head self-attention block and a partial deep convolutional feedforward network block are designed. A three-branch structure is adopted in the heterogeneous multi-head self-attention block to reduce redundant computation. One dense branch for transmitting complete information is retained, a sparse branch to filter out noise is introduced, and a channel fusion branch is incorporated to supplement high-frequency information. Meanwhile, in the partial deep convolutional feedforward network block, the similarity in the activation feature maps is utilized to perform a partial deep convolutional operation to reduce the computational cost of the existing convolutional feedforward network block. Experimental results illustrate that the proposed method achieves better reconstruction performance with less computational cost.
图像超分辨率重建是计算机视觉领域中的研究热点之一, 旨在设计高效重建算法, 从低分辨率(Low Resolution, LR)图像重建高分辨率(High Resolution, HR)图像.
近年来, 基于卷积神经网络(Convolutional Neu-ral Network, CNN)的图像超分辨率重建方法取得重大突破[1, 2, 3, 4].Dong等[5]提出SRCNN(Super-Resolu-tion Convolutional Neural Network), 将CNN引入图像超分辨率重建, 相比传统基于插值的重建方法, 性能大幅提升.此后, Kim等[6]提出VDSR, 利用残差连接, 拓展网络深度.Tong等[7]提出SRDenseNet, 引入稠密网络, 强化特征传递.Kim等[8]提出DRCN(Deeply-Recursive Convolutional Network), 引入递归思想, 使用较少参数构建深度网络.Lim等[9]提出EDSR(Enhanced Deep Super-Resolution Network), 去除网络中常用的批量归一化层, 以换取更多有效的参数层.
为了降低模型复杂度, Hui等[10]提出IDN(In-formation Distillation Network), 引入特征蒸馏, 简化模型结构.在此基础上, Hui等[11]提出IMDN(Light-weight Information Multi-distillation Network), 连接多级特征蒸馏模块, 提取多层次特征.进一步地, 为了提高浅层特征的利用率, 赵小强等[12]提出轻量化逆可分离残差信息蒸馏网络(Lightweight Inverse Sepa-rable Residual Information Distillation Network, LIR- DN), 设计逐步补偿残差连接方式, 融合多层特征.然而, 上述基于CNN的图像超分辨率重建方法依赖局部范围内的特征提取, 限制模型长距离范围内的特征交互能力.此外, 由于卷积核参数全局共享, 使其难以对图像的特定区域进行自适应建模.
近年来, 基于Transformer的重建方法能有效提升网络重建性能.究其原因, 主要是多头自注意力(Multi-head Self-Attention, MSA)机制能有效建立序列元素之间的全局依赖, 捕获图像中的远程特征相关性[13, 14, 15, 16].Chen等[17]提出用于底层视觉任务的预训练Transformer模型— — IPT(Image Processing Trans-former), 相比同代基于CNN的先进方法, 具有更优的重建性能.Lu等[18]提出ESRT(Efficient Super-Resolution Transformer), 在空间维度上分组计算自注意力, 避免计算全局自注意力.然而, 该方法未约束组内特征令牌数量, 难以处理大尺寸的输入图.Liang等[19]提出SwinIR, 将滑动窗口自注意力机制应用于图像超分辨率重建, 确保每个分组内具有固定数量的特征令牌, 能高效处理高分辨率图像.进一步地, Zhang等[20]提出ELAN(Efficient Long-Range Attention Network), 通过不同层共享自注意力分数结果, 简化计算.王庭伟等[21]提出基于轻量化对称CNN-Transformer的图像超分辨率重建方法(Image Super-Resolution Reconstruction Method Based on Light-weight Symmetric CNN-Transformer, LSCT), 计算自注意跨通道的协方差矩阵, 降低自注意力计算复杂度.Zhou等[22]提出SRFormer, 在转置注意力的前馈网络的激活层后增加一个全通道的深度卷积层(Depthwise Convolution), 实现网络对局部的依赖.
上述基于Transformer的图像重建方法重建能力出色, 但仍存在不足.一方面, 该类方法专注于优化注意力分数矩阵的规模, 忽略对MSA结构的深入探讨.Yun等[23]指出Transformer中的MSA存在计算上的冗余, 即少量的注意力头已具备足够的建模能力.此外, 头内的密集自注意力操作效率较低, 难以过滤不相关的像素交互, 容易引入噪声[24, 25].另一方面, 前馈网络中使用的全通道深度卷积层会带来较多的额外参数和计算消耗, 并且Chen等[26]指出深度网络中间层特征图在通道间存在高度的相似性, 因此此处再使用全通道深度卷积操作会带来大量的冗余计算.
针对上述问题, 本文提出基于异构注意力网络的图像超分辨率重建方法(Image Super-Resolution Reconstruction Method Based on Heterogeneous Atten-tion Network, HetANet), 主要包括异构多头自注意力模块(Heterogeneous Multi-head Self-Attention, HMSA)和部分深度卷积前馈网络模块(Partial Deep Con-volutional Feedforward Network, PDFFN).HMSA采取三分支结构, 即为了减少冗余计算, 保留单个密集自注意力分支用于传递完整信息, 引入稀疏自注意力分支过滤噪声, 引入通道融合分支补充高频信息.究其原因是在图像超分辨率重建任务中, 需要利用区域像素信息生成新的像素, 而区域的密集自注意力操作会带来不必要的噪声, 稀疏自注意力分支能有效过滤不相关的特征交互, 增强有效信息.然而, 这会造成难以控制的信息丢失问题, 因此HMSA仍保留一个密集自注意力分支, 保证完整信息的传递.同时, 考虑到自注意力机制的低通特性[22, 27, 28], HMSA使用通道融合分支补充高频信息, 产生高频特征.另外, PDFFN对部分激活层特征进行深度卷积运算, 旨在利用激活特征图中的相似性降低传统卷积前馈网络块的计算成本.
本文提出基于异构注意力网络的图像超分辨率重建方法(HetANet), 结构如图1所示.HetANet主要包含浅层特征提取、深层特征提取和像素重建三部分.
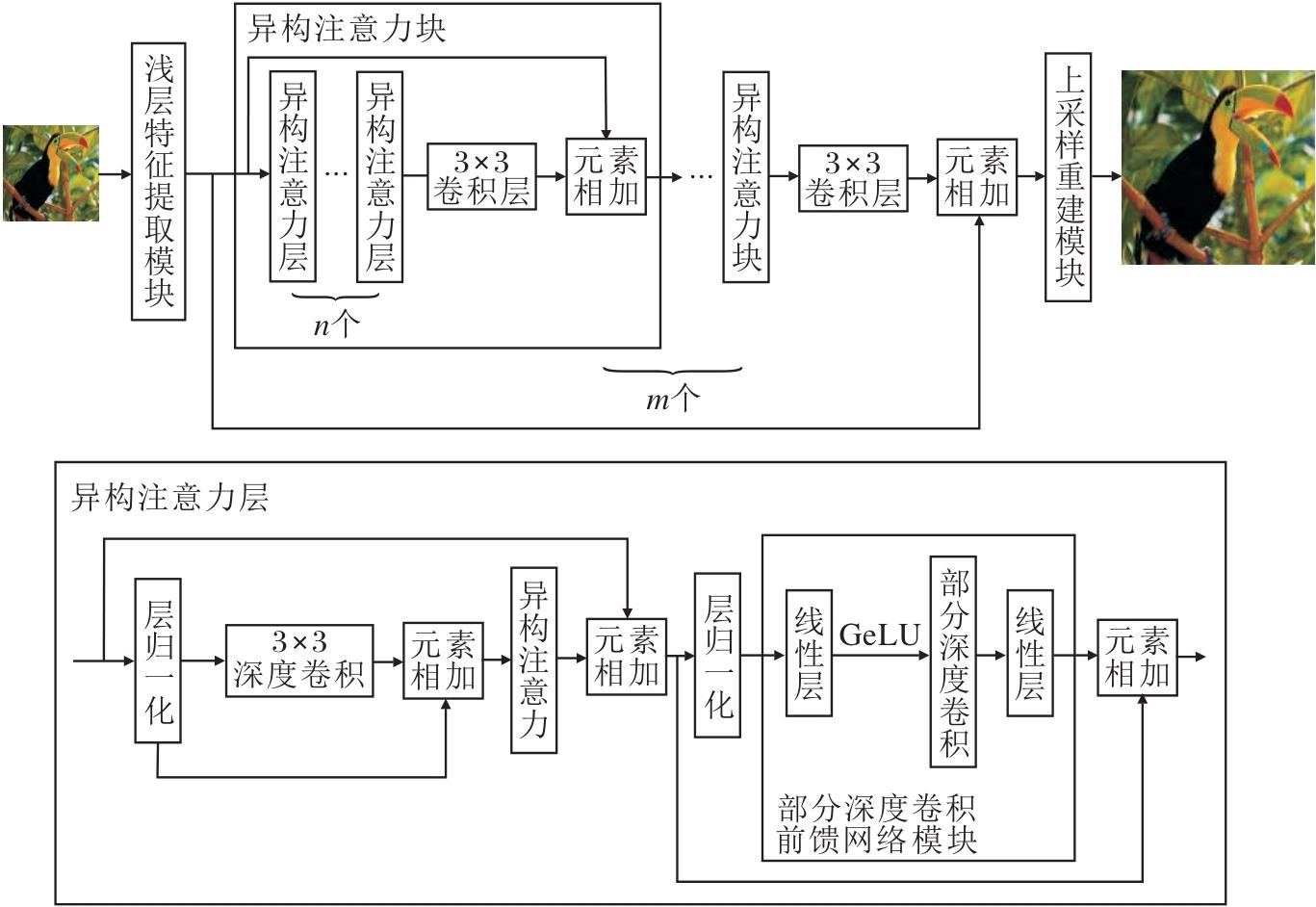 | 图1 HetANet结构图Fig.1 Architecture of HetANet |
首先, 对于输入LR图像XLR∈ RH× W× 3, 使用3× 3卷积层提取浅层特征XS∈ RH× W× C.然后, 将浅层特征XS输入深层特征提取部分.该部分包含n个异构自注意力块(Heterogeneous Self-Attention Block, HAB)和一个3× 3卷积层, 输出深层特征XD∈ RH× W× C.
最后, 将浅层特征XS和深层特征XD 建立残差连接, 将得到的特征输入上采样重建模块.本文选择亚像素卷积模块[1]作为上采样重建模块, 即先使用一个3× 3卷积层处理输入特征, 将特征的通道数量缩放为3× S2, 再使用像素重组操作(PixelShu-ffle)完成上采样, 得到重建的高分辨率图像XRC∈ RSH× SW× 3.
观察HetANet结构可发现, n个HAB为网络的核心模块.如图1 所示, 每个HAB由m个异构自注意力层(Heterogeneous Self-Attention Layer, HAL)、一个3× 3卷积层和一个残差连接组成.
如图1所示, 每个异构自注意力层(HAL)由预编码层、异构多头自注意力模块(HMSA)和部分深度卷积前馈网络模块(PDFFN)组成.
对于输入特征Xin, HAL使用层归一化操作、一个3× 3深度卷积和残差连接, 得到局部特征XPE后进行初步的位置嵌入, 即
$\boldsymbol{X}_{\mathrm{PE}}=L N\left(\boldsymbol{X}_{\mathrm{in}}\right)+D W \operatorname{Conv}_{3 \times 3}\left(L N\left(\boldsymbol{X}_{\mathrm{in}}\right)\right), $
其中, LN(· )表示层归一化操作, DWConv3× 3(· )表示3× 3深度卷积.
然后, 将局部特征XPE输入HMSA, 进行空间上的长距离特征交互, 并与输入特征Xin连接, 得到特征:
$\boldsymbol{X}_{\mathrm{HMSA}}=\boldsymbol{X}_{\mathrm{in}}+f_{\mathrm{HMSA}}\left(\boldsymbol{X}_{\mathrm{PE}}\right), $
其中fHMSA(· )表示HMSA操作.
最后, 将特征XHMSA输入一个归一化层和PD-FFN, 进一步融合通道信息和空间信息, 得到HAL的输出特征:
$\boldsymbol{X}_{\mathrm{HAL}}=\boldsymbol{X}_{\mathrm{HMSA}}+f_{\mathrm{PDFFN}}\left(L N\left(\boldsymbol{X}_{\mathrm{HMSA}}\right)\right), $
其中fPDFFN(· )表示PDFFN操作.
传统Transformer中的多头自注意力模块(MSA)一般先将输入特征图在通道维度上均匀划分为多个头, 再并行执行自注意力操作, 而文献[23]研究表明, 在高级视觉任务中, 传统的多头设计存在明显的计算冗余.同时, 传统MSA对每个头都执行密集自注意力操作, 这种对称的设计虽然能建立足够多的特征交互, 但也导致其难以过滤噪声.另外, 使用特征的正权值加权融合, 容易造成空间上的平滑, 难以提取高频特征[28].
因此, 本文提出异构多头自注意力模块(HMSA), 在传统MSA基础上, 采取非对称的三分支结构, 使用高效的稀疏自注意力分支和通道融合分支代替传统的密集自注意力头, 减少冗余计算, 并提高Trans-former对关键特征和高频特征的提取能力.具体HMSA结构如图2所示.
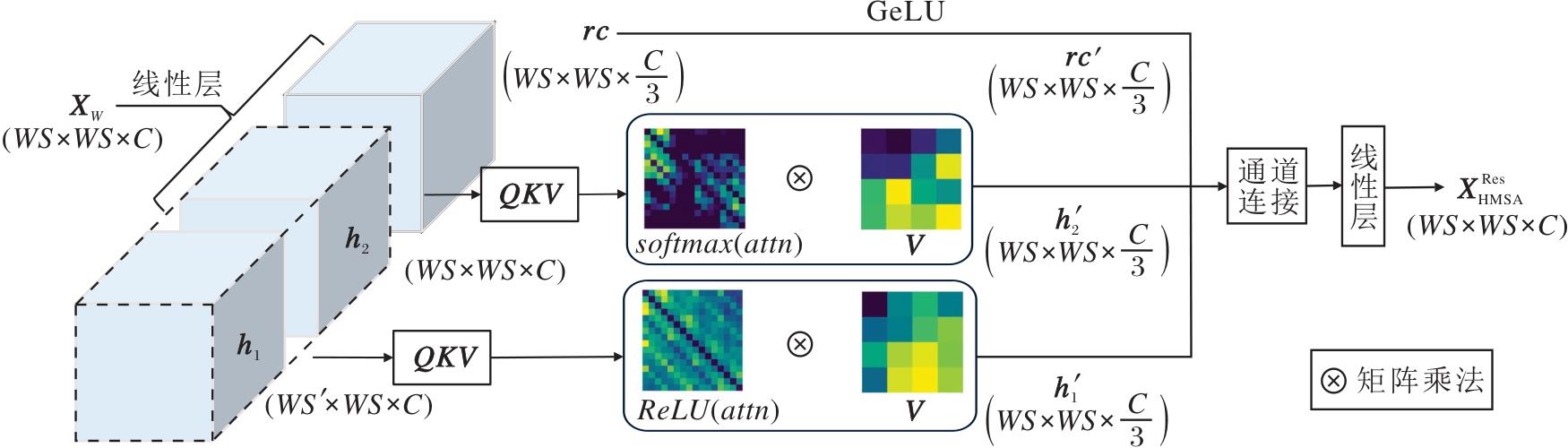 | 图2 HMSA的结构图Fig.2 Architecture of HMSA |
HMSA首先将特征图X∈ RH× W× C划分为多个大小为WS× WS的非重叠窗口特征XW∈ RWS× WS× C.每个窗口特征XW输入一个线性层, 生成多头特征:
$\begin{array}{l} \boldsymbol{h}_{i}=\operatorname{Linear}\left(\boldsymbol{X}_{W}\right) \in \mathbf{R}^{W S \times W S \times C}, i=1, 2, \\ \boldsymbol{r} \boldsymbol{c}=\operatorname{Linear}\left(\boldsymbol{X}_{W}\right) \in \mathbf{R}^{W S \times W S \times \frac{C}{3}} . \end{array}$
其中Linear(· )表示线性层.
为了避免产生冗余的注意力头, HMSA仅使用两个自注意力头h1和h2, 其中, h1表示密集自注意力分支, h2表示稀疏自注意力分支.
HMSA使用Softmax处理h1分支的注意力分数, 以保留充足的特征交互, 避免信息丢失.其过程可描述为:
$\begin{array}{l} \boldsymbol{Q}_{1}, \boldsymbol{K}_{1}, \boldsymbol{V}_{1}=\operatorname{Split}\left(\boldsymbol{h}_{1}\right) \\ \boldsymbol{h}_{1}^{\prime}=\operatorname{Softmax}\left(\boldsymbol{Q}_{1} \boldsymbol{K}_{1}^{\mathrm{T}} \cdot \text { scale }+\boldsymbol{R} \boldsymbol{P}\right) \end{array}$
其中, Q1∈
HMSA使用ReLU处理h2分支的注意力分数, 保留关键特征交互, 适合硬件部署.其过程可描述为:
$\begin{array}{l} \boldsymbol{Q}_{2}, \boldsymbol{K}_{2}, \boldsymbol{V}_{2}=\operatorname{Split}\left(\boldsymbol{h}_{2}\right) \\ \boldsymbol{h}_{2}^{\prime}=\operatorname{Re} L U\left(\boldsymbol{Q}_{2} \boldsymbol{K}_{2}^{\mathrm{T}} \cdot \text { scale }+\boldsymbol{R} \boldsymbol{P}\right) \end{array}$
其中, Q2∈
rc表示通道融合分支, 它不进行空间上的特征加权融合操作, 能有效补充高频信息.
最后, HMSA将三个分支的输出在通道维度进行级联, 并通过一个线性层得到HMSA的输出特征
值得注意的是, HMSA对h1和h2的注意力分数矩阵采取不同的处理方式, 因此, 它仍具备传统MSA的并行特性, 并且计算效率更高.究其原因主要为如下两点:1)HMSA只在h1、h2分支进行自关注计算, rc分支无需进行Q, K, V的维度扩展, 减少网络参数.2)使用稀疏注意力和简单的非线性映射取代部分低效的密集注意力.
为了说明HMSA的计算效率, 选择如下指标:参数量、每秒浮点运算次数(Floating Point Operations per Second, FLOPs)、激活值(Activation Values, Acts)、GPU内存、推理时间.实验在RTX 3080 GPU、1 280× 720的重建图像上进行测试, 放大倍数为4.HMSA和MSA相应指标值对比如表1所示.由表可得, 相比MSA, HMSA节省20%的参数量, 降低22%的FLOPs、 42%的Acts、51%的GPU内存占用, 缩短45%的推理时间.因此, 相比MSA, HMSA确实减少冗余计算.
| 表1 放大倍数为4时HMSA与MSA的计算成本对比 Table 1 Computational cost comparison between HMSA and MSA at a magnification factor of 4 |
现有一些Transformer使用全通道深度卷积层实现前馈网络部分的局部依赖, 但也造成计算上的冗余.如图3所示, SwinIR-light[19]前馈网络中间层特征图在某些通道上具有高度相似性, 这与文献[26]的研究结果一致, 说明通道间存在大量冗余信息.
 | 图3 SwinIR-light前馈网络中间层特征图的部分通道展示Fig.3 Visualization of partial channels from intermediate-layer feature maps of feedforward network in SwinIR-light |
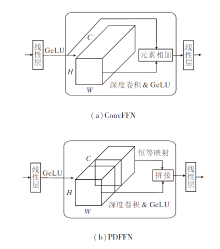
针对上述Transformer中的卷积前馈网络部分存在计算冗余问题, 本文设计部分深度卷积前馈网络模块(PDFFN).该模块主要将部分卷积操作引入卷积前馈网络模块中, 并在此基础上使用更高效的部分深度卷积(Partial Depthwise Convolution, PDW-Conv)结构.
传统卷积前馈网络(Convolutional Feedforward Network, ConvFFN)[22]和PDFNN结构如图4所示.如(b)所示, PDFFN首先通过一个线性层操作, 对输入特征X∈ RH× W× C进行通道混合和扩展, 得到特 征Xup∈ RH× W× rC.不同于传统的Conv-FFN, PDFNN将扩展后的通道均分为两部分, 一部分保持恒等不变, 另一部分经过一个3× 3深度卷积层, 建立特征图的空间局部依赖.最后, 将这两者在通道维度级联, 通过一个线性层融合所有通道并恢复通道数量, 得到PDFFN的输出特征
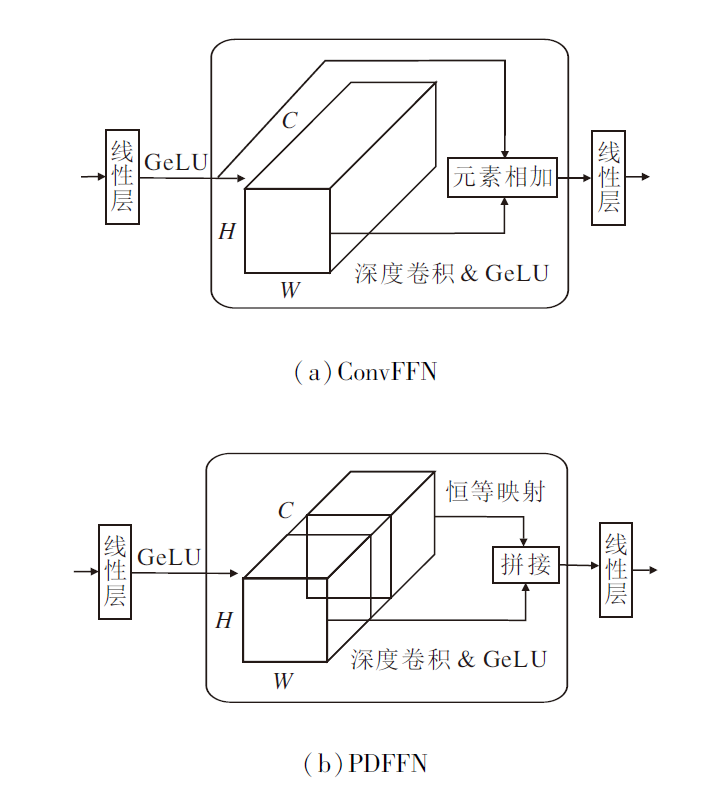 | 图4 不同的前馈网络结构图Fig.4 Structure of different feedforward networks |
为了说明PDFFN的重要作用, PDFFN和ConvFFN的指标值对比如表2所示.由表可见, 相比ConvFFN, PDFFN节省14%的参数量, 降低15%的FLOPs、20%的Acts、41%的GPU内存占用, 缩短43%的推理时间, 由此表明PDFFN性能较优.
| 表2 放大倍数为4时PDFFN与ConvFFN的计算成本对比 Table 2 Computational cost comparison between PDFFN and ConvFFN at a magnification factor of 4 |
本文使用DIV2K数据集[29]的800幅图像构建HetANet的训练集, 其中的低分辨率图像由真实图像的双三次下采样产生.将低分辨率图像裁剪成64× 64的图像块, 通过随机旋转和随机水平翻转等方式, 构建网络训练的数据集.测试集包括Set5[30]、Set14[31]、BSD100[32]、Urban100[33]、Manga109[34]、DIV- 2K100[29]数据集.
参照经典SwinIR-light[19]的超参数设置, HetANet使用6个通道数为60、自注意力窗口为8× 8的HAL构建HAB, 再使用6个HAB构建完整的HetANet.
采用Adam(Adaptive Moment Estimation)优化器训练网络, 设置学习率为2× 10-4, 批次大小为32, 训练轮次为5× 105, 在2.5× 105, 4× 105, 4.5× 105, 4.75× 105轮次时, 学习率减半.
所有实验采用计算YCbCr空间Y通道上的峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)和结构相似度(Structural Similarity, SSIM)作为重建性能的评价指标.
为了测试HetANet的性能, 选择如下对比方法:CARN(Convolutional Anchored Regression Net-work)[2]、EConvMixN(Lightweight Extended Convo-lution Mixer Network)[3]、LBNet(Lightweight Bimodal Network)[4]、IMDN[11]、DiVANet(Directional Vari-ance Attention Network)[13]、ESRT[18]、SwinIR-light[19]、ELAN[20]、LSCT[21].
2.2.1 定量对比
放大倍数为2、3、4时, 各方法在5个测试集上的性能对比如表3~表5所示, 表中黑体数字表示最优值.
| 表3 放大倍数为2时各方法的性能对比 Table 3 Performance comparison of different methods at a magnification factor of 2 |
| 表4 放大倍数为3时各方法的性能对比 Table 4 Performance comparison of different methods at a magnification factor of 3 |
| 表5 放大倍数为4时各方法的性能对比 Table 5 Performance comparison of different methods at a magnification factor of 4 |
由表3~表5可知, HetANet在5个测试集上取得最高的PSNR和SSIM值.对比SwinIR-light, HetANet可以以较少的参数量和FLOPs实现在所有放大倍数上的重建性能.特别是在Manga109测试集上, 放大倍数为3、4时, HetANet的PSNR值比SwinIR-light提升0.14 dB和0.13 dB.究其原因是HetANet使用HMSA和PDFFN这2个精简有效的结构设计.在HMSA中, 使用稀疏自注意力分支过滤噪声, 保证网络的稀疏性; 使用通道融合分支增强注意力模块的高频特征提取能力; 保留单个稠密自注意力分支, 保证完整信息的传递.这种三分支结构也大幅减少网络内存占用.在PDFFN中, 使用轻量的部分深度卷积, 在保证提取空间局部特征交互能力的同时, 减少额外的内存开销.
2.2.2 定性对比
放大倍数为4时, HetANet与CARN[2]、LBNet[4]、EDST[9]、IMDN[11]、DiVANet[13]、ESRT[18]、SwinIR-light[19]的重建图像对比如图5所示.
 | 图5 放大倍数为4时各方法重建图像视觉效果对比Fig.5 Visual result comparison of images reconstructed by different methods at a magnification factor of 4 |
由图5可看出, HetANet在恢复图像的纹理细节上具有明显优势.在Urban100测试集的img058图像和Manga109测试集的YumeiroCooking图像上存在很多密集相邻的曲线, HetANet能准确恢复这些曲线的轮廓, SwinIR-light生成的图像在线条密集处模糊不清, 而其它方法也出现不同程度的模糊和伪影.在Urban100测试集的img062图像和BSD100测试集的78004图像上存在大量面积线性变化的方格状图案, HetANet能恢复更多的小面积图案.在Urban100测试集的img076图像上, 只有HetANet生成清晰且准确的图案, 其它方法都出现严重的伪影和扭曲.究其原因, HetANet剔除冗余的结构和连接, 同时保持一定的稀疏性, 在处理这些密集复杂的图案时, 能提取更有效的关键特征, 过滤干扰信息.
本节设计相关实验, 说明HMSA的结构合理性, 实验中选择放大倍数为4.
首先, 分析MSA中注意力头数量对网络重建性能的影响, 说明多头注意力存在计算冗余.注意力头数量不同时, HetANet在5个测试集上的重建性能对比如表6所示.由表可知, 推理时间和占用GPU内存与注意力头数量呈正比.然而, 随着MSA中注意力头数量的减少, 网络重建性能并未降低, 甚至有所提升.这有效说明MSA的部分头存在冗余.当注意力头数量为3时, MSA能取得较优的性能与能耗的平衡, 因此后续实验选择注意力头数量为3.
| 表6 放大倍数为4时不同注意力头数量对重建性能的影响 Table 6 Effect of different numbers of attention heads on reconstruction performances at a magnification factor of 4 |
当MSA的注意力头数量为3时, 分析通道融合分支(rc)的数量对重建性能的影响, 结果如表7所示.
| 表7 放大倍数为4时MSA中不同通道融合分支数量对重建性能的影响 Table 7 Effect of different numbers of rc in MSA on reconstruction performances at a magnification factor of 4 |
由表7可知, 将其中1个注意力头替换为1个通道融合分支时, HetANet能在重建性能和计算成本间达到较优平衡, 此时HetANet在Set5、BSD100测试集上取得最优的重建性能, 与MSA(0个通道融合分支时)相比降低18%的GPU内存占用和17%的Acts.
进一步地, 通过特征图说明通道融合分支的作用.HetANet中最后一个HAB中的各HAL包含的通道融合分支和密集自注意力分支输出的特征图如图6所示.
 | 图6 放大倍数为4时最后一个HAB输出的特征图Fig.6 Feature maps output of the last HAB at a magnification factor of 4 |
由图6可知, 在各层HAL中, 通道融合分支输出的特征图比密集自注意力分支输出的特征图具有更清晰的边缘, 说明通道融合分支能提取图像的高频特征, 增强图像的边缘信息.
再在密集自注意力分支和通道融合分支的基础上, 讨论稀疏自注意力分支在HMSA中的作用, 结果如表8所示, 表中黑体数字表示最优值.由表可知, 在密集自注意力分支和通道融合分支的基础上, 组合稀疏自注意力分支要比组合密集自注意力分支的重建性能更优.究其原因, 稀疏自注意力分支能过滤噪声, 使模型捕获显著特征, 有效改善重建性能.另外, 由于稀疏自注意力分支采用ReLU作为激活函数, 相比密集自注意力分支中Softmax激活函数, 计算代价有所降低.
| 表8 放大倍数为4时HMSA中稀疏自注意力分支对重建性能的影响 Table 8 Effect of sparse attention branch in HMSA on reconstruction performance at a magnification factor of 4 |
最后, 探讨PDFFN的作用.FFN、ConvFFN和PDFFN对重建性能的影响如表9所示, 表中黑体数字表示最优值, r表示参与深度卷积运算的通道比例.由表可知, 当通道比例r=0.50时, PDFFN取得最优的重建性能.这说明PDFFN具有重要作用, 并且前馈网络激活层特征图中存在相似性冗余.结合表2中的计算成本分析, PDFFN以FFN级别的硬件负载实现与ConvFFN相当的重建性能.究其原因, PDFFN基于高效的部分深度卷积, 在高效捕获空间局部特征的同时, 降低网络的计算复杂度.
| 表9 放大倍数为4时前馈网络结构不同对重建性能的影响 Table 9 Effect of different feedforward network architectures on reconstruction performances at a magnification factor of 4 |
本节对比HetANet与LBNet[4]、、DiVANet[13]、ESRT[18]、SwinIR-light[19]、ELAN-light[20]的复杂度, 说明HetANet在计算效率和硬件负载上的优势.实验中采用参数量、FLOPs和GPU内存占用衡量方法的复杂度, 结果如表10所示, 表中黑体数字表示最优值.
| 表10 放大倍数为4时各方法的复杂度对比 Table 10 Complexity comparison of different methods at a magnification factor of 4 |
由表10可知, HetANet在各复杂度指标上均优于SwinIR-light, 与其它方法相比也极具竞争力.
特别地, HetANet具备最优的GPU内存占用, 相比SwinIR-light降低35%.与此同时, HetANet具有最优的重建性能.究其原因, HetANet通过大量实验剔除冗余的自注意力分支, 在不影响性能的前提下大幅降低模型的复杂度, 同时引入稀疏自注意力分支过滤噪声, 能关注显著的特征表示.
现有基于Transformer的重建方法由于其传统的多头设计和稠密自注意力机制存在大量冗余计算, 因此本文提出基于异构注意力网络的图像超分辨率重建方法(HetANet), 包括异构多头自注意力模块(HMSA)和部分深度卷积前馈网络模块(PDFFN).HMSA采取三分支结构, 即为了减少冗余计算, 保留单个密集自注意力分支用于传递完整信息, 引入稀疏自注意力分支过滤噪声, 引入通道融合分支补充高频信息.同时, PDFFN利用中间层特征图中的相似性进行部分深度卷积运算, 即以少量的硬件负载实现接近基于全通道深度卷积模块的重建性能, 降低现有卷积前馈网络的计算代价.实验表明HetANet的重建性能和计算效率更具竞争力.
HMSA是对传统的MSA结构进行的优化, 属于底层结构探讨, 未增加额外的复杂模型组件.因此, 今后可将HMSA与其它先进的重建模块结合, 构建高效的图像超分辨率重建方法.
本文责任编委 兰旭光
Recommended by Associate Editor LAN Xuguang
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|