








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于语义协同感知注意力的水下图像增强网络
[杨静1  , 梁辉
, 梁辉1 , 朱文瀚1 , 杨烁1 , 吴志泽1 ]
, 梁辉, 朱文瀚, 杨烁, 吴志泽]
|
|



作者简介: 
梁 辉,硕士研究生,主要研究方向为计算机视觉、深度学习、水下图像处理.E-mail:1178430581@qq.com. 
朱文瀚,硕士研究生,主要研究方向为计算机视觉、深度学习、图像处理.E-mail:1197234570@qq.com. 
杨 烁,硕士研究生,主要研究方向为计算机视觉、深度学习.E-mail:2846763538@qq.com. 
吴志泽,博士,教授,主要研究方向为深度学习驱动的图像、视频处理与分析.E-mail:wuzhize.ustc@gmail.com.
针对水下成像中光衰减与散射导致的图像退化难题,提出基于语义协同感知注意力的水下图像增强网络.首先,设计双路径竞争的感知注意力机制,将滑动窗口注意力与池化注意力融合于Softmax中进行计算.同步捕捉图像的粗粒度特征和细粒度特征,实现多尺度特征感知.然后,引入卷积门控线性单元,实现通道混合器的注意力化.在此基础上,构建集成感知注意力和卷积门控线性单元的级联感知注意力网络,用于捕获和融合水下退化图像的局部信息与全局信息.最后,设计特征主导模块,嵌入和协同语义特征,增强对水下场景语义的理解与表达能力,使增强过程不仅聚焦于像素级修复,还能实现语义层面的场景重建.实验表明,文中网络具有较优的泛化性和在下游视觉工程任务中的应用价值.
About Author:
LIANG Hui, Master student. His research interests include computer vision, deep lear-ning and underwater image processing.
ZHU Wenhan, Master student. His research interests include computer vision, deep learning and image processing.
YANG Shuo, Master student. His research interests include computer vision and deep learning.
WU Zhize, Ph.D, professor. His research interests include deep learning-driven image and video processing and analysis.
To address the image degradation caused by light attenuation and scattering in underwater imaging, an underwater image enhancement network based on semantic collaborative perceptual attention is proposed. First, a dual-path competitive perceptual attention mechanism is designed. Sliding window attention and pooling attention are integrated into Softmax to synchronously capture both coarse-grained and fine-grained features of images, thereby enabling multi-scale feature perception. Second, a convolutional gated linear unit is introduced to realize the attentionalization of the channel mixer. Based on the above, a cascaded perceptual attention network is constructed by integrating the perceptual attention mechanism and convolutional gated linear unit to capture and fuse local and global information of underwater degraded images. Finally, a feature dominant module is developed to embed and collaboratively integrate semantic features, and the capability of the model to understand and represent underwater scene semantics is enhanced. This elevates the enhancement process from mere pixel-level restoration to semantic-level scene reconstruction. Experiments demonstrate that the proposed network exhibits superior generalization ability and significant application value in downstream visual engineering tasks.
随着当前陆地空间与资源压力的日益增大, 水下空间探索与开发的紧迫性显著提升.基于光学视觉技术引导的自主水下航行器(Autonomous Under-water Vehicles, AUVs)逐渐成为水域探测的重要工具之一, 而高质量、清晰的水下光学图像是AUVs实现环境监测与资源勘探等一系列水下工程任务的重要保障之一.受长距离后向散射、选择性光吸收及散射等因素影响, 水下光学图像普遍存在光照不足、对比度较低、细节模糊、色彩偏移及亮度不均等问题[1, 2].如何获取高质量水下光学图像, 一直是水下图像增强(Underwater Image Enhancement, UIE)领域亟待解决的挑战性难题之一.
为了改善水下图像质量, 早期基于物理模型的传统方法多采用经验观察或图像先验知识[3].由于构建先验知识并对图像进行经验观察具有挑战性— — 经验观察通常在有限场景下进行, 难以涵盖所有可能的水下环境与图像退化情况, 因此, 基于经验观察构建的方法在特定案例中有效, 但在其它场景下效果欠佳, 缺乏稳定性与泛化性.另一方面, 基于非物理模型的传统方法[4]主要通过修改像素灰度值以提升图像视觉效果, 未考虑水下图像的退化过程.由于水下环境复杂多变, 不同场景中图像退化特征存在较大差异, 仅依赖固定算法处理的非物理模型的方法难以适应所有复杂场景的水下图像增强需求.此外, 由于未对水下图像特有的色偏、模糊与低对比度等退化特征进行针对性处理, 在增强图像时可能破坏结构或产生伪影.
近年来, 深度学习的发展为图像处理提供新的解决思路.基于卷积神经网络(Convolutional Neural Network, CNN)[5]、Transformer[6, 7, 8]、扩散模型[9]、语义引导[10]的方法相继涌现, 为UIE提供多样化解决方案.但是, 多数CNN方法感受野有限, 难以有效估计全局特征与多尺度特征.基于Transformer的方法虽能更好地捕获全局特征, 但其自注意力机制对局部特征的关注不足, 限制对水下图像局部细节的处理能力.扩散模型方法通常需要多次迭代去噪, 存在计算成本较高与推理时间较长的问题, 并且难以处理复杂的水下退化图像.语义引导方法虽可有效改善边缘、纹理及空间关系信息, 但需谨慎控制语义的引入, 未经合理处理的语义特征的过度表达会抑制水下图像的原有特征, 引发过增强与色偏等问题.
针对上述问题, 本文基于如下两项核心观点提出UIE解决方案:1)人眼以“ 从整体到局部” 方式接收视觉信息[11], 观测水下图像时会先关注整体信息, 再逐步聚焦局部细节, 因此, 通过感知注意力实现对图像粗粒度特征和细粒度特征的提取至关重要; 2)语义特征的引入虽可增强纹理、边缘、场景一致性等特性, 但未经处理的语义特征产生的视觉表现欠佳.
因此, 本文提出基于语义协同感知注意力的水下图像增强网络(Underwater Image Enhancement Network Based on Semantic Collaborative Perceptual Attention, SCPANet), 包含语义协同模块(Semantic Collaborative Module, SCM)、级联感知注意力网络(Cascaded Perceptual Attention Network, CPAN)和特征主导模块(Feature Dominant Module, FDM).SCM作为语义分支, 从水下图像中提取有效的纹理、结构、空间关系等底层视觉元素特征和高层视觉元素特征.CPAN作为增强分支, 设计感知注意力模块(Perceptual Attention Module, PAM), 通过引发细粒度和粗粒度特征之间的竞争, 将像素集中的注意力转换为多尺度注意力表征, 使每个查询(Query)附近具有细粒度的感知, 同时保持对全局信息的粗粒度感知.FDM通过执行通道特征调制, 选择重要的语义特征予以嵌入和表达, 改善过增强、色偏及细节模糊等问题.在公开数据集上的定性实验及定量实验表明, SCPANet性能较优.
在早期缺乏额外信息的情况下, 研究者通常采用特定先验作为约束条件以估计物理模型的参数.Jr Drews等[12]提出UDCP(Underwater Dark Channel Prior), 移除传统暗通道先验中的红色通道, 专门针对水下光学衰减特性进行优化.Peng等[13]提出基于图像模糊与光吸收的水下图像复原方法, 通过模糊度和光吸收特性估计水下场景深度.借助IFM(Image Formation Model)实现较精确的背景光和深度估计, 完成水下图像复原.Song等[14]提出ULAP(Scene Depth Estimation Model Based on Underwater Light Attenuation Prior), 通过监督线性回归训练获得模型参数.
另一方面, 基于非物理模型的方法忽略图像退化过程, 通过重新分配像素值以改善对比度和色偏问题.Zhang等[4]提出ACDC, 采用基于双直方图的迭代阈值技术, 结合瑞利分布推导的有限直方图, 实现对比度的提升.受视网膜皮层变分模型启发, Zhuang等[15]提出HLRP, 利用稀疏性促进反射分量整合, 在增强结构与细节的同时恢复真实色彩.
然而, 由于水下成像环境的复杂性, 基于物理模型的方法难以构建可靠的退化模型和先验知识体系, 而基于非物理模型的方法通过调整像素值以增强水下图像的策略往往具有单一性, 难以满足多样化退化水下图像的处理需求.
得益于深度学习的发展, 多项视觉任务的性能得到显著提升, 深度学习技术也开始通过多种解决方案融入水下图像增强领域.基于深度学习的方法可分为:基于CNN的方法[5]、基于生成对抗网络(Generative Adversarial Networks, GAN)的方法[16]、基于Transformer的方法[17]、半监督/无监督与对比学习的方法[18, 19]等.Fabbri等[20]利用CycleGAN生成的训练数据构建UGAN(Underwater GAN), 合成退化的水下图像.Li等[21]提出基于CNN的水下图像增强方法UWCNN.Li等[22]还利用UIEB数据集设计Water-Net, 融合输入图像与3个置信度图, 获得增强图像.Wang等[23]提出UIEC^2-Net(Underwater Image Enhancement Convolution Neural Network Using Two Color Space), 有效整合RGB与HSV色彩空间特征.Peng等[6]提出U-Shape Transformer , 建立包含更丰富水下场景和更高质量参考图像的大规模水下数据集(LSUI).该方法采用空间全局特征建模Transformer与通道多尺度融合Transformer, 增强网络对色彩通道和严重衰减空间区域的关注.Ren等[24]提出URSCT-SESR(U-Net-Based Reinforced Swin- Convs Transformer for Simultaneous Enhancement and Superresolution), 结合卷积与核心注意力机制, 构建增强Transformer模块, 捕获更多的局部注意力.在半监督对比学习方法方面, Huang等[18]提出Semi-UIR(Semi-supervised Underwater Image Restoration), 引入可靠样本库, 有效利用未标注数据, 提升对真实数据的泛化性.
然而, 现有的诸多方法在处理退化的水下图像特征提取时存在明显局限, 如UWCNN、Water-Net、UIEC^2-Net等, 由于感受野范围有限, 难以实现对全局特征及多尺度特征的有效估计.基于Transformer的方法虽然在捕获全局特征方面表现更优, 但其自注意力机制在关注局部特征时存在不足, 并且伴随较高的计算成本开销.基于均值教师的半监督框架过度依赖特征库, 在一定程度上削弱方法的泛化性.此外, 由于水下环境与光照条件的复杂性, 现有方法往往难以充分学习目标图像的分布特征或准确捕捉其纹理结构, 导致增强图像与目标图像存在明显差异, 并伴随色偏、细节丢失等问题.
语义引导技术已在计算机视觉任务中得到深入研究, 如图像配准和语义分割等.这些任务大多属于中高层视觉任务, 语义信息主要发挥引导与校正作用, 然而来自高层视觉任务的语义信息同样可为图像融合、图像去模糊等低层视觉任务提供指导.
当前图像增强领域引入语义信息主要存在两种技术路径.1)将语义概率图与退化图像直接拼接作为网络输入.例如, SGUIE-Net[10]通过跨图像共享语义区域, 感知不同语义区域的多尺度退化特征, 并反馈至原始尺度提取的全局注意力中.2)从语义标签提取特征以指导输入特征解码.例如, 基于语义感知纹理、结构特征协作的水下图像增强方法[25]通过与预训练高层语义感知模型关联, 利用层次化特征表示辅助低层图像增强, 获得纹理、结构清晰的水下图像.然而, 第1种方法难以应对水下场景的极端复杂性, 分割网络生成的语义概率图仅能处理类别相关的物体边界模糊问题, 无法精准恢复水下图像增强所需的纹理与结构信息.第2种方法虽然通过语义感知特征描述视觉任务, 利用更丰富的信息促进增强, 但这些语义特征并非完全有益, 若对语义信息的引入不加以控制, 会导致语义特征的过度表达, 抑制光学图像固有的水下特性, 引发过增强和色彩信息丢失等问题.
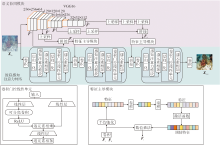
本文提出基于语义协同感知注意力的水下图像增强网络(SCPANet), 结构如图1所示.SCPANet分为三个部分:语义协同模块(SCM)、级联感知注意力网络(CPAN)、特征主导模块(FDM).
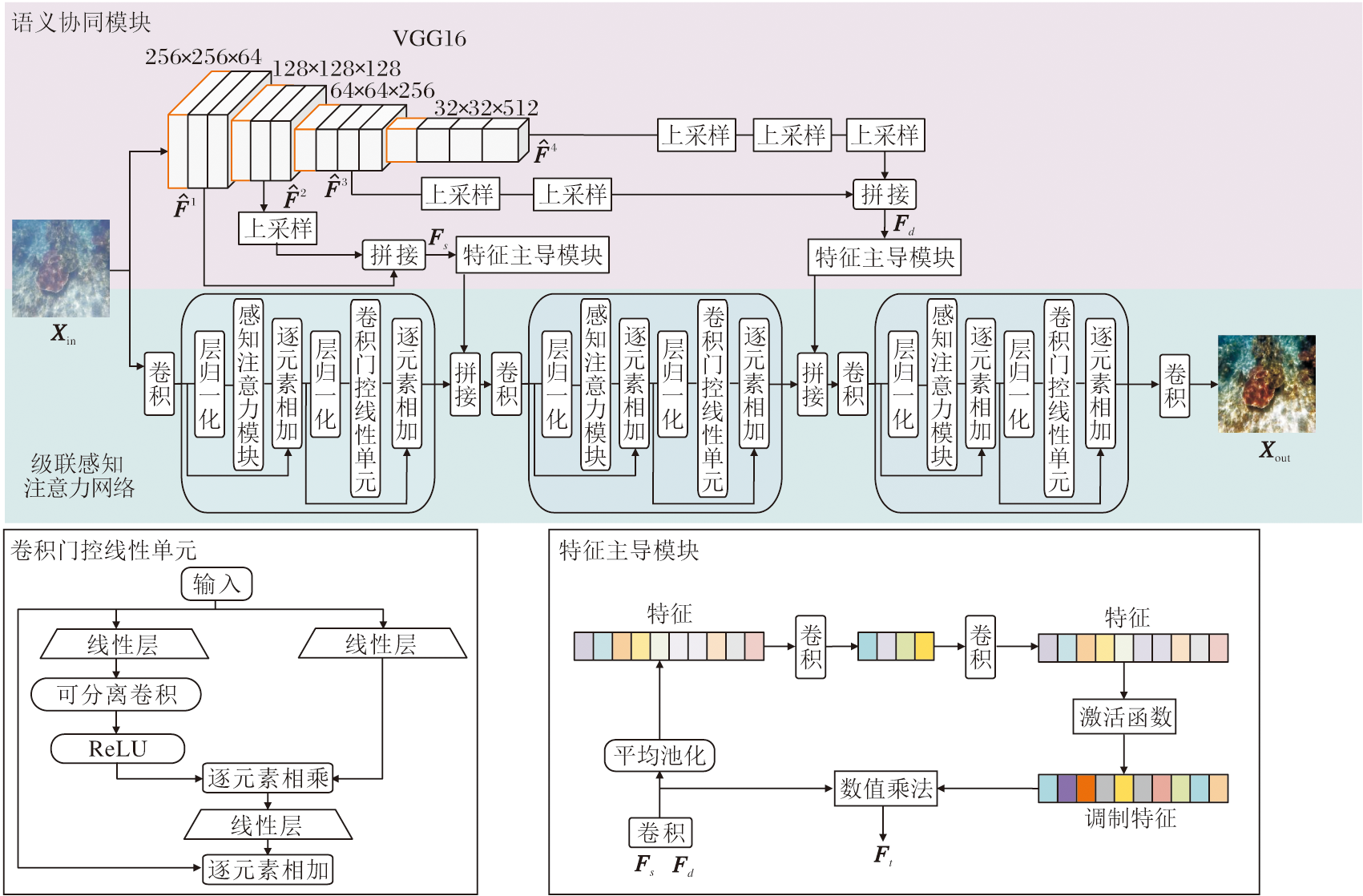 | 图1 SCPANet总体框架Fig.1 Overall framework of SCPANet |
给定水下原始退化图像Xin∈ RH× W× 3作为输入, 分别送入SCM和CPAN.SCM主要学习水下图像的语义特征, 融合特征后送入FDM.FDM执行通道特征调制, 学习特定于图像的特征和特定于区域的特征.CPAN将多个感知注意力级联, 较好地捕获图像的粗粒度特征及细粒度特征.最后, 将经过FDM调制后的语义特征送入CPAN, 得到重建后的水下清晰图像Xout∈ RH× W× 3.
在语义协同模块(SCM)中, 利用语义感知模型VGG16作为特征提取器.由于在超大规模的基准ImageNet上进行训练, 该模型具有强大的特征表示能力, 并且不需要在水下图像数据集上重新训练.直接将Xin输入VGG16中, 提取多尺度特征:
$\widehat{{{F}^{i}}}=VGG({{X}_{\text{in}}}), i=1, 2, 3, 4$.
由于太深的语义特征对底层任务的影响不明显, 这里只采用前四层进行特征提取.
VGG16的浅层网络较关注图像纹理、边缘信息, 而深层网络较关注图像的全局上下文信息, 因此按如下步骤处理.首先, 在特征提取时将一二层调整至语义特征图大小并聚合形成浅层特征:
${{F}_{s}}=Cat\left( \widehat{{{F}^{1}}}, Up\left( \widehat{{{F}^{2}}} \right) \right)$,
其中, Cat(· )表示拼接操作, Up(· )表示上采样.
然后, 将三四层聚合形成深层特征:
${{F}_{d}}=Cat\left( Up\left( Up\left( \widehat{{{F}^{3}}} \right) \right), Up\left( Up\left( Up\left( \widehat{{{F}^{4}}} \right) \right) \right) \right)$.
最后, 将融合后的浅层/深层语义相关的特征图送入特征主导模块(FDM), 筛选重要的语义信息进行嵌入.
级联感知注意力网络(CPAN)将感知注意力级联, 更好地获取图像的粗粒度特征及细粒度特征.首先, 将输入图像Xin使用1× 1的点卷积实现跨通道的交互和信息整合.再使用3组感知注意力进行特征提取.在第1组感知注意力之后通过 FDM整合浅层语义特征.在第2组感知注意力之后通过 FDM整合深层语义特征.
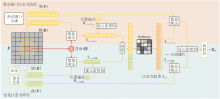
本文设计基于双路径竞争的感知注意力机制(PAM), 在每个查询(Query)附近具有细粒度的感知, 同时保持对全局信息的粗粒度感知.具体PAM结构如图2所示.
 | 图2 PAM结构图Fig.2 Architecture of PAM |
PAM采用双路径设计感知, 分别为以查询为中心的滑动窗口注意力和池化注意力.此外, 为了诱导两个注意力路径之间的竞争, 在同一个Softmax中计算两个路径的Query(Q)和Key(K)相似性结果的重要性.
上述操作实现细粒度特征和粗粒度特征之间的竞争, 可将像素集中的注意力转换为多尺度注意力机制.
对于滑动窗口注意力, 给定输入
X=LN(Conv1× 1(Xin)),
其中, LN(· )表示层归一化, Conv1× 1(· )表示1× 1卷积操作.
首先对输入特征图中单个像素执行操作.将输入图像X以像素(i, j)为中心的滑动窗口内的一组像素定义为ρ (i, j).对于固定的窗口大小k× k, 窗内的像素数量为k2.滑动窗口注意力特征为:
${{S}_{(i, j)\tilde{\ }\rho (i, j)}}={{Q}_{(i, j)}}K_{\rho \left( i, \text{ }\!\!~\!\!\text{ }j \right)}^{\text{T}}$.
对于池化注意力, 采用无参数自适应平均池化进行空间维度的下采样, 然而, 平均池化操作容易丢失部分信息.因此, 本文在特征图池化之前使用单层神经网络进行投影和激活, 提前压缩和提取有用信息, 提高下采样后的信息压缩率.池化后再次使用层归一化获得相应输出, 确保X和池化令牌σ (X)的方差一致性.具体池化令牌计算如下:
σ (X)=LN(AvgPool(ReLU(Linear(X)))),
其中, AvgPool(· )表示自适应平均池化, ReLU(· )表示激活函数, Linear(· )表示全连接线性层, LN(· )表示层归一化.
最终池化注意力特征为:
${{S}_{(i, j)\tilde{\ }\sigma (X)}}={{Q}_{(i, j)}}K_{\sigma \left( X \right)}^{\text{T}}$.
为了进一步增强感知注意力的外推能力, 本文采用不同的方法计算两条路径上的滑动窗口注意力位置偏差B(i, j)~ρ (i, j)和池化注意力位置偏差B(i, j)~σ (X).
在池化注意力路径上, 使用对数间隔连续位置偏差(log-CPB)[26].log-CPB是一个具有ReLU的2层MLP(Multilayer Perceptron), 计算${{Q}_{(i, j)}}K_{\sigma \left( X \right)}^{\text{T}}$的空间相对坐标Δ (i, j)~σ (X), 进而得出B(i, j)~σ (X).
在滑动窗口注意力路径上, 直接使用可学习的B(i, j)~ρ (i, j).一方面, 由于滑动窗口的大小固定, 不需要通过log-CPB外推未知的相对位置偏差, 从而节省计算资源.另一方面, 由于Δ (i, j)~σ (X)表示细粒度标记和粗粒度标记之间的空间相对坐标, 而Δ (i, j)~ρ (i, j)表示细粒度标记之间的空间相对坐标.因此不需要使用log-CPB计算B(i, j)~ρ (i, j), 则
B(i, j)=Cat(B(i, j)~ρ (i, j), LogCPB(Δ (i, j)~σ (X))),
其中LogCPB(· )表示对数间隔连续位置偏差.
对于得到的双路径特征和位置偏差, 送入统一Softmax进行细粒度特征和粗粒度特征之间的竞争, 并通过β 控制注意力权重的分散程度, 将像素集中的注意力转换为多尺度注意力:
${{A}_{(i, j)}}=Softmax\left( \frac{1}{\beta }at({{S}_{(i, j)\tilde{\ }\rho (i, j), }}{{S}_{(i, j)\tilde{\ }\sigma (X)}})+{{B}_{(i, j)}} \right)$.
随后通过权重分离操作(Split)
A(i, j)~ρ (i, j), A(i, j)~σ (X)=Split(A(i, j)),
使它们分别乘以滑动窗口注意力权重A(i, j)~ρ (i, j)和池化注意力权重A(i, j)~σ (X), 相加后再经过线性层, 得到感知特征
XPF=Linear(A(i, j)~ρ (i, j)Vρ (i, j)+A(i, j)~σ (X)Vσ (X)),
从而调整粗粒度和细粒度的感知, 其中, Linear(· )表示线性操作, Vρ (i, j)表示滑动窗口注意力值, Vσ (X)表示池化注意力值.
得到感知特征XPF后, 经归一化后将其送入卷积门控线性单元(Convolutional Gated Linear Units, CGLU).门控线性单元(Gated Linear Units, GLU)[27]是一种通道混合器, 已被证实在各种自然语言处理任务中性能优于MLP.GLU包含两个逐元素相乘的线性变换层, 其中一层经过门控函数激活.
本文中的CGLU在GLU门控分支的激活函数前添加一个最小形式的3× 3可分离卷积, 使其结构符合门控通道注意的设计理念, 并将其转化为基于最近邻特征的门控通道注意机制.
CGLU中每个令牌都拥有基于最近邻细粒度特征的独特门控信号, 可解决全局平均池化的过度粗粒度这一缺点, 使增强后的图像既保留全局特征又呈现丰富细节.
由于水下图像存在光照不均匀及各种退化, 直接将语义特征嵌入CPAN中是不适用的.若直接强制拼接或融合而无约束, 可能导致过增强、细节模糊、局部畸变和伪影等问题.
为了解决上述问题, 本文设计特征主导模块(FDM), 执行通道特征调制, 学习特定图像的特征和特定区域的特征并进行嵌入.
首先使用1× 1的卷积层进行变换, 再通过全局平均池化、1× 1卷积和Sigmoid函数得到自适应权重向量.
然后, 将自适应权重向量乘以经过1× 1卷积变换的聚合特征Fs和Fd, 得到调制特征:
${{F}_{t}}=S(Con{{v}_{1\times 1}}(Con{{v}_{1\times 1}}(AVG(Con{{v}_{1\times 1}}{{F}_{s}}, {{F}_{d}})))))\cdot Con{{v}_{1\times }}_{1}({{F}_{s}}, {{F}_{d}})$,
其中, S(· )表示Sigmoid函数, Conv1× 1(· )表示1× 1卷积, AVG(· )表示全局平均池化.
最后, 将调制特征嵌入CPAN中.
本文采用Charbonnier损失、梯度损失和多尺度结构相似性(Multi-scale Structural Similarity, MS-SSIM)损失的线性组合.
Charbonnier损失是L1范数的一种可微变体, 最小化恢复图像和参考图像之间的损失.给定恢复图像$\widehat{X}$和参考图像X, 它们之间的Charbonnier损失定义如下:
$L_{\mathrm{C}}=E_{\widehat{X} \sim P(r), X \sim P(g)} \sqrt{(\widehat{X}-X)^2+\epsilon^2}$,
其中, P(r)表示恢复图像$\widehat{X}$的分布, P(g)表示真实图像X的分布, $\epsilon$被经验性地设为1e-3.
Charbonnier损失仅像L1损失那样获得低频信息, 而梯度损失通过施加二阶限制捕获高频信息, 这有助于锐化图像的边缘.令$\widehat{G}$表示$\widehat{X}$的梯度图, G表示X的梯度图, L1梯度损失为:
${{L}_{\text{gd}}}={{E}_{\widehat{G}\tilde{\ }Q\left( r \right), G\tilde{\ }Q\left( g \right)}}{{\left\| \widehat{G}-G \right\|}_{1}}$,
其中, Q(r)表示$\widehat{G}$的分布, Q(g)表示G的分布.
MS-SSIM是一种结构相似性图像质量范式, 在结合图像分辨率和观察条件的变化方面具有更大的灵活性.因此, 相应的损失定义如下:
${{L}_{M}}\left( \widehat{X}, X \right)=1-MS-SSIM\left( \widehat{X}, X \right)$.
最后, 总损失函数:
L=ω 1LC+ω 2Lgd+ω 3LM.
为了保持收敛速度, 经验性设置ω 1=1, ω 2=1, ω 3=2.
为了训练SCPANet, 选择U-Shape Transformer[6]中的LSUI数据集.LSUI数据集涵盖更丰富的水下场景(水类型、光照条件和目标类别)和更好的视觉质量参考图像, 包含4 279幅真实水下图像和相应配对的清晰图像作为GT(Ground Truth).为了进一步扩充训练集, 从UIEB数据集[22]上随机挑选800幅配对图像作为补充, UIEB数据集上剩余的90幅配对图像作为测试集, 记为Test-U90.因此, 训练集共计5 079幅配对图像.
此外, 本文还在UIEB挑战集、EUVP 数据集[28]和RUIE数据集[29]上进行测试.UIEB挑战集包含60幅水下图像, 未提供相应的GT值, 记为Test-U60.在EUVP数据集上, 本文采用515对图像进行测试, 记为Test-E515.在RUIE数据集上, 采用UC-CS、UIQS两类真实水下图像进行测试.UCCS包含3种不同偏色的水下场景图像, 共300幅, 记为Test-UC.UIQS包含5个子集, 共3 630幅图像, 记为Test-UI.这5个子集分别表示图像质量的5个等级, 按照UCIQE(Underwater Colour Image Quality Evaluation)进行排序, 对应的图像质量依次递减.训练数据集及测试数据集的详细信息如表1所示.
| 表1 实验数据集 Table 1 Experimental datasets |
针对配对数据集Test-U90、Test-E515, 采用3种全参考客观质量评价指标:均方误差(Mean-Square Error, MSE)、峰值信噪比(Peak Signal-to-Noise Ra-tio, PSNR)和结构相似性指数(Structural Similarity, SSIM).
较低的MSE值和较高的PSNR值表明增强图像在内容上与真实图像更接近.SSIM综合考虑图像的结构、对比度和亮度信息, 值越接近1表示两幅图像的相似度越高.
对于未配对数据集Test-U60、Test-UC和Test-UI, 采用如下无参考评价指标:UIQM(Universal Image Quality Metric)、UCIQE、BRISQUE、PIQE(Per-ception Based Image Quality Evaluator)、图像熵(Entropy)、水下图像质量指数(U).
UIQM和UCIQE值越高, 表明图像的质量越优, 然而, 这两项指标未充分考虑颜色偏差和伪影的影响.因此, 进一步引入BRISQUE、PIQE、Entropy、U, 进行更全面的评估.BRISQUE判断图像是否存在失真, PIQE更关注对比度、锐度和色彩亮度, Entropy估计图像细节变化的程度, U值越低表明图像质量越优.
在PyTorch框架上执行SCPANet.在训练过程中, 权重通过Kaiming方法进行初始化.共计200个训练周期, 使用Adam(Adaptive Moment Estimation)优化器, 其中β 1=0.9, β 2=0.999, 学习率设为0.000 2.经过100个训练周期之后, 初始学习率线性衰减至0.训练图像分辨率调整为256× 256, 并采用随机翻转和裁剪的方式进行数据增强.
所有对比实验均基于NVIDIA RTX 3090显卡、2.89 GHz Intel Xeon处理器.
3.3.1 对比方法
本文选择如下8种水下图像增强方法作为对比方法.
1)传统方法.无物理模型的方法ACDC[6]、基于物理模型的方法ULAP[14].
2)基于深度学习的方法.基于CNN的方法Uco-lor[30]、基于半监督对比学习的方法Semi-UIR[18]、基于Transformer的增强方法Spectroformer[17]和CCMSR-Net(Deep Color-Corrected Multiscale Retinex Net-work)[31]、基于像素域注意力模块的方法WPF-Net(Wavelet-Pixel Domain Progressive Fusion Network)[32]、基于扩散模型的方法WF-Diff[9].其中, Semi-UIR为半监督方法, 本文将训练集一半设置为有标签、一半设置为无标签进行训练.需要强调的是, 为了客观公正地对比方法性能, 所有深度学习方法均在同一个数据集上进行训练与测试.
3.3.2 配对数据集实验结果
各对比方法在Test-U90数据集上的视觉效果对比如图3所示.测试图像选自两种场景:浅水场景和低光场景.由图可见, 两种传统方法ACDC和ULAP结果不尽如人意, 如ACDC整体泛灰白, 而ULAP整体呈现红色偏色.Ucolor和WPFNet的输出偏暗, 而Semi-UIR在改善低对比度和模糊细节方面效果不佳.由于扩散模型向退化图像注入高斯噪声时, 可能引入不可控的随机扰动, 所以, WF-Diff出现噪声和雾化现象, 特别是在低光场景下噪声和雾化现象更明显.在浅水场景中, Spectroformer在对比度增强方面的表现有待提高.SCPANet调整粗粒度特征和细粒度特征之间的竞争, 增强图像的局部细节和全局信息, 产生较令人满意的效果.
 | 图3 各方法在Test-U90数据集上视觉效果对比Fig.3 Visual comparison of different methods on Test-U90 dataset |
各方法在Test-E515数据集上的视觉效果对比如图4所示.由图可观察到, 传统方法ACDC和ULAP因依赖固定算法或物理模型, 难以适应水下复杂环境, 无法有效纠正颜色偏差和恢复细节.而Ucolor、Semi-UIR等深度学习方法因未充分针对水下图像退化特征进行优化或在设计网络结构时未平衡粗/细粒度特征, 导致增强图像仍存在颜色偏差.CCMSR-Net颜色补充不稳定, 源于网络结构或训练策略的不足.相比之下, SCPANet通过双路径竞争的感知注意力机制, 可同时捕捉粗粒度特征和细粒度特征, 实现多尺度特征感知.此外, SCPANet还整合特征主导模块和卷积门控线性单元, 增强方法的表达能力和鲁棒性, 可在颜色偏差严重的水下环境中实现稳健的颜色校正, 而且不引入不必要的色彩偏差.
 | 图4 各方法在Test-E515数据集上视觉对比Fig.4 Visual comparison of different methods on Test-E515 dataset |
各方法在Test-U90、Test-E515数据集上的指标值结果如表2和表3所示, 表中黑体数字表示最优值, 斜体数字表示次优值.在3个全参考评价指标(MSE、PSNR、SSIM)上, ULAP和ACDC指标值较低.这是因为基于物理模型的方法依赖一个精确的先验模型, 而这是极其难以获得的.同样, 基于无物理模型的方法的颜色校正技术只考虑颜色的补偿、对比度的提升, 未考虑水下图像的多样性及水下真实场景的复杂性.基于深度学习方法的全参考指标值也相对较低.SCPANet在Test-U90、Test-E515数据集上表现突出.总之, SCPANet具有较好的学习能力, 这得益于设计的感知注意力, 能提升图像细粒度特征和粗粒度特征.
| 表2 各方法在Test-U90数据集上的指标值对比 Table 2 Metric value comparison of methods on Test-U90 dataset |
| 表3 各方法在Test-515数据集上的指标值对比 Table 3 Metric value comparison of methods on Test-515 dataset |
此外, 从6个非参考评价指标(UIQM、UCIQE、BRISQUE、PIQE、Entropy、U)上可看出, 传统方法ACDC和ULAP的某些指标排名较靠前.这是因为传统方法在增强图像时会具体关注某些特性如对比度、亮度、颜色鲜艳程度等, 这就导致其某几个定量结果可能偏高, 但这种结果显然不为人们接受.人们追求的是增强后图像的整体质量, 而非某一种特性.相反, 基于深度学习的方法则更注重图像的整体质量和视觉观感.SCPANet对应的非参考指标在基于深度学习的方法中较优, 进一步验证SCPANet的优越性.
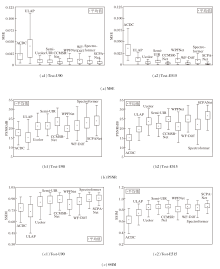
图5通过箱线图展示各方法在Test-U90、Test-E515数据集上的全参考指标分布.为了便于观察, 部分离群值已被剔除.
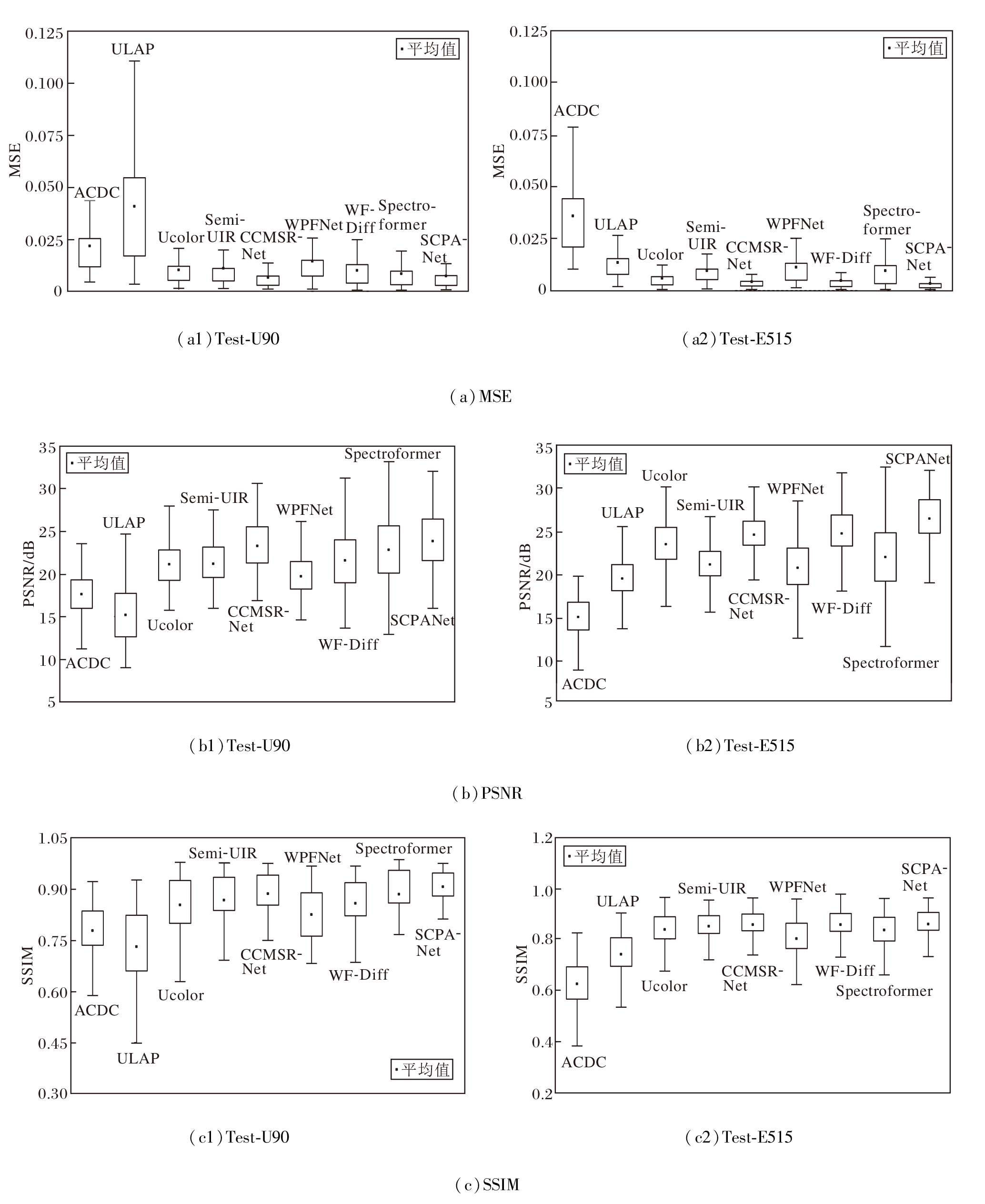 | 图5 各方法在2个数据集上的全参考指标分布Fig.5 Full-reference metrics distribution of different methods on 2 datasets |
由图5可观察到, SCPANet在MSE的数据波动、PSNR均值、SSIM均值、最小值及数据波动方面均具有明显优势.
3.3.3 未配对数据集实验结果
各方法在未配对的Test-U60数据集上的视觉效果对比如图6所示. Test-U60数据集上图像存在严重的后向散射和色彩失真.在增强这些具有挑战性的水下图像时, 大多数方法都表现不足.
 | 图6 各方法在Test-U60数据集上的视觉效果对比Fig.6 Visual comparison of different methods on Test-U60 dataset |
ULAP引入色彩偏差.ACDC整体偏白, 对比度较低.WPFNet对背景的恢复有待加强.Semi-UIR倾向于引入额外的颜色.CCMSR-Net对鱼类图像主体的颜色恢复不佳.WF-Diff增强后的图像不够清晰.
同时, 几乎所有对比方法在第2幅测试图像的黄色场景上都没有明显的改善效果, 增强后的图像仍存在明显的色彩偏差和细节模糊, 但SCPANet具有明显优势, 取得较令人满意的增强图像.
各方法在Test-UC、 Test-UI数据集上的视觉效果对比如图7和图8所示.由图可见, ACDC和UL-AP在增强图像的同时引入额外的颜色.Semi-UIR呈现出偏淡黄, 增强效果不理想.Ucolor对整体的颜色校正不够充分.WF-Diff整体偏暗, 亮度较低.WPFNet整体的对比度一般.CCMSR-Net消除绿色色调效果不佳.Spectroformer整体具有略微的曝光和水体绿色调残留.
 | 图7 各方法在Test-UC数据集上的视觉效果对比Fig.7 Visual comparison of different methods on Test-UC dataset |
 | 图8 各方法在Test-UI数据集上的视觉效果对比Fig.8 Visual comparison of different methods on Test-UI dataset |
相比之下, SCPANet由于引入有效的语义特征和感知注意力模块, 不论是对颜色的校正还是纹理边缘等细节的表达都更充分, 从而获得更优效果.
各方法在Test-U60、Test-UI、Test-UC数据集上的指标值如表4~表6所示, 表中黑体数字表示最优值, 斜体数字表示次优值.由表可见, 传统方法ACDC和ULAP同样会出现某几个指标排名较前, 但大部分指标偏低的情况.在基于深度学习的方法中, SCPANet在绝大多数指标上都获得最优值或次优值, 在UCIQE、Entropy、U非参考指标上表现较突出, 大部分均达到最优, 并且在UIQM指标上具有大幅提升、在U指标上具有大幅下降.同时, SCPANet对应的BRISQUE指标值也较优, 这说明该模型具有较低的失真率.
| 表4 各方法在Test-U60数据集上的指标值对比 Table 4 Metric value comparison of different methods on Test-U60 dataset |
| 表5 各方法在Test-UI数据集上的指标值对比 Table 5 Metric value comparison of different methods on Test-UI dataset |
| 表6 各方法在Test-UC数据集上的指标值对比 Table 6 Metric value comparison of different methods on Test-UC dataset |
综上所述, 各指标值的优越性也验证SCPANet拥有良好的泛化性和鲁棒性.值得注意的是, 基于深度学习的Semi-UIR对应的PIQE指标大幅领先其它方法.这是因为Semi-UIR使用可靠图像库提升增强图像视觉质量, 而这种可靠图像库是由非参考指标驱动的, 所以其在某些非参考指标上的性能特别突出.
3.3.4 复杂度分析
各方法的复杂度如表7所示.由表可见, 传统方法的表现普遍较差.在基于深度学习的方法中, Ucolor、WF-Diff、Semi-UIR的性能相对较弱.SCPA-Net在实时处理方面具有显著优势, 在耗时与图像增强性能之间实现更优平衡.
| 表7 各方法的复杂度和性能对比 Table 7 Complexity and performance comparison among different methods |
此外, 表7进一步展示用于对比的基于深度学习的SOTA方法的参数量、FLOPs、PSNR指标之间的关联性.SCPANet凭借计算开销较低、运行效率较高、工作流程精简等特性, 可为众多实际应用场景带来显著效益.
为了证实SCPANet中各核心组件的有效性, 在Test-U90、Test-E515数据集上进行消融实验, 具体结果如图9和表8所示.此处, 采用预训练的ResNet-18对消融实验图像进行特征提取, 并对该模型中间层(layer1)的前9个特征图进行可视化.由图、表可得如下结论.
 | 图9 消融实验的视觉效果对比Fig.9 Visual comparison of ablation experiment |
| 表8 消融实验的指标值对比 Table 8 Metric value comparison of ablation experiment |
1)当w/o SCM时, 方法表达边缘和纹理细节等的能力会受到影响, 同时颜色恢复也受到波及.特别地, 可观察到图像容易出现不一致和不均匀的纹理结构, 如测试图像的蓝色框内放大的纹理细节不够突出.同时, 在提取的第7幅特征图中, 纹理特征的表达甚至低于原始图像.
2)当w/o FDM时, 方法表现出语义信息的过度引入, 从而抑制原有的特征.由图可明显看出颜色色调的变化和不一致的结构信息.同时, 相比GT, 在提取的第5幅特征图中, 出现过增强.
3)当w/o PAM时, 即在无感知注意力时, 图像粗粒度特征和细粒度特征的提取明显不足.由图可明显看出, 相比SCPANet, 图像的颜色及细节增强不足.同时, 如表8所示, 消除PAM时, 定量指标值大幅下降.
4)当w/o CGLU.CGLU主要用于解决过度粗粒度的影响而导致的局部颜色和细节丢失等问题.如图中蓝色框所示, 消去CGLU时会造成局部区域的偏色和边界模糊.同时, 在提取的第1幅、第5幅、第6幅特征图中, 明显可看出局部细节的差异.
5)SCPANet集成上述核心组件, 其色彩校正、细节恢复等效果更自然、更接近参考图像.表8也显示其指标值可达到最优.
水下图像增强技术通常用于减轻复杂恶劣水下环境对光学图像的影响, 确保自主水下航行器(AUVs)能高效执行下游视觉相关工程任务.为此, 本文选取2种代表性的下游任务(目标检测和显著性目标检测), 6种代表性的水下图像增强方法(ACDC[4]、WF-Diff[9]、ULAP[14]、Semi-UIR[18]、CCMSR-Net[31]、SCPANet), 用于测试增强后的水下图像对提升水下视觉任务性能的实质性效果.
在显著性目标检测方面, 在USOD基准数据集[33]上进行测试.E-measure和S-measure两项显著性目标检测指标上的评估结果如图10(a)所示.由图可见, SCPANet的指标值最优.由图11的显著性目标检测结果可看出, SCPANet生成的显著图比其它方法具有更完整的结构特征和更精确的边界划分.
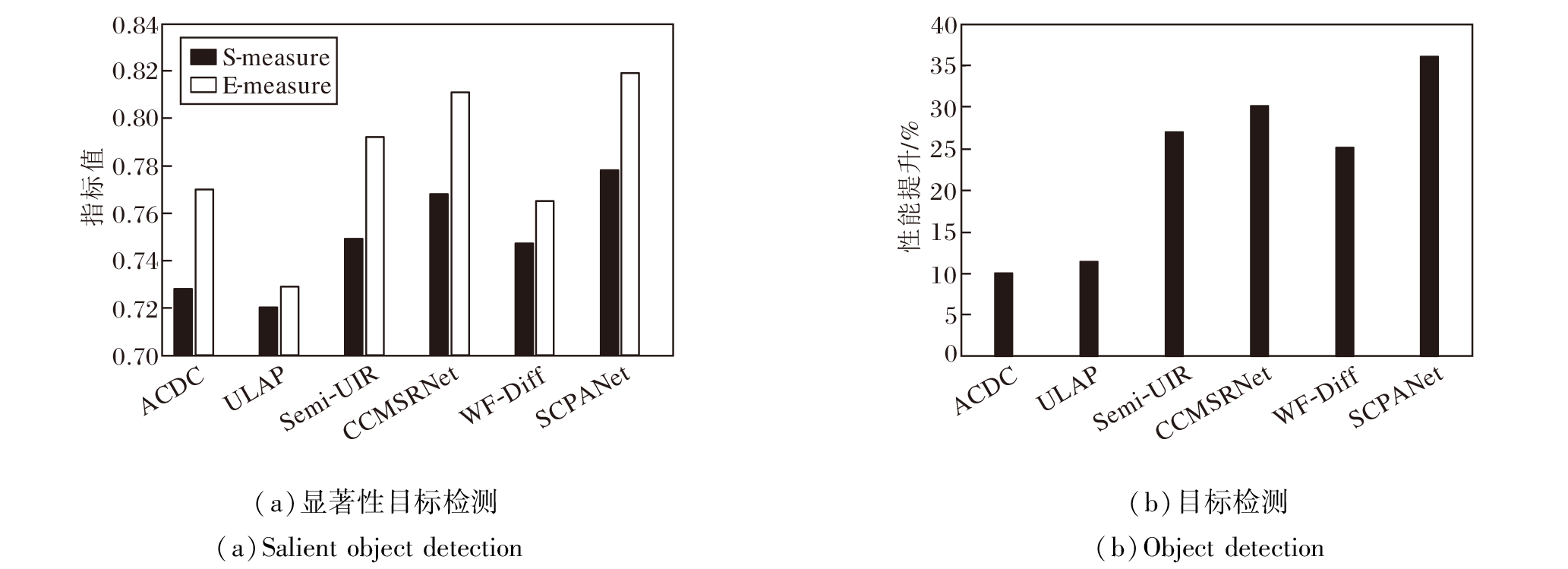 | 图10 各方法的显著性目标检测和目标检测结果对比Fig.10 Result comparison of salient object detection and object detection using different methods |
 | 图11 各方法的显著性目标检测结果Fig.11 Salient object detection results of different methods |
在目标检测任务中, 在基于水下目标检测数据集URPC[34]上对YOLOv5[35]进行训练.URPC数据集共有5 534幅图像, 包括海星、海胆、扇贝、海参这4类目标.由图12的水下目标检测结果可看出, 对于经由SCPANet增强后的图像能检测更多的目标.在图中, 1表示扇贝, 2表示海胆, 3表示海参, 4表示海星.由于测试图像中不存在海参目标, 因此图中未检测并标记海参.图10(b)的目标检测结果表明, 相比原始图像, SCPANet实现36.15%的性能提升, 凸显SCPANet对提升水下目标检测性能的显著优势.
 | 图12 各方法的水下目标检测结果Fig.12 Underwater object detection results of different methods |
本文提出基于语义协同感知注意力的水下图像增强网络(SCPANet).设计基于双路径竞争的感知注意力模块(PAM), 实现对粗粒度特征和细粒度特征的同时捕获.构建特征主导模块(FDM), 实现语义特征的嵌入与协同, 增强方法的表达能力.引入卷积门控线性单元(CGLU), 实现通道混合器的注意力化, 提升方法的鲁棒性及泛化性.实验表明, SC- PANet在公开数据集上的性能较优, 增强效果对下游视觉工程任务具有显著提升作用.今后将探索新型轻量化注意力机制, 降低计算开销并突破Trans- former在高分辨率水下图像处理中的分辨率限制.
本文责任编委 杨健
Recommended by Associate Editor YANG Jian
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|