





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于大语言模型双向协同的跨模态交互式图像编辑方法
[石慧1  , 金聪慧
, 金聪慧1 ]
, 金聪慧]
|
|



作者简介:
金聪慧,硕士研究生, 主要研究方向为人工智能安全、机器学习、图像处理.E-mail:1653527543@qq.com.
扩散模型在图像生成任务中表现出较高的视觉保真度,但在图像编辑方面仍面临用户意图理解偏差、局部细节控制不足、交互响应滞后等的问题.为此,文中提出基于大语言模型双向协同的跨模态交互式图像编辑方法(Cross-Modal Interactive Image Editing Method Based on Bidirectional Collaboration between Large Language Models and User Interaction, BiC-LLM),其核心是一种双向协同控制机制,将大语言模型自顶向下的高级语义引导与用户直接参与的自底向上底层视觉控制有机融合,通过语义增强、特征解耦与动态反馈机制提升图像编辑的可控性与精度.首先,设计层次化语义驱动模块,使用大语言模型对用户输入文本进行语义解耦与推理,生成细粒度语义向量,精准理解用户意图.然后,构建视觉-结构解耦的动态控制模块,结合多层视觉特征提取器与对象级建模,实现图像全局结构与局部风格的独立控制.最后,引入实时交互机制,支持掩膜标注与参数调节,实现图像编辑过程的动态优化.在LSUN、CelebA-HQ、COCO数据集上的实验表明,BiC-LLM在文本一致性、结构稳定性与交互控制方面均较优,能实现复杂场景下的多对象语义编辑,并保持非编辑区域的内容一致性,由此验证其在图像编辑任务中的有效性与鲁棒性.
About Author:
JIN Conghui, Master student. Her research interests include AI security, machine lear-ning, and image processing.
Diffusion models exhibit high visual fidelity in image generation tasks. However, they are confronted with critical challenges in image editing, such as ambiguity in user intent interpretation, insufficient control over local details, and lag in interactive response. To address these issues, a cross-modal interactive image editing method based on bidirectional collaboration with large language models(BiC-LLM) is proposed. A bidirectional collaboration mechanism is introduced as its core. The top-down semantic guidance from large language models is combined synergistically with bottom-up direct interaction from users. Therefore, controllability and precision in image editing are fundamentally enhanced by employing semantic enhancement, feature decoupling and a dynamic feedback mechanism. First, a hierarchical semantic-driven module is designed. The user-input text is decoupled and reasoned by the large language model, and fine-grained semantic vectors are generated to interpret user intent precisely. Second, a dynamic control module for vision-structure decoupling is constructed. Multi-level visual feature extractors and object-level modeling are combined to achieve independent control over global structure and local appearance. Finally, a real-time interaction mechanism is introduced to enable users to dynamically intervene in the editing process through mask annotations and parameter adjustments, thereby supporting iterative optimization. Experiments on LSUN, CelebA-HQ, and COCO datasets demonstrate that BiC-LLM significantly outperforms baseline models in terms of textual consistency, structural stability, and interactive controllability. Moreover, BiC-LLM effectively enables multi-object semantic editing in complex scenes while preserving the integrity of unedited regions, demonstrating its robustness and effectiveness in image editing tasks.
自Sohl-Dickstein等[1]首次提出扩散模型后, 基于该范式的图像生成方法已在艺术创作、虚拟场景构建等领域展示出卓越潜力.例如, 在此背景下, 黄金杰等[2]提出基于双重优化稳定扩散模型的文本生成图像方法(Text-to-Image Generation via Dual Optimization Stable Diffusion Model, DualOpt-SD), 通过融合结构与文本生成模型并设计双重优化策略, 有效提升多目标文本提示下图像的构图准确性与语义一致性.同时, 扩散模型强大的生成能力也为图像编辑这一重要下游任务提供广阔的应用前景.
然而, 现有方法在复杂场景的细粒度控制与用户意图的精准映射方面仍面临挑战.一个核心问题在于, 对特定区域的局部调整常因模型内部语义理解的偏差而导致全局结构失真或细节缺失.此外, 现有图像生成与编辑过程往往彼此独立, 由于缺乏统一的交互机制, 难以高效实现从生成到编辑的连续操作, 导致用户需在多环节间频繁切换, 整体效率较低.为此, 通过用户指令动态调整内容的交互式图像编辑已成为学术界与工业界的共同焦点之一.
尽管近年来基于扩散模型的文本驱动编辑取得显著进展, 但仍普遍面临用户意图理解偏差、局部特征兼容性较差、交互响应延迟等瓶颈.例如:在处理“ 添加物体” 这类特定任务时, 一些方法编辑区域边界融合不自然、目标元素轮廓模糊, 常导致非目标区域出现色彩异常或纹理错乱.此类问题并非源自模型对参考图像的“ 误记” , 而是由于自然语言描述涉及语义空间的内在不连续性, 以及布局结构与风格外观在模型内部的强耦合特性共同所致.
针对上述问题, 本文提出基于大语言模型双向协同的跨模态交互式图像编辑方法(Cross-Modal Interactive Image Editing Based on Bidirectional Colla- boration with Large Language Models, BiC-LLM).首先, 设计层次化语义驱动模块, 通过大语言模型(Large Language Model, LLM)对用户指令进行语义解耦与逻辑推理, 生成细粒度编辑引导信号.然后, 构建基于视觉-结构解耦的动态控制模块, 将全局结构与局部风格特征分离优化, 并引入自适应注意力机制, 实现多模态特征对齐.最后, 设计跨模态指令流处理模块, 高效融合用户的掩膜标注、参数调节等多模态指令, 通过实时反馈接口实现对生成过程的动态干预.实验表明, BiC-LLM在编辑精度、文本一致性、结构稳定性与交互控制方面均较优.
自Meng等[3]提出SDEdit(Stochastic Differential Editing), 首次验证扩散模型不仅可用于从噪声中生成图像, 还可作为受引导的图像编辑工具以来, 该领域涌现出多种方法.以InstructPix2Pix[4]和Prompt-to-Prompt[5]为代表的文本引导方法, 与以Paint by Example[6]和基于自编码器生成对抗网络的可配置文本图像编辑模型[7]为代表的图像引导方法, 共同构成主流的编辑范式.然而, 这些方法在编辑精度与控制的灵活性上普遍面临挑战:文本指令的内在模糊性常导致细粒度控制失效, 而图像引导则受限于参考样本, 难以泛化至复杂的跨语义任务.
为了实现对特定对象的高保真定制, 出现Dream-Booth[8]和Custom Diffusion[9]为代表的个性化方法.这类方法虽能精确还原个体属性, 但其高昂的模型微调成本和漫长的处理流程, 难以满足实时交互的需求, 在效率和泛化性上存在明显劣势.
为了克服上述缺陷, 夏垚铮等[10]提出基于语义分离和特征融合的人脸编辑方法, 但其应用场景多局限于面部等特定领域.同时, 尽管AttnGAN(Atten-tional Generative Adversarial Network)[11]、SSA-GAN(Semantic-Spatial Aware Generative Adversarial Net-work)[12]等致力于提升图文语义对齐, 但仍未从根本上解决在复杂场景下生成细节失真和局部语义控制能力有限的问题.
近期, 为了提升交互体验, DragDiffusion[13]通过点操作提升编辑自由度, 但面临响应延迟问题.SwiftEdit[14]、FluxSpace[15]等则显著提升编辑效率和属性调控能力, 而MagicQuill[16]更是引入多模态语言模型以自动推理用户意图.尽管上述工作在交互性上取得显著进展, 但更多是优化“ 操作层” , 并未从根本上解决前述的语义理解精度与个性化定制成本之间的核心矛盾.
对象层级的控制旨在对场景中多目标的姿态、位置等进行精细管理.ControlNet[17]和T2I-Adap-ter[18]等引入空间先验, 大幅增强生成图像的结构可控性.然而, 这类方法的核心局限在于缺乏对对象身份一致性的建模, 在多轮或复杂编辑中, 同一对象容易产生外观漂移或细节失真.
针对身份保持问题, RePaint[19]、MaskGIT(Masked Generative Image Transformer)[20]等修复方法虽能填充语义, 但未考虑身份一致性.为此, AnyDoor[21]实现对象级别的定向迁移, 能在保持身份的同时将其融入新背景, 但其瓶颈在于控制模态单一(仅支持图像和位置)且机制较初级(类似“ 记忆-粘贴” 而非深度理解), 导致融合边界不自然, 也无法响应更灵活的文本指令.
为了进一步提升结构感知与身份保持的协同效果, 学者们开始试图融合中高层语义.Edit-A-Video[22]、REEDIT[23]及InstaManip[24]等在增强身份特征保持方面做出有益尝试.尽管这些前沿方法在语义控制、多模态对齐等方面取得显著进展, 但仍普遍受限于边界漂移、对精确掩膜的依赖、对模糊指令的错误解析等问题, 距离鲁棒、高效的自动化编辑仍有差距.
现有方法虽然在语义控制、多模态对齐与风格泛化等方面取得显著进展, 但仍普遍存在边界漂移、掩膜依赖、Prompt歧义与个性化表达受限等问题, 这些局限源于不同技术路线的内在缺陷.传统文本引导方法, 如InstructPix2Pix[4]与Prompt-to-Prompt[5], 在处理复杂场景与细粒度操作时容易受限于语言表达的歧义性, 而ControlNet[17]等结构控制方法, 虽能引入空间先验, 却缺乏对对象身份特征的一致性建模, 难以支持多轮个性化编辑.个性化定制方法, 如DreamBooth[8], 则依赖模型微调或需多张样本, 限制其在交互效率与泛化能力上的适用性.
近年来, DDPM(Denoising Diffusion Probabilistic Models)[25]在图像生成领域取得突破性进展.该模型通过模拟噪声注入与逆向重建的迭代过程, 逐步将符合标准高斯分布的噪声样本转化为目标数据分布.其核心流程可分为两个阶段:正向噪声注入阶段和逆向重建阶段.正向噪声注入阶段通过马尔可夫链逐步向原始数据X0添加高斯噪声, 使经过T次迭代后的状态Xt趋近于各向同性高斯分布.该过程可形式化定义为
$q({{X}_{t}}|{{X}_{t}}_{-1})=N({{X}_{t}}; \sqrt[]{1-{{\beta }_{t}}}{{X}_{t}}_{-1}, {{\beta }_{t}}I)$,
其中, β t∈ (0, 1)表示预设噪声调度系数, 控制每一步的噪声强度.
根据马尔可夫性质, Xt可直接由初始状态X0通过闭式解计算, 即
${{X}_{t}}=\sqrt[]{{{{\bar{\alpha }}}_{t}}}{{X}_{0}}+\sqrt[]{1-{{{\bar{\alpha }}}_{t}}} \epsilon$,
$\epsilon \sim N(0, I)$,
${{\bar{\alpha }}_{t}}=\overset{t}{\mathop{\underset{s=1}{\mathop \prod }\, }}\, \left( 1--{{\beta }_{s}} \right)$.
逆向重建阶段以训练噪声预测网络${{\epsilon }_{\theta }}$估计当前步的噪声分量, 通过迭代去噪逐步恢复数据分布:
${{p}_{\theta }}({{X}_{t}}_{-1}|{{X}_{t}})$,
其中均值函数μ θ 由噪声预测结果推导得到, 即
${{\mu }_{\theta }}({{X}_{t}}, t)=\frac{1}{\sqrt[]{{{\alpha }_{t}}}}\left( {{X}_{t}}-\frac{{{\beta }_{t}}}{\sqrt[]{1-{{{\bar{\alpha }}}_{t}}}}{{\epsilon }_{\theta }}({{X}_{t}}) \right)$.
然而, 传统DDPM直接在像素空间操作, 生成高分辨率图像时面临计算复杂度较高、内存占用较大等问题.因此, LDMs(Latent Diffusion Models)[26]引入潜在空间压缩机制, 首先, 利用预训练变分自编码器(Variational Autoencoder, VAE)将高分辨率图像映射至低维潜空间Z∈ Rh× w× d, 其中, 潜空间特征图的高度和宽度分别为
h=H/f, w=W/f,
H、W表示原始图像的高度和宽度, f表示VAE编码器设定的下采样因子.然后, 在潜在空间内执行扩散过程, 将计算复杂度从像素空间的O(T· L· 262K· C2), 大幅降至O(T· L· 4K· C2).最后, 通过解码器将潜变量重建为像素空间图像.
大语言模型(LLM)通过海量语料训练实现对语言概率分布的建模, 具备文本理解、生成及逻辑推理等核心能力.以Transformer架构[27]为核心构建的预训练模型推动自然语言处理技术的发展, 其编码器在语义解析任务中通过双向上下文建模实现深层语义表征, 而解码器架构凭借自回归生成机制适配文本生成场景.这种性能优势源于Transformer特有的自注意力机制, 其通过动态权重分配捕捉长距离语义依赖, 有效提升语言表征的建模效率.
近年的开源大规模语言模型, 如Improving Generalization in Semantic Parsing by Increasing Na-tural Language Variation[28], 采用统一生成范式将语义解析与风格迁移功能结合, 通过自注意力机制对文本语义进行动态重构, 显著提升生成内容的准确性与一致性.其过程可描述如下:
$Attention(Q, K, V)=softmax\left( \frac{Q{{K}^{t}}}{\sqrt[]{{{d}_{k}}}} \right)V$,
其中, Q表示查询矩阵、K表示键矩阵、V表示值矩阵, dk表示键向量的维度.
在层次化语义驱动领域, LLM展现出强大的竞争力, 通过多模态语言模型的语义解析, 可将用户输入的模糊文本提示转化为结构化语义指令.利用生成式模型的上下文推理, 对文本中的关键实体及属性关系进行逻辑补全与细节扩展.深度语义理解能力可精准捕捉文本核心信息, 支持细粒度的实体关系抽取.提示工程(Prompt Engineering, PE)能有效激活模型的任务迁移能力, 降低对标注数据的依赖.预训练阶段吸收的海量知识库赋予模型零样本学习能力, 能直接处理未见的层次化语义驱动任务.训练过程中接触的噪声数据增强模型的鲁棒性, 可自动修正输入文本中的语义冲突或冗余噪声.
本文重点探索如何利用上述特性实现文本去噪, 通过语义摘要与结构化信息抽取构建鲁棒的信息处理方法, 为生成模型提供高精度的结构指导信号, 最终提升多模态内容生成的质量与可控性.
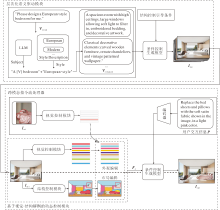
图1给出基于大语言模型的层次化语义驱动样例.
 | 图1 基于大语言模型的层次化语义驱动样例Fig.1 Hierarchical semantic-driven sample based on LLM |
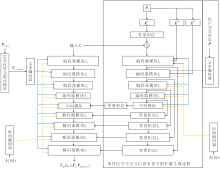
本文提出基于大语言模型双向协同的跨模态交互式图像编辑方法(BiC-LLM), 架构如图2所示.在层次化语义驱动模块中, 通过LLM对用户指令进行隐含语义解析与逻辑推理, 生成细节增强的语义向量, 解决语义稀疏性问题.为了避免特征耦合引发的结构失真问题, 设计基于视觉-结构解耦的动态控制模块, 分离全局结构与局部外观特征.针对动态交互响应滞后问题, 设计跨模态指令流处理器, 通过指令映射函数整合用户标注的掩膜与交互参数, 并借助扩散模型的交叉注意力机制, 实现对目标区域编辑的秒级响应优化.此外, 为了增强编辑区域的结构一致性, 在生成阶段引入结构控制引导条件, 通过显式空间结构约束与语义提示协同调控生成过程.同时编辑阶段与生成阶段分别引入条件控制生成模块, 融合多模态引导信息, 并统一注入扩散模型的多层特征空间中, 从而实现语义一致、结构可控的图像合成.
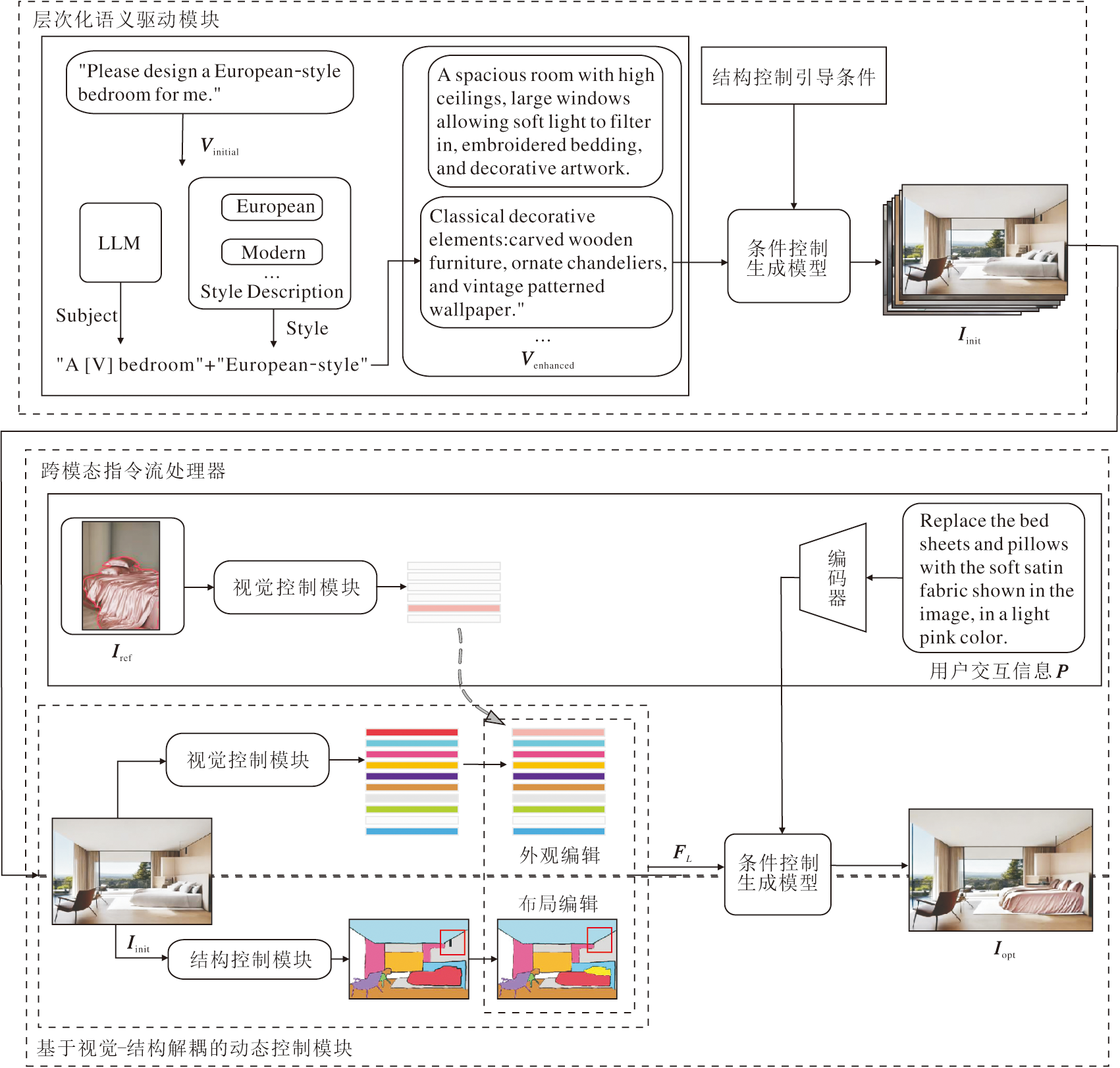 | 图2 BiC-LLM流程图Fig.2 Framework of BiC-LLM |
BiC-LLM核心在于构建一套双向协同的跨模态控制机制, 旨在解决传统编辑方法中用户意图理解不准和精细化交互控制不足的问题.双向协同是指两种不同性质但相辅相成的控制通路的协同作用:1)由LLM实现的自顶向下的高级语义引导通路, 2)由用户直接参与的自底向上的底层交互控制通路.这两个通路共同作用于扩散模型, 实现图像编辑过程在语义和物理层面的双重控制, 提升编辑的精度与灵活性.
在自顶向下的语义引导通路中, 首先利用LLM强大的语义理解与逻辑推理能力, 对用户输入的较模糊的初始自然语言指令进行深度解析、增强与解耦.LLM能将高级的编辑意图转化为一系列精细化、结构化的视觉引导信号, 如具体对象的风格描述、空间结构约束等.这些信号为后续扩散模型提供精准且丰富的全局语义上下文, 从而实现从高级语言意图到具体视觉呈现的有效映射.
同时, BiC-LLM通过自底向上的交互控制通路赋予用户直接干预生成过程的能力.与仅依赖文本的单向模型不同, BiC-LLM支持用户在观察到生成结果后, 通过更直接的视觉交互方式(如手动调整编辑区域的掩膜)或参数化调节(如调整编辑强度系数)提供修正意见.这些不经过LLM的底层控制信号, 能对图像的局部空间属性和编辑强度进行像素级的精准调控, 弥补纯语言引导在精细化操作上的不足.
BiC-LLM的创新性在于它能将来自LLM的高级语义引导与来自用户的底层交互控制这两种异构信息进行有效融合, 共同指导最终的图像生成, 从而在保证语义一致性的同时, 实现局部细节控制精度.
作为双向协同机制中自顶向下语义引导通路的关键环节, 受DELL-3使用Text-to-Text Transformer[29]的预训练模型生成图像描述性提示构建高质量图像-文本对的启发, 本文提出层次化语义驱动模块, 旨在解决现有方法在复杂场景中面临的用户意图理解偏差、难以准确生成符合要求的图像、生成图像不符合现代审美等问题.
上述问题的主要原因是生成模型对训练数据集的依赖性较高且泛化性较差.如果再重新使用符合现代审美的数据集进行训练, 需要耗费大量的计算资源和时间.
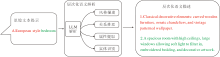
为了解决上述问题, 本文使用LLM作为优化工具, 对用户输入的文本提示进行语义解析与逻辑增强, 以细粒度语义扩展生成高精度结构指导信息, 为生成模型提供更丰富的指令支持.具体模块结构如图3所示.
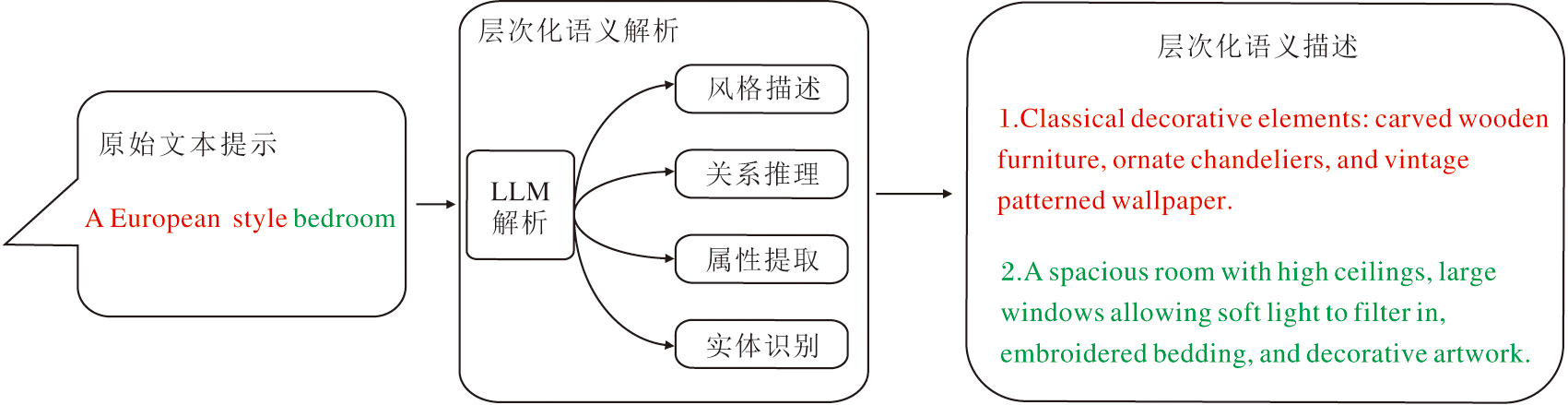 | 图3 层次化语义驱动模块结构图Fig.3 Architecture of hierarchical semantic-driven module |
初始文本提示Vinitial首先经过LLM和风格描述模块, 将复杂文本提示进行语义解析, 解析对应的目标和风格.本文依赖LLM的语言理解和推理能力, 将用户提示Vinitial解析为多个实体及属性的关系, 并识别提示中的关键短语进行层次化分解, 生成更具细节的文本提示Venhanced.具体计算公式如下:
$\{{{v}^{i}}\}_{i=0}^{n}=\{{{v}^{0}}, {{v}^{1}}, \ldots , {{v}^{n}}\}\subseteq {{V}_{\text{initial}}}$,
$\{{{\hat{v}}^{0}}, {{\hat{v}}^{1}}, \ldots , {{\hat{v}}^{n}}\}=Optimization(\{{{v}^{i}}\}_{i=0}^{n}\subseteq V{{e}_{\text{nhanced}}}$
增强后的语义向量Venhanced作为结构生成的指导条件输入扩散模型, 结合线稿图等结构控制信号生成初始图像Iinit.
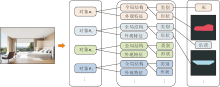
为了实现对图像中各个对象的精细控制, 特别是对全局结构和局部外观两方面进行独立编辑, 本文设计基于视觉-结构解耦的动态控制模块, 将图像视为多个对象的组合O={o1, o2, …, on}, 提取生成图像的全局结构和每个对象的局部外观特征, 并与参考图像特征进行特征融合.图像对象与属性的层次化结构如图4所示.
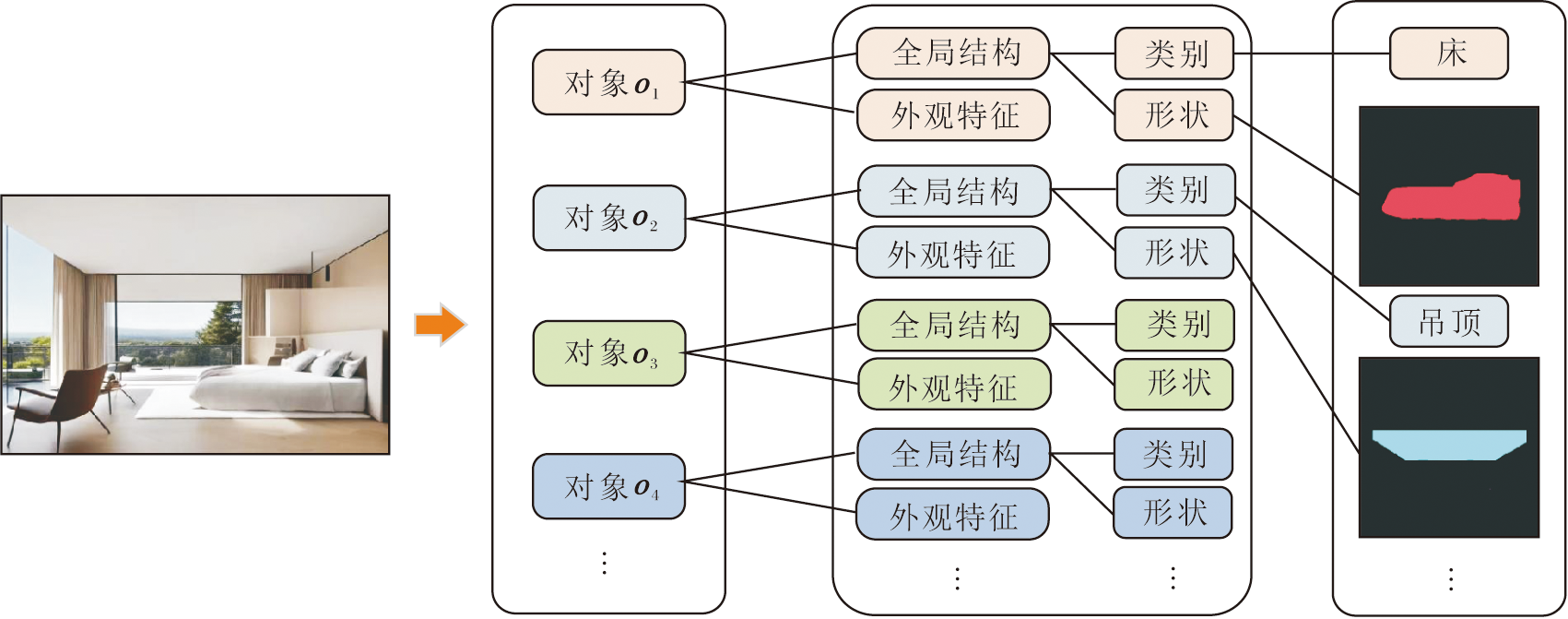 | 图4 图像对象与属性的层次化结构Fig.4 Hierarchical structure of image objects and attributes |
基于视觉-结构解耦的动态控制模块由外观提取模块和结构控制模块构成.结构控制模块通过全景分割网络Es(· )提取图像的分割图L, 外观特征图$\widetilde{X}$通过预训练的VGG(Visual Geometry Group)与DINOv2[30]分层提取, 其中, 使用VGG提取图像的浅层细节特征, 使用DINOv2提取图像的深层语义特征.在进行结构编辑和外观特征编辑时, 将图像结构与外观特征进行通道连接, 形成最终的条件信号.
假定初始图像Iinit, 将它的结构分为类别和特征两部分, 即
Li=(ci, mi),
其中mi∈ {0, 1}H× W, 最终得到
其中,
定义编码器提取特征图:
$\widetilde{X}=E_{X}^{l}({{I}_{init}})\in {{\mathbf{R}}^{C}}^{\times H\times W}$,
其中, l为编码器的第l层, H× W表示空间大小, C表示通道数量, EX(· )可以是DINOv2或VGG.
首先利用对象的形状模版mi进行空间维度的池化, 得到对象i的外观特征向量:
$x_{i}^{l}=\frac{\sum\limits_{j, k}{E_{X}^{l}\left( {{I}_{\text{init}}} \right){{m}_{i}}}}{\sum\limits_{j, k}{{{m}_{i}}}}\in {{\mathbf{R}}^{C}}$.
使用
${{g}_{i}}=(x_{i}^{V{{l}_{1}}}, x_{i}^{D{{l}_{2}}}, x_{i}^{D{{l}_{3}}})$.
在结构和外观特征向量编辑时, 将图像结构L与不同编码器提取的特征组合gi进行通道拼接, 形成最终的条件信号Fs.
为了确保在复杂和非常规场景下的鲁棒性, 基于视觉-结构解耦的动态控制模块在设计中充分考虑自动分割网络可能存在的失效情况.当网络无法准确识别用户意图编辑的对象时, 启动交互式修正机制.
具体而言, 用户可以通过提供的交互界面, 手动绘制或微调编辑区域的掩膜(Mask).该用户手动提供的掩膜将作为更高优先级的引导信号, 覆盖或替代由自动分割网络生成的、不准确的分割结果, 从而在保证编辑精确性的同时, 大幅增强方法的灵活性与实用性.这一交互式修正机制正是双向协同方法中自底向上底层控制通路的核心体现, 赋予用户最终的、像素级的控制权.
为了更充分理解用户意图, 提高方法的灵活性, 受InstructPix2Pix[4]引入双条件分类器的启发, 设计跨模态指令流处理器, 结合用户标注的参考图像与用户的区域调整文本指令, 实现用户直接参与编辑过程.
首先, 用户可通过标注工具自动或手动在待编辑图像中指定待编辑区域以修改待编辑图像的结构及外观特征.根据标注生成二值掩膜矩阵M.对于用户输入的交互图Iref, 一键式提取交互图像的外观特征.用户输入编辑指令后, 需要调节不同条件信号的强度以控制生成图像的编辑效果, 因此, 本文设定条件信号P为用户交互信息(无条件扩散模型中P为Ø ), 而结构条件L和外观风格条件F来自参考图像.由于P与F可能包含互补或冲突的信息, 通过估计数据分布的得分函数(Score Function)在生成过程中协调二者, 条件生成得分的对数可分解为
$\begin{align} & {{\nabla }_{{{z}_{t}}}}\ln p({{z}_{t}}|L, F, P)= \\ & {{\nabla }_{{{z}_{t}}}}\ln p({{z}_{t}}|L, F)+{{\nabla }_{{{z}_{t}}}}\ln p({{z}_{t}}|P)-{{\nabla }_{{{z}_{t}}}}\ln p({{z}_{t}}) \\ \end{align}$.
本文建模的生成概率分布p(· )表示在条件信号P、结构条件L与外观风格条件F给定下图像的条件概率.
为了灵活分配权重, 实现多模态条件的精准协同控制, 引入CFG(Classifier-Free Guidance)技术, 训练时以一定概率随机丢弃条件信号, 使单一模型能统一表示上述得分函数.具体地, 噪声预测模型${{\epsilon }_{\theta }}$的更新规则如下:
$\begin{aligned} & \tilde{\epsilon}_\theta\left(z_t, \boldsymbol{L}, \boldsymbol{F}, \boldsymbol{P}\right)=\epsilon_\theta\left(z_t, \emptyset, \emptyset, \emptyset\right)+ \\ & \left.s_L\left(\epsilon_\theta\left(z_t, \boldsymbol{L}, \emptyset, \emptyset\right)\right)-\epsilon_\theta\left(z_t, \emptyset, \emptyset, \emptyset\right)\right)+ \\ & s_F\left(\epsilon_\theta\left(z_t, \boldsymbol{L}, \boldsymbol{F}, \emptyset\right)-\epsilon_\theta\left(z_t, \boldsymbol{L}, \emptyset, \emptyset\right)\right)+ \\ & s_P\left(\epsilon_\theta\left(z_t, \boldsymbol{L}, \boldsymbol{F}, \boldsymbol{P}\right)-\left(z_t, \boldsymbol{L}, \boldsymbol{F}, \emptyset\right)\right), \end{aligned}$.
其中sL、sF、sP分别表示布局、外观和用户交互信息的引导强度系数, $\emptyset$表示空集.由于外观条件F包含的视觉信息比文本P更丰富, 方法在训练时倾向于忽略P的影响.因此, 在推理阶段需独立调节sP以凸显文本的作用.例如:若需增强文本控制(如风格描述), 可设置sP> sF; 若需优先参考图像外观, 设置sP< sF.
最后, 根据掩膜矩阵M和参考交互图Iref对初始图像Iinit掩膜区域内的像素进行调整优化, 非掩膜区域保持原值, 得到编辑后图像:
Iopt=M☉Iref+(1-M)☉Iinit,
其中, M∈ {0, 1}H× W, H× W表示图像尺寸, 掩膜M(i, j)=1表示该像素位于用户指定的编辑区域内, M(i, j)=0表示该像素位于非编辑区域, ☉表示逐元素相乘.
将最终的条件信号Fs输入扩散模型中, 使用Fs第1层提取的特征
其中:η ∈ (0, 1)表示迭代步长, 体现调整幅度; T(· )表示指令映射函数, 将用户输入的量化参数转换为像素级调整操作; Δ b表示亮度增量, c表示对比度因子, d表示色调调整参数.
至此, 所有用于引导图像编辑的条件信号均已生成, 这些异构的多模态信息将协同注入一个基于U-Net架构的扩散模型骨干网络中, 实现对生成过程的精细化控制.其完整流程如图5所示.
 | 图5 条件信号与交互信息引导下的扩散生成过程Fig.5 Generation guided by conditional signals and interactive information |
在每个去噪时间步t, U-Net接收当前的带噪潜变量zt作为基础输入, 并通过一个精密的双路引导机制预测噪声.为了施加全局级别的结构一致性约束, 从视觉信息中解耦的结构特征Fs经由一个专属的映射网络编码后, 通过零卷积层将其表征直接叠加至输入潜变量zt, 在整体生成过程中构建高层级的空间结构.同时, 全局约束并行处理, 对内容、外观及风格等局部属性的精细化调控则通过另一条路径实现, 增强后的文本语义Venhanced、来自用户的实时交互信息P、经由各自映射模块处理后的对象级布局与外观特征, 共同注入U-Net编码器各层级(l1、l2等)的跨注意力模块中.通过这种全局结构先验与局部多模态引导的协同作用, 方法得以在迭代去噪的过程中, 逐步生成既遵循整体布局又精确体现所有细节指令的最终图像Iopt.
为了更好地实现局部细粒度编辑, 使用语义重构损失函数L1和多模态感知损失函数L2作为BiC-LLM训练的约束, 则总损失函数:
L(Iinit)=α 1L1(Iinit, Iopt)+α 2L2(Iinit, Iopt),
其中, α 1、α 2表示权重系数, 实验中设置α 1=1.0, α 2=1.0.
语义重构损失函数L1计算输入图像与生成图像在各语义区域上的L2范数差异, 量化两者在视觉感知层面的偏差.在具体实现中, 对于源图像中的第i个语义区域mi, 评估其与生成图像对应区域的像素级差异, 并通过面积加权策略平衡不同尺度语义区域的影响.L1具体公式如下
${{L}_{1}}({{I}_{init}}, {{I}_{opt}})=\overset{n}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, {{\alpha }_{i}}\|{{I}_{init}}{{m}_{i}}-{{I}_{opt}}{{m}_{i}}{{\|}_{2}}$.
多模态感知损失函数基于深度学习的LPIPS(Learned Perceptual Image Patch Similarity)[31], 联合对比VGG-19提取的纹理风格特征与DINOv2提取的空间结构特征, 协调生成图像在局部细节保真度与全局语义一致性之间的平衡.L2具体公式如下:
$\begin{align} & {{L}_{2}}({{I}_{\text{init}}}, {{I}_{\text{opt}}})=\underbrace{\frac{1}{n}\overset{n}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, \|V_{\text{VGG}}^{i}\left( {{I}_{\text{init}}} \right)-V_{\text{VGG}}^{i}\left( {{I}_{\text{opt}}} \right){{\|}_{2}}}_{浅层纹理损失(\text{ LPIPS }) }+ \\ & \underbrace{\beta \frac{1}{m}\overset{m}{\mathop{\underset{j=1}{\mathop \sum }\, }}\, \|V_{\text{DINO}}^{j}\left( {{I}_{\text{init}}} \right)-V_{\text{DINO}}^{j}\left( {{I}_{opt}} \right){{\|}_{2}}}_{深层语义损失} \\ \end{align}$
其中, 权重系数β 用于平衡两种感知损失, 实验中设为0.5.
本文选择LSUN[32]、CelebA-HQ[33]、COCO[34]数据集作为基准数据集.LSUN数据集包含卧室和教堂等场景分区, 是图像生成领域的经典基准数据集.该数据集具有清晰的训练集和测试集划分, 能为模型性能评估提供公平可靠的测试数据.CelebA-HQ数据集专注于高质量的人脸图像生成任务, 标准化的数据划分和丰富的属性标注为面部特征编辑提供良好的实验基础.COCO数据集作为多对象场景理解的标杆数据集, 包含丰富的多对象交互场景和多样化的文本描述标注.该数据集上每幅图像都配有5个独立的文本描述, 详细记录场景中的对象类别、空间位置关系及行为特征.这种多模态标注特性使其特别适合验证生成模型在复杂真实场景下的语义理解和编辑能力.
本文基于DDPM[25]与LDMs[26], 结合LLM开展图像生成与编辑实验.模型训练在PyTorch 2.12框架下进行, 采用4张NVIDIA A800 GPU, 测试阶段在1张NVIDIA A100上完成.优化器统一使用AdamW(Adaptive Moment Estimation with Weight Decay), 在两类子模型中设置不同的学习率以适配网络结构复杂度与收敛速度差异.对层次化语义驱动模块设定学习率为3× 10-5, 训练轮数为100.对基于视觉-结构解耦的动态控制模块设定学习率为1× 10-4, 总迭代步数为10 000.两部分训练耗时约为11 h与32 h, 均采用全监督方式优化.
在训练过程中引入多指令流处理器机制, 用于支持语义、结构与外观的解耦式调控.为了提升表达能力, 由全景分割网络提取结构信息, 包括物体类别与掩膜; 外观表示结合低层视觉特征(由VGG提取)与中高层语义特征(由DINOv2提取), 并通过L2正则化与空间映射生成多层向量表示.
此外, 在 LSUN数据集[32]的Bedroom和Church子集、CelebA-HQ[33]、COCO[34]数据集上进行方法训练与评估, 涵盖结构编辑、外观迁移、对象添加、风格转换等任务.
为了全面、系统地验证BiC-LLM的有效性, 定量评估将围绕两个核心通路展开.首先, 评估自顶向下语义引导通路的性能, 即在外观编辑任务中, 模型能否精准理解文本指令并生成高质量、高保真的结果, 由FID(Fré chet Inception Distance)、图像重建精度L1距离衡量.然后, 评估自底向上物理控制通路的性能, 即在结构控制任务中, 模型能否严格遵循结构先验并保持非编辑区域的稳定性, 由平均交并比(Mean Intersection over Union, mIoU)、结构相似性(Structural Similarity Index Measure, SSIM)衡量.这种针对性的评估策略旨在验证模型对上述属性的控制能力, 而非单纯追求指标的最优值.
为了全面衡量图像编辑质量, 选择FID、L1距离和SSIM作为评估指标.
FID主要衡量待编辑的初始生成图像Iinit与编辑后图像Iopt的特征空间分布距离以及衡量编辑图像是否具备整体真实感, 数值越小, 表示生成图像与真实图像的分布越接近.具体计算公式如下:
$FID({{I}_{\text{int}}}, {{I}_{\text{opt}}})={{\left\| {{\gamma }_{\operatorname{int}}}-{{\gamma }_{\text{opt}}} \right\|}^{2}}+tr\left( \sum\nolimits_{\operatorname{int}}{+\sum\nolimits_{\text{opt}}{-2{{\left( \sum\nolimits_{\operatorname{int}}{\sum\nolimits_{\text{opt}}{{}}} \right)}^{\frac{1}{2}}}}} \right)$,
其中, γ 、Σ 分别表示图像在Inception网络中提取特征的均值和协方差矩阵.
L1距离用于衡量编辑是否局限于目标区域, 计算Iinit与Iopt在掩码区域内的像素级绝对差异, 数值越小, 表示生成图像与目标图像越接近.具体计算公式如下:
$L{{1}_{\text{masked}}}({{I}_{\text{int}}}, {{I}_{\text{opt}}})=\frac{1}{\left| M \right|}\underset{i\in M}{\mathop \sum }\, \left| {{I}_{\text{int}}}(i)-{{I}_{\text{opt}}}(i) \right|$.
SSIM从结构信息层面度量图像相似性, 数值越高, 表示生成图像与真实图像的结构相似性越优.具体计算公式如下:
$\operatorname{SSIM}\left(\boldsymbol{I}_{\mathrm{ref}}, \boldsymbol{I}_{\mathrm{opt}}\right)=\frac{\left(2 \mu_{\mathrm{ref}}\ \ \ \mu_{\mathrm{opt}}\ \ \ +C_1\right)\left(2 \sigma_{\mathrm{ref}} \ \ \ \sigma_{\mathrm{opt}}\ \ \ +C_2\right)}{\left(\mu_{\mathrm{ref}}^2\ \ \ +\mu_{\mathrm{opt}}^2\ \ \ +C_1\right)\left(\sigma_{\mathrm{ref}}^2\ \ \ +\sigma_{\mathrm{opt}}^2\ \ \ +C_2\right)},$
其中, μ 、σ 表示图像块的均值与标准差, C1、C2表示常数, 用于提升稳定性.
实验选择如下经典基准方法进行对比:Any- Door[21]、REEDIT[23]、LDM+Inpainting[26]、Copy-Paste[35]、Copy-Paste+Denoise(先进行Copy-Paste, 再使用LDM去噪)[35]、E2EVE(End-to-End Visual Editing)[36]、AnyEdit[37].
所有方法均在LSUN数据集的Bedroom子集上进行训练和评估, 每次实验均保证相同的输入条件, 确保对比实验的公平性.
各方法的指标值对比如表1所示, 表中黑体数字表示最优值.为了保证公平性, 每种方法均在相同遮罩条件与编辑区域设定下开展实验.由表可见, BiC-LLM展现出显著的综合优势.尽管LDM+In-painting的FID指标最优, 但其SSIM值较低, 表明其在保持图像结构一致性方面存在不足.Copy-Paste虽然取得最高SSIM值且L1距离为0, 但其较高的FID值和依赖人工操作的特性限制其实际应用价值.相比之下, BiC-LLM在多个关键指标上取得更好的平衡:SSIM值显著优于LDM+Inpainting、Copy-Paste+Denoise和E2EVE, 表明其生成图像具有更好的结构相似性; L1距离与最优方法Copy-Paste相当, 说明其具备出色的细节还原能力; FID值优于E2EVE, 表现出更优的全局特征匹配性能.
| 表1 各方法在Bedroom子集上的指标值对比 Table 1 Metrics of different methods on Bedroom subdataset |
为了进一步验证BiC-LLM在多样化编辑场景下的稳健性与泛化性, 表1还列举REEDIT、Any-Door和AnyEdit这3种代表性方法的指标值.REEDIT是一种不依赖推理阶段优化的端到端示例驱动图像编辑方法, 强调编辑表达的结构一致性与多模态适配性, 文献[23]中虽未公布FID和L1距离等传统指标值, 但提供SSIM值.REEDIT重点在于验证结构保持效果, 因此可能出于编辑目标更倾向于高层语义保持而未给出图像重建误差方面的度量.AnyDoor聚焦零样本对象级图像定制, 核心能力是实现任意目标对象在新场景中的自然融合, 并支持形状控制、位置指定等操作.由于方法更强调对象插入在空间结构、风格调和等方面的表现, SSIM的度量并非主要评估指标, 因此在实验中未予报告.AnyEdit旨在响应多样化的创造性指令, 常涉及对图像全局结构的显著改变, 因此衡量与原图结构相似性的SSIM指标并非其核心评估维度.相比之下BiC-LLM专注于高保真度的局部编辑, 其关键挑战之一是保持非编辑区域的稳定性, 故SSIM是衡量此项能力的关键指标.
这些方法关注的任务目标与评价维度存在显著差异, 部分未报告指标的缺失并不代表其性能不足, 而是反映其在方法设计与应用需求上的差异性选择.因此, 从整体上看, BiC-LLM在结构保持、细节还原与特征匹配等多个层面取得良好平衡, 具有更强的综合表现与泛用潜力, 尤其适用于实际应用中需要兼顾图像质量与结构一致性的生成场景.
在结构控制任务的评估中, 选择SEAN(Semantic Region-Adaptive Normalization)[38]作为代表性基线方法, 旨在确保对比的公平性和科学性.SEAN是语义布局到图像生成任务中公认的强基线方法, 其任务设置(仅从分割图生成图像)与BiC-LLM的核心功能高度一致, 允许通过mIoU指标进行直接的性能衡量.相比之下, 其它主流编辑方法通常不支持分割图像作为直接输入, 而一些基于扩散的结构控制方法(如ControlNet)则多为文本引导, 引入文本会使任务目标不一致, 难以进行公平对比.
本次实验在CelebA-HQ数据集(包含5 000幅图像)上展开, 以真实结构分割图像作为输入条件, 生成对应图像.为了定量分析结构控制效果, 使用mIoU和SSIM指标, mIoU衡量生成图像结构与参考结构在像素层面的重合度, 是表征结构控制精度的关键指标.
BiC-LLM与SEAN在结构控制方面的对比结果如表2所示.由表可见, BiC-LLM在两项关键指标上均更优.在衡量语义分割准确度的mIoU指标上, BiC-LLM达到0.671, 比SEAN提升4.4%; 在评估图像结构相似性的SSIM指标上, BiC-LLM为0.524, 比SEAN提升63.2%.这两个指标的显著提升充分表明BiC-LLM不仅能更精确理解并保持图像中的语义结构信息, 还能生成在视觉结构上更逼真、自然的图像.这种双重优势使得BiC-LLM在图像结构控制任务中具有更强的实用价值和应用潜力, 为高质量图像生成提供新的技术解决方案.
| 表2 SEAN和BiC-LLM在CelebA-HQ数据集上的结构控制能力对比 Table 2 Comparison of structural control performance between SEAN and BiC-LLM on CelebA-HQ dataset |
本文的定量评估采用差异化的指标体系, 选择遵循针对不同核心任务进行针对性评估的原则.对于外观编辑任务, 侧重通过FID、L1距离和SSIM指标评估其在视觉真实感、编辑保真度与结构保持方面的综合表现.对于结构控制任务, 采用该领域黄金标准mIoU精确度量其对空间结构的遵循能力.这种互补的多维度评估方案能更公正、全面地揭示BiC- LLM在不同能力象限的性能优势.
本节围绕外观控制、对象添加与形状编辑、风格迁移三类典型任务, 设计对比实验, 对比Paint by Example[6]、AnyDoor[21]、BiC-LLM, 进一步分析BiC-LLM在不同场景下的适应能力.
各方法在外观控制任务上的生成图像对比如图6所示.由图可见, BiC-LLM基于跨模态指令流处理器, 可实现输入图像中车辆外观、天空色调及草地纹理等局部区域的准确替换.通过引入基于视觉-结构解耦的动态控制模块, 能精准定位目标区域, 在保留原始结构的同时完成高质量外观迁移.相比之下, AnyDoor在面对复杂对象或多属性场景时, 编辑区域容易出现模糊、混色及语义漂移等问题, 缺乏对目标与背景的有效区分与协调.
 | 图6 各方法在外观控制任务上的生成图像对比Fig.6 Images generated by different methods on appearance control tasks |
各方法在对象添加与形状编辑任务上的生成图像对比如图7所示.由图可见, BiC-LLM预设物体位置与轮廓约束, 在图像中准确嵌入复杂纹理对象, 并在执行形状重构时, 保留原有装饰元素与材质光影, 整体自然融合.在湖泊等大尺寸物体的添加任务中, 编辑区域的边界清晰、过渡自然, 说明其在保持结构稳定性方面表现良好.相比之下, Paint by Example在处理此类任务时出现形变、不符合预期、纹理迁移失败等问题, 难以有效结合语义信息与空间结构实现编辑.
 | 图7 各方法在对象添加与形状编辑任务上的生成图像对比Fig.7 Images generated by different methods on object addition and shape editing tasks |
各方法在风格迁移任务上的生成图像对比如图8所示.由图可见, BiC-LLM引入对象级外观表示与多模态引导机制, 实现在多种背景与结构条件下对复杂纹理风格的精确迁移.在进行卧室场景风格替换时, BiC-LLM不仅能准确提取参考图像中的纹理细节、主色调与光影风格, 还能在保持原始图像结构稳定性的前提下实现高度逼真的风格融合.Paint by Example在风格适配能力与细节对齐一致性方面存在明显不足, AnyDoor在边界区域容易出现纹理错位、风格不连贯等问题.BiC-LLM则展现出更强的适应性与稳定性, 在面对复杂遮挡、光照条件变化及多目标干扰的场景时, 依然生成结构清晰、边缘平滑且风格统一的结果, 从而有效保障编辑区域的局部一致性与整体视觉协调性, 进一步说明其在真实图像风格迁移中的泛化能力与细节复现能力.
 | 图8 各方法在风格迁移任务上的生成图像对比Fig.8 Images generated by different methods on style transfer tasks |
综上所述, BiC-LLM在多类图像编辑任务中均具备稳定的表现, 能同时兼顾编辑区域的语义一致性与结构稳定性, 适应不同类型数据集与编辑目标, 展现出良好的鲁棒性与通用性.
为了系统衡量BiC-LLM在实际应用中的计算效率与资源需求, 对其性能开销进行量化评估.评估分别聚焦于初始生成与交互式编辑两个核心阶段, 并选取功能最接近的基线方法InstructPix2Pix[4]、AnyDoor[21]、REEDIT[23]进行对比分析, 以确保横向对比的科学性与合理性.
在实验配置上, 为了实现与部分仅在NVIDIA A100 GPU上报告性能的SOTA方法进行同台对比, 遵循其官方设定, 在A100环境下对这些方法进行效率评估, 关键对比结果如表3所示, 表中黑体数字表示最优值.
| 表3 各方法的效率与资源占用对比 Table 3 Comparison of efficiency and resource consumption among different methods |
在初始生成阶段, BiC-LLM以稳定扩散模型为生成核心, 辅以由层次化语义驱动模块提供的结构引导指令.在RTX 4090平台下, 语义解析耗时约0.8 s, 图像合成约3.5 s, 总生成时间为4.3 s.该阶段属于一次性计算开销, 为后续的精细化编辑提供高质量的起点.
在关键的交互式编辑阶段, BiC-LLM支持“ 文本+参考图像” 的多模态输入, 任务复杂度显然高于仅支持文本提示的REEDIT和InstructPix2Pix, 或机制相对简单的AnyDoor.这种多模态融合能力是实现精细化、高可控性编辑的基础, 带来的计算开销是合理的.由表3可见, REEDIT耗时最长, 其根本原因在于, 为了保证结构一致性, 该方法采用高达1 000步的DDIM(Denoising Diffusion Implicit Models)反演过程, 这是一个计算成本极高的操作.与之形成鲜明对比的是AnyDoor, 其速度优势源于其“ 复制-粘贴” 式的机制, 但这是以牺牲编辑的灵活性与融合的自然度为代价的, 使其在复杂场景下效果有限.InstructPix2Pix代表另一种技术路径, 作为一个无需反演的端到端模型, 速度虽快于REEDIT, 但生成质量高度依赖足够多的前向扩散步数.若为了追求速度将其步数降至与BiC-LLM相当的20步, 生成质量便会急剧下降.
在资源占用与稳定性方面, BiC-LLM峰值显存占用为23.89 GB. 需要指出的是, 由于REEDIT并未开源, 无法获取其峰值显存数据, 故表3中未进行对比.BiC-LLM产生这一数值, 是因为为了实现高质量的特征解耦与融合, 需在显存中同时维持对输入图像和参考图像的精细化特征表示, 这是为实现优良编辑可控性付出的合理资源成本.更值得强调的是, BiC-LLM在多轮交互式编辑中表现稳定, 每轮编辑的耗时保持一致, 并且能持续输出高质量图像, 避免部分方法在迭代中出现的质量衰减或伪影积累问题.该鲁棒性优势使用户可安心进行多轮精细调整, 这也进一步凸显BiC-LLM灵活的交互性在实际应用场景中的价值.
为了充分验证BiC-LLM中各关键模块在图像生成中的有效性, 设计3组消融实验, 涵盖层次化语义驱动模块、VGG与DINOD特征配置、跨模态指令流处理器.实验旨在分析不同模块对生成图像语义一致性、细节保留性及整体质量的贡献.
在层次化语义驱动模块的消融实验中, 构造不使用语义驱动向量与引入语义层级增强机制的对比实验, 生成图像如图9所示, 其中, (b)表示初始文本提示引导下的生成图像, (c)表示文本提示增强优化后的生成图像.
 | 图9 层次化语义驱动模块对BiC-LLM性能的影响Fig.9 Effect of hierarchical semantic-driven module on BiC-LLM performance |
由图9可见, 添加层次化语义驱动模块后的生成图像在目标边缘、结构一致性及语义完整性方面均有显著改善, 尤其是在多物体场景中, 该模块有效提升文本与图像之间的指令响应度, 使生成内容更符合预期语义表达.此外, 在推理过程中, 层次化语义驱动模块对生成结果的影响尤为显著, 特别是在多个对象的生成任务中, 该模块能将简短的文本提示解析为多个对象的组合, 并对提示中的每个对象进行细致化描述, 从而为生成任务提供更丰富的指令指导.
在基于视觉-结构解耦的动态控制模块的视觉控制模块中, 为了评估特征提取器对方法性能的影响, 设计关于VGG与DINOv2的消融实验, 分别测试仅使用VGG特征、仅使用DINOv2特征以及融合两者特征时的L1距离和LPIPS指标, 具体结果如表4所示.
| 表4 视觉控制模块中DINOv2与VGG的消融实验结果 Table 4 Ablation experiment results of VGG and DINOv2 in visual control module |
由表4可见, VGG特征有助于强化低层边缘细节, 在图像重建精度(L1距离)方面更具优势.DINOv2特征在捕捉语义层次深层特征方面发挥关键作用, 在感知相似性(LPIPS指标)方面表现更佳.BiC-LLM成功结合两种特征的互补优势, 在两项指标上均超越任一单特征模型, L1距离指标比w/o DINOv2降低3.3%, LPIPS指标比w/o VGG降低1.8%.这充分说明多特征融合策略的有效性, 通过协同利用VGG的局部纹理表征能力和DINOv2的全局语义理解能力, 可显著提升方法的综合性能.
在跨模态指令流处理器的消融实验中, 验证引导强度调控参数sL、sF、sP对生成图像质量的影响.为了实验的严谨性, 所有图像样本均基于相同的随机种子生成, 确保变量控制一致性, 具体结果如图10所示.
 | 图10 跨模态指令流处理器对BiC-LLM性能的影响Fig.10 Effect of cross-modal instruction stream processor on BiC-LLM performance |
对比不同参数配置下的生成结果可得出如下结论.
1)保持文本引导强度sP=8恒定时, 对比第1行参数组合(sL=8, sF=3)与第2行参数组合(sL=6, sF=4), 生成图像在视觉风格与空间结构上呈现显著差异, 这验证方法对结构引导sL与外观引导sF具备独立的调控能力.
2)在第2行中, 进一步固定结构与外观引导强度sL=6, sF=4, 并逐步提升文本引导强度sP, 结果表明, 随着sP值的增加, 生成图像在维持既定结构与风格的基础上, 内容与文本提示的语义一致性得到显著增强, 并展现出更丰富的细节.这证实sP能有效调控生成结果对文本指令的遵循程度, 并提升最终图像的语义保真度.
实验表明, 本文的跨模态指令流处理器中的噪声预测更新规则在多指令流协同控制方面具有显著优势, 该处理器不仅增强方法对复杂文本结构的解析能力, 还大幅提升生成图像的多样性与可控性.特别是在风格迁移和细节重构任务中, 该处理器使生成图像在内容表达质量和视觉保真度方面均获得显著提升, 由此验证BiC-LLM的有效性和实用性.
本文提出基于大语言模型双向协同的跨模态交互式图像编辑方法(BiC-LLM), 旨在解决传统扩散模型在图像编辑任务中面临的局部细节控制不足、用户意图理解偏差及交互响应滞后的问题.设计层次化语义驱动模块和基于视觉-结构解耦的动态控制模块, 高效解析用户输入的文本提示, 并生成精细化的语义向量, 引导图像生成与编辑过程.BiC-LLM在图像生成的语义一致性、结构稳定性及细节保真性方面均较优, 特别是在多物体场景和复杂编辑任务中, 能准确响应用户的编辑意图.通过引入实时交互机制, 支持掩膜标注与参数调节, 进一步提升用户在编辑过程中的精确控制能力.同时, 结合多层次视觉特征提取器(VGG和DINOv2), 能独立调整图像的全局结构与局部风格, 提升图像编辑的灵活性和精度, 特别适用于风格迁移和细节重构等生成图像多样性的任务.今后将进一步探索BiC-LLM在更多应用场景中的潜力, 如三维重建等领域.
本文责任编委 高隽
Recommended by Associate Editor GAO Jun
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|