









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于思维链和语义解耦的层次化主题模型
引用本文
王志华, 李旸, 李德玉, 王素格. 基于思维链和语义解耦的层次化主题模型. 模式识别与人工智能, 2025,38(7): 613-626
WANG Zhihua, LI Yang, LI Deyu, WANG Suge. Hierarchical Topic Model Based on Chain of Thought and Semantic Decoupling. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2025,38(7): 613-626.
Doi: 10.16451/j.cnki.issn1003-6059.202507003
WANG Zhihua, LI Yang, LI Deyu, WANG Suge. Hierarchical Topic Model Based on Chain of Thought and Semantic Decoupling. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2025,38(7): 613-626.
Permissions
Copyright©2025, 《模式识别与人工智能》编辑部
《模式识别与人工智能》编辑部
基于思维链和语义解耦的层次化主题模型

李 旸 ,博士,副教授,主要研究方向为文本情感分析.E-mail:liyang@sxufe.edu.cn.
作者简介: 
王志华,硕士研究生,主要研究方向为数据挖掘.E-mail:2113648144@qq.com. 
李德玉,博士,教授,主要研究方向为粒计算、机器学习.E-mail:lidy@sxu.edu.cn. 
王素格,博士,教授,主要研究方向为自然语言处理、情感分析.E-mail:wsg@sxu.edu.cn.
摘要
层次主题模型可以挖掘文档中的隐含主题,建模主题间的层次结构关系,为数据治理、信息检索、内容分类和知识管理等应用提供技术支持.文中提出基于思维链和语义解耦的层次化主题模型.首先,建立基于思维链的层次主题生成模块,设计层次化主题生成思维链,指导大语言模型(Large Language Model, LLM)生成初步的主题层次结构.然后,引入基于LLM的主题相似判别机制,生成精炼的主题,并利用样例指导LLM实现主题合并,提升生成主题的质量.最后,建立基于传输规划和语义解耦的主题层次优化模块,将初始层次主题结构作为下游建模的主题先验,构建主题关键词、文档主题分布和主题距离,并将主题层次关系建模为最优运输问题,结合上下层主题关键词进行父子主题解耦,优化主题层次结构.在NeurIPS、ACL、20 Newsgroups等涵盖新闻与学术论文的多个标准公开数据集上的实验表明,文中模型在主题质量指标和层次化指标上均取得较优值.
关键词:
层次主题模型; 标签自动生成; 思维链; 大语言模型(LLM); 提示学习; 语义解耦
中图分类号:TP311;TP391
Hierarchical Topic Model Based on Chain of Thought and Semantic Decoupling
LI Yang , Ph.D., associate professor. Her research interests include text sentiment analysis.
About Author:
WANG Zhihua, Master student. His research interests include data mining.
LI Deyu, Ph.D., professor. His research interests include granular computing and machine learning.
WANG Suge, Ph.D., professor. Her research interests include natural language processing and sentiment analysis.
Abstract
Hierarchical topic models can uncover latent topics in documents and model the hierarchical relationships between topics, providing technical support for applications such as data governance, information retrieval, content classification, and knowledge management. A hierarchical topic model based on chain of thought and semantic decoupling(CoT-SDHT-M) is proposed in this paper. First, a hierarchical topic generation module based on a chain of thought is established. An initial hierarchical topic structure is generated by a large language model(LLM) under the guidance of hierarchical topic generation chain of thought. Then, a topic similarity discrimination mechanism based on LLM is introduced to generate refined topics and to guide the LLM in merging topics through examples, thereby improving the quality of the generated topics. Finally, a hierarchical topic optimization module based on transport planning and semantic decoupling is designed. It incorporates the initial hierarchical structure as a topic prior for downstream modeling. The relationships between topics are modeled as an optimal transport problem, and parent-child topic decoupling is performed based on the keywords of upper-layer and lower-layer topics to optimize the hierarchical topic structure. The experiments on various standard public datasets, including NeurIPS, ACL and 20 Newsgroups, demonstrate that CoT-SDHT-M significantly outperforms existing baseline models in terms of topic quality metrics and hierarchical metrics.
Key words:
Hierarchical Topic Model; Automatic Label Generation; Chain of Thought; Large Language Model(LLM); Prompt Learning; Semantic Decoupling
主题建模旨在从文档集合中自动识别隐藏的主题结构, 为信息检索、内容分类和知识管理等应用提供技术支持.在现实场景中通常包含复杂的层次化主题结构, 如“ 人工智能→ 机器学习→ 有监督学习” 或“ 政治→ 国际关系→ 中美贸易” 等.传统主题模型, 诸如LDA(Latent Dirichlet Allocation)[1]等, 因假设主题处于同一层级, 难以捕捉层次化主题语义结构.层次主题模型旨在从语料库中发现潜在主题, 挖掘其层次化语义结构及层次间主题关系, 构建主题语义高度相关、层次结构合理且主题语义多样化的主题层次结构.然而, 构建具有高度一致性、合理性和多样性的主题层次结构是一项具有挑战性的任务.
现有层次主题方法主要分为两类:基于LDA的方法和基于深度学习的方法.Blei等[2]提出hLDA(Hierarchical LDA), 开创层次化主题建模范式.尽管后续有诸多改进变体[3], 但这类方法仍存在计算开销较大、收敛速度较慢且难以扩展的局限.
随着变分自编码器(Variational Autoencoder, VAE)[4]等深度学习技术的兴起, 研究者们逐步开始将各类深度学习方法引入层次主题建模领域.Isonuma等[5]和Chen等[6, 7]基于VAE架构构建树形主题层次, 分别采用双递归网络、SBP(Stick Brea-king Process)过程和流形正则化优化主题依赖关系.Xu等[8]提出HyperMiner, Lin等[9]提出hHTM, 利用双曲空间的树状几何特性生成复杂层次结构, 同时利用对比学习提高模型对数据分布的学习能力.此外, Chen等[10]提出NSEM-GMHTM(Nonlinear Structural Equation Model Guided Gaussian Mixture Hierarchical Topic Model), 采用高斯混合先验耦合结构方程建模主题层次依赖.Liu等[11]提出AP-HTM(Anchor Word Clustering and Path Guided Frame-work for Unsupervised Hierarchical Topic Modeling), 利用锚点词聚类与因果路径优化层次主题生成过程.Wu等[12]基于最优传输理论, 提出TraCo(Trans-port Plan and Context-Aware Hierarchical Topic Mo-del), 实现层次结构规范化.
上述方法在一定程度上实现高效且可扩展的层次主题建模, 但通常依赖预设的主题先验分布, 其原因是大部分基于深度学习的层次主题建模方法假设主题在潜在空间中服从正态分布, 使得先验分布与数据中主题真实分布不一致时模型存在先验偏置问题.
近年来, 大语言模型(Large Language Model, LLM)被用于主题模型的评估与参数优化, 或直接用于生成主题.这类方法主要分为两类.1)利用LLM进行主题模型的评估.Stammbach等[13]和Rijcken等[14]开发基于LLM的主题评估框架, 证实LLM评级与人类注释高度相关.2)研究如何利用LLM直接生成主题, Mu等[15]和Pham等[16]采用结构化提示方法引导LLM生成主题, 并证实LLM可生成粒度适宜、区分度较高且与人类标注相一致的主题.此类研究多聚焦于非层次化的平面主题生成任务, 虽有少数工作运用LLM构建层次化主题框架, 但并未明确建模层次间主题关系, 使生成的主题层次结构存在下层主题过度集中和父子主题关联割裂等问题.
针对上述问题, 本文提出基于思维链和语义解耦的层次化主题模型(Hierarchical Topic Model Based on Chain of Thought and Semantic Decoupling, CoT-SD-HTM), 设计层次化主题生成思维链, 引导LLM递归生成从抽象到具体的初始主题层次结构.在聚类任务上受Zhang等[17]启发, 对于思维链的主题精炼环节, 提出基于LLM的主题相似判别机制, 利用LLM的推理能力评估主题相似程度, 并动态调整合并操作, 使生成的初始层次主题分布更贴合实际数据特性.进一步地, 将初始层次化主题编码为下游建模任务的可学习先验分布, 利用语义解耦和最优运输规划, 获取主题关键词和文档主题类别分布, 并优化主题层次结构, 实现数据驱动的层次化主题构建.在3个公开语料库上的实验表明, CoT-SD-HTM在主题质量指标和层次化指标上均取得较优值.
1 基于思维链和语义解耦的层次主题模型
为了使主题层次结构中的标签在父子主题间具有一致性和合理性, 同时在兄弟主题间表现多样性,
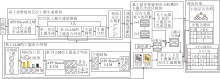
本文提出基于思维链和语义解耦的层次主题模型(CoT-SD-HTM), 整体架构如图1所示.
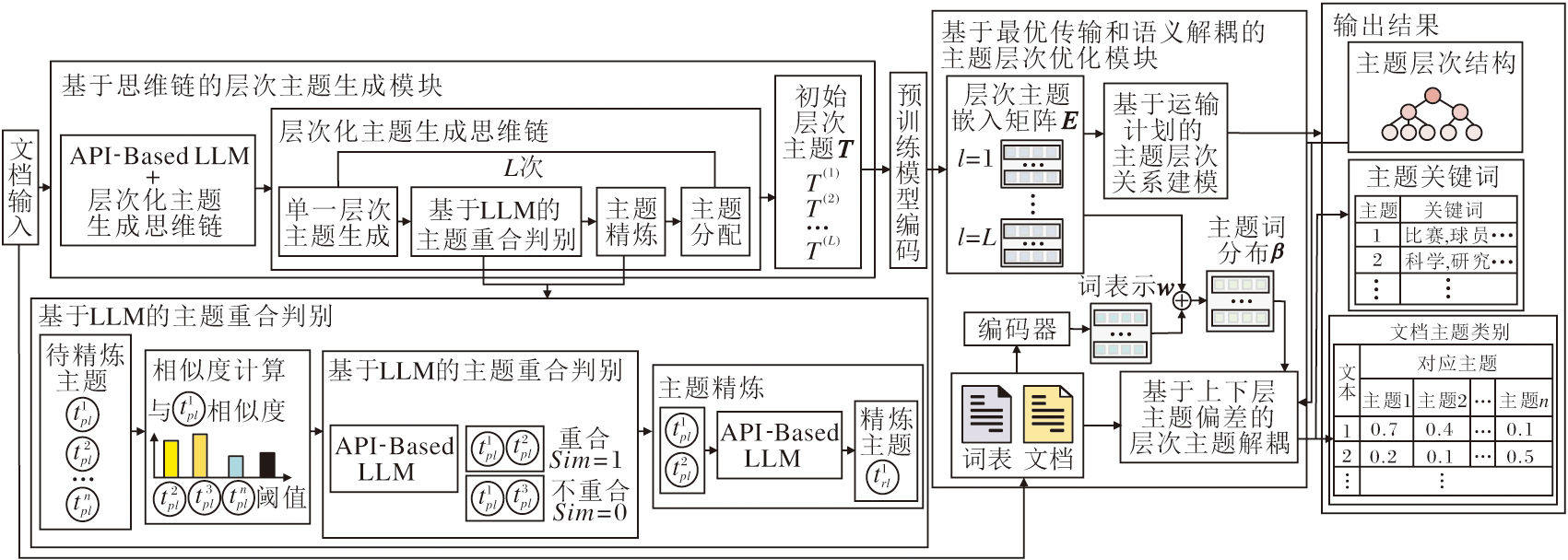 | 图1 CoT-SD-HTM整体架构Fig.1 Overall architecture of CoT-SD-HTM |
CoT-SD-HTM主要由两部分组成:1)基于思维链(Chain of Thought, CoT)的层次主题生成模块, 主要利用层次主题生成、相似度和LLM的主题精炼与主题分配三阶段引导LLM构建层次化主题结构.2)基于最优运输规划和语义解耦的主题层次优化模块, 主要对主题层次关系进行运输依赖建模以及上下层主题语义解耦, 进一步优化生成的主题层次.
1.1 问题定义
假设有N个文档
X=(x(1), x(2), …, x(N))
及释义文本包含V个词的词表, 本文的任务旨在从该集合挖掘一个具有L层的主题层次结构, 并推断文档的主题类别.在该主题层次结构中, 第l层包含K(l)个主题, 每个主题被定义为词集上的分布
1.2 基于思维链的层次主题生成模块
基于思维链的层次主题生成模块设计层次化主题生成思维链, 指导LLM从文档集合X中提取初始层次主题.该思维链包含单一层次主题生成、基于相似度和LLM的主题精炼和主题分配三步提示, 迭代实现层次化主题生成.
1.2.1 提示设计原则
文献[15]和文献[16]已证实, 结构化提示能有效引导LLM生成扁平主题, 但其层次化生成的能力尚未得到验证.本文在其基础上进行扩展, 设计层次化主题生成思维链, 生成层次化的初始主题.此外, 本文的各步提示设计遵守如下原则.
任务显性化原则:在提示首行明确声明任务目标, 确保LLM准确捕获意图.
示例驱动原则:第2~3个示范样例引导LLM理解层次化生成范式, 同时避免领域偏置.
格式规范原则:明确数据的输入要求和输出规范, 保障结果可控性.
领域泛化原则:提示模板中除提示样例外不预设特定领域词汇或结构, 并且提示样例设计不依赖特定数据集.
1.2.2 单一层次主题生成
为了生成单一层次主题, 利用图2的提示模板promptgenl, 引导LLM生成第l层主题tpl.对于顶层主题tp1, 直接由文档集合X生成.对于其它层主题tpl(l> 1), 结合上层精炼主题trl-1和上层主题分配文本集合Xal-1生成tpl.tpl由一个主题标签和一段句子描述组成:
其中, trl-1表示l-1层精炼后的主题, Xal-1表示trl-1经主题分配后对应的文本集合, X表示全体文档集合.
 | 图2 单一层次主题生成提示模板Fig.2 Module of single level topic generation prompts |
1.2.3 基于相似度和LLM的主题精炼
为了避免重复和无代表性主题, 需要对tpl中的主题进行精炼.该过程主要由基于相似度计算主题筛选和基于LLM的主题相似判别与精炼主题生成构成.
1)基于相似度计算主题筛选.利用余弦相似度计算结果, 初步筛选主题对, 将相似度超过相似度阈值γ 的主题对作为候选相似主题, 加入候选精炼主题集{tsl(i, j)}, 即
{tsl(i, j)}={(tpl(i), tpl(j))|cos(tpl(i), tpl(j))> γ },
其中, {tsl(i, j)}表示候选精炼主题集, γ 表示相似度阈值.
2)基于LLM的主题相似判别与精炼主题生成.为了进一步细化候选精炼主题集{tsl(i, j)}的相似判别, 并提升判别准确性, 提出基于LLM的主题相似判别机制, 设计图3的主题相似判断提示模板promptLTSJ, 指导LLM结合样例集{td}的正负样例判别验证候选主题集{tsl(i, j)}中主题是否可以合并, 最终输出LLM相似判断:
Sim=LLM({tsl(i, j)}, {td}, promptLTSJ),
其中{td}表示合并案例指导模型是否合并.Sim={0, 1}, 0表示不相似, 1表示相似.
 | 图3 主题相似判断提示模板Fig 3 Module of topic similarity judgment |
基于上述判别结果Sim, 利用图4所示的提示模板promptrefin, 引导LLM合并相似主题, 同时剔除低频主题, 生成精炼主题:
trl与tpl格式一致, 并且包含合并前的主题对.
 | 图4 主题精炼提示模板Fig.4 Module of topic refinement prompts |
1.2.4 主题分配
利用图5的提示模板promptass, 将精炼主题trl与文档集合X进行匹配, 生成匹配结果:
Xal=LLM(trl, X, promptass).
Xal包含与trl匹配的文档、推理原因及文本摘要.
 | 图5 主题分配提示模板Fig.5 Module of topic assignment prompts |
1.2.5 模块输出
模型中每层精炼后的主题trl经预训练模型编码为语义向量, 作为主题的先验分布, 指导主题层次优化模型对主题层次关系进行优化.
1.3 基于最优运输规划和语义解耦的主题层次优化模块
基于思维链的层次主题生成模块虽然利用LLM生成层次化的主题内容, 但部分父子主题之间的冗余性仍较高、语义关联性较差.为此, 本文借鉴TraCo[12], 构建基于最优运输规划和语义解耦的主题层次优化模块.该模块继承TraCo的核心思想, 将主题层次关系建模为最优运输规划问题, 利用传输代价构建目标函数, 并结合上下层主题偏差, 优化跨层主题间关联.在生成层次化精炼主题的基础上, 设计主题-词分布相似度与层级传输代价等参数, 将LLM挖掘的主题信息作为先验知识, 融入优化过程中.
1.3.1 初始主题分层参数化
将词汇表单词与其各层级精炼主题trl分别利用归一化正态分布和预训练模型编码映射至共享嵌入空间.
词表示矩阵如下所示:
W=(w1, w2, …, wV)∈ RD× V,
其中, D表示嵌入维数, V表示词表大小, wi表示词表示矩阵W中的主题表示.W由变分自编码器的编码器生成, 具体地, 利用神经网络将词映射为潜在空间的正态分布参数, 并经过重参数化采样得到词表示向量.
层次主题嵌入矩阵如下所示:
E(l)=(
其中, K(l)表示基于思维链的层次主题生成模块生成的l层主题数,
表示t
设计主题-词相关性矩阵, 构建主题-词分布具体过程如下:
$\beta_{\boldsymbol{e}_i^{(l)}, \boldsymbol{w}_m}^{(l)}=\frac{\exp \left(\ \ \frac{\ -\left\|\ \ \boldsymbol{e}_i^{(l)}-\ \ \boldsymbol{w}\ _m \ \ \right \|\ ^2\ \ \ \ }{\tau}\ \ \right)}{\sum_{j=1}^{K^{(l)}} \exp \left(\ \ \frac{-\left\|\ \ \boldsymbol{e}_j^{(l)}-\ \ \boldsymbol{w}\ _m\ \ \right\|\ ^2\ \ \ }{\ \tau\ \ }\ \ \right)},$
其中τ 表示控制主题-词分布的平滑性和稀疏性的超参数.
1.3.2 基于最优运输规划的主题层次关系建模
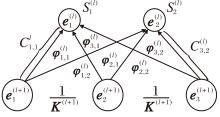
最优运输理论[18]的核心在于以最小成本实现源分布到目标分布的质量转移.为了有效建模层次化主题间的依赖关系, 本文利用最优运输理论将父子主题关联转化为跨层级主题间的质量最优运输规划过程, 在此基础上, 引入层次主题嵌入矩阵E(l), 构建主题嵌入欧氏距离C(l), 具体过程如图6所示.
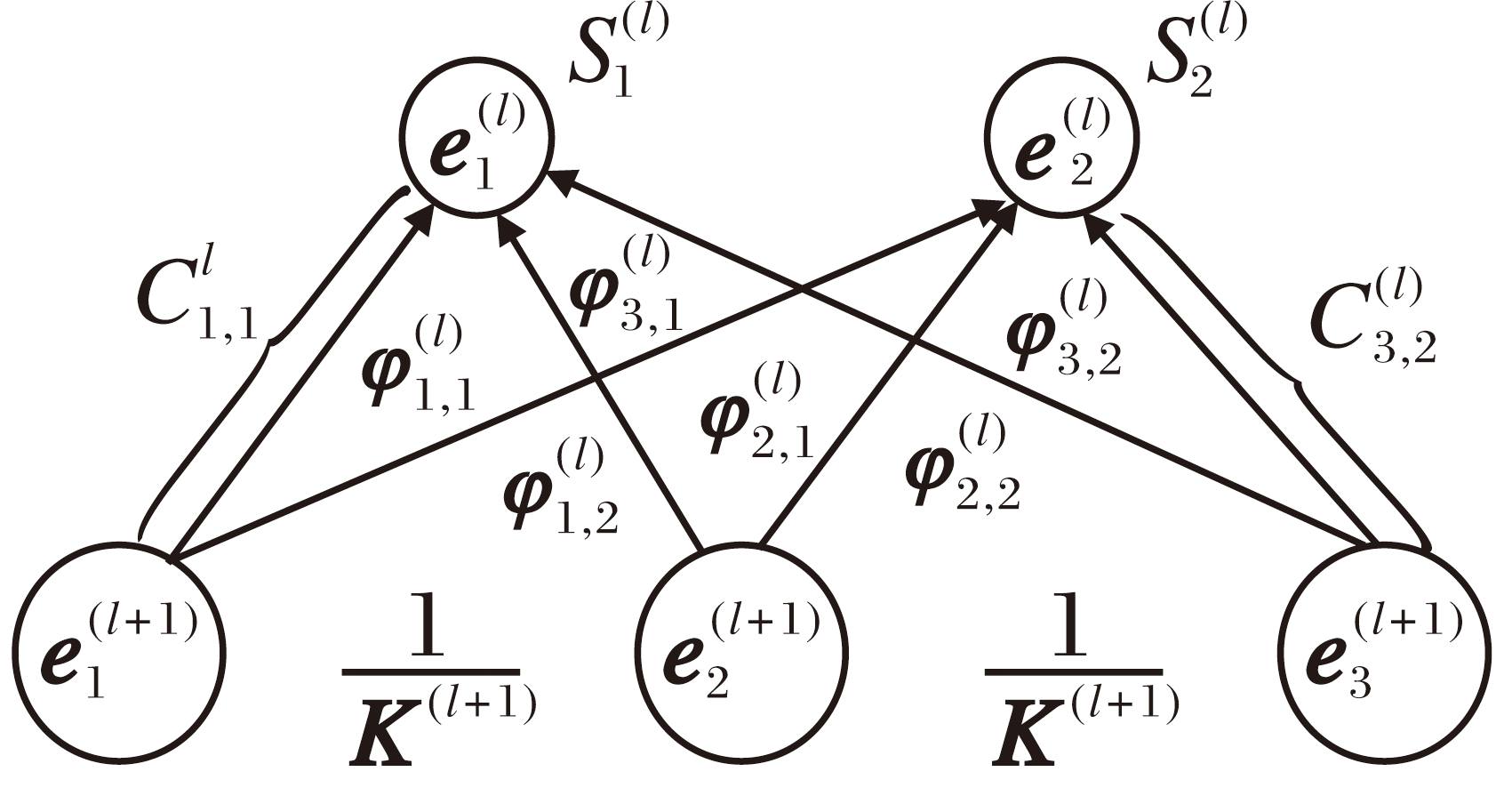 | 图6 基于最优运输规划的主题层次关系建模过程Fig.6 Process of modeling hierarchical topic relationships based on optimal transport planning |
首先, 计算l+1层第i个主题嵌入
其中,
其次, 基于主题嵌入欧氏距离C(l)和预设的层次间主题关联π (l), 构建层次关系建模的目标函数
$\begin{aligned}L_{\mathrm{OT}}^{(l)}= & \arg \min _{\boldsymbol{\pi}^{(l)}} \sum_{i=1}^{K^{(l+1)}} \sum_{j=1}^{K^{(l)}}\left(C_{e_{i}^{(l+1)}, e_{j}^{(l)}}^{(l)} \boldsymbol{\pi}_{e_{i}^{(l+1)}, e_{j}^{(l)}}^{(l)}+\right. \\& \left.\varepsilon \boldsymbol{\pi}_{e_{i}^{(l+1)}, e_{j}^{(l)}}\left(\log \boldsymbol{\pi}_{e_{i}^{(l)}, e_{j}^{(l)}}^{(l)}-1\right)\right), \\\text { s. t. } & \boldsymbol{\pi}^{(l)} \mathbf{1}_{K^{(l)}}=\frac{1}{K^{(l+1)}} \mathbf{1}_{K^{(l+1)}}, \left(\boldsymbol{\pi}^{(l)}\right)^{\mathrm{T}} \mathbf{1}_{K^{(l+1)}}=S^{(l)}, \end{aligned}$ (2)
其中, ε 表示超参数, 1/K(l+1)表示l+1层主题权重, S(l)表示l层主题权重, 两个权重集合各自所有项之和均为1, 1K表示全1的K维列向量,
最后, 利用Sinkhorn算法[19]近似求解目标函数
φ (l)=Sinkhorn(
为了迭代调整超参数, 本文基于传输成本矩阵主题嵌入欧氏距离C以及在该超参数环境下的主题层次关系的最优解φ , 构建运输依赖损失函数:
$L_{\mathrm{TPD}}=\frac{1}{L-1} \sum_{l=1}^{L-1} \sum_{i=1}^{K^{(l+1)}} \sum_{j=1}^{K^{(l)}} C_{i, { }_{j}}^{(l)} \varphi_{i, { }_{j}}^{(l)} .$(4)
利用上述关键技术, 设计详细的算法流程, 如算法1所示.
算法1 基于最优运输规划的主题层次关系建模
输入层次主题嵌入矩阵E=(E(1), E(2), …, E(L)),
E(l)=(
文档集合X, 词表示矩阵W
输出 主题层次关系最优解φ ={φ (l)}
for l in L:
初始化超参数ε , 层次间主题关联
根据式(1)计算层次间主题欧式距离C(l)
根据C(l)和
关系, 建立目标函数
使用Sinkhorn求解
系最优解φ
基于C(l)和φ (l), 逐层采用式(4)计算主题层次
损失LTPD, 迭代调整超参数
end for
1.3.3 基于上下层主题偏差的层次主题解耦
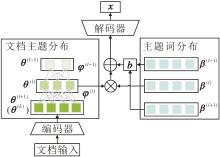
为了避免层级间语义重叠, 结合上下层主题语义构建上下层主题偏差, 进一步实现上下层主题解耦, 具体架构如图7所示.
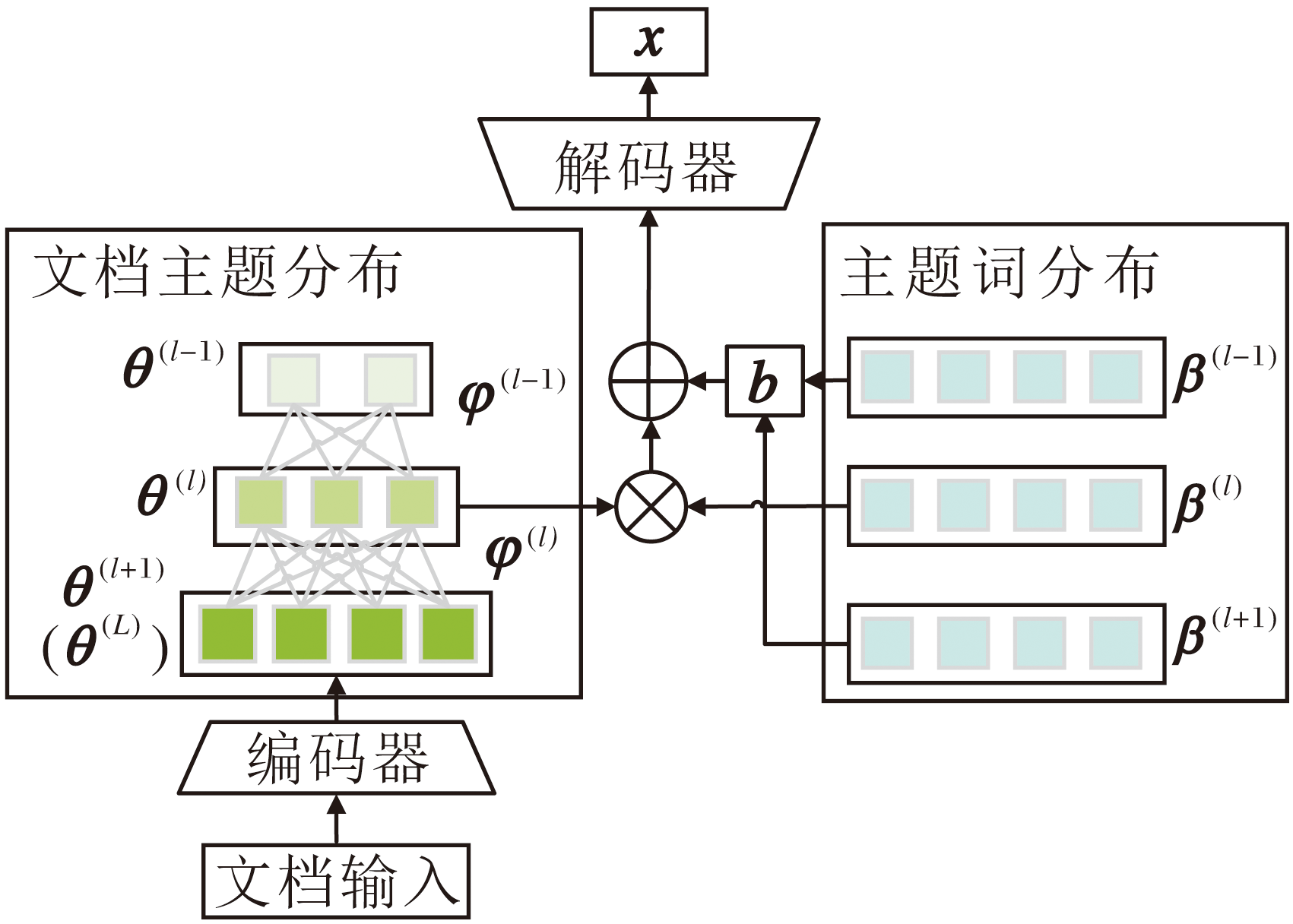 | 图7 基于上下层主题偏差的层次主题解耦过程Fig.7 Hierarchical topic decoupling based on upper-lower layer topic bias |
1)层次化文档-主题分布推断.基于VAE框架, 应用神经网络编码器Φ θ 近似文档x后验分布r, 并推断最底层L的文档-主题分布θ (L), 再根据主题层次关系最优解φ 逐层计算文档-主题分布θ (l).
2)上下层主题偏差.从上下层主题词分布β (l-1)和β (l+1)中提取顶部topK个相关词, 构建上下层主题偏差b(l)∈ RV, 屏蔽上下层覆盖语义.
3)基于上下层主题偏差的解耦解码器.解码器利用β (l)和θ (l)生成文档表示, 同时引入上下层主题偏差b(l), 通过主题建模损失LTM进行反向传播, 实现层次主题间的语义解耦:
$\begin{array}{l}L_{\mathrm{TM}}= \\ \frac{1}{N} \sum_{i=1}^{N}\left(\frac{1}{L} \sum_{l=1}^{L}\left(-\boldsymbol{x}^{(i) \mathrm{T}} y+K L\left[q\left(r \mid \boldsymbol{x}^{(i)}\right) \| p(r)\right]\right)\right), \end{array}$ (5)
其中
y=ln(softmax(β (l)θ (l)+λ bb(l))),
x(i)表示文档数据集合X=(x(1), x(2), …, x(N))中的文本, λ b表示上下层主题偏差的权重超参数.式(5)中第1部分为主题建模损失, 第2部分为变分分布q(r|x)和先验分布p(r)间的KL散度.
1.3.4 主题层次优化目标函数
整合式(4)和式(5)中的LTPD和LTM, 构造主题层次优化目标函数:
LTHOT=min(λ TPDLTPD+LTM), (6)
其中, LTPD用于调整主题层次结构, LTM用于分离上下层次主题语义, λ TPD表示主题层次调整的权重.依据上述关键技术, 设计基于上下层主题偏差的层次主题解耦算法.
算法2 基于上下层主题偏差的层次主题解耦算法
输入 文档集合X=(x(1), x(2), …, x(N)),
主题层数L, 主题词分布β
主题层次关系最优解φ ={φ (l)},
输出 主题词分布β ={β (l)},
文档-主题分布θ ={θ (l)}
初始化 神经网络编码Φ θ , 解码器ψ
for x in X:
r= Φ θ (x)
θ (L)= Softmax(MLP(r))
for l in L-1:
θ (l)=f(φ (l), θ (l+1))
end for
end for
for l in 1 to L-1:
$\boldsymbol{b}^{(l)}=\sum_{l^{\prime}=\{l-1, l+1\}} \sum_{k=1}^{K^{(l)}} \operatorname{top} K\left(\beta_{k}^{l^{\prime}}, \operatorname{top} K\right)$
end for
for x in X:
根据式(5)计算主题建模损失, 反向传播更新, 实
现主题解耦
end for
2 实验及结果分析
2.1 实验环境
与Wu等[12]的研究一致, 本文选取NeurIPS、ACL、20 Newsgroups数据集进行实验.
NeurIPS数据集包括1987年至2017年NeurIPS会议的全部出版物, 学术性较强、专业性较高, 适合评估模型在专业学术文献中的主题挖掘能力.
ACL数据集包括1970年至2015年ACL选集的论文, 涵盖自然语言处理和计算语言学领域的广泛研究, 适合评估模型在自然语言处理这一特定领域的主题挖掘能力.
20 Newsgroups数据集由标记为20个不同类别的新闻文章组成, 涵盖体育、政治、科技等多个领域, 适合评估模型在新闻舆情数据中的主题挖掘性能.
此外为了控制LLM的API(Application Progra-mming Interface)调用成本获取初始主题, 参考Pham等[16]的抽样方法, 从语料库中抽取部分代表性数据, 具体语料库及抽取语料情况如表1所示.
| 表1 语料库统计情况 Table 1 Dataset statistics |
本文采用Wu等[12]的评价指标:
1)主题质量, 包括TC(Topic Coherence)和TD(Topic Diversity);
2)主题层次结构质量, 包括PCC(Parent and Child Topic Coherence)、PCD(Parent and Child Topic Diversity)、SD(Sibling Topic Diversity)、PnCD(Pa-rent and Non-Child Topic Diversity).
实验的硬件配置为Intel Core i7-13650HX处理器(20核心)、16 GB内存及NVIDIA GeForce RTX 4060 Ti显卡, 软件环境采用Windows 11操作系统, 搭配PyTorch 1.12框架.
2.2 多种LLM作为基础模型时性能对比
为了测试多种LLM作为基础模型时CoT-SD-HTM的性能, 从主题质量和主题层次结构质量两个维度进行跨模型评测.主要选取如下3类LLM.
1)GLM-4[20].GLM-4是智谱AI开发的通用大语言模型, 采用自回归填空的统一框架.其核心原理
是利用双向注意力机制优化上下文建模, 并结合多阶段进行训练.
2)GLM-4-FLASH[20].作为GLM-4的轻量化版本, 利用知识蒸馏和动态量化技术实现高效部署, 适合需要快速响应和资源受限的应用场景.
3)Qwen-long(https://help.aliyun.com/zh/model-studio/long-context-qwen-long).由阿里云研发, 专注于处理超长上下文, 采用滑动窗口注意力和记忆压缩技术, 可支持长达128 K 词元的上下文窗口.
实验以GLM-4、GLM-4-FLASH和Qwen-long作为基础模型的CoT-SD-HTM分别记为M1、M2和M3, 并与基线模型TraCo对比.TraCo为实验中选择的最优基线模型, 也是参考的极低值.将基于不同LLM的CoT-SD-HTM与TraCo相比, 表明CoT-SD-HTM在不同大模型上都有优于或持平最优基线模型的性能.相应主题质量和主题层次结构质量结果如表2和表3所示.
| 表2 不同LLM下CoT-SD-HTM的主题质量 Table 2 Topic quality of CoT-SD-HTM under different LLMs |
| 表3 不同LLM下CoT-SD-HTM的主题层次结构质量 Table 3 Topic hierarchical structure quality of CoT-SD-HTM under different LLMs |
由表2可看出, 基于3种LLM的CoT-SD-HTM在主题质量层面的各指标值均超越TraCo, 这表明CoT-SD-HTM在不同的LLM上性能较优.
由表3的主题层次结构质量指标可看出, M1在PCC、PCD、SD、PnCD指标上全面领先或持平TraCo.M2在NeurIPS数据集上的SD指标值略低于TraCo, 但在其它场景下表现稳定.M3在PCC、PCD指标上表现突出, 尽管SD指标值略低, 但仍保持整体优势.实验表明, CoT-SD-HTM在不同LLM上均能构建高质量主题层次结构, 在层次主题指标上取得较优值.
结合表2和表3可看出, 以GLM-4为基础的M1在主题质量和主题层次结构质量两个维度的各项性能指标上, 表现出与M2、M3相当的性能优势.同时, M1在所有数据集上的指标值均优于或持平TraCo, 呈现出更均衡的优势.因此, 本文后续实验均采用GLM-4作为基础模型进行研究.
2.3 对比实验
为了验证CoT-SD-HTM的有效性, 选取如下8种基线模型进行对比实验.
1)nTSNTM(Nonparametric Tree-Structured Neu-ral Topic Model)[6].采用SBP分配主题路径权重, 确定叶主题数量, 并结合构建主题依赖矩阵, 建模主题层次结构.
2)HNTM(Hierarchical Neural Topic Model)[7].构建主题依赖矩阵, 建模主题的层次结构, 并引入流形正则化, 使相关文档的主题分布尽可能相似, 有效增强模型的鲁棒性.
3)HyperMiner[8].将主题和单词嵌入双曲空间, 利用几何特性表示层次结构.
4)NSEM-GMHTM[10].采用非线性方程建模主题间复杂依赖关系.
5)TraCo[12].将主题依赖关系建模为最优运输规划问题, 引入上下层主题偏差, 提升层次主题质量.
6)SawETM(Sawtooth Factorial Topic Embeddings Guided GBN)[21].把下层主题特征融入上层主题嵌入, 实现跨层主题语义共享, 提升主题层次建模能力.
7)dc-ETM(Deep-Coupling Hierarchical Embedding Topic Model)[22].利用跨层连接增强文档与多层潜在表示的关联以缓解“ 后验坍缩” , 同时运用强化
学习将解码过程转化为决策过程, 提升模型提取高质量潜在文档表示的能力.
8)ProGBN(Progressive Gamma Belief Network)[23].在文档中引入更多相关词, 优化高级别解码过程.
各模型在主题层次结构质量和主题质量两个维度上的对比结果如表4和表5所示.
| 表4 各模型在3个数据集上的主题质量 Table 4 Topic quality of different models on 3 datasets |
| 表5 各模型在3个数据集上的主题层次结构质量 Table 5 Topic hierarchical structure quality of different models on 3 datasets |
由表4的主题质量指标可看出, CoT-SD-HTM在TC、TD指标上均优于对比模型, 表明CoT-SD-HTM在保持并提升主题间多样性的同时, 可提升主题内部的一致性水平.
由表5的主题层次结构质量指标可看出, CoT-SD-HTM在PCC、PCD指标上均优于对比模型, 表明该模型不仅能提升父子主题间的语义关联, 同时可提高它们之间的区分度, 验证其在增强层次间主题语义关联的能力.此外, CoT-SD-HTM在SD指标上超越所有对比模型, 在PnCD指标上与最优基线模型持平, 这说明该模型生成的兄弟主题及非父子主题间同样具有良好的区分度, 进一步证实其构建多样化层次主题结构的能力.
2.4 消融实验
为了验证CoT-SD-HTM中各模块的作用, 分为如下3个模块进行消融实验.
1)A1.基于LLM的主题相似判别机制.该模块在思维链的主题精炼过程中介入, 判断该过程中候选的相似主题是否真实相似, 再决定是否合并.
2)A2.基于思维链的层次主题生成模块.该模块利用思维链, 引导LLM生成具有层次结构的主题.
3)A3.基于最优运输规划和语义解耦的主题层次优化模块.该模块通过最优运输规划和语义解耦方法优化主题间的层次关系.
各模块在主题层次结构质量和主题质量两个维度上的消融实验结果如表6和表7所示, 表中黑体数字表示最优值.
| 表6 各模块对主题层次结构质量的影响 Table 6 Effect of different modules on topic hierarchical structure quality |
| 表7 各模块对主题质量的影响 Table 7 Effect of different modules on topic quality |
由表6的主题层次结构质量指标可看出, 移除模块A3后, 各指标值均显著下降, 表明仅依赖A2、A1挖掘层次主题而未通过A3优化层次间主题关联, 会降低主题层次结构的上下层PCC、PCD指标.移除模块A2后, 主题层次结构质量的各项指标值均显著下降, 验证A2在生成层次主题中的作用.此外, 移除模块A1后, PCC、PCD、SD指标整体下降, 表明A1通过LLM决策主题相似度, 进一步提升主题层次结构上下层的PCC、PCD指标.
由表7的主题质量指标可看出, 移除模块A2后, TC、TD指标均显著下降, 验证A2在生成层次主题中的重要作用.移除模块A3后, TD指标显著下降, 而TC指标在NeurIPS、20 Newsgroups数据集上略微下降或保持不变, 在ACL数据集上有所提升, 表明A3通过优化主题层次关联, 在尽可能保持主题内聚的同时提升主题区分度.此外, 移除模块A1后, 在通用领域, 如NeurIPS、20 Newsgroups数据集, TD值分别下降0.024和0.054, 而在高度专业化领域, 如ACL数据集, TC、TD值略有提升, 表明A1的主题相似判断效果受领域特性影响, 需结合领域知识进一步优化.
2.5 提示样例在不同数据集上的适用性
为了验证CoT-SD-HTM中提示样例在不同数据集上的适用性, 在20 Newsgroups和NeurIPS这2个不同领域的数据集上, 分别采用数据集内和数据集外两种方式设计提示样例.从主题质量和主题层次结构质量两个维度评估提示案例的效果, 探究其在不同数据集上的适用情况, 具体结果如表8和表9所示, 表中NO表示提示样例采样自数据集内, NI表示提示样例采样自数据集外.
| 表8 不同提示样例下的主题质量 Table 8 Topic quality with different prompts |
| 表9 不同提示样例下的主题层次结构质量 Table 9 Topic hierarchical structure quality with different prompts |
由表8的主题质量指标可看出, 无论是基于数据集内还是基于数据集外设计的提示样例, 均优于TraCo.此外, 基于不同数据集设计的提示样例对TD指标的影响较小, 性能降幅不超过 0.04, 而对TC指标虽有一定影响, 性能降幅超过 0.05, 但不超过 0.1, 仍优于TraCo.这表明在主题质量层面, CoT-SD-HTM基本不受特定数据集的影响.
由表9的主题层次结构质量指标可看出, 无论是基于数据集内还是基于数据集外设计的提示样例, 主题层次结构质量的各指标值均优于TraCo.基于不同数据集设计的提示样例对主题层次结构质量各指标的降幅均不超过 0.04, 表明域外提示样例对主题层次结构质量的影响有限.这说明在主题层次结构质量层面, CoT-SD-HTM不受特定数据集的影响.
2.6 实例分析
为了对CoT-SD-HTM使用的提示模板及其结果样例进行展示, 并对主题结构样例进行可视化分析, 以20 Newsgroups数据集的体育比赛数据样本为例, 结合数据样本中的部分样例, 分别构建单一层次主题生成提示模板、主题精炼提示模板、主题分配提示模板及主题相似判断提示模板, 详见图8~图11.
 | 图8 单一层次主题生成提示模板及输出结果样例Fig.8 Example of single level topic generation prompt module and its outputs |
 | 图9 主题精炼提示模板及输出结果样例Fig.9 Example of topic refinement prompt module and its outputs |
 | 图10 主题分配提示模版及输出结果样例Fig.10 Example of topic assignment prompt module and its outputs |
 | 图11 主题相似判断提示模板及输出结果样例Fig.11 Example of topic similarity judgment prompt module and its outputs |
根据图8~图11的提示模板, 得到体育比赛数据样本的部分主题的层次结构, 如图12所示.由图可看出, “ 体育联赛” 的父主题下设的子主题涵盖“ 球队管理和球员选拔” 、“ 球队与比赛数据” 及“ 比赛细节” 等多个不同侧面.父子主题之间各有侧重且不存在过度重叠, 这一现象充分表明CoT-SD-HTM能有效捕捉主题的层次结构.
 | 图12 20 Newsgroups主题结构样例Fig.12 Topic structure sample on 20 Newsgroups dataset |
2.7 主题嵌入空间可视化
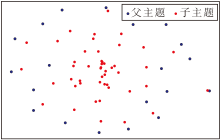
为了进一步展示主题嵌入空间的可视化, 采用t-SNE(t-Distributed Stochastic Neighbor Embedding), 对从20 Newsgroups数据集上挖掘的主题嵌入空间进行可视化分析, 结果如图13所示.
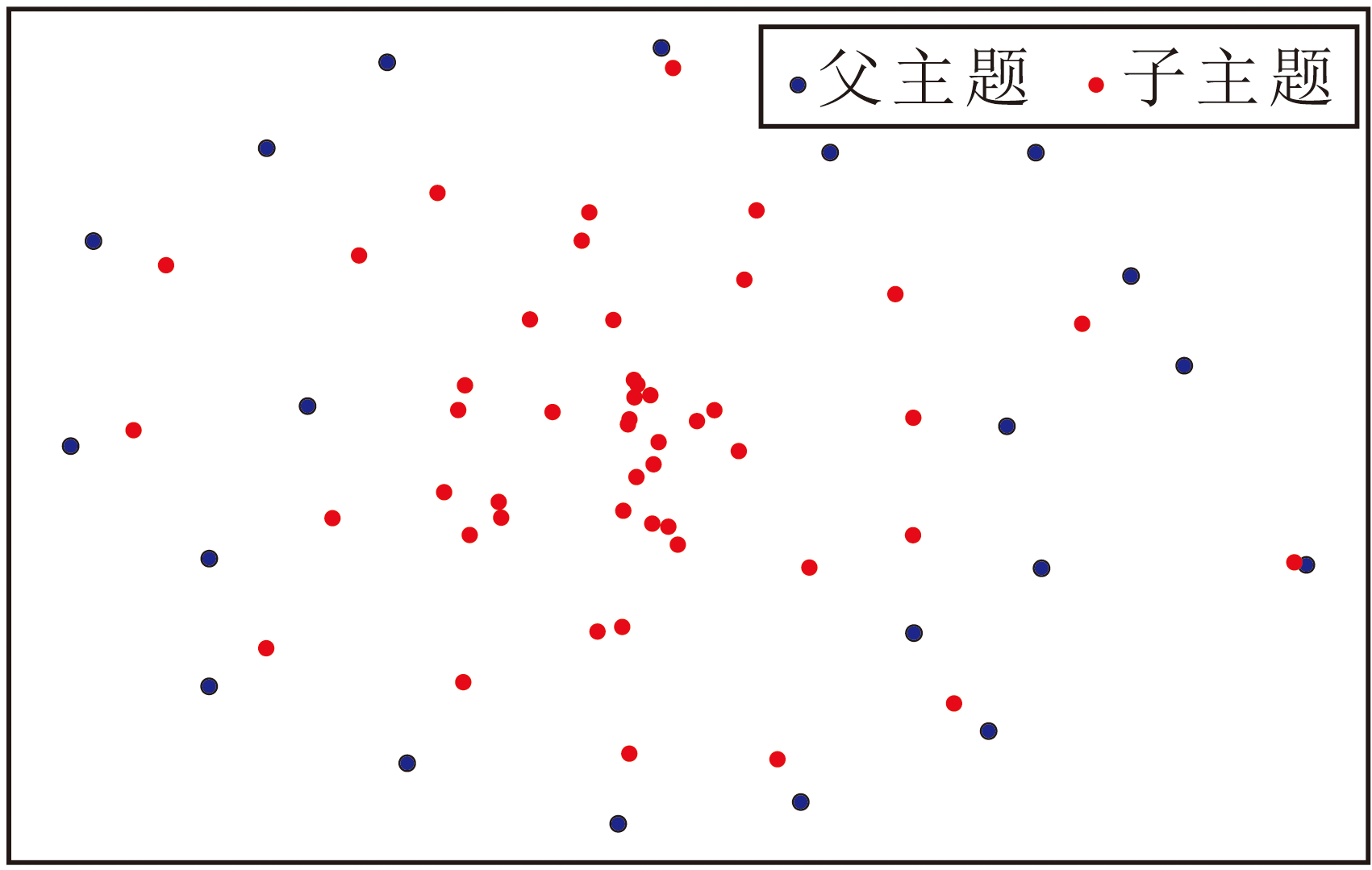 | 图13 基于欧氏距离的主题嵌入空间Fig.13 Topic embedding space based on Euclidean distance |
由图13可见, 利用CoT-SD-HTM的基于欧氏距离主题嵌入的层次化分布模式如下所述:父主题分布于外围, 子主题聚集于内侧.这一分布特征揭示父子主题之间的层次区分.具体而言, 父主题主要聚焦于主题的核心语义特征, 而子主题侧重于捕捉主题的不同维度差异, 父子主题具有不同的语义侧重, 从而在可视化结果中形成独特的分布模式.这种分布模式进一步验证2.3节对主题层次结构质量的分析结论, 即CoT-SD-HTM不仅能提升父子主题间的语义关联, 还能通过解耦父子主题语义以提高它们间的区分度.
2.8 LLM运行效率
为了验证LLM的运行效率是否满足本文应用需求, 选取首个词元延迟、端到端延迟和吞吐量指标, 在NeurIP、20 Newsgroups数据集上, 对思维链在GLM-4、GLM-4-FLASH、Qwen-Long这3种LLM上的运行效率进行测试, 结果如表10所示, 表中M1、M2、M3解释与2.2节一致.由表可见, 3种LLM可在3 s内返回首个词元, 在3~4 s内完成所有词元输出, 单位时间最大处理词元数超700, 满足本文非实时文档主题分析需求.
| 表10 LLM运行效率对比 Table 10 Comparison of LLM operational efficiency |
2.9 超参数分析
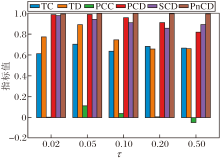
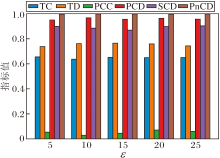
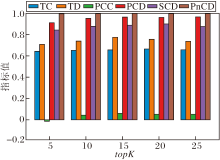
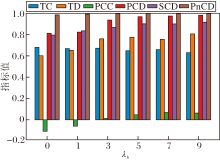
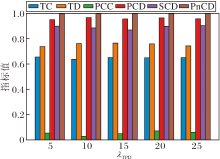
为了确定关键超参数的最优值并评估CoT-SD-HTM的鲁棒性, 在20 Newsgroups数据集上进行参数调优与敏感性分析实验, 重点考察主题-词分布平滑系数τ 、熵正则化系数ε 、相关词数topK、上下层主题偏差权重λ b、主题层次调整权重λ TPD对模型性能的影响, 并绘制相应性能指标随超参数变化的柱状图, 如图14~图18所示.
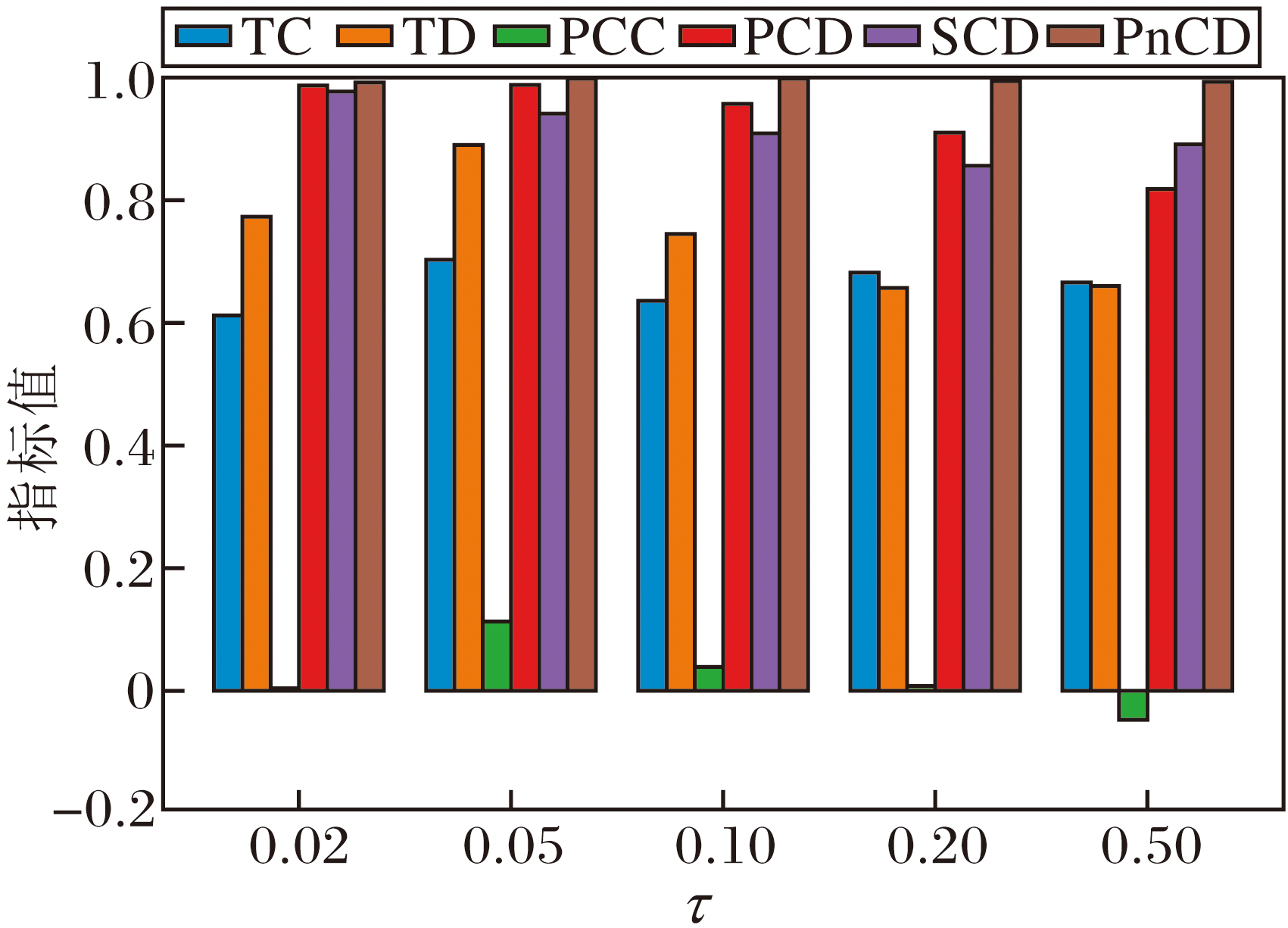 | 图14 τ 对CoT-SD-HTM性能的影响Fig.14 Effect of τ on CoT-SD-HTM performance |
 | 图15 ε 对CoT-SD-HTM性能的影响Fig.15 Effect of ε on CoT-SD-HTM performance |
 | 图16 topK对CoT-SD-HTM性能的影响Fig.16 Effect of topK on CoT-SD-HTM performance |
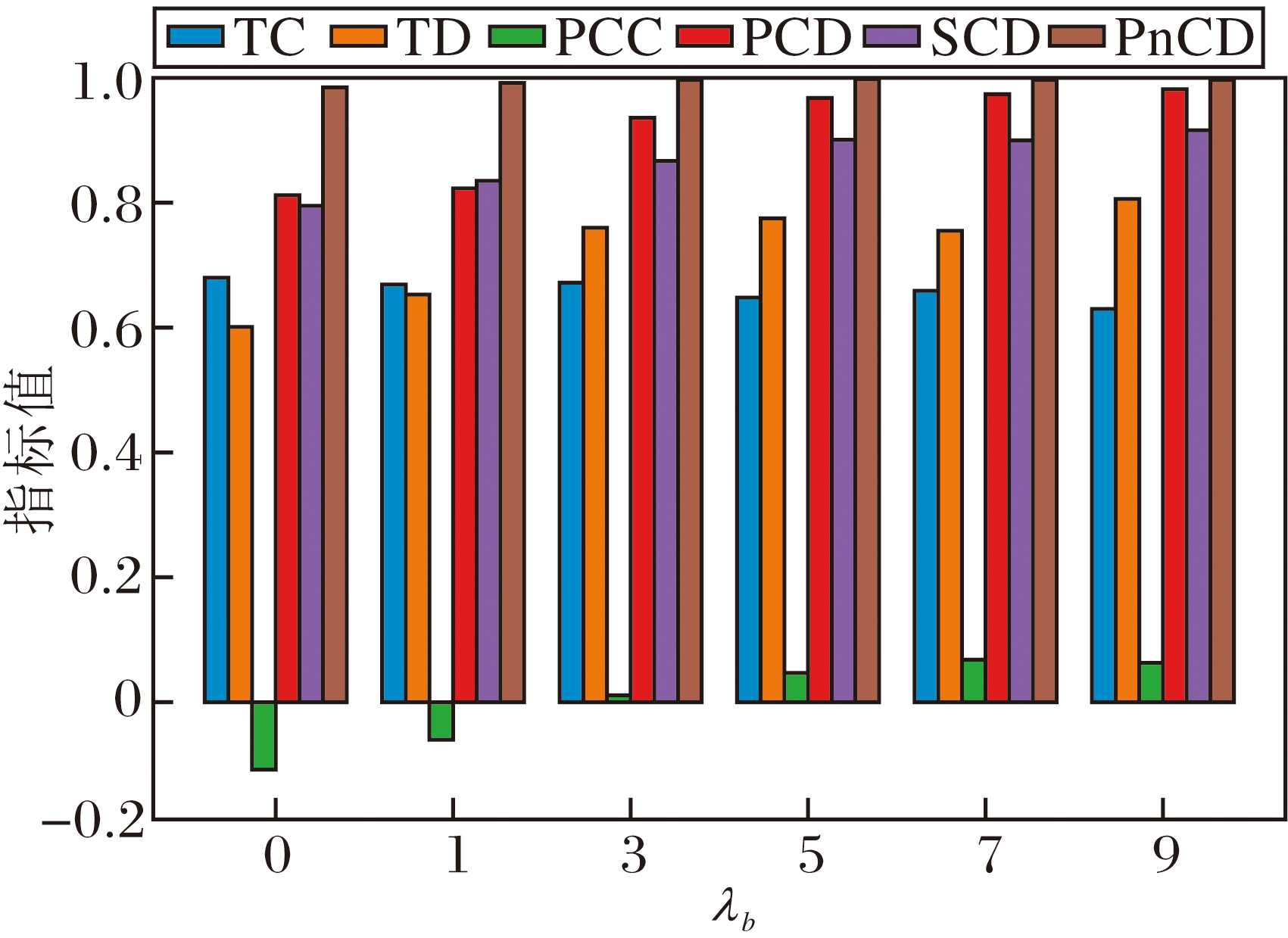 | 图17 λ b对CoT-SD-HTM性能的影响Fig.17 Effect of λ b on CoT-SD-HTM performance |
 | 图18 λ TPD对CoT-SD-HTM性能的影响Fig.18 Effect of λ TPD on CoT-SD-HTM performance |
如图14所示, 当主题-词分布平滑系数τ =0.05时, 主题质量指标TC、TD及主题层次质量指标PCC、PCD等均同时达到峰值, 表明该条件下主题的一致性与多样性达到最优平衡, 主题层次结构合理.此外, 当τ 降至0.02时, TC、TD指标均出现下降, 说明主题分布过于尖锐, 而当τ > 0.2时, TD指标显著降低, 反映出主题分布过度平滑.因此, 本文将τ 设为0.05.
如图15所示, 当熵正则化系数ε =5时, TC、TD、PCC、PCD指标均达到峰值, 而当ε > 15后, 各项指标均出现明显下降.因此, 本文将ε 设为5.
如图16所示, 当算法2中的相关词数topK=15时, 各项指标均达到或接近峰值.继续增加 topK, 性能指标并未显著提升, 逐渐趋于饱和.因此, 本文将topK设为15.
如图17所示, 上下层主题偏差权重λ b=5时, PCC、PCD、SCD指标均达到峰值.继续增大λ b, 各项指标提升有限并逐渐趋于平稳.因此, 本文将λ b设为5.
如图18所示, 当主题层次调整权重λ TPD=20时, PCC指标达到峰值, 同时SCD、PCD、TC、TD指标均维持在接近峰值水平.因此, 本文将λ TPD设为20.
此外, 通过敏感性分析验证CoT-SD-HTM的鲁棒性, 重点考察超参数τ 、ε 、topK、λ b、λ TPD对各项指标的影响.由图14~图18可见, 当参数值在其最优值邻近区间内变化时, 各项指标均未出现剧烈震荡, 始终保持稳定.这充分表明CoT-SD-HTM对上述关键超参数的变化不敏感, 具有良好的鲁棒性.
3 结束语
本文针对传统层次化主题模型因依赖预设主题先验分布而可能出现先验偏置, 以及LLM在生成层次化主题时主题层次结构不够完善的问题, 提出基于思维链和语义解耦的层次化主题模型(CoT-SD-HTM), 包括:构建并优化主题的层次结构、获取主题词和文档的主题分布.首先, 基于思维链技术, 指导LLM高质量递归生成初始层次化主题结构.然后, 在基于相似度和LLM的主题精炼环节中, 设计基于相似度计算主题筛选和基于LLM的主题相似判别与精炼主题生成方法, 提升主题精炼效率, 优化主题合并粒度.最后, 采用最优运输规划实现层次间主题关系的全局调优, 并在优化后的主题结构指导下, 采用上下层主题语义解耦, 获取主题关键词和文档主题分布.在3个公开数据集上的实验表明, CoT-SD-HTM不仅在TC、TD等主题质量指标上表现优异, 也在PCC、PCD等主题层次结构指标上较优, 由此验证模型的有效性.
尽管CoT-SD-HTM在多个数据集上表现出色, 但在结合领域知识以适应特定专业场景(如ACL数据集)以及处理动态数据流方面仍有改进空间.未来工作将重点探索领域知识增强和动态建模机制, 进一步提升方法的复杂场景适应性.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|