
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于边界信息与对比学习的图像篡改检测网络
引用本文
王轶群, 高燕程. 基于边界信息与对比学习的图像篡改检测网络. 模式识别与人工智能, 2025,38(7): 655-667
WANG Yiqun, GAO Yancheng. Image Tampering Detection Network Based on Edge Information and Contrastive Learning. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2025,38(7): 655-667.
Doi: 10.16451/j.cnki.issn1003-6059.202507006
WANG Yiqun, GAO Yancheng. Image Tampering Detection Network Based on Edge Information and Contrastive Learning. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2025,38(7): 655-667.
Permissions
Copyright©2025, 《模式识别与人工智能》编辑部
《模式识别与人工智能》编辑部
基于边界信息与对比学习的图像篡改检测网络

王轶群,博士,副教授,主要研究方向为智能计算、模式识别、机器视觉.E-mail:wyq6696@gsupl.edu.cn.
作者简介: 
高燕程,硕士研究生,主要研究方向为虚假新闻检测、计算机视觉等.E-mail:yan_c702@163.com.
摘要
针对复杂场景下图像篡改检测中边缘信息和高频特征利用不足的问题,提出基于边界信息与对比学习的图像篡改检测网络.首先,设计动态权重更新策略,优化图像高频信息的特征提取能力.然后,结合边缘检测算法与篡改区域检测算法,提取并增强图像的边缘特征,提升异常信息的显著性.最后,引入对比学习机制,构建正负样本对进行特征对比,优化对像素分布差异的判别能力,实现对篡改区域的精准定位.在多个公开数据集上的实验表明,文中网络在复杂场景下表现出良好的泛化能力和对细微篡改痕迹的识别能力,为图像篡改检测提供新的解决方案,具有较高的实际应用价值,可广泛应用于信息安全与数字取证等领域.
关键词:
图像篡改检测; 深度学习; 对比学习; 损失函数优化; 边界信息
中图分类号:TP391.41
Image Tampering Detection Network Based on Edge Information and Contrastive Learning
WANG Yiqun, Ph.D., associate professor. His research inte- rests include intelligent computing, pattern recognition and machine vision.
About Author:
GAO Yancheng, Master student. His research interests include false news detection and com- puter vision.
Abstract
To address the insufficient utilization of edge information and high-frequency features in image tampering detection under complex scenarios, an image tampering detection network based on edge information and contrastive learning(EICL-Net) is proposed. First, a dynamic weight update strategy is designed to enhance the feature extraction capability for high-frequency image information. Next, by integrating edge detection algorithms with tampered region detection algorithms, the edge features of images are extracted and enhanced, and the saliency of anomalous information is improved. Finally, a contrastive learning mechanism is introduced to optimize the ability to distinguish pixel distribution differences by constructing positive and negative sample pairs for feature comparison, thereby achieving precise localization of tampered regions. Experiments on multiple public datasets demonstrate that EICL-Net exhibits strong generalization performance and the ability to identify subtle tampering traces under complex scenarios. Therefore, EICL-Net offers a solution to image tampering detection. With its high practical application value, EICL-Net can be widely applied in the fields such as information security and digital forensics.
Key words:
Image Tampering Detection; Deep Learning; Contrastive Learning; Loss Function Optimization; Boundary Information
随着互联网和移动设备的普及, 网络已成为公众获取信息的主要渠道之一.然而, 大量虚假和误导性信息在网络空间中广泛传播[1, 2], 这些信息不仅误导个人认知, 还可能对公共舆论和社会决策产生深远影响.特别是在图像编辑技术日益普及的背景下, 图像篡改的门槛不断降低, 导致利用伪造图像传播虚假信息的案例急剧增加.图像篡改不仅可用于制造虚假新闻, 还可滥用于金融欺诈、司法取证、学术造假等领域, 对社会信任体系构成严重威胁.因此, 图像篡改检测技术的研究具有重要的现实意义.
根据Kaur等[1]的研究, 主要的图像篡改方法包括图像拼接、复制移动和区域删除.然而, 这些篡改操作后续往往需要处理不同的细节, 以确保篡改区域与原图风格统一.这种精细处理使观察者难以通过肉眼识别篡改痕迹, 从而有效达到歪曲事实的目的.鉴于图像篡改可能带来的负面影响, 图像篡改检测技术[3]现已成为研究热点.
早期的图像篡改检测方法主要基于图像的固有统计特征.这些特征会因图像来源不同而存在差异.研究人员通过收集大量统计特征以识别相机型号[4, 5], 或通过分析特定图像操作(如JPEG压缩[6]、中值滤波[7])产生的特征性伪影判断篡改操作.然而, 传统方法在面对复杂篡改场景时, 往往会使检测质量下降.传统方法虽然在某些特定场景下表现良好, 但其依赖于手工设计的特征, 难以应对多样化的篡改类型, 尤其是在篡改操作经过精细处理之后, 篡改区域的不可见性显著增强, 导致检测质量下降.
随着深度学习技术的引入, 图像篡改检测性能得到显著提升.传统方法由于容易受到语义信息的干扰, 难以充分利用周边区域的关联信息[8, 9].为了降低语义信息的影响, 研究者提出将噪声[10, 11]和边界[12, 13]等特征作为辅助信息与RGB信息联合输入, 增强方法对图像微观特征的感知能力, 但这些方法仍存在局限性:1)未将图像中的高频信息作为分析篡改的关键信息; 2)未着重分析篡改区域边界的影响; 3)对辅助信息只是使用单一的融合, 未重复利用辅助信息以提高方法的检测性能.
针对上述问题, 本文提出基于边界信息与对比学习的图像篡改检测网络(Image Tampering Detec-tion Network Based on Edge Information and Contras-tive Learning, EICL-Net).首先, 设计高频信息分析模块(High-Frequency Analysis Module, HAM), 通过动态权重更新策略, 自适应地提取图像的高频特征, 增强对篡改区域细节的感知能力.然后, 设计边界引导模块(Boundary Guidance Module, BGM), 提取并增强图像的边缘特征, 提升异常信息的显著性, 有效应对篡改区域的不可见性问题.最后, 引入有监督对比学习机制(Supervised Contrastive Learning, SCL), 对齐真实掩模与预测掩码, 构建正负样本对, 优化对不同像素分布差异的判别能力, 提升网络在低质量图像和复杂背景下的检测质量.在多个公开数据集上的实验表明, EICL-Net在复杂场景下表现出良好的泛化能力和对细微篡改痕迹的识别能力, 为图像篡改检测提供新的解决方案, 具有较高的实际应用价值, 可广泛应用于信息安全与数字取证等领域.
1 相关工作
1.1 图像篡改检测技术
图像篡改检测方法大致可分为传统方法与深度学习方法两类.传统方法主要基于图像的统计特性、成像过程模型或压缩伪影等线索进行篡改痕迹识别, 如噪声差异分析[14]、相机指纹识别[15]、JPEG压缩一致性检测[16]等.这类方法对简单篡改操作有效, 但在应对复杂背景、精细处理后的高隐蔽性伪造场景时性能有限.
近年来, 深度学习技术在图像篡改定位中表现出强大优势.典型方法包括卷积神经网络(Convo-lutional Neural Network, CNN)、生成对抗网络(Ge-nerative Adversarial Network, GAN)、注意力机制与多分支融合架构等.Zhou等[10]提出RGB-N, 采用双流Faster R-CNN结构引入噪声分支, 结合 Rich Model for Steganalysis(后文简记为SRM)[17]提取篡改区域中的高频伪痕.Chen等[11]提出MVSS-Net, 设计多视图多尺度监督机制, 通过频域、残差域、纹理域的特征组合实现多角度检测, 并引入多层次监督策略, 优化训练过程.Guillaro等[18]提出TruFor, 引入Noise-print++作为辅助模态, 与RGB图像进行跨模态融合, 基于Transformer结构实现端到端的检测与定位.Wang等[19]提出HRGR(Hierarchical Region-Aware Graph Reasoning), 基于内容一致的特征区域构建层次化图结构, 并结合结构不可知的图推理策略进行检测.
尽管上述方法在性能上取得一定进展, 但多数方法对篡改边界的建模不够充分, 未能有效挖掘高频信息并与结构信息协同作用, 限制其在复杂场景中的泛化能力.
1.2 利用边界信息的图像检测方法
边界区域通常是篡改与真实区域的过渡带, 包含最显著的结构变化与特征突变.因此, 近年来有研究者开始将边界信息引入检测框架中.Hu等[20]提出SPAN(Spatial Pyramid Attention Network), 利用局部注意力与金字塔结构建模多尺度特征, 提升对细粒度区域的感知能力.Liu等[9]提出PSCC-Net(Pro-gressive Spatio-Channel Correlation Network), 采用逐层细化的多阶段结构, 结合全局上下文建模模块, 增强语义表达, 在保持细节识别能力的同时提升全图一致性理解.Shi等[21]提出PR-Net(Progressively-Re-fined Neural Network), 引入旋转残差结构, 提升边缘区域的定位能力.Ding等[22]提出DCU-Net, 利用通道引导, 提升对边缘与伪痕的关注程度.这类方法已证实边界信息在提高检测精度中的重要性.然而, 大多数方法仍仅将边缘作为附加信息, 缺乏显式的边界增强模块设计, 未形成系统的边界指导机制.
1.3 基于对比学习的图像篡改检测方法
对比学习的研究核心在于深入挖掘实例间的差异性与相似性规律.通过精确刻画不同实例间的差异特征和相似实例间的共性特征, 获得更具判别力的特征表示.这种学习范式不仅促进同类实例的有效聚类, 同时通过扩大类间距离以强化特征的区分度.
在无监督学习领域, 对比学习经历从Instance-Level Discrimination[23]、SimCLR[24]到SimSiam[25]的范式演进, 实现从依赖负样本到无负样本学习的重要突破.在此基础上, 研究者开发基于对比学习的多任务网络.Wu等[26]提出FOCAL(Forensic Contras- tive Clustering), 将像素级对比学习与伪标签聚类结合, 有效挖掘图像中篡改区域与真实区域的结构差异.Zeng等[27]提出PCL(Proposal Contrastive Lear- ning), 通过双流网络结合像素级对比学习任务, 引导方法在局部区域构造正负样本对, 提升对篡改区域的区分能力.尽管已有部分方法探索监督对比机制, 但在精确掩模引导、有监督机制的选择以及特征图上的细粒度对比建模方面仍存在不足.
2 基于边界信息和对比学习的图像篡改检测网络
2.1 总体框架
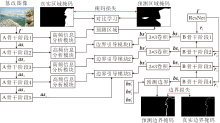
本文提出基于边界信息和对比学习的图像篡改检测网络(EICL-Net), 整体架构如图1所示, 旨在通过端到端的网络定位图像中的篡改区域.
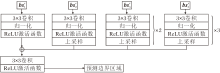
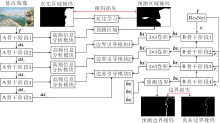 | 图1 EICL-Net整体构架Fig.1 Overall architecture of EICL-Net |
EICL-Net先将RGB图像输入固定滤波器SRM[17]和条件滤波器BayarConv[11], 获得更细节化的多通道信息:
I+=[Image, SRM(Image), Bayar(Image)].
多通道信息输入U-Net和ResNet骨干网络之后, 分别输出asi和ri.asi作为高频信息分析模块的输入, 重构高频信息的权重, 增强下采样阶段特征的表达.ri用于预测篡改区域的边界掩码, 并将下采样的信息输入边界引导模块中, 从篡改边界检测上引导方法识别篡改区域, 再生成篡改区域的预测掩码图像.在训练过程中, 将预测掩模与实际掩模进行映射, 并通过对比学习机制优化不同类别像素的分布差异, 增强方法的检测能力.
2.2 主干网络
如图1所示, 在A骨干阶段, 使用U-Net的架构对多通道信息进行编码, 可得
as1=MaxPool(Conv(I+)),
as2=MaxPool(Conv(as1)),
as3=MaxPool(Conv(as2)),
as4=MaxPool(Conv(as3)),
as5=Conv(as4).
其中, Conv(· )表示卷积操作, MaxPool(· )表示最大池化操作.
在B骨干阶段, 使用ResNet的部分特征作为输出, 这里只提供输出特征ri的形状:
其中W、H表示图像的宽和高.
随后, 将不同特征进行逐层下采样融合, 得到边界特征:
bsi=Conv(ri)+UP(bsi+1), i=1, 2, 3,
bs4=Conv(r4),
其中, UP(· )表示利用双线性插值进行上采样.采用这种方式, 将高层特征的低分辨率边界信息与底层特征的高分辨率边界信息逐层融合, 使每层特征都包含丰富的边界信息和空间细节, 提升方法对不同尺度篡改区域边界的检测能力.
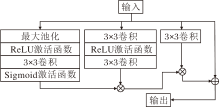
2.3 高频信息分析模块
为了有效挖掘图像中篡改区域蕴含的微观异常信息, 本文提出高频信息分析模块(HAM), 旨在增强方法对高频细节(如边缘、纹理突变、噪声变化等)的感知能力, 从而提升对篡改区域中细粒度伪痕的识别效果.图像中的高频信息通常反映像素之间的剧烈变化, 这些变化在篡改区域中往往具有特征性.尤其是在不同图像来源设备下, 真实图像呈现的白噪声分布往往较一致, 而篡改区域则因操作引入不一致的噪声或频率异常, 成为区分真伪的重要线索.
如图2所示, HAM由三个部分组成.首先, 针对输入的特征图, 采用最大池化操作在局部范围内提取响应最强的特征, 强化图像中普遍存在的噪声或边缘分布特征.该策略的核心在于, 最大池化可放大原图中“ 正常” 噪声或纹理在全局范围内的一致性, 从而在后续对比中更易突出篡改区域的异常特征.然后, 通过轻量卷积与激活函数, 生成通道权重图, 评估不同通道的敏感区域.最后, 将权重图与输入特征图进行点乘, 完成动态加权融合, 用于强调高频细节.
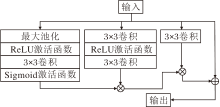 | 图2 HAM结构图Fig.2 HAM structure |
但是, 通过上述方式增强信息后, 仅提升高频信息在极小范围内的权重, 模块对高频信息的感知能力仍有所欠缺.因此, 相比传统的固定高频信息提取[17], 添加加权信息再卷积加权融合, 在保留低频信息的同时增强高频特征更大范围的表现能力.通过这种方式, HAM不仅能增强方法对细节区域的注意力, 还能从统计一致性角度反映篡改区域的异常性, 为后续边界感知与对比学习提供可靠的特征支撑.
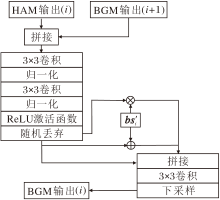
2.4 边界引导模块
在图像篡改任务中, 篡改区域与真实区域之间的边界往往表现出明显的纹理不连续、结构断裂等特征.这些异常虽然在视觉上可能被掩盖, 但在底层特征中, 特别是边缘信息中, 通常具有较强的可识别性.因此, 充分利用边界信息是提升对篡改区域感知能力的关键路径之一.
本文为此设计边界引导模块(BGM), 增强对篡改边界区域的关注.与直接依赖RGB图像提取结构信息不同, 本文采用多种滤波方式(如SRM、高通滤波等)经过预处理得到边界敏感特征, 相比原始图像, 这些高频边界特征更具代表性, 同时也减弱RGB通道中的语义干扰, 有助于从结构层面进行判别.
BGM的核心思想是利用篡改区域的边界信息作为引导, 增强方法对异常区域的感知能力.BGM结构如图3所示, 图中i表示不同层HAM的输出和边界特征.
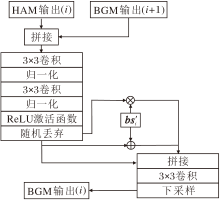 | 图3 BGM结构图Fig.3 BGM structure |
首先, 将HAM提取的高频增强特征作为主干输入, 同时获取由滤波器处理后的边界特征图bsi.为了保证与主干特征图尺寸一致, 并减少插值过程中引入的高频信息平滑问题, 对边界特征图bsi进行尺度对齐处理:
bsi'=UP(Conv(bsi)), i=1, 2, 3.
然后将HAM的输出与BGM的上层输出进行拼接融合, 获得高频信息与边界引导后的增强特征.最后, 将处理后的边界特征图在通道维度上利用点乘和求和的方式融合, 通过卷积操作生成边界引导图, 实现空间响应增强, 引导方法重点关注边界异常区域.由于as5未经过HAM而是直接输出, 并且不存在第5层的BGM的输出, 所以as5作为该层HAM的输出.这种融合方式充分利用边界在空间结构上的突变特性, 显著提升方法在篡改区域边界处的响应强度, 尤其是在模糊过渡或复杂背景条件下, 边界信息的强化对于定位篡改区域的性能起到关键作用.BGM设计可有效强化方法在篡改边界突变区域的响应, 特别适用于提升方法在边界过渡模糊场景中的定位表现.
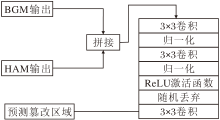
2.5 篡改区域掩码预测模块和篡改边界掩码预测模块
在预测篡改区域掩码时, 使用最后一个BGM的输出以及as1经过HAM的输出, 具体篡改区域掩码预测模块结构图如图4所示.
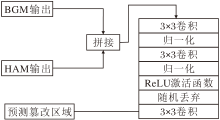 | 图4 篡改区域掩码预测模块结构图Fig.4 Structure of tampered area mask prediction module |
在预测篡改边界掩码时, 使用多层的边界特征bsi进行混合下采样预测, 具体篡改边界掩码预测模块结构如图5所示.
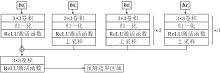 | 图5 篡改边界掩码预测模块结构图Fig.5 Structure of tampered boundary mask prediction module |
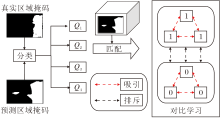
2.6 对比学习机制
对比学习的核心目标是通过优化不同类别在高维特征空间中的分布, 增强特征的判别能力.本文利用对比学习的特性, 对高维空间中不同类别像素点对应特征进行差异化划分.具体而言, 引入对比学习机制(CL), 使相同类别的特征在特征空间中分布更紧凑, 不同类别的特征分布之间具有明显的区分性.这种优化过程不仅增强特征的表征能力, 还能为预测掩码提供更强的先验知识, 从而显著提升预测掩码的准确率.
首先, 将真实掩模与预测掩模进行映射处理, 获取4类像素索引.由于真实掩模和预测掩模具有相同尺寸, 两者在相同位置的像素点可以一一对应.根据每个像素点在真实掩模和预测掩模中的取值(0或1), 将像素点分为如下4类.
1)预测掩码和真实掩码均为1的位置索引集合:
Q1=Pre_mask==1∩ Real_mask==1.
2)预测掩码和真实掩码均为0的位置索引集合:
Q2=Pre_mask==0∩ Real_mask==0.
3)预测掩码为0而真实掩码为1的位置索引集合:
Q3=Pre_mask==0∩ Real_mask==1.
4)预测掩码为1而真实掩码为0的位置索引集合:
Q4=Pre_mask==1∩ Real_mask==0.
将Q1~Q4映射至形状为(64, W, H)的特征图上, 得到4类像素点结合的特征数据.选择64通道特征层是为了平衡计算效率与特征表达能力.64表示模型在进行特征下采样时选取通道数为64的特征层, 并且该特征层的大小与图像的大小一致, 所以便于与原图进行映射.如果选取过大的通道数, 会影响对比学习的计算效率, 如果选取过小的通道数, 并不足以表现像素点的特征信息.
在预测准确像素点的类别Q1、Q2中, 分别计算两个类别特征向量的平均特征和:
${\boldsymbol{Q}_{1-\text{mean}}}=\frac{1}{m}\underset{i=1}{\overset{m}{\mathop \sum }}\,{\boldsymbol{Q}_{1-i}}$,
${\boldsymbol {Q}_{2-\text{mean}}}=\frac{1}{n}\underset{i=1}{\overset{n}{\mathop \sum }}\,{\boldsymbol {Q}_{2-i}}$,
其中, m表示Q1集合中元素数量, n表示Q2集合中元素数量, Q1-i表示在集合Q1中的第i个特征向量, Q2-i表示在集合Q2中的第i个特征向量.
随后, 从类别Q3、Q4中选择特征向量, 分别计算它们与Q1-mean和Q2-mean之间的成对余弦相似度:
$CosSim\left( {\boldsymbol {Q}_{3-i}},{\boldsymbol {Q}_{1-\text{mean}}} \right)=\frac{{\ \ \ \ \boldsymbol {Q}_{3-i}} \ \ \ \ \cdot \ \ \ {\boldsymbol {Q}_{1-\text{mean}}} \ \ \ \ \ \ \ \ }{{\ \boldsymbol {Q}_{3-i}}\ \ \ {\boldsymbol {Q}_{1-\text{mean}}}\ \ },$
$CosSim\left( {\boldsymbol {Q}_{3-i}},{\boldsymbol {Q}_{2-\text{mean}}} \right)=\frac{{\ \ \ \ \boldsymbol {Q}_{3-i}} \ \ \ \ \cdot \ \ \ {\boldsymbol {Q}_{2-\text{mean}}} \ \ \ \ \ \ \ \ }{{\ \boldsymbol {Q}_{3-i}}\ \ \ {\boldsymbol {Q}_{2-\text{mean}}}\ \ },$
$CosSim\left( {\boldsymbol {Q}_{4-i}},{\boldsymbol {Q}_{1-\text{mean}}} \right)=\frac{{\ \ \ \ \boldsymbol {Q}_{4-i}} \ \ \ \ \cdot \ \ \ {\boldsymbol {Q}_{1-\text{mean}}} \ \ \ \ \ \ \ \ }{{\ \boldsymbol {Q}_{4-i}}\ \ \ {\boldsymbol {Q}_{1-\text{mean}}}\ \ },$
$CosSim\left( {\boldsymbol {Q}_{4-i}},{\boldsymbol {Q}_{2-\text{mean}}} \right)=\frac{{\ \ \ \ \boldsymbol {Q}_{4-i}} \ \ \ \ \cdot \ \ \ {\boldsymbol {Q}_{2-\text{mean}}}\ \ \ \ \ \ \ \ }{{\ \boldsymbol {Q}_{4-i}}\ \ \ {\boldsymbol {Q}_{2-\text{mean}}}\ \ },$
其中, Q3-i表示在集合Q3中的第i个特征向量, Q4-i表示在集合Q4中的第i个特征向量.
再求和:
${{D}_{1}}=\underset{i=1}{\overset{a}{\mathop \sum }}\,\text{exp}\left( CosSim\left( {\boldsymbol {Q}_{3-i}},{\boldsymbol {Q}_{1-\text{mean}}} \right) \right)$,
${{D}_{2}}=\underset{i=1}{\overset{a}{\mathop \sum }}\,\text{exp}\left( CosSim\left( {\boldsymbol {Q}_{3-i}},{\boldsymbol {Q}_{2-\text{mean}}} \right) \right)$,
${{D}_{3}}=\underset{i=1}{\overset{b}{\mathop \sum }}\,\text{exp}\left( CosSim\left( {\boldsymbol {Q}_{4-i}},{\boldsymbol {Q}_{1-\text{mean}}} \right) \right)$,
${{D}_{4}}=\underset{i=1}{\overset{b}{\mathop \sum }}\,\text{exp}\left( CosSim\left( {\boldsymbol {Q}_{4-i}},{\boldsymbol {Q}_{2-\text{mean}}} \right) \right)$,
其中, a表示类别Q3中特征向量数量, b表示类别Q4中特征向量数量.最后, 计算对比学习损失:
图6通过图示的方式进行简要叙述.
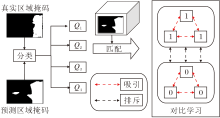 | 图6 对比学习机制说明图Fig.6 Illustration of contrastive learning mechanism |
2.7 损失函数
EICL-Net总损失函数综合篡改区域掩码损失Larea-mask、篡改边界掩码损失Ledge-mask和对比学习损失Lconf.
篡改区域掩码损失Larea-mask和篡改边界掩码损失Ledge-mask通过计算交叉熵损失实现, 专注于方法对篡改像素点和真实像素点的分类能力.这一损失函数的引入是为了提高方法在处理图像篡改检测任务时的鲁棒性, 具体公式如下:
${{L}_{\text{area-mask}}}=-\underset{j=1}{\overset{H}{\mathop \sum }}\,\underset{i=1}{\overset{W}{\mathop \sum }}\,({{W}_{1}}T{{M}_{\left( i,j \right)}}\text{lg}\left( P{{M}_{\left( i,j \right)}} \right)+\left( 1-T{{M}_{\left( i,j \right)}} \right)\text{lg}\left( 1-P{{M}_{\left( i,j \right)}} \right))$,
${{L}_{ed\text{ge-mask}}}=-\underset{j=1}{\overset{H}{\mathop \sum }}\,\underset{i=1}{\overset{W}{\mathop \sum }}\,(T\_{{E}_{\left( i,j \right)}}\text{lg}\left( \text{P}\_{{E}_{\left( i,j \right)}} \right)+\left( 1-\text{T}\_{{E}_{\left( i,j \right)}} \right)\text{lg}\left( 1-\text{P}\_{{E}_{\left( i,j \right)}} \right))$,
其中, W1表示篡改像素点的权重, 该权重是根据未篡改像素点与篡改像素点的比值计算得到, PM(i, j)表示预测篡改区域掩码, TM(i, j)表示真实篡改区域掩码, P_E(i, j)表示预测篡改边界掩码, T_E(i, j)表示真实篡改边界掩码.
本文方法通过优化对比学习损失Lconf, 捕捉图像特征之间的细微差别, 这对于后续的图像篡改区域的检测和像素点的分类任务至关重要.
综上所述, 总损失函数如下:
Ltotal=Larea-mask+Ledge-mask+Lconf.
3 实验及结果分析
3.1 实验数据集
本文选择CASIA[28]、Columbia[29]、COVERAGE[30]这3个标准图像篡改数据集作为实验数据集, 验证EICL-Net的性能.在CASIA数据集上进行拼接和复制操作, 部分被人为改变并进行后期处理, 包括滤波和模糊处理.通过计算篡改图像与原始图像的差值, 生成表示篡改区域的掩模图像.Columbia数据集主要关注未压缩图像的连接.COVERAGE数据集规模相对较小, 重点在于区域移动及其中的对象特征.具体数据集的统计信息如表1所示.
| 表1 实验数据集详细信息 Table 1 Detailed information of experimental datasets |
为了合理评估方法在不同操作类型下的检测能力, 并防止在训练过程中发生过拟合, 将所有图像数据按照8∶ 1∶ 1的比例划分为训练集、验证集和测试集.首先, 根据图像篡改的操作类型(图像拼接、复制移动、区域移除)对样本进行筛选与分类.然后, 对每类样本分别进行随机划分, 确保不同子集间篡改类型分布的均衡.验证集用于评估训练过程中的早停策略与超参数选择, 测试集用于最终性能评估.在整个数据集上, 不同篡改操作类型的图像数量如下:拼接图像2 184幅, 复制移动图像3 262幅, 区域移除图像878幅.
3.2 实验配置
在Ubuntu 18.04.1 LTS操作系统上进行实验, 使用NVIDIA A40 GPU(24 GB 显存)作为硬件平台.基于PyTorch 1.13.0框架进行开发与训练, 采用Python 3.8和CUDA 11.7进行环境配置.在训练阶段, 将输入图像统一缩放至256× 256, 批处理大小设为2, 初始学习率设为1× 10-4, 优化器采用Adam(Adaptive Moment Estimation).训练轮数上限为400, 若方法在验证集上的性能在连续10 个周期内未提升, 提前终止训练以防止过拟合.
3.3 训练过程
将经典的U-Net作为基础模型构建EICL-Net, 并结合边界感知与高频信息建模的设计理念提出改进.U-Net是一种广泛应用于医学图像与自然图像分割任务的对称型编码-解码结构, 具备强大的多尺度特征整合能力.考虑到U-Net在图像篡改检测领域中被多个主流方法(如MVSS-Net、SPAN)广泛采用, 具备良好的结构通用性与对比价值, 本文将其作为基线方法进行方法设计与性能评估.
EICL-Net的主干结构采用在PASCAL VOC 2012数据集上预训练的U-Net架构构建.编码器部分替换为预训练的ResNet-34, 用于提取多尺度图像语义特征, 每阶段获取的通道数分别为64、128、256、512、1 024.解码器部分保留U-Net对称解码结构, 并引入高频信息分析模块(HAM)与边界引导模块(BGM), 用于增强微观篡改区域的识别能力.同时, 采用预训练的ResNet34作为边界掩码预测分支的基础网络, 提升对篡改区域边缘的建模能力.
通过利用在大规模图像数据集上训练得到的预训练模型, EICL-Net可有效继承其丰富的低层感知能力与高层语义表示能力, 从而提升目标区域识别的准确性与鲁棒性, 并加快收敛速度.这一架构在具备良好基线可复现性的同时, 也为后续改进模块的插入与性能提升提供清晰的基础支撑.
3.4 评价指标
本文选择图像篡改检测方法常用的评价指标:F1-score分数和AUC(Area Under Curve).
F1-score作为精度的衡量指标, 综合考虑查准率(Precision Ratio)和查全率(Recall Ratio).具体公式如下:
受试者工作特征(Receiver Operating Charac- teristic, ROC)曲线广泛用于展示分类模型性能.该曲线以假阳性率和真阳性率为坐标轴, 反映两者关系.ROC曲线下面积(AUC)是评价分类模型性能的关键指标, 其值介于0和1之间, 数值越大表示模型分类性能越优.
3.5 对比实验
为了验证EICL-Net的有效性, 选择如下对比方法.
1)PSCC-Net[9].采用渐进式处理机制, 提供全局上下文信息, 增强特征表示能力.
2)RGB-N[10].采用双流架构, 用于发现图像内伪造特征和噪声的不一致性.
3)MVSS-Net[11].结合多视图特征学习和多尺度监督训练的深度网络.
4)文献[14]方法.基于噪声不一致性的高通小波系数局部噪声建模方法.
5)文献[15]方法.CFA(Color Filter Array)模式估计方法, 使用附近的像素近似相机滤波器阵列的模式, 产生每个像素的篡改概率.
6)ELA(Error Level Analysis)[16].错误级别分析方法, 旨在通过不同的JPEG压缩质量, 找出篡改区域和真实区域的压缩误差差异.
7)TruFor[18].结合RGB图像和学习型Noise- print++的跨模态融合框架, 利用Transformer实现对图像伪造的检测和定位.
8)HRGR[19].基于层次化区域感知图推理的图像操作检测方法, 通过可微分特征分割和跨层图建模.
9)SPAN[20].采用空间金字塔结构和自我注意机制.
10)PCL(Proposal Contrastive Learning)[27].基于双流架构和对比学习方法, 有效利用局部特征关系进行图像篡改检测.
实验数据将引用文献中结果, 对于部分未提供或未实验的数据, 将重新复现并评估.由于大部分方法以篡改区域检测作为性能评估的标准, 并且本文使用的篡改边界预测的目的是为了凸显不同尺度下的篡改区域特征, 所以未与其它方法在检测图像篡改边缘的性能上进行对比.
各方法在3个数据集上的指标值对比如表2所示, 表中黑体数字表示最优值.
| 表2 各方法在3个数据集上的指标值对比 Table 2 Metric value comparison among different methods on 3 datasets |
由表2可见, 传统方法如文献[14]方法、文献[15]方法、ELA虽然在特定情况下表现出一定的检测能力, 但由于其依赖手工设计的特征, 难以应对复杂的篡改场景.例如:文献[14]方法通过噪声不一致性进行检测, 但在高嵌入容量的情况下, 检测性能显著下降, F1分数和AUC值均低于深度学习方法.文献[15]方法和ELA虽然在Columbia数据集上表现尚可, 但在CASIA、COVERAGE数据集上的性能较差, 表明这3种方法在处理多样化的篡改类型时存在局限性.由于SPAN专注于识别具体的对象, 因此在具体篡改对象上的检测性能较优, 而对于不以对象为篡改区域的数据集上检测性能较差.RGB-N、PCL虽然引入噪声信息作为辅助特征, 但预测策略仍过度依赖RGB图像的语义信息, 在一定程度上限制方法对篡改特征的感知能力.MVSS-Net虽然在CASIA、Columbia数据集上表现较优, 但在COVER-AGE数据集上性能较差, 这可能是由于方法过度依赖噪声信息, 并且边缘信息可能与篡改区域的边缘特征相似, 从而导致方法误将正常区域判断为篡改区域.PSCC-Net采用的HRNet(High-Resolution Net)骨干网络虽然在关键点检测等任务上表现出色, 但对图像微观特征的提取能力相对不足, 影响方法在篡改检测任务上的整体表现.TruFor在Columbia数据集上检测性能较优, 但是可能由于方法训练数据专注于图像中人脸的篡改, 并不适用于其它数据集.PCL同样使用对比学习的思想, 但是对图像中不同类别的区分策略并不能产生较好的检测能力.在HRGR当中, 通过内容一致的特征区域进行建模, 在篡改对象检测上具有一定优势, 但是对于非固定对象或较小篡改区域的检测效果较差.
相比之下, EICL-Net结合高频信息分析模块(HAM)、边界引导模块(BGM)、对比学习机制(CL).首先, HAM利用高频信息更新特征图的权重, 增强篡改区域的表现能力, 全面感知篡改区域.其次, 方法使用BGM引导方法对篡改区域进行定位, 防止对其余过滤器边界关注.最后, CL有效增强对像素级微观特征差异的识别能力.这种设计不仅克服现有方法的局限性, 还使EICL-Net在整体检测性能上表现出明显优势, 并且相比现有的SOTA方法, 在F1分数和AUC值上平均提升0.063和0.045.尽管EICL-Net在Columbia数据集上的AUC值(0.985)略低于TruFor(0.996), 但这一差异主要源于TruFor在训练过程中可能更专注于特定类型的篡改(如人脸篡改), 而Columbia数据集包含较多此类样本.此外, TruFor采用跨模态融合框架, 结合特定的噪声敏感指纹, 这可能使其在特定数据集上表现更出色.然而, EICL-Net在整体性能上仍表现较优, 尤其是在CASIA、COVERAGE数据集上的AUC值均高于TruFor, 表明EICL-Net在处理多样化篡改类型时具有更强的泛化能力.
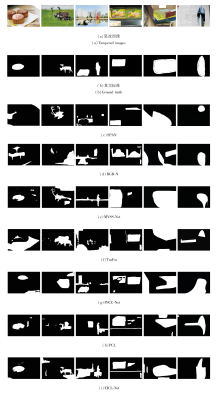
各方法在3个数据集上的预测结果如图7所示.图中白色区域表示被预测的篡改区域, 黑色区域表示未被改变的部分.由图可见, EICL-Net在篡改区域定位方面表现较优.
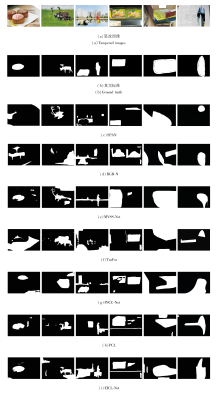 | 图7 各方法的预测结果对比Fig.7 Prediction result comparison of different methods |
3.6 消融实验
为了分析EICL-Net中每个组件或设计选择的影响, 进行一系列消融实验, 旨在分析EICL-Net中各组件的贡献.
在CASIA、Columbia和COVERAGE数据集上进行各模块的消融实验, 结果如表3所示.由表可知, 相比U-Net, 添加对比学习机制后, 可有效提高方法性能.
| 表3 各模块消融实验结果 Table 3 Results of ablation experiments for each module |
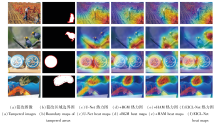
为了进一步从可视化角度验证HAM与BGM在特征增强方面的有效性, 本文给出不同模块组合后在典型图像样本上的特征响应热力图, 如图8所示.由图可观察到, 未引入模块时, U-Net的关注区域较分散, 难以聚焦真实篡改区域.加入HAM后, 方法能自适应关注图像中的高频信息, 提升对篡改边界高频细节的感知能力.引入BGM后, 方法更倾向于聚焦边缘突变区域, 显著减少对非篡改区域的误响应, 增强对篡改边界的划分能力.EICL-Net在两个模块的协同作用下, 进一步提升对篡改区域的响应强度与边界定位精度, 验证HAM和BGM在特征增强方面的有效性与合理性.
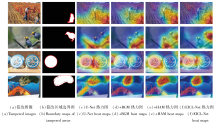 | 图8 添加不同模块后的热力图对比Fig.8 Comparison of heat maps after adding different modules |
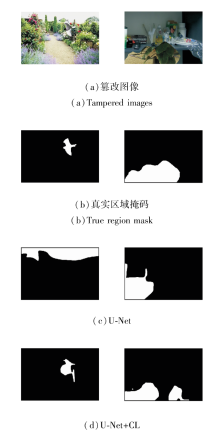
为了更直观地展示对比学习机制(CL)的实际性能, 给出U-Net和添加CL后预测结果对比图, 具体如图9所示.由图可看出, 在复杂背景和低质量图像中, U-Net往往难以准确识别篡改区域, 尤其是在背景纹理复杂或图像质量较差时, 容易倾向于检测某些较相近的区域, 导致出现误检或漏检.这表明CL通过增强像素级特征的分布, 能更好地捕捉篡改区域的细微差异, 提升方法的鲁棒性.此外, HAM和BGM的组合使用或与CL的组合使用, 均有助于提升方法性能.HAM通过高频信息更新特征图权重, 增强篡改区域的表现能力; BGM关注篡改区域, 防止对非篡改区域的误判.当使用EICL-Net时, 性能达到最优, 表明这些模块之间存在协同效应, 能显著提升方法整体表现.
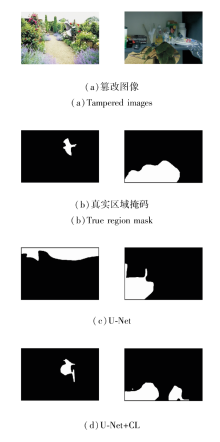 | 图9 添加对比学习机制前后预测结果对比Fig.9 Prediction result comparison before and after introducing contrastive learning mechanism |
4 结束语
本文提出基于边界信息与对比学习的图像篡改检测网络(EICL-Net), 通过边界引导模块(BGM)与对比学习机制(CL)的协同效应, 提升对篡改区域的检测精度.BGM通过提取和增强篡改区域的边界信息, 有效增强对篡改区域的关注, 而CL通过优化像素级特征表示, 增强对篡改区域与真实区域的区分能力.此外, 高频信息分析模块(HAM)通过动态权重更新策略, 进一步提升对篡改区域细节的感知能力.在不同数据集上的测试结果证实边界引导与对比学习的协同效应在提高特征判别性方面的有效性.EICL-Net可广泛应用于司法取证、社交媒体审核、新闻真伪性鉴定等领域.今后将重点围绕数据采样策略优化、特征融合机制改进及模型轻量化设计等方向展开研究, 进一步提升图像篡改检测的实用性.
本文责任编委 高 隽
Recommended by Associate Editor GAO Yun
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|