







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
多模态序列推荐场景下融合多维感知的自蒸馏多任务学习
[汤哲1  , 庞继芳
, 庞继芳1, 2 1, 2 , 王智强1, 2 ]
, 庞继芳, 解宇, 王智强]
|
|



作者简介:

汤 哲,硕士研究生,主要研究方向为推荐系统.E-mail:tangzhe@sxu.edu.cn.

解 宇,博士,副教授,主要研究方向为机器学习.E-mail:yuxie@sxu.edu.cn.

王智强,博士,副教授,主要研究方向为机器学习、数据挖掘、网络大数据分析.E-mail:wangzq@sxu.edu.cn.
作为推荐系统的一个重要应用场景,多模态序列推荐已成为当前工业界与学术界研究的焦点之一.然而,现有面向多模态序列推荐的多任务学习方法未充分考虑模态内部的高阶关系及短期序列的增强作用,在语义表达和兴趣表征学习方面能力有限,导致个性化程度不高.因此,文中提出多模态序列推荐场景下融合多维感知的自蒸馏多任务学习模型(Self-Distillation Multi-task Learning Integrating Multi-dimensional Perception for Multimodal Sequential Recommendation, SD-MTMP).首先,在对用户评论进行主题提取的基础上,构建用户-主题超图和项目-主题超图,分别建模用户群体与项目集合内部的高阶语义关联,生成主题感知的节点表征,并基于用户-项目评分矩阵构建加权二部图,生成评分感知的节点表征.然后,设计跨模态自蒸馏辅助任务,通过主题感知表征向评分感知表征的知识迁移实现语义对齐.同时,综合考虑用户评分与时间间隔对短期序列的影响,建立双重感知注意力机制,精准建模用户的短期兴趣.在此基础上,提出适用于多模态序列推荐的多任务学习策略,通过推荐损失与自蒸馏损失的联合优化,进一步增强表征语义,提升推荐性能.最后,在3个公开数据集上的实验表明SD-MTMP的有效性.
About Author:
TANG Zhe, Master student. Her research interests include recommender system.
XIE Yu, Ph.D., associate professor. His research interests include machine learning.
WANG Zhiqiang, Ph.D., associate professor. His research interests include machine learning, data mining and network big data analysis.
As an important application scenario of recommendation systems, multimodal sequential recommendation is a research focus in both industry and academia. However, existing multi-task learning approaches for multimodal sequential recommendation fail to fully consider the high-order relationships within modalities and the enhanced effect of short-term sequences of users. Consequently, these approaches exhibit a low degree of personalization due to their weak semantic representations and interest modeling. To address this issue, an approach for self-distillation multi-task learning integrating multi-dimensional perception for multimodal sequential recommendation(SD-MTMP) is proposed. First, based on the extraction of topics from user reviews, high-order semantic correlations in user groups and item collections are modeled respectively by constructing user-topic and item-topic hypergraphs. The topic-aware representations of nodes are generated through hypergraph convolution. Simultaneously, a weighted bipartite graph is built based on the user-item rating matrix to generate rating-aware representations of nodes. Second, a cross-modal self-distillation auxiliary task is designed to achieve semantic alignment by transferring knowledge from topic-aware representations to rating-aware representations. Additionally, a dual-aware attention mechanism is established by comprehensively considering the effects of user ratings and time intervals on short-term sequences to accurately model short-term interests of users. On the basis of the above, a multi-task learning strategy is proposed for multimodal sequential recommendation. It jointly optimizes the recommendation loss and the self-distillation loss, thereby further enhancing the semantic expressiveness of representations and improving recommendation performance. Finally, experiments on three public datasets demonstrate the effectiveness of SD-MTMP.
多任务学习(Multi-task Learning, MTL)是一种机器学习范式, 核心在于同时学习多个不同但相关的任务, 通过共享知识和信息以提高模型的整体性能[1], 现已成为推荐系统中广泛使用的技术之一.由于推荐系统类型众多, 如何针对不同推荐场景设计相应的多任务学习策略, 有效提升模型的个性化程度, 是当前推荐系统领域的热点问题之一[2].
序列推荐作为推荐系统的一个重要分支, 已成功应用于电子商务、在线教育、短视频平台等领域, 其主要任务是通过建模用户与项目在时间序列上的交互模式, 为用户提供个性化推荐服务[3, 4, 5].Hidasi等[6]利用门控循环单元建模用户行为序列中的时间模式, 提升推荐的准确性.Kang等[7]提出SASRec(Self-Attention Based Sequential Model), 采用自注意力机制捕捉序列中任意两个位置之间的关系, 在突破序列长度限制的同时, 增强模型对长期依赖关系的建模能力.
目前图卷积神经网络(Graph Convolutional Net-work, GCN)在推荐系统领域的应用[8]不断深入.Wu等[9]提出SR-GNN(Session-Based Recommenda-tion with Graph Neural Networks), 将会话序列转化为图结构, 利用GCN建模项目之间的二元关系.考虑到用户行为序列通常涉及多个项目之间复杂多元的高阶交互模式, 为了准确捕捉用户的兴趣变化, Ding等[10]提出HyperS2Rec, 引入超图网络, 建模用户行为序列中的高阶关系, 直接捕获用户行为序列中项目之间的高阶关联.
为了提升推荐性能, 学者们开始将多任务学习引入序列推荐中, 从多个视角挖掘用户的兴趣偏好[11].目前, 序列推荐中常见的多任务关系建模方式主要分为如下三种:并行任务关系建模[12, 13]、级联任务关系建模[14, 15, 16]、辅助任务关系建模[17, 18, 19, 20, 21].并行任务关系建模采用任务解耦策略, 将用户的行为序列(如点击、购买等)分解为多个独立但相关的任务, 利用固定权重对多个任务的损失进行加权求和.级联任务关系建模考虑任务之间的因果关联, 依据类似“ 点击-加购-购买” 的用户行为路径构建任务链, 捕捉用户行为的内在逻辑, 提升模型的预测能力.由于上述两种建模方式在联合优化过程中往往难以实现任务间的帕累托最优[17], 学者们进一步提出以推荐主任务性能最大化为目标的辅助任务关系建模, 允许适度牺牲辅助任务的性能.目前主要采用对比学习构建辅助任务, 在优化节点表征的同时增强推荐性能[18].Xie等[19]提出CL4SRec(Contras-tive Learning for Sequential Recommendation), 对项目序列进行随机裁剪、重新排序等扰动操作, 生成正负样本, 进而构建序列间的对比学习辅助任务.Wu等[20]提出SGL(Self-Supervised Graph Learning), 在对项目序列图进行节点丢弃、边丢弃及随机游走等操作的基础上, 生成多个视图, 并利用多视图对比学习优化节点表征.考虑到上述数据增强方式可能会破坏序列中的时序特征, Liu等[21]提出TimesURL, 通过裁剪和混频操作, 将时间序列变换为两个增广序列, 并作为正样本建立对比学习辅助任务.然而, 现有的序列推荐大多局限于单一模态数据, 对包含多模态信息(如评分、文本、图像等)的推荐场景缺乏深入研究[22].
多模态推荐由于融合不同模态的信息, 可有效提高推荐的准确性和个性化程度[23, 24].Guo等[25]提出LGMRec(Local and Global Graph Learning-Guided Multimodal Recommender), 将用户和项目在局部拓扑关系下的协同相关和模态相关进行表征, 并与利用超图网络和属性信息建模的全局依赖关系结合, 得到用户的综合表征.Lu等[26]提出ViLBERT(Vi-sion-and-Language BERT), 编码文本和图像, 计算候选项目与历史项目之间的跨模态关联度, 建模准确的用户表征.Yu等[27]提出MGCN(Multi-view Graph Convolutional Network), 基于视觉和文本两种模态的特征相似度构建项目-项目图, 并通过用户-项目图和项目-项目图中多模态表征的自适应融合建模用户偏好.Hu等[28]提出MMSR(Multi-modality En-riched Sequential Recommendation), 将用户的行为序列表示为多模态图, 通过图注意力网络学习各模态下的节点表征.Sun等[29]提出Alpha-CLIP, 通过图像与文本表征间的对比学习, 将不同模态数据映射至共享语义空间, 实现跨模态语义信息的融合.
采用对比学习构建辅助任务进行模态融合的基本原理是通过建模多模态表征之间的相似性和差异性以优化节点表征[30], 可有效提升模型的判别能力, 但其在语义表达方面能力较弱[31].相比之下, 自蒸馏学习通过让学生模型模仿教师模型的输出实现知识迁移, 可有效增强表征的语义表达能力[32].将自蒸馏学习与多任务学习结合, 有望为多模态序列推荐研究提供新的技术路径.
综上可知, 目前面向多模态序列推荐的多任务学习研究还处于起步阶段, 尚存许多有待深入探索的方向.例如:在推荐主任务的构建中, 现有研究大多将模态信息直接编码为用户和项目的初始表征, 进而结合用户、项目之间的二元关系学习节点表征.这种处理方式未考虑模态内部用户-用户、项目-项目之间的高阶语义关联, 表征学习质量受限, 同时, 忽视用户短期兴趣变化的影响, 导致推荐结果与用户即时需求之间偏差较大.另外, 在辅助任务的构建中, 常用的对比学习方法侧重于增强模型的判别能力, 存在信息损失较大和语义表达能力较弱的问题, 导致模态融合效果不够理想.
针对上述问题, 本文提出多模态序列推荐场景下融合多维感知的自蒸馏多任务学习模型(Self-Distillation Multi-task Learning Integrating Multi-dimen- sional Perception for Multimodal Sequential Recom- mendation, SD-MTMP).该模型在对用户评论进行主题提取的基础上, 通过构建用户-主题超图和项目-主题超图, 深入挖掘用户群体与项目集合内部的高阶语义关联, 生成细粒度语义层面的主题感知表征, 同时, 基于用户-项目评分矩阵构建加权二部图, 学习评分感知的节点表征.进而, 设计跨模态自蒸馏辅助任务, 通过语义丰富的主题感知表征向评分感知表征的知识迁移, 实现多模态表征的语义对齐, 有效增强模态融合效果.在此基础上, 进一步引入用户的短期兴趣, 提出考虑用户评分与时间间隔的双重感知注意力机制, 获得更精准的用户序列表征.最后, 结合自蒸馏辅助任务与推荐主任务, 设计适用于多模态序列推荐的多任务学习策略, 联合优化推荐损失与自蒸馏损失, 进一步增强语义表征, 提升推荐性能.
设用户集合U={u1, u2, …, um}, 项目集合I={i1, i2, …, in}.用户-项目评分矩阵为R∈ Rm× n, 其中每个元素rui∈ R表示用户u∈ U对项目i∈ I 的评分, m表示用户数量, n表示项目数量.用户对项目的所有评论构成集合D.用户u的短期交互序列Su={
为了充分挖掘评论中隐含的语义信息, 本文利用BERTopic技术[33], 对评论进行主题提取.首先, 将评论集合D中所有的评论划分为句子, 构成句子集合S={s1, s2, …, sh}, 其中h表示句子个数.评论中语义相似的句子属于同一主题.再利用BERT(Bidirectional Encoder Representations from Trans-formers)预训练模型[34], 对S中的所有句子进行编码, 得到句子表征集合:
e(S)={e(s1), e(s2), …, e(sh)}.
然后, 使用UMAP(Uniform Manifold Approximation and Projection)降维技术[35]将句子表征降至d维, 降维后的句子表征集合为:
u(S)={u(s1), u(s2), …, u(sh)}.
采用HDBSCAN(Hierarchical Density-Based Spatial Clustering of Applications with Noise)技术[36]对u(S)中的句子表征进行聚类, 生成多个簇C1, C2, …, Ck, 每个簇
Cg={u(
对应一个主题Tg, 主题集合T={T1, T2, …, Tk}, 其中k表示主题数量.对主题中的句子表征进行平均池化, 得到主题表征:
e(T)={e(T1), e(T2), …, e(Tk)},
主题表征矩阵ET∈ Rk× d.最后, 根据用户、句子与主题的对应关系, 导出涉及主题Tg的用户集合{
SD-MTMP的输入包括用户项目评分矩阵R、主题矩阵ET、用户u的短期交互序列Su及相应的时间戳信息tu; 输出为用户对所有项目的预测得分, 目标是从项目集合I中找到最有可能与用户u产生交互的下一个推荐项目.
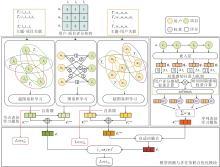
本文提出多模态序列推荐场景下融合多维感知的自蒸馏多任务学习模型(SD-MTMP), 由融合评分与主题感知的节点表征学习模块、融合评分与时间间隔感知的序列表征学习模块、模型预测与多任务联合优化模块构成, 总体框架如图1所示.
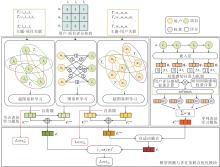 | 图1 SD-MTMP整体框架Fig.1 Overall framework of SD-MTMP |
1)在融合评分与主题感知的节点表征学习模块中, 首先, 根据用户、项目与主题之间的关联关系构建超图网络, 同时, 基于用户-项目评分矩阵构建加权二部图, 分别利用图卷积学习和超图卷积学习获得评分与主题感知的用户表征和项目表征.然后, 设计跨模态自蒸馏辅助任务, 实现主题感知表征向评分感知表征的知识迁移, 生成用户长期偏好表征与项目综合表征.
2)在融合评分与时间间隔感知的序列表征学习模块中, 分别基于用户评分与时间间隔计算各项目在用户交互序列中的权重, 再对两类权重的乘积进行归一化, 得到项目的双重感知注意力权重, 进而通过加权聚合生成用户的序列表征.
3)在模型预测与多任务联合优化模块中, 首先通过用户长期偏好表征与序列表征的自适应融合得到用户综合表征.然后计算用户与项目综合表征的内积, 得到预测得分.最后将推荐任务作为主任务, 自蒸馏学习作为辅助任务, 采用多任务学习策略训练模型, 实现对两类损失函数的联合优化.
为了获得语义丰富的用户表征和项目表征, 本节构建用户-项目加权二部图、用户-主题超图、项目-主题超图, 学习节点的评分感知表征和主题感知表征, 进而设计跨模态自蒸馏辅助任务, 融合两类表征, 生成用户长期偏好表征与项目综合表征.
2.1.1 评分感知的图表征学习
首先, 基于评分矩阵R∈ Rm× n构建用户-项目加权二部图Gui=(Vui, Eui), 其中, Vui=U∪ I表示节点集, Eui表示边集, 并将评分作为边的特征.用户初始表征矩阵P(0)∈ Rm× d, 项目初始表征矩阵Q(0)∈ Rn× d, 其中d表示嵌入维度.参考NGCF(Neural Graph Collaborative Filtering)[37], 堆叠P(0)和Q(0), 得到用户项目联合的初始表征矩阵:
E(0)=
将E(0)输入GCN中, 实现用户和项目表征的更新, 则第l+1层的节点表征矩阵:
$\begin{aligned} \boldsymbol{E}^{(l+1)}= & \operatorname{LeakyReLU}\left((\boldsymbol{L}+\boldsymbol{I}) \boldsymbol{E}^{(l)} \boldsymbol{W}_{1}^{(l+1)}+\right. \\ & \left.\boldsymbol{L} \boldsymbol{E}^{(l)} \odot \boldsymbol{E}^{(l)} \boldsymbol{W}_{2}^{(l+1)}\right), \end{aligned}$
其中, W1、W2表示可学习的参数矩阵, I表示单位矩阵,
L=
表示用户-项目二部图的拉普拉斯矩阵,
A=
R∈ Rm× n表示评分矩阵, D表示节点的度矩阵.
通过对各层的表征矩阵进行平均池化, 得到更新后的表征矩阵:
其中L表示卷积层数.
由此得到评分感知的用户表征
2.1.2 主题感知的超图表征学习
为了捕捉同一主题下的用户群体行为模式, 本文创新性地将各个主题及其关联的所有用户作为一条超边, 构建用户-主题超图:
Ghu=(Vhu, Ehu, Hhu),
其中, Vhu=U∪ T表示节点集, Ehu表示超边集, 超边eg∈ Ehu包含主题Tg及其关联的所有用户.超图Ghu对应的关联矩阵Hhu∈
其中vhu∈ eg表示超边eg包含节点vhu∈ Vhu.
将用户初始嵌入矩阵P(0)∈ Rm× d、主题初始嵌入矩阵ET∈ Rk× d堆叠成用户主题初始嵌入矩阵:
并将其与关联矩阵Hhu一起输入超图卷积网络, 得到更新后的用户主题嵌入矩阵:
其中,
超图卷积通过“ 用户-超边-用户” 的传播机制, 建模蕴含主题信息的群体高阶语义关联.由用户主题嵌入矩阵
2.1.3 基于自蒸馏的多模态表征融合
主题感知表征融合评论文本中的高阶语义知识, 具有较强的语义表达能力, 相比之下, 评分感知表征则是基于结构化的用户评分数据, 侧重于行为偏好建模, 语义信息相对缺乏.这两类表征在语义表达能力和信息丰富程度上存在天然差异, 是本文开展基于自蒸馏的多模态表征融合研究的基础和前提.为了增强模态融合效果, 可将主题感知表征作为教师表征, 评分感知表征作为学生表征, 同时引入分布对齐损失函数, 设计跨模态自蒸馏辅助任务, 实现模态间的语义对齐和知识迁移.
首先, 将主题感知的用户表征
Los
其中, KL(· ‖ ·) 表示KL散度, 用于衡量两个分布之间的差异, T(·)和S(·)均采用softmax归一化函数.
同理, 定义面向项目的跨模态自蒸馏损失函数:
Los
结合上述两种损失函数, 得到跨模态自蒸馏辅助任务的总损失函数:
LossSD=Los
教师表征向学生表征的知识迁移能使评分感知表征在保留行为特征的同时, 获得来自评论模态的语义增强, 有效提升表征质量.将优化后的评分感知用户表征
和项目综合表征
ei=
用户的短期兴趣对推荐模型的准确性具有重要作用, 本文综合考虑用户评分与时间间隔的影响, 建立双重感知注意力机制, 对用户短期交互序列Su中的项目进行加权融合, 可得到更精准的用户序列表征.
一方面, 采用softmax函数计算项目i的评分感知权重:
其中, γ1表示控制评分对权重影响程度的超参数, rui表示用户u对项目i的评分, ruj表示用户u对其它项目的评分.
另一方面, 采用指数衰减函数计算项目i的时间间隔感知权重:
其中,
融合上述两类权重, 得到项目i的双重感知注意力权重:
最后, 利用注意力权重
将用户的长期偏好表征
eu=α1
其中
α1=σ (
W
通过对用户综合表征eu与项目综合表征ei进行内积运算, 得到用户u对项目i的预测得分:
本文采用辅助任务关系建模的方式, 将推荐任务作为主任务, 跨模态自蒸馏学习作为辅助任务, 利用多任务学习策略训练模型.
主任务损失Lossbpr采用贝叶斯个性化排序方法:
$Loss_{\mathrm{bpr}}=\sum_{\left(u, i^{+}, i^{-}\right) \in O}-\ln \left(\operatorname{sigmoid}\left(\hat{y}_{u, i^{+}}-\hat{y}_{u, i^{-}}\right)\right), $
其中, ln(·)表示对数函数, O表示训练数据集, i+表示用户u交互的项目, i-表示用户u未交互的项目.
多任务联合损失Loss由主任务损失Lossbpr与2.1.3节中的跨模态自蒸馏总损失LossSD构成:
Loss=Lossbpr+γ2LossSD+λ ‖ θ
其中, γ2表示控制自蒸馏损失权重的超参数, λ 表示正则化系数, ‖ θ
为了验证SD-MTMP的有效性, 在3个数据集上进行实验.需要说明的是, 本文工作聚焦于序列推荐场景下模态内部高阶语义关联的深层次细粒度挖掘与模态融合机制的优化设计.在SD-MTMP中, 除了使用ID模态信息以外, 重点考虑评分与评论两类模态信息, 旨在通过深入挖掘评论模态内部的高阶关联关系, 实现细粒度语义层面的表征学习, 丰富评分模态下表征的语义信息, 达到提升模态融合效果及推荐准确性的目的.
本文选用Amazon 5-core数据集上的Digital Music、Instrument、Office Products子集作为实验数据集.3个子集上均包含用户ID、项目ID、用户评分、评论文本及时间戳信息, 其中, 每位用户或每个项目至少对应5条交互记录, 每条用户评分记录均有对应的评论, 具备较好的模态完整性, 满足基本的多模态推荐研究需要.各数据集的详细信息如表1所示.
| 表1 数据集统计信息 Table 1 Dataset statistics |
为了评估SD-MTMP在不同K值下的推荐性能, 将每位用户的交互序列按照时间顺序进行划分, 前80%的交互行为用于模型训练, 剩余20%的交互行为用于测试.采用命中率(Hit Ratio, HR)和归一化折损累计增益(Normalized Discounted Cumulative Gain, NDCG)作为评价指标, HR和NDCG值越高说明模型性能越优.
SD-MTMP采用PyTorch3.6框架, 实验环境包括:Windows11 64位操作系统、Pycharm2021、Python 3.6、128 GB内存、Intel Core i7-12700 CPU、NVIDIA T400 GPU.实验采用Adam(Adaptive Moment Estima-tion)优化器, 设置模型的训练批量大小为1 024, 学习率为0.001, 迭代周期为1 000, 嵌入维度d=64, 128, 256, 512, 图卷积层数L=1, 2, 3, 超参数γ1=0.4, 时间衰减系数β =0, 0.1, 0.2, 0.3, 0.4, 0.5, 控制自蒸馏损失权重的超参数γ2=0.20, 0.25, 0.40, 0.45, 0.60.使用Xavier作为网格参数初始化方法, 训练过程中采用早停技术防止模型过拟合, 设置推荐列表长度K=10, 20.
本文使用的对比模型分为单模态序列推荐模型和多模态推荐模型两类.
1)单模态序列推荐模型.
(1)文献[6]模型.运用GRU(Gated Recurrent Unit), 对用户的项目序列进行深度建模, 生成用户的长期偏好表征.
(2)SASRec[7].通过自注意力机制建模用户行为序列中的全局依赖关系, 并根据项目之间的相关性分配注意力权重, 得到用户的序列表征.
(3)SelfCF(Self-Supervised Collaborative Fil-tering Framework)[40].将自监督学习应用到基于深度学习的协同过滤框架中, 提高表征学习质量.
(4)XSimGCL(Extremely Simple Graph Contras-tive Learning Method)[41].通过特定的概率随机丢弃用户-项目二部图的边或节点, 生成不同的视图, 实现数据增强, 提升图对比学习对节点表征的优化效果.
2)多模态推荐模型.
(1)MISSRec(Multi-modal Interest-Aware Se-quential Recommendation)[42].通过预训练模态编码器获得基于ID模态、文本模态和图像模态的项目表征, 并引入动态融合模块, 自适应调整各模态对项目表征的贡献, 丰富用户的序列表征.
(2)RGCL(Review-Aware Graph Contrastive Lear-ning)[43].将评论作为边的特征, 根据评分对边进行分类, 进而基于评分和评论构建图对比学习框架, 学习用户和项目的综合表征.
(3)RRPU(Review-Based Recommendation with Preference Uncertainty)[44].利用多粒度注意力机制, 融合用户和项目的评论, 同时结合评分矩阵学习节点表征, 全面捕捉用户偏好.
参考现有融合长短期兴趣的推荐方法, 基于用户完整的历史交互记录挖掘用户长期兴趣, 并将最近20%的交互记录作为短期交互序列, 建模用户短期兴趣.
各模型在3个数据集上的指标值如表2所示, 表中黑体数字表示最优值.
| 表2 各模型在3个数据集上的指标值 Table 2 Metrics of different models on 3 datasets |
由表2可知, 文献[6]模型性能最差, 因为其结构相对简单, 并且未考虑不同项目对用户序列表征建模的贡献程度.SASRec在文献[6]模型的基础上引入自注意力机制, 可有效捕捉长序列中的依赖关系.XSimGCL和SelfCF综合运用GCN和自监督学习建模用户和项目间的复杂关系, 使推荐性能得到提升.MISSRec、RGCL和RRPU由于融合多模态信息, 可更全面地建模用户表征, 从而提高推荐准确度.SD-MTMP在绝大多数情况下均表现出良好的推荐性能, 这归因于SD-MTMP充分利用模态内部的高阶语义关系, 并通过自蒸馏引导的多任务学习实现模态间的知识迁移, 丰富节点表征的语义信息, 同时, 模型中的双重感知注意力机制可精准建模用户的短期兴趣, 进一步增强推荐效果.需要指出的是, 由于SD-MTMP目前未考虑图像模态信息, 因此在对比实验中复现MISSRec时同样未使用图像数据.
为了验证SD-MTMP中的三个关键组件— — 主题感知的超图表征学习、基于自蒸馏的多模态表征融合及融合用户评分与时间间隔感知的序列表征学习模块的有效性, 构建如下4个变体进行消融实验.
1)w/o-H.移除主题感知的超图表征学习.
2)w/o-S1.移除基于自蒸馏的多模态表征融合, 采用对比学习融合两个模态下的节点表征.
3)w/o-S2.移除基于自蒸馏的多模态表征融合, 采用拼接方式融合两个模态下的节点表征.
4)w/o-A.移除融合用户评分与时间间隔感知的序列表征学习模块.
K=10, 20时的对应消融实验结果如表3和表4所示.由表可知, SD-MTMP的性能优于w/o-H, 这说明主题感知的超图表征学习可获得语义丰富的节点表征, 从而提高学习质量.SD-MTMP的性能优于w/o-S1和w/o-S2, 表明基于自蒸馏的多模态表征融合能有效提升多模态信息的融合效果.SD-MTMP推荐效果优于w/o-A, 表明用户的短期序列能有效增强用户的兴趣表征.
| 表3 K=10时SD-MTMP关键组件的消融实验结果 Table 3 Ablation experiment results of key components of SD-MTMP at K=10 |
| 表4 K=20时SD-MTMP关键组件的消融实验结果 Table 4 Ablation experiment results of key components of SD-MTMP at K=20 |
SD-MTMP的时间复杂度主要涉及超图卷积学习、图卷积学习、双重感知注意力机制三个部分.
超图卷积学习由用户-主题与项目-主题两部分组成, 时间复杂度分别为O(mkd+md2)和O(nkd+nd2), 其中, m表示用户数量, n表示项目数量, k表示主题数量, d表示嵌入维度.
图卷积学习的时间复杂度为O(|Eui|Ld), 其中, |Eui|表示用户-项目二部图边的数量, L表示卷积层数.
双重感知注意力机制部分的时间复杂度为O(mS2d), 其中S表示序列最大长度.
综上可知, SD-MTMP的总时间复杂度为
O(md2+nd2+|Eui|Ld+mS2d).
单模态序列推荐模型SASRec的时间复杂度为O(mS2d), XSimGCL的时间复杂度为O(|Eui|Ld), 多模态推荐模型RGCL的时间复杂度包括图卷积O(|Eui|Ld)和对比学习O((m+n)kd), 其中k表示对比学习负样本数.相比之下, SD-MTMP的时间复杂度略高, 但其在性能方面提升明显, 较好地平衡性能与效率之间的关系.
通过上述分析可知, SD-MTMP的时间复杂度与用户数量、项目数量、交互数量及序列长度之间均呈线性关系, 其核心组件具备并行性.在处理具有大规模数据的真实推荐场景时, 可使用高性能的支持多线程或并行计算的硬件资源优化线性算法的执行效率, 使其时间代价在可承受范围内.此外, SD-MTMP的图卷积学习部分还包含失活机制, 可在一定程度上降低用户-项目二部图中的冗余连接, 缓解计算与存储开销.
为了直观体现模型在效率上的差别, 在Digital Music数据集上, 对比分析SASRec[7]、XSimGCL[41]、RGCL[43]和SD-MTMP在单次迭代周期下平均运行时间.结果表明, XSimGCL的运行时间最短, 仅为9 s.SASRec的运行时间为15 s.RGCL的运行时间为21 s.SD-MTMP由于模型结构更复杂, 运行时间为37 s.
虽然SD-MTMP单次迭代周期下的平均运行时间有所增加, 但其在3个数据集上均表现出较好的性能优势(见表2).以Digital Music数据集为例, 相比SASRec、XSimGCL和RGCL, SD-MTMP在HR@10和NDCG@10指标上都有所提升, 而在单次迭代周期下的平均运行时间仅增加约20 s.
在实际的推荐场景中, 数据规模不断扩大, 模态信息不断丰富, 都对模型的执行效率和部署能力提出更高要求.未来可结合如下先进技术对SD-MTMP开展轻量化研究和优化设计.
1)图结构边剪枝.引入边权评估机制, 去除低贡献边, 减少不必要的图计算开销.
2)知识蒸馏.将SD-MTMP作为教师模型, 通过模型压缩得到更小、更快、更高效的学生模型, 实现推理加速.
3)并行训练.通过图采样与子图划分策略, 将多个子图分配到不同计算单元并行执行, 提升训练效率.
本节分析SD-MTMP的4个关键超参数:嵌入维度d、卷积层数L、时间衰减系数β 、自蒸馏损失权重γ2, 研究它们在不同数据集上对模型性能的影响.
设置嵌入维度d=64, 128, 256, 512, 其在3个数据集上的HR、NDCG指标值如图2和图3所示.
 | 图2 d不同时在3个数据集上的HR值Fig.2 HR values at different d on 3 datasets |
 | 图3 d不同时在3个数据集上的NDCG值Fig.3 NDCG values at different d on 3 datasets |
由图可知, 在Digital Music数据集上, 当d=512时, 模型性能达到最优.在Instrument、Office Products数据集上, 当d=256时, 模型性能在绝大多数情况下达到最优, 但随着d的继续增加, 性能逐渐降低.
设置卷积层数L=1, 2, 3, 其在3个数据集上的HR、NDCG指标值如图4和图5所示.由图可知, 在Digital Music数据集上, 当L=3时模型性能最优.在Instrument、Office Products数据集上, 当L=2时模型性能最优.当L继续增加时, 模型出现过度平滑问题, 导致推荐性能下降.
 | 图4 L不同时在3个数据集上的HR值Fig.4 HR values at different L on 3 datasets |
 | 图5 L不同时在3个数据集上的NDCG值Fig.5 NDCG values at different L on 3 datasets |
设置时间衰减系数
β =0, 0.1, 0.2, 0.3, 0.4, 0.5,
其在3个数据集上的HR、NDCG指标值如图6和图7所示.
 | 图6 β 不同时在3个数据集上的HR值Fig.6 HR values at different β on 3 datasets |
 | 图7 β 不同时在3个数据集上的NDCG值Fig.7 NDCG values at different β on 3 datasets |
由图6和图7可知, 在Digital Music数据集上, 当β =0.2时模型性能最优.在Instrument、Office Products数据集上, 当β =0.4时模型性能最优.
结合表1中的统计信息可发现:Office Products、Instrument数据集上平均每个用户的评论数量在163条左右, 用户行为较活跃, 适合采用较大的β ; Digital Music数据集上用户平均评论数仅为30.6条, 采用较小的β 可保留更多的历史信息.
这一现象表明, 在选择β 时应充分考虑数据集规模及用户行为特征, 这样才能获得最优性能.
设置自蒸馏损失权重
γ2=0.20, 0.25, 0.40, 0.45, 0.60,
其在3个数据集上的HR、NDCG指标值如图8和图9所示.
 | 图8 γ2不同时在3个数据集上的HR值Fig.8 HR values at different γ2 on 3 datasets |
 | 图9 γ2不同时在3个数据集上的NDCG值Fig.9 NDCG values at different γ2 on 3 datasets |
由图8和图9可知, 当γ2=0.4时, 模型性能在3个数据集上均达到最优.
作为机器学习中一个极具潜力的学习范式, MTL在推荐系统领域已得到广泛应用, 然而, 目前在多模态序列推荐场景下的多任务学习研究还相对有限.本文在充分挖掘并利用多模态序列信息的基础上, 提出多模态序列推荐场景下融合多维感知的自蒸馏多任务学习(SD-MTMP).该模型分别利用图卷积学习和超图卷积学习获得评分与主题感知的节点表征, 并通过自蒸馏学习实现两类表征的跨模态知识迁移, 丰富表征的语义信息.同时, 基于用户的短期交互序列建立考虑用户评分与时间间隔的双重感知注意力机制, 精准捕捉用户的短期兴趣.在融合用户长短期兴趣的基础上, 将推荐任务作为主任务, 跨模态自蒸馏作为辅助任务, 建立自蒸馏引导的多任务学习策略, 通过两类损失函数的联合优化, 全面提升推荐效果.在3个公开数据集上的实验表明SD-MTMP性能较优.
SD-MTMP在多模态信息覆盖、多模态数据完整性、模型轻量化优化等方面的研究还有待进一步深入.未来工作将面向包含图像、视频、语音等更多模态数据的真实推荐场景开展研究.一方面, 围绕模态信息的完整性进行量化分析, 探讨无监督群体构建与跨模态信息补全等策略, 在此基础上, 深入挖掘各类模态内部的复杂语义关联, 在持续优化推荐主任务的同时, 设计更合理有效的跨模态知识迁移辅助任务和多模态融合机制, 进一步拓展多任务学习在不同推荐场景中应用的广度和深度, 并注重增强模型的可解释性.另一方面, 根据推荐系统在工业环境中的实际部署需求, 积极探索图结构边剪枝、知识蒸馏与并行训练等模型轻量化方法, 并结合图采样策略与分布式图计算平台, 在推荐模型的实用性、实时性、可扩展性等方面进行创新性研究.
本文责任编委 马少平
Recommended by Associate Editor MA Shaoping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|