
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
可信伪标签增强的模式兴趣主动学习评估框架
[王甜1  , 王璐
, 王璐1 , 谢文波1 , 王欣1
, 王璐, 谢文波, 王欣]
|
|



作者简介:

王 甜,硕士研究生,主要研究方向为数据挖掘、机器学习.E-mail:202422000617@stu.swpu.edu.cn.

王 璐,硕士研究生,主要研究方向为数据挖掘、机器学习.E-mail:202322000560@stu.swpu.edu.cn.

谢文波,博士,副教授,主要研究方向为数据挖掘、知识图谱.E-mail:wenboxie@swpu.edu.cn.
频繁模式挖掘(Frequent Pattern Mining, FPM)是图数据挖掘领域中的关键任务之一,目标是从大规模图数据中挖掘支持度高于预设阈值的模式.受评估指标单一且忽略主观偏好的制约,FPM往往面临挖掘结果与用户需求匹配度较低的问题.因此,文中提出可信伪标签增强的模式兴趣主动学习评估框架(Certified Pseudo-label Enhanced Active Learning Framework for Pattern Interest Evaluation, CPALF),旨在通过少量用户交互,精准预测用户对模式的主观偏好.CPALF采用主动学习策略,通过人机交互高效收集用户偏好,实现对用户兴趣的建模.考虑到仅依赖有限的标注数据训练模型面临的诸多挑战,CPALF进一步融合半监督学习机制,面向未标记数据生成带有可信伪标签的训练样本,在降低对标注数据依赖的同时,显著提升模型预测效果.实验表明,CPALF能高效捕捉用户的主观偏好,并在少量标注数据的情况下,获得较高的预测准确率.
About Author:
WANG Tian, Master student. Her research interests include data mining and machine learning.
WANG Lu, Master student. Her research interests include data mining and machine learning.
XIE Wenbo, Ph.D., associate professor. His research interests include data mining and knowledge graph.
Frequent pattern mining(FPM) is one of the key tasks of graph data mining. The objective of FPM is to extract patterns with support values higher than predefined thresholds from large-scale graph data. However, constrained by single-dimensional evaluation metrics and neglect of subjective preferences, traditional FPM methods often fail to align mining results with the expectations of users. To address this issue, a certified pseudo-label enhanced active learning framework for pattern interest evaluation(CPALF) is proposed. CPALF is designed to accurately predict subjective pattern preferences of users through minimal human interaction. An active learning strategy is employed to efficiently collect the preferences of users via human-computer interaction. CPALF incorporates semi-supervised learning to generate high-confidence pseudo-labeled training samples from unlabeled data, thereby significantly improving prediction performance while reducing annotation dependency. Experiments demonstrate that CPALF effectively captures the preferences of users with high prediction accuracy under limited labeled data.
单一大图上的频繁模式挖掘(Frequent Pattern Mining, FPM)作为图数据分析的关键任务之一, 始终面临效率与效用的双重挑战.为了约束结果集, 提升挖掘结果可用性, 传统算法大多采用支持度作为评估指标, 挖掘top-k频繁模式, 如GRAMI(Graph Mining)[1], 这导致结果集上以高频、简单的小模式为主, 如单边模式, 它们与用户需求相差甚远.因此, Wang等[2]引入模式规模特征, 提出APRTOPK, 近似挖掘满足支持度阈值的前k个有趣模式, 但该方法仍以模式的客观指标作为评价依据, 依然存在挖掘结果与用户实际兴趣不相符的情况.如何准确捕捉用户真实偏好已成为FPM任务中亟待解决的关键问题之一.
挖掘社交网络图中的top-k频繁模式, 对于理解其中的典型结构具有重要意义, 但不同模式度量指标的选择会直接影响挖掘结果与实际需求的匹配度.如前所述, 传统的FPM方法以支持度作为评估指标, 返回的top-k模式中包含大量高频却结构单一的模式.top-k模式集合虽结构复杂, 却与用户真实偏好存在偏差, 这是因为模式大小指标与具有“ 反单调” 特性的支持度指标相互“ 抵触” .当分析人员针对用户协作模式展开挖掘时, 上述两类“ 客观” 评估指标下的top-k结果离分析需求往往相去甚远.其原因在于:协作模式要么高频但过于简单, 要么复杂但结构冗余.相比之下, 若能理解用户的主观偏好, top-k模式将更契合用户需求, 即引入用户偏好作为度量指标后能更准确识别符合用户实际需求的模式组合.然而, 引入用户兴趣涉及兴趣建模, 作为关键任务之一的用户标注获取的代价极高, 耗费大量的人力和时间成本.因此, 设计兴趣评估模型, 引入用户主观评价面临两个关键挑战:1)高效筛选最具信息量的样本子集以优化标注质量; 2)在降低标注成本的同时确保模型精准捕捉用户的偏好特征.
另一方面, 预测模型的性能深受训练样本规模与质量的影响, 而精准建模用户兴趣需要大量的标注数据.近期研究表明, 借助可信伪标签, 可以在减少数据标注量的同时, 实现与监督学习接近的预测准确率[3, 4].
受此启发, 本文提出可信伪标签增强的模式兴趣主动学习评估框架(Certified Pseudo-Label Enhanced Active Learning Framework for Pattern Interest Evalu-ation, CPALF).采用主动学习策略与用户进行有限轮次的交互, 同时引入半监督学习范式, 使用高可信伪标签样本扩充训练集, 显著降低标注成本, 实现预测模型的高效学习.在主动学习环节, 设计基于最近邻搜索[5]的方法(Nearest Neighbor Search-Based Re-presentativeness, NNS-Repre), 评估候选模式的代表性, 依托构建的最近邻图, 提出融合节点度中心性和归一化边权重的模式代表性量化方法.进一步地, 结合模式代表性与不确定性度量(如信息熵), 形成模式选择机制.在真实数据集上的实验表明, CPALF在测试集上表现较优, 主观评价可保留用户感兴趣的模式.通过少量样本学习即可接近全监督学习的性能水平, 充分体现其在小样本场景下的优势.CPALF可有效缓解标注成本与模型性能之间的平衡问题, 为资源受限场景下的模型训练提供实用的解决方案.
在实际应用场景中, 用户通常只关注最感兴趣的前k个模式, 因此, 采用特定的约束条件识别前k个模式至关重要.当前研究引入不同方法挖掘前k个最频繁的子模式.Elseidy等[1]提出GRAMI, 使用支持度作为指标, 在模式数量约束下进行模式挖掘.Wu等[6]提出COPP-Miner, 发现时序数据中的关键模式.Wang等[7]提出DisMiner, 结合“ 前瞻回溯” 和“ 部分求值” 策略, 减少计算和内存开销.
为了满足用户对大规模模式的需求, Wang等[2]提出APRTOPK, 采用“ 逐层” 策略, 保证算法的提前终止性, 并且以模式大小作为指标, 衡量每个模式的趣味性, 近似挖掘前k个有趣的模式.邹杰军等[8]提出一种无需用户设置初始支持度阈值的Top-Rank-K模式挖掘算法(ItrMiner), 同时考虑将模式的支持度和模式大小作为兴趣度度量, 挖掘高兴趣度模式.针对动态增量数据库的持续更新特性, Lee等[9]提出ITHUI(Incremental Top-k High Utility Itemset Mining Algorithm), 构建列表结构, 存储模式的最小效用信息, 发现top-k高效用模式.
尽管上述方法通过多种客观指标识别top-k模式, 但未充分考虑用户的主观偏好.
主动学习(Active Learning)是一种机器学习策略.该类方法智能选择对模型训练最有价值的样本进行标注, 最大程度提升模型性能的同时降低标注成本.其核心问题是设计有效的样本查询策略, 使有限的标注资源被最合理利用.
一类通用的主动学习方法是根据模型预测的不确定性选择样本进行标记, 如使用熵[10]或BALD[11]等指标衡量.直观上, 这些样本是模型“ 最困惑”、“ 最难以判断” 的, 标注这些样本能最大化改进模型.近期工作如Nguyen等[12]提出梯度不确定性指标, 衡量样本对模型梯度的影响程度, 识别信息量最大的样本.Raj等[13]开发高效的二分类不确定性估计器, 确保算法在低标注成本下的有效收敛.然而, 过度关注高不确定性样本可能导致算法选择噪声样本, 难以准确拟合整体数据分布.
另一类方法旨在选择具有代表性的样本进行标注, 如通过核方法(Core-Set)[14]选择与已标记样本特征最不相似的样本, 但容易识别异常值.Wang等[15]提出CALS(Cost-Sensitive Active Learning Through a Unified Evaluation and Dynamic Selection), 从高密度区域选择样本, 避免异常值的影响.为了提升样本选择的代表性和均衡性, 基于聚类的主动学习方法挖掘数据内在的群集结构, 优化标注策略.Zhou等[16]提出的预聚类方法通过增强的聚类算法与多样性指标融合, 有效降低标注需求, 实现更均衡的样本选择.谢文波等[17]提出基于改进最近邻图的主动聚类方法(Active Clustering with Tailored Nearest Neighbor Graph, ACNNG), 设计动态邻域优化和混合查询策略, 显著提升聚类精度的同时降低标注成本.
基于代表性的查询策略避免只聚焦难以判别的“ 边界” 样本, 对整个数据分布具有较好的覆盖且较稳健, 不容易被异常点和噪声影响, 但可能忽略模型当前的困惑区域.于是, 一些研究结合上述两种策略, 充分兼顾样本的模型学习价值和数据覆盖多样性.Wu等[18]设计渐进式多样性约束策略, 在每轮迭代中动态调整不确定性与多样性的权重, 避免样本的重复和信息瓶颈.Doucet等[19]利用自监督预训练优化特征空间稳定性, 通过联合优化多样性和不确定性指标, 使主动学习模型仅需少量初始标注即可精准筛选高信息量样本.Wang等[20]针对3D空间中目标样本的稀疏性和复杂性, 设计多粒度选择策略, 平衡模型的不确定性, 识别样本空间的多样性, 在复杂3D场景中实现细粒度样本选择, 减少冗余标注.
为了降低深度学习对标注数据的依赖, 半监督学习通过协同利用少量标注样本与大量未标注数据, 显著减少人工标注成本.半监督训练通常通过伪标记技术[21]和一致性正则化方法[22]利用未标记的样本.伪标记涉及使用模型预测作为训练未标记数据的目标, 通常只使用高置信度预测, 减少错误目标对半监督训练的影响.一致性正则化旨在使模型的预测对于因一致性损失而引起的扰动输入保持一致.近期研究主要集中于提高伪标签质量, 如将伪标记和一致性正则化结合, 提高半监督训练性能.Sohn等[3]提出FixMatch, 在相同的输入图像上采用强增强和弱增强, 使用来自弱增强版本的高置信度模型预测作为强增强图像的目标, 但在训练初期, 模型对许多样本的预测置信度较低, 导致收敛缓慢.为了解决此问题, Zhang等[4]提出FlexMatch, 引入动态置信度阈值, 平衡收敛速度和伪标签准确性.
现有研究通过自监督预训练, 如多阶段GCN(Graph Convolutional Network)框架[23]、主动自监督学习[24]及异构模型一致性验证(如多模型加权投票机制[25]), 显著提高伪标签的可靠性.
虽然现有方法通过动态阈值[4]和模型集成[25]提升伪标签的质量, 但在硬标签形式下, 仍可能过拟合噪声预测, 导致性能下降[26].Mü ller等[27]研究表明, 在噪声环境下, 标签平滑通过软化目标分布, 能有效抑制模型对错误伪标签的过拟合.此外, 对于特定场景如医疗图像小病灶检测, Chen等[28]验证KL散度比交叉熵更鲁棒, 因为KL散度能更好地衡量概率分布之间的相似性.在GNN(Graph Neural Net- work)方面, Verma等[29]提出GraphMix, 通过KL散度约束下的节点特征混合操作, 在图结构感知框架中实现伪标签分布一致性优化, 显著提升节点分类性能.
定义1 图[30] 给定三元组标签图G=(V, E, L), 其中, V表示节点集合, E表示边集合, V中节点v附带标签L(v).图G的子图Gs=(Vs, Es, Ls), 其中Vs⊆V, Es⊆E, 并且对于∀ v⊆Vs, 都有Ls(v)=L(v).
定义2 模式[2] 一个模式Q被定义为一个图(Vp, Ep, fv), 其中, Vp表示节点集合, Ep表示边集合.对于节点u⊆Vp, 标签fv(u)为一组原子公式的连接, 每个原子公式被定义为“ A=a” , A表示节点u的一个属性, a表示属性A对应的值.
定义3 模式匹配[30] 给定图G=(V, E, L)和模式Q=(Vp, Ep, fv), 如果G中节点v满足Q中节点u的查询条件, 即对每个fv(u)中的原子公式A=a, 在L(v)中都有对应的属性A, 使得v.A=a, 则称v满足u, 并用v~u表示两者间的满足关系.
图G中模式Q的“ 匹配” 是一个从Q到G的同构映射f, 使得:1)对于每个节点u∈ Vp, fv(u)~L(f(u)); 2)对于每条边(u, u')∈ Ep, 当且仅当(f(u), f(u'))∈ E.当模式Q与G的子图Gs=(Vs, Es, Ls)存在同构映射关系f时, Gs为Q在G中的一个匹配.
沿用上述“ 匹配” 的语义, 称v∈ Vs是u∈ Vp(即f(v))的匹配.模式Q在G中的匹配通常不止一个, 本文使用M(Q, G)表示模式Q在图G中的所有匹配, 使用img(u)表示G中所有与节点u∈ Vp匹配的节点.
定义4 支持度[30] 模式Q在图G中的支持度记为Sup(Q, G), 表示Q在G中出现的频率.基于图像的最小支持度是一种广泛使用的支持度指标, 具有反单调的特性, 其计算公式如下:
Sup(Q, G)=min{|img(u)|, u∈ Vp},
其中img(u)表示模式Q中节点u在图G中匹配节点的集合.本文使用最小支持度作为支持度指标.
定义5 模式大小[2] 给定模式Q=(Vp, Ep, fv), 模式大小定义为
|Q|=|Ep|+|Vp|,
其中, |Ep|表示模式边数, |Vp|表示模式节点数.
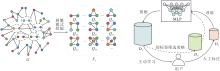
本文提出可信伪标签增强的模式兴趣主动学习评估框架(CPALF), 旨在通过有限次数的人机交互学习用户对模式的偏好, 并训练分类模型预测模式兴趣类别, 发现用户感兴趣的模式.CPALF总体框架如图1所示.
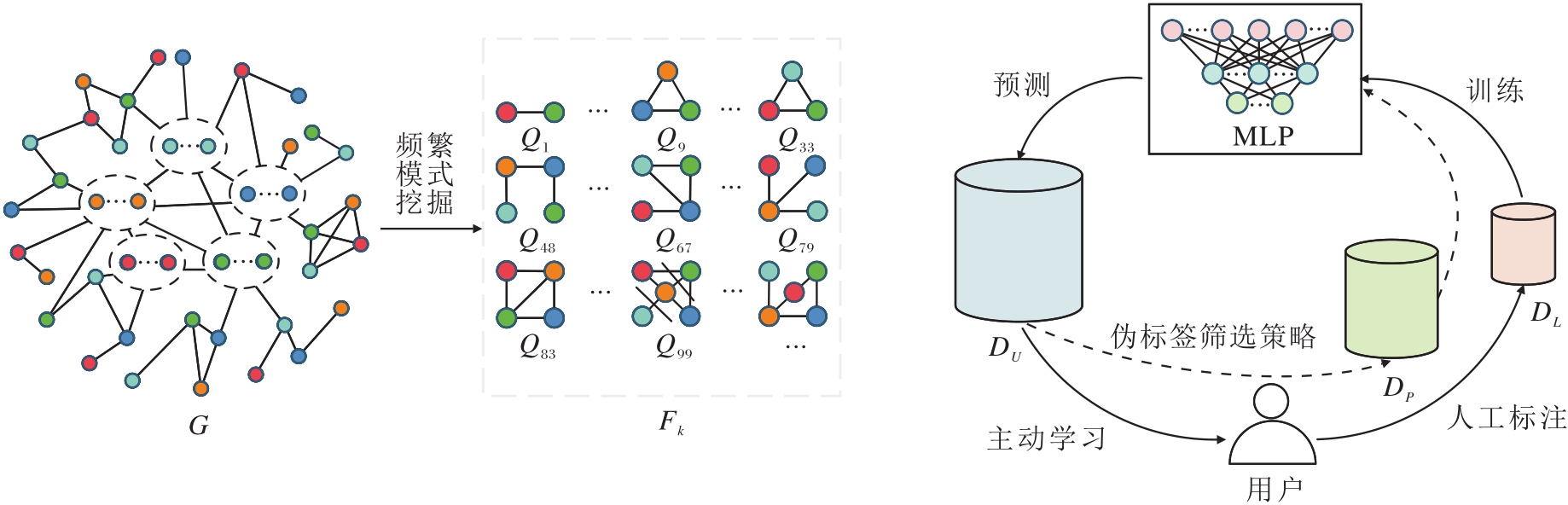 | 图1 CPALF总体框架Fig.1 Overall framework of CPALF |
首先, CPALF调用频繁模式挖掘算法[30], 在数据图G中挖掘, 获得频繁模式Fk.然后使用融合最小DFS Code[31]和基于二进制的标签编码策略对频繁模式进行编码, 并将编码集合存储于集合Fk中.最后, 设计基于最近邻搜索的方法(NNS-Repre), 评估模式的代表性, 获取一组代表性模式集合Pr及基于最近邻关系形成的近邻图Gp.通过多轮主动学习迭代优化标注集合, 形成训练样本.
为此, 一个融合代表性与不确定性的评估指标被用于候选模式的选择.具体而言, 在初始轮次, 根据用户预设参数(总交互轮数iter, 每轮交互数numt), 优先选择“ 代表性” 最高的numt个模式进行人工标注, 获取标注样本集合DL.根据用户反馈进行监督训练后, 多层感知机为未标记样本池DU中的模式生成预测结果.此时通过信息熵[32]量化无标签样本的不确定性, 并设计伪标签筛选策略(Pseudo-Label Filtering Strategy, PLFS), 提取可信伪标签DP.在后续轮次中, 通过线性加权结合不确定性与代表性得分, 筛选信息量最丰富的numt个候选模式进行人工交互, 同时整合用户标注样本与可信伪标签样本, 实现半监督训练.该过程持续迭代优化, 每轮均基于前次模型的预测结果重新计算模式的信息价值分数, 同时更新可信伪标签, 实现标注效率与模型性能的协同提升.最终输出符合用户主观兴趣的偏好预测.值得一提的是, 模型输入为DL(或DU)中模式对应的编码及其偏好类别Pkind(或伪标签Ptpl).在测试过程中, 模型输出每个模式的喜好类别, 使用整数表示用户对模式的喜好程度, 数字越小, 表示用户对该模式喜好的程度越高.
鉴于频繁模式挖掘、最小DFS code以及MLP(Multilayer Perceptron)预测等技术已有大量研究成果, 故本文将研究重点聚焦在NNS-Repre和PLFS上, 其它内容不再赘述.
在主动学习中, 查询策略的设计至关重要.有效的查询策略能从大量未标注数据中精准识别最具信息价值的样本, 实现模型学习效果提升与标注成本降低的双重目标.传统的查询策略往往依赖于单一指标, 如不确定性或代表性, 导致样本选择存在偏差.单纯依赖不确定性可能会导致偏向选择边界样本, 忽略数据分布的全局结构; 仅基于代表性的策略可能会忽略模型当前面临“ 困惑” 的样本, 而偏向选择对模型提升价值不大的样本, 导致学习效率低下.
为了克服上述问题, 本文设计基于不确定性和代表性的评估指标Ivs(·), 选择在模型预测中存在较大不确定性、同时在数据分布中具有较好代表性的样本, 从而提高模型的学习效果.具体计算公式如下:
Ivs(Qi)=α Uncert(Qi)+(1-α )γ (Qi), (1)
其中, γ (Qi)表示代表性分数, Uncert(Qi)表示不确定性分数, α 表示一个介于0和1之间的超参数, 用于线性加权平衡模式选择的两个关键指标.
为了确保不同数据能在相同范围内进行对比和分析, 对γ (Qi)和Uncert(Qi)分别采用最小最大归一化方法[33]:
s'=
将数据线性变换到[0, 1]内, 其中, s表示原始数据, s'表示归一化后的数据, min(s)、max(s)分别表示数据集上分数的最小值和最大值.这里γ (Qi)、Uncert(Qi)表示归一化后的结果.
最终, 从候选样本中筛选那些既具有高不确定性, 又能有效代表整体数据分布的样本进行标注.这种策略能在保证信息量丰富的同时, 确保选取的样本在提升模型性能上具有重要价值, 从而提升主动学习的效果.
本文设计NNS-Repre, 计算候选模式的代表性.具体伪代码如算法1所示.
算法1 NNS-Repre
输入Fk中所有模式的编码集$X=\left\{\boldsymbol{x}_{i}\right\}_{i=1}^{n}$
输出 近邻图Gp, 按代表性分数大小对模式降序排序的字典Pr
1. Gp∶ =(V=X, E=Ø );
2. E=$\cup_{v_{i} \in V}\left\{\left(e=\left\langle v_{i}, N N\left(v_{i}\right)\right\rangle, w=\operatorname{dist}\left(v_{i}, N N\left(v_{i}\right)\right)\right)\right\}$;
3. for each vertex vi in V do
4. calculate γ (vi) according to Eq(2);
5. end for
6. pr∶ =Patterns sorted in descending order by the value of γ (vi);
7. return Gp, Pr
NNS-Repre输入为一组模式的编码集合$X=\left\{\boldsymbol{x}_{i}\right\}_{i=1}^{n}$, 其中, xi为模式Qi通过其最小DFS code和基于二进制的标签编码嵌入得到的向量, X表示Fk中所有模式的编码集.算法输出为近邻图Gp, 以及根据代表性分数值对模式进行降序排序的结果, 收集于字典Pr中.
NNS-Repre首先为$X=\left\{\boldsymbol{x}_{i}\right\}_{i=1}^{n}$中的所有数据点构造对应的节点集合, 并作为图Gp的节点集V(第1行).再将每个节点vi与其最近邻节点NN(vi)相连, 形成图Gp的边集E.在此过程中, 设定最近邻节点数为3, 即每个节点将与除自身之外的两个最近邻节点建立连接, 节点vi的最近邻节点都是与其在样本空间中最相似的样本.同时, 为每个边(vi, vj)分配一个权重w(vj, vi), 权重值为连接节点之间的欧氏距离(第2行).基于构建完成的图Gp, 根据其拓扑结构评估Gp中节点的代表性, 即计算每个模式的代表性分数γ (·)(第3~5行):
$\gamma\left(v_{i}\right)=d\left(v_{i}\right)+\frac{1}{W} \sum_{e_{j i} \in E} \frac{1}{w\left(v_{j}, v_{i}\right)}$, (2)
其中, d(vi)表示点vi的邻居数, w(vj, vi)表示点vi与其邻居vj的权重, W表示整个图的边权值总和.γ (vi)分数越高, 节点vi的邻居数量越多且连接越紧密, 也意味着节点vi处于样本空间中相对密集的区域.这种密集性使节点vi能更好地代表这个集中区域内的样本特征.最后, NNS-Repre根据γ (vi)降序排序模式, 并收集到一个字典Pr中, 返回图Gp和Pr, 用于下一个交互阶段(第6~7行).
本文采用信息熵[32]计算模式的不确定性分数.当预测概率均匀分布时, 信息熵达到最大值, 反映模型对该模式的分类存在显著不确定性.当预测概率高度集中于某一类别时, 信息熵趋近于0, 表明模型对该模式的分类具有高度置信度.通过该量化方法, 可精确识别模型预测结果中的模糊样本, 为主动学习提供可靠的决策依据.模式Qi的不确定性分数:
Uncert(Qi)=-
将模型的预测分数logits转换为类别概率, 采用softmax函数, 该函数确保输出的概率值在0~1之间, 并且所有类别的概率之和为1.设模型对模式Qi的预测结果logits向量zi=[zi1, zi2, …, zic], c表示类别数.运用softmax公式计算每个类别的概率:
P(yij|Qi)=
其中, zij表示logits向量中的第j个元素, yij表示样本xi属于类别j的事件.模型的任务是评估P(yij|Qi), 即在给定模式Qi的条件下, 其属于类别j的概率.
例1 给定模式Q1和Q9(如图1所示), 其信息价值分数计算过程如下.
首先, 结合模式的最小DFS code及基于二进制的标签编码得到模式的向量表示, 将编码统一为固定维度, 不足位补0.模式Q1的DFS code为(0, 1, 3, 1, 2), 对应的最终编码为(0, 1, 011, 001, 010…); 模式Q9的DFS code为
(0, 1, 4, 1, 1), (0, 2, 4, 1, 2), (1, 2, 1, 1, 2),
对应的最终编码为
(0, 1, 100, 001, 001, 0, 2, 100, 001, 010, 1, 2, 001, 001, 010…).
再计算模式的代表性分数, 由NNS-Repre构建近邻图Gp, 其中每个模式被视为图中的一个“ 节点” , 用vi表示.Q1的邻居数d(v1)=3, 边权值集合
w(vj, v1)={w31, w41, w51}={1, 1, 2};
Q9的邻居数d(v9)=4, 边权值集合
w(vj, v9)={w29, w69, w79, w59}={1, 1, 1, 2}.
图Gp边权值总和W=100.根据式(2)可得
γ (v1)=3.025, γ (v9)=4.035.
然后, 基于模型预测计算不确定性分数, 两个模式的预测logits向量分别如下:
logits(Q1)=[2.0, 1.0, 0.5, 0.3, 0.2],
logits(Q9)=[0.1, 0.2, 0.9, 0.15, 0.1],
类别总数C=5.经过softmax处理后, 再根据式(3)计算不确定性分数:
Uncert(Q1)≈ 1.337, Uncert(Q9)≈ 1.549.
最后, 根据式(1)计算模式的信息价值分数.归一化Uncert(Qi)和γ (vi)后, 由于参数α 设为0.6, 最终可得
Ivs(Q1)< Ivs(Q9).
因此, Q9被认为是更具有标注价值的模式.
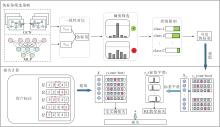
对于模型生成的预测结果, 本文提出伪标签筛选策略(PLFS), 流程如图2所示.PLFS包含3个实施步骤:1)伪标签一致性验证; 2)动态阈值下的伪标签筛选; 3)类别不平衡下的伪标签约束, 限制每类伪标签数量.
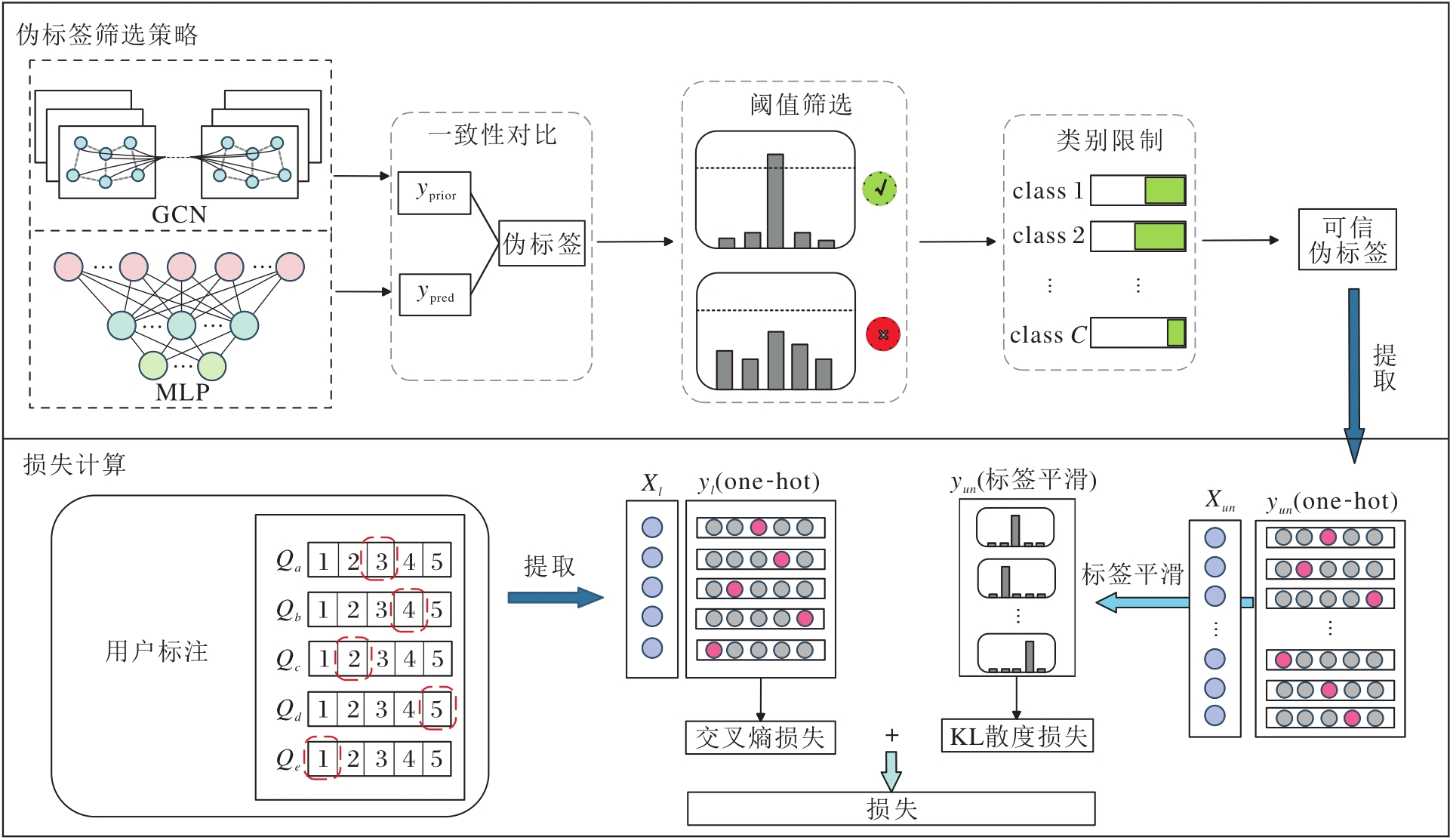 | 图2 伪标签筛选策略及损失计算Fig.2 Pseudo-label filtering strategy(PLFS) and loss computation |
为了选择可信伪标签, 建立标签预测结果一致性判别方法, 即分别搭建GCN和MLP, 验证标签在两个模型下的预测结果是否一致.
首先, 搭建GCN.该模型的输入是基于NNS-Repre构建的近邻图Gp, 具体包括:节点集合(每个节点对应一个模式的特征向量)、边连接关系(反映模式间的近邻拓扑结构)、边权重(量化模式间的相似性强度)、用户标注的模式真实类别.标注节点的标签信息通过多层消息传递机制逐步传播至未标注节点.GCN基于邻域聚合原理, 强制拓扑相邻节点在表示空间中平滑过渡, 能有效过滤与图拓扑冲突的MLP预测, 如相邻模式出现突变标签的情况.具体而言, GCN通过消息传递迭代聚合邻居节点特征, 传播运算可表示如下:
H(l+1)=σ (
其中,
然后, 搭建MLP预测模型.该模型输入为标注模式的特征向量及用户标注的模式真实类别, 模型输出为无标注节点的预测ypred.
GCN对无标签节点的预测本质是结构感知的标签传播.MLP捕捉模式的局部特征, 而GCN利用图结构建模全局模式关联, 二者一致性可反映样本在特征与关系层面上的双重可信度.当MLP(基于模式特征独立预测)与GCN(基于图结构传播预测)的预测结果一致时, 表明该伪标签同时满足特征判别性和图结构一致性.这种交叉验证可有效降低噪声标签的引入风险.
为了解决应用固定阈值筛选过程中存在的类别不平衡和过早采纳低质量标签的问题, 借鉴Flex-Match[4]动态阈值的思想, 设计伪标签筛选策略(PLFS).具体步骤如下.为每个类别单独维护一个自适应阈值, 该阈值会根据模型对该类别的学习状态动态调整.当模型在某个类别上的表现较优时, 阈值会相应降低, 从而放宽筛选条件, 允许更多置信度较低但仍有价值的伪标签被采纳; 对于学习较弱的类别, 阈值则维持较高水平, 从而保证只选取高置信度的伪标签.根据
Confi=
从计算得到的概率分布中选取最大概率, 为模式Qi的置信度分数.
类别c的阈值τiter(c)的动态更新依赖于当前轮次中该类别的平均预测置信度, 并通过平滑策略稳定调整, 避免剧烈波动影响训练过程.类别c在第iter轮的动态阈值为:
$\begin{array}{c} \tau_{\text {iter }}(c)=\frac{\sum_{i=1}^{B} \mathbb{I}\left(\hat{y}_{i}=c\right) \cdot \operatorname{Conf}_{i}}{B_{c}+\epsilon}, \\ \tau_{\text {iter }}(c) \leftarrow \lambda \tau_{\text {iter }-1}(c)+(1-\lambda) \tau_{\text {iter }}(c) . \end{array}$ (5)
其中:B表示当前无标签样本数; Bc表示类别c的预测数量;
式(5)引入平滑系数λ 稳定阈值调整, 通过融合历史阈值与当前估计, 避免因单次迭代的波动导致筛选条件突变.通过这种基于类别学习状态的阈值自适应调整, 动态阈值策略不仅提高伪标签的整体质量, 还有效缓解类别间不平衡问题, 提升模型训练效果和泛化能力.
为了进一步提升伪标签的整体质量并缓解标签类别不平衡问题, 增加对每类伪标签数量的限制.这一设计主要基于两方面考虑.1)当仅依赖伪标签一致性验证和动态阈值下的伪标签筛选时, 筛选的伪标签数量可能过多, 使错误伪标签的绝对数量显著增加.通过限制每类伪标签的数量, 可有效减少错误样本的引入, 降低噪声累积风险.2)在未限制类别数量的情况下, 模型对表现较好的类别(如A类)会生成大量伪标签, 而对表现较差的类别(如B类), 通过动态阈值下的伪标签筛选会导致伪标签数量极少数甚至没有.这种不平衡会加剧模型的偏差, 导致其进一步忽略少数类(如将真实B类样本误判为A类).通过限制每类伪标签的数量, 强制均衡各类别的参与度, 避免模型过度偏向多数类, 从而在维持精度的同时提升模型鲁棒性.
PLFS具体伪代码如算法2所示.
算法2 PLFS
输入 图Gp=(V, E), 图代表性模式集合Pr, 当轮各类阈值τiter(c), 类别总数C, 每轮交互数numt
输出 伪标签Ptpl
1. initialize DL∶ =Ø , DU∶ =Ø , Pkind∶ =Ø , Ptpl∶ =$\{c: \varnothing\}_{c=1}^{C}$;
2. DL∶ =the top-numt patterns are selected based on Ivs(·) computed from Eq(1);
3. present visual pattern Qi in DL to user for feedback to obtain Pkind;
4. DU∶ =Pr\DL;
5. GCN.train(V, E, Pkind), MLP.train(Pkind);
6. yprior∶ =GCN.predict(V, E);
7. yprior∶ ={yprior[Qi]|Qi∈ DU};
8. ypred∶ =MLP.predict(DU);
9. for each pattern Qi in DU do
10. if c∶ =(yprior[Qi]==ypred[Qi]) and Confi> =τiter(c) and Ptpl[c] isn't full
11. then Ptpl[c].append(Qi);
12. end if
13. end for
14. return Ptpl
PLFS首先初始化4个有限集合:已标注模式集DL、未标注候选集DU、用户反馈类别集Pkind、按类别分组的伪标签字典Ptpl(第1行).依据式(1)计算集合Pr 中各模式的信息价值分数Ivs(·), 并选取最具信息量的前numt个模式存入DL中; 同时将DL中的模式Qi可视化后与用户交互, 获取用户标注反馈, 生成一组用户偏好类别Pkind(第2~3行).剩余模式构成未标注候选集合DU(第4行).然后分别训练GCN与MLP, 开展伪标签严格筛选流程(第5~13行).具体而言, 先训练GCN与MLP(第5行), 再利用GCN和MLP对未标注候选集合DU进行预测, 分别输出预测结果yprior和ypred(第6~8行), 并展开如下伪标签筛选策略(第9~13行).对每个未标注模式Qi∈ DU执行三重过滤:1)要求GCN与MLP预测标签一致; 2)模式Qi的预测置信度Confi需超过当轮该类别阈值τiter(c); 3)伪标签所属类别c的伪标签集Ptpl[c]未达上限.满足条件的模式将被加入对应类别的伪标签集上(第9~13行).最终筛选可信任的伪标签Ptpl并返回(第14行).
接下来, 这些可信任的伪标签样本将与真实标签样本结合, 形成一个新的训练集.在训练过程中, 可使用这两种样本进行半监督学习:一种是可靠的真实标签样本, 另一种是可信任的伪标签样本.这种策略不仅能有效扩充训练数据集, 还能充分利用未标记样本的潜在信息.
针对标注来源的不同可靠性, CPALF采用差异化损失函数, 流程如图2所示.对于人工标注的硬标签(Hard-Label, HL), 使用交叉熵损失(Cross-Entropy Loss, CE)[34], 保留人工标注的确定性信号.对于模型生成的伪标签, 通过标签平滑(Label Smoothing, LS)[27]将伪标签转化为软分布后计算KL散度损失(KL-Divergence Loss, KL)[35], 缓解过拟合并增强训练稳定性.
损失函数由两部分组成:标记样本的交叉熵损失和伪标签样本的KL散度损失, 即
Loss=LL+Lun, (6)
其中,
Ll=CE(M(Xl), yl),
表示计算标记样本Xl上的交叉熵损失, yl表示用户的真实标注,
Lun=KL(M(xun), LS(yun)),
表示计算伪标签样本Xun上KL散度损失, LS(yun)表示对伪标签yun进行标签平滑, M(·)表示MLP.
伪标签的原始softmax输出可能包含模型预估偏差(如对预测类别过度置信), 而标签平滑通过为标签分布引入均匀分布先验, 有效抑制此类异常值的干扰.尤其在类别不平衡的低质量伪标签场景中, 标签平滑的正则化作用占据主导地位, 能显著降低模型对噪声伪标签的过拟合风险, 提升半监督学习的稳定性.
实验环境为一台配备3.31 GHz CPU和NVIDIA GeForce RTX 4060 Laptop GPU的Windows 11主机.实验代码均由Python 3.10编写, 所有实验均在CPU环境下完成.
实验选择如下6个真实数据集.1)Mico数据集[1], 对Microsoft合著信息进行建模的图表.2)Aviation数据集[1], 从航空安全报告中捕获事件关系的图表.3)Twitter数据集[8], Twitter网站社交网络图.4)Skitter数据集[30], Skitter网站互联网拓扑图.5)Twitch数据集[36], 流行的社交网络.6)DBLP数据集[37], 论文出版网络图.相关统计信息如表1所示.
| 表1 数据集统计信息 Table 1 Dataset statistics |
本文选择如下评价指标.
1)准确率.具体计算公式如下:
Accuracy=
其中, pred(N)表示CPALF对测试集的预测结果集合, N表示测试集大小, real(N)表示这N个模式的用户真实喜好评价集合, |pred(N)∩ real(N)|表示pred(N)和real(N)的交集个数, 即类别预测正确的个数.
2)Macro-F1[38].F1分数是衡量分类模型性能的综合指标, 是准确率和召回率的调和平均, 能在类别不平衡的情况下提供更全面的评估.具体计算公式如下:
F1=2(
其中
Precision=
表示模型预测为正例的样本中实际为正例的比例,
Recall=
表示所有正例中被模型正确预测的比例, TP表示模型正确预测的正例, FP表示模型错误预测为正的负例, FN表示模型错误预测为负的正例.
采用Macro-F1, 即对每个类别的F1分数F1c取算术平均值, 平等对待所有类别, 避免多数类主导结果, 具体公式如下:
Macro_F1=
模型训练采用端到端的方式, 为了最小化总损失函数(式(6)), 采用Adam(Adaptive Moment Esti-mation)优化器更新MLP的参数.具体而言, 在每轮迭代训练中, 优化器根据有标签数据计算的交叉熵损失和无标签数据计算的KL散度损失之和进行反向传播, 更新模型权重.
优化过程中的关键超参数设置如下:学习率0.001, 批量大小64(有标签数据)和64× 7(无标签数据).训练过程持续固定轮数为50.在每轮迭代中先清零梯度, 前向计算有标签数据和无标签数据的损失, 相加后执行反向传播与参数更新.
为了科学合理地选定式(1)中的α 值, 基于ADP(Active Density Peak)[39]的参数估计方法, 在6个真实数据集上系统研究α 对CPALF的影响.定义α =0.2, 0.3, …, 0.9, 固定每轮交互数numt=5.记Api(α )为CPALF在第i个数据集上预测结果的准确率.当CPALF通过主动学习选择交互模式和通过伪标签筛选策略选择可信伪标签并完成模型训练后, 得到不同α 值对应的算法准确率:
Api={Api(0.2), Api(0.3), …, Api(0.9)}.
鉴于准确率的变化, 本文定义平均缩放偏差对比α 值, 具体公式如下:
bias(α )=
其中, A
计算6个数据集上的平均缩放偏差, 结果如表2所示.由表可知, 当α =0.6时, 平均缩放偏差最小, CPALF的准确率最高.因此, 后续实验将参数α 设为0.6.
| 表2 α 对CPALF的影响 Table 2 Effect of α on CPALF |
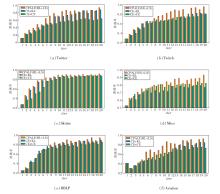
在6个数据集上定义初始阈值τ =0.941, 0.942, …, 0.960, 评估τ 对CPALF的影响.实验过程中固定其它关键参数, numt=5, α =0.6.针对不同初始阈值τ 对应错误率的变化情况, 每幅图聚焦展示在谷值(最低点)附近的局部变化情况, 选取的谷值均为全局最优, 并采用全监督方法作为评估CPA- LF效果的性能上限, 结果如图3所示.由图可发现, 在6个数据集上, CPALF的性能整体趋近于全监督方法的水平线, 表明CPALF在多数情况下能有效利用有限的标签数据逼近全监督学习的表现.
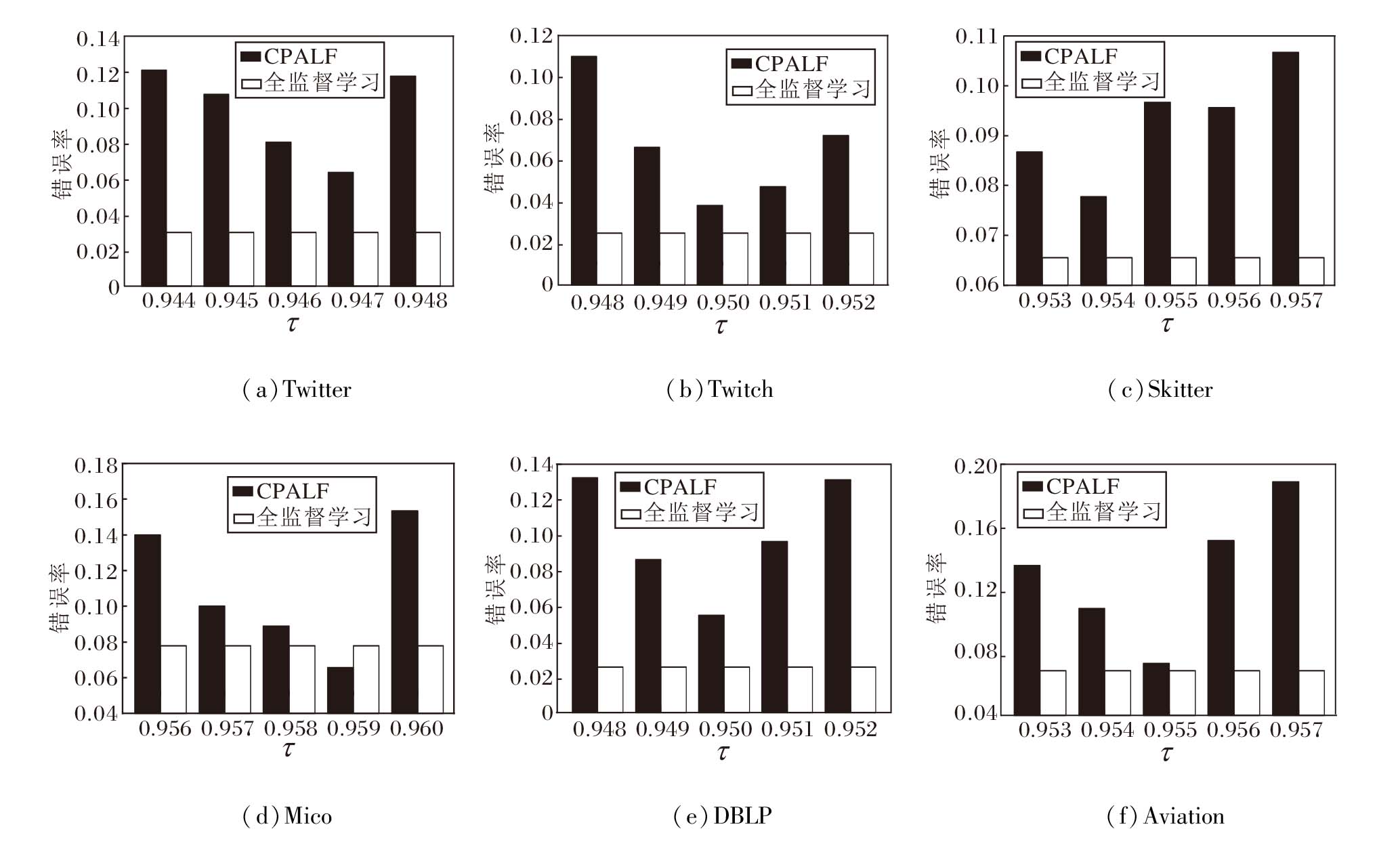 | 图3 τ 改变对CPALF的影响Fig.3 Effect of τ on CPALF |
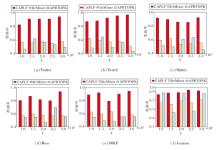
定义频繁模式数量k=1 000, 1 500, …, 3 000, 评估CPALF与两种传统频繁模式挖掘算法(APRTOPK[2]、ItrMiner[8])对模式集合进行排序的性能差异, 包括APRTOPK的模式大小|Q|和ItrMi-ner的兴趣分数
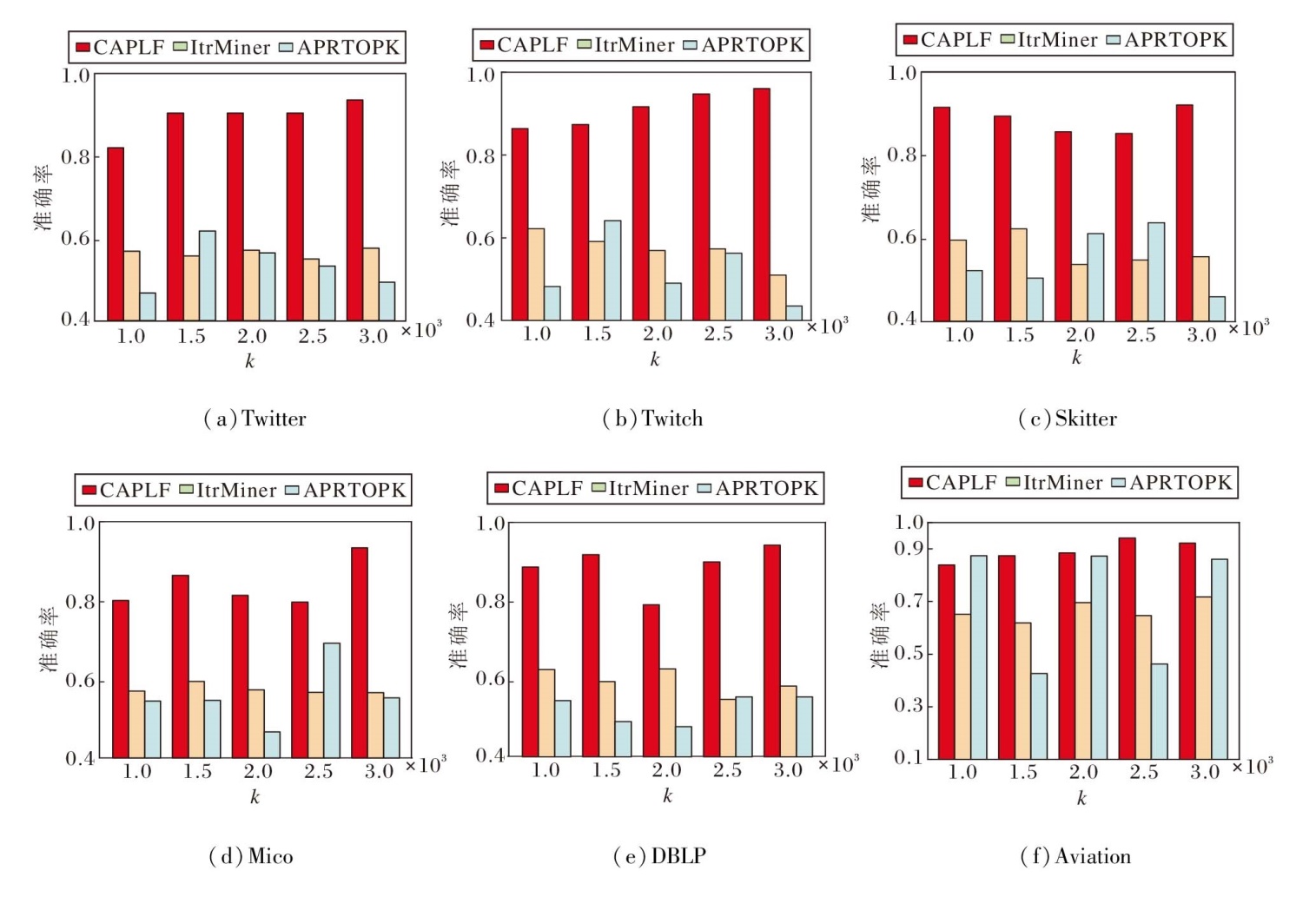 | 图4 k对3种算法的影响Fig.4 Effect of k on accuracies of 3 algorithms |
固定α =0.6和k=3000, 定义每轮交叉数numt=5, 10, 15, 20, 评估numt对CPALF的影响.
选择两种主观评价方法作为对比方法:1)基于主动学习的模式兴趣评估方法(Pattern Interesting-ness Evaluation with Active Learning, PIEAL)[40], 在人机交互时, 设计成对比较策略, 降低用户主观评价难度.2)PT4AL(Pretext Tasks for Active Learning)[41].基于自监督的主动学习方法, 高效选择最具信息量的模式进行标注, 实现模式的主观偏好预测.
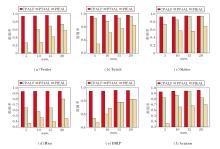
3种算法的准确率对比如图5所示.
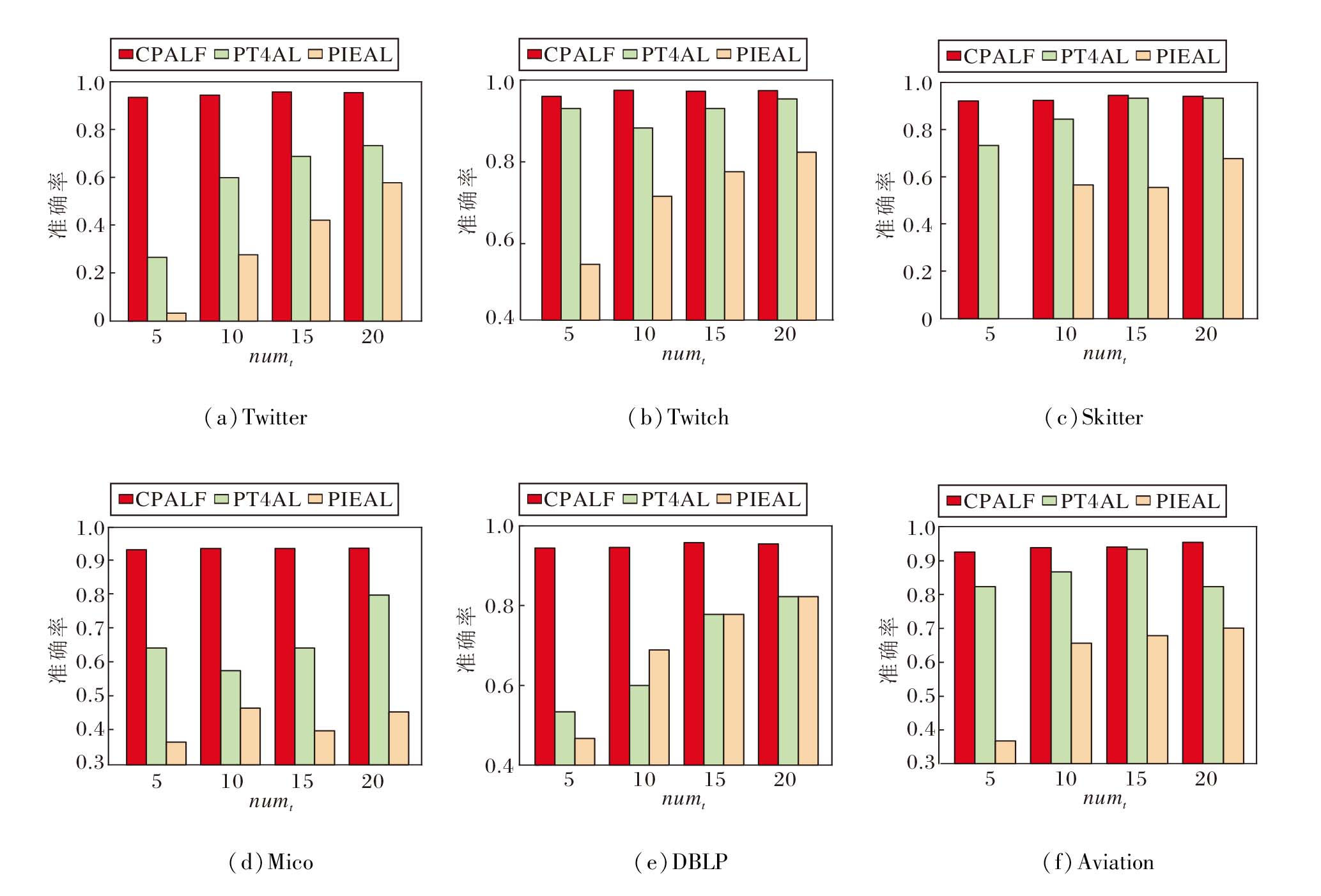 | 图5 numt对3种算法的影响Fig.5 Effect of numt on accuracies of 3 algorithms |
由图5可见, 当numt较低时, 相比对比方法, CPALF展现出更显著的优势, 性能提升幅度较大, 验证其能通过生成高质量伪标签有效弥补标注数据的不足.
值得注意的是, 随着numt的减少, CPALF在所有数据集上始终保持稳定性能, 准确率持续超过对比方法, 并稳定在0.9以上.相比之下, 对比方法需要更多的交互才能达到类似性能.这一结果有力证实CPALF能通过最小化的人机交互高效捕捉用户偏好特征, 实现准确预测.
综上所述, CPALF在资源受限情况下的表现优秀, 尤其在标注成本高昂或用户偏好快速变化的应用场景中, 显著的性能优势和较低的交互需求使其具有广阔的应用前景和实用价值.
为了验证伪标签筛选策略(PLFS)在筛选高质量伪标签方面的有效性, 设计如下实验, 采用监督学习进行性能对比, 分析PLFS中每个部分的指标值, 具体如表3所示.在表中, 策略1表示伪标签一致性验证, 策略2表示动态阈值下的伪标签筛选, 策略3表示类别平衡下的伪标签约束, PLFS(fixed τ )表示固定阈值下的伪标签筛选, Avg_num_pl表示平均每轮选择的伪标签数量, 黑体数字表示最优值.实验固定总轮次为20, numt=5, k=3 000, α =0.6.
| 表3 伪标签筛选策略性能对比 Table 3 Performance comparison of pseudo-labeling filtering strategies |
策略1中GCN以原始样本特征、样本真实标签及样本间的图结构关系为输入, 学习样本的拓扑关联特征, 输出经过与MLP一致性校验的伪标签集合.策略1充分利用图结构隐含的拓扑约束, 在一定程度上提高伪标签的可靠性, 如在Skitter数据集上取得最佳准确率和Macro-F1.虽然策略1在6个数据集上均取得优于监督学习的性能, 但Avg_num_pl值普遍偏高, 说明仅依靠拓扑一致性仍会保留较多的伪标签, 增加模型的计算负担, 存在优化空间.策略2仅选择置信度高于阈值的样本, 虽伪标签数量有所减少, 但仍可能因置信度校准不足或类别不平衡问题引入偏差.结合策略1与策略2后, 模型同时考虑拓扑一致性与置信度约束, 在多数数据集上取得更好的筛选效果.然而, 在部分数据集上, 联合策略未全面展现出相比单独策略的优势.这一现象的产生不仅与伪标签的质量相关, 也与伪标签数量的减少有关.这种减少可能导致一些虽然置信度不高, 但实际上预测正确的样本信息被遗漏, 而这些信息对于模型性能的提升可能是有帮助的.策略3通过对每类伪标签数量进行上限控制, 有效缓解类别不平衡导致的确认偏差问题.将其与策略1结合后, 在大幅降低伪标签数量的同时保持模型性能, 体现出良好的效率-效果平衡.
最终, 对比固定阈值下的PLFS(fixed τ )和动态阈值下的PLFS.结果表明, PLFS在显著降低伪标签数量的同时提升模型性能, 如在DBLP数据集上, Avg_num_pl值降至22, 准确率升至0.944 4.从总体上看, PLFS在降低计算成本的同时可显著提升伪标签的可靠性, 最终实现模型性能的系统性优化.
为了有效处理不同来源标注数据的可靠性差异, CPALF采用差异化损失函数框架.该框架针对高可靠性的人工标注硬标签(HL), 采用交叉熵损失(CE), 确保模型对可靠标注的精确学习; 对于模型生成的伪标签, 则通过标签平滑(LS), 将其转化为软分布后计算KL散度损失(KL), 缓解其潜在的噪声影响并增强训练稳定性.这种差异化处理具有三重优势:1)通过平滑机制有效抑制模型过度置信问题; 2)在类别不平衡场景下自动增强正则化效果; 3)有效过滤低质量伪标签中的噪声干扰.
实验固定α =0.6, numt=5, 定义总交互轮数iter=1, 2, …, 20.设置3种损失计算方法:有标签样本和伪标签概率分布分别使用CE和KL损失计算(CE+KL)、有标签样本和伪标签概率分布统一使用CE损失计算(CE+CE)、CPALF(HL+LS), iter改变时的准确率如图6所示.由图可见, 在模型训练早期阶段, 各方法的准确率接近, 表明模型尚未充分学习有效特征.随着迭代的进行, CPALF(HL+LS)开始出现提升趋势, 并逐渐超过其它方法.这种优势原因如下:伪标签筛选策略逐步筛选高质量伪标签, 针对不同标注来源的样本采用不同损失的计算方法, 缓解早期噪声积累问题, 有效抑制低质量伪标签的负面影响, 使模型在不同训练阶段始终保持稳定的学习能力.这一差异化的损失函数设计, 不仅有效应对混合质量标注数据的挑战, 还在保持模型学习能力的基础上, 增强模型在潜在错误标签情况下的鲁棒性.
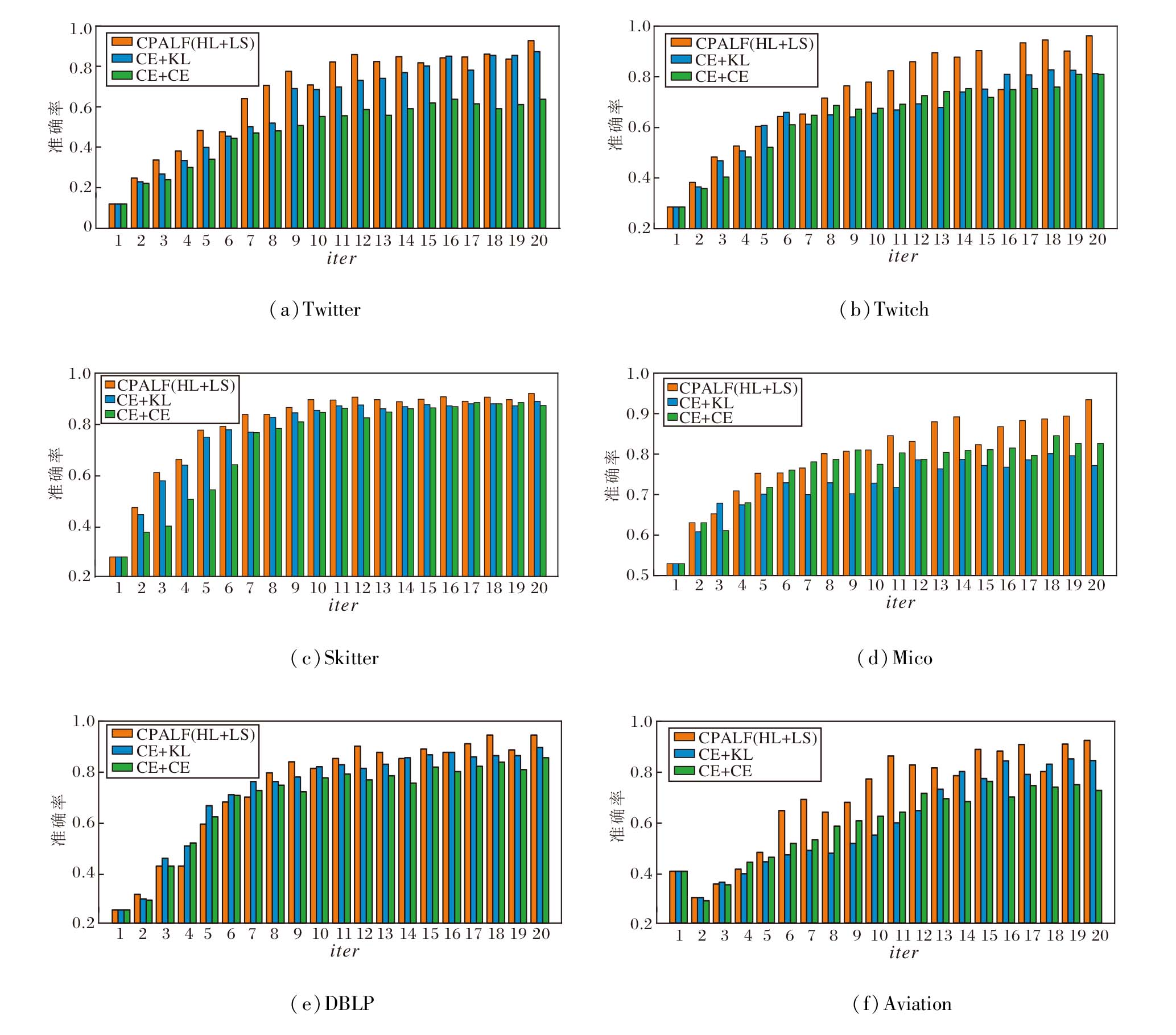 | 图6 损失计算方法对算法准确率的影响Fig.6 Effect of loss calculation methods on algorithm accuracy |
本文提出可信伪标签增强的模式兴趣主动学习评估框架(CPALF), 融合主动学习与半监督学习的优势, 实现用户偏好特征的高效建模与低成本标注, 有效解决传统频繁模式挖掘中因依赖客观评估指标而产生的与用户真实偏好不相符的问题.CPALF结合最近邻搜索与信息熵度量构建主动学习查询策略, 从图数据挖掘生成的候选模式集合中选择交互样本, 进行多轮人机交互, 动态捕获用户的偏好特征.设计严格的伪标签筛选策略, 扩充训练集, 在保证模型性能的同时大幅降低标注依赖.实验表明, CPALF仅需约3%的标注数据即可达到全监督学习性能的较高水平, 测试集上准确率最高达96%.本文通过可信伪标签生成与主动学习策略的协同优化, 为资源受限场景下的用户兴趣建模提供可扩展的解决方案, 为频繁模式挖掘中的个性化推荐提供新的思路.今后将考虑探索更复杂的用户兴趣表征方式及拓展伪标签筛选策略, 提升模型的泛化能力与计算效率.
本文责任编委 陶 卿
Recommended by Associate Editor TAO Qing
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|