
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于自适应粒球与纯净簇拆分的开放意图分类
[王景凯1  , 李艳花
, 李艳花1 , 刘家芬1 , 王向坤1 , 杨新1 ]
, 李艳花, 刘家芬, 王向坤, 杨新]
|
|



作者简介:

王景凯,硕士研究生,主要研究方向为多粒度学习、开放世界学习、少样本学习.E-mail:wjk_robin@163.com.

李艳花,博士研究生,主要研究方向为三支决策、多粒度学习、持续学习.E-mail:yyhhliyanhua@163.com.

王向坤,硕士研究生,主要研究方向为持续学习、开放世界学习、少样本学习.E-mail:xiangkunwang18@gmail.com.

杨 新,博士,教授,主要研究方向为可信联邦学习、持续学习.E-mail:yangxin@swufe.edu.cn.
开放意图分类是构建智能对话系统的重要任务之一,其目标是在识别已知意图的同时准确检测未知意图.然而,现有方法在建模复杂语义结构方面存在局限,难以刻画类别内部的多样性分布,容易导致类间混淆.为此,文中提出基于自适应粒球与纯净簇拆分的开放意图分类方法(Adaptive Granular-Ball and Pure Cluster Splitting for Open Intent Classification, AGPCS-OIC).首先,通过自适应粒球聚类构建反映数据真实分布的多中心子类结构,刻画类内异质性.然后,引入结构稀疏性驱动的纯净簇拆分策略,进一步划分边界松散但纯度较高的粒球,提升决策边界的表达能力和对未知类别的排斥能力.同时,结合粒球感知对比学习机制,以粒球中心为锚点构建结构级语义对,引导模型在特征空间中增强类内聚合性与类间可分性.实验表明,AGPCS-OIC在多个开放意图分类数据集上性能较优.
About Author:
WANG Jingkai, Master student. His research interests include multi-granularity lear-ning, open world learning and few-shot lear-ning.
LI Yanhua, Ph.D. candidate. Her research interests include three-way decision, multi-granularity learning and continual lear-ning.
WANG Xiangkun, Master student. His research interests include continual learning, open world learning and few-shot learning.
YANG Xin, Ph.D., professor. His research interests include trustworthy federated learning and continual learning.
Open intent classification is a critical task in building intelligent dialogue systems, and it is intended to detect unknown intents accurately while recognizing the known ones. However, existing methods are limited in modeling complex semantic structures and fail to represent the diversity within intent classes, resulting in inter-class confusion. To address this issue, a method for adaptive granular-ball and pure cluster splitting for open intent classification(AGPCS-OIC)is proposed. First, adaptive granular-ball clustering is applied to construct multi-center subclass structures reflecting the true data distribution, and thus intra-class heterogeneity is captured more effectively. Then, a structural sparsity-based pure cluster splitting strategy is introduced to further divide loosely bounded but high-purity granular-balls. The expressiveness of decision boundaries and the ability to reject the unknown intents are enhanced. Additionally, a granular-ball-aware contrastive learning mechanism is incorporated. Structural-level semantic pairs are built with granular-ball centers serving as anchors, to guide the model to improve intra-class compactness and inter-class separability in the feature space. Experiments show that AGPCS-OIC achieves strong performance on multiple open intent classification datasets.
随着智能对话系统与人机交互技术的快速发展, 意图识别作为理解用户语义需求的重要任务之一, 在金融助理、智能客服、语音助手等实际应用中发挥着关键作用[1].传统意图识别方法通常依赖封闭类别假设, 即默认测试阶段不会出现训练集上未涵盖的类别[2, 3, 4].然而, 现实环境中的用户请求具有高度开放性, 模型面临识别未知意图的挑战.因此, 如何在保持对已知类别判别性能的同时, 准确识别未知类别, 成为当前开放意图分类研究中的核心问题之一[5, 6].
为了提升开放识别能力, 已有研究者提出基于置信度阈值的方法[7, 8]、基于距离度量学习的方法[9, 10]和多粒度决策边界建模方法[11, 12, 13]等.基于多粒度决策边界建模的粒球聚类方法因其良好的边界可解释性和结构适应性, 受到广泛关注.该方法通过在特征空间中围绕同类样本构建不同半径的粒球, 对已知类别形成局部聚合结构, 以此划定判别边界, 实现对未知类别的检测[14, 15].尽管该方法在开放语义空间下展现出一定优势, 但仍存在如下两个关键局限.
首先, 在开放意图分类中, 基于多粒度决策边界建模的粒球划分策略主要依赖类别纯度作为拆分准则, 当粒球纯度较低, 即粒球内部包含多个类别样本时, 将视为“ 混合粒球” 并进行拆分[16, 17], 当粒球纯度较高时就不再对其进行拆分, 这种拆分方式缺乏对粒球内部结构特征的有效刻画.部分粒球虽然纯度较高, 但其内部样本分布可能极为松散、半径过大.这些“ 稀疏的纯净簇” 由于缺乏足够紧致的几何边界, 极易在推理阶段吸纳未知类样本, 形成伪判别区域, 从而对系统整体开放识别能力造成负面影响.因此, 仅依据类别纯度进行划分, 无法充分约束粒球边界的几何结构, 难以应对开放空间中“ 内嵌型” 未知意图的干扰.
其次, 现有表征学习方法难以有效利用粒球结构优化语义空间.传统表征优化多在样本层面进行, 忽略粒球间蕴含的结构语义关系, 尤其是在类内多中心结构普遍存在的语义场景中, 难以实现类内对齐与类间分离的最优表征, 缺乏结构感知的表征机制, 限制模型在复杂开放语义空间中的适应能力.
为了解决上述问题, 本文提出基于自适应粒球与纯净簇拆分的开放意图分类方法(Adaptive Gra-nular-Ball and Pure Cluster Splitting for Open Intent Classification, AGPCS-OIC), 从粒球结构构造与语义表征两个层面协同优化, 提升模型在开放语义空间下的判别能力与泛化性能.在判别边界构造方面, 引入结构稀疏性判定机制, 在传统类别纯度准则基础上, 进一步综合粒球的样本分布密度与半径尺度, 对结构松散但纯度较高的粒球纯净簇进行细化拆分, 增强粒球边界的表达精度.在语义建模方面, 设计粒球感知对比学习机制, 以粒球中心作为结构级语义锚点, 在粒球层面构建对比对, 优化同类粒球之间的一致性与异类粒球之间的可分性, 提升特征空间的结构感知能力.在5个主流开放意图分类数据集上开展系统实验, 从已知类别分类性能、未知类别识别能力这2个维度进行评估, 结果表明, AGPCS-OIC在各项指标上均较优, 表现出强大的开放语义识别能力与实用价值.
开放意图分类任务与开放集识别密切相关, 但又具有其特定挑战:一方面, 意图数据多为短文本, 信息密度较低、表述多样, 给表征学习带来困难; 另一方面, 意图之间边界模糊, 部分未知意图可能与多个已知类别具有语义相似性, 导致模型容易误判.近年来, 已有多种方法应用于开放意图分类任务.大致可分为如下三类.
1)基于置信度阈值的方法.此类方法通常借助神经网络分类器输出的概率分布, 设定一个固定或动态的置信阈值, 当预测概率不满足该阈值时, 将样本判为未知类别, 如DOC(Deep Open Classification)[5]、Maximum Softmax Probability[8]和OpenMax[18]等.方法尽管实现简单, 但是对于区分已知意图和未知意图的阈值, 经常难以定义.
2)基于距离度量学习的方法.此类方法强调样本间的特征空间关系, 尝试通过构建类别中心或学习样本间的距离度量函数, 使已知类别之间的边界更清晰, 从而更好地区分未知样本.Chen等[9]提出ARPL(Adversarial Reciprocal Points Learning), 引入互反点表征开放空间, 结合对抗学习优化样本与互反点的距离, 实现未知类检测.Xu等[10]提出MDF(Mahalanobis Distance Features), 利用马氏距离度量测试样本与已知类高斯分布的距离.这类方法在提升未知类检测能力方面表现较优, 但仍面临类别内部结构建模不足的问题.
3)多粒度与决策边界建模方法.近年来, 研究者开始关注如何通过显式建模类别边界以提升开放识别能力, 典型代表方法包括ADB(Adaptive Deci-sion Boundary)[11]、DA-ADB[12]与MOGB(Multi-gra-nularity Open Intent Classification Method via Adaptive Granular-Ball Decision Boundary)[14]等.其中, 粒球建模是一种有效的结构建模方式, 通过将类别表示为多个局部球形区域, 使决策边界不再依赖全局中心, 而是更贴合类别内部结构变化.
具体而言, 设训练集上每个样本xi的特征表示zi∈ Rd, 类别标签yi∈ {1, 2, …, K}.ADB假设每个已知类别k的特征表示服从以ck为中心、以Δk为半径的球形分布, 即
$\mathcal{B}_{k}=\left\{\boldsymbol{z}_{i} \in \mathbf{R}^{d}:\left\|\boldsymbol{z}_{i}-\boldsymbol{c}_{k}\right\|_{2} \leqslant \Delta_{k}\right\}$,
其中, ck表示类别k的样本中心, Δk表示通过Soft-plus函数映射的可学习半径.该定义以几何方式刻画每个类别在特征空间中的球形区域, 从而通过训练学习形成具备类内约束的闭合边界结构.模型通过最小化边界损失函数, 促进同类样本聚集在各自的球形区域内部, 并抑制样本越界, 提升分类器的判别能力.在此基础上, DA-ADB引入距离感知系数γi, 动态调节不同样本的训练贡献, 特别是边界模糊样本的判别学习.该系数定义如下:
γi=exp(‖ zi-
其中,
粒球计算是一种融合人类认知规律与多粒度计算思想的数据表示与分析方法, 最早由Xia等[16]提出.该方法源于人类“ 由粗到细” 的认知方式[19], 通过构建不同半径和中心的球形区域以近似和覆盖数据分布, 从而实现对数据的多尺度建模和分层表达.
粒球计算的核心在于利用自适应构造的“ 粒球” 结构划分和表达样本空间.每个粒球由其球心和半径定义, 分别表示球内数据的集中位置和离散程度.在构造初始结构时, 将所有样本聚合形成一个初始粒球, 在满足一定的纯度与样本数量条件下, 粒球会被进一步划分为更小的子球, 逐层细化.这种策略无需预设类别数量, 具有良好的结构适应性[20].具体而言, 粒球的中心通常为其内部样本向量的均值, 而半径可通过计算样本到中心的平均距离获得.通过设定最小纯度阈值和最小样本数限制, 算法能自动决定是否继续分裂当前粒球, 从而达到自动建模数据局部结构的目的[16].
粒球计算无需预设类别数量等超参数, 具备良好的结构适应性与可解释性, 广泛适用于分类、聚类、特征选择等任务, 并在实际应用中展现出较强的鲁棒性和泛化性.
设训练集
Dtrain={(xi, yi)
其中, xi表示输入语句, yi∈ Yknown表示对应意图标签, N表示意图样本个数.测试集
Dtest={(xj, yj)
标签空间Ytest包含已知类Yknown与未知类Yunknown, 即
Ytest=Yknown∪Yunknown.
开放意图分类任务的目标是构建一个分类模型, 使其在测试阶段能准确识别属于已知类别Yknown的样本, 并将来自未知类别Yunknown的样本判定为unknown, 从而实现对已知类别识别与开放类别检测的统一处理.
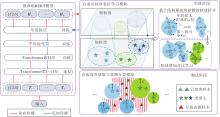
本文提出基于自适应粒球与纯净簇拆分的开放意图分类方法(AGPCS-OIC), 具体架构如图1所示.AGPCS-OIC主要包括两个模块:自适应粒球表征学习模块、决策边界获取与意图分类模块.自适应粒球表征学习模块在训练阶段构建并优化语义空间中的粒球结构, 通过有监督聚类生成初始粒球, 并结合类别纯度与结构特征动态拆分粒球:对纯度不足的“ 混合粒球” 执行类别驱动的拆分, 对半径过大、结构松散的“ 稀疏纯净簇” 执行结构敏感的精细划分.自适应粒球表征学习模块通过粒球聚类与基于最近子类质心的归属计算以调整语义表示, 从而增强类别表示的结构完整性与类别间的区分能力.在此基础上, 决策边界获取与意图分类模块以最终粒球结构为依据, 构建多粒度局部决策边界.在测试阶段, 样本若不落入任何粒球判别区间, 则被视为属于未知类别.
 | 图1 AGPCS-OIC架构图Fig.1 Architecture of AGPCS-OIC |
在表征学习阶段, 本文利用BERT(Bidirec-tional Encoder Representations from Transformers)预训练模型对意图文本进行编码.该模型的前11层Transformer层是被冻结的, 最保留最后一层用作训练, 从最后一层提取
[CLS, T1, T2, …, TL]∈ R(L+1)× H
的词元(Token)嵌入, 其中, CLS表示分类标记, L表示输入文本的词元数量, H表示嵌入维度.对其平均池化以获取句子的语义表示:
xi=MeanPooling([CLS, T1, T2, …, TL]),
其中MeanPooling(·)表示平均池化.
然后使用一个前馈神经网络层, 将语义表示映射为最终的意图向量:
zi=ReLU(Whxi+bh),
其中, Wh∈ RD× H表示权重矩阵, bh∈ RD表示偏置向量.
接下来, 为了刻画意图类别在特征空间中的多中心结构特征, 针对所有已知类别c∈ Yknown, 在特征空间中进行自适应粒球聚类.该过程以构建初始粒球为起点, 将所有同类样本聚为一个大粒球, 随后依据类别纯度与样本数量划分该粒球:当某粒球的纯度
$\boldsymbol{O}_{s}^{c}=\frac{1}{n_{s}} \sum_{z_{i} \in g b_{s}^{c}} \boldsymbol{z}_{i}, r_{s}^{c}=\frac{1}{n_{s}} \sum_{z_{i} \in g b_{s}^{c}}\left\|\boldsymbol{z}_{i}-\boldsymbol{O}_{s}^{c}\right\|_{2}$,
其中, ns表示粒球g
其中, max|· |表示粒球中占比最多类别(主标签
其中, 距离度量dis(· , ·)采用欧氏距离, 用于度量样本与各类中心的相对关系.进一步地, 为了实现可导训练过程, 定义基于粒球距离的类别概率分布:
p(y=c|zi)=
在上式中, 分子部分表示样本zi到类别c粒球中心的距离得分, 分母部分则对所有类别归一化, 形成概率分布.与MOGB[14]保持一致, 定义分类粒球分类损失函数:
Lgb=-
其中yi表示样本的真实标签.该损失旨在提升样本对其真实类别中心的亲和度, 从而提升类别判别能力.为了进一步增强类内一致性并拉开类间边界, 本文引入粒球感知对比学习机制.该机制以粒球中心为对比锚点, 对于每个样本zi, 其正样本定义为所属类别中所有粒球中心, 负样本为所有其它类别的粒球中心.具体地, 给定温度系数τ , 粒球感知对比损失定义如下:
Lcontrast=-
其中,
结合上述两种机制, 构建最终的联合训练目标:
Ltotal=Lgb+λ Lcontrast,
其中超参数λ 控制粒球感知对比损失的权重.该联合策略不仅提高表示的判别性, 还增强模型对开放类分布变化的鲁棒性.
粒球的拆分不仅应关注类别纯度, 还应兼顾其在特征空间中的结构合理性.仅依赖纯度判断, 难以处理那些虽由同类样本构成但分布稀疏的粒球.此类粒球可能覆盖过大的空间区域, 从而削弱对未知类的排斥能力.
为此, 本文在纯度拆分的基础上引入结构稀疏性判断机制, 进一步细化纯净但松散的粒球, 提升决策边界的精度与鲁棒性.当粒球纯度
其中, δ 表示结构稀疏系数,
在具体拆分过程中, 为了更有效识别粒球边缘结构, 采用基于双中心的再拆分策略.首先选取与几何中心
za=arg
随后, 以za为参照点, 选取粒球内距其最远的样本zb作为第二拆分中心:
zb=arg
若za≠ zb, 则以二者作为两个新子簇的初始中心, 依据最小距离原则, 将粒球内其余样本划分至距离更近的中心对应的簇中.随后, 分别对每个子簇重新计算其中心与半径, 从而生成两个新的子粒球.该过程不仅保持类别标签的一致性, 还显著提升粒球的结构紧致性与边界表达能力, 有助于增强模型对未知类的排异能力.为了避免过度划分引发的类别碎片化问题, 拆分操作仅在粒球样本数超过最小阈值(即ns> τn)时才会被执行.
在测试阶段, 模型使用训练阶段得到的子类粒球中心和半径构建每个类别的多粒度决策边界.对每个待测样本zi, 计算其与所有粒球中心的距离.若对所有粒球中心
基于文献[11]方法, 本文选择在如下5个常用数据集上进行实验.
1)BANKING数据集[21].涵盖77类意图的银行客服数据, 类别重叠较多, 分类难度较大.
2)OOS数据集[22].包含150个意图和1 200个未知查询, 适用于开放识别任务.
3)HWU64数据集[23].跨越21个领域的多意图数据集, 共计64类意图, 场景丰富.
4)SNIPS数据集[24].由14 484条语句组成, 包含7个不同的意图类别.
5)StackOverflow数据集[25].包含3 370 528个编程问题标题的数据集, 涵盖20类.
为了全面评估AGPCS-OIC在不同开放性水平下的表现, 设置不同的已知类别比例(25%、50%和75%)以模拟不同程度的开放场景.在表征学习阶段, 采用预训练的BERT作为特征提取器, 仅微调其最后一层参数以增强语义区分能力.训练批次大小设为128, 学习率设为2e-5, 最大训练轮次设为100.粒球拆分和筛选阶段使用的纯度阈值均设为0.9, 最小样本数阈值根据不同的数据集规模进行调整.
此外, 为了增强实验结果的稳定性和可靠性, 所有实验均在3个不同随机种子下独立运行3次, 最终结果取3次实验的平均值.
本文采用整体准确率(Accuracy, ACC)和整体F1分数(F1-A)作为评估方法综合性能的主要指标.此外, 为了更全面分析方法在开放场景下的识别能力, 进一步计算已知类别的F1分数(F1-K)和未知类别的F1分数(F1-U), 分别衡量方法在已知意图识别与未知意图检测方面的性能.
本文选取如下7个具有代表性的开放意图分类方法作为对比方法, 验证AGPCS-OIC的有效性.
1)DOC[5].通过高斯拟合建立概率阈值, 进行开放意图分类.
2)文献[8]方法.基于softmax最大值作为置信度进行开放意图分类.
3)ADB[11].基于类内样本自适应构建质心和决策边界.
4)DA-ADB[12].在ADB基础上学习距离感知的意图表示, 获得适当的决策边界.
5)MOGB[14].多粒度开放意图分类方法, 能精准建模复杂意图结构, 并提升未知意图的识别能力.
6)OpenMax[18].训练时学习类别中心, 并利用类间距离进行开放空间建模与重校准.
7)OLT(Open-World Lottery Ticket)[26].提出开放世界彩票票据假设, 通过剪枝获得可信子网络, 有效提升未知意图检测能力.
在BANKING、OOS、HWU64、SNIPS、Stackoverflow数据集上, 在不同已知类别比例(25%、50%、75%)下, 各方法的指标值对比如表1~表6所示, 表中黑体数字表示最优值.
| 表1 已知类别比例为25%时各方法在5个数据集上的F1分数对比 Table 1 F1 score comparison of different methods at a known class proportion of 25% on 5 datasets % |
| 表2 已知类别比例为50%时各方法在5个数据集上的F1分数对比 Table 2 F1 score comparison of different methods at a known class proportion of 50% on 5 datasets % |
| 表3 已知类别比例为75%时各方法在5个数据集上的F1分数对比 Table 3 F1 score comparison of different methods at a known class proportion of 75% on 5 datasets % |
| 表4 已知类别比例为25%时各方法在5个数据集上的总体性能对比 Table 4 Overall performance comparison of different methods at a known class proportion of 25% on 5 datasets % |
| 表5 已知类别比例为50%时各方法在5个数据集上的总体性能对比 Table 5 Overall performance comparison of different methods at a known class proportion of 50% on 5 datasets % |
| 表6 已知类别比例为75%时各方法在5个数据集上的总体性能对比 Table 6 Overall performance comparison of different methods at a known class proportion of 75% on 5 datasets % |
由表1~表6可见, 在F1-A和ACC指标上, AGPCS-OIC在多个数据集上均表现出显著优势, 尤其是在已知类别占比较低(25%)时.随着已知类别比例的提升, 性能优势依然存在但提升相对减小.这表明, AGPCS-OIC在高开放性场景下具备更强的泛化能力与未知意图检测能力, 同时在封闭程度较高时也能保持稳定的分类性能.
在已知类别比例较低的场景中, 类别间的分布往往更稀疏, 语义边界更模糊.AGPCS-OIC在该场景下表现出更明显的性能提升, 主要得益于AGPCS-OIC在复杂语义分布建模方面的结构优势.具体而言, AGPCS-OIC基于粒球的多中心结构建模, 有效刻画类别内部的分布异质性, 并通过结构稀疏性拆分机制细化边界区域, 从而提升类内紧致性和类间可分性.此外, 引入粒球感知对比学习, 增强样本与类别结构的匹配性, 进一步提高模型在复杂分布下的判别能力与鲁棒性.
已知类别比例为25%时, 在BANKING、OOS、HWU64数据集上对AGPCS-OIC中的两个核心组件进行消融实验.设定如下变体.
1)w/o AGRL(without Adaptive Granular-Ball Re-presentation Learning).去除自适应粒球表征学习模块, 即不进行聚类与粒球感知对比学习, 仅采用交叉熵损失进行表示学习.
2)w/o PCS(without Pure Cluster Splitting).去除纯净簇拆分组件, 仅依赖粒球纯度进行划分.
3)w/o AGRL+PCS.同时移除自适应粒球表征学习模块和纯净簇拆分模块.
各变体在3个数据集上的消融实验结果如表7所示.表中黑体数字表示最优值.由表可看出, AGPCS-OIC在所有指标上均取得最优值, 由此验证各模块的协同贡献.w/o AGRL会导致F1-A指标降幅明显, 如在BANKING数据集上从76.71%降至68.59%, 下降8.12%, 表明自适应粒球结构对于构建有效语义边界至关重要.同时ACC指标降至78.88%, 验证其在提升分类稳健性方面的作用.
| 表7 各变体消融实验结果 Table 7 Results of ablation experiments for each variant % |
对于w/o PCS而言, 尽管类内结构已被粒球聚类捕捉, 但由于忽略对结构稀疏簇的进一步细化, 仍在多个数据集上出现性能下滑.如在OOS数据集上, F1-A指标从82.14%降至62.25%, 下降近20%, 说明纯净簇拆分能有效规避由松散结构导致的开放类误判, 提升边界判别精度.
更进一步地, 对于w/o AGRL+PCS而言, 整体性能进一步下降, 如在HWU64数据集上F1-A指标从74.46%降至65.71%, ACC指标从85.32%降至67.10%.这一现象表明, 缺乏粒球结构建模与结构敏感拆分机制, 模型将难以刻画类内异质性, 边界表征模糊, 导致在已知类判别和未知类排斥方面均失效.
为了评估关键超参数对方法性能的影响, 选择粒球纯净度阈值τp、粒球最小样本数阈值τn、粒球感知对比学习权重λ 及结构稀疏性拆分系数δ 进行参数敏感性实验, 所选数据集与设置分别为HWU64数据集(已知类别比例为75%)、HWU64数据集(已知类别比例为50%)、OOS数据集(已知类别比例为25%)、BANKING数据集(已知类别比例为25%).
在HWU64数据集(已知类别比例为75%)上, 设定粒球纯净度阈值τp=0.80, 0.85, 0.87, 0.90, 0.95, 0.97, 评估τp不同时方法性能的变化, 结果如表8所示.当τp=0.87时, AGPCS-OIC在4项指标上均达到最优值.这一结果表明, 适当提高纯净度阈值有助于过滤低质量粒球, 增强类别区分度, 若阈值过高, 则可能导致粒球数量不足、覆盖不足, 进而降低已知类的覆盖率和整体判别能力.
| 表8 不同τp对方法性能的影响 Table 8 Effect of different τp on method performance |
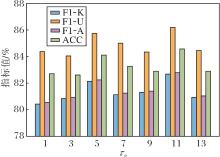
在HWU64数据集(已知类别比例为50%)上, 设定粒球最小样本数阈值τn=1, 3, …, 13, 不同τn对方法性能的影响如图2所示.由图可见, 当τn=11时, AGPCS-OIC在F1-U、F1-K、F1-A、ACC指标上均取得最优值.此外, 当τn=5时, AGPCS-OIC也取得相对较优的性能.然而, τn过小(如τn=1, 3)和τn过大均会导致性能下降, 这一结果说明:当τn设置过小时, 部分粒球仅由极少数样本构成, 结构稳定性差, 甚至可能由噪声或离群点构成, 若将这些粒球用于表征学习或判别边界构建, 容易导致模型过度拟合训练数据, 降低泛化性能; 当τn过大时, 虽可抑制噪声对粒球的影响, 但也可能忽略部分有意义的细粒度结构, 限制模型对复杂分布的适应能力.
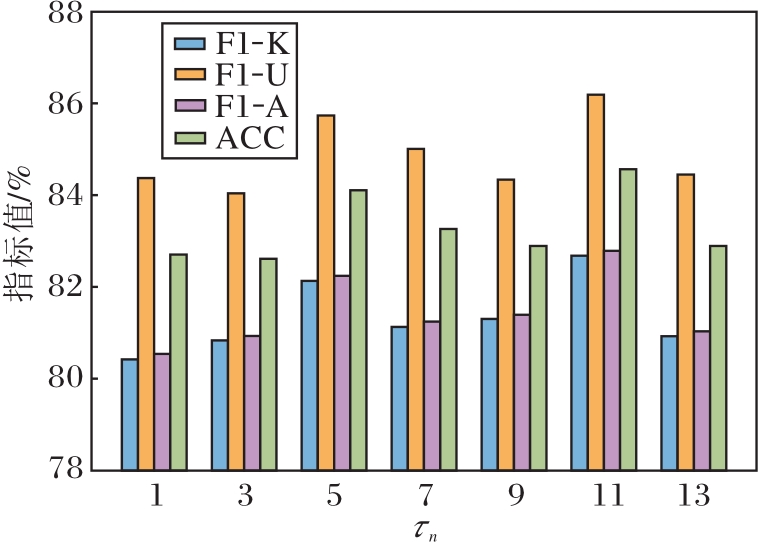 | 图2 不同τn对方法性能的影响Fig.2 Effect of different τn on method performance |
为了评估粒球感知对比学习在表征学习中的作用, 引入权重超参数λ , 用于控制粒球分类损失与对比学习损失在联合优化目标中的相对比例.在OOS数据集(已知类别比例为25%)上进行实验, 设定λ =0.1, 0.3, 0.5, 0.7, 0.9, 1.0, 评估λ 不同对方法性能的影响, 结果如表9所示.由表可见, 当λ =0.3时, AGPCS-OIC在多个指标上达到最优值.说明在该设定下, 分类损失与对比损失的协同优化最充分.粒球感知对比学习通过引入粒球中心作为结构锚点, 在保持类别区分性的同时提升语义表示的局部一致性.合理设置权重λ 能有效协调分类损失与对比损失之间的优化平衡, 进一步提升方法在开放意图分类任务中的表现与泛化性.
| 表9 不同λ 对方法性能的影响 Table 9 Effect of different λ on method performance |
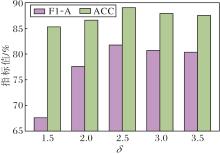
在BANKING数据集(已知类比例为25%)上, 设定结构稀疏性拆分系数δ =1.5, 2.0, …, 3.5, 不同δ 对方法性能的影响如图3所示.δ 表示粒球内最远样本距离与平均距离的比值, 用于度量粒球内部结构的离散程度.
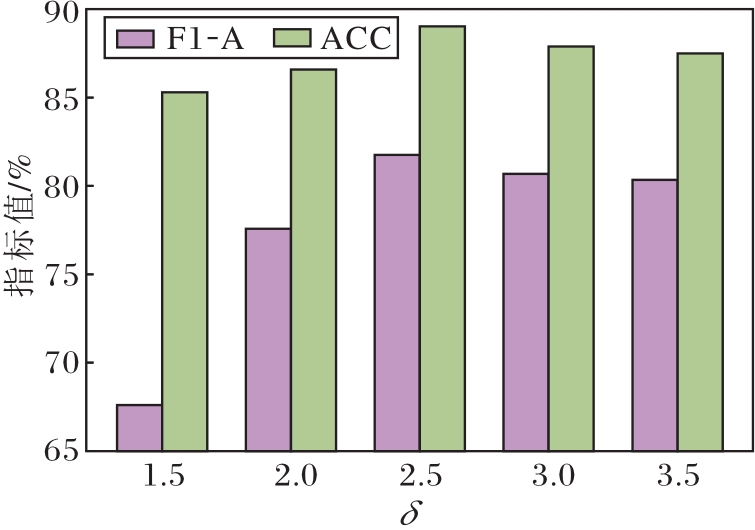 | 图3 不同δ 对方法性能的影响Fig.3 Effect of different δ on method performance |
由图3可见, 当δ =2.5时, AGPCS-OIC在F1-A和ACC指标上分别达到81.75%和89.03%, 取得最优值.合适的δ 值在粒球结构判别中具有良好的平衡性, 能有效缓解因“ 过拆分” 带来的粒球碎片化问题, 同时避免因“ 欠拆分” 造成的边界模糊现象, 因此可进一步提升类内一致性建模能力与开放类排斥能力.
为了验证AGPCS-OIC学习的粒球结构在语义空间中的可解释性, 从局部类内聚合性与全局类间可分性这2个角度进行可视化分析.
首先, 利用t-SNE将AGPCS-OIC在测试阶段提取的语义表示执行降维可视化.如图4所示, OOS数据集同一类别下的样本在特征空间中呈现出明显的多簇聚集结构, 说明存在内部语义子簇.相比传统的单质心建模策略, 本文引入的自适应粒球机制能更有效地捕捉这类内部异质性, 生成多个不同半径的子粒球, 实现对复杂类内结构的精细建模.
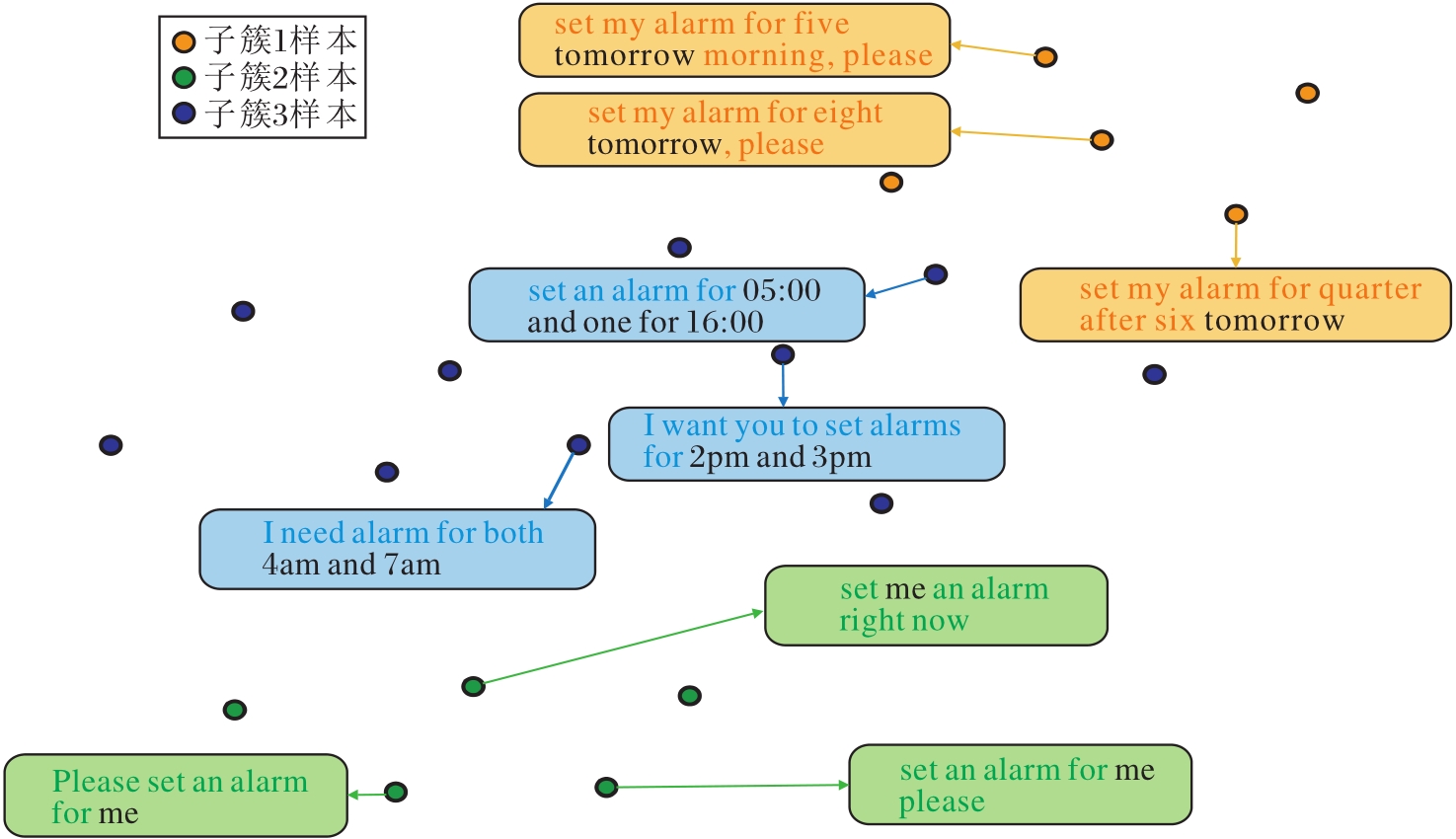 | 图4 “alarm” 类的3个子簇在特征空间中的分布Fig.4 Distribution of three subclusters of class “alarm” in feature space |
进一步地, 将所有已知类别的粒球中心与样本表示统一投影至二维空间, 不同类别样本使用不同的颜色进行标记.
意图样本的t-SNE(t-Distributed Stochastic Neigh-bor Embedding)可视化结果如图5所示.由图可见, 同类样本在特征空间中大多呈现单簇或多簇结构性聚集, 表明模型能有效捕捉类内多样性结构.同时, 不同类别之间的粒球结构相互分离、边界清晰, 显示出良好的类间可分性.这一结果充分体现AGPCS-OIC在建模类内紧致性与类间判别性方面的性能.
 | 图5 意图样本t-SNE可视化结果Fig.5 t-SNE visualization result of intent samples |
上述结果直观验证粒球结构在特征空间中的有效性和可解释性, 为开放意图分类任务中的判别鲁棒性提供理论支持.
本文提出基于自适应粒球与纯净簇拆分的开放意图分类方法(AGPCS-OIC), 旨在增强方法在开放场景下的判别能力与鲁棒性.该方法通过粒球聚类构建自适应半径的子类表示, 使决策边界能够细粒度刻画类内分布结构.同时, 引入结构稀疏性判断机制, 进一步细化部分虽具有高纯度但分布松散的粒球, 压缩边界范围, 提升对“ 内嵌型” 未知样本的排斥能力.在此基础上, 引入粒球感知对比学习策略, 以粒球中心为监督锚点, 优化表示的类内聚合性和类间可分性.在多个开放意图分类数据集上的实验表明, AGPCS-OIC在已知类别识别和未知类别检测方面性能均较优, 尤其在结构复杂或开放性较强的场景中表现更稳定.尽管如此, AGPCS-OIC还存在粒球构造成本较高的问题, 限制其在弱监督大规模数据上的应用.今后可围绕轻量化粒球建模及跨域泛化能力展开, 进一步提升方法的实用性与可推广性.
本文责任编委 苗夺谦
Recommended by Associate Editor MIAO Duoqian
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|