{kind=link}
基于模糊自信息的乐观多粒度模糊决策粗糙集的属性约简
[盖灿灿1  , 马建敏
, 马建敏1
, 马建敏]
|
|



作者简介:

盖灿灿,硕士研究生,主要研究方向为粗糙集、粒计算.E-mail:gaicancan7711@126.com.
现有多粒度模糊粗糙集的属性约简方法常以固定阈值定义属性集的模糊相似关系,然而模糊决策信息系统上每个属性取值范围不同,阈值也可能不一样.因此,文中提出基于自适应阈值的乐观多粒度模糊决策粗糙集,并探讨基于模糊自信息的属性约简.首先,在模糊决策信息系统上应用分位数引入单属性阈值,构造属性集上基于自适应阈值的模糊相似关系,建立属性子集族上的乐观多粒度模糊决策粗糙集.然后,利用乐观多粒度模糊决策下、上近似及边界域信息提出模糊自信息,并引入属性重要性度量,提出基于模糊自信息的属性约简算法.在10个数据集上的数值实验表明,文中算法可有效降低原始属性集的维数,提升分类器精度.
About Author:
GAI Cancan, Master student.Her research interests include rough sets and granular computing.
In current attribute reduction methods for multi-granularity fuzzy rough sets, the fuzzy similarity relationship within attribute sets is often defined using a fixed threshold. However, in fuzzy decision systems, different thresholds are required for different attributes, since each attribute has a different value range. To address this issue, the attribute reduction of optimistic multi-granularity fuzzy decision rough sets based on fuzzy self-information is proposed in this paper. First, within the fuzzy decision information system, the threshold for each attribute is introduced based on the quantile to construct an adaptive-threshold-based fuzzy similarity relation. An optimistic multi-granularity fuzzy decision rough set model for a family of attribute subsets is then established. Second, fuzzy self-information is proposed by utilizing the lower and upper approximations of optimistic multi-granularity fuzzy decision rough set model and boundary domain information. Furthermore, an attribute significance measure is introduced, and an attribute reduction algorithm based on fuzzy self-information is developed. The experimental results on ten datasets demonstrate that the proposed algorithm effectively reduces the dimensionality of the original attribute set and improves the classification accuracy.
随着网络技术的迅猛发展, 各领域数据量急剧增长, 部分数据存在模糊性且可能与分类任务无关.如何从海量数据中剔除冗余信息, 高效提取有价值的知识或信息, 成为亟待解决的难题[1].属性约简是解决该难题的有效方法之一, 即从原始数据集中去除冗余及与分类任务无关的属性, 提升分类效率和精度[2].
粗糙集理论是处理数据不确定性的有效方法, 因不需要任何先验信息而被广泛应用于属性约简[3].在此基础上, Qian等[4]提出MGRS(Multi-gra-nulation Rough Set Model), 并给出相应属性约简方法.谢立等[5]以正域和边界集变化度量粒度重要度, 提出改进的悲观多粒度粗糙集属性粒度约简方法.Cui等[6]提出DmlMNRS(Distance Metric Lear-ning-Based Multi-granularity Neighborhood Rough Set Model).刘凯等[7]提出基于辨识矩阵的不完备多粒度约简.张文娟等[8]提出基于图的悲观多粒度粗糙集粒度约简.Xu等[9]提出乐观和悲观两种多粒度模糊粗糙集.Zhang等[10]提出GMFNRS(Generalized Multi-granulation Fuzzy Neighborhood Rough Set Model), 给出相应启发式属性约简方法.
信息熵是信息论中一种不确定性度量方法[11].苗夺谦[12]将香农熵引入粗糙集, 为知识粗糙性提供一种信息解释.Zeng等[13]将经典信息熵扩展为乐观多粒度熵和悲观多粒度熵, 并据此提出OMGE(Optimistic Multi-granulation Entropy)和PMGE(Pe-ssimistic Multi-granulation Entropy).Wang等[14]在邻域粗糙集上提出基于邻域自信息的属性约简方法, 考虑决策下、上近似及边界域的信息, 降低误分类的可能性.Li等[15]在模糊粗糙集上引入局部模糊自信息和重叠度函数, 提升属性约简效率并增强对大规模数据的处理能力.Jiang等[16]在散度模糊粗糙集上提出SPESI(Spearman-Based Self-Information).陈东晓等[17]在决策形式背景上利用信息熵提出熵协调和熵不协调的决策形式背景的属性约简方法.李金海等[18]在多粒度决策形式背景中提出协调粒度约简方法、最粗协调粒度约简方法、最细协调粒度约简方法.
针对混合数据集, Sun等[19]在悲观多粒度模糊粗糙集上提出FNMRS(Feature Selection Based on Fuzzy Neighborhood Multi-granulation Rough Sets).鉴于信息系统中噪声、不确定性和模糊性等问题仍然存在, 基于信息熵的多粒度模糊粗糙集属性约简研究颇具意义.
模糊二元关系是构造多粒度模糊粗糙集的首要步骤, 学者围绕相似关系的构建方法展开研究.Zhang等[10]提出GMFNRS, 结合欧氏距离定义广义多粒度模糊粗糙集上属性子集的相似关系.Sun等[19]提出FNMRS, 在悲观多粒度模糊粗糙集上使用固定阈值, 对每个属性定义模糊相似关系, 进而定义属性子集的模糊相似关系.Yuan等[20]提出FRU- AR(Fuzzy Rough-Based Unsupervised Attribute Reduc- tion Algorithm), 采用标准差与经验参数定义单属性邻域阈值以构建模糊相似关系, 可适应数据分布.Sun等[21]应用标准差与极差确定混合数据的模糊邻域阈值, 并引入高斯核函数构建模糊相似关系.徐久成等[22]提出基于双空间模糊邻域相似关系的多标记特征选择算法, 在多标记数据中使用所有标记标准差的均值定义阈值, 进而定义模糊相似关系.Chen等[23]提出GDAD(Fuzzy Granule Density-Based Anomaly Detection Algorithm), 采用分位数定义邻域阈值, 构建基于距离的模糊相似关系, 降低对异常值的敏感性.
大多数多粒度模糊粗糙集常以固定阈值定义任意属性子集的模糊相似关系, 由此引入多粒度模糊粗糙下、上近似.然而, 对于模糊决策信息系统而言, 每个属性的类型不同、属性取值范围不一, 导致其数据分布也有差异, 对所有属性使用固定阈值难以准确刻画属性子集的模糊相似关系, 进而影响属性约简的分类性能.受文献[20]和文献[23]的启发, 本文使用分位数定义单属性阈值, 提出自适应阈值的乐观多粒度模糊决策粗糙集.首先, 在模糊决策信息系统上应用分位数定义单属性对应的阈值, 构建属性子集下基于自适应阈值的模糊相似关系, 建立属性子集族上的乐观多粒度模糊决策粗糙集.然后, 利用乐观多粒度模糊决策下、上近似及边界域的信息, 定义乐观多粒度模糊精度和粗糙度, 构建模糊自信息(Fuzzy Self-Information, FSI), 进而给出基于模糊自信息的属性约简算法(Fuzzy Self-Information-Based Attribute Reduction, FSIAR).最后, 通过数值实验验证FSIAR的有效性.
称FDS=(U, C∪ D, f, VD, g)为模糊决策信息系统[24], 其中, U为非空有限对象集, 称为论域, C为条件属性集, D={d}为决策属性, C∩ D=Ø , f ∶ U× C→ [0, 1], ∀ x∈ U, a∈ C, f(x, a)∈ [0, 1]表示对象x在条件属性a下的取值, g∶ U× D→ VD, VD为决策属性d的值域.使用P(U)表示U上经典子集全体, F(U)表示U上模糊集全体[24].
∀ A⊆C, RA为由A诱导的模糊关系, ∀ x∈ U, y∈ U, 若RA满足
RA(x, x)=1, RA(x, y)=RA(y, x),
称RA为U上的模糊相似关系[24].∀ x∈ U, y∈ U, 记
[x]A(y)=RA(x, y),
称[x]A为x关于RA的模糊信息粒.
定义1[24] 设FDS=(U, C∪ D, f, VD, g)为模糊决策信息系统,
U/D={D1, D2, …, Dr}
为U关于D的划分, RC为由C诱导的模糊相似关系.∀ x∈ U, Di∈ U/D, Di的模糊决策如下所示:
记
$\widetilde{D}=\left\{\widetilde{D}_{1}, \widetilde{D}_{2}, \cdots, \widetilde{D}_{r}\right\}$
为{D1, D2, …, Dr}上关于C的模糊决策粒覆盖.
定义2[9] 设U为论域, R为U上的模糊相似关系.∀ X∈ F(U), ∀ x∈ U, X关于一系列模糊相似关系Ri(1≤ i≤ m)的乐观多粒度模糊下、上近似分别定义如下:
$\underline{\underset{i=1}{\overset{m}{\mathop{\sum }}}\, R_{i}^{O}}(X)(x)=\vee _{i=1}^{m}{{\wedge }_{y\in U}}((1-{{R}_{i}}(x, y))\vee X(y)) $
$\overline{\underset{i=1}{\overset{m}{\mathop{\sum }}}\, R_{i}^{O}}(X)(x)=\wedge _{i=1}^{m}{{\vee }_{y\in U}}({{R}_{i}}(x, y)\wedge X(y)) $
传统的多粒度模糊粗糙集通常依赖固定阈值定义属性子集上的模糊相似关系.然而, 由于不同属性的取值范围与数据分布存在显著差异, 统一阈值难以适配所有属性, 容易导致相似性度量失真.为此, 本文借鉴文献[20]和文献[23]的思路, 将Hyndman等[25]提出的基于线性插值计算分位数的方法引入模糊决策信息系统, 设置可调节的位置修正项, 计算任意属性下对象间距离顺序统计量的第k分位数, 并将其作为该属性的自适应阈值.基于此阈值定义任意属性子集下的模糊相似关系及模糊信息粒, 进而构建基于自适应阈值的乐观多粒度模糊决策粗糙集模型.
给定模糊决策信息系统FDS=(U, C∪ D, f, VD, g), ∀ a∈ C, xi∈ U, xj∈ U, 对象xi、xj在属性a下的距离定义如下:
${{d}_{a}}({{x}_{i}}, {{x}_{j}})=\left| f({{x}_{i}}, a)-f({{x}_{j}}, a) \right|$.
记|U|=n, 则属性a下对象间的距离构成一个n阶矩阵, 记为
Ma=
由于
da(xi, xi)=0, da(xi, xj)=da(xj, xi),
因此, 仅需考虑该距离矩阵Ma不含主对角线元素的上三角部分, 记为
显然, 矩阵
采用统计学中由样本建立顺序统计量的方法, 将上述
下面利用分位数引入任意属性的阈值.
定义3 设FDS=(U, C∪ D, f, VD, g)为模糊决策信息系统, n=|U|, ∀ a∈ C,
$\delta _{a}^{k}=d_{a}^{(\left\lfloor tk+m \right\rfloor)}+(tk+m-\left\lfloor tk+m \right\rfloor)(d_{a}^{(\left\lfloor tk+m \right\rfloor +1)}-d_{a}^{(\left\lfloor tk+m \right\rfloor)}) $, (1)
其中, ⌊· 」表示向下取整, m∈ [0, 1]表示位置修正项.记
称为条件属性集C在分位数参数k下的自适应阈值集合.
式(1)在文献[25]的基础上将位置修正项m的取值范围由全体实数限制在区间[0, 1]内, 使
0≤ tk-⌊tk」≤ 1-m
时,
当
1-m< tk-⌊tk」< 1
时,
这样既能有效约束分位位置, 又能保证阈值
特别地, 当m=0.5时, 属性a的阈值
该式为文献[25]中关于分位数的第5个公式, 满足分位数的所有性质.
分位数是一个位置指标, 针对每个属性下对象间的距离值, 采用线性插值法计算分位数, 以此作为该属性的阈值, 使得至少100k%的对象关于单属性的距离值小于等于
定义4 设FDS=(U, C∪ D, f, VD, g)为模糊决策信息系统, ∀ a∈ C, k∈ (0, 1),
其中σ 为高斯核宽度.∀ A⊆C, 定义
则
∀ Di∈ U/D, x∈ U, Di的模糊决策为:
性质1 设FDS=(U, C∪ D, f, VD, g)为模糊决策信息系统, ∀ A⊆C, A1⊆C, A2⊆C, k∈ (0, 1), k1∈ (0, 1), k2∈ (0, 1), ∀ a∈ C, x∈ U, 下列性质成立:
1)k1≤ k2 ⇒
2)k1≤ k2 ⇒
3)A1⊆A2 ⇒
证明 先证1).∀ a∈ C, k1∈ (0, 1), k2∈ (0, 1), k1≤ k2, 有
t· k1+m≤ t· k2+m
且
⌊t· k1+m」≤ ⌊t· k2+m」,
则
t· k1+m-⌊t· k1+m」≤ t· k2+m-⌊t· k2+m」.
由定义3知
$\begin{array}{l} d_{a}^{\left(\left\lfloor t k_{1}+m\right\rfloor\right)}+ \\ \quad\left(t k_{1}+m-\left\lfloor t k_{1}+m\right\rfloor\right)\left(d_{a}^{\left(\left\lfloor t k_{1}+m\right\rfloor+1\right)}-d_{a}^{\left(\left\lfloor t k_{1}+m\right\rfloor\right)}\right) \leqslant \\ d_{a}^{\left(\left\lfloor t k_{2}+m\right\rfloor\right)}+ \\ \quad\left(t k_{2}+m-\left\lfloor t k_{2}+m\right\rfloor\right)\left(d_{a}^{\left(\left\lfloor t k_{2}+m\right\rfloor+1\right)}-d_{a}^{\left(\left\lfloor t k_{2}+m\right\rfloor\right)}\right) \end{array}$
即
再证2).设k1≤ k2.∀ a∈ A⊆C, 由1)知
da(x, y)≤
有
$R_{a}^{{{k}_{1}}}(x, y)=\exp \left( -\frac{{{d}_{a}}{{(x, y)}^{2}}}{2{{\sigma }^{2}}} \right)=R_{a}^{{{k}_{2}}}(x, y) $;
若
有
$R_{a}^{{{k}_{1}}}(x, y)=0\le \exp \left( -\frac{{{d}_{a}}{{(x, y)}^{2}}}{2{{\sigma }^{2}}} \right)=R_{a}^{{{k}_{2}}}(x, y) $;
若
有
由x、y的任意性得
由a的任意性知
进一步地, ∀ x∈ U, y∈ U,
由x的任意性得
最后证3).设A1⊆A2, 由定义4知,
$\begin{array}{c} R_{A_{2}}^{k}=\bigcap_{a \in A_{2}} R_{a}^{k}=\left(\bigcap_{a \in A_{1}} R_{a}^{k}\right) \cap\left(\bigcap_{a \in A_{2}-A_{1}} R_{a}^{k}\right)= \\ R_{A_{1}}^{k} \cap R_{A_{2}-A_{1}}^{k} \subseteq R_{A_{1}}^{k} . \end{array}$
∀ x∈ U, y∈ U,
故由x的任意性知
定义5 设FDS=(U, C∪ D, f, VD, g)为模糊决策信息系统,
$\begin{array}{l} \mathcal{A}=\left\{A_{1}, A_{2}, \cdots, A_{m}\right\} \subseteq \mathscr{P}(C), \\ \widetilde{D}=\left\{\widetilde{D}_{1}, \widetilde{D}_{2}, \cdots, \widetilde{D}_{r}\right\} \end{array}$
为U上的模糊决策粒覆盖, k∈ (0, 1).∀ B⊆A,
$\begin{array}{l} \underline{R}_{\mathcal{B}}^{O, k}(\widetilde{D})=\left\{\underline{R}_{\mathcal{B}}^{O, k}\left(\widetilde{D}_{1}\right), \underline{R}_{\mathcal{B}}^{O, k}\left(\widetilde{D}_{2}\right), \cdots, \underline{R}_{\mathcal{B}}^{O, k}\left(\widetilde{D}_{r}\right)\right\}, \\ \bar{R}_{\mathcal{B}}^{O, k}(\widetilde{D})=\left\{\bar{R}_{\mathcal{B}}^{O, k}\left(\widetilde{D}_{1}\right), \bar{R}_{\mathcal{B}}^{O, k}\left(\widetilde{D}_{2}\right), \cdots, \bar{R}_{\mathcal{B}}^{O, k}\left(\widetilde{D}_{r}\right)\right\} . \end{array}$
其中,
$\underline{R}_{\mathcal{B}}^{o, k}\left(\widetilde{D}_{j}\right)(x)=\bigvee_{A_{i} \in \mathcal{B}} \bigwedge_{y \in U}\left(\left(1-[x]_{A_{i}}^{k}(y)\right) \vee \widetilde{D}_{j}(y)\right), $(4)
$ \bar{R}_{\mathcal{B}}^{o, k}\left(\widetilde{D}_{j}\right)(x)=\bigwedge_{A_{i} \in \mathcal{B}} \bigvee_{y \in U}\left([x]_{A_{i}}^{k}(y) \wedge \widetilde{D}_{j}(y)\right) . $ (5)
$ \begin{array}{l} \operatorname{POS}_{\mathcal{B}}^{O, k}(\widetilde{D})=\bigcup_{j=1}^{r} \underline{R}_{\mathcal{B}}^{O, k}\left(\widetilde{D}_{j}\right), \\ \operatorname{BND}_{\mathcal{B}}^{O, k}(\widetilde{D})=\bigcup_{j=1}^{r} \bar{R}_{\mathcal{B}}^{O, k}\left(\widetilde{D}_{j}\right)-\bigcup_{j=1}^{r} \underline{R}_{\mathcal{B}}^{O, k}\left(\widetilde{D}_{j}\right) . \end{array} $
$ \alpha_{\mathcal{B}}^{O, k}(\widetilde{D})=\frac{\left|\underline{R}_{\mathcal{B}}^{O, k}(\widetilde{D})\right|}{\left|\overline{R_{\mathcal{B}}^{O, k}}(\widetilde{D})\right|}=\frac{\sum_{j=1}^{r} \sum_{x \in U} \underline{R}_{\mathcal{B}}^{O, k}\left(\widetilde{D}_{j}\right)(x)}{\sum_{j=1}^{r} \sum_{x \in U} \bar{R}_{\mathcal{B}}^{O, k}\left(\widetilde{D}_{j}\right)(x)}, $ (6)
$ \rho_{\mathcal{B}}^{O, k}(\widetilde{D})=1-\frac{\left|\underline{R}_{\mathcal{B}}^{O, k}(\widetilde{D})\right|}{\left|\bar{R}_{\mathcal{B}}^{O, k}(\widetilde{D})\right|}=\frac{\sum_{x \in U} B N D_{\mathcal{B}}^{O, k}(\widetilde{D})(x)}{\sum_{j=1}^{r} \sum_{x \in U} \bar{R}_{\mathcal{B}}^{O, k}\left(\widetilde{D}_{j}\right)(x)} . $ (7)
性质2 设FDS=(U, C∪ D, f, VD, g)为模糊决策信息系统,
A={A1, A2, …, Am}⊆P(C),
k∈ (0, 1), ∀ B⊆A, C⊆A,
1)
2)
3)C⊆B⇒
4)A1⊆A2⊆…⊆Am⇒
其中,
$\begin{align} & \underline{R}_{{{A}_{i}}}^{k}({{{\tilde{D}}}_{j}})={{\wedge }_{y\in U}}((1-[x]_{{{A}_{i}}}^{k}(y))\vee {{{\tilde{D}}}_{j}}(y), \ \\ & \overline{R}_{{{A}_{i}}}^{k}({{{\tilde{D}}}_{j}})={{\vee }_{y\in U}}([x]_{{{A}_{i}}}^{k}(y)\wedge {{{\tilde{D}}}_{j}}(y)) \\ \end{align}$
证明 由式(4)和式(5)可证2)成立, 由2)可证3)成立, 由性质1中3)和性质2中2)可证4)成立.下证1)成立.∀ Ai∈ B, x∈ U, y∈ U, 由定义4知
则有
$\begin{align} & {{\wedge }_{y\in U}}((1-[x]_{{{A}_{i}}}^{k}(y))\vee {{{\tilde{D}}}_{j}}(y))= \\ & \{{{\wedge }_{y\ne x}}((1-[x]_{{{A}_{i}}}^{k}(y))\vee {{{\tilde{D}}}_{j}}(y))\}\wedge {{{\tilde{D}}}_{j}}(x)\le {{{\tilde{D}}}_{j}}(x) \\ \end{align}$
故由Ai的任意性得
$\begin{array}{l} \underline{R}_{\mathcal{B}}^{o, k}\left(\widetilde{D}_{j}\right)(x)= \\ \quad \bigvee_{A_{i} \in \mathcal{B}} \bigwedge_{y \in U}\left(\left(1-[x]_{A_{i}}^{k}(y)\right) \vee \widetilde{D}_{j}(y)\right) \leqslant \\ \quad \widetilde{D}_{j}(x)\end{array}$
由x的任意性即得
类似可证
性质3 设FDS=(U, C∪ D, f, VD, g)为模糊决策信息系统,
A={A1, A2, …, Am}⊆P(C),
k∈ (0, 1), ∀ C⊆A, B⊆A, 下列性质成立:
1)0≤
2)C⊆B ⇒
3)A1⊆A2⊆…⊆Am⇒
证明 由性质2可证结论成立.
Wang等[14]应用决策的下、上近似及边界信息提出基于邻域自信息的属性约简方法.基于此方法, 本节在模糊决策信息系统上, 利用乐观多粒度模糊决策下、上近似及其边界域, 提出模糊自信息(FSI), 并应用其讨论乐观多粒度模糊决策粗糙集上的属性约简方法.
定义6 设FDS=(U, C∪ D, f, VD, g)为模糊决策信息系统,
A={A1, A2, …, Am}⊆P(C),
k∈ (0, 1), ∀ B⊆A,
性质4 设FDS=(U, C∪ D, f, VD, g)为模糊决策信息系统,
A={A1, A2, …, Am}⊆P(C),
k∈ (0, 1), ∀ C⊆A, B⊆A, 下列性质成立:
1)0≤
当
2)C⊆B⇒
3)A1⊆A2⊆…⊆Am⇒
证明 由性质3中1)与3)可证1)与3)成立.下证2)成立.设C⊆B, 由性质3中3)知
则
0≤ -ln
0≤
因此
定义7 设FDS=(U, C∪ D, f, VD, g)为模糊决策信息系统,
A={A1, A2, …, Am}⊆P(C),
k∈ (0, 1), ∀ ε ≥ 0, A∈ A, 若
称A在A中是ε -不必要的, 否则, 称A在A中是ε -必要的.∀ B⊆A, 若
且∀ A∈ B,
称B是A的ε -约简.记{Bi∶ 1≤ i≤ t}为A的所有ε -约简集.若
A∈
称A为ε -核心属性集, 并记
Coreε (A)=
定义8 设FDS=(U, C∪ D, f, VD, g)为模糊决策信息系统,
A={A1, A2, …, Am}⊆P(C),
k∈ (0, 1), ∀ B⊆A, A∈ B, A关于B和
Siginter(A, B,
∀ A∈ A-B, A关于B和
Sigouter(A, B,
定理1 设FDS=(U, C∪ D, f, VD, g)为模糊决策信息系统,
A={A1, A2, …, Am}⊆P(C),
k∈ (0, 1), ε ≥ 0, 下列结论成立:
1)Coreε (A)={A∈ A∶
2)A∈ Coreε (A)⇔ Siginter(A, A,
证明 由1)和式(9)可证2)成立.下证1)成立.记
L={A∈ A∶
∀ A∈ Coreε (A), 若
则∃B⊆A-{A},
且∀ B∈ B,
即存在ε -约简集B且A∉B, 这与A∈ Coreε (A)矛盾.于是
即A∈ L.由A的任意性知
Coreε (A)⊆L .
反之, ∀ A∈ L, 则
若存在ε -约简集B使得A∉B, 则
由
B⊆A-{A}⊆A
及性质3中2)可得
这与A∈ L矛盾, 故A∈ Coreε (A).由A的任意性知
L⊆Coreε (A).
综上可知,
Coreε (A)=L .
定理2 设FDS=(U, C∪ D, f, VD, g)为模糊决策信息系统,
A={A1, A2, …, Am}⊆P(C),
k∈ (0, 1), ε ≥ 0, ∀ A∈ A,
A在A中是ε -不必要的⇔
Sigouter(A, A-{A},
证明 由定义7和式(10)可证.
根据定理1和定理2可给出基于模糊自信息的属性约简算法(FSIAR), 具体过程步骤如算法1所示.
算法1 FSIAR
输入 模糊决策信息系统
FDS=(U, C∪ D, f, VD, g),
A={A1, A2, …, Am},
m∈ [0, 1], k∈ (0, 1), σ > 0, ε ≥ 0
输出 约简集B
step 1 设置初始值B← Ø ;
step 2 ∀ a∈ C, 根据式(1)和式(2)计算属性a的阈值
step 3 根据式(3)计算模糊决策粒覆盖
step 4 ∀ Ai∈ A,
step 5 根据式(9)计算Siginter(Ai, A,
step 6 根据式(8)计算
执行step 8, 否则执行step 7;
step 7 ∀ A∈ A-B, 根据式(10)计算Sigouter(A, B,
$\begin{array}{l} \operatorname{Sig}_{\text {outer }}(A, \mathcal{B}, \widetilde{D})= \\ \quad \max \left\{\operatorname{Sig}_{\text {outer }}(A, \mathcal{B}, \widetilde{D}): A \in A-B\right\}, \end{array}$
则
B← B∪ {A},
执行step 6;
step 8 输出约简集B.
为了验证FSIAR的有效性, 从UCI数据库上选取10个数据集进行实验, 实例数从70到1 482, 属性数从6到205, 具体信息如表1所示.
| 表1 数据集信息 Table 1 Dataset information |
由于部分数据存在缺失, 实验前对缺失数据运用均值法进行填充, 并应用最大最小归一化方法对数据进行归一化处理[26], 得到模糊决策信息系统.
为了便于与其它属性约简算法对比, 本文将单属性作为一个属性子集进行实验[5].实验中对所有数据集采用十折交叉验证, 使用CART(Classification and Regression Trees)和KNN(k-Nearest Neighbor)(K=3)两种经典分类器对属性约简算法的分类性能进行评估[20].
FSIAR含位置修正项m、分位数参数k、高斯核宽度σ 和约简参数ε , 其不同取值将对实验结果产生一定影响.为了分析各数据集上不同参数对约简结果的影响, 将高斯核宽度σ 设置为1[27], m以0.1步长在区间[0, 1]内间隔取值, k以0.1步长在[0.1, 0.9]内间隔取值, ε 以0.005步长在[0, 0.05]内间隔取值.首先分析m取不同值时在各数据集上获得的最高分类精度和选取的属性数.
为了直观展示这一现象, 在Ionosphere、Divorce Predictors数据集上, 分别采用CART、KNN分类器, 不同m值对应的最高分类精度及选取的属性数如表2所示, 其余数据集结果类似.
| 表2 m不同时2个数据集上的最高分类精度与选取的属性数 Table 2 Highest classification accuracy and the number of selected attributes under different m on 2 datasets |
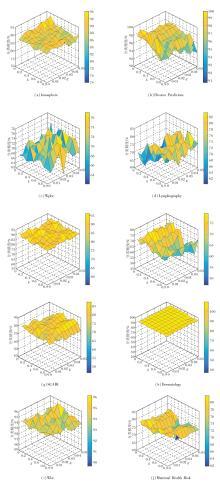
由表2可知, 不同m值下的分类精度差异较小, 表明FSIAR对[0, 1]区间上m的选择具有较强的鲁棒性.当m=0.5时, 式(1)满足分位数的所有性质, 故本文在后续实验中将位置修正项m设为0.5.在此设定下, 进一步分析分位数参数k、约简参数ε 对分类精度的影响, 在不同分位数参数k和约简参数ε 下, 在10个数据集上采用CART分类器得到的分类精度变化趋势如图1所示, 采用KNN分类器得到的曲面图与CART分类器大致相同.
 | 图1 不同k和ε 下CART分类器在10个数据集上的分类精度曲面图Fig.1 CART classification accuracy for 10 datasets under different parameters k and ε |
由图1可知, 随着参数的变化, CART分类器分类精度不同.10个数据集上两个分类器分类精度最高时选择的分位数参数和约简参数取值组合如表3所示.
| 表3 针对2个分类器选择的参数取值组合 Table 3 Parameter value combinations selected under two classifiers |
实验选取文献[5]方法、OMGE[13]、PMGE[13]、FRUAR[20]这4种属性约简算法作为对比算法.各算法在10个数据集上约简后选取的属性数如表4所示, 表中黑体数字表示各数据集上基于CART分类器选择的最少属性数, 斜体数字表示各数据集上基于KNN分类器选择的最少属性数.由表可知, 在CART分类器上, FSIAR在5个数据集上选取的属性数最少, 文献[5]方法和FRUAR在3个数据集上选取的属性数最少, PMGE在2个数据集上选取的属性数最少.在KNN分类器上, FSIAR在6个数据集上选取的属性数最少, 文献[5]方法和FRUAR在2个数据集上选取的属性数最少, OMGE和PMGE在1个数据集上选取的属性数最少.综上所述, FSIAR在多个数据集上表现出良好的约简效果.
| 表4 各算法选取的属性数对比 Table 4 Comparison of the number of attributes selected by different algorithms |
原始数据及各算法对表4所得约简结果在CART和KNN分类器下的分类精度如表5和表6所示, 表中黑体数字表示最优值.由表可知, 在CART分类器下, FSIAR在9个数据集上取得最高分类精度, 仅在Wpbc数据集上次于OMGE.在KNN分类器下, FSIAR在10个数据集上均获得最高分类精度.
| 表5 CART分类器下各算法的分类精度对比 Table 5 Comparison of classification accuracy among different algorithms under CART classifier % |
| 表6 KNN分类器下各算法的分类精度对比 Table 6 Comparison of classification accuracy among different algorithms under KNN classifier % |
本文提出基于自适应阈值的乐观多粒度模糊决策粗糙集, 并探讨基于模糊自信息的属性约简.首先, 针对多粒度模糊粗糙集上基于固定阈值构造模糊关系的问题, 采用分位数定义单属性的阈值, 构造属性子集下基于自适应阈值的模糊相似关系.然后, 在属性子集族上提出基于自适应阈值的乐观多粒度模糊决策粗糙集.利用乐观多粒度模糊决策下、上近似及边界域的信息, 提出模糊自信息(FSI), 给出基于模糊自信息的属性约简算法(FSIAR).实验表明, FSIAR在多个数据集上可有效降低原始属性集维数并提升分类精度.今后将考虑在不完备数据集上多粒度模糊粗糙集的属性约简方法.
本文责任编委 张燕平
Recommended by Associate Editor ZHANG Yanping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|