
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于知识重用的噪声环境谱聚类
[俞敏达1  , 叶绪伦
, 叶绪伦1
, 叶绪伦]
|
|



作者简介:

俞敏达,硕士研究生,主要研究方向为计算机视觉、无监督学习、聚类分析.E-mail:invaneeeee@gmail.com.
谱聚类因其在建模数据间成对相似关系方面的优越性而广泛应用于无监督学习领域.然而,传统谱聚类方法通常依赖干净、结构一致的数据分布,在现实应用中面临常见的噪声样本时,性能显著下降.针对该问题,文中提出融合CLIP(Contrastive Language Image Pretraining)先验知识的谱聚类框架——基于知识重用的噪声环境谱聚类(Noise Spectral Clustering with Assistance of Knowledge Reuse, NSCR).该方法充分利用多模态神经网络在跨模态语义理解上的先验能力,构建基于知识重用的伪标签生成机制,通过多模型语义一致性判别机制与基于信息熵的不确定性建模机制识别高可信样本.同时引入归一化指数熵作为伪标签不确定性度量指标,从多模型输出中筛选语义一致、信息熵较低的样本,并生成伪标签,监督信号形式,引导聚类过程.此外,引入联合优化目标,扩展传统谱聚类方法,通过特征对齐与正则化平衡因子缓解伪标签监督与聚类目标之间的语义冲突.在多个公开数据集上的实验表明,NSCR在不同类型噪声干扰下的鲁棒性与泛化性良好.
About Author:
YU Minda, Master student. His research interests include computer vision, unsupervised learning and cluster analysis.
Spectral clustering is widely used in the field of unsupervised learning due to its superiority in modeling pairwise similarity structures within data. However, conventional spectral clustering methods typically rely on the assumption of clean and structurally consistent datasets, and as a result their performance degrades significantly when the samples are noisy or mismatched in real-world applications. To address these issues, an extended spectral clustering framework, noise spectral clustering based on knowledge reuse(NSCR), is proposed. NSCR effectively leverages semantic knowledge from large-scale multi-model neural networks. A pseudo-label generation module is then designed by leveraging the prior capability of multi-modal neural network models in cross-modal understanding. Reliable samples are identified by semantic-consistency verification and saliency-aware confidence modeling. Softmax entropy is introduced as an uncertainty measure to filter pseudo-labels. Semantically consistent samples with low entropy across multiple models are selected and their pseudo-labels are generated to guide the clustering. Moreover, a joint optimization objective is employed to extend the traditional spectral clustering methods. A feature alignment term and a regularization balancing factor are utilized to mitigate semantic conflicts between pseudo-label supervision and clustering objective. Experiments on public datasets demonstrate that NSCR exhibits good robustness and generalization capability.
谱聚类[1]作为一种基于图的无监督学习方法, 凭借其在刻画复杂相似性结构和处理非凸数据分布方面的独特优势, 在图像聚类[2]、医学领域[3]及社交网络挖掘[4]等领域得到广泛应用.其核心思想是通过构建样本之间的相似图, 利用图拉普拉斯矩阵进行特征嵌入, 并在嵌入空间上执行聚类操作, 实现对数据的高效划分[5].然而, 经典谱聚类方法普遍建立在“ 数据分布清晰、结构干净” 的理想前提下, 难以适应现实应用中语义噪声(Semantic Noise)广泛存在的样本, 如分布偏离、标签错配、非任务相关样本等.这些干扰样本通常并不属于预期类别集合, 但又未必构成新类别, 从而造成语义结构模糊、特征分布紊乱, 严重削弱聚类性能与稳定性.
以往的含噪聚类研究多集中于应对结构或特征层面的干扰, 如通过鲁棒损失[6]、离群点检测[7]或基于密度的剔除[8]缓解像素/特征噪声与低密度异常点的影响.然而, 这类方法主要针对几何、密度或局部一致性破坏的问题, 对那些在低层表征上难以区分、但在语义层面与目标类别不匹配或边界模糊的样本效果有限.复杂语义噪声在低层特征或图结构上并不具有显著异常, 却存在语义内容与任务声明类别不一致或具有高度语义歧义的样本.典型情形如样本来源于数据源外的类别, 或样本内容并不属于任何声明目标类但与某类样本在外观上近似.传统方法对结构噪声有效, 但对这类复杂的语义噪声效果欠佳.
随着大规模预训练模型, 特别是CLIP(Con-trastive Language-Image Pre-training)[9]这类视觉-语言模型的兴起, 借助其语义泛化能力, 在无监督场景中实现知识重用(Knowledge Reuse), 产生了新的研究契机[10].CLIP联合训练图像与文本模态, 学习跨模态语义对齐[11], 在类间区分[12]、模糊识别[13]等任务中表现出色.如何将其泛化知识引入传统无监督聚类流程, 提升算法在现实语义扰动场景下的鲁棒性, 仍是一个值得探索的问题.
为此, 本文提出融合CLIP先验知识的谱聚类框架— — 基于知识重用的噪声环境谱聚类(Noise Spectral Clustering Based on Knowledge Reuse, NSCR).该方法引入基于知识重用的伪标签生成机制, 通过多模型语义一致性判别机制与基于信息熵的不确定性建模机制, 甄别并利用可靠样本作为聚类引导信号.引入Softmax熵作为伪标签不确定性度量指标, 仅选取在多个CLIP中语义预测一致且预测熵低于阈值的样本作为高质量伪标签, 纳入谱聚类的优化目标中.同时, 为了缓解伪标签监督与聚类结构学习间的语义冲突, 设计特征相似性对齐正则项与类别分布一致性约束项, 构建统一的联合优化框架, 有效提升聚类结果的判别性与稳定性.
谱聚类因其在非凸数据结构建模中的优越性, 成为无监督聚类研究中的经典方法.该类方法的核心在于通过构建相似度矩阵并计算其图拉普拉斯矩阵的特征嵌入[14], 将复杂结构映射至低维空间中进行聚类.然而, 当数据中存在结构噪声或异常时, 谱聚类性能会显著下降.
为了改进其鲁棒性, Liang等[15]基于低秩表示(Low-Rank Representation)构建鲁棒谱聚类框架, 利用数据的自表达结构抑制椒盐噪声和遮挡影响, 但框架仍依赖几何特征, 在语义级噪声上性能较差.Bai等[16]提出Self-SC, 在谱聚类中加入自监督约束, 提高对过度拟合的防护能力, 然而缺乏对复杂数据语义信息的建模.Mo等[17]提出SCHOOL(Spectral Clustering Inspired Heterogeneous Graph Learning), 利用多重一致性约束增强对噪声连接的抑制, 但仍集中于结构层面.上述方法进一步提升对结构层面异常点的鲁棒性, 但都未能有效识别因语义偏差导致的噪声样本.
为了应对密度及结构多样性的挑战, Cai等[18]提出CAMATS(Co-regularized Multi-view Clustering via Manifold Alignment on Tensor Spectral Embedding Method), 将张量学习引入多视图谱聚类, 通过高阶图结构融合多源视图信息, 显著提升在异构数据上的性能.同时, Yu等[19]提出FSC(Fuzzy Spectral Clu-stering), 通过模糊指数增强相似性图的鲁棒性, 有效缓解初始化敏感问题.虽然上述方法在处理结构噪声和视图间差异时表现突出, 但对语义层面的噪声识别未能形成机制化路径.
随着大规模预训练模型的兴起, 视觉-语言模型(Vision-Language Models, VLMs)[20]如CLIP展现出卓越的跨模态语义表示能力, 广泛应用于零样本分类[21]、迁移学习[22]等任务.CLIP通过联合学习图像与文本模态, 将语义知识编码为共享的嵌入空间, 使模型在没有明确标签的条件下也能捕捉语义关联信息, 为无监督学习任务引入先验知识提供新的可能.部分研究已尝试将其知识用于无监督任务.Ma等[23]为缓解对比学习中的假负样本问题, 提出 MoDE(Mixture of Data Experts), 通过数据聚类划分子集, 并为每个子集单独训练CLIP专家模型, 提升方法在特定子语义簇中的表现, 但该方法本质上仍依赖于对数据子集的明确划分.Lai等[24]针对无监督领域自适应任务, 利用CLIP的预训练知识弥合源域与目标域的差异, 提出PADCLIP(Pseudo-Labeling with Adaptive Debiasing in CLIP), 通过图像的强-弱增强一致性与动量平滑缓解微调过程中的灾难性遗忘问题, 并以因果推理建模伪标签偏差, 生成更适应目标域的伪标签.然而, 该方法的因果假设一旦不成立, 可能导致去偏方向错误甚至放大偏差.
构建高质量伪标签是利用CLIP知识的另一重要路径.Abdelfattah等[25]提出CDUL(CLIP-Driven Unsupervised Learning), 利用局部切块策略突破CLIP的单标签限制, 应用于多标签图像分类, 通过聚合全局与局部相似度生成伪标签, 但其标签质量控制仍依赖模板化初始化.Cai等[26]提出SIC(Se-mantic-Enhanced Image Clustering), 引入CLIP增强图像语义表达, 应对视觉相似而语义不同的聚类难题, 构建数据集相关的语义空间, 将图像特征与语义空间中的名词向量匹配, 用于优化语义中心并生成伪标签, 但方法高度依赖语义词汇的完备性与质量.
现有研究虽展示CLIP在伪标签生成中的潜力, 但多局限于标准数据集和相对干净的语义环境, 缺乏与谱聚类结构的有机结合, 也很少考虑在噪声环境下的标签可靠性.
含噪聚类问题在无监督学习中的核心挑战在于:数据中混入的噪声样本可能来源于非目标类别、错误标注或外部分布干扰[27], 既不可简单视为离群点, 也难以通过密度估计准确识别.尤其在缺乏标签信息的聚类场景下, 噪声样本会破坏相似度结构, 导致聚类结果严重偏移.传统的含噪聚类方法多依赖空间结构分析, 如DBSCAN(Density-Based Spatial Clustering of Applications with Noise)[28]通过密度连接识别低密度离群点, 或利用局部子图统计剔除样本[29], 但这些方法往往无法识别具有语义偏离的伪相似样本.
为了提升对复杂噪声的适应性, Li等[30]提出NCCAGR(Noise-Aware Clustering Based on Corren-tropy and Adaptive Graph Regularization Method), 采用相关熵最大准则筛除噪声点, 同时引入自适应图结构正则.Yang等[31]提出FCMCPF(Fast Correntro-py-Based Multi-view Clustering with Prototype Graph Factorization), Huang等[32]提出的SC2-Net(Self-Supervised Deep Convolutional Clustering Network), 都是引入原型图(Prototype Graph)与互信息一致性, 增强跨视图的鲁棒性, 降低噪声影响.然而, 上述方法依旧集中于结构和密度层面的噪声处理, 未利用语义信息.
现有含噪聚类方法一方面在噪声样本识别上过度依赖结构特征, 缺乏语义信息建模, 另一方面伪标签引导策略精度有限, 容易引发错误监督传播.
为了提升谱聚类在含噪声数据环境下的鲁棒性与聚类精度, 本文提出基于知识重用的噪声环境谱聚类方法(NSCR), 整体结构如图1所示.NSCR利用CLIP中蕴含的先验语义信息, 构建高可信伪标签, 对传统谱聚类过程进行有效引导, 从而在无监督条件下实现对噪声的感知与抑制.
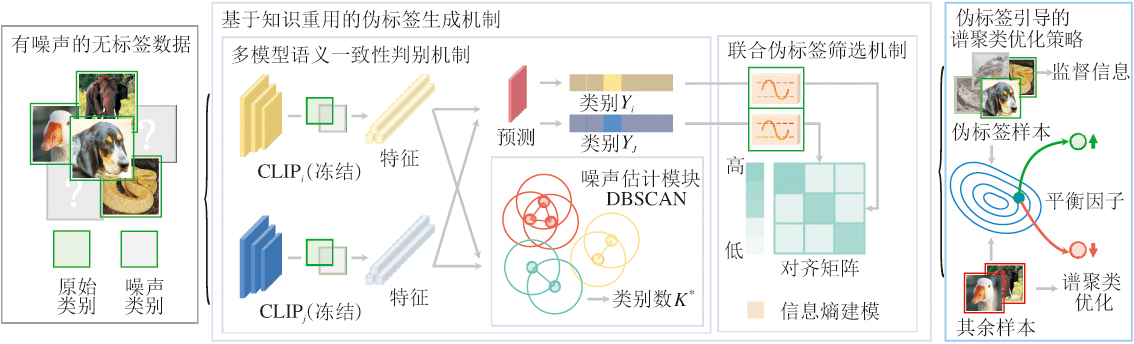 | 图1 NSCR框架图Fig.1 Framework of NSCR |
NSCR可分为如下两部分.
1)基于知识重用的伪标签生成机制.引入多个参数互异的CLIP, 对输入样本进行语义解析与类别预测, 初步获得伪标签分布.在此基础上, 设计多模型语义一致性判别机制与基于信息熵的不确定性建模机制, 筛除语义不一致或预测置信度较低的样本, 仅保留高可信伪标签用于后续训练.此外, 为了适应数据中潜在类簇数变化, 进一步引入密度估计方法, 动态调整聚类簇数, 增强对噪声结构的自适应能力.
2)伪标签引导的谱聚类优化策略.在谱聚类损失基础上, 引入伪标签监督损失, 构建联合优化目标.
针对伪标签与聚类结构间可能存在的语义冲突, 设计特征相似性对齐正则项与类别分布一致性约束正则项作为平衡因子, 动态调控不同损失项对梯度的贡献比例, 引导方法在保持结构聚类特性的同时有效利用语义监督信息.
设有未标注的数据集D=
本文旨在解决如下问题:在完全无监督的条件下, 利用CLIP蕴含的语义知识, 提升谱聚类在噪声环境下的性能.
在复杂开放环境中, 数据往往存在非目标类别样本混入、上下文歧义信息干扰、原始数据预处理过程中的信息错配等问题.这些噪声样本导致传统无监督聚类方法, 尤其是基于结构相似度的谱聚类方法, 在构图与拉普拉斯特征分解阶段产生显著偏差.为此, 本文提出基于知识重用的伪标签生成机制.首先利用CLIP集合的输出分布, 对样本进行先验推理与筛选操作, 再基于多模型一致性与归一化熵衡量样本的语义可靠性, 提供结构可信的辅助监督信息.CLIP在此阶段提供外部语义知识, 使伪标签筛选能充分利用预训练模型的语义判别能力.该流程旨在从潜在噪声混入的无标签样本中, 筛选一组语义可靠、置信度较高的伪标签样本集合, 为后续谱聚类阶段提供较高可信度的结构引导.
2.2.1 多模型语义一致性判别机制
单一预训练模型在面对跨分布迁移或模糊语义样本时, 预测稳定性存在较大波动.预测输出容易受到训练数据、参数初始化、文本提示模版等因素的影响, 导致同一图像在不同上下文中产生截然不同的解释结果.因此, 本节从模型间一致性出发, 设计多模型语义一致性判别机制.
对于无标签数据集D* =
$\begin{aligned} \boldsymbol{p}_{i}^{(j)}= & \sigma\left(M_{j}\left(\boldsymbol{x}_{i}\right)\right)= \\ & {\left[p_{i 1}^{(j)}, p_{i 2}^{(j)}, \cdots, p_{i K^{* }}^{(j)}\right] \in \mathbf{R}^{K^{* }}, } \end{aligned}$(1)
其中K* 表示模型语义覆盖空间的潜在类别总数.由此定义各模型对该样本的标签预测:
为了判定语义预测是否具备稳定性, 定义一致性判别函数:
C(xi)=
显然, C(xi)=1表示该样本在语义空间上获得模型间的一致确认, 属于语义分歧度较低的可信预测.
将所有满足一致性条件的样本构成初始候选集合:
Dconsist={xi∈ D* |C(xi)=1}.
这种一致性原则可视为一种投票式语义置信机制, 过滤出在语义上具有稳定共识的样本, 形成伪标签构建的候选集合.
2.2.2 基于信息熵的不确定性建模
仅依赖一致性判别仍不足以保证伪标签的语义可靠性, 原因在于:一致性可能在低置信条件下发生, 即多个模型均以较“ 勉强” 的方式给出相同预测结果.例如:对于语义边界模糊或视觉特征不清晰的样本, 模型间虽然预测结果一致, 但各自的Softmax输出分布可能非常平坦, 缺乏明显的类别偏向性.这种虚假一致样本若不加筛选, 将直接削弱伪标签的监督价值.
为此, 本节引入Shannon信息熵作为样本语义不确定性的度量指标.具体地, 定义样本xi的平均预测分布:
对应的信息熵表示如下:
H(xi)=-
其中
设定置信筛选阈值τ ∈ (0, 1), 可定义高置信样本集合:
Dconf={xi∈ D* |
该机制将Softmax输出作为分布整体的反映, 不再仅凭最大概率单点信息进行判断, 剔除多类别竞争性较强、预测信号较弱的伪标签.
2.2.3 联合伪标签筛选机制
基于上述两个维度的筛选机制, 本节构建联合伪标签筛选机制, 对候选样本集进行双重约束.定义最终伪标签样本集合:
Dpseudo=Dconsist∩ Dconf,
即同时满足语义一致性与Shannon信息熵的样本集合.对于xi∈ Dpseudo, 其伪标签由任一模型(如M1)提供的一致预测结果定义为
最终得到用于伪监督训练的伪标注数据集:
其余样本视为潜在语义噪声或语义歧义样本, 暂时归入未标注集合:
Dunlabeled=D* \Dpseudo.
此外, 考虑到不同数据集的噪声程度、类间差异与类别覆盖范围不一, 进一步引入动态熵阈调节机制, 定义如下:
$ \tau(t)=\tau_{0}\left(1-\gamma \frac{t}{T}\right) $, (5)
其中, γ 表示递减系数, t表示当前训练轮数, T表示最大训练轮数.该策略允许模型在训练前期容纳更多的伪标签, 后期逐步提升筛选严格度和整体伪标签质量.值得强调的是, CLIP的预测分布不仅用于初始化伪标签, 还会在训练过程中间隔地重新调用动态更新伪标签集合.
2.2.4 噪声估计
谱聚类依赖用户预设簇类数K, 难以动态感知数据中的真实语义结构, 在包含噪声样本时, 会导致低维嵌入空间过拟合或聚类数严重偏估.本节设计噪声估计模块(Noise Estimation Module), 辅助判断潜在噪声样本的存在与规模, 并基于此进行聚类数的自适应调整.
通过前述2个机制获得的伪标签集合
从中提取模型预测涉及的语义类别集合
Cpseudo={
设其元素个数K'=|Cpseudo|, 若K'> K, 表明伪标签结果中出现原始声明类别以外的新类, 噪声样本可能已构成稳定簇类结构.该判断提供语义视角下的类簇数估计初始值, 但该估计方式依赖伪标签质量.
为了更准确地估计实际类簇数K* , 引入DBSC-AN[28]作为辅助分析工具.将样本通过 CLIP的图像编码器, 获得特征向量表征:
F={fi=
将该特征集合输入DBSCAN, 得到聚类标签集合
K* =|{li|li≠ -1}|,
作为谱聚类阶段使用的最终簇类数量.
在无监督学习框架中, 谱聚类方法具有出色的非线性聚类能力与对非凸结构的建模优势, 然而若将监督信号直接强行引入优化目标, 极易破坏原始图结构的拉普拉斯嵌入特性.谱聚类的联合优化目标包含两类主要项:结构保留项(谱损失)与伪标签监督项.本文的伪标签监督项的标签由CLIP集合生成并通过周期性重估机制动态更新, 从而实现CLIP的外部语义知识与内部图结构的协同学习.因此, 如何在保证谱聚类结构稳定性的同时, 充分利用筛选后的高质量伪标签, 是本节关注的核心问题.
为此, 本节提出伪标签引导的谱聚类优化策略, 从优化目标函数层面对结构保留与伪标签监督的冲突进行建模, 引入特征相似性对齐正则项与类别分布一致性约束正则项.
2.3.1 谱聚类可微嵌入优化
谱聚类旨在通过图结构中的样本相似性信息, 构建拉普拉斯嵌入空间, 实现复杂数据在低维结构中的可分表示[33].对于输入样本集合X=
Lspectral=tr(HTLH), s.t.HTH=I,
其中H∈
Z=
对应谱聚类损失改写为
Lspectral=tr(ZTLZ). (6)
该重构实现谱聚类目标在神经网络框架下的可微转换, 使后续各类监督信号与结构优化统一于一套训练流程中.
2.3.2 伪标签监督损失
为了引入语义信息, 本节利用筛选机制获得伪标签集
对应标签矩阵Y∈
伪标签监督损失采用标准交叉熵形式:
Lpseudo=-
其中,
2.3.3 平衡因子引导的联合优化
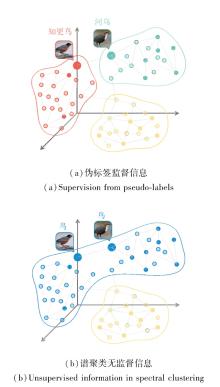
谱聚类强调样本间结构关系的保留, 通过相似图的拉普拉斯嵌入实现类内紧凑、类间分离, 而伪标签监督则更关注语义层面的类别可分性, 强制模型在特定样本上产生明确分类输出.如图2所示, 二者在优化目标上具有显著的语义差:谱聚类依赖结构流形, 伪标签监督依赖标签指导.如图所示, 当两者同时作用于模型时, 会导致梯度方向冲突、结构扰动或训练不稳定等问题.
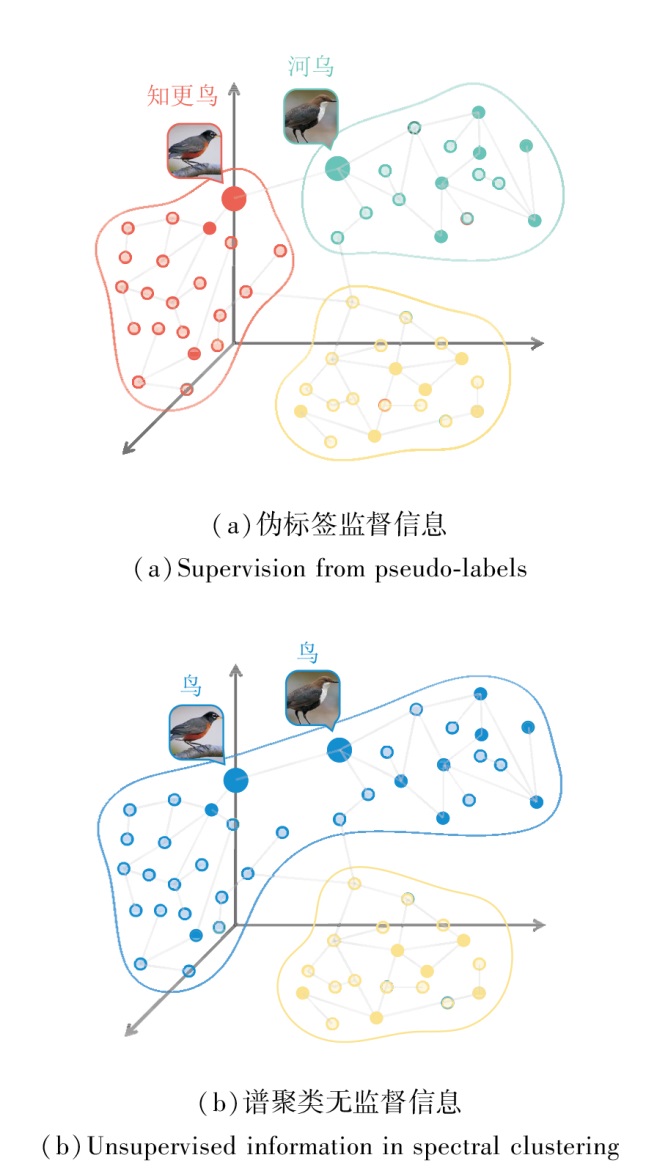 | 图2 伪标签监督信息与谱聚类无监督信息的语义差Fig.2 Semantic difference between supervision from pseudo-labels and unsupervised information in spectral clustering |
融合引导的平衡因子机制从特征空间聚合与类别分布均衡两个维度入手, 辅助实现谱聚类结构与伪标签监督之间平滑融合.
为了使未标记样本在嵌入空间中逐步靠近其语义邻域, 构建类中心引导的特征对齐机制.具体地, 基于伪标签样本Xp, 计算第k类伪标签的类中心:
ck=
其中
$R_{\mathrm{align}}=\frac{1}{\left|X_{u}\right|} \sum_{\boldsymbol{x}_{j} \in X_{u}} \min _{k \in\left\{1, 2, \cdots, K^{* }\right\}}\left\|f_{\theta}\left(\boldsymbol{x}_{j}\right)-\boldsymbol{c}_{k}\right\|_{2}^{2} .$(8)
通过特征对齐缓解伪标签信号对原始结构带来的扰动, 提升伪标签的可迁移性和结构兼容性.
进一步地, 为了避免训练过程中产生类别预测塌陷, 引入类别分布一致性约束正则项:
$R_{\mathrm{KL}}=\sum_{k=1}^{K^{* }} p\left(y_{k}\right) \ln \left(\frac{p\left(y_{k}\right)}{q\left(y_{k}\right)}\right), $(9)
其中, p(yk)表示参考的类别边际, q(yk)表示模型实际输出的类别边际.该正则项有助于保持各类输出的均衡性, 缓解因模型偏向部分伪标签样本而导致类间不均的问题.
最终的联合优化目标函数:
Ltotal=Lspectral+λ 1Lpseudo+λ 2(Ralign+RKL), (10)
其中, λ 1 表示伪标签监督损失的权重系数, λ 2 表示平衡正则项的权重系数.
NSCR步骤具体如算法1所示.
算法1 NSCR
输入 无标签数据集D=
CLIP集合M=
初始熵阈τ 0, 伪标签重估频率R, 类别数K* .
输出 聚类结果
1.对样本xi进行模型Mj的前向推理, 得到分布pj(xi)
2.基于式(1)和式(3)计算
3.基于式(4)计算
4.for t = 1 to T
5. if t = 1‖ t mod R = 0 then
6. 基于式(5)动态更新熵阈τ (t)
7. 重复步骤2、3, 更新伪标签集合
8. end if
9. 基于式(6)计算Lspectral
10. 基于式(7)计算Lpseudo
11. 基于式(8)和式(9)计算Ralign和RKL
12. 基于式(10)计算联合优化目标Ltotal
13. 反向传播更新参数
14.end for
15.完成聚类, 得到聚类结果
单次CLIP前向推理的常数代价记为CCLIP.CLIP推理与伪标签生成阶段的时间复杂度为
$O\left(M N C_{\mathrm{CLIP}}\left(1+\frac{T}{R}\right)\right)$.
当数据规模N较大时, 谱拉普拉斯的特征分解通常成为主导步骤, 整体时间复杂度可近似为O(N2), 空间复杂度为O(N).
为了系统验证NSCR在噪声类别聚类任务中的有效性, 在CIFAR-10[34]、CIFAR-100[34]、ImageNet-10[35]、ImageNet-Dogs[35]这4个标准图像数据集上开展实验.ImageNet-10数据集包含从ImageNet中挑选的10类, 约13 000幅图像.ImageNet-Dogs数据集包含15个犬类类别, 共计19 500幅图像.
为了模拟真实场景中的噪声干扰, 在各数据集上额外注入10%的噪声样本:噪声来源于ImageNet数据集上与目标数据集无交集的类别, 并通过均匀随机采样混入原始样本, 以此保证噪声类别与目标类别在语义上的显著差异.
选择如下3个评价指标:NMI(Normalized Mu-tual Information)、ACC(Accuracy)、ARI(Adjusted Rand Index).NMI用于衡量聚类结果与真实标签之间的互信息一致性, 取值范围为0至1, 数值越大表示聚类结果与真实分布越一致.ACC用于衡量聚类结果与真实标签的匹配精度.ARI用于评价聚类划分与真实标签划分之间的一致性, 能在不同类别数量和数据规模下提供稳定的对比标准.
为了评估方法在噪声环境下的稳定性与统计显著性, 在每个数据集及噪声配置下均独立运行5次实验, 每次重新随机采样噪声样本, 最终得出平均值.所有对比方法均在相同数据划分与噪声条件下运行, 确保实验结果的公平性与可复现性.
所有实验在配备NVIDIA RTX 4080 GPU的服务器上完成, 使用PyTorch 2.3.1框架, CUDA 版本为11.8, 固定随机种子为1, 学习率为0.1, 采用Multi-step学习率调度器(衰减因子设为0.1, 动量设为0.9).
在模型选择上, 使用open_clip提供的ViT-B-32架构的CLIP预训练模型:metaclip_fullcc与metaclip_400m.基于Vision Transformer架构, 应用快速GELU作为激活函数.参数大小和计算复杂度一致, 参数量为151.28 M, 浮点运算次数为14.78 B.
为了确保对比实验的全面性, 选取如下近年来在无监督图像聚类领域具有代表性的多类方法作为对比方法.
1)嵌入式聚类方法:DAC(Deep Adaptive Clus-tering)[35]、DEC(Deep Embedded Clustering)[36]、EDESC(Efficient Deep Embedded Subspace Clustering)[37]、DCSS(Deep Clustering with Self-Supervision)[38]、DCCM(Deep Comprehensive Correlation Mining)[39].
2)对比学习方法:CC(Contrastive Clustering)[40]、MoCo(Momentum Contrast)[41]、PICA(Partition Con-fidence Maximisation)[42]、MiCE(Mixture of Contras-tive Experts)[43]、IDFD(Instance Discrimination and Feature Decorrelation)[44]、NNM(Nearest Neighbor Ma-tching)[45].
3)多模态方法及伪标签增强类方法:SPICE(Semantic Pseudo-Labeling-Based Image Clustering)[46]、DXMC(Dual-Level Cross-Modal Contrastive Clus-tering)[47]、TAC(Text-Aided Clustering)[48]、LFSS(Lear-ning from Sample Stability)[49]、文献[50]方法、UACL(Uncertainty-Aware Contrastive Learning)[51]、Icicle-GCN(Image Clustering with Contrastive Learning and Multi-scale Graph Convolutional Networks)[52].
这些方法涵盖多种主流技术路线, 能充分反映现有领域研究的代表性与多样性.
首先分析有无噪声时方法对语义噪声干扰的鲁棒性.各方法在4个数据集上的性能对比如表1和表2所示, 表中黑体数字表示最优值.
| 表1 噪声环境下各方法的聚类效果对比 Table 1 Comparison of clustering results among different methods under noise |
| 表2 标准环境下各方法的聚类效果对比 Table 2 Comparison of clustering results among different methods on standard datasets |
由表1和表2可观察到, 无噪声环境下大多数方法(如 DXMC、SPICE、NNM 等)在多个数据集上表现良好, 尤其是在结构清晰的CIFAR-10、ImageNet-10数据集上, 这表明上述方法的特征建模能力在理想场景中的有效性.然而, 加入噪声后, 传统聚类方法(如 DEC、DAC、CC)性能出现明显下降.这些方法主要依赖输入空间的几何结构或初始特征对比, 缺乏针对语义噪声的适应机制.对比学习方法(如 Mo- Co、PICA、MiCE)和多模态方法(如 SPICE、DXMC)在特征提取方面仍具备一定优势, 在噪声比例较低的数据集上仍可维持中等水平.相比之下, NSCR在噪声环境下表现出优越的稳健性, 能有效处理噪声样本的干扰, 损失的性能被控制在可接受的范围内.从指标值上看, NSCR在噪声数据集上的表现显著优于传统聚类方法, 相比当前主流方法也具有一定优势.在标准数据集上的聚类性能可能略逊于LFSS、TAC等对比方法, 但总体性能上接近.
为了进一步分析各模块对最终性能的影响, 本节在CIFAR-10数据集上设计多个消融实验.
首先, 考察伪标签监督损失Lpseudo的重要性.以基础模型(设置伪标签监督损失的权重为0)为起点, 逐步提高其损失权重系数λ 1, 结果如图3所示.由图可见, 当λ 1较小时, 伪标签提供的语义信息较弱, 方法难以获得有效引导.随着λ 1增加, 监督信号增强, 性能稳步提升.当λ 1过大时, 无监督结构信号被抑制, 反而影响方法的稳定性.因此伪标签应在引导与扰动之间寻找平衡.
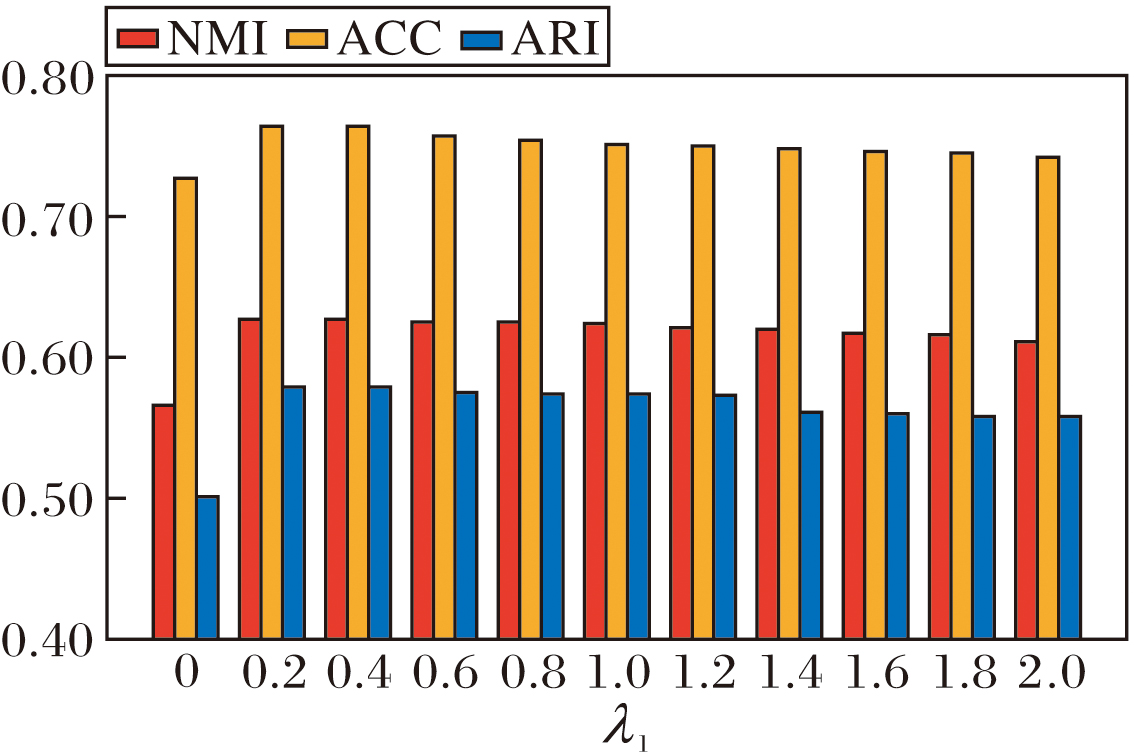 | 图3 Lpseudo对NSCR性能的影响Fig.3 Effect of Lpseudo on NSCR performance |
移除平衡因子中两个关键正则项RBF与RKL, 分别评估其作用, 结果如表3所示.由表可见, 移除RBF后, 方法结构对齐能力显著下降, 性能下降最明显.移除RKL后, 语义类别分布趋于极化, 影响伪标签与图结构间的分布一致性.
| 表3 RBF、RKL对NSCR性能的影响 Table 3 Effect of RBF and RKL on NSCR performance |
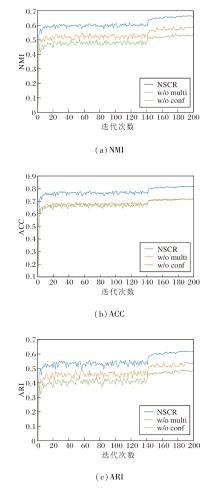
下面评估多模型语义一致性判别机制与基于信息熵的不确定性建模机制的性能, 结果如图4所示.图中, w/o multi表示移除多模型语义一致性判别机制, w/o conf表示移除基于信息熵的不确定性建模机制.
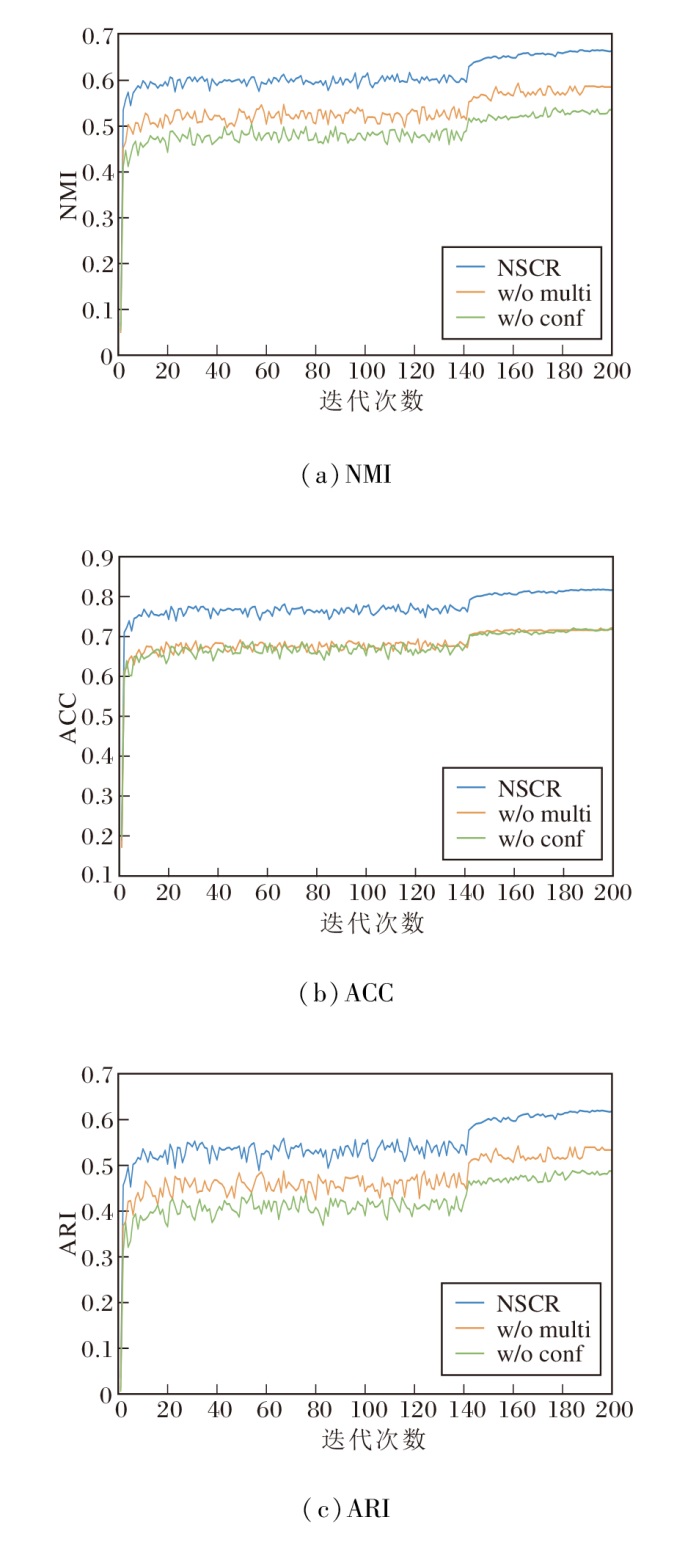 | 图4 两种机制对NSCR性能的影响Fig.4 Effect of two mechanisms on NSCR performance |
由图4可见:移除多模型语义一致性判别机制后, 伪标签数量虽保持稳定, 但错误率显著上升; 若移除基于信息熵的不确定性建模机制, 低置信样本也被误纳入监督, 引发语义冲突.因此两种机制的结合可有效提升伪标签质量, 减少监督误差传播.
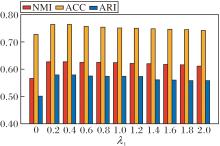
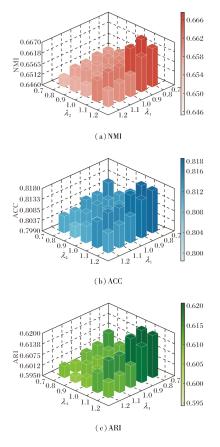
探索如下超参数对NSCR性能的影响:伪标签监督损失权重系数λ 1、平衡正则项权重系数λ 2, 评估NSCR在不同配置下的性能.不同超参数组合对NSCR性能的影响如图5所示.由图可见, 适度提升λ 1可增强语义引导效果, 促使方法在初始阶段收敛至更合理的类别空间.若λ 1过高, 容易掩盖图结构内在关系, 导致泛化能力下降.λ 2控制伪标签与无监督结构间的平衡, 适中设置可缓解目标冲突, 提升整体鲁棒性.当λ 1=1.2, λ 2=0.8时, NSCR在伪标签损失和谱聚类损失之间达到最佳平衡, 取得最优性能.
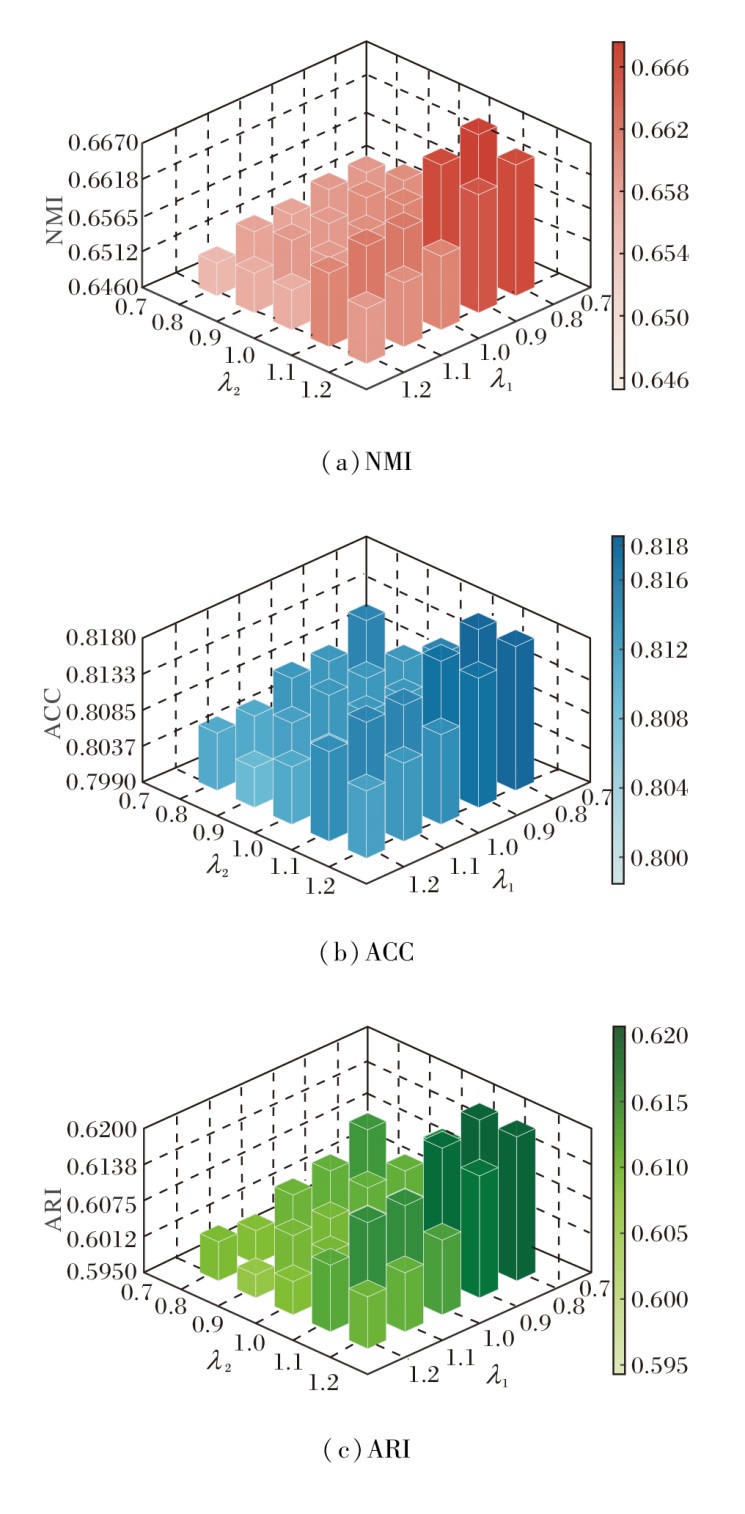 | 图5 λ 1、λ 2对NSCR性能的影响Fig.5 Effect of λ 1 and λ 2 on NSCR performance |
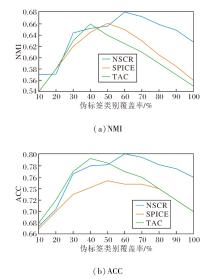
伪标签的类别覆盖范围直接决定外部语义监督的广度与深度, 因此是影响伪标签驱动聚类性能的关键超参数之一.为此在不同的伪标签类别覆盖率下对方法进行系统评估(每个设置独立重复5次, 结果以均值呈现), 并将NSCR与SPICE[46]、TAC[48]进行对比.
各方法的NMI与ACC随伪标签覆盖率变化的曲线如图6所示.由图可见, 实验结果呈现一致的倒U型趋势.当伪标签类别覆盖率过低(仅覆盖少数高置信类别)时, 伪标签提供的语义监督较少, 无法为聚类构建足够的类别约束, 导致性能受限.随着覆盖率的增加, 更多高质量的伪标签被引入, 聚类性能显著提升.当覆盖率继续扩大并纳入大量低置信或语义模糊的类别时, 错误伪标签的绝对数量增长, 错误监督开始影响训练, 性能出现回落.由图可见, NSCR在中高覆盖区(约60%)取得稳健的表现.
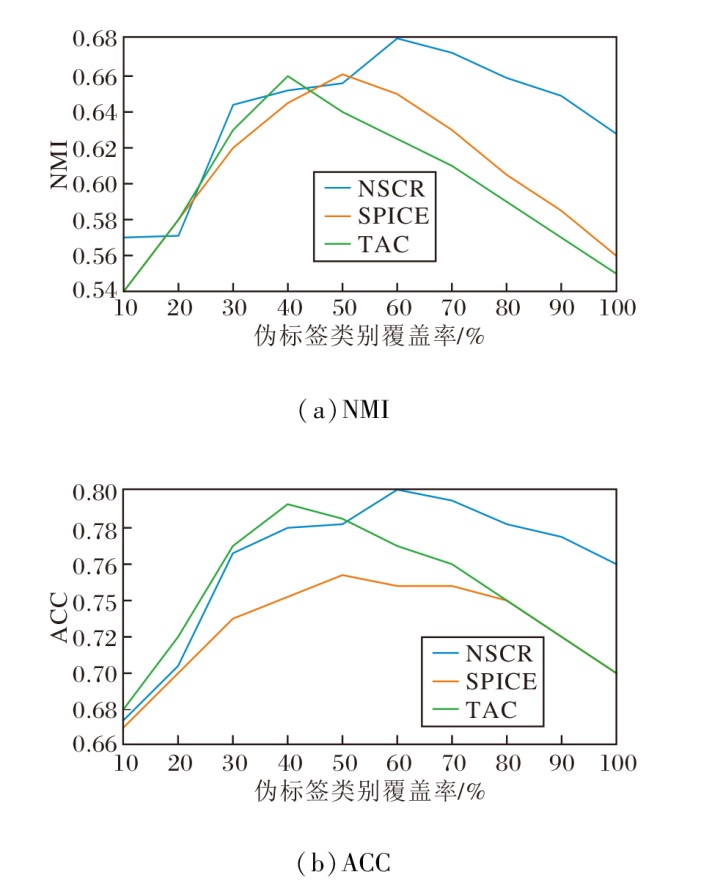 | 图6 伪标签类别覆盖率对方法性能的影响Fig.6 Effect of pseudo-label category coverage on method performance |
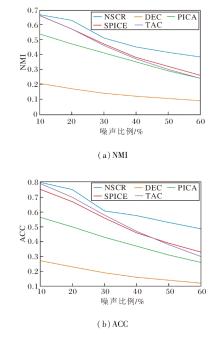
为了系统验证NSCR在不同噪声污染水平下的稳健性, 在CIFAR-10数据集上将来自ImageNet数据集的无交集样本按比例注入原始数据集, 噪声率在10%到60%之间并以10%为步长进行测试.对比方法包括:DEC[36]、PICA[42]、SPICE[46]、TAC[48].所有方法在相同噪声注入与实验设置下运行, 每个配置独立重复5次并求取均值.
各方法的NMI与ACC随噪声率变化的曲线如图7所示.由图可见, NSCR的ACC从80.1%(噪声 10%)降至48.7%, 下降约31.4%, 对应的NMI也从 0.681降至0.383, 下降约0.298.随着噪声率的增加, 所有方法的聚类指标呈下降趋势, 但下降幅度存在明显差异.与之相比, NSCR在不同噪声水平下表现出更平缓的退化曲线.
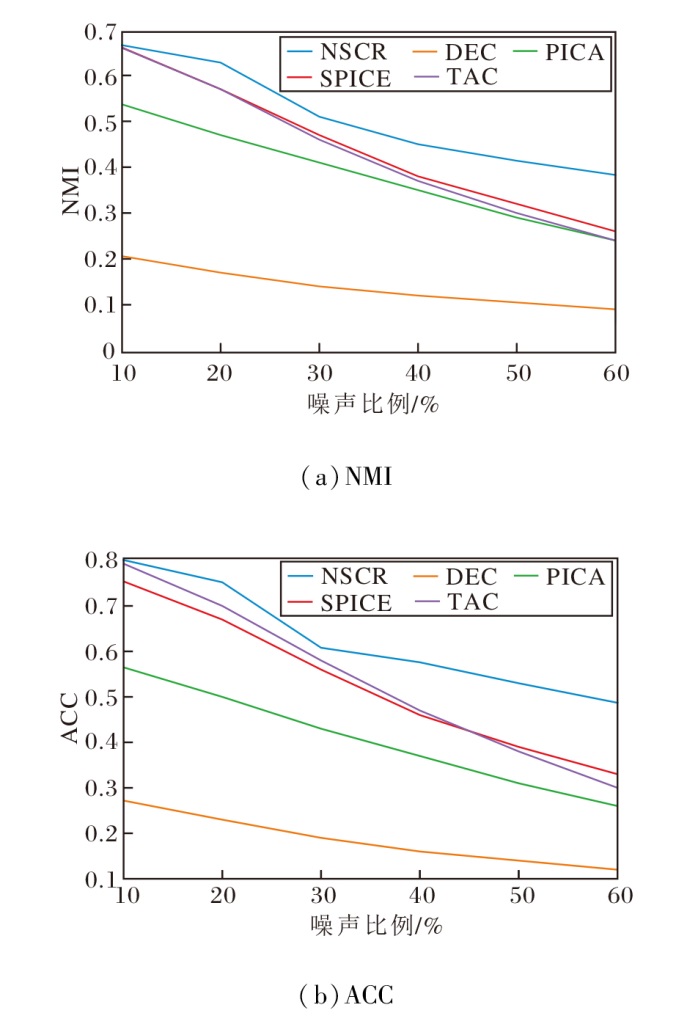 | 图7 噪声比例对方法性能的影响Fig.7 Effect of noise ratio on method performance |
本文针对在含噪声样本干扰下谱聚类性能显著下降的问题, 提出基于知识重用的噪声环境谱聚类方法(NSCR).该方法以大规模预训练模型CLIP为语义源, 构建基于知识重用的伪标签生成机制, 通过多模型语义一致性判别机制与基于信息熵的不确定性建模机制确保伪监督信息的可靠性, 并在谱聚类结构中引入平衡因子进行结构-语义融合优化.在4个数据集上的实验表明, NSCR在噪声条件下聚类性能较优.消融实验进一步验证基于知识重用的伪标签生成机制、平衡因子设计与参数设置对整体性能的关键作用.同时, 敏感性分析也揭示方法在伪标签选择与类别覆盖方面的潜在优化空间.未来工作将进一步拓展NSCR至开放集聚类与高噪声比例数据集等更具挑战性的无监督学习任务中, 探索大模型知识在不确定性建模和主动噪声控制方面的更深层次应用.
本文责任编委 陈松灿
Recommended by Associate Editor CHEN Songcan
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|