



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
双重小波增强的图像分类网络
[齐向明1  , 刘晓微
, 刘晓微1 ]
, 刘晓微]
|
|



作者简介:

刘晓微,硕士研究生,主要研究方向为图像与视觉信息计算.E-mail:1557674486@qq.com.
为了提升图像分类网络对关键信息的建模能力,增强特征表达的完整性与判别性,提出双重小波增强的图像分类网络(Dual Wavelet-Enhanced Network for Image Classification, DWENet).首先,在主干网络浅层特征提取阶段,构建小波门控卷积(Wavelet-Gated Convolution, WGConv),结合小波频域分解与门控机制,有效捕捉边缘与纹理信息,保留关键细节,抑制冗余噪声.然后,在最大池化层后引入小波核注意力(Wavelet Kernel Attention, WKA),融合频率感知与大感受野空间建模,增强结构建模与长程依赖感知,弥补池化操作造成的信息损失.此外,在网络深层加入双路径特征增强模块(Dual-Path Feature Enhancement Module, DFEM),通过空域频次分解重组并融合通道注意力机制,强化中高层语义表达与关键区域响应能力.DWENet在保持计算效率的同时,有效缓解浅层特征衰减与空间感知受限等核心问题.在CIFAR-10、CIFAR-100、SVHN、Imagenette、Imagewoof数据集上的实验表明,DWENet可提升分类准确率.
About Author:
LIU Xiaowei, Master student. Her research interests include image and visual information computing.
To improve the modeling capability of image classification networks for critical information and enhance the completeness and discriminability of feature representation, a dual wavelet-enhanced network for image classification(DWENet) is proposed. First, a wavelet-gated convolution module is constructed during the shallow feature extraction stage of the backbone network. By integrating wavelet frequency domain decomposition and a gating mechanism, edge and texture information are effectively captured with key details preserved and redundant noise suppressed. Second, a wavelet kernel attention module is introduced after the max-pooling layer. Frequency awareness and large receptive field spatial modeling are integrated to enhance structural representation and long-range dependency perception. As a result, the information loss caused by pooling operations is compensated. Furthermore, a dual-path feature enhancement module(DFEM) is incorporated into the deep network layers. DFEM enhances mid-and high-level semantic representation and key region responsiveness by reorganizing features through spatial-frequency decomposition and incorporating channel attention mechanisms. While maintaining computational efficiency, DWENet effectively mitigates core issues such as shallow feature decay and limited spatial perception. Experiments on CIFAR-10, CIFAR-100, SVHN, Imagenette, and Imagewoof datasets demonstrate that DWENet improves classification accuracy.
图像分类是计算机视觉领域中的重要任务之一, 旨在对给定的图像进行自动识别和分类, 广泛应用于人脸识别、自动驾驶、卫星遥感图像处理等任务.该技术能帮助提取图像中的关键信息, 提升计算机对复杂视觉数据的理解能力.
卷积神经网络(Convolutional Neural Network, CNN)通过其特有的卷积层、池化层和权值共享机制, 能自动学习图像的空间层次化特征表达.Lecun等[1]提出LeNet, 首次成功应用这一架构, 引入卷积层和池化层, 实现卷积层的权值共享.在此基础上, Krizhevsky等[2]提出AlexNet, 通过加深网络层数, 使用ReLU(Rectified Linear Unit)激活函数、Dropout技术及GPU(Graphics Processing Unit)加速训练, 推动CNN在大规模图像分类中的应用.Simonyan等[3]提出VGG(Visual Geometry Group Network), 采用多个3× 3的卷积核替代一个较大的卷积核, 证明卷积网络深度对分类性能的重要性.Szegedy等[4]提出GoogLeNet, 采用Inception Module, 并行使用不同尺寸的卷积核和池化层, 并在模块内进行通道维度融合, 实现高效的多尺度特征提取.He等[5]提出ResNet(Residual Network), 引入残差块结构, 利用跳跃连接将输入信息直接传至深层网络, 重构梯度传播路径, 有效缓解深度网络中的梯度消失问题.
虽然上述网络在处理图像分类任务时显著提升图像的空间特征表达能力, 但网络主要依赖空间域的标准卷积核, 对图像中具有方向性和多尺度特性的频域信息的捕捉能力有限, 容易导致复杂场景或细节敏感任务中关键信息的丢失.为了解决这一问题, Fujieda等[6]提出Wavelet Convolutional Neural Network, 将离散小波变换直接集成到CNN中作为频域下采样工具, 直接生成包含低频近似信息与高频细节信息的多尺度特征子带, 有效提升网络对方向性细节和多尺度结构的感知能力.Yang等[7]提出CRNet(Composite Refinement Network), 使用平均池化和最大池化分离高频特征和低频特征, 并使用多分支结构有效融合高低频信息, 提高图像的恢复和增强效果.此外, Chen等[8]在密集图像预测任务中提出FreqFusion(Frequency-Aware Feature Fusion), 通过离散余弦变换(Discrete Cosine Transform, DCT)对特征图进行频域分解, 并设计自适应加权模块, 实现多频段特征的选择性融合, 有效增强网络对图像全局结构与局部细节的建模能力.
上述网络通过频域分离策略有效缓解传统卷积在频域信息捕捉上的局限性.然而, 如何自适应地筛选与融合这些高低频特征, 仍是提升网络性能的关键瓶颈.针对该问题, Hu等[9]提出SENet(Squeeze-and-Excitation Network), 引入通道注意力机制, 通过全局信息聚合与自适应通道加权, 实现特征的重校准, 从而增强关键通道的响应强度.Woo等[10]提出CBAM(Convolutional Block Attention Module), 结合通道与空间注意力机制, 通过动态加权特征图的关键区域和通道, 进一步提升卷积特征的表征能力与判别性.
Qin等[11]提出FcaNet(Frequency Channel Atten-tion Network), 通过多频分量组合与自适应频率选择, 在DCT变换空间实现通道重校准, 突破传统全局平均池化的信息局限.Yee等[12]提出MEGANet-W(Wavelet Driven Edge Guided Attention Network), 通过小波变换提取高频边缘指引, 引导空间注意力, 使网络聚焦于微弱边界, 显著提升息肉分割性能, 明确小波变换可作为引导注意力机制的有效工具.Jing等[13]提出SWAN (Synergistic Wavelet-Attention Network), 构建小波变换与注意力机制的协同交互模块, 有效增强红外图像中的弱小目标并抑制背景杂波.Huang等[14]提出WFANet(Wavelet-Assisted Multi-frequency Attention Network), 将图像分解为多个频率子带并设计频率感知的注意力机制, 在全色锐化任务中实现对多尺度频谱特征的有效建模, 进一步验证小波变换与注意力机制结合在图像处理任务中的潜力.
鉴于频域分离和小波协同注意力机制在多个任务中的有效性, 本文提出双重小波增强的图像分类网络(Dual Wavelet-Enhanced Network for Image Classi-fication, DWENet).首先, 构建小波门控卷积(Wave-let Gated Convolution, WGConv), 在浅层特征提取阶段通过频域建模与小波重构强化对边缘、纹理等细节特征的捕捉.然后, 设计小波核注意力(Wavelet Kernel Attention, WKA), 在池化后利用小波卷积核引导空间注意力计算, 在扩大感受野的同时增强对关键结构的感知.最后, 提出双路径特征增强模块(Dual-Path Feature Enhancement Module, DFEM), 通过空域频次分解与通道注意力机制, 深化中高层语义特征的融合与判别能力, 提升图像分类性能.
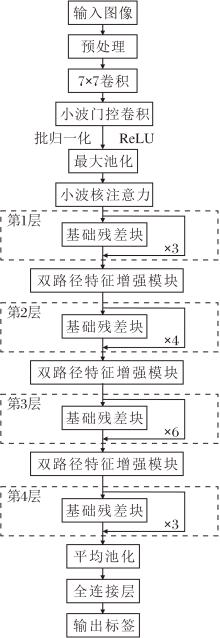
本文提出双重小波增强的图像分类网络(DWENet), 以ResNet-34[5]残差网络为基础, 设计小波门控卷积(WGConv)、小波核注意力(WKA)、双路径特征增强模块(DFEM), 增强其频域特征提取、空间结构感知与深层特征融合能力.DWENet整体架构如图1所示.
 | 图1 DWENet整体结构图Fig.1 Overall architecture of DWENet |
DWENet共包含5个训练阶段.
1)输入与数据预处理.输入图像采用随机翻转、随机填充后裁剪以及标准数据增强策略进行预处理, 增强网络对微小空间扰动与局部缺失的鲁棒性, 缓解过拟合.
2)浅层特征提取.将预处理后的图像首先通过7× 7卷积进行初步特征映射.然后, 特征图输入WGConv, 通过小波分解、小波域卷积与门控处理、逆小波重构, 有效捕获多尺度频域信息.处理后的特征图经批归一化(Batch Normalization, BN)和ReLU激活函数处理后, 由最大池化层进行空间下采样.
3)中级特征增强.将输出的特征图输入WKA, 利用小波卷积核生成空间注意力权重, 增强对关键结构信息的感知和建模能力.
4)深层特征优化.网络通过第1层~第4层这4个由基础残差块构成的残差块组进行层次化特征抽象.基础残差块作为核心基础单元, 由2个3× 3卷积层、批归一化层及跳跃连接构成, 保障梯度稳定传播与基础特征提取.为了在深层强化特征的语义整合与判别能力, 在第1层~第3层每个块组之后分别引入DFEM, 通过空域频次分解与重组模拟频带分离效应, 融合通道注意力机制对频域响应进行重校准, 显著增强特征的语义整合能力与频域判别性响应.
5)分类输出.经第4层输出的抽象特征输入全局平均池化层压缩后, 由全连接层输出最终图像分类结果.
ResNet-34在浅层特征提取阶段使用7× 7卷积核以扩大感受野、融合上下文信息, 并减少特征图尺寸.然而, 标准的空间卷积操作在早期阶段对图像频域细节响应不够敏感, 难以有效区分关键区域与背景, 容易造成特征模糊和信息冗余, 进而降低网络对关键特征的提取能力.为此, 本文在小波卷积(Wave-let Convolution, WTConv)[15]提供的多尺度频域分析基础上, 引入门控机制, 提出小波门控卷积(WGConv), 旨在突出关键区域响应, 提升特征提取的有效性.
1.2.1 小波卷积
小波卷积是卷积网络中引入多尺度频域分析的基础.WTConv采用Haar小波进行小波分解, 具体低通滤波器declo和高通滤波器dechi定义如下:
$\boldsymbol{d e c}_{\mathrm{lo}}=\left[\frac{1}{\sqrt{2}}, \frac{1}{\sqrt{2}}\right], \boldsymbol{\boldsymbol{d e c}}_{\mathrm{hi}}=\left[\frac{1}{\sqrt{2}}, -\frac{1}{\sqrt{2}}\right] .$
在输入特征X∈ RB× C× H× W中, B表示批量大小, C表示通道数, H、W分别表示图像的高度和宽度.对X进行二维滤波器外积卷积, 分解为4个频域子带:
$\begin{array}{l} X_{\mathrm{LL}}=\left(\operatorname{dec}_{\mathrm{lo}} * \operatorname{dec}_{\mathrm{lo}}\right) * X, \\ X_{\mathrm{HL}}=\left(\operatorname{dec}_{\mathrm{hi}} * \operatorname{dec}_{\mathrm{lo}}\right) * X, \\ X_{\mathrm{LH}}=\left(\operatorname{dec}_{\mathrm{lo}} * \operatorname{dec}_{\mathrm{hi}}\right) * X, \\ X_{\mathrm{HH}}=\left(\operatorname{dec}_{\mathrm{hi}} * \operatorname{dec}_{\mathrm{hi}}\right) * X . \end{array}$
其中:* 表示卷积操作, XLL表示低频近似子带, 承载图像的全局结构信息; XHL、XLH、XHH表示高频子带, 分别捕捉垂直、水平和对角方向的边缘和纹理细节.
WTConv支持多级分解以构建多尺度特征金字塔.第l层的分解过程如下:
{
其中, W(· )表示小波变换操作,
频域特征经学习与调制后, 通过逆小波变换(Inverse Wavelet Transform, IWT)进行重构, 得到空间域特征Xwavelet.最终, 由小波分支与一个并行的深度卷积分支通过残差连接融合生成WTConv输出特征:
Xout=Xwavelet+Xbase,
其中,
Xbase=γ 1· DWConv(X),
表示主分支通过深度卷积(Depthwise Convolution, DWConv)提取的基础特征, DWConv(· )表示深度卷积操作, γ 1表示可学习的通道缩放因子.此设计在引入频域增强能力的同时, 保留原始的空间特征以保证梯度稳定.
然而, 标准的WTConv对分解后的各频域子带通常采用固定或均等的处理策略, 难以根据输入内容自适应强化关键信息, 限制其特征选择的判别性.
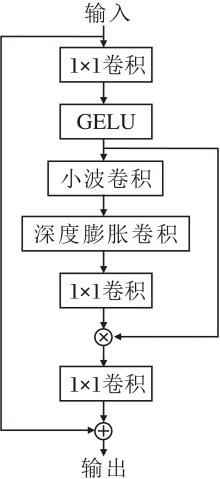
1.2.2 小波门控卷积整体结构
基于WTConv的多尺度频域分析能力, 引入门控机制, 构建WGConv, 旨在实现对关键频域信息的自适应增强.WGConv的整体结构如图2所示.
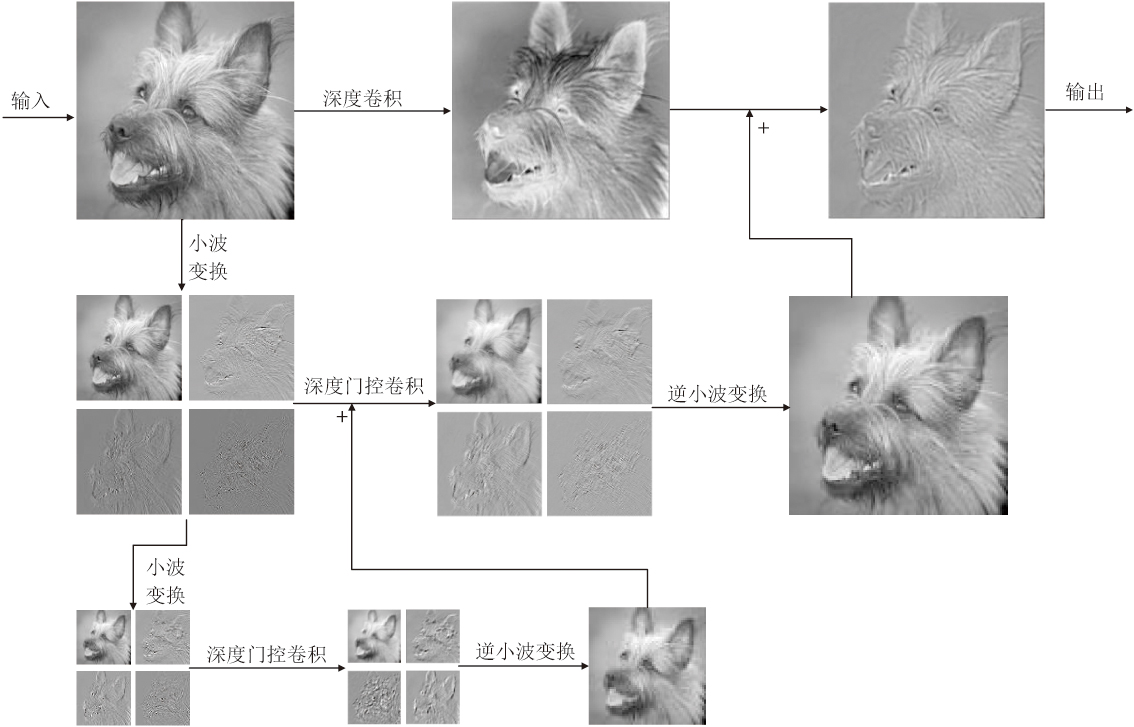 | 图2 WGConv结构图Fig.2 Structure of WGConv |
在特征处理阶段, 对于经7× 7卷积层初步映射后的输入特征X∈ RB× C× H× W, 基础特征响应由主分支提取, 公式如下:
Xbase=γ · DWConv(X),
其中, γ 表示初始化为1的可学习通道缩放因子, 用于确保训练初期的稳定性.
在小波分支中, 对输入特征X执行L层小波分解以构建多尺度特征金字塔.该过程遵循仅对低频分量进行逐级分解的递归策略:第1级对输入特征X进行分解, 第2级对第1级的低频子带
小波变换对输入特征进行二维离散小波分解, 生成LL、LH、HL、HH四个不同的频域子带.这些子带在张量表示中被组织在第三维, 形成五维张量B× C× 4× Hl× Wl, 其中第三维的大小4对应这四个固定的子带分量.为了适配后续的门控卷积操作, 将该张量在通道维度拼接, 形成增强的特征表示:
U(l)=Concat(
其中, Concat(· )表示通道维度拼接, 拼接后的特征维度为B× 4C× Hl× Wl.随后, U(l)输入深度门控卷积单元.该单元首先通过深度卷积提取响应, 再由门控路径生成空间注意力图:
其中,
V(l)=DWConvmain(U(l)),
表示主路径的输出特征图,
G(l)=σ (DWConvgate(U(l))),
表示门控路径的输出特征图, DWConvmain(· )表示主路径的深度卷积, DWConvgate(· )表示门控路径的深度卷积, σ (· )表示Sigmoid激活函数, ☉表示逐元素乘法, PWConv(· )表示逐点卷积操作.
逐点卷积(Pointwise Convolution, PWConv)采用1× 1卷积核, 核心作用是实现跨通道信息的交互与特征重组.PWConv的输入通道数和输出通道数均为4C, 通过可学习的权重矩阵对门控增强后的特征进行线性组合, 确保各频带间信息的有效融合, 为后续的逆小波变换准备合适的特征表示.这种设计使得门控机制能同时考虑4个子带的信息, 从而学习跨频带的注意力权重, 更有效突出重要特征.
为了进行逆小波变换, 将输出特征重塑为4个子带的形式:
其中Reshape(· )表示重塑操作.具体而言, 重塑操作将维度为B× 4C× Hl× Wl的特征图
在重构阶段, 采用自底向上的方式逐级进行逆小波变换T.该过程是递归的:从最深层级L开始, 并设
其中,
Xwavelet=
这种跨层级的残差连接设计使得每级的重构不仅依赖于本层增强后的子带, 还融合更深层级的语义信息, 既保留增强的细节特征, 又促进语义信息在不同尺度间的流动, 同时有助于梯度的稳定传播.
最终, 模块输出如下所示:
Xout=Xwavelet+Xbase.
为了评估WGConv对特征提取效果的影响, 在相同输入条件下, 网络浅层是否使用WGConv输出的特征图可视化结果如图3所示.
 | 图3 有无使用WGConv的特征图Fig.3 Feature maps with and without WGConv |
由图3可知, 加入WGConv后的特征图在边缘、纹理等细节上更清晰.可视化结果直观表明, WGConv能有效增强网络对图像细节与结构信息的捕捉能力, 使特征表达更具判别性.
在ResNet-34中, 最大池化层用于压缩空间维度并增强局部不变性, 但其下采样操作导致特征图的空间分辨率降低, 造成细节信息丢失, 难以区分局部结构的重要性差异, 限制特征表达能力.
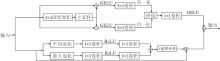
为了增强网络在下采样阶段的空间感知能力, 更聚焦显著区域与关键结构细节, 受VAN(Visual Attention Network)[16]启发, 本文设计小波核注意力(WKA).WKA结合小波变换的频域分析能力与大核注意力的空间建模能力, 通过频域与空域的协同优化特征响应分布, 具体结构如图4所示.
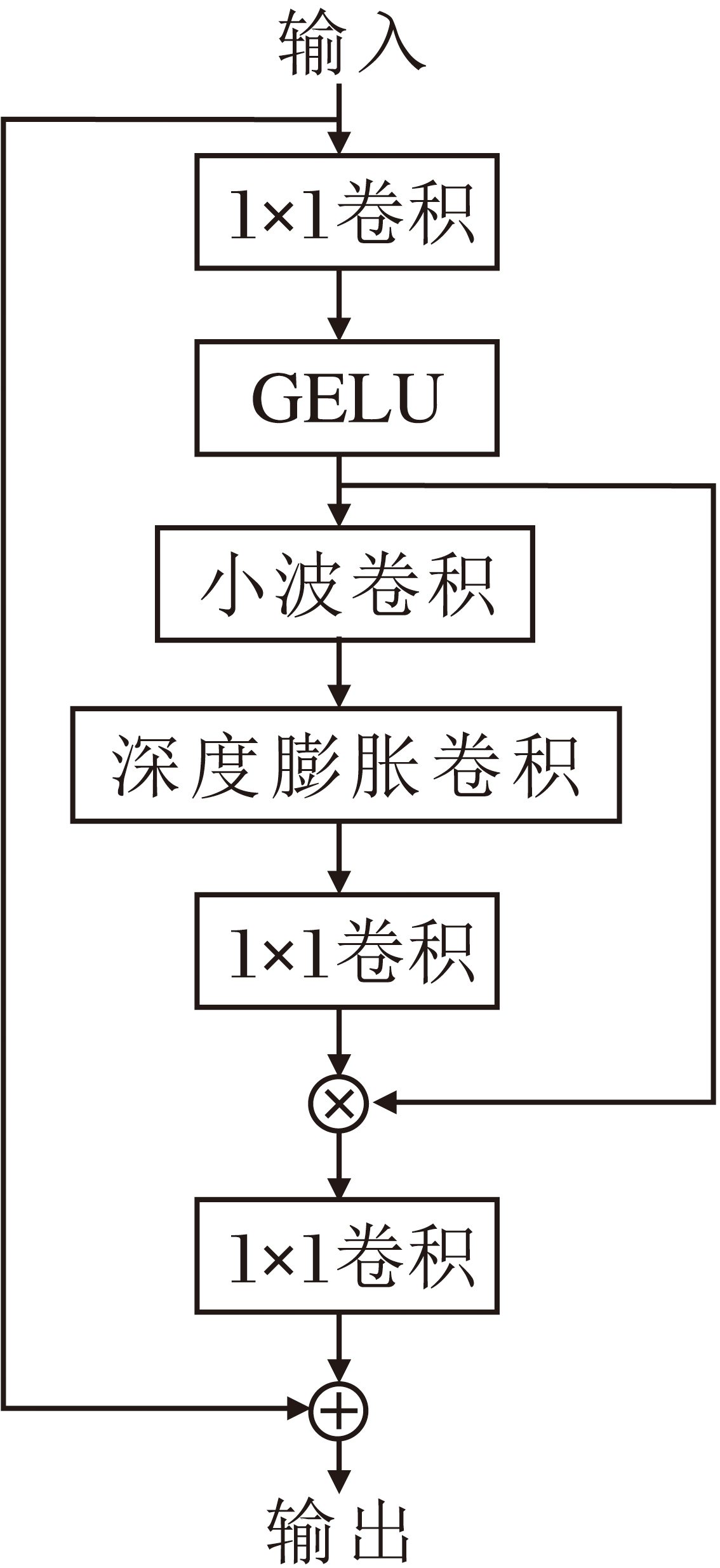 | 图4 WKA结构图Fig.4 Structure of WKA |
WKA由3部分组成:小波卷积(WTConv)、深度膨胀卷积、通道投影卷积(1× 1卷积).小波卷积通过小波变换增强局部特征提取能力; 深度膨胀卷积利用膨胀率扩大感受野, 捕捉长距离依赖关系; 1× 1卷积实现特征提取和降维.
对于来自WTConv并经下采样处理后的输入特征图X∈ RC× H× W, 首先经过一个1× 1卷积和非线性激活函数的通道映射与特征转换, 得到中间特征:
X1=GELU(Conv1× 1(X)),
其中, Conv1× 1(· )表示1× 1卷积操作.GELU(Gaussian Error Linear Unit)激活函数通过高斯分布对输入进行加权, 相比ReLU具有更平滑的梯度特性, 并且是非线性的, 有助于深层网络的收敛.
随后, X1输入WTConv.在小波增强分支中, 首先利用单层Haar小波变换将输入特征映射至频域, 得到多子带表示.然后在小波域内进行深度卷积与通道缩放操作, 并通过逆小波变换(IWT)将处理后的特征恢复到空间域.同时, 主干分支对X1应用一层3× 3的深度卷积以提取局部结构特征.最后, 将两路结果通过残差方式融合, 得到融合特征
X2=DWConv3× 3(X1)+IWT(γ · DWConvwavelet(WT(X1))),
其中, WT(· )表示单层小波变换, DWConvwavelet(· )表示小波域的深度卷积, DWConv3× 3(· )表示主干分支的深度卷积, IWT(· )表示逆小波变换操作.
然后, 将融合后的特征X2输入由深度膨胀卷积和逐点卷积构成的空间注意力构建模块, 得到注意力图:
X3=Conv1× 1(DW_G_Conv(X2)),
其中, DW_G_Conv(· )表示空洞率为3的7× 7深度卷积, 用于捕捉长距离空间依赖关系, Conv1× 1(· )表示1× 1卷积, 在此处作为输出投影, 将深度卷积特征映射为注意图.随后, 将注意力图X3与中间特征X1进行逐元素乘法, 并通过1× 1卷积进行通道映射, 最终与输入特征X残差相加, 得到输出特征图:
Xout=X+Conv1× 1(X1☉X3).
WKA在最大池化后引入, 能有效缓解池化操作导致的空间信息损失, 增强浅层特征的选择性表达与细节保持能力.
尽管ResNet通过跳跃连接可缓解梯度消失问题, 但其深层网络仍面临特征衰减、感受野受限与通道交互不足的挑战, 导致对关键结构的表达能力下降.
针对上述问题, 本文受传统图像增强技术的启发, 在网络深层引入双路径特征增强模块(DFEM).
图像锐化技术通过增强高频分量以突出边缘与纹理细节, 经典实现如拉普拉斯锐化:
g(x, y)=f(x, y)-c·
其中, g(x, y)表示锐化后的图像, f(x, y)表示原始图像,
$ q(x, y)=f(x, y) \circ m(x, y), $
其中, $\circ$表示逐元素相乘, m(x, y)表示增强权重.
DFEM将这两种在像素空间操作的思想迁移至深层特征的语义空间, 通过特征重组分支与通道建模分支的协同工作, 分别从空间维度和通道维度增强特征的判别性.DFEM在整体网络中的位置如图1所示, 详细结构如图5所示.
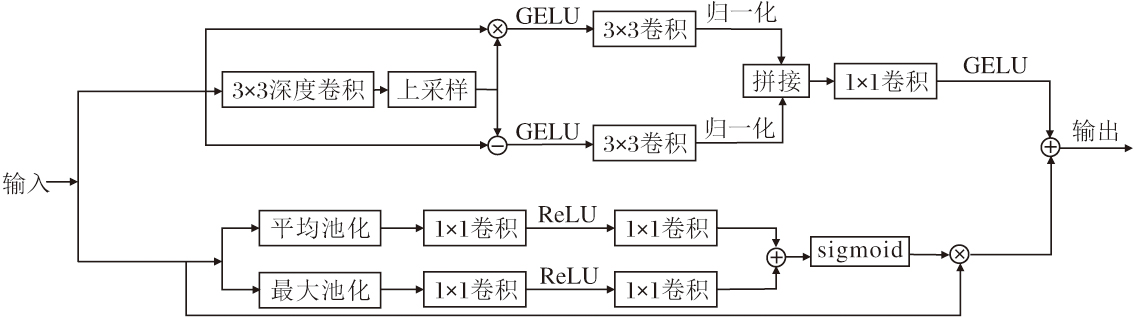 | 图5 DFEM结构图Fig.5 Structure of DFEM |
1.4.1 特征重组分支
特征重组分支的核心设计思路是在特征空间模拟图像锐化与对比度增强的效应, 通过显式分离与重组高频细节和低频结构成分, 增强空间结构的表达能力.
首先, 通过深度卷积获取粗粒度特征表示, 随后使用双线性插值恢复原始分辨率, 得到低频成分:
其中Interp(· )表示双线性上采样.
高频细节路径的设计灵感源于拉普拉斯锐化思想, 通过从原始特征T中减去其低频成分
Th=Norm1(DWConv(GELU(T-
其中Norm1(· )表示对高频特征进行归一化操作.
低频结构路径则借鉴对比度增强的理念, 旨在强化特征的结构信息.通过元素级乘法T☉
Tl=Norm2(DWConv(GELU(T☉
其中Norm2(· )表示对低频特征进行归一化操作.
最后, 通过1× 1卷积将增强后的高频细节特征与低频结构特征在通道维度进行拼接与融合, 形成信息互补的特征重组分支输出:
Tf=GELU(Conv1× 1(Concat(Tl, Th))).
1.4.2 通道建模分支
为了弥补空间卷积在通道维度建模能力的不足, DFEM集成一个通道注意力分支.设计思路是自适应校准通道维度的特征响应, 使网络更关注信息量丰富的特征通道.
首先, 对输入特征进行全局平均池化与最大池化, 并通过共享的1× 1卷积与ReLU激活处理, 得到平均池化通道响应
Tavg=ReLU(Conv1(AvgPool(T)))
和最大池化通道响应
Tmax=ReLU(Conv1(MaxPool(T))),
其中, Conv1(· )表示第1层映射卷积, AvgPool(· )表示全局平均池化操作, MaxPool(· )表示全局最大池化操作.然后, 将2条池化路径的特征分别通过第2个卷积层Conv2映射后相加, 通过Sigmoid激活生成权重并与输入相乘, 实现通道级的重校准, 得到通道注意力分支输出:
Tc=σ (Conv2(Tavg)+Conv2(Tmax))☉T.
1.4.3 输出特征图
最终, 将特征重组分支输出的空间增强特征Tf与通道建模分支输出的通道增强特征Tc相加, 得到模块输出特征图:
Tout=Tf+Tc.
DFEM通过联合特征重组分支与通道建模分支, 显著增强网络在空间结构建模与通道依赖建模方面的能力.特征重组分支通过上采样和下采样构建粗粒度上下文, 并将输入划分为近似低频特征与高频特征两部分, 从而细化空间结构与边缘细节表达.通道建模分支利用全局池化与注意力机制自适应调整通道权重, 增强对关键语义特征的响应.两条分支协同优化中间特征的结构表达与通道选择性, 弥补ResNet在高层特征建模中对结构细节与通道依赖刻画不足的缺陷, 提升网络判别能力.
实验使用NVIDIA Tesla P100显卡, 显存为16 GB, 操作系统为Linux 5.15.133.软件环境为PyTorch 2.0.0, CUDA 11.4, CUDNN 8.0.9, 编程语言为Python 3.10.12.
实验数据集选择CIFAR-10、CIFAR-100、SVHN、Imagenette、Imagewoof、CUB-200、COVID-19、UC Mer-ced数据集.在通用对象分类方面, CIFAR-10、CIFAR-100数据集作为广泛使用的基准数据集, 均由32× 32的小尺寸彩色图像构成, 分别包含10类物体和100类物体.SVHN数据集源于真实街景门牌号码图像, 适用于数字字符识别任务.Imagenette、Imagewoof数据集源于ImageNet的子集, 提供相对更高分辨率的图像, Imagenette数据集涵盖10类常见物体, Imagewoof数据集包含10个犬种, 适用于中等规模的分类场景.
在细粒度识别方面, 采用CUB-200鸟类数据集, 包含200种鸟类子类, 用于评估网络在高度相似类别间的区分能力.为了进一步验证网络在专业领域的泛化性, 还引入遥感图像分析数据集UC Merced及用于医学诊断的COVID-19胸部X光影像数据集.各数据集的详细配置如表1所示.
| 表1 实验数据集 Table 1 Experimental datasets |
实验采用随机梯度下降(Stochastic Gradient Descent, SGD)优化器和交叉熵损失函数.在训练过程中, CIFAR、SVHN数据集批次大小为128, Imagenette、Imagewoof、CUB-200、COVID-19、UC Mer-ced数据集批次大小为64, 总训练周期为200轮, 标签平滑率为0.1, 动量为0.9, 权重衰减为5× 104, 初始学习率为0.1.数据预处理包括随机水平翻转、随机裁剪等操作, 并对图像数据进行归一化处理.
主要评价指标为验证集的分类准确率.为了全面衡量网络的实用性与计算效率, 同时考察网络的浮点运算量(Floating Point Operations, FLOPs)、参数量、单幅图像推理时间等核心硬件指标.需要注意的是, 为了适应CIFAR-10、CIFAR-100、SVHN数据集上的小尺寸图像输入, 将首层的7× 7卷积核、步长为2的下采样卷积层替换为3× 3卷积核、步长为1的卷积层.
影响DWENet性能的主要参数包括:基础网络深度、小波变换选择的小波基类型、小波分解的层级、WKA中膨胀卷积尺寸、DFEM中通道注意力的压缩比率r、DFEM的插入位置和数量.
2.2.1 基础网络深度
网络深度是影响深度神经网络特征表达能力的关键因素, 层数不足会限制特征提取效果, 而过深的网络容易引发过拟合与特征冗余.为了探究基础网络深度对DWENet性能的影响, 在ResNet-18、ResNet-34、ResNet-50、ResNet-101、ResNet-152基础上分别嵌入WGConv、WKA及DFEM, 得到DWENet-18、DWENet-34、DWENet-50、DWENet-101、DWE-Net-152.
各网络在通用数据集上的分类准确率如表2所示.由表可知, DWENet-34在多数任务中表现最佳, 在CIFAR-10、CIFAR-100、SVHN数据集上的分类准确率分别达到96.79%、81.44%、97.62%, 显著优于其它深度网络.DWENet-18因结构较浅, 表达能力受限, 性能略低, 但随着网络深度进一步增加, 性能并未获得持续提升, DWENet-50、DWENet-101、DWENet-152在所有数据集上性能均呈现回落.这说明过深的结构可能引入冗余参数, 反而削弱网络的有效判别能力.因此, DWENet-34被选为后续实验的基础架构.
| 表2 不同网络层数的分类准确率 Table 2 Classification accuracies of different network layers % |
2.2.2 WGConv的小波基选择
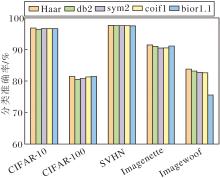
在WGConv中, 小波基的选择直接影响频域特征的提取质量.为了探究最优的小波变换方案, 选取Haar、db2、sym2、coif1、bior1.1这5种具有代表性的小波基进行实验.这些小波基在滤波器长度、平滑性、对称性及局部响应特性方面各有差异, 适用于不同频域特征的提取任务.Haar小波基因其结构简单、局部化强, 能在频域卷积过程中高效响应图像中的边缘信息和主结构信息, 有利于减少冗余特征, 提升通道间的辨别性.db2、sym2小波基提供更平滑的频率响应, 适用于纹理信息建模.coif1、bior1.1小波基在线性相位和细节重构方面更具优势.
不同小波基的计算效率如表3所示.由表可见, 尽管各小波基在FLOPs(4.04 G)和参数量(21.59 M)上完全一致, 但由于滤波器结构的复杂度不同, 其推理效率存在显著差异.Haar小波基凭借简单的滤波器结构, 实现最快的推理速度(6.20 ms); 最复杂的coif1小波基推理时间则为6.91 ms.
| 表3 WGConv中不同小波基的计算效率 Table 3 Computational efficiency of different wavelet bases in WGConv |
WGConv中不同小波基对分类准确率的影响如图6所示.结合表3可知, Haar小波基在CIFAR-10、CIFAR-100、SVHN、Imagenette、Imagewoof数据集上均取得最优的分类准确率, 同时在推理速度方面也展现出明显优势.这表明Haar小波基不仅能通过阶跃型滤波器高效捕捉图像局部边缘信息, 减少冗余特征, 提升通道辨识度, 而且在计算效率方面同样具有优秀表现, 实现精度与速度的最佳平衡.
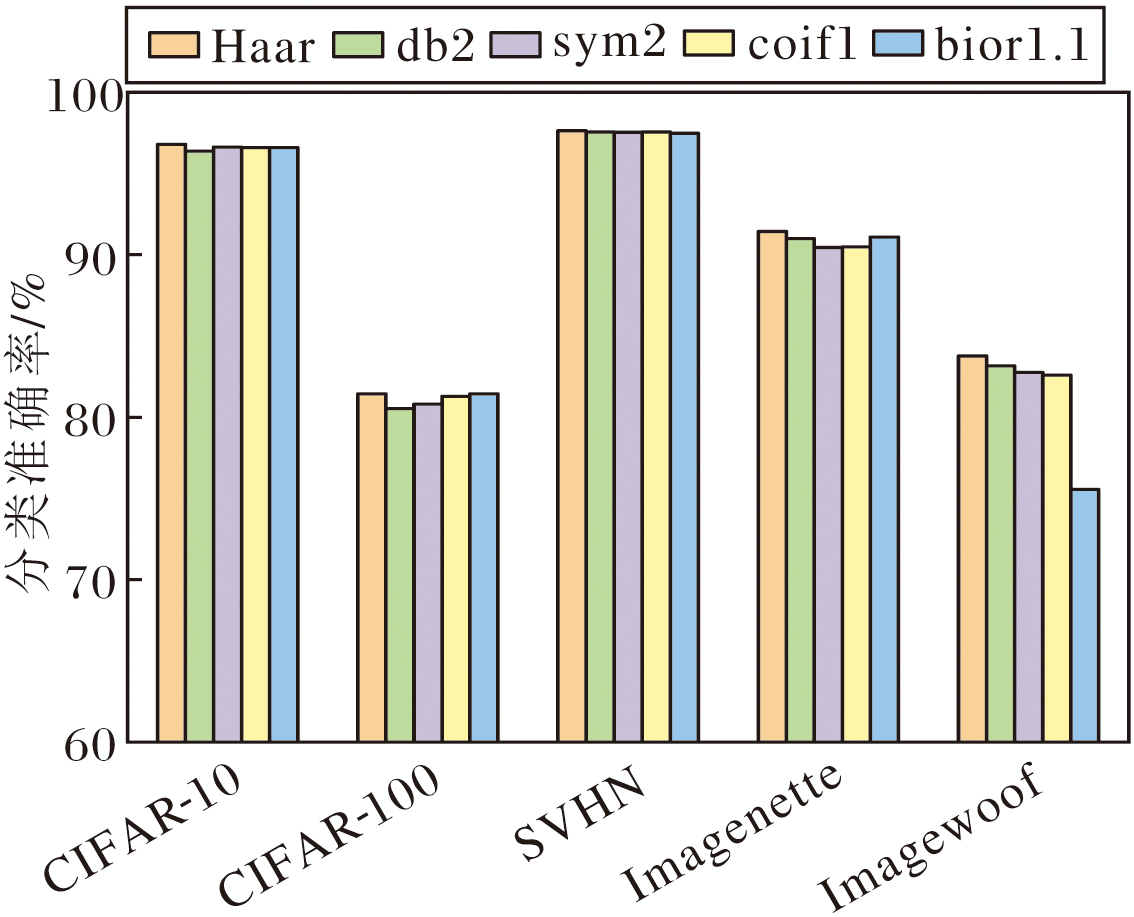 | 图6 WGConv中不同小波基对分类准确率的影响Fig.6 Effect of different wavelet bases in WGConv on classification accuracy |
2.2.3 WGConv小波分解层级
小波多级分解旨在高效构建具有大感受野的分层特征表示, 通过逐级应用离散小波变换, 将输入递归分解为不同分辨率的子带, 形成多尺度特征金字塔.该机制通过逐级分解, 在降低空间分辨率的同时, 显著扩展后续特征的原始输入感受野范围.因此网络能以较低计算成本高效融合多尺度上下文信息, 提升对大范围依赖和复杂结构的理解.然而, 鉴于更深层次的分解会因分辨率过低导致特征信息严重损失, 实验对比一至四层小波分解以探究不同层级对准确率的影响.
不同小波分解层级对分类准确率的影响如图7所示.
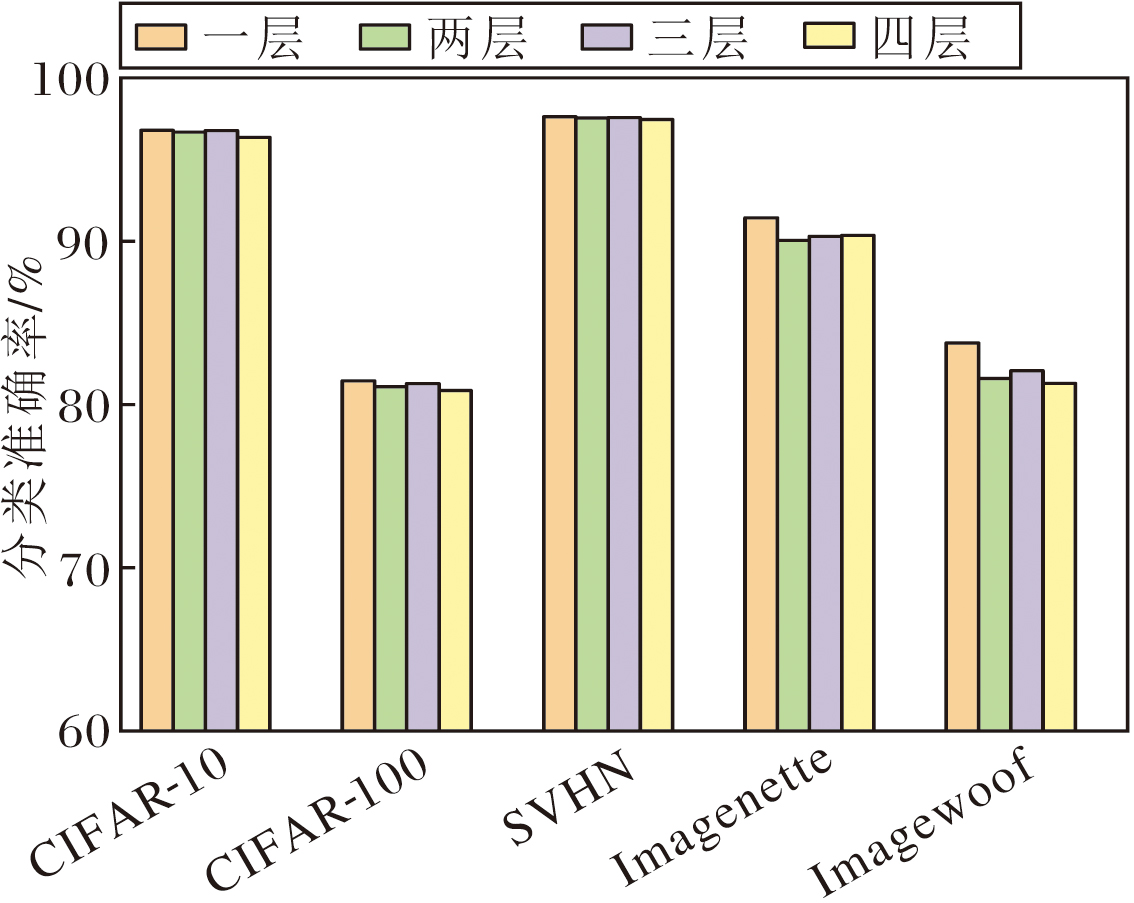 | 图7 WGConv中不同小波分解层级对分类准确率的影响Fig.7 Effect of different wavelet decomposition levels in WGConv on classification accuracy |
由图7可见, 针对浅层特征提取, 单层小波分解性能最优.这是由于浅层特征分辨率较高、语义信息较少, 单层分解可有效引入稍大感受野捕捉邻近上下文结构, 同时最大程度保留原始高分辨率空间细节, 避免多层分解在浅层造成的过度信息损失和不必要计算开销, 实现计算效率与特征丰富性的平衡.
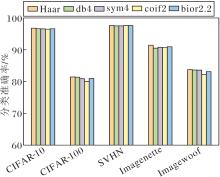
2.2.4 WKA的小波基选择
在WKA中, 除了最具基础性与局部响应特性的Haar小波基以外, 进一步选取支持域更长、平滑性更优的db4、sym4、coif2小波基及相位保持性更强的bior2.2小波基, 系统评估这4类高阶小波基在复杂空间结构下的注意力建模性能.这些高阶小波基通过扩展的滤波器长度增强对纹理连续性的表征能力, 凭借近似对称性减少几何结构畸变, 理论上更适配长距离依赖建模需求.
WKA中不同小波基对分类准确率的影响如图8所示, 不同小波基的计算效率如表4所示.
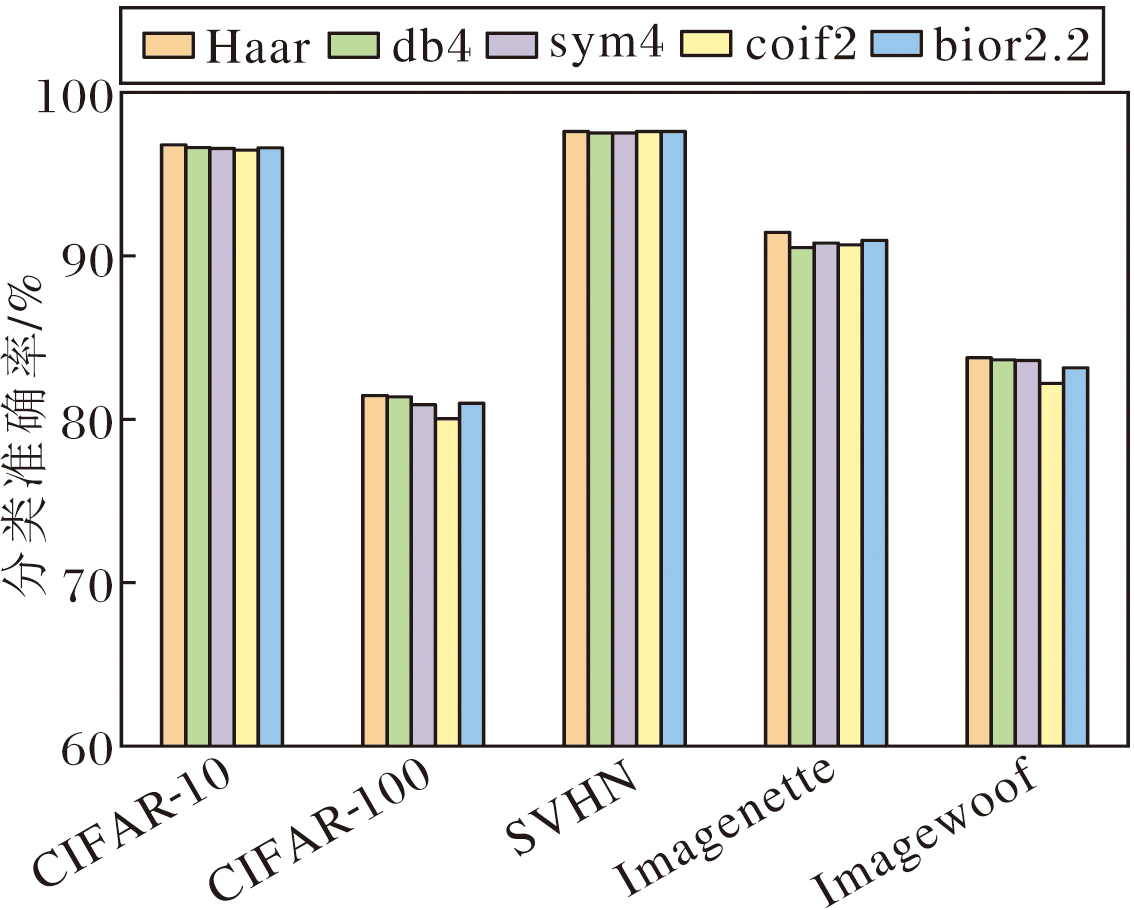 | 图8 WKA中不同小波基对分类准确率的影响Fig.8 Effect of different wavelet bases in WKA on classification accuracy |
| 表4 WKA中不同小波基的计算效率 Table 4 Computational efficiency of different wavelet bases in WKA |
由图8和表4可知, Haar小波基在分类性能与推理效率方面均表现最优, 其核心原因在于Haar小波基采用最简阶的分解结构, 具有最短支持域和非重叠滤波特性.在局部区域, Haar小波基的响应高度稀疏, 能精确定位图像中的突变区域, 如边缘和显著结构.这种局部化特性对于注意力机制中空间区域的精确加权尤为关键, 有助于网络准确聚焦于高响应区域, 提升注意力图的空间分辨能力与判别性.同时, Haar小波基计算复杂度较低, 适合集成于注意力路径中进行高效频域建模, 最终在性能与效率之间实现良好的平衡.该结论与2.2.2节中小波基选择实验结果高度一致, 表明Haar小波基的强局部化特性与阶跃型滤波器对于分类任务中关键结构特征的捕捉具有明显优势, 无论是浅层的多尺度特征提取还是在中层的注意力加权, 都能取得最优效果.
2.2.5 WKA中膨胀卷积尺寸
在WKA中, 膨胀卷积通过扩大感受野, 可有效增强对不同尺度特征的捕捉能力, 提升网络性能.第i层有效感受野(Effective Receptive Field, RF)计算公式如下:
RFi=(RFi+1-1)Sstride+Ksize,
其中, RFi+1表示i+1层有效感受野大小, Sstride表示当前层的步长, Ksize表示当前层的卷积核大小.
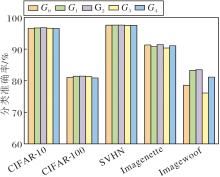
为了确定最优的膨胀卷积, 系统性地测试多种卷积核尺寸、填充和膨胀率的组合, 具体设置如表5所示.
| 表5 不同尺寸的深度膨胀卷积参数 Table 5 Deep dilated convolution parameters for different sizes |
不同膨胀卷积参数组合下的计算效率如表6所示, 对分类准确率的影响如图9所示.
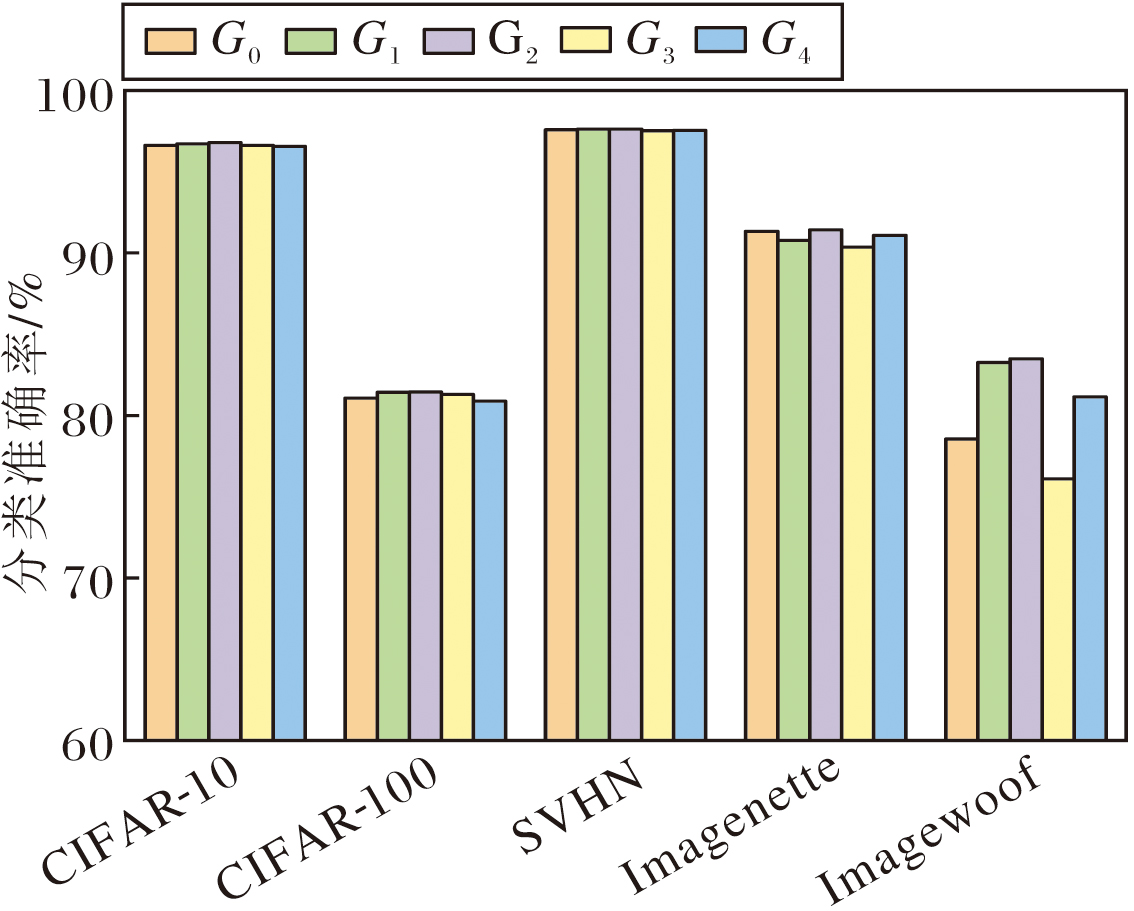 | 图9 WKA中不同膨胀卷积参数组合对分类准确率的影响Fig.9 Effect of different dilated convolution parameter combinations in WKA on classification accuracy |
| 表6 WKA中不同膨胀卷积参数组合的计算效率 Table 6 Computational efficiency of different dilated convolution parameter combinations in WKA |
由表6和图9可见, 卷积核尺寸为7、填充为9、膨胀率为3的组合G2在计算效率与特征提取能力间达到最佳平衡.该配置在保持较低计算成本的前提下, 提供适中的感受野, 并在所有数据集上取得最高的分类准确率.过大或过小的膨胀卷积配置都会影响网络性能, 可能引入过多与局部特征无关的背景噪声或无法充分建立有效的长程依赖关系.合理的膨胀卷积配置能平衡感受野和计算复杂度, 提升网络在不同数据集上的适应性和表现.
2.2.6 压缩比率
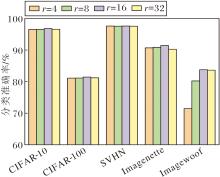
在DFEM中, 通道注意力分支通过对通道数进行压缩以减少计算量, 压缩比率r控制通道压缩的程度, 值越大, 压缩后的通道数越少(C/r), 计算量越低, 但可能造成更多的信息损失.压缩比率影响着特征选择和网络的表达能力.本文选择r=4, 8, 16, 32, 并在CIFAR-10、CIFAR-100、SVHN、Image-nette、Imagewoof数据集上进行实验.
不同r对分类准确率的影响如图10所示.
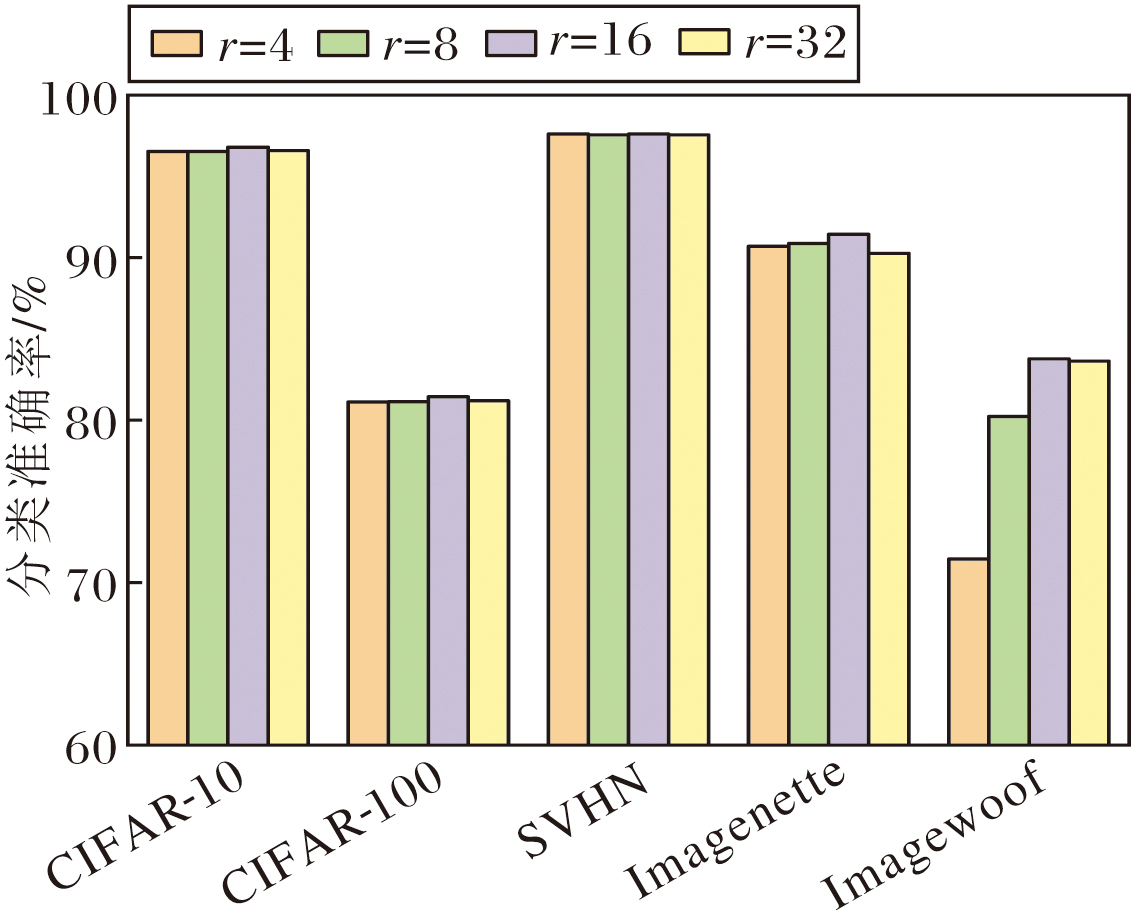 | 图10 r对分类准确率的影响Fig.10 Effect of r on classification accuracy |
由图10可见, 网络性能与r呈非线性关系, 随着r的增加, 性能先上升后下降, 并在r=16时达到最优.该结果表明, 当r=16时, 该网络能在减少计算复杂度的同时, 最大限度保留关键特征信息, 实现计算效率与网络性能的最佳平衡.
2.2.7 DFEM嵌入位置与数量
为了提高网络对关键特征的聚焦能力并减少特征降维过程中的信息损失, 在ResNet-34架构中引入DFEM.DFEM结合特征精炼和通道注意力分支, 有效提升网络特征表达和选择能力.
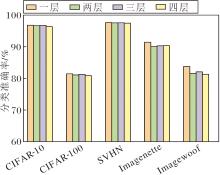
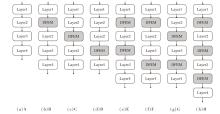
为了研究DFEM嵌入位置与数量对ResNet-34性能的影响, 设计8种DFEM嵌入策略, 具体如图11所示, 并在CIFAR-10、CIFAR-100、SVHN、Image-nette、Imagewoof数据集上进行实验.
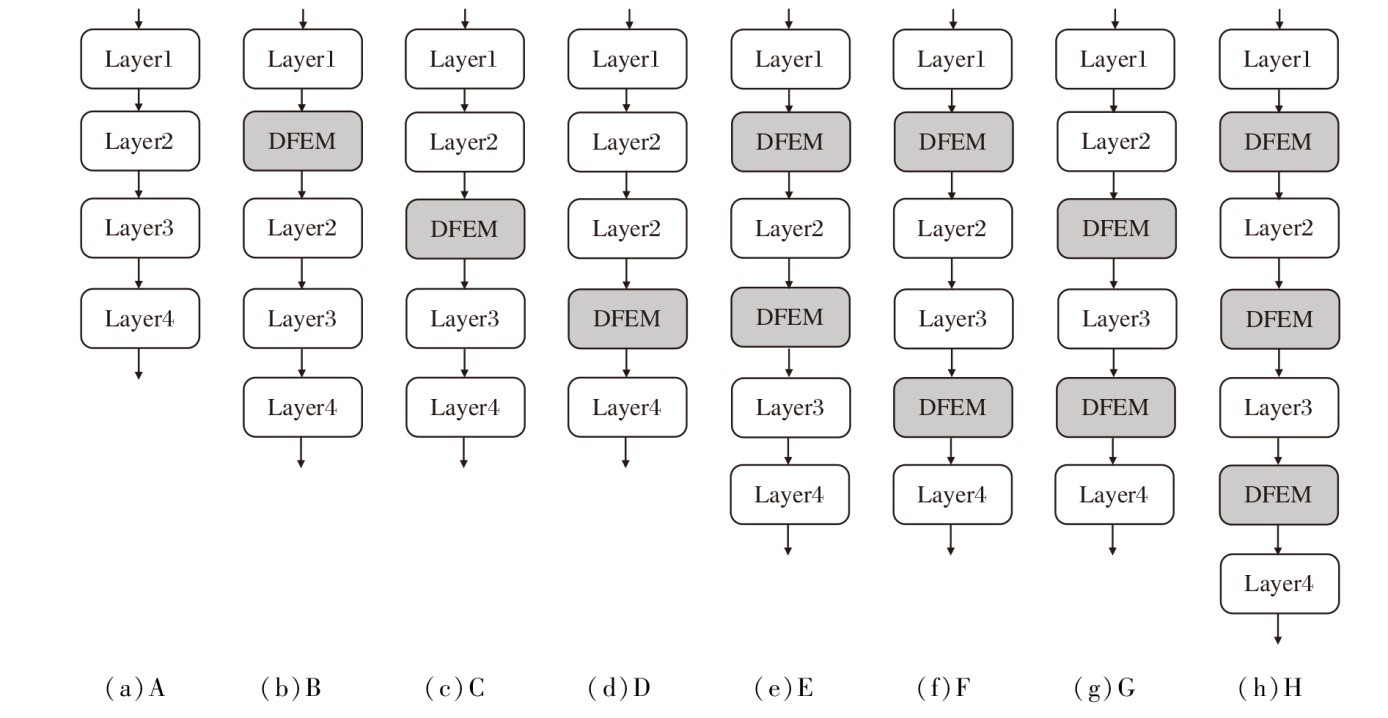 | 图11 DFEM嵌入位置与数量组合方式Fig.11 Configuration of DFEM embedding positions and quantity |
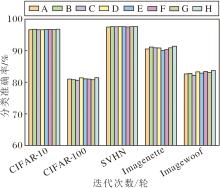
DFEM嵌入位置与数量对分类准确率的影响如图12所示.由图可见, 在多个数据集上, 方案H取得最佳的分类准确率, 性能显著优于其它组合方式.
 | 图12 DFEM嵌入位置与数量对分类准确率的影响Fig.12 Effect of DFEM embedding positions on classification accuracy |
DFEM通过精炼特征和增强通道注意力的方式, 有效提升网络对关键信息的提取与聚焦能力.实验表明:在网络的浅层嵌入DFEM, 由于语义信息不足, 增强效果有限, 而在网络的最深层嵌入时, 特征图分辨率过低, 可能导致空间增强分支无法有效工作.因此, 在网络的中间层级(layer1~layer4之间)嵌入DFEM, 能在语义信息和空间细节之间取得最佳平衡, 从而最大化模块的性能增益.总之, DFEM的嵌入显著增强ResNet-34的特征学习和表达能力, 为其在实际应用中获得更精准的分类性能提供有效方案.
2.3.1 通用数据集
为了验证DWENet的有效性, 在CIFAR-10、CIFAR-100、SVHN、Imagenette、Imagewoof数据集上进行对比实验.选择如下对比网络:ResNet-34[5]、EfficientNets[17]、GhostNet[18]、DenseNet(Dense Convolu-tional Network)[19]、WRN-28-10(Wide Residual Net-works)[20]、Couplformer[21]、FAVOR+(Fast Attention via Positive Orthogonal Random Features Approach)[22]、Multi-ResNet(Multi-residual Networks)[23]、ATO(Auto-Train-Once)[24]、双分支多注意力机制的锐度感知图像分类网络(Double-Branch Multi-attention Mecha-nism Network, DAMSNet)[25].
对比实验的数据来源如下.
1)对于代码未开源的对比网络, 优先采用该网络在其对应论文中提供的实验结果.
2)对于代码已开源的对比网络, 通过论文提供的开源代码进行复现.
各网络在5个数据集上的分类准确率如表7所示.由表可得, DWENet在5个数据集上表现最优, 这得益于其WGConv和WKA可有效增强网络的频率感知与长程建模能力, 尤其是在池化后能有效弥补信息损失并强化结构建模.
| 表7 各网络在5个数据集上的分类准确率 Table 7 Classification accuracies of different networks on 5 datasets % |
此外, DWENet在保持计算效率的同时, 通过DFEM解决浅层特征衰减、空间感知受限和通道利用不足等问题.DFEM通过融合上下文建模与通道注意力, 显著提升中高层语义表达能力, 使网络能更精准地响应图像关键区域.
总之, DWENet凭借创新的频域引导设计, 在图像分类任务中实现性能的显著提升, 尤其在细节捕捉、噪声抑制及长程依赖建模方面表现突出.
为了进一步验证DWENet的有效性, 应用Res- Net-34和DWENet在CIFAR-10数据集和Imagewoof数据集上生成分类混淆矩阵, 如图13所示, 图中列出数据集中各个类别的正确样本数与错误样本数.
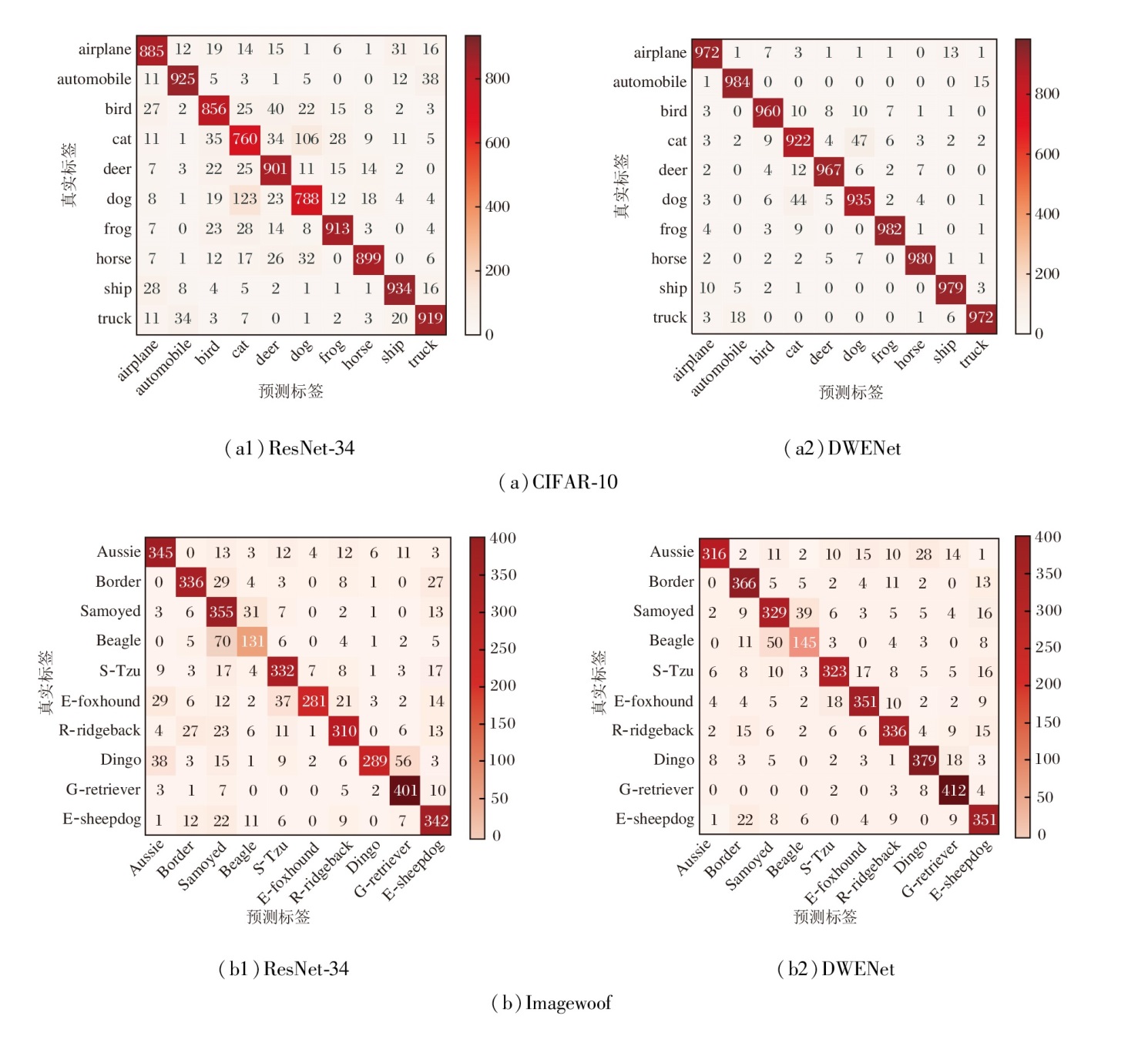 | 图13 ResNet-34和DWENet在2个数据集上的分类混淆矩阵Fig.13 Confusion matrices of ResNet-34 and DWENet on 2 datasets |
由图可见, 相比ResNet-34, DWENet在CIFAR-10、Imagewoof数据集上具有更多的正确样本数和更少的错误样本数, 这表明DWENet具有更优的类别区分能力和分类性能.
2.3.2 专业数据集
为了验证DWENet在专业图像分类任务中的分类性能, 实验选取具有挑战性的细粒度鸟类数据集CUB-200-2011、医学影像数据集COVID-19、胸部X光及遥感场景数据集UC Merced.采用的对比网络包括:经典残差网络ResNet-34及其宽变体WRN-28-10、轻量级卷积网络MobileNetV2[26]与GhostNet、面向复杂背景的ATO[24]、遥感专用网络CL-MG-Net[27]、医学图像网络MEGANet(Multi-scale Edge-Guided Attention Network)[28].
各网络在专业数据集上的分类准确率如表8所示, 表中黑体数字表示最优值.由表可见, 在CUB-200细粒度鸟类数据集上, DWENet达到74.30%的分类准确率, 仅次于专为细粒度任务设计的WRN-28-10.在COVID-19医学影像数据集上, DWENet的分类准确率达到90.08%, 优于其它对比网络, 展现出其在医学图像特征提取方面的优势.在UC Merced遥感数据集上, DWENet取得71.34%的分类准确率, 在对比网络中位列第三, 虽低于遥感专用网络CL-MGNet, 但仍优于多数通用网络.
| 表8 各网络在专业数据集上的分类准确率 Table 8 Classification accuracies of different networks on specialized datasets % |
细粒度、医学与遥感等专业数据集对网络的分类能力提出更高要求.在此背景下, DWENet通过WGConv频域引导机制增强对关键细节的捕捉能力, 借助WKA强化空间结构建模, 并结合DFEM通过双路径设计优化语义特征的融合与筛选.该协同机制使DWENet在多个专业场景下均表现出良好的鉴别能力与泛化性能, 验证其在复杂图像分类任务中的实用价值.
2.3.3 计算效率
为了验证DWENet在实际应用中的高效性, 对比分析各网络的参数量、推理速度与浮点运算量, 结果如表9所示, 表中黑体数字表示最优值.由表可知, DWENet的参数量为21.59 M, 处于中等水平, 与ResNet-34的21.28 M基本持平, 但显著低于EfficientNets的52.98 M与Multi-Resnet的51.23 M.这表明DWENet在网络复杂度控制方面表现良好, 未因引入频域组件而显著增加参数负担.与DenseNet的25.51 M和Couplformer的27.63 M相比, DWENet在参数量方面也具备一定优势.
| 表9 各网络的浮点运算量、参数量及推理时间 Table 9 FLOPs, parameters numbers, and inference time of different networks |
在推理速度方面, DWENet的单幅图像处理时间为6.20 ms, 虽略高于ResNet-34的5.80 ms, 但显著优于EfficientNets的9.83 ms与WRN-28-10的10.11 ms.这一结果说明, DWENet产生的推理速度具有竞争力, 为频域特征提取付出的时间代价处于可接受范围, 因此能满足实际部署对效率的基本要求.
DWENet的FLOPs为4.04 G, 虽高于ResNet-34的3.60 G, 但低于DenseNet的5.50 G与ATO的5.24 G, 更远低于Multi-ResNet的11.73 G.该结果表明DWENet在计算复杂度方面进行合理权衡, 通过适度增加浮点运算量以换取分类性能的显著提升, 同时保持良好的计算效率.
总之, DWENet在参数量、推理速度与计算复杂度之间取得良好平衡, 在未引入过量参数的基础上, 浮点运算量显著低于多数对比网络, 同时保持具有竞争力的推理速度.
为了验证DWENet各模块的有效性, 在CIFAR-10、CIFAR-100、SVHN、Imagenette、Imagewoof数据集上进行消融实验.
以ResNet-34为基线网络, 定义如下网络:1)Net1.在ResNet-34上引入WGConv与WKA.2)Net2.在ResNet-34上引入WGConv与DFEM.3)Net3.在ResNet-34上引入WKA与DFEM.4)Net4.在ResNet-34上引入WGConv.5)Net5.在ResNet-34上引入WKA.6)Net6.在ResNet-34上引入DFEM.
具体消融实验结果如表10所示, 由表可见, DWENet在全部数据集上均取得最优的分类准确率, 相比ResNet-34提升显著, 如在CIFAR-100、Imagewoof数据集上分类准确率分别提升3.79%和6.26%.这一结果验证WGConv、WKA与DFEM共同构成的频域增强网络在提升图像分类性能方面的有效性.
从模块独立贡献上看, WGConv(Net4)带来的性能提升最为显著, 在Imagewoof数据集上达到80.35%的分类准确率, 比ResNet-34提升2.85%, 凸显其在浅层特征提取中的关键作用.WKA融合频率感知与大感受野建模, 能有效缓解池化操作带来的特征损失, 并强化中程依赖关系建模, 因此仅添加该模块的Net5在CIFAR-100上取得79.03%的分类准确率, 比ResNet-34提升1.38%.DFEM通过通道注意力与频域重组优化高层语义表达, 使仅添加该模块的Net6在Imagenette、Imagewoof数据集上比ResNet-34提升约0.9%与1.45%的分类准确率.
不同模块组合的实验结果进一步揭示组件间的协同效应.同时引入WGConv与WKA的Net1在CIFAR-10上达到96.63%的分类准确率, 不仅高于Net4的95.54%和Net5的95.42%, 也超过Net2的96.59%, 表明WGConv提供的浅层频域特征与WKA的空间建模能力之间存在功能互补.同时, 引入WGConv与DFEM的Net2在Imagewoof数据集上达到82.26%的分类准确率, 显著高于Net4的80.35%和Net6的78.95%, 表明WGConv的特征提取为DFEM的语义重组提供有效基础.引入WKA与DFEM的Net3在多数数据集上表现优于单模块网络但不及Net1和Net2, 在Imagenette、Imagewoof数据集上的分类准确率为88.61%和80.83%, 低于Net1的90.52%和82.64%, 表明缺乏WGConv的底层频域支持会限制中高层模块的协同效果.
各网络在5个数据集上的分类准确率如图14所示.由图可知, DWENet在所有数据集上都取得最佳的分类准确率.在与其它组合的对比中, 包含WGConv的Net1与Net2表现最突出, 性能仅次于DWENet, 并显著优于其它组合, 这充分体现出WGConv在整体架构中的基础性作用与协同效应.
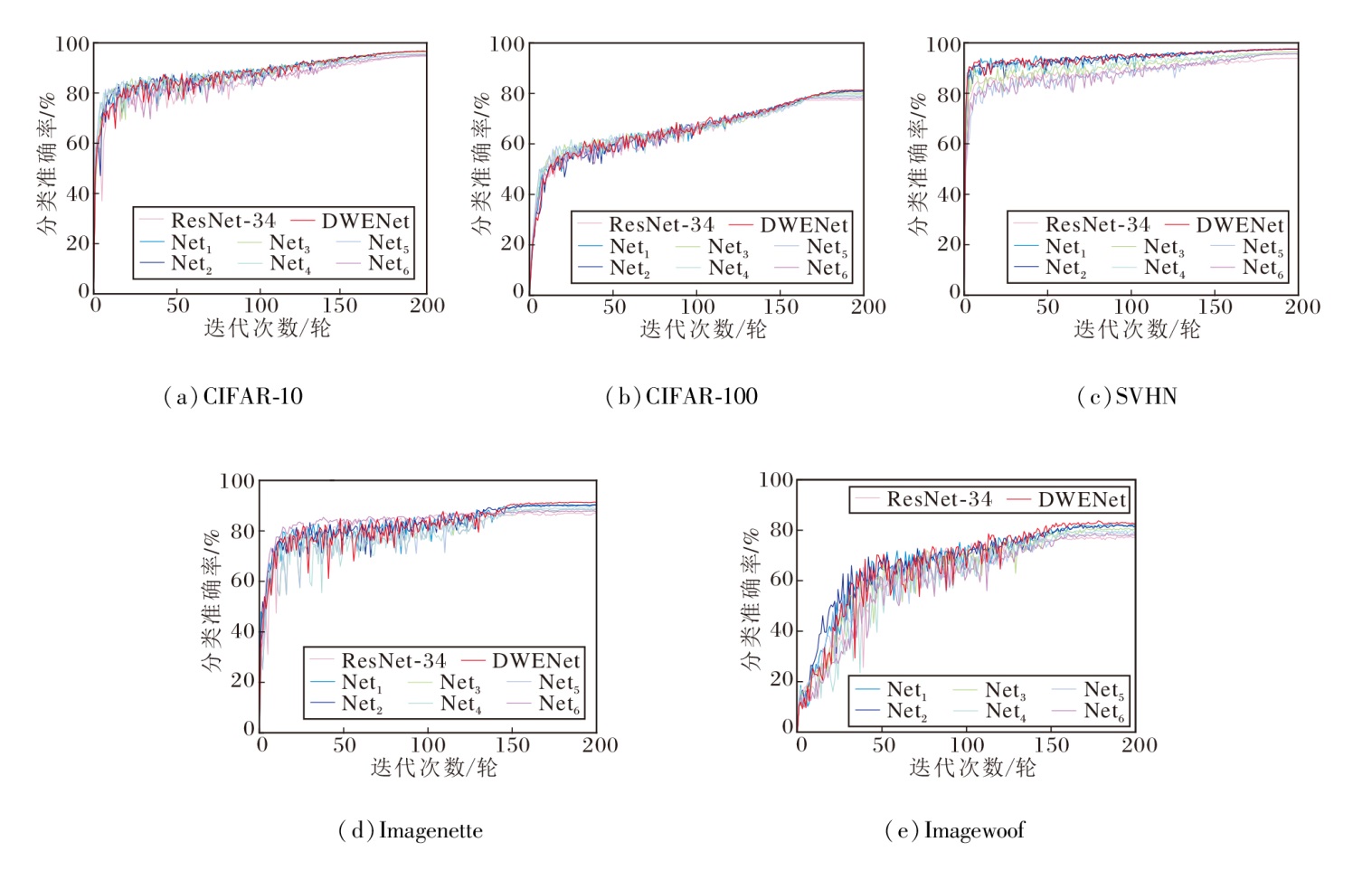 | 图14 各网络在5个数据集上的分类准确率Fig.14 Classification accuracies of different networks on 5 datasets |
DWENet通过WGConv、WKA与DFEM的层级化设计, 构建一个从频域细节感知、空间结构建模到全局语义增强的递进式特征学习网络.消融实验证实各模块的独立有效性及其协同作用, WGConv作为基础特征提取器, 为整体网络的表征能力提供重要支撑.
为了验证WGConv在不同网络架构中的适应性与有效性, 将其嵌入多种代表性的分类网络中进行实验, 包括轻量级网络ShuffleNet、密集连接网络DenseNet、高效架构EfficientNet, 并在5个图像分类基准数据集上系统评估其性能.嵌入WGConv的网络统一命名为XX-WGConv, 其中XX表示原始基线网络名称.
各网络嵌入WGConv前后的分类准确率如表11所示.由表可知, WGConv在不同网络架构中均获得稳定的分类准确率提升.在CIFAR-10数据集上, 各网络嵌入WGConv后分类准确率均有提升, 其中DenseNet201-WGConv取得94.85%的最高分类准确率.
| 表11 各网络插入WGConv前后的分类准确率 Table 11 Classification accuracies of different models before and after inserting WGConv % |
在类别数目更多的CIFAR-100数据集上, DenseNet201-WGConv的分类准确率从75.45%提升至77.03%, 表明WGConv通过小波卷积的多尺度频域分析与门控筛选机制, 有效增强网络对判别性特征的提取能力.在SVHN数据集上, DenseNet201-WGConv达到95.96%的分类准确率, 这得益于WG-Conv对字符边缘与纹理等高频细节的增强响应, 弥补传统空间卷积在频域细节感知上的不足.
在更具挑战性的Imagenette、Imagewoof数据集上, WGConv带来的提升更为显著.DenseNet121-WGConv在Imagenette数据集上的分类准确率从86.55%显著提升至89.19%, 在Imagewoof数据集上的分类准确率从72.97%提升至77.60%, 表明WGConv能通过门控机制对频域分量进行自适应加权, 强化网络对图像细微差异的感知与建模能力.
实验表明, WGConv在轻量级与深层网络中均展现出优秀的兼容性, 其基于小波卷积的频域分析与门控机制的结合, 能有效提升网络在多个分类任务中的特征提取质量与判别能力, 显示出作为频域增强组件的实用价值.
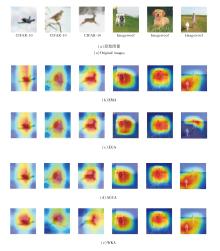
为了进一步观察WKA的效果, 选择如下注意力机制进行对比分析:EGA(Edge-Guided Attention Module)[28]、EMA(Efficient Multi-scale Attention Mo-dule)[29]、AGCA(Adaptive Graph Channel Attention Module)[30].各注意力机制在CIFAR-10、Imagewoof数据集上的热力图如图15所示.
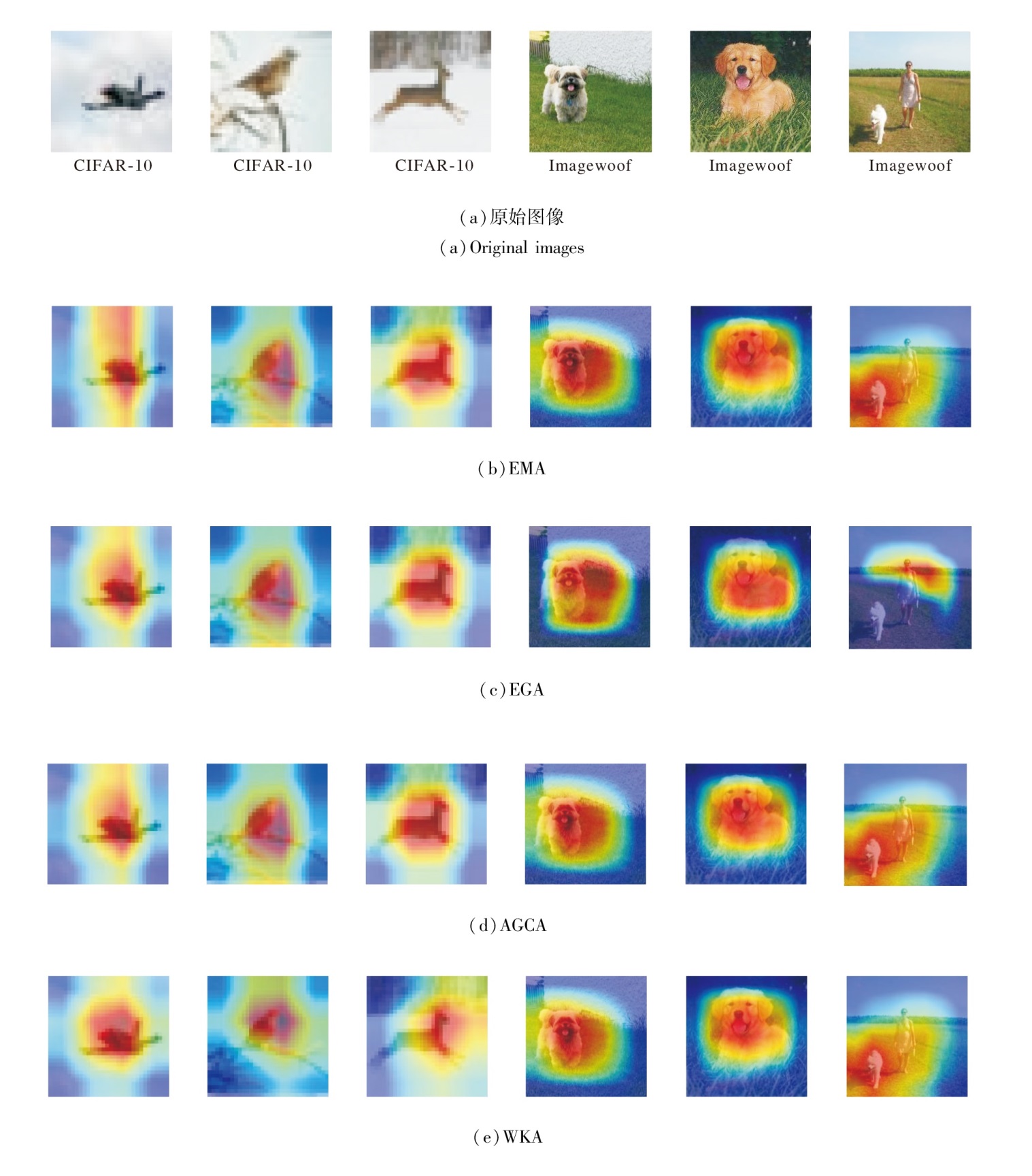 | 图15 不同注意力机制的热力图Fig.15 Heatmaps of different attention mechanisms |
由图15可观察到, 在CIFAR-10数据集上, WKA关注区域较小, 但其高响应区域完全聚焦于图像关键特征.同样在Imagewoof数据集上, WKA能准确关注狗脸部的细节特征.相比其它注意力机制, WKA能更有效地提高对关键区域的关注度.这种对关键判别区域的精准聚焦能力, 是其提升网络分类准确率的直接原因.
本文提出双重小波增强的图像分类网络(DWENet).首先, 设计小波门控卷积(WGConv), 通过小波变换对特征进行多尺度分解, 从频域角度提取更丰富的特征信息.然后, 在最大池化层后嵌入小波核注意力(WKA), 增强对边缘结构与显著区域的空间感知能力.最后, 在高层特征提取阶段插入双路径特征增强模块(DFEM), 显著增强特征表达能力.实验显示, DWENet在多个公开数据集上分类准确率较高.今后可继续优化DWENet的网络结构和参数配置, 进一步提升其在复杂图像场景下的分类性能.同时可尝试将频域分离方法与其它先进的视觉模型架构结合, 充分挖掘频域信息在图像分类中的潜力, 推动频域引导的图像分类技术向更高效、更精准的方向发展.
本文责任编委 徐 勇
Recommended by Associate Editor XU Yong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|