

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于自适应结构增强的对比协同多视图属性图聚类
[王静红1, 2, 3  , 陈潇
, 陈潇1, 3, 4, 5 , 王熙照6 , 王旭1, 3, 4, 5 , 杨宏博1, 3, 4, 5 , 王威1, 3 ]
, 陈潇, 王熙照, 王旭, 杨宏博, 王威]
|
|



作者简介:

陈 潇,硕士研究生,主要研究方向为数据挖掘、图表示学习.E-mail:3361731849@qq.com.

王熙照,博士,教授,主要研究方向为机器学习、不确定性建模.E-mail:xzwang@szu.edu.cn.

王 旭,硕士研究生,主要研究方向为图表示学习.E-mail:19833774855@163.com.

杨宏博,硕士研究生,主要研究方向为网络安全.E-mail:yanghongbo@stu.hebtu.edu.cn.

王 威,博士,副教授,主要研究方向为人工智能.E-mail:wangwei2021@hebtu.edu.cn.
目前多数聚类方法主要关注单视图数据,对于多视图聚类的研究相对不足,而现有的多视图聚类方法往往侧重于视图间的信息学习,忽略视图内信息的充分挖掘.对此,文中提出基于自适应结构增强的对比协同多视图属性图聚类(Contrastive Collaborative Multi-view Attribute Graph Clustering Based on Adaptive Structure Enhancement, ACCMVC).首先,设计自适应结构增强策略,结合节点重要性和节点特征复杂关系生成边权重,用于生成视图的新邻接矩阵,进而生成结构增强图.然后,将边权重引入邻域对比学习,对视图及其结构增强图使用视图内加强邻域对比学习,在多个视图间使用视图间加强邻域对比学习.最后,考虑到多视图中视图的重要性存在差别,引入注意力机制,计算每个视图的权重并进行融合.在数据集上的实验表明,ACCMVC的聚类性能较优.
About Author:
CHEN Xiao, Master student. Her research interests include data mining and graph representation learning.
WANG Xizhao, Ph.D., professor. His research interests include machine learning and uncertainty modeling.
WANG XU, Master student. His research interests include graph representation lear-ning.
YANG Hongbo, Master student. His research interests include information security.
WANG Wei, Ph.D., associate professor. His research interests include artificial intelligence
Most clustering methods mainly focus on single-view data, while the research on multi-view clustering remains relatively under-explored. Existing multi-view clustering methods often emphasize learning inter-view information while neglecting the thorough exploitation of intra-view information. In this paper, a contrastive collaborative multi-view attribute graph clustering based on adaptive structure enhancement(ACCMVC) is proposed. First, an adaptive structure enhancement strategy is designed to generate edge weights by combining node importance and the complex relationships among node features. These edge weights are applied to construct new adjacency matrices for the views, and thereby structure-enhanced graphs are generated. Second, edge weights are introduced into neighborhood contrastive learning. Intra-view enhanced neighborhood contrastive learning is applied to views and their structure-enhanced graphs, while inter-view enhanced neighborhood contrastive learning is utilized among multiple views. Finally, considering the varying view importance, an attention mechanism is introduced to calculate the weight of each view for effective fusion. Experiments on multiple datasets demonstrate that ACCMVC achieves superior clustering performance.
图对比学习在属性图聚类领域应用十分广泛.在单视图属性图聚类方法中, 图对比学习往往结合不同的图增强策略.Zhu等[1]提出GRACE(Deep Graph Contrastive Representation Learning), 随机丢弃边和掩蔽节点特征以生成不同的视图, 并通过最大化两个视图中节点表示的一致性以学习表示.Jin等[2]提出MERIT(Multi-scale Contrastive Siamese Net-work), 从局部视角和全局视角生成两个增强视图, 进行跨视图和跨网络对比, 从而最大化不同视图和网络中节点表示之间的一致性.Huang等[3]提出CoCGC(Confidence-Oriented Contrastive Graph Clus-tering), 通过混合图滤波生成增强图, 并构建置信度导向的样本集及设计跨视图邻居对比损失函数, 进行对比学习.Shen等[4]提出NCLA, 生成多个基于注意力的可学习图增强视图, 应用于邻居对比学习.
但是, 现实世界中的网络结构复杂, 包含丰富的视图信息[5], 难以通过单视图进行描述, 因此多视图聚类成为机器学习中一个快速发展的领域[6, 7].Lin等[8]提出DIAGC(Dual Information Enhanced Multi-view Attributed Graph Clustering), 为了挖掘视图中深度表示的丰富信息, 在每个视图表示与所有视图中的潜在高级表示之间进行对比学习.Li等[9]提出MVCG(Mutual-View Contrastive Generative Framework), 采用交互视图对比生成框架, 设计重建结构和属性信息的非对称生成机制.然而, 上述方法仅关注视图间的图信息, 忽视视图内存在的图信息.
传统的多视图聚类主要针对多源特征视图, 通过特征一致性或互补性实现样本层面的聚类.然而, 真实场景中的数据通常同时具有属性特征与结构关系, 仅考虑特征一致性难以充分表达节点间的潜在联系.为此, 研究者提出多视图属性图聚类方法, 在多视图框架下同时建模属性与结构信息, 更好地刻画视图间的关联性.早期, Nie等[10]提出PwMC(Parameter-Weighted Multiview Clustering), 引入超参数学习视图权重以实现聚类, 同时提出SwMC(Self-Weighted Multiview Clustering), 引入子空间学习机制, 自适应学习视图权重, 实现更精细的特征融合.
随后, 研究者开始将深度学习引入多视图属性图聚类中.Fan等[11]提出O2MAC(One2Multi Graph Autoencoder for Multi-view Graph Clustering), 结合深度学习自编码器框架进行多视图属性图聚类, 并增加聚类损失模块, 但由于使用单视图编码器, 对多视图的图信息学习造成一定影响.Liu等[12]提出MGCCN(Multilayer Graph Contrastive Clustering Network), 进一步将对比融合策略与多层图聚类自编码器框架结合.Yu等[13]提出SCMVC(Semantic Fusion and Con-trastive Learning Model for Multi-view Clustering), 将跨视图对比学习引入多视图属性图聚类.
除了上述完整多视图场景下的研究以外, 近年来也有学者关注不完备多视图聚类.Yuan等[14]提出PMIMC(Prototype Matching Learning for Incomplete Multi-view Clustering), 通过原型匹配策略实现不完备视图间的语义对齐.Huang等[15]提出TIME-FS(Tensorial Incomplete Multi-view Unsupervised Fea-ture Selection), 同时进行特征选择与缺失视图补全.Dong等[16]提出SCVT(Selective Cross-View Topology Incomplete Multi-view Clustering), 在深度学习框架下通过选择性跨视图拓扑学习缓解结构信息缺失问题.此类方法主要致力于解决视图缺失带来的补全与一致性学习问题.然而, 上述引入对比学习的多视图聚类方法聚焦于视图间的信息提取, 忽视视图内包含的丰富结构和特征信息.
为了解决上述问题, 本文提出基于自适应结构增强的对比协同多视图属性图聚类方法(Contrastive Collaborative Multi-view Attribute Graph Clustering Based on Adaptive Structure Enhancement, ACCMVC), 共分为3个模块:多视图对比协同模块、多视图结构重建模块、视图融合和自监督聚类模块.首先, 设计自适应结构增强策略, 为每个视图生成结构增强的新邻接矩阵, 将邻接矩阵与新邻接矩阵分别结合属性矩阵输入编码器, 生成视图及其结构增强图, 并设计视图间加强邻域对比学习策略.然后, 拼接视图及其结构增强图的嵌入表示, 获取视图的拼接矩阵, 对拼接后的视图嵌入表示进行视图间加强邻域对比学习, 并采用多视图解码器促进结构和特征学习.最后, 使用注意力机制, 生成视图权重以融合多视图, 同时采用基于KL散度(Kullback-Leibler Divergence)的分布一致性约束进行自监督聚类.在3个广泛使用的数据集上的实验表明, ACCMVC聚类性能较优.
定义G(m)={V, A(m), X}表示视图m的属性图, 其中, V={v1, v2, ……, vn}表示包含n个节点的节点集, X∈ Rn× d表示节点特征矩阵, d表示每个节点的属性特征维度, A(m)∈ Rn× n表示第m个视图的原始邻接矩阵, 如果节点vi、vj之间存在连接,
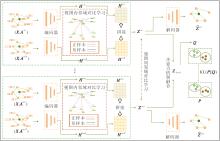
本文提出基于自适应结构增强的对比协同多视图属性图聚类方法(ACCMVC), 具体框架如图1所示.首先, 采用自适应结构增加策略, 为每个视图生成对应的结构增强图.将原属性图与结构增强图输入编码器, 获得嵌入表示并在视图内执行加强邻域对比学习.然后, 拼接嵌入结果, 在视图间进行加强邻域对比学习, 并通过解码器实现结构重建.为了捕捉完整的视图信息, 进一步采用注意力机制计算不同视图的权重, 获得融合视图, 并结合融合视图的分布一致性约束形成自监督聚类.
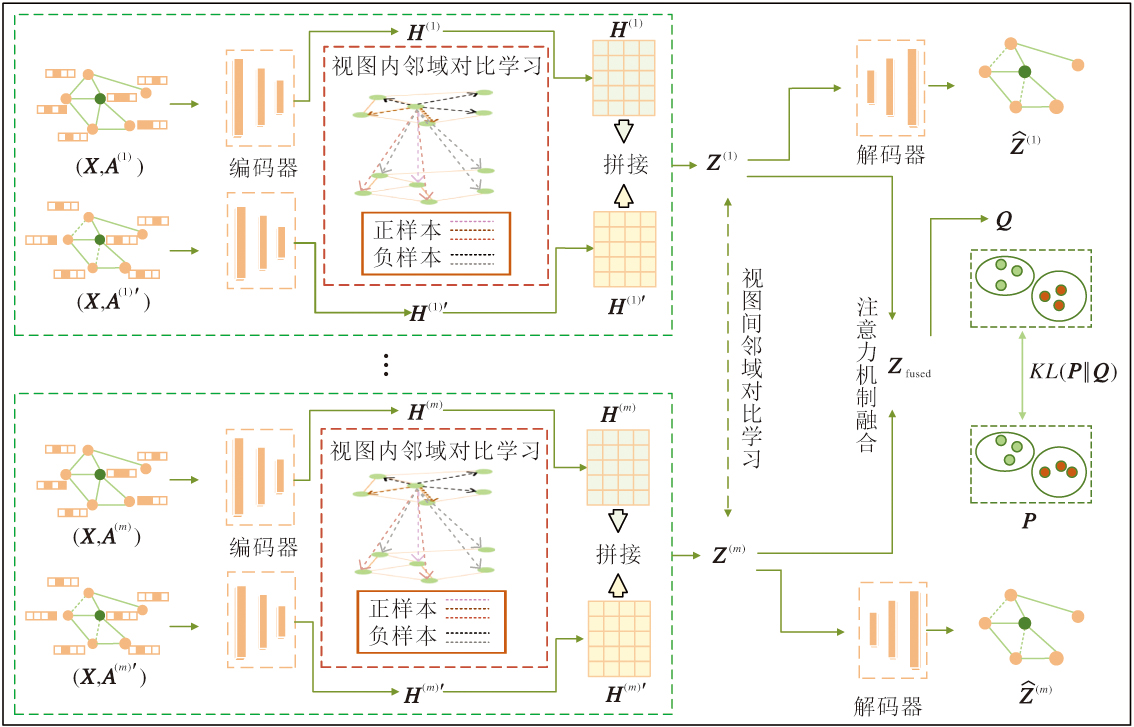 | 图1 ACCMVC框架图Fig.1 Architecture of ACCMVC |
常见的多视图属性图聚类方法往往更关注视图之间的一致性和特定信息, 忽略视图内部的信息提取, 导致未能充分利用视图内的结构和特征信息.
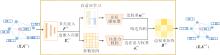
为了解决上述问题, 本文设计自适应结构增强策略, 用于保留图中的重要结构性信息, 并为邻域对比学习提供丰富的样本对.该策略的核心在于同时考虑节点重要性和节点特征复杂关系, 自适应进行边屏蔽.自适应结构增强策略具体流程如图2所示.
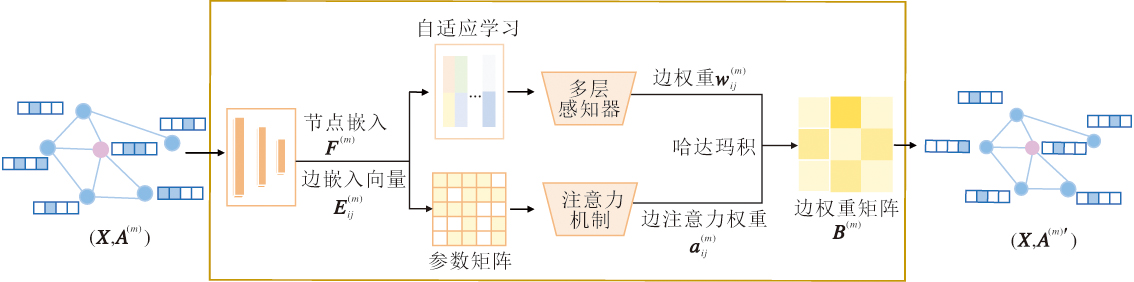 | 图2 自适应结构增强策略流程图Fig.2 Flowchart of adaptive structure enhancement strategy |
将节点特征矩阵X和视图m的邻接矩阵A(m)作为编码器的输入, 得到输出节点嵌入向量:
F(m)=Encoder(X, A(m))∈ Rn× d.
拼接视图m的中心节点vi嵌入向量
$\boldsymbol{E}_{i j}^{(m)}=\boldsymbol{f}_{i}^{(m)} \oplus \boldsymbol{f}_{j}^{(m)} \in \boldsymbol{A}^{(m)} .$
将边嵌入向量输入多层感知机, 得到边权重:
由于节点重要性对边权重值存在影响, 引入注意力机制, 计算基于节点重要性的边权重.首先计算视图m的中心节点vi与其一阶邻居节点vj的重要性:
其中, W表示可学习的参数矩阵, σ (· )表示激活函数.
然后计算边
其中Attention(· )表示计算注意力系数的线性层.
将节点重要性作为权重, 得到边
最终, 得到视图m基于节点重要性和节点特征复杂关系的边权重矩阵B(m).
本文将
如果节点vi、vj通过视图m中的边
由于自适应结构增强策略在训练过程中会动态调整图结构或结构权重, 在训练初期确实可能受到参数随机初始化和梯度波动的影响, 出现结构估计不准确的问题.为了缓解这种潜在的不稳定性, 在方法设计与训练过程中采取如下措施.
1)逐步启用策略.在训练初期仅更新特征表示模块参数, 自适应结构增强部分在方法基本收敛后再逐步参与训练, 从而避免早期不稳定参数直接影响结构重构.
2)平滑约束机制.对自适应结构更新引入平滑正则项, 使结构变化连续可控, 防止参数剧烈振荡造成误差放大.
3)学习率预热与参数归一化.通过学习率预热与归一化操作, 减弱初期梯度的不稳定性.
因此, 尽管自适应结构增强策略在训练初期存在一定的参数波动, 但通过上述措施, ACCMVC能逐步收敛至稳定结构, 并不会出现误差累积或策略失效的情况.
InfoNCE(Information Noise-Contrastive Estima-tion)[17]和NT-Xent(Normalized Temperature-Scaled Cross Entropy Loss)[18]是在图对比学习中广泛应用的对比损失, 都只允许每个锚点有一个正对.然而, 近期研究发现, 锚点的邻居不应该被视为图对比学习的负面因素[7].因此本文将邻域信息引入对比学习, 在去除冗余结构的同时, 学习视图内的重要语义信息.当结构增强图中锚点与其一阶邻居对应边的权重大于0.5时, 该邻居被视为正样本.
为了在对比学习中构建有效的样本对, 本文将锚点节点vi与其对应的正样本节点vj组合形成正样本对, 记为(vi, vj), 其中vj表示满足边权重大于阈值c=0.5的一阶邻居节点.同理, 未满足该条件的节点被视为负样本, 对应的锚点-负样本组合记为负样本对.基于此构建的正负样本对用于后续的邻域对比损失计算.
具体来说, 首先使用GCN(Graph Convolution Networks)编码器聚合视图中的邻居信息.第l层编码器的嵌入矩阵如下所示:
$\boldsymbol{H}_{(l)}^{(m)}=g\left(\boldsymbol{H}_{(l-1)}^{(m)}, \boldsymbol{A}^{(m)}\right)=\phi\left(\widetilde{\boldsymbol{A}}^{(m)} \boldsymbol{H}_{(l-1)}^{(m)} \boldsymbol{W}^{(m)}\right) .$
其中:
$\widetilde{\boldsymbol{A}}^{(m)}=\left(\boldsymbol{D}^{(m)}\right)^{\frac{1}{2}}\left(\boldsymbol{A}^{(m)}+\boldsymbol{I}\right)\left(\boldsymbol{D}^{(m)}\right)^{-\frac{1}{2}}, $
表示在视图m中每个节点上具有自环路的网络拓扑结构, I表示节点的单位对角矩阵, D(m)表示节点的度矩阵, Dii=
H(m)=g(X, A(m)),
视图m增强嵌入矩阵为
H(m)'=g(X, A(m)').
在视图内设计加强邻域对比学习策略, 每个节点的邻居数量N=2|
$\begin{array}{l} S_{\text {intra } a_{i j}}=f\left(\operatorname{sim}\left(\boldsymbol{H}_{i}^{(m)}, \boldsymbol{H}_{j}^{(m)}\right)\right), \\ S_{\text {inter }_{i j}}=f\left(\operatorname{sim}\left(\boldsymbol{H}_{i}^{(m)}, \boldsymbol{H}_{j}^{(m)^{\prime}}\right)\right), \end{array}$
其中,
$\begin{array}{l} \operatorname{loss}_{h_{i}}^{(m)}= \\ \quad-\ln \left(\frac{\frac{1}{N_{h_{i}}^{(m)}}\left(S_{\text {inter }_{i i}}+\sum_{j \in \text { nei }_{h_{i}}^{(m)}} S_{\text {intra }_{i j}}+\sum_{j \in \text { nei }_{h_{i}}^{(m)}} S_{\text {inter }_{i j}}\right)}{\sum_{j=1}^{N} S_{\text {intra }_{i j}}+\sum_{j=1}^{N}\left(S_{\text {intra }_{i j}}-S_{\text {intra }_{i i}}\right)}\right), \end{array}$
其中,
视图内邻域对比学习损失为:
$L_{\mathrm{conra}}^{(m)}=\frac{1}{2 N} \sum_{i=1}^{n}\left[\operatorname{loss}_{h_{i}}^{(m)}+\operatorname{loss}_{h_{i}}^{(m)'}\right]$,
其中los
将编码后的嵌入矩阵H(m)和增强嵌入矩阵H(m)'进行拼接, 得到视图m的完整嵌入矩阵:
Z(m)=concat[H(m), H(m)'],
其中concat(· )表示拼接操作.
对多视图中的两两视图进行加强邻域对比学习, 最小化节点在不同视图间的表示差异, 强化同一节点在多视图下的特征一致性.视图m基于视图锚点zi相关的一阶邻居对比损失如下所示:
$\begin{aligned} \operatorname{loss}_{z_{i}}^{(m)} & = \\ - & \ln \left(\frac{\frac{1}{N_{z_{i}}^{(m)}}\left(S_{\text {inter }_{i i}}+\sum_{j \in \text { nei }_{z_{i}}(m)} S_{\text {intra }_{i j}}+\sum_{j \in \text { nei }_{z_{i}}(m)} S_{\text {inter }_{i j}}\right)}{\sum_{j=1}^{N} S_{\text {intra }_{i j}}+\sum_{j=1}^{N}\left(S_{\text {intra }_{i j}}-S_{\text {intra }_{i i}}\right)}\right), \end{aligned}$
其中ne
其中los
$ L_{\mathrm{con}}=\frac{1}{M}\left(\sum_{m=1}^{M} L_{\mathrm{conra}}^{(m)}+\sum_{m=1}^{M} L_{\mathrm{conter}}^{(m)}\right) $.
其中M表示视图总数.
值得注意的是, ACCMVC在设计时基于图的同配性假设, 即认为一阶邻居节点往往具有相似的特征或标签, 因此可作为正样本进行对比学习.然而, 在异配图场景下, 该假设可能不再成立, 一阶邻居之间可能存在语义差异或类别差异, 从而影响对比目标的准确性.因此, ACCMVC在异配图上的适用性会受到一定限制, 今后可考虑引入基于关系类型或高阶结构的动态样本选择策略, 提升在异配场景下的鲁棒性.
多视图解码器重构视图结构, 可以为编码器提供有效指导, 帮助编码器捕捉视图中的真实结构和准确的特征表示.具体来说, 将第m个视图的节点嵌入矩阵Z(m)∈ Rn× d输入内积解码器, 得到重建结构矩阵:
其中, n表示节点数量, d表示嵌入维度, N(m)∈ Rd× d表示关系权重矩阵, 用于捕捉节点嵌入之间的关系.使用均方误差衡量输出的邻接矩阵与真实邻接矩阵的差异, 重建损失函数为:
$ L_{\mathrm{re}}=\sum_{m=1}^{M} \frac{1}{n}\left\|\widehat{\boldsymbol{Z}}^{(m)}-\boldsymbol{Z}^{(m)}\right\|_{\mathrm{F}}^{2} . $
由于不同视图信息的重要程度不同, 为了充分利用多个视图的互补性, 引入注意力机制, 计算视图的权重及分布一致性, 通过计算不同分布之间的KL散度以衡量两个概率分布之间的差异, 并通过最小化KL散度优化聚类结构.
将Z(m)映射至隐藏空间, 得
Z(m)'=WZ(m),
其中W表示权重矩阵.计算视图对应的注意力系数和权重:
$ \begin{array}{l} \boldsymbol{e}^{(m)}=\operatorname{LeakyReLU}\left(\boldsymbol{Z}^{(m) \prime} \boldsymbol{\alpha}^{(m)}\right), \\ \boldsymbol{a}^{(m)}=\operatorname{softmax}\left(\boldsymbol{e}^{(m)}\right), \end{array} $
其中α (m)表示参数向量.将所有的特征向量求和, 得到最终的特征融合向量:
Zfused=
使用Student's t-distribution度量融合特征向量后的嵌入节点zi和聚类中心uj之间的相似度, 得到软分配Q:
qij=
其中, α 表示t分布的自由度, 设置自由度α 值为1.目标分布P表示节点概率分布的相关性:
$ p_{i j}=\frac{q_{i j}^{2}}{\sum_{i} q_{i j}}\left(\sum_{K}\left(\frac{q_{i K}^{2}}{\sum_{i} q_{i K}}\right)\right)^{-1}, $
其中qiK表示节点i在集群K中的频率.最小化KL散度, 使得Q中学习的聚类分配与目标分布P的一致性最大化, 得到聚类损失函数:
Lclu=KL(P‖ Q)=
节点所属的标签类别可通过最终得到的真实分布Q'获得, 即
yi'=arg max q'ij.
本文引入的分布一致性约束不仅用于提升训练过程的稳定性, 还在自监督聚类阶段起到关键作用.通过在不同视图间最小化KL散度, 使各视图学习的嵌入分布趋于一致, 从而促使多视图特征在隐空间中形成更紧密可分的簇结构.这种一致性约束在本质上强化潜在聚类分布的对齐, 保证聚类中心在不同视图下的语义一致性.因此, 虽然该策略具有一定的稳定训练效果, 但其核心目的仍是通过分布对齐实现自监督聚类结果的优化.
ACCMVC整体损失函数为:
L=α Lcon+β Lclu+γ Lre,
其中α 、β 、γ 表示超参数.
ACCMVC具体步骤如算法1所示.
算法1 ACCMVC
输入 属性图G(m)=(V, A(m), X), 集群数量K,
训练轮次epoch, 更新间隔T
输出 节点所属集群类别y'
for i = 1< epoch do
采用自适应结构增强策略生成每个视图的新邻接矩阵;
分别将视图的邻接矩阵与新邻接矩阵结合属性矩阵输入编码器;
进行视图内加强邻域对比学习;
将同一视图的表示进行拼接;
对获取的每个视图拼接矩阵进行视图间加强邻域对比学习;
采用多视图解码器重建视图的邻接矩阵;
对所有视图的拼接矩阵进行视图融合;
计算融合视图的软分配Q;
if i%T==0 then
更新目标分布P;
end if
最小化聚类损失目标分布P和真实分布Q 的KL散度;
根据总体优化目标更新模型参数;
end for
计算节点标签y'并返回聚类结果.
本文选择在ACM、DBLP、IMDB这3种代表性多视图属性数据集上进行实验, 评估ACCMVC的聚类性能.ACM数据集为论文网络数据集, 包含3 025篇论文, 关系视图包括两篇论文同一作者和同一主题两种, 每篇论文的特征矩阵由1 830个关键词的词袋表示构成, 根据论文所属会议领域分为3类.DBLP数据集为作者网络数据集, 包含4 057篇论文, 关系视图包括两位作者共同撰写、两位作者在同一会议发表论文和两位作者发表相同术语的论文三种, 根据作者研究领域分为4类.IMDB数据集为电影关系网络, 包含4 780部电影, 关系视图包括电影由同一演员扮演和电影由同一演员指导两种, 每部电影的特征由电影情节的描述性关键字组成, 根据电影类型分为3类.数据集具体信息如表1所示.
| 表1 实验数据集 Table 1 Experimental datasets |
使用准确度(Accuracy, ACC)、标准互信息(Normalized Mutual Information, NMI)、调整兰德指数(Adjusted Rand Index, ARI)、F1分数(F1)评估方法的聚类性能, 指标值越大表示聚类效果越优.
实验基于PyTorch框架, 运行在CPU-Intel Core i5-12500H, GPU NVIDIA GeForce RTX 3090环境中.训练过程共计450个轮次以充分优化参数.设置优化算法中的学习率lr=0.000 1, 以确保训练过程的稳定收敛.
在损失函数方面, 为了平衡不同任务的贡献, 设置3个超参数:对比损失权重α =1, 聚类损失权重β =1, 重建损失权重γ =1.该配置旨在使方法在对比学习、聚类指导和数据重建这3个目标之间取得平衡.
本文选择如下对比方法验证ACCMVC的有效性.
1)LINE(Large-Scale Information Network Embe- dding)[19], 适用于多种类型的信息网络.
2) MNE(Multiplex Network Embedding)[20].可实现多种类型关系的联合学习.
3)PMNE(Principled Multilayer Network Embe-dding)[21].设计网络融合、结果融合和层协同分析这3种多层网络嵌入方法.
4)PwMC[10].结合超参数学习视图权重以进行多视图聚类的方法.
5)SwMC[10].将参数加权改进为自加权后进行权重学习的多视图聚类方法.
6)O2MA[11].应用深度学习自编码器框架进行多视图属性图聚类的方法.
7)O2MAC[11].O2MA的变体, 增加聚类损失模块, 用于生成面向聚类的深度表示.
8)MGCCN[12].结合多层图聚类自编码器框架和对比融合的多视图属性图聚类方法.
9)SCMVC[13].结合跨视图对比学习和语义融合的多视图属性图聚类方法.
10)MCBGA(Multi-view Clustering Method Based on Graph Attention Autoencoder)[22].采用图注意力自动编码器学习节点嵌入的多视图聚类方法.
11)CMGEC(Consistent Multiple Graph Embedding Clustering Framework)[23].使用多图注意力编码器和图融合网络进行多视图属性图聚类的方法.
12)MCGC(Multi-view Contrastive Graph Clustering)[24].采用对比图聚类学习共识图以进行多视图属性图聚类的方法.
13)基于共享和特定表示的多视图属性图聚类模型(Multi-view Attributed Graph Clustering Based on Shared and Specific Representation, MSAGC)[25].结合视图共享信息和特定信息的多视图属性图聚类方法.
各方法在3个数据集上的指标值如表2所示, 表中黑体数字表示最优值, 斜体数字表示次优值.由表可得如下结论.
| 表2 各方法在3个数据集上的指标值 Table 2 Metric values of different methods on 3 datasets % |
1)ACCMVC的性能显著优于MSAGC.在ACM数据集上, 相比MSAGC, ACCMVC的ACC、NMI指标分别提升1.63%和6.2%.MSAGC采用视图共享信息模块和特定信息模块以减少冗余信息并进行细粒度学习, 实验表明多视图对比协同学习模块在提取多视图信息方面具有更优效果.
2)SCMVC结合语义融合与跨视图对比学习, 然而实验表明ACCMVC的聚类性能优于SCMVC, 在DBLP数据集上的表现尤为突出.相比SCMVC, ACCMVC的ACC、NMI指标分别提升10.92%和20.09%, 这一结果凸显出ACCMVC采用自适应结构增强策略与加强邻域对比学习策略的有效性.
3)相比多视图聚类方法和多视图属性图聚类方法, ACCMVC在多数情况下取得更优的聚类结果, 表明多视图对比协同模块、多视图结构重建模块、视图融合与自监督聚类模块相结合的科学性和先进性.
为了验证ACCMVC中3个模块对性能的影响, 设计如下3种变体.
1)ACCMVC-con.不包括多视图对比协同模块, 通过多视图结构重建模块、视图融合与自监督聚类模块进行训练.
2)ACCMVC-clu.不包括视图融合与自监督聚类模块, 通过多视图结构重建模块和多视图对比协同模块进行训练.
3)ACCMVC-re.不包括多视图结构重建模块, 通过多视图对比协同模块、视图融合与自监督聚类模块进行训练.
3种变体的指标值如图3所示.由图可明显看出, 3个模块均对ACCMVC的聚类性能具有提升作用, 多视图对比协同模块对ACCMVC的聚类性能提升最明显.在ACM数据集上, 相比ACCMVC-con、ACCMVC-clu、ACCMVC-re, ACCMVC的准确率提升22.66%、2.00%、2.66%.
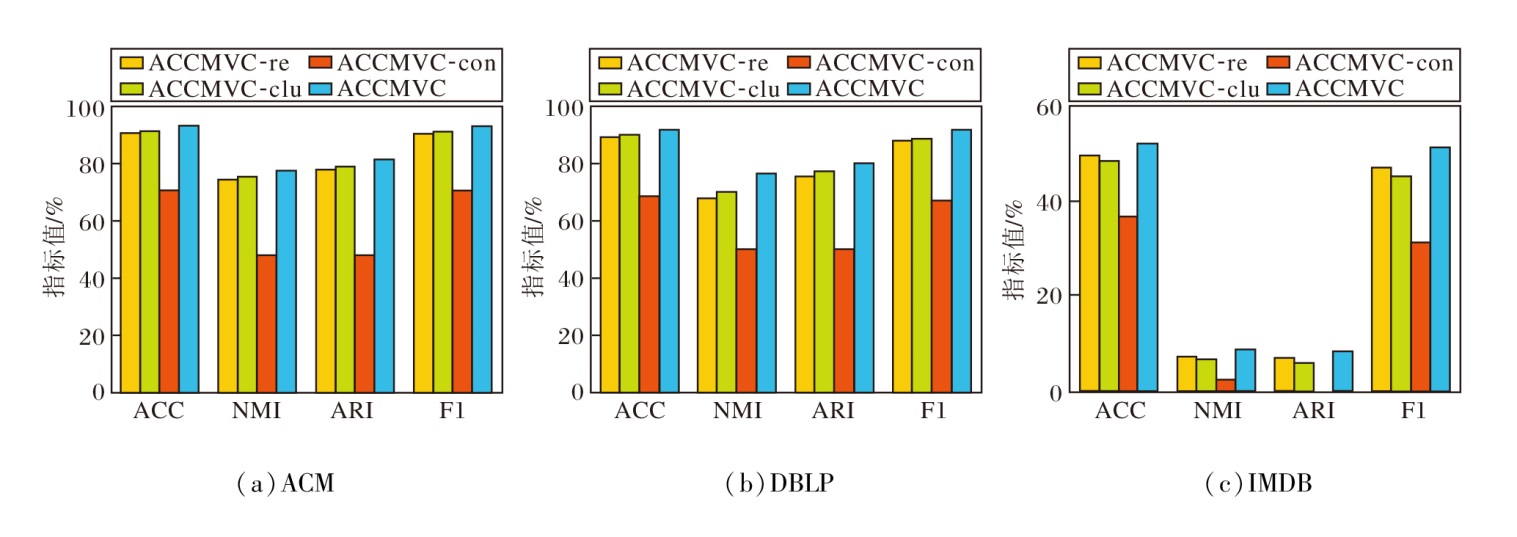 | 图3 各变体的消融实验结果Fig.3 Ablation experiment results of variants |
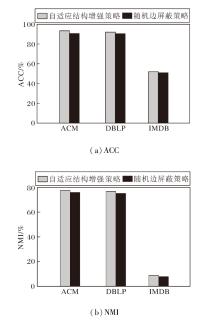
为了验证自适应结构增强策略对ACCMVC性能的影响, 在3个数据集上与随机边屏蔽策略进行对比实验, 结果如图4所示.由图可明显看到, 采用自适应结构增强策略在指标值上均优于采用随机边屏蔽策略.
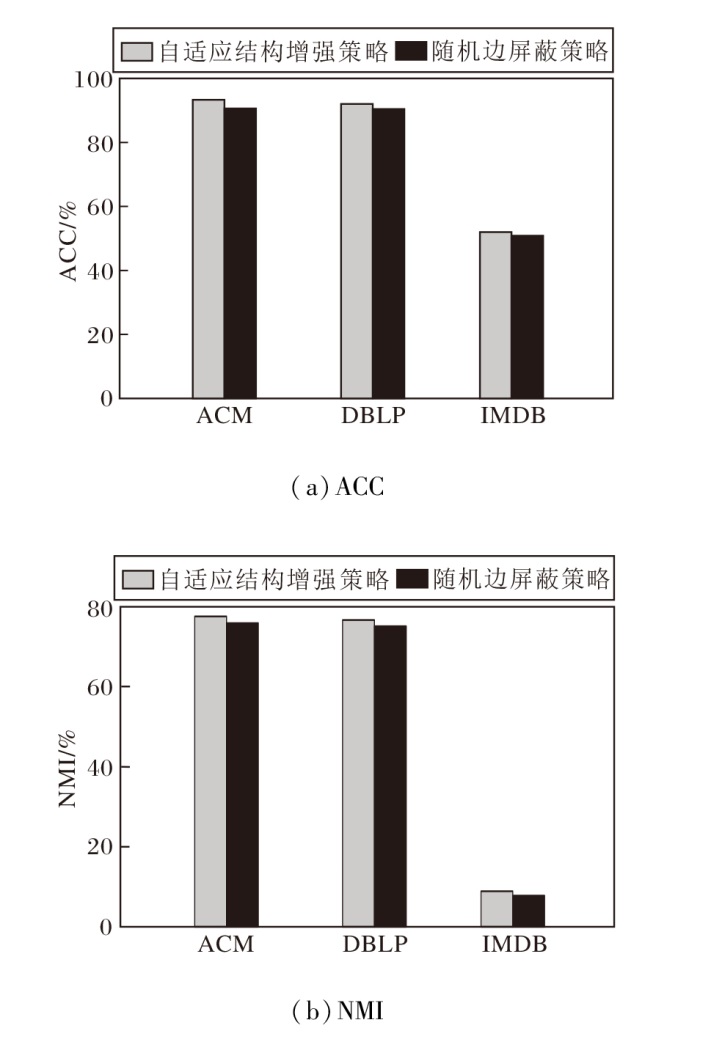 | 图4 两种策略的指标值对比Fig.4 Metric value comparison of 2 strategies |
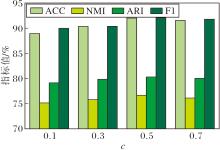
在DBLP数据集上, 探究多视图对比协同模块中阈值c对ACCMVC性能的影响, 定义c=0.1, 0.3, 0.5, 0.7, 具体指标值如图5所示.由图可清晰看出, 当c=0.5时, ACCMVC性能最优.
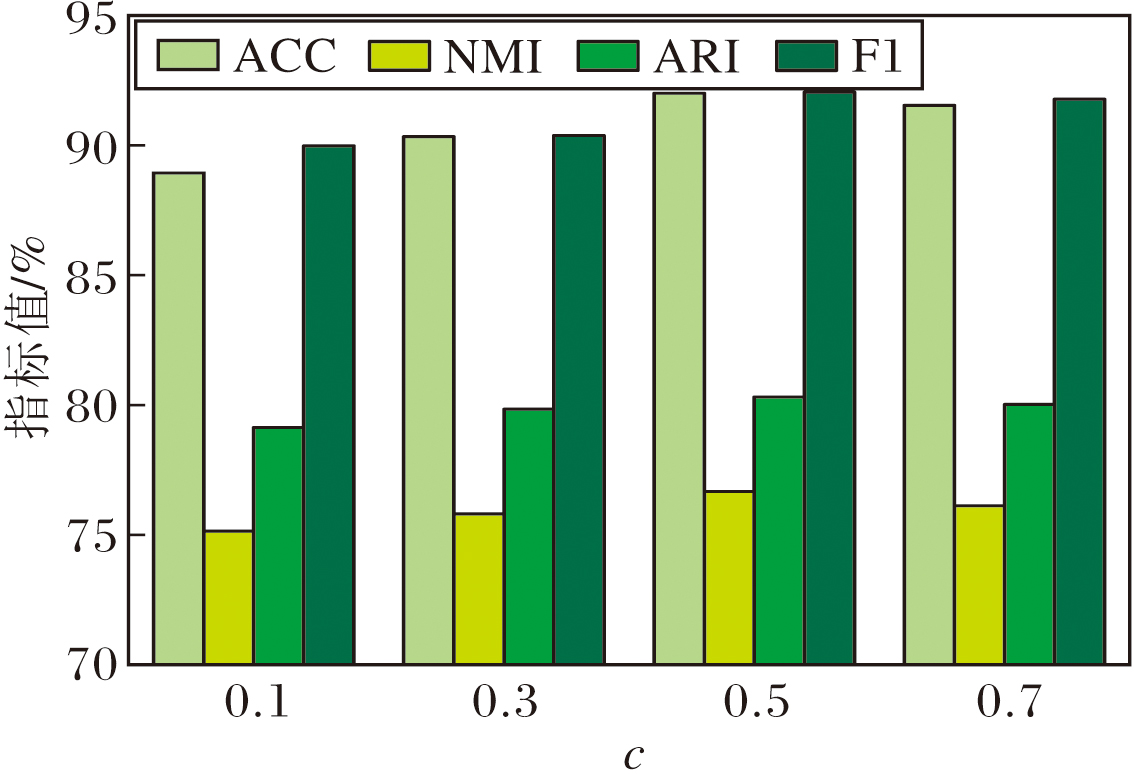 | 图5 c对ACCMVC性能的影响Fig.5 Effect of c on ACCMVC performance |
下面分析整体损失函数中超参数α 、β 、γ 对ACCMVC性能的影响.在ACM数据集上, 分别设置对比损失权重α =0.1, 1, 5, 聚类损失权重β =1, 5, 重建损失权重γ =1, 5, 具体ACC值如表3所示.由表可见, 整体聚类效果较稳定, α 对ACC的影响最大, 当α =1, β =1, γ =1时, 性能最佳.
| 表3 α 、 β 、 γ 对ACCMVC性能的影响 Table 3 Effects of α , β and γ on ACCMVC performance |
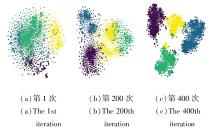
在ACM、DBLP数据集上, 通过t-SNE(t-distri-buted Stochastic Neighbor Embedding)可视化, 将聚类结果在二维空间中展示.ACM数据集包含3个簇, DBLP数据集包含4个簇, 不同颜色表示不同的簇.迭代次数为1, 200, 400时的可视化结果如图6和图7所示.由图可发现, 随着迭代次数的增加, 混乱的无界限的节点逐渐形成紧凑的有边界的簇, 表明在ACCMVC的训练下, 可取得良好的聚类效果.
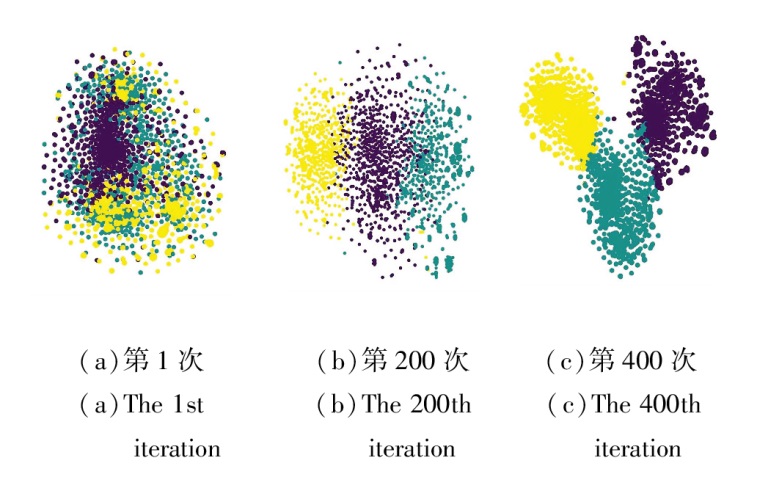 | 图6 ACM数据集上迭代次数不同时的可视化结果Fig.6 Visualization results on ACM dataset at different iterations |
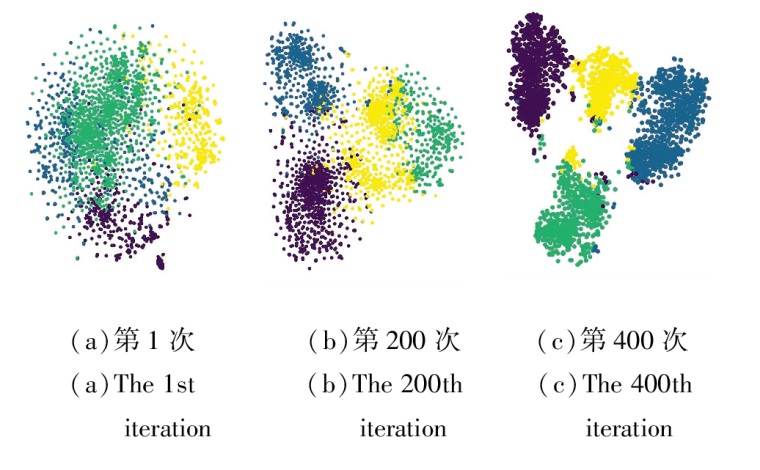 | 图7 DBLP数据集上迭代次数不同时的可视化结果Fig.7 Visualization results on DBLP dataset at different iterations |
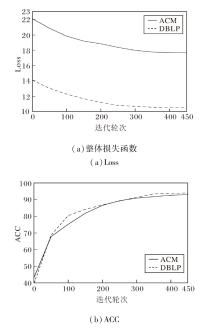
在ACM、DBLP数据集上进行收敛性分析, 具体如图8所示.由图可见, ACCMVC在2个数据集上均在训练400轮次时实现收敛, 但计算效率不同, 在ACM数据集上用时183 s, 在DBLP数据集上用时416 s.
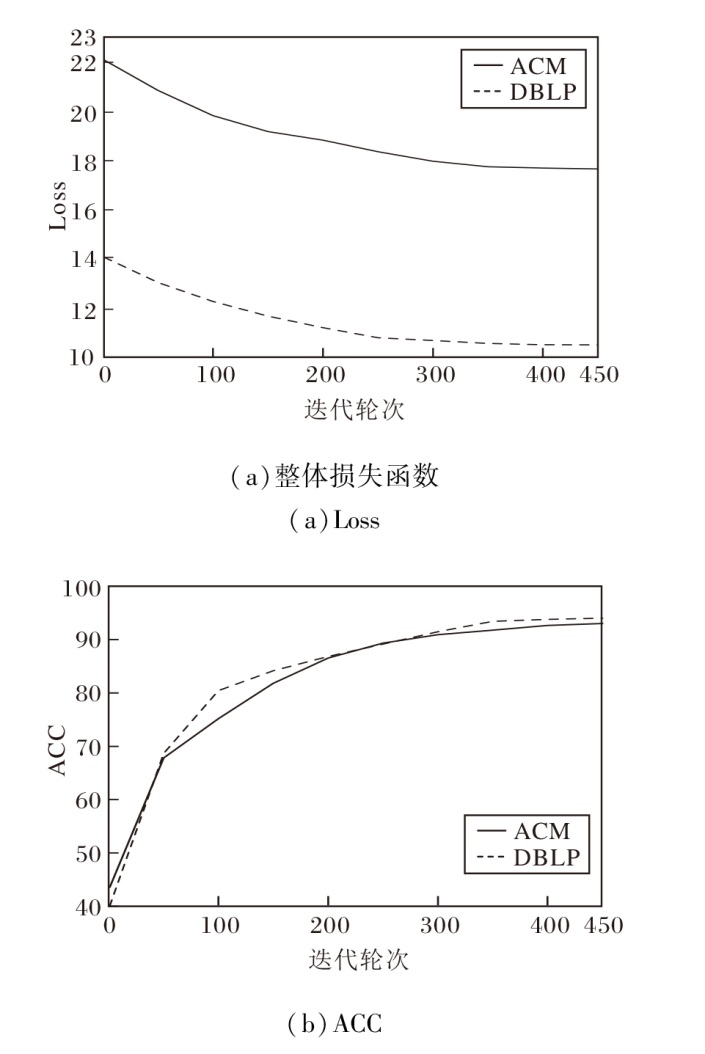 | 图8 ACCMVC在2个数据集上的收敛性分析Fig.8 Convergence analysis of ACCMVC on 2 datasets |
本文设计基于自适应结构增强的对比协同多视图属性图聚类方法(ACCMVC), 包含多视图对比协同模块、多视图结构重建模块、视图融合与自监督聚类模块.设计自适应结构增强策略, 较好地与邻域对比学习配合.多视图对比协同模块将加强邻域对比学习策略应用在视图内和视图间, 较好地捕捉视图内的相似性, 提取视图间的共享信息.多视图结构重建模块可学习更全面的特征表示.特征融合与自监督聚类模块关注更重要的视图和视图特征, 并结合自监督学习进行聚类优化, 获得全面的图结构和特征信息.在3个广泛使用的多视图数据集上的实验表明ACCMVC的有效性.与此同时, ACCMVC基于同配性假设, 在异配图上的性能可能受限.因此, 今后将重点研究如何动态识别并筛选语义相近的邻居节点, 提升方法在异配图场景下的鲁棒性与泛化性.
本文责任编委 陶 卿
Recommended by Associate Editor TAO Qing
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|