{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于文本语义增强图神经网络的计算机自适应测试方法
[蒲青松1  , 李艳丽
, 李艳丽1 1 , 李显勇1 , 陈晓亮1 , 刘佳1 ]
, 李艳丽, 杜亚军, 李显勇, 陈晓亮, 刘佳]
|
|



作者简介:

蒲青松,硕士研究生,主要研究方向为数据挖掘、智慧教育.E-mail:pino@stu.xhu.edu.cn.

杜亚军,博士,教授,主要研究方向为深度学习方法、自然语言处理、知识图谱、社交网络分析.E-mail:duyajun@mail.xhu.edu.cn.

李显勇,博士,教授,主要研究方向为人工智能、社交网络分析、情感分析、网络舆情演化与引导.E-mail:xian-yong@163.com.

陈晓亮,博士,教授,主要研究方向为AIGC、自然语言处理、社会计算、膜计算理论及应用.E-mail:chenxl@mail.xhu.edu.cn.

刘 佳,博士,讲师,主要研究方向为人工智能、数据挖掘、社交网络分析.E-mail:jialiu@mail.xhu.edu.cn.
计算机自适应测试(Computerized Adaptive Testing, CAT)主要通过动态选题实现高效测评,但现有方法在题目语义建模和能力估计上准确性不高.为此,文中提出基于文本语义增强图神经网络的计算机自适应测试方法(Text-Semantic Enhanced Graph Neural Network Based CAT Approach, TECAT).该方法利用预训练语言模型提取题目与概念的上下文语义表示,并在题目-概念图和概念先序图中引入图注意力网络,刻画题目与题目、题目与概念之间的多层依赖关系.应用基于加性注意力和SiLU激活函数的门控融合方法,自适应整合语义与结构信息,在保持结构感知的同时增强语义判别性,获得更具表达力的节点表示.在此基础上,将CAT建模为多目标强化学习任务,联合优化题目质量、多样性与新颖性,设计基于能力估计误差变化的质量奖励函数,直接反映题目对能力诊断的贡献.在Eedi、Junyi真实数据集上的实验表明,TECAT的能力估计准确性和概念表征质量方面均较优.
About Author:
PU Qingsong, Master student. His research interests include data mining and inte-lligent education.
DU Yajun, Ph.D., professor. His research interests include deep learning methods, natural language processing, knowledge graphs, and social network analysis.
LI Xianyong, Ph.D., professor. His research interests include artificial intelligence, social network analysis, sentiment analysis, and evolution and guidance of online public opinion.
CHEN Xiaoliang, Ph.D., professor. His research interests include AI-generated content (AIGC), natural language processing, social computing, and theory and applications of membrane computing.
LIU Jia, Ph.D., lecturer. His research interests include artificial intelligence, data mining, and social network analysis.
Computerized adaptive testing(CAT) is designed to achieve efficient assessment through dynamic question selection. However, existing methods still suffer from insufficient accuracy in semantic modeling and ability estimation. To address these issues, a text-semantic enhanced graph neural network based CAT approach(TECAT) is proposed. Contextual semantic representations of questions and concepts are extracted using a pretrained language model, and multi-level dependencies among questions and concepts are captured by applying graph attention networks on the question-concept and concept-prerequisite graphs. To integrate semantic and structural information, a gated fusion mechanism based on additive attention and SiLU activation is introduced for the above two types of information to be adaptively combined. As a result, more expressive node representations are obtained. The CAT process is further formulated as a multi-objective reinforcement learning task to jointly optimize question quality, diversity, and novelty. A quality reward function based on changes in ability estimation error is designed to better reflect the contribution of each question to ability diagnosis. Experiments on two real-world datasets, Eedi and Junyi, show that TECAT achieves superior ability in estimation accuracy and concept representation quality compared with the existing methods.
随着信息技术的迅速发展与在线教育的普及, 传统标准化考试面临测评效率低、反馈滞后、难以适应个体差异等问题.与此同时, 个性化学习需求日益增长, 亟需一种高效且精准的能力评估机制, 以支持教育资源的精准推送与个性化教学.
在此背景下, 计算机自适应测试(Computerized Adaptive Testing, CAT)[1, 2]逐渐成为教育评估领域的研究热点之一.作为一种个性化的测试模式, CAT旨在以尽可能少的题目, 高效准确地测量学生的能力.CAT的核心在于其自适应能力, 即能根据学生的作答表现动态调整后续题目的选择, 实现因材施测, 提升测试效率与诊断精度.CAT主要由两个部分构成:认知诊断模型(Cognitive Diagnosis Model, CDM)[3]和选择算法.在CAT的工作流程中, CDM根据学生在t-1步的答题记录估计学生能力值 θ t-1, 选择算法基于学生的能力估计值选择下一步的题目.两者交替工作, 不断迭代, 直至测试结束.
近年来, 图神经网络(Graph Neural Networks, GNNs)[4]在多个领域得到广泛应用, 并逐渐被引入CAT中, 用于建模题目与概念之间的复杂结构关系.然而, 传统GNNs往往仅基于邻居节点的信息聚合更新当前节点的表示, 难以有效区分不同邻居节点的重要性, 容易导致信息冗余, 表达能力受限.为此, Wang等[5]提出GMOCAT(Graph-Enhanced Multi-objective Method for CAT), 在CAT中引入图注意力网络(Graph Attention Networks, GATs)[6], 自适应分配注意力权重, 提升聚合的选择性与表达性.但是, GATs仍沿袭传统GNNs的设计范式, 缺乏对节点自身特征的充分刻画, 尤其是当网络层数增加时, 容易出现过平滑现象, 导致节点表示趋于一致, 削弱方法对题目与概念的判别能力, 影响CAT的状态建模与选题效果.
相关方法仅依赖图结构进行建模还存在另一层局限:节点表示缺乏对题目文本和概念定义等语义特征的直接利用.事实上, 题目描述和概念文本通常包含题目考察的知识要点及概念的适用范围, 这类语义信息能为结构关系建模提供重要补充.合理利用语义信息, 可在表示学习中突出关键特征、减少无关干扰, 并在一定程度上缓解过平滑问题, 增强节点表示的区分性与泛化性.
此外, 提升CAT的题目选择效果不仅需要精确的题目与概念表示, 也需要合理的指标衡量题目质量.现有方法通常以学生在作答前后, CDM对答题准确率预测值的变化量作为题目质量的衡量标准, 认为预测准确率提升越大的题目越具有更高的选题价值.然而, 该指标主要反映方法对学生作答行为的拟合能力, 难以给出准确评估其真实能力的诊断效果.由于学生答题行为可能受到猜测、粗心等偶然因素的影响, 仅依据准确率变化难以稳定实现方法对能力的真实刻画, 可能导致策略学习偏离目标, 降低选题策略的科学性与可靠性.
为了解决上述问题, 本文提出基于文本语义增强图神经网络的计算机自适应测试方法(Text Se-mantic Enhanced Graph Neural Network Based Compu-terized Adaptive Testing Approach, TECAT).为了缓解节点表示不足及GNNs存在的过平滑现象, 引入题目内容、概念定义等语义丰富的自然语言信息, 补充结构建模中对节点特征的建模缺失, 增强表示的完整性与判别力.为了充分利用这些语义特征, 采用预训练语言模型(Pre-trained Language Model, PLM)对其文本内容进行编码, 获得语义嵌入表示.同时引入基于注意力的门控融合机制, 有效整合语义信息与GATs提取的结构表示, 在保留结构特征的同时提升语义表达能力, 有效缓解过平滑问题, 提升状态表示的表达力和准确性.在选择算法方面, 将CAT建模为多目标强化学习任务, 综合考虑题目质量、多样性和新颖性这3个优化目标, 实现更全面的选题决策.特别地, 针对题目质量目标, 设计基于能力估计误差变化的奖励函数, 以学生作答前后方法估计能力与其真实能力之间差距的变化作为信号, 衡量题目对能力评估效果的实际贡献.在全量题库数据上训练CDM获得真实能力值, 作为能力评估的参考基准.相比以往基于预测准确率差值的指标, 该函数更关注能力估计的收敛性与稳定性, 降低对偶然作答行为的敏感性, 有助于学习更具判别价值和泛化能力的选题策略.在两个公开数据集上的实验表明, TECAT在能力估计准确性和概念表征质量方面均较优.
计算机自适应测试(CAT)根据考生的实时表现动态选择题目, 实现对学生能力的高效精准评估.现有的CAT主要包括启发式方法和基于强化学习(Reinforcement Learning, RL)的方法.
CAT最早通过启发式方法加以实现, 如基于最大费希尔信息(Maximum Fisher Information, MFI)[7]或Kullback-Leibler信息(Kullback-Leibler Information, KLI)[8]的策略, 这些方法通过量化题目提供的信息量选择题目.然而, 这些传统CAT依赖特定认知诊断模型(CDM), 如项目反应理论(Item Response Theory, IRT)[9], 在CDM变更时需要重新设计选择算法, 无法从大规模数据中自适应地学习和改进, 限制方法的灵活性和可扩展性.为了克服方法的局限性, Bi等[10]提出MAAT(Model-Agnostic Adaptive Tes-ting), 基于主动学习思想, 计算CDM的预期模型变化, 选择最能影响能力估计的题目, 提高模型的通用性.Ghosh等[11]提出BOBCAT(Bilevel Optimization-Based Framework for CAT), 将CAT问题重构为双层优化框架, 设计从数据中学习题目选择策略, 降低对特定模型的依赖, 提升系统的自适应性.
随着强化学习的发展, 以学习数据驱动的选题策略被引入CAT[12].CAT的选题过程可建模为一个马尔可夫决策过程:系统在每一步基于学生当前状态从题库中选择题目, 优化长期累积奖励.在此框架下, Zhuang等[13]提出NCAT(Neural Computerized Adap-tive Testing), 结合深度Q网络(Deep Q-Networks, DQN)[14]与注意力机制, 从作答数据中学习选题策略, 并通过Boltzmann分布[15]控制题目曝光.Wang等[16]采用DQN学习选题策略, 并在模拟题库与真实题库上与MFI、KLI等启发式方法进行系统对比, 结果表明其在能力估计误差上占优.Wang等[5]提出GMOCAT, 进一步将质量、多样性与新颖性这3个目标统一于多目标强化学习(Multi-objective Rein-forcement Learning, MORL)框架[17]下, 旨在同时提升预测精度、概念覆盖广度并降低题目曝光率.相比启发式方法, 基于RL的方法端到端地学习选题策略, 显式权衡多维优化目标, 更适应真实题库的复杂约束.
尽管上述方法取得一定进展, 但在节点表示方面仍面临挑战.多数工作仍将题目或概念的ID作为节点输入, 未有效利用题目与概念的文本语义, 导致GNNs在深层堆叠时容易出现过平滑现象, 削弱节点判别性.针对这一问题, 文本表示学习提供一种有效解决方案.Yin等[18]提出QuesNet, 利用PLM对题目文本进行统一编码, 构建面向教育场景的题目语义表示.Ning等[19]提出QuesCo, 通过对比学习对数学题目文本与其关联知识点描述进行语义对齐, 较好地捕捉题目考查意图.Xiao等[20] 提出C-Pack, 在多语言、多任务基准上展现出较强的泛化能力, 可为教育文本提供有效的语义向量.上述研究表明将题目、概念的文本编码为低维语义向量, 并与图结构特征协同建模, 有助于缓解过平滑问题, 并提升节点表示的区分性.此外, 在题目质量评估方面, 许多方法依赖作答前后预测准确率差值作为奖励信号, 该指标主要反映方法对作答行为的拟合效果, 难以衡量题目对真实能力估计的贡献.
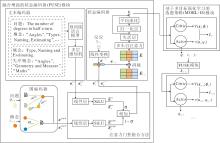
为了解决现有CAT对文本语义信息利用不足及题目质量评价不准确的问题, 本文提出基于文本语义增强图神经网络的计算机自适应测试方法(TECAT), 整体框图如图1所示.
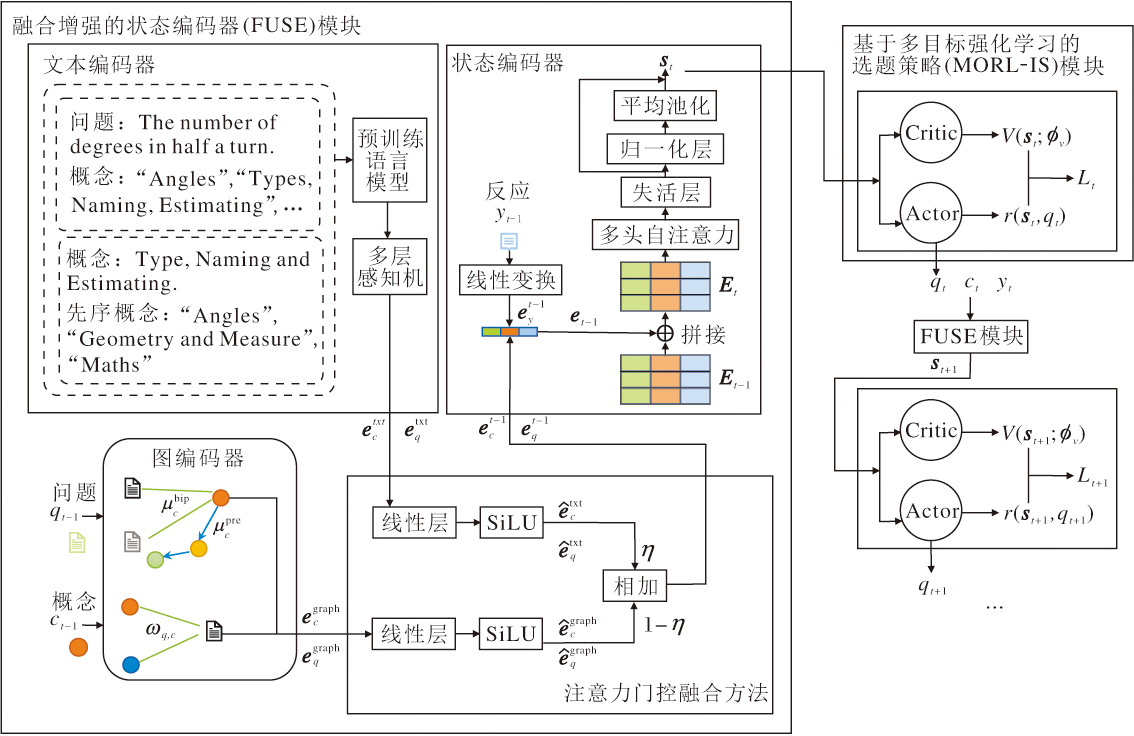 | 图1 TECAT整体框架图Fig.1 Overall framework of TECAT |
TECAT主要由融合增强的状态编码器(Fusion-Enhanced State Encoder, FUSE)模块和基于多目标强化学习的选题策略(Item Selection Policy Based on Multi-objective Reinforcement Learning, MORL-IS)模块组成.FUSE模块首先利用文本编码器对题目与概念的文本进行语义表征, 通过图编码器建模题目与概念之间的结构关系.然后, 设计注意力门控融合方法, 融合上述语义与结构信息.最后, 利用状态编码器进一步结合当前答题反应嵌入与历史答题记录(包括历史答题的题目、对应概念及反应), 生成当前时刻的环境状态表示.该状态综合反映学生当前的认知状态与知识上下文, 是后续选题决策的关键依据.MORL-IS模块围绕题目质量、多样性与新颖性这3个优化目标学习选题策略, 实现精准、高效且多样化的选择算法.
在构建强化学习状态表示时, 仅依赖图结构建模题目与概念之间的关系, 容易导致节点表示缺乏判别力, 尤其是在GNNs深层堆叠时容易出现过平滑现象, 造成表示趋同, 削弱节点的表达能力.为此, 本文设计融合增强的状态编码器(FUSE)模块, 联合建模图结构信息与文本语义信息, 提升表示的完整性与区分性.
FUSE模块首先利用文本编码器对题目与概念文本进行上下文增强编码, 获得更具语义表达力的嵌入表示.然后, 通过图编码器提取题目与概念节点之间的结构依赖关系, 获得融合语义和结构信息的嵌入表示.最后, 引入注意力门控方法, 有效融合结构信息与语义信息, 使节点特征在保留结构感知能力的同时增强语义判别性, 缓解信息传播过程中的表示退化问题.拼接融合后的特征与当前答题反应的嵌入表示, 与历史答题记录(包括过往题目、对应概念及答题反应)构成序列结合, 利用自注意力机制建模全局依赖关系, 并通过平均池化提炼关键信息, 最终生成当前时刻的状态表示.
FUSE模块为强化学习中的状态建模提供稳定、丰富的表示基础, 有助于提升选择算法的整体性能和鲁棒性.
2.1.1 文本编码器
现有一部分基于深度学习的CAT仅以题目或概念的ID作为节点输入, 并通过GNNs建模节点间的关系结构.这类方法由于初始特征表达有限, 且图神经网络在多层聚合中容易出现过平滑现象, 往往导致题目和概念表示的区分性不足.在现实场景中, 概念和题目包含丰富的文本描述信息, 对于理解题目考查的知识范围具有重要意义.此外, 先序概念是理解题目的认知基础并为建立不同题目之间的语义关联提供高价值的数据.例如:概念Types, Naming and Estimating本身含义宽泛, 语义较模糊.通过引入其先序概念, 如Angles和Geometry and Measure, 可进一步明确Types, Naming and Estimating的具体含义和应用范围, 提高表示的表达力与可判别性.
为此, 本文充分利用题目、概念及其先序概念的文本信息, 结合预训练语言模型(PLM)在文本处理上的强大优势, 挖掘题目和概念在文本层面的深层次语义特征, 提升题目和概念表示的区分性与表达能力.这一设计不仅弥补现有CAT在文本信息利用上的不足, 也为后续选题策略提供精准的知识表示基础.
在对题目的文本信息进行嵌入时, 将题目自身的文本描述信息以及题目关联的概念集合对应的文本描述信息作为输入, 引导PLM理解题目依赖的知识背景, 生成更具语义表达力的表示.
为了进一步提升题目的语义表示, 结合题目关联概念对应的先序概念的文本信息, 完善题目所需的认知基础.
基于上述讨论, 题目q和概念c的文本嵌入为:
$\boldsymbol{e}_{q}^{\mathrm{PLM}}=\operatorname{PLM}\left(\boldsymbol{s}_{q} \oplus O_{q}\right), \boldsymbol{e}_{c}^{\mathrm{PLM}}=\operatorname{PLM}\left(\boldsymbol{s}_{c} \oplus O_{c}\right) .$
其中:PLM(· )表示预训练语言模型, 本文中指text- embedding-ada- 002模型; 表示拼接操作; sq表示题目q的文本描述, sc表示概念c的文本描述;
Oq=
Cq表示题目q关联的概念集合, Pc表示概念c关联的先序概念集合.
由于PLM输出的嵌入维度较高, 难以直接应用于CAT, 本文使用多层感知机(Multi-layer Perceptron, MLP)将其映射至低维空间, 最终得到题目、概念的文本表示:
2.1.2 图编码器
可通过GNNs建模题目与概念之间的结构关系.然而, 不同概念在同一题目中的重要程度不同, 传统的图卷积网络无法体现这种差异.因此, 本文采用图注意力网络分别对题目-概念图和概念先序图进行编码.具体而言, 概念c的结构表示来自两个图, 即在概念先序图中的聚合表示
其中,
α c, c'=softmaxc'(attpre([Wpre
表示概念c和概念c'之间的注意力权重,
α c, q'=softmaxq'(attbip([Wbip
表示概念c与题目q'之间的注意力权重, att(· )表示带有LeakyReLU激活功能的线性层, Cc表示概念c关联的题目集合.由于概念在不同图结构中的贡献不尽相同, 此处使用全局注意力机制融合两个图中概念的聚合表示, 得到最终的结构编码:
$\begin{array}{l} \mu_{c}^{\text {pre }}=\left(\boldsymbol{p}^{\text {pre }}\right)^{\mathrm{T}} \tanh \left(\boldsymbol{W}^{\text {pre }} \boldsymbol{e}_{c}^{\text {pre }}+\boldsymbol{b}^{\text {pre }}\right), \\ \mu_{c}^{\text {bip }}=\left(\boldsymbol{p}^{\text {bip }}\right)^{\mathrm{T}} \tanh \left(\boldsymbol{W}^{\text {bip }} \boldsymbol{e}_{c}^{\text {bip }}+\boldsymbol{b}^{\text {bip }}\right), \end{array}$
其中ppre、 pbip表示可学习的投影向量.由此概念c的图结构信息表示为:
题目q的结构表示可由其关联的概念聚合得到, 即
$\boldsymbol{e}_{q}^{\text {graph }}=\sum_{c^{\prime} \in C_{q}} \omega_{q, c^{\prime}} \boldsymbol{W}^{\text {bip }} \boldsymbol{e}_{c^{\prime}}^{\text {graph }}, $
类似于式(1)和式(2)的方法得到ω q, c'.
2.1.3 注意力门控融合方法
题目和概念的语义表示与结构表示分别从节点本体特征与邻居关系中建模, 但两类表示在特征分布和表达方式上存在明显差异, 若直接拼接可能导致信息冲突或失真.为此, 本文设计注意力门控融合方法.考虑到相比常见的点积注意力机制, 加性注意力机制在低维度、短序列的情况下效果更稳定, 同时能捕捉融合对象之间的非线性关系, 本文基于加性注意力机制自适应地融合语义与结构信息, 提升节点表示的完整性与判别性.考虑到SiLU激活函数平滑可导, 并可有效缓解梯度消失的问题, 此处采用SiLU作为激活函数.具体地, 对于题目的文本表示
$\begin{array}{l} \hat{\boldsymbol{e}}_{q}^{\mathrm{txt}}=\operatorname{SiLU}\left(\boldsymbol{W}^{\mathrm{txt}} \boldsymbol{e}_{q}^{\mathrm{txt}}+\boldsymbol{b}^{\mathrm{txt}}\right), \\ \hat{\boldsymbol{e}}_{q}^{\text {graph }}=\operatorname{SiLU}\left(\boldsymbol{W}^{\text {graph }} \boldsymbol{e}_{q}^{\text {graph }}+\boldsymbol{b}^{\text {graph }}\right), \end{array}$
其中, Wtxt、Wgraph表示可学习投影矩阵, btxt、bgraph表示偏置项.
随后, 采用加性注意力机制, 计算文本表示与结构表示之间的融合权重.题目q的文本表示与结构表示在隐空间中的匹配程度为:
η q=sigmoid(vTtanh(
其中,
$\boldsymbol{e}_{q}=\eta_{q} \hat{\boldsymbol{e}}_{q}^{\mathrm{txt}}+\left(1-\eta_{q}\right) \hat{\boldsymbol{e}}_{q}^{\mathrm{graph}}$
类似可得到概念c的融合表示ec.
2.1.4 状态编码器
在CAT过程中, 学生的答题行为随着时间动态变化, 因此构建能反映学生当前知识状态与作答轨迹的强化学习环境状态表示, 是实现有效选题的关键.在时间步t-1, 学生的响应记录可表示为(qt-1, ct-1, yt-1), 其中, qt-1表示学生在t-1时刻回答的题目, ct-1表示题目qt-1包含概念的整体表示(在下文中表示所有概念表示的平均), yt-1表示学生对题目qt-1的回答, 若回答正确为1, 否则为0.为了构建时间步t的环境状态表示, TECAT基于学生在前t-1个时间步的交互历史{(qt', ct', yt')
$\boldsymbol{e}^{t^{\prime}}=\left(\boldsymbol{e}_{q}^{t^{\prime}} \oplus \boldsymbol{e}_{c}^{t^{\prime}} \oplus \boldsymbol{e}_{y}^{t^{\prime}}\right), $
其中,
表示答题结果的嵌入, ry表示学生回答y的独热编码, Wy表示可学习的投影矩阵.
将历史的回答记录嵌入进行拼接后, 得到时刻t对应的响应记录嵌入矩阵:
Et=[e1, e2, …, et-1]T.
考虑到不同响应记录包含的信息量不同, 使用多头自注意力机制捕捉关键行为信号.具体地, 首先可得到Et对应的查询矩阵
Qt=Et
键矩阵
Kt=Et
和值矩阵
Vt=Et
因此, 第t个注意力头
$\boldsymbol{h}^{t}=\operatorname{softmax}\left(\frac{\boldsymbol{Q}_{t} \boldsymbol{K}_{t}^{\mathrm{T}}}{\sqrt{d_{h}}}\right) \boldsymbol{V}_{t}, $
其中,
拼接所有注意力头的输出, 并通过线性变换整合, 获得自注意力编码的历史响应记录嵌入矩阵:
其中, WO表示输出投影矩阵, h表示注意力头的数量.
为了进一步提升稳定性与表达能力, 引入残差连接与层归一操作, 并使用失活层防止过拟合.
将注意力机制的结果输入平均池化层, 使用平均池化聚合序列维度, 得到第t步的环境状态向量st, 该状态向量作为多目标强化学习选题策略的输入, 用于决策下一题的选择.
在CAT场景中, 学生的学习记录被划分为候选问题集和元问题集.算法从候选问题集上选择题目, 旨在以最少的题目使学生的知识状态尽可能接近完成元问题集后的水平.此外, 所选题目的多样性和新颖性也成为现有CAT考察的重要评价指标.为了提升题目选择策略的综合性能, TECAT在强化学习过程中引入3个优化目标:质量、多样性、新颖性, 分别衡量题目对能力估计的准确度、知识覆盖的广度、题目的重叠度.
对于质量目标, 现有CAT将候选题目的质量高低视为学生学习该题后, 方法对元问题集上题目预测准确率的提升度.然而, 当算法预测本身存在误差时, 无法保证选题的最优性.针对该问题, 本文通过认知诊断模型评估学生在完成元问题题集后的知识状态, 并将候选题目与该状态的接近度作为质量指标, 同时引入基于能力估计误差变化的奖励机制, 使题目选择更精准.
首先利用完整数据集训练CDM(本文中主要考虑IRT[9]和NCD[21]), 获得学生的能力估计值θ * , 并作为学生真实能力的近似值.在CAT流程中, 每次选题后方法都会基于新的作答记录更新能力估计值.为了衡量当前题目对能力估计的实际贡献, 对比更新前后的估计值与θ * 差异的变化.如果学生在第t步答题后的能力估计θ t相比上一步的估计θ t-1更接近θ * , 即误差缩小, 说明当前题目在更新中带来更有效的信息, 可帮助方法更准确地逼近学生真实能力; 反之, 说明该题目对估计无益甚至带来偏差.因此, 当CDM得到的能力估计值为变量时, 质量奖励函数为:
rqua=
当能力估计值为向量时, 质量奖励函数为:
rqua=
相比传统基于预测准确率变化的方式, 此方法直接度量能力估计优化的幅度, 减少对偶然性作答行为(如猜测、粗心)的敏感性, 能更稳定地指导策略向真实能力建模目标收敛.
针对多样性奖励rdiv, 若当前题目涉及新的概念, 则多样性奖励奖励值为1, 否则为0, 旨在鼓励系统覆盖更广泛的知识维度.新颖性奖励rnov通过限制高频题目的重复使用以提升测试内容的新颖性.在训练集上选取出现频率最低的前10%题目作为低频题[22], 当所选题目属于此类时, 赋予奖励值1, 否则为0.
将上述奖励项组合, CAT过程可建模为一个多目标强化学习(MORL)框架下的马尔可夫决策过程, 目标函数如下:
$\begin{aligned} \max _{\pi} J= & \max _{\pi} \frac{1}{n} \sum_{i=1}^{n}\left[\boldsymbol{w}^{\mathrm{T}}\left(\sum_{t^{\prime}=1}^{T} \gamma_{t^{\prime}} r\left(\boldsymbol{s}_{t^{\prime}}^{i}, q_{t^{\prime}}^{i}\right)\right)\right]= \\ & \max _{\pi} E_{i \sim \pi}\left[\boldsymbol{w}^{\mathrm{T}}\left(\sum_{t^{\prime}=1}^{T} \gamma_{t^{\prime}} r\left(\boldsymbol{s}_{t^{\prime}}^{i}, q_{t^{\prime}}^{i}\right)\right)\right], \end{aligned}$ (3)
其中, π 表示选题策略函数, n表示学生数量,
r(
表示对应的奖励向量, 权重向量w∈ R3表示可学习的目标权重向量, 其中每个分量分别对应质量、多样性和新颖性奖励的贡献权重, γ t'表示折扣因子, 用于平衡短期与长期的奖励贡献.
在FUSE模块生成状态向量之后, TECAT使用Actor-Critic作为题目选择的策略推荐器.策略网络由一个全连接层(参数为ϕ π )构成, 根据当前状态st输出题目分布π (qt|st; ϕ π ) , 从中采样获得当前选择的题目qt.同时, 价值网络(参数为ϕ v )由一个全连接层构成, 用于评估当前状态在3个目标维度下的期望回报, 输出形式为:
V(st; ϕ v)=[
为了提升策略学习稳定性, TECAT使用多目标PPO(Proximal Policy Optimization)[23]对策略进行优化.具体地, 本文利用优势函数刻画当前选题行为相比基准策略的优势程度, 并定义为从当前步长t到总测试步长T的实际累计回报与当前状态价值预测之间差值:
A(st, qt)=
在PPO中, 策略网络的优化采用裁剪概率比值的方式构建, 损失函数形式化表示如下:
$\begin{aligned} L_{1}= & -E_{\tau \sim \pi_{\text {old }}}\left[\operatorname { min } \left\{\frac{\pi\left(q_{t} \mid \boldsymbol{s}_{t}\right)}{\pi_{\text {old }}\left(q_{t} \mid \boldsymbol{s}_{t}\right)} \boldsymbol{w}^{\mathrm{T}} A\left(\boldsymbol{s}_{t}, q_{t}\right), \right.\right. \\ & \left.\left.\operatorname{Clip}\left(\frac{\pi\left(q_{t} \mid \boldsymbol{s}_{t}\right)}{\pi_{\text {old }}\left(q_{t} \mid \boldsymbol{s}_{t}\right)}, 1-\epsilon, 1+\epsilon\right) \boldsymbol{w}^{\mathrm{T}} A\left(\boldsymbol{s}_{t}, q_{t}\right)\right\}\right], \end{aligned}$
其中,
同时, 为了提升回报估计的准确性, 价值网络的损失函数设计为预测值与实际累计回报之间的加权均方差:
$L_{2}=\frac{1}{2}\left\|\boldsymbol{w}^{\mathrm{T}}\left(\sum_{t^{\prime}=t}^{T} \gamma_{t^{\prime}-t} r\left(s_{t^{\prime}}, q_{t^{\prime}}\right)-V\left(s_{t} ; \phi_{v}\right)\right)\right\|_{2}^{2} .$
最终的损失函数是两个损失项的加权和, 二者之间的权衡由超参数μ 控制, 即
L=L1+μ L2.
本文在Eedi[24]、Junyi[25]这2个真实教育数据集上评估TECAT.Eedi数据集来源于2018年~2020年在线教育平台Eedi的学生作答日志.Junyi 数据集收集2018年~2019年Junyi Academy在线学习平台的学生练习记录.本文过滤交互序列长度少于40的学生记录, 处理后数据集的统计信息如表1所示.
| 表1 数据集统计信息 Table 1 Dataset statistics |
本文以学生为单位, 采用十折交叉验证, 将数据集按80%、10%、10%划分为训练集、测试集和验证集.同时, 进一步划分每位学生在3类数据集上的答题数据, 80%作为候选数据集用于选题, 20%作为元数据集用于评估.为了防止过拟合, 针对每位学生在不同实验阶段均随机划分候选数据集与元数据集.
实验中设置奖励权重w= [1, 1, 1], 以此保证质量、多样性与新颖性目标具有相同权重.折扣因子γ =0.5.采用Adam(Adaptive Moment Estimation)优化器[26], 批次大小为128, 嵌入维度为128, 学习率为0.001.强化学习中的探索率∊ 设为 0.2, 损失平衡因子μ 设为1.由于只有Junyi数据集包含明确的概念先序关系, 为了保证处理一致性, 本文在两个数据集上均采用RCD(Relation Map Driven Cognitive Diagnosis)[27]构建概念先序图.
本文采用准确率、多样性和新颖性这3类指标评价方法性能.
准确率包括分类准确率(Accuracy, ACC)与ROC(Receiver Operating Characteristic)曲线下面积(Area Under the Curve, AUC)[28].CAT领域中用于评价算法准确率的Ground-Truth 为学生在元数据集上的真实作答结果.
多样性评价指标由覆盖率量化, 形式化定义如下:
$Cov=\frac{\left|K \cap K_{T}\right|}{|K|}, $
其中, K表示概念集合, KT表示在第T步之前所选问题覆盖的概念集合.Cov值越大性能越优.
新颖性指标由平均重叠率量化, 该指标考察目标学生集合上推荐问题集合之间的平均重叠程度, 形式化定义如下:
$\text { Overlap }=\frac{2}{|U|(|U|-1)} \sum_{\substack{i \in U \\ j \in U \\ i \neq j}}\left|R_{i} \cap R_{j}\right| \text {, }$
其中, U表示学生集合, Ri、Rj表示学生i、 j测试的问题集合.Overlap值越小性能越优.
为了对比TECAT的有效性, 本文选取一些具有代表性的基线方法, 应用于如下两种CDM:传统的IRT和基于深度学习的NeuralCDM(NCD).这些方法均可用于CAT场景中的题目选择策略, 具体说明如下.
1)静态方法.基于启发式和不可学习的规则, 策略固定, 不依赖训练过程.
(1)Random.随机选题策略, 作为衡量其它方法性能提升的基线方法.
(2)MFI[7].选择Fisher信息量最大的题目, 仅适用于IRT.
(3)KLI[8].选择具有最大Kullback-Leibler信息移动平均值的题目, 仅适用于IRT.
(4)MAAT[10].基于主动学习的方法, 计算每道题目引起的预期模型变化, 衡量其信息量, 不依赖特定的CDM.
2)可学习的方法.数据驱动方法, 能从大规模数据中进行学习, 策略具有可训练性.
(1)GMOCAT[5].基于图结构的多目标强化学习方法, 采用Actor-Critic框架同时优化题目质量、多样性与新颖性.
(2)BOBCAT[11].CAT中首个双层优化框架, 通过近似梯度估计学习数据驱动的题目选择策略.
(3)NCAT[13].基于强化学习的方法, 采用融合注意力机制的DQN实现题目选择.
(4)BECAT(Bounded Ability Estimation Frame-work for CAT)[29].有界能力估计框架, 将CAT问题建模为子集选择问题, 并以全题库能力估计的理论近似为目标, 结合期望梯度差的贪心策略实现能力估计.
(5)UATS[30].统一的自适应测验方法, 引入层次化结构搜索机制, 在CAT框架下实现高效的题目选择与能力估计优化.
本文在Eedi、Junyi这2个真实教育数据集上, 评估所有方法性能.具体而言, 在每位学生的候选数据集上模拟CAT测试过程, 根据当前能力估计动态选择题目, 并在学生完成作答后实时更新其能力表示.为了确保公平性, 所有方法均采用统一的CDM.完成CAT流程后, 在该学生的元数据集上进行答题结果预测, 以此评估所学能力表示的泛化性和可靠性.在评估过程中, CDM根据CAT流程结束时所得的学生能力表示, 预测其对元数据集上每道题的作答正确概率, Ground-Truth为学生在元数据集上的真实作答结果.
各方法在2个数据集上的准确率指标如表2和表3所示, 表中黑体数字表示最优值, 斜体数字表示次优值, -表示该方法无法应用于NCD, T表示测试步长.由表可知, TECAT在不同认知诊断模型(IRT与NCD)和不同测试步数下均取得最优值.在AUC指标上, TECAT的表现优于对比方法, 反映出更强的判别能力和能力估计质量.在ACC指标上, TECAT同样保持较高的一致性与稳定性.
| 表2 各方法在2个数据集上的AUC指标 Table 2 AUC results of different methods on 2 datasets |
| 表3 各方法在2个数据集上的ACC指标 Table 3 ACC results of different methods on 2 datasets |
在Eedi数据集上, 测试步长为20时, 各方法的推荐多样性和新颖性指标如表4所示, 表中黑体数字表示最优值, 斜体数字表示次优值.由表可见, 即使未对TECAT的多目标贡献权重w进行专门调节, 仅采用w=[1, 1, 1]的默认设置, TECAT仍能在这两个指标上取得整体最优.
| 表4 各方法在Eedi数据集上第20步时的多样性和新颖性指标 Table 4 Diversity and novelty of different methods at the 20th step on Eedi dataset |
值得注意的是, 随着测试步长的增大, TECAT在准确率指标上的提升幅度变小.这可能是因为, 在有限的题目集合下, TECAT在初期倾向于选择信息量更大的题目, 从而更准确地评估用户的真实知识水平.然而, 这也意味着剩余题目的信息量相对有限, 导致后续的指标值提升速度相对缓慢.在理论上, 当题量较多时, 其它方法有可能超越TECAT.但是, 在CAT强调以更少题目更精准评估用户知识水平的背景下, 这种极端情况通常不会发生.
为了深入理解各模块对TECAT性能的影响, 通过消融实验, 重点分析语义信息融入、题目质量奖励设计、多目标优化中各环节的贡献.
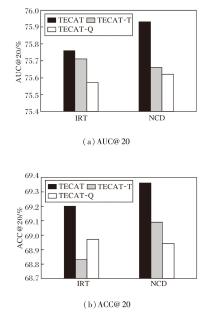
首先, 在Eedi数据集上, 分别对TECAT中的文本信息和质量奖励进行消融实验.设计如下两种方法.
1)TECAT-T.去除TECAT中的文本信息, 仅利用图结构进行建模.
2)TECAT-Q.在题目选择中采用传统的题目奖励定义方法(即考虑模型学习目标题目后对元问题集上题目预测准确率的提升度).
具体ACC、AUC指标如图2所示.由图可见, 无论是去除文本信息还是仅考虑传统的质量目标奖励方法, ACC和AUC指标均出现不同程度的下降.这表明题目与概念文本信息以及改进的质量目标奖励对提升TECAT的预测准确性和稳健性均具有重要作用, 其中, 质量奖励对TECAT效果影响最大.
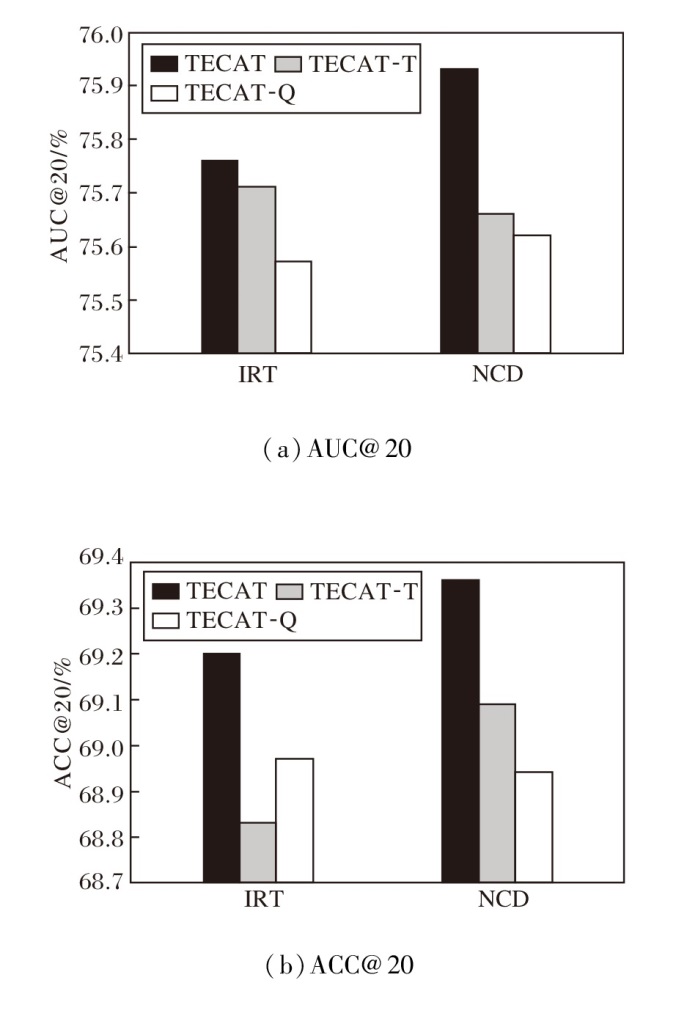 | 图2 各方法在Eedi数据集上第20步时的消融实验结果Fig.2 Ablation experiment results of different methods at the 20th step on Eedi dataset |
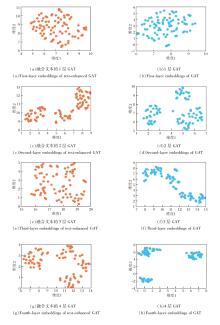
为了进一步验证TECAT中文本表示的有效性, 对不同GAT层数下的概念嵌入进行UMAP(Uniform Manifold Approximation and Projection)[31]可视化.在不引入文本表示和引入文本表示下的概念嵌入分布如图3所示.
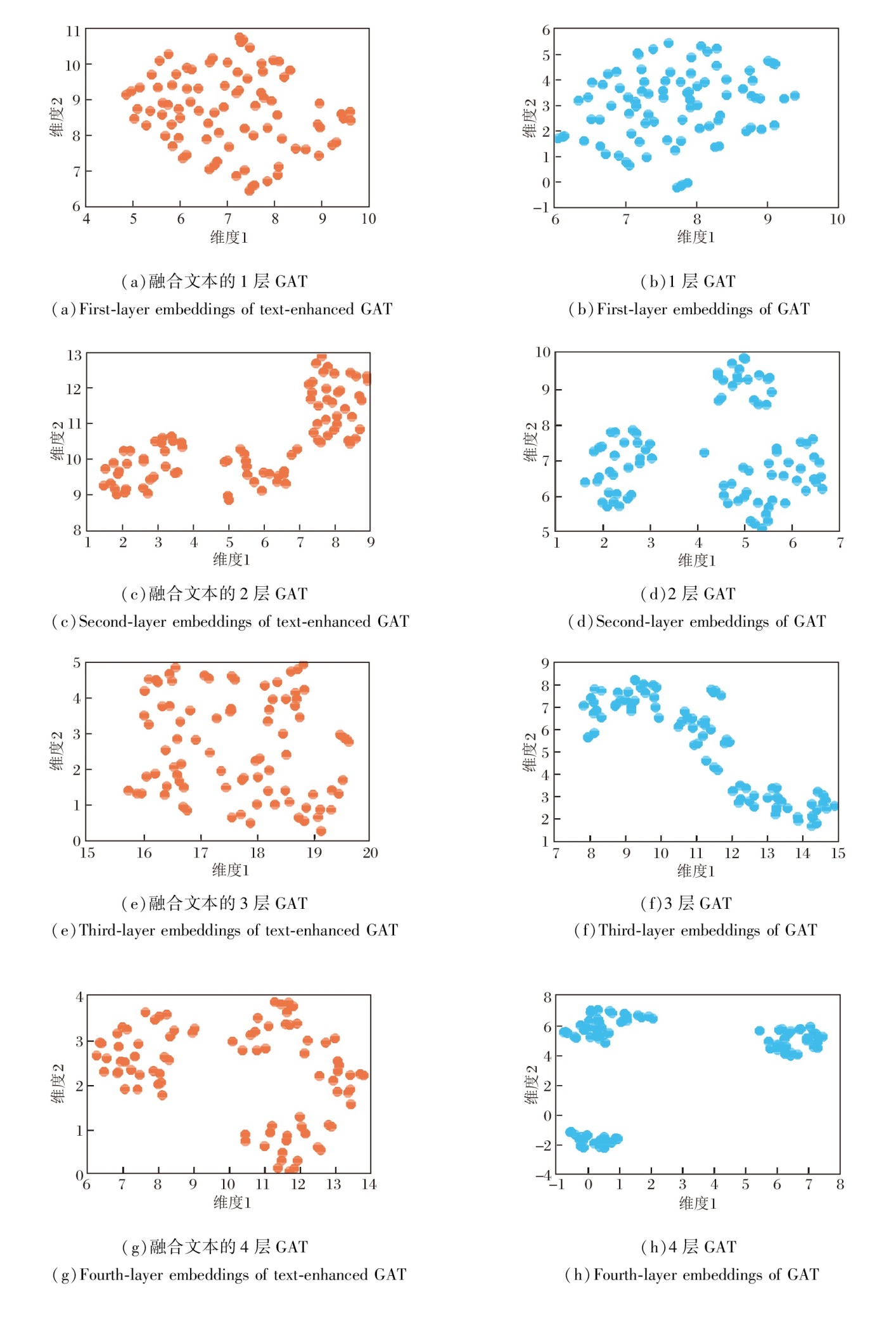 | 图3 Eedi数据集上IRT下GAT概念嵌入与文本增强GAT概念嵌入的UMAP可视化结果Fig.3 UMAP visualization results of GAT concept embeddings and text-augmented GAT concept embeddings with IRT model on Eedi dataset |
由图3发现, 仅使用图结构信息时, 随着GAT层数的增加, 概念嵌入逐渐趋于聚集, 呈现明显的过平滑现象, 导致不同概念之间的表示差异减小, 区分度下降.在引入文本表示后, 嵌入分布更分散, 概念间边界更清晰, 过平滑现象得到有效缓解.该结果表明, 将文本语义与图结构信息进行融合, 有助于缓解过平滑现象, 并在一定程度上增强概念表示的区分性, 由此说明文本信息的融入在提升概念嵌入质量方面具有积极作用.
同样在Eedi数据集上, 分别对多目标优化函数(式(3))中的3个目标奖励进行消融实验, 结果如表5所示, 表中黑体数字表示最优值.
| 表5 Eedi数据集上IRT下第20步时的多目标奖励消融实验结果 Table 5 Ablation experiment results of multi-objective reward at the 20th step with IRT model on Eedi dataset |
由表5可见, 不同奖励类型对推荐指标的影响存在明显差异.质量奖励对推荐准确性的影响相对更大(以AUC和ACC衡量), 对多样性和新颖性的影响相对有限.多样性奖励在提升推荐准确性方面居次, 对推荐多样性的提升效果最突出, 但对新颖性的提升起反作用.新颖性奖励对推荐准确性起反作用, 对推荐新颖性具有明显的促进作用.
为了揭示TECAT中各参数对性能的影响及可能存在的相互制约, 结合参数敏感性与参数冲突展开研究.
首先, 对多目标优化函数(式(3))中的长短期奖励贡献折扣因子γ 和多目标贡献权重w进行参数敏感性分析, 结果如表6和表7所示, 表中黑体数字表示最优值.
| 表6 Eedi数据集上IRT下第20步时的w敏感性分析 Table 6 Sensitivity analysis of w at the 20th step with IRT model on Eedi dataset |
| 表7 Eedi数据集上IRT下第20步时的γ 敏感性分析 Table 7 Sensitivity analysis of γ at the 20th step with IRT model on Eedi dataset |
在针对多目标贡献权重w参数的敏感性分析中, 调节其中一个奖励权重, 其余两个权重固定为0.5.由表6可见, 质量目标对推荐准确性和推荐新颖性的影响相对更大.具体地, 随着相应权重的增加, 推荐准确性逐渐提升, 推荐新颖性减小, 推荐多样性变化不大.相比之下, 多样性目标和新颖性目标对推荐准确性影响较小, 多样性目标对推荐多样性影响较大, 新颖性目标对推荐新颖性影响较大.进一步观察发现, 当优化特定的奖励目标时, 应确保与该目标对应的奖励因素权重高于其余两个因素的对应权重.例如:提升推荐准确性需要提高质量因素的相对权重; 若关注推荐多样性或新颖性, 分别需要提高多样性因素或新颖性因素的相对权重.
在针对折扣因子γ 的参数敏感性分析中, 当固定测试步长, γ 值越大(即更注重长期奖励), 算法的推荐准确性整体越好, 但是推荐多样性和新颖性都会下降.
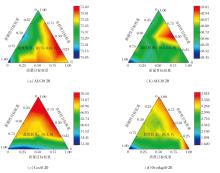
下面对多目标优化函数中3个奖励目标的贡献权重进行冲突分析.具体地, 将w中3个优化目标的贡献权重进行归一化设置, 分析在不同的贡献权重组合下, TECAT的准确性、多样性和新颖性指标, 效果如图4所示.
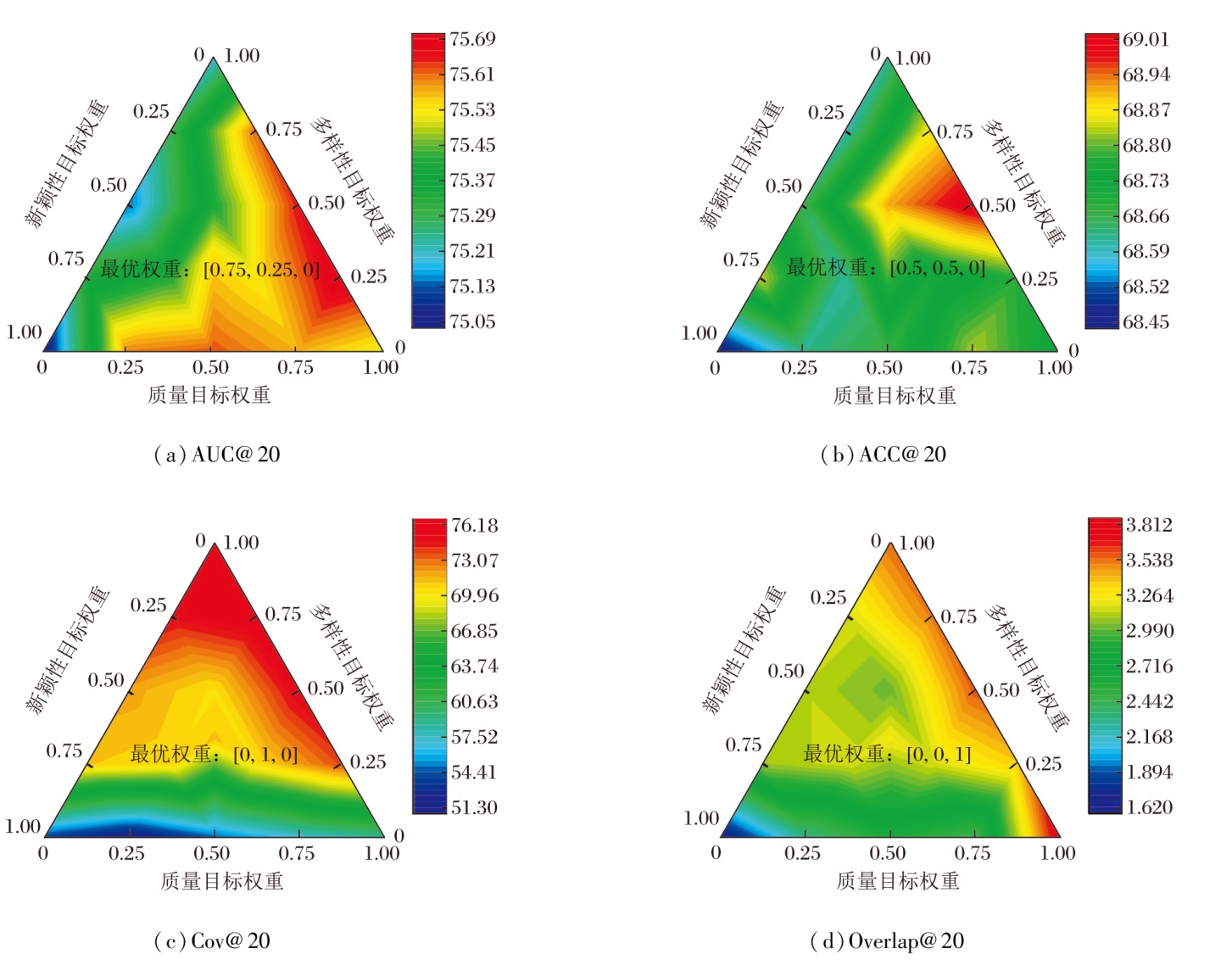 | 图4 Eedi数据上IRT下第20步时的多目标奖励权重冲突分析Fig.4 Conflict analysis of multi-objective reward weights at the 20th step with IRT model on Eedi dataset |
由图4可见, 当忽略新颖性优化目标时, 有效平衡多样性目标和质量目标贡献, 推荐准确性可取得最优效果.仅优化多样性目标或新颖性目标时, 相应指标可达到最优, 但准确性显著下降.这说明3个优化目标之间确实存在折衷关系, 最终权重的设计需根据实际应用场景和用户偏好进行选择.基于上述实验结果, 若以准确性为唯一评价指标时, 建议忽略新颖性优化目标.
本文提出基于文本语义增强图神经网络的计算机自适应测试方法(TECAT), 融合题目与概念的文本语义信息与图结构信息, 构建更具表达力的节点表示.引入门控融合机制, 有效整合语义嵌入与结构表示, 缓解GNNs中的过平滑问题, 提升状态建模的准确性.同时, 将题目选择建模为多目标强化学习任务, 联合优化质量、多样性与新颖性这3个目标, 并设计基于能力估计误差变化的质量奖励函数, 准确衡量题目对能力评估的实际贡献.实验表明, TECAT在能力估计准确性方面较优, 展现出良好的性能与应用前景.进一步的实验表明, 相比文本信息的增强, 质量奖励函数的改进在提升算法效果方面具有更显著的作用.在多目标优化环节, 质量奖励函数对于提升方法的准确性作用更大, 新颖性对于准确性的提升起到反作用效果.同时, 实验还表明, 不同目标下的最优奖励的权重设置存在冲突:当以准确性为目标时, 忽略新颖性奖励并有效平衡多样性和质量的奖励可取得最佳效果; 当以推荐多样性或新颖性为目标时, 相应的奖励函数需赋予更高权重.如何实现多目标权重的动态优化或自适应调节, 是未来需重点关注的问题.
本文责任编委 陈恩红
Recommended by Associate Editor CHEN Enhong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|