

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向边缘智能的交错式算子划分协同推理加速策略
[刘志邦1, 2  , 吴凡
, 吴凡1, 2 , 徐朝农1, 2 1, 2 , 马丹1, 2 ]
, 吴凡, 徐朝农, 张自晓, 马丹]
|
|



作者简介:

刘志邦,博士研究生,主要研究方向为边缘智能、协同推理.E-mail:2021310705@student.cup.edu.cn.

吴 凡,博士研究生,主要研究方向为无线通信、物联网.E-mail:2020310706@student.cup.edu.cn.

张自晓,硕士研究生,主要研究方向为边缘智能、嵌入式系统.E-mail:2023216045@student.cup.edu.cn.

马 丹,硕士研究生,主要研究方向为边缘智能、物联网.E-mail:2023216034@student.cup.edu.cn.
协同推理是在资源受限的边缘设备上实现模型部署并加速推理的有效方案,但目前的算子划分策略在设备间通信开销仍然较高.因此,文中提出面向边缘智能的交错式算子划分(Interleaved Operator Partitioning, IOP)协同推理加速策略,将相邻算子分别沿输入通道维度和输出通道维度进行划分,匹配前后级算子的通道数量,减少算子输出激活的拼接过程,降低协同推理的时间开销.首先,通过模型中的算子信息建模设备的计算开销和通信开销,建立最小化协同推理时间的整数规划模型.然后,设计启发式的算子配对算法,自前向后枚举相邻算子,对比IOP策略与OCP(Output Channel Partitioning)策略的推理时间开销,选择收益最高的算子进行配对.最后,对配对后的算子实施交错式划分和分散部署.实验表明,IOP策略在推理延迟时间、内存占用及能耗上均较优,同时在面对突发链路波动时仍具有良好的鲁棒性.
About Author:
LIU Zhibang, Ph.D.candidate.His research interests include edge intelligence and cooperative inference.
WU Fan, Ph.D.candidate.His research interests include wireless communications and Internet of Things.
ZHANG Zixiao, Master student.Her research interests include edge intelligence and embedded systems.
MA Dan, Master student.Her research interests include edge intelligence and Internet of Things.
Collaborative inference is an effective method for deploying models and accelerating inference on resource-constrained edge devices. However, the existing operator partitioning strategies still suffer from high inter-device communication overhead. To solve this problem, an interleaved operator partitioning(IOP) collaborative inference acceleration strategy for edge intelligence is proposed. The core mechanism is to partition adjacent operators along the input and output channel dimensions, respectively. By matching the number of channels between consecutive operators, the concatenation of output activations is reduced, and thereby the time overhead of collaborative inference is decreased. First, the computation and communication costs of devices are modeled based on operator information in the model. An integer programming model is established to minimize the total inference time. Second, a heuristic operator pairing algorithm is designed and adjacent operators are enumerated in a forward order. The inference time overhead of IOP and traditional output channel partitioning(OCP) is compared. The operator pair with the highest benefit is executed. Finally, interleaved partitioning and distributed deployment are applied to the selected operator pairs. Experiments demonstrate that IOP achieves superior performance in terms of inference time, memory usage, and energy consumption, while maintaining robustness under sudden link fluctuations.
随着深度学习技术的发展, 卷积神经网络(Convolutional Neural Network, CNN)的参数规模持续增长[1].同时, CNN在边缘设备上的部署与实时推理问题也受到广泛关注[2, 3].一方面, 边缘设备通常只具备较低的计算能力和存储资源[4], 对深度神经网络(Deep Neural Network, DNN)的部署构成挑战.另一方面, 诸如阀门内漏检测等应用场景对推理响应的实时性要求极高, 通常需要达到毫秒级别, 因此较高的推理延迟可能带来严重的安全隐患[5, 6].
协同推理是一种通过划分并分配DNN工作负载以缓解设备存储开销并加速模型推理过程的方案[7].作为一种有效的解决方案, 协同推理将推理任务划分并分配至不同设备以实现同步执行[8, 9, 10].当前主流的协同推理主要包括数据并行技术[11]、模型并行技术[12]和流水线并行技术[13].
数据并行技术是指将输入DNN的数据拆分成多份, 分别分配给不同设备进行处理.同时, 每个设备持有模型的完整副本, 用于执行推理任务[14, 15, 16].数据并行技术适用于同时输入DNN的数据量较多或单幅图像尺寸较大的场景[17, 18].典型的并行推理方案通常选择输入图像的高或宽进行划分.Hsu等[19]提出CONVENE(Cooperative CNN Deployment over Mobile Network Edges), Mohammed等[20]提出DINA(Distributed Inference Acceleration), 都是沿图像高或宽中尺寸最大的维度进行划分, 缓解设备的计算开销, 但并未考虑子图边界数据缺失的问题, 导致推理精度下降.Mao等[21]提出MoDNN, 在设备间共享划分的边界数据, 并根据设备的计算能力、存储容量和带宽将输入图像沿高或宽进行划分, 实现工作负载的合理分配.Zeng等[22]提出CoEdge(Coope-rative Edge), 基于MoDNN进行优化, 限制子图的最小行数, 有效缓解跨设备通信带来的延迟问题.然而, 由于卷积算子采用滑动窗口的计算方式, 当沿特征图的高或宽进行划分时, 相邻设备需要在图像划分边界进行数据交换, 因此, 仍不可避免地引入协同推理过程中设备间的通信开销.
模型并行技术是指将模型或算子的权重沿指定维度划分到多个设备上执行协同推理[23, 24, 25].Kri- zhevsky等[26]在部署AlexNet时首次采用模型并行策略, 沿输出通道维度将卷积算子划分至不同设备, 进而实现模型的并行执行.Kim等[27]提出μ Layer, 在沿输出通道维度划分算子的同时, 引入量化策略, 降低推理过程中的计算开销和通信开销, 但推理准确率有所下降.为了避免量化引起的推理精度损失, Jia等[28]提出CoDL, 分析划分维度与算子参数配置之间的关系, 并对卷积算子沿输出通道维度进行划分.虽然此方法可实现模型推理过程的并行化, 并且在减少设备内存占用方面具有一定优势, 但由于需要广播和拼接分布在各设备上的激活值, 仍在一定程度上限制推理速度的进一步提升.
流水线并行技术是指在模型并行的基础上, 通过重叠设备间的计算和通信过程, 增加模型吞吐量并降低推理延迟时间的技术.Huang等[29]提出GPipe, Narayanan等[30]提出PipeDream, 都是将训练数据分成多个微批次, 以流水线的方式执行每个阶段的计算, 通过重叠设备计算时间与通信等待时间, 降低推理延迟.Hu等[31]提出PipeEdge, 针对异构设备集群场景, 在流水线模型并行的基础上加入断点恢复机制, 确保在网络波动或设备突发故障时异构集群系统的稳定运行.流水线并行技术主要针对连续数据流输入的场景, 对于非连续推理场景下的延迟优化能力有限.
目前, 针对算子划分的协同推理方案均采用OCP(Output Channel Partitioning)策略.相比在单一设备上顺序执行的集中式推理场景, OCP策略将卷积算子沿输出通道维度划分为多个子任务, 并分别分配至不同设备并行执行推理.通过这种并行方式, 可有效降低单个设备的计算开销和存储开销, 实现推理过程的加速.然而, 在上述协同推理过程中, 随着卷积算子被划分至不同设备, 输出激活也会分布在不同设备上, 仅在完成当前算子输出激活的拼接之后, 后续算子才能继续执行推理任务.该拼接操作会引入额外的通信开销.
针对此问题, 本文提出面向边缘智能的交错式算子划分(Interleaved Operator Partitioning, IOP)协同推理加速策略, 将相邻算子分别沿输入通道维度和输出通道维度划分, 同时匹配前后级算子的通道数量.由于前后级算子的通道数量相等, 前级算子的输出激活无需拼接, 可直接输入下一级算子对应的卷积核通道执行后续计算, 从而有效减少设备间的通信开销, 进一步实现协同推理加速.
假设所有设备的通信带宽与计算能力相对稳定.为了确保问题建模的严谨性, 定义如下概念和符号.
1)模型结构O={1, 2, …, o}, 表示DNN中所有算子的集合, i∈ O表示模型中第i层算子.
2)设备集合D={1, 2, …, d}, 表示所有可用设备的集合, j∈ D表示设备集合中的第j个设备.
3)设备属性(f, r)j, 表示设备j的计算存储和通信能力, fj表示第j个设备的计算能力, rj表示设备的存储空间(如4 GB的LPDDR4X内存), 此外, 使用b表示设备的通信带宽.
4)算子配置
5)划分维度η i=
6)(
基于模型结构和算子的配置信息, 可计算DNN中执行各算子所需的计算量.在执行DNN推理时, 部署于设备j上第i层算子的理论计算量如下所示:
ci, j=
其中,
可根据算子配置的信息计算得到卷积算子输出特征图的宽度
其中,
由于全连接算子可等效为卷积核大小为1、输入特征图尺寸为1× 1× cin、输出特征图尺寸为1× 1× cout的卷积算子, 因此, 其执行推理时所需计算量为:
ci, j=
其中,
算子划分会导致设备之间产生通信开销, 并且该通信开销取决于算子的划分维度.算子划分引起的通信开销可归纳为如下三部分:
gi, j=e+g
其中, e表示设备间建立通信连接所需时间, g
对于卷积算子i, 如果相邻算子之间存在激活函数(如ReLU), 则沿输入通道维度划分所得的各部分输出必须在传递给后级算子之前进行拼接.因此, 对于算子i, 各设备计算生成的输出激活必须广播到其它设备, 该过程引起的通信量g
当设备j上算子i的输出通道数与其相邻下一级算子i+1的输入通道数相等, 即
对于全连接算子, 因其可视为一种特殊的卷积算子, 故其沿输入维度和输出维度划分引起的通信开销g
在执行协同推理时, 如果DNN在推理时的峰值内存占用超过设备自身的存储能力, 会因为内存溢出(Out of Memory, OOM)而导致推理过程无法继续进行.因此, 定义约束条件如下:
s.t.
约束(1)表示部署在每个设备上的算子权重的内存占用与其最大输出激活的内存占用之和应小于该设备的可用存储空间.
在此基础上, 对算子的划分维度及算子划分前后的通道数量进行如下约束:
s.t.
约束(2)表示模型中每个算子只能在输入通道和输出通道中选择一个维度进行划分.
划分后沿输入通道维度和输出通道维度拼接的各部分通道数之和应等于对应维度被划分前的通道数, 具体约束如下:
$\begin{array}{ll} \text { s. t. } & \sum_{j \in D} \eta_{i}(0) c_{i, j}^{\text {in }}=\eta_{i}(0) c_{i}^{\text {in }}, \\ & i \in O, c_{i, j}^{\text {in }} \geqslant 0, c_{i, j}^{\text {in }} \in \mathbf{Z} ; \end{array}$ (3)
$\begin{array}{ll} \text { s. t. } & \sum_{j \in D} \eta_{i}(1) c_{i, j}^{\text {out }}=\eta_{i}(1) c_{i}^{\text {out }} \\ & i \in O, c_{i, j}^{\text {out }} \geqslant 0, c_{i, j}^{\text {out }} \in \mathbf{Z} . \end{array}$ (4)
基于上述分析, 可得目标函数:
P1: min
函数约束条件如式(1)~式(4)所示.
模型的推理时间包括计算延迟和通信延迟.
$\begin{array}{l} T_{i, j}^{c}=\frac{c_{i, j}}{f_{j}}, i \in O, j \in D, \\ T_{i, j}^{g}=\frac{g_{i, j}}{b}, i \in O, j \in D, \end{array} $
其中, ci, j表示计算量, gi, j表示通信量, 这取决于采用的算子划分方式, fj和b则由设备的计算能力和通信带宽等属性决定.
将基于IOP策略的协同推理描述为一个整数规划问题P1, 其目标在于寻求一种最小化协同推理时间的模型划分方式, 主要分为两步.
1)将模型划分为Γ ={γ 1, γ 2, …, γ k}, 其中, γ i表示一个模型分段, 可以是单个算子, 也可以是一对算子的组合, 即前后级通道数匹配的算子对.
2)对于每个算子对, 采用IOP策略, 通过匹配前后级算子通道数量, 避免输出激活的拼接过程, 减少设备间的通信开销.将两个算子作为构成算子对的最小组合, 是因为考虑到多个算子组合的方案会增加计算复杂度, 该约定是为平衡算法性能和推理延迟所做的一种折衷.
为了确定模型中采用IOP策略进行划分的算子, 设计算子配对算法, 示意图如图1所示.由图可见, 从CNN中的第1个算子开始, 逐算子搜索符合IOP条件的算子对.具体而言, 对于算子i及其后级算子i+1, 分别计算IOP策略和OCP策略下的推理延迟时间.若IOP策略下的推理延迟时间更短, 则将这两个算子配对, 即IOP策略下算子i和算子i+1构成交错式划分, 否则对算子i使用OCP策略.由于算子配对算法针对模型中的卷积算子和全连接算子, 因此, 为了突出重点, 在图1中省略模型中的ReLU和Softmax等激活函数.
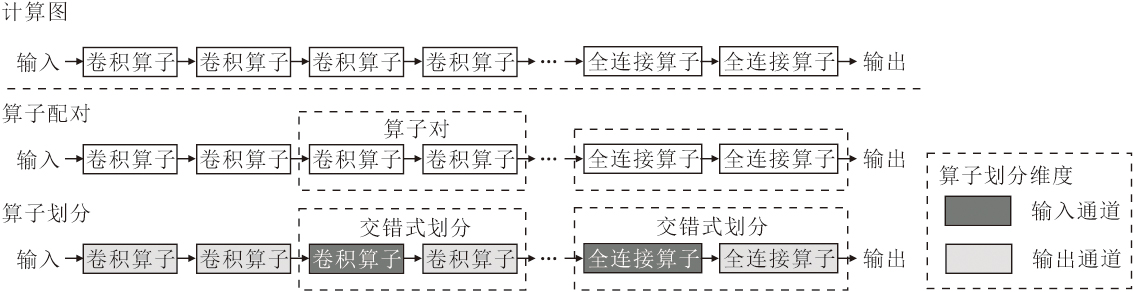 | 图1 算子配对示意图Fig.1 Schematic diagram of operator pairing |
算子配对算法具体步骤如下所示.
算法1 算子对配对算法
输入 算子集合O={1, 2, …, o},
设备集合D={1, 2, …, d},
算子配置
划分维度η i, 设备属性(f, r)j, b
输出 模型划分方案Γ ={γ 1, γ 2, …, γ k}
初始化变量k=1, i=1 //初始化索引
for i in range(1, N): //遍历模型中的算子
γ k=(i, i+1) //构造候选算子对
Tocp=Evaluateocp(γ k) //评估OCP策略下γ k的推理延迟时间
Tiop=Evaluateiop(γ k) //评估IOP策略下γ k的推理延迟时间
if Tiop< Tocp: //如果IOP策略下γ k的推理延迟时间更短
Γ ← γ k //配对成功
k+1, i+2 //更新索引
else:
γ k=(i) //单个算子作为分段
Γ ← γ k //加入模型划分方案
i+1 // 更新索引
return Γ //返回模型划分方案
为了进一步评估算子配对算法的计算效率, 对其复杂度进行理论分析.设模型中共有N个算子, 则算法的时间复杂度和空间复杂度如下所述.
算法主体为一个从前向后遍历算子集合的循环结构.每轮迭代尝试构建当前算子与其后级算子的候选配对, 并在OCP策略与IOP策略下分别评估对应的推理延迟时间.评估函数Evaluate(γ k)可基于算法输入的算子配置和设备属性参数, 在常数时间内完成计算.因此, 每轮迭代的时间复杂度为O(1).由于在匹配成功时索引i会递增两位, 否则递增一位, 因此, 整个循环最多执行N-1次.故算法的时间复杂度为O(N)× O(1)=O(N).
算法需存储生成的算子对集合Γ ={γ 1, γ 2, …, γ k}, 该集合中的算子对数量最多不超过模型中全部算子数量的一半, 即N/2.算法中使用的索引变量及中间结果Tocp和Tiop均为常量空间开销.因此, 算法的空间复杂度为O(N).
综上所述, 算子配对算法具有线性时间和空间复杂度, 适用于搜索大规模CNN的IOP部署方案.
本文实验平台包括i9-10980XE处理器、4张NVIDIA RTX 3090、1张NVIDIA RTX 4090、1张NVIDIA RTX 2080 Ti、1张NVIDIA GTX 1080 Ti、国产化设备寒武纪4芯MLU 220.运用torch.cuda.memory_allocated等函数限定设备可用的内存容量.同时, 引入冗余通信数据的方式调整设备间的传输带宽.
使用图像分类网络LeNet、AlexNet、VGG11、VGG13、VGG16、VGG19、ResNet-18、MobileNetv1和经典的目标检测网络YOLO-Fastest, 评估IOP策略下的推理延迟时间、异构设备环境的普适性、能耗及链路波动环境下的鲁棒性[32, 33].
输入模型的数据来自MNIST[34]、CIFAR-10[35]、ImageNet[36]、CelebA[37]、ISIC2018[38]、Food-101[39]、COCO[40]、Oxford-IIIT[41]数据集, 详细信息见表1.
| 表1 实验评估使用的模型和数据集 Table 1 Models and datasets utilized in experimental evaluation |
为了全面评估IOP策略的性能, 选择如下两种代表性的协同推理策略进行对比实验.
1)OCP策略.最早在经典的AlexNet实验原型中采用沿输出通道维度的划分方式, 可实现多个设备的并行计算, 有效降低单个设备在模型推理过程中的内存占用及计算量.在后续的工作如CoDL和FlexFlow等, 都在划分卷积算子时采用输出通道作为划分维度.
2)CoEdge策略.在MoDNN的基础上进行改进和优化, 沿输入图像高的维度进行划分, 从数据划分层面实现推理, 降低CNN的推理时间开销.但是, 由于卷积算子滑动窗口的计算特性, 为了确保模型推理的准确性, 仍需逐算子共享输出激活的边界数据, 导致通信开销较大.
首先, 使用4张NVIDIA RTX 3090设备, 在同构场景下评估LeNet、AlexNet、VGG11在3种策略下的协同推理任务.
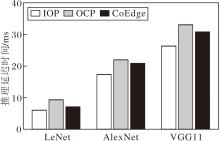
相同实验条件下3种策略对应的网络推理延迟时间测试结果如图2所示.由图可见, 对于LeNet, IOP策略分别比OCP策略和CoEdge策略节省35.34%和14.99%的推理延迟时间, 说明对于轻量级模型, IOP策略可有效减少激活值拼接带来的通信开销.对于AlexNet, IOP策略分别比OCP策略和CoEdge策略节省21.08%和16.83%的推理延迟时间.对于VGG11, IOP策略分别比OCP策略和CoEdge策略节省20.34%和14.52%的推理延迟时间.由此表明IOP策略在中等复杂度模型的协同推理任务中性能依然较优.
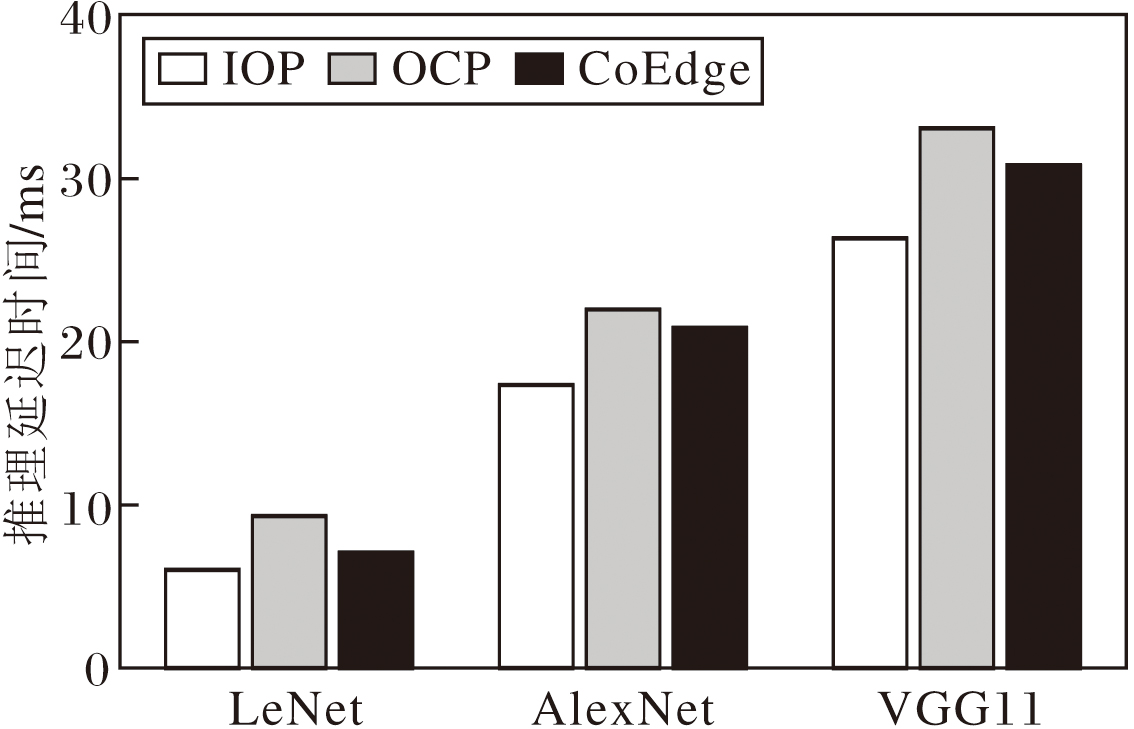 | 图2 3种策略下3种网络的推理延迟时间Fig.2 Inference latency of 3 networks with 3 strategies |
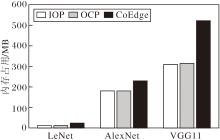
接下来, 分别评估在IOP、OCP和CoEdge策略下3种网络的峰值内存占用, 结果如图3所示.由图可见, 当整体加载划分后的模型参数并执行推理时, 对于LeNet, OCP策略与IOP策略的内存占用几乎一致, 而CoEdge策略的内存占用为24.43 MB, 几乎是OCP策略和IOP策略的两倍.对于AlexNet, 随着权重参数的增加, 3种策略的内存占用均显著上升, 其中, OCP策略和IOP策略的内存占用依然非常接近, CoEdge策略比OCP策略增加约27%的内存占用.
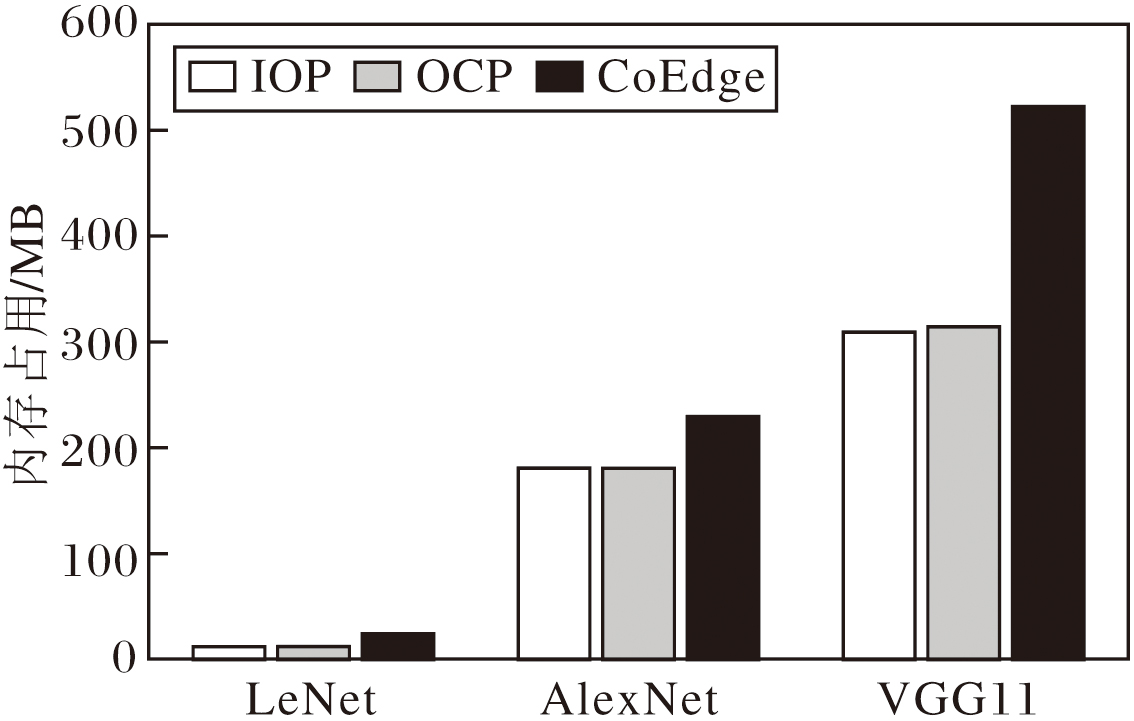 | 图3 3种策略下3种网络的峰值内存占用Fig.3 Peak memory usage of 3 networks with 3 strategies |
由于VGG11具有更多的权重参数, 因此, 3种方案的内存开销均大幅提升, 但IOP策略的内存占用略低于OCP策略, 比CoEdge策略减少40.79%.这是由于OCP策略和IOP策略通过算子划分方式降低设备在协同推理过程中的计算开销和存储开销, 而CoEdge针对图像进行划分, 在执行推理任务的设备上部署完整的模型副本, 随着模型权重参数的增加, 会导致更大的设备内存占用.
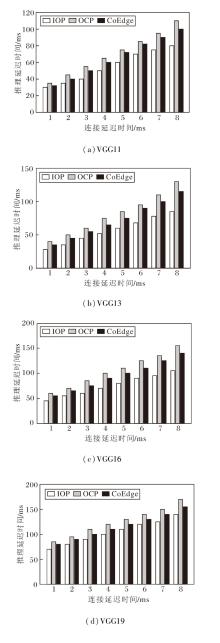
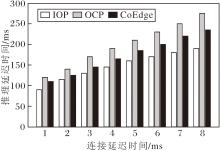
在上述实验分析中可发现, 随着模型结构的加深, 设备间的通信连接时间对协同推理的性能表现具有显著影响.为了进一步揭示该问题, 使用VGG11、VGG13、VGG16、VGG19这4种具有更深层次的VGG进行对比实验.在不同通信连接延迟场景下, 4种VGG网络在OCP、IOP、CoEdge策略下的推理延迟时间如图4所示.如图所示, 在相同的连接延迟条件下, IOP策略的推理延迟时间始终最低.对于VGG11, 当设备间连接延迟时间从1 ms增至8 ms时, IOP策略比OCP策略和CoEdge策略减少14.51%~26.74%的推理延迟时间.对于VGG13, IOP策略比OCP策略减少12.99%~24.99%推理延迟时间.这表明即使网络层次的深度略有提升, IOP策略仍能保持良好的扩展性与通信效率优势.
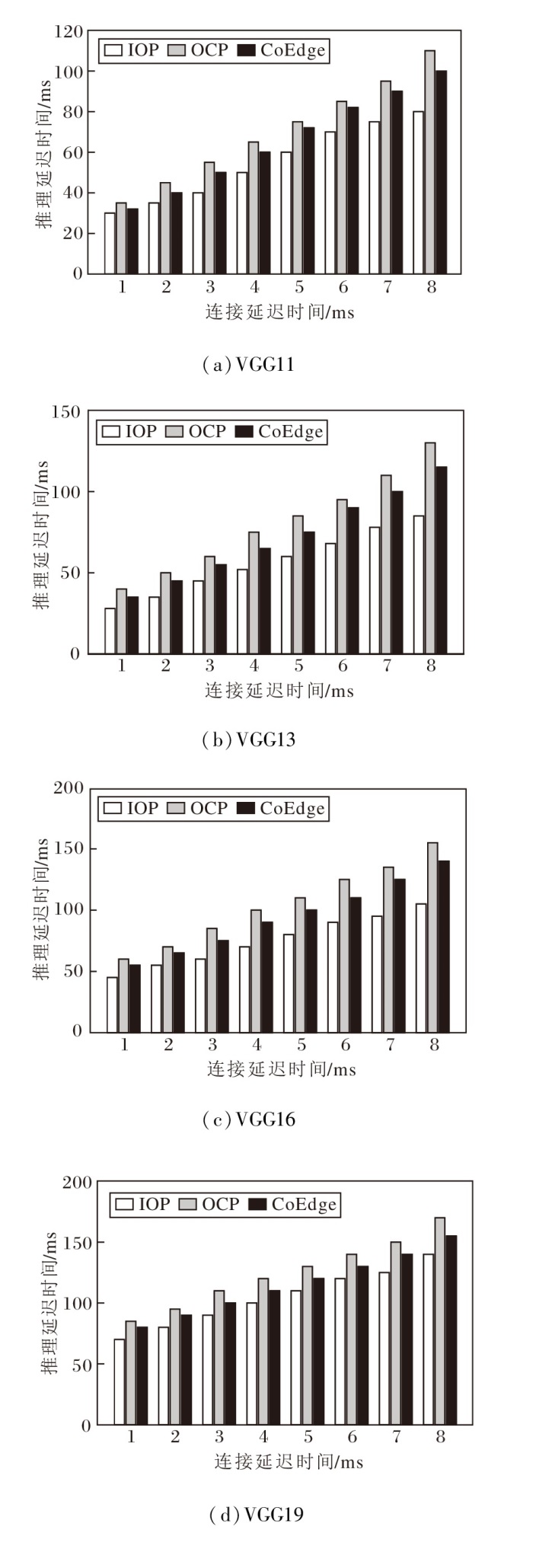 | 图4 3种策略下4种VGG网络的推理延迟时间Fig.4 Inference latency of 4 VGG networks with 3 strategies |
对于VGG16, 虽然IOP策略在连接延迟时间较低时的优势不明显, 但在高连接延迟场景下具有明显优势, IOP策略比OCP策略降低3.34%~31.01%的推理延迟时间.对于VGG19, IOP策略比OCP策略降低15.01%~34.87%的推理延迟时间, 提升幅度最大.由此表明随着网络规模和设备间通信连接延迟时间的增加, IOP策略的优势愈加明显.
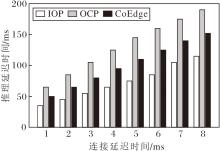
为了验证IOP策略在异构环境下的性能表现.由i9-10980XE、RTX 4090和RTX 2080Ti组成异构设备集群, 设备间连接延迟时间从1 ms增至8 ms时, 3种策略下VGG16的协同推理延迟时间如图5所示.如图所示, IOP策略比OCP策略节省约39.47%~48.28%的推理延迟时间, 表现出显著的推理性能优势.IOP策略比CoEdge策略节省约24.34%~31.82%的推理延迟时间, 说明IOP策略在异构设备条件下仍具有显著优势.
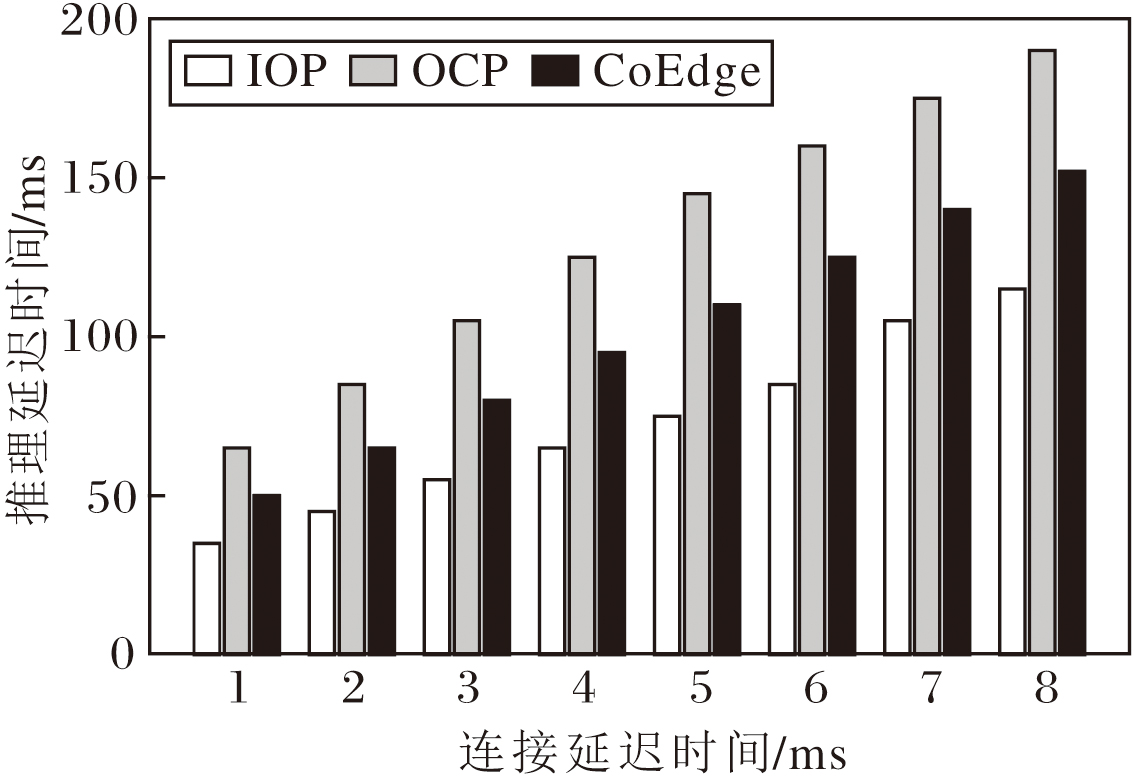 | 图5 4090和2080Ti组成异构场景时3种策略的推理延迟时间Fig.5 Inference latency of 3 strategies in heterogeneous environment with 4090 and 2080Ti |
为了进一步验证IOP策略在异构环境下的普适性, 将NVIDIA RTX 2080Ti更换为NVIDIA GTX 1080Ti并进行评估, 结果如图6所示.如图所示, 尽管推理延迟时间有所增加, 但IOP策略依然表现出良好的扩展性.IOP策略比OCP策略减少14.29%~30.43%的推理延迟时间, 比CoEdge策略减少4.26%~20.12%的推理延迟时间.由此说明对于异构协同推理场景, IOP策略仍具有良好的适应性.随着设备集群异构性的增加, IOP策略的加速优势略有下降, 但仍显著优于OCP、CoEdge策略.
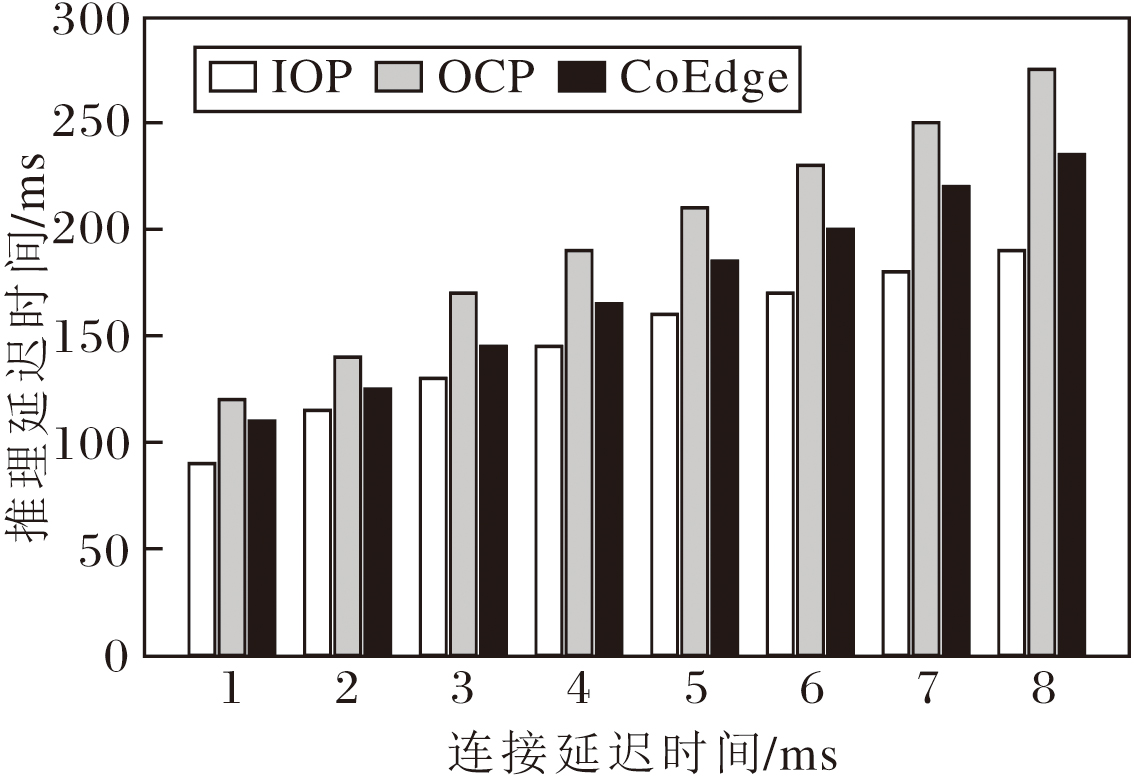 | 图6 4090和1080Ti组成异构场景时3种策略的推理延迟时间Fig.6 Inference latency of 3 strategies in heterogeneous environment with 4090 and 1080Ti |
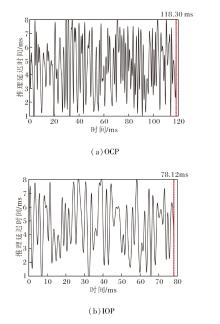
此外, 实验还评估链路波动环境下的容错能力.对于VGG16, OCP策略和IOP策略在链路波动状态下的推理延迟时间曲线如图7所示.
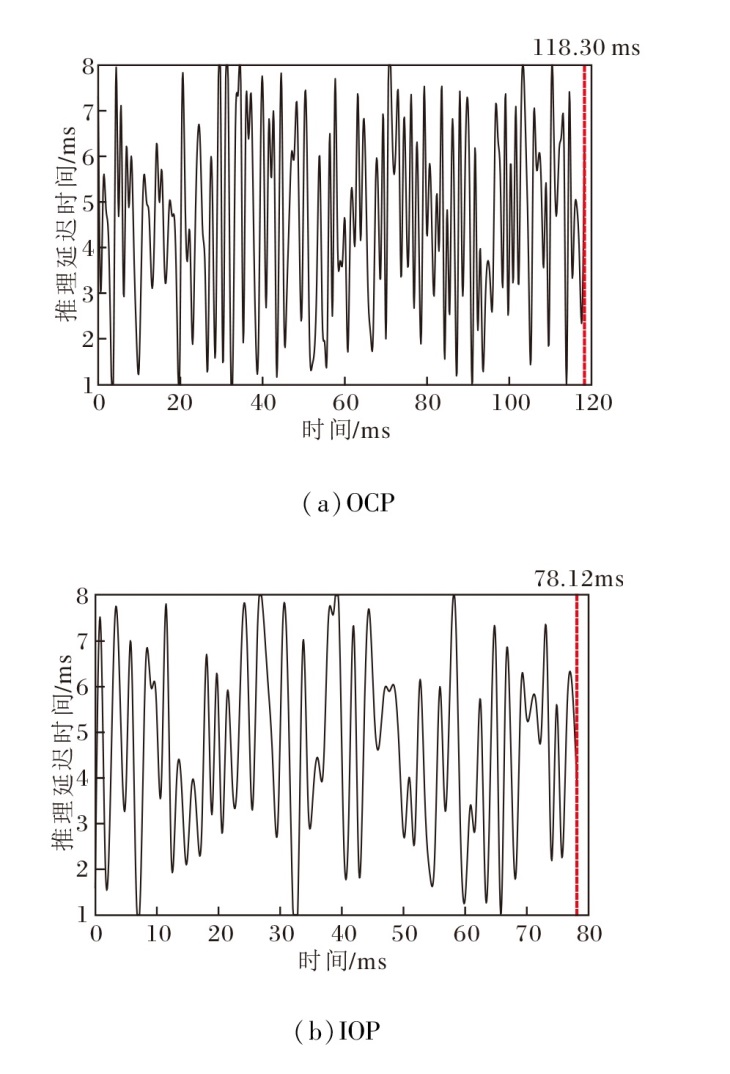 | 图7 链路波动状态下应用2种策略时VGG16的推理延迟时间Fig.7 Inference latency of VGG16 with 2 strategies under link fluctuation |
为了更好地测试IOP在突发链路波动时的容错能力, 在持续发生链路波动时进行评估.相比OCP策略的118.30 ms, IOP策略在78.12 ms内完成推理任务, 节省33.96%的推理延迟时间.这说明IOP策略可在突发持续的链路波动状态下依然保持较好的鲁棒性和容错能力.
为了验证IOP在端侧设备上执行协同推理的效率以及模型适用的广泛性, 使用国产化平台寒武纪4芯MLU 220全国产化实验平台(如图8所示), 评估图像分类模型MobileNetv1、ResNet-18和目标检测模型YOLO-Fastest在IOP策略和OCP策略下的推理延迟时间, 结果如图9所示.
 | 图8 寒武纪4芯MLU 220全国产化平台Fig.8 Cambricon 4-chip MLU 220 fully domestic platform |
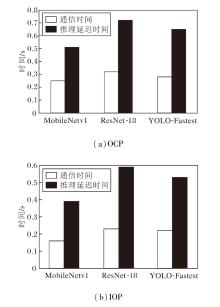
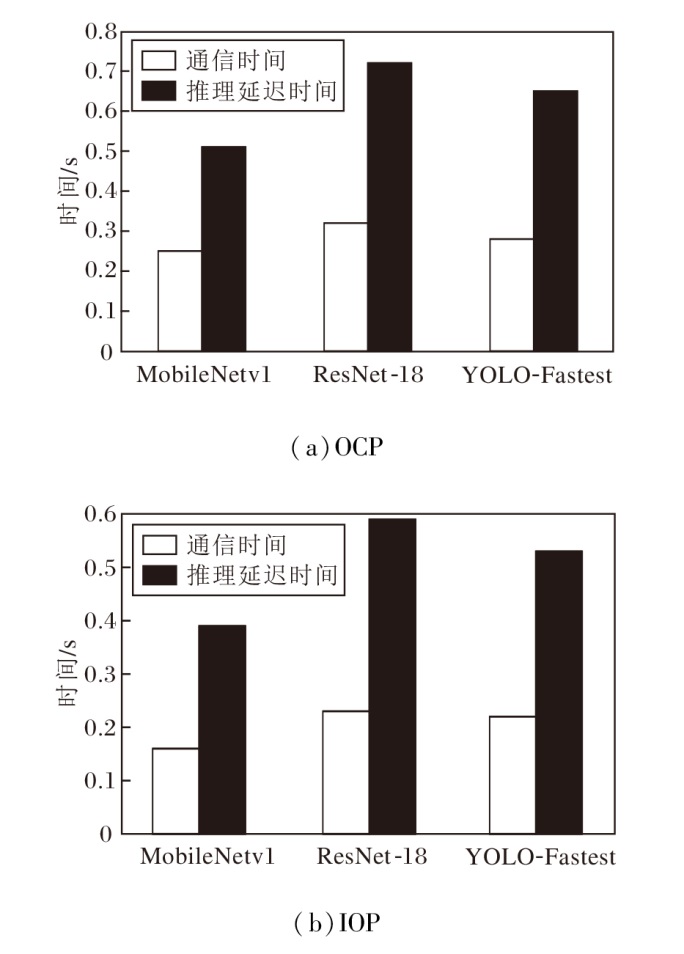 | 图9 寒武纪4芯MLU 220平台上2种策略的通信时间和推理延迟时间Fig.9 Communication time and inference latency of 2 strategies on Cambricon 4-chip MLU 220 platform |
由图9可见, 在寒武纪4芯MLU 220平台上, 使用OCP策略时MobileNetv1的推理延迟时间为0.51 s, 其中, 推理过程中的通信时间为0.25 s, 占总推理时间的49.02%.ResNet-18的推理延迟时间为0.72 s, 其中, 推理过程中的通信时间为0.32 s, 占总推理时间的44.44%.YOLO-Fastest的推理延迟时间为0.65 s, 其中, 推理过程中通信时间为0.28 s, 占总推理时间的43.08%.在使用IOP策略时, Mobile-Netv1的推理延迟时间为0.39 s, 其中通信时间为0.16 s.ResNet-18的推理延迟时间为0.59 s, 其中通信时间为0.23 s, YOLO-Fastest的推理延迟时间为0.53 s, 其中通信时间为0.22 s.IOP策略比OCP策略节省18.06%~23.53%的推理延迟时间, 同时节省21.43%~36.00%的通信时间.由此说明IOP策略可通过减少推理过程中设备间的通信频次, 降低通信开销, 实现模型的推理加速.
由于能耗是边缘计算场景的重要性能指标之一, 因此, 基于寒武纪4芯MLU 220国产化平台, 评估Mobile-Netv1、ResNet-18、YOLO-Fastest使用IOP策略和OCP策略执行单次推理时的能耗.使用IOP策略执行推理时, Mobile-Netv1、ResNet-18和YOLO-Fastest的能耗为分别为0.28 J、0.42 J和0.38 J, 而OCP策略对应的能耗分别为0.39 J、0.55 J和0.51 J.相比OCP策略, IOP策略可节省23.64%~28.21%的能耗.由此说明IOP通过减少协同推理过程中设备间的通信频次, 在节约通信时间和推理延迟时间的同时也能有效节约系统能耗.
针对边缘协同推理场景下算子输出通道划分(OCP)导致的通信时间开销问题, 提出交错式算子划分(IOP)的协同推理加速策略.首先, 基于模型和设备属性对算子划分后的计算和通信时间进行建模.然后, 设计启发式的算子配对算法, 分别评估OCP策略和IOP策略的时间开销收益.根据评估结果确定执行交错式划分的算子对, 得到最终的模型划分方案.最后, 分别评估同构环境、异构环境、不同设备间通信连接延迟与链路波动等场景下的协同推理延迟时间及能耗.实验表明, IOP策略对于典型的图像分类及目标检测模型均可显著降低推理延迟时间.在链路波动条件下具有一定的鲁棒性, 并且拥有较少的系统能耗.今后将探索适用于算子划分策略的通信数据压缩算法, 在保证性能的同时, 实现协同推理效率的进一步提升.
本文责任编委 何 清
Recommended by Associate Editor HE Qing
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|