{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向无监督磁共振图像配准的多窗口多层感知机特征金字塔网络
[于寒1  , 孙正
, 孙正1, 2 , 张胜楠1 , 高章硕1 , 丁港澳1 ]
, 孙正, 张胜楠, 高章硕, 丁港澳]
|
|



作者简介:

于 寒,硕士研究生,主要研究方向为图像处理、深度学习等.E-mail:17360794016@163.com.

张胜楠,硕士研究生,主要研究方向为图像处理、深度学习等.E-mail:ZZSSNN2000@163.com.

高章硕,硕士研究生,主要研究方向为医学图像处理.E-mail:gao_zhangshuo@163.com.

丁港澳,硕士研究生,主要研究方向为生物医学成像.E-mail:15136418713@163.com.
无监督磁共振图像(Magnetic Resonance Imaging, MRI)配准的主流方法通常基于卷积神经网络或Transformer架构,但二者均存在明显局限:卷积神经网络受局部感受野限制,难以建模长距离依赖;Transformer的自注意力机制计算复杂度较高,通常无法在全分辨率下实现精细配准.为此,文中提出基于多窗口多层感知机的特征金字塔网络(Multi-window Multi-layer Perceptron Feature Pyramid Network, PyraMLP-Net),旨在实现高效、精准的全分辨率脑部MRI配准.首先,设计权重共享特征提取模块,通过并行的双路卷积编码,从一对图像中提取多尺度特征.然后,构建特征金字塔解码模块,以相关感知多窗口多层感知机为核心,通过自下而上的路径,逐步融合不同尺度的特征信息,实现变形场的由粗到精优化.最后,设计空间变换网络模块,以变形场为参数,对待配准图像进行可微分重采样,生成最终配准结果.在3个公开脑部MRI数据集上的实验表明,PyraMLP-Net在配准精度、稳定性和效率方面均较优.
About Author:
YU Han, Master student. Her research interests include image processing and deep learning.
ZHANG Shengnan, Master student. Her research interests include image processing and deep learning.
GAO Zhangshuo, Master student. Her research interests include medical image processing.
DING Gang'ao, Master student. His research interests include biomedical imaging.
Current unsupervised magnetic resonance imaging(MRI) registration methods are typically based on convolutional neural networks(CNNs) or Transformer architectures. However, significant limitations exist in both of them. CNNs have difficulty in modeling long-range dependencies because they are constrained by the local receptive fields. Transformers often struggle to achieve fine-grained registration at full image resolution due to the high computational complexity of the self-attention mechanism. To address these issues, a multi-window multi-layer perceptron feature pyramid network(PyraMLP-Net) is proposed. It is designed for efficient and accurate full-resolution brain MRI registration. First, a weight-sharing feature extraction module extracts multi-scale features from a pair of images through parallel dual-path convolutional encoding. Then, with the correlation-aware multi-window multi-layer perceptron being its core, a feature pyramid decoding module gradually fuses feature information of different scales through a bottom-up path to achieve coarse-to-fine optimization of the deformation field. Finally, a spatial transformation network module applies the deformation field as parameters to perform differentiable resampling on the image to be registered and generate the final registration result. Experiments on three public datasets demonstrate that PyraMLP-Net outperforms mainstream models in terms of registration accuracy, stability and efficiency.
在医学图像分析领域, 数据采集参数、成像设备差异及个体生理特征变化等因素导致图像空间与解剖结构差异, 给临床诊断与疾病评估带来困难[1].图像配准是解决这一问题的关键技术之一, 主要应用于两种典型场景.1)在同一成像模态下, 对在不同时间点采集的图像进行时序对齐, 追踪病灶演进或评估治疗效果; 2)实现跨模态图像的空间配准, 融合不同成像技术提供的互补信息[2].图像配准技术的核心在于建立最优空间变换模型, 使不同图像中的对应解剖结构达到几何一致性对齐[3].因此, 开发能兼顾高精度与高效率的配准算法, 对于提升医学影像辅助诊断的可靠性与临床应用价值具有重要意义.
传统图像配准方法主要依赖相似性度量与目标函数优化实现图像空间对齐, 典型代表方法包括NCC(Normalized Cross-Correlation)、SyN(Symmetric Normalization)及概率图谱匹配方法等.NCC通过逐像素计算图像间灰度互相关以估计最优配准参数.其改进方法还引入高斯-拉普拉斯二阶矩, 并结合阶次微分算子作为相似性度量, 有效提高配准性能[4].SyN在微分同胚映射空间中通过最大化互相关实现配准, 在脑部图像配准中表现优异, 常被用作基准方法, 然而较高的计算复杂度限制其实时应用[5].概率图谱匹配方法通过构建概率图谱模型, 抑制低匹配概率图谱的亲和力, 并为匹配矩阵赋予合理权重, 从而增强配准鲁棒性[6].尽管上述传统方法能生成符合解剖结构形变规律的精确微分同胚位移场, 但普遍存在计算成本较高、效率低下的问题, 难以适应对实时性要求较高的应用场景[7].
基于深度学习的配准方法根据训练过程对标注数据的依赖程度, 可分为有监督配准方法与无监督配准方法[8].由于高质量标注数据获取困难且成本高昂, 当前研究更倾向于采用端到端的无监督配准方法.此类方法仅需输入一对待配准图像即可直接学习空间变换参数, 显著降低对人工标注的依赖[9].
在无监督配准方法的发展历程中, Jaderberg等[10]提出STN(Spatial Transformer Networks), 首次实现对网络内部数据的空间变换操作, 为无监督配准奠定技术基础.
当前主流的无监督配准方法主要基于卷积神经网络(Convolutional Neural Network, CNN)与Trans-former两类架构.以VoxelMorph[11]为代表的CNN方法采用经典U型结构, 通过编码-解码模块与跳跃连接学习变形场, 成为该领域的重要基准方法.然而, 受限于卷积的局部感受野, 此类方法难以有效建模图像中的长程依赖关系.具有全局建模能力的Transformer架构突破这一局限, 其自注意力机制能建立图像任意位置间的关联, 显著提高配准精度.代表性工作包括SymTrans(Symmetric Transformer Based Model)[12]及TransMorph[13].此外, Shi等[14]提出Xmorpher, 通过交叉注意力机制实现多尺度窗口间的注意力计算, 有效提升非线性形变配准效率.Chen等[15]提出TransMatch, 利用跨注意力机制完成多模态图像或跨域图像间的自适应特征匹配与语义对齐, 增强联合表征的判别能力.Meng等[16]提出NICE-Trans(Non-iterative Coarse-to-Fine Transformer Network), 首次将仿射配准与可变形配准整合于统一框架, 基于Swin Transformer实现非迭代的从粗到精配准过程.Zhou等[17]提出nnFormer(Not-Another Transformer), 交错使用卷积与自注意力操作, 在捕捉局部细节与全局依赖的同时, 引入跳跃注意力机制, 优化特征融合效果.
尽管Transformer架构在配准精度上表现突出, 但其自注意力机制存在计算复杂度较高的问题, 通常只能在降采样后的特征分辨率上运行, 难以在全图像分辨率下建立精细的像素级对应关系.
针对上述问题, 本文提出基于多窗口多层感知机的特征金字塔网络(Multi-window Multi-layer Perceptron Feature Pyramid Network, PyraMLP-Net), 用于脑部磁共振图像(Magnetic Resonance Imaging, MRI)的无监督配准.首先, 设计权重共享特征提取模块, 从待配准图像对中提取具有多尺度感受野的特征表达, 并通过特征金字塔网络的自下而上路径实现跨层级信息的高效传递, 从而在捕捉大位移形变的同时保持细节结构的完整性.引入CMW-MLP(Correlation-Aware Multi-window MLP)[18], 通过三维相关层建立特征空间对应关系, 利用多窗口并行架构捕获多范围依赖, 并借助残差通道注意力机制增强关键特征表达, 使PyraMLP-Net在保持全分辨率处理能力的同时, 有效避免Transformer架构的高计算开销问题, 实现在精度与效率之间的更好平衡.在3个公开数据集上的实验表明, PyraMLP-Net在配准精度、稳定性和效率方面均较优.
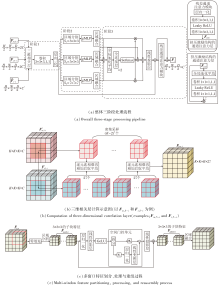
本文提出基于多窗口多层感知机的特征金字塔网络(PyraMLP-Net), 架构如图1所示.
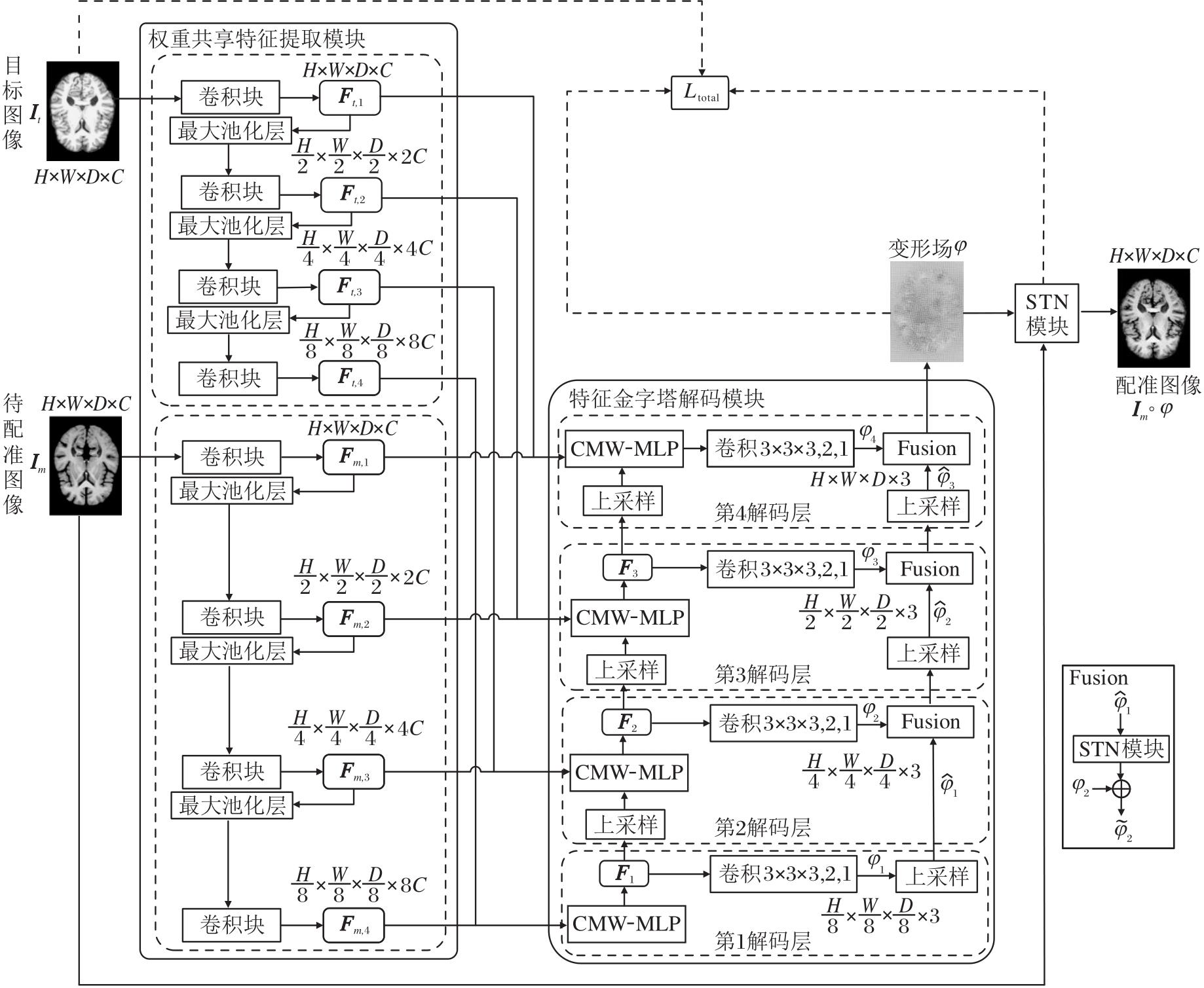 | 图1 PyraMLP-Net架构图Fig.1 Architecture of PyraMLP-Net |
PyraMLP-Net由权重共享特征提取模块、特征金字塔解码模块和空间变换网络模块(Spatial Transformer Network Module, STN)组成.首先, 权重共享特征提取模块分别处理目标图像和待配准图像, 生成多尺度特征表示.然后, 拼接提取的特征, 输入特征金字塔解码模块中进行上采样处理, 在此过程中, CWM-MLP计算输入特征之间的局部相关性, 借助多窗口并行机制捕获多范围依赖关系, 输出全分辨率的变形场.最后, 将待配准图像和变形场输入STN模块中, 得到配准图像.
权重共享特征提取模块旨在从目标图像和待配准图像中提取相同尺度的特征对, 为后续特征金字塔解码模块提供多尺度、高表达的输入.相比传统单路或不对称设计, 该模块采用权重共享的孪生网络结构, 对输入图像进行编码.这种设计不仅能减少参数规模、增强特征可比性, 而且确保两路特征在空间层次与语义层级上严格对齐, 有助于后续CMW-MLP模块的局部相关性计算.
权重共享特征提取模块具体结构如图2所示.输入尺寸为H× W× D(高度× 宽度× 深度)、通道数为C的目标图像与待配准图像, 输出2组4级层次化的特征金字塔Ft={Ft, l}和Fm={Fm, l}, l=1, 2, 3, 4, 其中Ft, l和Fm, l分别表示第l层卷积模块输出的目标图像特征和待配准图像特征.每个子网络由4个连续卷积块和3个最大池化层构成.每个卷积块内含2个3× 3× 3卷积层(步长1, 填充same), 各卷积层后接参数为0.2的Leaky ReLU激活函数和实例归一化(Instance Normalization, IN).相邻卷积块之间通过2× 2× 2最大池化层(步长2, 填充same)进行下采样, 使特征图尺寸逐级减半而通道数逐级倍增.这种层级化设计通过逐步扩大感受野, 构建包含不同抽象程度的特征金字塔.其中:深层特征具有较大感受野, 能捕捉全局上下文与高层次语义信息; 浅层特征的感受野较小, 保留局部细节与空间结构信息.
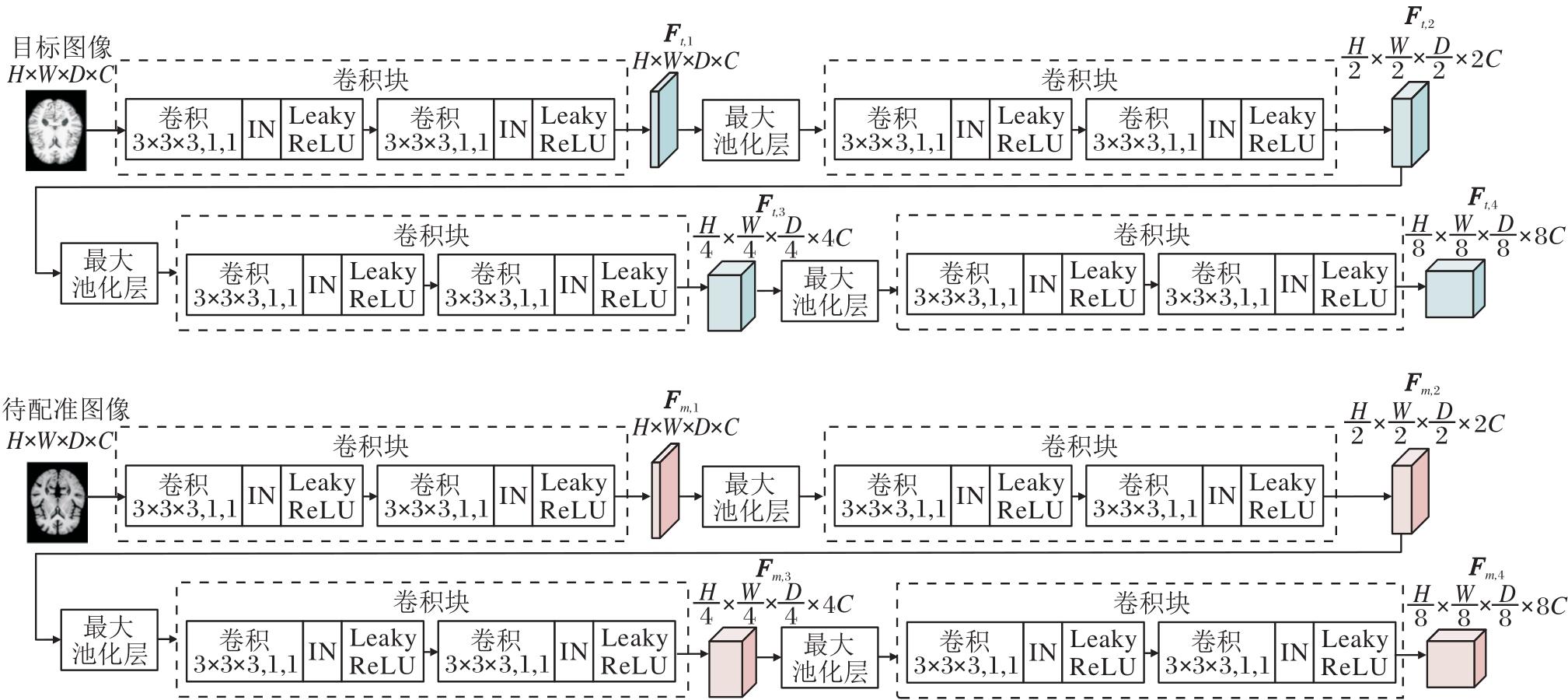 | 图2 权重共享特征提取模块结构图Fig.2 Architecture of weight-sharing feature extraction module |
权重共享特征提取模块与特征金字塔解码模块形成编码-解码对称架构, 提取的多尺度特征直接输入对应层级的解码层, 用于后续由粗到精的变形场优化.
特征金字塔解码模块是PyraMLP-Net实现变形场渐进优化的核心, 通过多层递归融合策略, 将权重共享特征提取模块输出的多尺度特征逐步融合并细化为全分辨率变形场.与传统解码结构不同, 该模块以CMW-MLP作为各层的核心处理器, 取代常见的卷积或注意力操作, 在保持较高计算效率的同时实现建模长程依赖与局部相关性的双重目标.同时, 利用由粗到精的变形场递进优化机制提升对大形变的处理能力, 并通过STN模块对齐保障跨尺度变形场的空间一致性, 避免上采样引起的累积误差.
如图1所示, 特征金字塔解码模块包含4个解码层, 分别与权重共享特征提取模块的4个层级对应, 形成对称结构.
第1解码层接收权重共享特征提取模块第4层输出的目标图像特征Ft, 4与待配准图像特征Fm, 4, 通过CMW-MLP计算特征间的相关性, 生成融合局部相关性与多范围依赖的特征:
F1=CMW-MLP(Ft, 4, Fm, 4).
F1经3× 3× 3卷积(通道数3, 步长1, 填充same)生成初始位移场φ 1, 尺寸为
后续解码层(第2层~第4层)采用双路径处理机制.首先拼接当前层目标特征Ft, 5-i、待配准特征Fm, 5-i与上层CMW-MLP输出的上采样融合特征
$ \boldsymbol{F}_{i}=C M W-M L P\left(\boldsymbol{F}_{t, 5-i}, \boldsymbol{F}_{m, 5-i}, \widehat{\boldsymbol{F}}_{i-1}\right) .$
将包含低分辨率下的全局空间对应关系和粗变形场信息的
随后网络分为两支.一支通过3× 3× 3卷积(通道数3, 步长1, 填充same)生成进一步细化的变形场φ i.另一支经Fusion层将φ i和上一层的上采样变形场
$ \widetilde{\varphi}_{i}=\operatorname{STN}\left(\hat{\varphi}_{i-1}\right).$
STN(· )将前一级得到的上采样变形场
接着, 对
最后, 第4解码层输出变形场为:
$\varphi=\operatorname{STN}\left(\hat{\varphi}_{3}\right) \oplus \varphi_{4} .$
将φ 与待配准图像Im输入STN模块生成配准结果:
$\boldsymbol{I}_{w}=\boldsymbol{I}_{m} \circ \varphi .$
其中$ \circ $表示STN模块执行的空间变换操作.
解码模块与权重共享特征提取模块紧密协同, 形成完整的编码-解码通路, 为变形场生成提供结构化的多尺度信息基础.
面向三维医学图像配准的特定需求, 本文对CMW-MLP[18]进行三维化适配与任务导向的整合, 使其成为实现全分辨率高效配准的关键组件.
首先, 将CMW-MLP结构化整合进特征金字塔解码模块, 使其承担跨层级特征融合与变形场渐进优化的关键任务, 实现从通用特征处理模块到专用配准核心组件的转变.
然后, 为了适应三维体数据特性, 对模块中的相关计算、窗口划分及注意力机制进行三维扩展与适配, 精确处理体素空间中的结构关系.CMW-MLP通过三维相关层建立空间对应关系, 利用多窗口MLP架构捕获多尺度依赖, 并借助残差通道注意力机制强化关键特征, 从而在效率与精度之间实现平衡.这一设计使得PyraMLP-Net能在较低计算量与内存开销下, 通过不同窗口尺寸的MLP分支有效整合局部细节与全局上下文信息, 同时结合渐进式的特征融合策略, 构建一个面向配准任务的端到端特征感知与融合解决方案, 确保多尺度信息的有效传递与整合.
CMW-MLP采用三阶段处理流程:局部相关性计算、多范围依赖捕捉、特征优化与输出.具体流程如图3(a)所示.
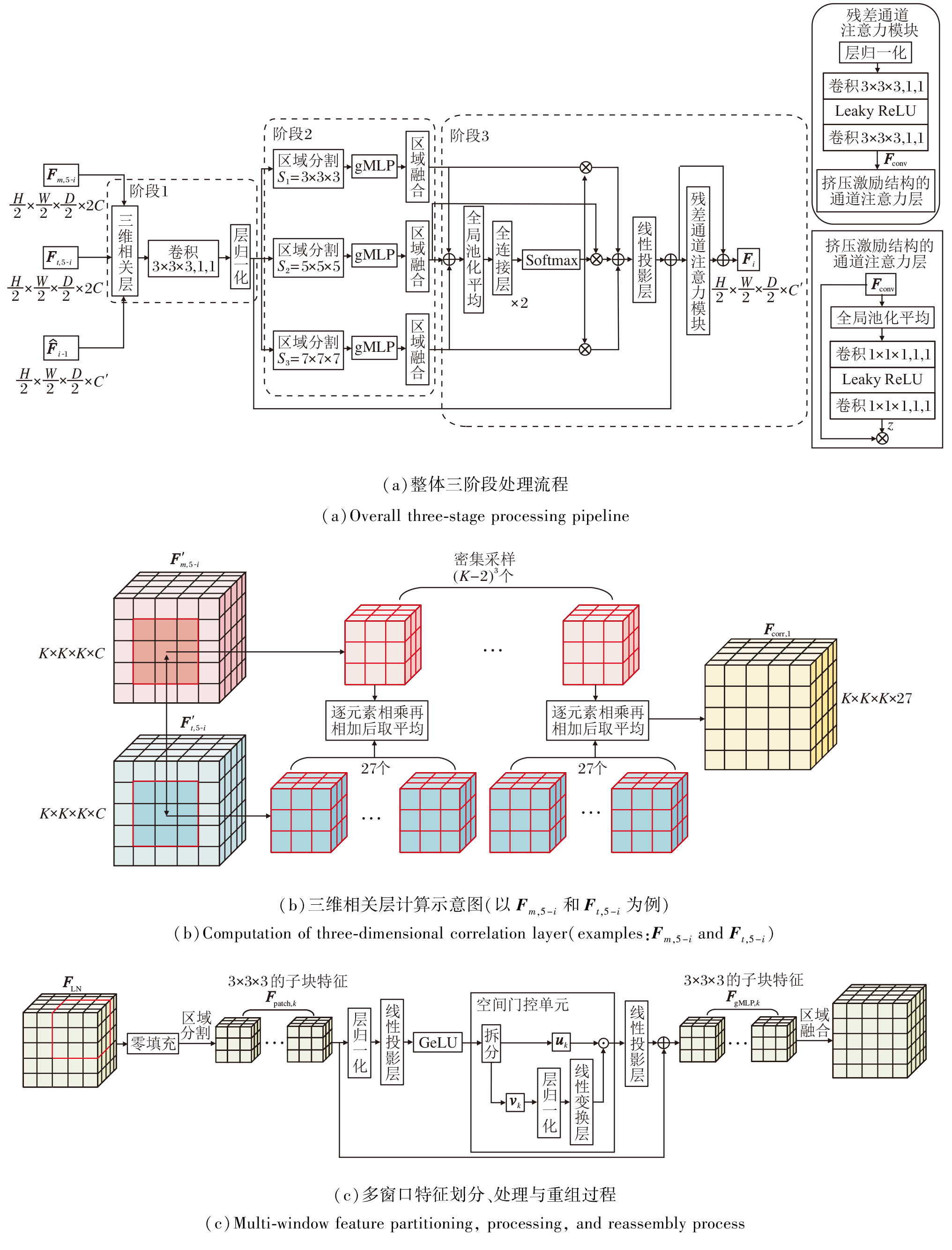 | 图3 CMW-MLP结构图Fig.3 Architecture of CMW-MLP |
1.3.1 局部相关性计算
局部相关性计算是以三维相关层为核心, 提取输入特征之间的局部关联信息.
首先, 输入3个待匹配特征图Fm, 5-i∈
以计算(Fm, 5-i, Ft, 5-i)为例, 如图3(b)所示, 首先对Fm, 5-i和Ft, 5-i执行填充操作, 保证边缘区域3× 3× 3块的完整采样, 填充后二者空间尺寸扩展为K× K× K, 分别记为F'm, 5-i和F't, 5-i.再对F'm, 5-i执行步长为1的3× 3× 3块密集采样, 得到(K-2)3个移动块.针对每个移动块, 在F't, 5-i对应位置的3× 3× 3局部邻域内, 按步长2采样得到27个3× 3× 3固定块, 并将每个移动块与其对应的27个固定块分别逐体素相乘后求和, 再归一化得到对应的相似性分数.将每个移动块对应的27个相似性分数映射为空间尺寸与原特征图空间尺寸一致(K× K× K)、通道数为27的相关性特征图Fcorr, 1.
然后, 将原始特征图Fm, 5-i、Ft, 5-i和
最后, 为了确保特征尺度的一致性, 对Fcorr进行层归一化, 获得初始归一化特征FLN.
1.3.2 多范围依赖捕捉
在多范围依赖捕捉阶段, 通过多窗口MLP的并行窗口分支捕捉不同尺度的特征依赖.该设计的关键在于:将全局空间依赖的建模问题分解为多个局部窗口内的特征交互, 再通过跨窗口的信息融合恢复全局上下文.
在每个非重叠的局部窗口内, 通过gMLP[19]充分混合窗口内所有位置的特征, 建立该局部区域内的空间依赖关系.然后, 针对多个不同尺寸窗口分支的输出通过自适应加权进行融合, 实现从细粒度到中等范围的多尺度上下文整合.这种基于窗口化MLP的结构化设计, 能避免标准自注意力机制中的全局成对交互计算, 转而通过层次化的局部特征变换与融合高效建模长程依赖.
如图3(c)所示, 具体处理过程如下.首先, 对FLN执行零填充操作, 分别按照3× 3× 3、5× 5× 5和7× 7× 7的窗口尺寸对其进行非重叠划分, 生成对应的子块特征Fpatch, k(k=1, 2, 3).这种多窗口划分策略能同时捕获FLN的细粒度、中等尺度和大尺度的空间特征.
然后, 采用gMLP[19]处理Fpatch, k(k=1, 2, 3), 挖掘子块区域内的长程空间依赖.具体步骤如下.
1)对Fpatch, k进行层归一化, 消除特征数值分布差异.
2)通过线性投影层将通道维度从C'扩展至2C', 并应用高斯误差线性单元(Gaussian Error Linear Unit, GELU)激活函数增强非线性表达能力, 得到中间特征Fproj, k.
3)将Fproj, k沿通道维度平均拆分为内容分支uk和门控分支vk, 其中, uk保留子块的语义内容特征, vk用于生成空间门控信号, 筛选uk中的关键配准位置(如结构边缘像素).
4)vk经过层归一化并通过线性变换层学习子块内的空间依赖关系, 生成空间门控信号:
v'k=Linear(
其中, W1∈ RP× P表示可学习的线性变换矩阵, P表示子块元素总数, Linear( · )表示线性变换.
5)将v'k与uk逐元素相乘, 得到门控融合特征uk☉v'k, 该特征经线性投影层将通道维度从2C'还原到C', 并与原始子块特征Fpatch, k通过残差连接相加, 形成最终输出:
FgMLP, k=Linear((uk☉v'k)+1; W2)+Fpatch, k.
其中:W2∈ RC'× C'表示线性投影层的权重矩阵, 用于将通道数还原为C'; (uk☉v'k)+1表示对uk☉v'k的逐元素加1操作, 目的是在训练初始阶段门控信号v'k较弱(接近0)时, 避免uk的原始语义信息被过度抑制.
最后, 将经gMLP处理后的子块特征FgMLP, k按照相同的空间索引重新合并为完整特征图, 则第k个窗口分支合并后的完整特征图为:
Fwin, k=unsplit_images(FgMLP, k; Gsize, k; Sk),
其中, k=1, 2, 3, unsplit_images(· )表示子块合并函数, Gsize, k表示第k个窗口分支中的子块网格尺寸(即特征图在深度、高度和宽度方向的子块划分数量),
Sk=
表示窗口尺寸.
这一过程中零填充区域随其它有效区域一同拼接, 后续卷积层和通道注意力模块将自动过滤无效信息, 不影响核心特征表达.
1.3.3 特征优化与输出
在特征优化与输出阶段, 首先对3个窗口分支的输出特征图Fwin, 1、Fwin, 2和Fwin, 3逐元素求和, 得到初步融合特征, 再采用全局平均池化(Global Average Pooling, GAP)压缩空间维度, 提取具有全局信息的特征向量:
$ \boldsymbol{a}=\operatorname{GAP}\left(\sum_{k=1}^{3} \boldsymbol{F}_{\mathrm{win}, k}\right) .$
特征向量a经过两个全连接层(Fully Connected Layer, FC)进行非线性变换, 学习通道信息与各窗口权重的映射关系, 再对输出的初步权重分数应用Softmax函数归一化, 生成各窗口分支的动态权重.第k个窗口分支的权重为:
wk=Softmax(FC(a)),
满足
将学习的动态权重和3个窗口分支的输出特征图进行自适应加权融合, 再将结果输入线性投影层调整特征维度, 最后与初始归一化特征进行残差连接, 得到融合特征:
$ \begin{array}{l} \boldsymbol{F}_{\mathrm{MLP}}= \\ \quad \text { Linear }\left(\sum_{k=1}^{3} \boldsymbol{w}_{k} \odot \boldsymbol{F}_{\mathrm{win}, k} ; \boldsymbol{W}_{3}\right)+\boldsymbol{F}_{\mathrm{LN}} \in \mathbf{R}^{N \times \frac{H}{2} \times \frac{W}{2} \times \frac{D}{2} \times C^{\prime}}, \end{array}$
其中W3∈ RC'× C'表示可学习的线性投影权重矩阵.该过程通过可学习的线性投影矩阵调整特征维度, 并与初始归一化特征建立残差连接, 有效保留原始特征信息.
为了进一步增强特征表达能力, 引入残差通道注意力模块(Residual Channel Attention Block, RCA-B).RCAB由层归一化、两个三维卷积层和基于挤压-激励(Squeeze-and-Excitation, SE)[20]结构的通道注意力层组成.具体处理过程如下.首先对FMLP进行层归一化处理, 再通过2个3× 3× 3三维卷积层(步长1, 填充same)进行特征变换, 其中第1卷积层用于空间特征提取, 第2卷积层进行特征细化, 中间采用LeakyReLU激活函数增强非线性表达能力, 得到卷积变换后的中间特征FConv∈
通道注意力机制采用改进的SE结构, 通过全局平均池化将FConv的每个通道的空间信息聚合为全局统计量, 从而避免局部噪声干扰, 突出通道的全局贡献.之后, 经过2个三维卷积层(1× 1× 1卷积核, 步长1, 填充same, 中间含LeakyReLU激活)学习通道间的依赖关系, 通过Sigmoid函数生成通道注意力权重z, z接近1表示该通道对配准关键, z接近0表示该通道冗余.
最后, 将z与FConv逐通道相乘并与融合特征FMLP进行残差连接, 得到相关感知融合特征:
Fi=FConv☉z+FMLP∈
本节基于每秒浮点运算次数(Floating Point Operations per Second, FLOPs)对比PyraMLP-Net与基于Transformer配准方法、基于CNN配准方法的计算复杂度, 验证PyraMLP-Net的效率优势.
假设所有方法的输入特征图尺寸均为H× W× D× C, PyraMLP-Net采用全分辨率处理, 无需降采样, 基于Transformer配准方法和基于CNN配准方法因复杂度限制需降采样至
PyraMLP-Net的计算开销主要来自权重共享特征提取模块、CMW-MLP和RCAB, 总计算复杂度为各模块复杂度之和.
在权重共享特征提取模块中, 池化层不影响复杂度的量级, 因此该模块的计算复杂度由卷积层决定.从量级角度分析, 卷积运算等效于逐像素的线性投影, 故整体计算复杂度为O(HWDCC'), 其中C'表示投影后的通道数.为了保持通道维度一致, 令C'=C, 则计算复杂度变为O(HWDC2).
CMW-MLP的计算开销主要来自多窗口线性变换, 三维相关层的相似性计算量可忽略不计.对于单个尺寸为k× k× k的窗口, 特征数为k3, 处理流程包含两次线性投影与一次门控激活, 因此单个窗口的MLP计算复杂度为O(2k3C2).由于单个分支包含H× W× D/k3个窗口, 3个并行窗口分支的总计算复杂度为O(6C2HWD).
RCAB的计算开销主要由两个1× 1× 1线性投影构成, 其中全局平均池化的计算量可忽略不计, 则计算复杂度为O(2C2HWD).
综上所述, PyraMLP-Net的总计算复杂度为O(9C2HWD).
基于Transformer配准方法的计算复杂度主要源于自注意力机制.该机制需计算所有像素对之间的相关性, 复杂度与序列长度的平方呈正比, 远高于前馈网络的开销, 故后者可忽略不计.由于方法通常在降采样后的特征上运行(尺寸为
基于CNN配准方法的计算复杂度主要源于其堆叠的3D卷积层.以VoxelMorph为例, 为了有效捕捉多尺度依赖, 需堆叠6层卷积.单个3× 3× 3卷积层在特征图尺寸为H× W× D、通道数为C时的计算复杂度为O(33C2HWD), 因此总计算复杂度为O(6× 27C2HWD), 即O(162C2HWD).
由上述分析可知, PyraMLP-Net(通过多窗口MLP与线性投影)与基于CNN配准方法(通过卷积层堆叠)的计算复杂度均随输入尺寸呈线性增长(O(HWD)), 而基于自注意力的Transformer配准方法则呈现平方级复杂度增长(O((HWD)2)).这一根本差异决定三者在大尺寸输入下的计算效率与可扩展性.
为了在配准精度和变形平滑性之间取得良好平衡, 网络总损失由图像相似性损失Lsim和空间正则化项Lreg两部分组成:
Ltotal=Lsim(It, Im$ \circ $φ )+λ Lreg(φ ),
其中, It表示目标图像, Im$ \circ $φ 表示配准图像, φ 表示变形场, λ 表示调节两项权重的超参数, 通过交叉验证确定.
图像相似性损失用于衡量目标图像与配准后图像之间的结构一致性.本文采用局部NCC作为相似性度量, 计算两幅图像在局部窗口内的灰度相关性, 评估其匹配程度, 具体公式如下:
$ L_{\mathrm{sim}}\left(\boldsymbol{I}_{t}, \boldsymbol{I}_{m} \circ \varphi\right)=-\sum_{\boldsymbol{p} \in \Omega}\left(\frac{\left(\sum_{\boldsymbol{p}_{i} \in N_{p}}\left[I_{t}\left(\boldsymbol{p}_{i}\right)-\bar{I}_{t}(\boldsymbol{p})\right]\left[I_{m}\left(\boldsymbol{p}_{i}+\varphi\left(\boldsymbol{p}_{i}\right)\right)-\bar{I}_{m}(\boldsymbol{p}+\varphi(\boldsymbol{p}))\right]\right)^{2}}{\left(\sum_{\boldsymbol{p}_{i} \in N_{p}}\left[I_{t}\left(\boldsymbol{p}_{i}\right)-\bar{I}_{t}(\boldsymbol{p})\right]^{2}\right)\left(\sum_{\boldsymbol{p}_{i} \in N_{p}}\left[I_{m}\left(\boldsymbol{p}_{i}+\varphi\left(\boldsymbol{p}_{i}\right)\right)-\bar{I}_{m}(\boldsymbol{p}+\varphi(\boldsymbol{p}))\right]^{2}\right)}\right), $
其中, Ω 表示图像体素空间, Np表示以体素p为中心的局部邻域(本文采用9× 9× 9立方邻域), pi表示Np内的第i个像素, φ (pi)表示变形场中pi处的值, It(pi)表示目标图像中pi处的强度值, Im(pi+φ (pi))表示配准后图像中体素pi+φ (pi)处的强度值,
为了保证变形场的平滑性与拓扑合理性, 引入基于变形场梯度L2范数的空间正则化项, 定义如下:
$ L_{\mathrm{reg}}(\varphi)=\sum_{p \in \Omega}\|\nabla \varphi(\boldsymbol{p})\|_{2}^{2}, $
其中,
$ \nabla \varphi(\boldsymbol{p})=\left(\frac{\partial \varphi_{x}(\boldsymbol{p})}{\partial x}, \frac{\partial \varphi_{y}(\boldsymbol{p})}{\partial y}, \frac{\partial \varphi_{z}(\boldsymbol{p})}{\partial z}\right)$
表示变形场φ 在体素p处的空间梯度, 通过中心差分计算,
本文实验所用数据来源于如下3个脑部MRI公开数据集:IXI数据集[13]、Learn2Reg挑战赛[21]提供的OASIS数据集[22]和LPBA40数据集[23].
IXI数据集由18~60岁健康成年人的576幅T1加权脑部MRI图像组成.本文使用FreeSurfer[24]对所有图像进行颅骨剥离和强度归一化, 再将图像统一裁剪至160× 192× 224.采用单待配准图像策略, 随机选择1幅图像作为待配准图像, 其余575幅图像作为目标图像, 按照7∶ 1∶ 2的比例划分为训练集(402幅)、验证集(58幅)和测试集(115幅).该数据集提供30个解剖结构的标注图谱, 用于评估配准精度.
OASIS数据集包含414幅T1加权脑部MRI图像, 来自416名18~96岁健康或轻度至中度阿尔茨海默病受试者, 所有图像均已完成颅骨剥离、对齐和归一化处理, 统一分辨率为160× 192× 224, 并按8∶ 1∶ 1的比例划分为训练集(333幅)、验证集(40幅)和测试集(40幅).该数据集还提供35个精细解剖结构的标注图谱.
LPBA40数据集包含40幅T1加权脑部MRI图像, 所有图像均进行颅骨剥离和强度归一化, 并统一至160× 192× 160.该数据集作为验证测试集, 验证方法的泛化能力.
将输入图像标准化至固定尺寸, 确保与网络训练时定义的输入维度一致, 旨在使卷积层输出的特征图尺寸固定, 从而确保后续层次化模块(如CMW-MLP)中基于固定窗口划分的参数化操作能正确进行.
实验环境配置如下.硬件平台使用配备24 GB显存的NVIDIA GeForce RTX 3090 Ti显卡, 运行于Windows 11 64位操作系统.软件环境基于Python 3.7与PyTorch 1.7深度学习框架构建.所有实验均在GPU加速环境下采用单精度浮点运算完成训练与推理, 并利用NVIDIA NVProf工具对GPU利用率进行监控, 确保计算资源的高效利用.
在上述环境下, 采用Adam(Adaptive Moment Estimation)优化器训练网络, 设置学习率为1× 10-4, 批量大小为1, 权重衰减系数为1× 10-3.通过交叉验证确定正则化系数:在IXI数据集上为1, 在OASIS数据集上为4.训练轮次为500轮, 总迭代次数为1.6× 105.每轮训练结束后通过验证集评估方法性能并保存检查点, 最终保留最优性能的方法参数.
采用Dice相似性系数(Dice Similarity Coeffi-cient, DSC)、95%Hausdorff Distance(HD95)和雅可比行列式负值百分比, 分别从配准的解剖学准确性、几何精度和生物力学合理性三个维度评估配准性能.
DSC用于量化配准前后解剖结构的对齐精度, 具体公式如下:
$ D S C=\frac{2\left|S_{m} \circ \varphi \cap S_{t}\right|}{\left|S_{m} \circ \varphi\right|+\left|S_{t}\right|}, $
其中, Sm表示待配准图像的分割掩码, St表示目标图像的分割掩码.DSC的值域为[0, 1], 数值越高表示解剖结构对齐效果越优, 当DSC=1时表示完全匹配.
HD95通过计算配准图像与目标图像解剖结构边界点集之间的95百分位距离, 评估边界的匹配程度.该指标对局部配准误差敏感, 值越小表示边界匹配越精确.
雅可比行列式分析用于评估变形场的微分同胚特性(即拓扑保持性).变形场φ 在点p=(i, j, k)处的雅可比行列式定义如下:
$ J_{\varphi}(\boldsymbol{p})=\operatorname{det}(\nabla \varphi(\boldsymbol{p}))=\left|\begin{array}{lll} \frac{\partial \varphi_{x}(\boldsymbol{p})}{\partial x} & \frac{\partial \varphi_{x}(\boldsymbol{p})}{\partial y} & \frac{\partial \varphi_{x}(\boldsymbol{p})}{\partial z} \\ \frac{\partial \varphi_{y}(\boldsymbol{p})}{\partial x} & \frac{\partial \varphi_{y}(\boldsymbol{p})}{\partial y} & \frac{\partial \varphi_{y}(\boldsymbol{p})}{\partial z} \\ \frac{\partial \varphi_{z}(\boldsymbol{p})}{\partial x} & \frac{\partial \varphi_{z}(\boldsymbol{p})}{\partial y} & \frac{\partial \varphi_{z}(\boldsymbol{p})}{\partial z} \end{array}\right| .$
当Jφ (p)< 0时, 表明变形场在该点存在拓扑折叠.实验中通过统计整幅图像中的雅可比行列式为负值的体素百分比以量化变形场的合理性.该百分比越低, 表明变形场越平滑且越有效保持拓扑结构.
为了全面评估PyraMLP-Net的性能, 选取如下方法进行对比.1)基于CNN配准方法:Voxel-Morph[11].2)基于Transformer配准方法:Trans-Morph[13]、TransMatch[15]、NICE-Trans[16]、nnFormer[17].
为了确保所有对比实验的公平性与可重复性, 遵循统一准则.所有方法均使用2.1节所述、经过相同预处理流程的IXI、OASIS数据集图像作为输入.各方法的配准结果均使用相同的定量指标进行评估.为了进行公平对比, 复现各方法时均严格遵循其原始文献或官方开源代码推荐的损失函数、正则化项及关键超参数设置, 旨在复现并对比各方法在其最优或标准配置下的性能.
在训练过程中, 所有方法均使用Adam优化器, 并确保充分训练至收敛.各对比方法的训练策略和超参数配置如下.
1)VoxelMorph.使用官方开源的两种变体VoxelMorph-1和VoxelMorph-2实现.VoxelMorph-1使用NCC损失和L2平滑正则化项作为损失函数, 平滑正则化项的权重设为1.VoxelMorph-2使用NCC损失、分割损失和L2平滑正则化项作为损失函数, 平滑正则化项的权重设为0.02, 分割损失权重设为0.01.二者学习率均设为1× 10-4, 批处理量设为1, 训练轮次设为300.
2)nnFormer.使用NCC损失和L2平滑正则化项作为损失函数, 平滑正则化项的权重设为1.采用Poly学习率衰减策略, 初始学习率设为1× 10-4, 批处理量设为1, 训练轮次设为400.
3)TransMorph.使用NCC损失和L2平滑正则化项作为损失函数, 平滑正则化项的权重设为1.初始学习率设为1× 10-4, 批处理量设为1, 训练轮次设为500.
4)TransMatch.使用NCC损失和L2平滑正则化项作为损失函数, 平滑正则化项的权重设为4.初始学习率设为4× 10-4, 批处理量设为1, 训练轮次设为500.
5)NICE-Trans.使用NCC损失和L2平滑正则化项作为损失函数, 平滑正则化项的权重设为1.初始学习率设为1× 10-4, 批处理量设为1, 训练轮次设为500.
2.4.1 整体配准性能定量评估
各方法在IXI测试集上的整体性能对比如表1所示, 表中黑体数字表示最优值.由表可见, PyraMLP-Net取得最优的配准精度.相比VoxelMorph-1、Voxel-Morph-2、nnFormer、TransMorph、TransMatch、NICE-Trans, DSC值分别提升约7.1%、6.5%、5.2%、3.3%、2.3%和1.4%, HD95值分别降低约19.9%、19.8%、18.3%、18.2%、13.9%和9%, 显示出该方法在配准精度与结构一致性方面的显著提升.在变形场平滑性方面, PyraMLP-Net的雅可比行列式负值百分比仅次于TransMatch, 但相比VoxelMorph-1、Voxel-Morph-2、nnFormer、TransMorph、NICE-Trans, 分别降低约80.3%、79.1%、80%、78.9%和34.8%, 体现出该方法在保持变形场拓扑合理性方面的优势.
| 表1 各方法在IXI测试集上的指标值对比 Table 1 Metric value comparison of different methods on IXI test set |
作为经典的基于CNN配准方法, VoxelMorph在基础配准任务中具有一定效果, 但其雅可比行列式负值百分比高达1.696%, 表明其变形场中存在较多折叠与畸变, 同时其较高的HD95值也反映出配准后图像的局部结构误差较大.相比之下, 基于Transformer配准方法(nnFormer、TransMorph、Trans-Match、NICE-Trans)在配准精度上普遍优于基于CNN配准方法, 其中NICE-Trans通过融合Trans-former的全局建模能力与由粗到精的分层优化策略, 在DSC、HD95指标上均取得次优值.
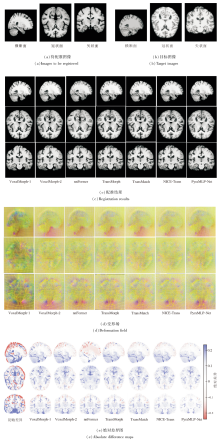
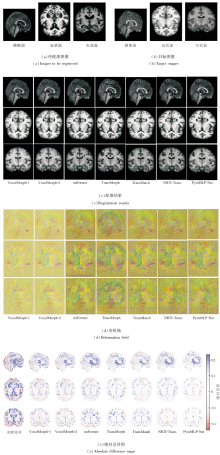
2.4.2 单样本配准结果可视化分析
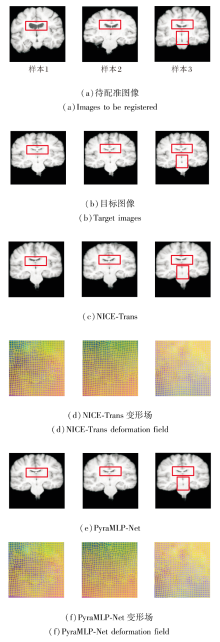
各方法对IXI测试集上一个样本的图像配准结果如图4所示.待配准图像与目标图像存在的显著结构差异.各方法估计得到的变形场通过ITK-Snap软件采用RGB颜色编码的方式进行可视化, 位移向量的x、y、z分量分别被映射至红、绿、蓝通道, 色彩明暗表征位移幅度大小, 而混合后的复合色彩表达位移方向信息.在配准结果与目标图像间的绝对差异图中, 红蓝色区域面积占比直接反映配准偏差的程度:该区域越大, 表明对应位置的配准误差越显著, 配准效果越差; 反之, 若图像以浅白色区域为主, 说明配准结果与目标图像的整体差异较小, 配准精度较高.由图可看出, VoxelMorph-1与VoxelMorph-2在边界区域出现大量不完整和模糊的体素, 导致边缘结构信息显著丢失.这一现象源于基于CNN配准方法固有的感受野限制, 难以有效捕捉长程依赖关系, 因此在处理大位移形变时表现出明显不足.相比之下, 基于Transfor-mer配准方法在边缘保持方面表现更优, 配准结果中可见更清晰的解剖结构边界, 这得益于自注意力机制对图像全局上下文信息的建模能力.但是, 这类方法在局部区域仍存在模糊及微小结构误匹配的问题, 原因在于自注意力机制的高计算开销迫使方法在降采样特征上操作, 从而限制对细微结构的表征能力.PyraMLP-Net取得最优的配准结果, 输出图像与目标图像的差异图最干净, 同时估计的变形场也表现出良好的平滑性.这一优势归因于其全MLP架构设计:一方面通过摒弃自注意力机制降低计算负担, 能直接在全分辨率特征上操作; 另一方面通过CMW-MLP有效捕捉多尺度的空间依赖, 在保持高计算效率的同时实现精细的像素级对齐.
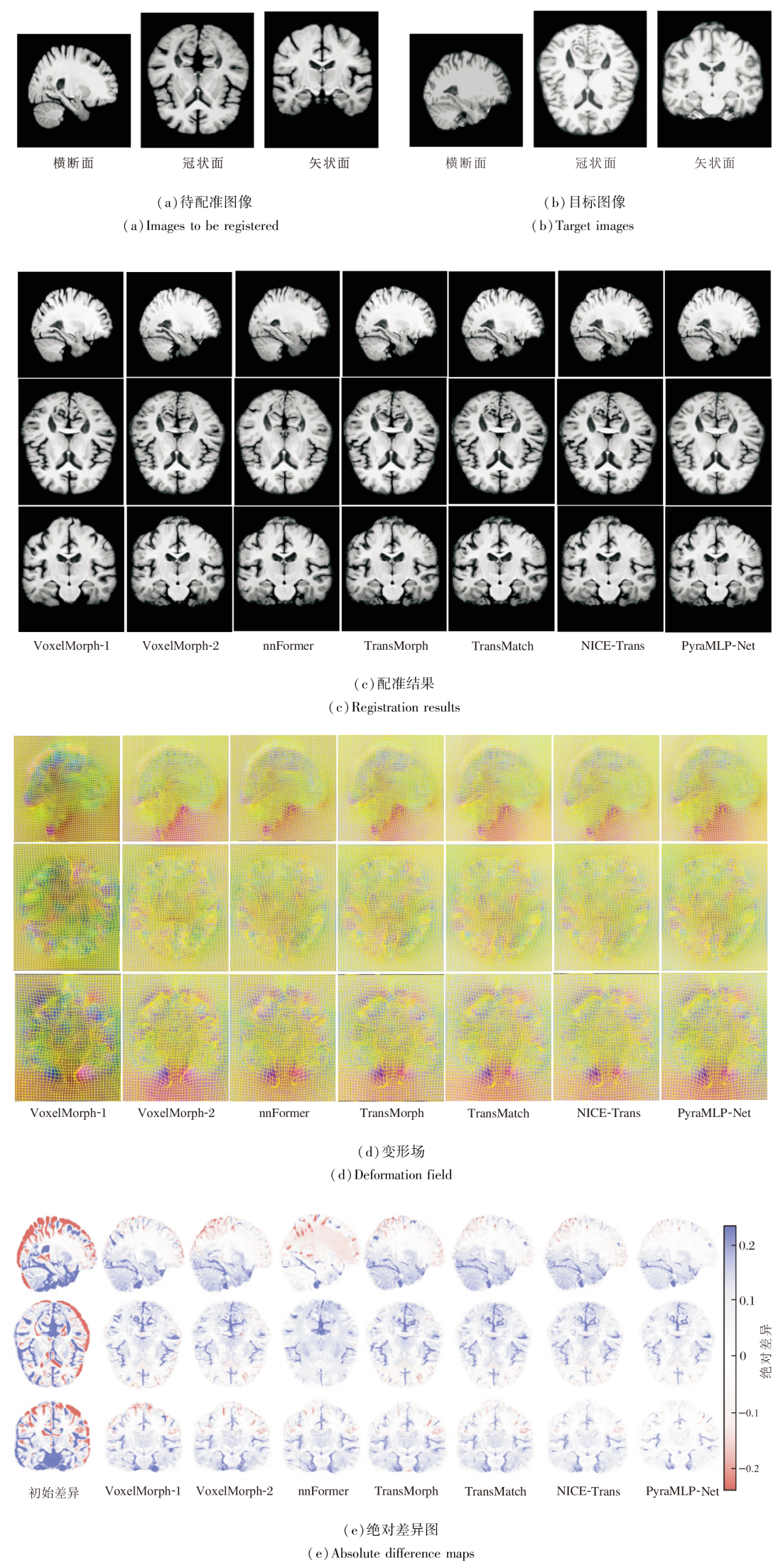 | 图4 各方法在IXI数据集上一个样本图像的配准结果Fig.4 Registration results of a sample image generated by different methods on IXI dataset |
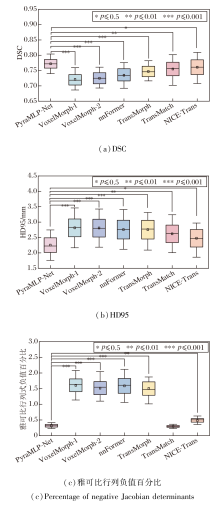
2.4.3 性能稳定性与计算效率分析
箱线图可直观反映方法的性能稳定性, 各方法在IXI测试集上的箱线图如图5所示.由图可见, PyraMLP-Net在评价指标上展现出显著优势, DSC中位数为0.772, HD95中位数为2.223 mm, 均处于最优区间, 对应的四分位距(Interquartile Range, IQR)最小(DSC中IQR=0.028, HD95中IQR=0.474 mm), 表明该方法在不同样本间具有最稳定的表现.在变形场平滑性方面, PyraMLP-Net的雅可比行列式负值百分比中位数为0.305%, 虽略高于TransMatch, 但IQR=0.086, 稳定性仅次于Trans-Match(IQR=0.056), 说明该方法在保持变形场合理结构的同时仍具备鲁棒性.这些结果表明PyraMLP-Net在精度与稳定性之间实现良好的平衡.相比之下, NICE-Trans在DSC指标上波动较大(IQR=0.048), VoxelMorph-1的HD95指标数值分布离散(IQR=0.58 mm), 而nnFormer在变形场平滑性上稳定性不足(雅可比负值百分比中IQR=0.474), 这些方法的较大波动性进一步印证PyraMLP-Net在处理复杂样本时的综合优势.
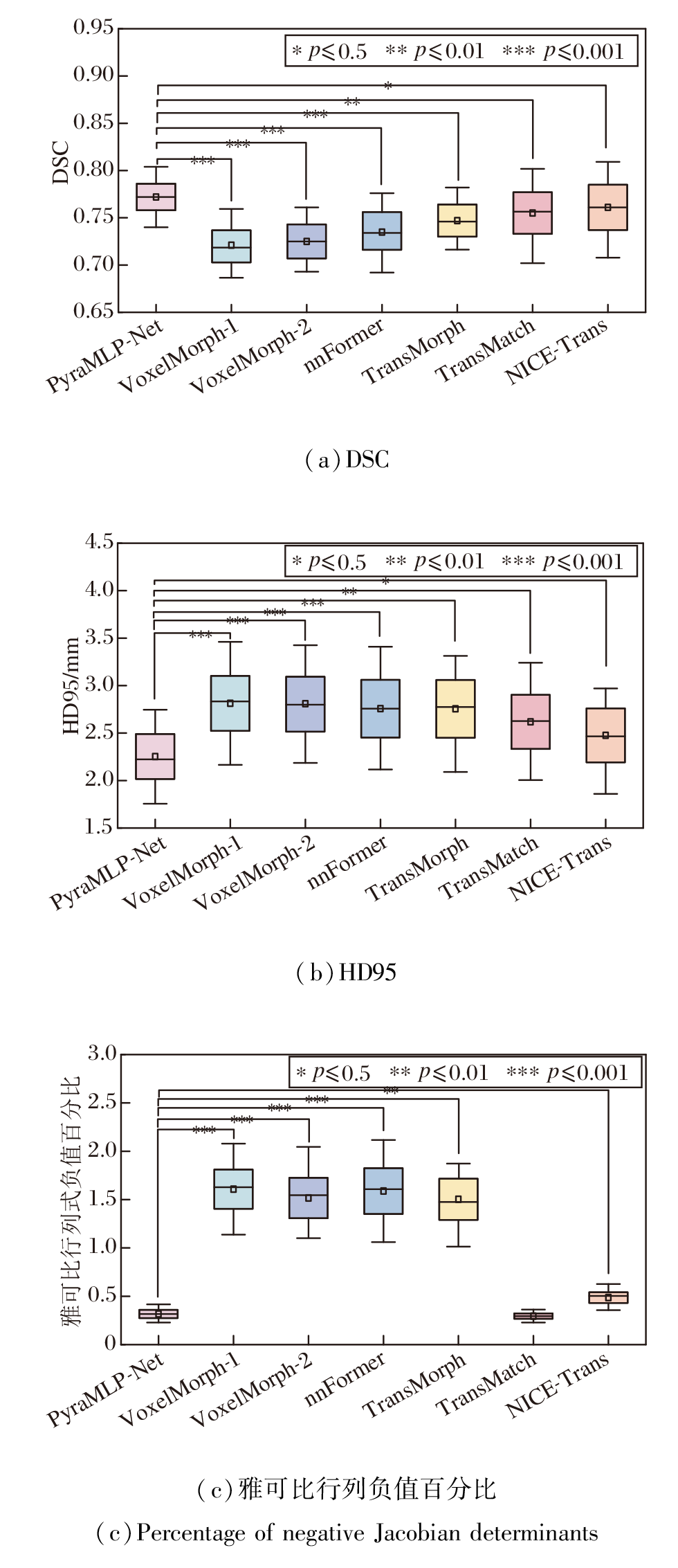 | 图5 各方法在IXI测试集上全部样本的配准指标箱线图Fig.5 Box plots of registration metrics for all samples generated by different methods on IXI test set |
进一步对比各方法的资源消耗与计算效率, 结果如表2所示.由表可见, VoxelMorph-1和Voxel-Morph-2得益于其轻量级结构和低分辨率特征处理机制, 推理速度最快, FLOPs和显存占用也显著低于其它方法.相反, 基于Transformer配准方法因自注意力机制的高计算复杂度, 计算负荷和显存需求较大, 这与其采用的由粗到精架构和多层次特征融合策略直接相关.PyraMLP-Net在其计算复杂度比NICE-Trans降低1.5%、运行时间比NICE-Trans降低约24.1%的情况下, 仍然保持最高的配准精度和优异的变形场平滑性, 展现出其在配准精度与计算效率之间的平衡能力.
| 表2 各方法在IXI数据集上的计算效率对比 Table 2 Computational efficiency comparison of different methods on IXI dataset |
PyraMLP-Net在取得最高配准精度的同时, FLOPs与运行时间均显著低于依赖全局自注意力的TransMorph、NICE-Trans, 符合1.4节的理论预期.这也验证PyraMLP-Net的效率提升并非源于局部的工程优化, 而是其多窗口MLP架构在算法层面带来的优势.该架构使得PyraMLP-Net能在全分辨率下高效进行长程依赖建模, 从而在三维医学图像配准任务中实现精度与计算效率之间更好的平衡.
2.4.4 模型复杂度与训练效率分析
为了更全面评估方法效率, 进一步对比各方法的参数量与单轮训练平均时间, 结果如表3所示.由表可见, 在IXI数据集上, PyraMLP-Net的参数量显著低于TransMorph、NICE-Trans等基于Transformer配准方法, 与轻量化的VoxelMorph-1处于同一量级.在训练效率方面, PyraMLP-Net每轮训练耗时仅比VoxelMorph-1增长约18%, 远少于计算密集的基于Transformer配准方法, 如PyraMLP-Net的训练速度约为NICE-Trans的2.1倍.这表明PyraMLP-Net不仅在前向推理中高效, 在模型规模与训练成本上也具有显著优势, 其通过在MLP架构内整合长程建模能力, 避免Transformer庞大的参数量与计算开销, 实现精度与效率的更优平衡.
| 表3 各方法的参数量与训练效率对比 Table 3 Comparison of number of parameters and training efficiency among different methods |
2.4.5 长程空间依赖关系建模能力分析
为了定量评估并对比PyraMLP-Net与基于CNN配准方法(以VoxelMorph为代表)对图像中长程空间依赖关系的建模能力差异, 引入跨区域特征相似度作为定量指标.该指标旨在度量模型对同一大类解剖结构在空间上相距较远的两个区域所学习特征表达的一致性, 相似度越高, 表明模型学习的特征对长程空间关系的建模能力越强.
首先, 在IXI测试图像中, 选取左侧大脑半球的额叶白质与枕叶白质作为感兴趣区域(Region of Interest, ROI), 选择依据在于二者在解剖上同属大脑白质, 具有相似的组织特性, 而且空间平均距离超过60 mm, 能有效检验模型对远端结构关联的建模能力, 同时大脑白质在T1加权MRI中灰度特征显著, 与灰质、脑脊液界限清晰, 便于精准标注ROI边界, 避免非目标区域干扰.
其次, 为了保证实验的代表性与客观性, 从IXI测试集上随机选取40个样本进行实验.样本选取遵循分层随机抽样原则, 确保样本年龄、性别分布与测试集整体分布一致, 避免抽样偏差.对于每个样本, 均采用基于解剖图谱引导的半自动方式对上述两个ROI进行手动标注, 最终获得80个ROI特征样本集.
具体标注流程如下.1)以IXI数据集提供的30个解剖结构标注图谱为基准, 手动定位左侧大脑半球额叶白质与枕叶白质的大致范围.2)在ITK-Snap软件中, 结合T1加权MRI的灰度特征微调边界, 确保ROI完全位于目标结构内, 且不包含其它组织成分.3)每个ROI设置为半径为5 mm的球形区域(约含125个体素), 记录其三维坐标, 用于后续特征提取.
基于前述坐标, 分别提取PyraMLP-Net与Voxel-Morph在第2解码层输出的特征图中对应这两个区域的所有体素的特征向量, 构成两个特征集合, 并计算两个集合间所有特征向量对的平均余弦相似度.
为了验证PyraMLP-Net与VoxelMorph相似度结果的统计显著性, 采用如下检验流程.首先采用经典正态性检验标准方法Shapiro-Wilk验证数据的正态性, 确认两组数据均符合正态分布.然后采用双样本独立t检验对比组间差异, 设定显著性水平α =0.01.最后计算Cohen's效应量, 评估差异实际意义.结果显示, PyraMLP-Net的跨区域特征相似度为0.82± 0.05, 显著高于(p < 0.01, 双样本t检验)VoxelMorph的0.61± 0.08.这一结果为PyraMLP-Net能有效克服CNN局部感受野的固有局限、建模长程空间依赖提供定量证据, 也从数据上解释其为何在处理整体性、大范围形变时具有优势.
2.4.6 关键脑区配准性能分析
为了评估PyraMLP-Net与对比方法对关键解剖结构的配准性能与泛化能力, 统计IXI数据集上17个脑部关键区域的DSC值, 结果如图6所示.由图可见, VoxelMorph-1和VoxelMorph-2在多数结构上DSC值较低, 尤其在壳核、脑干和脑脊液等区域表现较差.基于Transformer配准方法虽然整体优于基于CNN配准方法, 但在大脑白质和侧脑室等体积大、边界清晰、结构规则的区域上的配准精度低于PyraMLP-Net.例如:在侧脑室区域, NICE-Trans的DSC值约为0.824, 而PyraMLP-Net的DSC值高达0.841.此外, 对于脑脊液、脉络丛等边界模糊、形态变异较大的结构, 所有方法的DSC值均相对偏低, 但PyraMLP-Net仍保持优良性能, 表明其在捕捉细微解剖对应关系方面具有显著优势.
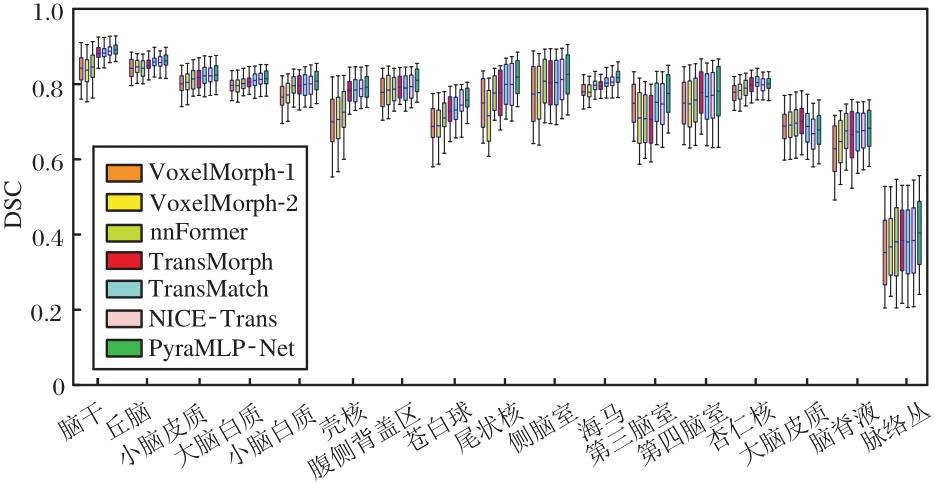 | 图6 各方法对IXI数据集上17个脑部结构进行图像配准的DSC值统计结果Fig.6 DSC statistical results obtained by different image registration methods for 17 brain structures from IXI dataset |
进一步分析发现, PyraMLP-Net的性能优势在不同尺度的解剖结构上呈现差异.对于体积较大或具有连续性的结构(如大脑白质), DSC值提升最显著.这源于CMW-MLP中7× 7× 7窗口分支对全局空间对应关系的有效捕捉, 以及利用三维相关层快速建立精准空间的核心能力, 二者协同保障大尺度规则结构的高效精准对齐.针对丘脑、壳核等中等尺度形变对应的核心灰质结构, 5× 5× 5窗口在配准中成为主导分支, 其覆盖范围与该类结构的解剖尺寸高度匹配, DSC均值保持在0.78以上.此外, 对于脑脊液、脉络丛等边界模糊、形态变化较大的细微结构, 受解剖特征本身复杂性的影响, 所有方法的DSC值均相对偏低, 但PyraMLP-Net仍保持领先.这得益于3× 3× 3窗口能精准捕捉此类结构的局部位移, 同时配合RCAB强化关键特征通道, 有效抑制模糊区域的噪声干扰, 由此验证PyraMLP-Net在捕捉细微解剖对应关系上的优势.
2.5.1 整体配准性能定量评估
各方法在OASIS数据集上的整体性能对比如表4所示, 表中黑体数字表示最优值.
| 表4 各方法在OASIS测试集上的指标值对比 Table 4 Metric value comparison among different methods on OASIS test set |
由表4可知, PyraMLP-Net在配准精度与结构一致性方面展现出显著优势, 相比VoxelMorph-1、VoxelMorph-2、nnFormer、TransMorph、TransMatch、NICE-Trans, DSC值分别提升约8.6%、8.0%、6.5%、4.7%、4.1%和2.2%, HD95值分别降低约17.3%、18.0%、10.4%、8.5%、6.4%和4.0%.在变形场平滑性方面, PyraMLP-Net的雅可比行列式负值百分比仅次于NICE-Trans, 但相比VoxelMorph-1、Voxel-Morph-2、nnFormer、TransMorph和TransMatch, 分别降低约34.7%、33.3%、21.8%、18.8%和11.3%, 体现出其优异的拓扑保持能力.
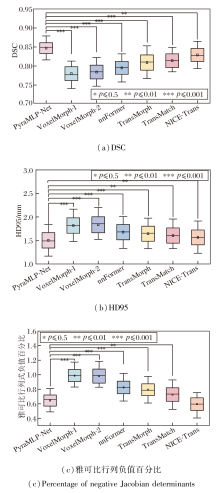
2.5.2 性能稳定性与计算效率分析
各方法性能稳定性的箱线图如图7所示.
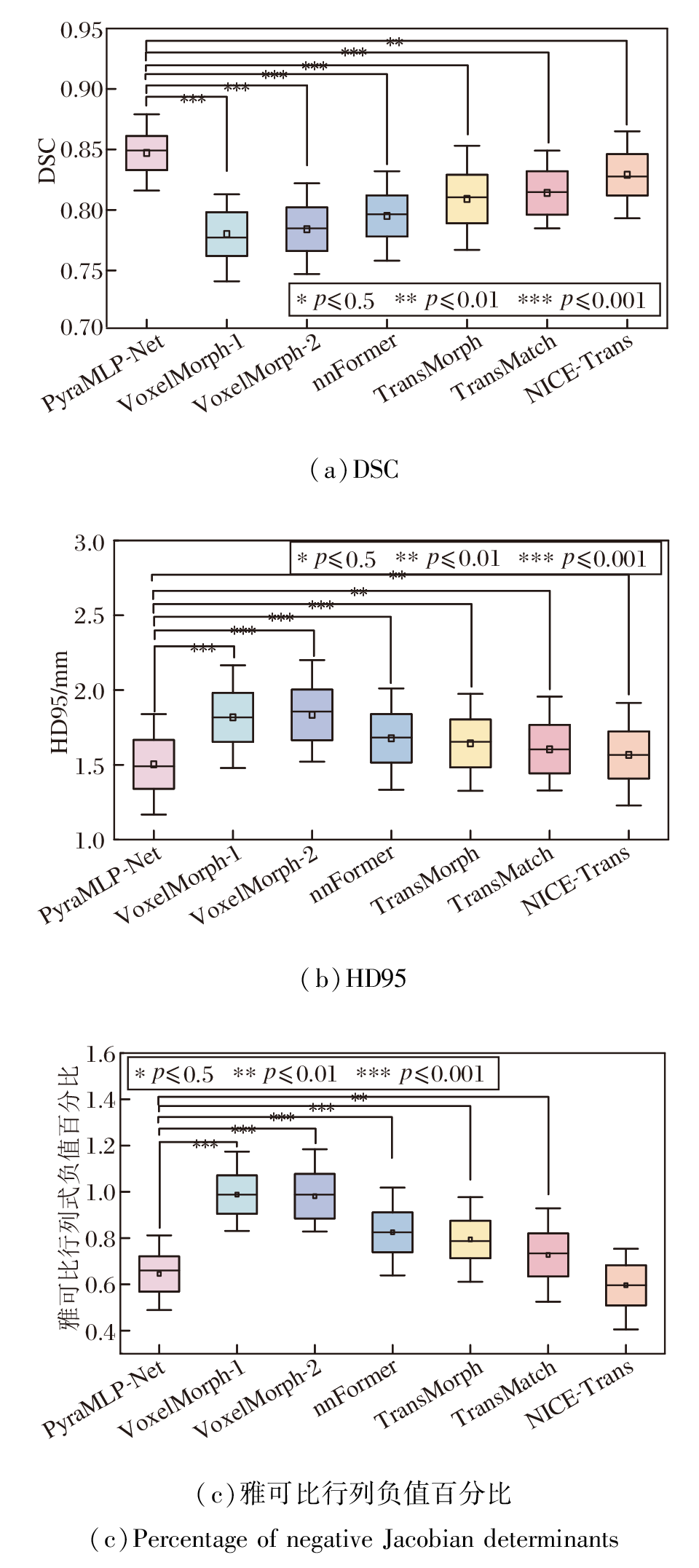 | 图7 各方法在OASIS测试集全部样本上的配准指标箱线图Fig.7 Box plots of registration metrics generated by different methods for all samples on OASIS test set |
由图7可见, PyraMLP-Net在DSC和HD95上均处于最优区间(中位数分别为0.85和1.495 mm), 且四分位距最小(DSC中IQR=0.028, HD95中IQR=0.326 mm), 说明其在不同样本间具有高度一致的性能表现.在变形场平滑性方面, PyraMLP-Net的雅可比负值百分比中位数虽略高于NICE-Trans, 整体处于次优区间, 但IQR=0.152, 稳定性最优, 显示出该方法在精度与鲁棒性之间取得良好平衡.
各方法的训练效率和计算资源消耗对比如表5所示.由表可见, PyraMLP-Net也具备明显优势.这一优势源于其MLP架构设计:既规避Transformer中自注意力机制的高昂计算与内存开销, 又突破CNN在高分辨率图像处理中的效率限制, 从而能在更低计算成本下实现高效的长程依赖建模与更优的配准性能.
| 表5 各方法在OASIS数据集上的计算效率对比 Table 5 Computational efficiency comparison among different methods on OASIS dataset |
2.5.3 单样本配准结果可视化分析
OASIS数据集上一个样本的配准结果如图8所示.
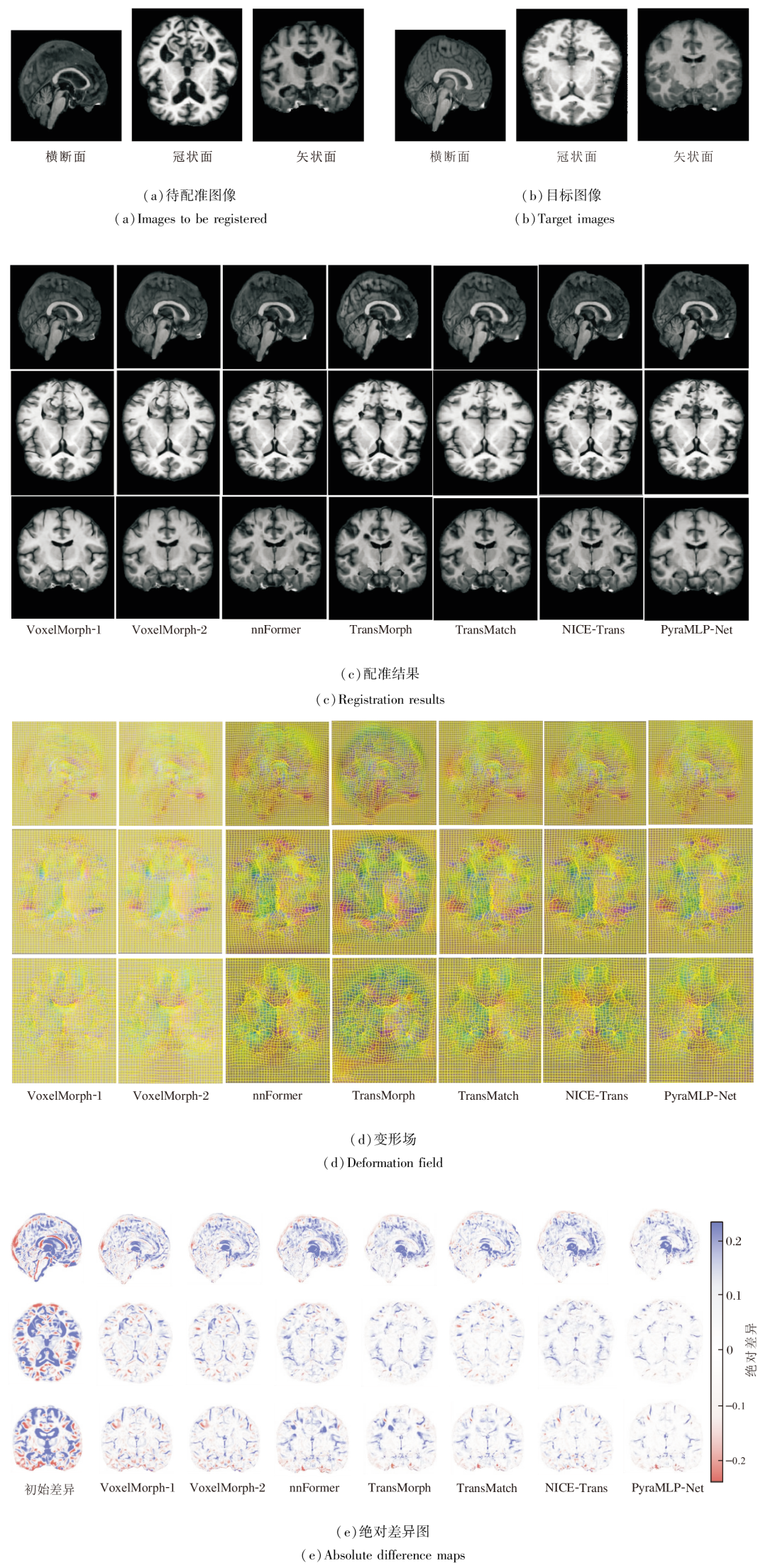 | 图8 各方法在OASIS数据集上一个样本图像的配准结果Fig.8 Registration results of different methods on a sample image from OASIS dataset |
由图8可见, 相比对比方法, PyraMLP-Net估计的变形场网格畸变范围更小, 配准结果在保留图像内部结构、恢复边缘清晰度与纹理细节等方面均表现更优, 由此表明PyraMLP-Net在局部细节保持与全局结构对齐方面的性能.
2.5.4 模型复杂度与训练效率分析
在OASIS数据集上的训练效率如表3所示, PyraMLP-Net在每轮训练时间上表现出明显优势, 训练速度是NICE-Trans的约2.2倍, 比VoxelMorph-1增加约17%.这表明PyraMLP-Net不仅在推理阶段高效, 在训练阶段也能有效控制计算开销.综合来看, PyraMLP-Net通过在MLP架构内高效整合多尺度与长程建模能力, 以接近基于CNN配准方法的参数量和训练成本, 实现超越主流的基于Transformer配准方法的配准精度, 展现更优越的精度-效率平衡特性.
2.5.5 长程空间依赖建模能力分析
为了验证长程依赖建模优势的泛化性, 在OASIS数据集上进行与2.4.5节相同的跨区域特征相似度分析.为了保证实验的代表性与客观性, 考虑到OASIS测试集共含40个样本, 涵盖健康人群与轻度至中度阿尔茨海默病患者, 故直接选取全部测试样本进行实验, 确保样本年龄、性别及病理状态分布与测试集整体分布完全一致, 无需额外抽样, 最大程度避免偏差.每个样本均采用基于解剖图谱引导的半自动方式对2个ROI进行手动标注, 最终获得80个ROI特征样本集.结果显示, PyraMLP-Net在该指标上达到0.85± 0.04, 依然显著高于(p< 0.01)Voxel-Morph的0.63± 0.07.这一结果与IXI数据集上的结论一致, 从不同数据源再次证实本文的多窗口MLP架构能有效捕获长程空间依赖关系, 相比传统CNN局部卷积操作具有明显优势.
2.5.6 关键脑区配准性能分析
各方法在OASIS数据集的17个脑部关键区域上的DSC值如图9所示.由图可见, PyraMLP-Net在绝大多数脑部区域的表现最优, 特别是在丘脑、大脑皮质和杏仁核等结构上优势更明显.这源于CMW-MLP的动态权重融合机制, 可根据结构特征自适应调整窗口权重.对于形态规则的丘脑, 5× 5× 5窗口权重占比大幅提升; 对于边缘不规则的杏仁核, 3× 3× 3窗口与7× 7× 7窗口权重协同提升, 有效平衡局部细节与全局形态的对齐精度.即使在脉络丛、脑脊液等结构复杂且边界模糊的区域, PyraMLP-Net仍保持领先, 但性能提升幅度相对有限.
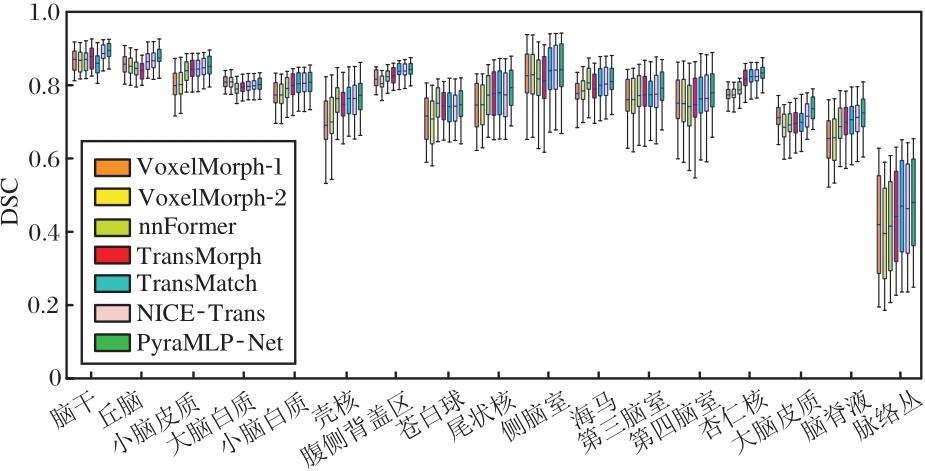 | 图9 各方法在OASIS数据集17个脑部结构上进行图像配准的DSC值统计结果Fig.9 DSC statistical results obtained by different image registration methods for 17 brain structures from OASIS dataset |
由于OASIS数据集包含轻度至中度阿尔茨海默病患者样本, 其脑部结构存在更复杂的萎缩形变与个体差异, 这进一步证实PyraMLP-Net在不同尺度与结构特征下的鲁棒性.
此外, 相比健康人群占比更高的IXI数据集, PyraMLP-Net在OASIS数据集脑脊液区域上的DSC值提升幅度更大, 表明其对病理状态下模糊结构的配准鲁棒性更强, 这一优势源于图像相似性损失中9× 9× 9窗口的合理选择, 在抑制噪声的同时完整保留病理结构的局部强度分布特征.
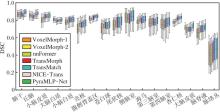
为了系统且全面地评估PyraMLP-Net与对比方法的性能差异和优劣, 采用Friedman检验, 分别对IXI、OASIS数据集上80个样本的DSC、HD95及雅可比行列式负值百分比等指标进行全局显著性分析(显著性水平α =0.05), 结果如表6与表7所示, 表中黑体数字表示最优值.
| 表6 各方法在2个数据集上的平均排名 Table 6 Average rankings of different methods on 2 datasets |
| 表7 不同数据集性能差异的Friedman检验结果 Table 7 Results of Friedman test on performance differences across different datasets |
由表6和表7可见, 所有指标在两个数据集上的p值均小于0.001, 表明不同方法间至少存在一对具有统计学意义的显著差异.
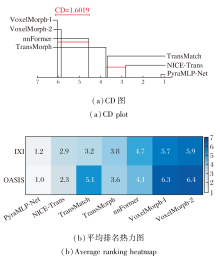
在算法数量k=7、样本数N=80的条件下, 查得qα =4.69, 计算得到临界差异值(Critical Diffe-rence, CD)为1.601 9.
图10(a)的CD图显示, PyraMLP-Net在2个数据集上的DSC值平均排名均显著优于对比方法, 差异超过临界值.
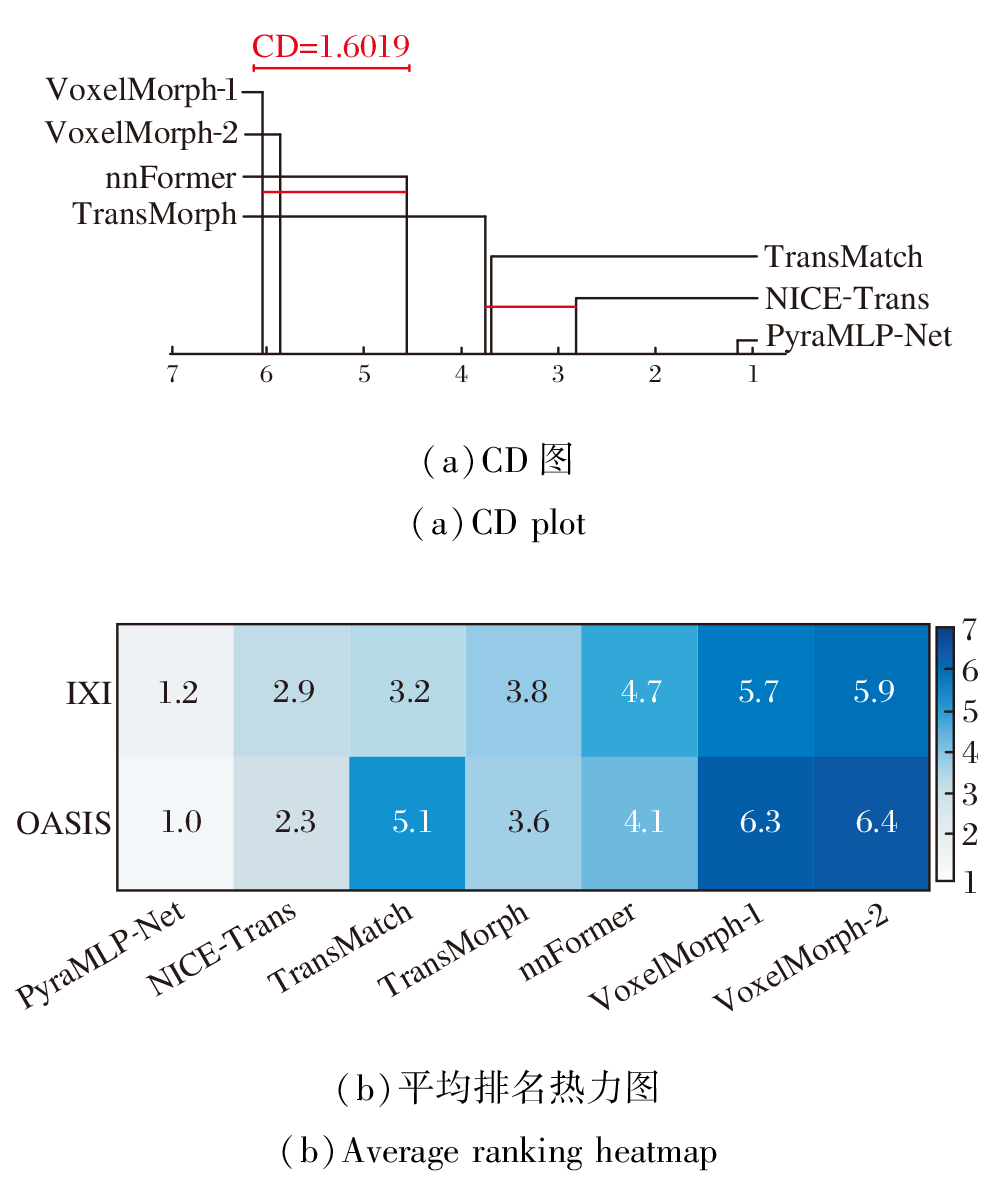 | 图10 各方法在IXI、OASIS数据集上DSC指标的CD图和平均排名热力图Fig.10 CD plot and average rankings of DSC metrics for different methods on IXI and OASIS datasets |
图10(b)以热力图直观呈现各方法在IXI、OASIS数据集上的DSC值具体排名情况.
由图10(b)可见, PyraMLP-Net在所有数据集上均保持最优排名.这些结果表明该方法的性能优势具有统计显著性, 展现出良好的泛化性与鲁棒性.
为了评估PyraMLP-Net的优势和结构的合理性, 分别设计系统级和组件级消融实验.所有实验均保持统一参数设置, 在IXI、OASIS数据集上进行验证.
2.7.1 系统级消融实验
网络深度需在特征覆盖能力与计算效率之间取得平衡:层数过少可能难以捕捉跨尺度的形变特征, 而层数过多则会引入不必要的计算开销与过拟合风险.
为此, PyraMLP-Net采用4个编码层与4个解码层构成的四级金字塔结构, 实现由粗到精的渐进式配准.为了验证该层级设计的有效性, 以网络层级数L=4为基准, 对比L=2, 3, 5时的性能表现.
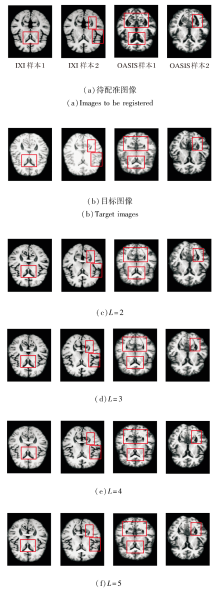
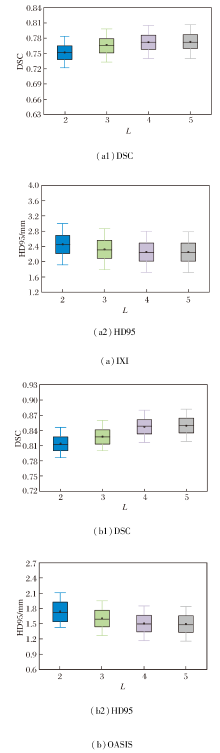
在IXI、OASIS数据集上各选取2个样本, 当网络层级数L改变时, 得到的图像配准结果如图11所示.L对PyraMLP-Net性能的影响如图12和表8所示.
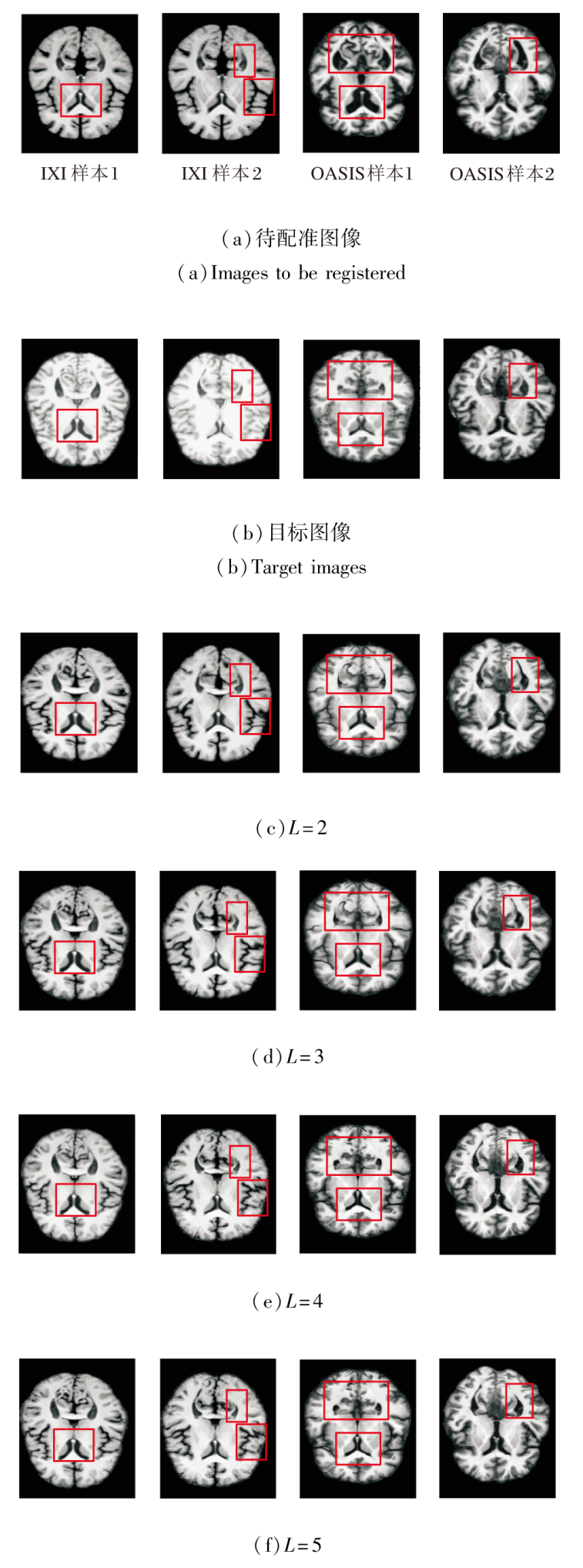 | 图11 L改变时的图像配准结果Fig.11 Image registration results with different L |
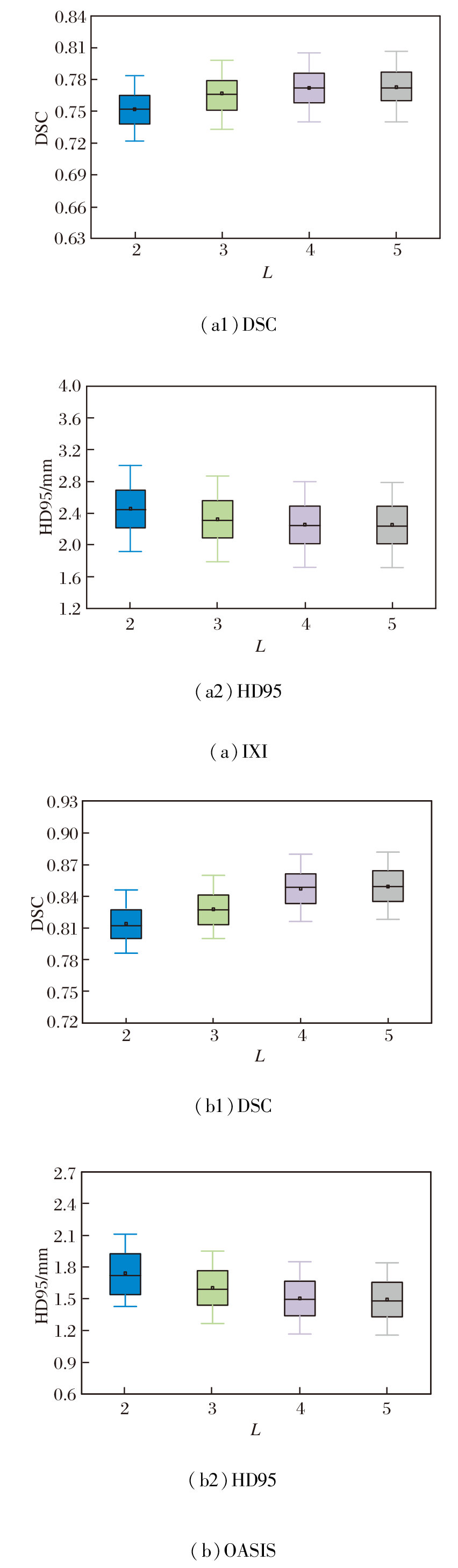 | 图12 L对PyraMLP-Net性能的影响Fig.12 Effect of L on PyraMLP-Net performance |
| 表8 L对PyraMLP-Net计算效率的影响 Table 8 Effect of L on computational efficiency of PyraMLP-Net |
由图11、图12和表8可见, 当L=2时, 网络深度不足, 导致多尺度特征提取不充分, 对细微解剖结构的匹配能力有限, 配准精度最低.L=3时, PyraMLP-Net能捕获更多的中等尺度特征, 性能优于两层网络, 但仍难以建模高分辨率细节.L=4时, PyraMLP-Net实现从低分辨率到全分辨率的完整特征覆盖, 能更精准地匹配解剖结构, 各项指标值均显著优于浅层结构.当L=5时, 其性能与4层网络相比未出现明显提升, 但计算开销显著增加.以IXI数据集为例, 单次运行时间从0.355 s增至0.418 s, 内存占用从14.823 GB升至16.018 GB.这表明对于具有典型分布和结构规律的脑部MRI数据, 4层网络已能充分学习其特征表示, 继续增加层数不仅无法带来性能增益, 反而会引入冗余参数并降低计算效率.
综合配准性能与资源效率, L=4能在满足精细解剖结构匹配要求的同时, 避免因层级不足或过度而导致的性能损失或计算资源浪费, 实现最佳平衡, 从而验证PyraMLP-Net四层架构的合理性.
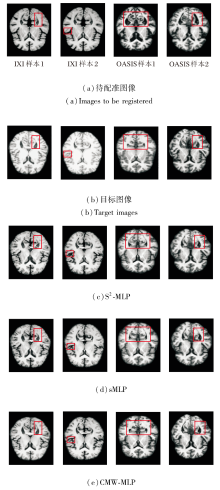
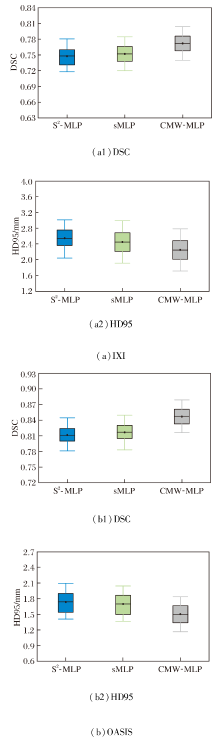
CMW-MLP作为PyraMLP-Net的核心组件, 通过计算输入特征间的局部相关性以捕获多范围依赖关系.为了验证其必要性, 以PyraMLP-Net为基准, 将CMW-MLP分别替换为S2-MLP(Spatial-Shift MLP)[25]和sMLP(Sparse MLP)[26]进行对比.
同样在IXI、OASIS数据集上各选取2个样本, 各模块的图像配准结果如图13所示, 对PyraMLP-Net性能的影响如图14所示.由图可看出, CMW-MLP在IXI、OASIS数据集上的配准精度均显著高于S2-MLP和sMLP.这一优势主要源于其两项核心设计.
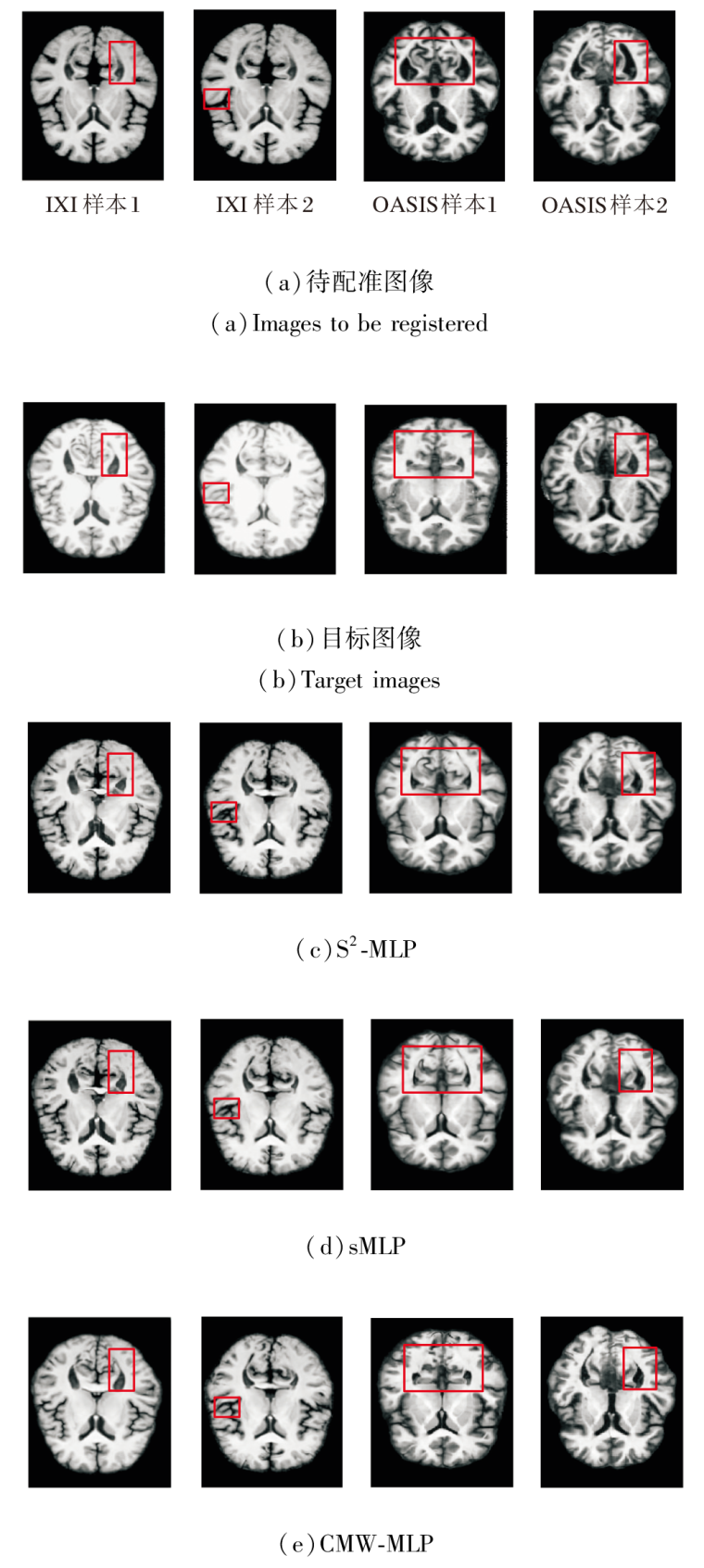 | 图13 各模块的图像配准结果Fig.13 Image registration results of different modules |
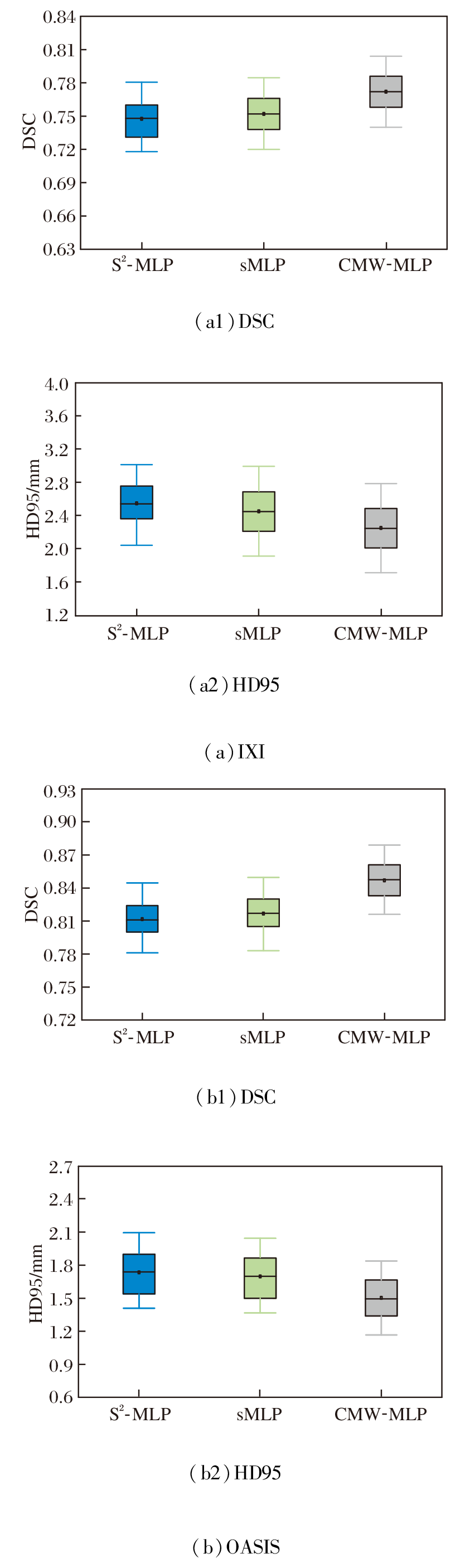 | 图14 各模块对PyraMLP-Net性能的影响Fig.14 Effect of each module on PyraMLP-Net performance |
1)三维相关层显式建立局部特征的空间对应关系, 提供像素级对齐的强引导信号.
2)多窗口并行架构能同时捕捉不同尺度的空间依赖.相比之下, S2-MLP和sMLP仅能进行全局、无差别的特征混合, 缺乏对局部结构关联的显式建模和对多尺度形变的针对性处理, 因此难以精准捕捉解剖细节的对应关系.
2.7.2 组件级消融实验
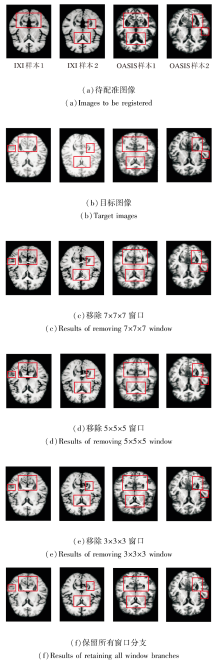
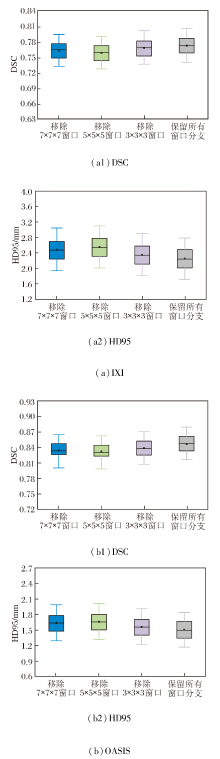
CMW-MLP采用多窗口设计, 分别捕获细粒度、中等尺度与大尺度的空间特征.为了验证该设计的有效性, 以包含全部3个窗口(3× 3× 3、5× 5× 5和7× 7× 7)的PyraMLP-Net为基准, 分别移除其中一个窗口, 在相同实验设置下分析各窗口对捕捉不同尺度形变的贡献.
在IXI、OASIS数据集上各选取2个样本, 分别移除其中一个窗口后的图像配准结果如图15所示, 对PyraMLP-Net性能的影响如图16所示.由图可见, 当分别移除7× 7× 7窗口、5× 5× 5窗口、3× 3× 3窗口时:PyraMLP-Net在IXI数据集上的DSC值分别下降约1.3%、1.8%和0.6%, HD95值分别上升约9.3%、11.7%和4.2%; 在OASIS数据集上, DSC值相应降低1.4%、1.7%和0.9%, HD95值相应提升8.1%、9.3%和3.5%.这一结果表明, 任意一种窗口的缺失都会导致PyraMLP-Net的配准精度下降, 由此凸显多窗口协同的有效性.
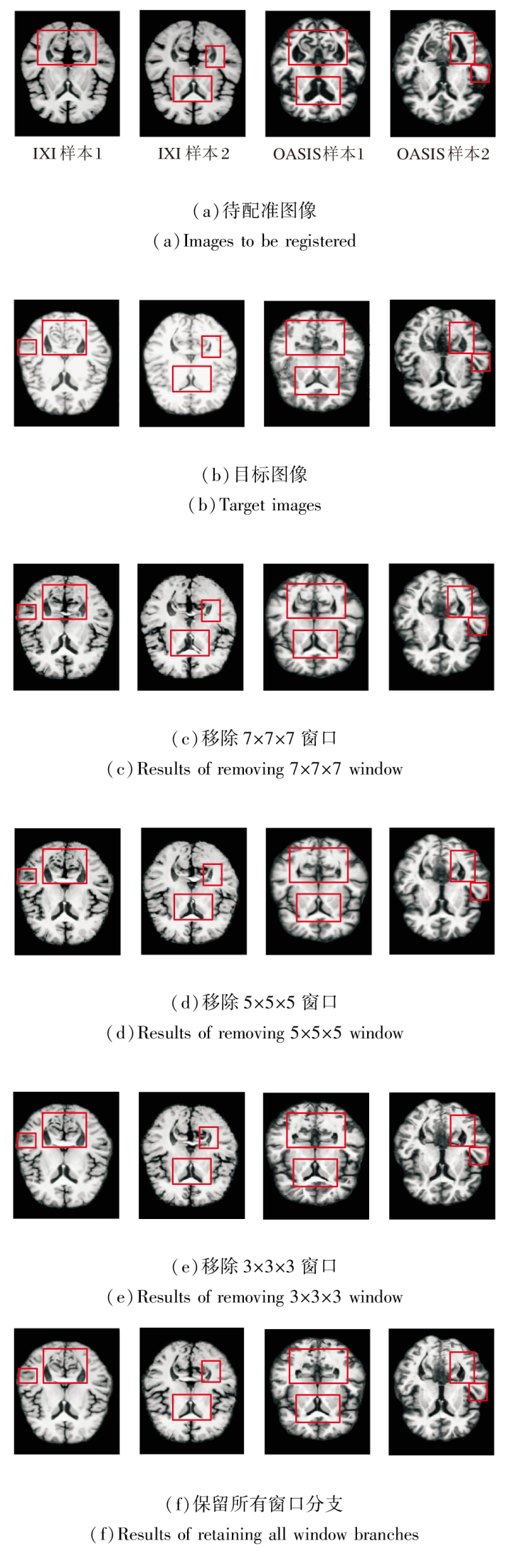 | 图15 移除不同窗口的图像配准结果Fig.15 Image registration results with different windows removed |
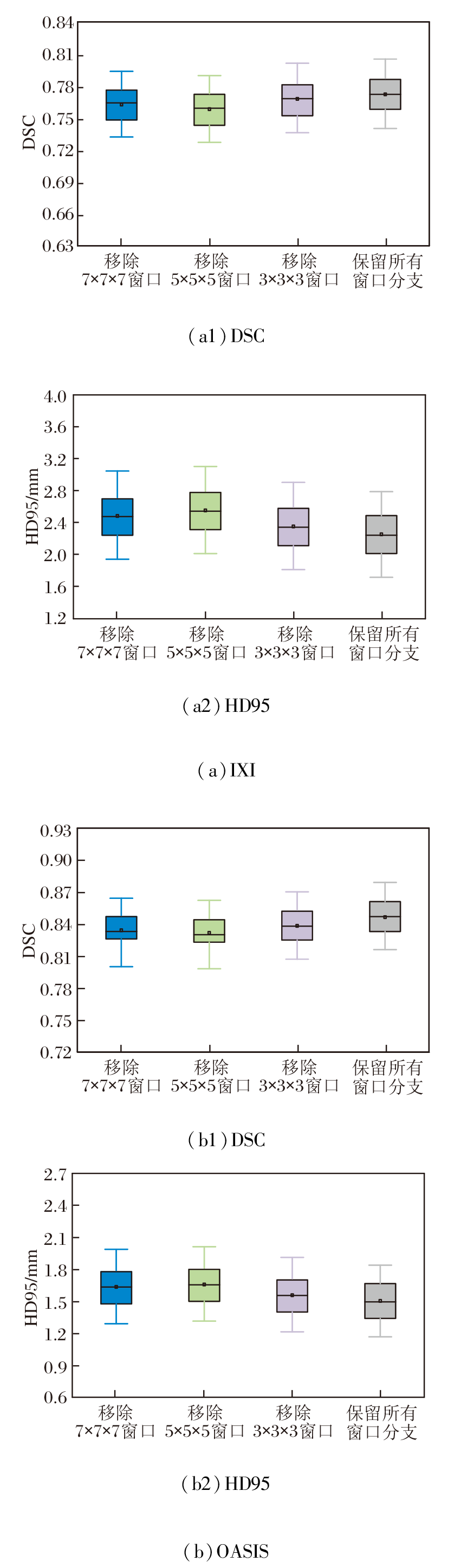 | 图16 移除不同窗口对PyraMLP-Net性能的影响Fig.16 Effect of removal of different windows on PyraMLP-Net performance |
造成这一现象的原因在于不同尺寸窗口建模的变形尺度及其在脑图像中的分布存在差异.5× 5× 5窗口专注于捕捉中等范围的局部变形, 这类变形在脑部结构中占比最高, 对整体配准精度影响最显著, 因此移除该窗口导致的性能损失最大.
7× 7× 7窗口用于感知较大尺度的局部变形, 该类变形在图像中虽存在但占比低于中等变形, 故移除7× 7× 7窗口后精度损失次之.3× 3× 3窗口主要捕捉细微解剖结构的局部位移, 对配准精度贡献相对较小, 因此移除时性能下降幅度最小.上述结果说明, 只有整合多尺度窗口的感知能力, 才能全面覆盖不同范围的依赖关系, 实现最优的配准精度, 也进一步验证CMW-MLP中多窗口协同架构设计的合理性与必要性.
作为核心组件, CMW-MLP捕捉多范围依赖与多尺度特征的能力依赖于其内部子模块的协同:三维相关层构建局部特征关联, gMLP中的空间门控单元(SGU)实现跨特征的空间交互, RCAB增强关键通道表达, 而动态加权融合机制则自适应整合多尺度信息.
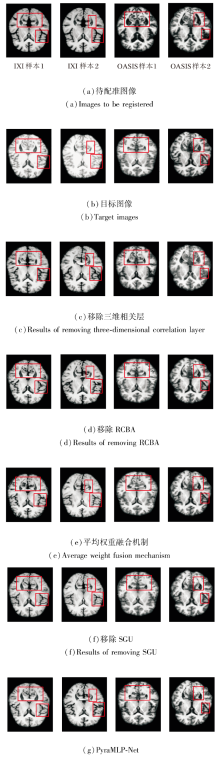
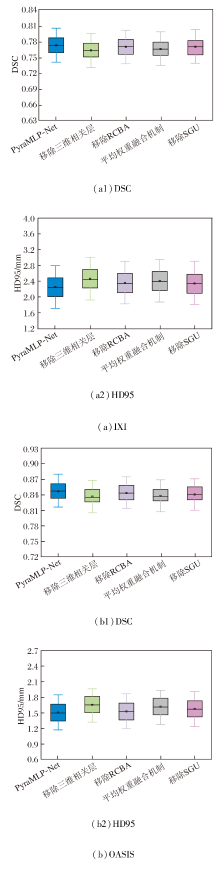
为了验证各子模块的必要性, 以完整模块为基准, 依次设置仅移除三维相关层、仅移除SGU、仅移除RCAB、将动态加权融合替换为平均权重融合机制这4个消融实验组.
在IXI、OASIS数据集上各自选取2个样本, 移除各子模块后图像配准结果如图17所示, 对PyraMLP-Net性能的影响如图18所示.由图可见, 移除三维相关层、SGU、RCBA及将动态权重融合机制替换为平均权重融合机制均会导致配准性能下降, 影响程度存在差异.
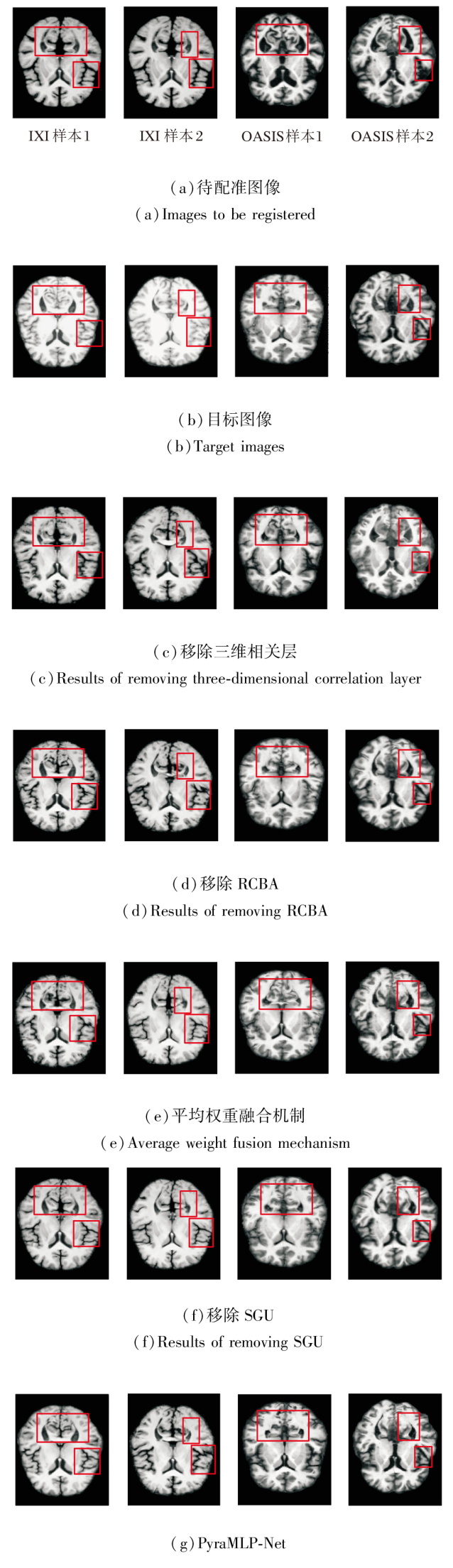 | 图17 改变子模块后的图像配准结果Fig.17 Image registration results with changes to different submodules |
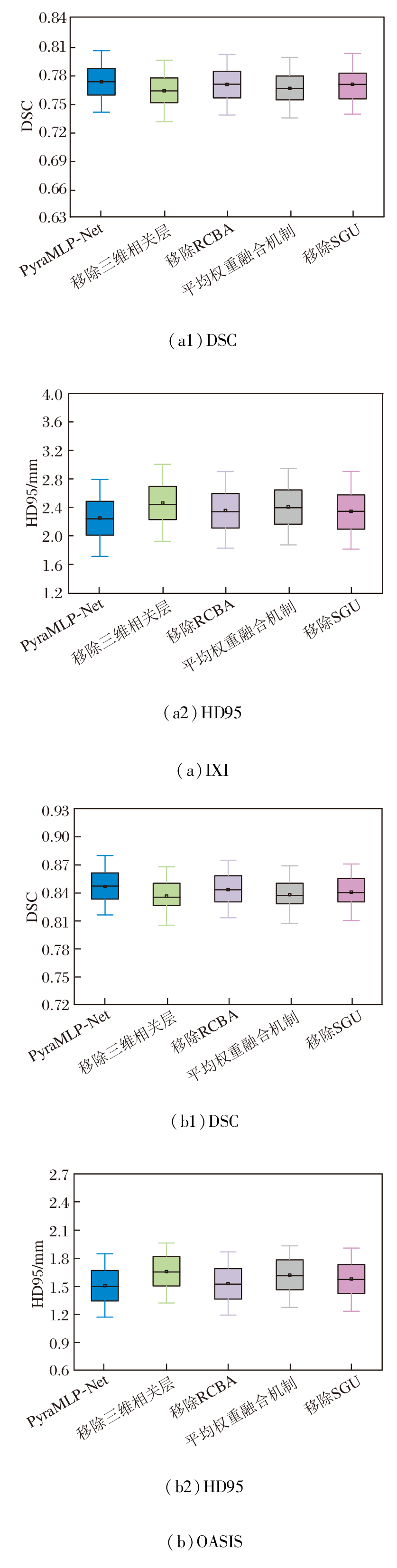 | 图18 各子模块对PyraMLP-Net性能的影响Fig.18 Effect of changes to different submodules on PyraMLP-Net performance |
移除三维相关层的影响最显著, 原因在于三维相关层作为CMW-MLP的核心, 直接计算固定图像与移动图像特征的局部相关性并生成相关性特征图, 移除后PyraMLP-Net丧失对跨图像特征空间关联的有效感知能力, 仅能依赖特征的全局混合推理, 难以建立精准的像素级空间对应关系.
将动态权重融合机制替换为平均权重融合机制对网络配准性能的影响次之.动态权重融合机制可根据输入特征的形变尺度动态调整3× 3× 3、5× 5× 5、7× 7× 7多窗口分支的权重, 实现对不同尺度形变的自适应多范围依赖融合, 这对于准确捕捉脑部图像中混合存在的不同尺度形变至关重要.平均权重融合机制采用静态等权重分配, 完全稀释多窗口设计的核心适配优势, 导致PyraMLP-Net无法灵活应对不同尺度形变.
移除gMLP中的SGU对网络配准性能的影响处于中等程度.SGU作为gMLP的核心单元, 通过门控机制筛选关键空间特征, 强化窗口内像素的局部空间关联.移除后gMLP退化为普通MLP, 窗口内空间信息建模能力削弱, 但由于其作用仅局限于窗口内局部优化, 未触及配准核心逻辑, 故性能下降程度低于前两种操作.
移除RCBA对网络配准性能的影响最小, 该模块本质是通过通道注意力与残差连接筛选关键特征通道并优化影响特征表达鲁棒性的后处理环节, 缺失仅会导致特征表达精准度下降, 并未破坏配准的核心逻辑, 因此对整体性能的影响最轻微.
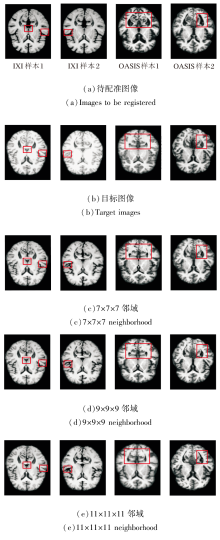
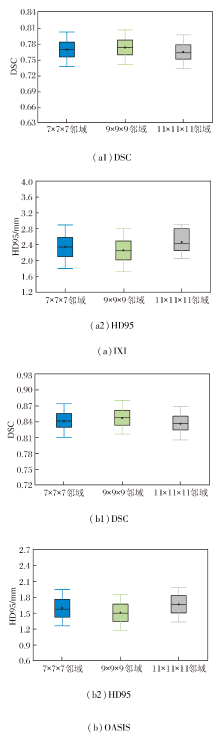
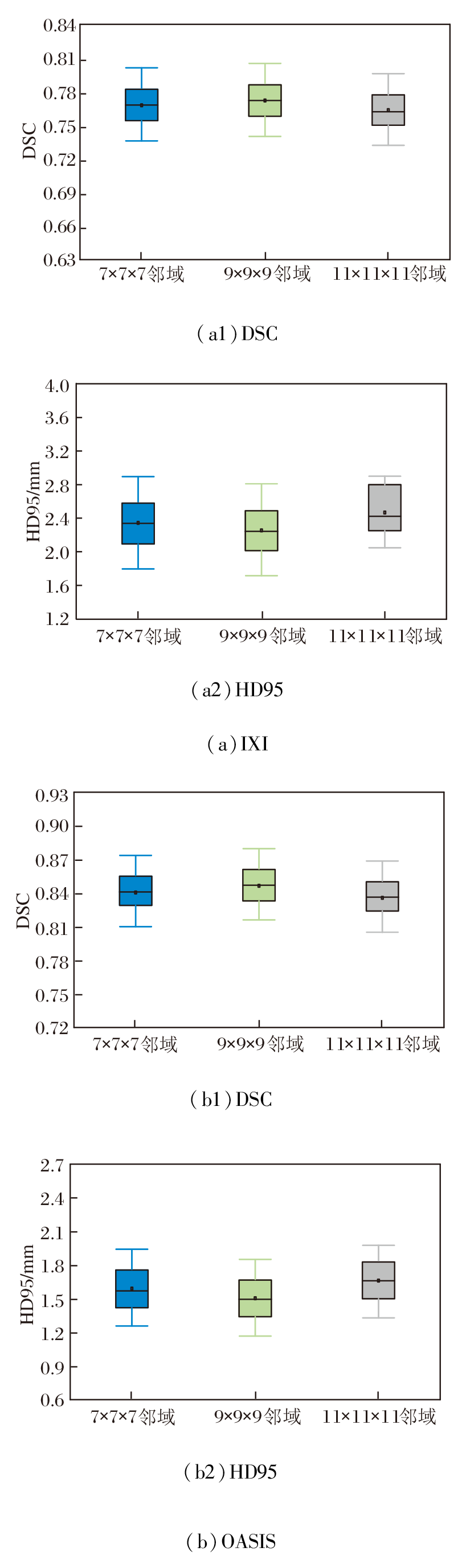
基于局部邻域内的像素强度统计相关性计算相似性损失函数, 邻域尺寸直接影响度量的鲁棒性.尺寸过小会导致局部采样不足, 难以捕捉完整的解剖强度分布, 降低对结构细节的敏感性; 尺寸过大容易引入无关区域的强度干扰, 模糊局部对应关系.为此, 本文设置7× 7× 7、9× 9× 9、11× 11× 11的邻域尺寸.
在IXI、OASIS数据集上各自选取2个样本, 邻域尺寸改变后图像配准结果如图19所示, 对PyraMLP-Net性能的影响如图20所示.
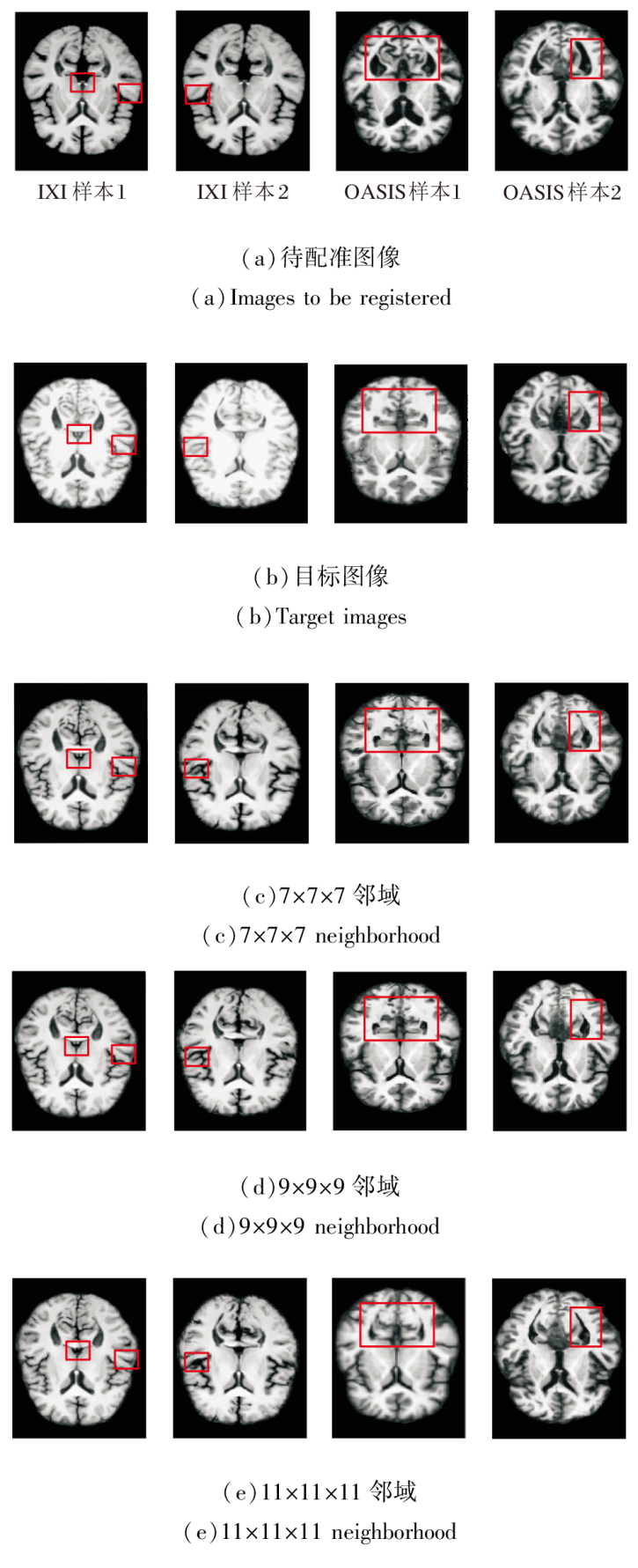 | 图19 不同邻域尺寸的图像配准结果Fig.19 Image registration results with different neighborhood sizes |
 | 图20 邻域尺寸对PyraMLP-Net性能的影响Fig.20 Effect of neighborhood size on PyraMLP-Net performance |
由图19和图20可见, 9× 9× 9邻域尺寸在DSC、HD95指标上均取得最优值.在IXI数据集上, 相比7× 7× 7邻域和11× 11× 11邻域, 9× 9× 9邻域的DSC值分别提高约0.6%和1.2%, HD95值分别降低约2.2%和8.3%.
在OASIS数据集上, 相比7× 7× 7邻域和11× 11× 11邻域, 9× 9× 9邻域的DSC值分别提高约0.7%和1.3%, HD95值分别下降约5.4%和9.5%.
性能差异源于不同邻域尺寸对图像噪声、解剖结构覆盖和相似性度量可靠性的影响.7× 7× 7邻域涵盖体素数量有限, 局部灰度均值容易受到图像噪声和伪影干扰, 降低相似性损失的稳定性, 从而影响配准精度.11× 11× 11邻域由于覆盖范围过大, 可能引入不相关解剖结构的干扰, 导致图像相似性度量无法准确反映目标解剖对应关系, 同样限制配准性能.相比之下, 9× 9× 9邻域在局部细节保留与噪声鲁棒性之间实现良好平衡, 既能抑制噪声敏感问题, 也能避免大邻域带来的结构混淆问题, 有效提高配准精度.
为了评估PyraMLP-Net对来自不同采集协议与人群分布的脑部MRI数据的泛化能力, 在独立的LPBA40公开数据集上进行零样本泛化实验.实验保持所有方法参数不变, 直接使用在IXI数据集上训练完成的模型权重, 对LPBA40数据集上的40幅图像进行配准.
选择3组代表性样本, 基于NICE-Trans和PyraM-LP-Net的配准结果及其对应变形场的矢状面可视化结果如图21所示.
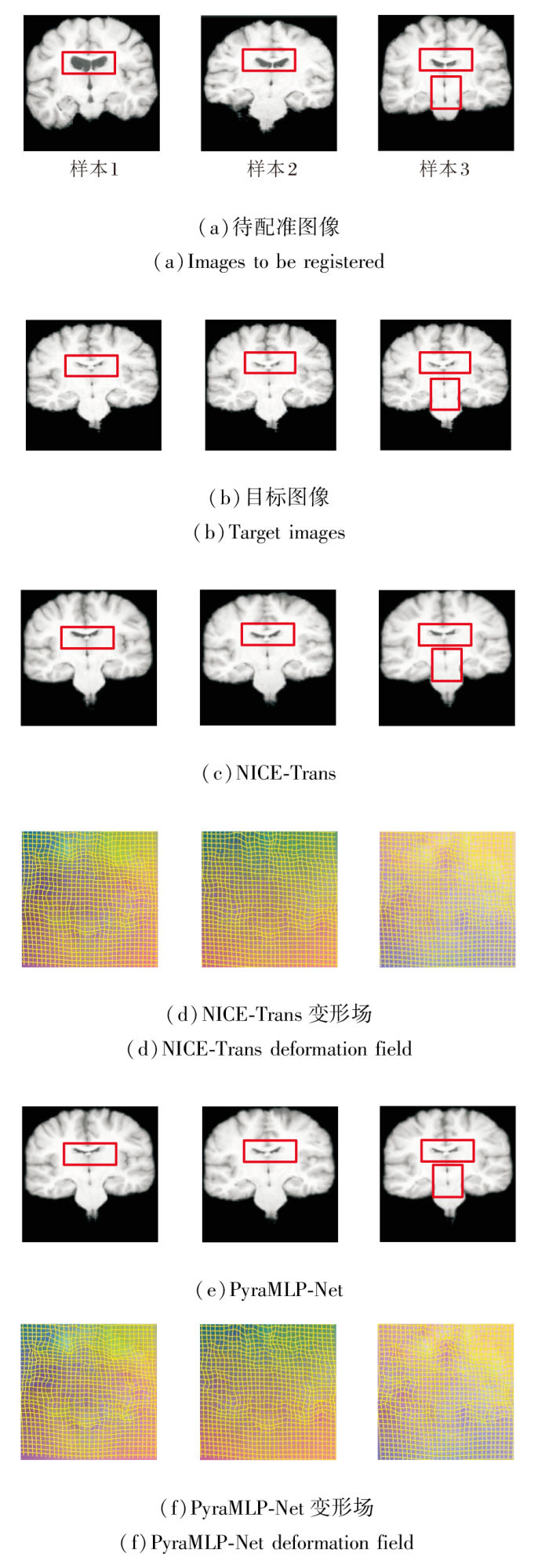 | 图21 NICE-Trans和PyraMLP-Net针对LPBA40数据集上3个样本的图像配准结果Fig.21 Image registration results generated by NICE-Trans and PyraMLP-Net for 3 samples from LPBA40 dataset |
由图21可看出, 即使面对与训练集分布存在差异的数据, PyraMLP-Net依然能实现准确的结构对齐, 并且估计的变形场保持良好的平滑性与拓扑合理性.
NICE-Trans与PyraMLP-Net在LPBA40数据集上的定量评价结果如表9所示.由表可见, 相比NICE-Trans, PyraMLP-Net的DSC值提升0.8%, HD95值降低5.3%, 同时雅可比行列式负值百分比下降22.2%.该结果在统计上具有显著性(p< 0.05), 一致证实PyraMLP-Net在脑部MRI配准任务中的优越性能并未过拟合于特定训练集, 而是具备可靠的跨数据集泛化能力.
| 表9 NICE-Trans和PyraMLP-Net在LPBA40数据集上的指标值对比 Table.9 Metric value comparison between NICE-Trans and PyraMLP-Net on LPBA40 dataset |
综合理论分析与实验结果发现, PyraMLP-Net展现出优异的精度和效率平衡特性.在理论层面, 其线性计算复杂度从根本上规避传统Transformer架构中二次复杂度带来的可扩展性瓶颈.这一设计在实践中转化为如下3方面的优势.模型规模显著精简, 参数量仅相当于基于Transformer配准方法的50%~60%; 训练速度大幅提升, 单轮训练时间明显减少; 推理效率显著提高, 表现为更低的FLOPs和更短的GPU运行时间.这些效率优势并未以牺牲精度为代价, 而是凭借全分辨率下的细粒度特征处理与有效的长程依赖建模机制, PyraMLP-Net在DSC、HD95等关键配准指标上均取得最优值.这一结果表明, 本文的网络架构为解决三维医学图像配准中精度要求与计算资源限制难以兼顾的问题提供有效的解决方案.
PyraMLP-Net在脑部MRI图像配准中取得良好性能, 但其应用仍存在一定的局限性, 这为未来研究指明方向.在处理极端大尺度或高度非线性的形变时, 受限于特征金字塔的尺度建模范围, PyraMLP-Net对解剖结构大幅度位移的捕捉能力有待提升.对于小体积或低对比度的细微结构, 由于现有特征提取机制对低维度、弱纹理特征的表征能力不足, 容易导致配准偏差.此外, PyraMLP-Net主要依赖图像局部强度的一致性, 对于强噪声干扰、场畸变等的鲁棒性有待进一步加强.
针对这些局限性, 今后将从如下方面展开研究.首先, 探索将生物力学约束等物理先验融入网络训练, 增强方法对超出经验范围的形变的估计能力, 提升对异常形变的处理能力.其次, 研究如何有效利用小尺度结构的解剖先验知识, 如在损失函数中增加针对性约束, 用于强化此类关键区域的配准效果.最后, 构造对成像干扰不敏感的特征表示方法, 或设计更具判别力的鲁棒相似性度量, 提升方法在复杂成像条件下的实际应用可靠性.
在临床场景中, 医学图像配准需面对包括CT、超声等在内的多种成像模态及伴随各类病理改变的图像数据.虽然当前工作主要聚焦于脑部MRI配准, 尚未在非MRI模态或具有明显病理特征的图像上进行实验验证, 但PyraMLP-Net的架构设计显示出向更广泛临床问题拓展的潜力.其核心CMW-MLP通过局部相关性计算与多窗口MLP建立空间对应关系, 该机制主要依据图像的结构特征而非绝对强度信息, 从而在理论上具备适应不同模态间对比度差异的基础.全分辨率的处理方式同样有助于保持对病理区域边缘等关键解剖细节的表征能力.
后续研究将系统评估PyraMLP-Net在多模态配准任务上的性能, 并验证其在包含肿瘤、水肿或术后缺损等复杂病理条件下的鲁棒性.同时, 后续研究也将探索无监督域自适应等策略, 增强方法对未知成像模态或采集协议的适应能力, 推动PyraMLP-Net向更广泛的临床应用场景拓展.
针对无监督脑部MRI图像配准领域中CNN局部感受野受限及Transformer架构计算开销过高的问题, 本文提出基于多窗口多层感知机的特征金字塔网络(PyraMLP-Net), 通过权重共享特征提取模块、含CMW-MLP的特征金字塔解码模块及空间变换网络模块(STN)的协同设计, 实现高精度配准和优良的变形场平滑性, 同时保持较低的计算开销.采用IXI、OASIS数据集对PyraMLP-Net进行训练、验证和测试.结果表明, 相比VoxelMorph、nnFormer、TransMorph、TransMatch、NICE-Trans等主流方法, PyraMLP-Net的DSC、HD95指标均达到最优值.消融实验从系统级和组件级综合验证各核心模块在配准精度和计算效率方面的有效性和必要性.未来有望将PyraMLP-Net拓展至MRI与CT、超声等多模态医学图像配准任务, 并针对体积更小、边界更模糊的解剖结构优化特征提取功能, 增强方法在疾病诊断场景中的鲁棒性, 进一步提升其泛化能力与临床实用价值.
本文责任编委 桑 农
Recommended by Associate Editor SANG Nong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|