
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于高阶相关性与双重冗余驱动的全局多标签特征选择
[邓文1  , 折延宏
, 折延宏2 , 郑文利2 , 贺晓丽2 , 钱婷2 ]
, 折延宏, 郑文利, 贺晓丽, 钱婷]
|
|



作者简介:

邓 文,硕士研究生,主要研究方向为模糊粗糙集、特征选择.E-mail:dw18866@163.com.

郑文利,博士,讲师,主要研究方向为机器学习、分层分类.E-mail:wlzheng@xsyu.edu.cn.

贺晓丽,博士,副教授,主要研究方向为不确定性推理、粒度计算.E-mail:qiant2000@126.com.

钱 婷,博士,副教授,主要研究方向为粗糙集、概念格、不确定性推理.E-mail:hexl@xsyu.edu.cn.
多标签特征选择是处理高维多标签数据的关键预处理技术.现有方法或因采用贪婪搜索策略而容易陷入局部最优,或在稀疏模型中对特征相关性与冗余性的度量不够充分.为此,文中提出基于高阶相关性与双重冗余驱动的全局多标签特征选择算法(Global Multi-label Feature Selection Algorithm Driven by Higher-Order Correlation and Dual Redundancy, GHC-DR).首先,引入基于多标签 k近邻的模糊依赖度,准确评估特征与标签系统间的高阶相关性.然后,专注于特征的局部几何结构,构建特征图,捕捉特征间的局部相似性,并设计融合信息论与局部结构的双重冗余评估机制.最后,将高阶相关性、双重冗余性及标签相关性整合至一个统一的稀疏学习目标函数中,并给出高效的闭式解.在15个公开多标签基准数据集上的对比实验表明,GHC-DR在多个评估指标上均表现出性能优势.
About Author:
DENG Wen, Master student. His research interests include fuzzy rough sets and feature selection.
ZHENG Wenli, Ph.D., lecturer. Her research interests include machine learning and hierarchical classification.
HE Xiaoli, Ph.D., associate professor. Her research interests include uncertainty reasoning and granular computing.
QIAN Ting, Ph.D., associate professor. Her research interests include rough sets, con-cept lattices and uncertainty reasoning.
Multi-label feature selection is a critical preprocessing technique for handling high-dimensional multi-label data. However, existing approaches are often trapped in local optima due to greedy search strategies or unadequate measuring feature correlation and redundancy within sparse models. To address these issues, a global multi-label feature selection algorithm driven by higher-order correlation and dual redundancy(GHC-DR) is proposed. First, a fuzzy dependency measure based on multi-label k-nearest neighbors is introduced to accurately evaluate the higher-order correlations between features and the label system. Second, GHC-DR is designed to focus on the local geometric structure of features by constructing a feature graph to capture local similarities among features, and a dual redundancy evaluation mechanism fusing information theory with local structure is developed. Finally, higher-order correlation, dual redundancy and label correlations are integrated into a unified sparse learning objective function, and an efficient closed-form solution is derived. Experiments on 15 public multi-label benchmark datasets demonstrate the superior performance of GHC-DR across multiple evaluation metrics.
作为机器学习领域一个富有挑战性的研究方向, 多标签学习近年来广泛应用于图像标注[1]、蛋白质功能分类[2]、文本分类[3]中.在多标签学习任务中, 每个样本通常与一个标签集合关联, 而非单一标签[4].在实际应用场景中, 数据往往呈现高维度特性, 这不仅带来巨大的计算成本, 还可能因包含无关特征或冗余特征而限制模型的泛化能力[5].因此, 多标签特征选择(Multi-label Feature Selection, MLFS)作为一种有效的降维技术, 已成为多标签学习中至关重要的预处理环节[6, 7].
现有的一大类多标签特征选择算法是基于信息论的过滤式算法.这类算法大多围绕mRMR(Mini-mal-Redundancy-Maximal-Relevance Criterion)[8]以评估特征的重要性.Lee等[9]提出基于互信息排序的快速多标签特征选择方法, 识别前景标签, 提高计算效率.Dai 等[10]提出RRMLFS(Multi-label Feature Selection with Removing Redundancy Features), 通过综合特征与标签及标签集的关联程度以评估特征的重要性.Zhang 等[11]提出LRFS(Feature Selection Based on Label Redundancy), 将标签分为独立标签和依赖标签, 引入条件互信息度量并结合特征冗余项, 优化特征选择, 提升多标签分类性能.上述算法多采用贪婪启发式的搜索, 逐一评估并选择候选特征, 直至达到预设子集规模.然而, 此类逐步搜索的方法容易陷入局部最优, 难以保证获得全局最优的特征子集[12].此外, 当评估标准涉及复杂的熵计算时, 启发式搜索往往非常耗时.
为了克服上述局限, Zhang 等[13]提出GRRO(Global Relevance and Redundancy Optimization), 将mRMR统一到一个可优化的全局模型中, 显著提升计算效率与可扩展性.尽管 GRRO 在全局优化方面取得较优效果, 但在两项关键环节仍有改进空间.1)相关性度量.GRRO 主要以成对互信息评估特征与标签的关系, 这种“ 分而治之” 的策略难以充分刻画单个特征与整体标签系统之间潜在的高阶依赖关系.2)冗余评估.GRRO对特征冗余的刻画主要基于信息论, 忽略数据的几何结构.换言之, GRRO仅关注统计冗余, 忽视局部结构的冗余.这一点常被传统信息论度量忽略[14].
为了应对上述挑战, 本文提出基于高阶相关性与双重冗余驱动的全局多标签特征选择算法(Glo- bal Multi-label Feature Selection Algorithm Driven by Higher-Order Correlation and Dual Redundancy, LGK-FR), 改进现有全局优化目标.首先, 在全局优化框架下, 以多标签k近邻模糊依赖度刻画相关性项, 捕获特征与标签集的高阶相关性.然后, 设计局部图结构引导的冗余项, 构建局部特征相似图, 挖掘数据的几何结构信息, 有效补充传统信息论对局部冗余刻画的缺失, 提升特征选择的质量与鲁棒性.最后, 融合高阶相关性、双重冗余性与标签相关性, 保持其优化的高效性与可扩展性.在15个公开多标签数据集上的实验验证GHC-DR的有效性.
特征选择作为数据预处理的关键环节, 旨在通过筛选信息丰富的特征子集以提升多标签学习的性能并降低计算开销[15].多标签特征选择算法根据其策略可分为包裹式算法、过滤式算法和嵌入式算法三类[16].本文研究与过滤式算法及嵌入式算法紧密相关, 因此本节将重点回顾这两类算法.
过滤式算法不依赖任何学习算法, 利用信息论等技术衡量特征质量[17].其中, 基于互信息(Mutual Information, MI)准则能有效评估非线性关系而备受关注, 其核心思想是遵循mRMR[8].为了衡量特征与标签集之间的依赖关系, Lee等[18]提出基于多变量互信息的方法, 最大化特征子集与标签集的相关性以筛选特征, 并利用近似计算提高效率.针对数据的不确定性, 基于模糊互信息, Lin 等[19]提出MSFS(Multi-label Streaming Feature Selection), 并在选择过程中引入标签相关性分析, 用于提升学习效果.除了上述介绍以外, 也有研究从更多角度描述相关性与冗余性, 如引入条件熵、互助信息与强相关标签增益等机制, 更细致地评估特征信息的贡献.Liao等[20]提出FCE-ML及其加速版本AFCE-ML, 增强算法的鲁棒性.Dai等[21]提出SRLG-LMA(Multi-label Fea-ture Selection Algorithm via Strongly Relevant Label Gain and Mutual Aid), 区分强弱标签并引入标签互助信息, 用于刻画标签差异和内部相关性.
近年来, 粗糙集理论及其扩展形式, 尤其是模糊粗糙集(Fuzzy Rough Sets, FRS), 凭借无需先验知识、能有效处理数据模糊性与不确定性的优势, 已被广泛应用于多标签特征选择[17, 22].Sun等[23]提出MFNRS(Feature Selection Method Based on Multi-label Fuzzy Neighborhood Rough Set), 通过标签补全和模糊邻域建模处理缺失标签问题, 并结合mRMR提升特征选择算法的鲁棒性.此外, 部分工作结合标签相关性, 通过标签增强, 将逻辑标签转化为更具信息量的标签分布, 更好地指导特征选择过程.Liu等[24]提出LDRS(Multi-label Feature Selection Based on Label Distribution and Neighborhood Rough Set), 利用实例信息分布的标签增强策略, 将原始逻辑标签转换标签分布, 挖掘潜在的标签重要性信息.然而, 传统FRS对噪声数据较敏感, 并且在复杂的多标签环境下, 如何构建鲁棒的模糊近似空间以准确评估特征价值, 仍是一个关键挑战.
相比过滤式算法, 嵌入式算法将特征选择融入算法优化过程中, 在模型训练的同时实现特征权重的学习与筛选.其中, 基于稀疏学习的模型是该领域的代表, 通过施加稀疏约束(如l1范数或l2, 1范数), 在优化过程中自动筛选特征[25].一般而言, l1范数常用于学习标签特定特征, 而l2, 1范数则识别标签共享的公共特征[26].一些先进的方法尝试将两者结合以同时捕获这两类信息.Ren等[27]设计双重正则化机制, 使用l1正则和l2, 1正则分别对权重矩阵进行稀疏化, 联合学习公共特征与特定特征, 提升算法性能.此外, 部分研究者开始利用图结构挖掘数据潜在的几何关系.Roffo等[14]提出Inf-FS(Infinite Feature Selection), 构建特征加权图, 利用图中路径的遍历性将特征选择建模为节点中心性排序问题, 评估特征的重要性.Cai等[28]提出MSSL, 引入图拉普拉斯正则项, 保持特征空间的局部几何结构, 用于辅助特征选择.然而, 现有基于图结构的算法多侧重于评估特征的重要性或保持流形结构, 较少探讨如何利用图结构显式度量特征间的冗余性, 尤其是识别那些在局部几何结构上表现出高度相似性的冗余特征.
总之, 现有研究在相关性与冗余性度量方面仍有改进空间.一方面, 多数算法以成对或低阶互信息评估相关性, 难以捕捉特征与复杂标签系统间的高阶依赖; 另一方面, 冗余性评估时较少考虑特征在数据局部几何结构的冗余.
本文提出基于高阶相关性与双重冗余驱动的全局多标签特征选择算法(GHC-DR).
在多标签数据中, 假设有n个样本, d个特征和q个标签类别, 特征集合C={f1, f2, …, fd}, 标签集合L={l1, l2, …, lq}.训练数据集的特征矩阵X∈ Rn× d, 对应的标签矩阵Y∈ {0, 1}n× q.特征矩阵的第i行xi ∈ Rd(i=1, 2, …, n)为样本xi的特征向量.类似地, 标签矩阵的第i行yi∈ {0, 1}q为与样本xi对应的标签向量.对于标签向量中的元素yij(j=1, 2, …, q), yij=1表示样本xi具有标签lj, 否则yij=0.
2.2.1 模糊粗糙集
给定一个模糊信息系统FIS=< U, C∪ D> , 其中U={x1, x2, …, xn}表示论域, C={f1, f2, …, fd}表示条件属性集, D={l1, l2, …, lq}表示决策属性集.
对于任意属性子集B⊆C, 可在论域U上诱导出相应的模糊关系RB.若对于论域中的任意元素x、y, 关系RB满足
1)自反性:RB(x, x)=1,
2)对称性:RB(x, y)=RB(y, x),
则称为模糊相似关系[29].
对于属性子集B⊆C, 诱导的模糊相似关系为:
$R_{B}(x, y)=\bigcap_{f \in B} R_{f}(x, y)$
其中Rf(x, y)表示样本x、y在属性f下的相似程度.此外, 由RB诱导出样本xi的模糊知识粒记为
在模糊信息系统FIS=< U, C∪ D> 中, 对于∀ B⊆C, Dh∈ U/D, ∀ x ∈ U关于B对Dh的下近似与上近似分别定义如下[30]:
$\underline{R}_{B}\left(D_{h}\right)(x)=\inf _{y \in U} \max \left\{1-R_{B}(x, y), D_{h}(y)\right\}, $
$\bar{R}_{B}\left(D_{h}\right)(x)=\sup _{y \in U} \min \left\{R_{B}(x, y), D_{h}(y)\right\} .$
进而, 决策D相对于属性子集B的模糊正域为[30]:
$\operatorname{POS}_{B}(D)(x)=\cup_{D_{h} \in U / D} \underline{R}_{B}\left(D_{h}\right)(x) .$
对于∀ B⊆C, 决策属性D对B的模糊依赖度为[30]:
$\gamma_{B}(D)=\frac{\left|\operatorname{POS}_{B}(D)\right|}{|U|}=\frac{\sum_{x \in U} \operatorname{POS}_{B}(D)(x)}{|U|} \in[0, 1], $
γ B(D)用于衡量正域在整个论域中所占的比例, 常刻画决策属性与条件属性之间的相关性.
2.2.2 全局框架构建
互信息作为信息论核心度量, 刻画变量间共享信息量.在特征选择中, mRMR[8]期望候选特征与标签高相关, 并与已选特征低冗余, 其基本形式如下:
$\max \left(f^{+}\right)=I\left(f^{+}, L\right)-I\left(f^{+}, S\right), $
其中 f+表示待选特征, L表示标签集合, S表示已选择特征子集, I(· , · )表示互信息.
对于任意两个随机变量X、Y, 互信息定义如下:
$I(X, Y)=\sum_{x \in X} \sum_{y \in Y} p(x, y) \log _{2}\left(\frac{p(x, y)}{p(x) p(y)}\right), $
其中, p(x, y)表示联合概率分布, p(x)、p(y)表示边缘概率分布.
在此基础上, 文献[13]构建全局相关性与冗余度的优化框架, 将特征选择形式化为
$\min _{\mathbf{Z}}\left[\sum_{u=1}^{q} \sum_{i=1}^{d}\left(I\left(\boldsymbol{f}_{i}, \boldsymbol{l}_{u}\right) z_{i u}-\sum_{j=1}^{d} I\left(\boldsymbol{f}_{i}, \boldsymbol{f}_{j}\right) z_{i u} z_{j u}\right)\right], $ (1)
其中, 矩阵Z∈ Rd× q表示特征系数矩阵, ziu、zju分别表示特征fi、 fj相对于标签lu的重要性, I(fi, lu)表示特征fi与标签lu之间的互信息, I(fi, fj)表示特征fi、 fj之间的互信息.式(1)表明, 一个特征的重要程度与特征-标签的相关性呈正相关, 并受其它特征的冗余抑制.
进一步地, 刻画标签间余弦相似关系, 建立标签相关性, 得到如下优化目标:
$\min _{Z}\|Z-C\|_{\mathrm{F}}^{2}+\alpha \operatorname{tr}\left(Z^{\mathrm{T}} \boldsymbol{G} \boldsymbol{Z}\right)+\beta \operatorname{tr}\left(\boldsymbol{R} \boldsymbol{Z}^{\mathrm{T}} \boldsymbol{Z}\right), $ (2)
其中, cij=I(fi, lj)表示特征与标签的相关性, gij=I(fi, fj)表示特征间冗余, rij=1-sij表示标签间的相关性,
$s_{i j}=\cos \left(\boldsymbol{l}_{i}, \boldsymbol{l}_{j}\right)=\frac{\boldsymbol{l}_{i}^{\mathrm{T}} \boldsymbol{l}_{j}}{\left\|\boldsymbol{l}_{i}\right\|\left\|\boldsymbol{l}_{j}\right\|}, $
表示标签li、lj之间的余弦相似度, li∈ {0, 1}n表示第i个标签的列向量, lj∈ {0, 1}n表示第j个标签的列向量, α 、 β 表示权衡系数.由式(2)可见, Z同时受特征相关性、特征冗余性及标签相关性的共同约束, 从而实现全局优化.
2.3.1 基于多标签k-近邻模糊依赖度的高阶相关性评估
在多标签特征选择中, 准确评估特征与标签集之间的相关性始终是一项核心挑战.现有方法, 如互信息, 多基于“ 成对” 思想, 即分别度量特征与单个标签之间的依赖关系, 从而构建相关性矩阵, 实现对特征相关性的评估.虽然这一思路在计算上直观且具备一定的可解释性, 但无法捕捉特征对复杂标签组合的高阶判别作用.
针对这一问题, 本节引入模糊粗糙集理论, 提出基于多标签 k-近邻的特征依赖度方法, 直接量化特征与整个标签集之间的高阶相关性, 全面揭示特征与标签系统之间的复杂依赖关系.
为了挖掘标签空间中隐含的分类信息, 同时针对传统标签空间离散且对噪声敏感的局限, 引入模糊粗糙集中的粒化思想, 利用模糊相似关系作为特征与标签的语义桥梁, 构建能反映标签分布特性的语义空间.不同于传统样本对标签非此即彼的确定性关系, 多邻域模糊决策将离散的类别标签转化为连续的模糊语义向量, 有效减少由标签错误引起的分类偏差.
定义1综合模糊相似关系 给定多标签信息系统, 包含样本集U={x1, x2, …, xn}和特征集C={f1, f2, …, fd}.对于∀ xi∈ U, xj∈ U, 在C上的模糊相似关系为:
$S\left(x_{i}, x_{j}\right)=\min _{t=1}^{d} R_{t}\left(x_{i}, x_{j}\right), $ (3)
其中
$\begin{array}{l} R_{t}\left(x_{i}, x_{j}\right)= \\ \left\{\begin{array}{ll} 1-\left|f_{t}\left(x_{i}\right)-f_{t}\left(x_{j}\right)\right|, & \left|f_{t}\left(x_{i}\right)-f_{t}\left(x_{j}\right)\right| \leqslant \xi_{t} \\ 0, & \text { 其它 } \end{array}\right. \end{array}$
表示样本xi、xj在特征ft上的模糊相似关系, ξ t=std(ft)/λ 表示由特征ft的标准差和调节参数λ 共同决定的自适应邻域半径.式(3)表明, 只有当两个样本在所有特征上都足够相似时, 相似度才较高.
定义2多邻域模糊决策 对于∀ xi∈ U, 其标签lp的多邻域模糊决策为:
$\widetilde{L}_{p}\left(x_{i}\right)=\frac{\sum_{j=1}^{n} S\left(x_{i}, x_{j}\right) y_{j p}}{\sum_{j=1}^{n} S\left(x_{i}, x_{j}\right)}, $ (4)
其中yjp表示样本xj关于标签lp的取值 (0或1).
$\widetilde{\boldsymbol{L}}\left(x_{i}\right)=\left[\widetilde{L}_{1}\left(x_{i}\right), \widetilde{L}_{2}\left(x_{i}\right), \cdots, \widetilde{L}_{q}\left(x_{i}\right)\right], $
该向量将样本xi映射到一个q维的标签语义空间.
在多标签空间中, 如何精准定义同类样本与异类样本是构建模糊粗糙集上下近似的关键, 为此, 借鉴皮尔逊相关系数的思想[31], 利用标签隶属度
定义3标签相似度 任意两个样本xi、xj在标签空间中的相似度SIM(xi, xj)由其模糊决策向量的皮尔逊相关系数计算得出, 即
$\operatorname{SIM}\left(x_{i}, x_{j}\right)=\frac{\left(\widetilde{\boldsymbol{L}}\left(x_{i}\right)-\widetilde{\widetilde{L}}\left(x_{i}\right)\right)\left(\widetilde{\boldsymbol{L}}\left(x_{j}\right)-\widetilde{\widetilde{L}}\left(x_{j}\right)\right)^{\mathrm{T}}}{\left\|\widetilde{\boldsymbol{L}}\left(x_{i}\right)-\widetilde{\widetilde{L}}\left(x_{i}\right)\right\|\left\|\widetilde{\boldsymbol{L}}\left(x_{j}\right)-\widetilde{\widetilde{L}}\left(x_{j}\right)\right\|}, $
其中
在上述软异类样本集的基础上, 通过模糊粗糙集下近似的思想度量特征的依赖度.直观上, 特征的分类能力体现在其能否有效区分样本与其软异类样本.
定义4 k-近邻模糊下近似 给定特征ft∈ C, 对于∀ xi∈ U关于标签集L的k-近邻模糊下近似(即正域)定义如下:
$\operatorname{POS}_{f_{t}}(L)\left(x_{i}\right)=\frac{1}{k} \sum_{x_{j} \in D T\left(x_{i}\right)}\left(1-R_{f_{t}}\left(x_{i}, x_{j}\right)\right), $ (5)
其中, DT(xi)表示xi的软异类样本集,
定义5 k-近邻模糊依赖度 对于特征ft, 其相对于标签系统L的 k-近邻模糊依赖度定义如下:
$F D\left(f_{t}, L\right)=\frac{1}{n} \sum_{i=1}^{n} \operatorname{POS}_{f_{t}}(L)\left(x_{i}\right) \in[0, 1] .$ (6)
FD(ft, L)值越高, 表明特征ft在全局标签下区分不同标签语义样本的能力越强, 即该特征与整个标签集的高阶相关性越强.
在GHC-DR中, 计算每个特征的k-近邻模糊依赖度, 得到一个高阶相关性向量:
$\boldsymbol{F}_{\text {H_Relevance }}=\left[F D\left(f_{1}, L\right), F D\left(f_{2}, L\right), \cdots, F D\left(f_{d}, L\right)\right] .$
不同于式(2)直接使用互信息矩阵作为稀疏学习模型的优化目标, GHC-DR在目标函数中将该高阶相关性向量作为奖惩机制融入互信息矩阵, 充分捕捉复杂标签结构中的潜在依赖关系.
因此, 优化目标定义如下:
$\min _{\boldsymbol{Z}}(\underbrace{\left\|\boldsymbol{Z}-\boldsymbol{C}_{\mathrm{FLH}}\right\|_{\mathrm{F}}^{2}}_{\text {相关性加权拟合项 }}+\underbrace{\alpha \operatorname{tr}\left(\boldsymbol{Z}^{\mathrm{T}} \boldsymbol{G} \boldsymbol{Z}\right)}_{\text {特征元余项 }}+\underbrace{\beta \operatorname{tr}\left(\boldsymbol{R} \boldsymbol{Z}^{\mathrm{T}} \boldsymbol{Z}\right)}_{\text {标签相关项 }}), $
其中
CFLH=diag(w)C,
w表示由FH_Relevance经过线性缩放得到的权重向量, diag(w)表示对角矩阵.该设计通过增强在全局标签系统中作用显著的特征权重, 并抑制仅对少数标签有效的特征, 使算法在特征权重学习过程中能更突出整体相关性, 更好地适应多标签学习的复杂性.
2.3.2 基于局部图结构的双重特征冗余性度量
现有特征选择方法在冗余性评估中通常依赖信息论度量, 如互信息与条件互信息, 忽视特征在数据空间中的几何结构.为此, 本节在互信息冗余度的基础上, 进一步引入局部图结构, 捕捉几何层面的潜在冗余性, 提出局部结构化的双重冗余性评估机制.
特征向量不仅描述样本的属性值, 数值分布也隐式刻画样本间的分布结构, 若两个特征诱导的样本空间结构相似, 可认为存在结构性冗余.基于此思想, 将所有特征视为图中节点, 并构建一个特征图相似性矩阵FFgraph, 量化其结构性冗余.
定义6特征间的结构距离 给定特征集C={f1, f2, …, fd}, 其中每个特征fi视为一个n维的向量(n为样本数), 记作fi∈ Rn.任意两个特征fi、 fj之间的距离采用余弦定义:
$\operatorname{dist}\left(\boldsymbol{f}_{i}, \boldsymbol{f}_{j}\right)=1-\frac{\boldsymbol{f}_{i} \boldsymbol{f}_{j}}{\left\|\boldsymbol{f}_{i}\right\|\left\|\boldsymbol{f}_{j}\right\|} .$
该度量反映特征向量在方向上的差异, 距离越小, 表明两者在样本中的作用越接近.为了关注局部结构, 进一步构建k-近邻图, 对于每个特征节点fi, 仅保留其在距离上最近的k个邻居特征, 从而更准确地反映局部的几何结构.
定义7基于图的结构局部相似度 特征fi、 fj之间的图结构相似度定义如下:
$F F_{\text {graph }}(i, j)=\left\{\begin{array}{ll} \exp \left(-\frac{\operatorname{dist}\left(\boldsymbol{f}_{i}, \boldsymbol{f}_{j}\right)^{2}}{2 \sigma_{i}^{2}}\right), & \boldsymbol{f}_{j} \in N_{k}\left(\boldsymbol{f}_{i}\right) \\ 0, & \text { 其它 } \end{array}\right.$
其中, Nk(fi)表示特征fi的k个最近邻集合,
$\sigma_{i}=\operatorname{dist}\left(\boldsymbol{f}_{i}, \boldsymbol{f}_{k}^{(i)}\right)$
表示fi与其第k个近邻
$\boldsymbol{F} \boldsymbol{F}_{\text {graph }}=\max \left(\boldsymbol{F} \boldsymbol{F}_{\text {graph }}, \boldsymbol{F} \boldsymbol{F}_{\text {graph }}^{\mathrm{T}}\right) .$
FFgraph(i, j)值越高, 表明特征fi、 fj在样本空间中结构作用越相似, 即是冗余的.通过在互信息的基础上引入结构冗余性, 形成 GHC-DR中一个局部精细和全局宏观的正则化项.
在GHC-DR中, 将基于互信息的冗余矩阵G与基于图的结构相似性矩阵FFgraph进行线性加权组合, 形成一个新的冗余矩阵:
$\boldsymbol{G}_{\mathrm{FGM}}=(1-\omega) \boldsymbol{G}+\omega \boldsymbol{F} \boldsymbol{F}_{\mathrm{graph}}, $ (7)
其中, ω ∈ [0, 1], 用于衡量两种冗余的权重.由于图结构是基于局部k-近邻构建的(k 自适应设为特征总数的 5%), 因此这里将ω 固定为 0.2.由此得到的GFGM同时捕捉特征间局部相似性和全局相似性.
最终GHC-DR优化目标函数定义如下:
$\min _{\boldsymbol{Z}}(\underbrace{\left\|\boldsymbol{Z}-\boldsymbol{C}_{\mathrm{FLH}}\right\|_{\mathrm{F}}^{2}}_{\text {相关性加䄺拟合项 }}+\underbrace{\alpha \operatorname{tr}\left(\boldsymbol{Z}^{\mathrm{T}} \boldsymbol{G}_{\mathrm{FGC}} \boldsymbol{Z}\right)}_{\text {双重特征元余项 }}+\underbrace{\beta \operatorname{tr}\left(\boldsymbol{R} \boldsymbol{Z}^{\mathrm{T}} \boldsymbol{Z}\right)}_{\text {标签相关项 }}) .$ (8)
该目标函数在互信息的基础上, 引入高阶相关性评估和双重冗余性度量, 更全面刻画多标签数据的内在结构.式(8)综合考虑高阶相关性、双重冗余性及标签相关性等因素.
本节简要介绍GHC-DR的优化目标求解过程.冗余矩阵GFGM为2个对称半正定矩阵(G和FFgraph)的非负加权和, 并且标签相关性矩阵R本身也是对称半正定矩阵.因此, 目标函数(8)是一个关于变量Z的严格凸函数, 从而保证全局最优解存在其唯一性[13].
对函数关于Z求梯度并令其为0, 可解得Z的方程:
(I+α GFGM)Z+Z(β R)=CFLH, (9)
其中I表示单位矩阵.式(9)是一个形如
AZ+ZB=C
的李雅普诺夫方程, 已有数值稳定且高效的求解方法[32], 在MATLAB环境中, 可直接调用lyap函数进行求解.解得Z后, 通过其向量zi∶ 的L2-范数计算每个特征fi, 最终排序得到特征选择结果.
算法 1 GHC-DR
输入 数据矩阵X∈ Rn× d, 标签矩阵L∈ Rn× q,
特征选择数量k, 超参数α , β , λ
输出 Top-k特征的索引
1.for 每个xi∈ U do
2. for 每个l∈ L do
3. 计算特征标签互信息矩阵C
4. end
5. for 每个xj∈ U do
6. 计算特征间冗余互信息矩阵G
7. end
8.end
9.计算标签间相关性矩阵
LR← CosineSimilarity(LT, LT)
// 计算高阶特征依赖度FH_Relevance
10.for 每个xt∈ U do
11. 对每个特征, 计算模糊关系矩阵Rt
12. 计算所有特征下的综合相似度S(式(3))
13.end
14.for 每个l∈ L do
15. 计算标签下多邻域模糊决策
16.end
17.基于
确定软异类样本集DT
18.for 每个xt∈ U do
19. 计算正域PO
20. 计算k-近邻模糊依赖度FD(ft, L)(式(6))
21. FH_Relevance(ft, L)← FD(ft, L)
22.end
23.计算基于图结构的特征冗余度矩阵FFgraph
24.计算特征-标签相关性
CFLH← Cdiag(w)← FH_Relevance
25.计算新特征冗余度矩阵GFGM(式(7))
26.构建李雅普诺夫方程AZ+ZB=C, 优化求解权
值矩阵Z
27.for 每个xt∈ U do
28. 计算全局得分 St=
29.end
30.返回排序后的Top-k特征
在GHC-DR中, 假设有n个样本, d个特征, q个标签.步骤1~9计算特征之间、特征-标签间及标签间的相关性, 时间复杂度为O(d2+dq+q2).步骤10~22计算特征与标签L的高阶依赖度, 用于调整相关性矩阵, 时间复杂度为O(d(n2+nk)), 其中k表示最小类别标签的10% 样本数.步骤23计算图特征冗余, 时间复杂度为O(nd2).因此, GHC-DR总体时间复杂度为O(nd2+n2+q2+nq).
在15个公开多标签数据集上进行实验, 这些数据集来源于Mulan项目库, 涵盖文本、图像、音频、生物学等多个领域.表 1 详细列出这些数据集的统计信息.按照惯例, 采用针对数据集原始划分的训练集和测试集进行所有实验, 确保对比的公平性.
| 表1 实验数据集 Table 1 Experimental datasets |
多标签学习的性能评估比单标签更复杂.本文采用如下5个广泛认可的多标签评估指标, 从不同角度衡量算法性能:HL(Hamming Loss)↓ , RL(Ran-king Loss)↓ , CV(Coverage)↓ , OE(One Error)↓ , AP(Average Precision)↑ .其中, 符号↑ 表示指标值越大性能越优, ↓ 表示指标值越小性能越优.
所有对比算法参数均采用文献中的建议或原始代码中设置.
对于GHC-DR, 超参数α 、 β 通过网格搜索策略进行寻优, 搜索范围设为{10-2, 10-1, 1, 101, 102}, 超参数λ 在{0.6, 0.8, 1, 1.2, 1.4}内搜索.参数通过平均分类结果(Average Classification Result, ACR)最小值确定[13].ACR定义如下:
$A C R(\text { para })=\sum_{i=1}^{30}\left(H L_{i}(\epsilon, U)+R L_{i}(\epsilon, U)\right), $
其中, para表示算法参数集合, U表示测试集, $\epsilon $表示分类器, 即ML-KNN.HLi($\epsilon $, U)和RLi($\epsilon $, U)分别表示选择前30%特征时的HL值和RL值.
在性能评估阶段, 所有算法均选取总特征数的 50% 作为筛选后的特征子集用于性能评估.使用ML-KNN(k=10, s=1) 进行分类评估.
所有实验均在一台配置Intel i9 CPU和32 GB RAM的PC上进行.
为了验证GHC-DR 的有效性, 选取如下9种具有代表性的多标签特征选择算法作为对比算法.1)基于互信息的多标签特征选择算法:文献[9]算法、GRRO[13]和Global Relevance and Redundancy Opti-mization with Label-Specific Features(简记为GRRO-LS)[13]、文献[18]算法.2)基于非负矩阵分解的多标签特征选择算法:SCNMF (Multi-label Feature Se-lection via Similarity Constraints with Non-negative Matrix Factorization)[33].3)结合互信息与稀疏约束的多标签特征选择算法:MFS-MFR[16].4)采用稀疏正则项的多标签特征选择算法:MDFS[34]、PMSNE[35]、SLOFS[36].
在15个数据集上对比各算法的指标值, 结果如表2至表6所示, 表中给出1%~50%特征范围内各指标的平均值, 黑体数字表示最优值.由表可知, GHC-DR在大多数数据集上均表现较优.特别是在AP指标上, GHC-DR在多达11个数据集上取得最优值, 此外, 对于RL、CV指标也在10个数据集上获得最优值, 这有力证实其在提升分类精度和减少排序错误方面的能力.此外, 一些对比算法在特定的数据集上也展现出较优性能.例如:MFS-MFR在Me- dical数据集上表现出色, 4个指标值均优于GHC-DR; GRRO-LS在Corel16k001数据集上取得4个指标的最优值.然而, 综合来看, GHC-DR在大多数数据集上的指标值均展现出一定领先优势, 由此可得出结论:GHC-DR在多标签特征选择方面是有效的, 与其它前沿算法相比具有性能优势.
| 表2 各算法在15个数据集上的AP值对比 Table 2 Comparison of AP values obtained by different algorithms on 15 datasets |
| 表3 各算法在15个数据集上的CV值对比 Table 3 Comparison of CV values obtained by different algorithms on 15 datasets |
| 表4 各算法在15个数据集上的RL值对比 Table 4 Comparison of RL values obtained by different algorithms on 15 datasets |
| 表5 各算法在15个数据集上的HL值对比 Table 5 Comparison of HL values obtained by different algorithms on 15 datasets |
| 表6 各算法在15个数据集上的OE值对比 Table 6 Comparison of OE values obtained by different algorithms on 15 datasets |
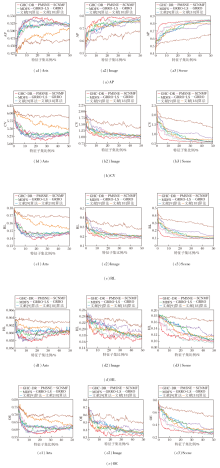
为了进一步验证GHC-DR的准确性和可靠性, 根据所选特征数量的变化, 在Arts、Image、Scene数据集上进行实验, 对比GHC-DR、文献[9]算法、GRRO[13]、GRRO-LS[13]、文献[18]算法、SCNMF[33]、MDFS[34]、PMSNE[35]的性能变化, 结果如图1所示.由图可知, 所有算法的性能均随着特征子集比例的增加而提高, 随后趋于稳定或下降.在Image、Scene 数据集上, GHC-DR表现出明显优势.在Arts数据集上, 特征子集比例少于 10% 时, 部分算法优于GHC-DR, 但随着特征子集比例的增加, GHC-DR性能迅速提升并超过对比算法.因此, GHC-DR在整体性能上优于对比算法.
 | 图1 各算法在3个数据集上的性能变化曲线Fig.1 Performance curves of different algorithms on 3 datasets |
为了更好对比GHC-DR与其它算法之间的性能差异, 采用Friedman检验[37]和Bonferroni-Dunn检验[38]进行统计显著性分析.
采用Friedman检验评估GHC-DR在全部数据集上的平均排名差异.显著性水平α =0.05时, Friedman检验的临界值为1.955 0.
各评价指标上统计量FF分别为:AP(14.126 5)、CV(14.798 2)、RL(13.491 3)、HL(9.641 1)、OE(9.847 2).统计量结果显示, 所有指标的FF值均远大于临界值, 因此拒绝“ 所有算法性能无显著差异” 的原假设.换言之, 所有算法之间的性能存在显著差异.
然后, 以GHC-DR为控制算法, 进行Bonferroni-Dunn事后检验, 检验GHC-DR与对比算法之间的性能差距.临界距离(Critical Distance, CD)定义为
$C D_{\alpha}=\rho_{\alpha} \sqrt{\frac{k(k+1)}{6 N}}, $
其中, N=15, 表示数据集个数, k=10, 表示算法个数.根据 Bonferroni-Dunn检验的临界值查询表[39], 当k=10, α =0.05时, 可得ρ α =3.164.因此, 在 N=15时, 计算可得CDα =3.497 9.
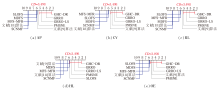
图2直观展示检验结果, 任何与GHC-DR平均排名之差小于CD值的算法都用线段连接.由图可见, GHC-DR 在5个指标上均排名第一, 并且与大部分对比算法(如文献[18]算法, MDFS, MFS-MFR, SCNMF, SLOFS)之间不存在连线, 表明GHC-DR在统计学意义上优于对比算法.
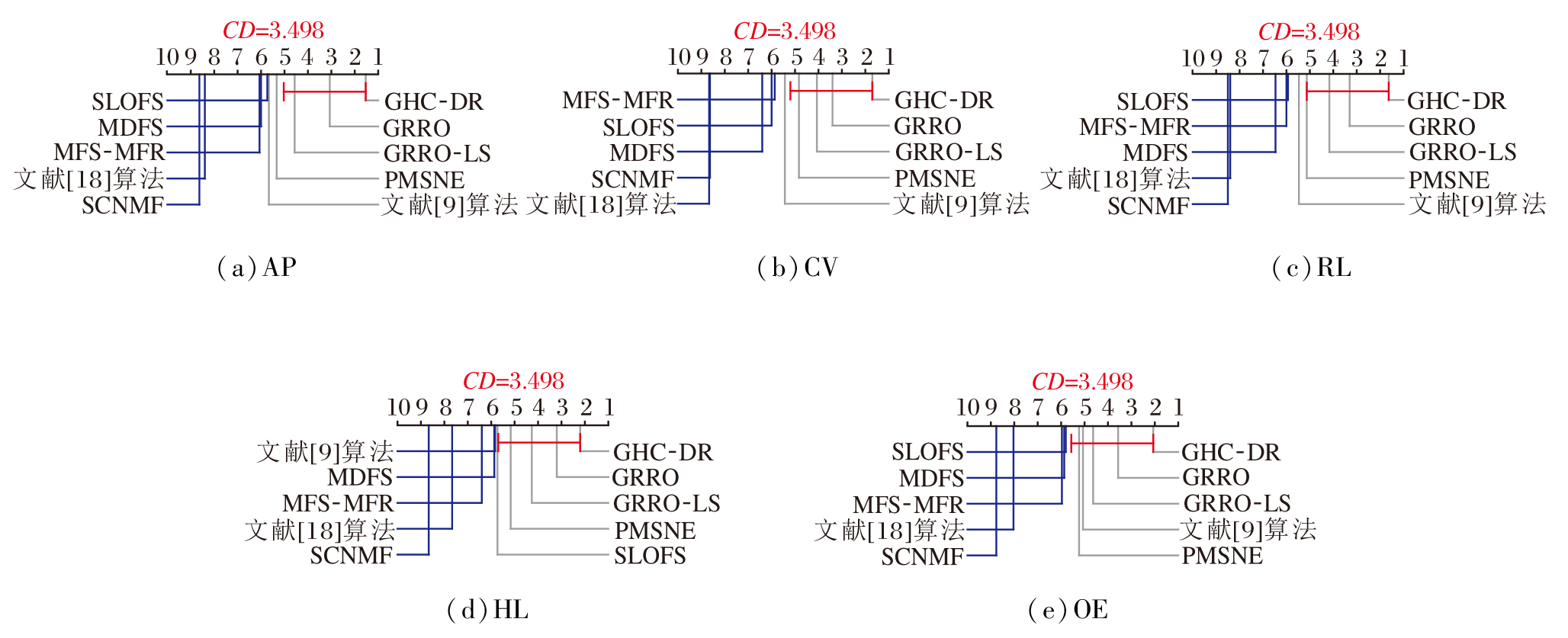 | 图2 各算法的Bonferroni-Dunn检验结果Fig.2 Results of Bonferroni-Dunn test for different algorithms |
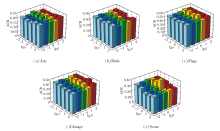
本节对GHC-DR中3个超参数α 、 β 、λ 进行敏感性分析.在分析α 、 β 时, 固定λ , 并通过不同(α , β )组合下ACR值评估其敏感性.在分析λ 时, 则固定(α , β )组合, 讨论λ 影响.具体结果如图3和表7所示.
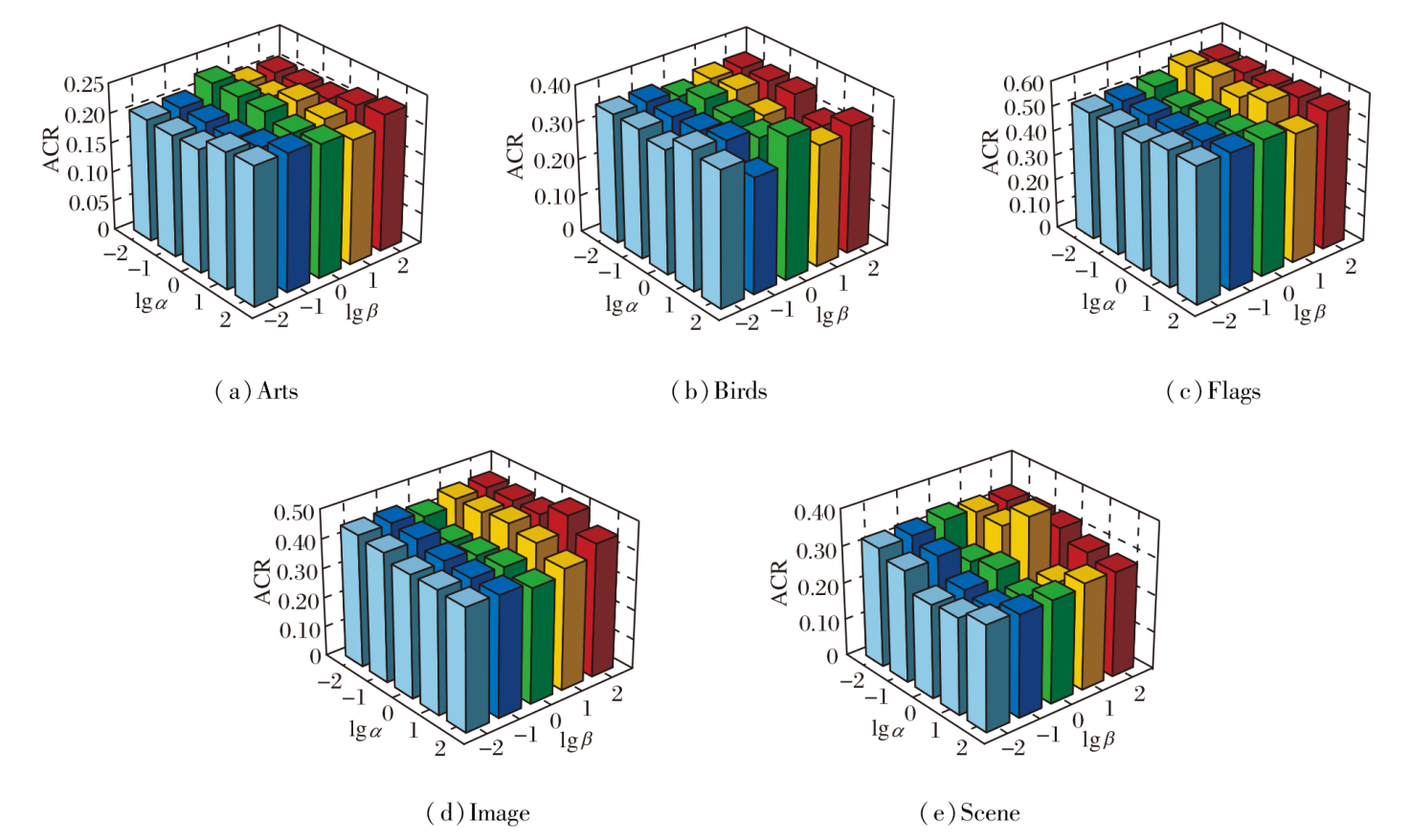 | 图3 α 、 β 对GHC-DR性能的影响Fig.3 Effect of α and β on GHC-DR performance |
| 表7 λ 对GHC-DR性能的影响 Table 7 Effect of λ on GHC-DR performance |
由图3和表7可见, 在5个数据集上, GHC-DR的性能在设定参数范围内是稳定的.(α , β )组合在Scene数据集上存在轻微波动, 但λ 对性能的影响相对平缓(各数据集上ACR值波动均在0.05以内), 整体稳定性较优, 这说明GHC-DR对参数的敏感性较低.
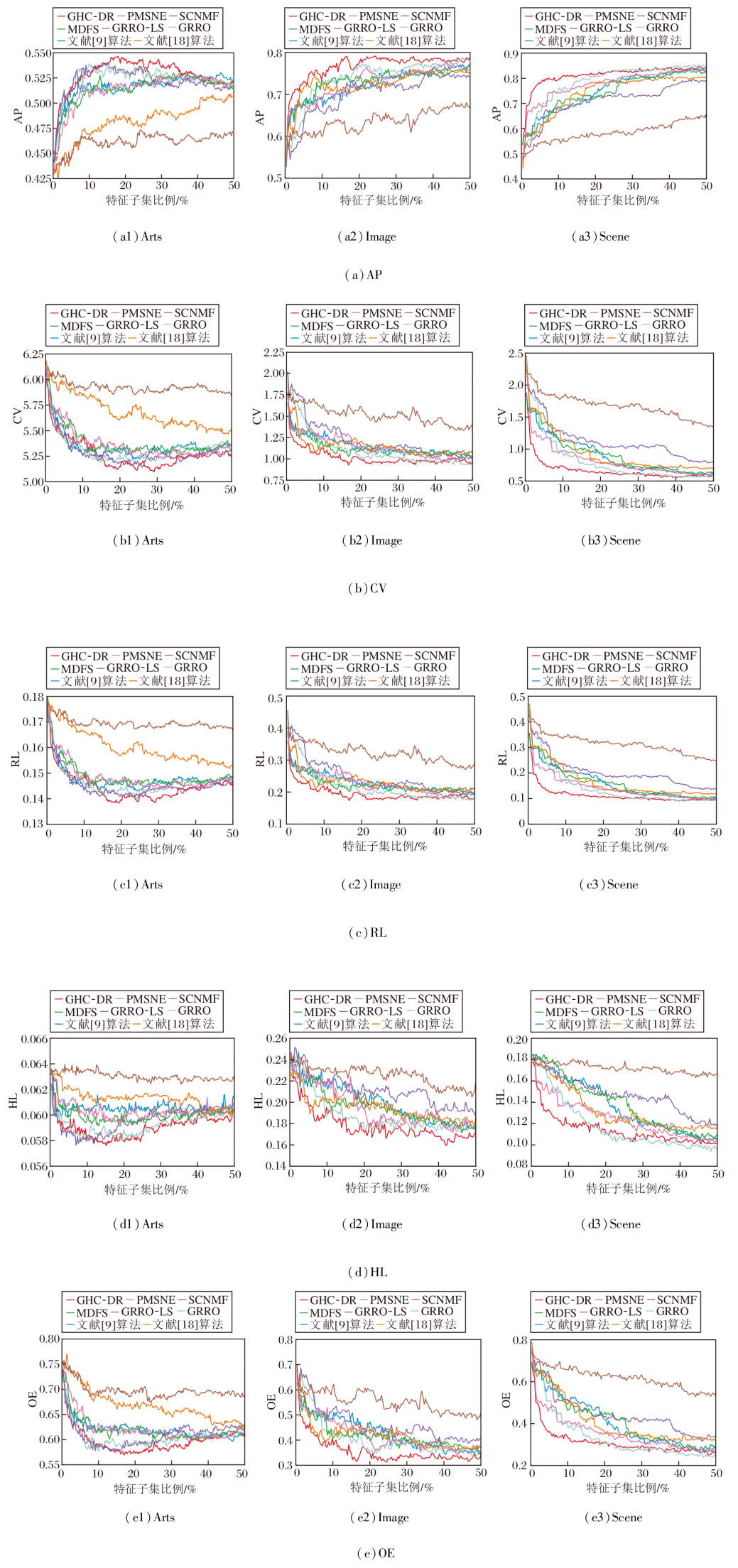
为了验证GHC-DR中高阶相关性与图冗余性的有效性, 在Emotions、Scene、Image数据集上进行消融实验.设计如下4种变体.1)Baseline:仅基于原始互信息框架.2)Baseline+FH:引入高阶相关性.3)Ba- seline+FFgraph:引入特征图结构冗余矩阵.4)GHC-DR.具体消融实验结果如图4所示.
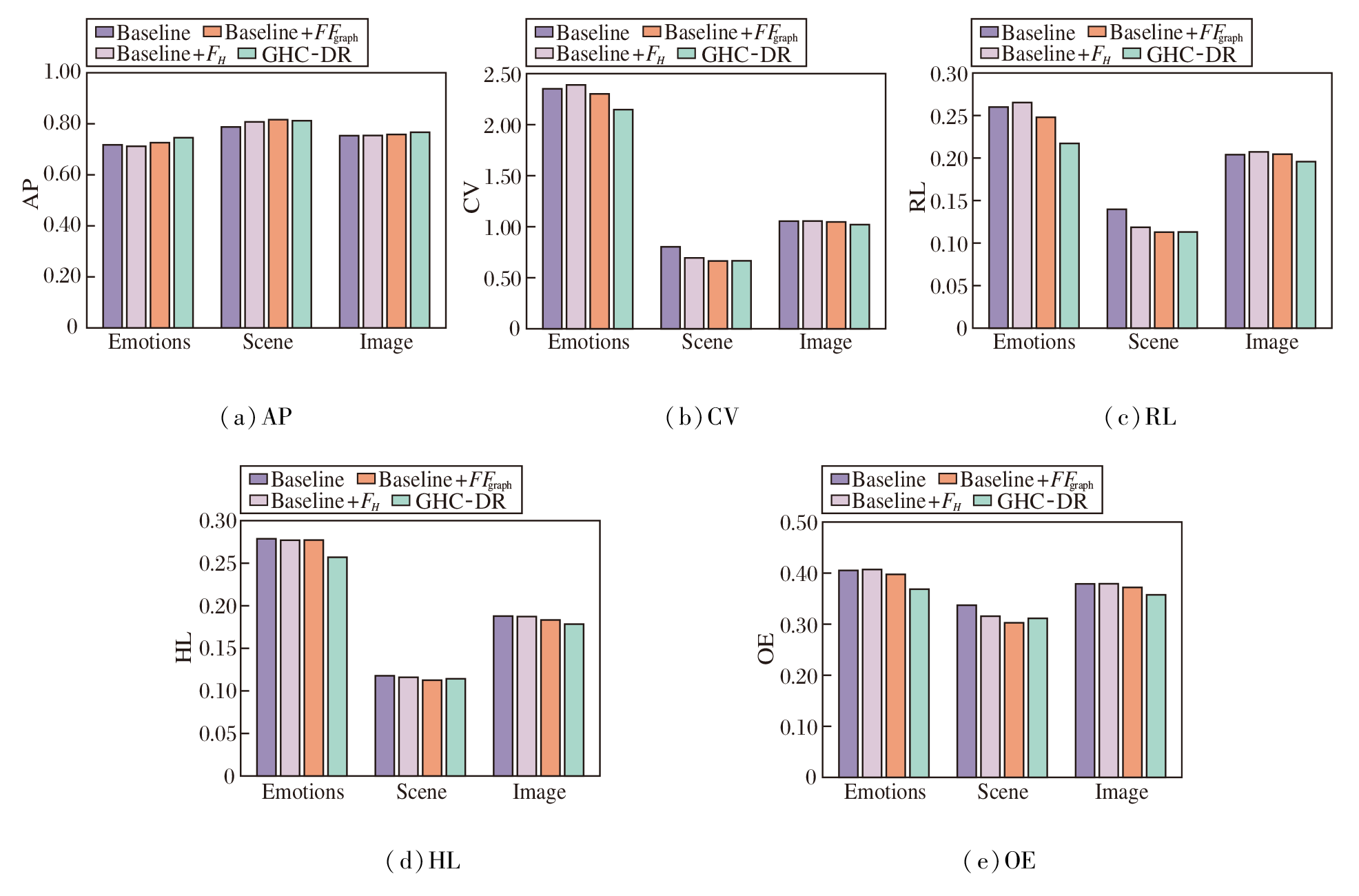 | 图4 GHC-DR及变体在3个数据集上的消融实验结果Fig.4 Ablation experiment results of GHC-DR and its variants on 3 datasets |
由图4可知, 相比Baseline, 单独引入FFgraph或FH的变体在多数指标上实现性能提升, 验证模糊依赖度在捕捉高阶依赖关系及图结构刻画冗余方面的有效性.值得注意的是, 在个别数据集的某个指标上(如Scene数据集的OE和Emotions数据集的RL), 单变体表现略差, 但从整体上看, GHC-DR在5个指标上均表现较优, 表明两个组件的协同作用可有效提升算法的整体性能.
在多标签学习中, 有效的特征选择对于提升分类器性能至关重要, 为此本文提出基于高阶相关性与双重冗余驱动的全局多标签特征选择算法(GHC-DR), 通过改进相关性与冗余性的度量方式, 克服现有方法的局限性.首先, 引入基于多标签k近邻的模糊依赖度, 准确捕捉特征与复杂标签系统之间的高阶依赖.然后, 设计双重冗余评估机制, 通过构建特征图, 结合两种冗余.最后, 将高阶相关性、双重冗余性与标签相关性共同融入一个统一的全局优化目标, 通过李雅普诺夫方程进行高效求解.实验及统计分析表明, GHC-DR在多个评估指标上均取得较优值, 表明其有效性.未来工作将在处理缺失标签及挖掘深层标签相关性方面, 探索构建更具鲁棒性的特征选择模型.
本文责任编委 张燕平
Recommended by Associate Editor ZHANG Yanping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|