{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高时间步长友好的分片并行脉冲神经元模型
[赖剑翔1  , 黄昉菀
, 黄昉菀1, 2, 3 , 吴越钟1, 2, 3 , 於志勇1, 2, 3 ]
, 黄昉菀, 吴越钟, 於志勇]
|
|



作者简介:

赖剑翔,硕士研究生,主要研究方向为脉冲神经网络.E-mail:laijianxiang2002@163.com.

吴越钟,博士,助理教授,主要研究方向为传感器网络系统.E-mail:yuezhong.wu@fzu.edu.cn.

於志勇,博士,教授,主要研究方向为普适计算.E-mail:yuzhiyong@fzu.edu.cn.
脉冲神经网络在时间序列预测领域面临时序映射难以平衡计算效率与信息处理能力,并行脉冲神经元在高时间步长拓展能力不足、容易陷入局部最优等问题.为此,文中提出高时间步长友好的分片并行脉冲神经元模型(High-Time-Step-Friendly Slice Parallel Spiking Neuron, HSPSN).首先,通过直接时序映射方法实现时间步的一对一匹配.然后,设计局部切片与全局切片协同的分片并行机制,实现局部与全局时序模式在神经元层面的整合.最后,采用收缩矩阵随机丢弃方法,有效引导神经元达到更优收敛.在7个真实世界时间序列预测数据集上的实验表明,HSPSN在预测精度、能耗效率及收敛稳定性等方面均较优,可有效提取多元时间序列和协变量时间序列的复杂时空依赖.
About Author:
LAI Jianxiang, Master student. His research interests include spiking neural networks.
WU Yuezhong, Ph.D., assistant profe-ssor. His research interests include sensor network systems.
YU Zhiyong, Ph.D., professor. His research interests include pervasive computing.
Spiking neural networks are faced with challenges in time series prediction, including the difficulty of balancing computational efficiency and information processing capability in temporal mapping, insufficient scalability of parallel spiking neurons at high time steps, and a tendency to fall into local optimum. To address these issues, a high-time-step-friendly slice parallel spiking neuron(HSPSN) is proposed in this paper. First, a direct temporal mapping method is employed to achieve one-to-one matching of time steps. Then, a slice parallel mechanism is designed to integrate local and global temporal patterns at the neuronal level through the synergy of local and global slices. Finally, a constriction matrix random dropout strategy is adopted to effectively guide the neurons toward superior convergence. Experiments on seven real-world time series prediction datasets demonstrate that HSPSN significantly outperforms existing spiking neural networks in terms of prediction accuracy, energy efficiency and convergence stability and it can effectively capture complex spatiotemporal dependencies in multivariate time series and covariate-based time series.
脉冲神经网络(Spiking Neural Network, SNN)因其高度的生物学合理性和低能耗的硬件部署优势, 已在学术界与产业界引发广泛关注.不同于传统人工神经网络(Artificial Neural Network, ANN)采用连续的数值信号传递信息, SNN利用离散的脉冲信号传递信息[1], 可高效模仿生物大脑神经元的工作模式.
SNN擅长捕捉数据的时间依赖关系、动态变化规律和多变量关联, 特别适用于时间序列类任务.以时序预测任务为例, 其本质是基于历史时序数据预测未来数据的变化.传统ANN往往需要通过循环结构、门控机制或时间卷积间接捕捉时序关系, 本质是使用“ 连续数值的迭代” 模拟时间.SNN的脉冲编码机制直接将“ 时间” 作为信息的一部分— — 脉冲的发放时刻、间隔、频率本身就是时序信号的载体[2].这种“ 时间即信息” 的编码方式使SNN无需复杂结构就能精准捕捉长期依赖.其次, 多数时间序列是多变量的, 核心难点是既要捕捉单个变量的时序变化, 又要关联不同变量的空间依赖.SNN 的时空动力学特性具备这种双维度处理能力, 既可通过脉冲发放的先后顺序刻画单个变量的时序趋势, 又可通过神经元之间的连接拓扑建模多变量的关联关系.最后, 时间序列预测可能面临高采样率数据[3], 传统模型需要计算每个时间步的连续数值, 能耗较高、实时性较差, 难以满足边缘设备的部署需求.SNN存在稀疏激活特性, 具有低能耗和高实时性的优点, 更适配高采样率时间序列[4].近年来, SNN 在多个时间序列预测场景中已表现出接近甚至优于传统模型的性能, 展现出较强的研究潜力与应用价值[5, 6].
当前, 基于SNN的时间序列预测模型首先需要解决的问题是如何将时间序列的时间步映射至SNN模拟神经动力学的离散时间步(简称“ 模拟时间步” ), 这决定时序信息如何被SNN感知与处理.现有做法主要有两种.1)将时间序列单个时间步扩展后映射为SNN的多个模拟时间步[5], 虽可保留高时间分辨率, 但不可避免地因序列冗余而导致计算量与能耗激增, 严重削弱SNN在低功耗硬件上部署的核心优势.2)将时间序列多个时间步映射至SNN的单个模拟时间步[3], 虽提升计算效率, 却进一步放大SNN模拟时间步间的时间跨度, 导致模型捕捉时间序列相邻时间步细微依赖关系的能力不足.这两种做法均未能同时在计算效率与信息处理能力之间取得良好平衡.
针对现有低效的时序映射方式、并行脉冲神经元在高时间步长拓展能力不足和容易陷入局部最优等问题, 本文提出高时间步长友好的分片并行脉冲神经元模型(High-Time-Step-Friendly Slice Parallel Spiking Neuron, HSPSN), 核心目标是在较短的训练、推理时间内, 实现准确率高、能耗低的时间序列预测.首先, 通过直接时序映射方法实现一对一的时间步匹配, 解决传统映射理论对映射粒度的两难选择, 充分利用SNN的时空处理能力.然后, 利用局部切片和全局切片的膜电位交互, 有效整合局部细粒度特征与跨片全局信息, 并采用基于训练轮次的收缩矩阵随机丢弃方法防止过早收敛, 促进SNN对于边缘设备的友好部署.在7个真实世界数据集上的实验表明, HSPSN在预测精度、能耗效率与收敛效果方面表现较优, 表明该模型能有效解决高时间步长下计算量平方增长的问题, 实现时间序列深层特性提取能力和模型推理效率的有机统一.
脉冲神经网络(SNN)的训练通常有两种方法:ANN到SNN的转换和直接训练SNN.ANN到SNN的转换是将预训练ANN的参数映射至其对应SNN模型中, 但忽略SNN固有的动态性[7].因此, 基于反向传播的直接训练SNN的方法逐渐受到关注.Zhou等[8]提出Spikformer V2, 采用基于脉冲的查询、键和值捕获稀疏视觉特征, 并融合自监督学习探索, 在ImageNet数据集上的分类准确率超过80%.Zheng等[9]提出SpiLiFormer(Lateral Inhibition-Inspired Spi-king Transformer), 模拟大脑的侧抑制机制, 引导模型增强对相关信息的注意力, 同时抑制对无关信息的注意力, 缓解脉冲 Transformer的注意力分散问题.
脉冲神经元是SNN的基本组成单元, 受到广泛的研究.Yao等[10]提出GLIF(Gated Leaky Integrate-and-Fire), 聚焦门控机制, 融合不同神经元行为中的不同生物学特征以扩展脉冲神经元的表示空间.Zhang等[11]提出TC-LIF(Two Compartment-Leaky Integrate-and-Fire), 采用精心设计的胞体和树突的双房室结构, 能准确模拟真实生物神经元中多种复杂的动力学行为, 促进长期时序依赖性的学习.但是, 上述神经元都面临因膜电位随时间步传递而导致的串行计算的制约.
针对上述局限, 在图像分类等领域, 已有研究者通过移除或模拟重置过程实现并行化.Fang等[12]提出PSN(Parallel Spiking Neurons), 移除重置机制, 设置可学习的阈值, 以非迭代的形式重新表述神经元动力学, 首次实现脉冲神经元的并行化, 并最大限度地利用时间信息.Feng等[13]提出FPT(Fixed Point Parallel Training), 首先利用下三角衰减矩阵建模历史输入的指数衰减, 得到全局定点映射, 再利用代理函数避免定点映射的不连续性, 最后通过若干次并行迭代逼近不动点, 膜电位会根据上一轮的脉冲分布, 动态注入重置效应, 准确率较高.Chen等[14]提出MPE-PSN(Membrane Potential Estimation Parallel Spiking Neurons), 基于输入电流, 通过伯努利分布和Sigmoid函数评估脉冲发放的概率, 进而估计脉冲发放后的膜电位, 最后将全部时间步的输入电流和估计的脉冲发放后膜电位输入LIF(Leaky Integrate-and-Fire)[15]神经元, 实现并行计算.Shen等[16]提出SDN(Surrogate Dynamic Network), 基于输入电流和输出脉冲的固定映射关系, 使用一个预先训练的ANN, 通过输入电流预测输出脉冲序列, 解耦神经元计算与时间的依赖性.
但是, 现有的并行化方法主要应用于较低的时间步长, 对较高时间步长的拓展能力不足, 阻碍它们在时间序列预测中的应用.
时间序列预测是在真实世界里具有广泛应用的研究领域[17].在多元时间序列预测方面, Liu等[18]提出iTransformer, 重新定义Transformer架构, 将每个时间序列的时间点嵌入变量标记中, 较好地捕获时间序列多元相关性和全局表示.Zhang等[19]提出AdaMixT(Adaptive Weighted Mixture of Multi-scale Expert Transformers), 采用自适应加权多尺度专家 Transformer 混合模型的架构, 实现通用预训练模型与领域专用模型的结合.Han等[20]提出AGCNDE(Adaptive Graph Convolution Neural Differential Equa-tion), 设计自适应图卷积模块, 并结合基于Koopman理论的神经微分方程, 动态建模非线性系统的状态, 能自主捕获多元时间序列之间的空间关联.在协变量时间序列预测方面, Wang等[21]提出TimeXer, 巧妙设计嵌入层, 并同时使用基于块的自我注意力和基于变量的交叉注意力, 较好地整合内生信息和外生信息.Zhou等[22]提出CrossLinear, 引入一个轻量级的即插即用互相关嵌入模块, 使用一维卷积捕捉内生变量与外生变量之间的依赖关系, 以较低的计算成本获得变量间的依赖关系, 降低建模中的过拟合风险.
在SNN领域, 时间序列预测任务也逐渐受到关注.Lü 等[5]提出一个用于时间序列预测任务的SNN框架, 包含复制、插值、卷积3类编码方式和Spike-TCN(Spike-Temporal Convolutional Network)、Spike-RNN(Spike-Recurrent Neural Network)、Spike-Trans-former这3种脉冲网络架构, 系统性地为时间序列预测任务提供一种能量高效和生物学上可信的替代方案.Lü 等[23]提出CPG-Spikformer(Central Pattern Generators-Spikformer), 为SNN提供一种兼具有效性和实用性的脉冲位置编码方式.Lü 等[24]提出Spikformer-XNOR, 将相对位置信息的对数表示直接整合至脉冲注意力机制, 能以衰减的方式感知位置关系, 提升模型的序列感知能力.Wu等[6]提出SpikF(Spiking Fourier Network), 引入无注意力的脉冲傅里叶网络, 采用创新的脉冲频域选择机制, 能从输入序列中识别并选择关键成分, 捕获时间序列的长期依赖, 较好地挖掘长期时间序列的时序特性.
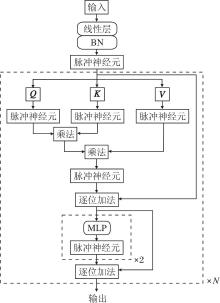
脉冲神经网络通过神经元充电、脉冲发放与膜电位重置的方式模拟生物神经元的动态行为.该动力学行为通常描述为如下3个离散时间方程.脉冲发放前的膜电位
$ \boldsymbol{H}[t]=F(\boldsymbol{V}[t-1], \boldsymbol{I}[t]), $ (1)
输出的脉冲信号
$ \boldsymbol{S}[t]=\boldsymbol{\Theta}\left(\boldsymbol{H}[t]-\boldsymbol{V}_{\text {th }}\right)=\left\{\begin{array}{ll} \mathbf{1}, & \boldsymbol{H}[t] \geqslant \boldsymbol{V}_{\text {th }} \\ \mathbf{0}, & \boldsymbol{H}[t]< \boldsymbol{V}_{\text {th }} \end{array}\right.$ (2)
重置后的膜电位
$ \boldsymbol{V}[t]=\boldsymbol{H}[t]-\boldsymbol{V}_{\mathrm{th}} \cdot \boldsymbol{S}[t], $ (3)
其中, I[t]表示输入电流, 函数F(V[t-1], I[t])表示充电方程, 具体形式取决于采用的脉冲神经元类型, Vth表示脉冲发放阈值, Θ (· )表示阶跃函数.式(1)模拟输入电流对神经元的充电过程, 式(2)模拟神经元脉冲发放过程, 式(3)模拟膜电位软重置, 即神经元放电过程.
在脉冲发放过程中, 当神经元的膜电位达到或超过发放阈值时, 神经元将产生脉冲, 输出为1, 否则输出为0.由于函数在阈值处不可导, 并且在非阈值点处的导数为0, 导致梯度无法有效传播, 从而阻碍基于梯度的反向传播算法的直接应用.因此, 本文采用基于代理梯度的直接训练方法训练SNN, 反向传播过程中的误差估计通过反正切函数实现, 相应输出脉冲信号为:
$ \boldsymbol{S}[t] \approx \frac{1}{\pi} \arctan (\boldsymbol{\pi} \boldsymbol{H}[t])+\frac{1}{2} .$
常见的脉冲神经元模型包括IF(Integrate-and-Fire)、LIF[7]和QIF(Quadratic IF)[25]等, 通过不同的充电方程刻画膜电位的演化过程.
例如:LIF 神经元动态行为充电方程
F(V[t-1], I[t])=β V[t-1]+(1-β )I[t],
其中,
I[t]=WinputX[t],
表示输入电流, X[t]表示输入序列, Winput表示输入权重, 衰减率β =e-1/τ , τ 表示时间常数.τ 越大, 受输入电流影响产生的动力学变化越慢.当前时间步脉冲发放前膜电位H[t]需要依赖前一时间步膜电位V[t-1], 而V[t-1]受膜电位是否发放脉冲及重置的影响, 这种依赖关系导致SNN只能依据串行顺序执行, 训练和推理效率较低.
为了解决此问题, Fang等[12]提出PSN, 移除LIF神经元中的重置操作, 使用H[t-1]代替V[t-1], 膜电位的计算公式可更改如下:
$ \boldsymbol{H}[t]=(1-\beta) \sum_{i=1}^{t} \beta^{t-i} \boldsymbol{I}[t] .$
上式建立每个时间步膜电位和输入电流之间的直接函数关系, 即仅依据1~t时刻的输入电流序列即可计算第t个时间步的膜电位.由于β 可被纳入输入权重Winput, 充电后的膜电位序列可进一步简化如下:
H=WX, (4)
其中, X表示输入序列, W表示一个可学习权重矩阵.由于移除重置操作, 为了实现自适应的脉冲发放, 最终输出的脉冲序列更改为
S=Θ (H-B), (5)
其中B表示可学习阈值向量.PSN有效解除传统脉冲神经元中的时序依赖关系, 从而满足并行计算的要求.
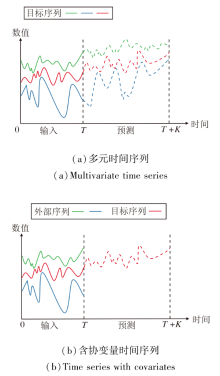
本文研究的时间序列预测主要涵盖两大核心任务:多元时间序列预测任务[5]和含协变量时间序列预测任务[21].相应预测示意图如图1所示.
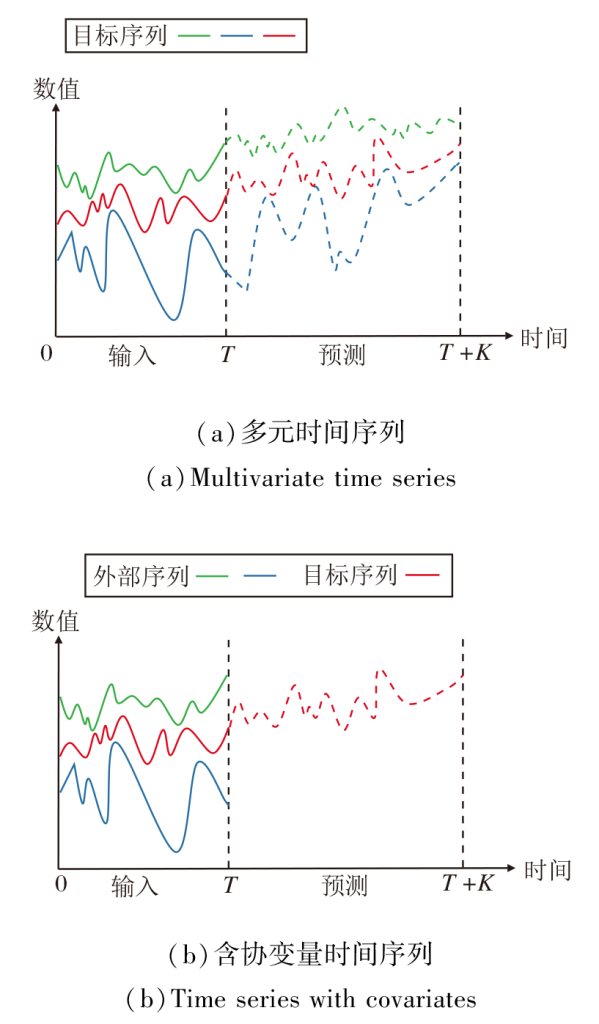 | 图1 两种预测任务示意图Fig.1 Schematic diagrams of two kinds of prediction tasks |
图1(a)表示多元时间序列预测任务, 模型需要同时预测多个相互关联的时间序列, 关键是捕捉多个目标变量之间的动态关联.具体而言, 输入历史观测时间序列:
X={x1, x2, …, xT}∈ RT× C.
使用模型预测之后的K步时间序列为:
Y={xT+1, xT+2, …, xT+K}∈ RK× C.
上述两式中C表示变量数量.
图1(b)表示含协变量时间序列预测任务, 当预测某个目标序列(如商品价格)时, 引入与目标相关但非目标本身的外部序列(如原材料成本、供应链状况、季节性需求等), 这些外部序列即为协变量.输入同样形式的历史观测时间序列X∈ RT× C, 假设目标变量为第d个变量, 使用模型输出之后的K步目标变量时间序列为:
$ \boldsymbol{Y}^{d}=\left\{x_{T+1}^{d}, x_{T+2}^{d}, \cdots, x_{T+K}^{d}\right\} \in \mathbf{R}^{K \times 1} .$
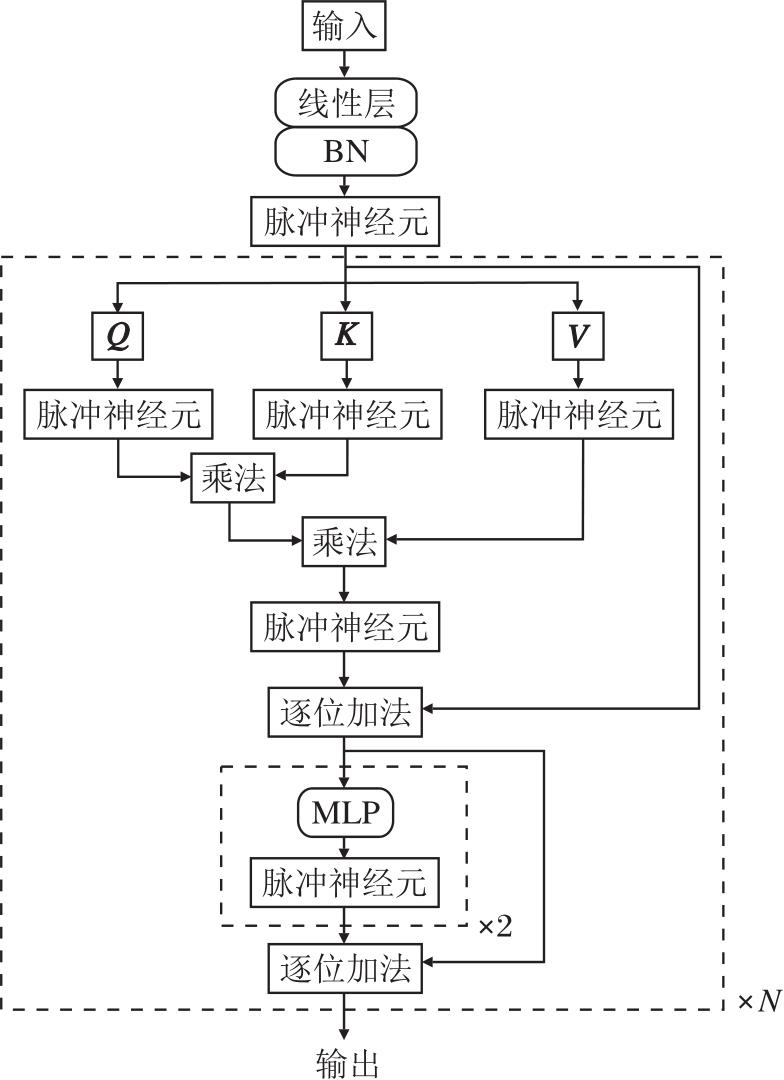
本文提出高时间步长友好的分片并行脉冲神经元模型(HSPSN), 并在图2所示的Spike-Transformer[5]中进行验证.Spike-Transformer使用脉冲神经元层替代传统的激活函数, 即使用二进制脉冲进行稀疏的事件驱动计算.此外, 为了更好地适配SNN, Spike-Transformer对iTransformer[18]进行结构性改造.由于通过脉冲形式的查询向量(Q)与键向量(K)计算得到的注意力图具有天然非负性, 且模型输入与值向量(V)同样为脉冲形式, 因此取消iTransformer自注意力机制中使用softmax规范化注意力矩阵的操作, 直接将Q、K和V相乘.此外, 由于层归一化不适用于SNN, 所以使用批量归一化(Batch Normali-zation, BN).网络采用早停策略进行训练.原始Spike-Transformer中使用LIF神经元进行串行计算, 并不适用于高时间步长.本文将LIF神经元转换为HSPSN神经元, 以便公平、系统地评估其性能表现.
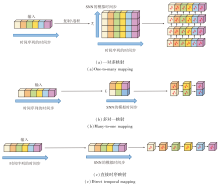
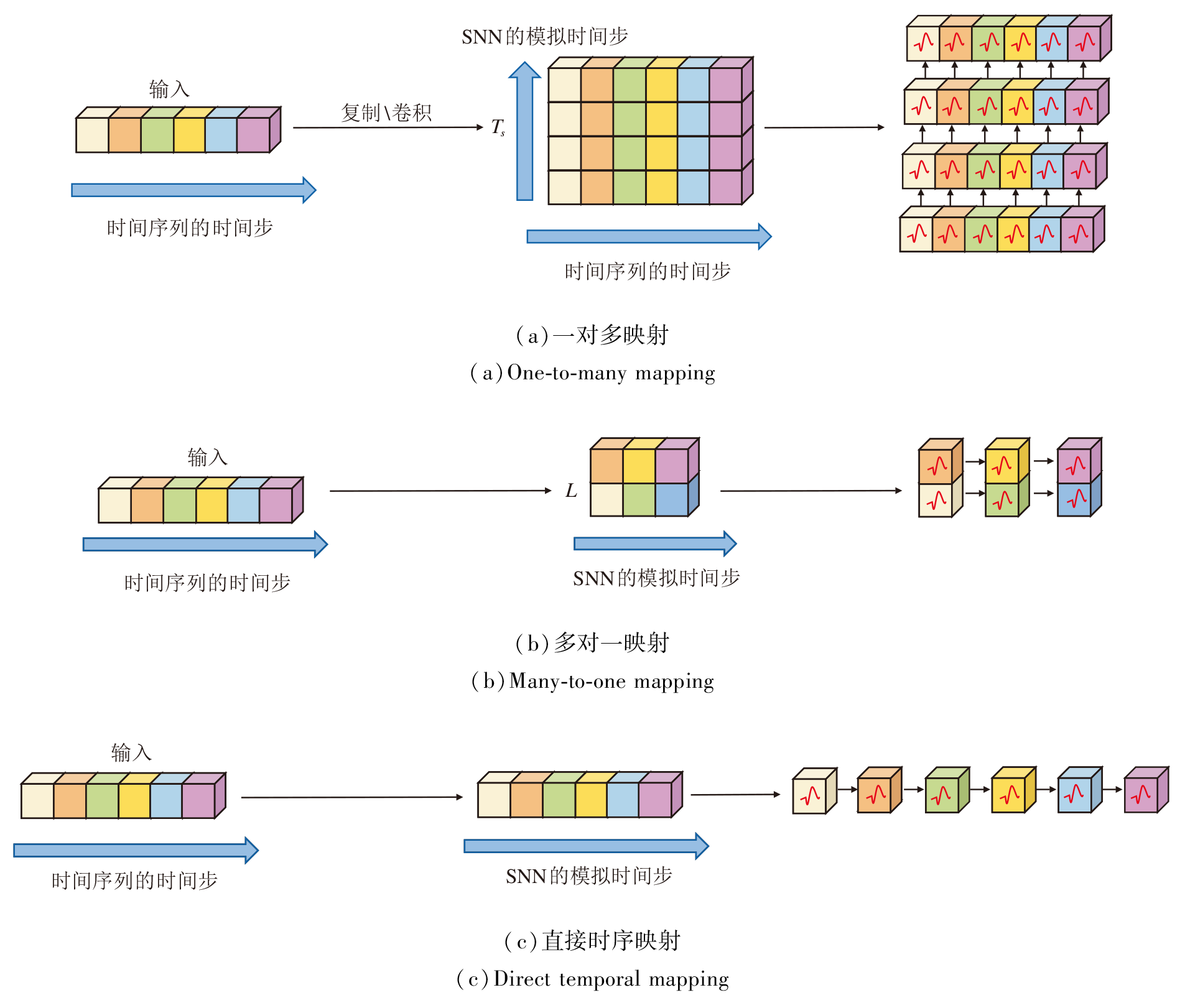
时序映射是指建立时间序列的时间步与SNN模拟时间步之间的对应关系.现有的研究主要面临映射粒度选择的困难.
文献[5]借鉴静态图像的处理方法, 先通过时序复制或滑动卷积操作将时间序列每个时间步扩展为一个长度为TS的特征序列:
$ f\left(\boldsymbol{x}_{t}\right) \rightarrow\left\{\boldsymbol{x}_{t}^{1}, \boldsymbol{x}_{t}^{2}, \cdots, \boldsymbol{x}_{t}^{T_{S}}\right\} \in \mathbf{R}^{T_{S} \times C} .$ (6)
然后LIF神经元需在生成的序列{
 | 图3 各种时序映射示意图Fig.3 Schematic diagram of temporal mappings |
该方法存在如下不足:1)函数f(x)为时序复制时容易忽视时间步间变化趋势; 为滑动卷积时容易受限于卷积核大小, 难以捕捉长程依赖关系.2)TS的选择需要权衡, 若TS过小则无法捕捉复杂时序模式; 若TS过大会大幅增加模型的计算量和能耗, 显著降低SNN低能耗的硬件部署优势.
文献[3]首先对时间序列进行非重叠时间窗分割(L为时间窗大小), 然后将一个时间窗内多个连续时间步的值映射为SNN一个模拟时间步的向量表示:
$ \left\{\boldsymbol{x}_{(i-1) L+1}, \boldsymbol{x}_{(i-1) L+2}, \cdots, \boldsymbol{x}_{i L}\right\} \in \mathbf{R}^{L \times C} \rightarrow \boldsymbol{x}_{i}^{\prime} \in \mathbf{R}^{1 \times C L}, $ (7)
随后LIF神经元在新序列{x'1, …, x'i…, x'T/L}中进行T/L步的串行计算, 得到输出脉冲信号.具体示意图如图3(b)所示.
这种方法虽表面上降低SNN的时间步长, 但同样存在如下不足.1)脉冲神经元膜电位信息无法在相邻时序的时间步上传递, 削弱模型对短期波动与局部依赖的提取能力.2)进一步放大SNN模拟时间步间的时间跨度, 使模型对输入序列中快速变化的动态模式响应迟钝, 限制其在时间序列建模中的表达能力.
针对上述不足, 本文设计直接时序映射方法, 将时间序列的时间步与SNN的模拟时间步进行一对一匹配, 避免对映射粒度的选择困难, 具体示意图如图3(c)所示.LIF神经元直接在时间序列{x1, x2, …, xT}上进行串行运算, 使神经元的膜电位传递在整个时间维度的所有时间步中进行, 确保脉冲神经元信息在更大的范围里通畅传递, 让神经元更直接受到时间序列长期趋势和短期波动的刺激, 更准确地发出脉冲信号.
直接时序映射方法在形式上可视为式(7)中L=1的特例, 也可视为式(6)中TS=1时调整SNN模拟时间步维度匹配后得到的结果, 但在功能上同时弥补现有两类方法的不足.直接时序映射方法不仅能充分利用时间序列各个时间步信息, 促进SNN强大的时空信息处理能力与时间序列时间步之间的内在时间相关性的深度融合, 同时能避免传统方法产生的TS倍额外计算量和能耗, 保证SNN在能耗方面的优势.然而, LIF神经元的膜电位串行传递机制造成直接时序映射方法的计算复杂度为O(T), 对于长时间序列而言, 训练和推理时间较长, 不利于在真实场景中的应用.因此, 本文设计高时间步长友好的分片并行脉冲神经元, 降低直接时序映射方法的时间复杂度.
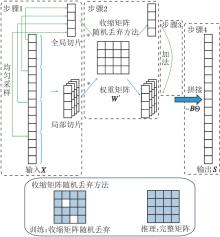
虽然已有研究引入PSN[12]以加快神经元的时序处理速度, 却未充分考虑PSN在高时间步长条件下的有效加速能力.当时间步长T较小时, PSN能有效降低训练、推理时间, 但是随着T增大, PSN加速效果逐渐减弱.导致PSN加速效果下降的主要原因是随着时间步长T增大, 式(4)中可学习权重矩阵W∈ RT× T规模随之增大, 引发计算量、参数量呈平方级增长, 这对实际应用构成双重挑战.一方面, 边缘设备通常算力较弱, 较大的计算量将严重制约运行速度, 而神经元作为一个基础计算单元, 微小的时间开销增加会在整个网络中累积, 从而导致模型的运行时间大幅增加.另一方面, SNN作为一个低能耗网络, 计算量的快速增加在一定程度上会导致能耗的快速增加, 这违背SNN受大脑高效运转启发并追求低能耗设计的初衷.因此, 本文提出HSPSN, 计算过程如图4所示, 运算步骤如下所示.
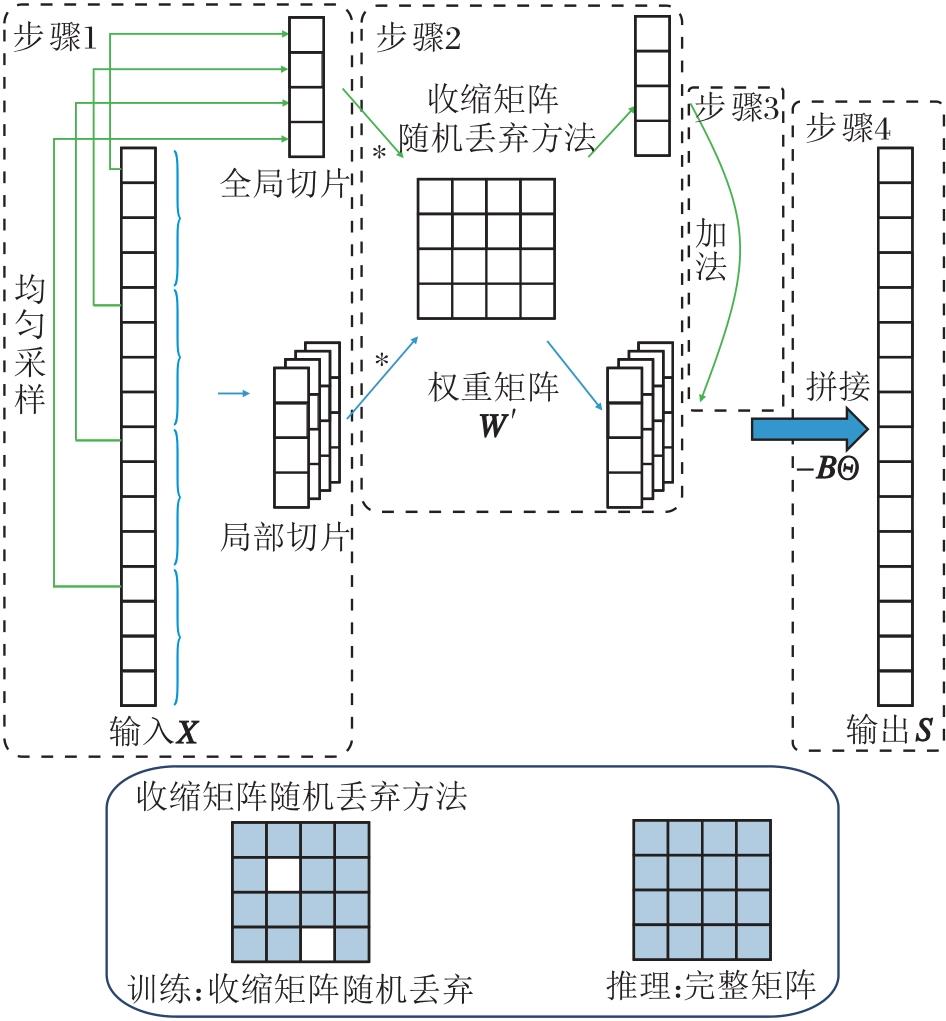 | 图4 HSPSN计算过程Fig.4 Computational process of HSPSN |
1)对输入序列进行切片.首先, 对于输入的长序列X, 假设长度为T, 将它按顺序均匀切分成N片, 每片长度L=T/N, 即可得到N片具有局部信息特征的切片序列, 将第i片局部切片命名为Xi(i=1, 2, …, N).然后, 对整个输入序列X进行均匀采样, 考虑到相近点数据较类似, 可取每N个点中第1个点作为采样点, 得到一个长度同样是T/N的具有全局信息特征的全局切片序列, 命名为X0.
2)计算各切片序列的膜电位.由于维度相同, 所有的局部切片和全局切片可共享可学习权重W'∈ RL× L, 即
$ \boldsymbol{H}^{j}=\boldsymbol{W}^{\prime} \boldsymbol{X}^{j}, j=0, 1, \cdots, N-1 .$
3)全局切片和局部切片的膜电位加权融合.为了弥补局部切片无法捕捉长期依赖的不足, 将全局切片的膜电位信息加权融入每片局部切片中, 让融合后的切片能包含全局信息和局部信息:
$ \boldsymbol{H}_{\text {new }}^{i}=\boldsymbol{H}^{i}+\alpha \boldsymbol{H}^{0}, i=1, 2, \cdots, N .$
4)输出脉冲序列.将各个局部切片的膜电位按顺序进行拼接, 得到最终的膜电位序列:
$ \boldsymbol{H}=\operatorname{concat}\left(\boldsymbol{H}_{\text {new }}^{1}, \boldsymbol{H}_{\text {new }}^{2}, \cdots, \boldsymbol{H}_{\text {new }}^{N}\right) .$
再利用式(5)得到输出的脉冲序列S.
通过分片并行脉冲神经元策略, 脉冲神经元能有效整合局部细粒度特征与跨片全局信息, 并且这一过程并未影响其原有的并行计算模式, 有效解决全局信息融合与并行计算效率之间的固有矛盾.
从工程可行性出发, 超参数N的配置需充分考虑边缘设备的实际算力, 该配置由目标边缘设备的峰值算力与任务可容忍的推理延迟决定, 旨在将权重矩阵的规模限制在与设备算力匹配的范围内.这一设计的核心目标在于确保并行计算优势得到充分发挥, 有效避免因计算资源过载而引发的性能瓶颈, 最终在模型表达能力和推理效率之间实现平衡.
采用分片并行脉冲神经元策略后, HSPSN收敛较快, 容易陷入局部最优解.为了解决上述问题, 本文借鉴Dropout方法[26], 提出基于训练轮次的收缩矩阵随机丢弃方法, 旨在帮助神经元达到更优的收敛状态.
在训练过程中, 随机丢弃权重矩阵W'中一定比例的参数, 模拟大脑中可能出现的“ 局部睡眠” 现象[27], 让部分神经元处于休眠状态.随着训练轮次的增加, 丢弃比例不断减少, 到一定轮次后不再丢弃.具体丢弃概率表示如下:
$ P_{\text {epoch }}=\left\{\begin{array}{ll} P_{0}-k \cdot \text { epoch }, & P_{0}> k \cdot \text { epoch } \\ 0, & P_{0} \leqslant k \cdot \text { epoch } \end{array}\right.$
其中, P0表示初始丢弃概率, k表示衰减率.
丢弃矩阵Q用于计算时确定标记位置是否丢弃:
$ Q\left[r_{1}, r_{2}\right]=\left\{\begin{array}{ll} 1, & \text { 概率 } 1-P_{e p o c h} \\ 0, & \text { 概率 } P_{e p o c h} \end{array}\right.$
其中, r1=0, 1, …, L-1, r2=0, 1, …, L-1.
最终输出膜电位序列为:
$ \boldsymbol{H}^{j}=\boldsymbol{Q} \boldsymbol{W}^{\prime} \boldsymbol{X}^{j}, j=0, 1, \cdots, N .$
通过这种方法, 在训练初期, 丢弃较多的参数可增加模型的随机性, 避免模型陷入局部最优, 防止对训练数据过度拟合.随着训练的进行, 模型逐渐学习数据的通用特征, 此时减少丢弃比例可让模型更细致地学习数据中的细节, 有利于找到更优解.上述过程只针对训练, 在推理中矩阵均不丢弃.
综上所述, HSPSN训练步骤如算法1所示.
算法1 HSPSN训练过程
输入 训练数据Dtrain, 初始丢弃概率P0, 衰减率k,
局部切片数量N
输出 训练完成的权重矩阵W', 权重α ,
可学习阈值向量B
初始化可学习参数W', B, α
While 未达到早停条件 do
For each (X={x1, x2, …, xT}∈ RT× C,
xT+2, …, xT+K}) in Dtraindo
//正向传播
X按顺序切成N片, 得到局部切片Xi, i=1, 2,
…, N
X均匀采样, 得到全局切片X0
Pepoch=0
if P0> k· epoch do
Pepoch=P0-k· epoch
End if
逐个计算Q[r1, r2]
H0=QW'X0
for v from 1 to N do
Hv=QW'Xv
End for
//将
H=concat(
S=Θ (H-B)
//反向传播
Loss = MSE(Y,
Loss.backward()
// 计算模型所有可训练参数的梯度
Optimizer.step() // 更新模型可训练参数
End for
End while
为了验证HSPSN的有效性, 在2个多元时间序列预测数据集[28]和5个协变量时间序列预测数据集[29]上进行全面评估.多元时间序列预测数据集包括Solar、Electricity数据集.Solar数据集为太阳能发电记录, 每10 min从亚拉巴马州的 137个光伏发电厂采样一次.Electricity数据集为居民用电量记录, 通过321名客户定时采样得到, 以kWh为单位进行测量.5个基于电力市场数据构建的短期协变量电价预测数据集包括NP(Nord Pool)、PJM(Pennsylva-nia-New Jersey Maryland)、BE(Belgium)、FR(Fran-ce)、DE(Germany)数据集, 分别表示北欧电力市场、美国宾夕法尼亚州-新泽西州-马里兰州电力市场、比利时电力市场、法国电力市场、德国电力市场.每个数据集覆盖6年时间跨度, 均以电价作为目标变量, 并结合2个实际应用中具有重要影响力的协变量.数据集详细的统计信息如表1所示.
| 表1 实验数据集统计信息 Table 1 Statistics of experimental datasets |
由于根相对平方误差(Root Relative Squared Error, RSE)和决定系数(Coefficient of Determina-tion, R2)对于时间序列预测方法评价效果较鲁棒, 因此, 在多元时序预测数据集上采用RSE和R2指标进行评价.由于平均绝对误差(Mean Absolute Error, MAE)更注重评价整体趋势, 均方误差(Mean Squared Error, MSE)更容易描述异常值的影响, 为了更充分地评估各个方法, 在协变量预测数据集上采用RSE、R2、MAE和MSE指标进行评估.具体指标计算公式如下:
$ M A E=\frac{1}{M C K} \sum_{m=1}^{M} \sum_{c=1}^{C} \sum_{k=1}^{K}\left|Y_{c, k}^{m}-\widehat{Y}_{c, k}^{m}\right|, $
$ M S E=\frac{1}{M C K} \sum_{m=1}^{M} \sum_{c=1}^{C} \sum_{k=1}^{K}\left(Y_{c, k}^{m}-\widehat{Y}_{c, k}^{m}\right)^{2}, $
$ R S E=\sqrt{\frac{\sum_{m=1}^{M}\left|Y^{m}-\widehat{Y}^{m}\right|^{2}}{\sum_{m=1}^{M}\left|\widehat{Y}^{m}-\bar{Y}\right|^{2}}}, $
$ R^{2}=\frac{1}{M C K} \sum_{m=1}^{M} \sum_{c=1}^{C} \sum_{k=1}^{K}\left[1-\frac{\left(Y_{c, k}^{m}-\widehat{Y}_{c, k}^{m}\right)^{2}}{\left(\widehat{Y}_{c, k}^{m}-\bar{Y}_{c, k}\right)^{2}}\right], $
其中, M表示测试集数量, C表示变量数量, K表示预测长度, Y表示预测值,
在HSPSN训练过程中, 采用Adam(Adaptive Moment Estimation)作为优化器, 学习率设为0.000 1, 批尺寸统一设为32, 并引入早停机制, 耐心值设为20轮.Spike-Transformer参照文献[5]的设置:Ele- ctricity数据集上Spikformer模块数设为2, 特征维度设为512, 前馈层的隐藏特征维度设为2 048; Electricity 数据集上Spikformer模块数设为2, 特征维度设为256, 前馈层的隐藏特征维度设为1 024.2个多元时间序列预测数据集损失函数定为MSE, 5个协变量时间序列预测数据集损失函数定为MAE.
所有实验均基于PyTorch框架上实现, 在单张NVIDIA P100显卡上完成.
在多元时间序列预测数据集上使用的对比模型如下.
1)ANN模型:TCN(Temporal Convolutional Neu-ral)[30]、门控循环单元(Gated Recurrent Unit, GR-U)[31]、两个基于Transformer的模型iTransformer[18]和Autoformer[32].
2)SNN模型:Spike-TCN[5]、Spike-GRU[5]、Spike-RNN[5]、iSpikformer[5]、SpikF[6]、CPG-Spikformer[23]、Spikformer-XNOR[24]、MITRQR(Mutual Information-Based Temporal Redundancy Quantification and Re-duction)[33].
在协变量预测数据集上使用的对比模型如下.
1)ANN模型:iTransformer[18]、TimeXer[21]、CrossLinear[22], 其中, TimeXer、CrossLinear是专门用于含协变量时间序列预测的模型.
2)SNN模型:iSpikformer[5]、SpikF[6]、CPG-Spik-former[23].
为了保证公平性, 对比实验均严格依据原文献及官方代码设置参数.iSpikformer、CPG-Spikformer与Spikformer-XNOR采用的参数与本文方法完全相同.SpikF遵循文献[6]的配置, 编码方式采用复制编码, 时间步长为4, 网络结构中层数为2, 隐藏层维度为360, 时间常数为2.0, 阈值为1.0.
设定预测步长为6, 24, 48, 96, 各模型在两个多元时间序列数据集上的R2和RSE值如表2所示, 表中黑体数字表示最优值, 斜体数字表示次优值, ↑ 表示值越高越好, ↓ 表示值越低越好.
| 表2 各模型在2个多元时序数据集上的指标值对比 Table 2 Metric value comparison of different models on 2 multivariate time series datasets |
由表2可见, HSPSN在大多数预测步长上取得最优值或次优值, 并且平均值最优, 由此验证HS- PSN核心设计的有效性.通过直接时序映射方法, 采用全局切片和局部切片结合的分片并行脉冲神经元, 并使用基于训练轮次的收缩矩阵随机丢弃方法, 可有效实现对时间序列长期趋势与短期变化的深度提取和高效融合.
现有模型存在若干固有瓶颈.SpikF在编码阶段注重局部信息, 采用的傅里叶变换对非平稳信号适应性有限, 可能影响对于全局信息和局部信息的充分利用.iSpikformer 及其变体CPG-Spikformer的性能瓶颈主要归因于它们的时序映射方式, 该方式严重制约不同时间步间膜电位的充分交互, 不利于捕获长期依赖.尽管CPG-Spikformer引入位置编码, 但未能根治此问题.Spikformer-XNOR采用近似的方法编码位置信息, 容易丢失细粒度的位置信息.MI-TRQR去除冗余脉冲的互信息估计在高维稀疏二值场景中的固有限制, 影响冗余量化的实际精度.Spike-GRU和Spike-RNN作为基础脉冲循环模型, 受限于自身相对简单的门控机制和循环架构, 难以捕捉复杂的非线性关系.Spike-TCN因其卷积核的感受野固有限制, 可能难以捕捉较长距离的依赖关系.
此外, 在4个ANN模型中, iTransformer在较短的预测时间长度上取得较优效果, 主要是因为SNN将连续输入转换为稀疏二值脉冲的过程本质上是一种有损编码, 会丢失部分微小的幅度变化.在短期预测中, 模型需要对最近时间点的细节做出高保真且即时响应, 此时脉冲编码的精度损失会被直接传导并放大, 导致误差.
同时, SNN固有的膜电位累积与发放延迟, 使其无法快速弥补这一信息损失, 两者叠加导致其处于劣势, 而在长期预测中, 核心任务是捕捉宏观趋势, SNN的延迟与记忆特性能平滑噪声, 提取稳健的长期模式.Autoformer采用单尺度卷积的季节分解模式, 在复杂多尺度周期模式上的表示能力有限, 难以准确捕捉数据的动态变化.经典的GRU与TCN则受限于其基础架构的表达能力, 在应对此类复杂多元时序预测任务时表现不佳.
各模型在5个协变量时间序列数据集上的指标值对比如表3所示.由表3可见, HSPSN在SNN模型中具有显著优势, 各项指标均为最优值.
| 表3 各模型在5个协变量时序数据集上的指标值对比 Table 3 Metric value comparison of different models on 5 time series datasets with covariates |
以PJM数据集为例, 相比iSpikformer, HSPSN的R2值提升6.7%, RSE、MAE、MSE值分别降低6.9%、8.2%和13.4%.相比SpikF, HSPSN优势更显著, R2值提升17.5%, RSE、MAE、MSE值分别降低14.7%、20.1%和27.5%.这充分说明HSPSN建模的优越性能.更为重要的是, HSPSN有效弥合SNN与ANN在协变量预测任务上的性能差距.
相比ANN模型, HSPSN在绝大多数指标上超过iTransformer.尽管HSPSN并未针对协变量预测任务进行任何特殊的架构设计, 但与专门用于协变量时间序列预测的方法TimeXer、CrossLinear相比仍具有竞争力.相比综合性能较优的CrossLinear, HSPSN的R2平均值仅降低0.003, MAE平均值仅提升0.008, 结果十分接近.该定量结果表明, HSPSN有效缩小SNN与ANN在协变量时序预测任务中的性能差距, 具有明显优越性.
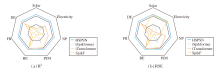
最后, 为了综合展示模型性能, 分别在7个真实世界数据集上, 选择有竞争力的对比模型与HSPSN, 相应R2、RSE指标的可视化结果如图5所示.由图可见, HSPSN在预测精度上均显著且一致优于对比模型, 充分验证其在处理各类时间序列数据上的有效性与泛化性.
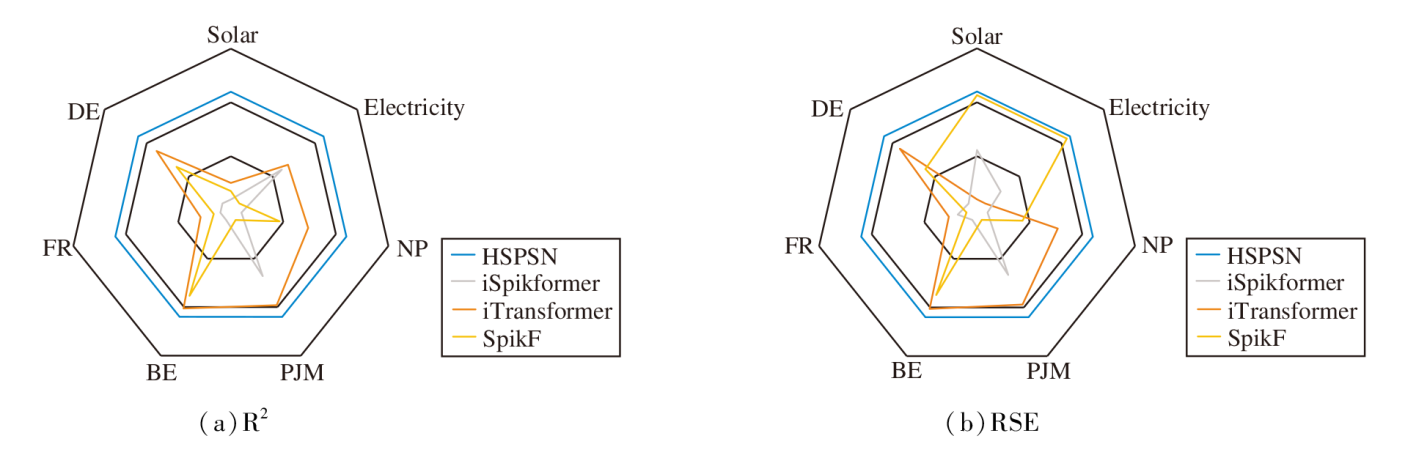 | 图5 各模型在7个数据集上的可视化对比Fig.5 Visual comparison of different models on 7 real-world datasets |
为了进一步验证HSPSN的核心组件— — 直接时序映射方法、分片并行脉冲神经元和收缩矩阵随机丢弃方法的独立贡献, 在Solar数据集上进行消融实验, 预测步长为24, 48, 96.共设置4个变体.1)Spike-Transformer:同时移除3个组件.2)时序映射模型:仅使用直接时序映射方法.3)双组件模型:仅移除收缩矩阵随机丢弃方法.4)HSPSN.
具体消融实验结果如表4所示.
| 表4 各变体的消融实验结果 Table 4 Ablation experiment results of each variant |
由表4可见, 在Spike-Transformer中加入直接时序映射方法, 性能出现提升, 说明直接时序映射方法能更好地建立时间序列时间步与SNN模拟时间步之间的映射关系, 充分释放SNN底层架构处理长程依赖的潜力.再添加分片并行脉冲神经元, 方法在R2、RSE指标上优于直接时序映射方法, 表明分片并行脉冲神经元通过在神经元结构层面引入局部精细处理与全局跨片信息的协同计算模式, 能有效提取并整合时间序列的长期趋势和短期波动.HSPSN在两个指标上均最优, 说明收缩矩阵随机丢弃方法可有效引导矩阵在前期学习稳健的通用特征, 在后期学习具有判别力的细粒度信息, 实现更优的收敛.
为了更好地体现收缩矩阵随机丢弃方法的效果, 在Solar数据集上以24步为预测步长进行训练实验, 并绘制各变体收敛曲线, 结果如图6所示.
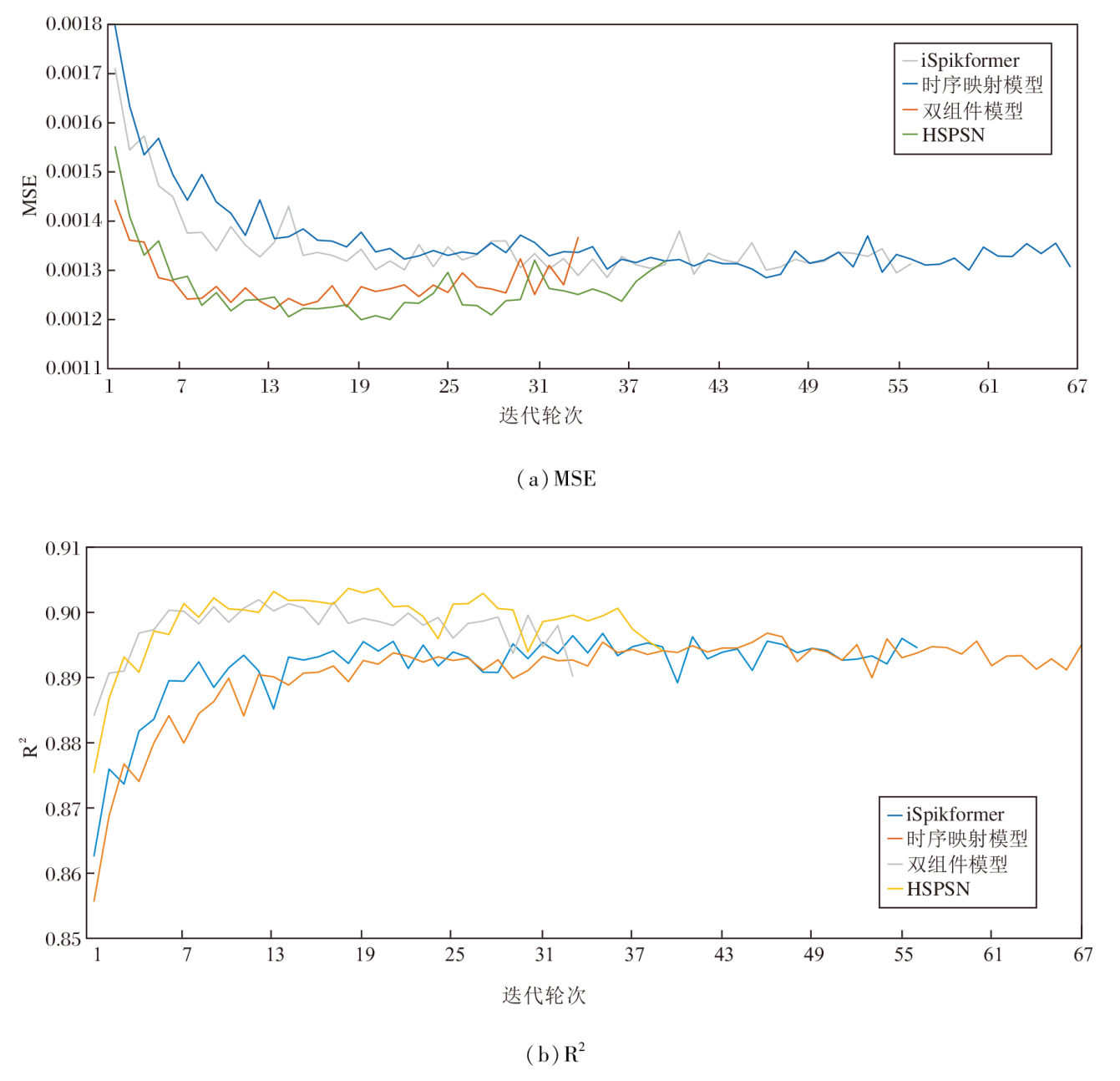 | 图6 各变体的收敛曲线对比Fig.6 Convergence curves of different variants |
由图6可见, iSpikformer和时序映射模型都需要较多轮次才能收敛.双组件模型在12轮即收敛, 收敛较快但容易陷入局部最优.HSPSN在18轮收敛, 并取得最大的R2值和最小的MSE值, 体现最优的收敛性能.收敛曲线对比表明收缩矩阵随机丢弃方法在引导模型收敛上的有效性.
综上所述, 消融实验验证本文设计的3个模块各自的有效性及其相互配合的协同效应.
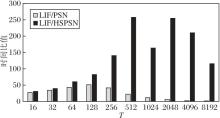
在Electricity数据集上分别测试PSN[12]、LIF[15]、HSPSN在不同时间步长上的训练时间.为了定量评估加速效果, 分别计算LIF与PSN、LIF与HSPSN的时间比值, 比值越大, 表示并行加速效果越优, 具体如图7所示.由图可见, LIF与PSN的时间比值呈现先增加后减小的趋势, 当时间步长T较小时, PSN能有效减少训练、推理时间, 但是随着T增大, PSN加速效果逐渐减弱.HSPSN由于采用分片机制且片间共享权重, 大幅缓解PSN随T增大带来的计算量激增、计算速度下降的问题.此外, HSPSN可根据时间步长灵活调整分片数以满足加速比的需求.例如:在图7中, 当时间步从512增至1 024时, 加速比出现下降, 可通过增加分片数以降低权重参数量, 将加速比继续保持在100~250倍之间, 充分发挥硬件算力, 实现高效的时间序列预测.
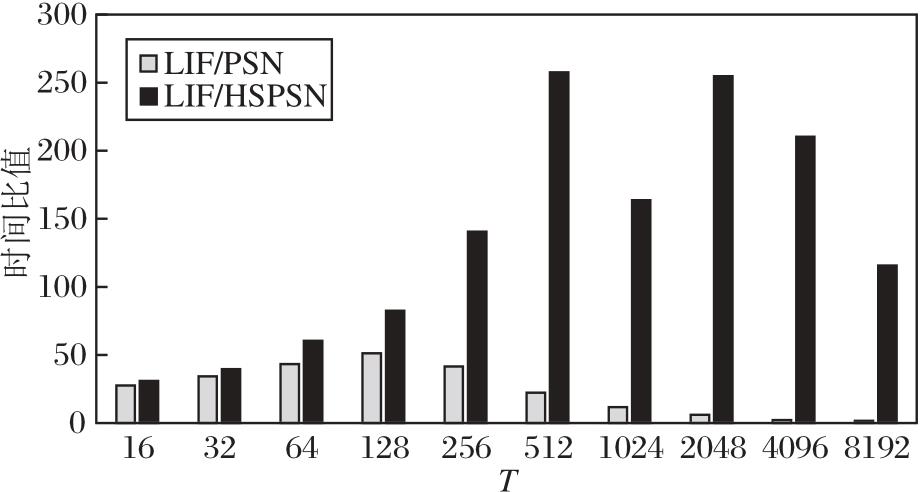 | 图7 LIF与PSN、HSPSN在不同时间步长的训练时间比值Fig.7 Training time ratios of LIF to PSN and LIF to HSPSN across different time steps |
为了系统评估计算效率, 选择iSpikformer[5]、SpikF[6]、iTransformer[18]、4.3节的时序映射模型和HSPSN, 计算平均单轮训练时长和单样本能耗, 结果如表5所示, 表中黑体数字表示最优值, 斜体数字表示次优值.由表可见, 时序映射模型由于采用线性串行膜电位传递机制, 训练效率最低, 单轮训练时长高出其它模型一个数量级还多.iSpikformer因时序映射引入的TS倍计算开销, 同样导致训练效率下降.SpikF受多维数据傅里叶变换的影响, 速度较慢.HSPSN通过合理的时序映射机制有效避免TS倍计算量增加, 并结合分片并行方法促使计算负载与计算设备的算力匹配, 有效缩小与iTransformer等ANN模型的训练时间差距, 为构建更高效的脉冲神经元提供可行的技术路径.
| 表5 各模型单轮训练时长和单样本能耗对比 Table 5 Comparison of per-epoch training time and per-sample energy consumption among different models |
推理的低能耗特性是SNN的重要优势, 因此, 本文使用Fvcore和PyTorch[34]的前向钩子计算各对比方法的操作数, 并根据Horowitz等[35]估算在45 nm神经形态硬件上的单样本理论能耗.ANN模型的能耗基于浮点运算次数(Floating Point Opera- tions, FLOPs)估算, 而SNN的能耗基于突触操作次数(Synaptic Operations, SOPs)计算, 理论能耗的计算公式如下:
$ \begin{array}{l} \text { Energy }_{1}=E_{\mathrm{AC}} \cdot \text { SOPs, } \\ \text { Energy }_{2}=E_{\mathrm{MAC}} \cdot \text { FLOPs, } \end{array}$
其中, 在45 nm神经形态硬件时, EMAC=4.6 pJ, EAC=0.9 pJ.
如表5所示, 相比iTransformer, HSPSN在操作数和能耗上不仅大幅降低, 与iSpikformer、SpikF等SNN模型相比也有较大优势.相比时序映射模型, HSPSN以显著低于时序映射模型训练时间的优势获得与之近似的计算量和能耗, 这得益于本文的直接时序映射方法, 从源头上避免因时序复制或卷积导致的计算与能耗倍增.同时, 分片并行脉冲神经元也缓解引入并行神经元可能带来的计算与能耗大幅增加的问题.
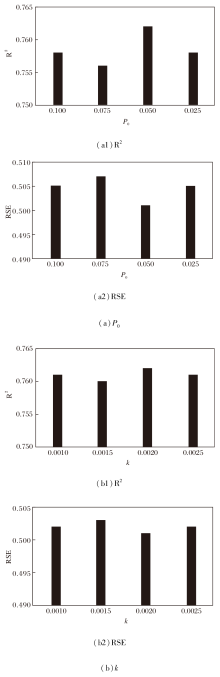
为了优化HSPSN训练过程中的随机性控制, 选择初始丢弃概率P0与衰减率k这2个关键超参数, 设置预测长度为96, 在Solar数据集上进行超参数敏感性实验, 结果如图8所示.
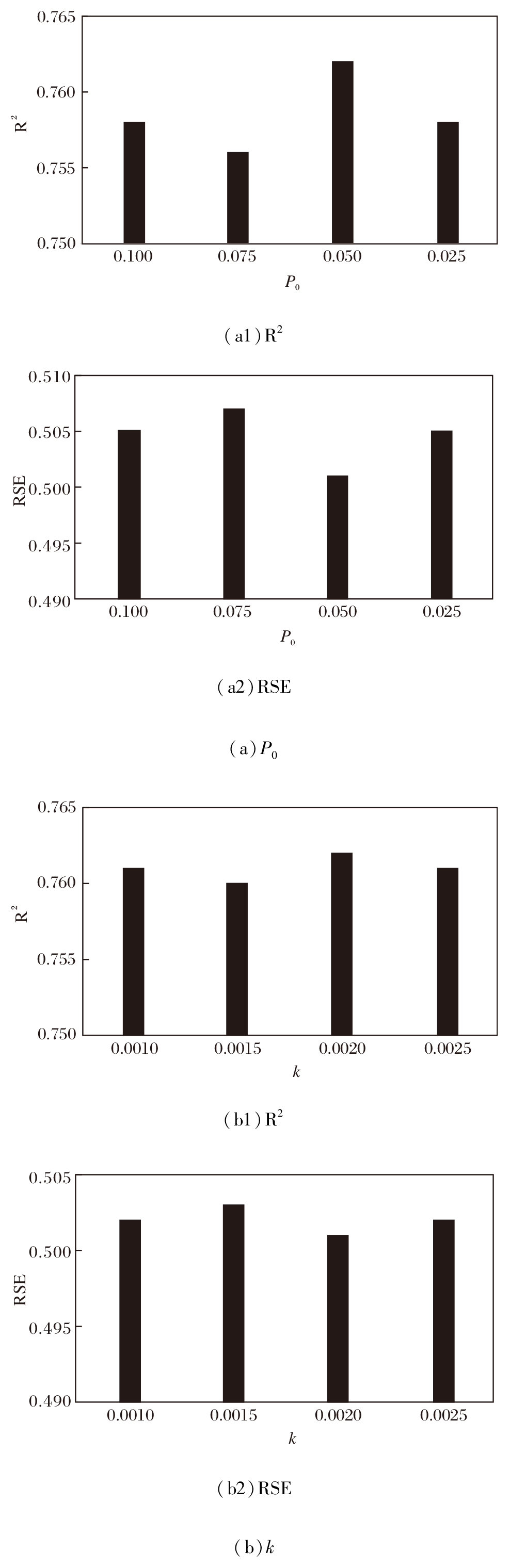 | 图8 P0和k对HSPSN性能的影响Fig.8 Effect of P0 and k on HSPSN performance |
初始丢弃概率P0用于调控模型初始阶段的随机性强度, 定义P0=0.100, 0.075, 0.050, 0.025, 其对HSPSN性能的影响如图8(a)所示.
由图8(a)可见, 当P0=0.050时HSPSN性能达到最优, 而且所有取值下的结果均优于未引入该随机丢弃机制的双组件模型, 反映出该参数具有一定的鲁棒性, 对具体取值不敏感.因此, 最终选定P0=0.050作为HSPSN的固定超参数.
衰减率k用于控制训练过程中随机性的衰减速度, 定义k=0.001 0, 0.001 5, 0.002 0, 0.002 5, 其对HSPSN性能的影响如图8(b)所示.由图可见, 不同k值下HSPSN性能整体保持稳定, 表明k同样是一个不敏感的超参数.在k=0.002 0时取得最佳值, 故确定k=0.002 0为最终的超参数取值.
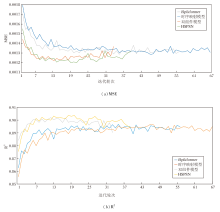
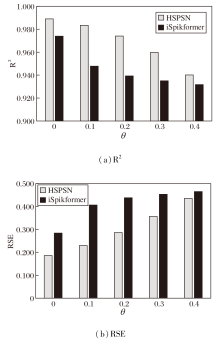
为了评估HSPSN在实际应用中应对数据噪声场景的鲁棒性, 在Electricity数据集上进行预测长度为24的噪声扰动实验.高斯噪声是时间序列中传感器误差与环境干扰的典型表现形式, 其全频带覆盖、完全随机的特性能有效测试模型对输入扰动的鲁棒性.本节在测试集的已知序列部分注入不同强度的高斯噪声, 其中标准差σ 由训练集标准差与强度因子θ 的乘积确定, 具体鲁棒性结果如图9所示.由图可见, 在轻度噪声下, HSPSN的性能未见显著下降, 即便在较强的噪声干扰下, 预测精度仍保持相对稳定, 未出现急剧退化.这表明HSPSN不仅能有效过滤输入噪声干扰, 还具备较强的分布外泛化能力, 在噪声环境中依然保持可靠的预测性能.
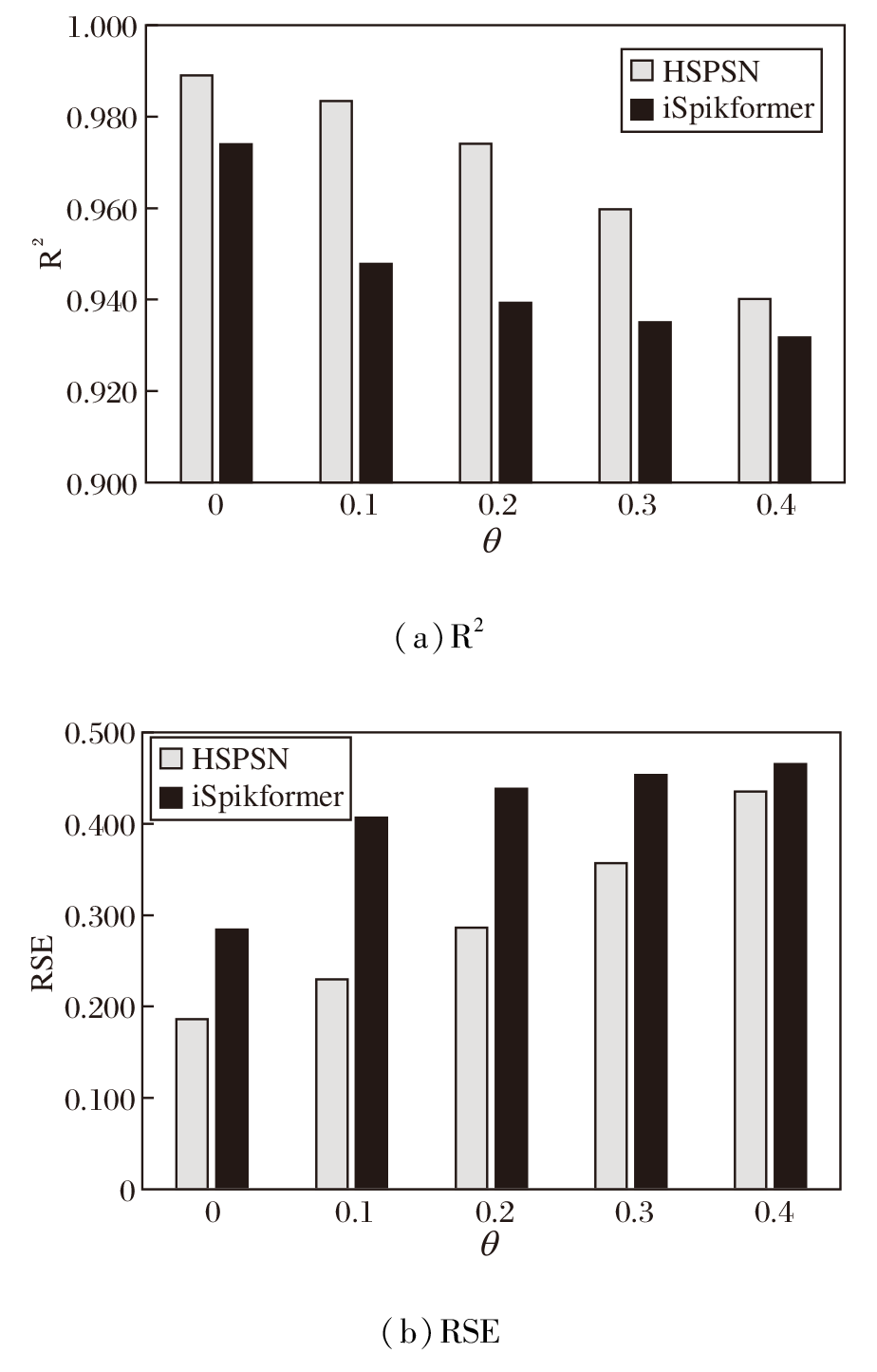 | 图9 数据噪声场景中的鲁棒性结果Fig.9 Robustness results in noisy data scenarios |
本文提出高时间步长友好的分片并行脉冲神经元模型(HSPSN), 将时间序列的时间步与SNN模拟时间步直接映射, 利用局部切片和全局切片的膜电位交互有效整合局部细粒度特征与跨片全局信息, 并采用基于训练轮次的收缩矩阵随机丢弃方法, 解决传统时序映射理论面临映射粒度选择的困难、并行脉冲神经元在高时间步长拓展能力不足和收敛效果较差的问题.实验表明, HSPSN在7个真实世界数据集上取得较优值, 充分验证其在各类时间序列预测任务上的有效性.消融实验充分展现分片并行脉冲神经元在性能上的优势和收缩矩阵随机丢弃方法在优化收敛过程上的有效性.在针对训练时间、推理理论能耗的实验中, HSPSN展现出较好的平衡性, 可有效缩短训练时间, 达到较低的计算量和能耗.此外, 本文通过系统的超参数实验与鲁棒性分析, 表明HSPSN在不同参数配置下均表现出稳定的高性能, 并对输入噪声具有良好的容错能力.综上所述, HSPSN在较短的训练、推理时间内, 实现高准确率、低能耗的时间序列预测的核心目标, 为将SNN模型应用于时间序列预测领域提供新的思路, 推动生物学合理和能量高效的类脑计算朝向高效训练、边缘设备友好的方向发展.今后计划设计面向协变量预测的专用SNN架构, 提升模型对变量间的建模能力; 探索更好结合并行脉冲神经元与神经形态硬件的物理特性的算法, 构建软硬件联合协作的并行计算框架, 合理优化调度任务、内存管理与使用, 促进SNN模型更好地应用于神经形态边缘硬件设备.
本文责任编委 杨 明
Recommended by Associate Editor YANG Ming
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|