




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
频域增强自适应通道注意力与特征金字塔融合的可逆流网络风格迁移
[葛斌1, 2  , 邵孜绎
, 邵孜绎1, 2 , 郑军帅1 , 夏晨星1 , 官骏鸣3 , 徐涛1 ]
, 邵孜绎, 郑军帅, 夏晨星, 官骏鸣, 徐涛]
|
|



作者简介:

葛 斌,博士,教授,主要研究方向为计算机视觉、模式识别、信息安全.E-mail:bge@aust.edu.cn.

邵孜绎,硕士研究生,主要研究方向为计算机视觉、深度学习.E-mail:2023201180@aust.edu.cn.

夏晨星,博士,副教授,主要研究方向为计算机视觉、模式识别、机器学习.E-mail:cxxia@aust.edu.cn.

官骏鸣,博士,副教授,主要研究方向为计算机视觉、模式识别.E-mail:105051@hsu.edu.cn.

徐 涛,硕士研究生,主要研究方向为计算机视觉、深度学习.E-mail:2023201180@aust.edu.cn.
针对风格迁移中内容失真、出现伪影与频域特性利用不足的问题,文中提出基于频域增强自适应通道注意力与特征金字塔融合的可逆流网络风格迁移方法.首先,以预训练VGG19为基础架构,设计可逆流网络,利用无偏差特征传递机制减少特征损耗,保障内容结构的完整性.然后,设计频域增强自适应通道注意力模块,解析风格图像频域分布,建立内容特征与风格特征的精准关联,提升风格化效果.最后,构建特征金字塔融合模块,对齐全局风格与局部纹理,提升迁移结果协调性.在MS-COCO、WikiArt数据集上的实验表明,文中方法能平衡风格传递与内容保留,在内容结构完整性、风格化效果及计算效率上均较优.
About Author:
GE Bin, Ph.D., professor. His research interests include computer vision, pattern re-cognition, and information security.
SHAO Ziyi, Master student. His research interests include computer vision and deep learning.
XIA Chenxing, Ph.D., associate pro-fessor. His research interests include compu-ter vision, pattern recognition, and machine learning.
GUAN Junming, Ph.D., associate pro-fessor. His research interests include compu-ter vision and pattern recognition.
XU Tao, Master student. His research interests include computer vision and deep learning.
To address the issues of content distortion, artifact appearance, and insufficient utilization of frequency-domain characteristics in style transfer, a reversible flow network for style transfer based on frequency-domain enhanced adaptive channel attention and feature pyramid fusion(FECANet) is proposed. Based on the pre-trained VGG19 architecture, a reversible flow network is designed to reduce feature loss and ensure the integrity of content structure by leveraging its unbiased feature transfer mechanism. A frequency-domain enhanced adaptive channel attention module is developed to analyze the frequency-domain distribution of style images, and accurate correlations between content and style features are established to improve the stylization effect. Additionally, a feature pyramid fusion scheme is designed to align global style with local textures, enhancing the coordination of transfer results. Experiments on MS-COCO and WikiArt datasets show that FECANet effectively balances style transfer and content preservation, and it shows superior performance in content structure integrity, stylization effect and computational efficiency.
风格迁移作为计算机视觉与深度学习交叉领域的重要研究方向, 旨在将参考图像的艺术风格有效迁移至内容图像, 同时完好保留内容图像的语义结构.目前, 风格迁移已取得显著进展, 并在艺术创作、图像编辑、增强现实等领域展现出广泛的应用前景.
尽管现有方法已取得一定进展, 但在复杂风格迁移场景中仍面临诸多挑战.1)内容结构失真与伪影问题突出[1].传统编码器-解码器架构的信息损失导致生成图像出现边缘模糊、语义信息丢失等现象.2)风格纹理细节表达不足.现有方法难以精准还原油画笔触、水彩晕染等细腻风格特征.3)局部细节与全局风格缺乏协同性, 导致生成图像在不同尺度上的风格一致性较差.这些问题严重制约风格迁移的质量与实用性, 限制其在实际应用中的推广.
为了解决上述问题, 本文提出频域增强自适应通道注意力与特征金字塔融合的可逆流网络风格迁移方法(Reversible Flow Network for Style Transfer Based on Frequency-Domain Enhanced Adaptive Channel Attention and Feature Pyramid Fusion, FECANet), 以预训练VGG19(Visual Geometry Group 19)为基础架构, 采用可逆流网络实现特征的无偏差映射.设计频域增强自适应通道注意力模块(Frequency-Domain Enhanced Adaptive Channel Attention Module, FE-CA), 利用离散余弦变换实现高低频分离, 根据风格的频率能量分布自适应调整内容特征的频域权重.引入双池化通道注意力机制, 动态调整特征通道权重.构建特征金字塔融合模块(Feature Pyramid Fu-sion Module, FFPM), 捕获不同层次的纹理信息.实验表明, FECANet能在保持内容结构完整性的同时实现高质量的风格迁移效果.
Gatys等[2]首次将VGG网络引入风格迁移领域, 利用VGG19对内容图像与风格图像分别进行特征提取, 构建内容损失函数与风格损失函数, 对初始化图像不断计算损失并反馈重绘, 最终生成具有目标风格的图像.Johnson等[3]提出基于VGG的端到端风格迁移网络, 通过训练生成器直接输出迁移结果.Simonyan等[4]提出的VGG网络结构能有效提取图像的层次化特征.林星等[5]提出主体结构保持的增强型网络传递方法, 设计LoG(Laplacian of Gaussian)算子的主体结构损失项和Gabor滤波器的局部风格损失项, 有效解决风格传递中主体结构变形问题.Huang等[6]提出AdaIN(Adaptive Instance Normalization), 对齐内容特征与风格特征的均值和方差, 实现全局风格迁移, 成为任意风格迁移的经典方法.Li等[7]提出WCT(Whitening and Coloring Trans-form), 调整特征分布, 增强风格迁移的灵活性.
上述方法均以VGG网络作为特征提取的骨干网络, 通过全局统计匹配实现高效迁移, 但普遍存在内容结构失真问题:当风格特征与内容特征差异较大时, 容易出现边缘模糊、语义信息丢失等现象.
随着注意力机制的引入, 基于VGG的方法开始尝试强化局部特征匹配.Park等[8]提出SANet(Style-Attentional Network), 通过自注意力机制建立内容与风格特征的局部关联, 提升细节迁移精度.Liu等[9]提出AdaAttN(Adaptive Attention Network), 设计融合自注意力机制, 通过加权均值方差增强局部风格表达.Peng等[10]设计ACMM(Attention-Wise and Covariance-Matching Module), 较好地保留内容结构, 减少伪影的产生.Yang等[11]提出PSANet(Pyramid Style-Attention Network), 应用自注意力机制, 旨在通过考虑内容图像和风格图像之间的长程依赖关系改善风格迁移效果, 同时保持语义内容信息.
此外, 为了解决传统基于VGG网络的风格迁移方法中内容结构保留不佳、伪影频发的问题, 现有研究多通过引入跳跃连接模块[12]或降低网络深度[13]的方式, 但这类策略受限于风格迁移过程中的图像信息损耗, 难以平衡内容完整性与风格贴合度, 导致出现内容泄露[14]及块状伪影[15].
SCFlow[16]与可逆架构通过特征无偏差传递打破VGG网络的局限, 成为风格迁移的重要方向之一.Dinh等[17]提出NICE(Non-linear Independent Com-ponent Estimation), 通过堆叠可逆变换建模数据分布, 为流网络风格迁移提供范式.Kingma等[18]提出Glow, 引入可逆1× 1卷积优化流网络结构, 被ArtFlow[19]应用于风格迁移, 通过正向投影-风格化-反向重建的流程, 减少内容泄漏.
流网络的可逆架构为风格迁移带来3个关键优势:1)信息无损传递.可逆性从数学上保证完美重建[17], 解决VGG网络中编码器-解码器因降维-升维导致的内容结构失真问题.2)训练稳定高效.流网络通过变量变换公式直接计算精确对数, 避免VAE(Variational Autoencoder)的近似误差和GAN(Generative Adversarial Network)的模式崩塌问题.3)推理速度较快.流网络支持双向映射, 仅需1次前向计算即可完成风格迁移.扩散模型通常需要50~1 000步迭代去噪, 速度明显低于流网络, 并且随机去噪过程容易导致内容语义漂移[20].在训练成本方面, 扩散模型训练数据量较大、训练周期较长, 而流网络对训练数据的需求更低, 无需大规模数据集即可完成训练[21].因此, 流网络在内容保真、实时性和训练效率上更适合风格迁移任务.
Wen等[22]提出CAP-VSTNet, 核心思想包括:1)可逆残差网络.通过堆叠可逆残差块实现深层特征提取, 在保证可逆性的同时, 学习更复杂的特征表示.2)无偏线性变换模块.基于WCT, 计算风格特征的协方差矩阵, 调整内容特征的统计分布, 达到与风格特征一致, 实现风格迁移.然而, CAP-VSTNET在风格化效果与网络设计细节上仍存在一定不足.一方面, 其核心依赖的无偏线性变换模块完成风格特征整合, 虽能实现基础风格迁移, 但对风格图像的多尺度纹理细节与全局风格关联性建模不足, 难以精准还原油画的笔触层次、水彩的晕染质感等细腻风格特征, 导致生成图像的风格表现力与真实艺术效果存在差距[23].另一方面, 其流网络结构中的可逆模块未针对风格迁移任务的特征分布特点进行优化, 进一步削弱风格化效果.
此外, 现有风格迁移方法对图像频域特征的挖掘和利用不足, 也是制约风格迁移质量的关键因素之一.图像的风格信息在频域中具有明确的分布特征, 其中低频分量主要对应图像的全局色调和整体风格趋势, 高频分量承载细节纹理和边缘特征等重要风格信息, 而通道注意力通过动态调整特征通道权重, 可自适应强化风格相关特征、抑制冗余信息, 二者的结合能突破单一维度注意力的表达局限.
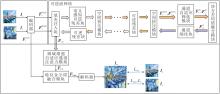
本文提出频域增强自适应通道注意力与特征金字塔融合的可逆流网络风格迁移方法(FECANet), 整体架构如图1所示.
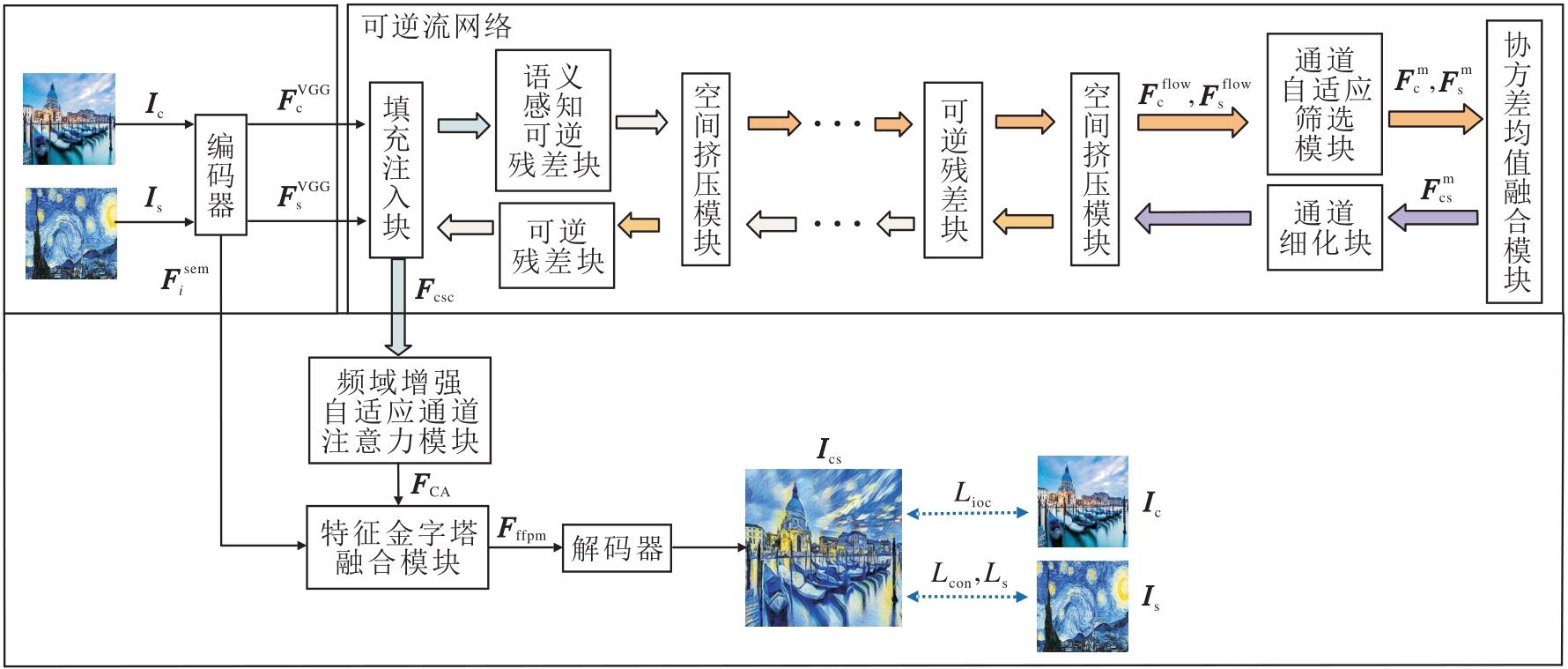 | 图1 FECANet整体框架Fig.1 Overall framework of FECANet |
本文采用预训练的VGG19编码器提取内容特征与风格特征, 编码器选用VGG网络的前四层, 解码器采用与编码器对称的结构, 需通过训练优化参数.FECANet流程如下.首先, 将内容图像Ic与风格图像Is并行输入预训练的VGG19网络, 提取其在ReLU(Rectified Linear Unit)层的语义特征
2.1.1 网络架构
本文构建的可逆流网络架构如图1所示, 结构与CAP-VSTNet[22]相近.首先, 通过填充注入块对输入的内容图像与风格图像进行预处理, 沿通道维度执行零填充操作以扩充特征维度, 进而将原始图像映射至适配可逆变换的潜在特征空间.前向推理阶段依赖级联的可逆残差块与空间挤压模块完成特征的无偏传递与维度适配.再通过通道自适应筛选模块(Channel Adaptive Screening Module, CASM)过滤与风格迁移无关的冗余通道, 提升特征交互效率.然后, 通过协方差均值融合模块实现内容特征与风格特征的统计分布对齐.最终通过反向推理过程, 将风格化后的潜在特征映射回像素空间, 得到初步风格化特征.
2.1.2 语义感知可逆残差块
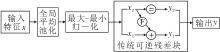
传统可逆残差块采用固定的通道均分策略, 将特征沿通道维度平均划分为两部分处理, 但这一方式未兼顾风格迁移任务中内容特征与风格特征的差异化表达需求:内容特征需重点保留关键语义结构, 风格特征需突出纹理细节的传递.为此, 本文设计SARRB(Semantic-Aware Reversible Residual Block), 结构如图2所示.在可逆流网络中, 仅将第一块残差块的通道分块策略替换为SARRB, 后续残差块仍沿用传统固定均分策略.
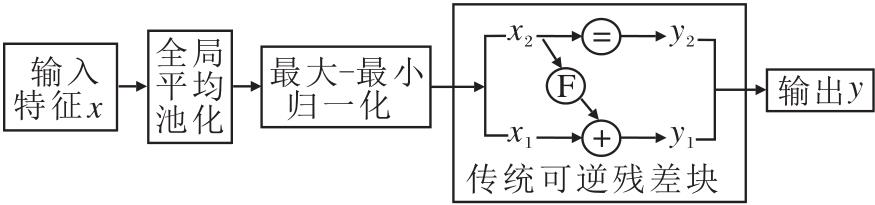 | 图2 SARRB结构图Fig.2 Structure of SARRB |
对于输入特征x, 通过轻量级语义评分模块计算各通道的语义贡献度.首先对特征图执行全局平均池化(Global Average Pooling, GAP), 将每个通道的特征信息压缩为单一响应值, 该响应值反映通道承载语义信息的活跃度.再通过最大-最小归一化将响应值映射至[0, 1]区间, 将响应值归一化后作为语义重要性评分:
$ s_{i}=\frac{v_{i}-\min \left(v_{j}\right)}{\max \left(v_{j}\right)-\min \left(v_{j}\right)}, j=1, 2, \cdots, C, $
其中, vi表示第i个通道的池化响应值, vj表示所有通道的池化响应值, C表示通道总数.改变传统均分方式, 将通道分为语义核心块x1和辅助细节块x2, 分块过程表示如下:
x1, x2=splitscm(x),
其中splitscm(· )表示语义感知分块函数.具体实现时, 先对所有通道的评分si按从大到小排序, 再将排序后评分较高的部分通道划分为语义核心块x1, 剩余通道划分为辅助细节块x2.
在特征变换阶段, 对语义核心块x1采用3× 3卷积层F(· )进行特征优化:
y1=F(x1).
辅助细节块x2直接传递以保留细节:
y2=x2.
最终融合输出:
y=y1+y2.
反向传播时, 根据可逆性从输出特征y拆分得到y1和y2:
y1, y2=split(y).
通过卷积操作恢复
x1=F-1(y1),
直接保留y2作为x2:
x2=y2.
最终合并为原始特征:
x=x1+x2,
保障信息无丢失.
2.1.3 特征筛选与风格化初步适配
经SARRB输出的特征y会依次在后续传统可逆残差块进行进一步处理, 最终形成可逆流网络输出的无偏底层特征
针对传统通道细化模块[22]未考虑特征与风格相关性的问题, 本文改进为通道自适应筛选模块(CASM), 在保留通道压缩功能的基础上增加风格相关性筛选机制.
首先对可逆残差块输出的特征y进行1× 1卷积操作, 将通道维度压缩至50%.再计算压缩后每个通道与风格特征对应通道的余弦相似度:
$ \operatorname{sim}\left(\boldsymbol{c}_{i}, \boldsymbol{s}_{i}\right)=\frac{\boldsymbol{c}_{i} \cdot \boldsymbol{s}_{i}}{\left\|\boldsymbol{c}_{i}\right\|\left\|\boldsymbol{s}_{i}\right\|}, $
其中, ci表示内容特征第i个通道, si表示风格特征第i个通道.最后将相似度从大到小排序, 根据相似度保留前80%的通道, 滤除与风格关联较弱的冗余通道, 输出筛选后的特征用于后续协方差融合.经CASM处理后, 得到的内容精炼特征
$ \boldsymbol{F}_{\mathrm{cs}}^{\mathrm{m}}=\boldsymbol{F}_{\mathrm{c}}^{\mathrm{m}} \operatorname{cov}\left(\boldsymbol{F}_{\mathrm{s}}^{\mathrm{m}}\right) .$
其中:
$ \operatorname{cov}\left(\boldsymbol{F}_{\mathrm{s}}^{\mathrm{m}}\right)=\frac{1}{N-1}\left(\boldsymbol{F}_{\mathrm{s}}^{\mathrm{m}}-\boldsymbol{\mu}_{\mathrm{s}}\right)\left(\boldsymbol{F}_{\mathrm{s}}^{\mathrm{m}}-\boldsymbol{\mu}_{\mathrm{s}}\right)^{\mathrm{T}}, $
表示风格特征经CASM处理后的协方差矩阵, 核心作用是量化风格精炼特征
融合特征经可逆变换恢复为
$ \boldsymbol{F}_{\mathrm{csc}}=\boldsymbol{F}_{\mathrm{cs}}^{\text {flow }}+\operatorname{Mean}\left(\boldsymbol{F}_{\mathrm{s}}\right), $
其中Mean(Fs)表示原始风格特征的均值.通过该补偿设计, 既保障融合特征继承可逆流网络的无偏性, 又实现内容结构与风格特征的深度融合.最终得到初步风格化特征Fcsc, 有效解决传统融合方法中风格注入不精准和均值偏移导致失真的问题, 因此可替代原始风格特征参与后续风格迁移流程, 有助于后续特征金字塔融合与细节优化.
在风格迁移任务中, 注意力机制旨在平衡风格特征精准传递与内容结构有效保留, 但现有方案在频域信息利用和通道-频域协同方面仍有优化空间.Hu等[24]提出FSANet(Flow Style-Aware Network), 在DRAM(Dynamic Regulation Attention Module)中引入CDRA(Channel Dynamic Regulation Attention Me-chanism), 采用全局平均池化+全局最大池化的双池化策略, 同时捕捉通道的全局统计规律与局部峰值信息, 显著提升通道权重对风格细节的判别性, 但该机制未关联频域信息, 无法针对风格在全局色调和细节纹理上的频率分布差异进行定向优化.Qin等[25]提出FcaNet, 通过频率域的通道注意力机制提升卷积神经网络的性能, 为风格迁移领域的频域注意力设计提供技术参考.然而, 现有风格迁移领域中涉及频域的相关研究仍存在局限:多数方法仅在图像像素层面进行频域操作, 未深入网络中间特征层面, 难以捕捉高层语义维度的风格频率特性.
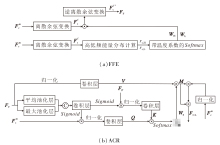
基于上述研究现状, 本文设计频域增强自适应通道注意力模块(FECA), 结构如图3所示.
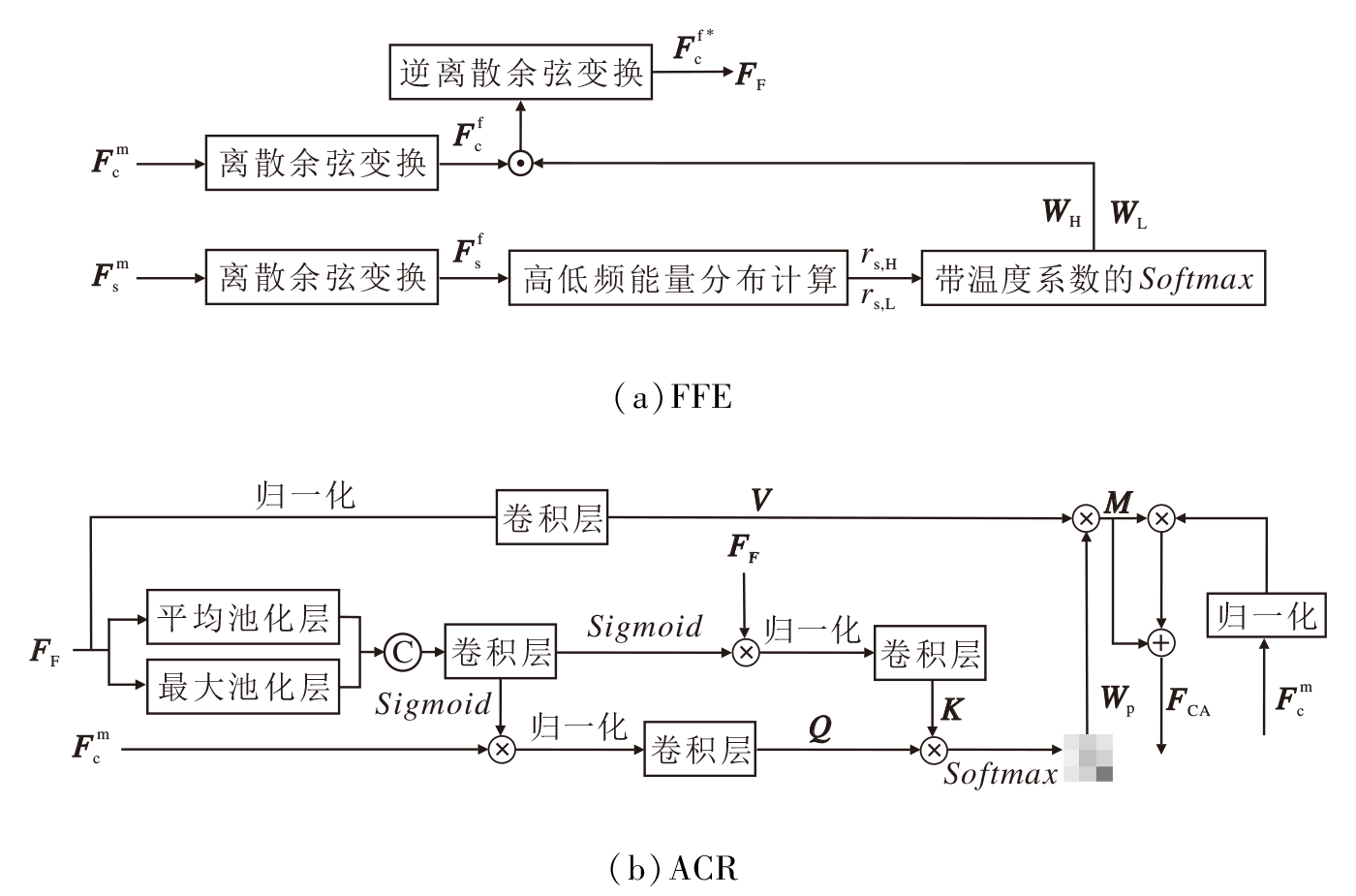 | 图3 FECA结构图Fig.3 Structure of FECA |
FECA由频域特征增强模块(Frequency Domain Feature Enhancement Module, FFE)和自适应通道调节模块(Adaptive Channel Regulation Module, ACR)组成.FECA通过离散余弦变换(Discrete Cosine Transform, DCT)实现频域特征提取, 结合双池化通道注意力机制实现特征增强.频域注意力的设计依据风格频率特性的二元分布, 此处采用DCT变换实现简洁高效的高低频分离.首先, 对CASM输出的内容精炼特征
$ \begin{array}{l} \boldsymbol{F}_{\mathrm{c}}^{\mathrm{f}}=\operatorname{DCT}\left(\boldsymbol{F}_{\mathrm{c}}^{\mathrm{m}}\right) \in \mathbf{R}^{B \times C \times H \times W}, \\ \boldsymbol{F}_{\mathrm{s}}^{\mathrm{f}}=\operatorname{DCT}\left(\boldsymbol{F}_{\mathrm{s}}^{\mathrm{m}}\right) \in \mathbf{R}^{B \times C \times H \times W}, \end{array}$
其中, B表示批次大小, C表示通道数, H、W分别表示高度和宽度.
DCT变换的核心优势在于实现频率分量的有序分布:低频分量集中于频域矩阵左上角, 主导全局色调; 高频分量分布于右下角, 重点控制细节纹理.这一分布特性与风格迁移领域“ 风格频率二元分布” 的核心认知高度契合— — 即全局色调由低频分量主导、细节纹理由高频分量主导.
因此, 本文将频域矩阵划分为两个关键区域:低频带(BL)与高频带(BH).BL对应频域矩阵左上角40%区域, 可覆盖主要低频分量; BH对应频域矩阵右下角60%区域, 可覆盖主要高频分量.为了量化风格的频率主导性, 计算风格频域特征在低频带和高频带的能量占比:
$ \begin{aligned} r_{\mathrm{s}, \mathrm{~L}}= & \frac{\sum_{(x, y) \in B_{\mathrm{L}}} F_{\mathrm{s}}^{\mathrm{f}}(b, c, x, y)^{2}}{\sum_{(x, y) \in \Omega} F_{\mathrm{s}}^{\mathrm{f}}(b, c, x, y)^{2}}, \\ r_{\mathrm{s}, \mathrm{H}}= & \frac{\sum_{(x, y) \in B_{\mathrm{H}}} F_{\mathrm{s}}^{\mathrm{f}}(b, c, x, y)^{2}}{\sum_{(x, y) \in \Omega} F_{\mathrm{s}}^{\mathrm{f}}(b, c, x, y)^{2}} . \end{aligned}$
其中:Ω 表示整个频域矩阵的空间范围(x∈ [1, H], y∈ [1, W]); b∈ [1, B]表示批量, c∈ [1, C]表示通道索引, 确保计算覆盖所有样本与特征通道, 提升统计可靠性.公式中分子为区域的风格特征能量, 分母为全频域风格特征总能量, 通过两者的比值, 可直接反映该风格是低频主导还是高频主导.
不同风格在高低频域能量占比上存在显著差异, Chen等[26]提出StyleBank, 验证油画风格的高频能量占比普遍高于水彩风格, 这一规律为本文设计提供实践依据.为了进一步强化风格主导频率的权重占比, 通过带温度系数的Softmax函数生成高/低频域注意力权重:
$ \begin{array}{l} W_{\mathrm{L}}=\frac{\exp \left(r_{\mathrm{s}, \mathrm{~L}} T\right)}{\exp \left(r_{\mathrm{s}, \mathrm{~L}} T\right)+\exp \left(r_{\mathrm{s}, \mathrm{H}} T\right)}, \\ W_{\mathrm{H}}=1-W_{\mathrm{L}} \end{array}, $
其中, T=0.8, 表示温度系数, 设计动机是通过缩小Softmax输出的分布熵, 让权重向风格主导频率倾斜, 避免权重过于平均导致的风格特征传递不突出.在得到频域权重后, 将内容频域特征
$ \boldsymbol{F}_{c}^{\mathrm{f}^{* }}(b, c, x, y)=\left\{\begin{array}{ll} \boldsymbol{F}_{\mathrm{c}}^{\mathrm{f}}(b, c, x, y) W_{\mathrm{L}}, & (x, y) \in B_{L} \\ \boldsymbol{F}_{\mathrm{c}}^{\mathrm{f}}(b, c, x, y) W_{\mathrm{H}}, & (x, y) \in B_{H} \end{array}\right.$
此处对内容频域的低频区域BL施加低频权重WL, 高频区域BH施加高频权重WH, 既避免风格无关频率分量的过度增强, 又确保内容特征在风格主导维度与风格特征对齐, 解决传统方法中的内容与风格频率不匹配导致的风格化失真的问题.最后通过逆离散余弦变换将增强后的频域特征转回空域, 得到频域增强特征:
$ \boldsymbol{F}_{\mathrm{F}}=\operatorname{IDCT}\left(\boldsymbol{F}_{\mathrm{c}}^{\mathrm{f}^{* }}\right) \in \mathbf{R}^{B \times C \times H \times W}, $
其中IDCT(· )表示逆离散余弦变换.FF既保留内容的核心结构信息, 又强化与风格频率特性匹配的分量, 有助于后续通道注意力的处理.
自适应通道注意力以频域增强特征FF为输入, 保留双池化核心, 用于捕捉全局统计与局部峰值信息.通过与风格特征的响应匹配实现权重的自适应调整, 形成与频域注意力的协同增强.首先对FF执行全局平均池化与最大池化, 提取通道注意力权重:
$ \boldsymbol{W}_{\mathrm{c}}=\operatorname{sigmoid}\left(\operatorname{Conv}\left(\operatorname{Concat}\left(R_{\mathrm{F}, \mathrm{avg}}, R_{\mathrm{F}, \max }\right)\right)\right) .$
其中:
$ \boldsymbol{R}_{\mathrm{F}, \mathrm{avg}}=G A P\left(\boldsymbol{F}_{\mathrm{F}}\right), $
表示频域增强特征的全局统计, 聚合每个通道的全局统计信息, GAP(· )表示全局平均池化;
$ \boldsymbol{R}_{\mathrm{F}, \text { max }}=G M P\left(\boldsymbol{F}_{\mathrm{F}}\right), $
聚焦每个通道的局部峰值响应, GMP(· )表示全局最大池化; Conv(· )表示1× 1的卷积层, 在保留通道维度信息的同时, 降低计算复杂度; sigmoid(· )表示sigmoid函数; Concat(· )表示拼接函数.Wc中每个元素对应一个通道的增强权重, 权重越高, 表示该通道与风格特征的响应匹配度越强.根据计算的权重, 通过将内容增强特征和频域增强特征相乘的方式, 对每个通道进行加权, 得到通道加权特征:
$ \boldsymbol{F}_{\mathrm{wc}}=\boldsymbol{W}_{\mathrm{c}} \times \boldsymbol{F}_{\mathrm{c}}, \boldsymbol{F}_{\mathrm{ws}}=\boldsymbol{W}_{\mathrm{c}} \times \boldsymbol{F}_{\mathrm{s}}, $
其中× 表示元素乘法.对内容特征Fc和风格特征Fs分别施加通道注意力权重Wc, 可避免内容结构被冗余风格信息干扰并使风格特征的通道响应与内容特征对齐.在获得通道加权特征后, 需要在内容增强特征和频域增强特征之间建立像素级的关联, 通过1× 1卷积将上述响应映射为Query、Key、Value矩阵:
$ \begin{array}{l} \boldsymbol{Q}=f\left(\operatorname{Norm}\left(\boldsymbol{F}_{\mathrm{wc}}\right)\right), \\ \boldsymbol{K}=g\left(\operatorname{Norm}\left(\boldsymbol{F}_{\mathrm{ws}}\right)\right), \\ \boldsymbol{V}=h\left(\operatorname{Norm}\left(\operatorname{Concat}\left(\boldsymbol{R}_{\mathrm{F}, \mathrm{avg}}, \boldsymbol{R}_{\mathrm{F}, \max }\right)\right)\right), \end{array}$
其中, f(· )、 g(· )、h(· )表示1× 1可学习的卷积层, Norm(· )表示采用通道方式的均值-方差归一化方法.
计算Q与K的相似度矩阵, 经Softmax归一化后与V加权, 得到融合内容与风格关联的加权特征图:
$ \boldsymbol{W}_{\mathrm{p}}=\operatorname{Softmax}\left(\frac{\boldsymbol{Q} \otimes \boldsymbol{K}^{\mathrm{T}}}{\sqrt{C / 4}}\right), $
其中, C/4表示缩放因子, 可避免维度过高导致内积数值饱和.然后计算注意力加权均值:
M=Wp× V,
其中, Wp表示像素级注意力权重, V表示包含风格全局信息和局部信息的特征矩阵, 二者相乘的目的是让内容特征的每个像素位置都匹配对应的风格细节.最后, 将M与内容精炼特征
$ \boldsymbol{F}_{\mathrm{CA}}=\boldsymbol{M} \times \operatorname{Norm}\left(\boldsymbol{F}_{\mathrm{c}}^{\mathrm{m}}\right)+\boldsymbol{M} .$
现有风格迁移方法在多尺度特征融合中存在明显不足:部分方法仅依赖单一尺度特征进行风格匹配, 导致生成结果出现局部细节模糊的问题.虽有方法尝试引入多尺度特征, 但多采用简单通道拼接的融合方式, 未能建立跨尺度特征间的深度关联; 还有方法忽视风格增强特征与多尺度语义信息的有机整合, 使不同尺度下的风格表达一致性较差.
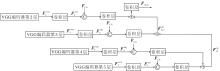
针对上述问题, 本文设计特征金字塔融合模块(FFPM), 核心是将VGG19网络提取的多尺度语义特征与双重增强特征FCA进行深度融合, 通过跨尺度信息传递实现全局结构和局部细节的共同优化.FFPM结构如图4所示.
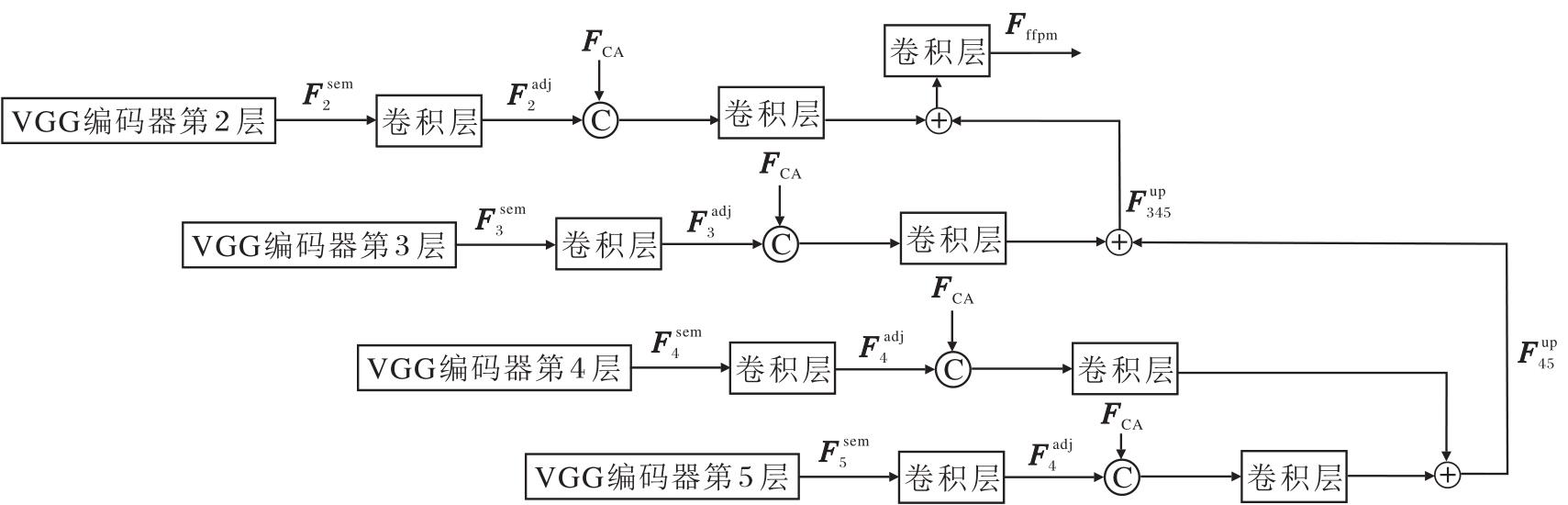 | 图4 FFPM结构图Fig.4 Structure of FFPM |
FFPM的处理流程分为特征适配阶段与特征金字塔融合阶段.
特征适配阶段完成通道统一与风格特征注入.通过1× 1卷积将VGG19提取的多尺度语义特征
$ \boldsymbol{F}_{i}^{\mathrm{adj}}=\operatorname{Conv}_{1 \times 1}\left(\boldsymbol{F}_{i}^{\mathrm{sem}}\right), i=2, 3, 4, 5 .$
考虑到仅靠内容语义特征无法实现精准风格化, 需将前期通道注意力增强的风格特征FCA注入多尺度特征中, 将FCA与
$ \boldsymbol{F}_{4}^{\text {fusion }}=\operatorname{Concat}\left(\boldsymbol{F}_{i}^{\text {adj }}, \boldsymbol{F}_{\mathrm{CA}}\right) .$
为了使
$ \boldsymbol{F}_{5}^{\mathrm{up}}=\operatorname{Upsample}\left(\boldsymbol{F}_{5}^{\mathrm{adj}}, \text { scale }=2\right), $
其中Upsample(· )表示上采样操作.
特征金字塔融合阶段通过自上而下的信息传递实现跨尺度特征交互.将
$ \boldsymbol{F}_{45}=\operatorname{Conv}_{1 \times 1}\left(\boldsymbol{F}_{4}^{\text {fusion }}\right)+\operatorname{Conv}_{1 \times 1}\left(\boldsymbol{F}_{5}^{\text {up }}\right) .$
此处使用1× 1卷积是对两类特征进行通道级加权处理, 让方法自主学习全局语义和风格细节的融合权重, 避免信息冗余, 通过逐元素相加的方式, 确保高、中尺度特征的信息互补, 保留高尺度的语义完整性与中尺度的风格精准性.
对F45执行2倍上采样后, 与经1× 1卷积处理的
$ \boldsymbol{F}_{345}=\operatorname{Conv}_{1 \times 1}\left(\boldsymbol{F}_{3}^{\text {adj }}\right)+\operatorname{Upsamlpe}\left(\boldsymbol{F}_{45}, \text { scale }=2\right) .$
将F45再次上采样, 与
$ \begin{aligned} \boldsymbol{F}_{\mathrm{ffpm}}= & \operatorname{Conv}_{3 \times 3}\left(\operatorname{Conv}_{1 \times 1}\left(\boldsymbol{F}_{2}^{\mathrm{adj}}\right)+\right. \\ & \left.\operatorname{Upsample}\left(\boldsymbol{F}_{345}, \text { scale }=2\right)\right) . \end{aligned}$
此处, 使用3× 3卷积是由于3× 3卷积的感受野大于1× 1卷积, 可捕捉特征的局部空间关联, 进一步整合全尺度信息, 得到风格与内容更协调的输出特征.
现有风格迁移方法普遍采用内容损失与风格损失作为基本约束, 虽能保证整体迁移效果, 但在细节保持与局部风格一致性方面仍有不足.为此, 本文设计复合损失函数, 引入局部结构约束与风格对比机制, 提升方法对细节的感知与生成能力.总损失函数如下:
Ltotal=λ locLloc+λ sLs+λ conLcon,
其中, 局部损失Lloc用于增强方法对图像局部结构的建模能力, 风格损失Ls负责整体风格匹配, 风格对比损失Lcon通过对比学习策略增强风格特征的判别性, λ loc、λ s、λ con用于平衡各项损失的贡献.
局部损失Lloc基于改进的AdaAttN[9]构建, 本文将其中的可学习参数固定, 使其仅作为特征对齐工具, 引导生成图像在细节层面与内容图像保持一致, 再通过L2范数计算生成特征Fcs与对齐后特征的差异, 差异越小, 说明生成图像的局部细节与内容图像越一致, 具体公式如下:
$ L_{\mathrm{loc}}=\| \boldsymbol{F}_{\mathrm{cs}}-\text { Adaattn' }^{\prime}\left(\boldsymbol{F}_{\mathrm{c}}, \boldsymbol{F}_{\mathrm{s}}, \boldsymbol{F}_{\mathrm{CA}}\right) \|_{2}, $
其中Adaattn'(· )表示固定参数版本的AdaAttN, 为自适应注意力对齐函数.
风格损失Ls通过在VGG网络的多个层级上匹配特征的均值和标准差, 确保生成图像在统计特性上与风格图像相似, 具体公式如下:
$ \begin{aligned} L_{\mathrm{s}}= & \sum_{l=1}^{5}\left(\left\|\mu\left(\phi_{l}\left(\boldsymbol{I}_{\mathrm{cs}}\right)\right)-\mu\left(\phi_{l}\left(\boldsymbol{I}_{\mathrm{s}}\right)\right)\right\|_{2}+\right. \\ & \left.\left\|\sigma\left(\phi_{l}\left(\boldsymbol{I}_{\mathrm{cs}}\right)\right)-\sigma\left(\phi_{l}\left(\boldsymbol{I}_{\mathrm{s}}\right)\right)\right\|_{2}\right), \end{aligned}$
其中, ϕ l(· )表示VGG19网络第l层特征提取函数, l=1, 2, …, 5, μ (· )表示特征图均值, σ (· )表示特征图标准差.
为了进一步提升风格表达的准确性和鲁棒性, 引入风格对比损失Lloc.该损失通过在批次内构建正负样本对, 拉近生成图像与对应风格图像的特征距离, 同时推远与其它风格样本的特征距离, 具体公式如下:
$ L_{\mathrm{con}}=\sum_{i=1}^{N}\left(\frac{\left\|\boldsymbol{I}_{\mathrm{cs}}^{i}-\boldsymbol{I}_{s}^{i}\right\|_{2}}{\sum_{j \neq i}^{N}\left(\left\|\boldsymbol{I}_{\mathrm{cs}}^{i}-\boldsymbol{I}_{\mathrm{cs}}^{j}\right\|_{2}\right)}\right) .$
其中,
通过上述3类损失的协同作用, FECANet能在保持全局风格一致的同时, 显著提升对局部内容结构和细节风格的保持能力, 实现更高质量的风格迁移效果.
为了全面评估FECANet的性能, 采用风格迁移领域的5项标准定量指标.
1)风格损失(Lstyle).度量生成图像与风格图像在风格特征上的相似度, 计算均值和方差, 评估图像的风格化效果, 数值越小表示风格转移精准性越高.
2)Gram损失(LG).深度学习领域中度量图像特征风格差异的核心损失函数, 目的是通过量化两幅图像特征Gram矩阵的偏离程度, 实现风格特征的精准捕捉与匹配.相比风格损失, Gram损失更强调全局的纹理和色彩统计特性, 对于捕捉风格的整体视觉特征更敏感.数值越小表示性能越优.
3)结构相似性(Structural Similarity Index, SSI-M).度量生成图像与风格图像在风格特征上的相似度, 综合考虑亮度、对比度和结构这3个维度, 取值范围为[-1, 1]区间, 数值越接近1表示内容结构保留得越完整, 反映生成图像与内容图像在视觉感知上的相似程度.
4)感知质量(Learned Perceptual Image Patch Similarity, LPIPS).度量生成图像与内容图像在感知层面的相似程度.基于预训练的卷积神经网络提取特征, 更贴合人类视觉对图像相似性的判断, 能有效捕捉图像的高层语义与风格细节差异.取值范围通常为[0, 1]区间, 数值越小表示生成图像与内容图像的感知相似度越高, 即内容保留效果越优.
5)推理时间(Inference Time).在256× 256、512× 512分辨率上计算网络的推理耗时, 评估方法的实用性.
实验时内容数据集采用MS-COCO数据集, 风格数据集选用WikiArt数据集.为了缩短训练周期, 输入图像需经过标准化预处理.先统一将图像缩放至512× 512, 再通过随机裁剪获取256× 256的训练样本.训练阶段采用Adam(Adaptive Moment Esti-mation)优化器, 初始学习率设为1× 10-4, 衰减值设为5× 10-5.在频域特征增强模块(FFE)中, DCT变换采用8× 8分块计算以平衡效率与精度, 温度系数T设为0.8.
训练在单块NVIDIA A4000-16G GPU上进行, 批量大小设为8, 经1.7× 105次迭代后, 得到最终训练网络.
为了全面验证FECANet的有效性, 选择如下代表性的不同技术路线的风格迁移方法进行对比.
1)统计匹配方法CCPL(Contrastive Coherence Preserving Loss)[13].基于传统特征统计和Gram矩阵的思想.
2)自注意力机制方法AdaAttN[9]和AesFA(Aes-thetic Feature-Aware Neural Style Transfer)[27].通过自适应的特征加权和空间对齐机制实现风格迁移.
3)流网络方法ArtFlow[19]和FSANet[24].通过可逆神经流进行无损特征变换.
4)生成对抗网络AAALNet(Aesthetic-Aware Adversarial Learning Network for Artistic Style Trans-fer)[28].利用对抗学习框架进行风格迁移, 通过生成器和判别器的博弈优化生成质量.
5)扩散模型方法StyleSSP(Style Transfer Method via Sampling Startpoint Enhancement)[29].利用扩散过程进行高质量图像生成, 可用于风格迁移任务.
3.3.1 可视化对比
为了确保所有测试均建立在公平的基础之上, 本文严格使用默认的权重配置测试其它网络.各网络可视化结果如图5所示.
 | 图5 风格迁移任务中各方法的生成图像Fig.5 Images generated by different methods in style transfer tasks |
由图5可看出, 不同方法在风格迁移任务中呈现出各自的局限性.自注意力机制方法(AdaAttN)在“ 翠鸟→ 人物素描” 任务中, 鸟体羽毛细节出现线条断裂, 头部与胸部区域的素描笔触不连续, 在上方及下方出现影响美感的黑色残影.在“ 风景→ 星夜” 任务中, 进一步放大细节可见(图6所示), 麦田区域色彩杂糅, 线条糊化, 缺乏韵律感, 人物区域失真严重, 山体部分纹理不清晰, 缺乏层次感.在“ 人物→ 质感图像” 的任务中, 人物面部出现冗余的点状重复纹理.
 | 图6 FECANet与AdaAttN生成图像的放大效果对比Fig.6 Magnification effect comparison of images generated by FECANet and AdaAttN |
在“ 翠鸟→ 人物素描” 任务中, 进一步放大细节可见(图7所示), AesFA素描线条粗细不均, 鸟喙和眼部的精细结构模糊, 原本层次分明的羽毛纹理完全糊化为杂乱色块, 核心内容细节的丢失直接破坏主体辨识度, 并且在枝干周围及图像边缘出现黑色残影.在“ 风景→ 星夜” 任务中出现较严重的重复状伪影问题, 干扰画面的整洁性.
 | 图7 FECANet与AesFA生成图像的放大效果对比Fig.7 Magnification effect comparison of images generated by FECANet and AesFA |
统计匹配方法(CCPL)在“ 翠鸟→ 人物素描” 任务中内容特征缺失严重.在“ 建筑→ 简笔画” 任务中, 水面倒影区域模糊不清, 上方建筑部分也有部分缺失, 显著降低生成结果的视觉质量.在“ 沙丘→ 抽象彩色” 任务中, 沙丘上的石墩明显出现多余的彩色残影, 影响视觉效果.
流网络方法(ArtFlow)在多类风格迁移任务中暴露的共性缺陷尤为突出.从细节表现上看, 所有生成结果的轮廓边缘均伴随明显的残影和重影干扰, 如翠鸟主体的羽毛纹理边缘、建筑轮廓的线条交界处, 均出现与主体无关的模糊拖影, 导致目标物体的边界辨识度大幅降低.同时核心线条的锐度严重不足, 如泰姬陵的穹顶轮廓、山水场景的山体边缘, 原本清晰的结构线条被过度柔化, 呈现出雾状模糊的视觉效果.
在“ 建筑→ 简笔画” 任务中, 进一步放大细节可见(图8所示), FSANet建筑本体的结构轮廓出现明显扭曲, 原本规整的屋顶与墙体线条发生不规则断裂, 甚至出现局部模块错位.此外水面倒影的纹理连贯性被完全破坏, 内容细节的丢失问题较严重.
 | 图8 FECANet与FSANet生成图像的放大效果对比Fig.8 Magnification effect comparison of images generated by FECANet and FSANet |
在“ 人物→ 木纹材质” 任务中, 生成对抗网络方法(AAALNet)面部呈现明显的纹理割裂感, 五官自然形态被过度扭曲.在“ 建筑→ 油画” 任务中, 建筑与背景的风格一致性较差, 局部出现色彩过渡断层, 视觉效果和内容细节保留效果较差.
在“ 翠鸟→ 人物素描” 任务中, 扩散模型方法(StyleSSP)虽然整体素描效果较优, 但羽毛纹理的线条密度过高, 导致局部区域出现过度风格化现象.在“ 风景→ 星夜” 任务中, 天空的漩涡笔触虽然流畅, 但麦田区域的笔触方向一致性不足, 部分区域出现笔触混乱.在“ 建筑→ 简笔画” 任务中, 线条虽然清晰, 但建筑结构的几何精确性略有欠缺, 水面倒影的简化程度不够均匀.
相比之下, FECANet在各类风格迁移任务中均表现出明显优势.在“ 翠鸟→ 人物素描” 任务中, 鸟的轮廓清晰流畅, 羽毛纹理的明暗过渡自然, 头部、胸部、背部的层次结构完整保留.在“ 风景→ 星夜” 任务中, 天空的漩涡笔触密集且富有动感, 麦田的笔触方向与生长走势高度吻合, 完美再现星夜风格的流动感.在“ 人物→ 质感图像” 任务中, 木纹纹理与面部结构高度贴合, 五官立体感完整, 纹理走向遵循面部曲面, 质感自然真实.在“ 建筑→ 简笔画” 任务中, 线条锐利清晰, 建筑结构的几何关系准确, 窗户、塔楼等细节层次分明.在“ 建筑→ 油画” 任务中, 建筑的白色大理石笔触层次表现丰富, 天空和水面的色彩过渡自然流畅, 倒影的笔触方向与水波律动一致.在“ 沙丘→ 抽象彩色” 任务中, 沙丘的曲线结构以抽象色块形式保留, 色彩对比强烈且过渡自然.
综上所述, FECANet通过频域增强自适应通道注意力模块和特征金字塔融合模块的协同作用, 在各类风格迁移场景中均实现风格细节的精准传递与内容结构的完整保留, 优越性明显.
3.3.2 定量评估
除了视觉定性对比以外, 本文还开展定量评估, 采用风格迁移领域常用的5项定量指标对20幅内容图像与40幅风格图像组合生成的800幅测试图像进行统计分析, 结果如表1所示, 表中黑体数字表示最优值.
| 表1 各方法指标值对比 Table 1 Metric value comparison of different methods |
由表1可得如下结论.
1)FECANet的LG值为1.29, Lstyle值为0.015, 在所有对比方法中表现最优.相比FSANet(LG=1.37, Lstyle=0.019), FECANet在两项风格指标上均有显著提升, 原因在于FFE通过风格频率能量占比定向优化内容特征, 使生成特征与风格特征的统计分布(均值、方差、Gram矩阵)更接近.StyleSSP作为扩散模型方法, 虽然在LG指标上表现较优(1.33), 但Lstyle值(0.034)略高于FECANet, 说明扩散模型在全局风格统计匹配上仍有优化空间.AAALNet因生成对抗网络训练不稳定导致全局风格偏向, Lstyle、LG值最大(分别为0.046和3.72), 风格传递精准性最差.
2)FECANet的SSIM值为0.512, 在所有方法中排名第一, 显著高于FSANet(0.465)、StyleSSP(0.478)、AdaAttN(0.422)和ArtFlow(0.452).这表明在引入FECA后, 网络通过内容损失与自适应通道注意力的协同作用, 在实现精准风格迁移的同时, 未牺牲内容结构的完整性.值得注意的是, StyleSSP虽然基于扩散模型进行内容保留, 但其SSIM值(0.478)仍低于FECANet, 这可能与扩散过程中的多步去噪导致的累积误差有关.
3)StyleSSP在LPIPS指标上表现最优(0.494), 这得益于扩散模型在生成高质量图像方面的天然优势.FECANet的LPIPS值为0.532, 虽略高于Style-SSP, 但仍优于AdaAttN(0.558)、CCPL(0.577)等网络, 表明其在保持感知真实性方面具有竞争力.
4)FECANet在256× 256分辨率上推理时间为0.072 s, 在512× 512分辨率上推理时间为0.153 s, 仅慢于AesFA(0.034 s, 0.071 s)、AdaAttN(0.041 s, 0.112 s)和FSANet(0.051 s, 0.129 s), 远快于Art-Flow(0.173 s, 0.545s)和CCPL(0.139 s, 0.446 s).值得特别关注的是, StyleSSP作为扩散模型方法, 推理时间分别为4.738 s和7.571 s, 是FECANet的65.8倍(256× 256)和49.5倍(512× 512).这一显著差距源于扩散模型需要进行多步迭代去噪, 每步都需要完整的UNet前向传播, 导致计算开销巨大.
3.3.3 用户调查结果
由于对任意风格迁移生成图像质量的评估具有较强的主观性, 为了更客观地评价其艺术表现, 邀请40名参与者对生成图像的内容完整性、风格还原度、整体美观度、人类欺骗度(风格化结果的真实性)进行盲评, 实验沿用3.3.2节中使用的图像集, 从中随机抽取10组样本, 每组包含1幅内容图像、1幅风格图像及7种网络生成的风格化结果, 每组中各方法生成的风格化图像顺序被完全打乱以消除偏差.相应用户盲评结果如表2所示, 表中黑体数字表示最优值.由表可见, FECANet在艺术表现方面更具感知优势, 并在人类欺骗度上优于现有对比网络.
| 表2 用户盲评结果 Table.2 Results of user blind evaluation |
为了验证FECANet中各关键组件的必要性, 以可逆流网络为基准框架, 设计消融实验.实验采用与对比实验一致的数据集、评估指标及训练配置, 结果如表3所示, 相应可视化结果如图9所示.
| 表3 各模块消融实验结果 Table.3 Ablation experiment results of different modules |
 | 图9 消融实验可视化结果对比Fig.9 Visual result comparison of ablation experiment |
由表3可见, FECANet的风格损失Lstyle、内容损失LG值均低于w/o FACA 、w/o FFPM、w/o FECA+FPFM.FECANet的SSIM值最高, 推理时间虽略高于w/o FECA、w/o FPFM、w/o FECA+FPFM, 但性能优势显著, 体现出在保证一定效率的同时, 具备更优的风格传递精准性与内容结构保留能力.
由图9可见, FECANet生成图像既精准呈现出与风格图像一致的印象派笔触(如类似《星夜》的漩涡状、动感的纹理), 又完整保留熊的形态结构(如清晰的肢体轮廓、毛发质感).w/o FECA生成图像笔触模糊, 熊身色彩与风格图像的色调偏差明显, 原因在于缺少FECA的频域特征增强与自适应通道筛选, 无法捕捉风格图像的高频能量分布, 导致风格细节传递失效.w/o FFPM生成图像存在内容失真, 熊的轮廓边缘变得模糊、毛发的层次感消失, 眼睛也出现失真现象, 这是由于缺少多尺度特征融合, 无法保留内容图像的层级结构(熊的边缘等底层特征与毛发纹理等高层语义特征脱节).w/o FFPM+FECA生成图像最差, 风格细节(如笔触密度)与内容结构(如熊的形态)均严重退化, 熊的轮廓和毛发都变得极为模糊, 由此印证双模块缺失对FECANet性能的破坏性影响.
本文围绕图像风格迁移任务, 提出基于频域增强自适应通道注意力与特征金字塔融合的可逆流网络风格迁移方法(FECANet).FECANet以预训练VGG19为基础架构, 设计语义感知可逆流网络, 减少特征损耗, 保障内容结构完整性.引入频域增强自适应通道注意力模块, 解析风格图像频域分布, 建立内容特征与风格特征的精准关联.构建特征金字塔融合模块, 实现全局风格与局部纹理对齐.在MS-COCO、WikiArt数据集上的实验验证FECANet的有效性, 其在内容结构保持、风格化质量与计算效率等关键性能上均表现优异.今后将考虑进一步优化频域特征提取粒度, 有针对性地解决“ 人像→ 密集纹理” 风格迁移任务中风格效果不佳的问题, 同时提升复杂风格场景中的迁移精度与灵活调控能力, 以便适配更多的实际应用需求.
本文责任编委 桑 农
Recommended by Associate Editor SANG Nong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|