{kind=link}
{kind=link}
{kind=link}
基于判别性表示与自适应校准推理的跨域少样本命名实体识别
[邱全安1  , 黄琪
, 黄琪1, 2 , 童梓荣1 , 罗文兵1, 2 , 易洁3, 4 , 王明文1, 2 ]
, 黄琪, 童梓荣, 罗文兵, 易洁, 王明文]
|
|



作者简介:
邱全安,硕士研究生,主要研究方向为自然语言处理、少样本命名实体识别.E-mail:ngh@jxnu.edu.cn.
童梓荣,硕士研究生,主要研究方向为自然语言处理、少样本命名实体识别.E-mail:tongzirong@jxnu.edu.cn.
罗文兵,博士,高级实验师,主要研究方向为自然语言处理、信息检索、知识图谱.E-mail:lwb@jxnu.edu.cn.

易 洁,博士研究生,主要研究方向为自然语言处理、信息管理、信息系统.E-mail:jyi@jxnu.edu.cn.

王明文,博士,教授,主要研究方向为自然语言处理、信息抽取、信息检索、数据挖掘.E-mail:mwwang@jxnu.edu.cn.
针对跨域少样本命名实体识别任务因源域特征与目标域特征分布偏移导致的边界模糊与误差累积问题,提出基于判别性表示与自适应校准推理的跨域少样本命名实体识别模型(Discriminative Representation and Adaptive Calibrated Inference for Cross-Domain Few-Shot Named Entity Recognition, DR-ACI).首先,设计非对称边界对比损失重塑跨度检测空间,采用实体中心的非对称约束策略,在保持背景语义多样性的同时显式锐化实体边界.同时引入自适应门控增强模块,通过多层级语义融合对稀疏原型进行动态校准,降低因支持集样本稀疏带来的表征不确定性与偏差.然后,设计场景感知的自适应校准推理机制,针对特征模长漂移与支持集偏差瓶颈,利用特征归一化与可靠性感知的双模式门控策略,动态重构判决边界,抑制迁移噪声.实验表明,DR-ACI在Few-NERD数据集上具有一定的竞争力,同时在跨域数据集上性能较优,由此验证判别性表示与自适应推理协同优化的有效性.
About Author:
QIU Quanan, Master student. His research interests include natural language processing and few-shot named entity recognition.
TONG Zirong, Master student. His research interests include natural language processing and few-shot named entity recognition.
LUO Wenbing, Ph.D., senior experimen-ter. His research interests include natural language processing,information retrieval and knowledge graph.
YI Jie, Ph.D. candidate. Her research interests include natural language processing, information management and information systems.
WANG Mingwen, Ph.D., professor. His research interests include natural language processing, information extraction, information retrieval and data mining.
To address the challenges of boundary ambiguity and error accumulation caused by feature distribution shifts between source and target domains in few-shot Named Entity Recognition(NER), a model of cross-domain few-shot NER via discriminative representation and adaptive calibrated inference(DR-ACI) is proposed. First, the span detection space is reshaped through an asymmetric boundary contrastive(ABC) loss. An entity-centric asymmetric constraint strategy is adopted. With this strategy, entity boundaries are explicitly sharpened while the semantic diversity of the background is preserved. Simultaneously, an adaptive gated enhancement(AGE) module is introduced to dynamically calibrate sparse prototypes through multi-level semantic fusion, thereby mitigating representation uncertainty and bias resulting from support set sparsity. Subsequently, a scenario-aware adaptive calibrated inference mechanism is designed to tackle the bottlenecks of feature norm drift and support set bias. By leveraging feature normalization and a reliability-aware dual-mode gated strategy, the above mechanism dynamically reconstructs decision boundaries to suppress transfer noise. Experimental results demonstrate that DR-ACI maintains competitive performance on Few-NERD dataset and is superior to the baseline models on cross-domain datasets. These results verify the effectiveness of the synergistic optimization of discriminative representation and adaptive inference.
作为自然语言处理领域的关键任务之一— — 命名实体识别(Named Entity Recognition, NER)在构建知识图谱、信息检索、智能问答等应用中发挥关键支撑作用, 该任务致力于从非结构化文本中定位并分类预定义的实体, 如人名、地名、组织机构名称等.近年来, 随着深度学习的蓬勃发展, 以预训练语言模型为骨干的神经网络方法大幅提升命名实体识别的准确率[1, 2, 3].然而, 此类监督方法依赖大规模标注数据, 在许多垂直领域, 如医疗、金融、法律等, 获取标注数据的过程不仅成本高昂、耗费人力, 并且往往需要深厚的领域专家知识, 从而形成“ 数据瓶颈” 问题.与此同时, 现实场景中常面临领域分布偏移的问题, 即模型仅在资源丰富的源域训练, 而预测时目标领域特征分布存在显著差异.这种分布不一致导致传统监督模型甚至常规少样本命名实体识别模型的性能急剧下降.因此, 跨域少样本命名实体识别成为当前命名实体识别领域研究的热点之一.
早期少样本命名实体识别研究大多采用基于度量学习的端到端模型, 如原型网络[4]及其变体.此类方法通常将命名实体识别任务建模为序列标注问题, 学习统一的度量空间, 对文本序列中的词元进行分类以识别实体.但是, 该范式将实体跨度检测与类型分类任务耦合至单一目标中, 导致模型在处理复杂实体结构及源域特征和目标域特征分布不一致时, 性能出现显著衰退.
为此, 近年来学者开始研究基于两阶段原型网络的少样本命名实体识别模型.此类模型将命名实体识别任务分解为实体跨度检测和实体类型分类两个任务, 能分别专注于不同阶段的特征学习, 因此在复杂场景中的性能优于早期的端到端模型[5].
然而, 现有的基于两阶段原型网络的少样本命名实体识别模型在应对跨域少样本场景时, 仍面临三个深层次的瓶颈.1)跨度检测中的边界混淆与假阳性干扰.现有模型在源域训练时, 往往采用对称约束强行聚类背景样本.然而, 非实体背景的语义本身极其庞杂, 这种强制聚类会破坏特征空间的自然分布, 导致模型在面对目标域的未知分布时, 实体边界变得极度模糊, 进而产生大量假阳性噪声.2)实体分类阶段的语义失真与原型漂移.在少样本极端稀疏的条件下, 单纯依赖高层语义特征聚合形成的类别原型极易受到局部样本偏差影响.在跨域迁移时, 源域学习的高层特定领域语义往往会失效或失真, 导致原型偏离真实类别中心, 严重削弱度量空间的鲁棒性.3)推理阶段的特征尺度失衡与静态度量失效.在面对目标域中大量未见的词汇或专业术语时, 特征向量的模长往往会发生剧烈波动.现有模型普遍采用固定的静态度量标准, 忽略特征空间尺度不一致带来的置信度偏差, 导致在处理域外特征时极易输出不可靠的预测结果.
为此, 本文提出基于判别性表示与自适应校准推理的跨域少样本命名实体识别模型(Discrimina-tive Representation and Adaptive Calibrated Inference for Cross-Domain Few-Shot Named Entity Recognition, DR-ACI).在训练阶段, 引入非对称边界对比(Asymme-tric Boundary Contrastive, ABC)损失与自适应门控增强模块(Adaptive Gated Enhancement, AGE), 通过实体中心约束与多层级特征融合, 分别解决实体边界模糊与原型稀疏难题.在推理阶段, 设计自适应校准推理机制(Adaptive Calibration Inference, ACI), 利用双模式门控策略动态校准跨域特征偏移并抑制噪声.通过训练机制与推理机制的协同优化, 显著提升其在跨域场景中的泛化性与鲁棒性.
少样本命名实体识别旨在从低资源场景中精准定位实体跨度并判别其类别, 核心目标是构建具备高效学习与强泛化能力的模型.少样本命名实体识别领域长期缺乏统一的评估标准, 直至2021年Ding等[6]发布大规模基准数据集Few-NERD, 构建这一领域的标准化评估体系, 并迅速成为推动该领域发展的核心基准之一.在此基准上, 目前少样本命名实体识别的主流模型在架构上主要分为基于端到端的模型和基于两阶段的模型.同时, 随着底层技术的演进, 这两大架构均向基于大语言模型(Large Lan- guage Model, LLM)的方向发展.
基于端到端的模型将少样本命名实体识别视为统一的序列标注任务, 直接对输入序列中的每个词元进行分类, Yang等[7]提出的NNShot(Token-Level Nearest Neighbor Classification System)是此类模型的典型代表.NNShot在词元级别上进行最近邻匹配, 计算词元嵌入与支持集原型的相似度, 再进行分类.在此基础上, Yang等[7]进一步提出StructShot(Structured Nearest Neighbor Learning), 引入结构化推理, 建模标签间的依赖关系, 提升标注序列的合法性.Fang等[8]提出MANNER, 利用记忆模块与最优传输机制, 将源域知识迁移并适配于目标域的少样本任务.近年来, 随着大语言模型的快速发展, 出现一批由LLM驱动的相关模型.Ashok等[9]提出PromptNER, 设计任务特定的提示模板, 直接利用LLM的生成能力进行端到端的实体提取.
然而, 基于端到端的模型试图在一个统一架构内同时处理实体跨度检测和实体类型分类两个高度耦合的子任务, 在少样本数据稀缺的约束下, 往往难以兼顾这两个复杂子任务的优化, 影响整体性能.
针对基于端到端的模型存在的问题, 近年来研究者提出一系列基于两阶段的少样本命名实体识别模型, 即将任务解耦为两个相对独立的子问题:实体跨度检测与实体类型分类.该架构先在实体跨度检测阶段识别所有潜在的实体候选片段, 再在实体类型分类阶段对实体候选片段进行分类.在实体跨度检测任务方面, Wang 等[10]提出SpanProto, 预测跨度的起始边界和结束边界, 完成检测, 并设计基于边缘的损失函数, 缓解假阳性问题.在随后的实体类型分类阶段, 以原型网络为代表的度量学习是主流模型之一, 核心在于为每类实体构建具有代表性的跨度级原型, 再将候选跨度的表示与跨度级原型进行相似度匹配, 判定其类别.为了获取更鲁棒的原型表示, Wang等[5]提出ESD(Enhanced Span-Based Decomposition), 进一步通过多个注意力机制促进信息交互, 提高分类准确性.
随着LLM的快速发展, 以 GPT-3、Llama、Gemini等为代表的模型在少样本任务乃至零样本任务中表现出卓越的泛化能力, 研究者开始将大语言模型驱动方法深度融入两阶段范式, 衍生出更强大的协同架构.Chen等[11]提出Double-Checker, 构建“ 生成-校验” 机制, 利用轻量级模型生成候选实体, 再由LLM充当“ 检查员” 进行置信度校验与筛选.Ye等[12]提出LLM-DA, 利用LLM的上下文改写与实体替换能力, 从上下文和实体两个层面对原始样本进行语义一致的数据增强, 提升模型的泛化性.Bogdanov等[13]提出NuNER, 利用LLM的自动标注与语义生成能力, 对大规模未标注语料进行实体标注, 构建专门用于命名实体识别任务的预训练语料库.基于该数据训练的轻量级NuNER在少样本命名实体识别任务中优于同体量的基础模型, 并在部分场景中接近LLM的表现, 上述情况验证利用LLM进行数据蒸馏以提升轻量级模型表征能力的有效性.Guo 等[14]提出BANER(Boundary-Aware LLMs for Few-Shot Named Entity Recognition), 在跨度检测阶段, 引入边界感知对比学习, 增强LLM对实体边界的感知能力, 缓解漏检与过度检测问题; 在类型分类阶段, 利用LoRAHub进行跨域自适应, 实现源域与目标域的知识对齐.这充分说明, 即使在LLM时代, “ 跨度检测-类型分类” 的解耦架构依然是解决少样本命名实体识别问题的高效途径之一.
尽管基于两阶段的模型通过任务解耦, 显著降低学习难度, 并在多个基准测试集上取得当前最优性能.然而, 在跨域少样本场景中, 模型仍面临严峻挑战.首先是跨度检测阶段的误差级联问题.源域预训练的检测器在迁至目标域时, 往往因无法适应新的特征分布而产生大量假阳性预测, 这些背景噪声会进一步传递至分类阶段, 严重损害整体精度.其次是实体分类阶段的原型漂移问题.支持集样本的极度稀疏导致类别原型表征存在高度不确定性, 严重削弱分类边界的鲁棒性.最关键的是, 现有模型在推理阶段普遍采用静态的度量策略, 忽略源域与目标域之间存在的显著特征分布偏移.在跨域迁移时, 目标域特征往往表现出剧烈的模长波动与分布不匹配, 直接应用源域的度量标准会导致置信度失准.缺乏领域感知的自适应校准机制已成为制约两阶段模型跨域泛化能力的核心瓶颈.
在自然语言处理中, 命名实体识别任务旨在从长度为n的输入序列X={x1, x2, …, xn}中, 定位并识别具有特定意义的实体跨度集合C, 并分类至预定义的实体类别集合Y={c1, c2, …, cm}中, 其中m表示预定义实体类别的总数.
本文将命名实体识别分为实体跨度检测和实体类型分类两个子任务.实体跨度检测任务旨在从输入序列X中识别所有候选实体跨度的集合C.每个候选跨度可表示为一个元组ck=(sk, ek), 其中sk、ek分别表示跨度的起始位置和结束位置, 满足
1≤ sk≤ ek≤ n.
在实体类型分类阶段, 为集合C中每个候选跨度ck分配一个实体类型yk(yk∈ Y), 若该跨度不属于任何一个预定义的实体类别, 会被赋予一个特殊的非实体标签O.
本文任务遵守N-way K-shot方式构建训练集和测试集.面对每个独立任务, 从数据集上随机采样N个实体类别, 并为每个类别抽取K个标注样本构成支持集.同时, 从N个类别中采样另外一批样本构成查询集.模型利用支持集进行学习, 通过查询集的预测结果进行性能评估.模型在源域数据集Dsource上训练, 源域数据集由(Ssource, Qsource, Tsource)构成, 其中, Ssource表示源域支持集, Qsource表示源域查询集, Tsource表示源域实体类型集.在测试阶段使用目标域数据集Dtarget进行测试评估, Dtarget由(Starget, Qtarget, Ttarget)构成, 其中, Starget表示目标域支持集, Qtarget表示目标域查询集, Ttarget表示目标域实体类型集.在测试评估阶段, 借助Starget微调模型后, 在Qtarget上完成模型评估, 同时
Tsource∩ Ttarget=Ø .
本文提出基于判别性表示与自适应校准推理的跨域少样本命名实体识别模型(DR-ACI), 整体架构如图1所示.
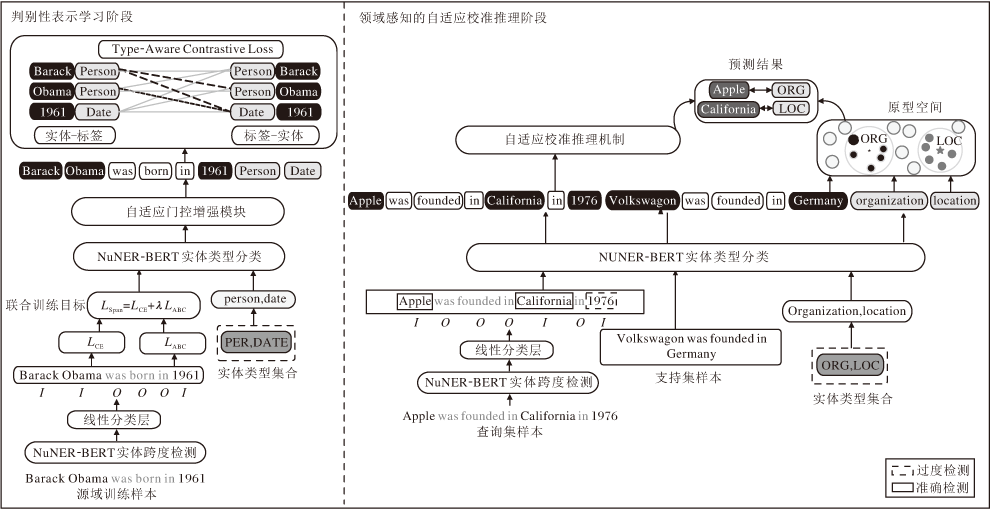 | 图1 DR-ACI整体架构Fig.1 Overall architecture of DR-ACI |
DR-ACI主要包含两个阶段:判别性表示学习阶段和领域感知的自适应校准推理阶段.首先, 在判别性表示学习阶段, 集成非对称边界对比损失(ABC)与自适应门控增强模块(AGE), 共同应对跨域场景中的背景多样性与原型稀疏性挑战, 构建高质量的判别性特征.然后, 在领域感知的自适应校准推理阶段, 引入自适应校准推理机制(ACI), 通过特征归一化与领域感知的双模式门控策略, 有效缓解目标域中的特征模长不稳定现象.最后, 基于校准后的分布输出最终预测结果.
作为DR-ACI的核心特征构建部分, 判别性表示学习阶段旨在应对跨域少样本场景中轻量级模型的表征泛化难题.该阶段的核心思路是通过任务解耦策略, 使两个轻量级编码器分别专注于边界定位与语义分类, 从而将预训练模型的通用能力转化为面向特定领域的判别性表征.
如图1所示, 判别性表示学习阶段采用两步处理流程.首先在跨度检测阶段利用跨度检测模型提取边界敏感特征, 定位候选实体, 然后在跨度分类阶段利用类型分类模型生成语义鲁棒特征, 判别实体类别.本文在上述两个独立模型中分别集成ABC损失与AGE模块, 前者在检测阶段重塑边界空间, 后者在分类阶段校准原型分布.相比传统少样本命名实体识别模型受限于特征耦合带来的表征混淆, DR-ACI通过特征的针对性提取与增强, 有效缓解实体边界模糊与原型特征稀疏的核心难题.
2.3.1 基于非对称边界对比的跨度检测
跨度检测阶段旨在从输入文本中精准定位实体的起止边界, 并不涉及具体的语义类别判定.为此, 本文将该任务建模为基础的序列标注问题.采用NuNER-BERT[13]作为一阶段预训练文本编码器
H={h1, h2, …, hn}=
其中, hi∈ Rd表示第i个词元的隐藏特征, d表示隐藏层维度.然后, 为了获取每个词元的跨度概率分布, 将hi输入线性分类层, 并通过Softmax函数进行归一化, 得到第i个词元在各标签上的预测概率分布:
P(xi)=softmax(Wcls· Dropout(hi)+bcls)∈ R|Z|.
其中:Wcls∈ R|Z|× d、bcls∈ R|Z|分别表示线性分类层的可学习权重矩阵和偏置向量; softmax(· )表示归一化指数函数, 将模型输出映射为概率值; Dropout(· )表示随机失活函数, 在训练过程中缓解模型过拟合.考虑到此阶段仅需区分实体与非实体, 本文使用IO标注模式数据, Z={I, O}, 其中, I表示实体部分, O 表示背景噪声.
为了在特征空间中重塑模糊的实体边界, 设计ABC损失, 旨在拉近实体标记与实体质心的距离, 同时推远其与背景质心的距离, 从而锐化检测边界.形式化地, 令H={h1, h1, …, hN}表示当前样本中所有词元的上下文特征集合.依据真实标签将H映射为两个互斥的子集:实体词元集合Sent 与背景词元集合So.再对各子集内的特征向量执行均值聚合, 分别获得当前批次下的实体质心cent和背景质心co:
$ \boldsymbol{c}_{\mathrm{ent}}=\frac{1}{\left|\boldsymbol{S}_{\mathrm{ent}}\right|} \sum_{\boldsymbol{h}_{i} \in S_{\mathrm{ent}}} \boldsymbol{h}_{i}, \boldsymbol{c}_{o}=\frac{1}{\left|\boldsymbol{S}_{o}\right|} \sum_{\boldsymbol{h}_{j} \in S_{o}} \boldsymbol{h}_{j^{* }}$
基于上述质心, ABC损失通过对比学习机制优化实体表征.考虑到背景噪声具有极高的语义多样性, 强制聚类会破坏语义结构.因此, 采用非对称优化策略, 仅对实体标记施加约束, 相应非对称对比损失函数如下所示:
$ \begin{array}{l}L_{\mathrm{ABC}}=-\frac{1}{\left|\boldsymbol{S}_{\mathrm{ent}}\right|} \cdot \\\sum_{\boldsymbol{h}_{i} \in S_{\mathrm{ent}}} \ln \left(\frac{\exp \left(\frac{\operatorname{sim}\left(\boldsymbol{h}_{i}, \boldsymbol{c}_{\mathrm{ent}}\right)}{\tau}\right)}{\exp \left(\frac{\operatorname{sim}\left(\boldsymbol{h}_{i}, \boldsymbol{c}_{\mathrm{ent}}\right)}{\tau}\right)+\exp \left(\frac{\operatorname{sim}\left(\boldsymbol{h}_{i}, \boldsymbol{c}_{\mathrm{o}}\right)}{\tau}\right)}\right), \end{array}$
其中, sim(· )表示余弦相似度, τ 表示温度超参数, 本文设为 0.1.
LABC迫使实体标记在特征空间中向cent靠拢并远离co, 从而在不干扰背景分布的前提下提升边界的判别性.
最终, 为了在跨度检测阶段兼顾基础标记分类精度与实体边界的敏感性, 构建联合优化目标.在保留标准交叉熵损失LCE以提供基础监督信号的同时, 引入LABC作为辅助正则项.两者协同工作, 共同指导模型重塑检测空间.最终的跨度检测总损失函数为:
Lspan=LCE+λ LABC,
其中, λ 表示超参数, 本文中设为0.1,
$ L_{\mathrm{CE}}=\frac{1}{n} \sum_{i=1}^{n} \text { CrossEntropy }\left(z_{i}, P\left(\boldsymbol{x}_{i}\right)\right) .$
其中, CrossEntropy(· )表示标准交叉熵损失函数, 度量模型预测的概率分布P(xi)与第i个词元的真实跨度检测标签zi(zi∈ Z)之间的差异, n表示输入序列长度.
2.3.2 基于自适应门控增强的类型分类
跨度分类阶段的目的是为跨度检测阶段预测的每个跨度分配一个特定类型.本文采用原型网络作为类型分类的主要网络组成.通过学习语义嵌入空间, 相同类型的实体跨度在该空间中彼此靠近, 而不同类型的实体跨度相互远离.同时在该阶段引入自适应门控增强模块(AGE), 使其能构建更丰富稳健的实体表示, 为原型网络分类时提供更丰富的语义信息.
在AGE模块中, 引入独立训练的NuNER-BERT[13]作为二阶段预训练文本编码器
$ \widetilde{\boldsymbol{H}}=\sum_{l=L-3}^{L} w_{l} \boldsymbol{f}_{\theta_{2}}^{(l)}(\boldsymbol{x}), \sum_{l=L-3}^{L} w_{l}=1, $
其中, L表示BERT(Bidirectional Encoder Represen-tations from Transformed)的总层数, l表示BERT的层索引, f
当得到融合后的特征
$ \boldsymbol{E}=\operatorname{Dropout}\left(\operatorname{Tanh}\left(\widetilde{\boldsymbol{H}} \boldsymbol{W}_{E}+\boldsymbol{b}_{E}\right)\right), $
其中, Tanh(· )表示双曲正切激活函数, 用于实现特征的非线性空间映射, WE∈ Rd× d、bE∈ Rd分别表示语义增强层的权重矩阵和偏置向量.这一过程旨在强化对实体类型分类任务有益的语义信息.
为了实现辅助增益特征的自适应集成, 并避免对原始特征造成不必要的扰动, 引入轻量级的门控策略, 根据输入特征动态计算贡献权重, 细化控制辅助增益特征融入程度, 相应门控权重为:
$ \boldsymbol{G}=\operatorname{Sigmoid}\left(\widetilde{\boldsymbol{H}} \boldsymbol{W}_{G}+\boldsymbol{b}_{G}\right) .$
其中, WG∈ Rd× d、bG∈ Rd分别表示门控层的权重矩阵和偏置向量.
最终通过残差连接, 融合门控调节后的辅助增益特征E与融合特征
F=
其中:γ 表示融合系数, 控制增强信息在残差融合中的贡献比例; ☉表示逐元素相乘, 实现门控权重G对增益特征E的逐维加权.
为了实现原始特征与语义增强特征的平滑融合, 将融合系数 γ 定义为可学习残差权重, 采用零初始化策略.在训练初期, γ 初始化为0, 使增强模块的输出被暂时抑制, 模型初始状态等价为仅使用原始特征的恒等映射.这一机制有效避免尚未收敛的增强特征对预训练原始特征分布造成破坏性扰动, 保证训练初期的数值稳定性.随着训练的进行, 通过反向传播算法自适应更新γ , 驱动模型根据损失函数的反馈动态调整原始特征与增强特征的融合比例.这种机制能在保留原始特征语义稳健性的基础上, 渐进地引入增强的语义信息, 提升模型的判别力.
在类型分类阶段的训练过程中, 为了构建语义信息更丰富且鲁棒的特征空间, 使用Li等[15]提出的Type-Aware Contrastive Loss进行训练, 构建实体-标签类型感知增强特征
和标签-实体类型感知增强特征
进行对比学习.其中:concat(· , · )表示向量拼接操作; map(yk)表示类别名称映射函数, 将第K个跨度样本的具体实体标签yk转换为对应的自然语言名称.基于这种对称式的特征增强表示, 损失函数能通过对比学习捕捉实体特征与类别语义之间更深层次的对齐关系.
为了让标签本身包含更丰富的语义信息, 建立映射关系map(yi), 将原始实体类型映射为其对应的自然语言名称, 如“ PER” 映射至“ person” , “ LOC” 映射至“ location” 等.基于这一增强的类型表示, 应用类型感知对比损失函数
$ L_{\text {type }}=-\frac{1}{M} \sum_{i=1}^{M} \sum_{j \in P(k)} \ln \left(\frac{\exp \left(L_{k v}\right)}{\sum_{k=1}^{M} \exp \left(L_{k w}\right)}\right)$
能更有效地进行对比学习, 其中
P(k)={v|yv=yk}
表示与第k个样本具有相同标签的正样本索引集合,
$ L_{k v}=\frac{S_{k v}}{\tau \sqrt{\sum_{w=1}^{M}\left(S_{w v}\right)^{2}}}, $
计算实体-标签和标签-实体之间的相似度, Skv表示
为了更直观、结构化地呈现DR-ACI的优化过程, 将判别性表示学习阶段的两阶段训练步骤归纳如下.
算法1 判别性表示学习阶段的两阶段训练过程
输入 源域训练数据集Dsource={(X, Y* )},
X表示输入序列,
Y* 表示该序列对应的真实实体标注集合,
预训练文本编码器fθ , 跨度检测学习率α 1,
类型分类学习率α 2, ABC损失平衡系数λ ,
温度系数τ
输出 训练后的跨度检测模型Mspan,
类型分类模型Mtype
第一阶段 跨度检测
初始化 加载预训练参数θ span至Mspan, 将标签yi映
射为二元IO格式
repeat
for每个训练批次B∈ Dsource do
提取特征H=
构建实体词元集合Sent与背景词元集合So, 计算对应质心cent、co
计算标准交叉熵损失LCE, 并仅针对Sent计算非对称边界对比损失LABC
计算跨度检测总损失Lspan
基于Ñ Lspan 执行反向传播更新θ span
end for
until Mspan 收敛
保存训练完成的跨度检测模型Mspan
第二阶段 类型分类
初始化 加载参数θ type至Mtype, 并初始化可学习残差权重γ ← 0
repeat
for 每个训练批次B∈ Dsourcedo
执行多层特征加权融合, 得到融合后特征
通过门控残差连接生成最终特征F
构建类型感知增强特征
计算特征与标签间的类型感知对比损失Ltype
基于Ltype同步更新模型参数θ type、层权重w、可学习残差权重γ
end for
until Mtype 收敛
保存训练完成的类型分类模型Mtype
return Mspan, Mtype
模型在源域完成判别性表示学习阶段值之后, 进入目标域领域感知的自适应校准推理阶段.为了缓解跨域迁移中普遍存在的特征分布偏移与模长不稳定问题, 本文提出自适应校准推理机制(ACI).
传统的少样本度量学习模型通常假设源域与目标域共享相似的特征空间结构, 直接基于静态的距离度量进行最近邻分类.然而, 在跨域场景中, 由于源域与目标域之间存在显著的语义鸿沟, 特征分布往往发生剧烈偏移, 导致特征模长与分布密度出现极不稳定的波动, 这使基于源域训练的判别边界在目标域的适用性大幅下降.此外, 仅依赖极少量支持样本构建的原型往往存在严重的稀疏性与噪声干扰, 难以精确表征目标类别的真实语义中心.
因此, ACI 机制旨在从分布适配、原型修正与决策校准三个维度重构推理过程.ACI机制包含3个核心步骤.1)通过支持集微调实现特征空间向目标域分布的自适应对齐.2)利用混合原型构建机制增强稀疏语义空间的表征完备性.3)引入可靠性感知的双模式门控策略, 依据支持集的分布可靠性, 在“ 跨域场景中的置信度截断” 与“ 同域场景中的精细化统计校准” 之间动态切换, 通过动态校准判决边界, 实现在不同场景中的高鲁棒性推理.
2.4.1 支持集微调和原型构建
首先, 利用目标域支持集Starget微调模型, 增强其对新任务的快速自适应能力.同时, 为了降低微调时的过拟合风险, 引入早停策略, 确定最佳的微调模型参数.
为了保证跨度向量与原型的维度一致性及语义互补性, 采用拼接操作融合标签的先验语义嵌入与支持集样本的上下文均值, 构建语义增强的类别原型:
$ \boldsymbol{P}_{j}=\boldsymbol{f}_{\theta_{2}}\left(\operatorname{map}\left(\boldsymbol{t}_{j}\right)\right) \oplus \frac{1}{\left|Z_{j}\right|} \sum_{i \in Z_{j}} \boldsymbol{e}_{i}^{s}, $
其中, 标签tj∈ Ttarget, Zj={i|
$ \boldsymbol{e}_{i}^{s}=\frac{1}{\left|s_{i}\right|} \sum_{k \in s_{i}} \boldsymbol{f}_{\theta_{2}}\left(\boldsymbol{t}_{k}\right), $
是通过对支持集中第i个实体跨度内部所有词元的向量进行平均池化得到, tk表示跨度中的词元, si表示第i个实体跨度.最终得到的组合原型能有效融合标签自身的先验语义信息与样本本身的上下文信息, 实现二者的优势互补.
2.4.2 可靠性感知的双模式门控策略
为了应对不同评估场景中的异构挑战, ACI机制引入可靠性感知的双模式门控策略.该策略并非采用单一的静态判别标准, 而是依据支持集的分布可靠性, 动态选择最优的判决边界校准策略.在跨域迁移场景中, 模型侧重于抑制由特征空间未对齐引起的误判, 采用基于领域先验的概率截断模式; 在背景分布一致的少样本场景中, 模型侧重于挖掘支持集的参考价值, 切换至基于统计信息的动态边界模式.
1)基于领域先验的概率校准.在跨域迁移任务中, 由于源域与目标域特征分布未完全对齐, 直接基于原始特征的点积计算容易受特征模长漂移的影响, 导致度量空间的尺度偏差.因此, 本文使用特征归一化的校准策略.针对目标域查询集上的候选跨度, 首先对其包含的每个词元特征ht进行L2归一化, 消除局部特征的模长不稳定性, 聚合生成跨度特征:
$ \boldsymbol{v}_{s}=\frac{1}{L_{s}} \sum_{t=\text { start }}^{\text {end }} \frac{\boldsymbol{h}_{t}}{\left|\boldsymbol{h}_{t}\right|_{2}} \text {, }$
其中Ls表示该候选跨度包含的词元数量.
为了保证与混合原型维度一致, 对vs进行自拼接, 得到查询向量
xs=vs⊕ vs.
在此基础上, 计算xs与混合原型Pj的点积, 并通过Softmax函数映射为后验概率分布:
$ P\left(y=j \mid \boldsymbol{x}_{s}\right)=\frac{\exp \left(\boldsymbol{x}_{s} \cdot \boldsymbol{P}_{j}\right)}{\sum_{k \in Y} \exp \left(\boldsymbol{x}_{s} \cdot \boldsymbol{P}_{k}\right)}, $
其中, y表示候选跨度xs对应的类别标签随机变量, j表示目标域交叉实体类别集合中的第j个类别.
最终的判别函数如下:
$ \begin{array}{l}\hat{y}= \left\{\begin{array}{ll}\arg \max _{j} P\left(y=j \mid \boldsymbol{x}_{s}\right), & \max _{j} P\left(y=j \mid \boldsymbol{x}_{s}\right)> \delta_{\text {domain }} \\O, & \text { 其它 }\end{array}\right.\end{array}$
其中, δ domain表示根据目标域特性预设的超参数, O表示非实体标签.
2)基于支持集统计的分布校准.在背景分布一致的小样本场景中, 源域与目标域语料均来源于同一分布, 领域背景相对一致, 核心挑战在于N-way K-shot任务配置带来的样本稀疏性与决策边界波动.此时, 支持集与查询集同分布, 支持集的统计信息具有极高的参考价值.为此, 利用目标域支持集Starget动态计算当前任务的置信度下界.
首先, 复用跨域迁移场景中的特征处理流程, 对查询跨度的特征vs进行自拼接增强:
$ \boldsymbol{x}_{s}=\boldsymbol{v}_{s} \oplus \boldsymbol{v}_{s} .$
然后, 计算支持集上所有真实实体样本与其对应原型的相关性, 取其下界作为当前任务的自适应判别阈值:
θ task=
其中:Strue表示支持集中所有真实实体跨度的集合; si表示集合中第i个真实实体样本,
在推理阶段, 为了缓解少样本下点积分布的尖峰现象, 引入缩放因子λ (λ > 1), 对决策边界进行平滑, 最终判别函数为:
通过这种可靠性感知的双模式门控策略, ACI机制既能在跨域场景中通过置信度截断有效抑制支持集偏差的影响, 又能在同域场景中深度挖掘支持集统计信息, 实现精细化判定, 从而在保证源域判别力的同时显著提升模型在未知领域上的综合泛化能力.
为了评估DR-ACI性能, 实验选取2个在少样本命名实体识别领域常用的公开数据集:Few-NERD数据集[6]和Li等[15]提供的跨领域数据集.数据集详细信息见表1.
| 表1 实验数据集详细信息 Table 1 Description of experimental datasets |
Few-NERD数据集是专门为少样本命名实体识别任务设计的基准评估数据集, 采用两层的实体类型结构, 包含8个粗粒度实体类型和66个细粒度实体类型.为了全面评估模型的少样本学习能力, 定义两种任务类型:Few-NERD(Inter)和Few-NERD(Intra).
在Few-NERD(Inter)设定下, 训练集、测试集、开发集上细粒度实体类型不相交, 但这三者共享相同的粗粒度类别.该设定主要考察模型在同一语义领域内对新细粒度实体的泛化能力.在Few-NERD(Intra)设定中, 训练集、开发集和测试集按照粗粒度类型进行划分, 三者之间互不重叠, 这意味着模型需要处理完全陌生的语义领域.该设定重点考察模型的跨语义域迁移与泛化能力.
在Li等[15]提供的跨域实验数据集上, 包含5个不同领域的少样本数据集, 为了公平对比, 本文遵守相同的实验设置.选择OntoNotes(General)作为源域数据集进行训练, 依次在I2B2'14(Medical), CoNLL'03(News), WNUT'17(Social), GUM(Wiki)这4个具有显著领域差异的目标数据集上评估模型性能.
所有实验均基于PyTorch深度学习框架实现.在模型架构方面, 为了充分捕获少样本场景中的语义特征, 选用NuNER-BERT[13]作为骨干网络, 并在实体跨度检测阶段和实体类型分类阶段分别采用两个独立的NuNER-BERT.这种解耦设计使两个子任务能独立优化各自的特征空间, 有效规避多任务学习中潜在的负迁移风险.在超参数配置上, 将NuNER-BERT的隐藏层维度设定为768维, 与标准BERT-base保持一致.考虑到计算效率与文本上下文长度的平衡, 输入序列的最大长度设为128.训练过程中的批次大小设为64.在源域的训练过程中, 为了获得更优的收敛性能, 采用AdamW(Adaptive Moment Estimation with Decoupled Weight Decay)[16]优化器进行参数更新.AdamW优化器通过解耦权重衰减策略, 有效提升模型的泛化能力.此外, 为了增强训练初期的稳定性并促进平稳收敛, 引入1%的学习率预热策略, 即在训练的前1% 步数内线性增加学习率, 再按策略衰减.
所有实验均在配备单块 NVIDIA GeForce RTX 3090 GPU的计算环境下完成, 以此保证实验结果的可复现性与公平性.
为了全面评估DR-ACI性能, 选取两类具有代表性的基准模型进行对比实验.
1)基于端到端的模型.
(1)Prototypical Networks[4].基于原型网络, 聚合支持集样本表示, 得到类别原型, 计算查询样本与原型的距离, 完成实体类型判别.
(2)NNShot[7].利用预训练模型提取词元表示, 并与支持集原型进行相似度匹配, 通过词元级最近邻匹配策略实现标签预测.
(3)StructShot[7].在NNShot基础上进一步建模标签依赖关系, 引入标签转移约束, 并结合Viterbi解码算法进行联合序列预测.
(4)MANNER[8].构建可变记忆增强网络, 存储源域信息, 借助最优传输机制进行自适应检索与转换, 缓解跨域少样本任务中的特征分布不一致问题.
(5)CONTaiNER(Few-Shot Named Entity Recog-nition via Contrastive Learning)[17].通过对比学习拉开类别间分布差异, 引入高斯分布嵌入建模词元表示的不确定性, 以此提升泛化性并缓解过拟合问题.
(6)文献[18]模型.利用标签名称的语义信息作为先验知识, 采用双编码器分别建模文本语义与标签语义, 通过匹配词元表示与标签表示进行预测.
2)基于二阶段的模型.
(1)ESD[5].将少样本序列标注问题转化为跨度级匹配任务, 通过注意力机制增强跨度表示, 并对O类进行细分建模, 提升区分度与泛化能力.
(2)NuNER[13].使用LLM自动标注大规模语料, 构建NER预训练数据集, 并对轻量级编码器(如RoBERTa[19])进行二次预训练, 实现从LLM到轻量级模型的知识迁移.
(3)BANER[14].面向LLM的少样本NER模型:检测阶段采用边界感知的对比学习, 提升边界定位; 分类阶段通过LoRA组合实现跨域自适应与原型对齐.
(4)TadNER(Type-Aware Decomposed Frame-work)[15].利用类型感知的跨度过滤策略剔除噪声, 并结合对比学习融合上下文与类别语义, 构建稳定的类别原型.
(5)文献[20]模型.采用分解式元学习框架, 结合无类别跨度检测器与 MAML(Model-Agnostic Meta-Learning Algorithm)[21]增强的原型网络, 分别实现快速适应与精准分类.
(6)文献[22]模型.采用师生架构生成软边界标签以平滑训练, 并在分类阶段融合提示学习与原型网络, 构建双语义空间, 提升领域自适应能力.
(7)BDCP(Boundary Discrimination and Correla-tion Purification)[23].检测阶段通过边界判别与多种损失增强边界表示的可分性; 分类阶段基于信息瓶颈抑制干扰信息, 提升鲁棒性与泛化性.
各模型在跨域数据集上的F1值对比如表2所示, 表中黑体数字表示最优值, 斜体数字表示次优值.
| 表2 各模型在跨域数据集上的F1值对比 Table 2 F1-score comparison of different models on cross-domain datasets % |
由表2可见, DR-ACI不仅在非LLM模型中保持领先, 在平均性能上也超越基于LLM的BANER.在1-shot和5-shot任务上, DR-ACI的平均F1值分别达到49.6%和56.9%, 相比BANER分别提升5.6%和3.0%.特别是在I2B2'14、CoNLL'03这两个领域差异巨大的数据集上, DR-ACI的优势尤为明显.在CoNLL'03数据集1-shot任务上, DR-ACI取得76.3%的F1 值, 远超BANER的72.6%; 在I2B2'14数据集1-shot任务上, DR-ACI的F1值达到46.8%, 大幅领先BANER的40.2%.这一结果表明, 通过判别性表示学习阶段构建的高质量特征, 配合自适应校准推理机制(ACI), 能比依赖大规模预训练知识的LLM更快、更精准地适应全新的目标领域分布, 展现出极强的跨域迁移与泛化能力.
各模型在Few-NERD数据集上的F1值对比如表3所示, 表中黑体数字表示最优值, 斜体数字表示次优值.
| 表3 各模型在Few-NERD数据集上的F1值对比 Table 3 F1-scores comparison of different models on Few-NERD dataset % |
由表3可见, 在Few-NERD(Intra)任务上, DR-ACI性能优异, 取得65.06%的平均F1值, 显著优于TadNER、文献[22]模型等现有主流两阶段模型, 同时也超越NuNER.虽然DR-ACI在数值上略低于BANER, 但考虑到DR-ACI作为轻量级模型, 参数量和计算开销远低于LLM, 这一性能表现足以说明其在同域少样本任务中的高效性与稳定性.
在Few-NERD(Inter)任务上, DR-ACI的平均F1值达到69.94%, 尽管与BANER相比仍存在约1.4%的差距, 但这符合预期.Inter设定侧重于同一粗粒度前提下的细粒度实体辨析, 对模型的外部世界知识储备提出极高要求, 而这正是LLM的优势所在.
尽管如此, DR-ACI通过非对称边界对比损失(ABC)与自适应门控增强模块(AGE)的有效结合, 在参数受限时最大限度地挖掘少样本数据的内部语义潜力.
为了进一步验证DR-ACI的有效性, 在I2B2'14、CoNLL'03、WNUT'17、GUM跨域数据集上进行消融实验, 结果如表4所示.
| 表4 在跨域数据集上的消融实验结果 Table 4 Ablation experiment results on cross-domain datasets % |
由表4可得如下结论.
1)移除自适应校准推理机制(w/o ACI)导致整体跨域性能出现断崖式下跌, 平均F1值降幅达5.1%, 且在领域差异最大的I2B2'14数据集1-shot任务上降幅高达13.7%.这表明跨域任务中特征模长不稳定与分布偏移是核心瓶颈, ACI机制通过动态概率门控与特征归一化, 在推理阶段有效修正偏差, 发挥克服领域漂移、实现跨域泛化的关键作用.
2)移除非对称边界对比损失(w/o ABC)之后, DR-ACI平均性能下降0.6%, 特别是在背景复杂的GUM数据集1-shot任务上性能显著降低.这说明ABC损失通过在第一阶段构建实体中心的非对称空间, 有效锐化检测边界, 增强模型在复杂语境下区分实体与背景噪声的能力, 防止由背景干扰导致的边界混淆.
3)移除自适应门控增强模块(w/o AGE)导致整体性能轻微下降0.3%, 但在极端少样本1-shot任务上性能波动明显.这验证AGE模块通过融合底层句法特征并利用残差门控进行补充, 对语义表征起到精细调优作用, 帮助模型在样本极度稀疏时捕捉更稳健的语义原型.
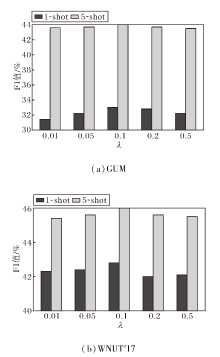
为了探究关键超参数对DR-ACI整体性能的影响, 在GUM、WNUT'17数据集上针对ABC损失中的平衡系数λ 进行参数敏感性实验.作为DR-ACI的核心参数, λ 负责平衡标准交叉熵损失与非对称对比损失, 取值直接影响模型在跨域场景中的边界识别精度.定义λ =0.01, 0.05, 0.1, 0.2, 0.5, 其在2个数据集上对DR-ACI性能的影响如图2所示.
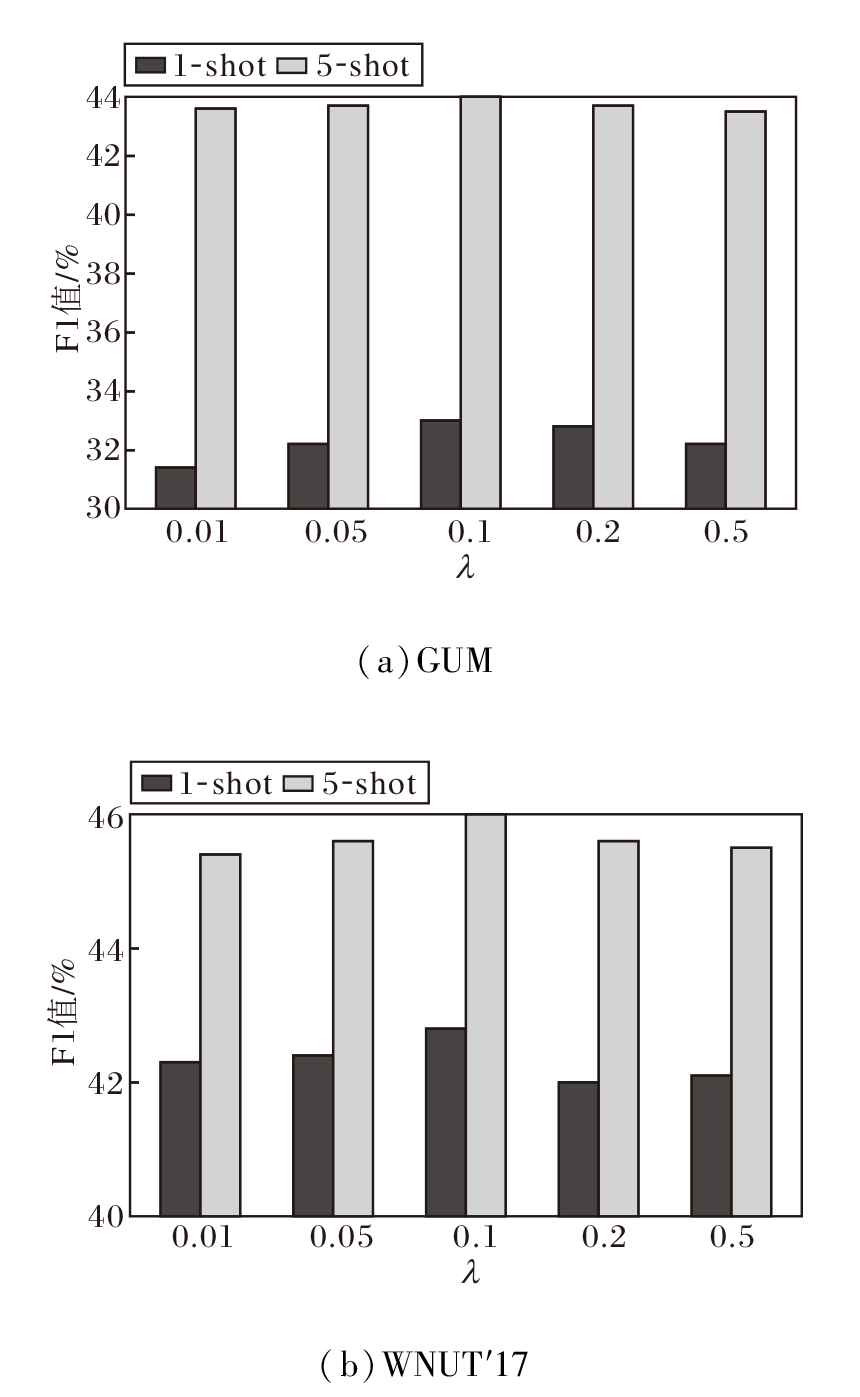 | 图2 λ 对DR-ACI性能的影响Fig.2 Effect of λ on DR-ACI performance |
由图2可观察到, 当λ 从0.01增至0.1时, F1值呈现上升趋势, 并在0.1处达到全局峰值.这一现象表明, 引入并适度增大非对称边界约束的力度, 能有效拉近实体内部特征并将其推离庞杂的背景, 从而显著锐化实体边界, 减少跨度检测阶段的假阳性误判.然而, 当λ 继续增至0.2、0.5时, 模型性能开始出现明显回落.其原因在于, 过大的λ 会导致对比损失项主导整体梯度更新方向, 进而削弱标准交叉熵损失的监督作用, 破坏模型对实体基础语义的表征稳定性.因此, 为了在“ 边界锐化” 与“ 基础分类特征保留” 之间取得最佳平衡, 在后续所有实验中均将λ 设为0.1.
为了评估DR-ACI的实际部署价值, 选取代表性的端到端轻量级模型MANNER[8]、大语言模型驱动的BANER[14]、二阶段轻量级模型TadNER[15]作为基线模型, 重点分析参数规模、训练时间及推理时间.所有效率对比实验均在单卡 NVIDIA RTX 3090 GPU 的统一环境下进行, 确保结果的可比性与公平性.
由于BANER未开源完整代码, 训练时间与推理时间为本文在 NVIDIA RTX 3090 GPU上复现其部分开源代码测得的近似值, 用于展示其计算量级.
BANER的F1值引用原文献的最优值.需要说明的是, BANER与本文采用的实验设置具有高度一致性:两者均严格遵循Few-NERD官方提供的划分标准以及跨域数据集的采样协议.在评估阶段, 均采用相同的N-way K-shot任务构建方式并以F1值作为核心衡量指标.尽管BANER采用参数量更大的LLM作为主干网络, 但其在相同测试集上的实验数据与本文具有直接的可比性, 足以反映不同架构在统一评价标准下的性能差异.
各模型在GUM数据集1-shot任务上的参数量及效率对比如表5所示.由表可见, DR-ACI在性能与效率的综合评估中展现出显著优势.在与参数量级相近的MANNER和TadNER对比中, DR-ACI取得显著的性能提升, F1值达到33.0%, 相比MANNER(23.1%)和TadNER(24.2%)分别提升9.9%和8.8%.与此同时, DR-ACI展现出更优的计算效率, 相比TadNER, 训练时间缩短约191 s, 推理延迟降低23 ms.这表明本文引入ABC损失与AGE模块, 通过高效的特征解耦与残差门控策略, 在不显著增加计算负担的前提下, 大幅增强模型对稀疏样本的判别能力.
| 表5 各模型在GUM数据集1-shot任务上的参数量和效率对比 Table 5 Comparison of the number of parameters and efficiency of each model on 1-shot task of GUM dataset |
更值得注意的是, 尽管BANER拥有7 B的庞大参数规模, 但F1值仍低于DR-ACI.与此同时, LLM带来高昂的计算代价:训练时间长达20 h左右, 推理时间高达1.4× 104 ms.DR-ACI通过ACI机制, 能在毫秒级推理中完成对目标域分布的实时修正, 避免LLM生成式推理的高昂计算代价.这一结果表明, 在特定领域的少样本识别任务中, 经过精心设计的轻量级专用模型能在大幅降低计算成本的同时, 取得与通用大语言模型相当甚至更优的识别精度, 从而展现出更具优势的实际部署潜力.
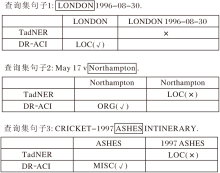
为了直观展示DR-ACI如何通过判别性表示学习阶段与领域感知的自适应校准推理阶段应对跨域少样本场景中的具体挑战, 并进一步探究模型对不同实体类别的细粒度判别能力, 在CoNLL'03数据集上随机选取3个典型查询句子进行案例分析, 并与TadNER[15]进行对比, 结果如图3所示.
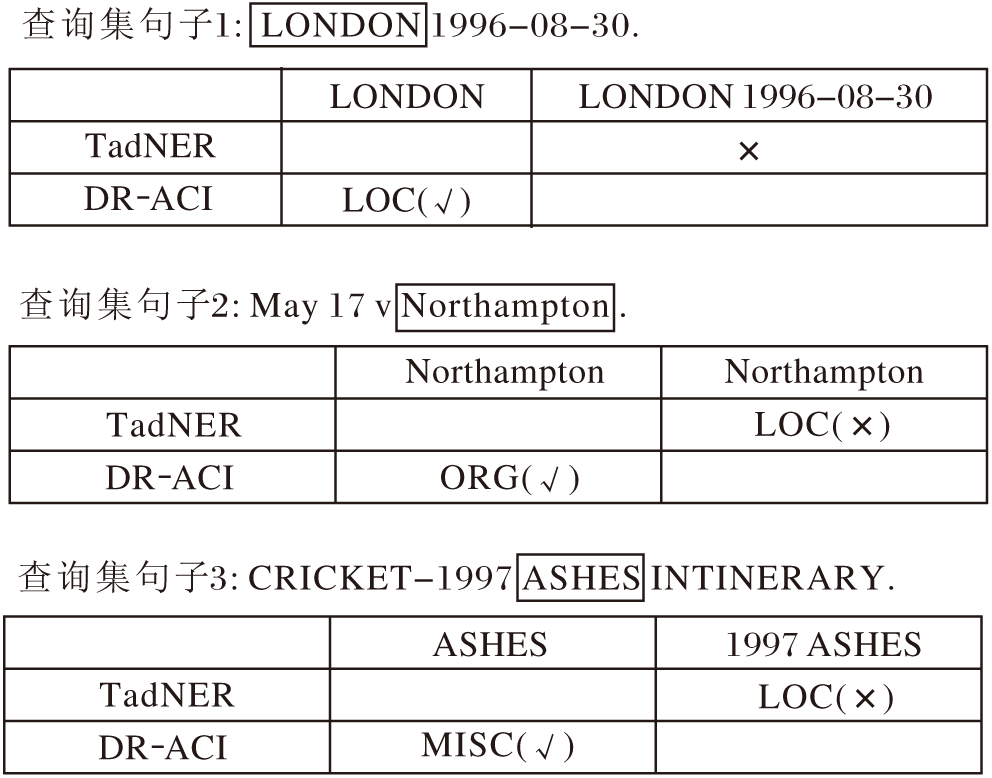 | 图3 TadNER和DR-ACI具体案例分析结果Fig.3 Case analysis of TadNER and DR-ACI |
在句子1“ LONDON1996-08-30” 中, TadNER错误地将日期“ 1996-08-30” 包含在实体跨度内, 产生典型的边界过检测错误.这往往是因为传统模型在特征空间中未能有效隔离实体与强相关背景噪声.相比之下, DR-ACI引入ABC损失, 构建“ 实体中心” 的非对称判别空间, 显式拉大实体(“ LON-DON” )与非实体背景(“ 1996-08-30” )之间的特征距离.这种非对称约束成功锐化实体的判别边界, 使模型能精准地在“ LONDON” 处截断, 避免对时间状语的错误扩展.
在句子2“ May 17 v Northampton” 中, “ Northamp-ton” 一词存在明显的语义歧义, 既可指代地点(LOC)也可指代组织(ORG).TadNER虽然定位准确, 但错误地将其归类为LOC.相比之下, DR-ACI正确将其分类为ORG, 这充分体现AGE模块与ACI机制的协同优势.首先, AGE模块通过残差门控策略捕捉上下文中关键的对抗介词“ v” (versus), 为稀疏的实体特征注入“ 体育竞技” 的互补语义.然后在推理阶段, ACI机制通过动态概率门控校准预测分布, 修正模型对“ 地名” 字面含义的过度自信, 最终实现对ORG类别的精准判定.
在句子3中复杂实体并列的情况下, “ CRI-CKET-1997ASHES ITINERARY” 对TadNER构成复合挑战, 导致其在边界识别(错误包含“ 1997” )和类型分类(误判为LOC)上双双失效.DR-ACI的两阶段解耦策略成功缓解该问题.在检测阶段, ABC损失凭借对边界的敏感性, 准确地将核心实体“ ASHES” 从年份修饰语中剥离; 在分类阶段, AGE模块有效利用上下文中“ CRICKET” 和“ ITINE-RARY” 等强语义信息, 为“ ASHES” 构建丰富的“ 体育赛事” 语义增强表示.最终, 模型将其精准分类为杂项(MISC), 展现其在处理复杂结构化文本上的强大能力.
上述针对不同实体类别的案例分析直观表明, 在少样本设定下, 即使缺乏各类别的充足训练数据, DR-ACI依然能有效克服特定类型的字面偏差与原型混淆, 实现高鲁棒性的细粒度类型分类.
针对跨域少样本命名实体识别任务中存在的实体边界模糊、少样本原型稀疏和目标域特征分布偏移问题, 本文提出基于判别性表示学习与自适应校准推理的跨域少样本命名实体识别模型(DR-ACI).首先, 通过非对称边界对比损失(ABC)与自适应门控增强模块(AGE)重塑特征空间, 分别利用实体中心约束与多层级语义融合解决边界混淆与表征偏差问题.然后引入场景感知的自适应校准推理机制(ACI), 利用双模式门控策略动态修正预测分布, 克服跨域特征漂移问题.实验表明, DR-ACI在跨域低资源场景中泛化能力与推理效率较优, 为轻量级模型的迁移应用提供新的范式.
然而, DR-ACI受限于轻量级参数规模, 在处理语义跨度极大的类别迁移任务时, 世界知识调用能力尚不及大语言模型.未来的工作将主要聚焦于两个方向.1)探索基于知识蒸馏的增强策略, 尝试将大语言模型的通用语义理解能力高效注入DR-ACI的判别性特征中, 应对复杂语境理解的短板.2)结合检索增强(Retrieval Augmented Generation, RAG)技术, 优化原型构建, 引入外部知识库, 辅助校准极端少样本(如1-shot)情况下的原型分布, 进一步提升模型在开放域环境中的鲁棒性.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|