

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
结合多级特征解耦与频域信息的深度伪造检测方法
[林力伟1, 2  , 李阳
, 李阳1, 2 , 朱恒亮1, 2 , 王猛强1, 2 , 黄川3 , 陈建伟3 , 章静1, 2 , 陈碧霞1, 2 ]
, 李阳, 朱恒亮, 王猛强, 黄川, 陈建伟, 章静, 陈碧霞]
|
|



作者简介:

林力伟,博士,讲师,主要研究方向为人工智能、深度伪造检测、物联网、信息安全.E-mail:llw02@fjut.edu.cn.

李 阳,硕士研究生,主要研究方向为计算机视觉、深度伪造检测.E-mail:2241308013@smail.fjut.edu.cn.

王猛强,硕士研究生,主要研究方向为计算机视觉、深度伪造检测.E-mail:2241308022@smail.fjut.edu.cn.

黄 川,博士,讲师,主要研究方向为网络通信、信息安全.E-mail:chuangfjnu@fjnu.edu.cn.

陈建伟,博士,副教授,主要研究方向为物联网、信息安全.E-mail:jwchenfj@fjnu.edu.cn.

章 静,博士,教授,主要研究方向为大数据隐私保护.E-mail:jingzhang@fjut.edu.cn

陈碧霞,硕士研究生,主要研究方向为计算机视觉.E-mail:2241308002@smail.fjut.edu.cn
深度伪造检测大多因泛化能力不足,难以应对未知伪造技术.因此,文中提出结合多级特征解耦与频域信息的深度伪造检测方法(Deepfake Detection Method Combining Multi-stage Feature Disentanglement and Frequency-Domain Information, MFD-FD).首先,设计多级特征解耦模块,并引入伪造抑制损失与重建损失,从浅到深逐步分离内容特征与伪影特征,既有效降低两者耦合程度又保留关键信息,使方法能聚焦于更高纯度的伪影特征.然后,引入频域信息,弥补空间特征在频谱信息上的不足,增强面对图像压缩等干扰条件下的检测稳定性.最后,设计余弦过渡融合增强模块,合成多样化伪造样本,增强鲁棒性.大量实验表明,MFD-FD的泛化性与鲁棒性较优.
, LI Yang, ZHU Hengliang, WANG Mengqiang, HUANG Chuan, CHEN Jianwei, ZHANG Jing, CHEN Bixia
About Author:
LIN Liwei, Ph.D., lecturer. His research interests include artificial intelligence, deepfake detection, Internet of Things, and information security.
LI Yang, Master student. His research interests include computer vision and deepfake detection.
WANG Mengqiang, Master student. His research interests include computer vision and deepfake detection.
HUANG Chuan, Ph.D., lecturer. His research interests include network communications and information security.
CHEN Jianwei, Ph.D., associate profe-ssor. His research interests include the Internet of Things and information security.
ZHANG Jing, Ph.D., professor.Her research interests include big data privacy protection.
CHEN Bixia, Master student. Her research interests include computer vision.
Deepfake detection is faced with significant challenges due to its limited generalization capability and poor adaptability to unseen forgery techniques. To address these issues, a deepfake detection method combining multi-stage feature disentanglement and frequency-domain information(MFD-FD) is proposed. First, a hierarchical feature disentanglement strategy is designed. By introducing a forgery suppression loss and a reconstruction loss, content features are progressively separated from artifact features from shallow to deep layers. Thus, the coupling between the two features is effectively reduced with critical information preserved and the model can focus on more purified artifact representations. Next, frequency domain information is introduced to compensate for the deficiency of spatial features in spectral information, thereby enhancing the detection stability of the model against perturbations such as image compression. Finally, a frequency-domain fusion data augmentation method based on a cosine transition mask is presented to enhance the model robustness by synthesizing diverse forged samples. Extensive experiments demonstrate that MFD-FD outperforms the state-of-the-art methods in both generalization and robustness.
随着各种生成模型[1, 2]的发展, 人脸伪造变得越来越逼真.这些伪造图像常被用于娱乐与营销, 但与此同时, 少数不法分子利用深度伪造技术生成并传播虚假内容, 给个人隐私、新闻真实性、社会稳定与国家安全带来严重的威胁和挑战.因此, 迫切需要设计高效的方法检测深度伪造内容.
早期针对深度伪造设计的一些检测器[3, 4]在同一个数据集内训练和测试时能取得较优效果, 但是在实际应用中, 测试样本通常由未知的伪造方法合成, 前述检测器在面对新型伪造方法时性能会有显著下降.因此, 提高检测方法的跨域泛化能力已成为研究重点方向之一.一些研究通常利用混合伪影特征[5]或基于对抗训练合成具有挑战性的伪造样本[6], 从而扩充训练集, 然而这类方法在图像压缩条件下往往性能较差.Frank等[7]发现, 伪造图像会在频域留下特定的伪影痕迹, 这些痕迹往往对常见的图像压缩、噪声等干扰具有相对稳定性, 因此在频域中挖掘此类伪造痕迹, 能在严重压缩条件下帮助检测方法保持较好的鲁棒性[8, 9].但是, 这些方法在整体特征空间上进行建模, 可能受到背景、身份等与伪造无关因素的干扰, 影响泛化能力.为了减少方法对内容信息的依赖, 一些研究者尝试将伪影特征和内容特征解耦[10, 11].然而, 现有的特征解耦策略通常采用单阶段方法, 虽然旨在抑制内容信息的干扰, 却往往忽略解耦后特征间仍可能存在的耦合残留问题.另外多数工作未充分利用频域信息, 因此在面对图像压缩或噪声干扰时性能仍较差.
综上所示, 当前伪造图像检测研究仍存在若干不足.首先, 现有特征提取过程存在语义内容与伪影特征耦合, 导致判别器容易受到图像语义变化影响而降低泛化能力.尽管已有方法尝试将伪影特征与内容特征解耦, 但大多为单阶段分离, 分离后的两类特征仍保留部分耦合.其次, 多数方法仅依赖RGB空间的表征, 难以充分捕获伪造图像在频谱域中微弱且分散的痕迹, 这种单一模态的表征方式不仅限制模型提取伪影特征的能力, 也导致其在面对图像压缩、噪声干扰时鲁棒性不足.最后, 训练样本通常缺乏足够多样且含判别信息的伪造样本, 使模型在遇到新的伪造方法或合成分布时性能下降.
针对上述问题, 本文提出结合多级特征解耦与频域信息的深度伪造检测方法(Deepfake Detection Method Combining Multi-stage Feature Disentanglement and Frequency-Domain Information, MFD-FD).首先, 设计多级特征解耦模块(Multi-stage Feature Disentanglement, MSFD), 进一步分离初次解耦得到的内容特征与伪影特征, 获得更独立的表示, 显著降低特征耦合程度并缓解对内容特征的过拟合风险.为了实现这一目标, 设计伪造抑制损失与重建损失, 使内容特征包含更少的伪影信息, 同时确保解耦后的特征保留原始特征的关键信息.其次, 为了弥补单一特征域的表征局限, 并充分利用频域信息在面对图像压缩、噪声干扰等具有相对稳定性的优势, 设计多分支特征提取与融合机制, 并行处理空域输入与频域输入, 并在特征层面融合, 能同时感知局部纹理异常与全局频谱统计差异, 提升对多样化伪造痕迹的感知能力.最后, 设计余弦过渡融合增强模块(Cosine Transition Fusion Augmentation, CTFA), 生成多样化的伪影分布样本, 扩展伪影类型并增强在压缩等干扰条件下的鲁棒性.大量实验表明, MFD-FD在面对未知数据时仍具有较优的泛化性与鲁棒性.
针对深度伪造技术的安全威胁, 已有许多研究人员致力于检测方法的设计与改进.Zhou等[12]设计双流结构, 分别捕捉面部篡改线索和局部块的不一致性.Wodajo等[13]提出CViT(Convolutional Vi-sion Transformer), 利用卷积神经网络(Convolutional Neural Network, CNN)提取人脸图像特征, 并输入单尺度 Transformer 完成伪造检测.Zhao等[4]提出多注意力深度伪造检测框架, 通过多重注意力图捕获篡改痕迹.Li等[14]提出Face X-ray, 利用边界处底层图像统计特征的不一致性, 定位混合边界, 实现检测.然而, 上述方法大多仅关注空间域特征, 性能高度依赖数据集的质量与分布.为了突破这一局限, 部分研究[15, 16]引入离散余弦变换(Discrete Cosine Trans-form, DCT), 将图像映射至频域, 分析频域统计特征.虽然这些基于CNN的方法在特征提取方面表现较优, 但是由于未能充分考虑特征中隐含的内容偏差, 检测器容易受到数据集自身偏差的干扰, 限制跨域的泛化性.
特征解耦旨在将高维耦合数据分解为若干语义独立的子特征, 每个子特征只刻画数据的某个特定因子, 分解后的子特征应具备良好的判别性并尽量降低互信息, 以保证独立性与可迁移性[17].已有研究将特征解耦应用于深度伪造检测, 目标是区分伪造相关特征与伪造无关特征.Hu等[10]仅利用伪造相关特征进行检测.Liang等[11]通过内容一致性约束与全局表征对比约束增强解耦特征的独立性.Yan等[18]将伪影特征进一步拆分为共同特征与特定特征, 并以共同特征作为检测依据.尽管上述方法在提升泛化性上取得一定进展, 但通常采用单阶段解耦策略, 难以进一步降低伪影特征与内容特征之间的耦合度, 仍有可能聚焦在内容特征上, 从而制约泛化性能的进一步提升.
为了提高深度伪造检测的泛化能力, 越来越多的研究聚焦于使用合成数据对模型进行训练.Li等[19]模拟面部区域的模糊特征, 再现生成对抗网络(Generative Adversarial Network, GAN)合成图像与真实图像的质量差异, 但随着伪造技术的发展, 在最新基准数据集上的有效性有所下降.Face X-ray[14]与I2G(Inconsistency Image Generator)[20]混合两幅面部关键点相近的真实图像, 模拟混合操作产生的伪造痕迹, 侧重捕捉具有方向性的表示(如混合边界或源特征一致性).Shiohara等[5]提出SBIs(Self-Blended Images), 对同幅图像的不同变换结果进行自融合, 生成训练样本.Chen等[6]提出SLADD, 利用对抗训练生成更具挑战性的混合场景.Bai等[21]提出AUNet, 建立动作单元之间的关系, 并在特征层面上使用被篡改的动作单元预测模块生成伪样本.上述方法强调通过数据增强使模型接触多样化伪造样本的重要性, 并在一定程度上提升泛化能力.然而研究表明图像压缩会显著削弱此类基于RGB的方法的检测性能[22].
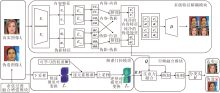
本文提出结合多级特征解耦与频域信息的深度伪造检测方法(MFD-FD), 整体框架如图1所示.首先, 设计余弦过渡融合增强模块(CTFA), 构建基于余弦过渡掩码的频域融合策略, 将真实图像与伪造图像的频谱特征在不同频段进行加权混合, 并经逆快速傅里叶变换(Inverse Fast Fourier Transform, IFFT) 生成具有多样伪影分布的增强样本, 从而扩展伪影特征并提升方法对压缩等干扰的鲁棒性.然后, 将增强后的图像输入多级特征解耦模块(MSFD), 通过图像编码器、特征编码器与损失函数的共同作用, 实现内容特征与伪影特征的渐进式解耦.与此同时, 构建频谱门控模块(Spectral Gate Block, SGB), 进一步提取图像的频域信息, 引入门控机制, 显式强化伪造区域的频谱响应, 提升对高频伪影的感知能力.最后, 设计空频融合模块(Space-Frequency Fusion Mo- dule, SFF), 融合来自空间域与频域的多层特征, 通过注意力加权融合与残差重组实现信息互补, 输出最终的伪造判别结果.
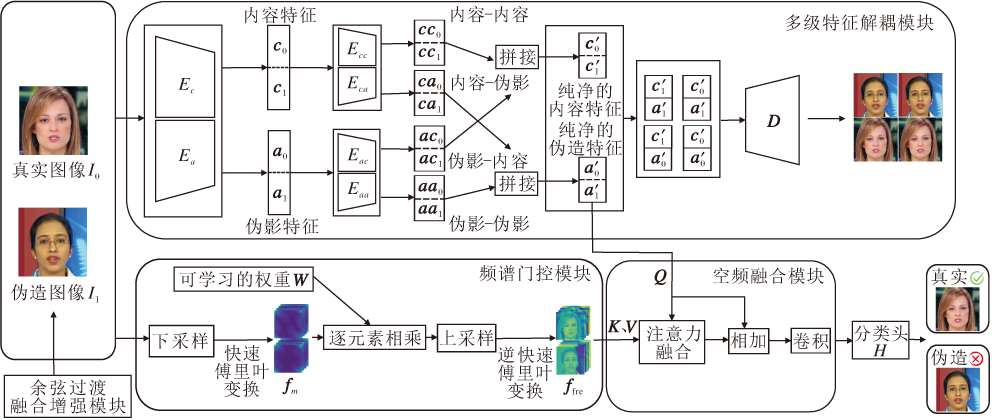 | 图1 MFD-FD整体架构Fig.1 Architecture of MFD-FD |
在伪造图像的检测场景中, 内容特征和伪影特征往往存在高度耦合, 导致分类器难以区分由伪造过程引入的细微痕迹[11].尽管现有的解耦方法旨在分离这两类特征, 但受限于伪造痕迹通常较微弱且分布于局部, 直接解耦往往难以彻底剥离这些细微线索[23], 导致解耦后特征间仍存在部分耦合残留, 即分离后的内容特征中隐含伪造痕迹或伪造特征中掺杂内容信息.针对这一问题, 本文设计多级特征解耦模块(MSFD), 并设计相应的损失约束.MSFD通过渐进式的解耦操作, 有效降低伪造特征和内容特征的互信息, 使两类特征在表征空间中更独立.在增强对伪影特征的识别能力的同时, 提升检测的鲁棒性与泛化性.
2.1.1 特征解耦层
给定一对图像(I0, I1), 其中, I0表示真实图像, I1表示伪造图像.内容编码器Ec和伪影编码器Ea分别提取图像对的内容特征和伪影特征, 这两个图像编码器均采用预训练的主干网络作为基础架构, 结构相同但参数不共享.其功能主要通过损失函数约束得以实现:在训练过程中, 内容编码器在损失函数的引导下侧重提取与图像内容相关的特征, 而伪影编码器被约束专注于捕获与伪造痕迹相关的判别信息.二者的特征解耦是在后续设计的多种损失函数的协同作用下逐步引导形成的.将这两个编码器应用于每对图像, 可获得相应的伪影特征和内容特征:
am=Ea(Im), cm=Ec(Im),
其中, m∈ {0, 1}表示图像索引, 0表示真实, 1表示伪造.此外, a0、a1表示每对输入图像对应的伪影特征, c0、c1表示每对输入图像对应的内容特征.但是这种单次解耦的方法使伪影特征和内容特征之间仍有部分耦合.
为了让二者解耦更彻底, 在第一级特征提取后引入二级解耦模块.该模块包含4个结构相同但参数不共享的特征编码器Eaa、Eac、Eca、Ecc.与前一级编码器不同的是, 二级解耦编码器由多层1× 1卷积和激活函数实现.为了公式表述简洁, 将处理伪影特征am的特征编码器组称为Eα , α ∈ {aa, ac}, 将处理内容特征cm的特征编码器组称为Eβ , β ∈ {cc, ca}.进一步的解耦过程如下:
α m=Eα (am), β m=Eβ (cm).
解耦后的特征aam表示伪影-伪影特征, acm表示伪影-内容特征, ccm表示内容-内容特征, cam表示内容-伪影特征.最终经过多次解耦得到纯净的伪影特征和内容特征为:
a'm=aam⊕ cam, c'm=ccm⊕ acm,
其中⊕ 表示通道拼接操作.这种双重解耦设计可显著降低特征间的互信息量.
2.1.2 伪造抑制机制
为了使解耦后的特征只包含相应信息, 本文提出伪造抑制损失:
Lsup=Lce(H(ψ ), 0),
利用内容特征训练辅助分类器, 对伪造样本施加“ 真实标签” 的监督, 迫使其丧失伪造检测能力, 其中, Lce(· , · )表示交叉熵损失, H(· )由分类头通过多个MLP(Multilayer Perceptron)层实现, ψ ∈ {cm, ccm, acm}, 标签0表示真实.Lsup通过最小化内容特征中的伪影噪声, 抑制伪影在内容空间的渗入, 提升特征纯度.
2.1.3 完整性约束
为了确保特征解耦过程中完整保留关键信息, 本文设计双层重建机制, 将重建损失Lrec划分为特征级重建损失
为了进一步优化特征解耦过程, 提出特征级重建损失:
确保经过解耦后提取的特征对能重构回原始特征, 从而验证信息保留的完整性, 其中, Ra(· , · )、Rc(· , · )表示特征重建模块, am、cm表示原始特征, aam、acm表示伪影特征解耦得到的两个特征分量.cam和ccm为内容特征解耦得到的两个特征分量.
为了保证重构图像和原始图像在像素级上的一致性, 重组解耦后的特征, 再重构成原始输入图像, 该约束使特征保留足够的视觉可重构信息, 增强特征的语义一致性.相应图像重建损失如下:
其中D(· , · )表示图像重建模块.
这种双层重建机制由特征级重建和图像级重建组成, 为特征解耦引入多层次、多视角的正则化约束.特征级重建通过最小化解耦前后特征的重构误差, 避免在解耦过程中丢失关键判别信息.图像级重建则基于重建图像与原始输入的像素一致性, 保持解耦特征与视觉语义的紧密对应, 抑制冗余特征或无关特征的学习.二者在正则化作用上相互独立又互为补充:特征级重建侧重微观伪造痕迹的保留, 图像级重建保障宏观语义的合理性.该双重约束机制不仅显著提升方法在未知伪造场景中的泛化性, 还增强特征表示的可解释性.
已有研究表明[7, 16], 频域分析能揭示仅依赖空间域特征难以捕捉的细微频谱异常, 且此类频域伪影在面对图像压缩等后处理干扰时稳定性更高.为此, 设计轻量化的频谱门控模块(SGB), 增强空间域表示的判别能力.
首先, 对下采样后的图像施加快速傅里叶变换(Fast Fourier Transform, FFT), 获得频谱表示fm.为了在保持模块轻量化的同时有效建模不同频带之间的依赖关系, 对每个频率通道引入可学习的权重进行逐通道滤波, 得到滤波后的频谱表示:
其中, ☉表示Hadamard乘积, W表示可学习的通道权重.再通过IFFT将滤波后的频谱表示
空频融合模块(SFF)旨在有效整合空间域特征与频域特征, 增强伪造痕迹的感知能力.首先通过1× 1卷积层将频域特征通道维度对齐至空间域特征空间.然后, 分别将解耦后的空间域伪影特征a'm嵌入为Q, 频域特征ffre嵌入为K和V.通过缩放点积注意力机制, 计算跨模态关联权重, 并按缩放点积计算注意力融合特征:
$ \boldsymbol{f}_{\text {attn }}=\text { Attention }(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})=\operatorname{softmax}\left(\frac{\boldsymbol{Q} \boldsymbol{K}^{\mathrm{T}}}{\sqrt{d}}\right) \boldsymbol{V} \text {, }$
其中, d表示通道维度的标度因子, 用于稳定梯度.将注意力融合特征fattn与原始空间域伪影特征a'm进行残差连接, 保护原始空间域伪影特征, 避免融合过程导致有效判别信息的丢失.最后, 通过 1× 1 卷积进行最终的通道调整, 得到融合后的伪影特征:
ffused=conv1× 1(a'm+fattn).
SFF能以较小的计算代价融合频域层面的伪影信息与空间域的判别特征, 在多模态信息下更精准地捕获与判别伪造痕迹.
常见训练集通常包含多种伪造痕迹, 如标记不匹配、融合边界、色彩失配、频域不一致等, 这些痕迹在视觉上差异显著, 部分表现为细微的高频噪声或纹理断裂, 另一些则体现为宏观的结构错位或色彩偏移.不同伪造方法通常具有独特的视觉特征, 同种方法生成的伪造样本视觉一致性较高, 而不同方法之间差异明显.若训练过程过度依赖某类显著痕迹, 容易对特定伪造方法产生偏置, 影响对其它伪造类型的检测, 限制泛化能力.为了提升检测器的泛化能力, 需在保持图像真实感的前提下, 强化具有代表性的判别性细节, 同时削弱方法间的表征差异.换言之, 应保留图像的整体结构与自然纹理, 避免引入明显的伪造痕迹, 同时适度引入有助于识别的局部特征(如局部频域信息、融合边界或微观纹理), 用于增强判别信号.这样构造的训练样本既保持真实感, 又包含多样的伪影特征, 从而显著提升模型在多样伪造类型下的鲁棒性与泛化性.
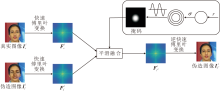
现有的研究[8, 16]表明, 伪造样本与真实样本的差异主要集中在高频区域, 篡改痕迹往往存在于高频成分中.受Yan等[24]启发, 本文尝试在频域融合真伪图像以构造训练样本.然而, 实验分析发现, 直接对频域部分进行拼接会导致融合后的图像产生明显的振铃效应, 使模型学习图像波纹特征, 进而影响泛化检测能力.针对这一局限性, 本文设计余弦过渡融合增强模块(CTFA), 结构如图2所示.与直接拼接不同, CTFA设计一个平滑过渡带, 实现真实图像Ir与伪造图像If在频谱域的平滑融合, 在保留伪造信息的同时, 有效抑制振铃干扰, 生成质量更高的训练样本.
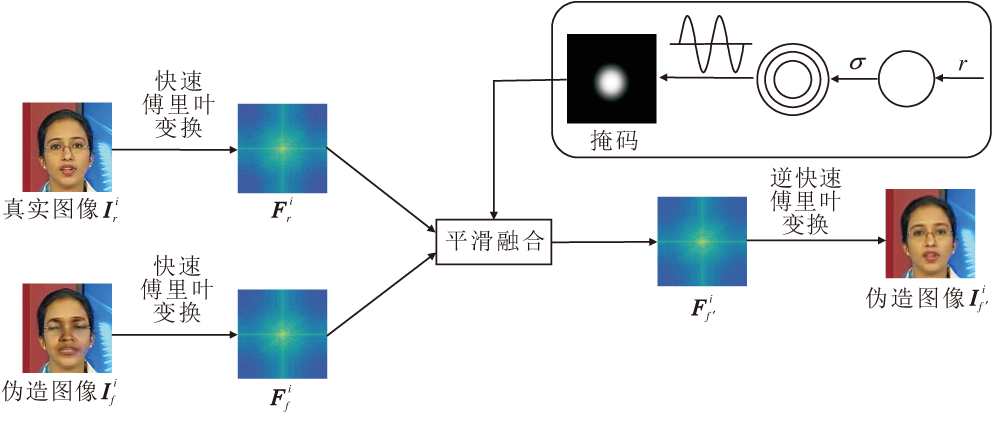 | 图2 CTFA结构图Fig.2 Architecture of CTFA |
给定样本I
$ \begin{aligned}\boldsymbol{F}_{m}^{i}(u, v)= & F F T\left\{\boldsymbol{I}_{m}^{i}(x, y)\right\}= \\& \sum_{x=0}^{H-1} \sum_{y=0}^{W-1} \boldsymbol{I}_{m}^{i}(x, y) \exp \left(-2 \pi \mathrm{i}\left(\frac{u x}{H}+\frac{v y}{W}\right)\right), \end{aligned}$
其中, (u, v)表示频域坐标, (x, y)表示空间域坐标, H、W表示图像高度和宽度, m∈ {r, f}, r表示真实样本, f表示伪造样本, i表示样本索引.再在空间域构造余弦过渡掩码M(x, y).令图像中心为$ \left(\frac{W}{2}, \frac{H}{2}\right)$, 对任一点(x, y), 计算到中心的欧氏距离:
d(x, y)=
给定掩码半径r和过渡带宽σ , 掩码M按内区、过渡区与外区三段定义如下:
M=
其中, 内区$ \left(d< r-\frac{\sigma}{2}\right)$保留真实图像的频谱分量, 外区\left(d)r+\frac{\sigma}{2}\right)保留伪造图像的频谱分量, 过渡带$ \left(r-\frac{\sigma}{2} \leqslant d \leqslant r+\frac{\sigma}{2}\right)$通过余弦函数实现掩码值从1至0的区间内平滑衰减.该余弦过渡确保掩码在空间域中具有连续且可控的衰减特性, 从而在频域融合时有效抑制振铃效应.
在频域融合阶段, 先给定一个伪造样本I
$ \begin{aligned}\boldsymbol{F}_{f^{\prime}}^{i}(u, v)= & \boldsymbol{F}_{r}^{i}(u, v) \odot \boldsymbol{M}(u, v)+ \\& \boldsymbol{F}_{f}^{i}(u, v) \odot[\mathbf{1}-\boldsymbol{M}(u, v)] .\end{aligned}$
通过在低频区域保留真实频谱而在高频区域引入伪造频谱, 可在保持整体结构一致性的同时增强局部伪影特征的表达能力, 使生成样本既真实又包含判别所需的微观痕迹.
最后, 对融合后的频谱执行IFFT, 重建时域图像:
$ \begin{aligned}\boldsymbol{I}_{f^{\prime}}^{i}(x, y)= & \operatorname{IFFT}\left\{\boldsymbol{F}_{f^{\prime}}^{i}(u, v)\right\}= \\& \frac{1}{H W} \sum_{u=0}^{H-1} \sum_{v=0}^{W-1} \boldsymbol{F}_{f^{\prime}}^{i}(u, v) \exp \left(2 \pi \mathrm{i}\left(\frac{u x}{H}+\frac{v y}{W}\right)\right) .\end{aligned}$
重建得到的图像在空间域中既保留真实图像的全局纹理, 又在细节尺度上嵌入伪影特征, 从而构成难以区分的高质量合成样本.
CTFA优点如下:一方面, 余弦过渡掩码提供平滑的频域衔接, 显著降低直接拼接带来的振铃现象; 另一方面, 在频域进行的加权融合能更细粒度地控制低频信息与高频信息的来源, 有利于生成既自然又含伪造痕迹的训练样本, 提升模型泛化性与对微弱伪造痕迹的敏感度.
训练过程的总损失函数如下所示:
Ltotal=Lcls+λ 1Lsup+λ 2
其中, Lcls表示二元交叉熵损失, λ 1、λ 2、λ 3表示用于平衡总损失的超参数.
本文在FaceForensics++(FF++)[3]数据集上进行训练.该数据集包含1 000个原始视频(即真实样本)和由4种操作方法(Deepfakes、Face2Face、FaceSwap、Neural Textures)伪造的4 000个视频.此外, FF++数据集对于这些视频提供3种压缩质量级别:原始版、高质量(HQ)版和低质量(LQ)版.本文默认采用FF++数据集的HQ版本, 并遵循官方协议, 将FF++数据集上所有样本按视频级别分为训练集、验证集和测试集.
为了评估MFD-FD的泛化能力, 分别在Cele- bDF-v1(CDFv1)[25]、Celeb-DF-v2(CDFv2)[25]、Face-Shifter(Fsh)[26]、DeepFake Detection[27]、Deepfake De- tection Challenge Preview(DFDC-p)[28]、Deepfake De- tection Challenge(DFDC)[29]这6个大规模基准数据库上进行实验.Li等[25]提出用于伪造检测的CDFv1数据集.不久之后, 在CDFv1数据集上添加更多视频, 产生CDFv2数据集.CDFv2数据集包含890个真实视频和5 639个合成视频, 是伪造检测领域中最受欢迎的跨域数据集之一.Fsh数据集是利用双阶段生成对抗网络方法创建的伪造数据集, 更逼真且更难于检测真伪.DFD数据集是一个基于Deep- fake的数据集, 包含363个真实视频和3 068个虚假视频.DFDCP、DFDC数据集来自Deepfake Detec- tion Challenge, 包含大量受干扰的视频, 如压缩、下采样和噪声.
与大多数现有伪造检测方法一致, 本文采用接收者操作特征曲线下面积(Area under the Receiver Operating Characteristic Curve, AUC)作为检测性能的评估指标.在人脸伪造检测中, AUC是一种客观且使用最广泛的评估指标.除非另有说明, 实验中的评估结果默认为视频级AUC, 通过平均视频各帧的分类得分计算得出.
本文采用改进的Xception[30]作为主干网络, 并以ImageNet 预训练参数初始化.数据预处理中使用DLIB[31]进行面部检测、裁剪和对齐, 图像尺寸统一调整为256× 256, 用于训练和测试.训练阶段采用学习率为0.000 2的Adam(Adaptive Moment Estima-tion)优化器, 批量大小设为16, 每个视频采样32帧进行训练和测试.实验中设定λ 1=0.2, λ 2=0.05, λ 3=0.1.
MFD-FD基于PyTorch框架, 并在NVIDIA Ge-Force RTX 4090上训练.
3.2.1 域内评估
为了评估MFD-FD在域内的检测性能, 与如下8种主流深度伪造检测方法进行对比实验.对比方法包括:文献[4]方法、F3-Net(Frequency in Face Forgery Network)[8]、Xception[30]、ADDNet[32]、RECCE(Reconstruction-Classification Learning)[33]、TALL++[34]、AIM-Bone[35]、IDCNet[36].在FF++、CDF- v2数据集上分别进行训练与评估.
各方法在2个数据集上的指标值对比如表1所示, 表中黑体数字表示最优值, 斜体数字表示次优值.
| 表1 各方法在2个数据集上的域内评估结果 Table 1 In-domain evaluation results of each method on 2 datasets |
由表1可见, MFD-FD在2个数据集上的平均AUC值达到0.999 6, 为最优, 其中在FF++数据集上达到0.999 9, 这表明在数据分布一致时, MFD-FD能有效挖掘和识别伪造痕迹.
3.2.2 跨域评估
为了验证MFD-FD在跨域上的泛化性, 在具有代表性的6个数据集上进行全面实验.具体地, 在FF++数据集上进行训练, 并分别在CDFv1、CDFv2、DFD、DFDC、DFDCP、Fsh测试集上进行评估.此外, 选择经典的和近期较先进的方法进行对比.对比方法如下:F3-Net[8]、文献[11]方法、Face X-ray[14]、SPSL(Spatial-Phase Shallow Learning)[16]、UCF[18]、Xception[30]、RECCE[33]、IDCNet[36]、FFD(Facial For- gery Detection)[37]、文献[38]方法、文献[39]方法、CORE(Consistent Representation Learning)[40]、Noise- DF[41]、文献[42]方法、FoCus(Forgery Cues Disco- very)[43].
各方法的指标值对比如表2所示, 表中黑体数字表示最优值, 斜体数字表示次优值.
| 表2 各方法在6个测试集上的跨域评估结果 Table 2 Cross-domain evaluation results of each method on 6 test sets |
由表2可见, MFD-FD在多数测试集上AUC值显著优于现有方法, 在CDFv1、CDFv2、DFD、Fsh测试集上分别取得0.829 8、0.809 1、0.857 7 和0.667 0的AUC值.在更具挑战性DFDC测试集上, 也取得具有竞争力的结果.实验表明MFD-FD在跨域评估上具有明显优势, 验证其在提升伪造图像检测泛化能力方面的有效性.
3.2.3 跨伪造方法评估
在实际应用中, 面部伪造的生成方式往往未知且多样, 因而要求检测模型具备良好的方法间泛化能力.为此, 在FF++ 数据集上使用单一伪造方法进行训练, 然后在4种主流伪造类型(Deepfakes、Face2Face、FaceSwap、Neural Textures)上进行交叉测试.对比方法如下:UCF[18]、文献[42]方法、M2TR(Multi-modal Multi-scale Transformer)[44]、CFM(Cri- tical Forgery Mining)[45].
各方法在跨伪造方法测试中的AUC值对比如表3所示, 表中黑体数字表示最优值, 斜体数字表示次优值.由表可见, MFD-FD在使用Face2Face和Neural Textures单一训练时取得最高的平均AUC值, 在使用Deepfakes与FaceSwap单一训练时也达到次优.在使用Deepfakes和FaceSwap单一训练时未能取得最高平均AUC值的原因可能与伪造类型本质差异有关, Face2Face与Neural Textures使用面部表情编辑方法, 而Deepfakes与FaceSwap使用人脸身份互换技术, 两类操作在伪造痕迹和特性上存在差别.总之, 实验表明MFD-FD在检测未见过的伪造方法方面具有良好的泛化能力.
| 表3 各方法在跨伪造方法上的评估结果 Table 3 Evaluation results of different methods on cross-manipulation methods |
3.2.4 多级特征解耦模块性能评估
为了对比多级特征解耦模块(MSFD)与文献[11]方法、UCF[18]、Xception[30]在跨域场景中的性能, 在FF++数据集上训练方法, 并分别在 CDFv1、DFD、DFDC测试集上进行评估.
各方法的对比结果如表4所示, 表中黑体数字表示最优值, 斜体数字表示次优值.
| 表4 各特征解耦方法的性能对比 Table 4 Performance comparison of different feature disentanglement methods |
由表4可见, MSFD在DFD测试集上的AUC值优于Xception和UCF.UCF在DFDC测试集上的表现最优, AUC值达到0.719 1, 但在CDFv1、DFD测试集上表现相对较弱.相比之下, MSFD在所有测试集上的平均AUC值均高于文献[11]方法和UCF.相比文献[11]方法, MSFD在DFD测试集上提升约1.7%, 相比UCF, MSFD平均AUC值提升约1.8%.上述结果验证MSFD在提升跨域泛化能力方面的有效性.
此外, 为了探究MSFD的性能潜力与瓶颈, 在MSFD基础上进一步添加第三解耦层.该层结构与二级编码器保持一致, 并沿用相同的特征约束机制, 在表4中记为MSFD* .由表可见, 三级解耦与二级解耦的效果相近, 但由于参数量的增加, 模型复杂度有所提升, 这也进一步证实在当前特征表示与损失约束框架下, 解耦性能在二级之后趋于饱和.
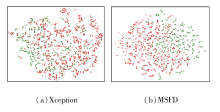
最后, 为了更直观地展示MSFD在CDFv1数据集上的判别能力与泛化表现, 对网络最后一层输出的高维特征向量进行降维, 并采用t-SNE(t-Distri-buted Stochastic Neighbor Embedding)进行可视化, 结果如图3所示, 图中红点表示伪造样本, 绿点表示真实样本.由图可观察到, 相比Xception, MSFD在特征空间中的类内聚合性更强, 类间区分更明显, 同时错误簇中的异常点也更少.这进一步表明所学特征不仅具备良好的区分能力, 还展现出较强的跨数据集泛化性.
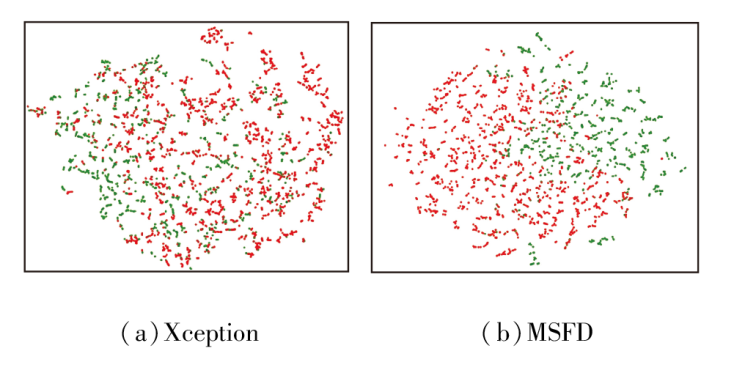 | 图3 Xception和MSFD的特征空间可视化结果Fig.3 Visualization results of feature space for Xception and MSFD |
3.3.1 余弦过渡融合增强模块的有效性
为了验证余弦过渡融合增强模块(CTFA)的有效性, 并系统评估过渡带宽σ 对检测性能的影响, 以Xception为基线网络进行对照实验, 将融合半径r固定在取值区间(10, 20], 并选取多个不同的σ 取值区间进行对比.所有方法均在FF++数据集上进行训练, 再分别在FF++数据集(域内)与CDFv1数据集(跨域)上评估检测性能.
σ 对MFD-FD性能的影响如表5所示, 表中黑体数字表示最优值.
| 表5 σ 对MFD-FD性能的影响 Table 5 Effect of σ on MFD-FD performance |
由表5可见, 当σ 取值区间为(0, 10]时, 平均AUC值最高, 为0.894 0.当σ 增至(10, 20]区间时, 平均AUC值下降0.88%.这一现象可解释为:较大的σ 导致掩码的平滑过渡区域较宽, 融合后图像保留较多的真实图像特征而伪造痕迹被弱化.相反, 当σ =0时, 平均AUC值下降1.21%, 这是因为σ =0即不存在平滑过渡带, 直接生成半径为r的硬掩码, 导致融合后的图像具有明显的振铃现象, 这种人工痕迹损害图像质量, 造成测试性能的下降.另外作为对照, 表5中还列出仅使用Xception训练后的指标, 对比可知CTFA的引入显著提升方法在不同测试场景中的性能.
为了直观展示融合后的视觉效果, 在r=15时, 设置σ =0, 5, 15, 对融合图像进行可视化, 结果如图4所示.由图可明显看到, σ 的引入明显减少图像的振铃现象.因此, 适度的平滑过渡有助于在保留伪造痕迹与避免产生视觉伪影之间取得平衡, 提升检测的鲁棒性.
 | 图4 σ 不同时融合图像的可视化结果Fig.4 Visualization results of fused images under different σ |
3.3.2 不同模块的有效性
为了评估CTFA、MSFD和频谱门控模块(SGB)的有效性, 以FF++数据集作为训练集, 在Xception的基础上逐个加入, 观察其在CDF v1、CDFv2、DFD这3个跨域数据集上AUC指标的变化, 结果如表6所示.
| 表6 不同模块的消融实验结果 Table 6 Ablation experiment results of different modules |
由表6可见, CTFA、MSFD、SGB均能有效提升方法的跨域泛化能力.在跨域测试中, CTFA通过数据增强在CDFv1、CDFv2、DFD测试集上分别使AUC值提升2.95%、2.17%与2.32%, 显著增强方法特征表示的判别能力.在此基础上, MSFD通过多级解耦, 在CDFv1、CDFv2测试集上进一步实现2.01%与3.36%的AUC值提升, 该模块有效降低内容特征的干扰, 使方法能更准确地关注伪造特征.最后, SGB通过向空间域补充细微的频域信息, 进一步在CDFv2、DFD测试集上分别实现1.73%与1.09%的性能增加, 这验证频域线索对空间特征的有效互补.从方法跨域的平均AUC值来看, 3个模块的依次引入使AUC值从基线的77.74%逐步升至83.22%, 表明各模块在协同增强方法整体性能与泛化能力上的有效性.
3.3.3 伪造抑制损失和重建损失的有效性
为了评估伪造抑制损失与重建损失对泛化能力的贡献, 在FF++数据集上训练模型, 并对比在域内(FF++数据集)与跨域(CDFv1数据集)上的AUC值, 结果如表7所示.
| 表7 伪造抑制损失和重建损失的消融实验结果 Table 7 Ablation experiment results of forgery suppression loss and reconstruction loss |
由表7可见, 去除伪造抑制损失, 平均AUC值下降1.16%, 在CDFv1数据集上下降1.73%.其原因在于缺失该约束会导致内容特征混入部分伪造信息, 使伪影特征与内容特征的解耦不足.去除重建损失, 平均AUC值下降2.28%, 在CDFv1数据集上下降更多, 达到3.85%, 这表明无重建约束时解耦过程中容易丧失特征完整性, 削弱对细粒度伪造痕迹的保持.若同时去除二者, 平均AUC值进一步降至87.80%, 说明两类损失在提升跨域泛化性方面具有互补且累积的正向作用.
为了直观验证MFD-FD的有效性, 在 FF++ 数据集上, 对Xception与MFD-FD分别应用Grad-CAM(Gradient-Weighted Class Activation Mapping)[46]进行可视化, 结果如图5所示.由图可见, Xception常过度拟合局部小区域或关注与伪造无关的内容特征(如背景), 激活分布较分散.相比之下, MFD-FD注意力更集中, 主要聚焦于人脸区域而非背景.这一差异源于本文提出的解耦框架, 该框架能有效消除内容特征的干扰, 引导检测器挖掘判别性的伪影特征.反之, 在仅依靠标签且无额外约束的情况下, 检测器难以定位判别性伪影, 容易产生内容偏差, 导致过拟合甚至误导优化方向.
 | 图5 Xception和MFD-FD类激活图对比Fig.5 Comparison of class activation maps between Xception and MFD-FD |
本节评估MFD-FD的计算复杂度, 结果如表8所示, 表中分别列出方法在推理阶段的参数量、浮点运算数及帧率, 并与IDCNet[36]、文献[38]方法、文献[47]方法、EFIMD-Net[48]进行对比.
| 表8 各方法的计算复杂度对比 Table 8 Computational complexity of different methods |
由表8可见, 在效率方面, MFD-FD的参数量为69.73 M, 与对比方法规模相近.浮点运算量为53.68 G, 显著低于EFIMD-Net和IDCNet, 但74.42帧/秒的计算速度低于文献[38]方法和IDCNet.这主要源于MFD-FD为了提升判别能力而引入的多级特征解耦结构, 以及融合频域信息的检测机制, 这两项设计在增强特征表征与跨域泛化能力的同时, 也增加方法的计算负担.但是, 这种以适度计算开销换取检测性能显著提升的权衡是合理且必要的.在深度伪造检测任务中, 细微伪造痕迹的捕捉与高泛化性往往依赖于更丰富的特征表示和更复杂的模型结构.
本文针对深度伪造检测在泛化性与鲁棒性方面的不足, 提出结合多级特征解耦和频域信息的深度伪造检测方法(MFD-FD).设计多级特征解耦模块, 在初步解耦的基础上进一步深化内容特征和伪影特征的分离, 并通过伪造抑制损失和重建损失有效降低二者耦合度并保留判别性信息.同时, 将频域信息作为空间域特征的频谱补偿, 设计余弦过渡融合增强模块, 合成多样化且自然的伪造痕迹分布, 扩展可识别的伪影特征, 并增强对压缩等干扰的稳健性.大量实验表明, MFD-FD在多种伪造场景中均能保持稳定性, 展现出优越的泛化性与鲁棒性.未来工作将致力于探索更高效的特征解耦策略, 进一步推动深度伪造检测的发展.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|