



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
融合Mamba-Transformer的节奏感知舞蹈生成模型
[胡正平1, 2  , 徐传鑫
, 徐传鑫1 , 董晓云1 , 吴一凡1 ]
, 徐传鑫, 董晓云, 吴一凡]
|
|



作者简介:

徐传鑫,硕士研究生,主要研究方向为视频生成.E-mail:xuchuanxin0805@163.com.

董晓云,硕士研究生,主要研究方向为人体行为识别.E-mail:1506887239@qq.com.

吴一凡,硕士研究生,主要研究方向为拉班舞谱生成.E-mail:15507068379@163.com.
针对音频驱动舞蹈生成任务中较难同时兼顾生成舞蹈动作质量及动作同音乐节拍对齐的问题,文中提出融合Mamba-Transformer的节奏感知舞蹈生成模型(Beat-Aware Dance Generation Model Integrating Mamba-Transformer, BeatDG).首先,设计上下肢动作特征编码网络,以无监督形式自主学习有意义的舞蹈单元,组成码本库.然后,为了有效提升音乐节拍提取能力,设计节拍特征提取模块,在保证计算效率的同时,注重音乐节拍与舞蹈动作的时序建模.在此基础上,构建节拍门控因果注意力模块,用于音乐信息与上下肢特征之间的信息交互.最后,设计基于Mamba-Transformer的节拍对齐舞蹈生成模块,同时考虑连续的帧间特征和全局信息,融合上下肢及音乐信息,生成符合空间标准和范式的舞蹈动作.在AIST++数据集上的实验表明,BeatDG在有效提升音乐节拍与舞蹈动作对齐程度的同时,可保证生成舞蹈动作的质量.
About Author:
XU Chuanxin, Master student. His research interests include video generation.
DONG Xiaoyun, Master student. Her research interests include human action recognition.
WU Yifan, Master student. His research interests include Labanotation generation.
To address the challenge of simultaneously balancing both dance motion quality and beat alignment in audio-driven dance generation tasks, a beat-aware dance generation model integrating Mamba-Transformer(BeatDG) is proposed. First, an upper and lower limb motion feature encoding network is designed to autonomously learn a codebook of meaningful dance units in an unsupervised manner. Second, a beat feature extraction module is designed to effectively enhance music beat extraction capability. Therefore, the computational efficiency is ensured while the temporal modeling between music beats and dance motions is taken into account. On the basis of the above, a rhythm-gated temporal causal attention module is constructed to facilitate information interaction between music signals and upper and lower limb features. Finally, a hybrid generative architecture based on Dance Mamba and Transformer layers is designed to simultaneously consider continuous inter-frame features and global context. In this architecture, body and music binformation are fused and dance motions bconforming to spatial norms and paradigms are generated. Experiments on the AIST++ dataset demonstrate that BeatDG effectively improves the alignment between music beats and dance motions and ensures the quality of the generated dance.
音频驱动舞蹈视频生成是当前人工智能领域的热门问题之一[1], 对于虚拟人物的刻画和电影行业的发展至关重要.作为跨模态生成领域的核心任务, 旨在以无监督或自适应的方式, 根据输入音乐自动生成在视觉上富有表现力, 同时与音乐节拍精准同步的人体姿态序列[2].然而, 自动生成与音乐节拍精准同步的高质量舞蹈动作仍面临巨大挑战, 需要准确捕捉音乐节拍与舞蹈动作之间的动态时序关系.
近年来, 随着生成模型在文本任务[3]和图像任务[4]上的成功应用, 也被应用于音频驱动舞蹈视频生成领域.当前主流方法主要包括扩散模型[5]和自回归生成网络[6].扩散模型将舞蹈视频生成视为迭代去噪过程, 在音乐特征的指导下, 从无序的噪声状态逐步恢复成有序的舞蹈动作.自回归生成网络将舞蹈生成视为动作预测任务, 根据给定的音乐特征和历史动作, 自回归地预测下一时刻可能出现的舞蹈动作.基于自回归生成网络的舞蹈动作模型善于捕捉长时序依赖关系和动作实时生成, 同时符合舞者的舞蹈动作习惯, 现已成为音频驱动舞蹈视频生成领域的主流范式之一.
目前自回归生成网络在建模音乐与人体姿态间的上下文语义联系时, 通过标准的交叉条件因果注意力机制[7], 捕捉音乐与人体姿态间的局部对应关系.该机制显著提升舞蹈动作生成质量, 但是, 由于未充分利用音乐内部的全局节奏特征, 限制生成舞蹈动作的多样性和节拍对齐效果.为了进一步提高舞蹈生成网络的性能:一方面, 研究人员尝试加入外部约束实现强制对齐.Wang等[8]提出MIDGET(Music Condition 3D Dance Generation), 在生成模型中引入可微节拍损失, 增强音乐节拍和舞蹈动作的对齐程度.Huang等[9]提出Beat-It, 在训练过程中, 设计节拍对齐损失进行显式监督, 确保生成的舞蹈动作与节拍同步.然而, 在生成过程中进行强制约束, 会牺牲舞蹈动作的多样性.另一方面, 有研究者发现对齐精度受提取音乐特征的质量影响.为此, Huang等[10]使用预训练的音乐模型提取与风格和节拍相关的特征, 整合音乐风格信息.Li等[11]提出MERT(Music Understanding Model with Large-Scale Self-Supervised Training), 在掩码语言建模风格的声学预训练中引入教师模型, 提供相应的伪标签, 获得丰富的音乐特征.然而, 上述模型未关注复杂音乐特征中关键节拍信息, 导致节拍信息被掩盖, 从而限制音乐节拍与舞蹈动作的对齐程度.
为此, 本文提出融合Mamba-Transformer的节奏感知舞蹈生成模型(Beat-Aware Dance Generation Model Integrating Mamba-Transformer, BeatDG), 在保证生成舞蹈动作质量的基础上, 提高和音乐节拍的对齐能力.首先, 设计节拍特征提取模块, 从输入的音乐信息中解耦动态的节拍强度, 并作为全局的节奏信号, 指导舞蹈动作生成全过程.然后, 设计节拍门控因果注意力模块, 通过门控机制加强交叉条件因果注意力机制的全局节奏信号, 确保生成的舞蹈序列反映全局节奏信号, 生成具有连贯性和多样化的舞蹈动作.此外, 为了充分利用Mamba网络在连续细粒度的动作依赖建模中的优势, 以及Trans- former网络整合全局上下文信息的能力, 设计基于Mamba-Transformer的节拍对齐舞蹈生成模块, 整合帧间特征和全局整体性结构, 实现高质量的舞蹈动作重建.
音乐驱动舞蹈视频生成任务旨在根据输入音乐自动合成时序连贯的舞蹈动作.由于在数字人、虚拟现实及游戏中的成功应用, 自动生成与音乐节奏对齐的舞蹈动作任务受到广泛关注.
在早期研究中, 为了改善传统舞蹈生成过程需要编舞师手动设计动作序列的局限, Shiratori等[12]采用运动图驱动的方式实现音乐特征与动作特征的自动匹配, 然而生成动作的时空连贯性不足, 导致生成的舞蹈动作不够自然流畅.随后, 研究人员分别尝试通过音乐特征学习子动作间的转移概率[13]和真实动作数据[14], 提高生成舞蹈动作的空间质量和动作连贯性, 但由于真实舞蹈数据有限, 无法生成数据集之外的舞蹈动作.近期, Li等[6]提出FACT(Full-Attention Cross-Modal Transformer), 利用Transformer实现音乐与舞蹈动作之间跨模态时序对应关系, 可通过历史动作预见性地生成未来动作.同时, 为了定量评估音乐节拍与舞蹈动作的对齐程度, 首次提出BeatAlign(Beat Alignment Score), 但是, 在生成过程中, 过早地融合音乐特征与舞蹈动作, 导致音乐节拍与舞蹈动作在时间维度上不能有效同步.进一步地, Li等[7]提出Bailando, 通过强化学习网络设计奖励函数, 优化音乐节拍与舞蹈动作的对齐程度.在Bailando的基础上, Li等[15]提出Bailando++, 引入音乐上下文编码, 使动作GPT(Generative Pre-trained Transformer)能掌握更长期的音乐模式.然而, 强化学习网络在训练过程中不稳定, 训练后期模型会逐渐偏离真实舞蹈姿态, 导致生成舞蹈质量下降.这表明在保证舞蹈动作生成质量的情况下, 提高音乐节拍的对齐程度仍存在提升空间.
指导舞蹈动作生成和节拍对齐的关键是提取音乐内容中的节奏、韵律等关键信息.随着扩散模型的发展, Tseng等[16]提出EDGE(Editable Dance Gene-ration), 设计Jukebox提取全谱和语义特征, 通过扩散交叉注意力机制强化音乐与舞蹈动作的对齐程度.在此基础上, Li等[17]提出Lodge, 通过粗粒度到细粒度的扩散模型网络, 引导从全局结构到局部细节的动作重建.虽然扩散模型表现出色, 但计算复杂度过高, 训练开销过大.基于自回归网络模型, Marchellus等[18]提出M2C(Music-to-Codes), 将音乐分为小节令牌和节拍令牌, 分别捕捉长短时间及高低频率的音乐节奏.Fan等[19]提出Danceba, 设计相位的节奏特征提取模块, 利用节奏感知固有的时间相位信息, 增强舞蹈序列和音乐间的节奏一致性.
人体运动序列建模的发展推动音频驱动舞蹈视频生成任务的研究.Tang等[20]将音乐和舞蹈动作序列分别编码至隐空间, 再进行联合训练, 实现音乐到舞蹈的生成.然而该方法难以捕捉全局编舞模式, 导致潜在空间表现力效果不佳.为此, Zhou等[21]将舞蹈动作序列在音频条件下编码映射至潜在空间后, 解码得到舞蹈动作序列, 但在长序列建模舞蹈动作时难以有效保持动作的一致性和连贯性.
Transformer[22]因为在长序列建模和跨模态关联中优势显著, 有效缓解上述问题, 因此成为音频驱动舞蹈视频领域主流方法之一.Li等[7]提出Bailando, 包含VQ-VAE(Vector Quantized Variational Autoencoder)和Transformer, 基于VQ-VAE分别处理上下肢, 将专业舞蹈动作编码至离散码本, 通过交叉条件因果注意力机制, 保证生成舞蹈动作的空间标准和范式.后续研究者在Bailando的基础上进一步进行网络优化.为了填补文本驱动舞蹈视频生成领域的空白, Gong等[23]提出TM2D(Text-Music to Dance), 基于VQ-VAE将文本匹配的动作和音乐匹配的舞蹈编码共享至码本空间, 码本序列采用Transformer建模, 实现多模态语义控制的舞蹈动作生成.为了解决输入音乐与舞蹈动作风格不匹配的问题, Zhuang等[24]提出GTN-BAILANDO, 把“ 曲风” 作为预训练特征向量, 实现长序列舞蹈风格的一致性.基于VQ-VAE预训练的字典方法可保证生成舞蹈序列的运动质量, 但限制生成舞蹈动作的多样性和模型的泛化性.Transformer在融合多模态信息和接受外部条件引导方面具有潜力, 但对于连续的舞蹈动作建模仍有提升空间.
近年来, 基于Mamba的动作生成网络具有高效的建模能力[25].Motion Mamba[26]作为开创性工作, 表明Mamba网络能生成高质量的运动序列.在此基础上, Zhang等[27]提出InfiniMotion(Infinite Motion Generation), 进一步融合Mamba与Transformer, 利用Mamba网络的状态更新扩展Transformer的上下文感受野, 生成任意长度的连贯动作.此外, Li等[28]提出FTMoMamba, 将Mamba网络应用于文本生成动作任务, 展示其在对齐文本与动作信息上的潜力.Qian等[29]提出SMCD(Style Motion Conditioned Di-ffusion), 结合Mamba网络与扩散模型, 使用Mamba网络作为去噪网络的高效主干, 生成连贯的风格化动作序列.
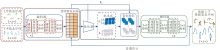
为了实现音乐节奏与舞蹈动作的时序对齐, 同时保证生成舞蹈动作的质量, 本文提出融合Mamba-Transformer的节奏感知舞蹈生成模型(BeatDG), 整体架构如图1所示.BeatDG由上下肢动作特征编码网络和节奏感知舞蹈生成网络组成, 旨在协同解决舞蹈生成的空间合理性和时序一致性问题.在第一阶段中, 使用上下肢动作特征编码网络, 学习符合人体动力学约束与舞蹈姿态的离散码本单元, 并存储在码本库中.第二阶段工作基于节奏感知舞蹈生成网络展开, 核心内容是根据处理后的音乐特征和码本库中预设的一段起始码本, 融合Mamba-Transformer, 自回归地编排和预测后续所有与音乐信息精准同步的舞蹈序列.最终, 基于卷积神经网络的上下肢动作特征解码器将连续的量化特征重建为符合舞蹈标准和空间范式的动作序列, 完成整个舞蹈动作的编排任务, 实现音频自动驱动舞蹈视频生成.
 | 图1 BeatDG整体架构Fig.1 Overall architecture of BeatDG |
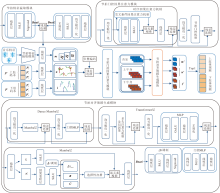
编舞过程可看作是对不同动作之间的排列组合.为了学习不同码本序列, 扩大码本库, 将上下肢动作特征编码网络作为第一阶段网络, 结构如图2所示.
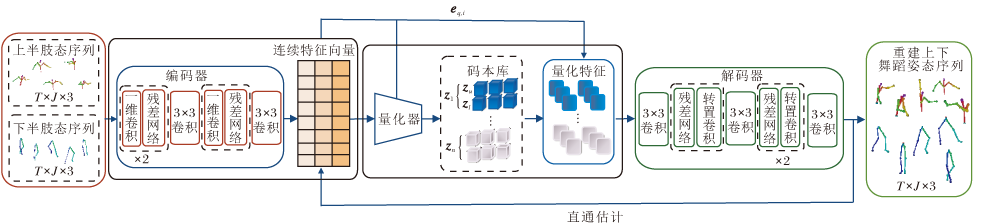 | 图2 上下肢动作特征编码网络结构图Fig.2 Architecture of upper and lower limb motion feature encoding network |
对上下肢分别应用特征编码器, 学习符合舞蹈空间标准和范式的舞蹈动作, 为后续的节奏感知舞蹈生成网络提供丰富的舞蹈姿态码本序列.
上下肢动作特征编码器由编码器、量化器和解码器构成.输入任意一段舞蹈动作均可表示为P∈ RT× (J× 3), 其中, T表示时间长度, J表示关节数.编码器首先将输入的三维姿态序列通过3× 3卷积进行特征提取, 残差块加深网络深度、扩大模型的感受野, 从而有效提取符合空间标准和范式的舞蹈姿态, 输出为连续的特征向量eq∈ RT'× C, 其中, T'=T/d, d表示时间下采样率, C表示通道维度.量化器作为上下肢动作特征编码器的核心部分, 旨在维护可学习的码本z={z1, …, zk, …, zn}, z包含上肢码本zu和下肢码本zl.本文使用最邻近量化方法更新码本库中的码本单元, 计算编码器输出ei和所有码本zj的距离, 并选择最小码本向量索引zk, 则第i个时间步的量化特征向量:
eq, i=arg
由于量化操作不可导, 编码器无法通过梯度下降进行训练, 因此在反向传播阶段, 设计直通估计, 跳过不可导的量化层, 将解码器得到的关于eq, i的梯度直接传递给编码器的输出ei, 即
使用嵌入查找函数, 通过索引从码本中提取对应的连续量化特征.最后解码器通过转置卷积操作进行上采样, 从历史码本中重建相应舞蹈姿势序列
上下肢动作特征编码网络通过学习有意义且高质量的离散表示, 为舞蹈生成提供符合空间标准和范式的码本单元, 保证生成的舞蹈动作符合人体动力学约束.
为了有效建模音乐与舞蹈序列的时序对齐关系, 提高音乐节奏与舞蹈动作之间的上下文语义关联, 设计节奏感知舞蹈生成网络, 结构如图3所示.该网络旨在解决传统模型在生成舞蹈动作过程中无法有效对齐节拍的问题.
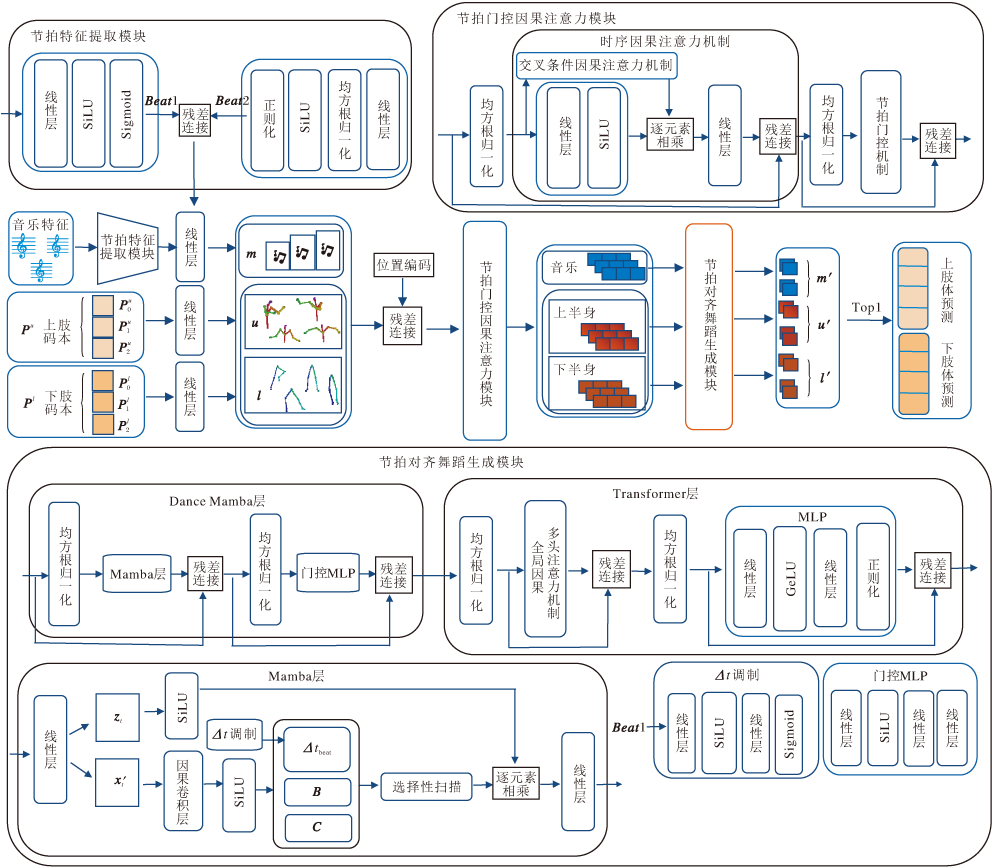 | 图3 节奏感知舞蹈生成网络结构图Fig.3 Architecture of rhythm-aware dance generation network |
节奏感知舞蹈生成网络主要包括节拍特征提取模块、节拍门控因果注意力模块和节拍对齐舞蹈生成模块.音乐是贯穿舞蹈生成全过程的重要元素, 节拍特征提取模块负责从音乐中提取精确的节奏信息.然后, 节拍门控因果注意力模块对音乐、上下肢进行全局上下文信息融合.进一步地, 节拍对齐舞蹈生成模块利用Dance Mamba与Transformer的混合架构, 自回归地生成高质量且与音乐节拍同步的舞蹈序列.
2.2.1 节拍特征提取模块
为了克服传统方法依赖手工处理信号或通用音频特征的局限性, 本文设计节拍特征提取模块, 旨在通过端到端的可学习方式, 从原始音乐信号中自适应解耦并提取音乐特征, 动态捕捉音乐节拍信息.该模块采用双分支并行结构, 接收原始音乐特征m∈ RT× 438作为输入, 分别提取音乐的节奏强度与内容特征, 其中, T表示时间步长, 438表示每帧的特征维度.
节拍强度分支的核心任务是直接从复杂的信号中学习并识别节拍的动态模式.该分支采用轻量级的多层感知机(Multilayer Perceptron, MLP), 直接处理输入音乐特征m.与需要预定义的相位计算方法不同, 该MLP通过非线性变换自动捕捉与节拍相关的特征, 最终通过激活函数, 输出范围在[0, 1]内的节拍强度:
Beat 1=Sigmoid(SiLU(linear(m)))∈ RT× 1,
其中, SiLU(· )表示激活函数, linear(· )表示全连接层, Sigmoid(· )表示每个时间步下音乐节拍出现的概率, 将输出限制在[0, 1]区间.Beat 1的大小直观反映每个时间步的节拍强弱, 峰值位置对应音乐中的重拍或关键节奏点.
音乐特征编码分支旨在将原始音乐特征m通过线性层和非线性激活函数, 映射并增强与模型维度匹配的深层语义特征表示, 提取音乐的主要内容信息, 如旋律、和声等.编码后输出的音乐特征为:
Beat 2= Drop(SiLU(RMSNorm(linear(m))))∈ RT× d,
其中, Drop(· )表示正则化操作, RMSNorm(· )表示均方根归一化.
最终, 节拍强度作为动态门控信号, 对音乐特征Beat 2进行加权调制.这种门控机制使得在音乐节拍显著位置上增强音乐内容特征, 而在节奏平缓处相应减弱音乐内容特征.
通过上述方式, 得到增强的音乐特征:
Beat=Beat 1☉Beat 2∈ RT× d,
其中☉表示逐元素乘积.同时, 提取的节拍强度信号Beat 1也将作为关键的外部条件, 在后续的Dance Mamba层中动态调整时间步长参数, 从而在更深层次上实现音乐节奏与舞蹈动作的耦合.
2.2.2 节拍门控因果注意力模块
节拍门控因果注意力模块旨在有效建模音乐与舞蹈姿态的上下文语义联系, 其中时序因果注意力机制负责增强全局节奏建模, 节拍门控机制引入外部节奏信号和可学习的调节参数, 使门控信号随节奏实时变化, 强化音乐节拍与舞蹈动作的对齐程度.
传统交叉条件因果注意力机制在进行舞蹈动作与音乐对齐时, 只注重局部音乐而忽视全局节奏信息, 缺乏对外部上下文信息的适应性.时序因果注意力机制在传统因果注意力机制的基础上引入线性层和非线性激活函数, 生成动态门控信号, 筛选关键的全局时序特征.
在时间维度上拼接节奏感增强的音乐特征Beat与上下肢的动作嵌入u、l, 并融入位置编码, 形成融合特征作为时序因果注意力机制的输入.然后, 交叉条件因果注意力机制(Cross-Feature Causal Attention, CFCA)负责捕捉音乐、上肢和下肢之间的基本时序依赖关系, 通过计算查询(Q)、键(K)和值(V)的注意力权重, 建立特征间的关联:
$ C F C A\left(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}, \boldsymbol{M}_{\mathrm{mask}}\right)=\operatorname{softmax}\left(\frac{\boldsymbol{Q} \boldsymbol{K}^{\mathrm{T}}+\boldsymbol{M}_{\mathrm{mask}}}{\sqrt{C}} \boldsymbol{V}\right), $
其中, 因果掩码Mmask为3× 3重复矩阵块, 确保推理过程只传递历史信息, 同时保证不同模态间的有效交互.
节拍门控机制的输入为节奏r, r融合节拍特征提取模块获取的特征节拍强度Beat 1和原始音乐特征.通过线性变换和激活函数生成可自学习调整的门控信号, 适配不同的音乐节奏.
最终, 将时序因果注意力机制得到的输出和节拍门控机制得到的门控信号通过残差连接进行融合, 实现全局时序依赖建模以及节奏与舞蹈动作的动态融合.
2.2.3 节拍对齐舞蹈生成模块
舞蹈作为复杂的时空序列, 生成模型需要同时具备精细化的帧与帧之间的建模能力和全局依赖捕捉能力.为了协同完成舞蹈动作生成任务, 本文设计基于Mamba-Transformer的节拍对齐舞蹈生成模块, 包括Dance Mamba层和Transformer层.
输入经节拍门控因果注意力模块处理后增强的音乐特征和上下肢特征, 经Dance Mamba层处理上下肢与音乐的连续帧之间的信息交互, 完成短时序内舞蹈动作细节的建模.Dance Mamba层的核心是选择性状态扫描机制, 核心的循环更新过程在Mamba层中实现.首先通过线性投影将输入特征分解为两部分:用于状态更新的x't和用于输出门控的zt.x't首先经过因果卷积层捕捉局部上下文.模型根据处理后的x't动态生成选择性参数, 包括离散化时间步长Δ tbeat、输入投影矩阵B和输出投影矩阵C.隐藏状态的更新过程遵循状态空间模型(State Space Model, SSM)的离散化形式.当前t时刻的隐藏状态为:
ht=
其中,
为了使音乐节拍能有效指导Dance Mamba层的运动建模过程, 进一步设计节拍感知的调制机制Δ t, 将节拍强度信号作为外部条件, 动态调整Dance Mamba层中的离散化步长:
Δ tbeat=Δ tbase☉Δ tscale☉Δ tmod.
其中:Δ tbase表示Dance Mamba层原始基础时间步长; Δ tscale表示可学习的全局缩放因子, 初始化设置为1× 10-6;
Δ tmod=0.5+Sigmoid(MLP(Beat 1)),
表示调制因子, MLP(· )表示多层感知机.Δ tmod促使模型在该处产生更显著的状态变化.
隐藏状态ht经过动态投影矩阵Ct投影后, 再与门控信号zt的激活函数相乘, 得到Dance Mamba层输出:
xMamba=SiLU(zt)☉(Ct· ht).
最后在每个Mamba层的输出端添加门控残差连接, 使模型能自适应筛选由Mamba层提取的特征, 增强动作的协调性, 同时抑制潜在干扰.通过上述方式, 音乐节奏被直接输入Mamba层的核心状态转移过程中, 最终输出在连续帧之间流畅且与节拍精准对齐的特征.
Dance Mamba层具有高效的长程依赖建模能力, 但本质上仍是一种循环机制, 善于捕捉存在连续因果关系的时序动态.然而, 舞蹈编排除了包含流畅的动作以外, 更涉及高层次、非连续的结构性关联, 如音乐鼓点对应特定动作、主歌与副歌的节拍具有重复性等.为了精准捕捉这类全局信息, 在Dance Mamba层后引入Transformer层, 负责全局一致性优化.Transformer网络中的自注意力机制允许序列中任意两个时间步进行信息交互, 弥补Mamba网络在结构性长程依赖上的不足.
Transformer层将经过Mamba层处理的上下肢特征与原始的音乐特征沿序列维度拼接, 形成一个包含连续动态信息的融合序列x'mb.再将全局因果多头注意力机制(Global Causal Multi-head Attention, GCMHA)作用于该拼接序列上, 捕捉动作序列在全局范围内的一致性和协调性, 相应Transformer层内残差连接输出特征为:
x'attn=GCMHA(RMSNorm(x'mb))+x'mb.
最终, 通过非线性变换, 实现生成舞蹈动作的整体协调性和连贯性, 得到输出特征:
xTransformer=MLP(RMSNorm(x'attn))+x'attn.
2.3.1 上下肢动作特征编码网络损失函数
上下肢动作特征编码网络损失函数由3部分组成:重构损失函数(Reconstruction Loss)LREC、码本损失函数(Codebook Loss)LCB和承诺损失函数(Commitment Loss)LPRO, 即
L=LREC+LCB+β LPRO,
其中β 表示权重系数.
重构损失函数LREC衡量解码器解码后重建的三维舞蹈姿势序列和原始姿势序列之间的差异.分别考虑三维坐标位置、速度、加速度, 定义的重构损失函数计算公式如下:
LREC=‖
其中,
码本损失函数LCB和承诺损失函数LPRO衡量编码后的特征和量化后特征之间的差异.码本损失函数LCB使用直通估计器, 将解码器的梯度直接传递至编码器, 从而使码本向量靠近编码器输出, 计算公式如下:
LCB=‖ sq[e]-eq‖ 2,
其中, sg[· ]表示停止梯度, 停止梯度最邻近矢量eq作为矢量量化约束.
承诺损失函数LPRO促使编码器的输出靠近被选中的码本向量, 从而防止编码器输出无序变化, 使编码器输出特征和解码器输入特征之间的距离尽可能接近, 计算公式如下:
LPRO=‖ e-sg[eq]‖ 2,
其中停止梯度最邻近矢量eq作为矢量量化约束.上下肢动作特征编码网络损失函数用于优化和训练上下肢动作特征编码网络, 从而有效学习符合空间标准规则和范式的舞蹈动作, 确保模型可根据动作单元指导生成有意义的舞蹈动作, 完成舞蹈编排.
2.3.2 节奏感知舞蹈生成网络损失函数
在设计的Transformer层中, 为了优化生成动作概率分布和真实动作标签之间的差异, 引入交叉熵损失.Transformer层的输出是舞蹈动作的概率分布预测, 无法直接反映生成舞蹈动作的质量程度.为此, 将Dance Mamba层处理后的特征作为Transfor-mer层的输入.首先分别对所有时间步t从1到T'求和, 评估整个舞蹈序列中每个时间步的预测.然后对上下肢动作特征编码网络输出的上半身u和下半身l分别求和, 同时考虑上半身和下半身的动作预测.最后通过交叉熵损失衡量每个时间步t和身体部分b, 计算预测的概率分布
$ L_{\mathrm{CE}}=\frac{1}{T^{\prime}} \sum_{t=1} \sum_{b=u, l}\left\|\boldsymbol{p}_{t}^{b}-\boldsymbol{a}_{t}^{b}\right\|_{2} .$
通过最小化交叉熵损失训练Transformer层, 使模型能准确预测未来时间步的动作标签.在训练过程中, 模型会根据交叉熵损失函数自动调整参数, 提升预测的准确性.
本文选择在AIST++数据集上进行实验.AIST++数据集是在AIST Dance Database数据集的基础上构建的大规模舞蹈数据集, 包含10种不同风格的舞蹈.共邀请30名舞者参与数据采集, 涵盖1 408个舞蹈序列, 总长达到5.2 h.此外, 数据集包含的舞蹈序列有对应的音乐匹配, 每个舞蹈持续时间从7.4 s~48.0 s不等, 这为研究音乐驱动舞蹈视频生成提供丰富的素材.在实验中, 使用992个SMPL格式, 三维姿势序列为60帧/秒, 训练集包含952个位姿序列, 测试集包含40个位姿序列, 对生成舞蹈序列进行采样, 采样长度为20 s, 用于性能评估.
实验中上下肢动作特征编码网络中的承诺损失函数权重β 设为0.02, 重建损失函数中的速度、加速度权重均设为1.上下半肢码本大小N设为512, 编码器的特征通道数设为512, 时间下采样d设为8.在将音乐送入BeatDG之前, 使用Librosa工具箱提取音乐特征, 包含梅尔森倒谱系数、连续梅尔森倒谱系数的变化率、常数Q色图、高音图、起始强度五种音乐特征, 拼接成特征维度为438维的特征向量序列, 作为节拍特征提取模块的输入.
在节奏感知舞蹈生成网络中, 将音乐特征维度通过嵌入层映射至768维, 通过时间下采样, 将音乐特征长度压缩为30, 截断处理后长度变为29, 从而确保音乐特征和舞蹈向量在时间步长上匹配.
Transformer层的注意力头数为12, 基础模块和头部模块各包含6层, 总计12个核心处理层.
在ubuntu20.04操作系统上使用NVIDIA RTX3090 GPU, 基于Pytorch深度学习框架训练该模型, 使用Adam(Adaptive Moment Estimation)优化器优化网络.上下肢动作特征编码网络的学习率设为3× 10-5, 训练周期设为500轮次, 批量大小设为32.为了更好地学习舞蹈特征, 上下肢动作特征编码网络分别在第100轮次和第200轮次将学习率降至原来的0.1.在Dance Mamba层和Transformer层中, 学习率设为3× 10-4.
为了验证舞蹈动作的生成质量及音乐节拍与舞蹈动作的对齐程度, 引入如下5个评价指标.
1)FIDk、FIDg.分别从运动学特征和几何学特征评估生成舞蹈动作的质量.运动学特征基于运动速度和能量, 反映舞蹈的物理特征.几何学特征基于多种人为定义的动作模板, 反映编排舞蹈的质量.
2)DIVk、DIVg.分别从运动学特征和几何学特征评估生成舞蹈动作的多样性, 通过计算生成运动序列的平均特征距离进行衡量.运动学特征主要关注舞蹈动作的速度、加速度等动力学信息及变化的丰富程度.几何学特征主要关注舞蹈动作的姿势、形状的多样性.
3)音乐节拍对齐分数(Beat Alignment Score, BAS).评估音乐节拍与舞蹈动作的对齐程度, 计算音乐节拍与舞蹈动作最近节拍之间的平均时间距离延迟, 计算公式如下:
$B A S=\frac{1}{\left|B^{m}\right|} \sum_{t^{m} \in B^{m}} \exp \left(\frac{\min _{\forall d^{d} \in B^{d}}\left\|t^{d}-t^{m}\right\|_{2}}{2 \sigma^{2}}\right), $
其中, td表示舞蹈动作节拍发生的时间点, tm表示音乐节拍发生的时间点, Bd记录舞蹈中节拍时间, Bm记音乐中节拍时间, $ \exp \left(\frac{\min _{\forall t^{d} \in B^{d}}\left\|t^{d}-t^{m}\right\|_{2}}{2 \sigma^{2}}\right)$表示高斯加权距离, σ 表示归一化参数, 实验中设为3.BAS值越接近1, 表示对齐效果越理想.
实验选择如下对比模型:E3D2(Exploratory 3D Dance Generation Framework)[1]、FACT[6]、Bailando[7]、MIDGET[8]、Bailando++[15]、EDGE[16]、Lodge[17]、Danceba[19]、acRNN(Auto-Conditioned Recurrent Neural Network)[30]、DanceNet[31].各模型在AIST++测试集上的指标值对比如表1所示, 表中黑体数字表示最优值, Ground Truth表示真实世界舞蹈动作的理想标准.
由表1可见, BeatDG的FIDk指标值仅次于Danceba, DIVk、DIVg、BAS指标都为最优值.DIVk指标比次优的MIDGET提升0.34%, DIVg指标比次优的Danceba提升23.42%, BAS指标比次优的Danceba提升29.43%.这表明BeatDG在追求节拍对齐的同时, 可生成丰富的舞蹈序列.BeatDG的FID系列指标未达到最优值, 主要原因是在训练过程中通过显式节拍信号的调制, 可提升音乐节拍与舞蹈动作的对齐程度以及生成舞蹈动作的变化幅度, 使生成动作的运动学和几何分布相比测试集统计存在偏移.BeatDG的FIDk指标为18.16, 优于Bailando和Bailando++等主流自回归方法, 并与Ground Truth(17.10)基本持平, 这表明BeatDG生成动作的运动学特征分布得到有效改进.然而, FIDg指标由于对全局几何分布更敏感, 当模型生成肢体幅度较大和动作多样化的舞蹈动作编排时, 分布偏移会被放大, 导致FIDg值略高.从整体结果来看, BeatDG在AIST++测试集上表现较优.
| 表1 各模型在AIST++测试集上的指标值对比 Table 1 Metric value comparison of different models on AIST++ test set |
为了验证BeatDG中各模块的有效性, 在AIST++数据集上使用控制变量法进行消融实验, 结果如表2所示.
| 表2 各模块消融实验结果 Table 2 Ablation experiment results of different modules |
由表2可见, 移除Transformer层后, FIDk、FIDg指标明显提升, FIDk提升83.89%, FIDg提升82.21%, 这说明尽管Dance Mamba层擅长处理长程时序依赖, 但Transformer层的自注意力机制在高层次的全局信息整合与结构编排上仍具有不可替代的作用.它不仅确保生成的舞蹈在帧间是流畅的, 更在宏观上具有统一的风格和与音乐结构匹配的编排逻辑.移除Dance Mamba层之后, FIDk和FIDg指标明显提升, FIDk提升89.99%, FIDg提升34.24%, 这表明Dance Mamba层以其线性计算效率和强大的时序建模能力, 高效捕捉连续帧之间的精细运动细节(如姿态的平滑过渡、肢体间的微小协调).如果缺少Dance Mamba层对帧间动态的精细化处理, 仅靠Transformer层将难以生成足够自然流畅的动作.移除节拍门控因果注意力模块之后, FIDk、FIDg指标明显提升, FIDk提升53.40%, FIDg提升30.73%, DIVk指标下降28.83%.这表明节拍门控因果注意力模块对跨模态信息进行初步融合与筛选的重要性.此外, 为了充分建模音乐与舞蹈动作之间的语义联系, 使生成舞蹈动作与音乐节拍在时间维度上对齐, 设计的节拍特征提取模块可有效提升对齐精度, 移除之后, BAS指标由原来的0.384 6降至0.343 0, 下降10.81%, 表明节拍特征提取模块可提升音乐节拍与舞蹈动作的对齐程度.
为了说明BeatDG的效率, 选择如下指标:参数量、推理时间、峰值显存占用.分别移除Transformer层和Dance Mamba层后对BeatDG推理效率的影响如表3所示.
| 表3 消融不同模块后模型的推理效率对比 Table3 Inference efficiency of BeatDG with different modules ablated |
由表3可见, 移除Transformer层之后, 参数量和推理效率与BeatDG几乎相同.移除Dance Mamba层之后, 因参数量变小, 推理速度变快, 然而舞蹈动作质量严重下降.相比w/o Transformer层, BeatDG在几乎相同的计算开销下, 生成舞蹈动作质量和丰富度得到显著提升.相比w/o Dance Mamba层, BeatDG以增加参数量和降低推理速度换取舞蹈动作质量的提升.
3.6.1 码本单元的可视化分析
上下肢动作特征解码器以无监督形式学习的舞蹈单元被总结为潜在代码.为清楚了解学习得到舞蹈单元的姿态形式, 将潜在代码进行可视化, 如图4所示.
 | 图4 上下肢动作特征解码器码本单元可视化结果Fig.4 Visualization of codebook units in upper and lower limb feature decoder |
图4(a)中人体姿态为两手臂伸直, 双腿成交叉状态.(b)中人体姿态为两手臂向下延展, 双腿交叉微微向侧面呈下蹲姿态.(c)展示从(a)过渡到(b)的人体姿态, 两手臂由伸直平滑向下延展, 双腿由正面交叉平滑转向侧面, 并微微弯曲下蹲.这说明任意两个代码的组合可表示流畅的动作, 由此表明网络学习的码本单元对应的舞蹈姿态序列符合空间标准和范式.
3.6.2 生成舞蹈动作质量的可视化分析
为了研究生成舞蹈的质量、多样性和表现力, 进行可视化分析, 同一段音乐驱动下Bailando和BeatDG的舞蹈生成效果如图5所示.由图可见, 在同一段音乐下, BeatDG未因追求精准卡点而陷入局部最优的最小化动作.从music2可见, 相比Bailando的单一动作, BeatDG包含更丰富的身体扭转、重心变化和四肢的协同运动.
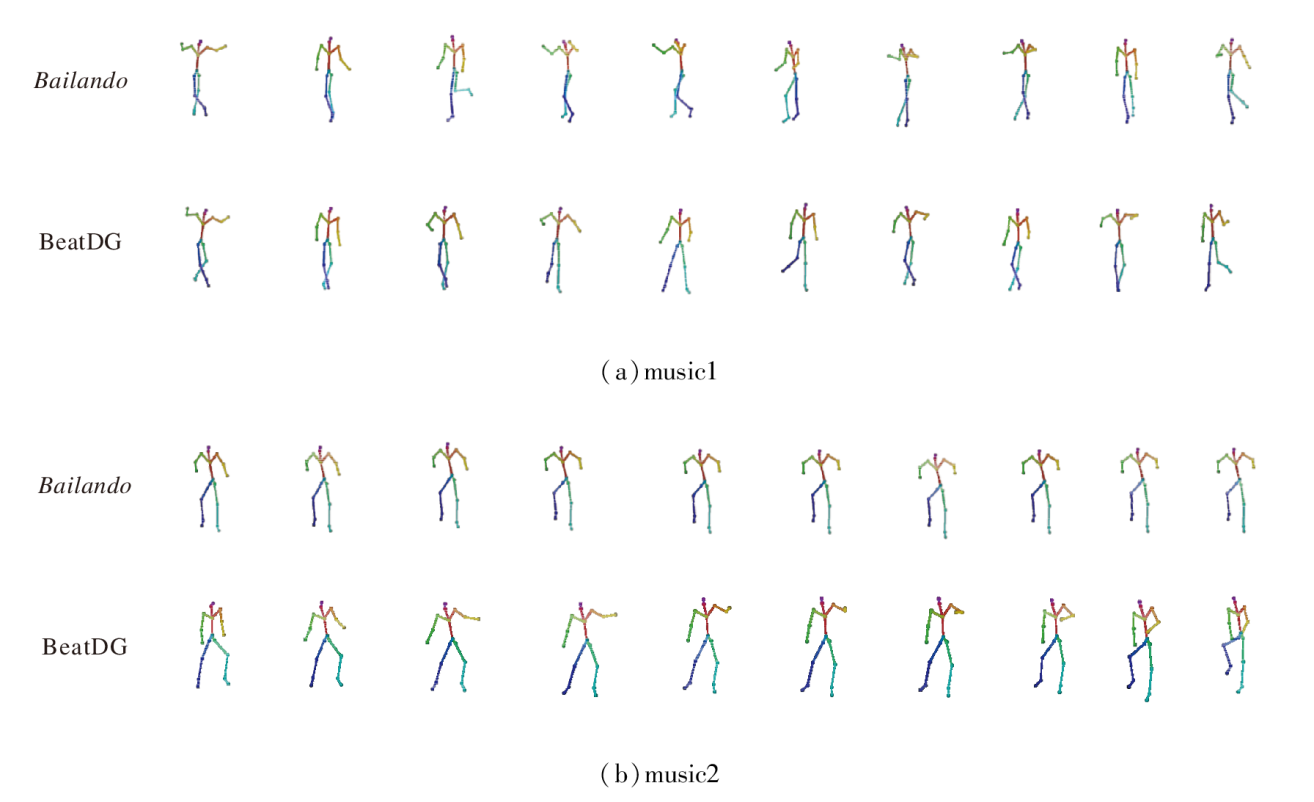 | 图5 同一音乐驱动下的舞蹈生成效果对比Fig.5 Comparison of dance generation results driven by same music sequence |
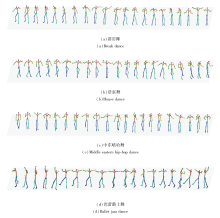
为了直观展示BeatDG的有效性, 在AIST++数据集上进行训练, 输入不同类型音乐, 对生成舞蹈视频进行人体骨骼点的可视化, 得到生成的各类别舞蹈动作的视频帧, 如图6所示.由图可见, 针对不同音乐类型可生成丰富度较高的舞蹈动作, 表明BeatDG可保证生成舞蹈动作的质量和丰富程度.
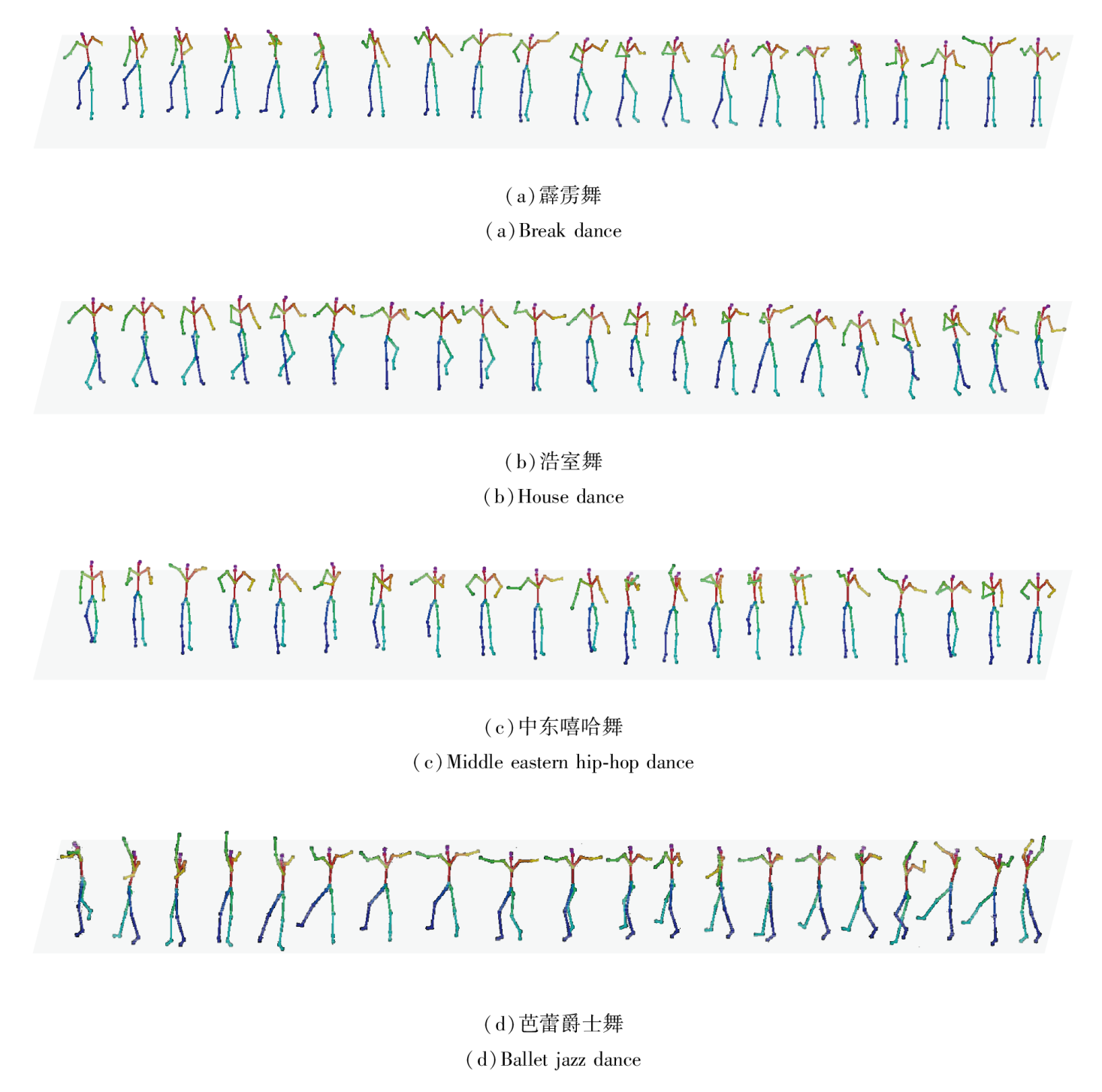 | 图6 基于不同舞种生成的动作序列可视化结果Fig.6 Visualization results of generated dance sequences for different dance genres |
为了评估生成舞蹈动作的质量, 对Bailando和BeatDG的关节损失进行热力图可视化, 结果如图7所示.
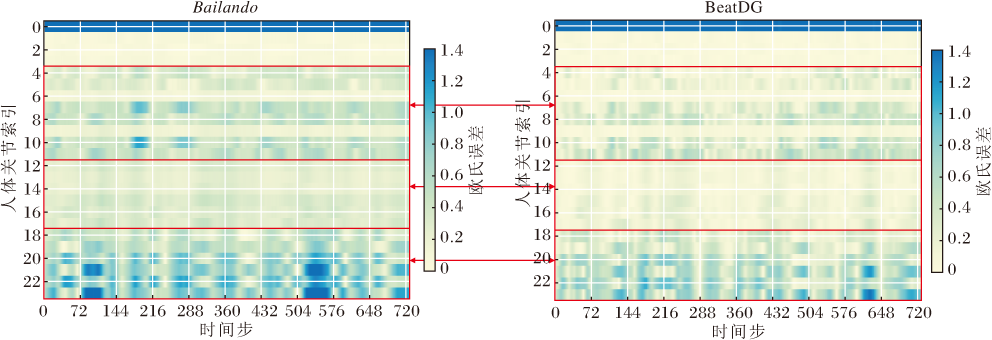 | 图7 Bailando与BeatDG热力图对比Fig.7 Visual heatmaps of Bailando and BeatDG |
两幅图像展示在关节维度和时间维度上, 生成舞蹈动作的关节位置与真实舞蹈关节位置之间的欧氏误差.图中以颜色深浅体现误差大小, 浅黄色表示欧氏误差较小, 接近0.2, 深蓝色表示欧氏误差较大, 接近1.4.对比两图的颜色分布和误差量化可清楚看出, BeatDG在舞蹈生成任务中对关节位置的估计精度更高.
3.6.3 节拍对齐效果的定性分析
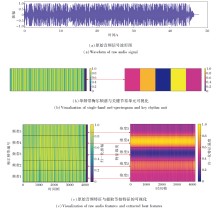
音乐信号波形与频谱特征生成图如图8所示, (a)表示原始音频信号的振幅随时间变化的波形, (b)表示一个频带下的梅尔森谱和关键节奏单元的可视化, (c)展示从原始音频特征到节拍特征提取模块特征提取的可视化结果, 颜色深浅表示对应频带的能量大小.在0~500时间帧内, (c)左图中原始梅尔森频谱可视化的前5个频带从特征维度上呈现密集且无规律的纹理, 表明有效的音乐节奏信息受噪声干扰, 难以直接反映音乐的节拍信息, 因此无法有效指导舞蹈视频生成.
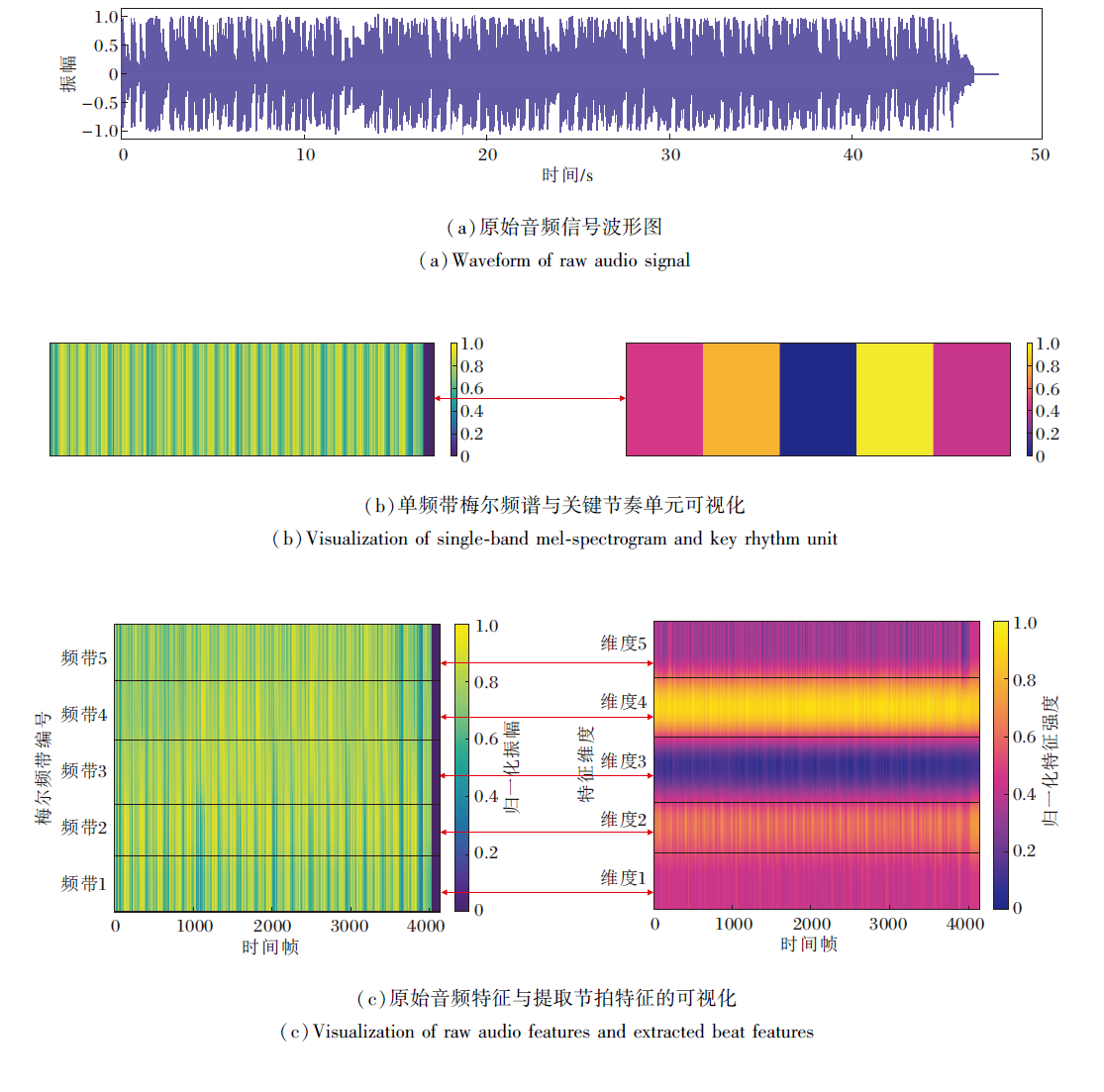 | 图8 音乐信号波形与频谱特征生成图Fig.8 Generation diagram of music signal waveform and spectral features |
相比原始特征频谱, (c)右图中由节拍特征提取模块提取的音乐特征前5个频带能量集中, 音乐节奏呈周期性变化, 表明模型可去除冗余噪声信息, 提取的特征聚焦音乐节拍, 为舞蹈生成提供更具有表达力的音乐节拍指导.
为了验证本文设计的节拍特征提取模块的有效性, 对音乐节拍和舞蹈动作节拍对齐效果进行可视化, 结果如图9所示, 绿色虚线与粉色虚线重叠度越高表明对齐结果越精准.由图可见, 音乐节拍与舞蹈动作的重合度较高, 表明BeatDG生成的舞蹈动作可有效卡点音乐节拍.
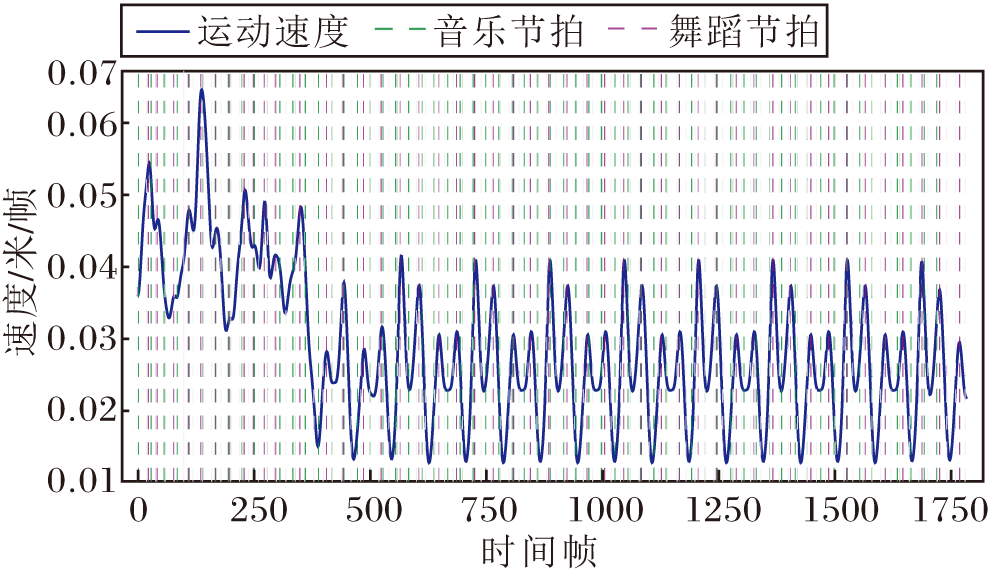 | 图9 音乐节拍与舞蹈动作节拍可视化结果Fig.9 Visual result of music beats and dance motion |
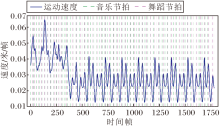
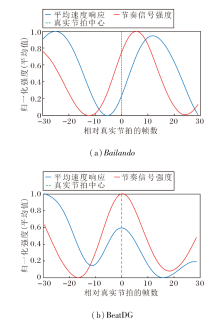
Bailando和BeatDG获取的音乐节拍可视化结果如图10所示, 图中横轴中0表示所有真实音乐节拍的位置, 负值区表示节拍发生前的帧, 正值区表示节拍发生后的帧, 纵轴表示动作速度在当前时刻的相对强弱, 蓝线表示生成舞蹈动作的平均速度响应, 波峰表示动作力度最大或速度最快的瞬间, 也是舞蹈的卡点时刻, 橙线表示模型节奏信号强度.由图可见, Bailando具有相位失配现象, 动作严重滞后, 橙线的峰值出现在第5帧, 蓝线的峰值在第12帧, 相比真实节拍位置滞后12帧, 相比Bailando提取的节拍信息延后7帧.由此说明仅依靠强化学习的奖励函数进行微调, 虽能增强动作幅度, 但难以捕捉精准的时序对齐.
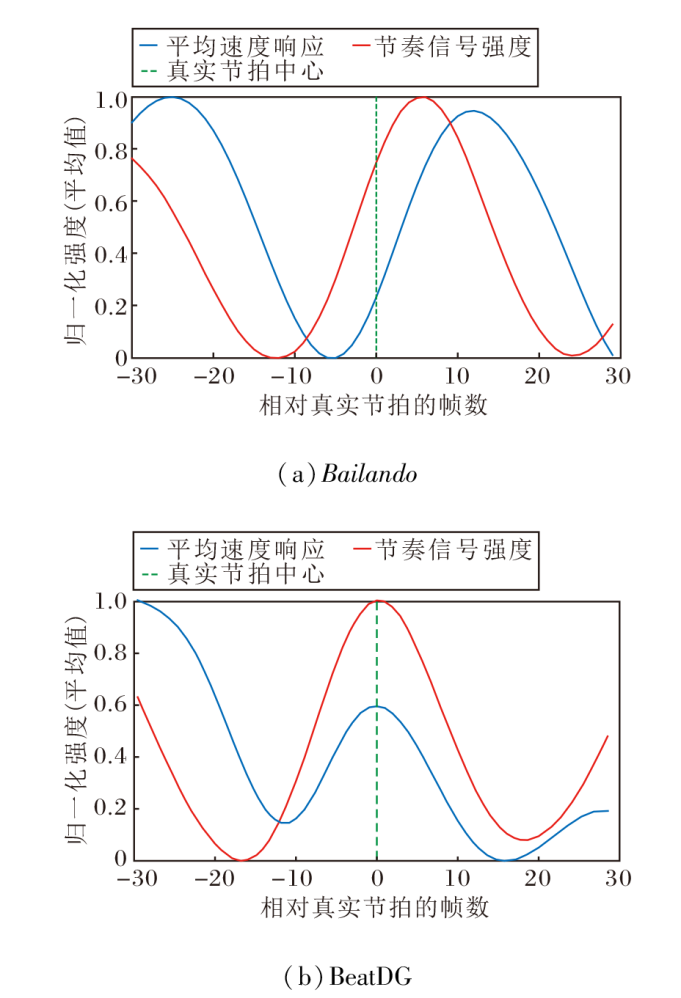 | 图10 不同节奏信号与平均速度响应的可视化结果Fig.10 Visual result of signals of different rhythms and average action responses |
相比Bailando, BeatDG中橙线的峰值几乎重合于真实节拍位置, 表明节拍特征提取模块能精准地从音乐特征中解耦节奏信号, 无任何相位偏移.
3.7.1 节拍特征提取模块的有效性分析
为了验证节拍特征提取模块的有效性, 分别将该模块替换为简单的线性映射(Linear Mapping, LM)、相位特征提取模块(Phase-Based Rhythm Feature Extraction, PRE)、w/o Δ t进行对比, 相应指标值如表4所示.
| 表4 节拍特征提取模块的消融实验结果 Table 4 Ablation experiment results of beat feature extraction module |
由表4可见, 节拍特征提取模块的BAS值为0.384 6, 优于LM的0.373 0和PRE的0.381 8, 表明该模块通过自适应的方式从原始音乐信号中学习节拍特征, 可获得更精确的节奏信息以引导舞蹈生成.此外, 移除调制机制Δ t后, 节拍特征提取模块的BAS值下降为0.379 1, 进一步表明将提取的节拍信号深度融入Mamba核心状态转移机制的有效性.
3.7.2 生成舞蹈动作的流畅度分析
本文引入加速度(Jerk)衡量动作自然流畅度.Jerk是加速度对时间的变化率, 能有效量化运动的平滑度.Jerk值越低, 动作越流畅, 反之表示动作机械卡点.在AIST++测试集上, 对真实值(Ground Truth)、Bailando及BeatDG生成的舞蹈进行Jerk值计算, 相应值为5.336 926, 5.478 802, 5.412 931.
Ground Truth是由AIST++数据集计算得到的真实标准, 由Jerk值可看出, BeatDG在流畅度上更接近人类真实状态.相比Ground Truth, Bailando的Jerk值高出约2.6%, BeatDG的Jerk值提升约1.4%.因此在运动平滑度和自然度上, BeatDG比Bailando更接近于真实舞者.
3.7.3 参数敏感性分析
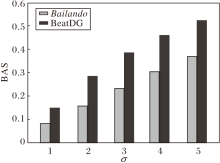
在BAS计算公式中, σ 表示高斯核函数的标准差.BAS的核心思想是计算每个音乐节拍与其最接近的舞蹈动作节拍之间的距离, 通过指数衰减函数惩罚两者之间的距离, σ 值越小, 表示惩罚越严格.在评估阶段, 定义σ =1, 2, 3, 4, 5, 计算Bailando和BeatDG的BAS指标, 结果如图11所示.由图可见, BeatDG在不同σ 下的BAS值均优于Bailando, 证实其有效性.为了确保与Bailando公平对比, 实验严格遵循AIST++数据集官方推荐的基准设置, 将BAS计算公式中的标准差参数设为3.
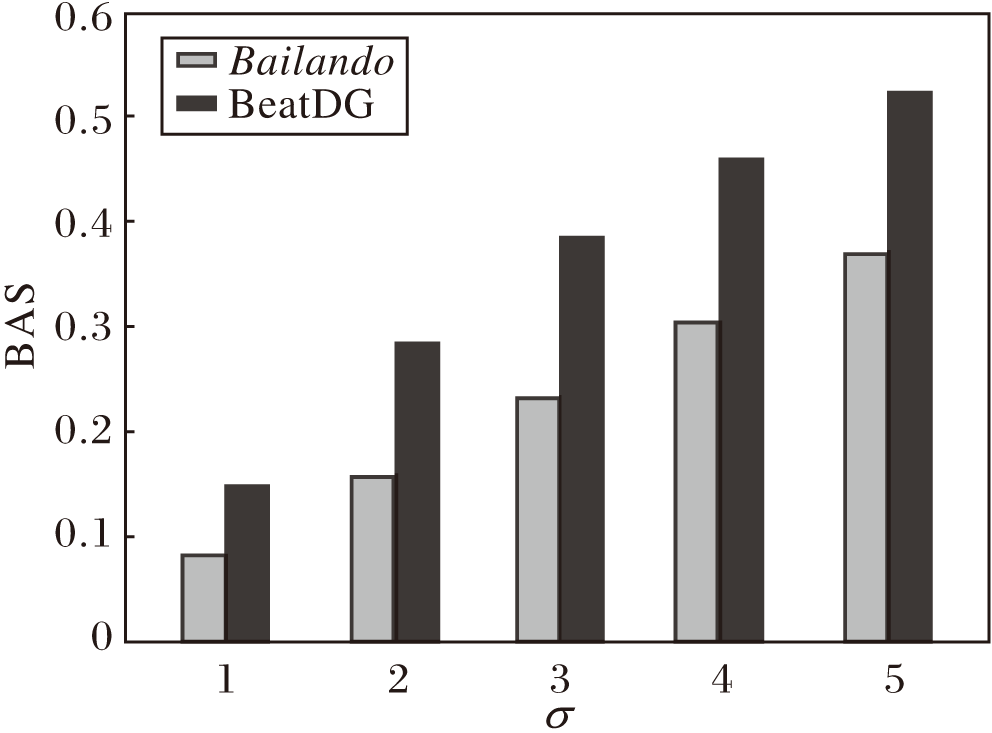 | 图11 σ 对Bailando和BeatDG性能的影响Fig.11 Effect of σ on the performance of Bailando and BeatDG |
为了解决音乐驱动舞蹈视频生成任务中音乐节拍与舞蹈动作无法有效对齐及生成的舞蹈动作不符合空间标准和范式的问题, 本文提出融合Mamba-Transformer的节奏感知舞蹈生成模型(BeatDG), 用于音频自动化驱动舞蹈视频生成.首先, 引入节拍特征提取模块, 以端到端的方式, 从原始音频中自适应解耦并提取具有高优先级的动态节拍信号.然后, 构建节拍门控因果注意力模块, 初步建模音乐与舞蹈姿态的上下文语义联系.设计基于Mamba-Transformer的节拍对齐舞蹈生成模块, 分别处理连续帧之间的信息和全局范围内的舞蹈编排.最后, 设计节拍感知调节机制Δ t, 将提取的节拍信号融入Dance Mamba的核心状态转移过程, 实现音乐节奏与舞蹈动作生成的深度耦合.在AIST++数据集上的实验表明, BeatDG在保证生成舞蹈动作质量和多样性的前提下, 显著提升节拍对齐精度.因此, 本文对音频驱动舞蹈视频生成研究具有一定的借鉴意义.未来工作将继续探索分区量化操作, 构建从粗粒度动作到细粒度细节的层次化码本, 进一步提升生成舞蹈动作的质量.
本文责任编委 吴飞
Recommended by Associate Editor WU Fei
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|