



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于单步扩散和量化语义的极端图像压缩方法
[张洲弘1  , 乔欣
, 乔欣1, 2 , 李智远1 , 安宁3, 4 , 孔贺5 ]
, 乔欣, 李智远, 安宁, 孔贺]
|
|



作者简介:

张洲弘,硕士研究生,主要研究方向为计算机视觉.E-mail:zaczhang@stu.xjtu.edu.cn.

乔 欣,博士,助理教授,主要研究方向为三维感知、计算机视觉.E-mail:wudiqx@xjtu.edu.cn.

李智远,硕士研究生,主要研究方向为计算机视觉.E-mail:lizhiyuan2839@163.com.

孔 贺,博士,副教授,主要研究方向为机器人智能感知与决策.E-mail:kongh@sustech.edu.cn.
近年来,基于扩散模型的极端图像压缩方法在极低码率场景中性能显著优于传统方法.然而,这类方法依赖扩散模型的逐步去噪策略,通常需要多次采样才能完成解码,在重建保真度与推理效率之间存在一定的局限性,并且现有方法难以精准保留航拍场景中的地形结构与细节特征.因此,文中提出基于单步扩散和量化语义的极端图像压缩方法.设计单步扩散策略,从压缩特征而非纯噪声出发,仅通过一次采样即可实现高质量的图像重建.同时,引入量化CLIP特征替代文本条件,兼顾语义表达与传输效率,为重建过程提供精细稳定的语义约束.此外,在训练中融合像素级损失,结合潜在特征空间优化与像素域监督,缓解分布差异问题,进一步提升重建质量.大量实验表明,文中方法在仅使用一次采样的情况下即可达到较优的重建效果.
About Author:
ZHANG Zhouhong, Master student. His research interests include computer vision.
QIAO Xin, Ph.D., assistant professor. His research interests include 3D perception and computer vision.
LI Zhiyuan, Master student. His research interests include computer vision.
KONG He, Ph.D., associate professor. His research interests include robot intelligent perception and decision-making.
Diffusion-based extreme image compression methods exhibit significant performance advantages under extremely low bitrate scenarios. However, existing methods typically decode the image after multiple sampling steps due to their reliance on the step-by-step denoising strategy of diffusion models, resulting in a trade-off between reconstruction fidelity and inference efficiency. To address this issue, a toward extreme image compression method with one-step diffusion and quantization semantics is proposed. A one-step diffusion strategy is designed. It starts from compressed latent features rather than pure noise. High-quality image reconstruction is achieved with only a single sampling step. Moreover, quantized contrastive language-image pretraining(CLIP) features are introduced to replace text as semantic conditions, providing more fine-grained and reliable semantic guidance for reconstruction. Finally, a pixel-level loss is added to the training to alleviate the distribution discrepancy caused by optimization in the latent feature space, further improving reconstruction quality. Extensive experiments demonstrate that the proposed method achieves superior reconstruction quality with only a single sampling step.
随着互联网技术和智能设备的普及, 图像和视频等视觉内容已成为人们获取和传递信息的主要媒介.无人机航拍、遥感监测等场景产生海量高分辨率图像, 对存储和传输的需求日益迫切.这类图像通常包含复杂的地形纹理、动态细节, 面临带宽有限的传输环境, 因此人们开始探索更高效的图像压缩技术.JPEG(Joint Photographic Experts Group)[1]和VVC(Versatile Video Coding)[2]等传统压缩标准采用“ 预测-变换-熵编码” 的混合编码框架, 在中高码率场景中压缩性能较优.然而, 由于依赖手工设计的规则和基于图像块的冗余去除策略, 传统压缩标准在低码率场景中会产生严重的块效应和模糊伪影.
随着神经网络技术的快速发展, 基于深度学习的图像压缩方法受到越来越多的关注.这类方法在大规模数据集上进行端到端训练, 能自适应学习最优的压缩特征表示与编码策略, 性能显著优于传统方法.根据优化目标的不同, 基于深度学习的图像压缩方法可大致分为面向失真的图像压缩方法和面向感知的图像压缩方法.面向失真的图像压缩方法优化率失真函数, 在低码率条件下的重建结果通常缺乏细节信息.面向感知的图像压缩方法引入对抗性训练策略与感知损失, 提升重建图像的感知质量.上述方法主要针对中高码率进行优化, 在极低码率(本文将每像素比特数(Bits per Pixel, bpp)低于0.1的场景定义为极低码率)下的表现较差.
最近, 扩散模型[3]在图像和视频生成领域表现出的强大生成能力, 推动基于扩散模型的图像压缩方法的发展.特别是一些工作使用预训练扩散模型补偿极低码率场景中丢失的细节信息, 获得较优视觉质量和重建细节.Pan等[4]将待压缩图像编码为简短的本文嵌入, 并在解码段利用预训练的T2I(Text-to-Image)扩散模型对文本嵌入进行解码, 生成细节丰富的重建图像.Lei等[5]利用第三方算法从图像中提取文本描述和轮廓草图, 并对这两种信息进行压缩传输.在解码端, 直接将文本描述和压缩后的轮廓草图作为条件输入预训练的ControlNet[6]中, 生成与原图语义一致的重建图像.Careil等[7]提出PerCo, 结合类VQ-VAE(Vector Quantized Varia-tional Autoencoder)[8]编码器与基于扩散的解码器, 利用矢量量化后的图像潜在特征与文本描述共同传递图像信息.然而, 上述方法仍存在局限性, 限制其在实际场景中的应用.首先, 这些方法受扩散模型逐步去噪策略的影响, 需要进行多次采样操作才能解码图像, 推理效率不高.其次, 它们通常采用文本作为额外的语义条件, 但文本在描述精细语义表达和局部细节方面存在一定局限.最后, 这些方法大多在潜在特征空间中优化模型, 与像素域重建目标之间存在分布差异, 重建结果的像素保真度较差.
为了解决上述问题, 本文提出基于单步扩散和量化语义的极端图像压缩方法(Toward Extreme Image Compression with One-Step Diffusion and Quan-tization Semantics, OQEIC).首先, 与现有方法从纯噪声开始重建图像不同, OQEIC直接使用压缩后的潜在特征作为扩散解码的初始点.由于压缩潜在特征中仍保留大量图像信息, 方法能在此基础上进行高效解码, 仅需一次采样即可实现高质量的图像重建, 提升推理效率.其次, 引入量化CLIP(Contrastive Language-Image Pretraining)语义特征替代文本描述作为辅助条件, 获取细致稳定的语义约束, 有效弥补极低码率下细节信息的缺失.相比文本描述, 量化语义特征不仅表达能力更强, 而且获取过程更直接高效.最后, 在潜在空间重建的基础上进一步结合像素级损失, 缩小潜在表示与像素域之间的分布差异, 提升重建结果的像素保真度.
早期图像压缩方法主要借助熵编码减少图像中的统计冗余, 实现数据压缩.Huffman编码[9]、Golomb编码[10]和算数编码[11]等根据符号出现概率的分布特性, 分配较短的码字给概率较大的字符.20世纪60年代末, 研究人员提出变换编码技术, 进一步提升压缩效率.1974年, Ahmed等[12]提出DCT(Discrete Cosine Transform), 将图像能量集中于频域的低频部分, 大幅提升压缩效率.随后, 连续的变换系数会被量化为离散数值, 有效降低数据表示精度, 减少存储与传输成本.在变换编码的基础上, 研究者进一步提出预测编码技术, 降低图像中的空间冗余和视觉冗余.
随着分块策略、预测模式及变换方法等核心模块的持续优化, 传统图像压缩方法性能不断提升, 并在实际场景中得到广泛应用.然而, 此类方法仍存在明显局限:一方面, 其优化过程高度依赖人工设计的规则与先验知识, 缺乏对不同图像内容的自适应能力; 另一方面, 在极低码率场景中, 容易产生块效应与模糊伪影, 难以满足高质量重建需求.上述问题推动研究者探索更智能、通用的新型图像压缩方法, 突破传统压缩方法的性能瓶颈.
随着神经网络的快速发展, 基于深度学习的图像压缩方法受到广泛关注, 压缩性能已超越传统图像压缩方法.Ballé 等[13]提出基于变分自编码器(Variational Autoencoder, VAE)的图像压缩方法, 通过深度神经网络优化端到端的联合率失真性能, 从根本上突破传统方法依赖手工设计规则进行局部优化的局限性.随后, Ballé 等[14]进一步引入额外的辅助信息, 建模潜在表示的概率分布, 降低其空间依赖性, 显著提升压缩性能.同时, 部分研究者通过设计更先进的熵模型提升压缩性能.Minnen等[15]结合层级超先验与自回归模型, 降低潜在表示中的空间冗余.He等[16]假设潜在表示中的冗余信息在空间维度和通道维度上具有正交性, 并据此提出ELIC.然而, 仅对模型的率失真性能进行优化容易导致重建图像产生明显的视觉不真实感, 通常表现为图像模糊与过度平滑[17].
为了提升重建图像感知质量, 面向感知的图像压缩方法将生成模型引入图像压缩任务.Agustsson等[18]添加对抗性损失, 生成压缩过程中丢失的细节信息, 显著提升重建图像的视觉真实感.Mentzer等[19]提出HiFiC(High Fidelity Compression), 探索归一化层、生成器和鉴别器架构、训练策略和感知损失, 在较低码率下实现视觉友好的重建图像.
近年来, 得益于扩散模型在图像生成任务中展现的强大且稳定的生成能力, 研究者开始尝试将其引入图像压缩领域.Yang等[20]将条件扩散模型作为压缩网络的解码器, 取得较优性能.Kuang等[21]提出CGDM(Consistency Guided Diffusion Model), 有效提升重建结果的保真度.但是, 上述方法大多针对中高码率场景进行优化, 在极低码率条件下的压缩性能较差.
近年来, 极端图像压缩方法成为图像压缩领域的研究热点之一, 其核心目标是在极低码率条件下, 尽可能实现高质量的图像重建.为了解决极端图像压缩中的信息丢失问题, 研究者从不同角度提出优化方案.Gao等[22]提出ULCompress, 利用可逆先验缓解极端压缩导致的图像质量退化问题, 借助可逆神经网络的双射性和信息无损性, 确保前向压缩与逆向重建过程在理论上无信息丢失.为了提升重建图像与原始图像的语义一致性, Jiang等[23]提出TGIC(Text-Guided Image Compression), 在压缩过程中引入文本作为引导信息, 有效避免极端压缩造成的严重语义失真.此外, Lu等[24]提出HybridFlow, 在极低码率下获得较高质量的重建图像.
由于扩散模型在各类图像恢复任务中取得的显著成功, 一些研究者尝试利用预训练扩散模型的强大生成能力, 补偿极端图像压缩过程中丢失的细节信息.Pan等[4]先将待压缩图像编码为简短的文本嵌入, 再在解码端利用预训练的T2I扩散模型对文本嵌入进行解码, 生成细节丰富的重建图像.Lei等[5]从图像中提取文本描述与轮廓草图, 并对这两种信息进行压缩传输, 在解码端将文本描述与轮廓草图作为条件输入预训练的ControlNet[6]中, 生成与原始图像语义一致的重建结果.Careil等[7]结合类VQ-VAE[8]的编码器与基于扩散的解码器, 利用矢量量化后的图像潜在特征与文本描述共同传递图像信息.Vonderfecht等[25]结合反向信道编码技术, 在扩散模型的反向去噪过程中逐步传输每步的去噪误差, 实现极低码率下的图像压缩与解码.然而, 现有基于扩散模型的极端图像压缩方法往往依赖多次采样才能获得较高质量的重建图像, 导致重建效率较低.
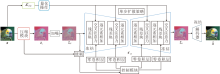
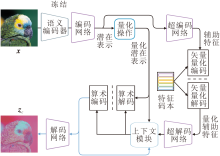
本文提出基于单步扩散和量化语义的极端图像压缩方法(OQEIC), 整体架构如图1所示.首先使用压缩模块对输入图像x进行压缩, 并将压缩信息初步解码为压缩潜在特征zc, 压缩模块的具体流程如图2所示. 在压缩模块中, 上下文模块Cm采用ELIC[16]中的时间-空间上下文模块, 有效减少压缩表示中的时空冗余, 特征码本Cb大小为16 384.再通过语义编码器ε clip从原始图像x中提取全局语义信息, 并对全局语义信息进行二值量化, 以便后续传输.然后, 以压缩潜在特征zc和随机噪声为基础构建反向去噪过程的起始点zN, 并结合量化语义特征, 通过单步去噪过程重建无噪声的潜在特征z0.该过程通过冻结的预训练Stable Diffusion中的噪声估计器$\epsilon_{\mathrm{sd}}$和可训练的控制模块共同完成, 其中控制模块用于实现对噪声估计器中间特征的动态调制.最后, 使用图像解码器D将去噪后的潜在特征z0映射回原始图像空间, 获得最终的重建图像
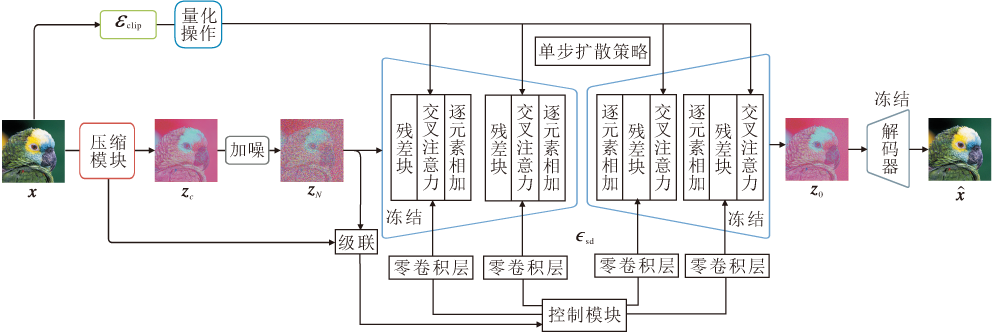 | 图1 OQEIC整体架构Fig.1 Overall architecture of OQEIC |
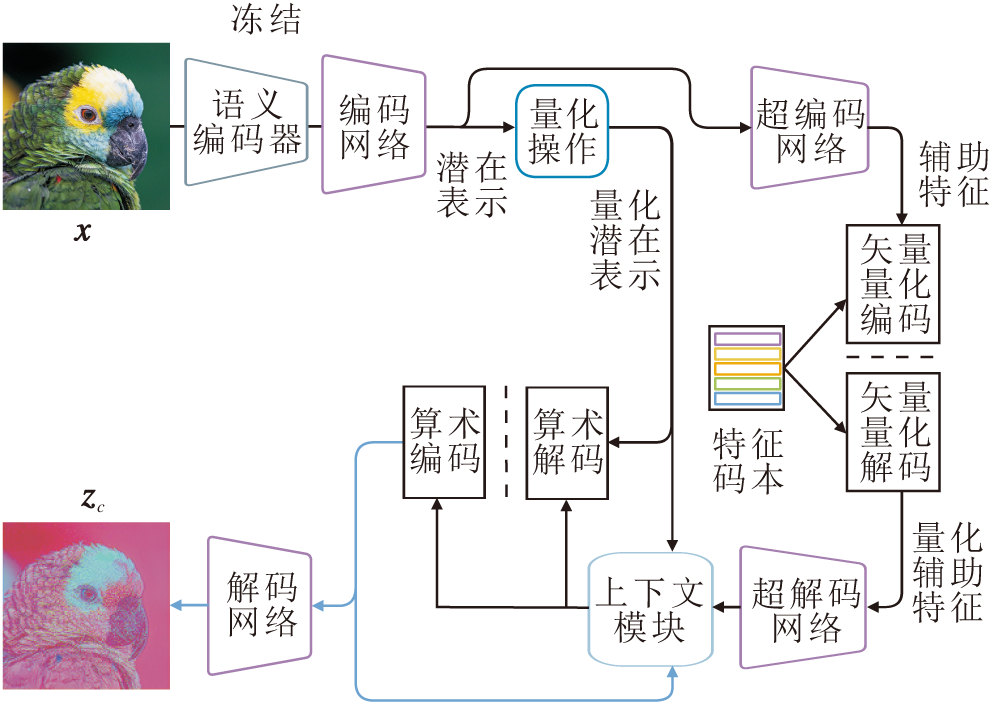 | 图2 压缩模块流程图Fig.2 Flow chart of compression module |
遵循Stable Diffusion中的扩散策略, 现有基于扩散先验的极端图像压缩方法逐步向无噪声潜在特征z0中添加方差为β t∈ (0, 1)的高斯噪声, 获得带噪声的潜在表示:
zt=
其中, $\epsilon$t~N(0, I)表示从标准高斯分布中采样的噪声,
$\alpha_{t}=1-\beta_{t}, \bar{\alpha}_{t}=\prod_{i=1}^{T} \alpha_{i} .$
当扩散步数t足够大时, 潜在表示zt的分布将趋于标准高斯分布.在实际应用中, 通常将总扩散步数T设为较大数值(如1 000), 并且在推理过程中使用纯随机高斯噪声作为反向去噪过程的起始点.
然而, 这种逐步去噪方式虽能在一定程度上保证重建质量, 但也带来显著的推理效率问题:大量的采样步骤导致解码过程耗时严重, 难以满足实际应用中对实时性的需求.同时, 纯噪声作为反向去噪的起始点, 使方法在初始阶段缺乏有效的图像信息引导, 不仅需要更多的步数才能收敛, 还可能在去噪过程中引入与原始图像语义或结构不一致的伪影, 进一步制约极低码率下重建保真度的提升.
针对上述问题, 本文使用压缩潜在特征zc与方差为β N∈ (0, 1)的高斯噪声构建反向去噪过程的起始点:
zN=
其中$\epsilon$N~N(0, I)表示第N步从标准高斯分布中采样的噪声,
$\bar{\alpha}_{N}=1-\beta_{N}, \bar{\alpha}_{N}=\prod_{i=1}^{N} \alpha_{i} .$
该设计使方法在单步采样中即可利用压缩特征中的结构信息, 避免从纯噪声起步带来的信息缺失问题.因压缩潜在特征zc可看作目标潜在特征加上特定残差, 可将zN改写为
zN=
其中,
e=zc-z0,
表示压缩潜在特征zc与目标无噪声特征z0之间的残差信息,
此时, 方法被训练为预测噪声和残差的混合信息
Lne=
其中,
ω =
表示权重系数, c表示量化语义特征,
现有基于扩散模型的图像压缩方法通常采用文本描述作为辅助条件, 为图像重建提供额外的语义信息.然而, 文本在表达精细语义和局部细节方面存在一定局限.一方面, 文本描述往往过于抽象, 难以精准刻画图像中的细节信息; 另一方面, 文本生成和对齐过程依赖额外的标注或预处理, 增加实际应用中的复杂性与不确定性.
为了解决这一问题, 本文提出更直接、稳健的语义表征方式.具体而言, 利用CLIP直接从图像中提取全局语义特征:
s=ε clip(x),
其中ε clip(· )表示CLIP编码器.为了获得更紧凑且可传输的语义表示, 首先对其逐维进行截断操作, 将每个分量限制在[-1, 1]区间, 即
sc=clip(s, -1, 1),
其中clip(· )表示逐元素的截断操作.该步骤能保证量化范围的一致性.
然后在每维上进行二值量化, 得到量化后的语义特征:
sq=2[sc/2]+1∈ {-1, 1}d.
本文语义向量的维度d设为768, 即对于任意输入图像, 仅需传输768 bit即可完成全局语义信息的表达, 这种极低的传输开销保证方法在极端低码率下的高效性, 同时为扩散解码提供稳定的语义约束, 后续实验的总码率已计入CLIP语义比特.
在极低码率下使用不同语义条件的重建结果如图3所示.由图可见, 基于文本信息的重建图像(图3(b))尽管能提供高层次的语义信息, 但容易引入与原始场景不一致的内容, 难以保持图像结构的一致性.采用量化语义特征(图3(c))时, 尽管bpp更低, 却能更好地保留场景结构与语义一致性, 说明二值量化已能包含足够的语义信息, 无需再增加量化精度, 由此表明OQEIC在极低码率下的稳健性与保真度.
 | 图3 使用不同语义信息生成的图像示例Fig.3 Examples of generated images using different semantic information |
在基于扩散模型的图像压缩中, 现有方法通常在潜在特征空间中进行优化.然而, 潜在空间与像素空间之间存在显著的分布差异, 仅依赖潜在空间的一致性约束, 容易导致重建结果与真实图像在低层次纹理和局部细节上出现偏差.值得注意的是, 传统多步扩散方法由于重建过程是逐步去噪的, 中间结果难以与原始像素空间直接对齐, 因此通常无法显式引入像素级监督.
OQEIC采用单步扩散解码, 能在压缩潜在特征的基础上直接生成最终的重建图像.这一特性使OQEIC能在训练阶段引入像素级损失, 从而有效缩小潜在表示与像素域之间的差距.
给定原始图像x及其重建图像
Lpix=‖ x-
其中, Llpips表示LPIPS(Learned Perceptual Image Patch Similarity)损失[26], λ lpips=0.5表示权重.
最终, 总训练损失由Lne、率失真损失Lrd、码本损失Lcb及像素级损失Lpix共同构成:
L=Lcb+λ rLrd+λ rLne+λ rLpix,
其中
$\begin{array}{l}L_{\mathrm{cb}}=\left\|s g\left(\boldsymbol{I}_{p}\right)-\widehat{\boldsymbol{I}}_{p}\right\|_{2}^{2}+\beta\left\|s g\left(\widehat{\boldsymbol{I}}_{p}\right)-\boldsymbol{I}_{p}\right\|_{2}^{2}, \\L_{\mathrm{rd}}=\left\|\boldsymbol{z}_{0}-\boldsymbol{z}_{c}\right\|_{2}^{2}+R(\hat{y}), \end{array}$
Ip表示辅助信息,
OQEIC在LSDIR数据集上进行训练.该数据集包含84 911幅高质量图像.在评估阶段, 使用Kodak、Tecnick、CLIC2020这3个常用的基准数据集.Kodak数据集包含24幅分辨率为768× 512的自然图像.Tecnick数据集包含140幅分辨率为1 200× 1 200的高质量图像.CLIC2020数据集包含428幅分辨率不一的高质量图像.参照Yang等[20]采用的策略, 调整Tecnick、CLIC2020数据集上的图像.先采用缩放操作, 使图像的短边长度统一为768, 再将调整后的图像从中心裁剪为尺寸为768× 768的图像块.此外本文还构建一个包含30幅无人机电力巡检图像的额外测试集.
本文选用Stable Diffusion 2.1-unclip作为预训练T2I扩散模型的具体实现.在所有实验中, Stable Diffusion的模型参数均保持冻结状态, 不进行更新.与DiffEIC(Diffusion-Based Extreme Image Compre-ssion)[27]类似, OQEIC中的控制模块在结构上复用Stable Diffusion中的编码块和中间块, 同时, 为了减少计算消耗并提高推理效率, 控制模块中的特征通道数被压缩为原始噪声估计器的20%.扩散过程中用于添加噪声的方差序列{β t
在训练阶段, 优化器选用Adam(Adaptive Mo-ment Estimation)[28], 设置参数β 1=0.9、 β 2=0.999, 批尺寸大小为1, 共训练3× 105次迭代.为了达到不同的压缩率, OQEIC训练3个模型, λ r取值分别为2, 0.75和0.2.输入图像被随机裁剪成尺寸为512× 512的图像块.与DiffEIC[27]类似, OQEIC的训练采用两阶段策略.第一阶段在λ r=2的设定下训练2× 105次迭代, 学习率设为1× 10-4, 获得高质量的初始模型.第二阶段根据目标压缩比重新选择λ r, 再训练1× 105次迭代, 此时学习率降至2× 10-5.在推理过程中, 采用Nichol等[29]的策略进行去噪重建, 采样步数设为1.
所有实验测试均在NVIDIA GeForce RTX 4090 GPU和13th Core i9-13900K CPU上进行.
为了直观评估OQEIC性能, 采用多个主流质量评估指标, 从不同维度对重建图像的视觉质量进行分析.在有参考感知质量指标方面, 本文选取如下指标:LPIPS[26]、DISTS(Deep Image Structure and Texture Similarity)[30]、FID(Fré chet Inception Dis-tance)[31]、KID(Kernel Inception Distance)[32].
此外, 还引入传统的像素级保真度指标:PSNR(Peak Signal-to-Noise Ratio)[33]、SSIM(Structural Similarity)[33]、MS-SSIM(Multi-scale Structural Similarity)[34], 准确衡量重建图像与原始图像在像素层面的相似程度.
为了评估方法的压缩效率, 还采用bpp指标.需要指出的是, 由于Kodak数据集上图像数量较少, 无法可靠地计算FID和KID指标, 本文将省略各方法在Kodak数据集上的FID与KID评估结果.
为了验证OQEIC的有效性, 选择如下多种基于深度学习的图像压缩方法进行对比:Text+Sketch[5]、PerCo[7]、ELIC[16]、HiFiC[19]、DiffEIC[27]、MS-ILLM(Mean Scale Implicit Local Likelihood Model)[35]、文献[36]方法、ResULIC[37].由于PerCo未公开其官方代码与预训练模型, 本文使用其开源复现版本PerCo(SD)[38]作为对比方法, 确保实验结果的可复现性与公平性.
此外, 还与传统压缩标准BPG(Better Portable Graphics)和VVC[2]进行对比.其中, BPG以“ YUV444” 采样模式、“ x265” HEVC 编码、“ 8-bit” 位深, 以及“ YCbCr” 色彩空间的参数进行配置.VVC标准则是基于其官方参考软件VTM-23.0进行实验, 并启用intra帧编码模式.
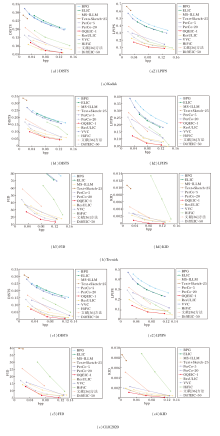
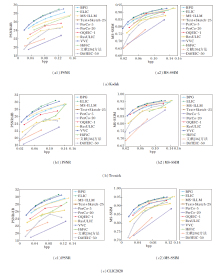
各方法在3个基准数据集上的感知质量指标曲线和像素级保真度指标曲线如图4和图5所示.在图中, 基于扩散模型的极端图像压缩方法采用的去噪步数已在方法后面注明.
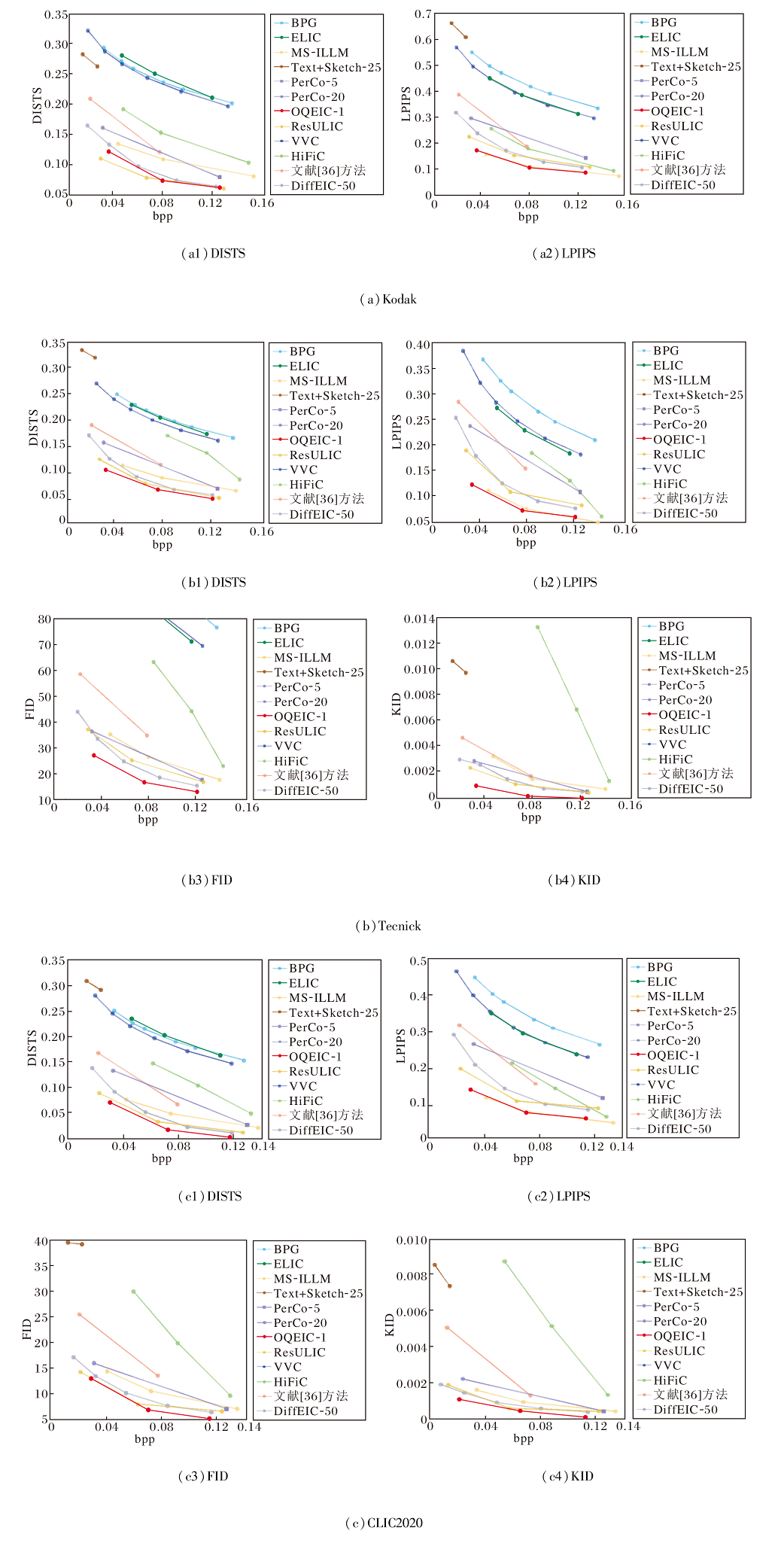 | 图4 各方法的感知质量指标曲线Fig.4 Perceptual quality metric curves of different methods |
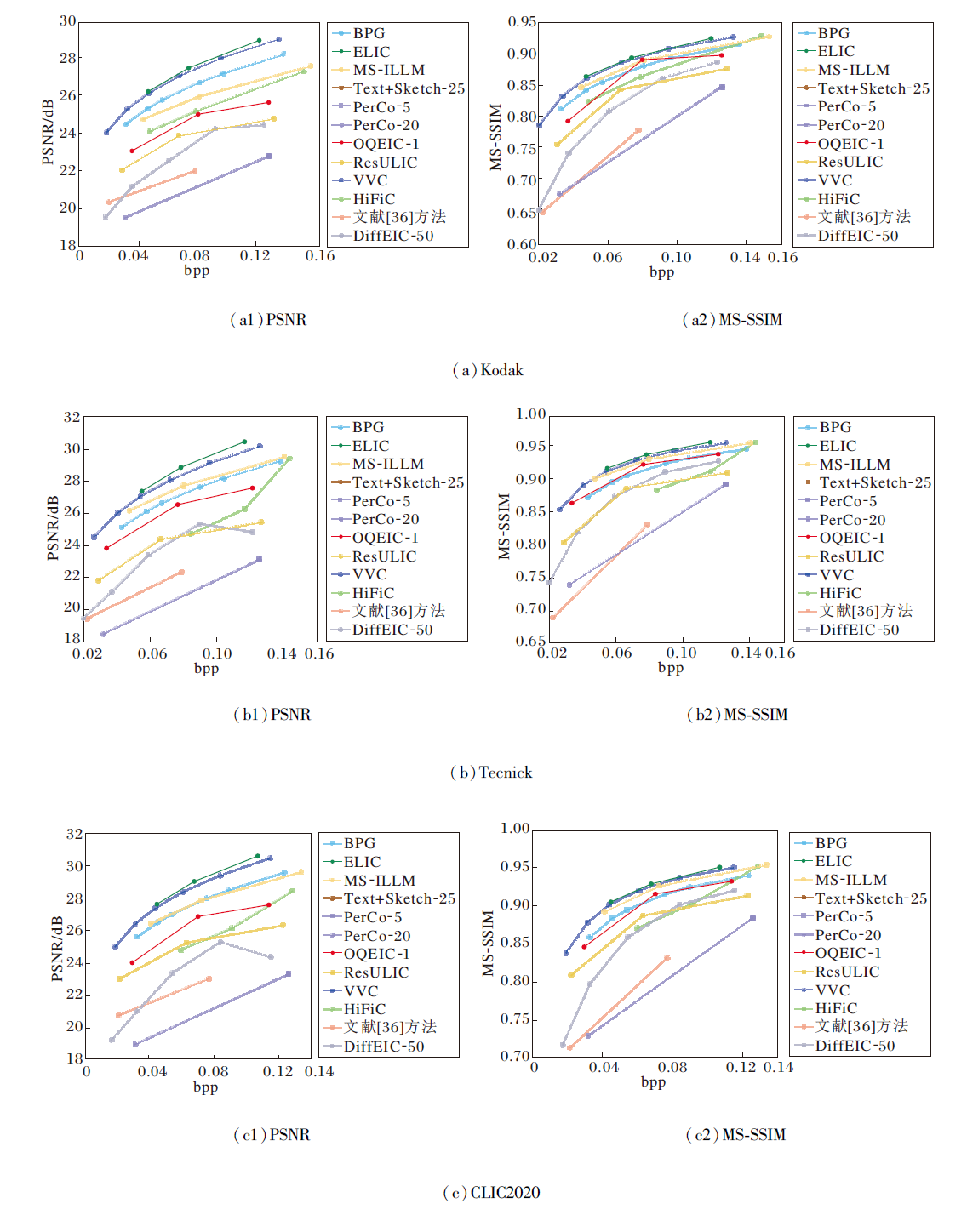 | 图5 各方法的像素级保真度指标曲线Fig.5 Pixel-level fidelity metric curves of different methods |
由图4可观察到, OQEIC在各项感知质量指标上均具有明显优势, 尤其是在DISTS、FID、KID指标上取得当前最优值.
上述结果表明OQEIC能较好地还原原始图像的结构特征与细节信息, 生成的重建图像具有较高的视觉真实性与感知一致性.
由图5可见, 尽管在像素级保真度指标上, OQ- EIC的性能稍差于传统压缩标准(如VVC、BPG)和面向失真的图像压缩方法(ELIC), 但相比已有的基于扩散模型的极端图像压缩方法(如PerCo、DiffEIC等)和基于VAE的感知图像压缩方法(HiFiC), OQEIC在像素保真度方面具有显著提升.相比基于Stable Diffusion的图像压缩方法, OQEIC的性能更接近于Stable Diffusion自编码器在无压缩条件下的重建性能, 这进一步说明OQEIC能更充分地利用预训练Stable Diffusion的强大生成能力, 有效补偿压缩过程中丢失的细节信息.
各方法在极低码率条件下的重建效果如图6所示.由图可见, 相比其它方法, OQEIC能生成更真实且与原始图像更一致的重建结果.
 | 图6 各方法在CLIC2020数据集上的重建图像对比Fig.6 Reconstruction results of different methods on CLIC2020 dataset |
VVC与MS-ILLM在结构信息(如门框)的重建上具有一定优势, 但在纹理与细节保留方面存在明显不足.基于扩散模型的图像重建方法(Text+Sketch、PerCo、DiffEIC、ResULIC)能在极低码率下生成较真实的重建图像, 但往往会产生与原始图像不一致的细节和结构.相比之下, OQEIC能在极低码率下生成具有更高视觉质量的重建结果, 伪影更少、结构更真实.
各方法在Kodak数据集上的平均编码时间和解码时间如表1所示.在表中, BD率指标以 VVC为基准, 并基于 CLIC2020 数据集上的 DISTS 指标进行计算, 越低的BD率表明方法在相同图像质量下可实现越高的压缩效率.
| 表1 各方法在Kodak数据集上的平均编码时间和解码时间 Table 1 Average encoding time and decoding time of different methods on Kodak dataset |
对于基于扩散先验的图像压缩方法, 解码时间被拆分成去噪时间和剩余时间.由于基于扩散先验的图像压缩方法依赖预训练的Stable Diffusion进行解码, 通常比基于VAE的方法和基于GAN的方法需要更长的编解码时间, 而OQEIC通过将重建图像所需的去噪步数减少为1, 去噪时间显著低于其它基于扩散先验的图像压缩方法.例如:相比DiffEIC, OQEIC的去噪时间降至1/50左右, 实现更优的重建质量.
OQEIC与JPEG在无人机电力巡检图像上的重建结果如图7所示.由图可观察到, JPEG在低码率压缩后, 航拍图像的连续纹理区域(如农田、山地植被)出现明显的块分割与模糊失真, 地形轮廓的边缘信息丢失严重, 甚至出现局部区域的像素融合, OQEIC可在比JPEG更小码率的条件(降低65%以上)下更好地还原无人机图像中的地形结构和目标细节信息, 生成的重建图像具有更高的视觉真实性与感知一致性.
 | 图7 OQEIC和JPEG航拍图像重建结果Fig.7 Reconstruction results of aerial images captured in OQEIC and JPEG |
为了更全面地分析OQEIC性能, 设计消融实验, 验证单步扩散策略、量化语义特征和像素级损失的有效性, 相应指标值如表2所示.由表可见, 去除任一模块均导致性能下降, 由此验证三者协同优化的必要性.
| 表2 各模块的消融实验结果 Table 2 Ablation experiment results of different modules |
首先验证单步扩散策略的有效性.在去除单步扩散策略以后, 即使将去噪步数增至50, 各项指标值依然出现显著下降.这表明, 依赖逐步去噪的方式不仅难以充分利用压缩潜在特征中的信息, 而且在实际应用中需要更多的采样步数, 导致推理效率大幅降低.相比之下, OQEIC采用单步扩散策略, 仅需一步即可完成高质量重建, 在感知质量与推理效率之间实现良好的平衡, 由此充分验证单步扩散策略设计的有效性.这一优势的原因在于:以压缩潜在特征而非纯噪声作为去噪起点, 可有效避免在去噪初期产生的误差累积, 并为后续的细节生成提供更稳健的基础.
去除量化语义特征以后, DISTS、LPIPS指标均出现一定程度的下降.这一结果表明, 量化语义特征在为图像重建过程提供可靠语义约束方面发挥关键作用.相比现有基于扩散模型的极端图像压缩方法通常依赖的文本描述, 本文的量化语义特征具有两大优势.1)通过CLIP直接从输入图像中提取全局语义特征, 不仅避免文本描述抽象且容易产生歧义的问题, 而且精准捕捉图像中的细节信息与局部结构.2)通过二值量化将语义特征映射为离散表示, 仅需传输768 bit即可完成全局语义信息的传递, 大幅降低语义约束所需的比特率开销, 在极低码率场景的实际应用中更具高效性与可行性.通过表2也可看出, 增加量化比特数会导致方法出现性能下降, 并且量化比特数越多, DISTS、LPIPS等指标下降越显著.
现有基于扩散模型的极端图像压缩方法通常仅在潜在空间中进行优化, 容易导致潜在空间与像素空间之间的分布不匹配, 从而在低层次纹理和局部细节的保真度上表现不足.相比之下, OQEIC在整体训练目标中直接引入像素级损失, 有效提升性能.在去除像素级损失之后, 方法性能均有所下降, 尤其在PSNR指标上出现显著退化.
此外, 像素级损失对重建图像的影响如图8所示.由图可见, 缺乏像素级损失的重建图像会产生伪影和细节丢失, 而引入像素级损失之后, 重建图像能呈现更清晰的边缘与更高的感知质量.这些结果验证在单步扩散策略中引入像素级损失的必要性.
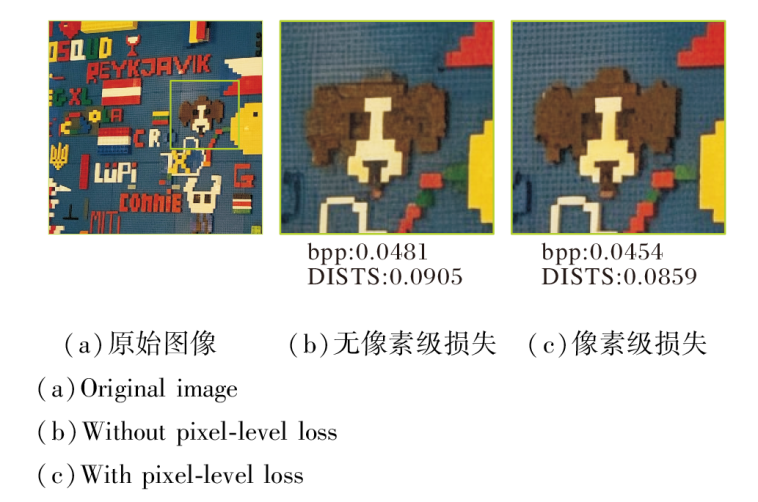 | 图8 像素级损失对重建结果的影响Fig.8 Effect of pixel-level loss on reconstruction results |
本文针对基于扩散模型的极端图像压缩方法在极低码率场景中存在的效率与保真度不足的问题, 提出基于单步扩散和量化语义的极端图像压缩方法(OQEIC), 直接以压缩潜在特征为解码起点, 仅需一次采样即可实现高质量图像重建, 从而显著提升解码效率.在语义建模方面, 引入量化语义特征, 替代文本描述, 为图像重建提供更细粒度的全局语义指导.此外, 进一步结合像素级损失, 缓解潜在空间与像素域之间的分布差异, 增强重建结果的保真度与细节表现.大量实验表明, OQEIC尽管在像素级保真度方面, 性能稍差于VVC等传统压缩标准和面向失真的图像压缩方法, 但OQEIC在感知质量、重建保真度和推理效率方面均显著优于现有的基于扩散模型的极端图像压缩方法, 并在多个基准数据集上更接近Stable Diffusion自编码器的性能上界, 为无人机航拍、遥感监测等实际场景中海量图像数据的高效传输与存储提供可行方案.今后将进一步探索将文本提示、图像标签或语义分割图像等多模态条件与压缩潜在特征协同输入扩散模型, 构建更具语义理解能力的多模态图像压缩系统.
本文责任编委 徐勇
Recommended by Associate Editor XU Yong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|