{kind=link}
{kind=link}
基于知识图谱与指代消解的对话式问答
[王笳辉1, 2  , 赵林超
, 赵林超1, 2 , 尹兆睿1, 2 , 岳昆1, 2 , 陈兴通1, 2 , 段亮1, 2 ]
, 赵林超, 尹兆睿, 岳昆, 陈兴通, 段亮]
|
|



作者简介:
王笳辉,博士,助理研究员,主要研究方向为数据与知识工程、领域知识挖掘、不确定性知识推理.E-mail:wjh@ynu.edu.cn.
赵林超,硕士研究生,主要研究方向为数据与知识工程.E-mail:zlc@stu.ynu.edu.cn.

尹兆睿,硕士研究生,主要研究方向为数据与知识工程.E-mail:yinzhaorui@stu.ynu.edu.cn.

岳 昆,博士,教授,主要研究方向为图数据分析、大数据知识工程、神经符号计算、贝叶斯深度学习.E-mail:kyue@ynu.edu.cn.

陈兴通,硕士,助理工程师,主要研究方向为数据与知识工程.E-mail:cxt_79@qq.com.
如何解决对话式问答中的指示代词和长依赖现象,有效利用依赖信息,以及如何有效维护上下文查询子图,避免因不当扩展而导致的子图过度增长的风险,在上下文查询子图中精准检索问题的答案是当前对话式问答亟待解决的问题.为此,文中提出基于知识图谱与指代消解的对话式问答模型.首先,将指代消解应用于对话式问答,利用指代消解模块获取指代簇,并提出索引替换算法,完善问题的语义信息.同时,提出词汇指代结构和字符语义两种依赖计算方式,获取依赖信息,指导上下文查询子图的扩展和答案检索.然后,为了有效扩展上下文查询子图并避免过度增长,基于依赖信息扩展查询子图,得到准确的查询子图,进而根据对话轮次和查询子图大小提出奖惩机制,有效防止子图过度增长.最后,将依赖信息用于答案检索,有效提升答案检索准确率.在ConvQuestions数据集上的实验表明文中模型的有效性.
About Author:
WANG Jiahui, Ph.D., assistant profe-ssor. His research interests include data and knowledge engineering, domain knowledge mining and uncertain knowledge reasoning.
ZHAO Linchao, Master student. His research interests include data and knowledge engineering.
YIN Zhaorui, Master student. His research interests include data and knowledge enginee⁃ring.
YUE Kun, Ph.D., professor. His research interests include graph data analysis, big data knowledge engineering, neural symbolic computation and Bayesian deep learning.
CHEN Xingtong, Master, assistant engineer. His research interests include data and knowledge engineering.
There are two urgent challenges in conversational question answering to be addressed at present. One is how coreference and long range dependencies can be resolved to effectively utilize dependency information. The other is how contextual query subgraphs can be effectively maintained to avoid the risk of excessive expansion, thereby enabling more precise answer retrieval within them. In this paper, a model of conversational question answering based on knowledge graph and coreference resolution is proposed. First, coreference resolution is employed to obtain coreference clusters and an index replacement algorithm is introduced to enhance the semantic information of questions. Additionally, two types of dependency information, word coreference structure and character semantics, are proposed to guide the expansion of contextual query subgraph and answer retrieval. The contextual query subgraph is effectively expanded based on dependency information to obtain accurate query subgraph while avoiding overgrowth. Then, a reward-and-punishment mechanism is designed based on the number of dialogue rounds and the size of the query subgraph to effectively prevent the subgraph from overgrowing. Finally, dependency information is utilized to effectively improve the accuracy of answer retrieval. Experiments on the ConvQuestions dataset verify the effectiveness of the proposed method.
随着人工智能技术的飞速发展, 人们对于能进行自然对话的智能系统的需求日益增长.传统的问答系统主要基于关键词匹配或模式匹配, 无法理解用户的自然语言表达, 限制系统的应用场景和交互能力.对话式问答旨在通过理解和生成自然语言, 实现智能系统与用户之间的自然对话交流[1].
知识图谱(Knowledge Graph, KG)[2]和深度神经网络技术不断发展及其应用快速普及, 使得基于知识图谱的对话式问答(Conversational Question Answering, CQA)成为当前的研究热点[3].Kacupaj等[4]提出PRALINE(Path Ranking for Conversational Question Answering), 有效排序KG路径, 结合对话历史信息和邻居信息等会话上下文, 共同学习其与KG路径的同构表示, 实现有效的答案路径排序.Kaiser等[5]将回答过程建模为多个代理在KG上并行游走, 由策略网络采样动作决定游走路径, 有效、准确地回答带有干扰词汇的问题.
然而, 在对话式问答中, 当前问题往往与历史对话相关, 并且会出现上下文指代和省略现象[6], 导致理解当前问题的语义信息较困难, 需建立对话的长期依赖关系[7]并结合上下文语义信息进行解析.当使用一个上下文查询子图(Contextual Query Sub-graph)捕捉历史信息时, 在后续问题达到以后需要对子图进行适当的扩展以回答当前问题.同时, 由于KG中的节点有大量1跳(One-Hop)和2跳(Two-Hop)邻居, 在扩展时容易导致上下文子图过大[8], 并且随着对话轮次的增加和对话分支范围的扩大, 上下文子图过度增长的风险也相应增加.此外, 巨大的上下文子图将难以关注当前问题的主题, 大幅降低对话式问答的准确率.因此, 基于KG的对话式问答存在如下挑战:1)如何解决对话式问答中的指示代词和长依赖现象, 从而有效利用依赖信息; 2)在大规模知识库中, 如何有效维护上下文查询子图, 避免因不当扩展而导致的子图过度增长的风险, 从而在上下文查询子图中更精准检索问题的答案.
由此, 本文提出基于知识图谱与指代消解的对话式问答模型(Conversational Question Answering Based on Knowledge Graph and Coreference Resolu-tion, CKC), 通过时序索引替换实现高效语义复原, 利用三维拓扑增强算子动态构建知识子图, 并引入多级剪枝奖惩机制抑制推理噪声, 将指代结构与子图扩展深度融合, 在保证语义完整性的同时, 大幅提升在长对话场景中的答案检索精度.
基于知识库的对话式问答模型的核心流程是将问题中的指称映射至知识库中对应的实体, 再提取适配问题的查询子图以获取答案[9].Yih等[10]提出STAGG(Staged Query Graph Generation), 通过语义解析生成类似于知识图谱子图的查询图, 并映射成问题的逻辑形式, 最后在KG中执行逻辑查询, 获取答案.Sun等[11]提出SPARQA, 将问题解析成语法骨架, 使用多策略方法, 结合句子级语义和词汇级语义, 生成查询图, 并在KG中执行逻辑查询.Wang等[12]在生成阶段提取问题的结构性查询意图, 在查询阶段生成候选查询并选择执行语义相似度最高的查询.上述基于语义解析查询图的方式具有较强的可解释性, 但需要手工标记大量指定语法和规则的训练数据, 可扩展性不强.
基于图搜索的对话式问答模型将查询子图中的实体作为候选答案, 聚焦子图内实体以缩小检索范围, 有效降低大规模知识库的答案检索难度.Christmann等[13]提出CONVEX(Conversational KG-QA with Context Expansion), 使用上下文查询子图维护对话中的历史实体, 使用图搜索算法进行扩展, 得到后续问题的候选答案.Jin等[14]提出GStar, 以问题的主题实体为中心向外扩展子图, 每一跳扩展时都判断实体是否在Top-k的答案范围内, 若候选答案实体数已达到Top-k则停止扩展子图.成凌云等[15]提出基于对抗强化学习的多跳知识推理模型, 设计KG嵌入框架, 衡量嵌入空间中< 主题实体, 问题, 答案实体> 的可信度, 将多维信息融入强化学习框架的状态表示中, 使用生成器计算候选实体的概率并生成答案.Lan等[16]使用实体转换图和图构造器, 对每轮问答中的实体进行建模, 使用图模型捕获每轮对话的主题实体, 根据主题实体构造当前问题的查询图并预测答案.李凤英等[17]提出融合语义信息的知识图谱多跳推理模型, 使用推理路径和查询关系的语义相似度度量推理路径的可靠性, 并作为奖励函数反馈给智能体.上述模型能有效减小大规模KG中的答案检索空间, 但可能导致空答案或错误答案[18].
基于检索的对话式问答模型通过检索相关文档或知识以回答问题, 通常使用信息检索技术, 从大规模文档库中检索与问题相关的文档, 再从检索的文档中提取答案.Qu等[19]提出位置历史答案嵌入的方法, 有效处理对话依赖, 可动态表示历史轮次对当前问题影响的不同权重值, 但在轮次较多的对话中对整个对话历史的建模可能会出现大量冗余信息, 导致花费更多的计算资源.Qiu等[20]捕捉和回溯相关历史对话, 采用机器阅读理解(Machine Reading Comprehension, MRC)解析选定的历史轮次, 帮助回答当前问题.该类模型计算资源较少, 可专注于更相关的历史轮次, 但选择策略的质量直接影响答案预测的性能.
基于生成式的对话式问答模型通过生成式模型直接生成答案, 通常使用序列到序列模型或预训练语言模型生成自然语言答案.Kim等[6]提出EXCORD(Explicit Guidance on How to Resolve Conversational Dependency), 将CQA任务分解为问题重写(Question Rewriting)和QA任务.Liu等[21]提出CORNNET, 利用大语言模型生成高质量重述, 并结合强化学习定位答案.Kaiser等[22]通过强化学习生成问题的变体, 增强模型的鲁棒性.Ke等[23]为了克服重写监督信号的缺失, 引入知识增强的自训练机制, 从其它数据集中迁移问题重写器以适应当前的知识库.Su等[24]把指代词消解和补全作为多轮对话建模的预处理步骤, 先将历史对话及当前问题通过句子重写模型补全问题的语义信息再进行对话处理.Quan等[25]提出GECOR(Generative Ellipsis and Co-reference Resolution Model), 有效结合多轮任务型对话和句子重写.张诗安等[26]通过端到端指代消解模型识别对话中蕴含的表示同一实体的指代簇, 使用两种不同方法, 利用指代簇增强对话模型.此类模型效果显著, 但对大规模预训练模型的计算资源依赖较高.
还有模型结合多种技术的优势, 如检索和生成、知识图谱和预训练语言模型、基于神经符号推理与智能体等.Sun等[27]提出ToG(Think-on-Graph), 利用LLM(Large Language Model)作为智能体, 在图上执行波束搜索, 实现免训练推理.Kaiser等[28]提出PRAISE(Preference-Based Learning with Retrieval Aug-mented Iterative Sequence Generation for ConvQA), 引入偏好学习, 优化检索增强过程.Agarwal等[29]提出NS-KGQA, 基于预训练知识图谱嵌入与大模型逻辑解析机制, 实现在无需标注数据训练的前提下对复杂知识图谱问题的深度推理.
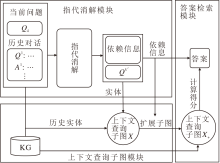
本文提出基于知识图谱与指代消解的对话式问答模型(CKC), 主要包括指代消解模块、上下文查询子图模块和答案检索模块, 框架如图1所示.
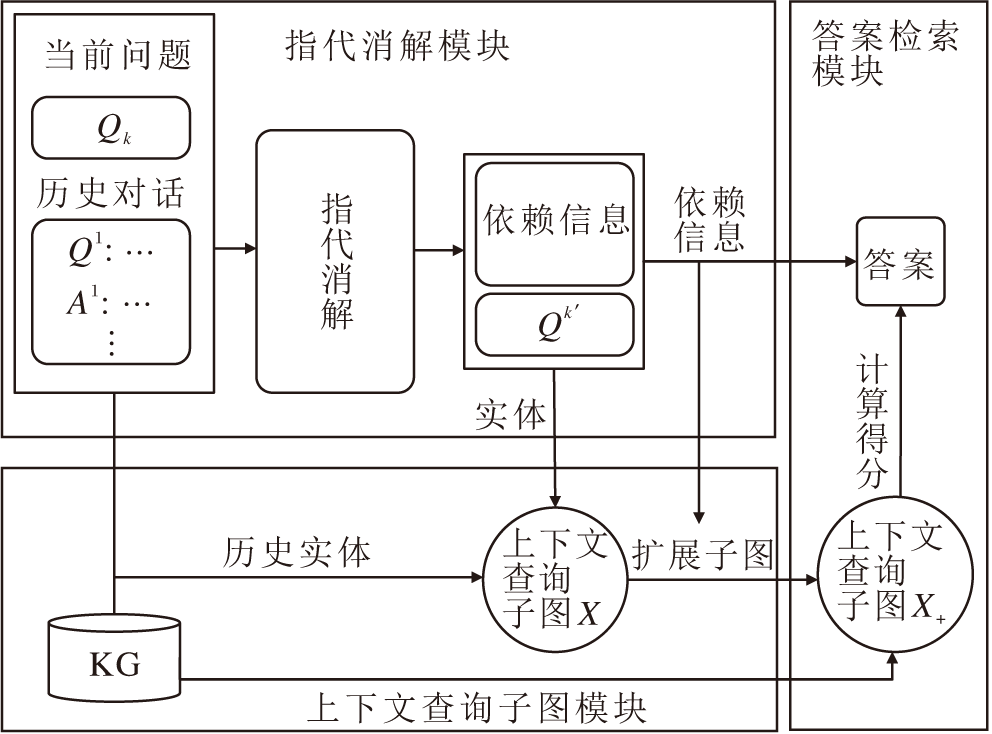 | 图1 CKC框架图Fig.1 Framework of CKC |
定义1 指代簇(Coreference Cluster) Cr={c1, c2, …, cm}表示对话文本中指向同一实体的所有指代簇, ci∈ Cr表示指代簇中的第i个指称, 包含名词性实体.集合内的元素根据其在对话历史中的出现索引进行升序排列.
为了充分考虑历史对话和当前对话中的所有指称, 对当前问题Qk和历史问答对
H={(Q1, A1), (Q2, A2), …, (Qk-1, Ak-1)},
使用e2e-coref(End-to-End Neural Coreference Reso-lution)[30]实现指代消解, 并得到指代簇
Cr={c1, c2, …, cm}
和注意力权重
Cw={w1, k, w2, k, …, wk-1, k},
计算两两指称表示同一实体的概率, 选择得分较高的形成指代簇, 最后通过指代簇完善当前问题的语义信息.
指代簇表示指代消解模型识别的表示同一实体的指称集合.例如, 在对话“ Q2:主演是谁?A2:吴京; Q3:他还演过哪些电影?” 中, 指代簇{吴京, 他}表示“ 吴京” 和代词“ 他” 表示同一个实体.
以对话“ Q2:主演是谁?A2:吴京; Q3:他还演过哪些电影?” 为例, 指代消解过程如下.
1)使用e2e-coref对历史对话和当前问题进行指代消解, 得到指代簇{吴京, 他}.e2e-coref计算两两指称表示同一实体的概率, 选择得分高的形成指代簇.本例中, “ 吴京” 在Q2中首次出现, 索引为2, “ 他” 在Q3中出现, 索引为3, e2e-coref计算得到“ 吴京” 和“ 他” 表示同一实体的概率为0.95, 超过阈值0.5, 因此形成指代簇{吴京, 他}.
2)对指代簇中的实体进行升序排序, 先出现实体的索引在前.在本例中, 排序后的指代簇为[吴京, 他], 其中“ 吴京” 的索引为2, “ 他” 的索引为3.
3)将第一个实体作为基准实体, 从后往前逆序使用该实体替换同类中的其它实体.本例中基准实体为“ 吴京” , 从后往前替换, 将“ 他” 替换为“ 吴京” , 得到指代消解后的问题“ Q3:吴京还演过哪些电影?” .
4)识别消解后问题中的实体“ 吴京” , 并加入上下文查询子图中.
消解前, 问题“ Q3:他还演过哪些电影?” 与历史轮次的依赖权重为0.3(因为“ 他” 是一个代词, 依赖信息较弱); 消解后, 问题“ Q3:吴京还演过哪些电影?” 与历史轮次的依赖权重为0.7(因为“ 吴京” 是一个明确的实体, 依赖信息较强).这说明指代消解能有效增强问题的语义信息和依赖信息.
为了使用指代簇完善当前问题语义信息的描述, 首先对指代簇中的实体进行升序排序, 先出现实体的索引在前.然后将第一个实体作为基准实体, 从后往前逆序使用该实体替换同一类中的其它实体, 并删除多余索引, 得到指代消解后的问题Qk'.进一步识别Qk'中的实体信息并加入上下文查询子图中, 使用轮次为k的问答
γ k=wβ FFNN(
与当前问题最相关的实体, 对上下文查询子图进行扩展, 使Qk'主题转换时尽可能将新主题的实体扩展至子图中, 提高答案检索的准确率, 其中, wβ 表示可学习权重矩阵, FFNN(· )表示前馈神经网络(Feedforward Neural Network),
为了从词汇指代结构的角度计算依赖权重, 考虑对话历史中的实体与当前问题中的实体是否表示为同一类, 若是, 历史轮次将对当前问题产生影响.当节点有依赖信息时, 首次出现的轮次依赖权重最大, 距离当前轮次越近的历史轮次权重也越大, 依赖权重的计算如下所示:
wι =φ +
其中:C表示当前轮次; T(x)∈ dr表示节点x的轮次, dr表示轮次信息; φ =1或0时分别表示问题Qk'是否依赖于第一轮次且在依赖信息中; α 表示超参数衰减因子, 控制历史信息权重随轮次变化的衰减速率.
为了从字符语义的角度计算依赖权重, 扩展注意力机制, 由跨度区间向量拼接成整轮对话的注意力向量:
其中
利用前馈神经网络计算历史轮次对当前问题的影响权重:
$w_{j, k}=\frac{\exp \left(\boldsymbol{\gamma}_{k}\right)}{\sum_{i=1}^{k-1} \exp \left(\boldsymbol{\gamma}_{i}\right)} .$
为了更好地表示依赖的整体情况, 计算待加入节点与上下文查询子图的相关性, 最终权重为:
wd=
定义2 上下文查询子图Gsub=(Vsub, Esub, Q* , wd)是从全局知识图谱中动态提取的语义关联图, 用于支撑当前问题的推理.设全局知识图谱G=(V, E), 其中, V为节点集, E为边集, Vsub由基于消除歧义并恢复问题的完整语义信息Q* 的种子节点集与动态扩展节点集组成, 子图的演进过程受融合词汇指代结构与字符语义的双重依赖权重wd引导, 在保证证据链召回准确性的同时, 确保能通过相似度门槛实现对冗余空间的有效抑制.
对话式问答中的第一轮次不存在历史对话, 为了使第一轮次的答案搜索方式与其它轮次相同, 利用中心主题实体Ect和第一轮问题中的实体, 初始化上下文查询子图X1.
选择与问题Q1最相似的Top-k关系, 将与所选关系相连的所有三元组加入X1中, 生成扩展后的上下文查询子图
进一步提出构造和扩展上下文查询子图的方法, 融入依赖信息, 扩展上下文查询子图, 并给出相应的奖惩机制以限制子图过度增长, 具体步骤如下.
1)上下文查询子图实体添加.使用TAGME[31]识别问题Qk'中的实体, 并计算链接到Wikidata对应实体的可能性.将可能的实体加入上下文查询子图, 并在扩展时将这些实体赋予更大的权重, 保证扩展的实体与Qk'具有更高的相关性.
2)上下文查询子图扩展.基于下述3个特征, 计算节点加入查询子图的可能性, 将Xk的t(t≥ 1)跳(t-Hop)邻域内的可能实体或关系扩展至上下文子图中.
(1)待加入节点与当前问题的相关性.问题Qk'中的词为KG中的相关节点提供直接线索, 由于用户在问题词中的内容与KG术语之间存在词汇不匹配的现象, 因此, 基于word2vec[32]等词嵌入技术, 使用节点标签和问题词中词汇嵌入的余弦相似度定义待加入节点η 与问题词的相关性得分:
req(η , Qk')=cosnorm(ω v1, ω v2),
其中
ω v1=w2v(label(η )), ω v2=w2v(
cosnorm表示余弦相似度, w2v(· )表示word2Vec, label(· )表示节点标签, η ∈ N(Xk), N(Xk)表示上下文查询子图Xk的t跳邻域节点.
使用问题词的平均相似度分数定义待加入节点与当前整个问题的相似度分数:
$\operatorname{req}\left(\eta, Q^{k^{\prime}}\right)=\frac{1}{\tau} \sum_{i=0}^{\tau} \operatorname{req}\left(\eta, Q_{i}^{k^{\prime}}\right), $
其中τ 表示问题词去除停用词后的长度.
(2)待加入节点与上下文查询子图的相关性.在一段对话问答中, 当前谈论内容与历史对话往往具有相关性, 因此, 考虑待加入节点与上下文查询子图的相关性, 保证待加入节点与当前对话是同一主题内容.已知待加入节点η , 与问答qa相关的节点集合记为Lqa, 计算η 与Lqa中所有节点在上下文查询子图Xk中的最短跳数之和dt的相关性, 节点间的距离越近, 相关性越高.相关性计算公式如下:
$\operatorname{rec}\left(\eta, X^{k}\right)=\frac{\sum_{x \in X^{k}}\left(\frac{w_{d}(x) L_{q a}(x)}{d_{t}(\eta, x)}\right)}{\sum_{x \in X^{k}} L_{q a}(x)} .$
其中:Lqa(x)=1或0分别表示节点x是否为qa节点; wd(x)表示权重, 由式(1)计算得到; dt(η , x)表示节点η 与x之间的最短跳数.
(3)KG先验.利用KG中节点的使用频率反映该节点在用户问题中被询问的可能性, 初始时利用频率最大值进行归一化处理, 待加入节点η 的KG先验为:
prior(η , Kg)=freqnorm(η , Kg).
其中, freqnorm(· )表示节点在KG中出现的概率函数, Kg表示知识图谱.
3)边缘扩展分数计算.考虑待加入节点与问题的相关性、与上下文查询子图的相关性及KG先验, 使用FA(Fagin's Algorithm)[33]对上述3个指标进行聚合, 为不同的指标分配不同的权重, 计算边缘扩展分数:
$\begin{aligned}\text { frontier }\left(\eta, Q^{k^{\prime}}, X^{k}, K_{g}\right) & =h_{1}^{F} \operatorname{req}\left(\eta, Q^{k^{\prime}}\right)+ \\h_{2}^{F} \operatorname{rec}\left(\eta, X^{k}\right) & +h_{3}^{F} \operatorname{prior}\left(\eta, K_{g}\right), \end{aligned}$
其中,
4)扩展节点数量约束.为了防止上下文查询子图随对话轮次扩展而过度增长, 考虑上下文查询子图大小及对话轮次, 上下文查询子图越大或对话轮次越多, 上下文查询子图的扩展能力越弱.每轮次扩展节点的数量为:
Tr=
其中, Turn表示节点标签, numnodes表示实体加入当前问题后上下文查询子图的节点数.
5)子图扩展终止规则.选择Tr个节点加入上下文查询子图中, 考虑知识图谱中实体分支发散导致的语义噪声干扰及检索空间冗余, 当待加入节点的边缘扩展分数低于阈值θ 时, 停止扩展.同时, 单轮扩展节点数不得超过动态计算的阈值Tr, 也不得超过当前子图节点数的50%.对话轮次增加时, 为了防止由于历史上下文堆叠导致的扩展节点数随轮次呈爆炸式增长, 引入衰减因子, 对远距离轮次的扩展预算进行惩罚, 使旧轮次实体的扩展节点数呈受控衰减.当前上下文查询子图的规模增加时, 为了防止搜索空间无限扩张, 设计饱和度惩罚机制, 实时监测子图大小, 当规模接近预设阈值时, 自动提高由权重
ExpandNum(k, num(Xk))=⌊h2Fγ (k-i)
其中:num(· )表示上下文查询子图; h2F表示初始状态下每一跳允许的最大分支数, 保证搜索空间的初始覆盖率; γ (k-i)表示对话轮次增加时的惩罚机制;
最终生成扩展后的上下文查询子图
将当前轮次加入的节点称为边缘节点, 在对答案候选节点评分时, 将边缘节点视为问题Qk'最相关的节点.考虑当前问题Qk'依赖历史轮次节点的可能性, 利用候选答案节点到历史节点的距离及历史节点影响候选节点的权重大小, 从
Ak=arg
其中
$\begin{array}{l}\theta_{1}(A)=\frac{h_{1}^{B}}{r}\left(\sum_{i=1}^{r} \frac{\operatorname{rec}\left(F_{i}^{k}, X_{+}^{k}\right)}{d_{t}\left(A, F_{i}^{k}\right)}\right), \\\theta_{2}(A)=h_{2}^{B}\left(\frac{\sum_{x \in X_{+}^{k}} \frac{w_{d}(x) L_{q a}(x)}{d_{t}(A, x)}}{\sum_{x \in X_{+}^{k}} L_{q a}(x)}\right), \end{array}$
rec(
最后, 从候选答案集合Ak中, 筛选得分最高的一个或多个实体节点作为问题Qk'的最终预测答案.
CKC具体步骤如算法1所示.
算法1 CKC
输入 对话中心主题实体Ect, 总对话轮次T,
对话的所有问题Q={Q'1, Q'2, …, QT'},
知识图谱Kg
输出 每轮预测的答案Apre={A1, A2, …, AT}
k← 1; X1← Ect
while k≤ T do
Xk← Xk∪
for each η ∈ N(Xk) do
req(η , Qk') //计算与问题相关性
rec(η , Xk) //计算与上下文查询子图的相关性
prior(η , Kg) //计算先验
L←
{
end for
$\begin{array}{r}\operatorname{Tr} \leftarrow \min \left(\frac{2}{\operatorname{Turn}-1} \log _{2}\left(\text { num }_{\text {nodes }}\right), \right. \\\left.\operatorname{ExpandNum}\left(k, \operatorname{num}\left(X^{k}\right)\right)\right)\end{array}$
//计算扩展节点数
{
for each A∈
answerscore(A)=θ 1(A)+θ 2(A) //计算候选答案
end for
Ak← arg
k← k+1
end While
return {A1, A2, …, AT}
每轮次Xk邻域的节点数为n, 第一轮后上下文查询子图中的节点数为m, 每轮次选择Tr个与节点相关的三元组加入上下文查询子图, 当上下文查询子图并不包含待加入三元组时, 最多将2Tr节点加入上下文查询子图.当上下文查询子图包含待加入的三元组时, 最少有Tr个节点加入上下文查询子图.因此, 最坏情况下T轮的时间复杂度为
O(T(n+m)+2T(T-1)Tr),
最好情况下的时间复杂度为
O(T(n+m)+T(T-1)Tr).
本文使用Christmann等[13]创建的大规模对话KBQA数据集— — ConvQuestions数据集(https://convex.mpi-inf.mpg.de/).该数据集将Wikidata作为知识库, 包含books、movies、music、soccer、tv_series领域的主题, 每段对话包含5轮问答对.训练集包含6 720段对话, 验证集包含2 240段对话, 测试集包含2 240段对话, 训练集、验证集、测试集的对话数量在5个领域中都均匀分布.
由于本文方法是对候选答案实体进行评分并生成答案排序列表, 针对某一问题可能包含一个或多个正确答案, 因此使用Top-1准确率(P@1)、Top-5命中率(Hit@5)和平均倒数排名(Mean Reciprocal Ranking, MRR)评估模型性能.P@1表示得分最高的候选答案是否为正确答案.Hit@5表示前5个最高得分候选答案中是否命中正确答案, 用1和0分别表示是否命中.MRR表示正确答案排名的倒数, 值越大效果越优.使用正确率评判查询子图的有效性, 表示上下文查询子图中包含正确答案子图的比例.P@1、Hit@5和MRR的计算公式分别如下:
$\begin{array}{l} P @ 1=\frac{1}{N} \sum_{i=1}^{N} \sigma(\operatorname{rank}(A)=1), \\ H i t @ 5=\frac{1}{N} \sum_{i=1}^{N} \sigma(\operatorname{rank}(A) \leqslant 5), \\ M R R=\frac{1}{N} \sum_{i=1}^{N} \frac{1}{\operatorname{rank}(A)}, \end{array}$
其中, rank(A)表示正确答案A的排名, σ (· )表示指示函数, 通过取值为1或0表示内容是否为真.
操作系统为Ubuntu 20.04.1, CPU处理器为Intel(R) Xeon(R) Silver 4210R @2.40 GHz, GPU为RTX 2080 Ti, 内存64 GB.
本文选择如下7种对比模型进行性能对比.
1)CONVEX[13].无监督的图探索模型, 在每一轮次中将问题与相邻的实体匹配, 用于扩展子图, 通过节点分类器在子图中找到候选答案, 是Conv-Questions数据集上的基准方法.
2)文献[16]模型.基于图神经网络的焦点实体预测模型, 建模对话中出现的实体信息, 采用基于图神经网络的焦点实体预测器分别预测对话中的焦点实体和当前生成的新焦点实体, 将预测后的焦点实体输入预测器中并生成答案.
3)ToG[27].基于思维树图的模型, 在知识图谱上构建思维树以指导答案检索, 利用图结构捕捉对话中的推理路径.
4)D2A(Dialog-to-Action)[34].端到端的KGQA神经网络模型, 使用基于灵活语法的生成模型管理对话记忆, 包含查找、比较、计数、复制历史逻辑表达等多种逻辑操作, 使用自顶向下的方式预测当前问题的逻辑表达.
5)GCoQA(Generative Retrieval for Conversational Question Answering)[35].为段落分配独特的标识符, 通过编码器-解码器体系结构逐个标记生成标识符以检索段落, 在每个解码步骤中关注对话上下文的关键标记, 高效实现对话式问答.
6)EXPLAIGNN(Explainable Conversational Ques-tion Answering over Heterogeneous Graphs via Iterative Graph Neural Networks)[36].基于解释图神经网络的对话式问答模型, 构建解释图以捕捉对话中的推理路径, 利用图注意力机制学习实体和关系的表示.
7)OntoTune(Ontology-Driven Self-Training Fine-Tuning Framework)[37].基于本体驱动自训练的知识增强大语言模型, 利用知识图谱中的本体(Onto-logy)结构指导大语言模型的自训练过程, 在无监督状态下实现大语言模型与结构化知识的语义对齐.
为了测试各模型在对话式问答任务上的性能, 在ConvQuestions数据集上进行对比测试, 结果如表1所示, 表中黑体数字表示最优值, 斜体数字表示次优值.由表可见, 相比CONVEX, CKC在P@1指标上提升6.6%, 在MRR指标上提升6.8%, 在Hit@5指标上提升6.7%.由此可看出, CKC效果较优, 可提升答案检索的准确率.原因在于CKC有效利用对话中的依赖信息, 提出的子图扩展方式使得更多的正确答案能加入上下文查询子图中, 验证其有效性.
| 表1 各模型在ConvQuestions数据集上的测试结果 Table 1 Test results of different models on ConvQuestions dataset |
本文还在ConvQuestions数据集各领域上进行测试, 结果如表2~表4所示, 表中黑体数字表示最优值, 斜体数字表示次优值.由表2可见, 在P@1指标上, 相比CONVEX, CKC最高在tv_series领域上提升9%, 最低在books领域上提升3.4%.相比ToG, CKC最高在movies领域上提升9.1%.相比文献[16]模型, CKC在tv_series领域上提升7%.结果表明, CKC在一定程度上能提升对话式问答的准确率.
| 表2 各模型在ConvQuestions各领域上的P@1值 Table 2 P@1 of defferent models in different fields of ConvQuestions dataset |
| 表3 各模型在ConvQuestions各领域上的MRR值 Table 3 MRR of different models in different fields of ConvQuestions dataset |
| 表4 各模型在ConvQuestions各领域上的Hit@5值 Table 4 Hit@5 of different models in different fields of ConvQuestions dataset |
由表3可见, 在MRR指标上, 相比CONVEX, CKC最高在tv_series领域上提升10.1%, 最低在books领域上提升3.4%.相比ToG, CKC最高在movies领域上提升5.3%.结果表明, CKC得到的正确答案排名更靠前, 效果也更优.由表4可见, 在Hit@5指标上, 相比CONVEX, CKC最高在music领域上提升10%.相比ToG, CKC最高在soccer领域上提升8.2%.结果表明, CKC在面对复杂知识实体检索时展现出更强的召回能力和更高的覆盖率.
ConvQuestions各领域上的数据特征统计结果如表5所示, 表中实体密度=实体数/词数.由表可看出, tv_series领域上的平均每轮对话指代次数为0.65, 显著高于其它领域, 远高于books领域的0.32.同时, tv_series领域上的实体密度为0.28, 也高于books 领域的0.24.这说明tv_series 领域的对话中包含更密集的指代现象和实体分布, 文本的上下文依赖性更强.由于CKC的核心之一是指代消解模块, 能有效还原对话中的隐式语义, 因此对于这种具有高频指代的tv_series领域, 能更显著地捕捉实体间的复杂关联, 从而实现9%的性能提升, 而对于指代频率较低、语义联系相对独立的books领域, 仅提升3.4%.这从数据特征维度验证CKC的有效性, 也进一步说明指代消解对于高频指代领域的对话式问答任务具有重要的实用价值.
| 表5 ConvQuestions各领域上的数据特征统计结果 Table 5 Data characteristic statistics in different fields of ConvQuestions dataset |
3.3.1 指代消解
本文中的指代消解主要用于完善当前问题的语义信息和计算依赖信息, 相当于对话式问答的预处理步骤.因此, 分别从将不同指代消解模型与对话式问答模型结合、指代消解对对话式问答所起作用两个方面测试指代消解模块的有效性.选择如下指代消解模型:e2e-coref[30]、BERT(Bidirectional Encoder Representations from Transformers)[38]、SpanBERT[39].它们分别与CQA结合后, 在ConvQuestions数据集上的指标值对比如表6所示.
| 表6 各指代消解模型在ConvQuestions数据集上的测试结果 Table 6 Test results of different coreference resolution models on ConvQuestions dataset |
由表6可见, 仅使用基于指代消解得到的依赖信息时, 指代消解模型的准确率和召回率会影响对话式问答准确率, 效果越优的指代消解模型得到的指代簇越精准、全面, 越有利于将更丰富的依赖信息用于指导CQA, 越能提升其依赖信息利用的有效性.此外, 在e2e-coref的基础上加入注意力机制(Attention)后计算依赖信息, 效果优于未使用注意力机制的其它模型, 由此也验证CKC的有效性.
针对指代消解在对话式问答模型中每个部分的作用进行测试, 选择如下模型.1)CONVEX+inidata, CONVEX未使用指代消解数据.2)CONVEX+crr- data, CONVEX加上指代消解数据.3)crrdata+dt, 在指代消解数据上添加依赖信息.4)crrdata+qsm, 在指代消解数据上结合问题相似度均值.5)crrdata+addentity, 使用指代消解数据, 在扩展上下文子图前加入当前问题的实体.6)CKC.综合crrdata+dt、crr- data+qsm和crrdata+addentity.
完整ConvQuestions数据集上的指代消解的有效性测试结果如表7所示, ConvQuestions数据集各领域上的指代消解的有效性测试结果如表8和表9所示, 表中黑体数字表示最优值.
| 表7 各模型在ConvQuestions数据集上指代消解测试结果 Table 7 Coreference resolution test results of different models on ConvQuestions dataset |
| 表8 各模型在books、movies领域上的指代消解测试结果 Table 8 Coreference resolution test results of different models in the fields of books and movies |
| 表9 各模型在music、soccer、tv_series领域上的指代消解测试结果 Table 9 Coreference resolution test results of different models in the fields of music, soccer and tv_series |
1)若对CONVEX不作任何改进而直接使用指代消解数据(CONVEX+crrdata), 由于缺少对依赖信息的充分利用, 难以有效提升准确率.
2)相比CONVEX+crrdata, 指代消解数据上添加依赖信息(crrdata+dt), 得到的指标值都有所提升, 说明添加依赖信息的有效性.P@1指标在books领域上提升最大(约5%), 在tv_series领域上提升最小(约0.1%).MRR、Hit@5指标有升有降, 但MRR指标总体呈上升趋势.因此, 添加依赖信息更有利于提高查询子图的正确率和答案检索的准确率.
3)相比CONVEX+crrdata, 在指代消解数据上结合问题相似度均值(crrdata+qsm), 得到的指标值都有所提升, 说明相似度均值的有效性.使用均值表示问题相似度可更好地反映问题总体的相似度, 受特殊情况影响较小, 从而提升指代消解的有效性.P@1指标在music领域上提升约7.2%, 在tv_series领域上下降约1.5%, 但总体呈增长趋势.MRR指标在tv_series领域上下降约0.7%, 总体也呈增长趋势.Hit@5指标在movies领域上下降约1.4%, 在其它领域上均呈上升趋势, 故总体也呈增长趋势.由于每个领域的数据上下文指代和省略分布不均匀, 使得单个领域上各指标升降不一致.
4)相比CONVEX+crrdata, 使用指代消解数据, 在扩展上下文子图前加入当前问题的实体(crrdata+addentity), 得到的指标值中P@1、MRR值均呈上升趋势, Hit@5值略微下降, 说明加入当前问题实体再进行上下查询子图扩展这一方法是有效的.P@1指标在movies领域上提升最大(约8.2%), 在soccer领域上提升最小(约1.4%).Hit@5指标在books、music、soccer领域上呈下降趋势, 但总体上也是略微下降.结果表明在上下文查询子图扩展前先加入当前问题的实体并赋予更大权重, 可有效提升答案检索的准确率.
5)相比CONVEX+crrdata, CKC的所有指标值都有所提升.相比CONVEX+inidata, CKC的P@1、MRR指标都有一定提升, P@1指标提升约5%, Hit@5指标超过CONVEX+crrdata并与CONVEX+inidata几乎相同.上述情况说明加入指代消解的有效性, 也验证使用均值表示相关性、添加依赖信息辅助答案检索、上下文查询子图扩展前先加入问题实体等策略都有利于提升P@1值.MRR指标的提升也表明上述策略可使更多的正确答案排名靠前.
3.3.2 上下文查询子图
为了验证改进的上下文查询子图的有效性, 设计轮次扩展数与CONVEX一致, 从第2轮开始每轮依次扩展10, 4, 5, 5个节点, 最后在测试数据集上统计上下文查询子图中包含正确答案的子图的正确率, 结果如表0所示.由表可见, CKC中子图扩展方法能获得更多的正确答案, 更有利于答案检索.
为了验证CKC中各模块对性能的贡献, 进行消融实验, 依次移除指代消解模块、奖惩机制、依赖信息后的性能如表11所示.
由表11可看出, 移除指代消解模块后, P@1指标从0.230降至0.125, 降幅约45.6%, 表明指代消解模块在补全对话语义、精准定位关键实体中的决定性作用.移除奖惩机制或依赖信息虽然对P@1指标的影响略小于指代消解模块, 但导致MRR指标从0.257骤降至0.113, 降幅达56%, 揭示这两个机制在抑制子图噪声、优化答案排序方面的关键作用.
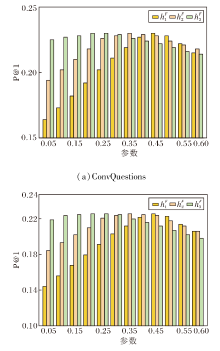
在ConvQuestions数据集上验证超参数的敏感性.首先定义
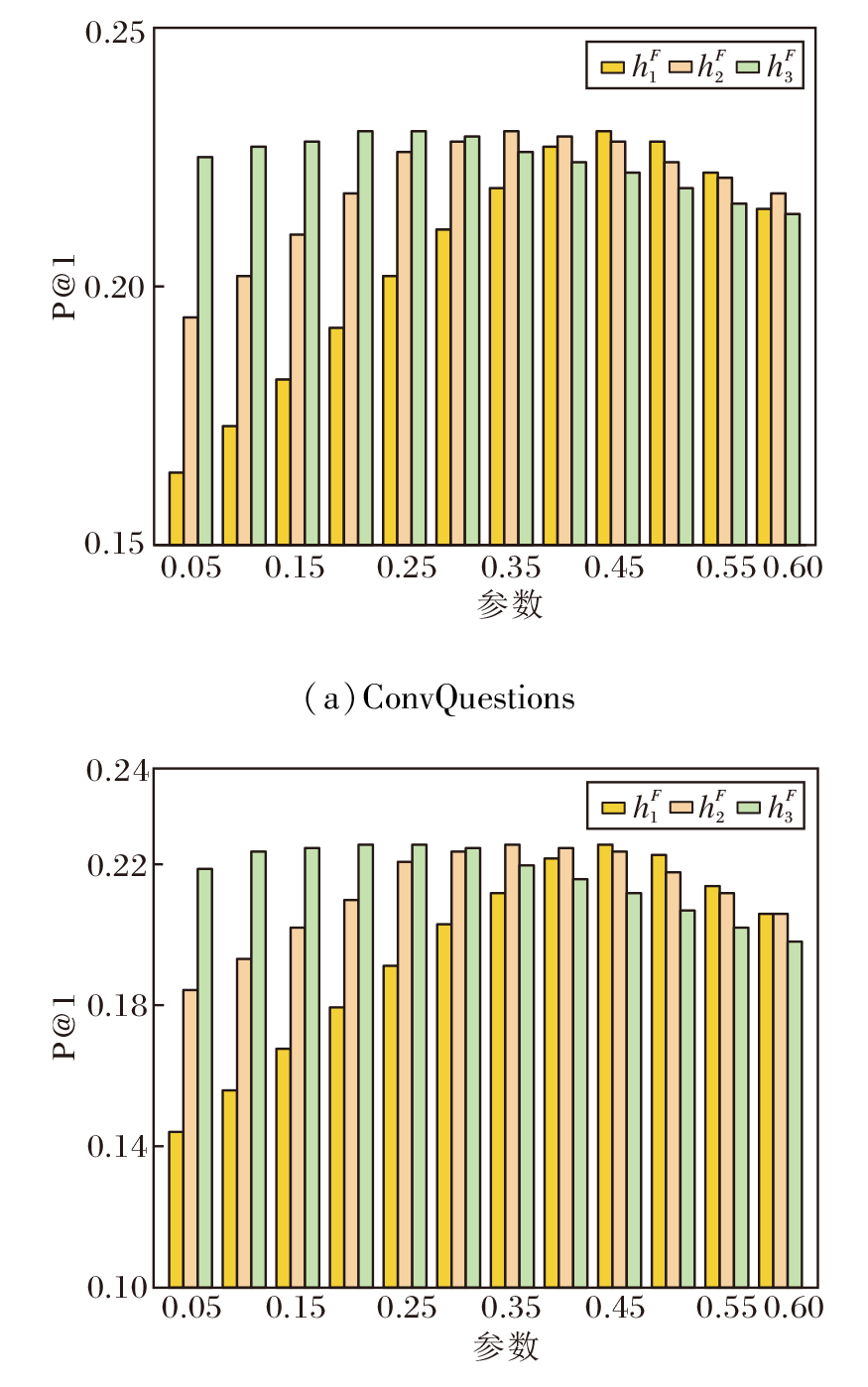 | 图2 |
由图2可见,
为了验证子图扩展终止条件中阈值θ 对CKC性能的影响, 在ConvQuestions验证集上进行敏感性测试.实验设置Kmax=15, τ =0.01, 相应结果如表12所示.
由表12可见, 当θ =0.5时, P@1值(0.230)与MRR值(0.257)均达到峰值, 表明θ 是语义过滤的帕累托最优解, 能有效平衡证据的完整性并抑制干扰信息.当θ < 0.4时, 虽然子图涵盖更多的候选节点, 但由于引入大量弱相关的背景噪声, 导致注意力机制分散, 使得P@1指标显著下降, 单轮推理耗时大幅增至482 ms.反之, 当θ > 0.6时, 子图规模迅速缩减, 过于严苛的约束导致在处理长程依赖或复杂多跳问题时, 关键推理节点被提前剪枝, 导致MRR指标下降.最终, 选定θ =0.5, 不仅保证检索精度, 还将单轮推理耗时优化至186 ms左右, 相比θ =0.3时, 降低约61.4%的计算开销.上述分析充分验证该终止条件在提升模型工程实践效率方面的显著作用.
本文提出基于知识图谱与指代消解的对话式问答模型(CKC), 利用指代消解完善问题的语义信息.将依赖信息用于指导上下文查询子图扩展和答案检索, 利用奖惩机制防止查询子图过度增长, 提升对话式问答的准确率.在ConvQuestions数据集上的实验验证CKC的有效性.今后考虑将模型用于口语化问句的解析, 进一步提升上下文查询子图的准确率.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|