
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
空-频域交替自注意力的可见光遥感图像超分辨率重建网络
[刘杰1  , 程立明
, 程立明1 ]
, 程立明]
|
|



作者简介:
程立明,硕士研究生,主要研究方向为深度学习、图像处理等.E-mail:chengliming1220@163.com.
可见光遥感图像的超分辨率重建需协同优化局部纹理恢复与长程结构一致性,传统Transformer网络虽能建模长程依赖,却在高频纹理上敏感度不足.为此,文中提出空-频域交替自注意力的可见光遥感图像超分辨率重建网络,通过串行交替的频域自注意力与空间自注意力,分别建模图像的局部纹理关系与跨区域长程依赖.设计相位感知频域自注意力机制,实现频域自注意力计算,显式建模频域相位差,增强高频纹理重建能力.构建通道增强置换自注意力机制,实现空间域自注意力计算,加入通道注意力,增强特征表征能力,强化全局结构一致性.实验表明,文中网络可有效解决高频信息缺失与结构断裂问题,提升图像重建质量.
About Author:
CHENG Liming, Master student. His research interests include deep learning and image processing.
Super-resolution reconstruction of visible-light remote sensing images requires collaborative optimization of local texture recovery and long-range structural consistency. Although traditional Transformer networks can model long-range dependencies, they lack sufficient sensitivity to high-frequency textures. To address this issue, a visible-light remote sensing image super-resolution network based on space-frequency alternating self-attention(SFASR) is proposed. Local textures and cross-regional long-range dependencies are modeled respectively through serially alternating frequency domain and spatial domain self-attention. Specifically, a phase-aware frequency self-attention mechanism is designed to enable frequency domain self-attention computation, explicitly modeling phase differences for enhanced high-frequency texture reconstruction. Furthermore, a channel-enhanced permutation self-attention mechanism is constructed to implement spatial domain self-attention computation. By incorporating channel attention, the mechanism strengthens feature representation and global structural consistency. Experimental results show that SFASR effectively addresses the issues of high-frequency information loss and structural breakage, and improves image reconstruction quality.
遥感图像反映依托卫星、航空飞行器、无人机等平台获取的地球表面信息, 其有助于实现地球表面全域覆盖监测.作为现代地球观测的核心手段, 遥感技术凭借其全球覆盖、多维度信息融合和动态监测能力, 在环境监测[1]、土地利用[2]、地物目标检测[3]等领域发挥不可替代的作用.遥感图像分辨率越高, 捕捉的地表细节越丰富, 地物目标识别精度越高, 动态监测敏感性越强.受限于物理硬件及动态环境带来的退化影响, 通常难以直接得到高分辨率(High Resolution, HR)遥感图像.因此, 从软件角度出发, 利用遥感图像超分辨率重建(Remote-Sensing Image Super-Resolution, RSISR)技术, 将成像后的低分辨率(Low Resolution, LR)遥感图像重建为高分辨遥感图像是目前研究热点之一[4].
自Dong等[5]在卷积神经网络(Convolutional Neural Network, CNN)的基础上提出SRCNN(Super-Resolution Convolutional Neural Network)以来, 基于CNN的超分辨率重建技术因优秀的性能而备受关注[6].随后, Leibel等[7]提出msiSRCNN, 利用遥感数据集训练SRCNN, 首次实现基于CNN的RSISR网络.相比传统RSISR网络, CNN可直接学习低分辨率图像与高分辨率图像之间的复杂映射关系, 重建更自然的纹理和结构.
尽管基于CNN的超分辨率重建网络在图像重建领域取得巨大成功, 但是CNN存在全局上下文感知能力受限的问题, 难以建模图像中的长距离依赖关系.为此, Transformer[8]架构因其自注意力机制可直接建模长程依赖而受到研究者的关注, 其自注意力机制动态计算全图像素间的长程依赖权重, 突破CNN的局部感知瓶颈.2020年, Dosovitskiy等[9]提出ViT(Vision Transformer), 将Transformer框架应用于视觉任务领域, 取得优越性能, 推动视觉模型从CNN向Transformer的范式转变, 但ViT极大的计算复杂度严重制约其在高分辨率图像超分辨率重建上的应用.为了解决上述问题, Liang等[10]提出用于图像恢复领域的SwinIR, 将全局计算拆解为局部窗口内的密集交互与跨窗口的稀疏关联, 将计算复杂度由平方式增长变成线性增长, 显著降低计算复杂度.但是, SwinIR存在窗口间信息交互受限的问题, 增大窗口会增加计算复杂度.Zhou等[11]提出基于置换注意力的SRFormer, 大幅减少因使用大窗口而激增的计算复杂度.Chen等[12]提出RG-SA(Recursive-Generalization Self-Attention), 利用递归聚合输入特征, 生成固定大小的特征图, 使用交叉注意力捕获全局特征.
2021年, Ye等[13]首次将Transformer引入RSISR领域, 此后各种基于Transformer的RSISR网络被陆续提出.Lei等[14]考虑到遥感图像的复杂性, 提出TransENet(Transformer-Based Enhancement Net-work), 构建多阶段增强的Transformer结构, 融合多尺度高低维特征, 突破传统模型依赖上采样层且忽略高维空间特征的限制.Shang等[15]提出HSTNet(Hybrid-Scale Hierarchical Transformer Network), 设计混合尺度特征模块, 挖掘单幅遥感图像在不同尺度下的内部结构相似性, 并引入跨尺度增强Trans-former, 捕获长距离依赖关系, 提升网络判别能力.针对遥感图像超分辨率中Transformer网络计算冗余和缺乏多尺度建模的问题, Xiao等[16]提出TTST(Top-k Token Selective Transformer), 动态筛选重要Token, 精简自注意力计算, 显著降低计算复杂度.
综上所述, 基于Transfomer的超分辨率重建网络虽能直接建模长程依赖, 但在重建过程中容易丢失细节信息.遥感图像中不同频率的信号分布不均, 高频细节的丢失将直接导致重建图像的地物结构失真, 这使得遥感图像的超分辨率重建对网络的高频特征提取能力要求严苛.传统空间自注意力机制不仅计算复杂度较高、缺乏对通道维度的显式建模, 而且仅在单一空间域进行计算, 难以有效重建遥感图像中的高频细节信息.
为此, 本文提出空-频域交替自注意力的可见光遥感图像超分辨率重建网络(Visible-Light Remote Sensing Image Super-Resolution Network Based on Space-Frequency Alternating Self-Attention, SFASR).设计频域与空间域协同优化的超分辨率重建网络框架, 利用一个跳跃连接模块校正频域特征和空间域特征之间的语义错位, 兼顾局部细节恢复与长程结构一致性.设计相位感知频域自注意力机制(Phase-Aware Frequency Self-Attention, PAFSA), 判别性地调整不同频段信息, 精准增强关键频率成分, 提升遥感图像细节纹理重建能力.空间自注意力部分引入通道增强置换自注意力机制(Channel-Enhanced Permutation Self-Attention, CPSA), 加入通道注意力分支, 显式建模通道重要性, 在提升特征表征能力的同时显著降低模型参数量.
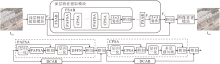
本文提出空-频域交替自注意力的可见光遥感图像超分辨率重建网络, 主要由浅层特征提取模块、深层特征提取模块、图像重建模块组成.网络整体架构如图1所示.
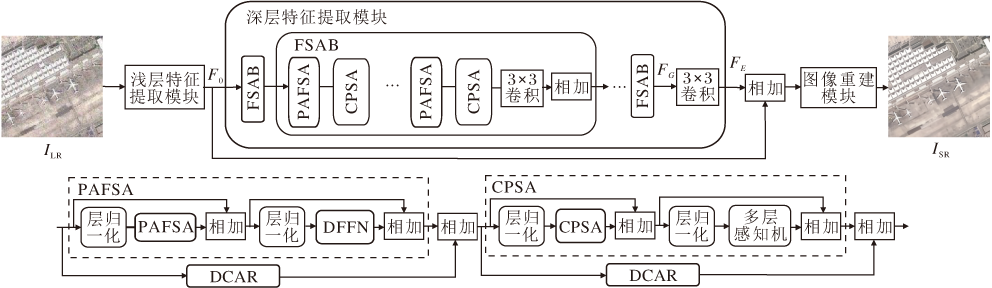 | 图1 SFASR整体架构Fig.1 Overall architecture of SFASR |
浅层特征提取模块由一个3× 3卷积构成, 将低分辨率图像映射至高维空间, 得到浅层特征:
F0=Conv3× 3(ILR),
其中, ILR表示低分辨率图像, Conv3× 3(· )表示3× 3卷积.
深层特征提取模块由G个频域-空间域自注意力残差块(Frequency-Space Self-Attention Block, FSAB)和1个3× 3卷积级联构成, 得到深层特征:
FE=Conv3× 3(FG),
其中, Conv3× 3(· )表示3× 3卷积,
FG=FSAG(FSAG-1(…FSA1(F0)…)),
表示第G层特征, FSAi(· )表示第i个FSAB, F0表示浅层特征.
FSAB由M个频域与空间域串行交替的Trans- former块和1个卷积层构成, 形成频域-空间域闭环优化路径.频域自注意力使用本文设计的相位感知频域自注意力机制(PAFSA), 负责捕获局部细节特征; 空间自注意力使用通道增强置换自注意力机制(CPSA), 负责直接建模长程依赖.该串行结构通过有序交替的频域自注意力和空间域自注意力提取图像特征, 每一阶段的输出不仅反映当前域的特征优化结果, 同时也承载前序阶段提取的互补信息.随着网络深度的增加, 局部纹理细节与全局结构语义在交替中不断相互优化, 最终实现局部纹理恢复与长程一致性的统一.
图像重建模块通过3× 3卷积和亚像素卷积进行图像上采样, 最终输出重建图像:
ISR=Hup(F0+FE),
其中Hup(· )表示重建模块.
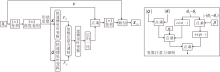
遥感图像超分辨率重建需精准重建高频细节[17].研究证明, 传统空间自注意力机制可视为一个低通滤波器[11], 单一的空间自注意力机制虽然可直接建模长程依赖, 但在重建过程中容易丢失细节信息.为此, 本文设计相位感知频域自注意力机制(PAFSA), 结构如图2所示.
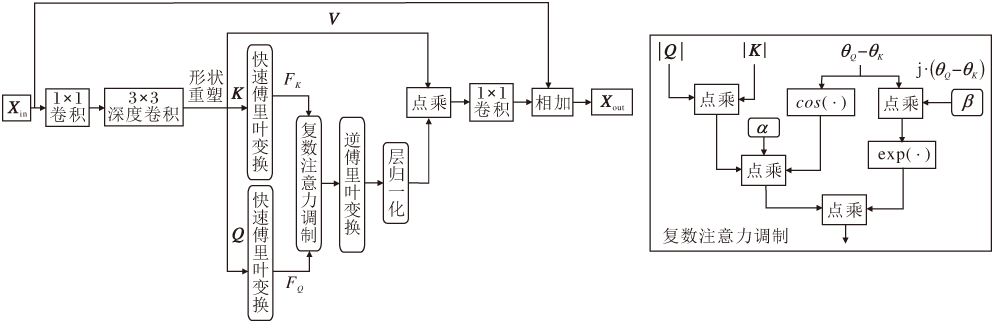 | 图2 PAFSA结构图Fig.2 PAFSA architecture |
PAFSA利用复数注意力调制(Complex Atten-tion Modulation, CAM)显式建模频域中的相位差, 并引入注意力缩放因子与相位偏移补偿因子, 动态调节幅度交互与相位偏移, 实现频率响应的自适应校正.针对遥感图像中对相位变化敏感的地物轮廓和复杂纹理, CAM可精准增强关键频率成分, 提升几何结构的保真度.
在PAFSA中, 给定输入特征Xin∈ RH× W× C, 其中, H、W分别表示特征图的高、宽, C表示通道数.首先通过1× 1卷积和3× 3深度卷积得到查询Q、键K及值V.然后将Q和K分成T个不重叠的正方形窗口并进行快速傅里叶变换(Fast Fourier Transfor-mer, FFT), 得到查询和键的频域表示:
FQ=F(Q), FK=F(K),
其中F(· )表示快速傅里叶变换.随后在频域中估计FQ与FK的相关性, 分别对FQ与FK进行幅度交互和相位交互.
幅度交互通过相位差余弦值加权幅度的乘积, 量化相位一致性, 抑制非一致频率分量.本文引入可学习通道缩放因子, 增强关键特征并抑制噪声, 相应幅度交互结果为:
amp =α |FQ|☉|FK|cos(θ Q-θ K),
其中, θ Q表示FQ的相位角, θ K表示FK的相位角, α 表示可学习通道缩放因子, cos(· )表示余弦变换, ☉表示逐元素相乘.
相位交互通过相位差计算相位相似度, 引入可学习相位偏移因子, 对各通道相位偏移强度进行动态补偿, 从而保留结构敏感的高频信息, 相应相位交互结果为:
phase =exp(j· β (θ Q-θ K)),
其中, j表示虚数单位, β 表示可学习相位偏移因子.
最终, 融合两者的频域交互结果, 经傅里叶逆变换恢复空间特征, 得到注意力权重:
A=F-1(amp☉phase),
其中F-1(· )表示傅里叶逆变换.
对注意力权重A进行层归一化, 再与V逐元素相乘, 实现频域感知的空间加权调制.最后, 通过一个1× 1卷积生成输出特征:
Xout=Xin+Conv1× 1(L(A)☉V),
其中, Conv1× 1(· )表示1× 1卷积计算, L(· )表示层归一化.由于频域特征的特殊性, 传统的前馈网络难以提高特征表达能力, 因此PAFSA后续的前馈网络采用Kong等[18]提出DFFN(Discriminative Frequency Domain-Based Feed-Forward Network).
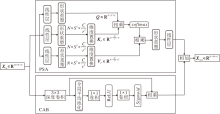
传统空间自注意力机制计算所有空间位置之间的成对相似性以建模长程依赖, 计算复杂度和内存消耗随图像空间尺寸呈平方级增长, 存在严重的计算复杂度瓶颈[19].并且, 基于空间相关性生成注意力权重, 无法根据各通道的语义内容或特征显著性进行自适应调整, 缺乏对通道维度重要性的显式建模能力.为此, 本文提出通道增强置换自注意力机制(CPSA), 结构如图3所示.
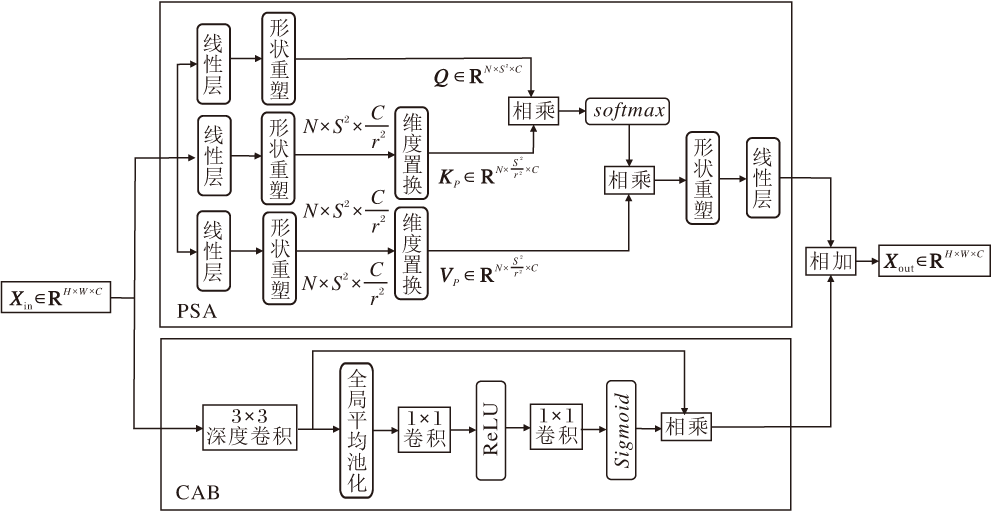 | 图3 CPSA结构图Fig.3 CPSA architecture |
CPSA由两个并行分支构成.1)置换自注意力分支(Permuted Self-Attention, PSA), 采用通道压缩策略对键、值矩阵进行通道降维, 并将空间维度信息置换通道维度, 扩大窗口的同时, 不引入额外的计算负担.2)通道注意力分支(Channel Attention Block, CAB).由于自注意力机制仅建模序列元素间的全局依赖, 忽视特征向量内部通道维度的重要性建模, 所有通道被平等处理, 导致关键特征容易被噪声淹没.此外, PSA通过线性投影进行通道压缩, 缺乏对特征语义的上下文感知, 容易在降维中丢失关键重建信息.CAB通过全局平均池化聚合空间上下文信息, 自适应地增强判别性通道和抑制噪声响应.将CAB置于PSA外部, 既保留其高效性, 又有效弥补语义信息保留方面的缺陷.
置换注意力分支中, 给定输入Xin∈ RH× W× C, 将Xin分成N个固定大小的窗口X∈
Q=LQ(X)∈
K=LK(X)∈
V=LV(X)∈
其中L(· )表示线性变换.为了避免大窗口带来的计算量增加, K与V的通道压缩率设为r2.随后将K与V的空间维度信息置换到通道维度, 得到Kp∈
$\operatorname{PSA}\left(\boldsymbol{Q}, \boldsymbol{K}_{p}, \boldsymbol{V}_{p}\right)=\operatorname{softmax}\left(\frac{\boldsymbol{Q} \boldsymbol{K}_{p}^{\mathrm{T}}}{\sqrt{d_{k}}}+\boldsymbol{B}\right) \boldsymbol{V}_{p}, $
其中, B表示相对位置偏置, dk表示自注意力头的维度.
通道注意力分支由1个通道注意力和1个3× 3深度卷积组成, 为了避免通道注意力分支和置换注意力分支在优化视觉表征上可能存在的冲突, 将一个常数γ 与通道注意力分支输出相乘, 得到输出特征:
Xout=PSA(Xin)+γ · CAB(Xin),
其中CAB(Xin)表示通道注意力分支计算.
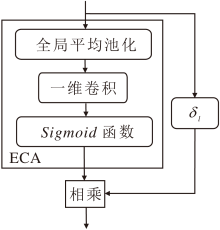
在频域与空间域Transformer交替架构中, PAFSA输出局部频域特征, CPSA输出长程空间特征, 二者特征维度存在语义错位.这种跨域特征的语义不一致会削弱网络对高频细节与长程依赖的联合建模能力.为此, 本文设计双分支通道自适应残差模块(Dual-Branch Channel-Adaptive Residual, DCAR), 结构如图4所示.DCAR部署于Transformer块外侧, 通过校正频域与空间域之间的语义错位, 实现频域特征与空间域特征的串行协同优化.
DCAR包含两个互补分支.
1)静态通道缩放因子, 引入可学习的全局权重参数, 系统性地增强关键通道的特征响应强度, 同时显著抑制冗余通道中的噪声干扰.
2)ECA(Efficient Channel Attention)[20], 基于一维卷积机制实现轻量级通道注意力计算, 通过局部跨通道交互自适应生成通道权重, 精准建模特征层间的分布差异.
DCAR并行连接Transformer块的输入与输出, 实现通道维度的动态-静态联合校准.具体输出:
Zl=Bl(Zl-1)+δ l· ECA(Zl-1)· Zl-1,
其中, Bl表示第l个Transformer块, Zl-1表示输入, δ l表示第l个静态通道缩放因子, ECA(· )表示高效通道注意力计算.
DCAR整合不同自注意力模块特征, 促进更多信息向深层网络流动, 提升网络特征提取能力.
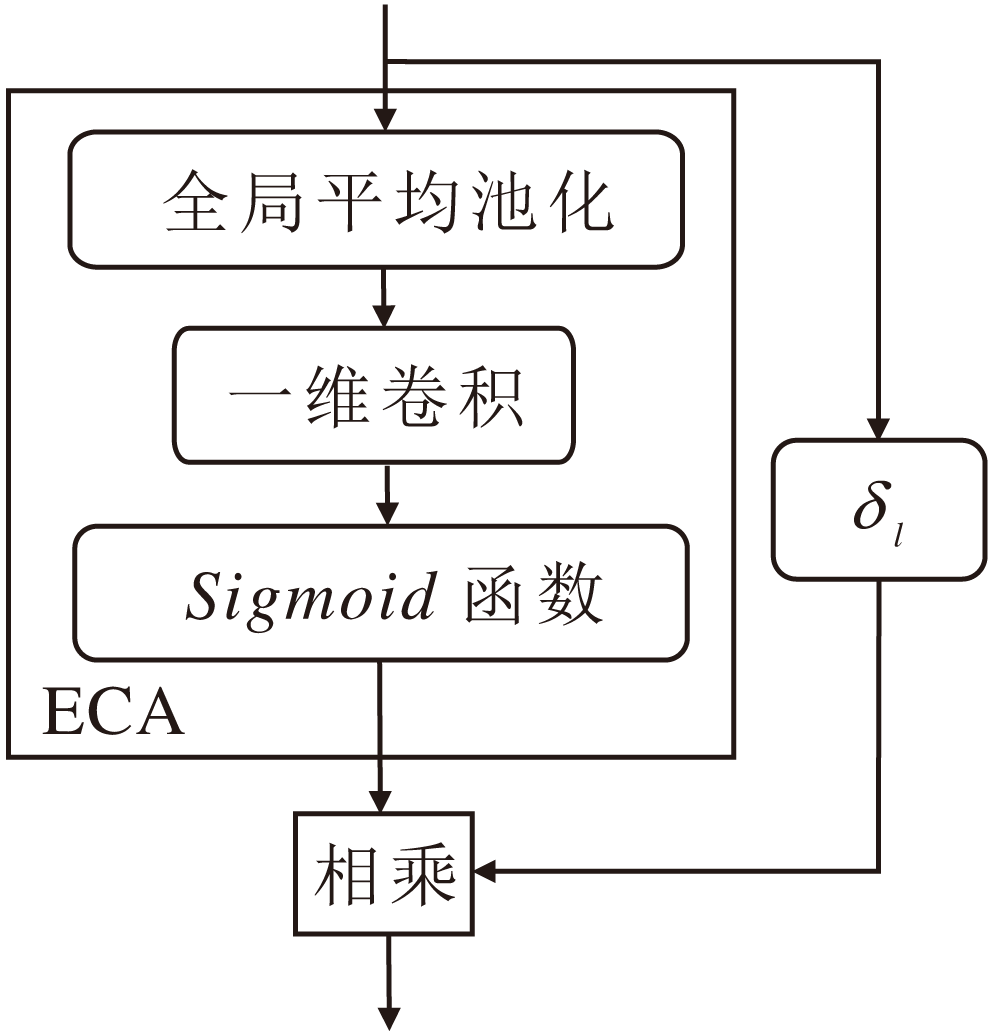 | 图4 DCAR结构图Fig.4 DCAR architecture |
本文选取公开的大规模遥感数据集AID[21]作为训练集与测试集, 另外选取WHU-RS19数据集[22]作为独立测试集.
AID数据集数据均采集自Google Earth, 覆盖全球不同区域, 具有地理多样性, 涵盖机场、车站、城市、乡村、沿海、沙漠等30类遥感场景, 共计10 000幅图像, 图像像素大小为600× 600.该数据集凭借其地理多样性特点, 在基于CNN的场景识别与超分辨率重建任务中表现突出.在训练过程中, 将每个场景的前40幅图像作为测试样本, 共计1 200幅图像, 剩下8 800幅图像作为训练样本.
WHU-RS19可提供0.5 m的高分辨率遥感图像, 包含农田、机场、公园、河流等19类遥感场景, 共计1 005幅图像.为了验证SFASR的泛化能力, 所有图像不参与训练, 从中随机选取100幅图像构成独立测试集.因WHU-RS19数据集和AID数据集的图像像素大小均为600× 600, 为了样本的多样性, 将WHU-RS19测试集上高分辨率图像裁剪为256× 256.
实验采用二阶级联退化模型, 在退化过程中使用随机洗牌策略[23].模糊核大小在{7, 9, 11, 13, 15}中随机选取.第一阶段高斯模糊核标准差σ ∈ [0.15, 1.5], 其中, 以70%概率采用各向同性高斯模糊核, 以30%概率生成椭圆拉伸比例γ ∈ [0.5, 4]的各向异性模糊核, JPEG压缩质量因子区间为[50, 95].第二阶段仅采用标准差σ ∈ [0.1, 0.6]的各向同性高斯模糊核, JPEG压缩质量因子区间为[50, 95].下采样倍率设为应用最广的4倍下采样, 高斯噪声的标准差设为0.03.
网络训练基于PyTorch 1.11.0深度学习框架, 在Ubuntu 20.04操作系统上训练.硬件平台搭载Intel(R) Xeon(R) Gold 6430处理器与NVIDIA GeForce RTX 4090 24 GB GPU.
使用Adam(Adaptive Moment Estimation)优化器, 初始学习率设为2× 10-4, 先后在迭代次数为5× 105、8× 105、9× 105、9.5× 105时将学习率衰减一半, 总迭代次数为1× 106.将输入图像尺寸设为64, 批处理大小设为4, FSAB个数设为6.MLP的扩展比率设为2, PAFSA窗口数设为8, 通道压缩率r2设为4, CPSA窗口数设为32.采用L1损失函数作为网络训练的目标函数.
超分辨率重建的评价指标主要用于衡量重建图像与原始高分辨率图像之间的相似度或感知质量, 本文使用的评价指标为峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)[24]和结构相似性(Structural Similarity Index Measure, SSIM)[25].PSNR计算均方误差, 量化重建图像与原始图像的差异, 值越高, 说明两幅图像的像素级差异越小.SSIM从亮度、对比度和结构三个维度评估图像质量, 更符合人类视觉感知, 值越高, 表示视觉感知质量上越接近原始图像.由于人类视觉系统对亮度变化比色度变化更敏感, 因此在图像质量评估中, 测试结果在YCbCr颜色空间的Y通道(即亮度通道)上进行计算.
为了验证SFASR在遥感图像超分辨率重建领域的有效性, 通过消融实验量化分析各模块对重建性能的贡献.从AID数据集上每个遥感场景中随机选取40幅图像, 共计1 200幅图像构成AID测试集, 并且随机选取机场与公园这2个遥感场景进行单独对比.基线网络选取所有Transformer块全部使用普通空间自注意力的SwinIR.分别验证CPSA、PAFSA、DCAR的有效性, 结果如表1所示, 表中黑体数字表示最优值.由表可见, 在SwinIR中加入CPSA之后, 参数量下降的同时, PSNR值提升0.08 dB, SSIM值提升0.004, 这表明CPSA的置换注意力和通道注意力的双分支结构能显著降低参数量, 提升重建图像几何结构保真度.
| 表1 各模块的消融实验结果 Table 1 Ablation experiment results of each module |
将网络改为PAFSA与CPSA的串行结构, PSNR值只提升0.01 dB, SSIM值提升0.000 9.由此可看出简单的加入PAFSA, 性能提升并不可观, 这是由于频域特征与空间域特征维度存在语义错位, 难以实现频域与空间域协同优化.
在CPSA的基础上仅加入DCAR, 性能提升有限, PSNR值只提升0.01 dB, SSIM值提升0.000 3.这是因为DCAR旨在校正PAFSA与CPSA串行处理过程中产生的语义偏移, 单独添加该模块导致性能提升有限.
在PAFSA与CPSA的串行结构的基础上加入DCAR, 相比单独的CPSA结构, PSNR值提升0.04 dB, SSIM值提升0.001 2, 表明DCAR有效校正PAFSA与CPSA之间的语义错位.
综上所述, 相比SwinIR, SFASR在PSNR指标上提升0.12 dB, 在SSIM指标上提升0.005 2.此外, 在随机选取的两个遥感场景中, SFASR均表现出显著的性能优势.上述结果充分验证SFASR的有效性与优越性, 在提升遥感图像超分辨率重建领域具有较大的潜力.
选择如下先进网络进行对比实验:SwinIR[10]、SRFormer[11]、RGT(Recursive Generalization Transformer)[12]、TTST[16]、EDSR(Enhanced Deep Super-Resolution Network)[26]、RCAN(Residual Channel Attention Network)[27]、CAT-A[28]、HAUNet(Hybrid Attention-Based U-Shaped Network)[29].其中基于Transformer的网络的MLP扩展比都设为2.
在AID、WHU-RS19数据集上进行实验, 采用PSNR和SSIM指标对比网络性能, 结果如表2所示, 表中黑体数字表示最优值, 斜体数字表示次优值.
| 表2 各网络在2个数据集上的指标值对比 Table 2 Metric value comparison of different networks on 2 datasets |
由表2可见, 在AID数据集上, SFASR在PSNR、SSIM指标上均优于对比网络, 相比次优的RGT, SFASR的PSNR值提升0.01 dB, SSIM值提升0.000 6, 这表示SFASR的重建图像在像素级差异和视觉结构上都与真实的高分辨率图像更接近.
另外, 针对具有显著空间特征差异的机场与公园两类典型遥感场景进行的子集测试表明, SFASR在复杂场景中的性能仍保持优势.这得益于使用通道增强置换自注意力机制建模长程依赖的同时, 通过相位感知自注意力机制增强网络的高频细节重建能力.
为了严格验证网络的泛化能力, 额外采用完全独立的测试集评估方案.从训练过程完全未涉及的WHU-RS19数据集上选择机场、公园这两个遥感场景, 随机抽取100幅遥感图像构成测试集, 确保评估结果不受训练数据影响.
由表2还可看出, 在独立测试集上, SFASR的PSNR、SSIM指标值均优于目前主流网络, 相比次优的RGT, SFASR的PSNR值提升0.05 dB, SSIM值提升0.002 1.这充分验证SFASR不仅具备较强的图像重建能力, 还具有良好的泛化能力.
为了更直观地对比各网络, 随机选取3幅图像, 直接对比在不同网络上的重建图像, 并添加双三次插值(Bicubic)进行对比, 结果如图5所示.在图中, 对图像的关键区域进行局部放大处理, 该区域用红框标记.
 | 图5 各网络重建的视觉效果对比Fig.5 Comparison of visual reconstruction results among different networks |
由图5(a)机场可见, RCAN、EDSR、SwinIR、HAUNet、TTST重建的SR图像均存在不同程度的失真与边缘纹理错误问题, SFormer、RGT重建的SR图像存在较严重的模糊.SFASR的重建图像更接近高分辨率图像, 不仅展现出更清晰的边界和更连贯的纹理结构, 还在视觉感知质量与几何结构保持方面均具有显著优势.这是因为本文的相位感知频域自注意力机制能精准增强关键频率成分, 重建更真实的地物轮廓.
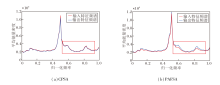
为了量化评估相位感知频域自注意力机制与通道增强置换自注意力机制在不同频段特征处理上的差异, 设计频谱分析方法, 旨在对比不同注意力机制输入输出特征图的频域能量分布, 结果如图6所示.在图中, 纵坐标为平均能量密度, 为各通道傅里叶变换后的平均幅值平方, 无单位, 可客观反映特征图在不同频率成分上的能量分布特性[30], 相对变化可有效表征网络对高低频信息的增强或抑制能力.
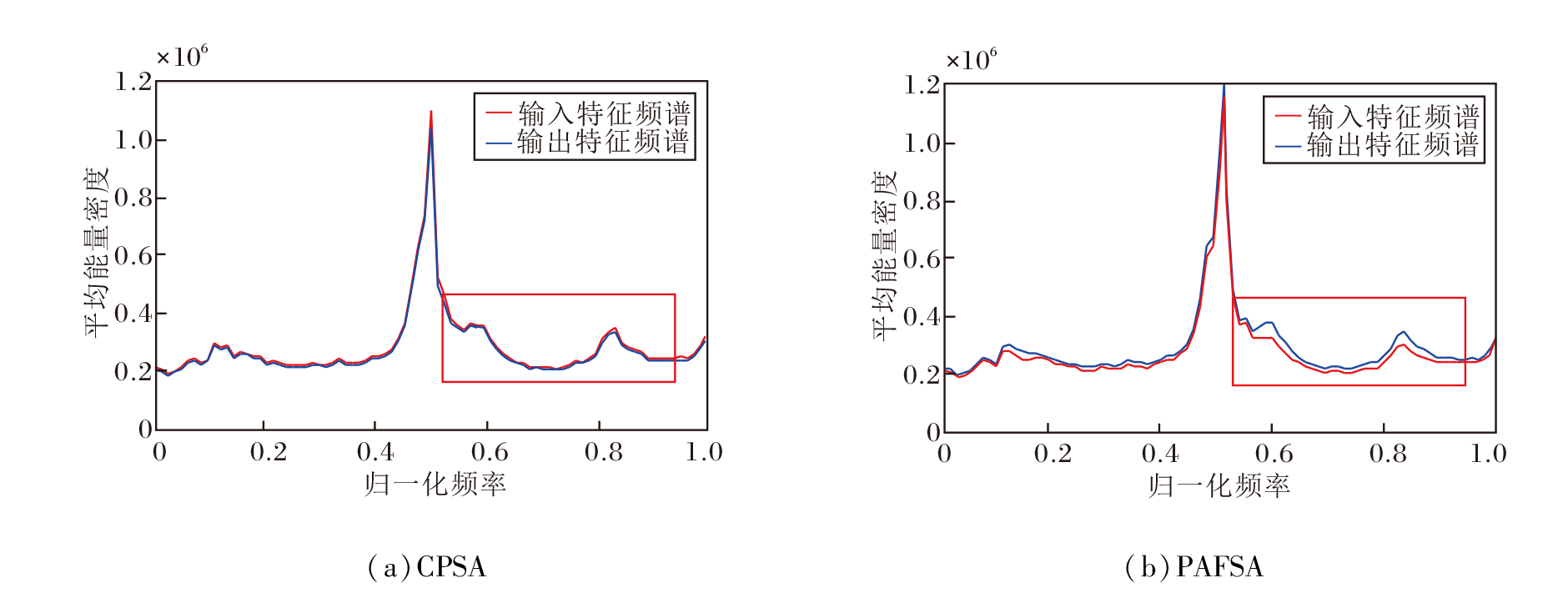 | 图6 2种机制的输入与输出频域能量分布对比Fig.6 Comparison of frequency domain energy distribution in inputs and outputs of 2 mechanisms |
由图6可明显看出, 通道增强置换自注意力机制的输入特征图和输出特征图之间在各频段能量几乎没有变化.与之相比, 相位感知频域自注意力机制实现对特定频率信息的选择性增强, 尤其对中高频信息(归一化频率约为0.5~0.9, 图中已用红框标记)的增强最明显, 而中高频信息对应遥感图像中的地物轮廓、纹理边缘, 能量强化直接提升超分辨率结果的空间细节表达能力.
综上所述, 本文的相位感知频域自注意力机制在超分辨率重建任务中可判别性地调整不同频段信息, 显著提升轮廓与纹理细节重建能力, 为保证遥感图像的重建质量提供有力的技术支持.
本文提出空-频域交替自注意力的可见光遥感图像超分辨率重建网络(SFASR), 兼顾局部细节恢复与长程依赖建模.设计相位感知频域自注意力机制(PAFSA)与通道增强置换自注意力机制(CPSA), 交替级联.PAFSA可判别性地确定应增强哪些低频信息和高频信息, 有效重建高频细节信息; CPSA解决长程依赖与计算复杂度之间的矛盾.另外, 设计双分支通道自适应残差模块(DCAR), 整合不同维度特征.实验表明SFASR可重建质量更高的高分辨率遥感图像.尽管本文在相位感知频域自注意力机制后引入判别式前馈网络, 增强网络表达能力, 但也导致参数量的增加, 因此今后将考虑模型轻量化研究, 旨在为频域自注意力机制构建更高效紧凑的前馈网络结构.
本文责任编委 桑农
Recommended by Associate Editor SANG Nong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|