



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
语义引导局部扰动的扩散模型对抗样本生成方法
[赵宏1  , 许明婷
, 许明婷1 , 刘泽1 ]
, 许明婷, 刘泽]
|
|



作者简介:

许明婷,硕士研究生,主要研究方向为计算机视觉、对抗攻击等.E-mail:1636807087@qq.com.

刘 泽,硕士研究生,主要研究方向为模式识别、人工智能等.E-mail:15755269725@163.com.
针对DiffAttack在语义引导、显著性区域及图像自然性等方面存在的问题,提出语义引导局部扰动的扩散模型对抗样本生成方法.首先,设计文本嵌入模块,在扩散模型去噪过程开始前对文本嵌入进行迭代优化,生成用于引导语义偏移的对抗性文本嵌入,作为引导去噪的条件.然后,在去噪过程中,加入局部掩码融合模块,在潜空间中对显著区域注入局部扰动,提升对抗样本的攻击性.最后,采用多层次联合感知损失函数,在图像与潜在空间层面联合约束感知差异,保持对抗样本攻击性的同时增强图像的自然性.在ImageNet-Compatible子集上以Inception作为代理模型生成对抗样本,并迁移至3种不同的模型架构中进行评估.结果显示,相比DiffAttack,文中方法的平均Top-1准确率降低2.8%,FID(Fréchet Inception Distance)指标提升0.4,说明文中方法生成的对抗样本在保持图像自然性的同时具有更强的攻击性,能更好地检测模型在安全性和鲁棒性方面存在的问题,具有更强的实用价值.
About Author:
XU Mingting, Master student. Her research interests include computer vision and adversarial attacks.
LIU Ze, Master student. His research interests include pattern recognition and artificial intelligence.
To address the issues of diffusion-based adversarial example generation methods(DiffAttack) in semantic guidance, salient regions, and image naturalness, an adversarial example generation method based on semantic-guided local perturbation diffusion model is proposed in this paper. First, a text embedding module is designed to iteratively optimize the text embedding before the denoising process of the diffusion model. The adversarial text embeddings used to guide semantic shifts are generated and adopted as the conditions for denoising. Second, a local mask fusion module is incorporated into the denoising process. The local perturbations are injected into salient regions in the latent space to enhance the attack effectiveness of the adversarial examples. Finally, a multi-level joint perceptual loss function is employed to jointly constrain perceptual differences at both the image and latent space levels. The image naturalness is enhanced while the attack effectiveness of the adversarial examples is maintained. Adversarial examples are generated on the ImageNet-Compatible subset using Inception as a proxy model, and are evaluated across three different model architectures. The results show that, compared with DiffAttack, the proposed method reduces the average Top-1 accuracy by 2.8% while improving the FID(Fréchet Inception Distance) score by 0.4. These results demonstrate that the proposed method generates adversarial examples with both stronger attack effectiveness and enhanced image naturalness. The proposed method can better detect the issues in security and robustness of the model, exhibiting strong practical value.
近年来, 深度神经网络(Deep Neural Network, DNN)在图像分类[1]、人脸识别[2]、自动驾驶[3]等领域取得显著成果, 然而, 相关研究表明, DNN在安全性和鲁棒性方面存在潜在隐患.在输入DNN的图像中添加视觉难以察觉的微小扰动[4], 即可生成对抗样本[5], 导致错误输出.其中, 以Inception系列模型为代表的图像分类网络因应用广泛, 已成为对抗样本攻击的主要目标之一.因此, 研究对抗样本的生成方法, 对于模型安全性和鲁棒性的检测具有重要意义.
现有对抗样本的生成方法大致可分为3类:基于梯度的方法、基于优化的方法、基于生成模型的方法.
Goodfellow等[6]提出Fast Gradient Sign Method, 是基于梯度的方法典型代表之一.该方法沿损失函数梯度方向施加微小扰动, 生成对抗样本, 步骤简单, 仅需一次梯度计算即可完成.随后, 研究者提出多种改进策略, 提升方法的攻击性与迁移性.Xie等[7]提出DI2-FGSM(Diverse Inputs Iterative Fast Gradient Sign Method), 通过随机变换输入避免过拟合.Dong等[8]提出TI-FGSM(Translation-Invariant Fast Gradient Sign Method), 利用卷积网络的平移不变性增强扰动的鲁棒性.Gao等[9]提出PI-FGSM(Patch-Wise Iterative Fast Gradient Sign Method), 在频谱域优化扰动, 稳定性较强.
在基于优化的方法中, Carlini等[10]构造由扰动幅度和攻击成功性两部分组成的目标函数, 并利用高效数值优化器直接搜索最优扰动, 有效提升攻击成功率.相比基于梯度的方法, 基于优化的方法直接求解最优扰动, 获得更精确、稳定且攻击成功率更高的对抗样本, 但其跨模型迁移性较弱, 对特定模型较依赖.
基于生成模型的方法分为基于生成对抗网络(Generative Adversarial Network, GAN)[11]的方法和基于扩散模型(Diffusion Models)[12]的方法.
在基于GAN的方法中, Xiao等[13]提出Adv- GAN, 通过条件生成网络直接将原始样本映射为对应的对抗样本.针对AdvGAN在迁移性方面的局限, Jandial等[14]利用潜在特征对扰动的敏感性作为先验, 提出AdvGAN++, 改善对抗样本的生成效果.基于GAN的方法虽然能生成视觉上自然、连贯的样本[15], 但在精细语义控制方面仍存在一定局限.
随着扩散模型在生成图像的丰富性和质量方面取得的显著进展, 该类模型逐渐成为对抗样本生成的重要工具之一.在基于扩散模型的方法中, Chen等[16]提出AdvDiffuser, 在预训练扩散模型的反向去噪过程中注入对抗扰动, 同时利用Grad-CAM(Gradient-Weighted Class Activation Mapping)生成显著目标掩码, 根据掩码调整不同区域的去噪强度, 从而在保持重要区域不变时在次要区域引入扰动, 实现高自然性对抗样本的生成.Dai等[17]提出AdvDiff, 在扩散模型的反向生成过程中引入分类器梯度作为引导信号, 生成无限制对抗样本.Guo等[18]提出AdvDiffVLM, 通过自适应集成梯度估计结合掩模生成, 在反向扩散过程中实现语义相关的扰动控制, 生成自然、高迁移性的对抗样本.Chen等[19]提出DiffAttack, 结合稳定扩散模型与DDIM(Denoising Diffusion Implicit Models)[20]反演技术, 在扩散潜在空间扰乱潜在变量并累积注意力图, 生成视觉难以察觉且迁移性良好的对抗样本.
相比其它方法, DiffAttack生成的对抗样本在攻击性能上表现优异, 同时, 在视觉质量上也保持较高的自然性, 但仍存在部分局限.首先, 生成过程主要依赖原始文本嵌入作为条件, 缺乏对语义层面的引导.其次, 在潜在空间注入扰动时缺少显著性引导, 导致局部扰动定位不够精确.此外, DiffAttack在生成对抗样本时, 仅通过自注意力保持图像结构细节, 未在图像空间和潜在空间建立联合约束, 难以在攻击性与自然性之间取得平衡.
针对DiffAttack在语义引导、扰动精确性和多层次联合约束等方面的问题, 本文提出语义引导局部扰动的扩散模型对抗样本生成方法(Adversarial Example Generation Method Based on Semantic-Gui-ded Local Perturbation Diffusion Model, SLPD).设计文本嵌入模块(Adversarial Text Embedding Module, ATEM), 在反向去噪开始前对初始文本嵌入执行迭代优化, 生成能在语义层面引导偏移的对抗性条件嵌入, 指导后续去噪过程.在去噪过程中, 引入局部掩码融合模块(Localized Mask Fusion Module, LMFM), 在潜在空间中注入局部攻击, 在图像显著区域保留扰动的潜在表示, 在非显著区域使用原始潜在表示, 提升攻击效果.此外, 为了提升对抗样本的视觉质量与结构一致性, 引入多层次联合感知损失函数, 对图像层面和潜在空间层面的感知差异进行联合约束, 保证攻击有效性的同时最大限度地保持图像的自然性.
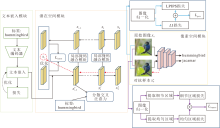
本文提出语义引导局部扰动的扩散模型对抗样本生成方法(SLPD), 整体架构如图1所示.SLPD基于开源预训练的Stable Diffusion, 由3部分组成:文本嵌入模块(ATEM)、潜在空间模块、像素空间模块.ATEM用于生成对抗性文本嵌入.潜在空间模块包括局部掩码融合模块(LMFM)与潜在空间感知损失Llatent, 用于在扩散模型去噪过程中对潜在表示进行可控扰动.像素空间模块包含像素感知损失Lperc和结构感知损失Lstrperc, 约束生成的对抗样本, 在保持高视觉质量的同时实现有效的对抗攻击.
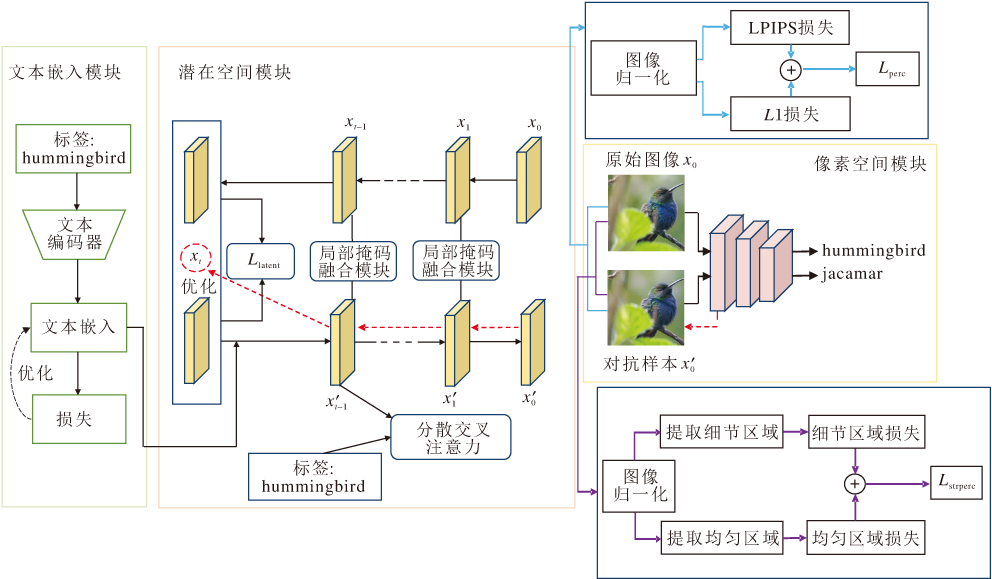 | 图1 SLPD整体架构Fig.1 Overall architecture of SLPD |
对抗样本的生成过程如下.首先, 给定原始图像及其真实类别标签, 通过DDIM反演将图像从像素空间映射至扩散模型的潜在空间, 得到一系列潜在表示.然后, 在去噪开始之前将ATEM生成的对抗性文本嵌入作为条件信息, 引导扩散模型的去噪过程.在每个去噪步骤中, LMFM对对抗潜在表示与原始潜在表示进行局部掩码融合, 得到新的潜在表示, 同时, 利用潜在空间感知损失Llatent约束潜在表示, 并累积新的潜在表示与真实标签之间的交叉注意力映射的平均值.去噪过程结束后, 最终的潜在表示通过解码器映射回像素空间, 生成对抗样本.最后, 计算包括潜在空间感知损失Llatent、像素感知损失Lperc和结构感知损失Lstrperc在内的所有损失项, 并将其梯度反向传播至去噪前的潜在表示, 优化整个去噪过程.通过多次迭代, SLPD在保持图像视觉质量的同时, 生成的对抗样本被模型错误预测为另一种类别.
从图1可看到, 标签为hummingbird的原始图像经过上述生成过程后, 所得对抗样本在保持视觉质量的同时, 会被目标模型错误预测为jacamar, 从而实现预期的攻击效果.
以Stable Diffusion为代表的扩散模型使用文本编码器, 将自然语言输入映射为文本嵌入表示, 并通过文本嵌入引导去噪过程, 生成符合语义的高质量图像.
在该过程中, 文本嵌入作为关键条件决定生成内容的语义方向与视觉特征.这表明模型对文本嵌入的变化极为敏感, 输入的细微差异会在潜在表示及最终输出中被逐级放大, 导致显著的语义偏差或视觉偏差.
基于上述特性, 关键问题在于如何在保持对抗样本语义合理性的前提下, 有效优化文本嵌入, 使生成图像沿对抗性语义方向偏离原始类别, 误导目标分类器.为此, 本文引入语义引导机制, 优化原始文本嵌入, 生成对抗性文本嵌入, 并作为扩散模型的条件信息, 引导扩散模型在反向去噪过程中沿对抗性语义方向生成图像.其中, 语义偏移指文本嵌入在优化过程中发生的语义表示变化, 即在高维语义空间中偏离其原始语义位置形成对抗性文本嵌入.该语义偏移在后续去噪过程中被逐步放大, 并最终体现在生成图像的高层语义特征中, 使其偏离原始类别的判别分布, 导致分类器产生错误预测.
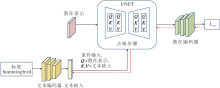
为了实现上述目标, 本文设计文本嵌入模块(ATEM), 在扩散去噪开始之前对文本嵌入向量进行迭代优化, 生成对抗性文本嵌入.ATEM结构如图2所示.
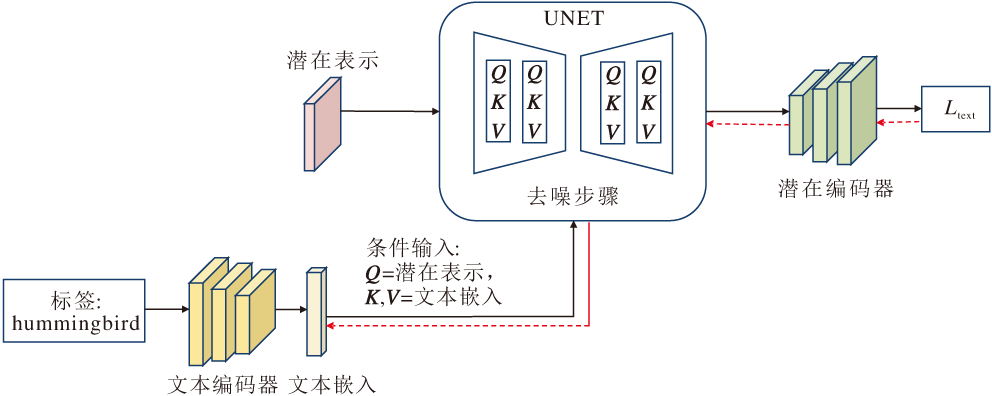 | 图2 ATEM结构图Fig.2 ATEM architecture |
首先, 将真实标签输入文本编码器, 获得文本嵌入, 并作为条件信息参与扩散生成.在扩散过程的每个时间步上, UNET(U-Shaped Convolutional Net-work)根据条件信息预测噪声分量并更新潜变量, 解码器生成中间图像, 并输入目标分类器中计算预测结果与真实标签之间的交叉熵损失.为了避免生成的对抗样本出现明显的视觉失真, 同时引入图像约束项, 平衡攻击有效性与对抗样本的感知质量.该约束项通过计算对抗样本与原始图像之间的均方误差实现.最终, 将分类损失与图像约束损失加权求和, 反向传播以优化文本嵌入, 得到一系列优化后的文本嵌入序列, 用于指导正式的去噪过程.对应的损失函数为:
Ltext=λ advLadv+λ simLsim,
其中, Ladv表示模型输出的预测分布和真实标签的差异, Lsim表示生成的对抗样本和原始图像之间的像素差异, λ adv、λ sim分别表示平衡两项损失重要性的权重.
通过上述优化过程, 原始的文本嵌入逐步优化为对抗性文本嵌入, 在扩散模型的反向去噪过程中, 这一变化持续引导潜在语义表示逐步偏离原始类别分布, 最终使生成图像的高层语义特征跨越分类器的判别边界, 导致分类器产生错误预测.
扩散模型的潜在空间通过VAE(Variational Autoencoder)将图像从高维像素空间映射至低维潜在表示, 保留图像的语义特征和结构特征, 使生成过程可在潜在空间中进行语义控制.因此, 相比像素空间扰动, 直接在潜在空间进行干预能更有效地影响扩散过程的语义生成.然而现有潜在空间攻击大多采用全局扰动方式, 导致扰动缺乏针对性, 并可能破坏潜在语义结构, 降低攻击的稳定性与生成样本质量.
为了解决上述问题, 本文在潜在空间内引入局部掩码融合模块(LMFM)与潜在空间感知损失Llatent.LMFM对关键语义区域进行局部扰动, Llatent保持潜在语义结构的一致性, 两者共同实现可控而稳定的潜在空间攻击.
1.3.1 局部掩码融合模块
现有的潜在空间攻击方法大多采用全局扰动策略, 即在整个潜在表示上均匀施加扰动, 并未考虑潜在空间各区域对生成结果的不同影响.这种粗粒度的干预方式通常会带来如下问题.一方面, 攻击效果可能分散在并不重要的区域, 降低对关键语义的干扰力度; 另一方面, 过度的全局扰动可能破坏潜在表示的整体语义结构, 使生成结果出现失真或不可控的偏移, 进一步降低攻击的稳定性与精确性.
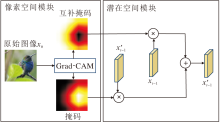
为了克服上述局限, 本文构建局部掩码融合模块(LMFM), 结构如图3所示.
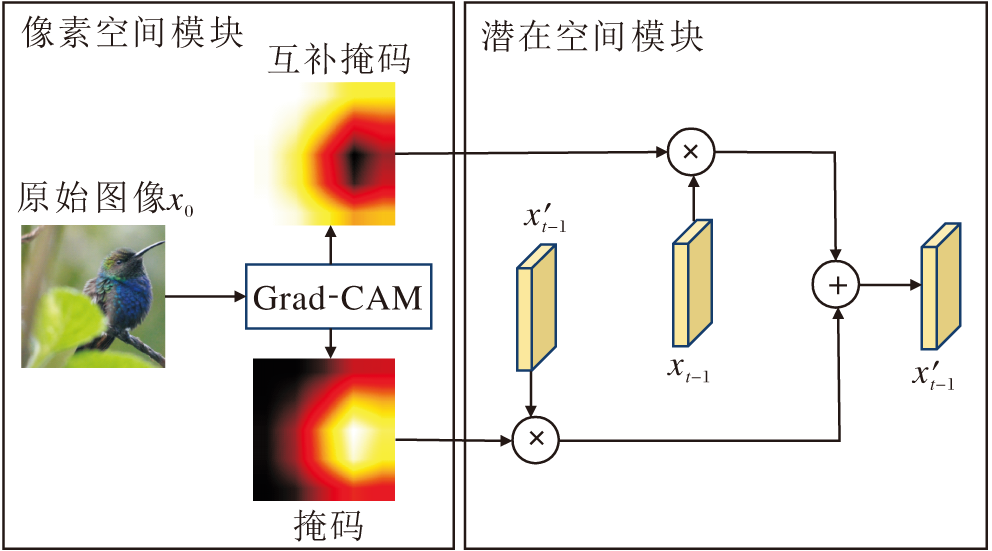 | 图3 LMFM结构图Fig.3 LMFM architecture |
在像素空间模块中, Grad-CAM对原始图像生成显著性掩码及其逆掩码, 具体生成的显著性掩码表示如下:
m=GradCAM(f, x0, y),
其中, f表示目标分类模型, x0表示原始图像, y表示真实标签.同时插入与潜在表示一致的空间分辨率.在扩散模型的去噪过程中, 对于每个时间步, 显著性掩码与对抗潜在表示逐元素相乘, 逆掩码与DDIM反演得到的对应时间步原始潜在表示逐元素相乘, 随后将二者相加, 得到最终的对抗性潜在表示:
x't-1=m☉x't-1+(1-m)☉xt-1,
其中, xt-1表示扩散前向加噪过程中在t-1时间步的原始潜在表示, 即未经过攻击扰动的表示, 等式右边x't-1表示扩散反向去噪过程在t-1时间步得到的未经掩码融合的临时潜在表示.
LMFM在关键区域中集中嵌入攻击扰动, 同时在非关键区域维持原有的语义一致性.此外, 这种局部注入的扰动能在后续迭代中逐渐扩散影响范围并累积语义偏移, 在对抗样本中表现出攻击效果.
1.3.2 潜在空间感知损失
虽然LMFM实现局部扰动, 但若扰动过强, 仍可能破坏扩散模型的潜在语义结构, 导致生成内容失真或出现不可控语义偏移.为此, 在潜在空间中引入约束, 即潜在空间感知损失函数:
Llatent=‖ (
其中,
Llatent将在总损失中与像素空间损失Lperc及结构感知损失Lstrperc加权结合, 形成多层次联合感知约束, 旨在保持攻击效果的同时限制潜在特征的偏移.最小化Llatent可在高层语义特征空间中约束扰动幅度, 保证攻击效果的同时, 保持图像的整体内容与结构.
在扩散模型的去噪过程中, 潜在空间扰动决定生成语义的偏移方向, 而最终输入分类模型的仍是解码后的像素图像.因此, 像素空间不仅影响攻击的最终效果, 也在维持对抗样本的自然性与隐蔽性中发挥重要作用.然而, 在对抗攻击中, 存在一个核心矛盾.一方面, 需要在输入中注入足够的扰动以确保攻击的成功率; 另一方面, 又需要维持对抗样本的质量与自然性.若仅针对攻击目标进行优化, 往往会导致对抗样本出现明显的伪影或失真, 削弱攻击的隐蔽性.为此, 在像素空间中引入两类感知约束:像素感知损失Lperc与结构感知损失Lstrperc, 从全局视觉质量与局部结构一致性两个层面约束对抗样本.
1.4.1 像素感知损失
Zhang等[21]提出LPIPS(Learned Perceptual Ima-ge Patch Similarity), 利用预训练的VGG(Visual Geometry Group)提取图像特征, 并计算两幅图像的特征向量的L2相似度, 评估两幅图像之间的感知差异.在基于噪声的方法中, 大多数方法使用L1损失限制添加的对抗性噪声的幅度.受此启发, 本文引入像素感知损失函数Lperc, 结合LPIPS与L1损失, 具体公式如下:
Lperc=Lpips(x0, xp)+‖ (x0, xp)‖ 1,
其中, x0表示原始图像, xp表示对抗样本, Lpips(· , · )表示LPIPS感知损失, ‖ · ‖ 1表示L1损失.
1.4.2 结构感知损失
在潜在空间生成对抗样本的过程中, 模型通常更关注图像中显著的高频区域.对于低频的均质区域, 即颜色变化较平缓的部分, 如天空、墙面等缺乏足够的约束.这种关注分布的不平衡容易引发两类问题.一方面, 均质区域可能出现不自然的伪影或颜色漂移; 另一方面, 结构细节区域可能产生纹理模糊或边缘失真.为了同时提升模型在全局一致性与局部细节方面的感知能力, 本文引入结构感知损失函数Lstrperc, 旨在对生成的对抗样本的均质区域与结构细节区域进行联合优化.
为了约束均质区域, 首先, 使用离散小波变换(Discrete Wavelet Transform, DWT)[22]提取输入图像的低频分量, 并利用离散小波逆变换(Inverse DWT, IDWT)[22]将其重构回图像域, 从而产生均质区域:
Fhom(x)=iDWT(DWT(x)ll),
其中, DWT(· )表示离散小波变换运算, iDWT(· )表示离散小波逆变换运算, ll表示低频分量.
然后, 原始图像Xo和对抗样本Xadv之间均质区域的损失为:
Lhom=SmoothL1(Fhom(Xadv), Fhom(X0)),
其中, SmoothL1(· , · )表示平滑L1损失, Fhom(Xo)表示原始图像的均质区域, Fhom(Xadv)表示对抗样本的均质区域.
优化Lhom, 生成的对抗性样本在均质区域保持与原始图像的一致性, 降低对抗扰动的可感知程度.
为了约束结构细节, 首先定义结构细节区域:
Fstru(x)=x-Fhom(x).
原始图像Xo和对抗样本Xadv之间结构细节的损失定义为:
Lstru=SmoothL1(Fstru(Xadv), Fstru(Xo)),
其中, Fstru(Xo)表示原始图像的结构细节区域, Fhom(Xadv)表示对抗样本的结构细节区域.
最小化Lstru可在一定程度上保持对抗样本在结构细节区域的纹理信息和边缘信息, 防止局部模糊或失真.
基于上述设计, 结构感知损失表示为:
Lstrperc=Lhom+Lstru.
最小化Lstrperc, 对抗样本在均质区域保持整体一致性的同时, 在结构细节区域保留关键的纹理特征与边缘特征.
SLPD总体损失函数由如下4个部分组成:对抗损失函数Lattack、交叉注意力损失函数Lcross、自注意力损失函数Lself、多层次联合感知损失函数Ljoin.
对抗损失函数表示如下:
arg
其中,
$ x^{\prime}=\text { Denoise ∘ } \cdots \circ \text { Denoise }\left(x_{t}\right), $
表示对抗样本, xt表示潜在表示, Denoise(· )表示扩散去噪过程, y表示真实标签, Gϕ 表示生成对抗样本的代理模型, J(· )表示交叉熵损失.最小化Lattack等价于最大化分类器对真实标签的预测误差, 能误导目标模型的判别结果.
交叉注意力损失函数表示如下:
arg
其中, Var(· )表示输入的方差, Cross(· )表示去噪过程中所有交叉注意力图的累积, SDM表示Stable Diffusion, t表示时刻, Average(· )表示取平均.最小化Lcross能将注意力均匀分布到每个像素.
自注意力损失函数为:
arg
其中, St表示潜在表示xt的自注意力图, xt(fix)表示未经过扰动的潜在表示, St(fix)表示xt(fix)的自注意力图, ‖ ·
多层次联合感知损失函数Ljoin由潜在空间感知损失Llatent、像素感知损失Lperc和结构感知损失Lstrperc加权组合而成:
Ljoin=λ percLperc+λ latentLlatent+λ strpercLstrperc,
其中, λ perc、λ latent、λ strperc表示超参数, 系用于调节3个损失函数之间平衡的因子.Ljoin在潜在空间与像素空间同时施加约束, 实现语义一致性与视觉质量的平衡, 提升攻击的稳定性与隐蔽性.最小化Ljoin, 能在图像空间层面和潜在空间层面共同约束图像质量.
由此, SLPD总损失函数表示如下:
L=λ attackLattack+λ crossLcross+λ selfLself+Ljoin,
其中, λ attack、λ cross、λ self表示超参数, 用于调节各损失函数的相对权重和影响, 以便更好地生成对抗样本.
为了评估SLPD生成对抗样本的性能, 选择在ImageNet-Compatible子集上进行实验.该子集由1 000个类别组成, 原始图像大小为299× 299× 3, 由于Stable Diffusion无法处理ImageNet-Compatible子集的原始输入尺寸, 原始图像调整为224× 224× 3.此外, 为了验证方法在细粒度分类任务上的泛化性, 还使用CUB-200-2011数据集.该数据集包含200类鸟类图像.
实验环境为Linux操作系统, 系统版本为Ubuntu18.04.6LTS64位, 处理器为Intel(R)Xeon(R)Gold5218 CPU@2.30 GHz 24-core processor48, 内存17 GB, 并且配备NVIDIA A100 GPU.实验中利用DDIM作为Stable Diffusion的采样器, 采样步数设为20, 并对初始干净图像进行5步DDIM反演.在反演过程中, 引导尺度设为0.在去噪阶段, 引导尺度设为2.5.在优化潜在变量时使用AdamW(Adaptive Moment Estimation with Weight Decay)优化器, 学习率设为0.01, 迭代次数设为30.设置权重因子λ attack=10, λ cross=10 000, λ self=100.上述实验设置均严格遵循原有的推荐结果.在消融实验中选择最佳多层次联合感知损失函数权重因子λ perc=1 000, λ latent=1 000, λ strperc=0.01.
为了评估生成对抗样本在不同网络结构上的可转移性, 采用CNN(Convolutional Neural Network)、Transformer、MLP(Multi-layer Perceptron)的网络结构.
1)CNN.采用的预训练模型包括ConvNeXt[23]、ResNet-50[24]、VGG-19[25]、Inception-v3[26]、MobileNetV2[27].
2)Transformer.采用的预训练模型包括ViT-B/16[28]、Swin-B[29]、DeiT-B[30]、DeiT-S[30].
3)MLP.采用的预训练模型包括Mixer-B/16[31]、Mixer-L/16[31].
此外, 实验还采用对抗训练模型Adversarially Trained Inception-v3(后文简记为Adv-Inc-v3)[32]、v
实验采用Top-1准确率和FID(Fré chet Inception Distance)[34]作为评价指标.
Top-1准确率表示模型预测的概率最高的类别与真实标签一致的样本比例, 具体公式如下:
$\text { Accuracy }=\frac{1}{N} \sum_{i=1}^{N} I\left(f\left(x_{i}^{\mathrm{adv}}\right)=y_{i}\right), $
其中, N表示对抗样本数量, yi表示真实标签, f(
FID用于衡量两幅图像在高维特征空间中的分布差异.假设对抗样本的特征分布为(μ g, Σ g), 原始图像的特征分布为(μ r, Σ r), 两者多元高斯分布的Fré chet距离定义如下:
$F I D=\left\|\boldsymbol{\mu}_{r}-\boldsymbol{\mu}_{g}\right\|_{2}^{2}+\operatorname{tr}\left(\boldsymbol{\Sigma}_{r}+\boldsymbol{\Sigma}_{g}-2\left(\boldsymbol{\Sigma}_{r} \boldsymbol{\Sigma}_{g}\right)^{\frac{1}{2}}\right), $
其中, μ r、Σ r表示针对原始图像在Inception网络Pool3层提取的特征均值和协方差矩阵, μ g、Σ g表示针对对抗样本在Inception网络Pool3层提取的特征均值和协方差矩阵, tr(· )表示矩阵的迹, (Σ rΣ g
SLPD在正常训练模型上与其它基于传输的黑盒攻击方法进行系统对比, 选择4种基于像素的攻击方法(DI2-FGSM[7]、TI-FGSM[8]、PI-FGSM[9]、S2I-FGSM[35])和3种不受限攻击方法(ReColorAdv[36]、cAdv[37]、NCF(Natural Color Fool)[38]).除了分辨率改为224× 224× 3以外, 对比方法的实现都遵循原文献的最优设置.所有基于像素的攻击方法都在
2.4.1 无防御方法评估结果
SLPD以Inception-v3作为代理模型, 用于生成对抗样本.若代理模型与目标模型相同, 即代理模型直接攻击自身, 属于白盒攻击; 当代理模型与目标模型不同, 对应黑盒攻击.具体指标说明如下.
1)CNNs AVG(w/o self).在CNN架构中排除与代理模型相同的模型后, 基于所有黑盒目标模型计算得到平均Top-1准确率.
2)Transformers AVG(w/o self).在Transformer架构中排除与代理模型相同的模型后, 计算得到平均Top-1准确率.
3)MLPs AVG(w/o self).在MLP架构中排除与代理模型相同的模型后, 计算得到平均Top-1准确率.
4)AVG(w/o self).在CNN、Transformer和MLP所有目标模型上, 排除代理模型(即Inception-v3)后, 计算得到平均Top-1准确率.
5)FID.通过1 000幅生成的对抗样本与ImageNet验证集计算得到, 用于衡量图像质量.
各方法在CNN模型上的平均Top-1准确率如表1所示, 表中clean表示未经攻击的原始样本在模型上的性能, 后文相同.
| 表1 各方法在CNN模型上的平均Top-1准确率 Table 1 Average Top-1 classification accuracy of each method on CNN model % |
由表1可见, PI-FGSM展现出最强的攻击效果, 平均准确率仅为42.4%, 显著优于其它方法.SLPD在CNN模型上取得59.4%的Top-1平均准确率, 超过ReColorAdv、cAdv等近10%, 在黑盒迁移攻击场景中表现较优.
各方法在Transformer模型上的平均Top-1准确率如表2所示.由表可见, SLPD同样展现出优异的跨模型迁移性能, 平均Top-1准确率降至70.4%, 在所有对比方法中达到最优.各方法在MLP模型上的平均Top-1准确率如表3所示.由表可见, SLPD依然保持良好的攻击性能, 平均Top-1准确率降至53.4%.
| 表2 各方法在Transformer模型上的平均Top-1准确率 Table 2 Average Top-1 classification accuracy of each method on Transformer model % |
| 表3 各方法在MLP模型上的平均Top-1准确率 Table 3 Average Top-1 classification accuracy of each method on MLP model % |
各方法的综合性能对比如表4所示.由表可见, 在涵盖CNN、Transformer、MLP的全部目标模型(排除代理模型Inception-v3)上, SLPD在攻击有效性与图像质量之间取得平衡.SLPD尽管在平均Top-1准确率上略高于PI-FGSM(4%), 但在图像质量方面具有显著优势, FID指标比PI-FGSM降低近30%.
| 表4 各方法的综合性能对比 Table 4 Overall performance comparison of different methods |
同时, 由表4可见, 相比DiffAttack, SLPD在其FID值仅略高0.4的情况下, 平均Top-1准确率降低2.8%, 表明SLPD在保持视觉质量的同时, 能在一定程度上提升攻击有效性.
各类攻击方法生成的对抗样本可视化结果如图4所示.
 | 图4 各方法生成的对抗样本可视化结果对比Fig.4 Visualization comparison of adversarial examples generated by different methods |
由图4可观察到, 不同攻击方法生成的对抗样本在视觉特征上存在明显差异.传统方法(如DI2-FGSM、TI-FGSM、PI-FGSM、S2I-FGSM)往往引入显著的高频噪声.
SLPD生成的扰动较隐蔽, 在图像纹理上呈现平滑连续的变化.相比ReColorAdv、cAdv、NCF, SLPD在色彩空间中表现出更自然的过渡, 进一步表明该方法在生成难以察觉且高保真对抗样本方面具有较优的性能表现.
PI-FGSM和SLPD生成的对抗样本局部细节的放大效果对比如图5所示.由图可见, PI-FGSM处理后的区域存在明显的色彩噪点与纹理失真现象, 细节呈现杂乱无章.SLPD在保持图像结构完整性的同时, 有效抑制噪声干扰, 局部纹理与色彩过渡自然平滑.
 | 图5 PI-FGSM与SLPD局部细节可视化对比Fig.5 Comparison of local detail visualization between PI-FGSM and SLPD |
为了进一步验证不同方法间性能差异的可靠性, 对DiffAttack、NCF、cAdv进行统计显著性分析.在相同设置下, 采用不同随机种子重复实验5次, 以平均Top-1准确率作为评价指标, 对各方法间的性能差异进行t检验及95%置信区间分析.
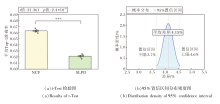
SLPD与DiffAttack的对比分析如图6所示.DiffAttack的平均Top-1准确率为66.2%, SLPD的平均Top-1准确率为62.1%, 平均差异为4.05%.统计检验结果表明, 该差异具有显著统计意义(p< 0.001), 其95%置信区间为[3.4%, 4.7%], 对应的置信区间未跨越零点, 说明该性能差异具有较好的稳定性.
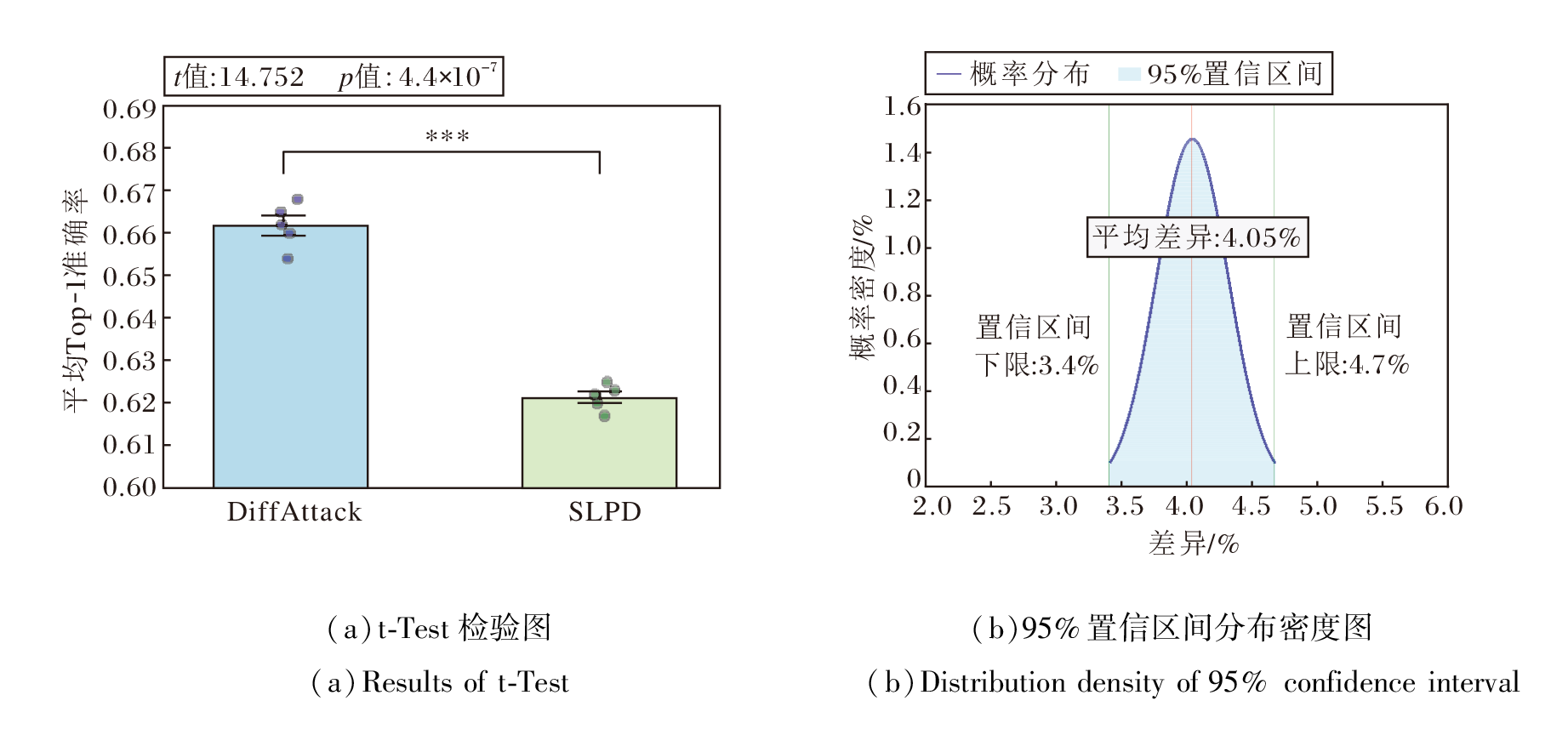 | 图6 SLPD与 DiffAttack的统计显著性与置信区间分析结果Fig.6 Statistical significance and confidence interval analysis for SLPD and DiffAttack |
NCF与SLPD的对比分析如图7所示, NCF的平均Top-1准确率为66.3%, SLPD的平均Top-1准确率为62.1%, 平均差异为4.15%, 其95%置信区间为[3.7%, 4.6%], 对应的统计检验结果p< 0.001, 表明该差异同样具有统计显著性.
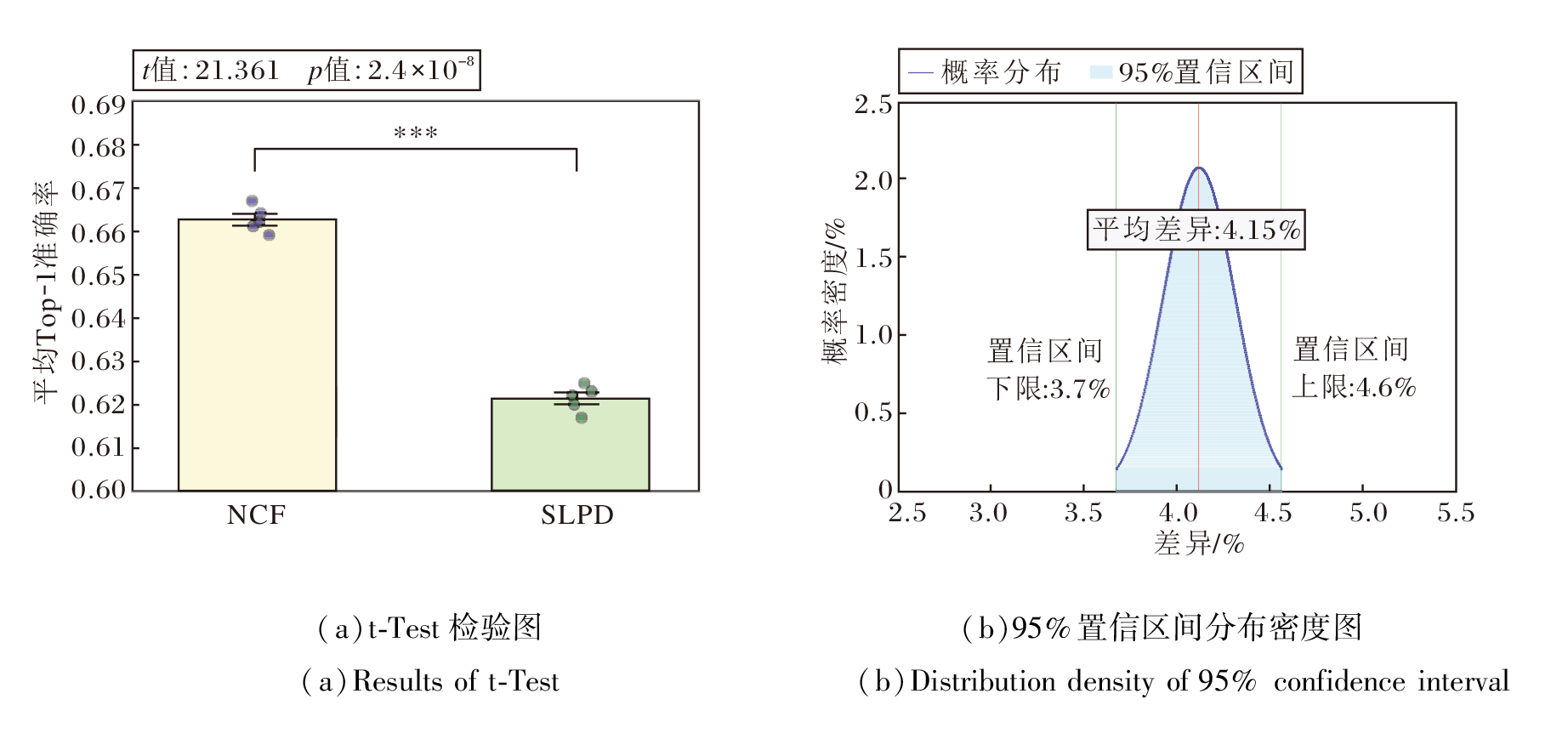 | 图7 SLPD与 NCF的统计显著性与置信区间分析结果Fig.7 Statistical significance and confidence interval analysis for SLPD and NCF |
cAdv与SLPD的对比分析如图8所示, cAdv的平均Top-1准确率为76.4%, SLPD的平均Top-1准确率为62.1%, 二者的平均差异为14.30%.该差异在统计上同样显著(p< 0.001), 其95%置信区间为[13.8%, 14.8%], 且置信区间完全不包含0.
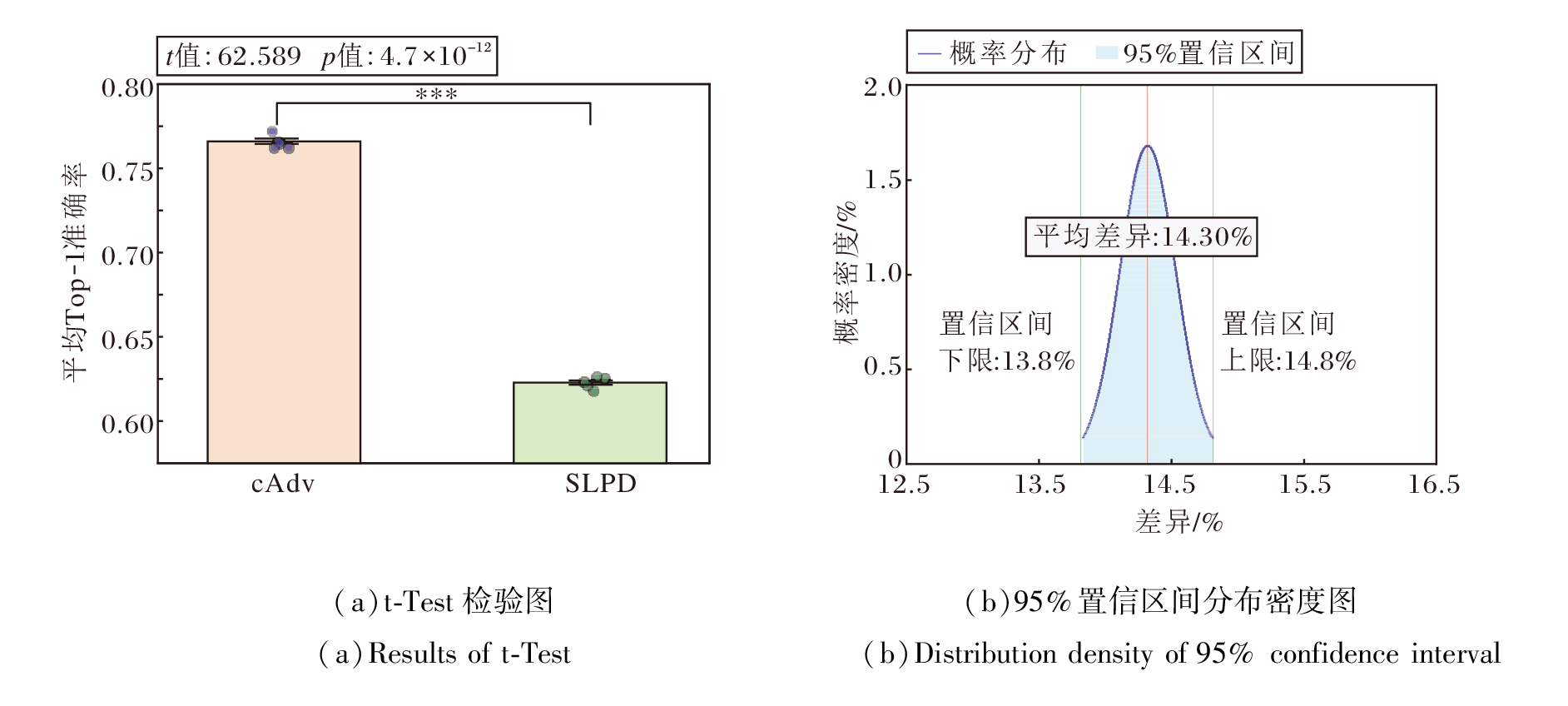 | 图8 SLPD与cAdv的统计显著性与置信区间分析结果Fig.8 Statistical significance and confidence interval analysis for SLPD and cAdv |
综上所述, SLPD在多组对比方法上的性能差异均通过统计显著性检验, 验证实验结论的可靠性和稳定性.
2.4.2 泛化性评估结果
为了进一步验证SLPD在不同数据分布与细粒度分类场景中的泛化能力, 在具有代表性的细粒度图像分类数据集CUB-200-2011上进行扩展实验.
在实验设置上, 统一以SE-ResNet-101[39]作为代理模型生成对抗样本, 并将生成的对抗样本迁移至ResNet-50与SENet-154[39]的目标模型上进行测试, 从而评估方法在跨模型场景中的攻击有效性与稳定性.评价指标仍采用平均Top-1准确率与FID, 分别衡量攻击有效性与生成样本的视觉自然性.
各方法在CUB-200-2011数据集上的性能对比如表5所示, 在表中, CUB AVG(w/o self)表示在目标模型(ResNet-50, SENet-154)上, 排除SE-ResNet-101代理模型自身之后, 计算得到的平均Top-1准确率, 用于衡量模型的攻击有效性, FID用于衡量生成样本的视觉自然性.
| 表5 各方法在CUB-200-2011数据集上的性能对比 Table 5 Performance comparison of different methods on CUB-200-2011 dataset |
由表5可见, SLPD在ResNet-50与SENet-154上的平均Top-1准确率进一步降至24%, 表明该方法在细粒度语义差异显著的数据分布下仍保持较强的跨模型迁移能力.同时, FID指标与DiffAttack基本持平, 说明在增强攻击性的同时并未显著破坏图像的自然性.
2.4.3 有防御下的方法评估结果
在防御场景中的攻击是指在目标模型部署防御机制的情况下, 对抗样本依然能成功误导模型预测的情形.若攻击在防御条件下仍保持较高的有效性, 表明生成的对抗样本具有较强的鲁棒性与迁移性.
防御模型下各攻击方法的平均Top-1准确率如表6所示, 表中黑体数字表示最优值, 斜体数字表示次优值.对于防御措施, 目标型号与官方文件相同.
| 表6 各方法的平均Top-1准确率对比 Table 6 Average Top-1 accuracy comparison of different methods % |
从表6可看出, SLPD在应用防御的情况下性能最优, 尤其在v3adv-ens3和IRv2adv-ens这2种防御模型上, 平均Top-1准确率比次优方法降低约7%, 由此验证SLPD的健壮性和设计的有效性.
为了进一步验证SLPD中各模块的作用, 进行系统的消融实验, 依次加入ATEM、LMFM、Lperc、Llatent、Lstrperc, 并在相同的训练设置下重新优化, 评估其对整体性能的影响, 相应指标值如表7所示.由表可看出, 未加入任何模块时平均Top-1准确率为65.4%, FID值为62.3.加入ATEM后, 平均Top-1准确率降至56.0%, 表明ATEM能有效引导扩散模型在语义层面产生对抗性偏移, 增强攻击效果.加入LMFM后, 平均Top-1准确率降至61.9%, 表明局部注入的扰动能在后续迭代中逐渐扩散影响范围, 提升攻击强度.同时加入ATEM和LMFM, 平均Top-1准确率降至49.1%, 但FID值升至71.1, 说明对抗性文本嵌入和局部扰动在提升攻击强度的同时略微影响样本自然性.随后, 依次引入多层次联合感知损失函数的3个损失项(Lperc、Llatent、Lstrperc), 平均Top-1准确率由49.1%升至62.6%, 而FID值逐步降至62.7, 表明在多层次联合约束模块作用下, 方法在保持视觉自然性的同时可实现更高的攻击性能与跨模型迁移性.整体而言, ATEM与LMFM对提升攻击性能的贡献较明显, 而各损失项在平衡自然性方面发挥关键作用, 由此验证SLPD中各模块设计的合理性与互补性.
| 表7 各模块消融实验结果 Table 7 Ablation experiment results of different modules |
此外, 为了进一步分析Lperc、Llatent、Lstrperc在SLPD中的作用强度, 进行权重参数的消融实验.具体地, 分别固定其它两个损失项的权重, 仅将目标损失项的权重取不同值(低、中、高), 在相同训练设置下重新训练SLPD并评估性能, 结果如表8所示.
| 表8 不同权重因子的消融实验结果 Table 8 Ablation results of different weight factors |
仅调整Lperc的权重λ perc=900, 1 000, 1 100, 其余训练超参数及模块保持一致.结果表明, 当λ perc=900, 1 100时, 模型的平均Top-1准确率低于或略高于λ perc=1 000时的结果, 同时FID值更高.综合考虑平均Top-1准确率与FID的平衡性, 最终确定Lperc的权重λ perc=1 000.
仅调整Llatent的权重λ latent=900, 1 000, 1 100, 其余条件保持不变.结果显示, λ latent=900, 1 100时, 模型的平均Top-1准确率与λ latent=1 000时的结果相当或略高, 但对应的FID值均高于λ latent=1 000时的结果.为了兼顾平均Top-1准确率与生成质量, 最终选取Llatent的权重λ latent=1 000.
仅调整Lstrperc的权重λ strperc=0.005, 0.01, 0.02, 其余参数设置不变.结果显示, 当λ strperc=0.005, 0.02时, 平均Top-1准确率均低于λ strperc=0.01时的结果, 且FID值更高.综合两项指标的表现, 最终选取Lstrperc的权重λ strperc=0.01.
综合3项损失的消融结果可观察到, Lperc和Llatent分别作用于像素空间与潜在空间的高层语义一致性, 梯度幅度本身较大, 对模型整体优化起主导作用, 因此需要将权重因子设置为较高且相对稳定方能取得最佳攻防平衡.Lstrperc关注均质区域与结构细节的局部纹理约束, 梯度相对较小, 对图像细节扰动更敏感.当权重因子设置过高时会引入过强的局部限制, 导致攻击能力下降; 权重因子过低又无法有效压制伪影.因此最优值出现在0.01附近.
本文针对DiffAttack在语义引导、扰动精确性和多层次联合约束等方面的问题, 提出语义引导局部扰动的扩散模型对抗样本生成方法(SLPD).在扩散模型去噪前, 设计文本嵌入模块(ATEM), 生成对抗性文本嵌入, 引导去噪过程, 从语义层面推动样本偏离原始图像.在去噪过程中, 构建局部掩码融合模块(LMFM), 在潜在空间按局部掩码注入扰动, 保留非显著区域的反演潜在表示, 提升攻击性.此外, 引入多层次联合感知损失函数, 对像素与潜在空间的感知差异进行联合约束, 在保证攻击效果的同时尽量保持图像自然性.
虽然SLPD可生成高质量的对抗样本, 但仍存在一些不足, 泛化能力有限.因此在后续工作中, 需要进一步深入探索在其它数据集及其它模型上生成对抗样本的迁移能力.
本文责任编委 杨健
Recommended by Associate Editor YANG Jian
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|