{kind=link}
{kind=link}
多尺度决策系统中基于可变精度熵的属性约简与最优尺度组合选择
[郭芮利1, 2  , 张清华
, 张清华2, 3 , 杨莹1, 2 , 程云龙4 , 钟杭1, 2 ]
, 张清华, 杨莹, 程云龙, 钟杭]
|
|



作者简介:

郭芮利,硕士研究生.主要研究方向为粒计算、粗糙集.E-mail:2719864662@qq.com.

杨 莹,博士研究生,主要研究方向为粒计算、粗糙集、三支决策、不确定信息处理.E-mail:1608559026@qq.com.

程云龙,博士,副教授,主要研究方向为粒计算、粗糙集、三支决策、不确定信息处理.E-mail:chengyl@cqupt.edu.cn. 
钟 杭,硕士研究生,主要研究方向为自然语言处理、情感分析.E-mail:2631950280@qq.com.
现有多尺度决策系统大多基于Pawlak粗糙集构建,对噪声数据的容错能力有限.尽管引入可变精度以增强不确定环境下的适应性,但现有方法通常先进行尺度选择再进行属性约简,难以充分发挥属性约简在降低计算复杂度方面的作用.同时,信息熵在可变精度多尺度粗糙集模型中对不确定性关系的刻画仍有进一步的拓展空间.针对上述问题,文中提出基于可变精度熵的属性约简与最优尺度组合选择方法.首先,提出单调的可变精度互补条件熵,刻画任意尺度组合下条件属性与决策属性之间的不确定性关系,并据此提出协调的属性约简方法,在保证决策信息不丢失的前提下有效消除冗余属性.然后,为了增强约简结果在分类任务中的有效性,提出基于分类性能的最优属性约简方法.在此基础上,进一步结合约简结果,设计最优尺度组合选择算法,有效降低尺度搜索空间.在UCI 数据集上的实验表明文中方法在分类性能和鲁棒性上的有效性.
About Author:
GUO Ruili, Master student. Her research interests include granular computing and rough sets.
YANG Ying, Ph.D. candidate. Her research interests include granular computing, rough sets, three-way decision, and uncertain information processing.
CHENG Yunlong, Ph.D., associate professor. His research interests include granular computing, rough sets, three-way decision, and uncertain information processing.
ZHONG Hang, Master student. Her research interests include natural language processing and sentiment analysis.
Most existing multi-scale decision systems are built on Pawlak rough sets and their tolerance to noisy data is limited. Although variable precision is introduced to enhance the adaptability in uncertain environments, current methods typically perform scale selection before attribute reduction. Thus, it is difficult to fully leverage attribute reduction in reducing computational complexity. Though information entropy is applied to multi-scale data analysis, its capability to characterize uncertainty relationships within variable precision multi-scale rough set models still needs to be improved. To address these issues, an attribute reduction and optimal scale combination selection method based on variable precision complementary conditional entropy is proposed. First, a monotonic variable precision complementary conditional entropy is presented to characterize the uncertainty relationships between condition attributes and decision attributes under arbitrary scale combinations. Based on this entropy, a consistency-based attribute reduction method is developed. Redundant attributes are effectively eliminated while decision information is preserved. Second, an optimal attribute reduction method based on classification performance is proposed to enhance the effectiveness of the reduction results in classification tasks. On this basis, an optimal scale combination selection algorithm is further designed by incorporating the obtained reduced attribute set to effectively reduce the scale search space. The experiments on UCI datasets demonstrate the effectiveness of the proposed method in terms of classification performance and robustness.
粒计算(Granular Computing)[1]是一种以模拟人类认知过程进行知识表示与知识发现的新兴计算范式.通过引入粒化结构, 粒计算为复杂现实问题提供有效的解决思路.在大数据背景下, 粒计算利用层次化粒度结构对信息处理过程进行形式化描述, 推动传统计算模型的转变.其中, 三支决策理论为粒计算提供不确定性处理的决策框架[2], 模糊多粒度空间的研究进一步丰富粒计算的结构化表示能力[3], 面向复杂问题求解的多粒度计算框架拓展粒计算在认知计算领域的应用[4], 而面向大数据挖掘的粒计算理论与方法则为大规模数据分析奠定方法基础[5].
粗糙集理论[6]作为粒计算中的一种基础模型, 是处理不确定、不完备信息的重要工具.经典粗糙集, 也称为 Pawlak 粗糙集, 基于不可分辨关系将论域划分为等价类, 并以此作为基本的信息粒, 刻画目标概念的上下近似.基于这一近似机制, 粗糙集理论在知识发现中得到广泛应用, 如属性约简[7]、不确定性度量[8]、规则获取[9]等.然而, 经典粗糙集缺乏容错能力, 对噪声数据高度敏感.为了克服这一缺陷, 研究者提出概率粗糙集[10]和可变精度粗糙集[11, 12]等扩展模型, 增强其对噪声数据的处理能力, 但上述模型假设每个属性仅在固定尺度下进行分析.
在实际应用中, 同一属性往往可在多个尺度层次上进行描述.因此, 如何在多尺度数据环境中有效开展知识发现, 成为亟需解决的重要问题.为此, Wu等[13]提出多尺度粗糙集模型, 又称为Wu-Leung模型, 允许对象在同一属性下具有多个尺度取值.然而, 该模型要求所有属性具有相同数量的尺度, 这在一定程度上限制其实际应用.针对这一问题, Li等[14]提出广义多尺度粗糙集模型, 允许不同属性具有不同数量的尺度, 从而消除Wu-Leung模型中的结构性约束.在广义多尺度粗糙集模型中, 多尺度信息系统通常被转化为若干个单尺度信息系统进行分析.单尺度信息系统中采用的尺度由各条件属性选取的具体尺度共同决定.针对给定的决策目标, 在满足相关约束条件的前提下, 选取能保持决策信息的最粗尺度组合, 这一过程称为最优尺度组合选择, 并在该尺度组合下构建单尺度决策表, 进行属性约简和知识发现.因此, 最优尺度组合选择是广义多尺度粗糙集数据分析中的关键问题之一.近年来, 围绕最优尺度组合选择与属性约简的研究取得一定进展[15, 16].
为了进一步提升模型对噪声数据的鲁棒性, 研究者将可变精度思想引入多尺度粗糙集框架中.Wu等[17]将概率粗糙集模型引入多尺度决策系统, 研究最优尺度组合问题.在此基础上, 牛东苒等[18]提出可变精度广义多尺度粗糙集模型, 定义4类最优尺度组合, 系统分析它们之间的关系.Gong等[19]提出覆盖可变精度广义多尺度粗糙集模型, 研究最优尺度组合选择方法及相应的知识获取规则.然而, 在可变精度多尺度粗糙集模型中, 随着尺度组合由粗到细, 上下近似通常不满足单调性, 这给最优尺度组合选择带来显著挑战.针对这一问题, Guo等[20]提出单调的可变精度多尺度粗糙集模型, 从理论上解决非单调性带来的困难.
信息熵是刻画信息不确定性的重要工具, 已广泛应用于粗糙集数据分析的属性约简与规则获取中[21, 22].现有研究主要基于Shannon熵[23]、互补条件熵[24]等信息度量形式构建属性重要性评价方法.与 Shannon 熵不同, 互补条件熵从粗糙集的信息粒结构出发, 刻画等价类及其补集之间的对偶关系, 度量系统不确定性, 具有良好的单调性和可解释性, 并能同时刻画粗糙集上的不确定性与模糊性, 因此更适用于粗糙集及其扩展模型.
近年来, 信息熵也被引入多尺度数据分析领域, 用于最优尺度组合选择和属性约简问题.Bao等[25]以 Shannon 熵为指导原则, 提出保持知识不确定性度量的最优尺度组合选择方法.Wang等[26]引入多尺度模糊熵, 实现不同尺度层次粒信息的融合.Yang等[27]基于信息熵刻画多尺度属性与决策之间的相关性以及属性之间的冗余性, 实现属性子集筛选.Xie等[28]在多尺度区间集决策表的框架上提出修正条件熵和正域互补条件熵, 并分析不同熵度量对应的最优尺度关系.
尽管可变精度多尺度粗糙集模型已受到研究者的广泛关注, 但现有方法主要聚焦于最优尺度选择, 通常是在获得单尺度决策系统后, 再应用现有的属性约简方法.然而, Yang等[27]指出, 先进行属性约简能显著降低计算成本并提高效率.因此, 在最优尺度组合选择之前如何有效进行属性约简, 仍是一个值得进一步研究的方向.此外, 相比传统粗糙集方法, 信息熵能基于不确定性更有效量化属性对决策的区分能力, 在属性重要性评估与约简中具有明显优势.基于这一优势, 将互补条件熵引入可变精度多尺度模型, 可为属性约简与最优尺度组合选择提供更合理的不确定性度量.
因此, 本文在单调的可变精度多尺度粗糙集模型基础上, 进一步研究基于熵的属性约简与最优尺度组合选择问题, 并分别给出相应的属性约简算法和最优尺度组合选择算法.
定义1[6] 称S=(U, A∪ D)为一个单尺度决策系统, 其中,
U={x1, x2, ···, xn}
表示论域,
A={a1, a2, ···, am}
表示非空有限条件属性集, D={d}表示决策属性集, 满足
A∩ D=Ø .
对于∀ j=1, 2, ···, m, 令aj∶ U→ Vj为一个映射, 其中
$V_{j}=\left\{a_{j}(x) \mid x \in U\right\}$
表示aj的值域.同理, 对于∀ d∈ D, 也存在一个从U到值域Vd的映射, 即d∶ U→ Vd, 其中Vd表示决策属性d的值域.
对于任意非空子集B⊆A, 等价关系RB定义如下:
$R_{B}=\{(x, y) \in U \times U \mid a(x)=a(y), \forall a \in B\}, $
其中, RB将U中的对象划分为互不相交的等价类, 记作U/B, 即
$U / B=\left\{[x]_{B} \mid x \in U\right\}, $
其中
$[x]_{B}=\left\{y \in U \mid(x, y) \in R_{B}\right\}, $
表示包含元素x的等价类.
对于X⊆U, X关于B的下近似$\underline{R_{B}}(X)$与上近似$\overline{R_{B}}(X)$定义如下:
$\underline{R_{B}}(X)=\left\{x \in U \mid[x]_{B} \subseteq X\right\}, $
$\overline{R_{B}}(X)=\left\{x \in U \mid[x]_{B} \cap X \neq \emptyset\right\} . $
决策属性d决定的等价关系如下所示:
$R_{d}=\{(x, y) \in U \times U \mid d(x)=d(y)\}, $
则由d决定的U的划分
$U / D=\left\{D_{1}, D_{2}, \cdots, D_{r}\right\} . $
若RA⊆Rd, 则称单尺度决策系统S=(U, A∪ D)是协调的; 否则称S是不协调的.
熵度量是刻画粗糙集不确定性的重要工具.为了定量分析可变精度多尺度决策系统中的信息, 本节回顾互补条件熵.
定义2[24] 设U为一个非空有限集合,
$Q=\left\{Q_{1}, Q_{2}, \cdots, Q_{n_{1}}\right\}, P=\left\{P_{1}, P_{2}, \cdots, P_{n_{2}}\right\}$
均为U上等价关系诱导的划分, 其中, Q包含n1个等价类Q1, Q2, ···,
$E(Q \mid P)=\sum_{i=1}^{n_{1}} \sum_{j=1}^{n_{2}}\left(\frac{\left|Q_{i} \cap P_{j}\right|}{|U|} \cdot \frac{\left|Q_{i}^{C} \cap P_{j}\right|}{|U|}\right), $
其中,
$Q_{i}^{C}=U-Q_{i}=\left\{x \in U \mid x \notin Q_{i}\right\}, $
表示Qi在U中的补集.
定义3[14] 称S=(U, A∪ D)为一个广义多尺度决策系统, 其中U={x1, x2, ···, xn}表示论域, A={a1, a2, ···, am}表示非空有限条件属性集, 且每个属性aj∈ A均表示多尺度属性.D={d}表示决策属性集, 决策属性d表示单尺度属性.设aj有Ij个尺度层次,
$S=\left(U, \left\{a_{j}^{k} \mid k=1, 2, \cdots, I_{j}, j=1, 2, \cdots, m\right\} \cup D\right) .$
本文约定, 随着
$g_{j}^{k, k-1}: V_{j}^{k} \longrightarrow V_{j}^{k-1}$,
使得
$a_{j}^{k-1}(x)=g_{j}^{k, k-1} 。\left(a_{j}^{k}(x)\right), $
即
其中
定义4[14] 设S=(U, A∪ D)为一个广义多尺度决策系统.对于属性aj∈ A, 若取其第lj个尺度标记, 1≤ lj≤ Ij, j=1, 2, ···, m, 则K=(l1, l2, ···, lm)为S的一个尺度组合.该组合下的属性集记为
AK={
由K形成的单尺度决策系统记为SK=(U, AK∪ D).S中所有尺度组合的集合称为尺度组合全集, 记为
$\Omega^{+}=\left\{\left(l_{1}, l_{2}, \cdots, l_{m}\right) \mid 1 \leqslant l_{j} \leqslant I_{j}, j=1, 2, \cdots, m\right\} . $
由于
I=(I1, I2, ···, Im),
最粗尺度组合
CSC=(1, 1, ···, 1).
设
K=(l1, l2, ···, lm)∈ Ω +,
$K^{\prime}=\left(l_{1}^{\prime}, l_{2}^{\prime}, \cdots, l_{m}^{\prime}\right) \in \Omega^{+}, $
若对∀ j=1, 2, ···, m, 有lj≥ l'j, 则称K比K'细, 或K'比K粗, 记作K⪰K'.若K⪰K'且至少存在一个j使lj> l'j, 则称K严格细于K', 或K'严格粗于K, 记作K≻K'.若K和K'满足K⪰K'或K'⪰K, 称二者可比; 否则不可比.
命题1 设S=(U, A∪ D)为一个广义多尺度决策系统.对于任意尺度组合K∈ Ω +, 由AK决定的等价关系定义如下:
$\begin{array}{l} R_{A^{K}}= \left\{(x, y) \in U \times U \mid a_{j}^{l_{j}}(x)=a_{j}^{l_{j}}(y), j=1, 2, \cdots, m\right\}, \end{array}$
则由AK决定的U的划分表示如下:
$U / A^{K}=\left\{[x]_{A^{K}} \mid x \in U\right\}, $
其中
$[x]_{A^{K}}=\left\{y \in U \mid(x, y) \in R_{A^{K}}\right\} . $
假设K∈ Ω +, K'∈ Ω +且K⪰K', 则
$R_{A^{K}} \subseteq R_{A^{K^{\prime}}}, [x]_{A^{K}} \subseteq[x]_{A^{K^{\prime}}} $.
现有广义多尺度决策系统的上、下近似多基于Pawlak粗糙集, 缺乏对噪声数据的容错能力, 因此在实际含噪数据处理中鲁棒性受限.为此, 将可变精度引入广义多尺度决策系统, 提升模型的泛化能力.
定义5[18] 设S=(U, A∪ D)为一个广义多尺度决策系统, 对于K∈ Ω +, 0.5< β ≤ 1, X⊆U, 则X关于AK的β 下近似与β 上近似定义如下:
$\underline{R_{A^{K}}^{\beta}}(X)=\left\{x \in U \mid P\left(X \mid[x]_{A^{K}}\right) \geqslant \beta\right\}, $
$\overline{R_{A^{K}}^{\beta}}(X)=\left\{x \in U \mid P\left(X \mid[x]_{A^{K}}\right)> 1-\beta\right\}, $
其中
$P\left(X \mid[x]_{A^{K}}\right)=\frac{\left|[x]_{A^{K}} \cap X\right|}{\left|[x]_{A^{K}}\right|} . $
对于U/D={D1, D2, ···, Dr}, 有
$\underline{R_{A^{K}}^{\beta}}(D)=\bigcup_{i=1}^{r} \underline{R_{A^{K}}^{\beta}}\left(D_{i}\right), $
$\overline{R_{A^{K}}^{\beta}}(D)=\bigcup_{i=1}^{r} \overline{R_{A^{K}}^{\beta}}\left(D_{i}\right) . $
D关于AK的β 正域定义如下:
${POS}_{A^{K}}^{\beta}(D)=\underline{R_{A^{K}}^{\beta}}(D) . $
然而, 上述经典可变精度广义多尺度粗糙集模型不具备单调性.具体而言, 当尺度组合由粗变细时, 其上、下近似与正域并不呈现单调的变化规律, 这为最优尺度组合的选择带来挑战.为了解决此问题, 学者提出单调的可变精度多尺度粗糙集模型.
定义6[20] 设S=(U, A∪ D)为一个广义多尺度决策系统, 对于K∈ Ω +, 0.5< β ≤ 1, X⊆U, 最细尺度组合I, 则X关于AK的β 下近似、 β 上近似和β 正域定义如下:
$\underline{M R_{A^{K}}^{\beta}}(X)=\underline{R_{A^{K}}}\left(\underline{R_{A^{I}}^{\beta}}(X)\right), $
$\overline{M R_{A^{K}}^{\beta}}(X)=\overline{R_{A^{K}}}\left(\overline{R_{A^{I}}^{\beta}}(X)\right), $
${MPOS}_{A^{K}}^{\beta}(X)=M R_{A^{K}}^{\beta}(X) . $
定理1 设S=(U, A∪ D)为一个广义多尺度决策系统, 对于0.5< β ≤ 1, I=(I1, I2, ···, Im), X⊆U, 若K∈ Ω +, K'∈ Ω +满足K⪰K', 则如下性质成立:
1) $\underline{M R_{A^{K^{\prime}}}^{\beta}}(X) \subseteq \underline{M R_{A^{K}}^{\beta}}(X)$,
2) $\overline{M R_{A^{K^{\prime}}}^{\beta}}(X) \supseteq \overline{M R_{A^{K}}^{\beta}}(X) $,
3) ${MPOS}_{A^{K^{\prime}}}^{\beta}(X) \subseteq {MPOS}_{A^{K}}^{\beta}(X)$ .
本节研究多尺度决策系统中基于可变精度的最优尺度组合选择与属性约简问题.众所周知, 熵是刻画信息不确定性的有效量化工具, 为此, 在属性约简和最优尺度组合选择过程中引入熵的概念.
为了刻画粗糙集上的不确定性与模糊性, 并降低噪声影响, Liang等[24]提出互补条件熵并用于冗余特征约简.然而, 可变精度的引入虽提升广义多尺度决策系统的泛化性与鲁棒性, 却破坏单调性.为此, 基于互补条件熵与单调的可变精度粗糙集模型, 提出单调的可变精度互补条件熵.
定义7 设S=(U, A∪ D)为一个广义多尺度决策系统, 对于K∈ Ω +, 0.5< β ≤ 1, 最细尺度组合I, U/D={D1, D2, ···, Dr}, 则D关于AK的可变精度正域互补条件熵定义如下:
$\begin{array}{l} {VPPE}_{\beta}\left(D \mid A^{K}\right)= \\ \qquad \sum_{i=1}^{p} \sum_{j=1}^{r}\left(\frac{\left|\widetilde{X}_{i} \cap D_{j}^{\beta}\right|}{|{POS}|} \cdot \frac{\left|\widetilde{X}_{i} \cap\left(D_{j}^{\beta}\right)^{c}\right|}{|{POS}|}\right), \end{array}$
其中,
表示最细尺度组合I下决策类Dj的β 正域, 且
${POS}={POS}_{A^{I}}^{\beta}(D)=\bigcup_{j=1}^{r} D_{j}^{\beta}, $
$\widetilde{X}=P O S / A^{K}=\left\{[x]_{A^{K}} \mid x \in P O S\right\}, $
满足
$\bigcup_{i=1}^{p} \widetilde{X}_{i}=P O S . $
需要注意的是, 下文始终假设关于最细尺度组合I的决策属性D的β 正域为非空集.
命题2 设S=(U, A∪ D)为一个广义多尺度决策系统, 对于0.5< β ≤ 1, 最细尺度组合I, K∈ Ω +, 则有
1) ${VPPE}_{\beta}\left(D \mid A^{I}\right)=0, $
2). ${VPPE}_{\beta}\left(D \mid A^{K}\right) \geqslant 0 . $
证明 对于1), 在最细尺度组合I下, 记
U/AI={X1, X2, ···, Xp}.
根据可变精度粗糙集的定义, 决策类Dj的β 下近似
$D_{j}^{\beta}={POS}_{A^{I}}^{\beta}\left(D_{j}\right)=\left\{x \in U: P\left(D_{j} \mid[x]_{A^{I}}\right) \geqslant \beta\right\}, $
正域
${ POS }=\bigcup_{j=1}^{r} D_{j}^{\beta} . $
对于∀ Xi∈ U/AI, 若Xi⊆POS, 则存在唯一的j使得Xi⊆
$\left|\widetilde{X}_{i} \cap D_{j}^{\beta}\right|=\left|\widetilde{X}_{i}\right|, \left|\widetilde{X}_{i} \cap\left(D_{j}^{\beta}\right)^{c}\right|=0. $
对于 j'≠ j, 则
$\left|\widetilde{X}_{i} \cap D_{j^{\prime}}^{\beta}\right|=0 . $
代入定义7得
${VPPE}_{\beta}\left(D \mid A^{I}\right)=0 . $
对于2), ∀ K∈ Ω +, 由定义可知, $\left|\widetilde{X}_{i} \cap D_{j}^{\beta}\right|$与$\left|\widetilde{X}_{i} \cap\left(D_{j}^{\beta}\right)^{c}\right|$均为非负整数, 且$|{POS}|> 0$.因此, 定义式中的每项均为非负实数, 其有限和仍为非负, 即
${VPPE}_{\beta}\left(D \mid A^{K}\right) \geqslant 0 . $ 证毕.
定理2 设S=(U, A∪ D)为一个广义多尺度决策系统, 对于0.5< β ≤ 1, 若K∈ Ω +, K'∈ Ω +, 满足K⪰K', 则
${VPPE}_{\beta}\left(D \mid A^{K}\right) \leqslant {VPPE}_{\beta}\left(D \mid A^{K^{\prime}}\right) . $
证明 记
${POS}={POS}_{A^{I}}^{\beta}(D)=\bigcup_{j=1}^{r} D_{j}^{\beta}$
为最细尺度组合I的β 正域,
$\widetilde{X}=P O S / A^{K}=\left\{\widetilde{X}_{1}, \widetilde{X}_{2}, \cdots \widetilde{X}_{p}\right\}$
为K在POS下划分出的等价类,
$\widetilde{X}^{\prime}=\operatorname{POS} / A^{K^{\prime}}=\left\{\widetilde{X}_{1}^{\prime}, \widetilde{X}_{2}^{\prime}, \cdots, \widetilde{X}_{p^{\prime}}^{\prime}\right\}$
为K'在POS下划分出的等价类.
由于K⪰K', 由命题1可知对∀ x∈ U有
$\widetilde{X}_{i}^{\prime}=\bigcup_{t \in I^{i}} \widetilde{X}_{t}$.
考虑乘积项:
$T_{K}(t, j)=\left|\widetilde{X}_{t} \cap D_{j}^{\beta}\right| \cdot\left|\widetilde{X}_{t} \cap\left(D_{j}^{\beta}\right)^{c}\right|, $
$T_{K^{\prime}}(i, j)=\left|\widetilde{X}_{i}^{\prime} \cap D_{j}^{\beta}\right| \cdot\left|\widetilde{X}_{i}^{\prime} \cap\left(D_{j}^{\beta}\right)^{c}\right| . $
当
$\left|\widetilde{X}_{i}^{\prime} \cap\left(D_{j}^{\beta}\right)^{c}\right|=0, \left|\widetilde{X}_{t} \cap\left(D_{j}^{\beta}\right)^{c}\right|=0 . $
从而有
$T_{K}(t, j)=0, T_{K^{\prime}}(i, j)=0 . $
当
$\left|\widetilde{X}_{i}^{\prime} \cap\left(D_{j}^{\beta}\right)^{c}\right|> 0, $
因为
$T_{K}(t, j) \leqslant T_{K^{\prime}}(i, j) . $
综合上述两种情况, 对∀
$T_{K}(t, j) \leqslant T_{K^{\prime}}(i, j) $
对于下标集合Ii, 有
$\begin{array}{l} \sum_{t=1}^{p} \sum_{j=1}^{r}\left|\widetilde{X}_{t} \cap D_{j}^{\beta}\right| \cdot\left|\widetilde{X}_{t} \cap\left(D_{j}^{\beta}\right)^{c}\right|= \\ \quad \sum_{i=1}^{p^{\prime}} \sum_{t \in I_{i}} \sum_{j=1}^{r}\left|\widetilde{X}_{t} \cap D_{j}^{\beta}\right| \cdot\left|\widetilde{X}_{t} \cap\left(D_{j}^{\beta}\right)^{c}\right| \leqslant \\ \quad \sum_{i=1}^{p^{\prime}} \sum_{t \in I_{i}} \sum_{j=1}^{r}\left|\widetilde{X}_{i}^{\prime} \cap D_{j}^{\beta}\right| \cdot\left|\widetilde{X}_{i}^{\prime} \cap\left(D_{j}^{\beta}\right)^{c}\right|= \\ \quad \sum_{i=1}^{p^{\prime}}\left|I_{i}\right| \sum_{j=1}^{r}\left|\widetilde{X}_{i}^{\prime} \cap D_{j}^{\beta}\right| \cdot\left|\widetilde{X}_{i}^{\prime} \cap\left(D_{j}^{\beta}\right)^{c}\right| \leqslant \\ \quad \sum_{i=1}^{p^{\prime}} \sum_{j=1}^{r}\left|\widetilde{X}_{i}^{\prime} \cap D_{j}^{\beta}\right| \cdot\left|\widetilde{X}_{i}^{\prime} \cap\left(D_{j}^{\beta}\right)^{c}\right| . \end{array}$
根据定义7, 得
${VPPE}_{\beta}\left(D \mid A^{K}\right) \leqslant {VPPE}_{\beta}\left(D \mid A^{K^{\prime}}\right) . $ 证毕.
定理2表明, 随着尺度组合由粗变细, 可变精度正域互补条件熵具有单调性, 因此可使用局部的思想定义最优尺度组合.
定义8 设S=(U, A∪ D)为一个广义多尺度决策系统, K=(l1, l2, ···, lm)∈ Ω +.对于任意满足lj> 1的属性aj (1≤ j≤ m), 将aj的尺度变粗一级后得到的子尺度组合K'j定义如下:
$K_{j}^{\prime}=\left(l_{1}, \cdots, l_{j-1}, l_{j}-1, l_{j+1}, \cdots, l_{m}\right) . $
K在Ω +中所有子尺度组合集合定义如下:
${Child}_{\Omega^{+}}(K)=\left\{K_{j}^{\prime} \in \Omega^{+} \mid\right.$
$\left.K_{j}^{\prime}=\left(l_{1}, \cdots, l_{j-1}, l_{j}-1, l_{j+1}, \cdots, l_{m}\right), j=1, 2, \cdots, m\right\} . $
定义9 设S=(U, A∪ D)为一个广义多尺度决策系统, 0.5< β ≤ 1, 若K* ∈ Ω +, 且K* 符合如下条件, 则称K* 为S的可变精度互补条件熵最优尺度组合:
1)K* 是关于S的可变精度互补条件熵协调的尺度组合, 即
${VPPE}_{\beta}\left(D \mid A^{K^{* }}\right)={VPPE}_{\beta}\left(D \mid A^{I}\right)=0 . $
2)对∀ K∈ Chil
${VPPE}_{\beta}\left(D \mid A^{K}\right) \neq {VPPE}_{\beta}\left(D \mid A^{I}\right) . $
在广义多尺度决策系统中, 传统基于正域变化的单尺度属性重要性评价方法对噪声较敏感, 而常规约简算法通常依赖最优尺度组合.为了提高计算效率, 本文在最优尺度选择前进行属性约简, 并基于可变精度正域互补条件熵设计协调的与分类驱动的属性约简方法.
定义10 设S=(U, A∪ D)为一个广义多尺度决策系统, 对于任意属性子集B⊆A, 设
B={
则可得到一个新的广义多尺度决策系统SB=(U, B∪ D), SB中所有尺度组合的集合记为
$\Omega_{B}^{+}=\left\{\left(l_{s_{1}}, l_{s_{2}}, \cdots, l_{s_{t}}\right) \mid 1 \leqslant l_{s_{j}} \leqslant I_{s_{j}}, j=1, 2, \cdots, t\right\}, $
其中最细尺度组合IB=(
KB=(
在KB下构成的属性集记为
定理3 设S=(U, A∪ D)为一个广义多尺度决策系统, 对于B1⊆A, B2⊆A, 0.5< β ≤ 1,
${VPPE}_{\beta}\left(D \mid B_{2}^{K_{B_{2}}}\right) \leqslant {VPPE}_{\beta}\left(D \mid B_{1}^{K_{B_{1}}}\right) . $
证明 由于B1⊆B2, SK=(U, AK∪ D)为一个单尺度决策系统, 任取(x, y)∈
定理3表明, 属性子集之间的可变精度正域互补条件熵是具有单调性的, 因此可使用局部的思想定义属性约简.
定义11 设S=(U, A∪ D)为一个广义多尺度决策系统, 0.5< β ≤ 1, 若属性子集B⊆A, 且B符合如下条件, 则称B为S的可变精度互补条件熵约简:
1)B是关于S的一个可变精度互补条件协调集, 即
${VPPE}_{\beta}\left(D \mid B^{I_{B}}\right)={VPPE}_{\beta}\left(D \mid A^{I}\right)=0 ; $
2)B的真子集都不是关于S的一个可变精度互补条件协调集, 即对于∀ c∈ B, 有
${VPPE}_{\beta}\left(D \mid\{B-c\}^{I_{\{B-c\}}}\right) \neq {VPPE}_{\beta}\left(D \mid A^{I}\right) . $
在广义多尺度决策系统中, 由命题2可知, 最细尺度组合本身是可变精度正域互补条件熵协调的, 并包含系统的最完整信息.鉴于此, 判断属性冗余性时, 可使用最细尺度组合下的条件熵作为参考:若某属性在最细尺度下不提供额外信息, 其对决策的贡献可忽略, 从而可从约简子集中删除.通过逐步选择那些能显著降低互补条件熵的属性, 得到协调的约简子集.
基于上述定义及相关定理, 本文进一步设计前向启发式协调的属性约简算法, 具体步骤如下.
算法1 多尺度决策系统中基于可变精度正域互补条件熵的前向协调的属性约简算法
输入 S=(U, A∪ D), 精度β , 最细尺度组合I
输出 协调的约简子集B
B=Ø ; // 初始化已选属性子集为空
while VPPEβ (D|
VPPEmin=∞ , abest=None; // 初始化最小目标函数值与最优属性
for (each a∈ A-B) do
计算 ${VPPE}_{\beta}\left(D \mid\{B \cup\{a\}\}^{I_{\{B \cup\{a\}\}}}\right)$;
// 计算加入候选属性后的可变精度正域互补条件熵
if ${VPPE}_{\beta}\left(D \mid\{B \cup\{a\}\}^{I_{\{B \cup\{a\}\}}}\right)<{VPPE}_{\min }$
then
VPPEmin=VPPEβ (D|
abest=a;
end if
end for
if abest=None then
break; // 没有属性可以降低条件熵
end if
B← B∪ {abest};
VPPEβ (D|
end while
return B
在算法1中, 计算可变精度互补条件熵的时间复杂度在最坏情况下为O(n2), 其中n=|U|表示论域对象总数.算法1的核心循环为for语句, 每轮需要对所有候选属性计算一次熵的值, 最多有m=|A|个候选属性, 每轮时间复杂度为O((m-|B|)n2).整个循环最多进行m轮选择, 因此算法1的最坏时间复杂度为:
$O\left(\sum_{i=0}^{m-1}(m-i) n^{2}\right)=O\left(m^{2} n^{2}\right) . $
算法1实现多尺度决策系统中在最优尺度选择之前的协调的属性约简.在迭代过程中, 算法依据可变精度互补条件熵的下降程度逐步选取属性, 并最终返回一个按照属性贡献度排序的属性集合.需要注意的是, 算法1返回的结果是一个协调的属性集, 该属性集仍可能包含冗余特征.正如Yang等[27]指出:即使属性集是协调的, 其分类性能不一定最优; 通过去除部分冗余属性, 属性集的分类精度反而可能得到提升.基于此启发及算法1, 对约简子集进行优化, 寻找分类效果最优的属性子集, 设计如下算法2.
算法2 多尺度决策系统中的最优属性约简算法
输入 算法1得到的B={
最细尺度组合I
输出 最优约简子集B*
令B1={
for i=1 to t do
使用选定的分类器计算Acc(
end for
if Acc(
B* ←
end if
return B*
算法2基于算法1所得约简子集进行增量构造.若某候选特征子集的可变精度正域互补条件熵不为0, 并能实现最高分类精度, 则将其作为最优近似约简.根据定义11, 协调的约简子集可保证与最细尺度组合是保持协调的.然而, 对于包含大量对象的单尺度决策系统, 算法1往往会选择全部特征, 导致关键属性难以识别.因此, 算法2在协调的约简基础上进一步筛选特征, 获得更适于分类的近似约简子集.
在算法2中, 针对单尺度决策系统S=(U, A∪ D)使用选定分类器进行分类, 分类精度定义为正确预测样本所占比例:
Acc(A)=
其中, NC表示正确预测样本数, NT表示总样本数.时间复杂度主要取决于分类器的训练与验证过程.在最坏情况下, 算法2的时间复杂度为
O(KmTmax(n, m)),
其中, n表示样本数, m表示属性个数, K表示交叉验证折数, Tmax(n, m)表示分类器T在样本和属性中训练与测试的最坏时间复杂度.
在广义多尺度决策系统中, 最优尺度组合的选择直接影响知识表示粒度及分类性能.现有方法通常基于完整属性集进行尺度选择, 默认与最细尺度组合是保持协调的.然而, 在实际应用中, 经过属性约简, 尤其是基于分类性能的约简后, 约简子集与最细尺度组合可能不再保持协调.因此, 本研究基于可变精度互补条件熵, 提出基于属性子集的最优尺度组合定义及选择算法.
定义12 设S=(U, A∪ D)为一个广义多尺度决策系统, 0.5< β ≤ 1, B⊆A, IB为SB=(U, B∪ D)的最细尺度组合.若
1)
${VPPE}_{\beta}\left(D \mid B^{K_{B}^{* }}\right)={VPPE}_{\beta}\left(D \mid B^{I_{B}}\right) $
2)对∀ KB∈ Chil
${VPPE}_{\beta}\left(D \mid B^{K_{B}}\right) \neq {VPPE}_{\beta}\left(D \mid B^{I_{B}}\right) . $
逐步式最优尺度组合选择方法虽然能在大规模数据集上获得最优尺度组合, 但其从细到粗逐一检验尺度的搜索策略容易引入冗余计算, 且多数方法未充分考虑属性贡献度排序对尺度搜索效率的影响.
为此, 本文提出结合二分查找策略与属性贡献度排序的最优尺度选择算法, 具体步骤如下.
算法3 基于约简子集的最优尺度组合选择算法
输入 S=(U, A∪ D), 精度β , 最细尺度组合I, 最粗尺度组合CSC, 最优约简子集B*
输出 关于B* 的可变精度互补条件熵最优尺度组合
计算VPPEβ (D|
lower← CSC=(1, 1, ···, 1),
upper← I=(I1, I2, ···, Im); // 初始化尺度组合搜索区间
while true do
mid← 「(lower+upper)/2⌉;
计算VPPEβ (D|
if ${VPPE}_{\beta}\left(D \mid\left(B^{*}\right)^{\operatorname{mid}_{B} *}\right)={VPPE}_{\beta}\left(D \mid\left(B^{*}\right)^{I_{B} *}\right)$
then
upper← mid;
else
lower← mid;
end if
new_mid← 「(lower+upper)/2⌉;
if new_mid=mid then
break;
end if
end while
for(each a∈ B* ) do //按约简顺序
while
//属性a的尺度大于其最粗尺度
K'(a)←
计算${VPPE}_{\beta}\left(D \mid\left(B^{*}\right)^{K^{\prime}(a)_{B^{*}}}\right)$;
if ${VPPE}_{\beta}\left(D \mid\left(B^{*}\right)^{K^{\prime}(a) B^{*}}\right)={VPPE}_{\beta}\left(D \mid\left(B^{*}\right)^{I_{B^{*}}}\right)$
then
K* (a)← K'(a);
else
break;
end if
end while
end for
return
算法3主要包括两个阶段.第一阶段通过二分查找策略确定一个协调的尺度组合; 第二阶段依据算法2得到的属性贡献度顺序, 对约简子集B* 中的各属性尺度逐一进行调整, 获得最终的最优尺度组合.在第一阶段中, 每次迭代均将搜索空间缩小一半, 因此最多进行O(log2K)次迭代, 其中K表示最细尺度组合I中的最大尺度值.第二阶段按照属性约简子集B* 中的顺序进行尺度调整.在最坏情况下, 对于任意属性a∈ B* , 其尺度需要从初始值K* (a)逐步调整至最粗尺度CSC(a), 最多进行K* (a)-CSC(a)次尝试.综合上述两部分, 算法3的总体时间复杂度为:
$O\left(n^{2}\left(\log _{2} K+\sum_{a \in B^{* }}\left(K^{* }(a)-\operatorname{CSC}(a)\right)\right)\right) . $
实验选用 UCI 公共数据库上12个数据集, 数据集具体信息如表1所示.
| 表1 实验数据集 Table 1 Experimental datasets |
实验平台为一台个人计算机, 配置包括Intel Core i7-10700处理器、16 GB内存, 操作系统为Windows 11, 整个算法在Matlab环境下运行.
由于表1中列出的数据集为单尺度决策系统, 因此本文使用文献[15]中方法将其转换为对应的广义多尺度决策系统, 核心步骤简述如下.
1)给定属性aj, 其取值集合定义为
$V_{j}=\left\{a_{j}(x) \mid x \in U\right\} . $
令δ j表示Vj的标准差, mj表示其最小值, 则对于∀ x∈ U, 最细尺度组合下的属性值为⌊(aj(x)-mj)/δ j」, 其中⌊y」表示小于或等于y的最大整数.
2)基于
3)对于每个属性, 应用1)和2), 得到完整的广义多尺度决策系统.
本节首先开展最优约简子集选择实验, 采用逻辑回归(Logistic Regression, LR)、支持向量机(Support Vector Machine, SVM)和K近邻(K-Nearest Neighbor, KNN)这3种分类器, 并通过 10 折交叉验证确定最优约简子集, 交叉验证前固定随机种子以保证结果可复现.在分类器参数设置方面, LR采用基于一对一编码的二元逻辑回归模型(使用MATLAB的template Linear, 设置Learner为'logis-tic'); SVM采用线性核函数(Kernel Function, 设为'linear'); KNN的近邻数k设为5, 距离度量采用欧氏距离.其余参数均保持MATLAB默认设置.
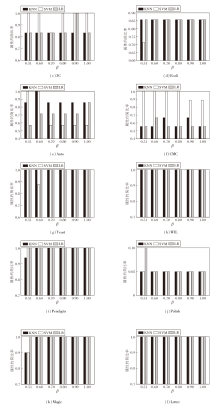
为了分析β 取值的影响, 取β ∈ (0.5, 1], 步长为0.1, 因 0.5不可用, 所以以0.51为起始值, 最终 β 取值集合为{0.51, 0.6, 0.7, 0.8, 0.9, 1.0}.计算各β 取值下的最优约简, 使用属性约简比率(约简后属性数除以原属性数)评估效果, 结果如图 1 所示.
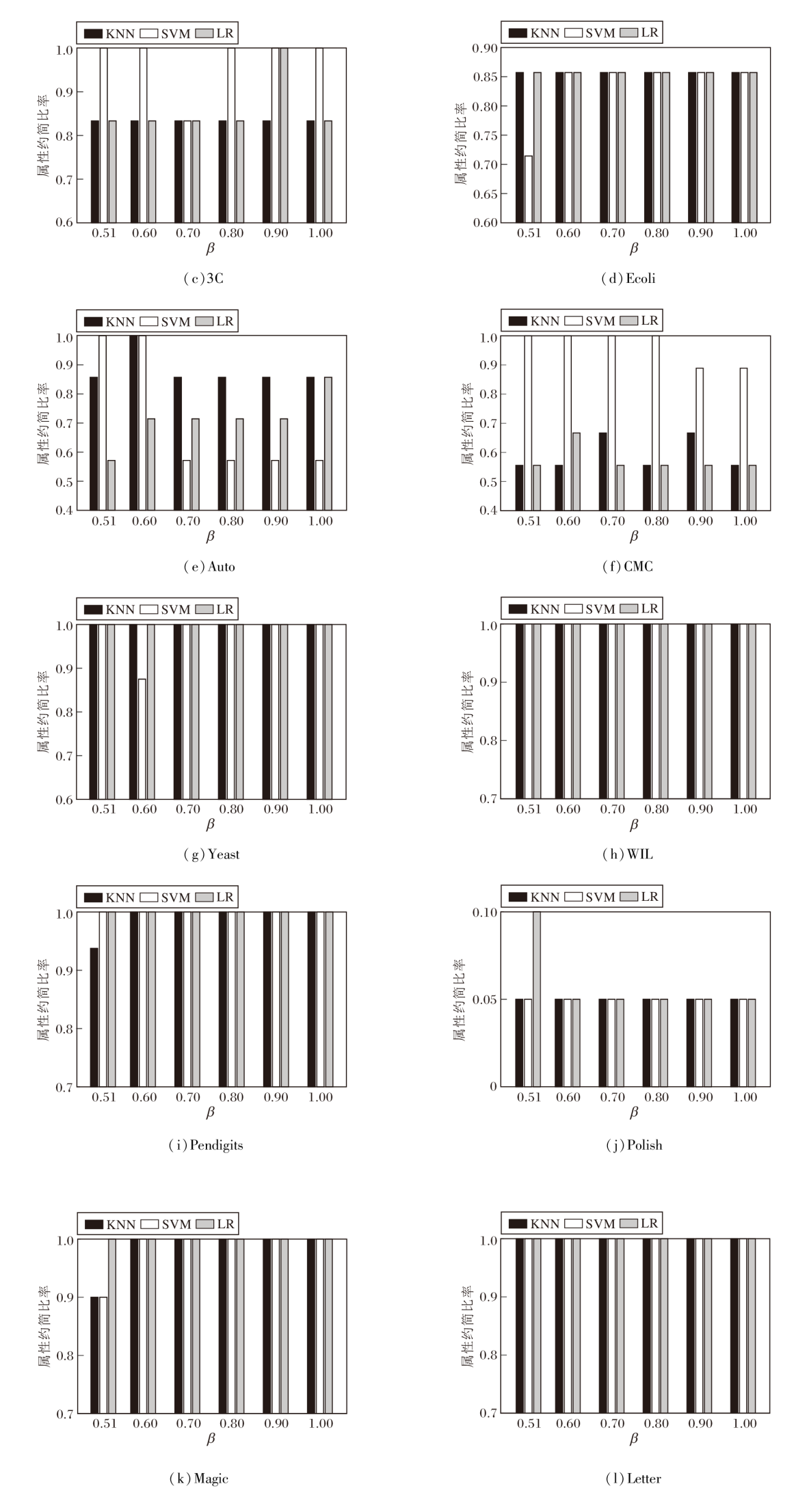 | 图1 算法2在各数据集上的属性约简比率Fig.1 Attribute reduction ratios of Algorithm 2 on different datasets |
从图1可看出, 在不同β 取值下, 大多数数据集上的属性约简比率变化较小, 表明所得约简子集规模整体较稳定.进一步观察发现, 随着β 的增大, 多数数据集上的属性约简比率呈上升趋势, 即约简子集包含的属性数相对增多.少部分数据集上在β 较小时获得更大的约简子集, 其原因是低精度条件可能会加剧决策的不确定性, 从而需要更多的属性以维持较优的分类性能.
下面分析不同β 取值下算法所得最优尺度组合对分类性能的影响.采用各分类器的平均分类精度作为综合评价指标, 结果如表2所示, 表中黑体数字表示最优值.
| 表2 不同β 下最优尺度组合的分类精度 Table 2 Classification accuracy of optimal scale combinations with different β |
由表2可见, 对于大多数数据集而言, 方法在β ∈ [0.6, 0.8]区间内取得较优性能, 这表明引入可变精度机制有助于平衡噪声容忍与判别能力, 提升分类效果.不同数据集对β 取值的敏感度存在差异:Polish数据集不敏感, 各取值结果相同; Magic、Letter数据集在较大参数时精度略升.总之, β 取值处于中等区间时在大部分数据集上表现出更优且更稳定的分类性能.
为了分析不同尺度组合在分类任务中的表现差异, 固定β =0.7进行对比实验, 并选取如下6种代表性的尺度组合.1)可变精度正域互补条件熵最优尺度组合(Variable Precision Positive Region Comple-mentary Conditional Entropy Optimal Scale Combina-tion, VPOSC), 算法 3 获得的最优尺度组合.2)MO- SC[20], 单调的最优尺度组合.3)最细尺度组合(Finest Scale Combination, FSC).4)最粗尺度组合(Coarsest Scale Combination, CSC).5)文献[29]的组合, 扩展的逐步最优尺度组合.6)文献[30]的组合, 约简的逐步最优尺度组合.VPOSC和MOSC基于可变精度机制构建, 具备容错能力, 其余尺度组合均未引入容错机制.
不同尺度组合下的分类精度如表3所示, 表中黑体数字表示最优值.由表可见, VPOSC在大多数数据集上取得最优分类性能, 这主要得益于将可变精度机制与属性约简结合并用于最优尺度选择, 可有效减少冗余属性, 提高分类性能.
| 表3 不同尺度组合下的分类精度 Table 3 Classification accuracy of different scale combinations % |
为了验证在噪声数据集上基于可变精度互补条件熵的属性约简与最优尺度选择算法的鲁棒性, 为每个数据集生成3种噪声水平的数据集, 通过最终分类精度评估鲁棒性.噪声样本数量分别占原始数据的10%、20%和30%.噪声生成方式如下:随机选取一定比例的样本, 并将其标签随机更改为剩余类别中的一种.
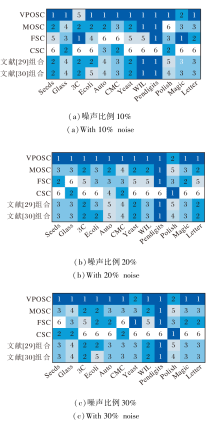
在不同噪声比例下, 各尺度组合在3个分类器上的平均分类精度排名如图2所示.
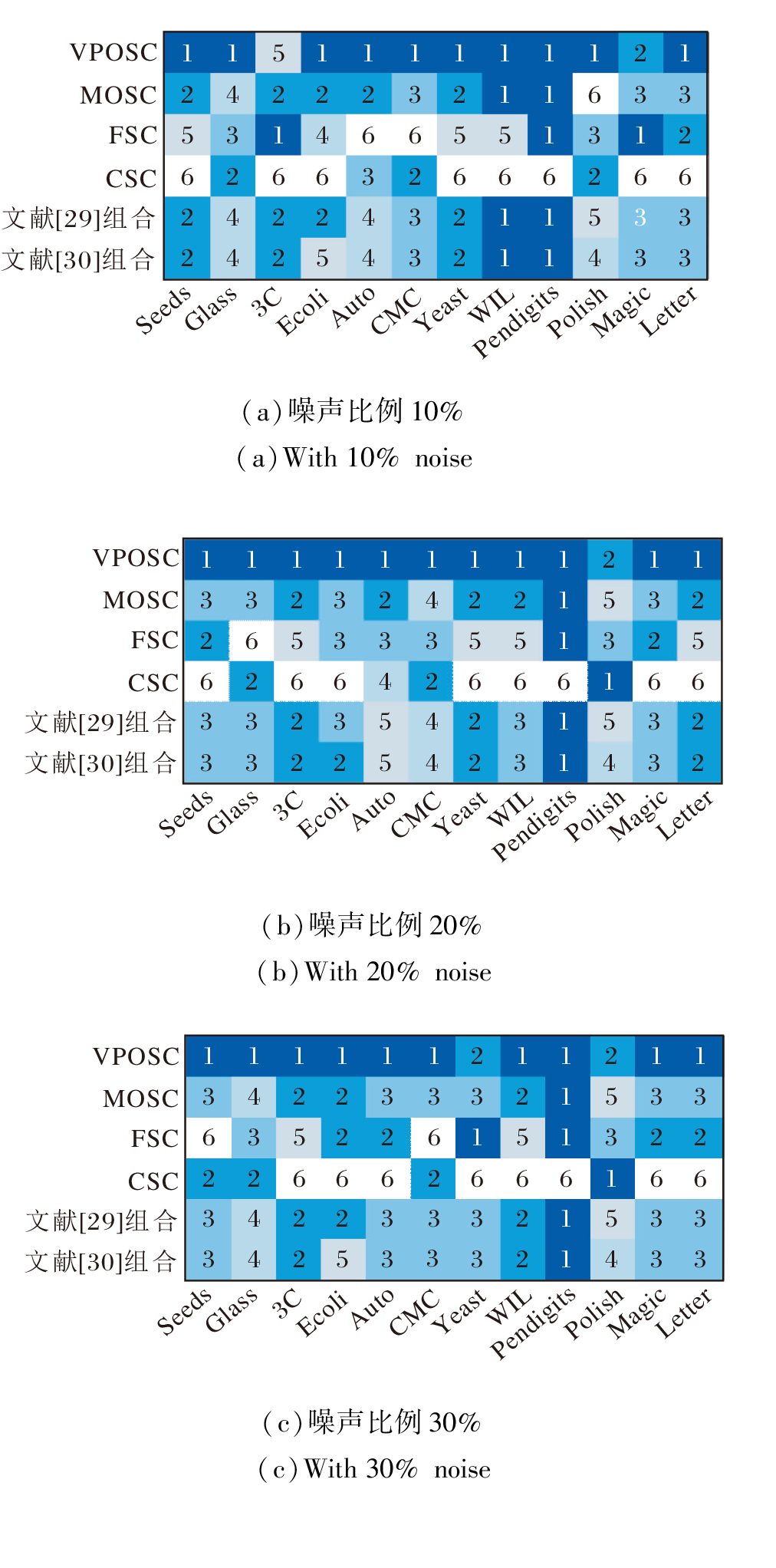 | 图2 不同噪声比例下的分类精度Fig.2 Classification accuracy with different noise levels |
由图2可见, VPOSC在3种噪声水平下, 分别在10个、11个和10个数据集上取得最优分类效果, 明显优于其它参与对比的尺度组合方法.
各尺度组合在不同噪声比例下的平均分类精度如表4所示, 表中黑体数字表示最优值.
| 表4 不同噪声比例下各尺度组合的平均分类精度 Table 4 Average classification accuracy of each scale combination with different noise levels % |
由表4可见, VPOSC在每种噪声水平下均保持最优, 表明其具有良好的鲁棒性, 并且随着噪声比例的增加, VPOSC 的平均分类精度优势进一步扩大.同时可观察到, MOSC的平均分类精度仅次于VPO-SC, 其优势在于同样具有可变精度的容错机制, 但由于未进行属性约简, 在实际分类中可能存在冗余属性, 从而性能略低于VPOSC.实验表明, 结合可变精度与属性约简的最优尺度选择能有效增强算法在噪声数据下的鲁棒性, 同时减少冗余属性对分类的干扰.
综合上述实验结果可知, VPOSC通过引入可变精度互补条件熵实现算法的容错功能, 并结合属性约简进行最优尺度选择, 从而在实际数据集上取得较优的分类性能.
同时, 在噪声数据集上的实验也表明VPOSC具有良好的鲁棒性, 这进一步验证算法的有效性与实用性.
现有的可变精度多尺度粗糙集模型虽然考虑噪声数据集并具备容错能力, 但尚未考虑属性冗余问题, 且缺乏有效的属性约简.为了解决上述问题, 本文提出基于可变精度互补条件熵的属性约简与最优尺度组合选择方法.首先, 提出可变精度互补条件熵, 用于刻画不同尺度下条件属性与决策属性之间的不确定性关系.进一步提出属性约简算法, 去除冗余属性, 并在此基础上进行分类最优属性子集的约简, 得到更适用于分类任务的属性子集.基于约简后的属性子集, 设计基于可变精度互补条件熵, 并结合二分查找算法的最优尺度组合选择算法.在多个数据集上的实验表明, 本文算法得到的最优尺度组合在大多数情况下分类性能较优, 尤其在含噪数据集上表现更稳定.相比传统缺乏容错能力的算法, 本文算法在噪声数据环境下具有更强的容错能力和更优的鲁棒性.今后将进一步探讨如何同步进行属性约简和最优尺度组合选择, 并优化算法效率, 从而推动其在实际场景中的更广泛应用.
本文责任编委 张燕平
Recommended by Associate Editor ZHANG Yanping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|