

{kind=link}
{kind=link}
融合人格特征的共情回复生成
[王鸿杰1, 2  , 阴爱英
, 阴爱英2, 3 , 叶成龙1, 2 , 吴运兵1, 2 ]
, 阴爱英, 叶成龙, 吴运兵]
|
|



作者简介:

王鸿杰,硕士研究生,主要研究方向为共情对话生成.E-mail:1794061907@qq.com.

叶成龙,硕士研究生,主要研究方向为共情对话生成.E-mail:231020027@fzu.edu.cn.

吴运兵,硕士,副教授,主要研究方向为知识表示、情感分析.E-mail:wyb5820@fzu.edu.cn.
共情回复生成旨在生成能理解用户情感并做出恰当回应的答复.现有方法较少考虑人格特征对共情表达方式的影响,容易导致回复风格单一、个性化不足.为了解决该问题,文中提出融合人格特征的共情回复生成模型.首先,为了有效利用人格信息,设计人格增强编码模块,获取对话双方的人格特征并进行独立适配与风格化处理.然后,构建迭代推理与人格调制模块,深化情境理解,同时根据对话双方的人格特征,动态计算人格在当前情境中的影响强度,据此调整回复的情感倾向与语言风格.同时,结合情绪预测模块,精准感知用户的潜在情感.最后,在个性化门控解码模块中,通过门控整合机制有效融合情境、情绪、知识与人格信息,生成符合个体特质且具备深度共情能力的回复.在公开数据集上的实验表明文中模型的多个指标值较优.
About Author:
WANG Hongjie, Master student. His research interests include empathetic dialogue generation.
YE Chenglong, Master student. His research interests include empathetic dialogue generation.
WU Yunbing, Master, associate professor. His research interests include knowledge representation and sentiment analysis.
Empathetic response generation is aimed at understanding user emotions and generating appropriate responses. The influence of personality traits on empathetic expression is seldom considered in existing methods. As a result, generated responses are likely to be limited in single style and insufficient personality. To address this problem, a personality-fused empathetic response generation model(PFEG) is proposed in this paper. First, a personality-enhanced encoding module is designed to effectively utilize personality information. The personality traits of both interlocutors are obtained and independently adapted and stylized. Then, an iterative reasoning and personality modulation module is constructed to deepen situational understanding. The influence intensity of personality in the current situation is dynamically calculated according to the personality traits of both interlocutors. The emotional tendency and language style of the response are adjusted accordingly. An emotion prediction module is introduced to accurately perceive the potential emotions of the user. Finally, in the personalized gated decoding module, situation, emotion, knowledge, and personality information are effectively fused through a gated integration mechanism. Responses that conform to individual traits and demonstrate deep empathy are generated. Experiments on public datasets show that PFEG outperforms baseline models on multiple metrics.
共情是指人际关系互动中理解并分享他人情感体验的能力[1].在人机对话领域中, 共情回复生成旨在赋予机器理解和回应用户情感的能力, 进而实现更加自然且富有人性化的交互体验[2, 3].共情回复生成已在多个领域中得到广泛应用, 如心理健康、智能教育、虚拟陪伴、客户服务等, 在不同场景中均有助于提升用户的情感体验[4, 5, 6].
当前, 共情回复生成的研究在情感共情和认知共情的建模上取得较多进展[3].情感共情侧重于模拟人类的感同身受, 通过情绪感染分享和呼应用户的情感状态.认知共情则强调换位思考, 理解用户所处情境及其情感产生的深层原因, 从而在逻辑上把握情感根源.
然而, 现有大多数模型仅注重于提升通用的情感理解与回应能力, 忽视情绪表达背后的个体差异性, 尤其是人格特征在人机对话中的作用, 导致模型在共情回复的多样性和个性化等方面表现不足.心理学研究表明, 个体的人格特征会影响其在理解和回应他人情感时的策略选择.具体而言, 大五人格模型中的宜人性维度, 与个体的亲社会行为倾向及共情关怀能力之间存在稳定的显著正相关关系[7, 8, 9].现有模型未能将人格特质的影响纳入情感交互框架, 导致生成回复缺乏基于个体差异的个性化表达, 难以构建具有真实感的深层次情感连接.
为了解决这一问题, 研究者进行多方面探索, 从不同方向尝试克服这一问题, 例如:利用情绪分类器实现表层情绪模仿[5], 引入外部知识库增强对用户处境的认知理解[6], 探索自我-他人意识等高阶心理学概念.此外, 部分研究者还开始引入角色信息[10], 进一步增强共情回复的个性化表现.然而, 现有共情对话中的角色信息多指身份档案或角色设定, 主要用于保持角色一致性与风格稳定.
基于上述分析, 本文提出融合人格特征的共情回复生成模型(Personality-Fused Empathetic Response Generation Model, PFEG), 通过深度融合情境、上下文信息与人格特征, 构建一个高效的个性化共情生成框架.首先提取对话双方的人格信息用于语义增强, 然后利用迭代推理与调控机制自适应调节人格影响强度, 最后通过门控解码器动态整合多源信息, 生成回复.在EmpatheticDialogues[2]、ESConv[4]数据集上的实验表明, PFEG在各项评价指标上都取得较优值, 表明其在生成高度个性化、富有深度的共情回复方面的有效性.
早期研究主要集中在情感层面的共情建模.这些方法通常利用显式的情感信号, 模仿人类的情绪反应.Rashkin等[2]通过情绪分类器识别用户的主导情感并注入生成过程, 提升回复的情绪一致性.Xie等[11]提出MEED(Multi-turn Emotionally Enga-ging Dialog Model), 细致捕捉情感动态变化, 生成连贯的情绪轨迹.Lin等[12]提出MoEL(Mixture of Empathetic Listeners), 为不同情绪设计专属解码器, 实现情绪特定的生成策略.Majumder等[13]提出MIME, 模仿用户的情绪极性, 生成具有情绪倾向的回复.
然而, 上述方法仅停留在表层的情绪识别与模仿, 未能深入建模情绪背后的成因或复杂的情绪动态结构.它们虽然在捕捉情感动态方面有所进展, 但缺乏对情感产生的深层次推理与分析, 未能充分考虑情感的复杂性和多维度特征.
为了实现从表层情绪模仿到深层认知理解的跨越, 研究者在常识推理、因果推理和知识增强方面展开大量探索.Sabour等[14]提出CEM(Commonsense-Aware Empathetic Chatting Machine), Li等[15]提出KEMP(Knowledge-Aware Empathetic Dialogue Gene-ration Method), 均借助COMET(Commonsense Transformers)[16]等外部知识库推理用户的意图与处境.为了提高知识与对话的相关性, Cai等[17]提出DCKS, 设计情绪感知的知识选择策略, 确保知识与用户情感状态的一致性.Zhou等[18]提出CASE(Cog-nition and Affection for Responding Empathetically), 构建认知和情感图谱, 在不同粒度上实现情感与知识的对齐.部分学者尝试从情绪的因果关系入手.Gao等[19]从因果视角识别对话中的情绪成因.Qian等[20]提出ECTG(Emotion Cause Transition Graph), 通过情绪因果图进一步强化推理链路.近期, 学者们在检索增强的认知共情方向取得进一步发展.Wang等[21]提出Emp-EEK(Empathetic Response Genera-tion Model Guided by Exemplars and External Know-ledge), 通过微调稠密检索器同时检索对话范例与外部知识, 并结合多专家解码器模拟多维认知机制, 从而有效提升复杂情境中的理解能力.
尽管认知共情方法通过外部知识和因果推理提升模型对用户处境的理解能力, 但仍高度依赖知识库的质量、完整性与时效性, 容易出现知识缺失或不匹配的情况.同时, 在跨轮次、跨语境的推理场景中, 模型的长程推理能力仍显不足.
随着研究的深入, 学者们开始关注共情背后更高层次的心理机制及个体差异在共情中的影响.Yang等提出SDAM(Situation-Dialogue Association Mo-del)[22]与IAMM(Iterative Associative Memory Mo-del)[23], 显式建模情境与对话之间的关联, 提升系统对语境的理解能力.Zhao等[24]提出EmpSOA(Empathetic Response with Explicit Self-Other Aware-ness), 引入自我-他人意识, 强调共情应同时包含对他人情绪的准确感知与对自我立场的理性保持.在策略层面的共情对齐中, Ma等[25]提出EmpRL(Em- pathetic Response Generation Framework Using Reinfor-cement Learning), 构建“ 情感反应-解释-探索” 三类心理机制奖励函数, 并采用PPO(Proximal Policy Optimization), 实现共情表达的分层调控.Yuan等[26]提出ReflectDiffu, 将社会心理学中的情绪感染、意图模仿等机制引入RL-Diffusion框架, 通过情绪意图反射式对齐提升共情策略的灵活性与可控性.
尽管心理机制建模在情境理解、心理机制和策略调控方面取得重要进展, 但仍未能有效解决如何将人格特征融入共情对话中的问题.人格作为稳定的个体差异因素, 对情绪理解方式与表达风格具有深刻影响, 然而现有研究尚未构建系统的人格融合机制, 使得共情回复生成仍然缺乏个性化与真实感.
为了实现更具个性化和共情能力的回复生成, 本文提出融合人格特征的共情回复生成模型(PFEG), 融合说话者与回答者人格特征, 并进行上下文感知的动态调控.
PFEG遵循编码器-解码器框架, 主要由3个核心模块与1个辅助模块紧密构成:人格增强编码模块、迭代推理与人格调制模块、个性化门控解码模块, 并结合情绪预测模块, 精准感知用户情感.PFEG整体架构如图1所示.
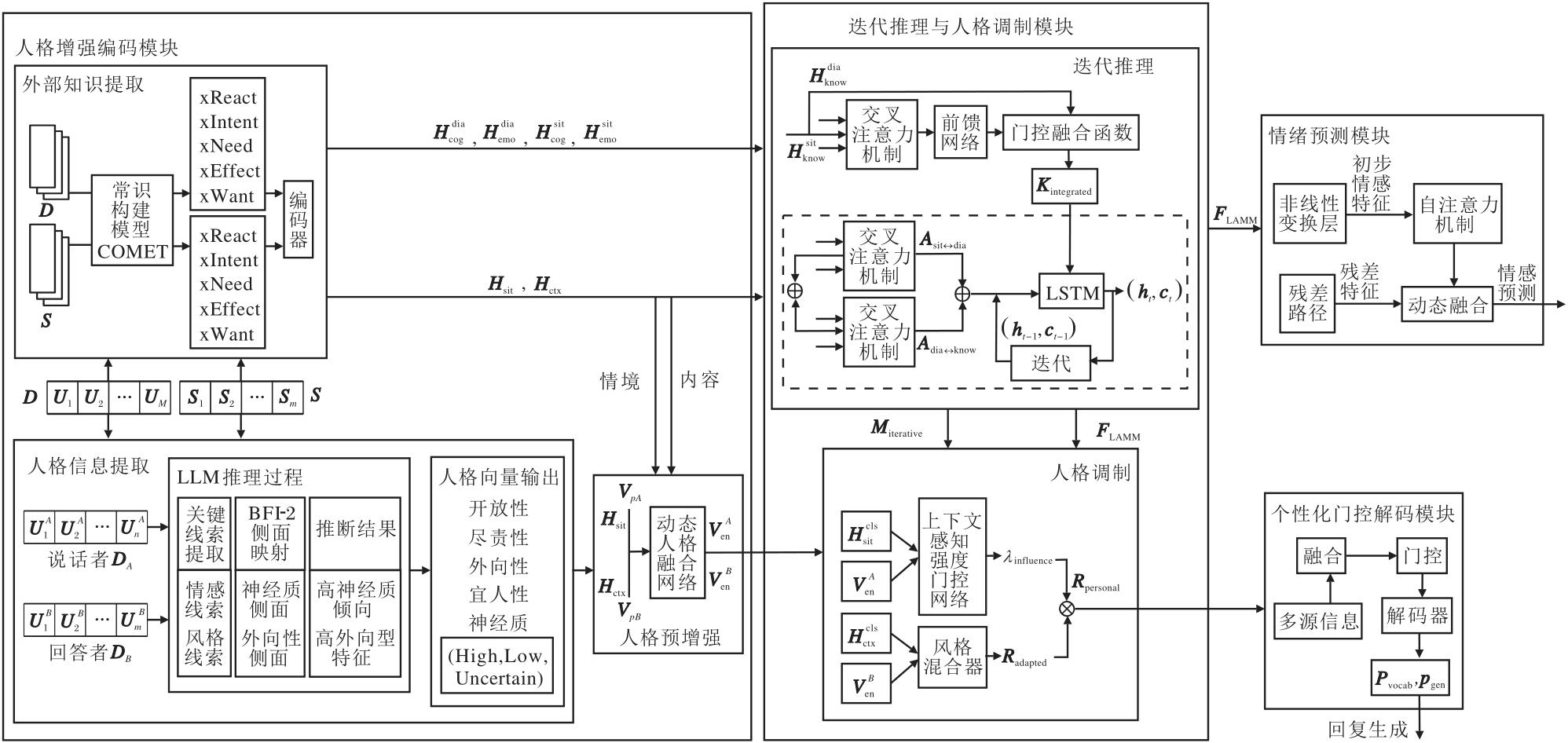 | 图1 PFEG整体架构图Fig.1 Overall architecture of PFEG |
给定对话内容、情境信息及说话者和回答者的人格特征, 模型需要生成一个有效的共情回复.模型输入包括:上下文
D=[U1, ···, Ui, ···, UM],
其中
Ui=[
表示第i个用户输入, 包含mi个单词; 情境
S=[S1, S2, ···, Sm],
表示由m个单词组成的情境描述; 说话者的人格信息
和回答者的人格信息
每个分量分别对应开放性(Openness)、尽责性(Conscientiousness)、外向性(Extraversion)、宜人性(Agreeableness)、神经质性(Neuroticism).
基于这些输入, 模型生成适当的响应:
Y=[y1, y2, ···, yN],
其中yi表示输出回复的第i个单词.
2.2.1 人格信息提取
为了实现更好的个性化共情, 模型不仅需要理解用户情感, 还需要理解其背后的人格特征.本文引入在心理学界得到广泛验证的大五人格理论构建人格特征标注体系.该理论将人格结构化为5个维度:神经质性、外向性、开放性、宜人性和尽责性[27].同时采用BFI-2(Big Five Inventory-2)[28]作为理论依据.BFI-2将大五人格维度进一步细化为15个侧面, 每个侧面均包含具有明确心理学含义的正向描述与负向描述, 有利于从自然语言中提取可解释的人格证据.
由于在现有的数据集普遍缺乏人格特征标注, 本文借鉴Sun等[29]提出的标注方式, 设计基于大语言模型的零样本思维链(Zero-Shot Chain-of-Thought, CoT)人格自动标注方法, 并在EmpatheticDialogues数据集上生成五维大五人格标签.具体而言, 本文构造CoT提示, 引导模型在给出人格预测之前先生成可解释的证据链.证据链包含:体现心理特质的关键语句、相关语言线索与互动风格, 与BFI-2侧面对应的推理依据.在此基础上, 对每个人格维度输出三态标签(High, Low, Uncertain), 得到结构化的人格向量表示.
为了直观验证上述标注方法的有效性与可解释性, 选取EmpatheticDialogues数据集上一个典型对话样本进行案例分析, 具体如图2所示.
 | 图2 大五人格提取过程示例Fig.2 An example of big five personality traits extraction |
分析左侧说话人可看出, 模型捕捉说话人在看烟花这一具体情境下表达的感伤情绪标签及孤独感描述, 将这些证据准确映射至神经质维度下的情绪波动和抑郁两个侧面, 从而推断出说话人具有较高的神经质倾向.相应地, 分析右侧回答者可看出, 模型注意到回答者并未关注环境描写, 而是直接询问对方的人际关系状态.这种直接且以人际关系为导向的提问方式, 被模型识别为外向性维度中社交性和果断性侧面的体现, 进而判定回答者具有高外向性特征.这一推理过程表明, PFEG不仅能输出分类标签, 还能通过自然语言推理过程揭示标签背后的心理学依据, 确保标注结果的逻辑自洽性和心理学效度.
基于上述标注流程, 本文将数据集上的对话及其人格特征提取过程进行形式化定义.对于给定对话, 上下文D由说话者A和回答者B的交替对话序列构成:
D=[
其中
再从上下文D分别提取说话者和回答者的对话历史:
$\begin{array}{l} \boldsymbol{D}_{A}=\boldsymbol{U}_{1}^{A} \oplus \boldsymbol{U}_{2}^{A} \oplus \cdots \oplus \boldsymbol{U}_{n}^{A}, \\ \boldsymbol{D}_{B}=\boldsymbol{U}_{1}^{B} \oplus \boldsymbol{U}_{2}^{B} \oplus \cdots \oplus \boldsymbol{U}_{n-1}^{B} \end{array}$
其中$\oplus$表示序列拼接操作.
下面利用大语言模型(Large Language Model, LLM)的上下文理解和推理能力, 在EmpatheticDia-logues数据集上标注大五人格的各个维度, 即为每段对话的说话者与回答者生成五维的人格向量
在长对话场景中, 鉴于人格特质相对稳定且变化缓慢, 并不需要为每轮使用全量历史重新计算人格表示, 而是可采用缓存与滑动窗口的增量更新策略:缓存上一轮人格表示, 仅基于最近K轮进行更新, 或采用低频更新以降低延迟.上述策略可将每轮更新的时间复杂度由O(D)降为O(K), 从而适配长对话场景.
2.2.2 外部知识提取
人类对话的理解不仅依赖于字面文本, 还需要借助常识推理弥补语义空缺.例如:当有人说他摔倒, 人们通常会自然推断“ 他可能受伤” 或“ 他可能需要帮助” , 这种推理能力并非通过字面表达获得, 而是基于人类大脑中的知识与经验.
为了使对话系统能够模仿人类思维, 利用推理知识深入理解用户的情感, 本文采用基于权威知识图谱ATOMIC[30]预训练的生成式模型COMET[16]获取知识.ATOMIC经过严格的人工审核, 确保推理规则的逻辑性和权威性, 有助于缓解开放域检索可能引入的幻觉问题.本文利用COMET分别对上下文D的最后一句话和给定的情境描述S进行推理, 生成涵盖5种关系(xIntent, xNeed, xWant, xEffect, xReact)的具有高置信度的常识推断序列, 作为后续推理的候选知识支撑.通过该过程生成对话常识信息Kdia和情境常识信息Ksit, 为模型提供更丰富的认知支持.
2.2.3 信息编码
信息编码分为上下文编码、情境编码和知识编码.
1)上下文编码.上下文D是理解对话历史、捕捉语义流动和识别用户意图的基础.通过将多轮历史对话D按顺序拼接, 并在最前端加入一个特殊的[CLS]标记, 形成一个扁平化的上下文序列:
$\boldsymbol{C}=[C L S] \oplus \boldsymbol{U}_{1} \oplus \boldsymbol{U}_{2} \oplus \cdots \oplus \boldsymbol{U}_{M}, $
使用[CLS]标记的最终输出向量将作为历史对话的聚合语义表示.
再将C转化为一个嵌入矩阵Ectx, 该矩阵由词元嵌入、发言者嵌入和位置嵌入三种信息叠加而成.具体而言:词元嵌入将离散的单词映射为连续的稠密向量空间; 发言者嵌入用于区分当前话语是属于用户还是系统, 以此明确对话角色; 位置嵌入为Transformer结构提供序列化的时序信息.三者维度相同, 按元素相加, 融合为最终的输入表示.
最终, 将嵌入矩阵Ectx输入多层Transformer编码器, 得到上下文的隐层表示矩阵:
Hctx=Encctx(Ectx)∈
其中, Encctx(· )表示上下文编码器, Lctx表示上下文序列长度, d表示隐藏层维度.
2)情境编码.情境S描述对话发生的具体背景和事件, 为理解对话提供至关重要的外部参照[22].情境编码流程与上下文编码类似, 唯一区别在于情境编码不包含发言者嵌入, 并且使用独立的编码器实例.经过词嵌入和位置嵌入相加后, 构建情境输入嵌入矩阵Esit, 输入情境编码器, 生成情境隐层表示矩阵:
Hsit=Encsit(Esit)∈
其中, Encsit(· )表示情境编码器, Lsit表示情境序列长度.
3)知识编码.基于COMET得到的常识知识, 根据其内在属性, 划分为情绪状态Kemo和认知状态Kcog.情绪状态由xReact关系构成, 该关系描述主体对一个事件可能产生的情感反应.认知状态由xIntent、xNeed、xWant、xEffect构成, 分别描述事件前的意图、需求、期望及事件后的影响.本文对COMET生成的5种关系进行编码.
将获取的对话常识Kdia和情境常识Ksit分别拆分为
其中, A∈ {cog, emo}表示认知状态或情绪状态, B∈ {dia, sit}表示对话或情境, E表示知识序列的输入嵌入, Enc(· )表示编码不同类型常识的编码器实例,
最后, 拼接得到对话和情境总的知识表示:
$\begin{array}{l} \boldsymbol{H}_{\mathrm{know}}^{\mathrm{dia}}=\left[\boldsymbol{H}_{\mathrm{cog}}^{\mathrm{dia}} ; \boldsymbol{H}_{\mathrm{emo}}^{\mathrm{dia}}\right], \\ \boldsymbol{H}_{\mathrm{know}}^{\mathrm{sit}}=\left[\boldsymbol{H}_{\mathrm{cog}}^{\mathrm{sit}} ; \boldsymbol{H}_{\mathrm{emo}}^{\mathrm{sit}}\right], \end{array}$
其中 [; ] 表示沿序列维度的拼接操作.
拼接后的知识表示提供多层语义信息支撑, 为后续的融合与推理过程提供丰富的知识特征.
2.2.4 人格预增强
在信息提取中获得的说话者人格向量
基于2.2.3节的编码结果, 本文使用上下文与情境的全局语义表示动态调节人格特征.具体地, 记
对于说话者的人格, 将原始说话者的人格向量
IpA=[VpA;
之后将IpA送入融合网络中进行非线性变换, 旨在学习静态人格特征与动态情境特征之间的交互.最终输出增强的说话者状态向量:
其中:MLPspk(· )表示一个动态人格融合网络, 目的是将拼接后的高维特征映射回低维的隐藏空间, 旨在提取静态人格向量与动态情境语义的交互特征; Tanh(· )表示激活函数.
对于回答者的人格, 类似地, 将原始回答者人格向量VpB与全局对话历史表示
IpB=[VpB;
旨在学习人格与对话语义的关联模式, 并生成贴合当前对话语境的风格倾向.最终输出增强的回答者状态向量:
其中, MLPrsp(· )表示回答者人格融合网络, 结构与MLPspk(· )类似, 用于对回答者的人格特征与对话语义进行非线性融合与特征映射, 从而获得与当前语境一致的个性化表示.
2.3.1 迭代推理
迭代推理主要包括知识融合、迭代关联及全局输出三个阶段, 旨在通过多次迭代推理, 深化模型对情境、对话及常识之间复杂交互关系的理解.
1)知识融合.常识知识可能包含与当前语境无关的噪声信息.为此, 本文设计相关性筛选机制.利用交叉注意力机制, 以当前对话的候选常识为Query, 以情境常识为Key和Value.通过注意力权重的计算, 评估每条常识与当前语境的语义相关度, 赋予高相关性常识更大的权重, 并抑制无关噪声.再通过门控机制进一步过滤, 确保只保留对理解当前对话有益的知识.融合并筛选后的对话相关常识表示为:
Kintegrated=Gate(
其中
Attncross=Mul(Q=
表示交叉注意力机制输出; Q、K、V分别表示查询向量、键向量和值向量, K、V共享同一情境知识表示
2)迭代关联.为了模拟人类逐步推理与记忆更新的思维过程, 进入N次迭代循环.在每次迭代中, 并行计算两种关联信息, 分别为情境-对话的关联表示Asit↔ dia, 对话-知识之间的关联表示Adia↔ know, 将上述关联表示与情境的全局语义表示
cell_inputt=[Asit↔ dia; Adia↔ know;
用于综合刻画情境、对话与知识之间的交互关系, 其中[; ]表示特征维度上的拼接操作.
在记忆更新阶段, 采用LSTMCell对推理过程进行建模, 第t轮迭代后的隐藏状态ht与细胞状态ct表示如下:
$\begin{aligned} \boldsymbol{h}_{t} & ={LSTMCell}_{h}\left( { cell\_input }_{t}, \boldsymbol{h}_{(t-1)}, \boldsymbol{c}_{(t-1)}\right), \\ \boldsymbol{c}_{t} & ={LSTMCell}_{c}\left({cell}\_{input_t}, \boldsymbol{h}_{(t-1)}, \boldsymbol{c}_{(t-1)}\right), \end{aligned}$
其中, LSTMCellh(· )、LSTMCellc(· )分别表示LSTM-Cell对当前隐藏状态和细胞状态的更新过程.
在每轮LSTM状态更新之后, 引入Transformer编码层, 对隐藏状态进行进一步建模, 得到经特征重整后的推理记忆表示:
其中, TransEnc(· )表示Transformer编码器, 用于建模特征间的全局依赖关系并进行归一化处理, 从而提升表示的判别能力与稳定性.经过N轮迭代后, 模型输出最终的推理表示
3)全局输出.经过N次迭代后, 得到一系列精炼的推理表示
$\begin{array}{l} \boldsymbol{M}_{\text {iterative }}={Projection}_{\text {gen }}\left(\left[\hat{\boldsymbol{h}}_{1} ; \hat{\boldsymbol{h}}_{2} ; \cdots ; \hat{\boldsymbol{h}}_{N}\right]\right), \\ \boldsymbol{F}_{\text {IAMM }}={Projection}_{\text {emo }}\left(\left[\hat{\boldsymbol{h}}_{1} ; \hat{\boldsymbol{h}}_{2} ; \cdots ; \hat{\boldsymbol{h}}_{N}\right]\right), \end{array}$
其中, Projectiongen(· )和Projectionemo (· )表示任务相关的投影函数, 分别用于将拼接后的多轮迭代信息映射到回复生成任务和情感预测任务对应的特征空间.Miterative表示面向回复生成的迭代推理表示, 用于保留对话上下文与推理细节信息, 从而指导后续回复生成.FIAMM表示融合多轮迭代信息的情感表示, 用于情感预测任务.
2.3.2 人格调制
人类在对话中的个性表达并非固定不变, 而是会随着交谈对象和情境的不同进行动态调整[31, 32].人格调制是指在对话过程中, 不仅考虑用户静态的、基本的人格特征, 还能根据对话的上下文、情境及用户的实时情感反馈, 动态调整和表达回应的人格风格.
因此, 本文设计人格调制模块, 旨在对预增强得到的人格状态进行更精细化的调整, 生成一个高度定制化的人格表示, 直接指导回复生成.具体过程如下.
1)上下文感知强度门控网络.在该阶段, 根据对话情境和说话者状态, 决定回答者的人格应当表现强度.具体而言, 将情境的全局表示
Iinput=[
输出一个体现表现强度的原始影响分数:
scoreinf=Sigmoid(MLPcontrol(Iinput)).
其中:MLPcontrol(· )表示强度控制网络, 用于对输入的情境语义与说话者人格特征进行非线性映射, 建模当前语境下人格介入强度的调节关系; Sigmoid(· )表示Sigmoid激活函数.最终得到影响力标量:
λ influence=scoreinfw1,
其中, w1表示可学习的参数, 用于自适应控制人格特征介入对话生成的最大强度.本文在实验中将其初始化为0.15, 并通过反向传播进行端到端优化.
2)回应风格自适应.在确定回应的强度后, 根据回答者的人格状态进行回应风格的高维度混合.该过程接收3个输入信息:预增强的回答者人格向量
Ainput=[Eproto;
生成的高维适应性人格向量为:
Radapted=Tanh(MLPadapt(Ainput)),
其中, MLPadapt(· )表示风格自适应映射网络, 用于建模潜在风格原型、回答者人格特征与当前对话语境之间的非线性交互关系.
3)人格表示生成.将1)、2)计算的强度和风格结合, 得到最终注入解码器人格表示:
Rpersona=λ influence☉Radapted.
Rpersona影响后续每一次生成决策, 确保回复能准确反映在特定情境下的个性化表现.
在共情对话中, 准确感知说话者的情感是生成恰当回复的基础.情感往往隐含于完整语境中, 单纯从字面文本进行情感分类, 容易忽略情境、常识及对话历史中累计的深层信息.为此, 本文设计情感预测模块, 基于深度融合得到的全局表示FIAMM, 实现高精度的情感预测.
为了确保情感预测的准确性, 对全局表示进行多轮迭代推理, 充分吸收对话的语义、情境背景及隐含的常识信息.首先进行初步的特征提取, 通过非线性变换层将融合信息映射至高维的隐藏空间, 进行初步结构化处理, 得到情感特征表示:
$\boldsymbol{H}^{(0)}=G L\left(\boldsymbol{W}_{0} \boldsymbol{F}_{\text {IAMM }}+\boldsymbol{b}_{0}\right) \in \mathbf{R}^{d_{\text {hidden }}}, $
其中, GL(· )表示非线性激活函数, W0、b0分别表示可学习的参数矩阵与偏置项, dhidden表示隐藏特征的维度.
为了模拟人类在做出情感判断时对关键信息的关注过程, 利用自注意力机制计算H(0)中不同特征维度的重要性权重, 对其进行逐维加权, 从而突出与情感判断更相关的特征, 得到加权情感表示:
$\boldsymbol{H}_{\mathrm{ag}}=\boldsymbol{\alpha}_{\text {attn }} \cdot \boldsymbol{H}^{(0)} \in \mathbf{R}^{d_{\text {hidden }}}, $
其中,
$\boldsymbol{\alpha}_{\text {attn }}=S\left(\boldsymbol{W}_{2}\left({Tanh}\left(\boldsymbol{W}_{1} \boldsymbol{H}^{(0)}+\boldsymbol{b}_{1}\right)\right)\right) \in \mathbf{R}^{d_{\text {hidden }}}, $
表示特征权重向量, S(· )表示激活函数, W1、b1分别表示可学习的参数矩阵和偏置项.
为了进一步提炼情感表示, 将Hag送入一个包含多层网络的深层解码路径, 得到高阶情感表示:
Hdeep=Layers(Hag),
其中Layers(· )表示深层映射网络.引入并行的残差路径, 防止梯度消失同时保留最原始的情感信号.经线性变换后情感表示为:
Hresidual=WresFIAMM+bres,
其中Wres、bres分别表示残差路径的投射矩阵与偏置项.
最后, 将深层路径与残差路径的输出进行动态融合, 得到最终的情感表示:
Hfinal=α Hdeep+(1-α )Hresidual,
其中α 表示深层路径与残差路径之间的融合系数.将Hfinal投射到情感类别空间, 得到模型的情感预测logits向量:
Lemo=WoutHfinal+bout∈
其中, Nemo表示情感类别总数, Wout、bout分别表示输出层的权重矩阵和偏置项.
在训练阶段, 采用标准交叉熵损失Lemo优化情感预测:
$L_{\mathrm{emo}}=-\ln \left(p_{c}\right)=-\ln \left(\frac{\exp \left(l_{c}\right)}{\sum_{j=1}^{N_{\mathrm{emo}}} \exp \left(l_{j}\right)}\right), $
其中, pc表示模型对于正确情感类别c的预测概率, lc表示模型输出的向量Lemo中对应类别c的分值, lj表示在向量Lemo中第j个情感分类的分值.
在对话中, 只有部分信息能直接体现人格特征, 而这些信息的表达需要与认知、情感和情境因素深度融合.为了将这些信息合理且动态地融入回复中, 本文采用门控机制.该机制在解码的每一步都充当一个信息调度中心, 根据当前对话状态动态调整不同信息源的权重, 精细调控最终生成的回复.
2.5.1 动态上下文构建
在解码的每个时间步t, 为生成一个最优的上下文向量以指导当前词的生成, 通过门控机制对4路关键信息进行动态加权融合.这4种信息反映生成最终回复需要考虑的4个核心维度:通用认知上下文Ccog、情感上下文FIAMM、人格上下文Rpersona和情境上下文
ei=
其中, i∈ {cog, emo, per, sit}, Sdec表示当前解码时刻的解码器状态表示, Ci表示第i路候选上下文向量, Wi、bi、vi表示门控网络的可学习参数.随后, 对各路得分进行Softmax归一化, 得到门控权重:
$\alpha_{i}=\frac{\exp \left(\boldsymbol{e}_{i}\right)}{\sum_{j} \exp \left(\boldsymbol{e}_{j}\right)} . $
最终, 通过加权求和, 得到门控上下文表示:
$\boldsymbol{C}_{\text {gated }}=\sum_{i} \alpha_{i} \boldsymbol{C}_{i} \in \mathbf{R}^{d_{\text {model }}}, $
其中dmodel表示模型隐藏表示的维度.
2.5.2 响应生成
响应生成主要分为增强记忆构建、解码与指针生成两个方面.
1)增强记忆构建.在获得动态的门控上下文Cgated后, 将其与编码阶段的两个关键记忆进行融合, 形成一个增强记忆
$\boldsymbol{M}_{\text {en }}=\boldsymbol{C}_{\text {cog_ref }}+\boldsymbol{M}_{\text {iterative }}+ { unsqueeze }\left(\boldsymbol{C}_{\text {gated }}, 1\right), $
作为解码的知识库, 其中, Ccog_ref∈
2)解码与指针生成.利用增强记忆Men为交叉注意力提供Key与Value.解码器的输出在经过指针生成器[33]处理后, 生成最终词汇概率分布.指针生成网络允许模型既可从预定义的词汇表中生成词汇, 也可从原始输入文本中直接复制词汇.
首先, 解码器在时间步t, 接收之前生成的词嵌入E(y< t)和增强记忆Men, 经交叉注意力交互与语义编码后, 输出解码器在时间步t的隐藏状态
$\begin{array}{l} \boldsymbol{H}_{ {dec }_{t}}={Decoder~}_{h}\left(E\left(y_{< t}\right), \boldsymbol{M}_{\mathrm{en}}\right), \\ \boldsymbol{a}_{t}={Decoder}_{a}\left(E\left(y_{< t}\right), \boldsymbol{M}_{\mathrm{en}}\right), \end{array}$
其中, Decoderh(· )、Decodera(· )分别表示解码器对隐藏状态和注意力权重的输出过程.然后, 计算生成概率:
pgen=σ (
其中,
与此同时, 计算生成词汇的概率分布:
Pvocab=Softmax(Wvocab
其中, Wvocab、bvocab分别表示词汇生成层的权重矩阵与偏置项, 用于将解码器隐藏状态映射到词汇表空间, 得到各候选词的生成概率.
最终输出词yt的概率由生成和复制两种模式的加权和得到, 即
$P\left(y_{t}\right)=p_{\text {gen }} \cdot P_{\text {vocab }}\left(y_{t}\right)+\left(1-p_{\text {gen }}\right) \sum_{j: w_{j}=y_{t}} a_{t, j}, $
其中, wj表示源序列第j个词元, at, j表示解码器第t步对源位置j的注意力概率.
在模型优化方面, 采用标准的交叉熵损失
$L_{\mathrm{gen}}=-\sum_{t=1}^{T} \ln P\left(y_{t} \mid y_{< t}, \boldsymbol{D}, \boldsymbol{S}, \boldsymbol{V}_{p_{B}}\right) $
优化生成任务, 旨在最大化模型生成真实回复序列的对数似然.
此外, 为了提升回复多样性, 避免模型生成通用、重复的回复, 采用Sabour等[14]提出的多样性损失:
$L_{\mathrm{div}}=-\sum_{t=1}^{T} \sum_{i=1}^{V} w_{i} \delta_{t}\left(c_{i}\right) \ln P\left(c_{i} \mid y_{< t}, C\right), $
其中, T表示目标回复序列长度, V表示词汇表大小, C表示生成阶段的条件上下文信息, ci表示词汇表中的候选标记, δ t(ci)表示指示函数, 当且仅当ci=yt时δ t(ci)=1, 否则δ t(ci)=0.
最终得出模型的总损失是情绪损失、生成损失和多样性损失的加权和:
Ltotal=λ 1Lemo+λ 2Lgen+λ 3Ldiv,
其中λ 1、λ 2、λ 3表示平衡不同损失项的超参数.
本文在如下2个数据集上进行实验:通用共情对话数据集EmpatheticDialogues[2]、情绪支持长对话数据集ESConv[4].
EmpatheticDialogues数据集是一个包含约2.5万段对话的共情对话数据集, 对话内容围绕特定情境引发的情感展开, 并带有对应的情绪标签.训练时以标签作为监督信号, 评估时隐藏标签, 仅依据对话历史生成共情回复.为了公平对比, 本文沿用文献[2]划分:训练集包含17 802段对话, 验证集包含2 628段对话, 测试集包含2 494段对话, 共22 924段对话.平均轮次为4.2, 平均上下文长度为45.5, 平均回复长度为13.5.
ESConv数据集面向心理支持场景, 包含1 053 组专业辅导对话, 平均约为16轮, 最长90轮, 每轮平均长度约为1 023个词元, 更适合评测长对话共情生成.本文对ESConv数据集进行领域过滤与信息抽取(去除显性治疗策略, 保留情境、情绪标注与上下文), 构建长对话共情任务子集, 包括:训练集9 957条、验证集2 098条、测试集2 270条.
基于PyTorch框架实现PFEG.为了引入丰富的先验语义知识, 词嵌入层由预训练的300维GloVe[34]词向量进行初始化, 模型内部所有核心组件的隐藏维度均统一为300.在训练配置上, 批处理大小设为16, 结合早停策略防止过拟合.优化器选用Adam(Adaptive Moment Estimation), 设置参数β 1=0.9, β 2=0.98.同时, 采用带有8 000步预热的Noam动态学习率调度器, 实现更稳定高效的收敛过程.与文献[24]类似, 设置损失的权重系数λ 1=1.0, λ 2=1.0, λ 3=1.5.
整个实验流程在一块NVIDIA GeForce RTX 3090显卡上完成, 迭代约2× 104次, 最终均达到稳定的收敛状态.
由于共情对话的质量不仅取决于语言流畅度和多样性, 还受到情感恰当性等主观因素的影响, 因此, 遵循文献[14]和文献[15]评价指标体系, 分为自动评价指标和人工评价, 全面评估模型生成回复的质量.
在自动评价方面, 从3个核心维度对模型生成的回复进行自动、量化的评估.
1)困惑度(Perplexity, PPL).衡量生成文本的流畅度和语法连贯性, 具体公式如下:
PPL=P(y1, y2, ···, yM
其中, yi表示生成回复中第i个词, M表示生成回复中的词汇总数, P(· )表示回复序列的联合概率.
2)多样性(Distinct).选择Distinct-1(Dist-1)、Distinct-2(Dist-2)指标, 计算生成文本中独特的n-gram占比, 衡量其词汇和句法结构的多样性.本文的Dist-1和Dist-2均为百分比数值, 具体公式如下:
${ Dist }-n=\frac{ { Distinct }\left(\sum_{i=1}^{N} n- { gram }_{i}\right)}{\sum_{i=1}^{N} \mid n- { gram }_{i} \mid} \times 100 \%, $
其中, n表示n-gram的粒度, N表示生成回复的总数量, n-grami表示第i个回复中包含的n-gram集合, $\mid n \text {-gram }{ }_{i} \mid$表示第i个回复中n-gram的总数, Distinct(· )表示统计所有回复中互不重复的n-gram数量.实验遵循文献[14]与文献[15], 设置n=1, 2.
3)准确率(Accuracy, Acc).衡量模型预测情感类别的准确性, 具体公式如下:
Acc=
自动评价指标能提供量化参考, 但难以完全捕捉共情性、相关性等高级语义质量.为此, 本文引入系统的人工评价指标.依据文献[22]和文献[23], 邀请3位具有心理学背景的专家参与评价, 从测试集上随机抽取200段对话样本进行评测(按情绪类别进行均衡抽样), 针对PFEG和其它模型的回复质量进行细致评估.
在每个评估案例中, 评注者会看到相同的对话历史与情境描述, 以及分别由PFEG与某一基线模型生成的两条回复.为了避免偏置, 生成的回复以A/B匿名形式呈现且顺序随机.评注者需在每个维度上从3种选项中做出判断:若认为PFEG回复更优, Win加一; 若认为基线模型更优, Lose加一; 否则记为平局.为了使评判标准具体化、可操作化, 评注者从如下3个维度进行综合考量.
1)共情性.评估模型是否能准确识别并恰当回应说话者的情感, 回复是否表现出理解、关心和支持.
2)相关性.回复是否紧扣当前话题与上下文关键信息, 是否对用户核心内容做出回应, 避免明显跑题、无关泛化或引入与上下文不一致的信息.
3)流畅性.回复是否语言自然通顺、语法正确、表达连贯, 没有明显病句、逻辑断裂或重复啰嗦.
为了评估LLM标注范式的可靠性, 依据文献[35]的方式进行抽检.本文采用3种不同的LLM对数据集进行标注, 并邀请3名具备心理学知识背景的领域专家依据BFI-2量表, 在不可见模型预测结果的情况下, 独立对随机抽取的200段对话进行人格特征标注.随后, 将LLM的标注结果与该人工标注结果进行对比, 计算准确率和Kappa系数, 量化评估机器标注与专家判断的一致性水平, 具体如表1所示.表中O表示开放性, C表示尽责性, A表示宜人性, E表示外向性, N表示神经质性, 黑体数字表示最优值.
| 表1 LLM人格标注质量评估结果 Table 1 Quality assessment results of LLM personality annotation |
由表1可看出, DeepSeek-70B在大多数人格维度上表现最佳, 尤其在神经质性(N)和宜人性(A)上, 准确率均达到较高水平.该模型整体人格标注准确率为0.82, Kappa系数为0.68, 表明其与人工标注的结果一致性较高.Llama3.1-70B整体表现稍差, 准确率为0.79, Kappa系数为0.65, 虽然在尽责性(C)和外向性(E)上表现较好, 但在其它维度上的标注一致性相对较低.Qwen2.5-72B在准确率上略低于Llama3.1-70B, 尽管在神经质性(N)和宜人性(A)表现较突出, 但整体标注准确率为0.78, Kappa系数仅为0.63, 显示其与人工标注的一致性较差.
综上所述, DeepSeek-70B在准确率和一致性检验上均较优, 因此, 本文最终选用DeepSeek-70B对整个EmpatheticDialogues数据集进行人格特征标注.
考虑到人工校验的高昂成本, 同时鉴于ESConv数据集也是基于人际沟通对话构建, 语言表达模式与EmpatheticDialogues数据集是一致的, 因此本文将经过验证的零样本标注范式直接推广应用于ESConv数据集.
为了全面公平地评估模型性能, 选择如下基线模型进行对比.
1)CEM[14].是一种典型的常识增强模型, 不仅专注于利用外部知识, 而且更侧重于常识推理.借助在COMET上预训练的模型, 为对话动态生成常识性推断, 帮助模型更深入理解用户的内在状态和未言明的意图.
2)KEMP[15].利用外部知识库(如ConceptNet)构建情感上下文图谱, 捕捉对话中隐含的情感, 丰富情感表达, 生成合适的共情回应.
3)CASE[18].强调常识推理和情感概念, 在粗粒度和细粒度上与用户的认知和情感对齐, 生成信息丰富的共情回应.
4)Emp-EEK[21].结合范例检索与外部知识, 使用DPR(Dense Paragraph Retriever)按语义与上下文检索高相关示例, 并以3个解码器建模情绪反应、解释与探索, 提升共情回复质量.
5)EmpSOA[24].从认知科学中的“ 心智理论” 获得启发, 首次在共情对话中显式建模“ 自我-他人意识” .利用常识分别构建关于用户和模型自身的认知与情感状态表示, 生成一个更具换位思考能力且逻辑清晰的回复.
6)EmpDG[36].多分辨率的交互式共情对话生成模型, 结合对话级别和词语级别的情感, 并利用多粒度的情感建模和用户反馈, 生成更富同理心的对话.
7)SEEK(Serial Encoding and Emotion-Knowledge Interaction)[37].对情感与知识之间动态、双向的相互作用进行建模.设计序列化编码与情感-知识双向交互的机制, 旨在捕捉情感的流动过程, 并动态选择与当前情感状态最相关的知识, 从而模拟一个更动态的共情推理过程.
8)CSTM(Combining Trait and State Emotions for Empathetic Response Model)[38].结合心理学中静态的、与上下文无关的“ 特质情感” 和动态的、依赖于上下文的“ 状态情感” , 通过对这两种情感进行编码和引导, 全面感知对话中的情感, 并生成更精准、更具同理心的回应.CSTM通过一个情感引导模块和一个跨对比学习解码器增强情感感知和表达能力.
9)Llama3.1-8B[39].作为基于指令LLM的生成式强基线模型, 选用Llama3.1-8B指令模型进行零样本共情回复生成与情绪预测, 并通过如下两种提示设置考察人格信息的作用:1)在提示词中仅输入情境描述与对话上下文, 2)在相同输入基础上进一步显式加入人格特征描述以引导回复生成.
10)Qwen2.5-7B[40].同样选用Qwen2.5-7B指令模型构建LLM生成的基线模型, 保持与9)一致的两种提示设置(是否加入人格描述), 以此保证对比的公平性与可复现性.
为了全面评估模型性能, 在EmpatheticDialo-gues、ESConv数据集上, 采用自动评价指标进行对比实验, 结果如表2和表3所示, 表中黑体数字表示最优值.
| 表2 各模型在EmpatheticDialogues数据集上的自动评估结果 Table 2 Automatic evaluation results of different models on EmpatheticDialogues dataset |
| 表3 各模型在ESConv数据集上的自动评估结果 Table 3 Automatic evaluation results of different models on ESConv dataset |
由表2可观察到, PFEG在自动评价指标上整体表现良好.
在准确率上, PFEG达到47.61%, 超越绝大多数基线模型, 但是对比EmpSOA的48.32%, 略显不足.这可能主要归因于EmpSOA显式建模自我-他人意识的机制, 该机制在精准识别情感状态上具有优势.PFEG在准确率上与最优基线模型EmpSOA接近, 同时在多样性上取得最优表现, 表明引入人格调制模块有助于缓解模板化回复并提升表达丰富度.
在多样性上, 相比表现次优的Emp-EEK, PFEG在Dist-1、Dist-2指标上都有所提升.这说明通过引入量化的人格特征, 并利用人格调制模块和个性化门控解码机制, 可突破现有模型容易生成通用、重复回复的瓶颈, 生成更丰富的词汇和更多变的短语结构, 体现个性化的共情回复.
在困惑度上, PFEG低于对比模型, 表明其生成文本在语言流畅性与局部连贯性上更优.一种可能的解释是:迭代推理促进对情境、对话与常识的综合建模, 而门控机制在解码阶段对多源信息贡献进行动态调节, 减少语义跳跃与风格突变的风险.
本文进一步引入Llama3.1-8B与Qwen2.5-7B作为LLM并生成基线模型, 并设置无人格提示和有人格提示两种方式.实验表明, 在相同上下文的条件下加入人格相关提示可进一步提升Dist-1、Dist-2指标, 说明人格条件对提示驱动生成同样有效.由于LLM推理接口通常难以稳定获取逐词元概率, 本文不对其PPL进行直接对比.
由表3可见, PFEG在ESConv数据集上取得较均衡的表现.
在准确率上, PFEG的Acc值为42.78%(最高值), 这一结果表明, 基于迭代更新的记忆表征能在多轮对话中充分累积与筛选情绪相关线索, 并通过融合机制将关键信息聚合到情绪预测中, 从而提高情绪识别的稳定性与一致性.
在多样性上, PFEG的Dist-1、Dist-2指标分别为1.65, 4.92, 均为最高值, 说明其能更好地避免模板化与重复句式.
在困惑度上, PFEG的PPL值为62.75, 低于对比模型, 表明其在长对话语境中更能保持语义连续与生成稳定.迭代推理提升关键信息整合质量, 门控机制在解码时动态控制信息注入强度, 从而减少长程语境下的波动.
为了评估自动指标无法捕捉、更深层次的对话质量, 进行一系列严格的人工A/B测试.鉴于EmpatheticDialogues数据集作为共情回复生成领域的基准数据集及人工评测的高昂成本, 本文在此数据集上对PFEG、CASE[18]、EmpSO-A[24]和CSTM[37]的共情性、相关性和流畅性进行评估, 结果如表4所示.表中K表示Fleiss[41]的Kappa系数, 测量测试者一致性程度, 0.4< K≤ 0.6表示中等的一致性.
| 表4 各模型在EmpatheticDialogues数据集上的人工评估结果 Table 4 Manual evaluation results of different models on EmpatheticDialogues dataset |
由表4可见, 在共情性上, PFEG整体表现更优, 这源于其独特的个性化表达能力.借助人格信息, 生成风格独特且符合角色设定的回复.这种个性化表达可减少套话式回应, 使回复更贴近真实对话语境, 从而更容易被评估者认为具有共情性.
在相关性上, PFEG具有一定优势, 体现其深度情境理解的能力.通过迭代式的深度融合, 构建一个对对话、情境和常识知识全面、客观的理解, 从而有助于减少模型产生逻辑跳跃现象的可能性, 提升对话的连贯性.
在流畅性上, PFEG同样表现更优, 这得益于动态融合机制, 它能在每步解码时平衡并调制来自认知、情感、人格和情境四个维度的信息贡献程度, 避免信息源间的冲突或生硬拼接, 生成更自然、连贯的回复.
为了验证本文提出的核心模块的有效性, 设计一系列模型变体进行消融实验.每个变体通过移除特定的输入信息或计算路径, 旨在检验该模块在整体架构中的必要性及对模型性能的贡献.具体变体如下.
1)w/o sp:移除说话者的人格信息.
2)w/o rp:移除回答者的人格信息.
3)w/o ap:移除所有人格信息.
4)w/o ctx_k:移除对话上下文知识.
5)w/o sit_k:移除情境知识.
6)w/o all_k:移除所有知识.
在EmpatheticDialogues数据集上各模块消融实验结果如表5所示.表中黑体数字表示最优值.
| 表5 各模块在EmpatheticDialogues数据集上的消融实验结果 Table 5 Ablation experiment results of each module on EmpatheticDialogues dataset |
由表5可得如下结论.
1)移除说话者的人格信息, 情感预测的准确率从47.61%降至46.11%.PPL值略微下降更可能源于缺少说话者人格约束后输出更趋高频保守, 从而更容易降低困惑度.这一点也可从多样性指标的同步下降中得到印证.
2)移除回答者人格信息后, 困惑度出现明显上升, 表明回答者人格特征有助于维持回复的风格一致性与语言连贯性.当该信息被移除时, 生成文本更容易出现风格漂移或局部不连贯的现象.
3)移除所有人格信息时, 多样性指标出现明显下降, Dist-1值从2.92降至1.38, Dist-2值从10.14降至4.83, 这表明人格信息有助于提升语言表达的丰富性与风格差异性.在缺乏人格条件时, 模型更容易生成模板化、重复度较高的回复.
4)分别移除上下文知识和情境知识时, 情感预测准确率和多样性指标均出现不同程度的下降.当移除所有知识时, 情感预测准确率出现明显下降, 降低3.27%.这表明在模型识别用户深层感受的过程中, 情境知识发挥重要作用, 引入外部知识, 能让模型更好地把握用户的处境, 做出更准确的情感判断, 同时提升回复的多样性.
在ESConv数据集上, 各模块消融实验结果如表6所示.表中黑体数字表示最优值.
| 表6 各模块在ESConv数据集上的消融实验结果 Table 6 Ablation experiment results of each module on ESConv dataset |
由表6可得如下结论.
1)当移除说话者人格信息或回答者人格信息时, 准确率均出现小幅下降, PPL值也相应上升, 同时Dist-1、Dist-2值有所降低.其中, 移除回答者人格信息带来的PPL值上升更明显, 原因在于回答者人格信息更直接参与生成阶段的表达调制, 为模型提供稳定的语气与风格约束, 使解码过程更容易保持一致的表达轨迹.回答者人格信息一旦缺失, 模型更倾向生成较通用的措辞分布, 从而带来一定的困惑度上升.进一步移除全部人格信息后, Dist-1、Dist-2值降至1.18和3.70, 下降幅度相对更集中体现在多样性指标上, 说明人格条件主要用于减少通用模板回复、丰富表达方式, 使模型不必反复依赖少量高频安慰短语.
2)移除对话上下文知识后, 准确率降至41.13%, PPL值升至64.27, 同时Dist-1、Dist-2值降至1.13和3.55.移除情境知识后, 准确率降至40.91%, PPL值增至66.14.该趋势表明, 知识信息一方面为情绪预测提供更完整的依据, 另一方面也为回复生成提供更具体的内容支撑, 从而降低只靠通用安慰语完成回复的倾向.进一步移除全部知识后, 准确率降至39.68%, PPL值升至66.42, 说明缺少上下文与情境的补充线索后, 模型更依赖局部表面文本进行判断与生成, 既难以稳定把握用户深层感受, 也更容易产生内容空泛、信息量不足的回复, 最终在准确率与流畅性指标上出现退化.
为了进一步说明迭代推理模块中采用LSTM-Cell进行记忆状态更新的合理性, 在EmpatheticDia-logues数据集上进行实验, 采用一个结构替代变体:将原本的更新器替换为Transformer记忆更新器.除了更新器结构以外, 其余网络结构与训练配置保持一致, 以此确保对比结果的公平性.
两种更新器指标值如表7所示, 表中黑体数字表示最优值.
| 表7 不同更新器对PFEG性能的影响 Table 7 Effect of different updaters on PFEG performance |
由表7可看出, Transformer更新器在PPL值上略有改善, 但在更关键的准确率上出现明显下降, 同时在多样性指标上也未获得稳定增益.总之, 本文最终保留LSTMCell作为迭代推理模块的默认记忆更新器.
为了分析损失函数中不同权重对PFEG性能的影响, 在EmpatheticDialogues数据集上分别对情绪损失参数λ 1、生成损失参数λ 2和多样性损失参数λ 3进行实验, 结果如表8~表10所示, 表中黑体数字表示最优值.
| 表8 λ 1对PFEG性能的影响 Table 8 Effect of λ 1 on PFEG performance |
| 表9 λ 2对PFEG性能的影响 Table 9 Effect of λ 2 on PFEG performance |
由表8~表10可得如下结论.λ 1过小时情绪约束不足, 难以稳定对齐说话者情感, 过大又会压缩表达空间, 导致多样性指标回落, 因此取中等值更稳健.λ 2用于平衡语言建模与任务目标:当λ 2过小时生成约束不足, 流畅性变差, 当λ 2过大模型趋于保守高频回复, 从而抑制准确性与多样性, 因此取中等值可获得更均衡表现.λ 3用于鼓励多样性, 增大λ 3通常能提升表达丰富度, 但过大会引入更多的发散性生成并损害准确性.权衡后发现, λ 3取适中的值更利于在保证质量的前提下提升多样性.据此, 本文最终采用λ 1=1.0, λ 2=1.0, λ 3=1.5作为权重设置.
为了说明PFEG在共情回复方面的有效性, 深入分析模型如何根据对话语境自适应地融合高外向性、高宜人性或低神经质性等人格特质, 选取案例1和案例2, 分别对比 CASE[18]、EmpSOA[35]、CSTM[37]和PFEG的回复, 结果如表11和表12所示.
在案例1中, 说话者表达由客观情境(交通拥堵)引发的强烈恼火情绪(Annoyed).对比各模型表现发现, 基线模型虽然在一定程度上感知负面情绪, 但其回复呈现明显的模板化与通用化倾向.CASE与CSTM仅给出“ 发生什么?” 这类信息导向的询问, 忽视上下文中已明确提及的交通这一核心实体, 导致回复显得机械且缺乏对话的实质性推进.EmpSOA虽然试图通过情感词进行验证, 但由于缺乏对具体情境的锚定, 共情仅停留在表层, 难以引发说话者的共鸣.相比之下, PFEG表现出更强的情境锚定与风格调控能力.得益于人格增强编码模块, PFEG在此场景中激活高外向性与高宜人性的特征组合, 通过“ 糟糕的交通” 与“ 我也讨厌这种情况” 主动与说话者建立情感联系, 有效拉近与用户的心理距离.
在案例2中, 说话者表达对即将到来的面试感到能力不足的担忧.基线模型在语义对齐与时态理解上出现明显偏差.CSTM的回复“ 什么工作?” 过于任务导向, 缺乏对焦虑情绪的必要关怀, 表现出情感上的冷漠.CASE和EmpSOA错误地询问“ 你得到什么工作?” , 不仅忽略说话者的当前心理状态, 也出现时态逻辑偏差.EmpSOA虽使用“ oh no!” 试图表达关心, 但这种惊叹式的反应过于泛化, 甚至可能加剧说话者的紧张感.与之相比, PFEG根据语境动态调整其人格设定, 展现出高宜人性与低神经质性的特征, 面对说话者的焦虑, 未受负面情绪干扰, 给出“ 确信你会表现出色” 的肯定性预测.这种回复兼顾逻辑正确性与心理抚慰功能, 进一步表明模型能根据情境对风格进行自适应调整.
对案例1和案例2的分析可看出, PFEG在情感理解和个性化回复生成方面整体表现更优.在这两个案例中, PFEG更好地兼顾情绪回应、语境相关性与表达自然度, 体现出人格条件与推理融合在个性化共情生成上的潜在收益.
本文提出融合人格特征的共情回复生成模型(PFEG), 通过深度融合人格信息、情境背景和对话上下文, 为共情回复生成提供更个性化的能力.通过迭代推理、个性化调控和动态门控解码机制, 模型能根据不同的对话情境和说话者人格生成具有情感深度的个性化回复.无论是在自动评价指标上还是在人工评测中, PFEG的有效性均被验证.未来将进一步探索将该框架与LLM结合, 更充分利用先验知识与生成能力, 提升共情回复的效果与可控性.
本文责任编委 马少平
Recommended by Associate Editor MA Shaoping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|