
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向小样本3D点云语义分割的多层次全局感知模型
[严唯书1  , 袁健
, 袁健1 , 杨明睿1 , 许嘉汇1 ]
, 袁健, 杨明睿, 许嘉汇]
|
|



作者简介:

严唯书,硕士研究生,主要研究方向为计算机视觉.E-mail:233360786@st.usst.edu.cn.

杨明睿,硕士研究生,主要研究方向为人工智能生成内容.E-mail:232340583@st.usst.edu.cn.

许嘉汇,硕士研究生,主要研究方向为图像处理.E-mail:233360797@st.usst.edu.cn.
小样本点云语义分割在全局上下文建模、特征对齐及语义引导方面存在不足,难以应对结构复杂、语义模糊及噪声干扰等场景.因此,文中提出面向小样本3D点云语义分割的多层次全局感知模型,基于多层窗口划分,逐步扩展感受野,实现局部几何与全局语义协同建模.设计双域注意力融合模块,结合通道注意力与点域注意力,融合局部信息与全局信息.构建全局辅助点机制,在关键层嵌入可学习的全局点,增强跨层特征传递功能.设计全局类别感知损失,在点级监督上增加类别分布约束,突出小类别目标.消融实验验证各模块的有效性和互补性,对比实验表明文中模型性能较优,尤其在复杂场景中表现出色.
About Author:
YAN Weishu, Master student. His research interests include computer vision.
YANG Mingrui, Master student. His research interests include AI-generated content.
XU Jiahui, Master student. His research interests include image processing.
Few-shot point cloud semantic segmentation struggles to handle complex structures, ambiguous semantics and noise interference due to its limitations in global context modeling, feature alignment and semantic guidance. To address these issues, a multi-level global-aware model for few-shot 3D point cloud semantic segmentation(MGAM) is proposed. On the basis of multi-level window partitioning, the receptive field is progressively expanded to achieve collaborative modeling of local geometry and global semantics. A dual-domain attention fusion module(DAFM) is designed. Channel attention and point-wise attention are integrated to fuse local and global information. A global auxiliary point mechanism(GAPM) is constructed. Learnable global points are embedded into key layers to enhance cross-layer feature propagation. A global category-aware loss(GCAL) is developed. Category distribution constraints are added to point-level supervision to highlight small-class targets. Ablation experiments verify the effectiveness and complementarity of each module. Comparative experiments show superior performance of MGAM, particularly in complex scenarios.
点云是一种由大量三维坐标点组成的数据集合, 每个点表示物体或环境表面上的一个位置.点云通常通过3D扫描技术(如激光扫描、立体视觉或深度相机)获取, 现已成为3D建模、地理信息系统、机器人导航等场景中不可或缺的数据形式.
点云语义分割[1]是一项关键的三维视觉任务, 旨在对点云数据中的每个点进行分类, 识别其所属的语义类别.相比2D图像语义分割, 点云语义分割面临更高的挑战, 因为点云数据稀疏、不规则且无固定拓扑结构, 因此在处理过程中需要更复杂的特征提取与表示方式.点云语义分割现被广泛应用于自动驾驶[2]、机器人感知[3]、增强现实[4]及三维室内环境的理解与建模[5]中, 尤其在智能建筑管理、室内机器人导航、场景重建与空间布局分析等领域中具有重要价值.
现有大多数点云语义分割方法[6]依赖大量精细标注的数据, 但数据获取和标注的成本较高.此外, 现有方法在面对样本极少甚至未知类别时, 通常缺乏足够的泛化能力, 难以保持良好性能.因此, 如何在数据有限的条件下实现准确有效的点云语义分割, 成为当前研究的一个重要方向.小样本点云语义分割[7]正是为了解决这一难题而提出的技术路线, 它旨在利用极少量的标注数据, 训练具有良好泛化能力的模型, 为解决数据匮乏问题、提升三维视觉系统的适应性提供新的可能.
本文提出面向小样本3D点云语义分割的多层次全局感知模型(Multi-level Global-Aware Model for Few-Shot 3D Point Cloud Semantic Segmentation, MG-AM), 旨在提升小样本条件下的点云分割性能.
首先, 设计双域注意力融合模块(Dual-Domain Attention Fusion Module, DAFM), 采用双分支并行结构分别建模通道注意力与空间注意力, 并通过门控融合策略进行动态加权, 有效提升复杂场景中特征表达的区分性.
然后, 提出全局辅助点机制(Global Auxiliary Point Mechanism, GAPM), 在扩大感受野的同时, 有效降低计算开销, 并提升对语义模糊与结构复杂区域的理解能力.
最后, 构建全局类别感知损失函数(Global Cate-gory Awareness Loss, GCAL), 基于全局特征预测各类别出现概率, 并与真实标签计算二元交叉熵, 同时结合类别权重增强小样本类别影响力, 形成点级与全局联合优化策略, 显著提升模型对低频类别的敏感性、区分能力及小类泛化性.
目前, 点云语义分割方法已取得显著进展, 主要分为两类.1)基于局部特征建模的方法, 采用共享MLP(Multi-layer Perceptron)或点卷积结构建模局部几何信息, 缓解点云的无序性并增强结构感知能力.典型方法包括:PointNet[1]引入体素-点云特征映射; PointNet++[8]通过层次化特征提取, 提升局部建模效果; ShellNet[9]与PointSIFT[10]分别通过球面壳层和方向编码聚合, 强化细粒度语义表达; PointWeb[11]利用密集点对关系, 提升分割性能; KPConv(Kernel Point Convolution)[12]通过可变形卷积, 适应点云的非均匀分布; DGCNN(Dynamic Graph Convolutional Neural Network)[13]借助KNN(K-Nearest Neighbors)图和动态边卷积, 建模拓扑结构.2)基于注意力机制的方法, 引入自注意力以建模远程依赖.典型方法包括:PointASNL[14]融合局部-非局部模块; RandLA-Net[15]结合随机采样与注意力机制; Point Transfor- mer[16]借助Transformer架构实现点级全局感知; PointMLP[17]通过残差MLP与几何仿射模块, 进一步优化特征聚合能力.
近年来, 小样本3D点云语义分割研究取得诸多突破, 很多模型分别从原型适应、对比学习、注意力机制和鲁棒性增强等方面提升泛化能力.Zhang等[7]提出AttMPTI, 通过多原型传递推理, 改进基于原型学习的方法, 提高对几何依赖关系和语义关联的捕获能力.随后研究者在此基础上进行进一步扩展.He等[18]提出QGPA(Query-Guided Prototype Adap-tion), 调整跨通道注意力, 支持样本的原型特征, 匹配查询特征, 提高类内一致性.Wang等[19]引入局部最近邻和全局最远点的注意力机制, 有效提升模型对局部信息和全局信息的捕获能力.Zhang等[20]提出SCAT, 在不使用池化操作的前提下, 通过多尺度Transformer模块实现对支持样本与查询点云之间细粒度语义关系的建模, 提升小样本点云分割性能.Xu等[21]提出R3DFSSeg(Robust Few-Shot Point Cloud Semantic Segmentation), 构建组件级清噪分离和多尺度度量噪声抑制, 专注于增强模型的鲁棒性.An等[22]提出COSeg(Correlation Optimization Segmenta-tion), 直接优化查询点云和类别原型的关系, 提高泛化能力.Liang等[23]提出FDA-Net(Few-Parameter Den-sity Attention Network), 利用核密度估计建模点云密度, 并通过密度注意力模块加强局部特征与全局特征, 显著增强模型在噪声和旋转干扰下的鲁棒性.Li等[24]提出LARM(LLM-Assisted Hyper-Relation Mat-ching), 引入大语言模型(Large Language Model, LLM)的先验知识, 丰富类别原型, 并采用超关系匹配策略, 缓解类间混淆问题, 提升广义小样本场景中的分割精度.受泰勒级数启发, Wang等[25]提出TaylorSeg, 将局部结构表示视为多项式拟合问题, 同时设计无须预训练的TaylorConv卷积算子, 捕捉低阶基本信息与高阶精细特征, 在减少计算开销的同时有效提升对不规则几何结构的建模能力.
尽管上述模型在提升小样本点云语义分割性能方面取得显著进展, 但仍存在一些共性问题亟待解决.
首先, 面对点云数据自身存在的非结构化特性、结构多样性与采样非均匀性等问题, 现有模型大多采用静态KNN或基于距离的特征提取方式, 缺乏动态感知语义结构的能力, 这使得在不同样本或不同场景中, 同类结构可能被编码为不一致的特征表示, 进一步造成跨样本的结构一致性建模不足.
其次, 大多数模型在全局上下文建模方面能力不足, 其原因在于模型主要依赖局部感受野内的邻域特征或仅通过简单的原型聚合策略进行类表示生成, 缺乏对跨样本全局语义一致性的感知能力.这种设计限制模型对类别间长距离依赖关系的建模能力, 因此在结构复杂或语义模糊的场景中, 类表示容易受到局部扰动影响而不稳定, 导致性能下降.同时, 部分模型未显式考虑语义引导机制, 使得支持集与查询集之间的特征对齐能力有限, 难以保证传递的类特征具有足够的判别性.
此外, 尽管有部分工作尝试提升模型的鲁棒性, 但大多数模型在应对实际噪声干扰、极端采样密度差异或小类别目标识别等场景时仍表现不稳定.这一问题的根本原因在于其特征提取与融合过程对局部几何扰动或点云缺失敏感, 并且类别感知机制通常仅在分类阶段进行弱引导, 未能在特征层面实现充分约束.
基于AttMPTI[7], 本文研究的点云语义分割任务可定义为遵循情景范式(Episodic Paradigm)的N-way K-shot分割学习问题.首先利用一组从训练数据集Ctrain中采样的N-way K-shot任务训练模型, 然后测试和评估模型在另一组测试数据集Ctest采样任务上的表现.训练和测试使用的类别集互不重叠, 即
Ctest∩ Ctrain=Ø ,
以此确保模型的泛化能力.
在每个N-way K-shot任务(即一个情景)中, 给定的支持集
$\boldsymbol{S}=\left\{\left(\boldsymbol{P}_{n, k}^{s}, \boldsymbol{Y}_{n, k}^{s}\right)\right\}_{n=1, k=1}^{N, K}$
包含需分割的N个目标类别, 每个类别提供K个带标注的支持点云, 其中,
Q={(
其中,
小样本点云语义分割的目标是通过一个参数化分割模型Fθ (· )学习目标, 使其能在支持集S的引导下, 对查询点云进行点级语义预测, 预测结果为:
$\widehat{\boldsymbol{Y}}_{i}^{q}=F_{\boldsymbol{\theta}}\left(\boldsymbol{P}_{i}^{q} \mid \boldsymbol{S}\right) . $
参数θ 通过最小化查询集上的分割损失进行优化, 最优模型参数为:
$\boldsymbol{\theta}^{* }=\arg \min _{\boldsymbol{\theta}} \sum_{i=1}^{Q} L\left(F_{\boldsymbol{\theta}}\left(\boldsymbol{P}_{i}^{q} \mid \boldsymbol{S}\right), \boldsymbol{Y}_{i}^{q}\right), $
其中L(· , · )表示对查询点云中样本点的交叉熵损失求和.
小样本点云语义分割的学习过程通常分为预训练阶段和小样本学习阶段.在预训练阶段, 采用全监督学习训练一个基础点云特征提取器, 获得较优的初始特征表征能力, 提升后续小样本学习的效果.小样本学习阶段采用标准的情景学习方式进行训练和测试, 其中每个情景由N× K个支持点云及N个查询点云组成, 构成N-way K-shot任务.
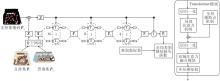
本文提出面向小样本3D点云语义分割的多层次全局感知模型(MGAM).受Swin Transformer[26]及SCAT[20]的启发, 设计如图1所示的四层窗口结构组成的MGAM, 每层窗口数依次为16、8、4、1, 形成从局部到全局逐步扩展的特征感受野.第1层中, 输入点云被划分为16个局部窗口, 捕捉细粒度的局部几何结构.第2层将相邻窗口合并为8个中等尺度窗口, 逐步扩大感受野并聚合相邻区域的上下文信息.第3层进一步整合为4个更大尺度窗口, 捕获广域语义关联.第4层使用1个全局窗口, 统一建模整个点云中的长程依赖与全局结构特征.这种自底向上的多层次窗口划分设计, 使模型在低层注重微观结构细节, 在高层逐步整合宏观语义表示, 有效实现局部几何感知与全局语义理解的协同建模.
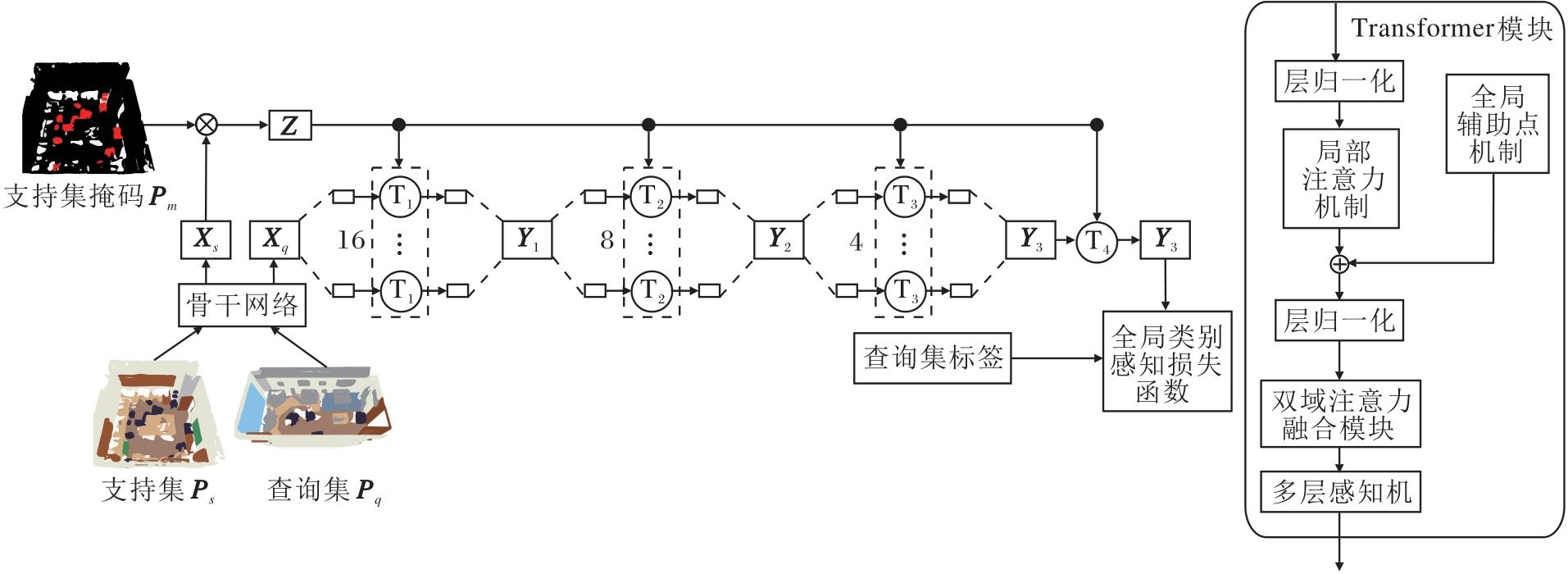 | 图1 MGAM整体架构Fig.1 Overall architecture of MGAM |
在上述多层次窗口划分结构基础上, 使用如图1所示的Transformer模块结构, 实现局部信息与全局信息的高效融合与深层特征建模.Transformer模块给出该层级的标准特征提取流程, 即局部注意力机制+DAFM.对于关键层级, 额外增加GAPM以增强全局感受野; 对于非关键层级, 仅执行标准的局部特征建模与DAFM:通过这种灵活的配置实现局部细节与全局语义的协同平衡.图中T1~T4表示分布在4个不同空间分辨率层级上的Transformer实例化对象.
具体而言, 输入首先经过层归一化处理后, 送入局部注意力机制提取局部空间关联特征, 同时在关键层级的Transformer模块中引入GAPM, 生成全局辅助点信息, 并通过残差连接与局部注意力结果相加, 实现全局信息的引导与补充.然后, 再次进行层归一化处理, 并进入DAFM, 从通道维度与空间维度同时增强特征表达能力.最后, 通过MLP进一步完成特征变换与增强, 输出供后续层级使用的特征.
在点云语义分割任务中, 如何兼顾局部几何结构的细粒度建模与全局语义信息的长距离依赖建模, 是影响性能表现的关键因素.点云数据本身存在无序性和非结构化特性, 使得传统卷积机制在处理其空间关系时表现受限.现有方法往往侧重某一方面.例如:PointNet++[8]通过分层采样与局部区域聚合强化局部特征的学习能力, 但其全局上下文建模能力有限.Point Transformer[16]和Stratified Trans-former[27]利用自注意力机制增强上下文感知能力, 有效捕捉点域长程依赖, 但在几何边界保持和局部细节建模方面存在不足.AttMPTI[7]在小样本场景中融合跨类别上下文, 增强语义感知, 然而在点域与通道域之间缺乏解耦建模, 限制特征表达的充分性.
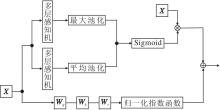
综上所述, 为了进一步缓解“ 局部-全局” 建模之间的结构性矛盾, 提升特征表达的多样性与稳健性, 本文设计双域注意力融合模块(DAFM), 从点域与通道域两个互补维度建模特征间的显著性关联.DAFM以注意力机制为核心, 在点域捕获全局点间依赖关系的同时, 引入通道注意力机制, 对语义通道进行自适应重标定, 提升关键语义通道的响应强度, 实现语义增强与特征抑噪的协同建模, 相应结构图如图2所示.
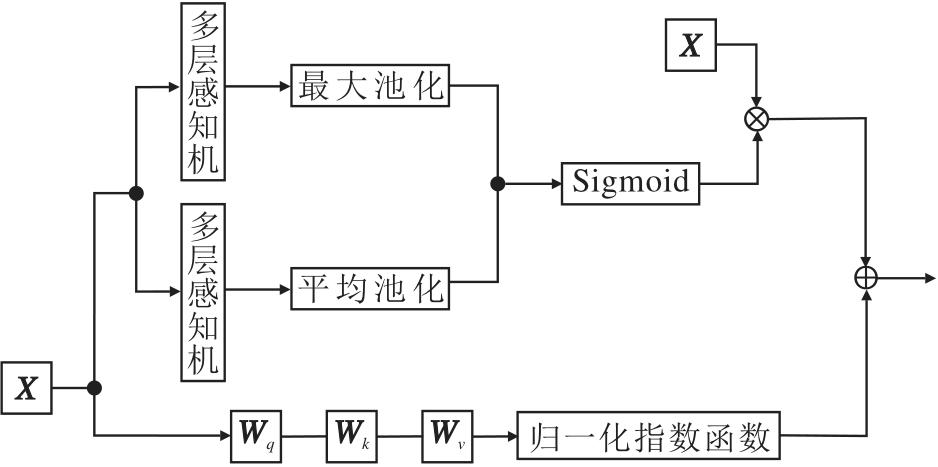 | 图2 DAFM结构图Fig.2 Architecture of DAFM |
给定特征矩阵X∈ RN× C, 其中, N表示点数量, C表示每个点的特征通道数.DAFM采用缩放点积注意力机制[28], 基于特征相似性建模全局点间依赖, 具体输出特征如下:
$\boldsymbol{F}_{s}=\boldsymbol{A} \boldsymbol{V} \in \mathbf{R}^{N \times C}, $
其中
$\boldsymbol{A}=\operatorname{softmax}\left(\frac{\boldsymbol{Q} \boldsymbol{K}^{\mathrm{T}}}{\sqrt{d}}\right) \in \mathbf{R}^{N \times N}, $
表示注意力矩阵,
Q=XWq, K=XWk, V=XWv,
分别表示查询矩阵、键矩阵、值矩阵, Wq, Wk, Wv表示可学习权重矩阵, d表示缩放因子.注意力矩阵A编码点与点之间的语义相似性, 使特征聚合不受空间距离限制.
为了强化任务相关通道, 通道注意力分支采用全局上下文统计, 生成通道加权后的特征矩阵:
Fc=Mc☉X∈ RN× C,
其中,
Mc=σ (MLP(AvgPool(X))+MLP(MaxPool(X)))∈ RC,
表示通道注意力权重向量, σ (· )表示Sigmoid函数, MLP(· )表示两层感知机, AvgPool(· )表示平均池化, MaxPool(· )表示最大池化, ☉表示逐通道相乘.该分支通过抑制冗余通道, 提升关键语义特征响应.最后通过可学习系数自适应融合两个分支, 融合后的输出特征矩阵为:
Fout=α Fs+β Fc,
其中α 、 β 表示可学习参数.
MGAM在每个DAFM中独立设置一组融合系数, 即不同层之间的α 与β 不共享.之所以采用逐层独立策略, 是因为不同层级特征具有不同的语义抽象程度与感受野范围:浅层特征更侧重局部几何结构表达, 深层特征更强调全局语义依赖.若采用全局共享融合系数, 将限制模型在不同层级对点域建模与通道重标定重要性的自适应调节能力.因此, 逐层独立设置能提升表示的灵活性, 使各层根据特征分布自动学习合适的融合比例.
在训练策略方面, α 、 β 初始化为0.5, 使双分支在训练初期贡献均衡, 从而避免由于单分支主导导致的梯度偏置问题.融合过程采用线性加权形式, 不引入额外归一化或非线性约束, 因此梯度可直接通过标准反向传播机制稳定传递.由于融合参数仅为标量, 引入不会显著增加优化难度, 也不会对整体收敛性产生不利影响.
为了提升MGAM在小样本点云语义分割任务中的全局感知能力, 提出全局辅助点机制(GAPM), 建模跨空间范围的语义关联.需要说明的是, 在点云语义分割任务中, “ 全局” 与“ 局部” 的含义不同于物体识别任务.物体识别通常以单个目标为输入样本, 对整幅图像进行特征汇聚可视为对“ 物体整体语义” 的建模, 而点云语义分割的输入通常包含多个语义类别, 目标是完成点级分类, 而不是对场景进行单标签判别.因此, 本文所指的“ 全局语义” 并非某一类别的整体表达, 也不是类别特征的简单加权平均, 而是指在当前输入点云范围内, 通过对所有点特征进行结构化聚合形成的点云级语义结构表示.该表示用于刻画不同语义类别在场景中的整体分布模式及其空间关联关系.其中:“ 局部语义” 指窗口或邻域范围内由空间邻近点构成的几何与语义结构; “ 全局语义” 指跨越整个输入点云的长程依赖关系、类别共现关系及空间布局约束.
传统的点云处理方法大多依赖局部邻域特征提取或滑动窗口机制, 虽然在建模局部几何结构方面具有一定优势, 但在捕捉长距离依赖关系和全局语义一致性方面存在明显不足.这一问题在稀疏或结构复杂的场景中尤为突出, 容易导致语义割裂和识别误差[16].受TokenLearner[3]启发, 可通过引入少量可学习特征单元(Token)自适应提取全局表示, 验证在视觉任务中压缩全局特征并维持语义完整性的有效性.类似地, MGAM在关键层级的Transformer模块中引入GAPM, 采用注意力机制从点中汇聚语义, 构建结构感知的全局表示向量.
为了使全局辅助点能刻画点云整体语义结构, 设计基于注意力机制的特征聚合策略.对于某一层级s的点云特征集合$\left\{\boldsymbol{f}_{i}^{s}\right\}_{i=1}^{N}$, 全局辅助点加权整合这些点的特征, 构建第s层级生成的全局语义向量:
$\boldsymbol{g}^{s}=\sum_{i=1}^{N} \beta_{i}^{s} \cdot M L P_{1}\left(\boldsymbol{f}_{i}^{s}\right) . $
其中:MLP1(· )表示两层感知机函数, 用于对输入点特征进行非线性变换;
$\beta_{i}^{s}=\frac{\exp \left(M L P_{2}\left(\boldsymbol{g}^{s-1}\right) \cdot M L P_{3}\left(\boldsymbol{f}_{i}^{s}\right)\right)}{\sum_{j=1}^{N} \exp \left(M L P_{2}\left(\boldsymbol{g}^{s-1}\right) \cdot M L P_{3}\left(\boldsymbol{f}_{j}^{s}\right)\right)}, $
其中, MLP2(· )、MLP3(· )表示参数独立的非线性变换函数, 用于将上一层全局表示gs-1与当前点云特征
为了缓解点云特征在多层处理过程中的语义衰减问题, GAPM设计高效的跨层信息传递机制.每层计算得到的全局语义向量用于增强下一层点特征的表达能力.对于s+1层级的每个点云特征
$\boldsymbol{f}_{i}^{s+1}=\boldsymbol{f}_{i}^{s+1}+\lambda_{s} \cdot M L P_{4}\left(\boldsymbol{g}^{s}\right), $
其中, MLP4(· )表示全局信息注入映射函数, λ s表示可学习的缩放因子, 用于动态调节全局语义的注入强度.与此同时, 全局语义向量本身也进行跨层更新, 增强其语义一致性与表达稳定性, 即
$\boldsymbol{g}^{s+1}=\boldsymbol{g}^{s}+\delta_{s} \cdot M L P_{5}\left(\boldsymbol{g}^{s}\right), $
其中, MLP5(· )表示全局特征自更新函数, δ s表示可学习的缩放系数, 用于自适应控制残差更新强度.此处引入的残差更新方式可有效防止深层网络中全局特征的退化问题, 使GAPM在多尺度特征融合中持续发挥作用.
为了将全局语义信息有效引入点特征表达中, 同时避免直接拼接或相加带来的语义干扰, GAPM采用稳定的门控融合机制, 基于残差引导思想, 引入注意力门控映射:
$\boldsymbol{G}=\sigma\left(M L P_{6}\left(\left[\boldsymbol{X}, \boldsymbol{g}^{s}\right]\right)\right), $
按通道维度控制全局信息的注入, 其中, MLP6(· )表示门控权重生成函数, X表示当前层的点特征矩阵, [X, gs]表示将全局语义向量gs在点维度上进行复制扩展后, 与点特征X在通道维度进行拼接, 最终融合特征为:
$\widetilde{X}=X+G \odot\left(g^{s}-X\right) . $
该门控融合机制本质上是一种通道选择性引导的残差融合策略, 通过学习融合权重G, 动态调整全局信息对各通道的影响, 兼顾局部几何细节与全局语义抽象, 提升模型对复杂场景的理解能力.
在每个引入GAPM的关键层级中, 设置1个全局辅助点, 用于表征当前输入点云场景的整体上下文信息.该全局辅助点并非独立的可学习参数, 也不是预定义的静态向量, 而是由当前层所有点特征通过注意力加权聚合动态生成.在后续计算中, 该全局辅助点再与点特征进行双向交互, 实现全局语义对局部特征的调制与增强.由于全局辅助点在每个前向传播过程中均由当前层特征动态生成, 因此不会引入额外独立参数, 也不会显著增加模型的复杂度.
在多类别点云场景中, 点级分类不仅依赖局部几何特征, 还受到点云整体类别分布结构的约束.例如:在室内场景中, 某些类别之间具有稳定的空间关系或共现模式, 局部结构相似的区域往往需要借助整体语境进行判别.因此, 引入场景级上下文表示有助于缓解局部特征歧义问题, 提高语义一致性建模能力.全局辅助点通过注意力汇聚形成低维场景级语义编码, 功能类似于Transformer结构中的全局token, 用于建模跨区域依赖关系.该表示并不替代点级分类, 而是作为全局引导信号, 通过残差注入方式增强点特征表达.
在小样本3D点云语义分割任务中, 小类别目标由于其数据量较少, 往往难以被网络充分学习.为了解决此问题, 本文提出全局类别感知损失函数(GCAL), 引导模型学习整个场景的类别分布, 增强对小类别的关注度, 提高分割精度.
由于传统的交叉熵损失(Cross-Entropy Loss, CE-Loss)仅在点级别进行监督, 容易导致小类别特征在网络中被弱化.因此, 本文在网络的全局特征提取阶段额外增加一个类别存在性预测分支, 用于估计当前点云场景中哪些类别可能存在.具体而言, 在模型的全局特征Fg上附加一个全连接层, 输出类别概率分布如下:
$\boldsymbol{p}=\sigma\left(\boldsymbol{W} \boldsymbol{F}_{g}+\boldsymbol{b}\right) \in[0, 1]^{C}, $
其中, W、b表示可学习参数, C表示类别总数, σ (· )表示逐元素的Sigmoid函数.
为了增强网络的全局类别感知能力, GCAL对类别存在性预测向量p与真实类别标签
$L_{g}=-\sum_{k=1}^{C} \alpha_{k}\left[\hat{y}_{k} \ln p_{k}+\left(1-\hat{y}_{k}\right) \ln \left(1-p_{k}\right)\right] . $
其中:
为了平衡点级监督和全局类别感知, 最终的损失函数由CE-Loss与GCAL组合而成:
$L_{\text {total }}=\lambda L_{p}+(1-\lambda) L_{g}, $
其中,
$L_{p}=-\frac{1}{N} \sum_{i=1}^{N} \sum_{k=1}^{C} w_{k} y_{i, k} \ln \left(\frac{\exp \left(z_{i, k}\right)}{\sum_{j=1}^{C} \exp \left(z_{i, j}\right)}\right), $
表示传统点云分割损失, yi, k表示第i个点在第k类上的真实标签, zi, k表示模型对第i个点属于第k类的预测得分, wk表示类别权重, 针对小类别赋予更高的权重, 可进一步增强其学习能力, λ 控制两种损失的权重.
GCAL的设计目标并非要求模型在小样本条件下精确回归点级类别比例, 而是学习场景级的类别存在性分布.在N-way K-shot设定中, 每个情景仅涉及少量候选类别(如1-way或 2-way), 模型的预测空间被自然限制在当前任务的类别子集内.因此, 类别预测问题由“ 全类别比例估计” 转化为“ 候选类别存在性判断” , 决策空间显著收缩, 学习难度相应降低.在此框架下, GCAL更关注类别是否在场景中出现及其相对语义强度, 而非精确刻画每个类别的点级占比.
从统计学角度分析, 整个点云场景中每个类别是否出现可以看作点级标签在类别维度上的汇总.对于一个包含Npoints个点的查询点云, 逐点分割需要在高维标签空间中进行判别, 而场景级分布仅涉及当前情景的Nway个类别, 维度远低于点级预测空间.本质上, 这是一种从高维离散标签空间向低维类别子空间的压缩映射问题, 统计复杂度显著低于逐点语义分割任务.因此, 在小样本条件下学习稳定的场景级类别存在性表示在理论上是可行的.
此外, 类别存在性分布为模型提供一种场景级语义先验约束, 作用类似于图像级标签正则化、全局上下文校准及多标签辅助监督策略.该类全局监督信号并不直接替代点级分割, 而是通过类别层面的约束改善特征空间的组织结构, 增强类别间可分性与语义一致性.因此, GCAL的学习目标并非重构真实类别比例, 而是在小样本设定下引入稳定的全局语义引导, 从优化角度分析具有合理性与可行性.
本文选择在S3DIS[29]、ScanNet[30]数据集上进行实验.S3DIS数据集涵盖来自3栋不同建筑的5个大规模室内区域, 展现多样性的建筑风格和外观特征, 共12种语义分割类别.ScanNet数据集包含来自707个特定室内场景的1 513个点云扫描, 共计20种语义分割类别.相比S3DIS数据集, ScanNet数据集上数据涵盖更多类型的房间, 如浴室和客厅等, 点云场景结构也更复杂和不规则, 给语义分割任务带来更大挑战.在每个数据集上, 分别构建互不重叠的训练类别集Ctrain和测试类别集Ctest, 并在该基础上进行交叉验证, 其中训练和验证使用Ctrain, 测试采用Ctest进行评估.
MGAM采用Lai等[27]的数据处理策略及An等[22]的新标准化设置, 克服现有小样本3D点云分割方法中存在的“ 前景泄漏” 和“ 稀疏点分布” 问题.具体地, 将三维场景沿X-Y平面划分为1 m× 1 m的局部块, 每块包含该区域内的全部点, 并以0.02 m的网格对点云进行采样.若处理后点数超过20 480, 随机下采样控制输入规模.相比传统2 048点的稀疏输入, 这一密集采样方式保留更多细节信息, 如物体边缘与小尺寸结构, 从而提升模型的识别能力.同时, 统一采样策略可避免前景区域的重复采样, 缓解密度偏差对模型训练的干扰, 促使模型依赖语义特征进行分割.
MGAM采用DGCNN[13]作为特征提取模块的主干网络, 并在其后追加三层MLP作为分割头, 在基础训练集Ttrain上进行监督训练.预训练阶段采用Adam(Adaptive Moment Estimation)优化器, 初始学习率设为0.001, 批尺寸设为32, 总共训练100个迭代周期.在完成预训练后, 使用习得的权重初始化MGAM中的特征提取模块.
进入元训练阶段后, 采用学习率为0.000 05的AdamW(Adam with Weight Decay)优化器, 权重衰减设为0.01.在训练过程中, 每次迭代会随机采样一个小样本分割任务, 其中支持集与查询集中的点云样本将被施加一系列数据增强操作.这些增强策略包括添加微量噪声以模拟传感器误差, 以及围绕垂直轴进行随机旋转以增强模型对不同姿态和几何变化的鲁棒性, 目的是进一步提升模型的泛化性.
为了保证实验对比的公平性, 所有对比模型均严格遵循原有文献中公开的训练流程与参数设置, 包括训练/测试类别划分、情景任务构建方式及评估指标等.MGAM仅在保持上述设置不变的前提下, 引入双域注意力融合模块(DAFM)、全局辅助点机制(GAPM)和全局类别感知损失函数(GCAL), 其余网络结构与训练超参数均与基线模型保持一致.
实验采用S0和S1这2种不同的数据划分协议, 用于验证模型的小样本泛化能力.将原始数据集的类别划分为互不相交的子集, 在S0组中设定特定的类别作为基础类进行训练, 将剩余类别作为新类进行推理验证, 并在S1组中通过改变类别的组合方式构建另一套独立的训练测试集, 旨在通过多组不同类别划分下的性能对比, 排除特定类别分布对实验结果的干扰, 客观证实模型在面对未知物体时具备稳定的跨类别学习能力.同时, 使用平均交并比(Mean Intersection over Union, mIoU)作为评价指标, 计算模型预测的点云区域与真实标签区域之间的交集与并集之比, 量化模型对不同语义类别在空间拓扑与几何边界上的分割精度.
本文选择与如下4个基线模型进行对比:AttMPTI[7]、QGPA[18]、文献[19]模型、COSeg[22].各模型在S3DIS、ScanNet数据集上的定量对比结果如表1和表2所示, 两表给出S0、S1两种协议下的mIoU值, 还给出这两种协议下mIoU值的平均值.由表可观察到, 随着支持样本数量的增加(从1-shot到5-shot), 所有模型的性能都有明显提升, 这也验证更多的标签样本有助于模型泛化能力的提升.MGAM在两个数据集上均取得最优值, 表现出显著的性能优势.
| 表1 各模型在S3DIS数据集上的mIoU值对比 Table 1 mIoU comparison of different models on S3DIS dataset % |
| 表2 各模型在ScanNet数据集上的mIoU值对比 Table 2 mIoU comparison of different models on ScanNet dataset % |
在S3DIS数据集的1-way和2-way任务上, MGAM的mIoU值分别比COSeg提升1.54%、2.07%和1.41%、1.29%, 而在场景更复杂, 涵盖更多类型的ScanNet数据集上, 也分别获得1.62%、2.16%和2.96%、2.24%的性能提升.这些结果充分说明, MGAM的多层次全局感知框架在语义一致性建模和长程依赖关系捕捉方面性能较优, 特别是在样本极少及复杂场景中, 能显著提升点云语义分割的鲁棒性和泛化性.
值得注意的是, 在挑战性较高的1-shot任务上, MGAM仍表现出强大的泛化能力, 表明引入GAPM为特征学习提供有力的语义先验, 可有效提升表征能力.在数据极度稀缺的情况下, GAPM通过跨样本的结构关系补充点云之间的全局语义信息, 即便在单个支持样本的条件下, 模型也能捕捉丰富的上下文特征和几何特征.此外, MGAM中的DAFM可进一步融合不同尺度的信息, 有效缓解点云在空间密度和结构复杂性上的不一致问题, 提升分割的细粒度准确性.
相比AttMPTI等基线模型, MGAM在所有设置下均获得最优性能, 这表明MGAM提出的层次化增强策略不仅在表达能力上更优, 同时在训练阶段更容易收敛, 在推理时也更稳健.尽管AttMPTI也尝试利用多原型机制建模类间差异性, 但由于缺乏高层次语义关联建模能力, 容易受到支持样本局部噪声或特征偏移的影响, 导致原型表达能力不足, 尤其是在类内结构复杂时性能下降更明显.MGAM在原型生成过程中引入全局感知特征, 显著增强类别表示的稳健性.COSeg在某些场景中表现较优, 但由于其对跨样本语义关系的建模能力有限, 难以在复杂场景中构建一致性的语义结构, 因此泛化性不足.相比之下, MGAM在ScanNet数据集上表现出较强的实际应用潜力, 尤其适用于实际采集数据中类别分布不均或标签稀缺的情况.
综上所述, MGAM在不同数据集和多种设置下都表现出良好的通用性和稳定性, 验证其在小样本3D点云语义分割任务中的有效性与先进性.通过GAPM, MGAM不仅提升原型表示的质量, 也增强模型在极少标签条件下的推理能力, 在实际应用场景中表现出较强的鲁棒性和实用价值.
尽管MGAM在室内数据集上表现优异, 但其对“ 场景先验” 的依赖性值得探讨.从架构上看, MGAM的GAPM完全基于当前输入动态生成全局表示, 而非依赖预定义模板, 本质上是捕捉样本内部的结构相关性.DAFM通过特征相似性自适应建模长距离依赖, 具备较强的场景无关性.然而, GCAL中的类别存在性预测分支在训练中确实利用类别共现统计信息, 这可能使其在跨场景(如室内转室外)或类别分布发生剧烈变化时受到影响.总之, MGAM的核心建模机制并不依赖特定空间拓扑先验, 但类别预测模块可能存在统计偏见.
3.3.1 双域注意力融合模块消融实验
为了验证DAFM在小样本3D点云语义分割任务中的有效性, 在保持网络主干结构、GAPM及GCAL不变的前提下, 对DAFM进行消融实验.在S3DIS、ScanNet数据集2-way 5-shot的小样本任务上开展实验, 并以mIoU作为评价指标, 所有结果均为多次独立运行的平均值.
本文设置4种对比方案:1)完全移除DAFM, Transformer主干结构保持不变, 保留各层自注意力与前馈网络, 仅去除插入Transformer模块中的DAFM, 直接基于原始点特征进行分割预测; 2)仅引入通道注意力; 3)仅引入点域注意力; 4)同时引入通道注意力与点域注意力, 构成完整的DAFM.具体消融实验结果如表3所示.
| 表3 DAFM消融实验结果 Table 3 Ablation experiment results of DAFM % |
由表3可见, 当移除DAFM后, S3DIS、ScanNet数据集上的mIoU值分别降至42.35%和 36.62%, 表明在缺乏双域注意力引导的情况下, 模型对局部几何结构与语义判别特征的联合建模能力明显受限.单独引入通道注意力或点域注意力均可在一定程度上提升分割性能, 其中通道注意力在语义判别方面略优, 而点域注意力在空间结构建模上具有一定优势, 但二者的性能均低于完整的双域融合设置.相比之下, DAFM在2个数据集上分别取得44.22%和38.74%的最优mIoU值, 说明通道注意力与点域注意力在小样本点云语义分割任务中具有显著的互补性.通过在特征通道维度与点域空间维度同时进行自适应加权, DAFM能有效平衡类别判别信息与空间结构信息, 提升模型的整体分割性能.
3.3.2 全局辅助点机制消融实验
为了验证GAPM在小样本点云语义分割任务中的有效性及在不同网络层级插入对模型性能的影响, 在S3DIS、ScanNet数据集2-way 5-shot任务上进行消融实验.将MGAM中的前三层分别记为Stage1、Stage2和Stage3.实验选择在Transformer模块中不插入GAPM、分别在单一阶段插入GAPM、在两个阶段组合插入GAPM、在全部阶段均插入GAPM, 评估不同插入策略对小样本点云语义分割性能的影响
相应消融实验结果如表4所示, 表中黑体数字表示最优值.由表可见, GAPM在各个阶段的引入均能带来不同程度的性能提升, 但插入位置对最终效果的影响存在显著差异.相比不插入GAPM, 在任意单独阶段插入GAPM均能带来一定程度的性能提升, 在Stage2单独插入时效果最佳, 这表明在中间层阶段融合全局辅助信息, 有助于提升特征表达的判别性.在Stage1单独插入带来的性能提升相对有限, 可能由于初期特征尚不稳定, 过早引入全局信息反而干扰局部特征提炼.在多阶段组合插入中, Stage2+Stage3取得最优性能, mIoU值超过单阶段插入和其它组合插入.这表明在中后期特征处理中持续引入全局感知, 有助于更好地融合局部细节与全局上下文, 提升模型对稀有类别的识别能力.
| 表4 GAPM消融实验结果 Table 4 Ablation experiment results of GAPM % |
值得注意的是, 当在3个阶段均插入GAPM时, 性能提升却不如Stage2+Stage3.这一现象表明, 过度地在浅层引入全局信息可能导致噪声累积, 削弱局部特征的区分性.因此, 合理选择插入位置, 比盲目在所有阶段插入更有效.
此外, GAPM在较复杂的场景中带来的性能提升幅度更明显, 这验证其在处理空间结构复杂、类别分布不均的室内点云场景中的鲁棒性.相比传统的仅利用支持点进行语义传播的模型, GAPM通过全局建模不同类别之间的上下文信息, 使得模型在推理阶段能更充分地利用支持集与查询集之间的长距离语义联系, 显著提升点级标签推理的准确性.
总之, GAPM不仅提升模型对局部特征的补充能力, 还增强对全局上下文的建模能力, 是MGAM取得优异性能的关键组成部分之一.
3.3.3 全局类别感知损失函数消融实验
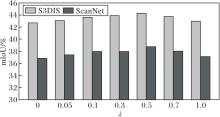
为了进一步验证GCAL对小样本点云语义分割性能的影响, 以及探究其权重系数λ 的最佳设置, 设计系统性的消融实验.定义λ =0, 0.05, 0.1.0.3, 0.5, 0.7, 1.0, 在S3DIS、ScanNet数据集2-way 5-shot任务上进行实验.当λ =0时, 模型退化为不使用GCAL的基线设置.为确保公平性, 其余设置均与主体实验保持一致.
具体实验结果如图3所示.首先, 当λ =0, 即不引入GCAL时, MGAM在两个数据集上均表现较差.这一现象表明, 在小样本条件下, 缺乏类别感知指导的模型容易陷入局部特征过拟合, 难以充分挖掘类别间的判别性信息, 导致整体识别能力受限, 特别是在小类别分割任务上表现尤为明显.随着λ 值从0逐步增至0.5, MGAM在2个数据集上的mIoU值持续提升, 说明适量引入类别感知监督, 可有效补充局部特征学习的不足, 促进模型在特征空间中更好地聚合同类点, 同时增大异类点之间的区分度.当λ =0.5时, MGAM在S3DIS、ScanNet数据集上分别达到44.22%和38.74%的最高mIoU值, 这表明适度增强类别感知, 有助于引导模型学习更具判别性的特征表示, 特别是在小样本类别识别上效果明显.然而, 当λ 进一步增大至0.7及以上时, 模型性能出现轻微下降, 推测可能是由于类别引导过强, 导致局部几何细节特征的学习受限, 引发过拟合现象.
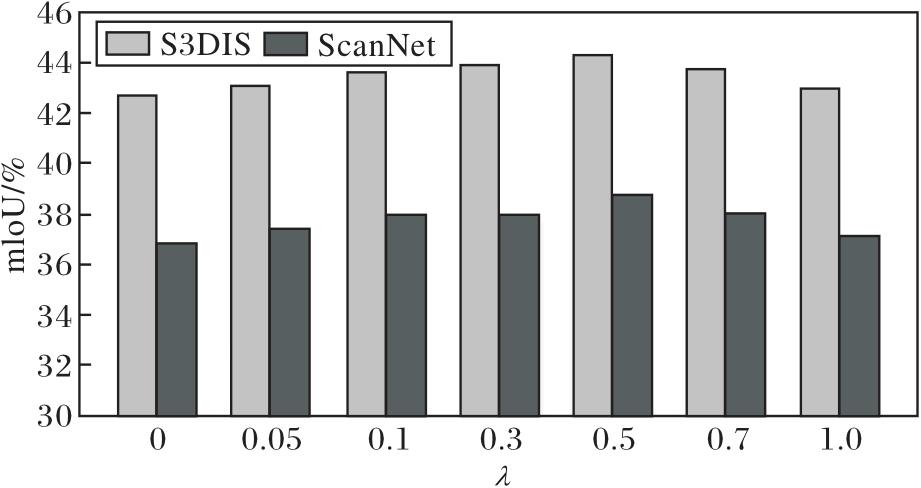 | 图3 λ 对MGAM性能的影响Fig.3 Effect of λ on MGAM performance |
总之, 适度引入GCAL可有效提升小样本点云语义分割性能.此外, 实验进一步揭示在小样本条件下, 类别感知与几何建模之间需保持合理的平衡, 过弱或过强的类别引导都会影响最终分割效果.
为了验证类别存在性预测分支的有效性, 对预测分布与真实类别分布之间的一致性进行统计分析.GCAL的目标并非精确回归场景中各类别的点数比例, 而是学习场景级类别存在性分布, 即判断在当前情景中各候选类别是否出现.因此, 为了验证该
预测是否具有统计意义, 从预测分布与真实类别分布之间的一致性角度进行定量评估.
在S3DIS、ScanNet数据集2-way 5-shot任务上进行实验.选择该任务的原因在于其包含多个候选类别, 支持样本数量相对充分, 更有利于观察类别分布预测的稳定性.
在测试阶段, 随机采样200个情景.对于每个情景, 记录GCAL输出的类别存在性预测概率向量, 同时根据查询点云真实标签构建对应的类别存在性二值向量:若某类别在该情景中至少出现一次, 记为1, 否则记为0.
在此基础上, 计算预测概率向量与真实类别存在性向量之间的皮尔逊相关系数(Pearson Corre-lation Coefficient, PCC).为了保证统计结果的稳定性, 基于上述过程重复进行5次独立采样, 统计相关系数的均值与标准差.
具体实验结果如表5所示.由表可见:在S3DIS数据集上, 类别分布预测与真实类别存在性之间的PCC值达到0.871, 标准差为0.026; 在ScanNet数据集上, PCC值为0.848, 标准差为0.031.两个数据集均呈现出显著的正相关关系, 且方差较小, 说明类别存在性预测在不同情景间具有较好的稳定性.
| 表5 类别存在性预测一致性分析结果 Table 5 Analysis results of category existence prediction consistency |
从统计角度上看, PCC值接近或超过0.85, 意味着预测结果与真实类别存在性之间具有高度线性相关关系, 说明GCAL定义的类别存在性预测分支确实学习场景级类别结构信息, 而非随机输出.与此同时, 需要强调的是, 类别存在性预测属于低维场景级判别任务, 难度远低于逐点语义分割.因此, 即便类别分布预测具有较高的相关性, 仍需要依赖局部几何建模与特征对齐机制完成点级精细分类.换言之, GCAL并非替代分割任务, 而是通过提供全局类别约束, 对点级预测起到正则化与引导作用.
结合整体性能可发现, 在引入GCAL并使用最优权重后, S3DIS、ScanNet数据集上的mIoU值分别获得约1%~2%的稳定提升.虽然提升幅度相对温和, 但类别分布预测与真实分布之间的高相关性说明该分支确实发挥场景级语义约束作用, 能降低类别遗漏风险并增强小类别响应能力.
总之, 通过对类别预测分布与真实分布一致性的统计分析, 可验证GCAL在小样本点云语义分割任务上的合理性与可行性, 同时也为模型的有效性提供直接的实验支撑.
3.3.4 速度-精度权衡分析
在小样本点云语义分割任务中, 引入新的特征建模模块虽然能提升模型的分割精度, 但同时也可能带来额外的计算开销.因此, 从工程应用角度出发, 有必要进一步分析模型性能提升与推理效率之间的权衡关系.为此, 在S3DIS数据集上对不同模块组合下模型的分割精度与推理时间进行对比分析, 评估MGAM在计算效率与性能提升之间的平衡性.
在实验设置上, 所有模型均在相同硬件环境下进行测试, 输入点数统一为4 096, 批尺寸设为1, 仅统计前向传播阶段的平均推理时间.每个模型独立运行100次并取平均值作为最终结果, 以减少偶然波动带来的影响.实验对比DGCNN、引入DAFM、引入GAPM、同时引入DAFM与GAPM、MGAM的性能, 具体结果如表6所示.
| 表6 不同模块组合下的速度-精度权衡结果 Table 6 Trade-off between speed and accuracy under different module combinations |
从表6可看出, 在基础模型上引入DAFM后, mIoU值由41.56%升至43.18%, 提升1.62%, 而推理时间由21.3 ms增至24.7 ms, 增加约3.4 ms.该结果表明, DAFM通过在通道维度与空间维度对点云特征进行自适应增强, 能在较小时间开销下有效提升模型对局部几何结构与语义特征的表达能力.当仅引入GAPM时, mIoU值达到42.88%, 相比DGCNN提升1.32%, 同时推理时间增至23.9 ms.相比DAFM, GAPM的计算开销略低, 但仍能带来稳定的性能提升.这主要得益于GAPM通过构建全局辅助点并进行注意力聚合, 建立跨区域语义关联, 增强全局上下文建模能力.当同时引入DAFM与GAPM后, mIoU值进一步升至43.76%, 表明两种机制在特征建模方面具有一定的互补性.DAFM主要增强局部特征表达, GAPM侧重于建模跨区域的全局语义信息, 两者结合能在局部结构细节与全局语义关系之间取得更好的平衡.进一步加入GCAL后, mIoU值达到44.22%, 相比DGCNN提升2.66%, 而推理时间为28.1 ms, 相比DGCNN增加约6.8 ms.虽然推理时间有所增加, 但整体开销仍处于可接受范围, 通过约32%的时间增加换取显著的分割性能提升, 体现出较合理的速度-精度权衡关系.
此外, 在4 096点输入规模下, MGAM的推理速度约为35帧/秒, 已接近实时处理需求.在实际应用中, 通过适当降低输入点数或采用混合精度推理策略, 推理效率仍有进一步提升空间.因此, 综合考虑分割精度与计算效率, MGAM在获得较高分割性能的同时, 仍具备良好的工程部署潜力.
为了进一步评估MGAM的工程化应用潜力, 对其参数规模、浮点计算量及推理延迟进行统计分析.实验环境基于2块NVIDIA RTX 3090 GPU, 输入点数固定为4 096, 批尺寸设为1.推理时间定义为仅包含前向传播的平均耗时, 连续运行200次取平均值得到.
统计结果表明, 相比DGCNN, MGAM在大幅提升分割性能的同时, 仍然保持较低的计算开销.MG- AM的参数量为2.89 M, 相比DGCNN(2.41 M)仅增加约0.48 M(19.9%); 浮点计算量为4.96 G, 增幅仅为1.14 G.在推理速度方面, MGAM的单样本平均前向传播耗时为28.1 ms, 折合处理速率约为35.6帧/秒.
分析MGAM内部结构, 模型参数量的增长主要源于DAFM中用于特征重标定的MLP及点域注意力映射矩阵.GAPM凭借其特征动态聚合机制, 仅引入极少量的线性映射参数.GCAL在推理阶段仅保留轻量级线性预测层, 对整体复杂度影响有限.在4 096点的输入规模下, MGAM仍能保持约35帧/秒的推理速度, 满足工业级三维感知任务对实时性的需求, 表明其在计算效率与分割精度之间取得良好的平衡.
在1-way 1-shot小样本3D点云语义分割任务中, AttMPTI[7]、COSeg[22]、MGAM在4个典型类别(Chair、Floor、Table、Door)上的可视化结果如图4所示.由图可见, 在仅使用单个支撑样本进行训练时, MGAM能在细粒度目标(如Chair和Door的边界)及大尺度区域(如Floor和Table的整体结构)上保持更高的预测精度和区域一致性.总之, MGAM在存在遮挡、结构复杂或类别间几何特征相似的场景中, 表现出较强的全局上下文感知与跨层语义对齐能力, 显著减少漏检与误分割现象.
 | 图4 各模型在1-way 1-shot任务上的点云语义分割结果可视化对比Fig.4 Visualization comparison of point cloud semantic segmentation results of different models on 1-way 1-shot task |
本文提出面向小样本3D点云语义分割的多层次全局感知模型(MGAM), 应对小样本点云语义分割任务.设计全局辅助点机制(GAPM), 增强局部特征的全局感知能力.构建双域注意力融合模块(DAFM), 实现局部-全局特征的高效融合.引入全局类别感知损失函数(GCAL), 引导特征分布向类别一致性优化.消融实验验证各模块的有效性与互补性.对比实验表明MGAM在S3DIS、ScanNet数据集上的优越性能.后续研究可考虑进一步提升模型的自适应性与跨域迁移能力.
本文责任编委 封举富
Recommended by Associate Editor FENG Jufu
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|