
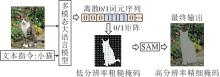
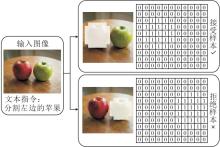

{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向生成式视觉感知的细粒度直接偏好对齐框架
[谢涛1  , 袁玉轩
, 袁玉轩1 , 左旺孟2 , 李瑞峰1 , 赵立军1 ]
, 袁玉轩, 左旺孟, 李瑞峰, 赵立军]
|
|



作者简介:

谢 涛,博士,副研究员,主要研究方向为智能移动机器人感知技术、人机智能交互技术、具身智能等.E-mail:xietao1997@hit.edu.cn.

袁玉轩,硕士研究生,主要研究方向为同时定位与地图构建、具身智能.E-mail:24S008093@stu.hit.edu.cn.

左旺孟,博士,教授,主要研究方向为计算机视觉、机器学习等.E-mail:cswmzuo@gmail.com.

李瑞峰,博士,教授,主要研究方向为移动机器人自主定位与环境感知、动态环境下服务机器人运动规划及人机交互、智能机器人设计、系统创新集成等.E-mail:lrf100@hit.edu.cn.
基于多模态大语言模型的生成式指代分割方法缺乏对生成质量提升途径的深层探索,受限于监督微调的模仿机制,在复杂场景中面临语义定位偏差与掩码边界粗糙的挑战.为此,文中提出面向生成式视觉感知的细粒度直接偏好对齐框架(Fine-Grained Direct Preference Alignment Method for Generative Visual Perception, FG-DPA),将DPO(Direct Preference Optimization)从文本领域迁移至像素级分割任务中,构建高-低质量的掩码偏好对,引导方法在隐空间学习精准的视觉表征.利用SAM(Segment Anything Model)的交互特性构建两类负样本:为了解决边缘不精细问题,在真值包围盒内引入对抗性点提示,生成局部缺失或溢出的低质量掩码作为边缘负例;为了解决目标定位错误问题,在背景区域随机采样生成非重叠掩码,构建语义级定位负例.经过多样本偏好对的训练,结合SAM实现高精度的掩码分割.在多个数据集上实验表明,FG-DPA可有效抑制定位幻觉,显著提升掩码生成的完整性与边缘准确度,在提升多模态生成式视觉感知性能方面是有效的.
About Author:
XIE Tao, Ph.D., associate professor. His research interests include intelligent mobile robot perception technology, intelligent human-robot interaction technology, and embodied intelligence.
YUAN Yuxuan, Master student. His research interests include simultaneous localization and mapping and embodied intelligence.
ZUO Wangmeng, Ph.D., professor. His research interests include computer vision and machine learning.
LI Ruifeng, Ph.D., professor. His research interests include autonomous localization and environmental perception for mobile robots, motion planning and human-robot interaction for service robots in dynamic environments, inte-lligent robot design, and innovative system integration.
Generative referring segmentation methods based on multimodal large language model(MLLM) are limited by the mechanism of Supervised Fine-Tuning and lack in-depth exploration of ways to improve generation quality. Therefore, these methods are faced with the challenges of semantic localization bias and rough mask boundaries in complex scenarios. To address these issues, a fine-grained direct preference alignment framework for generative visual perception(FG-DPA) is proposed. The direct preference optimization(DPO) algorithm is transferred from text understanding to the pixel-level segmentation task. High-quality and low-quality mask preference pairs are constructed to guide the method toward learning more accurate visual representations within the latent space. Two types of negative samples are produced by leveraging the interactive characteristics of the segment anything model(SAM). To address the issue of imprecise edges, adversarial point prompts are introduced into the ground-truth bounding box to generate low-quality masks with local omissions or overflows as negative examples. To solve the problem of incorrect target localization, non-overlapping masks are randomly sampled in the background region to construct semantic-level negative examples. Through training with multiple samples, accurate segmentation is finally achieved in conjunction with SAM. Experiments on multiple public datasets show that FG-DPA effectively suppresses localization hallucination and significantly improves the completeness and edge accuracy of mask generation, validating its effectiveness in enhancing multimodal generative visual perception performance.
随着深度学习技术的飞速发展, 多模态大语言模型(Multimodal Large Language Model, MLLM)在视觉问答、图像描述等理解类任务上取得突破性进展[1, 2, 3, 4].然而, 为了实现更深层次的人机交互与智能体控制, 仅停留在语义理解层面是远远不够的, 模型迫切需要具备细粒度的视觉感知能力, 即像素级的指代表达分割(Referring Expression Segmentation, RES).RES任务要求模型根据给定的文本指令, 在图像中精准分割特定的指代对象[5].
目前, 实现多模态RES的主流范式主要分为两类:端到端(End-to-End, E2E)模型与非端到端(Non-End-to-End, Non-E2E)模型.
E2E模型将分割结果的生成过程内化到MLLM自身的预测框架中, 在统一的训练与推理流程中直接得到像素级输出, 结构简洁、部署简单.以GFMLLM[6]、Text4Seg[7]为代表的工作尝试让模型直接生成掩码, 其中Text4Seg提出Text-as-Mask范式, 将二维分割掩码序列化为0/1文本矩阵或压缩的语义标记, 使MLLM能像生成文本一样自回归地产生分割结果, 实现真正意义上的端到端训练与推理.尽管E2E模型在范式统一性上具有显著的吸引力, 但其分割性能仍面临挑战:一方面, 模型通常依赖监督微调(Supervised Fine-Tuning, SFT), 通过交叉熵损失提升真值掩码序列的生成概率, 这种模仿学习机制仅能学习“ 什么是对的” , 却无法感知“ 什么是错的” 以及“ 不同错误之间的差异” , 导致复杂场景中容易出现语义定位错误(模型未能正确理解指令, 进而将无关区域误分割为目标物体)以及掩码边界粗糙(虽定位正确, 但生成的0/1矩阵出现边界模糊、区域不完整或存在噪声点等)两类典型问题.另一方面, 以离散序列形式生成掩码时, 高分辨率与像素级细节的稳定表达仍较困难, 因此仅依靠增加SFT数据规模往往难以从根本上解决上述问题.
相比之下, Non-E2E模型通常采用级联式架构:先由MLLM输出中间表征(常见为几何提示, 如点、框坐标等), 再调用外部视觉基础模型完成掩码解码.该类模型的突出优势在于充分利用分割基础模型在边界细化与区域完整性方面的强先验, 相比虽然简单但精度不足的E2E模型, 能获得更高质量、更具像素级精细度的掩码输出.例如:SAM4MLLM[8]利用MLLM产生提示信息, 并借助外部分割模型生成最终掩码, 在复杂场景中通常能显著改善边界质量与局部细节.然而, Non-E2E模型也存在不可忽视的局限:系统耦合更复杂, 在一定程度上破坏MLLM原生的自回归生成模式, 训练与部署需要额外加载外部视觉模型, 可扩展性受限于外部视觉编码器的能力.
在Text-as-Mask范式下, 二维的二值分割掩码被降维并离散化为0/1词元序列, 使得掩码生成过程在数学形式上与自然语言文本生成几乎等价.因此, 将自然语言处理领域的DPO(Direct Preference Optimi-zation)[9]引入RES任务成为可能.传统的SFT机制仅通过交叉熵损失进行单向的特征模仿, 难以感知生成错误时的特征偏差, 而DPO能在无需显式训练奖励模型的情况下, 通过构建正负样本对, 直接在隐空间中优化模型的概率分布, 拉大高质量掩码序列与低质量掩码序列的对数似然差, 使模型能深刻理解并主动规避边界粗糙与语义漂移等错例分布, 从而赋予MLLM更精准的像素级判别与生成能力.
因此, 本文提出面向生成式视觉感知的细粒度直接偏好对齐框架(Fine-Grained Direct Preference Alignment Framework for Generative Visual Percep- tion, FG-DPA), 实现级联式的高精度分割.为了解决视觉任务中偏好数据匮乏的问题, 利用SAM(Seg- ment Anything Model)[10]的交互式分割能力, 自动化构建两类针对性的偏好数据集.针对语义定位问题, 在背景区域采样生成非重叠掩码作为语义负样本.针对边界质量问题, 由对抗性点提示生成局部缺失或溢出的掩码作为质量负样本.通过双重偏好数据构造策略, FG-DPA不仅学会“ 定位哪里” , 更学会“ 如何生成更完美的边界” , 从而让MLLM生成定位更准确、形状更贴合的0/1矩阵, 获得更精确的分割结果.
早期的MLLM主要关注文本生成, 无法直接处理像素级任务.为了赋予MLLM分割能力, 主流方案通常采用Embedding-as-Mask范式, 即训练MLLM输出特定的嵌入向量, 再送入外部视觉解码器生成掩码.Lai等[11]提出LISA(Large Language Instructed Segmentation Assistant), 作为该范式的代表性工作, 通过扩展词表引入< SEG> 标记, 将其隐层特征经由多层感知机(Multilayer Perceptron, MLP)投影后作为提示输入SAM解码器中, 实现指代分割能力的初步注入.随后学者在此基础上进行广泛扩展.Xia等[12]提出GSVA(Generalized Segmentation Vision Assistant), 进一步增强模型生成的语义一致性, 支持在单次推理中分割多个目标.Ren等[13]提出PixelLM, 设计轻量级的像素解码器和多尺度特征融合模块, 显著提升多目标指代分割精度.Rasheed等[14]提出GLaMM(Grounding Large Multimodal Mo-del), 构建大规模的Grounding数据集, 实现从粗粒度检测到细粒度分割的全任务覆盖.Zhu等[15]提出POPEN, 在LISA架构的基础上, 利用策略梯度优化< SEG> 的嵌入表示, 进一步适配分割任务.
尽管这类模型通过集成强大的视觉基础模型(如SAM)取得优异性能, 但本质上是一种级联系统.MLLM与掩码解码器之间的解耦导致训练流程复杂, 且推理过程中需要加载额外的视觉模型显存, 限制系统的整体效率与扩展性.
为了打破级联系统架构的限制, 研究者开始探索Text-as-Mask范式, 旨在利用MLLM强大的自回归生成能力直接输出分割结果.Wu等[16]提出VisionLLM v2, 将掩码轮廓转换为多边形坐标序列, 让大语言模型(Large Language Model, LLM)像生成代码一样生成坐标点, 但在处理复杂形状时表现欠佳.Chen等[8]提出SAM4MLLM, 采用一种中间路线, 通过MLLM生成边界框或点的坐标文本, 再利用这些坐标索引图像特征并生成掩码, 虽然形式上统一文本输出, 但本质上仍依赖坐标作为中介.相比之下, Text4Seg[7]与GFMLLM[6]设计更彻底的文本化方案.Text4Seg引入语义描述符, 将图像块映射为反映语义类别的文本序列.GFMLLM提出感知文本矩阵的概念, 将分割掩码直接离散化为0/1文本序列或压缩后的词元, 实现完全端到端的像素预测, 无需引入任何额外的损失函数或外部模型的范式, 大幅简化训练部署流程.然而, 由于缺乏针对序列生成质量的显式约束, 这类模型在生成高分辨率掩码时往往面临边缘不连贯或语义定位漂移的问题.
将预训练模型与人类意图对齐是提升生成质量的关键.Lambert[17]提出RLHF(Reinforcement Lear-ning from Human Feedback), 通过RM(Reward Mo-del)并结合PPO(Proximal Policy Optimization), 已在ChatGPT(Chat Generative Pre-trained Transformer)等纯文本模型中取得巨大成功.然而, RLHF流程繁琐、训练不稳定、计算开销较大.Rafailov等[9]提出DPO, 推导RLHF目标的闭式解, 证明可直接通过二元交叉熵损失在偏好数据对上优化策略, 无需显式建模奖励函数.
在多模态分割领域, 利用反馈机制优化模型的研究尚处于起步阶段.虽然POPEN尝试在LISA架构中引入偏好学习, 但其优化对象是连续的嵌入向量.对于GFMLLM这类基于离散词元生成的分割模型, 如何有效构建偏好对并应用DPO进行细粒度的空间感知校准, 仍是该领域的难点之一.
本文提出面向生成式视觉感知的细粒度直接偏好对齐框架(FG-DPA), 整体架构如图1所示.
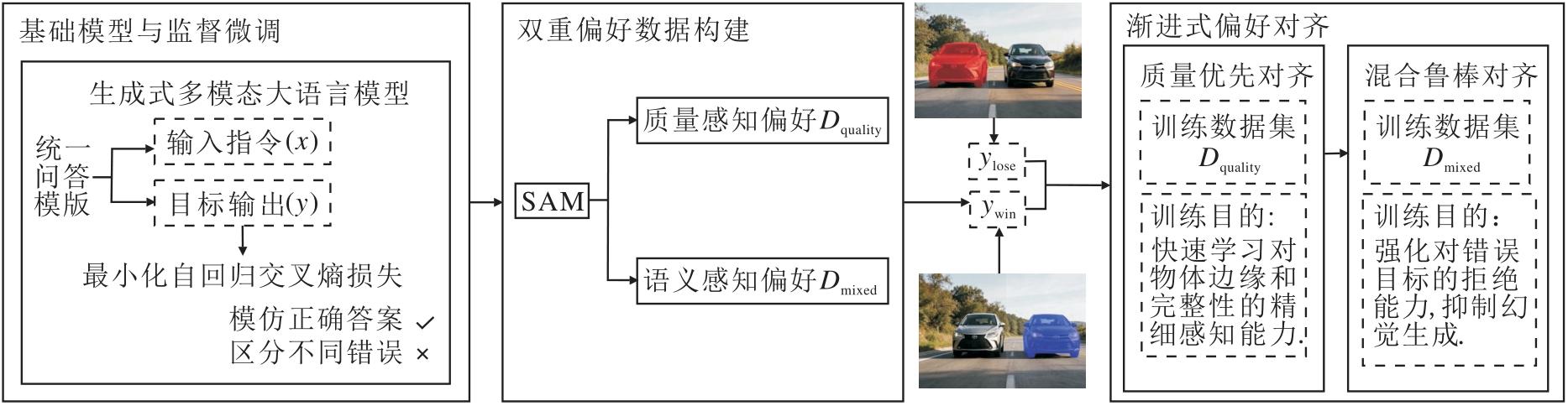 | 图1 FG-DPA整体架构Fig.1 Overall architecture of FG-DPA |
在引入FG-DPA之前, 首先明确两个关键环节:1)确立掩码生成与表征范式, 即定义如何输出分割结果并结合外部专家模型实现精细化; 2)通过SFT赋予基础模型生成正确表征序列的能力, 这里的基础模型是指在DPO训练前, 用于SFT的模型架构, 仅包含视觉编码器和MLLM.
在掩码生成与表征范式上, 如图2所示, 本文借鉴Text-as-Mask范式的思想, 将图像的二维二值掩码降采样为低分辨率版本, 并展平为离散的0/1词元序列.具体而言, MLLM接收图像与文本指令, 自回归生成该词元序列, 得到包含目标粗略形状和位置信息的粗糙掩码.由于MLLM生成的0/1矩阵分辨率受限, 在前向推理流程中引入权重冻结的SAM作为后处理细化器, 用于解码出高分辨率的最终掩码.
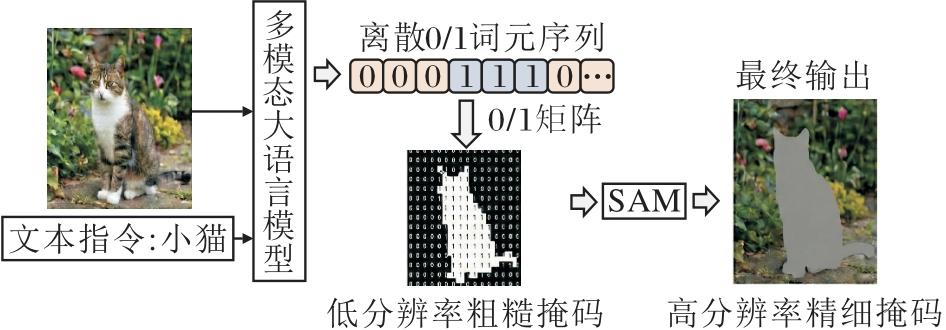 | 图2 0/1矩阵与SAM分割Fig.2 Schematic diagram of 0/1 matrix and SAM segmentation |
为了使基础模型具备上述自回归生成0/1掩码矩阵的能力, 首先对其进行SFT.在此阶段, 外部的SAM并不参与训练与参数更新.本文的SFT阶段区别于Text4Seg 仅依赖部分分割数据, 而是构建更具鲁棒性的混合训练数据集, 主要包含:RefCOCO系列(RefCOCO、RefCOCO+、RefCOCOg) 指代分割数据集、ADE20k 语义分割数据集、LLaVA-665k 多模态指令微调数据集.
将所有分割任务统一转化为文本生成任务.对于涉及掩码生成的指令, 设计统一的问答模版.
输入指令(x):
Please provide the mask of [reference_expression].
目标输出(y):
Here is the segmentation mask:
< seg> [mask_sequence]< \seg> .
其中:[mask_sequence]表示二维二值掩码被展平并压缩后得到的词元序列, [reference_expression]表示指代文本或语义类别名称.
SFT 阶段的目标是最小化自回归交叉熵损失[18], 相应训练目标函数为:
$L_{\mathrm{SFT}}\left(\pi_{\theta}\right)=-E_{\left(I, x, y_{\mathrm{gt}}\right) \sim D_{\mathrm{SFT}}}\left[\sum_{t=1}^{T} \ln \pi_{\theta}\left(y_{t} \mid I, x, y_{< t}\right)\right]$,
其中,
为了解决SFT在掩码质量与语义定位上的不足, 引入DPO[9], 旨在通过构建正负样本对(ywin, ylose), 在无需显式奖励模型的情况下优化策略模型π θ .优化目标是在满足参考模型π ref(即SFT)的KL散度(Kullback-Leibler Divergence)约束下, 最大化偏好数据的似然差[9], 相应训练目标函数如下:
$L_{\mathrm{DPO}}\left(\pi_{\theta} ; \pi_{\mathrm{ref}}\right)=-E_{D_{\mathrm{pref}}}\left[\ln \sigma\left(\beta\left(\Delta_{\mathrm{win}}-\Delta_{\mathrm{lose}}\right)\right)\right], $
其中,
$\Delta_{\mathrm{win}}=\ln \left(\frac{\pi_{\theta}\left(y_{\mathrm{win}} \mid I, x\right)}{\pi_{\mathrm{ref}}\left(y_{\mathrm{win}} \mid I, x\right)}\right), $
$\Delta_{\mathrm{lose}}=\ln \left(\frac{\pi_{\theta}\left(y_{\text {lose }} \mid I, x\right)}{\pi_{\mathrm{ref}}\left(y_{\text {lose }} \mid I, x\right)}\right), $
分别表示偏好输出与非偏好输出相对于参考模型的对数似然比, $\pi_{\theta}(y \mid I, x) $表示模型在给定图像I与指令x条件下生成序列y的概率, $\pi_{\mathrm{ref}}(y \mid I, x) $表示参考模型对同一序列的生成概率, π θ 表示待优化的策略模型(参数为θ 的条件生成分布), π ref表示参考策略模型(通常选取的是SFT阶段得到的模型, 用于提供KL约束),
LDPO(π θ ; π ref)通过最大化Δ win-Δ lose, 促使模型在提升高质量输出的相对概率的同时降低低质量输出的相对概率, 实现偏好对齐.
为了给DPO提供高质量的信号, 利用SAM强大的交互分割能力, 设计2种针对性的负样本构造策略.在所有构造过程中, 正样本ywin始终由真值掩码Mgt下采样并序列化得到.
2.3.1 质量感知偏好
质量感知偏好旨在解决掩码边缘不准确、区域不完整或过分割问题.构造逻辑在真值区域附近引入对抗性干扰, 生成“ 定位正确但形态稍差” 的掩码.具体步骤如下.
提示构建:计算真值掩码Mgt的包围盒作为SAM的基础提示.
对抗采样:
1)欠分割生成.在Mgt内部随机采样点作为SAM的负向提示点, 诱导模型生成内部缺失的掩码.
2)过分割生成.在Mgt外部且距离边界ε 像素范围内采样相应点作为SAM的正向提示点, 诱导模型生成边界溢出的掩码.
筛选标准:计算生成掩码Mnoise与Mgt的交并比(Intersection over Union, IoU).仅保留0.4< IoU< 0.8的样本作为ylose, 确保负样本既保留基本的定位信息, 又在质量上显著劣于正样本.
2.3.2 语义感知偏好
语义感知偏好旨在解决模型幻觉及定位错误物体的问题.构造逻辑是在背景区域生成与指令无关的“ 干扰物” 掩码.具体可视化示意图如图3所示.
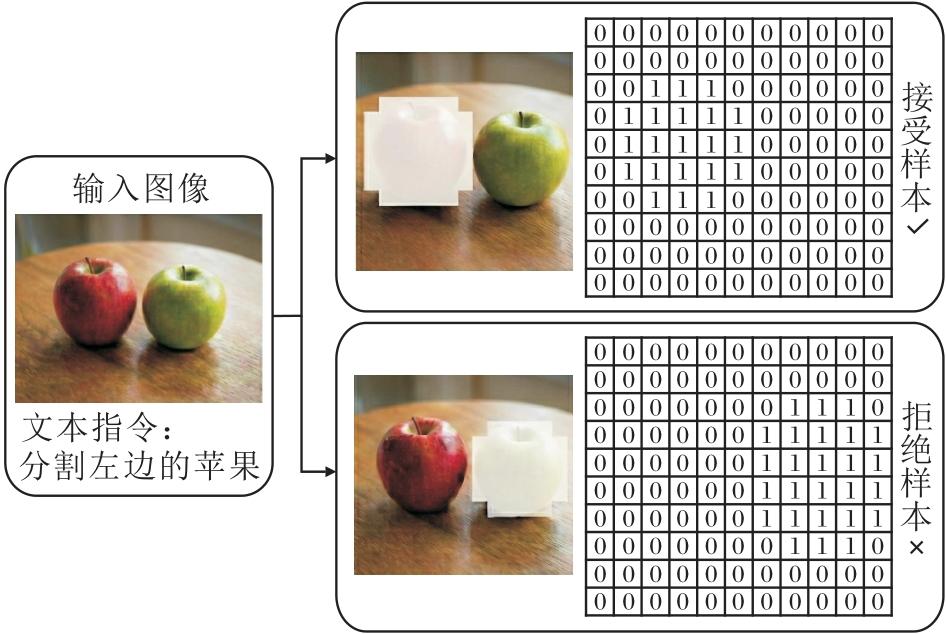 | 图3 偏好数据可视化示意图Fig.3 Schematic diagram of preference data visualization |
语义感知偏好具体步骤如下.
背景提取:确定图像的背景区域Mbg=1-Mgt.
幻觉生成:在Mbg区域内随机采样K个点作为正向提示点输入SAM, 强制其分割图像中的其它无关物体作为干扰.
筛选标准:验证生成掩码Mhallucination与真值Mgt的重叠情况, 仅保留IoU≈ 0的样本作为ylose, 确保负样本在语义上是完全错误的.
考虑到同时学习边界细化与语义校准的难度较大, FG-DPA提出两阶段渐进式偏好对齐训练策略, 确保优化过程的稳定性.
阶段一:质量优先对齐.首先使用仅包含质量感知偏好对的数据集Dquality进行DPO训练.此阶段的目标是让模型在已具备初步定位能力的基础上, 快速学习对物体边缘和完整性的精细感知能力.
阶段二:混合鲁棒对齐.在阶段一训练后, 使用包含质量感知偏好对与语义感知偏好对的混合数据集Dmixed进行进一步训练.此阶段旨在巩固边界质量感知能力的同时, 引入语义负样本, 强化模型对错误目标的拒绝能力, 抑制幻觉生成.
通过这种从“ 精细化” 到“ 鲁棒化” 的学习方式, FG-DPA能平稳收敛, 最终生成精准可靠的分割掩码.
为了验证FG-DPA的有效性, 在多项视觉语言任务上进行充分的实验评估.
FG-DPA采用的架构包括视觉编码器、开源的MLLM和SAM.视觉编码器用于提取图像的视觉特征表示, 将输入图像划分为固定尺寸的图像块并编码为视觉词元序列.开源的MLLM为Qwen3-VL-4B[19].
利用LoRA(Low-Rank Adaptation)[20], FG-DPA整体框架分为SFT与DPO两个阶段进行训练.LoRA适配器的配置如下:秩为128, α =128, 失活率为0.05.首先, 对基础模型进行SFT.然后, 通过FG-DPA构建的双重偏好数据, 使用两阶段渐进式偏好对齐训练策略进行DPO, 缓解SFT在掩码质量与语义定位上的问题.DPO是一种轻量高效的模型对齐技术, 无需训练单独的奖励模型, 而是利用偏好反馈微调模型参数, 通过最大化正负样本之间的差距直接优化偏好目标, 使生成结果更符合人类偏好.
在配备8张NVIDIA A800-SXM4-80G GPU的设备上进行训练, 利用DeepSpeed的ZeRO-2策略[21], 实现高效的多GPU分布式训练.整个训练过程采用bfloat16精度.优化器采用AdamW(Adaptive Mo-ment Estimation with Weight Decay)[22], 配合具有3%预热阶段的余弦退火学习率调度器, 加速大模型训练过程.
为了提高训练效率, 在SFT训练过程中, 学习率设为1× 10-4, 批尺寸设为128, 共训练10个轮次.在DPO训练过程中, 使用较小的学习率1× 10-5, 批尺寸设为64.两个训练阶段分别训练50步.
为了全面评估FG-DPA的性能, 在指代表达分割(RES)任务、指代表达理解(Referring Expression Comprehension, REC)任务及推理分割任务上进行实验.RES任务上采用累计交并比(Cumulative In-tersection over Union, cIoU)作为主要指标.该指标计算所有样本的累积交集与累积并集的比率, 用于衡量预测掩码与真值掩码在像素层面的重叠程度.REC任务上通过计算测试样本中预测值与真实值之间的IoU超过阈值0.5的百分比以量化空间定位的准确性, 该指标定义为Acc@0.5(Accuracy at IoU Threshold 0.5).推理分割任务上除了使用cIoU外, 还引入广义交并比(Generalized Intersection over Union, gIoU).该指标计算所有样本中每幅图像的平均IoU, 能较好地平衡和反映模型对不同尺寸目标的定位能力.
本文的SFT训练过程涉及4类公开数据集:1)RefCOCO、RefCOCO+、RefCOCOg表达分割数据集, 2)ReasonSeg推理分割数据集, 3)ADE20K语义分割数据集, 4)LLaVA-665k多模态指令微调数据集.RefCOCO系列数据集是标准的单目标指代分割基准数据集, 用于学习从指代表达文本到像素级目标掩码的映射, 本文严格采用其官方划分的训练集训练模型.ReasonSeg数据集侧重于复杂的推理任务, 要求模型基于隐式的查询意图而非显式的视觉描述进行目标定位, 用于评估模型的逻辑推理能力.ADE20K数据集是一个广泛使用的语义分割数据集, 提供像素级语义标注, 可利用其扩充训练数据.LLaVA-665k数据集包含大规模图文指令对, 用于强化模型的通用视觉-语言对齐与指令跟随能力.
在DPO训练阶段, FG-DPA使用在RefCOCO数据集上构建的双重偏好数据.
各数据集均按照官方标准进行验证集(val)与测试集(test)的划分.特别地, 对于RefCOCO、RefCOCO+数据集, 测试集进一步细分为testA和testB, testA测试集主要包含带有人物类目标的图像, testB测试集主要包含带有常见物体类目标的图像, 以全面评估模型在不同类别上的泛化能力.RefCOCOg、ReasonSeg数据集则仅采用标准的val和test划分.
在RefCOCO系列数据集上以cIoU为核心指标, 将FG-DPA与现有的主流模型进行全面对比.参与对比的基线模型涵盖传统的专家模型与近年来新兴的MLLM.专家模型包括MABP(Model with Adap-tive Binding Prototypes)[23]和UNINEXT(Universal In-stance Perception as Object Discovery and Retrieval)[24].基于MLLM的模型包含E2E架构的LIS-A[11]、GSVA[12]、GLaMM[14]、POPEN[15]、VisionLLM v2[16], 以及Non-E2E架构的Text4Seg[7]和SAM4MLLM[8].
为了清晰区分各基线模型的具体配置, 在模型名称后标注相应的结构参数或训练设置后缀.“ R50” 表示模型采用深度为50层的残差网络(Residual Neural Network-50, ResNet-50)作为视觉主干网络; “ v2” 表示该模型为其系列的第二代升级版本; “ ft” 表示该模型在原始预训练权重的基础上, 针对当前分割任务进行全参数微调; “ 3B” 、“ 7B” 与“ 13B” 等后缀则分别标识基于MLLM的模型使用的基座模型参数规模, 即对应30亿、70亿和130亿参数量.
MABP与UNINEXT属于面向RES任务的专家模型, 依赖较强的分割先验与针对性训练.其余模型主要围绕MLLM构建生成式分割能力, 涵盖E2E路线与Non-E2E路线.在E2E模型中, LISA作为较早将MLLM引入分割任务的代表工作, 实现“ 语言理解-掩码生成” 的统一框架, 但受限于早期结构设计与训练配置, 在性能上仍有提升空间.随后, POPEN引入偏好优化思想, 增强对错误输出的抑制能力, 缓解定位幻觉等问题, 整体性能得到显著改善.GLaMM等模型进一步通过更充分的指令、对齐数据及训练策略增强E2E模型生成掩码的稳定性与精细度, 展现出更强的综合表现能力.E2E模型的优势在于训练与推理流程统一、部署简洁, 能直接在自回归生成过程中输出掩码, 但需要在训练阶段额外引入掩码预测损失项, 大幅限制MLLM的可扩展性.在Non-E2E模型中, SAM4MLLM将几何提示(如点、框等)与分割基础模型结合, 显著提升掩码边界质量与完整性, 在多个划分上达到与E2E模型相媲美的水平.Text4Seg进一步采用信息密度更高的文本化掩码表达方式, 提升生成式分割的上限表现.这类模型通常在掩码细节上更有优势, 但推理时整体链路更长, 资源开销相对更高.
各模型在RefCOCO系列数据集上的指标值对比如表1所示, 表中黑体数字表示最优值, 斜体数字表示次优值.由表可见, FG-DPA取得最优值.FG-DPA采用Non-E2E架构, 通过双重偏好数据构造策略同时约束“ 语义定位正确性” 与“ 边界完整性质量” , 在RefCOCO系列数据集上超越对比方法.特别地, 在RefCOCO testB、RefCOCO+数据集上, 模型面临更多复杂遮挡、更多同类物体干扰及纯属性区分的挑战.相比Text4Seg等基线模型, FG-DPA在这些困难划分上取得更显著的性能提升.这充分验证双重偏好数据构造策略的多面优势:不仅通过质量感知偏好优化掩码边缘的平滑度与完整性, 还通过语义感知偏好大幅增强模型在复杂语境下的视觉歧义消除能力, 在“ 看准” 和“ 画对” 两个维度上实现同步提升.
| 表1 各模型在RES任务上的cIoU值对比 Table 1 cIoU comparison of different models on RES task % |
在RefCOCO系列数据集上以Acc@0.5为核心指标, 将FG-DPA与现有的主流模型进行全面对比.对比模型主要划分为两类.1)面向REC任务的经典专家模型:CLIP-VG[25]、MDETR[26]、FCTR(Further Comprehension via Transformers)[27]、DGC(Dynamic Gate Constraint)[28]; 2)基于MLLM的生成式模型:Text4Seg[7]、VisionLLM v2[16]、Qwen2.5-VL[29].
各模型在RefCOCO系列数据集上的指标值对比如表2所示, 表中黑体数字表示最优值, 斜体数字表示次优值.
| 表2 各模型在REC任务上的Acc@0.5值对比 Table 2 Acc@0.5 comparison of different models on REC task % |
由表2可见, CLIP-VG、MDETR、FCTR与 DGC等面向REC任务的经典专家模型依赖显式的检测、匹配结构进行指代定位.以VisionLLM v2、Text4Seg等为代表的基于MLLM的生成式模型, 强调统一的视觉-语言建模与指令跟随能力.作为一种视觉语言基座模型, Qwen2.5-VL具备原生边界框预测能力.从数据上看, 基于MLLM的生成式模型在REC任务上已具备较强竞争力, 特别是Text4Seg, 通过更高信息密度的表示提升定位性能上限.
FG-DPA通过双重偏好数据构造策略训练模型, 有效降低歧义定位与漏检问题.值得强调的是, 尽管Qwen2.5-VL已在相关数据上进行过SFT并具备边界框输出能力, FG-DPA仍能在其基础上获得3.25%的增益.
相比MDETR等经典专家模型及现有主流的基于MLLM的模型, FG-DPA在定位准确性与鲁棒性方面表现更优.值得深入探讨的是, REC 任务对目标的全局语义定位精度要求极高.FG-DPA在无需显式引入边界框回归损失的条件下, 通过语义感知偏好, 直接在文本化掩码生成的隐空间中排除错误干扰物的概率分布.这种由像素级掩码反推而来的空间定位框, 在极度依赖细粒度视觉线索的RefCOCO+验证集上展现极强的鲁棒性.
为了进一步评估模型在利用包含视觉信息在内的广泛世界知识进行复杂逻辑推理方面的能力, 在ReasonSeg数据集上进行实验.
选取3种具有代表性的对比模型:传统架构下的LLM指令分割模型LISA[11]、结合基础分割模型的SAM4MLLM[8]、专门针对推理分割任务优化的SegLLM[30].
各模型在ReasonSeg数据集上的指标值对比如表3所示, 表中黑体数字表示最优值, 斜体数字表示次优值.
| 表3 各模型在推理分割任务上的指标值对比 Table 3 Metric value comparison of different models on reasoning segmentation task % |
由表3可见, 在SFT阶段, FG-DPA仅使用极少量的数据便实现高效对齐.结合渐进式偏好对齐训练策略后, FG-DPA在验证集和测试集上的表现均实现大幅跨越.具体而言, FG-DPA在验证集上取得64.4%的cIoU值和65.0%的gIoU值, 在测试集上取得61.3%的cIoU值和62.2%的gIoU值, 这一结果不仅显著优于基于传统架构的LISA与SAM4- MLLM, 而且全面超越专门针对推理分割优化的SegLLM(测试集上cIoU值仅为52.4%).这表明FG-DPA不仅在显式感知任务上表现优异, 在面对高度语义歧义和需要深层逻辑推理的视觉任务时, 依然能有效抑制判别性幻觉, 表现出强大的跨任务泛化能力.
为了分析FG-DPA中各组成部分的作用, 在RefCOCO testB、RefCOCO+ testB、ReasonSeg数据集上进行消融实验, 具体结果如表4所示.
| 表4 各模块的消融实验结果 Table 4 Ablation experiment results of different modules % |
由表4可得出如下结论.
首先, 仅引入质量感知偏好即可在RES任务中带来稳定的掩码边缘和完整性增益, RefCOCO testB数据集上的cIoU值从77.3%升至78.8%, RefCOCO+testB数据集上的cIoU值从69.9%升至70.7%, 验证对抗性点采样对纠正过分割/欠分割的有效性.
其次, 当进一步引入语义感知偏好后, 不仅在RES任务上继续提升性能, 还在REC任务和推理分割任务上提升性能.RefCOCO testB数据集上的Acc@0.5值从88.0%升至89.1%; ReasonSeg测试集上的gIoU值从61.4%升至62.2%.这有力证实语义感知偏好对于消除目标混淆、提升深层逻辑理解能力至关重要.两类偏好的叠加实现从“ 精确形状生成” 到“ 鲁棒语义定位” 的互补, 最大程度释放生成式视觉感知模型的潜力.
为了全面评估FG-DPA的实际部署效率, 在单张NVIDIA A800 GPU上, 将FG-DPA与近期的生成式分割模型(GFMLLM与Text4seg)进行单图平均推理耗时的对比分析.
各模型在单幅图像上的平均耗时如下:GFM-LLM为5.7 s, Text4seg为5.9 s, FG-DPA约为9.5 s.这主要是因为FG-DPA在掩码的中间表征上选用更大尺寸的0/1文本矩阵(采用16× 16分辨率, 而GFMLLM等模型通常采用10× 10分辨率).为了保留更细粒度的密集空间信息以获得高质量的分割先验, 更大尺寸的矩阵导致模型需要生成的离散词元序列显著变长, 从而大幅增加MLLM自回归生成的耗时.
为了更直观地验证FG-DPA在实际复杂场景中的有效性, 在图4中对比基线模型(仅经过SFT训练, 未进行DPO训练的模型)与FG-DPA的分割结果.
 | 图4 基线模型与FG-DPA可视化结果对比Fig.4 Comparison of visualization results between baseline model and FG-DPA |
由图4可见, 第1行图像中当指令要求分割“ 灰色的猫” 时, 基线模型虽然定位到小猫的大致区域, 但生成的掩码边界十分粗糙, 出现明显的边缘不精细、分割不完整问题.FG-DPA在DPO训练中拉大优质掩码序列与劣质掩码序列的概率差, 主动规避内部缺失, 最终输出与真实值高度贴合的精细边界.
在第2行图像中, 当指令要求分割“ 右侧的椅子” 时, 由于画面中存在多个椅子干扰项, 基线模型出现严重的语义定位幻觉, 错误分割左侧形状相似的椅子.由于应用针对性的偏好对齐优化, FG-DPA成功克服视觉歧义, 精准锁定目标.
这些可视化结果有力证实, FG-DPA能从“ 精细边界生成” 和“ 鲁棒语义定位” 两个维度实质性地改善多模态生成式分割模型的感知质量.
针对MLLM在生成式表达分割任务中常见的语义定位偏差与掩码边界粗糙问题, 本文提出面向生成式视觉感知的细粒度直接偏好对齐框架(FG-DPA).在4类公开数据集上完成SFT以获得基础分割能力后, 引入DPO并借助SAM的交互式分割能力自动构建面向“ 语义幻觉” 和“ 边界质量” 的两类偏好数据对, 结合渐进式偏好对齐训练策略分阶段优化模型, 使其同时实现准确的目标定位与精细的边界生成, 最终结合SAM获得精确的分割掩码生成.大量实验表明, FG-DPA能有效抑制定位幻觉并显著提升掩码完整性与边缘精度, 整体性能较优.
尽管FG-DPA在分割性能方面取得提升, 但仍存在一定的局限性.首先, 采用密集的0/1文本矩阵作为掩码表征导致大模型自回归生成的词元序列较长, 且推理过程强依赖外部视觉专家模型, 这在一定程度上增加系统的时间复杂度与计算开销.其次, 受限于MLLM的上下文长度与显存瓶颈, 当前生成的文本矩阵分辨率存在上限, 在处理极小目标时可能会引入量化误差.今后将着重围绕上述局限性展开研究.一方面, 探索词元压缩技术与高效的序列解码算法, 缩短文本化掩码的序列长度, 降低推理延迟.另一方面, 研究如何将高质量视觉解码器与MLLM进行更深层次的融合, 摆脱对级联式后处理架构的依赖, 实现更高效、统一的生成式视觉感知新范式.
本文责任编委 陈松灿
Recommended by Associate Editor CHEN Songcan
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|