




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
融合异构注意力与拓扑知识扩散的跨域目标检测
[张慧立1  , 苏如祺
, 苏如祺1 , 朱松豪1 , 梁志伟1 ]
, 苏如祺, 朱松豪, 梁志伟]
|
|



作者简介:

张慧立,硕士研究生,主要研究方向为图像处理、深度学习等.E-mail:12250558276@njupt.edu.cn.

苏如祺,硕士研究生,主要研究方向为图像处理、深度学习等.E-mail:njuptzsl@163.com.

梁志伟,博士,副教授,主要研究方向为图像处理、智能感知等.E-mail:14883913@qq.com.
针对无人机航拍、低光照、雾天等复杂跨域场景中目标检测精度较低、背景干扰较强及难样本挖掘不足等问题,文中提出融合异构注意力与拓扑知识扩散的跨域目标检测方法.首先,设计动态融合特征增强模块,通过双路异构注意力机制捕获空间多粒度信息和通道多粒度信息,筛选高迁移性特征,抑制背景噪声.然后,设计类别感知拓扑知识扩散模块,构建全局拓扑结构矩阵.同时引入哈密顿图论,构建类别原型记忆库,通过类内紧致性与类间分离性约束跨域对齐语义关系.最后,设计空间感知难样本挖掘模块,通过置信度-几何-特征三级筛选机制优化难样本权重,缓解前景-背景失衡问题,提升难样本检测能力.在4个数据集上的实验表明,文中方法性能较优,尤其在小目标检测和大目标检测上表现突出.可视化热力图进一步证实方法对复杂场景的特征聚焦能,广泛的消融实验也验证各模块的必要性.
About Author:
ZHANG Huili, Master student. His research interests include image processing and deep learning.
SU Ruqi, Master student. His research interests include image processing and deep learning.
LIANG Zhiwei, Ph.D., associate profe-ssor. His research interests include image processing and intelligent perception.
To address the challenges of low detection accuracy, strong background interference, and insufficient hard sample mining in complex cross-domain scenarios such as UAV aerial photography, low-light conditions, and foggy weather, a cross-domain object detection method integrating heterogeneous attention and topological knowledge diffusion(HATKD) is proposed. The method is synergistically optimized through three core modules. First, a dynamic fusion feature enhancement(DFFE) module is designed. A dual-path heterogeneous attention mechanism is employed to capture multi-granularity spatial information and multi-granularity channel information, thereby filtering highly transferable features and suppressing background noise. Second, a category-aware topological knowledge diffusion module is designed to construct a global topological structure matrix. Hamiltonian graph theory is introduced to build a category prototype memory bank. Cross-domain semantic relationships are aligned through intra-class compactness and inter-class separability constraints. Finally, a spatial-aware hard sample mining(SAHSM) module is designed to optimize the weights of hard samples through confidence-geometry-feature three-level filtering. Thus, the foreground-background imbalance problem is alleviated and the detection capability for hard samples is improved. Experimental results on four datasets demonstrate the superior performance of the proposed method, particularly in small object detection and large object detection. The feature focusing ability of the proposed method is further confirmed through visual heatmaps. Moreover, ablation experiments validate the necessity of each module.
近年来, 随着无人机、自动驾驶和智能监控等技术的快速发展, 作为计算机视觉的核心任务之一, 目标检测在复杂场景中的应用需求日益增长.然而现有方法在应对高密度目标、低光照条件、跨域泛化等挑战时仍存在显著不足.例如:在无人机航拍场景中, 目标通常呈现小尺度、高密度的特点, 容易受云层遮挡和视角变化的影响; 在自动驾驶领域, 夜间或极端天气条件下的数据稀缺问题严重制约方法的泛化能力; 在跨域场景中, 源域与目标域之间的分布差异(如城市白天与夜晚)导致方法性能急剧下降.这些问题不仅影响检测精度, 同时也严重制约目标检测技术在现实世界的实际应用.
截至目前, 已有大量研究集中在目标检测领域.在算法层面, 基于卷积神经网络(Convolutional Neu-ral Network, CNN)的YOLO(You Only Look Once)系列[1]和基于Transformer的DETR(Detection Trans-former)系列[2]代表当前目标检测的两大主流方向.YOLO系列通过多尺度特征融合和动态损失函数优化实时检测性能, 但其依赖的非极大值抑制的冗余框处理机制会影响检测效率.DETR系列虽然通过自注意力机制实现端到端检测, 避免非极大值抑制的局限性, 但收敛速度较慢, 计算资源消耗较多.近期, 研究者尝试结合两者优势, 如通过可变形卷积改进DETR的空间适应性(Deformable DETR[3]), 或引入轻量化设计(Drone-DETR[4])以适配无人机场景, 但上述方法在目标重叠和极端光照场景中的检测性能仍有待进一步提升.
数据稀缺问题在低光照场景中尤为突出.现有公开数据集(MS COCO[5]、PASCAL Visual Object Cla- sses(VOC)[6])中低光照样本占比不足1%, 而直接采集夜间数据面临标注成本昂贵、场景覆盖有限等挑战.生成对抗网络虽能生成低光照图像, 但存在语义失真和伪影问题.频域方法可保留语义细节, 生成夜间图像, 但传统矩形频域替换忽略频谱的对称性, 导致图像质量下降.此外, 跨域目标检测中的类别不平衡和背景噪声问题也亟待解决.现有域适应方法在特征对齐时往往会过度关注背景噪声, 忽略实例级语义一致性, 从而影响方法在复杂场景中的泛化能力.
针对上述挑战, 本文提出融合异构注意力与拓扑知识扩散的跨域目标检测方法(Cross-Domain Object Detection Integrating Heterogeneous Attention and Topological Knowledge Diffusion, HATKD), 包含3个重要模块.1)动态融合特征增强模块(Dynamic Fusion Feature Enhancement, DFFE).先根据源域样本和目标域样本间的凸组合动态生成跨域混合样本, 再设计双路异构注意力机制, 为混合特征的不同通道和空间位置自适应加权, 进一步强化前景目标的强迁移特征.2)类别感知拓扑知识扩散模块(Category-Aware Topological Knowledge Diffusion, CA-TKD).首先, 在局部层面引入哈密顿图论, 构建类别原型记忆库, 并通过对比学习聚合同类样本特征, 增强类内紧致性, 缓解小样本类别的特征退化问题.然后, 在全局层面构建类别原型间的结构关系矩阵, 最小化跨域拓扑差异, 实现知识扩散, 优化语义对齐.3)空间感知难样本挖掘模块(Spatial-Aware Hard Sample Mining, SAHSM).首先, 引入可变形注意力机制, 提高空间感知能力, 较好地聚焦形状不规则、分布密集的目标.然后, 构建三级筛选机制, 动态分配难样本权重, 优化前景-背景失衡问题.在Vis- Drone-DET2019[7]、UAVDT[8]、RTTS(Real-World Task- Driven Testing Set)[9]、ExDARK[10]数据集上的对比实验和消融实验表明, HATKD的检测精准性取得一定提升, 域适应性明显优于现有多种方法.
近年来, 目标检测在CNN和Transformer的双重推动下取得显著进展.CNN通过层次化特征提取和多尺度预测实现高效检测, 其中, YOLO系列通过跨阶段局部网络和路径聚合网络优化特征融合效率, 但在高密度场景中容易出现漏检, 且小目标检测精度不高.Transformer的DETR系列通过自注意力机制实现全局建模.Zhu等[3]提出Deformable DETR, 采用稀疏采样, 有效降低计算复杂度, 但其动态查询机制在遮挡场景中容易产生冗余预测.Song等[11]提出DAF-DETR(Dynamic Adaptation Feature Detection Transformer), 引入可学习位置编码和ResynNet(Resynthetic Network)骨干网络, 有效降低小目标漏检率, 但多头注意力机制同时也消耗过多计算资源.这两种架构在复杂场景中普遍面临目标形变、遮挡、跨域泛化等挑战.
域自适应旨在解决源域与目标域间的分布差异问题, 核心挑战在于如何在缺乏目标域标注时实现有效的知识迁移.现有方法主要围绕3个关键方向展开:基于数据增强的方法通过风格转换或混合样本生成弥合域间差异, 但对光照、尺度等复杂变化的适应性有限[12]; 基于特征分布匹配的方法通过最小化域间统计差异(如最大均值差异或对抗训练)学习域不变特征, 但往往忽略局部几何结构对齐[13]; 基于原型学习的方法构建类别特征中心, 保持语义一致性, 但在动态场景中面临原型漂移的挑战[14].
近期, Westfechtel等[15]提出GSDE(Gradual Source Domain Expansion), 迭代筛选高置信度目标样本作为伪标注数据, 逐步缩小域间差距.Zhu等[16]提出PMTrans, 通过跨注意力机制实现图像块的自适应采样.上述方法虽取得一定进展, 但仍面临对齐粒度不足、动态适应缺失等挑战, 特别是在跨模态场景中的适应性有限.
本文提出融合异构注意力与拓扑知识扩散的跨域目标检测方法(HATKD), 具体架构如图1所示.
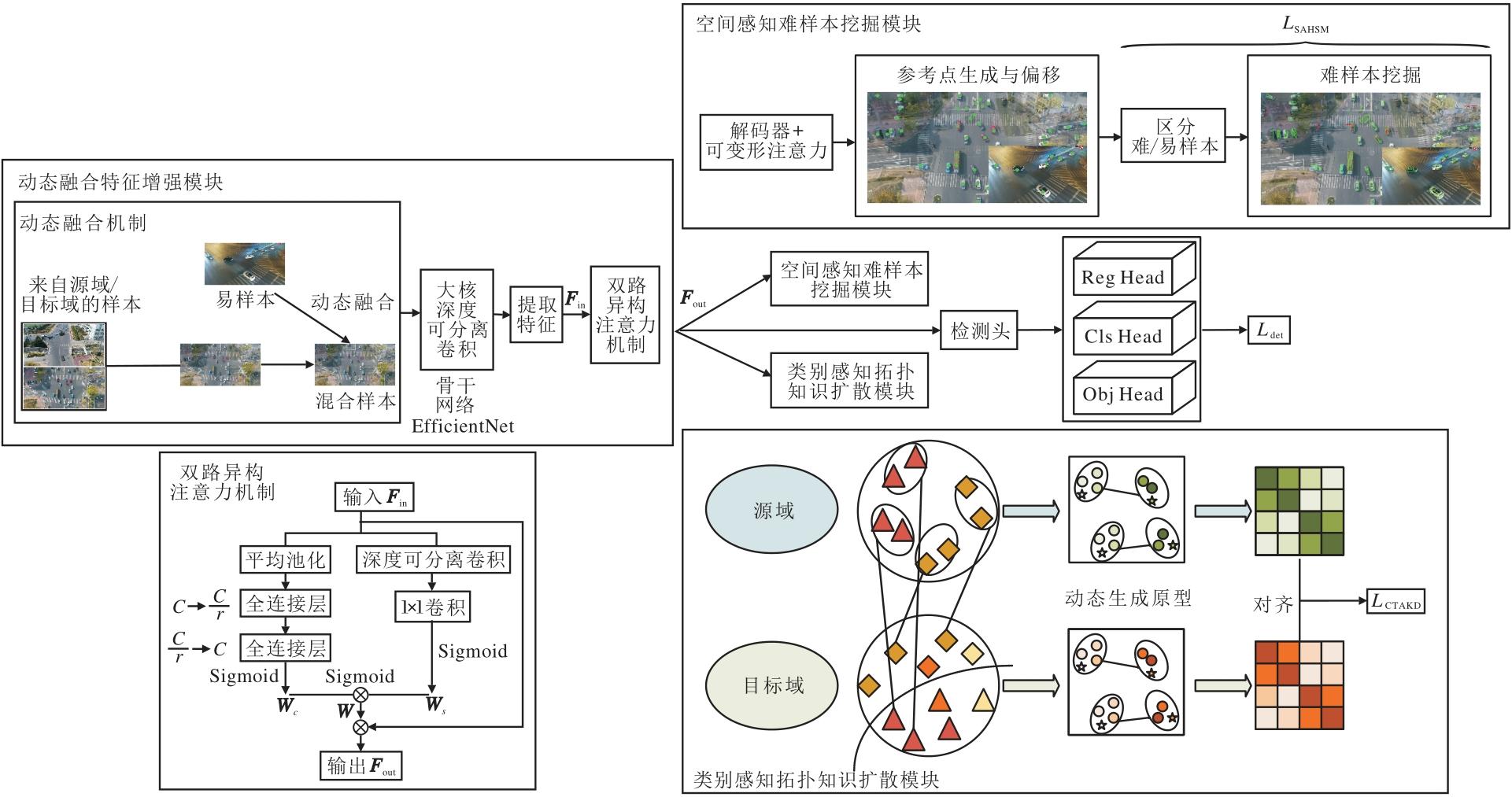 | 图1 HATKD整体架构图Fig.1 Overall architecture of HATKD |
HATKD以典型的一阶段目标检测模型YOLO- v8s[20]为原型, 通过对其进行改进以提升域自适应目标检测性能, 提升应对复杂场景的检测精度与计算效率.HATKD包含动态融合特征增强模块(DFFE)﹑类别感知拓扑知识扩散模块(CATKD)、空间感知难样本挖掘模块(SAHSM).
针对现有域自适应方法在复杂场景中对背景干扰敏感、特征迁移效率较低的问题, 本文提出动态融合特征增强模块(DFFE), 通过数据集层面的动态融合与特征层面的自适应加权, 实现跨域特征的鲁棒增强.
在数据集层面上, 利用动态融合机制生成源域与目标域的混合样本, 缓解域偏移问题.在特征层面上设计双路异构注意力机制, 同时捕获空间多粒度信息和通道多粒度信息, 对混合特征进行空间与通道的选择性强化, 突出迁移性强的目标特征(如车辆、行人等), 抑制背景噪声与非迁移性特征.
2.1.1 动态融合机制
在无监督领域自适应方法中, 源域Ds={(xi, s, yi, s)
给定来自源域数据集的一对样本(xi, s, yi, s)和目标域数据集的一个样本及对应的独热(One-Hot)标签($x_{i, t}, \hat{y}_{i, t}$), 其中$\hat{y}_{i, t}$表示目标域样本的伪标签.通过动态融合机制得到第i个源域侧的混合样本
$\hat{x}_{i, s}=\lambda x_{i, s}+(1-\lambda) x_{i, t}$
和对应的混合标签
$\hat{y}_{i, s}=\lambda y_{i, s}+(1-\lambda) \hat{y}_{i, t}, $
其中λ 表示融合比.考虑到λ ∈ (0, 1), 这里选择与定义域(0, 1)匹配的β 分布(λ ~β (a, a))进行动态采样.相比高斯分布需额外截断或归一化的缺陷, β 分布可直接生成有效融合比, 实现源域特征与目标域特征的平滑插值.
在训练过程中, 通过调整a值以适应不同阶段的优化需求, 从而避免因固定比值导致的方法过拟合或随机性不足.
2.1.2 双路异构注意力机制
针对混合特征中前景目标与背景噪声的域迁移差异性, 设计双路异构注意力机制, 通过通道-空间感知注意力协同, 实现跨域特征的动态筛选, 增强方法的背景干扰抵抗能力.
由于动态融合生成的跨域特征中不同通道对目标检测任务的贡献度不同, 即高迁移通道注重车辆边缘纹理等跨域共享的语义特征, 而低迁移通道注重光照敏感的背景噪声.因此, 本文设计通道感知注意力策略, 通过自适应权重分配, 解决跨域特征迁移中的通道级偏差问题, 强化高迁移通道, 抑制低迁移通道.
首先, 提取混合样本的多尺度混合特征Fmix∈ RC× H× W, 并沿空间维度进行全局平均池化, 生成通道描述符:
$\operatorname{GAP}\left(\boldsymbol{F}_{\mathrm{mix}}\right)=\frac{1}{H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W} \boldsymbol{F}_{\mathrm{mix}}[:, i, j] \in \mathbf{R}^{C}, $
保留全局信息, 其中C表示通道维度.然后, 利用两层轻量多层感知机(Multilayer Perceptron, MLP)生成通道权重:
Wc=sigmoid(MLP(MLP(GAP(Fmix))))∈ RC.
第1层MLP将维度C压缩至C/r(r为压缩比, 通常设为16), 第2层MLP将维度恢复至C, 增强非线性表达能力.该路径聚焦于跨域共享的通道特征, 如车辆纹理的频域特性.
空间感知注意力策略主要用于解决跨域特征的空间分布偏差问题, 通过空间权重强化目标密集区域的特征响应, 同时抑制无关区域干扰.
首先, 利用EfficientNet[21]中的大核深度可分离卷积(Depthwise Convolution, DWConv)捕获上下文特征:
Fspatial=DWConv7× 7(Fmix)∈ R1× H× W.
然后, 利用1× 1卷积对特征进行线性映射, 并结合Sigmoid激活函数生成空间权重:
Ws=sigmoid(Conv1× 1(Fspatial))∈ R1× H× W.
将通道权重Wc及空间权重Ws通过加权及逐元素相乘等操作后, 得到最终权重:
Wfused=sigmoid((ϕ · Wc)☉Ws+β ),
用于后续残差增强, 其中, ☉表示逐元素相乘, β 表示可学习参数, 用于提供偏置补偿, ϕ 表示可学习系数, 用于调节通道注意力和空间注意力的贡献比例.
在特征预处理阶段, 对提取的多尺度混合特征Fmix进行1× 1卷积, 降维至C/4通道, 得到原始特征:
Fre=Conv1× 1(Fmix),
平衡特征冗余抑制与计算资源开销.
之后, 多尺度混合特征Fmix与原始特征Fre通过残差连接, 获得增强特征:
Fen=Fmix+FreWfused,
有效保留关键域不变信息.
DFFE总体损失函数构造如下:
$\begin{array}{l} L_{\mathrm{DFFE}}= \left\|\boldsymbol{F}_{\text {en }}-\boldsymbol{F}_{\text {mix }}\right\|_{2}^{2}+\lambda_{\mathrm{DFFE}} {KL}\left({GAP}\left(\boldsymbol{F}_{\text {mix }}\right) \| \boldsymbol{F}_{\text {spatial }}\right), \end{array}$
约束增强特征Fen与多尺度混合特征Fmix的语义一致性, 其中, λ DFFE表示超参数, KL(· )约束通道权重Wc和空间权重Ws分布对齐.
针对现有域自适应方法在类别不平衡和结构失配问题上的不足, 设计类别感知拓扑知识扩散模块(CATKD), 在局部层面通过类别原型构建每个类别的中心特征, 解决样本分布偏移问题.在全局层面以原型之间的拓扑关系为结构先验, 通过哈密顿回路约束构建全局原型记忆库, 并保持跨域语义一致性.
2.2.1 类别感知拓扑
首先, 采用动量更新策略构建当前迭代时刻t上源域和目标域中第m类原型:
$\boldsymbol{p}_{m}^{t}=\eta \boldsymbol{p}_{m}^{t-1}+(1-\eta) \frac{1}{\left|x_{m}\right|} \sum_{\boldsymbol{x}_{i} \in x_{m}} f\left(\boldsymbol{x}_{i}\right), $
其中,
然后, 分别计算源域和目标域的原型归一化相似度矩阵S, 第(i, j)个元素
$S_{i, j}=\frac{\boldsymbol{p}_{i} \cdot \boldsymbol{p}_{j}}{\left\|\boldsymbol{p}_{i}\right\| \cdot\left\|\boldsymbol{p}_{j}\right\|}, i=1, 2, \cdots, M, j=1, 2, \cdots, M . $
矩阵S主要用于构建车辆-行人、车辆-交通灯等类别间的固有空间关系.
为了获得覆盖全部类别的全局拓扑序列, 将类别原型视为节点V={1, 2, ···, Ca}, 以相似度矩阵定义加权完全图G, 其中图边权重wi, j=Si, j.哈密顿回路π 表示一个可访问每个类别一次且首尾相连的闭环序列, 通过下式得到一个π * :
$\pi^{* }=\arg \max _{\pi \in \Pi} \sum_{t=1}^{C a} w_{\pi_{t}, \pi_{t+1}}, \pi_{C a+1}=\pi_{1}, $
其中Π 表示所有哈密顿回路集合.定义哈密顿拓扑邻接矩阵Aham, 第(i, j)个元素
$A_{i j}^{\mathrm{ham}}=\left\{\begin{array}{ll} 1, & (i, j) \text { 在回路 } \pi^{* } \text { 中相邻 } \\ 0, & (i, j) \text { 在回路 } \pi^{* } \text { 中不相邻 } \end{array}\right. $
由此得到行归一化后的拓扑扩散矩阵:
$\widehat{A}^{\mathrm{ham}}=D^{-1} A^{\mathrm{ham}}, $
其中D表示度矩阵.
2.2.2 双层知识扩散
首先, 通过对比学习聚合同类样本特征, 实现类内特征紧致性和类间特征分离性, 增强目标类别的跨域一致性并缓解小样本类别的特征退化问题, 相应对比损失如下:
$L_{\mathrm{cont}}=-\sum_{i=1}^{N_{s}} \ln \left(\frac{\exp \left(\frac{\boldsymbol{x}_{i} \boldsymbol{p}_{y_{i}}}{\tau}\right)}{\sum_{m=1}^{M} \exp \left(\frac{\boldsymbol{x}_{i} \boldsymbol{p}_{m}}{\tau}\right)}\right) .$
其中:τ 表示温度系数, 用于控制分布尖锐度; xi 表示第i个样本的特征表示向量, yi表示xi的标签; Ns表示源域样本数, M表示类别原型总数;
然后, 利用哈密顿归一化拓扑扩散算子$\widehat{\boldsymbol{A}}^{\mathrm{ham}}$对原始原型矩阵P进行一次或多次的扩散更新, 得到拓扑扩散后的原型矩阵:
$\widetilde{\boldsymbol{P}}=\left(1-\alpha_{\mathrm{diff}}\right) \boldsymbol{P}+\alpha_{\mathrm{diff}} \widehat{\boldsymbol{A}}^{\mathrm{ham}} \boldsymbol{P}, $
其中α diff∈ (0, 1)表示扩散系数.该更新使得每类原型在回路的相邻类别之间传递结构信息.
为了保持跨域类别关系的拓扑一致性, 最小化跨域矩阵差异, 相应结构损失如下:
$L_{\text {struct }}=\left\|\widehat{\boldsymbol{A}}_{\text {src }}^{\mathrm{ham}} \boldsymbol{S}^{\text {src }}-\widehat{\boldsymbol{A}}_{\mathrm{tgt}}^{\mathrm{ham}} \boldsymbol{S}^{\mathrm{tgt}}\right\|_{\mathrm{F}}^{2} $.
该函数保持车辆-行人、车辆-交通灯等类别关系的跨域稳定性, 提升对场景信息变化的鲁棒性, 其中, F表示约束全局结构一致性的Frobenius范数, $\widehat{\boldsymbol{A}}^{\mathrm{ham}}_{\mathrm{src}}$表示行归一化后的源域拓扑扩散矩阵, $\widehat{\boldsymbol{A}}^{\mathrm{ham}}_{\mathrm{tgt}}$表示行归一化后的目标域拓扑扩散矩阵, Ssrc表示源域相似度矩阵, Stgt表示目标域的相似度矩阵.
同时, 为了进一步强化回路约束, 额外加入回路平滑正则, 得到哈密顿约束损失:
$L_{\mathrm{ham}}=\sum_{(i, j) \in E_{\mathrm{ham}}}\left\|\widetilde{\boldsymbol{p}}^{i}-\widetilde{\boldsymbol{p}}^{j}\right\|_{2}^{2}, $
使相邻类别原型不致发生剧烈跳变, 其中
$E_{\text {ham }}=\left\{\left(n_{t}, n_{t+1}\right) \mid t=1, 2, \cdots, C a, n_{c_{a+1}}=n_{1}\right\}, $
表示哈密顿回路的边集合(回路中相邻类别节点构成的边对集合),
2.2.3 损失函数
最终得到CTAKD总体损失函数:
$L_{\text {CTAKD }}=\lambda_{\text {cont }} L_{\text {cont }}+\lambda_{\text {struct }} L_{\text {struct }}+\lambda_{\text {ham }} L_{\text {ham }}, $
解决样本分布偏移问题, 实现跨域语义一致性, 其中λ cont、λ struct、λ ham表示相应损失的超参数.
在复杂场景(如无人机航拍、夜间/雨雾天驾驶)中, 目标检测面临两大核心挑战:空间形变与难样本检测.DAF-DETR[11]引入可变形注意力机制, 但未与难样本挖掘结合.ESDA(Enhanced Soft Domain Adaptation)[17]虽然关注前景-背景区分, 但缺乏空间形变适应能力.因此本文设计空间感知难样本挖掘模块(SAHSM), 通过空间-任务进行协同优化.空间层面通过可变形注意力机制适应不规则目标(如遮挡物), 解决空间形变问题.任务层面设计三级筛选机制, 动态分配前景-背景权重, 解决难样本检测问题.
2.3.1 可变形注意力机制
首先, 通过3× 3深度可分离卷积生成2K个空间偏移量, 其中K表示采样点数.采用高斯核函数对偏移特征软加权, 突出关键区域.第k个偏移采样点对应的软权重系数为:
$w_{k}=\exp \left(-\frac{\left\|\Delta \boldsymbol{p}_{k}\right\|^{2}}{2 \sigma^{2}}\right), $
其中, Δ pk表示第k个偏移采样点的空间偏移量, σ 表示高斯核标准差, 控制权重衰减速率(默认为1.0).
然后, 采用可变形注意力机制动态获取感受野, 加权聚合偏移特征, 增强对遮挡目标的形变适应能力.聚合后的输出特征为:
$y_{p}=\sum_{k=1}^{K} w_{k} \varepsilon\left(\boldsymbol{p}+\Delta \boldsymbol{p}_{k}\right), $
其中, ε (p+Δ pk)表示特征图ε 在位置p+Δ pk处的特征值, 即偏移后采样点的特征.
最后, 形变对齐损失如下:
$L_{\text {deform }}=\sum_{k}\left\|\Delta \boldsymbol{p}_{k}-\Delta \boldsymbol{p}_{k-1}\right\|_{1} . $
2.3.2 三级筛选机制
由文献[22]可知, 学习过程中存在大量如图2所示的不匹配难样本和易样本.相比简单背景中样本的置信度, 复杂背景中样本的置信度往往较低.因此, 在融合软标签思想的基础上, 本文构建三级筛选机制, 在任务层面聚焦关键难样本.
 | 图2 不同背景中的目标样本Fig.2 Target samples under different backgrounds |
三级筛选机制实现过程如下.
1)筛选并保留置信度位于区间(0.2, 0.8)内的样本, 相应样本集合为:
ω conf={0.2<
该方式过滤高/低置信度噪声.值得注意的是:置信度大于0.8的样本通常已收敛, 再学习获得收益较低; 置信度小于0.2的样本多为背景噪声或其它内容, 强行学习容易导致模型退化.
2)计算预测框与真实框间的CIoU(Complete Intersection over Union Loss)差异, 剔除部分预测框, 进行几何一致性筛选, 满足几何条件筛选的候选样本集合为:
ω geo={CIoU(
其中,
3)通过类别原型距离过滤异常样本, 进行特征空间筛选.满足特征距离条件的样本集合为:
ω feat={
其中, fi表示第i个样本的特征向量, τ 表示特征距离阈值(默认为0.5).τ 设为0.5, 等价于要求样本与原型的余弦相似度低于0.875(强正样本对的判别边界).通过执行偏保守的筛选策略, 确保被挖掘的样本确实是显著偏离语义中心的异常值.
4)难样本集合
ω =ω conf∩ ω geo∩ ω feat,
采用指数加权, 获得相应难样本加权损失为:
$L_{\text {hard }}=\frac{1}{|\omega|} \sum_{i \in \omega} \exp \left(\mu\left(1-p_{\text {conf }}^{(i)}\right)\right) L^{(i)}, $
其中, μ 用于控制聚焦强度, 即控制对难样本的重视程度(默认为2.0), L(i)表示第i个样本的原始监督损失.
5)SAHSM总体损失函数如下:
LSAHSM=λ deformLdeform+λ hardLhard,
优化空间-任务双层协同机制, 解决空间形变与难样本检测挑战, 其中λ deform、λ hard表示相应模块的超参数.
方法最终的损失函数表示如下:
L=Ldet+λ 1LDFFE+λ 2LCTAKD+λ 3LSAHSM,
其中, λ 1、λ 2、λ 3表示平衡相应损失项的超参数, Ldet表示目标检测主损头, 用于监督模型完成目标分类与边界框回归等基本检测任务.
由实验可知, λ 1=0.05, λ 2=0.2, λ 3=0.15时性能最优.
基于PyTorch框架实现HATKD.HATKD以YOL-Ov8s[20]为基线方法, 将原先的骨干网络CSPDarknet替换为EfficientNet[21]进行图像特征提取, 并在Ima- geNet上进行预训练.
所有训练和测试均在单张NVIDIA4090(显存24 GB)上进行, 批量大小设为8, 输入图像尺寸设为640× 640, 优化器选用AdamW(Adaptive Moment Esti-mation with Weight Decay), 初始学习率设为0.005.
实验选择在如下数据集上进行.
1)VisDrone-DET2019数据集[7].不仅为目标检测、目标跟踪等任务提供丰富的数据支持, 还因差异显著的目标尺寸、复杂多样的背景等因素为研究引入巨大挑战.数据集由6 471幅训练图像和548幅测试图像组成, 涵盖各种天气状况下的城市街道、乡村区域等场景, 包含行人、汽车、自行车等类别.
2)UAVDT数据集[8].面向无人机目标检测的基准数据集, 专为复杂场景中的算法验证而设计.数据集由24 143幅训练图像和16 592幅验证图像组成, 涵盖不同时段和不同天气下的城市街道、乡村道路、交通枢纽等场景.
3)RTTS数据集[9].专门针对雾天场景目标检测任务构建的基准数据集, 共4 322幅图像, 涵盖不同时段、不同天气、不同雾霾下的城市道路、高速公路、乡村环境等场景, 包含行人、自行车、轿车等五种类别.
4)ExDARK数据集[10].作为目前唯一公开的低光照条件下目标级标注数据集, 为极端光照条件下的研究提供关键基准.数据集由7 363幅图像组成, 涵盖月光环境、人工弱光源等10类典型低光照条件下的城市道路、室内环境等场景.
实验使用平均精度(Average Precision, AP)、IoU(Intersection over Union)阈值为0.5时的平均精度(AP50)、IoU阈值为0.75时的平均精度(AP75)作为核心评估指标.AP用于评估所有类别上的综合检测性能, AP50、AP75分别评估高IoU阈值及严格定位标准下的鲁棒性.
此外, 为了进一步评估HATKD在不同目标尺度下的检测性能, 使用小目标平均精度(Average Precision for Small Objects, APs)、中等目标平均精度(Average Precision for Medium Objects, APm)、大目标平均精度(Average Precision for Large Objects, APl)指标.
选择如下一系列代表性的目标检测方法进行对比实验:Deformable DETR[3]、DAF-DETR[11]、YOLO-v8s[20]、DINO(DETR with Improved Denoising Anchor Boxes)[23]、WDFS-DETR(Wavelet-Based Dual-Stage Feature-Enhanced DETR)[24]、Faster R-CNN[25]、CD-MNet(Coarse-Grained Density Map Network)[26]、GL-SAN(Global-Local Self-Adaptive Network)[27]、Clus-Det(Clustered Detection)[28]、YOLOv5s[29]、YOLO-v10-S[30]、YOLOv11s[31]、OD-DDA(Object Detector with Dual Dynamic Adaptation)[32]、VSTDet[33]、LEAF-YOLO[34]、HIC-YOLOv5(Head, Involution and CBAM-YOLOv5)[35]、AdaZoom(Adaptive Zoom Network)[36]、SDPDet(Scale-Separated Dynamic Proposals for End-to-End Drone-View Object Detection)[37]、YOLC(You Only Look Clusters)[38]、DDQ(Dense Dis- tinct Queries)[39]、MTW-DETR[40]、SCSA(Spatial and Channel Synergistic Attention Module)[41]、RT-DETR(Real-Time Detection Transformer)[42].
3.2.1 定量对比
各方法在VisDrone-DET2019数据集上的指标值如表1所示, 表中黑体数字表示最优值, 斜体数字表示次优值.
| 表1 各方法在VisDrone-DET2019数据集上的指标值 Table 1 Metric values of different methods on VisDrone-DET2019 dataset % |
由表1可见, HATKD的综合检测性能最优, HATKD的AP值达到34.5%, 优于OD-DDA的32.6%和GLSAN的30.7%.在大目标检测指标APl上, 相比达到66.6%的OD-DDA, HATKD提升0.6%, 验证动态融合特征增强模块对无人机航拍图像中大尺度目标的适应性.在小目标检测指标APs上, 相比YOLOv8s的21.7%, HATKD提升2.8%, 验证空间感知难样本挖掘模块对小物体检测的有效性.
各方法在UAVDT数据集上的指标值如表2所示, 表中黑体数字表示最优值, 斜体数字表示次优值.由表可见, HATKD的AP值达到24.1%, 优于OD-DDA的22.7%及AdaZoom的19.6%.在大目标检测指标APl上, 相比达到46.7%的OD-DDA, HATKD提升1.6%, 由此验证动态融合特征增强模块对无人机航拍图像中大目标的捕捉能力.在小目标检测指标APs上, 相比达到13.0%的YOLOv8s, HATKD提升3.2%.在中等目标检测指标APm上, 相比达到35.1%的OD-DDA, HATKD提升1.3%, 表明类别感知拓扑知识扩散模块有效提升多尺度目标适应性.
| 表2 各方法在UAVDT数据集上的指标值 Table 2 Metric values of different methods on UAVDT dataset % |
各方法在RTTS数据集上的指标值如表3所示, 表中黑体数字表示最优值, 斜体数字表示次优值.由表可见, HATKD的AP值达到45.2%, 相比OD-DDA的43.8%, 提升1.4%, 验证动态融合特征增强模块与类别感知拓扑知识扩散模块在雾天场景中的协同有效性.在AP75指标上, 相比OD-DDA的47.1%, HATKD提升0.9%, 验证其具有更强的模糊目标边界回归能力.在小目标检测指标APs上, 相比达到31.8%的MTW-DETR, HATKD提升0.5%, 验证空间感知难样本挖掘模块可有效提升雾霾环境下小物体检测的准确性.
| 表3 各方法在RTTS数据集上的指标值 Table 3 Metric values of different methods on RTTS dataset % |
各方法在ExDARK数据集上的指标值如表4所示, 表中黑体数字表示最优值, 斜体数字表示次优值.由表可见, HATKD的AP值达到45.5%, 显著超越SCSA的43.0%和OD-DDA的43.2%.在小目标检测指标APs上, 相比达到21.7%的OD-DDA, HATKD提升1.8%.
| 表4 各方法在ExDARK数据集上的指标值 Table 4 Metric values of different methods on ExDARK dataset % |
3.2.2 定性对比
YOLOv8s和HATKD在UAVDT数据集上的检测结果如图3所示.由图可见, HATKD显著增强目标检测性能.由(d)、(h)可知, 在暗光源阴影或路边路灯干扰下, 即使检测目标仅显露局部特征(如车辆顶部或部分车体), HATKD依然能准确识别被遮挡车辆, 这说明结合动态融合特征增强模块与类别感知拓扑知识扩散模块可实现鲁棒检测.
 | 图3 YOLOv8s和HATKD在UAVDT数据集上的检测结果Fig.3 Detection results of YOLOv8s and HATKD on UAVDT dataset |
RT-DETR[2]、DAF-DETR[11]、YOLOv8s[20]、MTW-DETR[40]、HATKD在UAVDT数据集上低光照场景中的检测结果如图4所示.由图可见, YOLOv8s在强光源干扰和暗区域情形下存在明显的漏检和误检.虽然DETR系列具有不错的货车检测精度, 但小目标检测精度有待进一步提高.HATKD利用动态融合特征增强模块有效抑制光斑噪声对特征提取的干扰, 利用类别感知拓扑知识扩散模块建模包括车辆-道路边缘等在内的上下文关系, 成功消除YOLOv8s的类别混淆(如将发光的车辆等候站点误检为卡车)问题, 同时利用可变形注意力机制精准捕捉密集场景中被部分遮挡的目标(如被路灯灯杆遮挡的黑色轿车), 最终在确认检测框数量、目标定位精度、类别识别准确率上获得满意结果, 由此验证HATKD对低光照环境的鲁棒性.
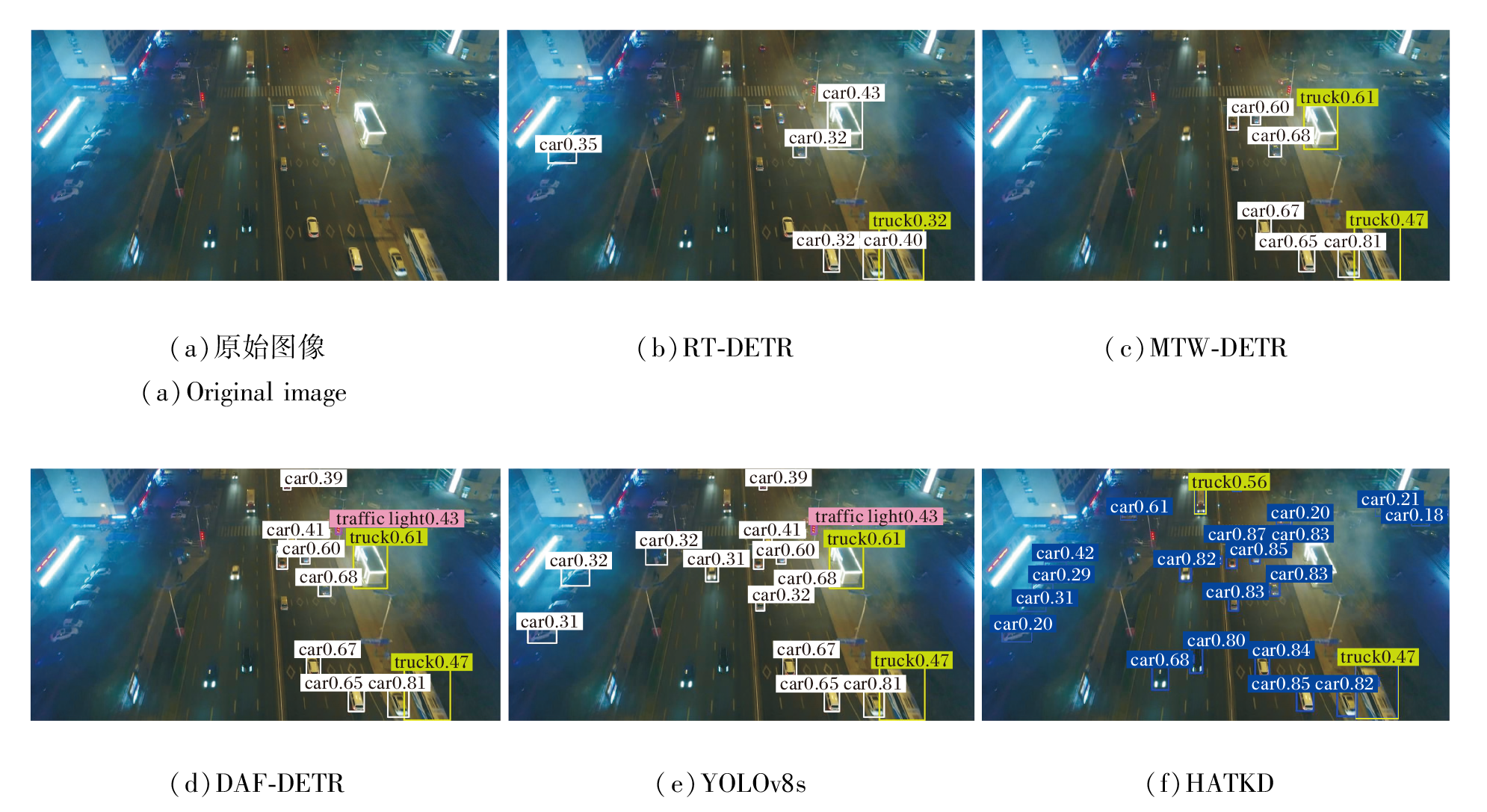 | 图4 各方法在UAVDT数据集上低光照场景中的检测结果Fig.4 Detection results of different methods under low-light scenes on UAVDT dataset |
3.3.1 模块消融实验
HATKD包含3个模块:动态融合特征增强模块(DFFE)、类别感知拓扑知识扩散模块(CATKD)、空间感知难样本挖掘模块(SAHSM).使用基线方法YOLOv8s, 在其上分别加入相应模块, 验证各模块的性能, 相应消融实验结果如表5所示.
| 表5 各模块的消融实验结果 Table 5 Ablation experiment results of different modules |
由表5可见, 仅使用基线YOLOv8s时, AP值为16.6%.引入DFFE后AP值升至18.7%(+2.1%), 这表明动态融合机制和双路异构注意力机制结合的DFFE可有效抑制复杂背景的干扰, 相应APs值提升1.5%.
进一步引入CATKD后, AP值升至21.3%(+2.6%), CATKD通过构建类别原型拓扑(如车辆-行人空间关系矩阵), 优化跨域语义一致性对齐, 显著改善中等目标检测精度(APm值上升4.8%)和大目标检测精度(APl值激增11.4%).
最终添加SAHSM后, AP值达到24.1%(+2.8%), 其可变形注意力机制聚焦于遮挡目标(如被树冠遮挡的车辆), 配合三级筛选机制, 使小目标检测指标APs达到16.2%, 相比YOLOv8s, 提升3.2%.尽管浮点运算量因空间注意力计算增至44.4 G, 但参数量仅为11.5 M, 由此验证SAHSM的高效性.各模块间的协同工作— — DFFE提供抗干扰特征、CATKD优化语义结构迁移、SAHSM强化空间感知, 形成从数据到任务的闭环优化.
在NVIDIA GeForce RTX 4060 Laptop GPU(CU- DA:0)上以相同推理设置对方法进行端到端测速.具体设置如下:批次大小为1, 输入图像尺寸为640× 640, 使用半精度, 置信度为0.25, 交并比为0.7, 预热50次, 统计200次, 并使用150幅图像.相应测速结果如表6所示.
| 表6 端到端测速结果 Table 6 End-to-end inference speed |
由表6可见, 针对每幅图像, YOLOv8s的平均推理延迟为8.525 ms, 加入3个模块后平均延迟为10.105 ms, 延迟开销提高约18.5%.在稳定性方面, 每幅图像的95百分位延迟由8.738 ms增加至10.381 ms提高约18.8%).因此, 尽管浮点运算量增幅较大, 但实际端到端推理速度下降幅度显著小于浮点运算量的增加比例, 这表明本文3个模块带来的部署开销总体上处于可控范围内.
各模块热力图的可视化结果如图5所示, 由图可见各模块对特征聚焦能力的递进式优化.相比YOLOv8s在复杂背景区域(如建筑物阴影)的弥散性响应, 引入DFFE后, 双路异构注意力机制通过捕获跨域混合样本的通道多粒度信息和空间多粒度信息, 使车辆等目标区域的热力响应更聚焦, 噪声干扰显著降低.叠加CATKD后, 进一步聚焦多目标场景中特征分布, 目标边缘的热力响应更清晰, 有效避免密集车辆间的特征混淆.
 | 图5 各模块热力图可视化结果Fig.5 Visualization results of heatmaps for different modules |
再加入SAHSM后, 可变形注意力机制精准捕获被遮挡目标特征(如被树木部分遮挡的车辆), 配合三级筛选机制, 原本模糊的目标热力响应变得锐利, 且多尺度目标(从小型轿车到大型货车)的特征响应强度与目标尺度匹配度显著提升, 由此验证HATKD能有效应对无人机航拍图像中多尺度、高干扰特征.
下面选取一个具有代表性的漏检样本进行定性分析.YOLOv8s和HATKD的检测结果如图6所示.由图可观察到, YOLOv8s明显存在漏检及误检车辆目标的问题.
 | 图6 YOLOv8s和HATKD在漏检样本上的检测结果Fig.6 Detection results of YOLOv8s and HATKD on missed detection samples |
结合图5的热力图可视化结果发现, YOLOv8s在目标及其邻近区域的特征响应分布较分散, 在密集背景区域存在明显的响应混淆.相比之下, HA- TKD在目标区域及其上下文范围内能产生更集中且边界更清晰的特征响应, 同时有效抑制密集区域中的无关干扰信息, 这有助于保留部分可观察目标的判别性线索, 有效缓解由遮挡或尺度变化引起的漏检或误检问题.
3.3.2 骨干网络消融实验
本节从替换骨干网络和引入模块两个方向分析HATKD的性能:骨干网络分别使用CSPDarknet[20]和EfficientNet[21], 再在基线方法YOLOv8s上添加3个模块.相应指标值如表7所示, 表中C表示CSP-Darknet, E表示EfficientNet.由表可见, 将骨干网络由CSPDarknet替换为EfficientNet后, 整体指标值稳定提升, 表明通过EfficientNet的上下文建模可获取一定收益.在不替换骨干网络时, 仅加入3个模块, 相比YOLOv8s, 性能也有显著提升.这表明Efficient- Net与3个模块在全局上下文建模和多尺度检测能力上可以互补, 促进检测性能的提升.
| 表7 骨干网络的消融实验结果 Table 7 Ablation experiment results of backbone networks % |
3.3.3 跨域场景消融实验
为了深入剖析CTAKD与SAHSM在极端跨域场景(RTTS数据集上的雾天场景与ExDARK数据集上的低光照场景)中的核心作用, 设计两组消融实验.第1组实验移除CTAKD中的全局原型记忆库, 仅保留基于对比学习的类内特征紧致性约束, 旨在单独量化类别拓扑一致性对于建模跨域场景中上下文语义关系(如雾天中车辆-道路的相关性)的贡献.第2组实验采用功能替代式对比, 将SAHSM中的可变形注意力机制替换为均匀随机矩形遮挡(Random Erasing, 遮挡比例为30%)这一被动、均匀的数据增强策略.该设计旨在严格验证:相比静态的、由数据驱动的噪声注入, SAHSM采用的动态的、内容感知的空间聚焦机制是否为处理真实世界非结构化遮挡(如树枝交错、光斑干扰)的关键优势来源.
实验中骨干网络及DFFE保持一致, 通过跨域自适应损失LCD-AP 、AP、APs、APl验证模块间的协同机制.
$L_{\mathrm{CD}-\mathrm{AP}}=A P_{\text {source }}-A P_{\text {target }}, $
其中, APsource表示模型在源域数据上的平均精度, APtarget表示模型在目标域数据上的平均精度.具体消融实验结果如表8所示.表中A表示HATKD, B表示仅保留类内特征紧致性约束的方法, C表示可变形注意力机制替换为均匀随机矩形遮挡的方法.
| 表8 跨域场景的消融实验结果 Table 8 Ablation experiment results on cross-domain scenarios % |
由表8可见, 在RTTS数据集上, 移除CTAKD的全局原型记忆库后AP值下降3.7%, 大目标检测指标APl骤降7.2%, 而LCD-AP由2.1%增至5.8%, 这表明仅利用类内特征对齐难以有效构建雾天场景中目标特征的空间相关性, 而原型记忆库通过存储源域拓扑结构(如车与道路的相对位置), 为目标域提供上下文先验知识, 缓解雾霾导致的特征漂移问题.使用均匀随机矩形遮挡替代SAHSM中的可变形注意力机制后, 在RTTS数据集上的AP75值下降2.8%, 在ExDARK数据集上的APs值下降1.6%, 这表明均匀随机矩形遮挡仅能模拟局部像素缺失情形, 但可变形注意力机制可动态聚焦目标关键区域(如雾中车辆的车灯区域), 实现对非结构化遮挡的精准建模.无论是雾天场景还是低光照场景, 大目标检测指标APl对拓扑结构更敏感(B中APl值下降幅度大于APs值), 而小目标检测指标APs对空间注意力机制更依赖(C中APs值下降幅度大于APl值), 由此可见大目标检测精度受上下文影响更大, 而小目标检测精度受局部特征完整性影响更强.
3.3.4 三级筛选机制消融实验
为了验证SAHSM中置信度-几何-特征三级筛选机制对难样本挖掘的贡献, 在RTTS、ExDARK数据集上进行实验, 逐级移除筛选条件, 量化各阶段(置信度筛选、几何一致性筛选、特征空间筛选)对检测性能的影响.使用如下3类变体:仅保留置信度筛选及几何一致性筛选、仅保留置信度筛选及特征空间筛选、仅保留置信度筛选.
实验中DFFE、CTAKD及骨干网络保持一致, 仅调整SAHSM的三级筛选机制, 通过AP、AP75、APs、APl指标揭示多层次过滤的必要性.难样本召回率表示方法在预先定义的难样本集上的召回能力, 即被正确检测的难样本数占全部难样本真实目标数的比例, 该指标值越高, 说明方法对遮挡、密集分布、小尺度及低对比度等复杂场景中目标的检测能力越强.相应消融实验结果如表9所示.表中A表示HATKD, B表示仅保留置信度筛选及几何一致性筛选的方法, C表示仅保留置信度筛选及特征空间筛选的方法, D表示仅保留置信度筛选的方法.
| 表9 三级筛选机制的消融实验结果 Table 9 Ablation experiment results of three-level filtering mechanism % |
由表9可得, 移除特征空间筛选会导致雾天场景中APl值下降3.2%, 低光照场景中APs值下降1.7%, 这验证特征空间筛选通过原型距离过滤异常样本, 有效避免几何一致的错误样本(如被树影遮挡的车辆)干扰方法训练, 同时显著提升雾天大目标检测的鲁棒性.移除几何一致性筛选后, 雾天场景中AP75值下降0.8%, 低光照场景中AP75值下降0.9%, 这验证几何一致性筛选通过筛选高精度定位框提升目标边界预测的准确性, 对小目标检测精度提升尤为关键.仅保留置信度筛选导致AP值显著下降, 这验证单一筛选的局限性.高置信度目标可能包含语义模糊目标, 需要结合几何一致性筛选与特征空间筛选, 避免过拟合噪声.
综合数据集场景差异性与三级筛选机制的多层过滤可知:由于光照噪声引发低光照场景(ExDARK数据集)中的特征空间分布混乱, 导致APs值对特征筛选的依赖性显著高于雾天场景(RTTS数据集); 由于雾霾导致雾天场景中的目标边缘模糊, 导致AP75值受几何筛选的影响幅度更大, 这凸显定位偏差修正的重要性.因此, 本文的三级筛选机制(置信度筛选初步过滤低质量预测、几何一致性筛选保障定位准确性、特征空间筛选优化语义一致性)显著提升对遮挡和模糊目标的检测鲁棒性, 为跨场景目标检测提供兼顾精准性与泛化性的难样本处理范式.
为了验证三级筛选机制的有效性, 选取如下经典难样本处理方法作为对比方法:OHEM(Online Hard Example Mining)[43]、Focal Loss[44]、GHM(Gra-dient Harmonizing Mechanism)[45].OHEM在线挖掘高损失样本, 强化困难样本训练.Focal Loss引入调制因子, 降低易分类样本权重, 提升对难样本的关注.GHM基于梯度分布对样本进行自适应加权, 缓解样本不均衡问题.上述方法均从不同角度对难样本进行挖掘与优化, 将它们引入基线方法(Base-line)有助于全面评估HATKD在复杂场景中的性能, 其中, Baseline表示移除三级筛选机制的HATKD.
基于相同设置, 在VisDrone-DET2019数据集上进行训练, 相应消融实验结果如表10所示.
由表10可看出, HATKD在AP、APs、APl指标上均最优.值得注意的是, 在对域间差异最敏感的大目标检测(APl)上, HATKD取得显著的性能提升, 这验证通过几何一致性与特征空间筛选, 能有效缓解因域偏移导致的目标上下文信息损失问题.相比仅依赖损失排序的OHEM、平等对待所有难样本的Focal Loss及进行全局梯度均衡的GHM, 本文的置信度-几何-特征三级筛选机制能更精准地辨识并强化在跨域适应性上具有较高价值的样本, 为复杂场景中的鲁棒检测提供更优的解决方案.
本文提出融合异构注意力与拓扑知识扩散的跨域目标检测方法(HATKD), 通过动态融合特征增强模块(DFFE)、类别感知拓扑知识扩散模块(CT-AKD)与空间感知难样本挖掘模块(SAHSM)的协同作用, 有效解决跨域目标检测中的背景干扰、语义偏移、难样本挖掘问题.
多场景数据集上的实验表明:DFFE通过数据及特征双层增强, 显著提升对无人机航拍图像中复杂背景的抵抗能力; CTAKD的全局原型拓扑确保车辆-行人-道路等类别关系的跨域语义一致性, 缓解雾天/低光照等场景中的特征漂移问题; SAHSM的可变形注意力机制与三级筛选机制实现对遮挡目标与小尺度物体的精准检测.广泛的对比实验与消融实验表明HATKD在精度(AP)、定位鲁棒性(AP75)、跨域适应性(LCD-AP)上均较优, 为复杂场景中的实时目标检测提供高效解决方法.
未来工作将从如下两方面展开.一方面, 探索更高效的结构设计, 降低整体浮点运算量与推理延迟, 并研究如何解耦训练阶段与推理阶段, 从而在不影响性能的前提下减小部署成本.另一方面, 探索多模态数据融合(如可见光-红外)及结合模型剪枝、量化及蒸馏等轻量化技术, 进一步提升方法在资源受限场景中的实用性、可扩展性及部署效率.
本文责任编委 黄 华
Recommended by Associate Editor HUANG Hua
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|