






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
多模态注意力感知与相邻尺度建模的Transformer网络
[宋霄罡1, 2  , 张浩泽
, 张浩泽1 , 张小龙1 , 赵钦2, 3 , 黑新宏1, 2 , 何敏3 ]
, 张浩泽, 张小龙, 赵钦, 黑新宏, 何敏]
|
|



作者简介:
宋霄罡,博士,教授,主要研究方向为计算机视觉、无人自主导航系统.E-mail:songxg@xaut.edu.cn. 
张浩泽,硕士研究生,主要研究方向为显著目标检测、人工智能安全.E-mail:1056zhznb@gmail.com. 
张小龙,硕士研究生,主要研究方向为显著目标检测.E-mail:1786200244@qq.com.
赵 钦,博士,教授,主要研究方向为人工智能、大数据.E-mail:zhaoqin6688@xaut.edu.cn.
黑新宏,博士,教授,主要研究方向为计算机视觉、人工智能.E-mail:heixinhong@xaut.edu.cn.
RGB-D显著目标检测旨在从配对的彩色图像与深度图像中识别最具视觉吸引力的目标,关键问题在于实现多模态特征与多尺度特征的有效融合.现有方法在RGB特征与深度特征融合过程中,模态互补信息表达、边缘细节保持及尺度间关联利用仍有进一步提升空间.为此,文中提出多模态注意力感知与相邻尺度建模的Transformer网络(Transformer Network with Multimodal Attention Perception and Adjacent-Scale Modeling, MATNet).首先,采用双分支金字塔池化Transformer编码器,分别提取RGB模态和深度模态的多层级特征,并在各层引入多模态注意力融合模块,联合通道注意力与空间注意力,增强模态互补信息表达和关键区域语义一致性.然后,构建相邻尺度建模模块,自上而下逐级聚合相邻尺度特征,有效融合高层语义信息与低层边缘纹理信息,提升显著目标的结构完整性与边界表征能力.最后,结合多尺度预测与监督机制,构建端到端检测框架.在5个公开数据集上的实验表明,MATNet在提升检测精度与边缘保持能力方面具有稳定性与有效性.
About Author:
SONG Xiaogang, Ph.D., professor. His research interests include computer vision and autonomous unmanned navigation systems.
ZHANG Haoze, Master student. His research interests include salient object detection and artificial intelligence security.
ZHANG Xiaolong, Master student. His research interests include salient object detection.
ZHAO Qin, Ph.D., professor. Her research interests include artificial intelligence and big data.
HEI Xinhong, Ph.D., professor. His research interests include computer vision and artificial intelligence.
RGB-D salient object detection aims to identify the most visually attractive objects from paired color images and depth images, and the key challenge is the effective fusion of multimodal and multiscale features. The existing methods still need the improvement in modal complementary information representation, edge detail preservation and utilization of cross-scale association during the fusion of RGB features and depth features. Therefore, a Transformer network with multimodal attention perception and adjacent-scale modeling(MATNet) is proposed. Multilevel RGB features and depth features are extracted by dual-branch pyramid pooling Transformer encoders. A multimodal attention fusion module is introduced at each stage. The modal complementary information representation and semantic consistency in key regions are jointly enhanced by channel attention and spatial attention. Then, an adjacent-scale modeling module is constructed to aggregate adjacent-scale features progressively in a top-down manner. High-level semantic information and low-level edge texture information are fused effectively. The structural integrity and boundary representation capability of salient objects are improved. Finally, an end-to-end detection framework is constructed by combining multi-scale prediction and the supervision mechanism. Experiments on five public datasets demonstrate that MATNet is effective and stable in improving detection accuracy and edge preservation capability.
显著性目标检测(Salient Object Detection, SOD)旨在从图像中定位最具视觉显著性的目标区域[1].随着深度传感器的普及, RGB图像与深度图像的联合应用成为当前SOD研究的新趋势.相比单一RGB模态, 深度信息能为显著目标定位提供有效补充, 从而提升检测性能.
在RGB-D显著目标检测领域, 如何有效融合深度模态信息与RGB模态信息始终是一个关键问题.为了充分利用两种模态之间的互补性, 研究者提出多种融合方法, 主要包括早期融合方法、中期融合方法和晚期融合方法.
早期融合方法通常在特征提取阶段将RGB图像与深度图像直接级联为四通道输入, 并采用单流网络开展显著目标检测.此类方法结构相对简单, 计算开销也较可控.然而, 由于RGB图像与深度图像在特征分布上存在较明显差异, 直接拼接容易引入模态间的信息干扰, 导致两种模态之间的互补特征难以充分挖掘, 检测效果往往受到一定限制.
晚期融合方法通常可进一步分为晚期特征融合和晚期结果融合两种形式.晚期特征融合采用多流网络分别提取RGB图像特征与深度图像特征, 并在高层阶段进行拼接融合.晚期结果融合通过多流网络分别生成RGB图像与深度图像的显著性预测图, 再利用卷积等操作融合预测结果.晚期融合方法的优势在于能使网络分别学习两种模态的特征表示, 并在高层语义层面实现信息整合.但是, 由于其融合过程更多发生在偏后阶段, 对模态间复杂交互关系的刻画仍然有限, 容易出现信息利用不充分的问题, 从而影响性能的进一步提升.
与早期融合方法和晚期融合方法不同, 中期融合方法通常在双流网络中分别提取 RGB 图像与深度图像的中间特征, 并在中间层完成特征融合, 随后借助后续网络或解码器生成显著图.此类方法能在特征层面建模两种模态之间的复杂关联, 在保留各自特性的同时, 有效利用模态间的互补信息, 获得较优的检测效果.
尽管已有研究在中期融合方法上取得一定进展, 但在显著目标结构完整性保持与边缘细节表征方面仍有进一步提升空间.例如, HAINet(Hierar-chical Alternate Interaction Network)[2]和C2DFNet(Criss-Cross Dynamic Filter Network)[3]在部分场景中仍存在目标结构不完整或边缘信息表达不足的情况, 其主要原因在于:一方面, RGB图像与深度图像之间仍存在不一致细粒度信息, 模态互补特征尚未得到充分利用; 另一方面, 不同尺度特征之间的多样性与互补性在直接融合过程中仍可能挖掘不足, 影响最终检测效果.
为了应对上述挑战, 本文提出多模态注意力感知与相邻尺度建模的Transformer网络(Transformer Network with Multimodal Attention Perception and Adjacent-Scale Modeling, MATNet), 在保持显著目标整体性的同时可有效增强边缘细节的表现.MAT- Net使用2个具有多尺度池化能力的P2T(Pyramid Pooling Transformer)[4]作为多模态编码器, 分别从RGB图像与深度图像中提取多尺度特征.首先, 设计多模态注意力融合模块(Multi-modal Attention Fusion Module, MAFM), 结合空间注意力机制与通道注意力机制, 挖掘模态间的互补信息并增强模态一致性.然后, 构建相邻尺度建模模块(Adjacent-Scale Modeling Module, ASMM), 自上而下逐层融合相邻尺度特征, 有效利用不同尺度特征间的多样性与互补性, 显著增强边缘细节表达能力, 并确保最终生成显著图中显著目标的完整性.最后, 在5个公开数据集上的实验表明, MATNet性能较优.
RGB-D显著性目标检测最初的研究方法与传统的单模态方法类似, 主要依赖人工设计特征.Lang等[5]最早将深度先验引入显著性检测任务中, 利用高斯混合模型建模深度图像中的显著区域分布.Ciptadi等[6]结合深度图像的三维结构信息与形状特征, 有效提升显著区域的定位能力.
由于深度图像具备较高的对比度特性, 因此成为传统RGB-D显著性检测研究的重点.Ren等[7]将区域对比度、深度、方向先验与背景信息融合, 用于显著性预测.Feng等[8]以深度对比度作为主导特征, 抑制背景中高对比区域的干扰, 提升显著区域的预测能力.
上述传统方法主要依赖图像的低层视觉特征, 难以捕捉高层语义信息.随着深度学习技术的快速发展, 越来越多基于深度学习的RGB-D显著性检测方法被提出, 突破传统方法的性能瓶颈, 取得显著进展.Zhou等[9]提出CCAFNet(Crossflow and Cross-Scale Adaptive Fusion Network), 融合跨模态信息与跨层次信息, 从RGB-D图像中提取互补特征.Bi等[10]提出HINet(Cross-Modal Hierarchical Interac-tion Network), 引入具有反馈机制的CIE模块(Cross-modal Information Exchange Module), 实现跨尺度的共享特征学习.Pang等[11]设计基于Transformer架构的CAVER(Cross-Modal View-Mixed Transformer), 级联多层跨模态融合模块, 构建自顶向下的信息传播路径, 采用混合视角注意力机制, 实现上下文信息的递进融合与更新.Chen等[12]提出AFNet(Adaptive Fusion Network), 对多层特征进行迭代式细化与自适应融合, 增强显著性检测性能.
Chen等[13]提出首个基于三维卷积神经网络的RGB-D显著性检测模型— — RD3D(RGB-D 3D CNN Detector for SOD), 在编码阶段进行早期融合, 在解码阶段实现高级特征整合, 提升两种模态间的信息融合能力.Zhang等[14]提出FCFNet(Feature Cali- brating and Fusing Network), 针对低质量深度图像及其与RGB图像前景不一致容易引入误导性深度特征的问题, 采用先校准再融合的策略, 有效降低不可靠深度信息对最终显著性预测结果的影响.Fang等[15]提出Group-TransNet(Group Transformer Net- work), 设计聚类融合单元, 通过集群内错位偏差机制, 实现高低层特征的稳健融合.Gao等[16]提出面向RGB-D显著性检测的自监督预训练框架, 通过多模态特征增强与交互建模, 提升深度特征与外观特征的互补性.
本文提出多模态注意力感知与相邻尺度建模的Transformer网络(MATNet).具体架构如图1所示.
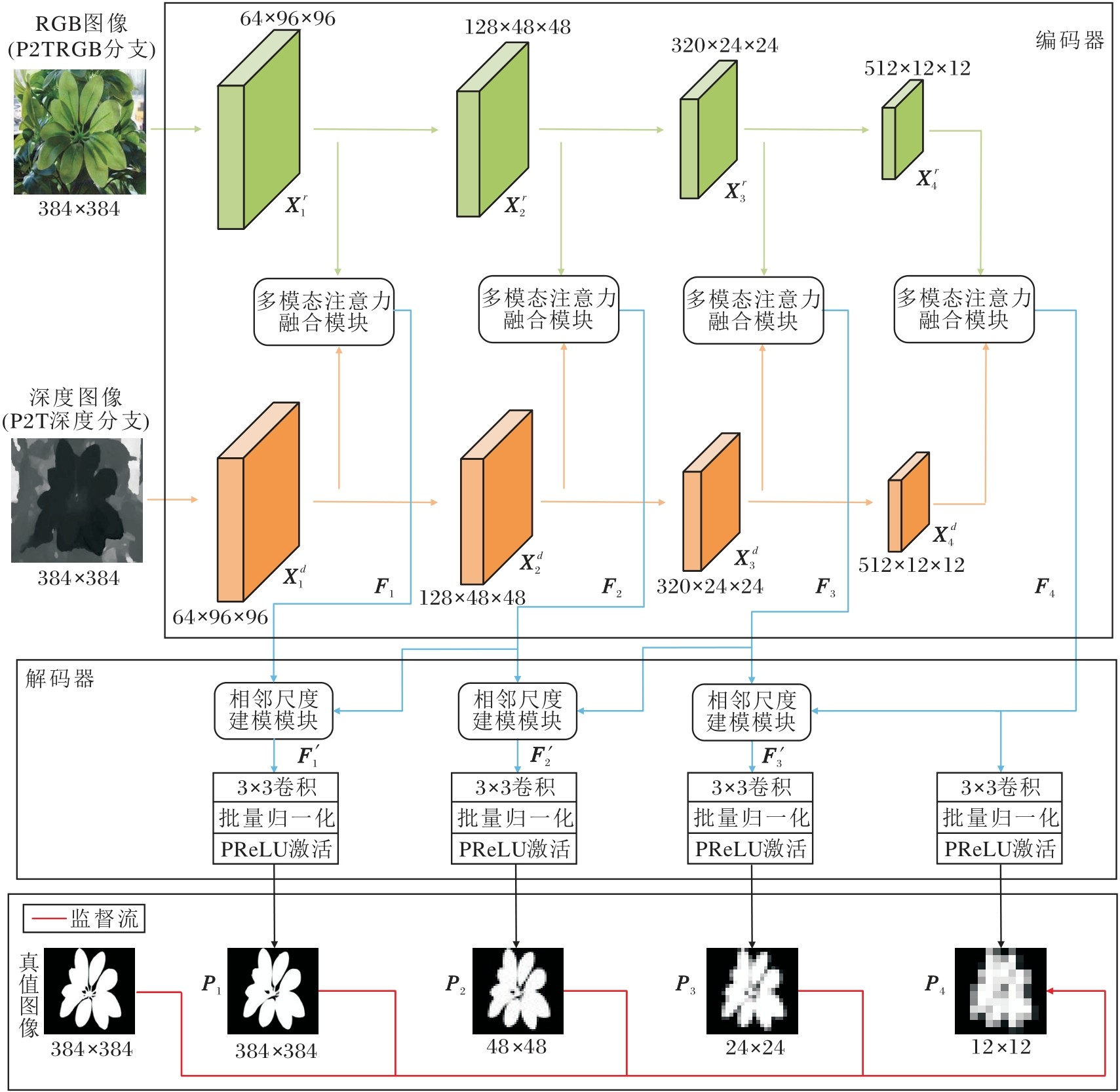 | 图1 MATNet整体架构Fig.1 Overall architecture of MATNet |
MATNet主要由三部分组成:主干编码器、多模态注意力融合模块(MAFM)、相邻尺度建模模块(ASMM).
主干编码器采用双分支结构, 由两个基于P2T的编码器组成.P2T编码器采用四阶段层级化表示, 本文沿用其四层输出作为后续建模基础, 在保证网络结构一致性的同时, 充分保留从浅层边缘纹理到深层全局语义的多尺度信息.
具体而言, 2个编码器分别对RGB图像和深度图像进行特征提取, 获得4个层级的特征表示, 其中, 第i层RGB特征记为X
在每层的编码阶段, 均利用MAFM对双模态特征进行增强与融合, 输出融合特征记为Fi(i=1, 2, 3, 4).然后, 4个层级的融合特征F1~F4被送入解码器.前三层特征F1~F3与其相邻层的低分辨率特征输入ASMM, 完成跨尺度特征融合, 输出跨尺度融合特征F'1~F'3.由于第4层融合特征F4位于编码器最深层, 承载高层语义信息, 且不存在可进一步融合的低分辨率相邻层特征, 因此直接用于生成预测结果.
最后, 通过一系列上下文感知瓶颈预测(Con-text-Aware Bottleneck Prediction, CBP)模块[17]生成多尺度预测结果P1~P4, 并进行多尺度监督, 从而构建一个端到端可训练的RGB-D显著目标检测框架.
在多模态特征聚合阶段, 设计多模态注意力融合模块(MAFM), 增强RGB特征与深度特征之间的互补性与语义一致性, 并实现自适应融合.MAFM具体结构如图2所示.
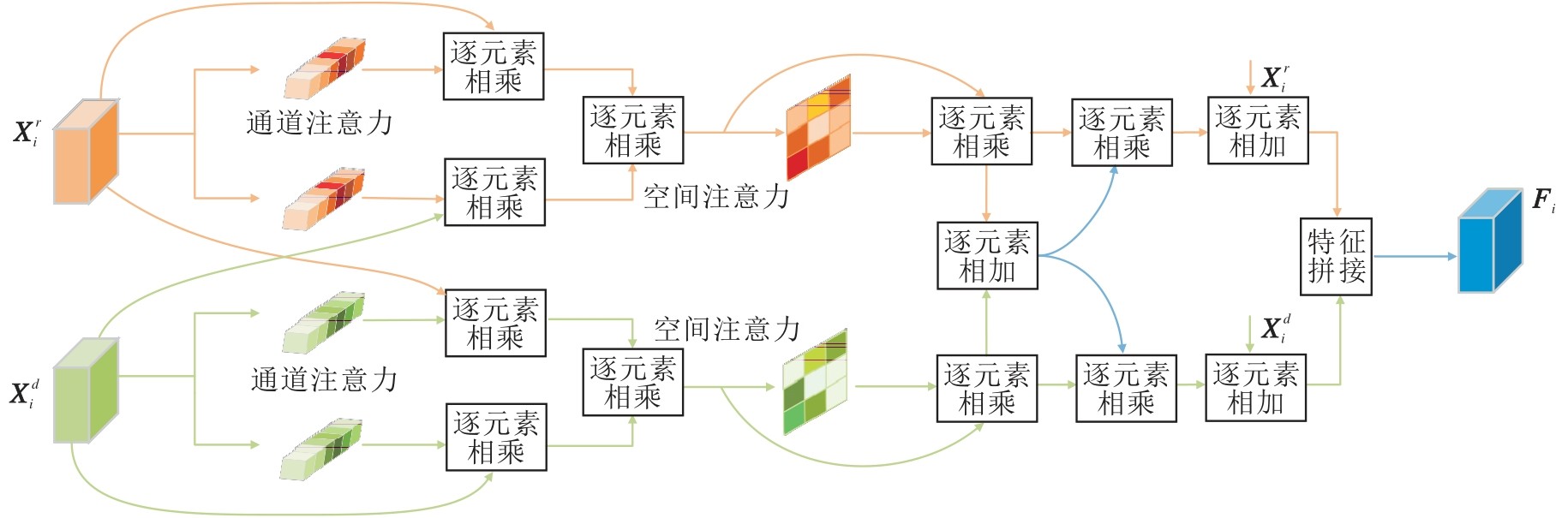 | 图2 MAFM结构图Fig.2 MAFM architecture |
MAFM主要包括如下3个步骤.
1)在通道维度上, 分别对RGB特征与深度特征应用通道注意力操作, 获取通道权重.这些权重一方面用于给对方模态的通道维度进行加权, 挖掘两种模态间的互补信息线索; 另一方面用于对自身模态的通道维度进行加权, 降低噪声干扰.再针对每种模态, 将两个分支的特征进行逐元素相加, 生成初步融合特征.
2)对1)中得到的两组初步融合特征进一步施加空间注意力, 引导网络重点关注两种模态在语义表达上较一致的区域, 同时保证两种模态在重要区域的特征表达一致, 进而增强语义一致性.然后通过逐元素加法与乘法操作, 进一步提升融合特征中的语义一致性表达能力.
3)考虑到融合过程中原始模态的部分关键信息可能被削弱, 使用残差连接, 将原始模态的关键信息补充到融合特征中, 防止关键信息在融合过程中丢失.最后, 通过特征拼接操作获得最终融合特征.
在1)中, 对于给定的第i层RGB特征X
CA(Xi)=σ (Conv1× 1(Conv1× 1(gmps(Xi)))),
其中, Xi表示输入特征(即X
再通过逐元素乘法完成通道层级的特征交互, 获得处理后的RGB特征
$\begin{array}{l} \boldsymbol{X}_{i}^{r c}=C A\left(\boldsymbol{X}_{i}^{r}\right) \otimes \boldsymbol{X}_{i}^{d}, \\ \boldsymbol{X}_{i}^{c^{\prime}}=C A\left(\boldsymbol{X}_{i}^{r}\right) \otimes \boldsymbol{X}_{i}^{r}, \end{array}$
和深度特征
$\begin{array}{l} \boldsymbol{X}_{i}^{d c}=C A\left(\boldsymbol{X}_{i}^{d}\right) \otimes \boldsymbol{X}_{i}^{r}, \\ \boldsymbol{X}_{i}^{d c^{\prime}}=C A\left(\boldsymbol{X}_{i}^{d}\right) \otimes \boldsymbol{X}_{i}^{d} . \end{array}$
其中, ⊗ 表示逐元素相乘.随后, 再进行逐元素乘法, 得到初步融合的RGB特征与深度特征为:
$\begin{array}{l} \boldsymbol{F}_{i}^{r}=\boldsymbol{X}_{i}^{r c} \otimes \boldsymbol{X}_{i}^{r c^{\prime}}, \\ \boldsymbol{F}_{i}^{d}=\boldsymbol{X}_{i}^{d c} \otimes \boldsymbol{X}_{i}^{d c^{\prime}} . \end{array}$
为了增强RGB特征和深度特征在重要区域的语义一致性, 对初步融合特征
$\begin{array}{l} \boldsymbol{F}_{i}^{r s}=S A\left(\boldsymbol{F}_{i}^{r}\right) \otimes \boldsymbol{F}_{i}^{r}, \\ \boldsymbol{F}_{i}^{d s}=S A\left(\boldsymbol{F}_{i}^{d}\right) \otimes \boldsymbol{F}_{i}^{d}, \end{array}$
其中,
SA(Yi)=σ (Conv7× 7(gmpc(Yi))),
表示空间注意力操作, Yi表示输入空间注意力的初步融合特征(即
完成空间注意力操作后, 对于加权后的RGB特征
其中,
表示
这一特征保留两种模态在重要区域的一致性信息, 再通过逐元素相乘将一致性信息传递回两个分支的特征中, 进一步增强多模态特征的语义一致性表达, 获得相应输出特征.
最后, 通过残差连接补充两种特征的原始重要信息, 再沿通道维度拼接两个分支的输出特征, 最终得到多模态融合特征:
Fi=Concat(
其中Concat(· )表示通道维度上的特征拼接操作.
在跨尺度特征聚合阶段, 设计相邻尺度建模模块(ASMM), 对相邻尺度的特征进行上采样与融合.ASMM具体结构如图3所示.
 | 图3 ASMM结构图Fig.3 ASMM architecture |
首先, 将后续层的低分辨率特征进行上采样操作, 使其与前一层的高分辨率特征在空间尺寸上保持一致.将来自不同尺度的特征进行简单拼接, 并引入ECA(Efficient Channel Attention)模块[18], 建模多尺度特征之间的相互依赖关系.然后, 深度可分离卷积和逐点卷积组成双分支结构, 分别提取局部空间信息与通道语义信息, 提升融合特征的表达能力.随后, 通过GELU激活函数实现非线性变换.最后, 在ASMM末端引入P2T中的逆残差块(Inverted Resi- dual Block, IRB)[4]作为特征细化单元, 进一步增强相邻尺度融合特征的上下文表达能力.
首先, 对低分辨率特征进行双线性插值上采样, 并与相邻尺度的高分辨率特征拼接.由于拼接后特征通道数增加一倍, 因此采用3× 3卷积将特征通道数减半, 得到初步融合特征:
其中, Fi表示当前层的高分辨率特征, Fi+1表示后一层的低分辨率特征, Bi(· )表示双线性插值.
再通过一个ECA子模块探索不同尺度特征之间的相互依赖性, 得到相应融合特征:
其中ECA(· )表示ECA子模块.将
其中, DWConv3× 3(· )表示3× 3深度可分离卷积, PWConv(· )表示1× 1逐点卷积, BN(· )表示批归一化层.
最后, 将融合特征
在训练阶段, 本文采用与文献[17]一致的损失设计对网络进行优化.对于第i个预测层, 损失由加权二值交叉熵损失和加权交并比损失共同构成, 第i层预测结果与真实标签之间的差异损失为:
Li=
其中:
训练过程中对各层损失求和, 得到总损失:
Lsod=L1+L2+L3+L4.
对各层预测结果采用等权监督, 从而在不引入额外超参数的情况下兼顾多尺度预测约束与训练稳定性.
本文在NLPR、NJUD、STERE、SIP、DUT-RGBD这5个公开可用的RGB-D数据集上进行实验.NLPR数据集包含由Microsoft Kinect采集的1 000对RGB-D深度图像.NJUD数据集包含1 985幅来源于互联网的图像, 深度信息由立体图像生成.STERE数据集包含来自真实场景与虚拟场景的1 000对RGB-D图像, 深度图像同样由立体图像生成.SIP数据集包含929对高分辨率人像图像, 深度图像由华为Meta10获取.DUT-RGBD数据集包含多种真实环境条件下采集的1 200对图像, 深度图像由Lytro光场相机获取.
为了评估各网络的性能差异, 选取如下4种具有代表性的评估指标:结构相似度(S-measure, S)[19]、加权F值(F-measure, F)[20]、增强E值(E-measure, E)[21]、平均绝对误差(Mean Absolute Error, MAE)[22].此外, 还绘制精确率-召回率(Precision-Recall, P-R)曲线与F-measure曲线.
S-measure同时考虑区域相似度与目标相似度, 衡量预测结果与真实标注之间的结构相似性, 计算公式如下:
S=α So+(1-α )Sr,
其中, So表示目标相似度, Sr表示区域相似度, α =0.5, 对两者给予相同权重.
F-measure计算精确率与召回率的加权调和平均值, 公式如下:
F=
其中, P表示精确率, R表示召回率, β 2表示平衡精确率与召回率相对重要性的权重系数.本文采用显著性检测任务中的常用设置β 2=0.3, 更强调精确率.
E-measure同时考虑全局统计信息与局部像素匹配, 计算公式如下:
E=
其中, ϕ (· , · )表示增强对齐矩阵在坐标(x, y)处的元素值, W、H分别表示图像宽度与高度.
MAE计算预测值与真实值在像素维度上的平均绝对差, 公式如下:
$M A E=\frac{1}{W \times H} \sum_{i=1}^{W} \sum_{j=1}^{H}|P(i, j)-G(i, j)|, $
其中, P(· , · )表示预测结果, G(· , · )表示真实标注.
在NVIDIA RTX 4090 GPU上进行实验, 将RGB图像与深度图像的输入尺寸调整为384× 384.为了防止过拟合, 采用随机翻转、旋转与裁剪等数据增强策略.P2T主干网络在ImageNet上进行预训练, 其余参数通过PyTorch初始化.优化器选用Adam(Adap-tive Moment Estimation), 批量大小设为2, 初始学习率设为5× 10-5, 并在每100个训练周期衰减为原来的十分之一.模型在200个周期内收敛, 训练耗时约15 h.
为了评估MATNet在RGB-D显著目标检测任务中的性能, 选择与如下19种RGB-D显著目标检测网络进行对比:HAINet[2]、CCAFNet[9]、HINet[10]、CAVER[11]、AFNet[12]、RD3D[13]、文献[16]网络、DCF(Depth Calibration and Fusion)[23]、SPSN(Superpixel Prototype Sampling Network)[24]、CIRNet(Cross-Moda- lity Interaction and Refinement Network)[25]、DMRA[26]、JL-DCF(Joint Learning and Densely Cooperative Fu- sion)[27]、文献[28]网络、DAIR(Depth-Aware Inverted Refinement Network)[29]、HiDAnet(Hierarchical Depth Awareness Network)[30]、TSVT[31]、SPCNet(Scenario Potentiality-Constrain Network)[32]、RMFDNet(Redun- dant and Missing Feature Decoupling Network)[33]、PLFRNet(Perceptual Localization and Focus Refine- ment Network)[34].为了确保公平性与透明性, 对比网络的实验结果均由原文献直接提供或利用其公开代码复现所得.
| 表1 各网络在NLPR、NJUD、STERE数据集上的指标值 Table 1 Metric values of different networks on NLPR, NJUD and STERE datasets |
| 表2 各网络在SIP、DUT-RGBD数据集上的指标值 Table 2 Metric values of different networks on SIP and DUT-RGBD datasets |
由表1和表2可见, MATNet均取得最优值.相比次优网络, MATNet在NLPR、NJUD、STERE、SIP、DUT-RGBD数据集的MAE指标值分别降低19.0%、13.8%、6.2%、8.1%和23.1%.这一显著的性能提升表明, MATNet能更准确地定位显著目标并有效减少误检, 尤其在复杂场景中展现出更强的鲁棒性.值得强调的是, 在DUT-RGBD数据集上, MATNet的性能提升最显著, 相比次优方法, 在S-measure、F-measure、E-measure、MAE指标上分别实现13.9%、16.9%、10.3%、23.1%的性能增益.
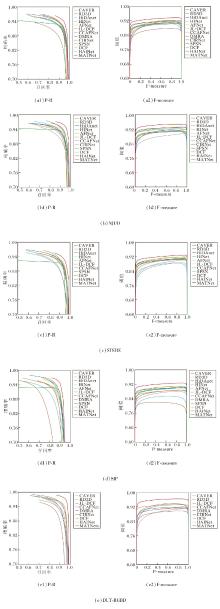
MATNet与部分对比网络在NLPR、NJUD、STERE、SIP、DUT-RGBD数据集上的P-R曲线与F-measure曲线由图4所示.由图可见, 在5个数据集上, MATNet对应的P-R曲线和F-measure曲线均处于较优水平, 说明该方法在不同阈值设置下都能取得较好的精确率-召回率平衡.
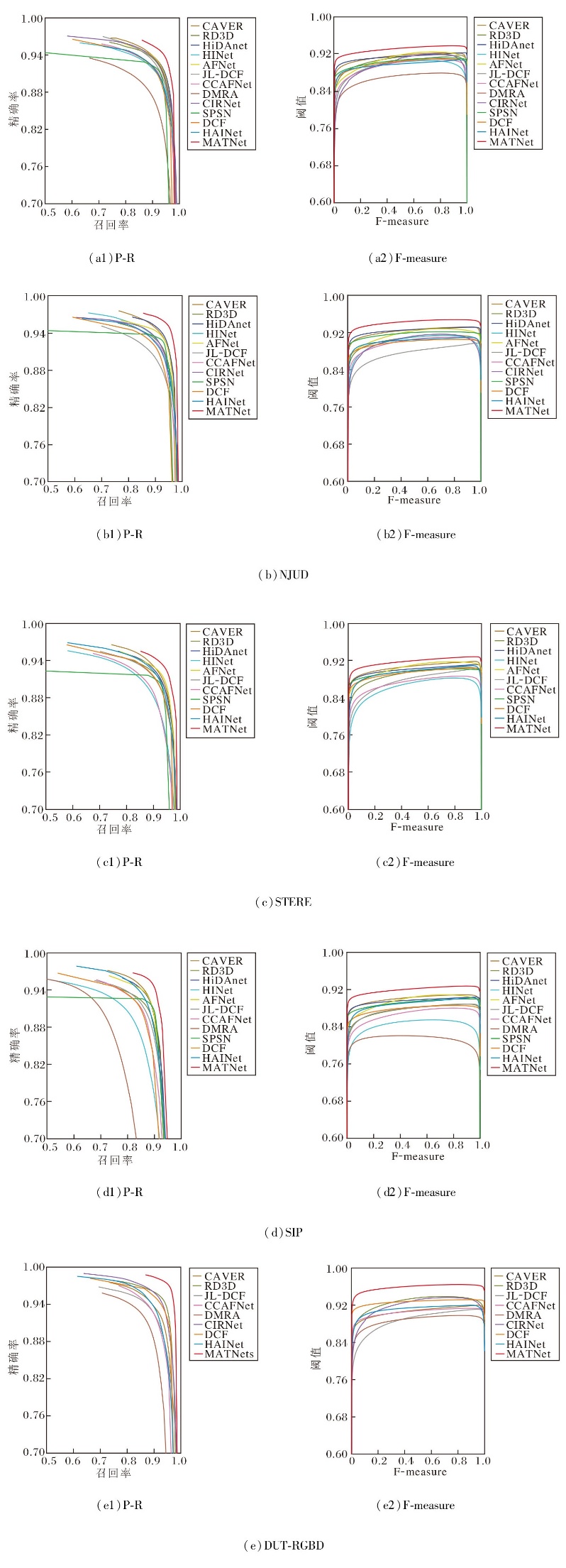 | 图4 各网络在5个数据集上的P-R曲线和F-measure曲线Fig.4 P-R curves and F-measure curves of different networks on 5 datasets |
各网络在不同场景中的可视化结果对比如图5所示.在图中, 第1幅图像和第2幅图像取自完整性分割场景, 第3幅图像和第4幅图像取自细粒度分割场景, 第5幅图像和第6幅图像取自多目标分割场景.由图可见, 在完整性分割场景中, MATNet能保持显著目标的整体性.在细粒度分割场景中, MATNet在保留显著目标边缘细节方面表现出色.在多目标分割场景中, MATNet不仅能准确识别多个显著目标, 还能有效区分前景与背景, 展现出更强的显著性检测能力.
 | 图5 各网络在不同场景中的可视化结果对比Fig.5 Visualization result comparison of different networks on various scenarios |
本节进行消融实验, 验证多模态注意力融合模块(MAFM)和相邻尺度建模模块(ASMM)的有效性.选择样本数量最多的两个数据集DUT-RGBD和NLPR上进行实验.
为了验证MAFM的有效性, 移除MAFM后对剩余网络进行训练, 分析其对MATNet性能的影响.具体而言, 在多模态特征融合之前, 不再采用多种注意力操作增强RGB特征与深度特征之间的互补性和一致性, 而是仅通过简单的相加操作进行融合.
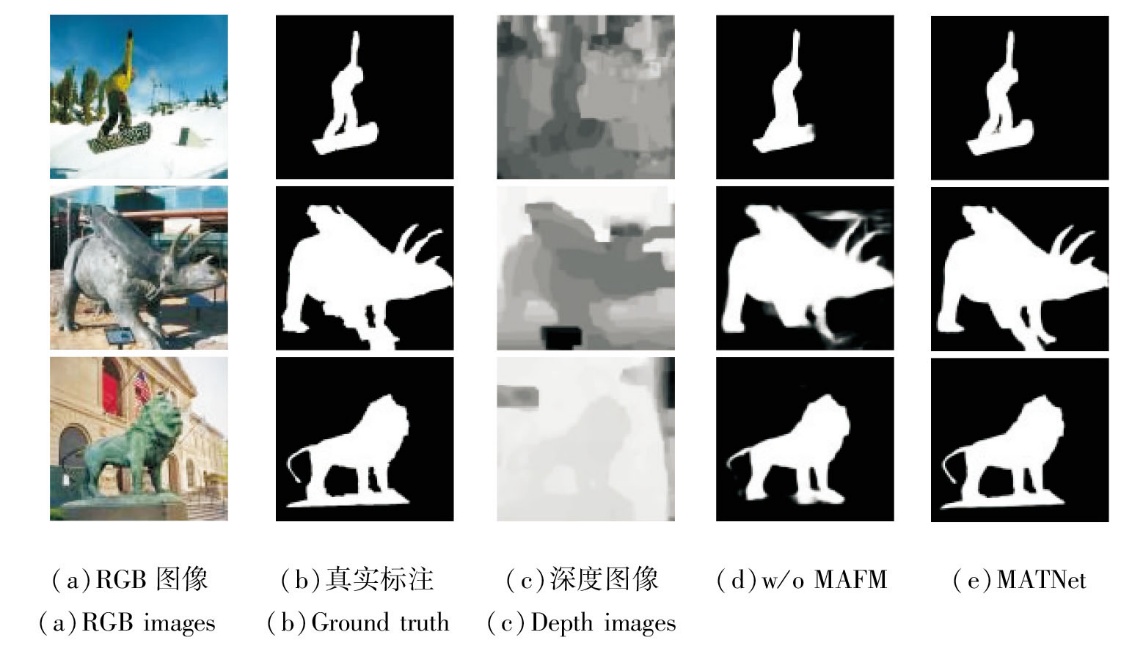
w/o MAFM和MATNet的指标值对比如表3所示, 相应可视化结果如图6所示.
| 表3 MAFM移除前后的消融实验结果 Table 3 Ablation experiment results before and after the removal of MAFM |
 | 图6 MAFM移除前后的可视化结果对比Fig.6 Comparison of visualization results before and after the removal of MAFM |
由表3和图6可见, MAFM能显著提升性能, 并有效缓解边缘模糊问题.这表明充分挖掘不同模态之间的互补信息并增强其一致性, 对于提升显著目标检测网络的有效性至关重要.MAFM结合空间注意力与通道注意力操作, 不仅能从两种模态中获取互补信息, 还能探索模态间的一致性, 性能提升在两个数据集上均得到验证.
为了验证ASMM的有效性, 将其移除并训练剩余网络, 分析其对MATNet性能的影响.具体而言, 在多尺度特征融合阶段, 首先将后一层的低分辨率特征上采样至与前一层高分辨率特征相同的尺寸.将不同尺度特征简单拼接后, 不再使用ECA子模块、深度可分离卷积和逐点卷积以充分整合多尺度特征, 而是直接将拼接后的特征用于后续操作.
w/o MAFM和MATNet的指标值对比如表4所示, 相应视觉可视化结果如图7所示.由表可见, ASMM同样显著提升MATNet性能, 在NLPR数据集上的提升最明显.这归功于ASMM中的ECA子模块充分挖掘不同尺度特征间的依赖关系, 同时深度可分离卷积和逐点卷积有效增强多尺度融合特征.图7的可视化结果也表明, ASMM能有效保证显著目标的完整性.
| 表4 ASMM移除前后的消融实验结果 Table 4 Ablation experiment results before and after the removal of ASMM |
 | 图7 ASMM移除前后的可视化结果对比Fig.7 Comparison of visualization results before and after the removal of ASMM |
HAINet[2]、CCAFNet[9]、HINet[10]、CAVER[11]、RD3D[13]、DCF[23]、DMRA[26]、MATNet的参数量和浮点运算量对比如表5所示.由于不同网络在原文献中采用的输入尺寸不完全一致, 本文在统计时保持其常用输入配置不变.因此, 表中参数量主要反映网络本身规模, 而浮点运算量主要反映各网络在对应输入设置下的计算开销.
| 表5 各网络在常用输入设置下的运算量与参数量对比 Table 5 Comparison of FLOPs and parameter count of different networks under common input settings |
从表5可看出, 尽管MATNet的输入分辨率为384× 384, 高于大多数对比网络, 但其浮点运算量仅为45.2 G, 显著低于HAINet和HINet等网络, 并与RD3D基本接近.这表明, MAFM和ASMM虽然引入额外的特征交互, 但整体计算开销仍保持在较可控范围内.同时, MATNet的参数量为83.2 M, 也处于可比范围内, 未出现明显的参数膨胀现象.
总之, MATNet在当前输入设置下取得较好的性能与复杂度平衡.未来可进一步探索更高效的注意力机制或轻量化结构, 并在统一输入尺寸设置下开展更细致的效率评估与优化.
为了进一步验证MATNet在更具挑战性场景中的鲁棒性, 从NJUD、STERE、SIP、DUT-RGBD测试集上筛选32幅具有代表性的低质量深度图像样本, 构建低质量深度图子集.筛选时主要考虑深度图像边界模糊、前景与背景深度对比不明显及深度图像局部失真的情形.在这类场景中, 深度图像往往难以为显著目标检测提供稳定有效的结构线索.
基于该子集, 对比CCAFNet[9]、CAVER[11]、RD3D[13]、DCF[23]、MATNet的指标值, 具体如表6所示.由表可看出, MATNet在4个指标上均取得最优值.相比次优的CAVER, MATNet在S-measure、F-mea-sure、E-measure指标上分别提升0.037、0.065和0.023, 同时在MAE指标上降低0.015. 上述结果表明, 在深度信息质量较差的情况下, MATNet仍能保持相对较优的检测性能, 体现出较强的鲁棒性与适应能力.
| 表6 各网络在低质量深度图场景中的指标值 Table 6 Metric values of different networks in low-quality depth map scenarios |
各网络在低质量深度图场景中的可视化结果如图8所示.由图可见, 相比对比网络, MATNet能更稳定地保持显著目标的整体结构, 并取得更好的边缘细节恢复效果, 进一步验证其在挑战性场景中的有效性.
 | 图8 各网络在低质量深度图场景中的可视化结果对比Fig.8 Comparison of visualization results of different networks in low-quality depth map scenarios |
为了进一步评估MATNet在其它视觉任务中的适用性, 在CVC-ClinicDB[35]、Kvasir[36]、CVC-Colon-DB[37]、ETIS[38]这4个息肉分割数据集上进行实验.选取U-Net[39]、U-Net++[40]、PraNet(Parallel Reverse Attention Network)[41]、SINet(Search Identification Net- work)[42]作为对比方法.
实验在4个数据集的训练集上进行训练, 在CVC-ColonDB测试集上进行测试, 相应指标值如表7所示.
| 表7 各网络在CVC-ColonDB数据集上的指标值 Table 7 Metric values of different networks on CVC-ColonDB dataset |
由表7可看出, MATNet在4个指标上均取得最优值.相比次优的SINet, MATNet在S-measure、F-measure、E-measure指标上分别提升0.024、0.101、0.034, 同时MAE指标值降低0.006.这表明MAT- Net学习的特征表示不仅适用于RGB-D显著目标检测任务, 在息肉分割场景中同样具有较优的区域表征能力.
MATNet在CVC-ColonDB数据集上的可视化结果如图9所示.由图可看出, MATNet能较好地贴合目标区域轮廓, 并在边界位置和整体形状上与标注结果保持较高的一致性.尤其是在目标区域较小或局部形态较细长的情况下, MATNet仍能较完整地恢复目标区域, 并保持较清晰的边缘过渡.这表明MATNet在边缘细节与结构完整性建模方面具有一定优势, 也体现其在相关医学场景中的潜在应用价值.
 | 图9 MATNet在CVC-ColonDB数据集上的可视化结果Fig.9 Visualization results of MATNet on CVC-ColonDB dataset |
尽管MATNet展现出优秀的性能, 但在某些特殊场景中依然存在一定的局限性, 具体案例如图10所示.
 | 图10 MATNet的两个失败案例Fig.10 Two failure cases of MATNet |
由图10可见, 在第1个场景里, 摩托车具有中空结构, MATNet分离其内部区域与背景, 而没有把整个物体当作一个完整的显著目标加以分割.这是因为MATNet过于关注局部细节, 忽视对目标整体结构的认知能力.
在第2个场景中, MATNet错误地将目标上重叠的非显著物体一并分割.这一现象表明, 网络在处理重叠场景时对显著目标的语义理解能力还有待增强.具体来讲, MATNet可能难以精准区分显著目标与其周围重叠的非显著物体, 从而引发误检.
针对上述场景出现的问题, 未来可通过引入额外的功能模块或采用后处理策略, 让网络动态判定是否对显著目标的整个区域进行分割, 进而提高对复杂结构目标的检测能力.这些特殊场景带来的挑战既揭示MATNet的局限性, 也为今后的研究指明重要的改进方向.未来将考虑从如下方面入手.1)增加多模态显著目标检测训练集上重叠场景的样本量, 增强网络对此类场景的适应能力.2)引入更强大的语义理解模块, 提升网络对显著目标与背景之间语义关系的判别能力.
本文提出多模态注意力感知与相邻尺度建模的Transformer网络(MATNet).首先, 利用多尺度编码器P2T获取RGB模态与深度模态的分层特征, 并通过多模态注意力融合模块(MAFM)增强跨模态互补信息表达.然后, 利用相邻尺度建模模块(ASMM)逐层融合高层语义信息与低层边缘纹理信息, 从而提升显著目标的结构完整性与边界刻画能力.最后, 结合多尺度预测与端到端训练策略, 实现对不同层级监督信号的有效利用, 从整体上增强对复杂场景的适应性.5个公开数据集上的实验表明, MATNet在误差指标与边缘保留方面具有更优或更具竞争力的表现, 消融实验进一步验证MAFM与ASMM的有效性.低质量深度图场景中的实验验证MATNet在复杂深度条件下具有较优的鲁棒性, 医学场景实验则进一步表明, MATNet在息肉分割任务中能较好地保持目标区域的轮廓完整性与边界细节, 从而体现出其在边缘敏感医学场景中的应用价值.未来将进一步探索轻量化与高效融合设计, 提升网络在复杂场景中的鲁棒性, 并在更大规模和跨数据集设置下验证其泛化能力与实际应用价值.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|