{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于Transformer的单目标跟踪研究进展
[张大伟1, 2  , 徐东升
, 徐东升1 , 余哲晨1 , 蒋凯薇1 , 田卫刚1 , 郑忠龙1, 3 ]
, 徐东升, 余哲晨, 蒋凯薇, 田卫刚, 郑忠龙]
|
|



作者简介:
张大伟,博士,副教授,主要研究方向为深度学习、计算机视觉、模式识别等.E-mail:davidzhang@zjnu.edu.cn. 
徐东升,硕士研究生,主要研究方向为计算机视觉、目标跟踪等.E-mail:dongshengxu@zjnu.edu.cn. 
余哲晨,博士研究生,主要研究方向为人工智能、计算机视觉等.E-mail:yzc1201@zjnu.edu.cn. 
蒋凯薇,硕士研究生,主要研究方向为深度学习、计算机视觉等.E-mail:viviaaannn@zjnu.edu.cn. 
田卫刚,硕士研究生,主要研究方向为计算机视觉、目标跟踪等.E-mail:weigangtian@zjnu.edu.cn.
单目标跟踪(Single Object Tracking, SOT)是计算机视觉领域的核心任务之一.然而,在复杂场景中,传统的相关滤波和孪生网络架构已难以满足更高的精度与鲁棒性要求.近年来,Transformer架构凭借其卓越的全局建模能力,在SOT中表现出显著优势.因此,文中系统梳理基于Transformer的SOT研究进展.依据整体结构的设计,将现有算法分为双流双阶段跟踪算法与单流单阶段跟踪算法,并深入归纳分析其中具有代表性的跟踪算法,同时总结轻量化Transformer跟踪方法的研究现状.此外,进一步探讨基于Mamba的跟踪方法和通用模型等前沿热点,它们在模型效率与通用性方面展现出良好潜力.在多个主流数据集上对不同Transformer跟踪算法的性能进行全面评估和对比分析.最后,展望SOT在模型轻量化、多模态融合、长时跟踪、大模型驱动跟踪等方面的研究趋势,期望为单目标跟踪的研究与发展提供参考.
About Author:
ZHANG Dawei, Ph.D., associate profe-ssor. His research interests include deep lear-ning, computer vision and pattern recognition.
XU Dongsheng, Master student. His research interests include computer vision and object tracking.
YU Zhechen, Ph.D. candidate. His research interests include artificial intelligence and computer vision.
JIANG Kaiwei, Master student. Her research interests include deep learning and computer vision.
TIAN Weigang, Master student. His research interests include computer vision and object tracking.
Single object tracking(SOT) is recognized as one of the fundamental tasks in the field of computer vision. However, traditional correlation filters and Siamese network architectures struggle to meet the growing demands for accuracy and robustness in complex and dynamic environments. Transformer exhibits significant advantages in SOT by virtue of its powerful global modeling capability. Therefore, the recent research advances in Transformer-based SOT are reviewed systematically. Based on the overall pipeline design, existing tracking algorithms can be categorized into two primary types: two-stream two-stage algorithms and one-stream one-stage algorithms. Representative algorithms of each category are analyzed in depth to highlight their relations and characteristics, while the research status of lightweight Transformer-based tracking methods is summarized. In addition, recent emerging trends, such as Mamba-based tracking algorithms and unified model architectures, are further investigated and their promising potential in model efficiency and generalizability is discussed as well. The performance of different Transformer-based tracking methods is comprehensively analyzed and evaluated on multiple mainstream datasets. Finally, several promising directions for future research in SOT, including lightweight models, multimodal fusion, long-term tracking and foundation models-driven tracking, are outlined, providing valuable references for the research and development of SOT.
单目标跟踪(Single Object Tracking, SOT)是计算机视觉领域的核心任务之一, 算法旨在视频序列的第一帧中给定目标的边界框位置, 需在随后每一帧中准确预测该目标的位置和尺度变化, 并在目标出现遮挡、形变或快速运动时保持鲁棒性[1].SOT在智能监控、自动驾驶、人机交互、增强现实、无人机导航等实际场景中具有重要应用[2, 3, 4].例如:在自动驾驶中, SOT可用于稳定跟踪行人或车辆, 提高环境感知的连续性; 在视频分析和行为识别中, 持续追踪目标个体对于理解场景动态具有重要意义[5, 6].尽管研究者已在该任务上研究多年, 且当前SOT算法在简单场景中已取得较满意的跟踪效果, 但仍有诸多挑战尚未得到彻底解决[7, 8].例如:目标在复杂环境中可能被部分或完全遮挡, 导致跟踪失败; 背景中存在相似纹理或干扰物时, 容易造成跟踪漂移; 在光照变化剧烈、运动模糊或图像噪声增强时, 目标边界模糊不清, 进一步影响跟踪的准确性和稳定性.如何在上述条件下实现稳健、实时、泛化性强的视觉跟踪, 仍是当前SOT研究的重要方向之一.
为了应对上述跟踪过程中存在的挑战, 学者们提出多种单目标跟踪算法.早期算法主要依赖手工特征.2010年, 基于相关滤波(Correlation Filters, CF)的跟踪算法[9]被提出, 此后, 研究者在特征优化[10, 11]与模型改进[12, 13]两个方向上进行相关探索.基于CF的跟踪算法虽凭借计算效率较高、跟踪速度较快等优点逐渐成为单目标跟踪领域的主流算法, 但在目标发生剧烈外观变化(如旋转、遮挡、尺度变化)时, 难以保持足够精度, 表现出明显的性能瓶颈[14, 15].
多年前, 随着深度学习的兴起, 卷积神经网络(Convolutional Neural Networks, CNN)被广泛引入跟踪器设计.2016年, MDNet(Multi-domain Net-work)[16]与SiamFC(Siamese Fully-Convolutional)[17]被提出, 前者是基于多域分类网络, 后者则标志目标跟踪进入孪生网络(Siamese Networks)时代, 并以其高效的相似度匹配机制与端到端的训练方式逐渐成为主流的目标跟踪算法.此后, 一系列基于Siamese结构的改进方法陆续涌现, 在区域候选网络[18, 19]、无锚框预测[20, 21]、注意力机制[22]等方面不断优化.此外, 研究者还提出结合离线训练与在线更新的判别式算法[23, 24], 以达到更优的跟踪效果.尽管基于CNN的算法在特征表达上显著优于手工算法, 但仍存在如下局限.一方面, CNN依赖卷积核提取局部特征, 难以捕捉长距离依赖关系, 缺乏全局建模能力.并且, CNN在不同空间位置上使用相同的卷积核, 导致对前景目标与复杂背景的区分能力有限, 难以抑制背景干扰.另一方面, 基于CNN的跟踪器普遍采用双分支结构, 需要并行提取模板和搜索区域特征, 依赖后续的特征匹配过程, 从而使跟踪器架构臃肿复杂, 扩展性不强, 应用场景受限.
近年来, 随着Transformer[25]在自然语言处理(Natural Language Processing, NLP)中的成功应用, 自注意力机制被引入计算机视觉任务, 出现新的建模范式.2021年, Transformer首次被引入跟踪任务[26].随后, 双流双阶段算法[27, 28]开始使用CNN提取特征和应用Transformer进行特征增强.之后部分算法尝试单纯使用Transformer替代CNN进行特征提取[29, 30].2022年, 单流单阶段算法[31, 32]开始出现, 统一特征提取和特征融合, 使跟踪框架简洁高效.这一系列算法在展现强大性能的同时也凸显出Transformer在目标跟踪领域的建模优势.首先, Transformer通过全局自注意力机制捕捉长距离依赖关系, 打破卷积的局部感受野限制.此外, 其注意力计算会根据输入特征动态生成注意力权重, 为目标区域分配更高的响应, 同时抑制背景干扰, 使得在复杂场景中仍能精确定位.另外, 单流Transformer跟踪器将模板和搜索区域序列化后拼接输入编码器中, 在每层通过自注意力计算完成全局特征提取和交互, 结构简洁、跟踪性能较优、易于迁移与扩展至多模态跟踪的下游任务.
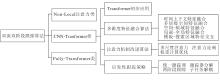
目前, 基于Transformer的单目标跟踪算法已成为该领域的研究热点之一, 相关技术不断发展, 应用潜力也日益凸显.因此, 本文旨在系统梳理Trans-former在单目标跟踪中的研究进展, 深入分析其核心技术发展、性能优势与现阶段存在的局限性, 为后续研究提供支撑与参考.相比现有综述工作, 本文在内容组织与分析视角上进行拓展.不同于以往多聚焦于传统相关滤波算法或基于深度学习的跟踪技术, 本文聚焦于当前主流的Transformer跟踪算法, 从模型结构的角度, 将其划分为双流双阶段算法(包括Non-Local注意力类、CNN-Transformer类及Fully-Transformer类)和单流单阶段算法(包括经典单流类、自回归类及基于提示类), 系统梳理其技术演变和进展, 此外还梳理归纳轻量化Transformer跟踪算法.考虑到当前跟踪领域正涌现出一系列新的研究趋势, 本文进一步涵盖Mamba架构和通用模型等热点方向的最新进展, 更全面呈现该领域的发展态势.由于大规模的公开数据集与统一的评估指标在跟踪算法的性能评价中发挥关键作用, 为此, 本文也系统总结主流的跟踪数据集, 并对典型算法在多个数据集上性能进行对比与统计分析, 为场景化模型选择与优化提供量化参考.当前Transformer单目标跟踪算法已成为主流趋势, 为其它跟踪任务的发展奠定基础.本文聚焦单目标跟踪算法, 集中、深入地呈现Transformer架构在该任务中的发展态势与核心贡献.
2017年, Vaswani等[25]提出Transformer, 作为Seq2Seq模型, 完成NLP领域的机器翻译任务.在此之前, NLP领域的主流模型以循环神经网络(Re-current Neural Network, RNN)为基础, 存在无法并行训练、消耗大量内存等问题.Transformer使用编码器-解码器结构, 利用注意力机制进行并行计算, 大幅缩短训练时间, 实现当时最优的机器翻译性能[2].此后, 基于Transformer的各种算法被提出并在各种NLP任务中取得成功[33, 34], 这使得研究者开始尝试将其应用在计算机视觉领域中.早期学者提出用于图像分类的ViT(Vision Transformer)[35]、Swin Transformer[36], 用于目标检测的DETR(Detec-tion Transformer)[37]、Deformable DETR[38], 用于语义分割的SETR(Segmentation Transformer)[39]、PVT(Pyramid Vision Transformer)[40]等.
1.1.1 Transformer架构
Transformer原始架构由编码器和解码器构成.编码器专注于序列特征提取与交互, 每层包含多头自注意力和多层感知机(Multi-layer Perceptron, MLP).自注意力机制计算序列间关联, 捕捉全局上下文, MLP增强特征表达能力.每个子层后附加残差连接与层归一化操作, 确保梯度稳定传播并优化特征分布.在编码器基础上, 解码器增加关键设计:采用掩码多头自注意力, 屏蔽后续位置信息, 强制模型仅依赖已生成序列; 第二子层引入交叉注意力, 动态关联编码器输出与当前解码序列, 指导后续预测, 最终输入MLP层进一步处理.
位置编码的引入弥补Transformer缺乏内置序列顺序信息的问题.Transformer的原始输入是一个由若干单词组成的句子, 每个单词首先经过嵌入层映射为向量.这种向量只包含输入序列的文本信息, 无单词间的位置信息.最常见的做法是使用绝对位置编码, 即在每个输入序列的元素上添加一个位置向量, 表示该元素在序列中的具体位置.这个位置向量通过固定函数生成, 与输入数据无关.固定函数使用正弦函数和余弦函数, 生成结果在区间(-1, 1)内.这种编码具有很强的周期性,
能捕捉序列中的相对位置信息.对于序列中第pos位置的单词, 绝对位置编码向量的第i维的值定义如下:
其中, 2i表示偶数维, 2i+1个表示奇数维, dmodel 表示位置编码维度, 通常与嵌入层映射后的向量维度保持一致.位置编码与具有相同维度的输入向量相加, 作为Transformer的初始输入.
Transformer编码器和解码器的核心都是多头注意力层, 遵循标准缩放点积注意力机制进行序列相似度计算.该机制通过计算查询(Query)与每个键(Key)的点积得到相似度, 用于衡量每个值(Value)的重要性, 并通过加权求和得到对应值输出.假设当前输入为dk 维的Q和B, 及dv 维的V.较大的dk 可能导致点积计算后的权值差距较大, 进一步导致softmax输出分布趋于极端.因此, 通常会对点积结果除以$\sqrt{d_{k}}$.缩放点积注意力的计算公式如下:
$\text { Attention }(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})=\text { softmax }\left(\frac{\boldsymbol{Q} \boldsymbol{K}^{\mathrm{T}}}{\sqrt{d_{k}}}\right) \boldsymbol{V} \text {. }$
考虑到单一注意力函数难以捕捉多维复杂关系, 多头注意力(Multi-head Attention)机制通过将模型分为多头以形成多个子空间, 从而能关注不同维度的信息.该机制将原始查询、键、值分成i份:
$\boldsymbol{Q}_{i}=\boldsymbol{Q} \boldsymbol{W}_{i}^{Q}, \boldsymbol{K}_{i}=\boldsymbol{K} \boldsymbol{W}_{i}^{K}, \boldsymbol{V}_{i}=\boldsymbol{V} \boldsymbol{W}_{i}^{V}, $
其中$\boldsymbol{W}_{i}^{Q}, \boldsymbol{W}_{i}^{K}, \boldsymbol{W}_{i}^{V}$ 表示线性变换投影时的参数矩阵.每份使用不同线性层投影至特定维度, 分别进行注意力计算, 第i个注意力头计算得到的特征矩阵为:
$\boldsymbol{h}_{i}=\operatorname{Attention}\left(\boldsymbol{Q}_{i}, \boldsymbol{K}_{i}, \boldsymbol{V}_{i}\right) .$
之后拼接得到的结果, 再进行统一线性投影, 获得最终结果:
$\text { MultiHead }(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})=\operatorname{Concat}\left(\boldsymbol{h}_{1}, \boldsymbol{h}_{2}, \cdots, \boldsymbol{h}_{i}\right) \boldsymbol{W}^{o}, $
其中WO 表示线性交换投影时的参数矩阵.
多头注意力机制在不显著增加参数量的前提下, 通过多个子空间协同建模显著提升模型表达能力, 有效缓解单头注意力结构的过拟合风险.
1.1.2 Vision Transformer
ViT[35]是首个将纯Transformer架构应用于计算机视觉领域的模型, 由Google团队提出以完成图像分类任务.该工作围绕“ 如何把图像当作语言序列进行处理” 的核心问题, 提出3个设计思想.1)图像分块, 又称图像序列化.模型在图像预处理时会将输入图像划分成固定大小的非重叠块, 每块视为一个“ 视觉词汇” , 从而实现图像向序列的转换.2)序列化处理.每块仍是二维图像, 而标准Transformer要求输入的是一维向量形式.因此, 将每个图像块展平, 使用线性层投影成固定维度的特征向量, 称为Patch Embedding.同时加入相同尺寸的位置编码, 以保留空间信息.3)类标签加入.研究者参考BERT(Bidirectional Encoder Representations from Transfor- mers)中的“ [CLS]” 标记, 引入额外的可学习类别标签, 作为整个模型的分类依据.
基于上述思想, 一个结构简洁且高度灵活的ViT得以构建.图像块映射而成的Patch Embedding加上位置编码后, 与类标签一起送入标准Transfor- mer编码器进行信息聚合.编码器的最终输出为经过层归一化的类标签.该输出会被输入至由MLP组成的分类头中, 作为分类结果的预测依据.
ViT通过将改进的Transformer架构用于图像分类任务, 证实Transformer在计算机视觉领域的巨大潜力.之后, Swin Transformer[36]进一步展现Transfor-mer能作为一种通用骨干网络在视觉任务中替代CNN并取得理想效果.Swin Transformer的核心创新在于分级架构与局部窗口注意力机制.输入图像被分割为非重叠块并映射编码后:通过Swin Trans-former模块逐级处理, 交替执行局部窗口自注意力与移动窗口自注意力, 前者固定在包含M× M个块的窗口内计算自注意力, 使复杂度降至与图像尺寸线性相关; 后者通过窗口边界的循环位移, 实现跨窗口信息交互, 间接达成全局建模.同时, 通过块合并层逐步扩大窗口尺寸, 生成多尺度特征图, 适配不同视觉任务.
ViT与Swin Transformer通过将纯Transformer引入视觉领域, 打破CNN的长期主导地位, 成功推动Transformer在视觉领域的广泛应用, 也为基于Transformer的跟踪方法奠定研究基础.
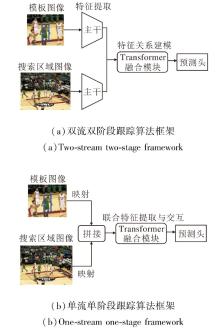
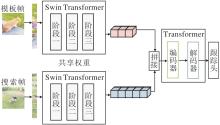
基于Transformer的目标跟踪算法主要分为双流双阶段算法与单流单阶段算法, 具体框架如图1所示.两类算法核心差异在于对特征提取与融合流程的设计.
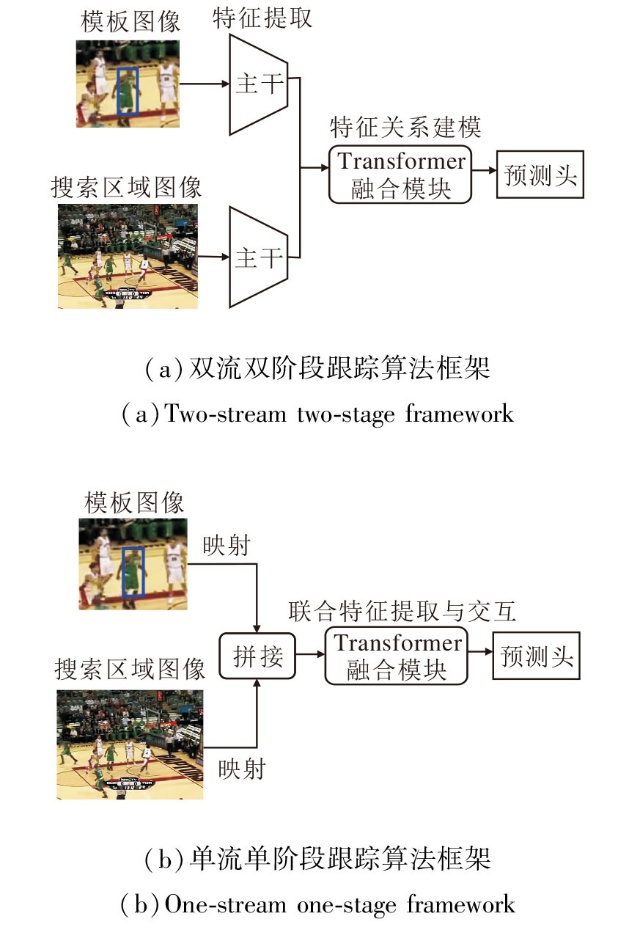 | 图1 两类Transformer目标跟踪算法框架Fig.1 Two types of Transformer-based object tracking frameworks |
双流双阶段算法采用分步策略:首先通过共享主干网络(通常为卷积网络或Transformer编码器)独立提取模板和搜索区域的特征, 再一并输入Transformer融合模块中, 利用注意力机制实现关系建模与特征融合, 聚合后的特征最终输入预测头中, 预测跟踪结果.这类算法的研究重点通常为融合阶段的创新, 如“ 如何设计注意力以增强信息交互, 获取更具判别力的聚合特征” 、“ 如何降低注意力计算复杂度, 实现更轻量高效的融合” 等.相比之下, 单流单阶段算法采用一体化策略, 将分块展平后的图像嵌入直接拼接成一个序列, 输入Transformer主干网络, 最终输出的搜索区域特征用于跟踪预测.在主干网络中, 注意力机制天然适用于联合特征提取与融合:序列中的每个图像块特征通过注意力计算, 可在特征提取的同时完成模板对搜索区域特征的交互与增强, 实现“ 边提取特征, 边融合信息” 的统一.因此, 单流单阶段算法的关注点在于如何设计主干网络以促进充分的特征学习与交互.
1.3.1 目标跟踪数据集
单目标跟踪任务发展至今, 许多场景丰富、规模庞大的公开数据集被提出并应用.早期算法基本采用OTB[41]、UAV123[42]及VOT竞赛数据集等进行评估, 如今以类别更广、质量更高的TrackingNet[43]、LaSOT[44]、GOT-10k[45]、VastTrack[46]数据集等为主要基准.
TrackingNet数据集[43]是目前跟踪领域规模最大、帧数最多、时长最长的基准数据集, 包含从YouTube公开视频中收集的30 132个视频序列, 目标框总标注数和视频帧总数超过1 400万.该数据集涵盖丰富的现实场景, 是衡量单目标跟踪算法性能的核心基准.
LaSOT数据集[44]是一个高质量、大规模且具备密集标注特性的长期视觉跟踪基准, 包含1 400个视频序列, 涵盖85种类别, 总帧数超过350万.视频每帧图像都经过精细的手动标注, 这一特点使其成为迄今为止规模最大的密集标注数据集.
GOT-10k数据集[45]是一个具有挑战性大规模数据集, 由中国科学院发布, 广泛涵盖563种常见的户外物体.GOT-10k的主要特点是训练集和测试集之间没有类别重叠, 并以此提出one-shot协议:算法应严格仅使用该数据集的训练集进行训练, 那么后续测试结果就可有效反映算法的泛化能力.
TNL2K数据集[47]是首个文本引导的长短期目标跟踪数据集, 包含2 000个视频片段, 平均时长为5 000帧, 每个视频初始帧中不仅包含指示目标位置的边界框, 还包含一段英文文本, 从位置、属性、类别等多个角度描述跟踪目标.该数据集可用于训练和评估基于文本提示的目标跟踪算法, 推动单目标跟踪在视觉-语言理解方向的发展.
表1按照时间顺序展示代表性目标跟踪数据集的详细信息.此外, 除了可见光单模态的跟踪数据集, 近年来, 研究者也致力于推动多模态目标跟踪的发展, 构造DepthTrack[48]、VisEvent[49]、LasHeR[50]等多模态跟踪数据集, 通过将深度图、事件流、热红外图像作为补充模态, 显著提升在光照变化、快速运动、遮挡等复杂场景中的跟踪精度与鲁棒性.
| 表1 单目标跟踪数据集 Table 1 Single object tracking datasets |
1.3.2 评价指标
精确率(Precision), 又称目标中心定位精度, 是指预测的目标中心与真实结果的误差.通常使用欧氏距离进行计算, 具体公式如下:
其中, (x1, y1)表示预测框中心坐标, (x2, y2)表示真实框中心坐标.
通常将阈值设为20像素, 即两个中心点的距离小于等于20像素就认定为跟踪成功.其不足之处是对目标尺寸考虑欠佳, 小目标即使和真实位置距离较远, 也会被认定为跟踪成功.
为了解决精确度存在的不足, 归一化精确度(Normalized Precision)把尺寸因素也考虑进来, 即对精确率(Precision)进行归一化操作, 取值在[0, 0.5]区间, 计算两个框的欧氏距离与真实框斜边的比值, 具体公式如下:
其中,
成功率(Success Rate)用于衡量跟踪框和真实框的重叠程度, 基于预测框和真实框的交并比(Intersection over Union, IoU)计算.IoU又称为重叠率(Overlap Precision, OP), 以两个框的交集面积与并集面积的比值计算得到, 具体公式如下:
其中, A表示预测框, B表示真实框.通过上式得到每帧预测的IoU后, 可使用两种统计方法计算成功率.1)阈值法, 将IoU超过预设阈值(如0.5或0.75)的视频帧视为预测成功的帧, 统计成功总帧数占视频总帧数的百分比, 得到成功率.2)面积法, 绘制不同IoU阈值对应的成功率曲线, 计算曲线下面积, 评估整体成功率.
平均重叠率(Average Overlap, AO)通过计算所有视频帧IoU的算术平均值获得, 能直观反映算法的平均跟踪质量, 但未考虑跟踪失败(如严重遮挡)的影响, 具体公式如下:
其中, T表示视频总帧数, At表示第t帧的预测框, Bt表示第t帧的真实框.
单目标跟踪算法的运行速度通常使用帧率描述, 由算法在一定时间内处理的总视频帧数除以总秒数计算而得.现有的单目标跟踪算法基本使用25帧/秒的相机进行拍摄, 因此, 当跟踪算法速度大于25帧/秒时, 可认为达到实时性要求.
本节系统回顾Transformer在单目标跟踪中的具体算法, 重点围绕3类具有代表性的跟踪算法展开论述.
本节介绍Transformer双流双阶段跟踪算法.其中双流是指在特征提取阶段采用两条并行路径分别处理模板和搜索区域, 双阶段是指在特征提取阶段的基础上, 使用Transformer定制模块对提取的模板和搜索区域特征进行关系建模.双流双阶段跟踪算法的分类结构如图2所示.
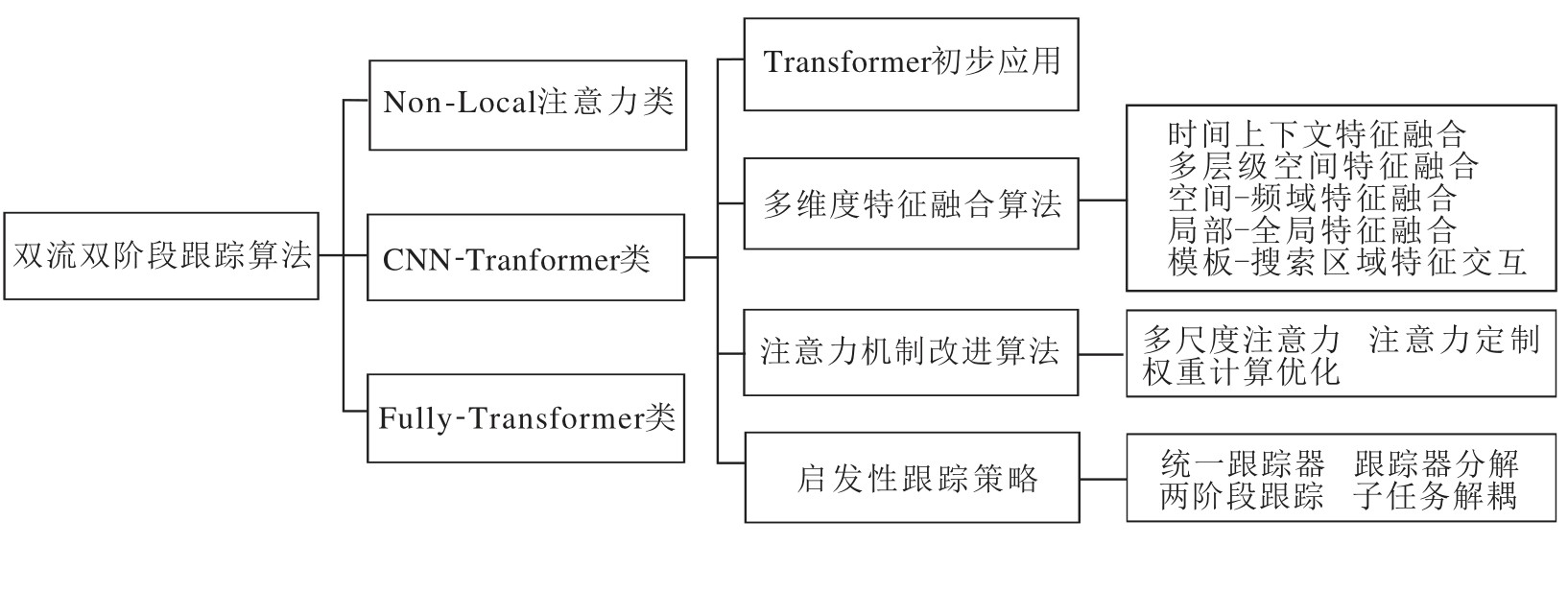 | 图2 双流双阶段跟踪算法分类图Fig.2 Classification framework of two-stream two-stage tracking algorithms |
2.1.1 Non-Local注意力类
Non-Local注意力是一种用于捕捉长距离依赖关系的自注意力机制.该机制突破传统CNN只能处理局部信息的限制, 能直接建模图像任意两个区域的关系, 从而提升模型对全局特征的理解能力.2018年, Wang等[51]提出RASNet(Residual Attentional Sia-mese Network), 设计通用注意力机制、残差注意力机制与通道注意力机制, 将注意力机制引入孪生网络目标跟踪任务中.2020年, Yu等[52]提出SiamAtt(Deformable Siamese Attention Networks), 通过可变形注意力提升孪生网络跟踪器的特征学习能力, 这种注意力机制为跟踪器提供一种搜索区域信息引导的隐式模板更新方法.2021年, Fu等[53]提出STM-Track, 融入历史信息的建模, 该时空记忆网络以像素级的相似度注意力为桥梁, 建立当前帧与历史多帧之间的关联, 引导当前帧关注与目标相关的区域.同年, Guo等[22]提出SiamGAT(Siamese Graph Atten-tion Tracking), 引入图注意力机制, 将模板和搜索区域的特征点建模为图结构中的节点, 采用完全二分图连接方式, 并通过图注意力机制在搜索区域节点之间传播目标信息.
2.1.2 CNN-Transformer类
尽管Non-Local注意力类跟踪算法在一定程度上突破传统CNN的局部建模限制, 增强跟踪算法的全局建模能力, 但此类算法多局限于局部结构的增强, 全局融合不充分, 在处理复杂场景时鲁棒性仍显不足.为此, 研究者开始尝试将Transformer与CNN深度融合, 从而出现CNN-Transformer类跟踪算法.该类算法将Transformer结构引入CNN, 有效增强跟踪器的特征表达能力与跨区域建模能力.
2.1.2.1 Transfomer初步应用
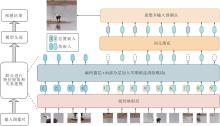
鉴于Transformer在目标检测任务的成功应用, 研究者将其应用于单目标跟踪领域.2021年, Wang等[26]提出TrDiMP和TrSiam.TrDiMP的核心思想是使用Transformer增强CNN提取后的特征, 结构如图3所示.TrSiam和TrDiMP在没有复杂优化的前提下展示Transformer在跟踪领域的有效性.同年, Chen等[27]提出TransT(Transformer Tracking), 设计创新的特征融合方式, 利用注意力机制加强跟踪模型的判别能力.具体来说, 与原始Transformer的编码器-解码器结构不同, TransT使用对称双分支的自注意力模块和交叉注意力模块进行模板和搜索区域的特征融合.同年, Yu等[54]提出DTT(Discriminative Tra- cking with Transformers), 使用CNN提取输入特征, Transformer进行特征增强与交互.2022年, Mayer等[55]提出ToMP, 将Transformer应用至判别性相关滤波跟踪架构上, 替代传统的模型优化器.上述算法都初步将Transformer应用至目标跟踪网络中, 提升跟踪的准确率与鲁棒性, 为后续算法的发展奠定理论基础.
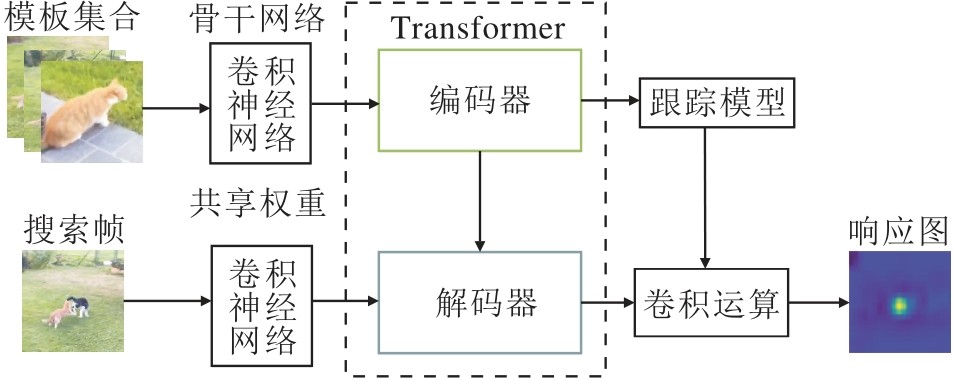 | 图3 TrDiMP结构图Fig.3 TrDiMP architecture |
2.1.2.2 多维度特征融合算法
早期基于注意力机制的目标跟踪算法通常仅使用空间特征作为Transformer的输入, 忽视特征的多样性, 在一定程度上限制鲁棒性的提升.多维度特征为Transformer的长距离依赖建模提供多样化的输入, 因此越来越多的研究者致力于将时序、多层级空间域与频域等多维特征输入Transformer进行深度融合与交互, 增强算法的感知能力.
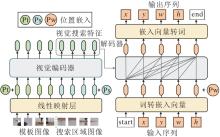
1)时间上下文特征融合.视频序列天然具有时空连续性, 目标在相邻帧的变化关系可为Trans-former提供时间上下文输入, 融合后的时空特征有助于提升Transformer对动态目标的建模能力.2021年, Yan等[28]借鉴DETR的设计与Transformer编码器-解码器结构, 提出STARK, 结构如图4所示.STARK引入动态模板, 通过Transformer对初始模板、动态模板和当前帧进行时空建模, 从而增强算法在复杂场景中的跟踪鲁棒性.经过Transformer处理后的特征用于目标角点预测, 并根据得分判断是否更新动态模板, 整个过程无需额外的后处理.2023年, Chen等[56]在TransT基础上提出TransT-M, 引入多个历史帧, 构建目标外观模型.初始帧与历史帧特征经过基于Transformer的融合模块, 生成更具判别性的特征.STARK与TransT-M均采用在线打分机制以判断是否更新模板, 但对时间上下文的利用局限于筛选模板帧层面, 尚未充分挖掘跨帧间的深层语义关联.2022年, Cao等[57]提出TCTrack, 将当前帧的特征与上一帧的时序特征输入编码器以进行特征交互, 并作为新的时序特征传递至下一帧.在TCTrack的基础上, Cao等[58]提出TCTrack++, 进一步引入基于注意力机制的骨干网络, 并优化在线模板更新策略, 显著提升算法的时序建模能力.
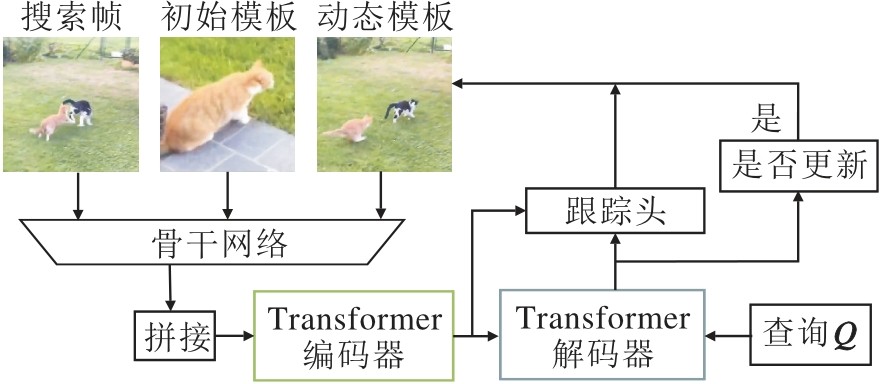 | 图4 STARK结构图Fig.4 STARK architecture |
2)多层级空间特征融合.浅层特征主要表征图像中的纹理、边缘与颜色等低层次视觉信息, 具备分辨率高、定位精确、细节丰富等优势.相比之下, 深层特征更偏向于目标类别、高层语义等抽象内容, 具备较强的鲁棒性和识别能力, 但由于多次下采样, 导致位置信息模糊、细节丢失、分辨率较低.许多单目标跟踪算法仅使用骨干网络最后一层的深层特征, 忽略有助于目标定位的浅层特征, 从而限制定位精度的提升.2021年, Cao等[59]提出HiFT(Hierarchical Feature Visual Transformer), 将骨干网络的层次化特征输入Transformer进行特征融合与增强.同时, 将Transformer结构改造为层级式特征融合模块, 取代原始目标查询向量, 并引入特征调制层, 强化空间语义的互补性, 从而建模更具判别力的特征空间.然而, 由于HiFT在无人机平台上采用AlexNet[60]骨干网络, 其浅层结构在面对复杂场景或超小目标时可能存在特征表达不足的局限性, 影响整体跟踪性能.2022年, Xing等[61]提出SiamTPN(Siamese Trans-former Pyramid Network), 将模板和搜索区域分别输入共享的轻量级网络, 提取多层级特征, 再输入Transformer金字塔网络进行跨尺度语义融合.最后, 通过互相关匹配, 由分类与回归分支预测目标位置.
3)模板-搜索区域特征交互.基于孪生网络的跟踪算法通常使用骨干网络进行独立特征提取, 模板与搜索区域缺乏交互, 导致输出的搜索帧特征无法感知目标信息, 从而限制跟踪网络的目标判别能力.2022年, Guo等[62]提出InBN(Interaction Inside the Backbone Network), 设计GIM(General Interac-tion Modeler), 在多个阶段交互模板特征与搜索特征, 引导骨干网络提取更具目标感知的特征表示.在推理过程中, 模板与搜索区域分别通过共享权重的骨干网络提取特征, 并在各阶段进行GIM交互.InBN引入特征交互机制, 强化特征学习过程的目标建模能力, 并适用于多种网络类型, 为后续基于交互式结构设计的目标跟踪研究提供有效参考.
4)局部-全局特征融合.Transformer在建模长距离的全局依赖关系方面表现出色, 但由于缺乏类似CNN结构中的局部感受野与归纳偏置, 难以有效捕捉图像中的局部特征.相比之下, CNN具备良好的局部建模能力与空间不变性.然而, 由于其感受野大小受限, 在全局建模方面仍存在一定局限.为了弥补上述缺陷, 2024年, Ni等[63]提出LGFF, 有机融合Transformer的全局建模能力与CNN的局部感知能力.具体地, 首先模板与搜索区域经过骨干网络提取特征后, 通过局部-全局特征交互模块增强语义信息, 然后经过特征融合模块实现跨区域交互和增强, 最后进行目标定位.2024年, Wang等[64]提出MKF-Track(Matching Knowledge Fusion Tracker), 引入可交互的双分支匹配通路, 使Transformer特征与CNN特征在交互阶段实现协同融合, 增强算法对目标区域的响应.
5)空间-频域特征融合.大部分跟踪算法主要聚焦在空间域或通道域进行特征增强, 较少关注频域信息的挖掘与利用.然而, 研究表明, 注意力机制擅长建模低频结构, 而CNN在捕捉高频纹理方面较有效.因此, 单一特征域的建模方式难以兼顾不同频段的信息表达, 限制跟踪算法的性能.为此, 2025年, Xiong等[65]从空间频域融合角度出发, 结合掩码引导机制, 提出MGTrack(Mask-Guided Siamese Tra- cking), 首先提取多尺度空间特征, 通过频域-空间域融合模块实现特征融合.然后, 融合结果与模板特征和掩码共同输入频域-空间注意力模块, 进一步完成空间-频域的特征交互.
多维度特征融合算法表现出相对统一的设计思想:在模板与搜索特征的基础上显式引入不同维度的特征, 并通过注意力机制完成特征交互和融合, 获得更具判别性的目标表征.不同算法的本质差异主要体现在两点.1)在融合位置上存在骨干网络内部的早期融合与经过骨干网络之后的后期融合之分, 前者侧重细粒度局部建模, 后者偏重高层语义整合.2)在特征维度选择上, 有的算法依赖置信度驱动的模板更新, 有的算法通过时序特征传递历史信息, 也有算法通过融合多尺度、多层级或频域特征提升跟踪鲁棒性.
2.1.2.3 注意力机制改进算法
由于Transformer的计算复杂度随输入序列长度呈二次增长, 限制算法在计算资源受限设备上的实际部署.此外, 图像与文本序列在结构与分布上差异显著, 使得直接迁移NLP中的Transformer架构面临诸多挑战.因此, 研究者围绕Transformer的注意力机制开展大量改进性探索, 挖掘其在目标跟踪任务中的潜力.本节从注意力机制改进角度, 针对多尺度注意力、权重计算优化与注意力定制三个方面梳理代表性的目标跟踪算法.
1)多尺度注意力.2022年, Song等[66]受到Swin Transformer的启发, 提出CSWinTT(Cyclic Shifting Window Transformer Tracker), 增强Transformer在不同尺度的建模能力和窗口之间的特征交互能力.CSWinTT将注意力机制从像素级扩展至窗口级, 通过循环位移策略扩大感受野, 同时有效保留目标的结构信息.此外, CSWinTT还设计空间正则化注意力掩码, 缓解窗口边界因位移带来的性能退化问题, 有效提高注意力的空间选择性.在推理阶段, 首先将骨干网络特征按照多尺度划分为窗口, 并对每个窗口执行循环平移操作, 生成多个样本, 然后通过Transformer进行特征融合.CSWinTT在建模过程中兼顾多尺度融合与局部结构保持, 跟踪效果较优.
2)权重计算优化.原始Transformer在计算Query与Key之间的相关性时采用独立计算, 未考虑全局上下文之间的一致性, 容易在背景复杂时引入错误或模糊的注意力权重, 制约Transformer在跟踪任务中的性能表现.为了应对上述挑战, 2022年, Gao等[67]提出AiATrack(Attention in Attention for Trans-former Visual Tracking), 设计嵌套注意力模块, 嵌入一个内层注意力, 细化原始相关性矩阵, 利用其它Query与Key对之间的共识信息, 对每个相关性向量进行全局再聚合, 从而动态增强权重相关性, 抑制不合理权重.这一设计将注意力内部的相关性作为显式建模对象, 使得Transformer结构在跟踪任务中获得更强的判别能力.同年, Fu等[68]提出SparseTT, 显式选择最相关的若干Key进行注意力计算, 实现注意力稀疏化.该稀疏化机制使注意力集中于与目标强相关区域, 显著增强算法区分前景与背景的能力.同时, SparseTT在权重计算上的优化为后续的Transformer跟踪提供有效思路.
3)注意力定制.为了进一步提升Transformer对目标跟踪任务的适应性, 研究者逐步探索针对Transformer进行结构层级的定制与语义增强设计, 应对复杂环境下的动态变化与背景干扰.2023年, Liang等[69]提出GdaTFT, 设计全局膨胀注意力模块, 引入稀疏采样与通道增强机制, 在增强语义表达的同时保留局部结构细节.此外, GdaTFT还引入目标聚焦网络模块, 采用模板作为Query建立点对点相似性矩阵, 对目标特征在搜索区域中进行选择性增强, 实现语义层级的精准聚焦.得益于全局膨胀注意力与目标聚焦网络的协同作用, GdaTFT在遮挡、形变等复杂场景中展现出优异的跟踪精度.
上述算法旨在保留Transformer全局上下文建模优势的同时, 引入适合视觉跟踪的归纳偏置, 使注意力由通用的NLP版本演化为面向跟踪任务的专用设计.在此思想下, 不同算法的本质差异主要体现在切入角度上:多尺度注意力侧重于“ 看哪里” , 通过多尺度与局部窗口机制提升对尺度变化与局部细节的建模能力; 权重计算优化关注“ 如何加权” , 通过嵌套注意力或稀疏选择改善相关性矩阵的质量; 注意力定制将任务先验直接编码进注意力结构.
2.1.2.4 启发性跟踪策略
双流双阶段跟踪算法通常采用模板与搜索区域作为输入, 经过骨干网络后利用Transformer进行特征交互与全局建模, 最后由预测头完成目标定位.为了进一步提升跟踪算法的定位精度与鲁棒性, 研究者从模型结构与任务机制出发, 提出一系列具备启发性设计的跟踪策略.本节围绕启发性跟踪策略展开讨论, 从统一跟踪器、跟踪器分解、两阶段跟踪与子任务解耦等方面, 系统梳理代表性的相关算法.
1)统一跟踪器.单目标跟踪算法与多目标跟踪算法各自独立发展, 二者在训练范式与推理结构上存在显著差异, 难以实现资源共享与结构协同.在实际部署中, 往往需要加载两个模型, 导致计算冗余.2022年, Ma等[70]提出UTT(Unified Transformer Tra- cker), 打破单目标跟踪与多目标跟踪之间的壁垒.在统一主干与解码结构下同时支持单目标与多目标的处理, 单目标跟踪以初始帧标注目标为参考完成单目标位置回归, 多目标跟踪以检测结果为参考实现多目标的位置预测与身份关联.UTT通过统一的Transformer跟踪结构、多任务训练策略及目标解码模块, 为多任务跟踪提供借鉴方法.
2)跟踪器分解.大多数跟踪算法都依赖单一全局跟踪器完成整图范围内的目标定位, 缺乏对特定区域独立的建模能力.2022年, Zhou等[71]提出GTELT, 使用多个局部跟踪器组成一个全局跟踪器, 实现局部-全局切换策略和全局重检测方法.GTELT在图像全域均匀布置多个局部跟踪器, 每个跟踪器负责在局部区域内搜索目标.当某一局部跟踪器成功捕获目标, 通过时间上下文聚合模块持续维护目标状态.若当前跟踪器失效, 算法将自动激活其邻近区域的候选跟踪器接管任务, 从而实现无缝切换与高效恢复.该策略通过分解全局视野为多个区域子任务并协同运作, 实现高效的全局跟踪.
3)两阶段跟踪.多数现有跟踪算法采用单阶段推理完成目标定位, 缺乏对任务复杂度差异的动态适应能力, 进而限制算法在多样场景中的泛化表现.2024年, Liu等[72]提出SRTrack(Saliency Region Tra- cker), 由轻量跟踪阶段与显著性跟踪阶段构成.首先利用轻量级Transformer对粗划分的图像块进行快速匹配, 生成初步注意力图.若预测置信度高于预设阈值, 直接输出目标位置, 否则进入显著性跟踪阶段.在该阶段, 依据初步注意力图构建显著性区域指示器, 聚焦更精细区域, 提升定位精度.SRTrack采用显著性驱动的计算资源调度机制, 实现高效的目标跟踪推理.
4)子任务解耦.2025年, Sun等[73]发现目标跟踪中的分类与回归子任务在特征偏好上存在显著差异, 然而现有方法普遍缺乏有效的协同机制, 容易导致“ 高分类置信度却大回归偏差” 的语义不一致性, 影响整体跟踪性能.为此, 提出MAPNet(Multi-attention Associate Prediction Network), 分别为分类与回归子任务构建独立的特征处理分支, 并引入注意力机制, 对分类、回归网络进行协同处理.其中, 设计的类别感知与空间感知匹配器分别提取用于分类与回归的初始特征, 再通过对齐模块进行特征融合与任务适配, 为解决特征冲突和决策错位问题提供可行思路.
尽管CNN-Transformer类算法通过结合CNN的特征提取能力与Transformer的长距离建模优势, 在跟踪任务中取得显著进展, 但是, 这类算法普遍依赖CNN骨干网络, 局部感受野与固定模式的特征提取方式限制算法对全局语义与结构信息的建模能力, 在面对遮挡、形变或背景干扰时, 表现不够鲁棒.
2.1.3 Fully-Transformer类
CNN由于局部感受野机制限制其特征提取能力, 同时也难以进行全局特征交互.与CNN不同, Transformer具备天然的全局关系建模能力.因此, 初期的研究者尝试使用Transformer替代CNN作为骨干网络, 以此提升算法对目标区域的全局感知能力.这类算法实现从局部增强到全局建模的初步转变, 为后续跟踪算法的发展提供新的方向.
2021年, Xie等[29]提出DualTFR(Dual-Branch Transformer), 是一种完全基于Transformer的端到端目标跟踪框架, 采用双分支结构, 分别对模板和搜索区域进行Transformer编码, 通过局部注意力、全局注意力和跨分支注意力模块, 实现跨空间尺度与语义层级的特征交互与融合.实验表明, Fully-Trans-former架构在跟踪性能方面显著优于先前的混合结构, 鲁棒性与可扩展性更优.2022年, Lin等[30]提出SwinTrack, 结构如图5所示.SwinTrack构建一个端到端的Transformer跟踪框架, 有效强化特征表示能力.在推理阶段, 模板与搜索区域分别经过Swin Transformer编码, 生成对应的视觉词元, 并在拼接后共同作为编码器的输入, 在多层自注意力模块与前馈网络中完成视觉语义的融合建模.在解码器阶段, 引入额外的运动词元, 通过交叉注意力机制实现视觉信息与运动信息的有效融合.SwinTrack验证Transformer在特征建模中的有效性, 同时展现出运动轨迹信息在提升跟踪鲁棒性方面的重要作用.2023年, He等[74]提出TATrack, 使用Transformer作为骨干网络, 设计长时上下文注意力模块, 可同时处理目标模板、历史搜索帧及当前搜索区域, 通过跨帧注意力机制有效融合目标特征与时间上下文特征, 增强算法对目标的判别能力.上述算法使用Transformer代替CNN, 并探索多样化特征, 提升跟踪性能.
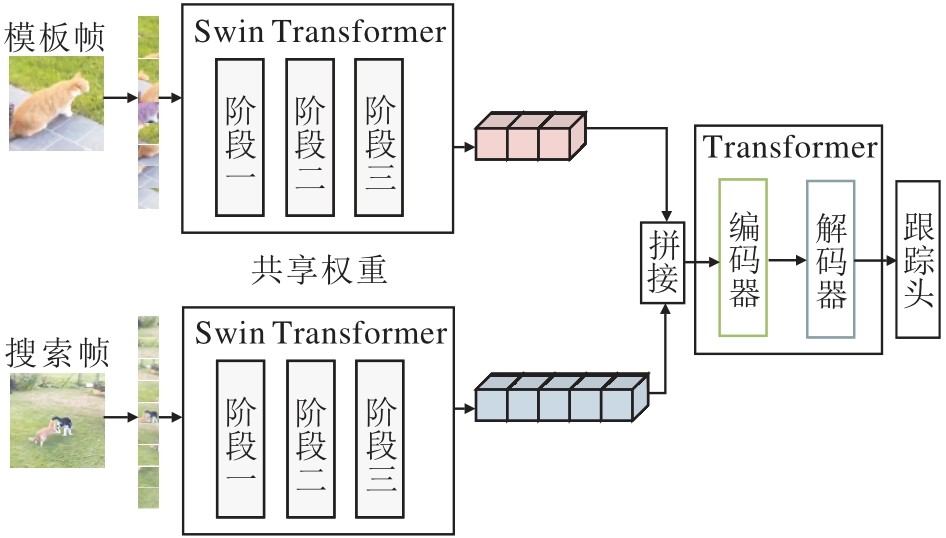 | 图5 SwinTrack结构图Fig.5 SwinTrack architecture |
在后续研究中, 研究者提出诸多改进的算法.2023年, Tang等[75]提出SFTransT, 构建空间-频域联合建模的Transformer, 利用高斯空间先验机制保留输入特征的空间结构, 同时引入频域增强注意力模块, 突出高频细节信息, 实现更具判别力的目标特征表达.同年, Tang等[76]提出TSMtrack(Transformer Sub-patch Matching Network for Tracking), 是一种基于子块匹配机制的Transformer跟踪算法, 将图像划分为多个子区域, 并分别提取特征.再通过交错迭代子块匹配模块计算模板与搜索区域中各子块之间的相似度评分, 并将融合特征用于预测目标位置.2024年, Chen等[77]提出LGSAT(Local-Global Self-Atten-tion for Tracking), 引入局部-全局联合建模的自注意力机制, 能在同一注意力模块中同时捕捉局部细节与全局上下文.此外, 设计并行的局部与全局注意力分支, 通过通道融合生成更丰富的特征表示.LGSAT实现统一的局部目标区域与全图范围的关系建模, 有效提升复杂场景中的跟踪稳定性.
Fully-Transformer类算法使用Transformer完全替代CNN, 实现从特征提取到信息交互的端到端建模, 在目标跟踪任务展现出较大潜力.然而, 此类算法仍延续传统的双流架构设计, 即模板与搜索区域分别编码后再交互, 导致特征提取与关系建模分离, 影响特征判别性.为了进一步提升特征交互与建模质量, 研究者开始探索基于Transformer的单流单阶段跟踪算法[31].该类算法将模板与搜索区域统一输入Transformer, 进行联合的特征提取与信息交互, 避免双流双阶段跟踪算法的结构设计, 更简洁高效.
基于Transformer的单流单阶段跟踪算法从2022年开始出现并逐渐发展.双流双阶段跟踪算法大多遵循孪生网络架构的双阶段范式, 尽管通常使用参数共享的骨干网络保证特征空间的一致性, 但这种分离设计仍存在显著的性能瓶颈— — 目标特征交互不足.模板和搜索区域往往具有不同的尺寸和形变差异, 导致特征匹配困难, 跟踪精度下降.在计算量方面, 双流双阶段架构会增加内存占用与计算开销, 限制算法在资源受限环境中的部署和应用.
为了克服上述问题, 研究者利用Transformer的全局建模能力与注意力机制, 提出基于Transformer的单流单阶段跟踪算法.该算法将模板与搜索区域统一编码, 在特征提取的同时进行信息交互, 从而保证捕获更多与目标相关的线索.
单流单阶段跟踪算法发展至今, 已产生一系列研究成果.本节将梳理2022年以来的代表性算法, 分为经典单流算法、自回归算法和基于提示的算法, 按照发展脉络对其进行介绍和论述.
2.2.1 经典单流算法
本节对经典单流Transformer跟踪算法按照时间发展脉络进行梳理和介绍, 为后续跟踪工作奠定模型基础与理论启发.
Cui等[78]提出MixFormer, 是最早利用注意力操作的灵活性做出的创新性工作, 实现一种端到端的Transformer单流跟踪架构.受CvT(Convolutional Vi- sion Transformer)[79]启发, 在自注意力基础上引入交叉注意力, 设计MAM(Mixed Attention Module), 对模板和搜索区域分别进行自注意力计算, 用于提取特征, 同时对两者进行交叉注意力计算, 促进信息交互.MixFormer由两部分构成:由若干个MAM堆叠而成的主干和一个预测头部.为了利用时间信息提升模型鲁棒性, 引入在线模板更新机制, 使用一个额外的分数预测模块评估何时更新.此时算法输入会包含多个模板图像, 因此采用创新的非对称混合注意力, 提高MAM的计算效率, 保证模板和搜索区域之间高效的信息交互.
Xie等[80]提出SBT(Single Branch Transformer), 也是一种基于注意力机制的创新实现, 与MixFormer的混合注意力不同, SBT设计的EoC(Extract-or-Co-rrelation)模块可指定实现自注意力或交叉注意力.输入图像通过卷积和层归一化操作映射成特征图像后, 先使用EoC-自注意力层执行自注意力计算, 增强特征表示, 再交替使用EoC-自注意力层与EoC-交叉注意力层.EoC-交叉注意力层通过特征交互过滤与目标无关的特征, 并保留相关特征.最后, 将融合后的搜索区域特征送入分类与回归头, 利用多层感知器建模特征空间和通道维度的依赖关系并预测结果.在后续研究中, Xie等[81]提出SuperSBT, 通过分层架构设计、浅层特征增强和计算效率优化等改进措施, 在保持简洁单流框架的同时, 优化跟踪精度与运行速度之间的平衡, 为Transformer在视觉跟踪中的应用提供更优的解决方案.
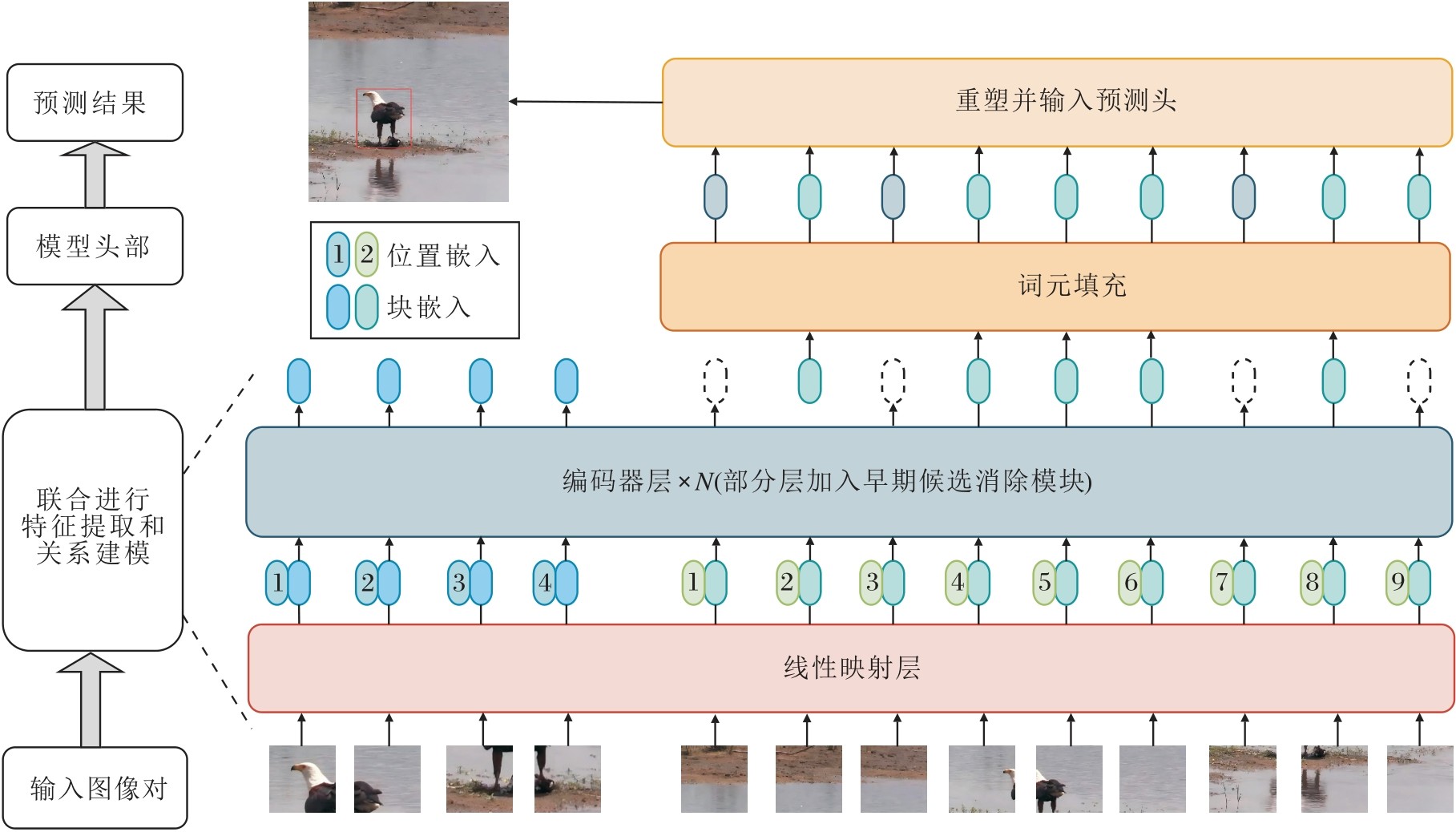
SBT和SuperSBT灵活利用注意力机制, 实现双流向单流的演变, 而Ye等[31]提出更完整的单流跟踪框架OSTrack(One-Stream Tracking), 联合特征提取和关系建模, 建立信息流的自由流通, 实现面向目标的特征学习, 避免判别性信息丢失.OSTrack参照ViT基本流程, 将映射后的模板和搜索区域拼接并输入堆叠的Transformer编码器中, 通过自注意力机制的全局建模特性实现联合特征提取和信息交互, 相应结构如图6所示.编码器中引入早期候选消除模块, 根据目标和搜索区域的相似性自适应丢弃潜在背景词元.这不仅在一定程度上减轻计算负担, 还避免背景区域对特征学习的负面影响.另外, 采用高效简单的自监督学习方法MAE(Masked Autoenco- ders)[82]进行ViT主干的预训练, 掩盖输入图像的一部分并重建这些被掩盖的部分, 实现图像的自监督表征学习.实验表明, MAE预训练的ViT具有较鲁棒的上下文建模能力和较优的泛化性, 后续工作都将其作为主干[83, 84, 85], 也有一些工作对MAE预训练做出改进[86, 87].同期, Chen等[32]提出SimTrack(Simplified Tracking), 同样使用标准ViT作为主干, 实现联合的特征提取与交互学习.在图像序列化时, 模拟人类视觉的注视机制, 设计中心凹窗口策略, 增强目标相关线索.该策略从模板中心裁剪一个更精细的目标区域, 将其作为额外的输入词元, 为算法提供更多的目标信息.
 | 图6 OSTrack结构图Fig.6 OSTrack architecture |
现有单流跟踪器在编码器层让模板和搜索区域所有词元交互, 这可能会导致前景背景混淆、特征质量降低.针对这一问题, 2023年, Gao等[88]提出GRM, 在注意力计算之前通过自适应分类模块对搜索区域词元进行动态分类, 分为目标词元和背景词元.模型限制背景词元与模板交互, 在编码器中对模板和目标词元、两类搜索词元进行注意力计算, 有效融合信息.此外, 在处理搜索区域词元时, 引入Gumbel噪声结合Softmax函数, 将离散分类问题转化为可微分问题, 完成端到端训练.
单流单阶段跟踪算法在发展初期主要专注于如何使用单流架构实现联合特征提取与融合, 缺乏时序增强方面的研究推进.现有算法大多仅以第一帧目标模板作为视频序列全程的参考信息, 因此无法较好地适应目标外观变化, 导致长时跟踪容易失败.为了解决这一问题, Lan等[83]提出ProContEXT(Progressive Context Encoding Transformer Tracker), 利用时空信息进行渐进式上下文编码.主要包括三方面改进:1)将单个静态模板拓展成多个静动态模板组成的模板组, 用于编码跟踪过程中的物体外观变化.2)在编码器中引入上下文感知的自注意力机制, 实现上下文信息聚合.3)忽略带有噪声背景的搜索词元, 降低计算成本.另一方面, Xie等[85]首次将Video Transformer应用于跟踪任务, 提出Video-Track.不同于孪生跟踪算法的输入规范, VideoTrack允许模型直接以视频中的连续帧作为输入, 将经典的成对匹配提升至序列级目标匹配范畴.为了利用视频序列中的先验信息, VideoTrack采用三分支架构, 将输入序列分为3类— — 包含强外观信息的初始帧、包含目标动态线索的中间帧和包含预测目标的搜索帧, 使用非对称注意力机制进行处理.另外, 为了消除视频序列中的大量冗余信息, 将目标外观信息沿时间方向上的固定线索与变化线索分别解耦至静态模板和动态模板, 确保鲁棒高效的视频目标跟踪.
为了提升算法在复杂场景中的跟踪能力, 除了利用上述时间信息, 研究者还从目标建模、特征学习、模型预训练等多个角度进行改进和创新.
对于目标建模, Cai等[84]将现有的Transformer跟踪算法按建模方法分为3类:双流混合建模方法通过两次交叉注意力操作与搜索区域交互学习模板特征; 双流分离建模方法保持固有模板流以确保模板特征的纯净性; 单流混合建模方法直接利用ViT架构, 通过自注意力联合学习混合模板和搜索区域特征.为了结合上述方法的优点, Cai等[84]提出ROM-Track(Robust Object Modeling Framework for Visual Tracking), 同时对固有模板特征和混合模板特征进行建模, 实现干扰因素抑制与空间特征鲁棒性提升.此外, ROMTrack还利用变体词元描述目标不断变化的外观, 将模型鲁棒性拓展至时间层面.
在特征学习上, Transformer跟踪器之所以容易受到复杂环境干扰, 主要有如下两方面原因.1)从初始模板中挖掘前/背景信息的模型无法较好地学习判别性特征.2)采用简单注意力机制进行特征交互, 通过外观相似度计算注意力分数, 可能引入与目标相似的背景干扰.为此, Yang等[89]提出FBDM-Track(Foreground-Background Distribution Modeling Transformer for Tracking), 整体结构与OS-Track类似, 核心创新包含FBAL(Fore-Background Agent Learning)模块和DA2(Distribution-Aware Attention)模块.FBAL模块计算每块和前/背景代理之间的相似性, 得到前/背景分布, 再通过计算各块的分布相似性, 用于后续的特征聚合.这种前/背景判断方法能在目标和背景外观相似的情况下获得鲁棒的区分性.DA2模块利用FBAL模块得到的前/背景分布结果替换注意力机制中的外观特征, 充当注意力操作中的Query和Key, 使算法拥有更优的目标感知能力.
大部分Transformer单流跟踪算法[30, 31]主干使用在ImageNet上通过MAE技术预训练的ViT, 以此保证特征提取的质量.MAE自监督学习方法在计算机视觉领域具有优秀的泛化性, 但由于离散图像和连续视频之间存在时间维度的差异, 限制其在目标跟踪任务上的应用.针对这一问题, Wu等[86]提出DropMAE, 是一种为时间匹配型下游任务(如目标跟踪)服务的视频级模型预训练方法.DropMAE将MAE的单图输入改良为跟踪任务的模板-搜索区域图像对, 设计空间注意力丢弃机制.该机制在注意力计算时丢弃权重矩阵, 限制Query和同帧词元进行信息交互, 鼓励与其它图像帧词元交互.这种方式强制算法在掩码重建时关注时序线索而非局部空间特征, 显著提升时序建模能力.另外, DropMAE采用渐进式训练策略, 逐步增加掩码比例, 使注意力模型能逐渐适应目标跟踪任务的需求.
DropMAE是在时间信息层面对MAE进行优化, Zhao等[87]提出MAT(Masked Appearance Trans- fer), 是从空间特征交互维度进行创新.作为一种面向目标跟踪任务的新型表征学习范式, MAT的核心在于构建模板与搜索区域的空间特征映射关系.首先将模板和搜索区域的视觉外观联合编码, 然后分别解码.在解码时, MAT对两种图像的重建制定不同目标, 搜索区域词元被重建成原始搜索图像, 模板词元被要求重建成从搜索区域中裁剪得到的“ 新模板” .这种目标外观迁移机制迫使编码器建立跨视图的语义对应, 使模板特征能自适应接近搜索区域中的目标表征, 从而学习具有强判别性的跟踪专用特征.
2.2.2 自回归算法
现有目标跟踪算法通常采用多任务范式, 将跟踪主任务视为分类、回归、角点预测等子任务, 并利用多个独立分支完成这些任务.然而, 每个子任务都需要人工定制的网络, 提升算法结构的设计难度.此外, 每个子任务都涉及一个或多个损失函数, 增加算法训练难度.近年来, 研究人员参考NLP领域常用的自回归序列生成范式, 提出基于Transformer的自回归目标跟踪算法.这类算法将目标状态预测建模为序列生成问题, 避免传统跟踪算法对复杂头部网络和冗余损失函数的硬性需求, 在简化架构设计的同时实现端到端优化.
Chen等[90]提出Pix2Seq, 将目标检测任务转换为以像素标记输入为条件的语言建模任务, 将边界框和类别标签表示为离散序列, 简化处理流程.受此启发, Chen等[91]在2023年提出SeqTrack(Sequence-to-Sequence Tracking), 首次将目标跟踪任务建模为目标框坐标的自回归序列生成问题, 具体结构如图7所示.编码器工作流程和传统ViT主干类似, 仅在最后一层额外加入线性映射层进行特征维度对齐.解码器初始输入为由边界框转化而成的离散词元序列(如[x, y, w, h]), 每个解码器层先对离散序列执行掩码自注意力, 约束自回归生成过程, 确保坐标的预测仅依赖前序信息.之后, 序列与来自编码器的搜索特征进行交叉注意力计算, 引入视觉线索指导.此外, 序列中还加入start和end两个辅助标记, 指导目标边界框序列生成的开始和结束.
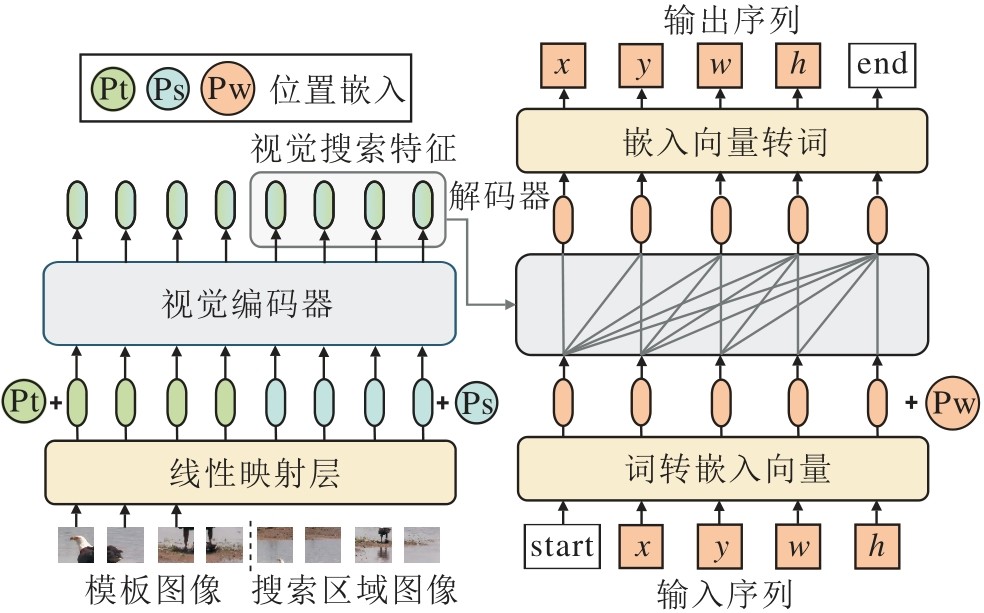 | 图7 SeqTrack结构图Fig.7 SeqTrack architecture |
同样受Pix2Seq启发, Wei等[92]提出ARTrack, 首次将多帧轨迹序列纳入自回归坐标序列生成过程, 显式利用历史轨迹信息辅助当前帧目标的位置序列生成.ARTrack包含构建离散词元序列、编码器提取视觉特征、解码器联合外观历史信息生成当前帧目标位置序列三个阶段.核心创新在于引入历史帧的离散坐标序列, 并与Command Token拼接, 通过掩码注意力聚合历史序列中的有效信息.聚合序列再与外观特征进行交叉注意力操作, 实现时空特征联合指导并生成最终预测序列.后来, Bai等[93]提出ARTrackV2, 是一种联合轨迹-外观的自回归跟踪算法, 在ARTrack基础上拓展“ 外观” 概念, 使用一组外观提示, 在序列预测的同时重建目标图像, 加强算法对目标外观变化的描述能力.此外, 针对解码器自回归效率低下的问题, 通过纯编码器结构并行处理所有词元, 显著提升自回归方法的效率.
2025年, Shi等[94]针对现有单流单阶段跟踪算法时序信息利用不足的问题, 提出TGTrack(Trajec-tory Guided Tracking).与ARTrack类似, TGTrack采用编码器-解码器架构, 使用历史信息自回归生成当前位置预测.两者区别在于:1)ARTrack重复利用历史坐标, 以顺序方式单独预测每个坐标, TGTrack借助历史轨迹构建候选位置词元, 根据词元查询目标位置, 直接预测坐标.2)ARTrack把所有历史坐标序列输入注意力层进行处理, 但由于注意力操作中位置和尺度之间的模糊性, 可能引起模型判断混乱.TGTrack将历史边界框都嵌入轨迹词元中, 通过历史信息帮助跟踪器感知目标的当前潜在位置, 实现稳定跟踪.
自回归式单目标跟踪算法通过将目标状态预测重构为序列生成问题, 开创跟踪范式从多任务解耦到端到端生成的革新路径.以SeqTrack、ARTrack为代表的一系列工作, 通过坐标序列化、历史轨迹建模等核心创新, 有效解决传统目标跟踪框架中存在的训练复杂、分类回归不对齐等问题.
2.2.3 基于提示的算法
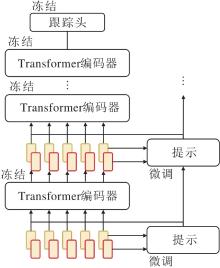
在NLP领域, 得益于全局注意力机制和并行训练特性, Transformer能高效编码长距离依赖关系, 在大规模语言数据集上快速训练.但是, 由于语言任务种类繁多, 任务间差异不大, 为每种任务单独微调整个大模型成本较大.同样, 在计算机视觉领域, 对于不同下游任务也需要微调整个模型以适应任务特性, 训练开销较大.提示学习为上述问题提供可行的解决思路, 目前已在视觉任务中广泛应用.
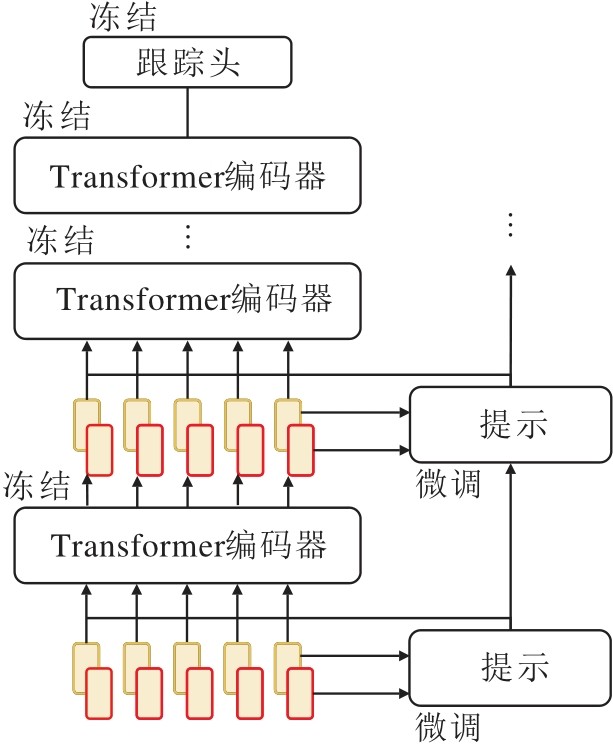
提示学习是机器学习中的一种特殊学习方法, 设计特定的提示(Prompt), 将下游任务的输入转换为预训练模型可理解的格式, 无需大量调整参数即可适配任务.这种方法的核心思想是“ 让任务适应模型” , 而非传统的“ 让模型适应任务” .受到提示学习的启发, 研究者尝试引入少量可学习的提示模块, 引导预训练模型适应跟踪任务, 显著降低模型的训练成本.根据提示信息的生成方式和作用机制, 现有方法可分为隐式提示优化与显式提示建模.隐式提示优化遵循提示学习的基本定义, 以隐式提示的方式实现低成本模型适配.显式提示建模将显式提示信息在视频帧间传播, 有效利用时序轨迹或外观变化信息.
隐式提示优化的代表性跟踪算法有LoRAT[95]和HIPTrack(Historical Prompt Network for Tra-cking)[96].Lin等[95]提出LoRAT, 是一种基于PEFT(Parameter-Efficient Fine-Tuning)的目标跟踪算法, 引入LoRA(Low-Rank Adaptation)技术, 显著降低ViT的训练成本.传统Transformer跟踪器在训练时需要全微调参数, 导致资源消耗.LoRAT通过冻结预训练的ViT主干, 仅对低秩分解矩阵进行微调, 在减少训练参数的同时缩短延迟.针对视觉跟踪任务中模板与搜索图像位置嵌入、卷积归纳偏差等问题, LoRAT将位置嵌入解耦为共享的绝对坐标嵌入和独立的目标类型嵌入, 并保留预训练模型的空间结构.
同年, Cai等[96]提出HIPTrack, 动态聚合历史目标信息, 增强复杂场景中的跟踪鲁棒性.针对大多数跟踪器依赖静态模板的局限, HIPTrack设计由编码器和解码器组成的历史提示网络.编码器通过精细化前景掩码提取目标位置与视觉特征, 并生成提示值; 解码器利用当前搜索区域特征作为Query, 基于欧氏距离注意力从记忆库中自适应聚合历史提示.该方法创新性地将提示学习引入跟踪任务, 仅需完成轻量级提示网络的训练即可为冻结主干提供动态历史提示.同时, 作为即插即用的模块, 历史提示网络还可无缝集成至其它现有跟踪器, 通用性较好.
与上述隐式提示方法不同, 显式提示建模方法脱离提示学习定义, 其“ 提示” 是指算法中引入的额外信息.代表性算法有EVPTrack(Explicit Visual Prompts Tracking)[97]、ODTrack[98]、AQATrack[99], 均于2024年发表.
Shi等[97]提出EVPTrack, 采用HiViT(Hierar-chical Vision Transformer)作为视觉编码器, 创新性地构建多尺度模板提示和时空提示令牌.多尺度模板提示通过不同粒度的模板特征增强目标表示, 时空提示令牌利用连续帧间的时空关系建模目标运动轨迹.Zheng等[98]提出ODTrack, 设计时序令牌传播注意力机制, 将历史帧的目标信息压缩为动态令牌序列, 并通过跨帧的令牌迭代更新实现视频级时空建模.Xie等[99]提出AQATrack, 引入自回归查询机制, 使用时序解码器对目标查询进行跨帧状态演化建模, 通过时序注意力捕捉目标运动轨迹, 在复杂场景中表现突出.
提示学习为视觉跟踪领域开辟高效适配预训练模型的新范式, 通过“ 任务适配模型” 的核心思想推动跟踪算法性能与效率的协同进化.隐式提示优化类算法通过参数高效微调和历史上下文聚合, 在冻结主干的前提下实现低成本动态建模, 验证轻量化适配策略的可行性.显式提示建模类算法突破传统定义, 通过时空令牌传播、自回归查询等机制构建目标运动轨迹的显式表征, 解决复杂场景中的动态推理难题.上述算法共同推动视觉跟踪算法从静态模板匹配向动态时空推理的范式迁移, 为实际应用场景中的鲁棒性需求、可扩展性提供多样化解决方案.
2.2.4 分类与总结
综合2022年以来单流单阶段Transformer跟踪算法的发展脉络, 根据网络架构与跟踪范式的核心差异, 可将现有代表性的单流Transformer跟踪算法归纳为3类:经典单流算法、自回归算法、基于提示的算法.图8直观展示这三类单流跟踪算法及其代表性工作的分类关系, 其中经典单流算法作为基础分支, 自回归算法与基于提示的算法分别从序列生成范式与模型适配角度提供新的解决路径, 共同构成当前单流单阶段跟踪算法的研究全景.
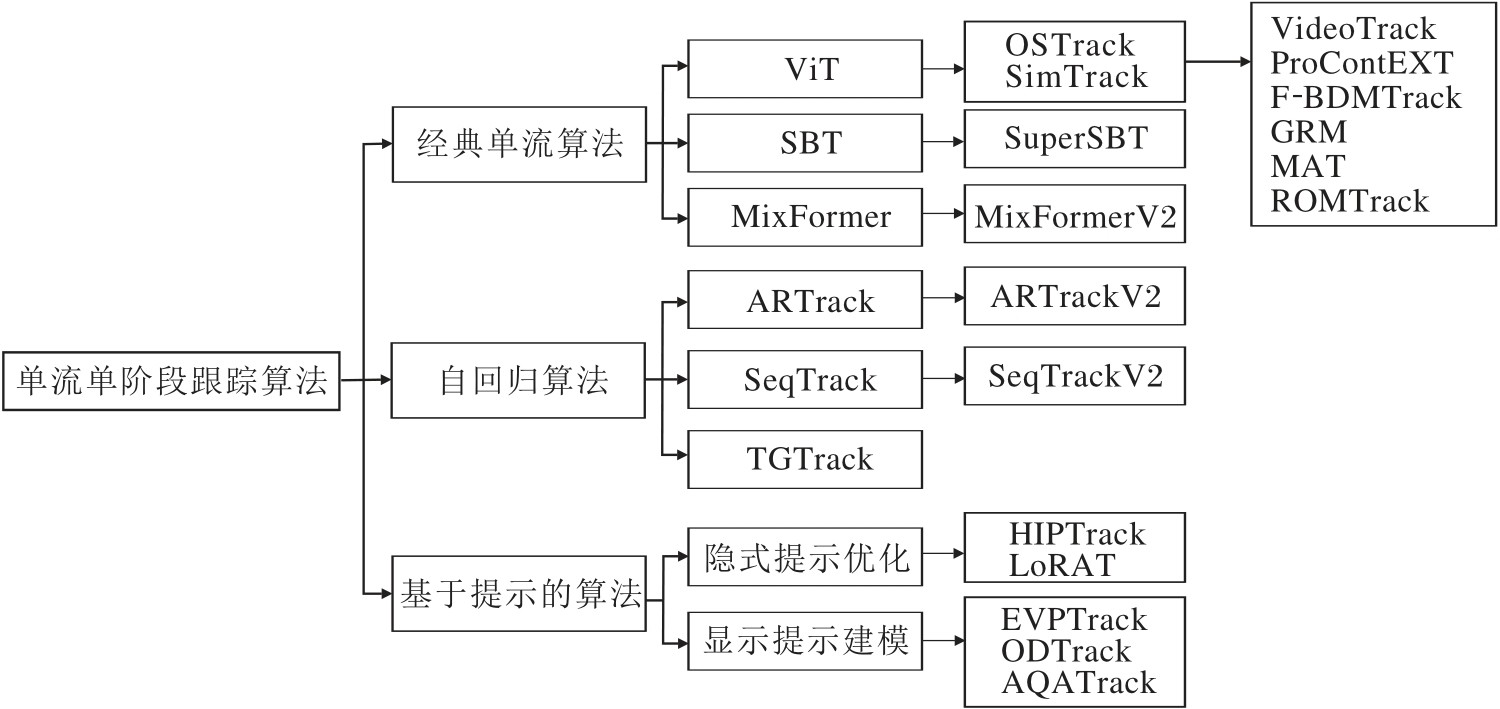 | 图8 单流单阶段跟踪算法分类图Fig.8 Classification framework of single-stream single-stage tracking algorithms |
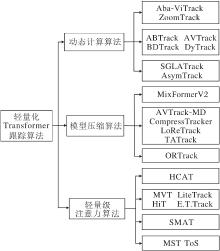
Transformer动态构建全局上下文关联, 捕捉长距离依赖, 在视觉目标跟踪任务中展现出较好的优越性, 成为里程碑式架构.然而, 随着算法的设计复杂度和序列长度的增加, Transformer固有的高计算复杂度使其难以在资源受限的设备上高效运行.针对这一问题, 现有跟踪算法主要从3个方面展开研究:1)动态计算与自适应推理优化, 实现Transformer的轻量化; 2)采用纯Transformer架构, 并借助模型压缩等技术降低计算成本; 3)设计轻量化注意力以满足实时需求.本节将从这3个方面介绍现有的代表性轻量化Transformer跟踪算法.
2.3.1 动态计算算法
2023年, Li等[100]提出Aba-ViTrack(Adaptive and Background-Aware Vision Transformer for Tracking), 遵循联合特征学习与模板-搜索区域交互建模的单流架构, 通过自适应令牌剪枝机制, 采用动态停止概率预测网络生成空间令牌重要性评分, 并结合门控单元实现层级式渐进剪枝, 优先终止背景区域令牌的注意力计算.同年, 为了解决输入尺寸与模型计算效率的矛盾, Kou等[101]提出ZoomTrack, 构建16× 16控制网格, 通过二次规划优化缩放因子, 设计缩放能量项与刚性约束项.此外, 通过双线性采样实现连续坐标映射, 在缩小整体输入尺寸的同时, 保持目标中心区域的高分辨率.该方案可无缝集成至主流跟踪框架, 在保持速度优势的前提下显著缩小轻量版算法与完整版算法的性能差距, 实现计算资源的合理分配.
针对现有Transformer跟踪器在资源受限设备上速度不足的问题, Yang等[102]提出ABTrack, 动态绕过ViT中的冗余编码器层, 降低计算量.核心是旁路决策模块, 根据输入场景特征生成绕过概率, 决定是否跳过当前编码器层, 对于简单场景仅需浅层特征, 而在存在遮挡干扰的复杂场景中则需激活深层编码器.同时, 为了减少旁路决策模块带来的计算开销, ABTrack进一步设计局部排序剪枝方法, 压缩各编码器层中词元的隐层维度, 在保持跟踪精度的同时有效提升推理速度.
为了解决无人机跟踪中极端视角变化导致的特征不一致问题及非结构化计算引发的额外时延等问题, Li等[103]提出AVTrack, 率先引入AM(Activation Module), 通过结构化方式动态激活ViT编码器层.AM仅以部分词元作为输入, 输出激活概率以决定是否执行当前层计算, 避免非结构化访问.同时, AVTrack还提出视角不变特征学习策略, 最大化目标模板与搜索区域之间的互信息, 增强模型对不同视角下目标表征的一致性, 提升跟踪鲁棒性.同年, 针对无人机快速运动导致的图像模糊、深层ViT处理简单帧产生的计算冗余等问题, Wu等[104]提出BDTrack, 在动态计算基础上进一步细化, 设计动态早期退出机制, 根据输入复杂度动态决定提前退出层数, 对于简单帧仅需浅层特征即可预测, 而对于模糊帧或复杂帧则需激活深层编码器.BDTrack同时引入模糊不变特征学习, 最小化原始清晰特征与模糊特征之间的均方误差, 学习运动模糊的鲁棒表示.
为了解决静态网络的计算冗余问题, Zhu等[105]提出DyTrack, 将动态计算扩展至实例级, 设计多级终止分支决策机制:在Transformer中间层插入置信度评估模块, 根据当前帧的可靠性动态退出计算, 如静态目标在浅层即可获得高置信度定位, 而遮挡目标或形变目标则需激活深层特征交互.此外, 引入特征回收机制, 对浅层输出与深层特征进行加权融合, 提高特征复用率, 减少不必要的注意力计算.
由于视觉Transformer在无人机跟踪中因全结构计算会导致实时性瓶颈及深层特征冗余问题, Xue等[106]提出SGLATrack, 揭示ViT跟踪器中深层特征存在显著相似性.SGLATrack创新性设计结构化层动态裁剪机制:先设定固定饱和层, 再引入轻量级MLP选择模块, 仅需输入饱和层首词元特征, 就可动态输出后续层激活概率, 并利用层间特征余弦相似性生成监督信号以优化选择过程, 确保在禁用大量冗余层时仅保留单一最优层执行推理计算.
针对单流框架在推理阶段重复计算模板、模板-搜索区域密集交互给边缘设备带来负担的问题, Zhu等[107]提出AsymTrack(Asymmetric Siamese Tra- cker), 将模板与搜索分支解耦:模板分支仅在初始化时运行一次, 生成用于后续推理的调制信号, 以单向注入方式把模板线索融入搜索特征以完成关系建模.AsymTrack进一步提出目标感知增强模块, 融合语义与局部细节.该模块还可在推理阶段重参数化为等价的单层卷积, 降低额外推理开销.
2.3.2 模型压缩算法
为了构建Transformer轻量化跟踪算法, Cui等[108]提出MixFormerV2, 通过Transformer注意力捕获跨区域关联, 引入可学习预测令牌和MLP以直接回归目标状态.设计概率分布预测层, 输出坐标的高斯混合模型参数, 实现定位蒸馏.结合渐进式深度剪枝策略与隐层维度蒸馏, 大幅压缩模型复杂度.进一步地, Wu等[109]提出AVTrack-MD, 在AVTrack的基础上引入多教师蒸馏, 利用多个预训练模型的多样性知识提升学生模型的泛化能力, 首次将蒸馏与视图不变性学习结合.AVTrack-MD聚合多个教师模型的软特征与互信息对齐, 指导轻量级学生网络在保持性能的同时显著降低复杂度.针对Transformer跟踪算法在资源受限设备部署时效率与精度失衡的问题, Hong等[110]提出CompressTracker, 采用阶段划分策略, 将教师模型的Transformer层划分为多个阶段, 指导学生模型分阶段模仿对应层的特征.结合替换训练技术, 随机将学生阶段替换为教师阶段, 增强行为一致性, 并通过预测指导和分阶段特征模仿提供监督信号.CompressTracker支持异构结构设计, 实现轻量化的同时支持灵活调整模型结构.
针对低分辨率输入导致跟踪精度下降的问题, Dong等[111]提出LoReTrack(Low-Resolution Transfor-mer Tracker), 通过全局视角的QKV知识蒸馏继承高分辨率模型提供的细粒度特征交互, 结合目标感知视角的区分性知识蒸馏增强目标-背景辨别能力.两种蒸馏机制协同作用, 使低分辨率模型在减少计算量的同时弥补信息损失, 实现与高分辨率模型相当的跟踪精度, 并且支持分辨率灵活缩放以适应不同硬件需求.Li等[112]提出TATrack(Target-Ori-ented Adaptive Vision Transformer for Tracking), 致力于解决ViT跟踪算法因背景令牌主导导致的特征弱化问题.通过目标感知的互信息最大化机制构建基于Jensen-Shannon散度的互信息估计器, 强制实现模板图像像素空间与ViT输出的特征空间信息依赖最大化, 抑制背景令牌的干扰.TATrack结合互信息驱动的知识蒸馏, 以教师模型特征与学生模型特征之间的互信息作为蒸馏损失, 为低空场景提供高精度、低延迟的跟踪范式.此外, 为了解决无人机跟踪中目标频繁遮挡导致的特征退化问题及实时性瓶颈, Wu等[113]提出ORTrack, 首先设计遮挡的鲁棒表征学习机制, 通过空间Cox过程生成空间分布非均匀的随机遮挡掩码, 模拟真实场景中的目标局部遮挡.然后, 强制掩码前后目标模板的ViT特征保持一致性, 模拟真实遮挡场景以提升跟踪鲁棒性.同时设计自适应特征知识蒸馏, 对困难样本强化师生特征对齐、简单样本弱化对齐, 保留学生模型泛化性, 生成轻量化学生模型ORTrack-D, 显著提升资源受限平台的高效目标跟踪性能.
2.3.3 轻量级注意力算法
为了满足边缘设备对计算资源与跟踪速度的双重要求, 学者研究轻量级注意力结构的Transformer模型.Chen等[114]提出HCAT, 设计四层全交叉注意力堆叠结构, 每层采用多头低维注意力计算, 通过跳跃连接聚合多尺度特征.HCAT结合特征稀疏化模块, 使用可变形卷积生成空间掩膜, 动态选择30%高响应模板特征, 构建轻量化特征融合网络, 在GPU、CPU、边缘设备上均实现高效运行, 其分层连接策略在减少计算量的同时维持深层网络的特征表达能力.此外, Gopal等[115]提出MVT(Mobile Vision Transformer-Based Tracking), 核心创新在于设计Siam-MoViT(Siamese Mobile Vision Transformer)模块:将模板和搜索区域输入4层标准Transformer编码器的混合路径中, 通过自注意力实现跨特征交互.同时结合MobileNetV2轻量化卷积模块构建五级金字塔架构, 并采用无参数像素级互相关操作, 避免复杂特征融合计算.同年, 针对Transformer计算延迟较长的问题, Wei等[116]提出LiteTrack, 通过异步特征提取将模板与搜索区域特征解耦, 模板图像经过完整12层ViT编码器并缓存最后一层输出, 搜索区域仅在前几层进行自注意力计算.然后将模板特征与搜索区域中间特征拼接后输入剩余层进行交叉注意力交互, 并且结合分层剪枝策略, 从完整ViT中逐步移除编码层, 调整特征提取阶段与异步交互阶段的层数比例, 优化自注意力和交叉注意力的交互流程.
针对分层Transformer主干网络在跟踪中的信息丢失问题, Kang等[117]提出HiT, 设计双路径桥接模块, 使用1× 1卷积压缩深层语义特征, 通过双线性插值上采样实现与浅层特征逐元素融合.此外, HiT结合轻量级LeViT主干构建高效单流架构, 通过特征补偿机制有效缓解大步长下采样导致的目标细节丢失问题.同年, Blatter等[118]提出E.T.Track(Exemplar Transformer Tracker), 设计基于实例级注意力的范例Transformer模块.核心创新在于通过自适应平均池化, 将输入特征压缩为单个全局查询向量, 而非传统Transformer中逐位置的查询.引入可学习的共享示例键作为数据集的全局记忆, 替代传统自注意力中的动态键生成.进一步地, Gopal等[119]提出SMAT, 构建基于Transformer的主干网络和预测头模块.针对主干网络, 创新性设计可分离混合注意力Transformer架构, 在特征提取的同时融合模板与搜索区域的信息, 连接特征计算混合注意力, 避免传统双流编码的信息隔离.同时, 预测头采用可分离自注意力Transformer模块, 对融合后搜索特征进行全局上下文建模, 有效提升目标状态估计的精度.这种Transformer主干和预测头的定制化架构设计使SMAT可实现高效的视觉跟踪.
为了提升高效跟踪器的表征能力, Wang等[120]提出MST(Multi-state Tracker), 设计多状态生成模块, 在骨干网络后期提取多状态表征, 利用状态特定增强模块强化各状态表示, 再借助跨状态交互模块实现状态间信息交换与自适应融合.上述两种模块均基于隐藏状态自适应的状态空间对偶结构, 在仅引入极少额外开销的同时提升跟踪鲁棒性.
为了挖掘双流框架在跟踪中的天然优势, Zong等[121]提出ToS(Two-Stream Tracking), 引入三项关键策略:1)通过特征聚合模块整合多阶段多尺度特征, 提升表征能力; 2)提出通道维特征融合, 将模板与搜索区域特征按通道维度对齐拼接, 并仅用单个Transformer块完成轻量化融合; 3)采用扩大模板策略, 扩大裁剪范围与分辨率, 获得更多参考信息, 在几乎不影响速度的前提下提升精度.通过上述设计, ToS在多个基准数据集上实现面向边缘部署的较优性能与效率.
2.3.4 分类与总结
综合近年来轻量化Transformer跟踪算法的发展脉络, 根据优化策略与计算范式的核心差异, 可将现有代表性算法归纳为3类:动态计算算法、模型压缩算法、轻量级注意力算法.动态计算算法侧重于通过自适应推理与稀疏计算降低冗余操作; 模型压缩算法依托剪枝、蒸馏等技术对Transformer架构进行精简; 轻量级注意力算法从设计源头出发, 构造高效的注意力机制, 替代标准自注意力.图9直观展示这3类算法及其代表性工作的分类关系.整体而言, 动态计算算法体现效率提升的直接路径, 模型压缩算法与轻量级注意力算法分别从模型精简与注意力优化角度提供互补的解决路径, 三者共同构成当前轻量化Transformer跟踪算法的研究全景.
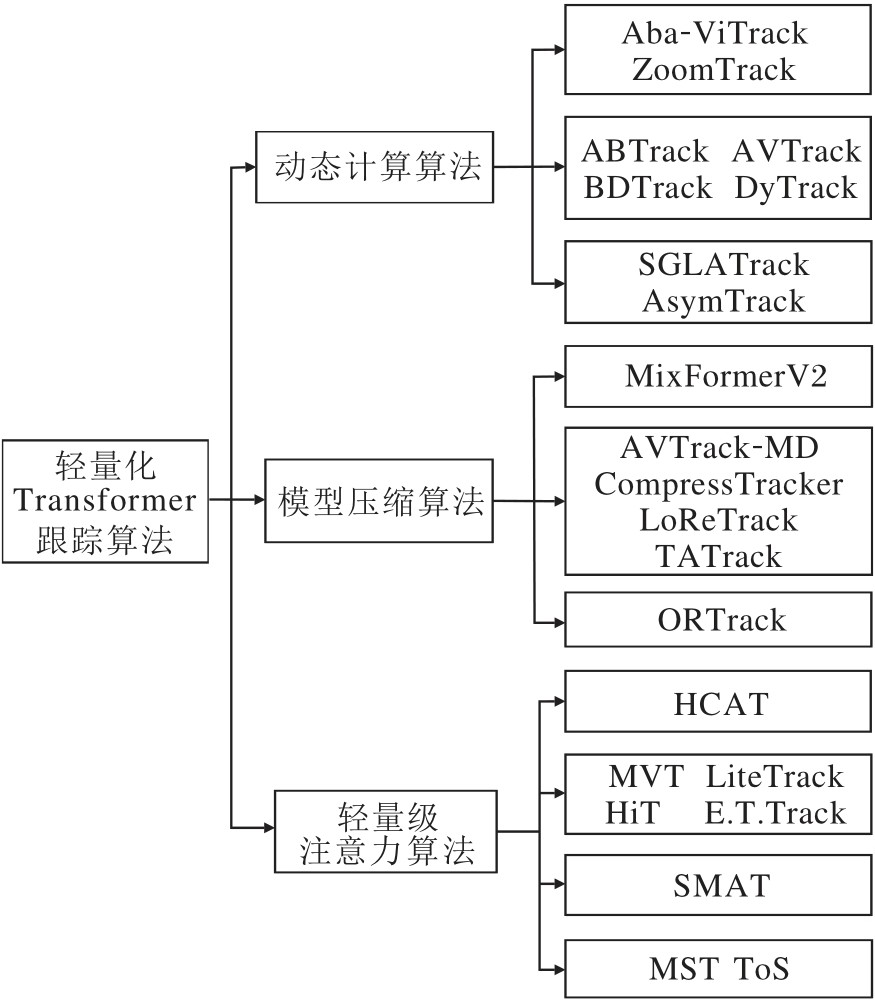 | 图9 轻量化Transformer跟踪算法分类图Fig.9 Classification framework of lightweight Transformer tracking algorithms |
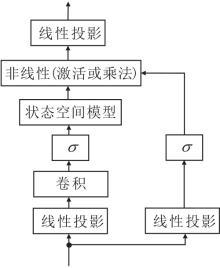
目标跟踪长期面临长序列建模的挑战.CNN局部感知较强但缺乏全局上下文建模能力, RNN并行性较差, Transformer虽支持并行计算且能捕获全局关系, 但注意力对长度为N的序列计算复杂度为O(N2), 难以应对高分辨率、长时序建模跟踪.近年来, 状态空间模型(State Space Model, SSM)因在长序列建模中的高效性和线性计算复杂度受到广泛关注.Mamba[122]是一种基于状态空间模型的序列建模算法, 由Gu等在2023年提出, 结构如图10所示.Mamba将SSM与多层感知机整合, 解决自注意力机制的计算复杂度问题.核心创新包括:1)选择性扫描机制动态调整时间步长等参数, 实现上下文感知的序列建模, 避免全局注意力冗余计算; 2)采用并行扫描替代传统卷积操作, 提升计算效率; 3)提出极简统一架构, 将SSM与MLP深度融合.
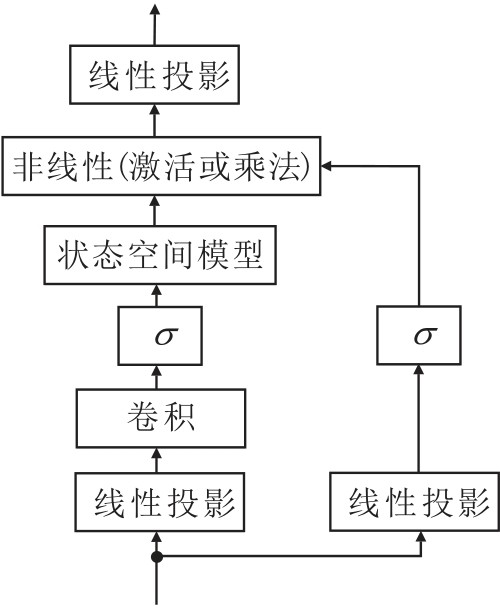 | 图10 Mamba结构图Fig.10 Mamba architecture |
考虑到Transformer的高计算复杂度导致的在资源受限场景中的局限性, 研究者开始将Mamba架构引入目标跟踪任务, 发挥其线性复杂度和长序列建模的优势.Zhang等[123]提出TrackMamba, 是Mamba和Transformer的混合模型, 设计Mamba前后向扫描机制和目标增强模块, 有效融合模板和搜索区域特征.2025年, Xie等[124]提出TemTrack(Tem-poral Tracker), 将时间信息学习与外观建模分离, 以滑动窗口的方式从一组代表性标记中提取时间关系, 并设计一个高效Mamba模块, 用于上下文信息建模.此外, Mamba的输出特征与原始词元通过交叉注意力机制进行信息交互, 从而融合全局上下文信息, 提升跟踪鲁棒性.为了应对复杂场景中无人机跟踪的挑战, Wang等[125]提出TrackingMamba, 以Vision Mamba为骨干网络, 通过双向处理机制增强空间感知和长程依赖建模能力.针对夜间低光环境, Zhang等[126]提出MambaTrack, 结合基于Mamba的低光增强器和跨模态Mamba网络, 实现图像低光增强与跨模态特征融合, 有效解决光照不足导致的特征退化问题.进一步地, Kang等[127]提出MCITrack, 引入上下文信息融合模块, 利用Mamba的内部记忆状态(即隐状态)对时序上下文信息进行持续更新与逐帧传递.该核心模块由Mamba和交叉注意力组成, 能在不同层次上深度融合上下文信息, 提高算法感知能力.同年, 考虑到现有方法仅使用少量标记传递上下文, Li等[128]提出MambaLCT, 采用分层ViT对模板与搜索区域进行多尺度特征编码, 并设计单向Mamba模块, 保证以较低的资源消耗构建长期的上下文信息.
综上所述, Mamba凭借其线性复杂度特性, 在处理长序列视觉跟踪任务时展现出较好的效率优势, 但其与Transformer的差异不仅体现在计算复杂度方面.在长序列建模机制上, Transformer通过自注意力机制显式构建全局关联, 能捕获更完整的上下文信息, 而Mamba通过状态空间模型中隐状态进行序列建模, 虽然具有效率的优势, 但在面对复杂场景时, 精度可能略有不足[129].另一方面, 从空间感知角度, Transformer的注意力使其能自适应聚焦关键区域(如目标形变、遮挡), 具备较强的跟踪鲁棒性, 而Mamba采用状态扫描机制, 在空间关系建模上的灵活性存在一定局限性.因此, 今后算法选择需根据不同场景权衡这两种架构:在对长时序、高实时性要求极为苛刻且空间背景相对简单的场景中, Mamba的高效序列建模方案可能是较合适的选择; 在面对复杂空间环境时, Transformer及其注意力机制仍是当前更可靠的选择.同时, 也可将二者的优势有机结合, 通过混合架构实现更稳健高效的目标跟踪.
由于传统的视觉专用模型参数冗余、泛化能力受限, 构建同时解决多种任务的通用模型成为计算机视觉领域的重要研究方向之一.通用模型通过统一的架构和共享参数, 实现对多个任务的协同建模, 提升计算效率, 增强跨任务迁移能力.Transformer的自注意力机制和模块化设计为多任务建模提供灵活支持.近年来, 基于Transformer的通用模型在目标检测、跟踪、实例分割等任务上均展现出显著优势.本节将从多模态跟踪和多任务跟踪两个方面介绍通用模型的相关研究.
3.2.1 多模态跟踪
随着深度学习和多模态数据处理技术的进步, 单一模态跟踪方法已无法满足处理复杂场景的需求.多模态数据的引入, 尤其是深度图像、热成像和事件数据等, 显著丰富视觉图像的表现力, 使跟踪算法在不同场景中具有更好的判别性和鲁棒性.多模态跟踪需要处理不同模态之间的异质性, 使得模型设计更为复杂化.现有的RGB跟踪器通常学习一组参数, 难以有效解决模态的异质性和数据稀缺性问题, 并且多模态跟踪通常依赖特定模态组合, 导致模型间可迁移性较差、性能不稳定.因此, 如何设计统一的架构处理多模态数据以实现目标跟踪成为一个挑战.
在上述背景下, 2023年, Zhu等[130]提出ViPT(Visual Prompt Multi-modal Tracking), 结构如图11所示.ViPT学习与模态相关的提示, 适应预训练基础模型, 支持不同的多模态跟踪任务, 即RGB-Depth、RGB-Thermal和RGB-Event跟踪, 体现视觉提示学习在多模态跟踪中的潜力.然而, ViPT需要针对特定模态进行不同数据集上的微调, 未实现参数统一.为此, 2024年, Wu等[131]提出Un-Track(Unified Tracker), 是适用于任何模态的单组参数的统一跟踪器, 无需模态特定微调, 旨在通过学习共同的潜在空间处理任意模态.Un-Track的创新之处在于利用低秩分解和重构技术, 在仅给定RGB-X输入对的情况下学习通用的潜在表示, 有效结合不同模态数据, 并能处理缺失模态的情况.
 | 图11 ViPT结构图Fig.11 ViPT architecture |
为了将大规模预训练跟踪器转移到其它跟踪任务(如RGB-Mask和RGB-Language跟踪), Chen等[132]进一步提出SeqTrackv2, 将统一序列学习框架扩展至更广泛的多模态跟踪任务, 延续SeqTrack的编码器-解码器架构, 将目标状态预测建模为自回归序列生成任务.同期, Hang等[133]提出One-Tracker, 也被用于处理各种形式的跟踪任务, 包括RGB跟踪和RGB-L、RGB-M、RGB-D、RGB-T、RGB-E跟踪, 增强模型合并其它模态的能力.但是, One- Tracker并未实现参数级的统一, 每个任务仍需单独训练模型参数.2025年, Chen等[134]提出SUTrack, 进一步推进SOT任务的统一.使用预训练的HiViT提取特征, 处理多模态信息, 并设计软令牌类型嵌入和任务识别训练策略, 增强模型对任务特性的感知, 提升多任务学习能力.
具有代表性的多模态统一的单目标跟踪算法在任务和参数上的对比如表2所示.从任务类型上看, ViPT和Un-Track专注于RGB-D、RGB-T、RGB-E等模态组合, 而OneTracker、SeqTrackv2和SUTrack进一步扩展至RGB-L、RGB-M等模态, 覆盖范围更广.在参数设计上, ViPT和OneTraker需为不同模态单独微调, 不同模态间参数独立, 而Un-Track、Seq-Trackv2和SUTrack采用共享参数, 无需针对不同模态进行特定的调整.
| 表2 多模态统一的单目标跟踪算法在任务类型和参数学习方面的对比 Table 2 Comparison of multi-modal unified single object tracking algorithms in task types and parameter learning |
上述多模态跟踪算法在一些多模态任务中具有明显优势, 但仍存在性能和统一性上的不足.今后需致力于构建更通用的统一模型, 自适应融合多种模态信息, 实现对更多跟踪场景的覆盖.值得注意的是, 除了上文论述的参数共享与任务统一的通用多模态框架以外, 针对特定多模态任务的Transformer跟踪算法研究近年来也取得长足进步[48, 49].鉴于目前特定多模态跟踪研究的规模体系[135], 以及已有专门针对特定多模态跟踪的综述文献对相关算法进行详尽的归纳与分类分析[136, 137], 本文主要聚焦于Transformer在单目标跟踪中的通用演变范式与建模趋势, 故不针对各类模态特定的独立算法展开详细介绍.
3.2.2 多任务跟踪
多模态跟踪主要聚焦于单目标跟踪, 通过引入红外、深度、事件等不同模态, 提升在遮挡、弱光等复杂条件下的鲁棒性.其统一性更多体现在如何在一个框架内提取并融合异质模态, 实现多模态统一表征.本节介绍的多任务跟踪, 则进一步拓展统一模型的应用范围, 整合多种任务(如SOT、多目标跟踪(Multiple Object Tracking, MOT)、视频目标分割(Video Object Segmentation, VOS)等), 提升模型的灵活性和跨任务能力.多任务跟踪在研究中面临诸多挑战.首先, 目标跟踪任务的多样性使得任务间的相互影响较为复杂, 单目标跟踪与多目标跟踪在特征提取和信息处理上存在显著差异, 这可能导致模型难以实现有效的联合建模.其次, 现有模型往往针对单个任务构建, 从而限制其跨任务学习的能力.
为了解决上述问题, Yan等[138]于2022年提出Unicorn(Unification of Object Tracking), 这是首个实现SOT、MOT、VOS和多目标跟踪与分割(Multiple Object Tracking and Segmentation, MOTS)任务统一的模型.Unicorn通过共享输入、骨干网络、特征嵌入和头部结构, 利用目标先验和像素对应, 弥合四种任务间的差距.在此基础上, Yan等[139]提出UNINEXT(Universal Instance Perception Model of the Next Ge-neration), 进一步扩展统一模型的应用范围, 设计通用的实例感知模型, 能处理10类实例感知任务, 包括目标检测、实例分割等.通过提示生成模块和对象发现与检索机制, 处理不同任务的数据, 增强模型的灵活性.Wang等[140]提出OmniTracker, 引入“ Tra-cking-with-Detection” 范式, 其中跟踪使用外观先验补充检测以更准确定位目标, 而检测为关联提供候选框的跟踪目标, 并且所有任务共享记忆库和匹配策略, 提升跟踪效率.2024年, Wang等[141]受到NLP的启发, 提出OmniViD, 统一输出空间, 通过语言标签结合时间标记和框标记表示视频任务的输出, 将视频任务转化为基于视频的标记生成问题, 实现多任务视频任务.
在多任务跟踪方面, 未来的发展需要朝着进一步跨任务、跨场景的统一模型方向前进.利用更强大的预训练基础模型实现对多种任务共同特征的提取, 同时通过共享嵌入和记忆机制提升各任务间的信息流通, 并且需要根据输入数据动态调整各任务处理的权重, 使多任务模型能自适应选择最优策略.
视频跟踪在动态场景中面临众多挑战, 尤其是在处理复杂背景和被遮挡的物体时.近期的SAM(Segment Anything Model)能准确提供分割掩码, 展现出较好的通用性.Yang等[142]指出, 虽然SAM 2在图像分割任务上表现出色, 但在处理人群密集场景时性能显著下降.此外, 动态场景中目标可能会出现快速移动和遮挡现象, 这也要求模型具备时序建模能力, 捕捉物体的运动轨迹和位置变化.
针对SAM在动态场景中的局限性, Yang等[143]提出TAM(Track Anything Model), 结合SAM的高精度分割与长时记忆模型的时序跟踪能力, 实现用户友好的视频交互式跟踪框架.TAM允许用户仅通过极少的人为参与(如点提示)跟踪感兴趣的对象, 单次推理即可获得准确的分割结果.同年, Zhu等[144]提出HQTrack(High Quality Tracking), 由视频多目标分割器和掩码优化器组成.分割器负责在视频帧中传播多个目标, 而掩码优化器是一个大规模的预训练分割模型, 负责优化分割掩码.HQTrack在视觉对象跟踪和分割(VOTS2023)挑战赛中排名第二.虽然TAM与HQTrack都旨在实现视频分割与跟踪任务的统一, 但TAM更关注于在交互式跟踪中减少人工干预, 而HQTrack专注于高质量的分割.此外, Cheng等[145]提出SAM-Track, 支持多模式交互, 并且能跟踪视频中出现的感兴趣新对象.借助DeAOT(AOT-Based Tracking Model)的高效跟踪模式, SAM-Track能根据用户特定要求在视频中快速跟踪多个对象.2024年, Yang等[142]提出SAMURAI(SAM-Based Unified and Robust Zero-Shot Visual Tracker with Motion-Aware Instance-Level Memory), 结合时间运动线索和运动感知的记忆选择机制, 预测目标运动并优化分割结果, 无需重新训练或微调即可实现稳健、准确的跟踪.Videnovic等[146]指出, 基于记忆内存的跟踪器在面临干扰物影响时容易产生错误跟踪, 主要因为内存冗余和更新策略不完善, 因此提出跟踪器SAM2.1, 通过干扰物感知内存机制和基于自省的更新策略, 共同提升分割和跟踪鲁棒性.
目前在视频分割与跟踪的联合任务上, 仍需进一步探索时序记忆建模与多任务特征交互的深度结合, 未来需要聚焦于如何在动态场景中高效处理复杂的时序变化和目标遮挡问题, 进而提升跟踪模型的鲁棒性和精度.
为了评估不同跟踪算法的性能, 在LaSOT、TrackingNet、GOT-10k数据集上进行性能对比和分析, 使用如下指标:成功率(Success Rate, SR), 精度(Precision, P), 归一化精度(PNorm), 平均重叠率(AO), 0.5和0.75阈值下的成功率SR0.5、SR0.75.
双流双阶段跟踪算法的性能对比如表3所示, 表中黑体数字表示最优值, 斜体数字表示次优值, -表示原文献中无该项数据.
| 表3 双流双阶段跟踪算法在3个数据集上的性能对比 Table 3 Performance comparison of two-stream two-stage tracking algorithms on 3 datasets |
由表3可见, 早期的TrDiMP和TransT在3个数据集上表现出良好的跟踪精度.同期STARK通过Transformer学习时空特征, 取得更优的跟踪精度.进一步地, 通过Swin Transformer主干与运动编码模块, SwinTrack在TrackingNet数据集上以84.0%的精度刷新记录, 同时以45帧/秒的跟踪速度实现效率和性能的良好平衡.TATrack利用长时上下文注意力, 提升特征表征能力, 以85.0%的AO值在GOT-10k数据集上取得领先地位, 但6.6帧/秒的运行速度限制其应用.近期MGTrack引入空间-频域融合机制, 在LaSOT数据集上取得71.3%的成功率.此外, SRTrack通过显著性建模, 以69帧/秒取得较好的速度优势.
单流单阶段跟踪算法的性能对比如表4所示, 表中黑体数字表示最优值, 斜体数字表示次优值, -表示原文献中无该项数据.
| 表4 单流单阶段跟踪算法在3个数据集上的性能对比 Table 4 Performance comparison of single-stream single-stage tracking algorithms on 3 datasets |
整体来看, 相比双流双阶段跟踪算法, 单流单阶段跟踪算法的跟踪精度和速度都有所提升.早期算法MixFormer通过混合注意力取得优良的跟踪精度, OSTrack利用早期候选消除模块, 在保证精度的同时实现更优的跟踪效率.后续的SeqTrack和ARTrack将跟踪建模为自回归生成任务, 使用编码器-解码器架构融合视觉线索, 分别获得85.5%和84.2%的AUC值, 但其运行速度显著低于其它算法.为此, ARTrackV2联合外观提示和轨迹建模, 精度与速度均获得明显提升.LoRAT基于低秩适应的参数高效微调, 以极低的训练成本达到209帧/秒的最优跟踪速度.得益于历史提示和时序建模, ODTrack和HIPTrack分别在LaSOT、GOT-10k数据集上表现出显著的性能优势.
前沿跟踪器在3个数据集上的性能对比如表5所示, 表中黑体数字表示最优值, 斜体数字表示次优值, -表示原文献中无该项数据.由表可见, 相比之前的双流双阶段跟踪算法和单流单阶段跟踪算法, 近期前沿的跟踪算法在跟踪性能上实现显著突破.SAMURAI结合SAM分割模型, 在GOT-10k数据集上, SR0.5、SR0.75值分别达到92.2%和76.9%, 展现出优异的跟踪性能.MCITrack通过Mamba隐状态持续传递时序上下文, 在精度上表现最突出, 但受限于5帧/秒的运行速度.MambaLCT通过层次化ViT编码与单向Mamba模块, 低资源建模时序上下文, 在跟踪性能与速度间取得更好的平衡.进一步地, SUTrack采用预训练HiViT提取特征, 通过软令牌类型嵌入和任务识别感知的训练策略, 提升跨任务上的泛化能力, 在3个数据集上性能均处于较领先的水平.
| 表5 前沿跟踪器在3个数据集上的性能对比 Table 5 Performance comparison of advanced trackers on 3 datasets |
进一步地, 先进的Transformer轻量化跟踪算法在3个数据集上的性能对比如表6所示, 表中黑体数字表示最优值, 斜体数字表示次优值, -表示原文献中无该项数据.
| 表6 轻量化Transformer跟踪算法在3个数据集上的性能对比 Table 6 Performance comparison of lightweight transformer tracking algorithms on 3 datasets |
从整体趋势来看, 近年来轻量化Transformer跟踪算法在精度、速度与硬件适应性方面取得显著进展.早期的HCAT利用分层交叉注意力, 以76.6%的AUC值和195帧/秒的GPU运行速度实现硬件高效推理.之后的MixFormerV2通过预测令牌和渐进式深度剪枝策略, 在精度上处于领先地位, 并且保持较快的GPU速度.MVT与SMAT虽然在多个数据集上的精度值与当前先进算法相比存在一定差距, 但通过轻量化设计可减少计算量和参数量, 在资源受限环境下实现高效跟踪.ABTrack通过动态决策和排序剪枝, 实现最低的模型参数量和计算量.此外, ZoomTrack和HiT通过优化图像尺寸和轻量化注意力, 分别达到先进的GPU和AGX推理速度.
本文研究表明, Transformer在单目标跟踪领域取得显著突破, 推动模型架构向简洁高效的单流范式演进.尽管如此, 由于目标跟踪本身面临的问题以及Transformer架构的灵活性, 未来研究仍存在机遇和挑战.本节从模型轻量化、多模态融合、长时跟踪、大模型驱动跟踪与具身视觉跟踪这5个角度, 探讨Transformer跟踪的未来发展方向.
1)模型轻量化.现有单目标跟踪研究多聚焦于提升跟踪性能, 忽视模型复杂度.传统Transformer跟踪算法计算成本较高, 难以满足实时性和低功耗的要求.尽管已有一些轻量化跟踪算法[108, 118]被提出, 但仍有潜在的发展空间.例如:利用模型压缩与剪枝技术, 减少参数量和计算量, 通过动态推理优化模型跟踪效率, 设计高效的注意力机制.针对不同硬件需求, 可开发优化策略, 提高运行效率.
2)多模态融合.单目标跟踪大多仅依赖RGB信息, 在复杂场景中表现不佳.尽管近年来的多模态跟踪算法探索利用交叉注意力实现跨模态的像素级特征交互[147], 或采用基于频域的特征融合方法[148], 显著提升跟踪鲁棒性.然而, 上述融合策略往往伴随着较高的计算复杂度, 并且仍未充分挖掘多模态间的互补优势.为此, 后续研究应针对不同模态的特性, 在保留互补信息的同时, 设计高效的动态融合模块, 实现精度与速度的平衡.同时构建和优化参数共享的统一跟踪框架, 引入提示学习或轻量级适配器, 设计通用的跨模态表示模块, 有效处理不同模态的输入.此外, 现有研究大多基于模态对齐的理想假设, 但在真实场景中, 传感器抖动等原因导致的模态缺失会使跟踪器失效.未来研究应多关注非对齐动态融合, 并增强算法在某一模态失效情况下的鲁棒性, 从而推动多模态目标跟踪的发展.
3)长时跟踪.Transformer跟踪算法在短时跟踪方面表现优异, 但在长时跟踪场景中仍存在不足.当跟踪器因目标外观变化、遮挡等因素丢失目标后, 后续跟踪就容易发生持续性失败或不可逆漂移.因此, 未来有望研究更强大的时序建模Transformer与外部记忆机制, 实现历史目标信息的高效存储、检索与更新.同时, 结合目标重检测与验证模块, 可在目标重新出现时准确定位并确认其身份.此外, 可针对现实场景构建更具针对性的长时视频目标跟踪基准数据集, 推动Transformer跟踪算法在实际长时跟踪场景中的应用与发展.
4)大模型驱动跟踪.随着各类大规模预训练模型的迅猛发展, 如何将其能力迁移应用至单目标跟踪任务已成为重要研究方向之一.为了有效利用大模型提升跟踪性能, 后续研究可借助语言大模型生成外观、运动及语义提示, 为跟踪器提供丰富先验, 也可利用SAM辅助提升跟踪的准确性.另外, 由于跟踪过程还涉及判断目标是否丢失、是否更新模板等决策, 跟踪器可借助大模型的上下文理解能力和强大推理机制, 动态调整跟踪策略, 优化跟踪流程, 提升推理效率与跟踪鲁棒性.
5)具身视觉跟踪.具身智能(Embodied Intelli-gence)强调智能体在物理环境或虚拟环境中通过感知-决策-动作闭环不断学习与交互, 最终目标是在真实场景中实现自主导航、控制与协作等功能.具身跟踪要求跟踪器理解场景、规划移动并执行控制指令, 核心在于感知与控制的协同作用.近期有研究者[149, 150]进行主动跟踪的探索, 但仍面临较大挑战, 如模拟空间与现实环境差异、硬件平台限制、3D空间推理不精确、感知决策闭环中延迟过高等问题, 尚未形成真正实用的系统级方案.在后续研究中, 可进一步探索协同强化学习策略与世界模型, 并利用Transformer统一多任务感知, 同时建立高保真仿真平台, 结合机器人真机实验, 推动具身视觉主动跟踪迈向可用性.
本文对基于Transformer的单目标跟踪算法进行系统综述.首先, 介绍Transformer的基础原理与常用的跟踪数据集.然后, 全面梳理Transformer架构在目标跟踪领域的发展脉络和技术演进, 并将现有算法归类为双流双阶段跟踪算法与单流单阶段跟踪算法两种典型跟踪范式, 同时总结相关的轻量化Transformer跟踪算法.此外, 进一步聚焦当前研究热点, 探讨基于Mamba的跟踪算法及通用模型的研究.在此基础上, 对各类代表性Transformer跟踪算法在多个主流数据集上的性能表现进行评估对比, 全面分析不同算法的优势与局限.在未来研究中, 模型轻量化、多模态融合、长时跟踪等仍是持续优化的关键方向, 而Transformer架构可有望通过注意力优化和模型压缩、混合专家统一视觉建模、时序提示和记忆机制等技术取得进一步突破.
本文责任编委 高 隽
Recommended by Associate Editor GAO Jun
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
|
| [80] |
|
| [81] |
|
| [82] |
|
| [83] |
|
| [84] |
|
| [85] |
|
| [86] |
|
| [87] |
|
| [88] |
|
| [89] |
|
| [90] |
|
| [91] |
|
| [92] |
|
| [93] |
|
| [94] |
|
| [95] |
|
| [96] |
|
| [97] |
|
| [98] |
|
| [99] |
|
| [100] |
|
| [101] |
|
| [102] |
|
| [103] |
|
| [104] |
|
| [105] |
|
| [106] |
|
| [107] |
|
| [108] |
|
| [109] |
|
| [110] |
|
| [111] |
|
| [112] |
|
| [113] |
|
| [114] |
|
| [115] |
|
| [116] |
|
| [117] |
|
| [118] |
|
| [119] |
|
| [120] |
|
| [121] |
|
| [122] |
|
| [123] |
|
| [124] |
|
| [125] |
|
| [126] |
|
| [127] |
|
| [128] |
|
| [129] |
|
| [130] |
|
| [131] |
|
| [132] |
|
| [133] |
|
| [134] |
|
| [135] |
|
| [136] |
|
| [137] |
|
| [138] |
|
| [139] |
|
| [140] |
|
| [141] |
|
| [142] |
|
| [143] |
|
| [144] |
|
| [145] |
|
| [146] |
|
| [147] |
|
| [148] |
|
| [149] |
|
| [150] |
|