


{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于路径积分强化学习方法的蛇形机器人目标导向运动
[方勇纯1  , 朱威
, 朱威1 , 郭宪1 ]
, 朱威, 郭宪]
|
|


作者简介:
 方勇纯,博士,教授,主要研究方向为机器人视觉控制、无人机、欠驱动吊车系统、微纳米操作.E-mail:fangyc@nankai.edu.cn.
方勇纯,博士,教授,主要研究方向为机器人视觉控制、无人机、欠驱动吊车系统、微纳米操作.E-mail:fangyc@nankai.edu.cn.
 朱 威,硕士研究生,主要研究方向为蛇形机器人、深度强化学习.E-mail:zhuwei@mail.nankai.edu.cn.
朱 威,硕士研究生,主要研究方向为蛇形机器人、深度强化学习.E-mail:zhuwei@mail.nankai.edu.cn.
 郭 宪,博士,讲师,主要研究方向为蛇形机器人、深度强化学习.E-mail:guoxian@nankai.edu.cn.
郭 宪,博士,讲师,主要研究方向为蛇形机器人、深度强化学习.E-mail:guoxian@nankai.edu.cn.
路径积分方法源于随机最优控制,是一种数值迭代方法,可求解连续非线性系统的最优控制问题,不依赖于系统模型,快速收敛.文中将基于路径积分强化学习的策略改善方法用于蛇形机器人的目标导向运动.使用路径积分强化学习方法学习蛇形机器人步态方程的参数,不仅可以在仿真环境下使蛇形机器人规避障碍到达目标点,利用仿真环境的先验知识也能在实际环境下快速完成相同的任务.实验结果验证方法的正确性.
About the Author: ZHU Wei, master student. His research interests include snake-like robot and deep reinforcement learning.
GUO Xian, Ph.D., lecturer. His research interests include snake-like robot and deep reinforcement learning.
Path integral is derived from stochastic optimal control. It is a numerical iteration method and solves the problem of the optimal control about continuous nonlinear systems at a high convergence speed without system model. A policy improvement algorithm based on path integral reinforcement learning is proposed for the target-directed locomotion of a snake-like robot in this paper. The path integral reinforcement learning approach is employed to learn the parameters of the snake-like robot serpentine equation, and the robot is controlled to arrive at the target position fast without contacting obstacles in simulation environment. Moreover, the robot with the priori knowledge from the simulation in real environment can complete the task well. Experimental result verifies the validity of the propose algorithm.
蛇形机器人的研究开始于20世纪70年代, 1972年Hirose[1]研制第一台蛇形机器人.蛇形机器人是一种多自由度冗余机构, 因其高度的运动灵活性而适用于各种复杂环境, 如水陆两栖蛇形机器人[2]、废墟搜救蛇形机器人[3]、管道蛇形机器人[4]、爬台阶蛇形机器人[5].
由于蛇形机器人自由度较高, 因此控制非常复杂, 主要方法有:1)基于蛇形机器人步态方程控制[6, 7], 不依赖于动力学或运动学模型, 模拟生物蛇的运动(“ S曲线” 蜿蜒运动, “ 响尾蛇” 侧向运动); 2)中枢模式发生器(Central Pattern Generator, CPG)[8, 9], 同样不依赖于模型的方法, 利用中枢模式发生器的生物学概念; 3)基于运动学或动力学模型设计控制率[10, 11, 12].方法1)和2)虽然不需要模型, 但是内部参数和蛇形机器人的运动状态之间的对应关系停留在定性分析, 即参数的调整需要人为参与, 或需要经验知识, 无法精准控制, 方法3)虽然可以完全自主稳定控制, 但是目前的研究都停留在仿真环境, 难以用于实际蛇形机器人的控制.
近几年, 人工智能发展迅速, 强化学习方法广泛应用于机器人的自动控制[13, 14, 15].实验平台主要是移动机器人、机械臂等控制相对较易的机器人, 基于Q函数的强化学习方法训练规模较大, 特别引入深度信息后, 训练效率更低.基于主成分分析机器学习方法[16]可以有效用于蛇形机器人的控制, 但是样本数据也较大.
路径积分强化学习方法基于随机最优控制理论[17], 既不需要矩阵求逆, 也不需要梯度更新, 因此学习效率较高, 数值求解方法较稳定.路径积分强化学习方法还可用于连续非线性系统的控制[18, 19, 20].Chatterjee等[21]利用路径积分强化学习方法, 实现带有螺旋传动单元的蛇形机器人的自动控制, 通过对参数的迭代学习, 最终完成蛇形机器人从起始点到达目标点这样一个简单任务.
本文基于路径积分强化学习方法, 学习蛇形机器人步态方程的参数, 最终实现蛇形机器人的完全自主精准控制.实验表明, 本文方法不仅能在仿真环境下控制蛇形机器人规避障碍到达目标点, 在实际实验环境中也能完成, 而且可以在很少的迭代次数内使损失函数收敛.
随机最优控制用于控制随机动态系统, 使性能指标函数最小.下面基于贝尔曼最优性准则(Bellman Principle of Optimality)及HJB方程分析随机最优控制和路径积分之间的关系.
性能指标函数为损失函数, 根据轨迹τ i定义:
J(τ i)=ϕ [x(tN), tN]+
其中, ti为初始时刻, tN为终止时刻, x(t)为t时刻状态, u(t)为t时刻控制量, ϕ [· ]为在终止时刻tN处损失函数, L[· ]为立即损失函数.随机最优控制目的是找到控制量u(t)并使评估函数最小:
其中
其中, xt∈ Rn× 1为系统状态量, Gt=G(xt)∈ Rn× p为控制矩阵, ft=f(xt, t)∈ Rn× 1为模型方程, ut∈ Rp× 1为控制向量, ε t∈ Rp× 1为协方差矩阵为Σ ε 的高斯噪声.即时回报定义如下:
Lt=L[x(t), u(t), t]=qt+
其中, qt=q(xt, t)为任意依赖于状态的损失函数, R为半正定权值矩阵.随机最优控制的HJB方程为
-∂ tVt=min(Lt+
其中
Ft=f(xt, t)+G(xt)ut.
式(1)代入式(2), 得到最优控制量:
u(xt)=ut=-R-1
式(3)代入式(2), 得到非线性二阶偏微分方程:
-∂ tVt=qt+
其中, Δ x为雅克比(Jacobian)矩阵, Δ xx为黑森(Hessian)矩阵.直接求解HJB方程很复杂, 可把HJB方程转化为线性偏微分方程, 令Vt=-λ lgΨ t, 根据文献[17]有
-∂ tΨ t=-
根据边界条件有
方程式(4)的解析解为
这样就把随机最优控制的问题转化为近似路径积分问题, 式(5)可转化为
其中, τ i=(
p(τ i|xi)=
其中(
S(τ i)=
最优控制量:
式(6)概率的求解是解析解, 依赖于系统模型ft, 可以利用路径积分方法进行数值求解, 路径积分方法不要求已知模型.在初始状态
P(τ i, k)=
其中
S(τ i, k)=
更新控制量:
u← u+
通过数值迭代, 最终使指标函数即损失函数收敛.
本节使用路径积分强化学习方法优化蛇形机器人步态方程的参数.蛇形机器人步态方程的参数与其运动状态之间的模型较复杂, 理论模型在实际实验中也会存在误差, 而基于路径积分的强化学习方法可以不依赖模型, 通过端到端的训练优化参数.
Hirose[1]提出蛇形机器人步态方程:
φ i(t)=Asin(ω t+(i-1)β )+γ , (7)
其中, φ i(t)表示t时刻第i个关节的角度.参数组
U=[
分别表示幅值、角频率、相位和中心调整因子.A用于控制蛇形曲线的幅值角, ω 用于控制运动速度, β 用于控制蛇形曲线波的数目, γ 用于控制转弯半径.
参数组U与蛇形机器人的运动状态存在复杂的耦合关系, 理论计算的定量关系在实验过程中也会存在误差, 本文利用路径积分强化学习方法, 回避这两个问题.
路径τ i由控制量ui产生, 对应的损失函数为R(τ i), 目标是寻找控制量u, 使值函数最小:
V=
其中, P(τ i)为路径τ i对应的概率:
P(τ i)=
其中, K表示路径总数,
S(τ i)=exp(-
为通过R(τ i)计算的指数损失函数,
R=[
λ 为常数.
P(τ i)为路径τ i对应的概率, 同时也是产生该路径的控制量ui占有的权重, 优化后的控制量u* :
u* =
蛇形机器人目标导向运动是指控制蛇形机器人的运动, 使其到达指定位置, 文献[2]和文献[22]研究蛇形机器人的运动步态, 实现蛇形机器人的运动, 但还不能跟踪给定路径或到达给定目标点.本文使用路径积分强化学习方法, 可使蛇形机器人规避障碍到达目标点.
(xT, yT)为目标点位置, (x, y)为蛇形机器人头部位置, 头部初始位置为(0, 0), 使用欧氏距离表示损失函数:
R(τ i)=
路径积分强化学习方法通过迭代训练, 优化步态方程参数, 使蛇形机器人最终能从初始位置到达目标位置.步态方程参数初始值
U0=[
第ξ 次迭代后的参数
Uξ =[
每次迭代训练会随机产生K条路径, 第i条路径的随机控制量
ui=[
其中, ε 服从均值为0的正态分布.第ξ +1次训练第i条路径的参数:
其中, 第i条路径对应的损失函数为R(τ i), 第ξ +1次迭代后的参数更新为
Uξ +1=Uξ +u* , (11)
u* 根据式(8)~式(10)计算.
ε 的方差与损失函数是相关的, 利用第ξ 次迭代后的参数Uξ 产生一条路径, 损失函数为r, 在第ξ +1次训练中ε 的标准差为
σ =f(r), (12)
其中
σ =[
基于路径积分强化学习方法的蛇形机器人目标导向运动算法步骤如下所示.
算法1 基于路径积分强化学习方法的蛇形机器人 目标导向运动算法
初始化U0, σ 2
for ξ =1, 2, …, M:
for i=1, 2, …, K:
根据σ 2随机产生ui
根据式(7)产生轨迹τ i, 对应损失函数为R(τ i)
根据式(8)~式(11)更新参数Uξ +1
利用Uξ +1产生路径, 对应损失函数r, 根据式(12)更新方差
算法1给出无障碍环境下的算法, 对于有障碍环境, 需利用无障碍环境下最终训练得到的参数作为先验知识.
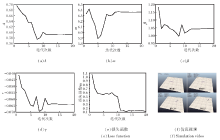
实验目的是让蛇形机器人从起始位置到达目标位置, 同时规避障碍.实验包括仿真实验和实际实验, 仿真实验包括无障碍和有障碍两种环境, 仿真物理引擎为V-REP.图1(a)为无障碍仿真环境, 图1(b)为有障碍环境, 无障碍仿真环境的训练结果为有障碍环境的训练提供先验知识.实际实验包含障碍, 如图1(c)所示, 有障碍仿真环境的训练结果为实际实验的训练提供先验知识, 在很大程度上减少实际实验训练迭代的次数.图1中3种环境的起始点和目标点位置相同, (b)和(c)中障碍物位置相同.实际蛇形机器人机构利用3D打印技术完成, 拥有8个驱动偏航关节.
 | 图1 仿真和实际实验环境Fig.1 Simulated and real experiment environment |
图1(a)为无障碍仿真环境, 蛇形机器人头部初始位置为(0, 0), 绿色目标位置
(xT, yT)=(1.5, 1.5),
单位为m.蛇形机器人步态方程参数初始值为
U0=[
正态分布标准差初始值为
σ 0=[
迭代次数M=20, 每次迭代路径数K=30, 常数λ =30.标准差与损失函数之间的关系如下:
σ =f(r)=
仿真结果如图2所示, (a)~(d)分别对应步态方程的4个参数随着迭代次数增加的变化曲线, (e)为损失函数, (f)为第17次训练后的仿真视频.第17次训练后的参数为
U17=[
损失函数r=0.135 m.
 | 图2 无障碍仿真结果Fig.2 Simulation result without obstacle |
文献[21]利用路径积分强化学习方法实现蛇形机器人在无障碍环境下到达目标位置, 在此基础上, 本文实现有障碍环境下让蛇形机器人规避障碍到达目标位置, 迭代次数相对更少.
蛇形机器人步态方程中ω 控制速度, γ 控制转弯半径, A、β 控制蛇形曲线构型.对于图1(b)的有障碍仿真环境, 可以把运动分成两段, 让蛇形机器人从两个障碍物之间穿过.初始时刻到中间时刻Tm为第一段, 步态方程参数
U(1)=[
中间时刻Tm到终止时刻T为第二段, 步态方程参数
U(2)=[
这样每次迭代训练需要8个参数, 需要增加迭代次数M及路径数K, 而且无法收敛可能损失函数, 所以利用无障碍仿真实验中先验知识, 令A(1)、β (1)、A(2)、β (2)为常数, 取值为无障碍仿真实验第17次训练后对应的参数:
A(1)=A(2)=U17[1]=0.592, β (1)=β (2)=U17[3]=1.046,
这样训练参数减少到4个.定义新的训练参数
ω 初始值由U17给定,
ω (1)=ω (2)=U17[2]=6.361, β (1)=β (2)=0,
初始参数
新的标准差定义为
初始值
障碍物位置
O1=(0.25, 0.7), O2=(0.95, 0.4),
迭代次数M=30, 路径数K=30, 中间时刻Tm=6 s, 终止时刻T=12 s, 常数λ =30.标准差和损失函数关系如下:
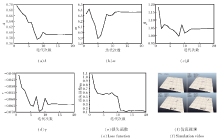
仿真结果如图3所示, (a)~(d)分别对应步态方程的4个参数随着迭代次数增加的变化曲线, (e)为损失函数, (f)是第30次训练后的仿真视频.第30次训练后的参数
损失函数r=0.107 m.
 | 图3 有障碍仿真结果Fig.3 Simulation result with obstacles |
为了减少实际实验中迭代次数M及路径数K, 需要利用有障碍仿真实验的先验知识.实际实验训练参数
初始值根据有障碍仿真实验第30次训练后的参数
给出,
标准差
初始值
障碍物位置
O1=(0.25, 0.7), O2=(0.95, 0.4),
迭代次数M=3, 路径数K=10, 中间时刻Tm=3 s, 终止时刻T=5.5 s, 常数λ =30.第2次迭代训练的标准差
第3次迭代训练的标准差
实际实验结果如图4所示, (a)~(d)表示训练过程中每条路径随机产生的参数, (e)~(g)分别表示训练过程中第一次、第二次、第三次迭代中每条路径对应的损失函数.
在图4(e)中, 损失函数达到峰值4.243 m, 这是因为训练过程碰到障碍物.每次迭代后的参数和损失函数如表1所示, 第三次迭代后的损失函数r=0.027 m.实验结果表明, 仅需3次迭代就能使损失函数收敛.
 | 图4 有障碍实际实验结果Fig.4 Experimental results with obstacles |
| 表1 每次迭代后的参数和损失函数 Table 1 Parameters and loss function of each iteration |
实验分成3组进行, 第1组无障碍仿真实验用到的先验知识很少, 训练参数的初始值选择随机性较强, 因此所需的迭代次数M和路径数K较大, 才能保证训练参数和损失函数的收敛.第2组有障碍仿真实验利用第1组实验训练得到的参数作为先验知识, 同时为了减少训练参数量, 选取直接影响蛇形机器人运动的2个参数ω 和γ 作为待训练的参数.因为还需要规避障碍物, 因此M和K仍然较大, 才能保证训练参数和损失函数收敛.第3组实际实验利用第2组实验训练得到的参数作为先验知识, 仅需3次迭代就能使损失函数收敛, 说明基于路径积分的强化学习方法可以较快达到收敛.
本文提出基于路径积分强化学习方法, 实现蛇形机器人的目标导向运动.路径积分方法源于随机最优控制, 基于贝尔曼最优性准则及HJB方程求解最优解.实验包括仿真实验和实际实验, 仿真实验分为两个部分.无障碍仿真实验的训练结果作为有障碍仿真实验的先验知识, 同时削减非直接相关的步态方程参数, 保证损失函数以较快的速度收敛.有障碍仿真的训练结果作为实际实验的先验知识, 仅需3次迭代就能使损失函数收敛到误差范围内, 这也证明路径积分强化学习方法可以不依赖机器人的运动学或动力学模型, 可以实现损失函数的收敛, 而且收敛速度较快.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|