



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于关键点估计的实时道路元素检测算法
[刘贤梅1  , 景雅虹
, 景雅虹1 , 田枫1 , 刘芳1 ]
, 景雅虹, 田枫, 刘芳]
|
|



作者简介:

景雅虹,硕士研究生,主要研究方向为目标检测跟踪.E-mail:j-berly@hotmail.com.

田 枫,博士,教授,主要研究方向为计算机视觉、虚拟现实.E-mail:tianfeng1980@163.com.

刘 芳,博士研究生,副教授,主要研究方向为虚拟现实、计算机视觉.E-mail:lfliufang1983@126.com.
针对手工设计神经网络结构成本较高、基于锚框的分类回归任务计算量较大以及小目标检测能力较弱的问题,文中使用基于神经网络结构搜索的EfficientNet-B3作为特征提取网络,改进基于双向特征金字塔网络的特征融合方法作为特征融合网络,利用关键点估计代替锚框,执行分类与回归任务,提出基于关键点估计的实时道路元素检测算法.在BDD100K数据集上的实验表明,文中算法在实时检测的基础上可达到较优的检测效果,在小目标上检测精度较高.
AboutAuthor:
JING Yahong, master student. Her research interests include target detection and tracking.
TIAN Feng, Ph.D., professor. His research interests include computer vision and virtual reality.
LIU Fang, Ph.D. candidate, associate pro-fessor. Her research interests include virtual reality and computer vision.
Aiming at the problems of high cost of manually designing neural network structure, large amount of calculation of the classification and regression task based on the anchor boxes, and weak detection ability for small targets, a real-time road element detection model based on keypoint estimation is proposed. NAS-based EfficientNet-B3 is employed as the feature extraction network. An improved bi-directional feature pyramid network(BiFPN) method is exploited as the feature fusion network. Instead of anchor boxes, keypoint estimation is utilized for classification and regression tasks. The experiment on BDD100K dataset shows that the proposed model achieves a good precision in real-time detection and a high precision for small objects.
本文责任编委 高隽
Recommended by Associate Editor GAO Jun
近些年, 深度学习与实际应用结合愈发紧密, 基于深度学习的道路元素检测成为研究热点之一, 但却无法同时满足高检测精度和实时检测的需求.以一阶段算法EfficientDet[1]为例, EfficientDet-D0模型检测精度为32.9%, 运行速度为97帧/秒, 但是对于检测精度提升到50.9%的EfficientDet-D6, 运行速度降至2.6帧/秒, 无法应用在自动驾驶、视频监控等需要实时检测的领域.因此, 为了在实时检测的基础上达到较高的检测精度, 需要构建高效的特征提取网络、特征融合网络及分类和回归网络.
特征提取网络应尽可能多地获取特征信息.两阶段的快速的基于区域的卷积网络(Fast Region-Based Convolutional Network, Fast R-CNN)[2]、更快的基于区域的卷积网络(Faster Region-Based Convo-lutional Network, Faster R-CNN)[3] 、基于蒙版的区域卷积网络(Mask Region-Based Convolutional Net-work, Mask R-CNN)[4]和一阶段的单发多边框检测器(Single Shot Multibox Detector, SSD)[5]、RefineDet(Refine Detection)[6]使用视觉几何组(Visual Geo-metry Group, VGG)[7], 网络深度可达到16~19层.实验表明一定深度的卷积神经网络(Convolutional Neutral Network, CNN)在视觉任务中的重要性.两阶段的基于区域的全连接卷积网络(Region-Based Fully Convolutional Networks, R-FCN)[8]、级联的基于区域的卷积网络(Cascade Region-Based Convo-lutional Network, Cascade R-CNN)[9]和一阶段的反卷积单发检测器(Deconvolutional Single Shot Detec-tor, DSSD)[10]使用残差网络(Residual Networks, ResNet)[11] , 利用快捷连接(Shortcut Connection)解决训练过程中网络过深导致的梯度消失的问题, 可实现152层网络的训练.
实验也表明[12]网络深度对检测精度的作用有限.YOLOv3(You Only Look Once v3)[13]使用Dark-net-53作为特征提取网络, 同样使用快捷连接, 在较简单的网络内完成多尺度的检测.虽然手工设计网络取得较大进步, 但很难全面考虑所有参数, 构建最优网络架构.神经网络结构搜索(Neural Architecture Search, NAS)为了弥补这一缺陷, 使用搜索空间获取较优性能, 如EfficientNet[12]和RegNet(Regular Network)[14], 但目前两者仅支持在ImageNet[15]、MNIST[16]数据集上构建模型.EfficientDet[1]在EfficientNet基础上加入双向特征金字塔网络(Bi-directional Feature Pyramid Network, BiFPN), 构造适合目标检测任务的模型.
特征融合网络用于融合高分辨率的浅层特征信息和高语义的深层特征信息, 达到更高的检测精度.早期的检测算法(如Fast R-CNN)直接在提取特征上进行目标分类和位置预测, 检测效果较差.特征金字塔网络(Feature Pyramid Network, FPN)[17]提出从上到下进行特征融合的思路, 在不同尺寸的特征图上进行预测, 达到多尺度检测的目的.受FPN启发, 深度层聚合(Deep Layer Aggregation, DLA)[18]使用融合不同尺寸特征的迭代深度聚合(Iterative Deep Aggregation, IDA)和融合不同通道间特征的分层深度聚合(Hierarchical Deep Aggregation, HDA)两种特征融合的结构, 但大量不同维度的融合操作导致网络更复杂.ResNet[11]采用快捷连接, 将之前任意层的特征信息传递到当前层, 弥补经数次下采样导致的特征信息丢失、深层语义信息丰富但分辨率较低导致预测失败的缺陷.因此不同层的特征实现连接非常重要, 不仅避免网络太深导致梯度消失的情况, 而且有效提高多尺度目标的检测能力.路径聚合网络(Path Aggregation Network, PANet)[19]采用双向特征融合方式, 缺少快捷连接, 因此并未充分获取特征信息.神经网络架构搜索特征金字塔网络(Neural Architecture Search FPN, NAS-FPN)[20]通过神经网络架构搜索(Neural Architecture Search, NAS)推导双向特征融合, 可解释性较弱, 难以修改.BiFPN[1]在双向特征融合的基础上加入快捷连接, 实现同层特征的跨越连接, 同时关注权重较高的特征, 提高检测精度.
分类和回归网络可用于确定目标的类别和位置.近年来, 大多数检测算法采用基于锚框的分类与回归方法, 通过矩形框的回归确定目标位置.但是, 使用锚框也有较明显缺点.1)目标大小不一, 锚框很难覆盖所有目标尺寸, 需要预设多组不同大小的锚框, 并在多个尺度的特征图上进行分类与回归, 因此整个网络的计算量巨大.2)较难定位到远距离的小目标, 因此召回率较低.全卷积一阶段目标检测(Fully Convolutional One-Stage Object Detection, FCOS)[21]使用中心点到预测框四条边的距离对目标进行定位, 减少复杂计算.CornerNet(Corner Network)[22]对目标的角点(左上角和右下角)进行分类与回归, 代替原有的锚框方法, 但对目标边缘敏感, 同时无法确定哪一对角点属于同一目标.ExtremeNet(Extreme Network)[23]检测4个极端点(最顶部、最左侧、最底部、最右侧)和1个中心点, 用于生成对象边界框.Zhou等[24]使用关键点估计找到对象的中心点, 实现3D目标检测、姿态估计等其它视觉任务.CenterNet(Center Network)[25]同时使用左上角点、右下角点和中心点定位目标, 较好地缓解针对小目标召回率较低的问题.
针对上述分析, 综合考虑方法特征提取能力、运算效率、硬件条件限制等多方面因素, 本文提出基于关键点估计的实时道路元素检测算法.采用一阶段算法EfficientNet-B3[12]作为特征提取网络, 保证算法的运行速度.改进BiFPN作为特征融合网络, 改进后的BiFPN更简单, 计算量更少, 同时尽可能保证图像中各类目标有足够的特征信息用于分类和回归网络中, 提高检测精度.使用基于关键点估计的方法对目标进行分类和定位, 分别对左上角点、右下角点、中间点生成关键点位置热图, 并对左上角点和右下角点进行配对, 使用基于关键点估计的方法, 因为其对特征图的尺度不敏感, 无需在多个尺度上进行分类和定位, 也能识别不同尺度的目标.相比锚框的方法, 基于关键点估计的方法计算量更少, 同时更容易定位到小目标, 提高对小目标的检测精度.在BDD 100K数据集[26]上训练与测试本文算法, 实现对人、车、交通信号等道路元素的检测, 在实时检测的基础上可达到较好的检测效果, 在小目标上的检测精度较高.
随着手工设计的模型架构越来越复杂, 可调整的参数越来越多, 通过大量实验验证模型性能的方法效率愈发低下, 因此NAS在模型架构上获得大量应用, 并逐渐得到重视.由NAS搜索得出的EfficientNet针对图像的不同分辨率, 构建深度、宽度不同的模型, 其中, EfficientNet的B3版本在达到实时的基础上, 特征提取效果良好[12].因此本文以EfficientNet-B3作为特征提取网络, 改进BiFPN进行特征融合(较低的计算量和较高的检测精度), 将融合后的特征送入分类与回归网络, 使用关键点代替锚框, 最终在112× 112的特征图上估计关键点, 得出最终的候选框.模型整体架构如图1所示.
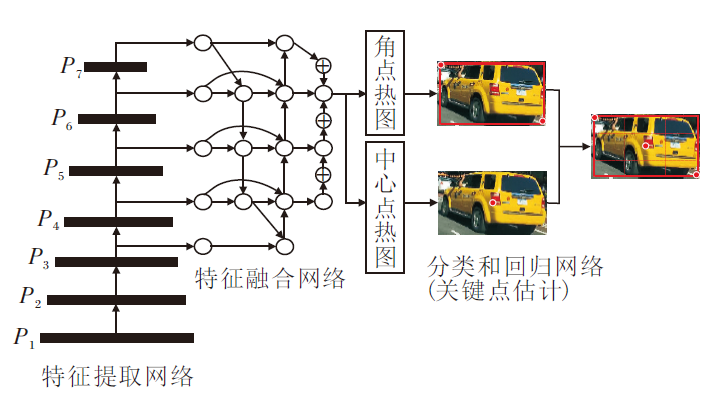 | 图1 模型整体架构图Fig.1 Model architecture |
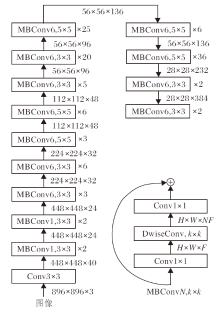
本文以EfficientNet-B3作为特征提取网络, 接收的输入图像分辨率为896× 896, 共由26个移动网络块卷积(MobileNet Block Convolution, MBConv)构成, 每个MBConv均由2个1× 1的卷积核及1个3× 3或5× 5的卷积核构成.
移动神经网络搜索网络(Mobile Neural Network Search Network, Mnas-Net)[27]观察到在MBConv中使用较大(如5× 5)的卷积核效率更高, 每秒浮点运算次数(Floating Point Operation per Second, FLOPS)更少.
特征提取网络的详细设计如图2所示.本文的Conv包括卷积、批量归一化(Batch Normalization, BN)和ReLU激活3个操作, 深度可分离卷积(Depth-wise Separable Convolution, DwiseConv)为MnasNet中深度可分离卷积, 卷积核k=3或k=5, H× W× F表示特征图的高度× 宽度× 深度(通道数), × n(n=2, 3, 5, 6, 20, 25)表示MBConv重复的次数.
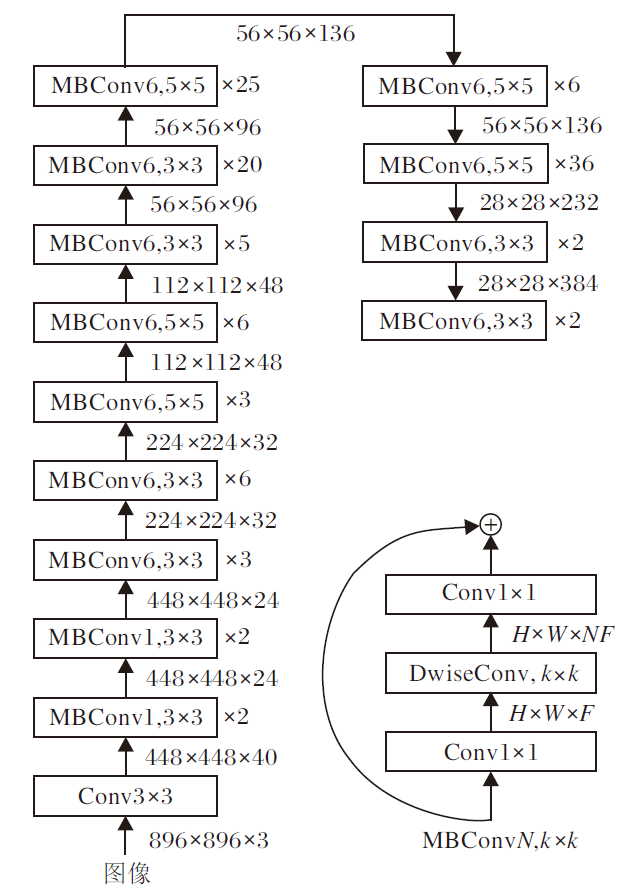 | 图2 特征提取网络Fig.2 Feature extraction network |
谷歌大脑团队在EfficientNet[12]的基础上加入可解释、易修改的双向FPN— — BiFPN, 提出更适合检测任务的EfficientDet[1].但为了确保可识别不同尺度的目标, EfficientDet需要在不同尺度的特征图上使用锚框, 计算量较大.
图3为3种不同特征融合网络的对比.(a)为从上到下的特征融合方法FPN, 可实现在多个尺度上执行分类和回归任务.(b)为双向特征融合方法BiFPN, 对特征进行从上到下和由下至上的双向融合, 加入同尺度的特征融合, 同样实现在多个尺度上执行分类和回归任务.(c)为本文特征融合网络, 与EfficientDet使用多次BiFPN、最终输出5个尺度特征图的方式不同, 本文仅在使用1次BiFPN后, 将不同尺度的特征融入同一尺度, 用于最终的分类和回归.
 | 图3 三种特征融合网络对比Fig.3 Comparison of 3 kinds of fusion networks |
参照EfficientDet[1]的BiFPN特征融合计算公式, 设

其中:i∈ [3, 6]; ε =0.000 1, 用于避免数值不稳定造成的显著误差; ω 表示第li层特征的权重, 通过ReLU进行归一化; Resize表示统一不同尺度特征图的函数;
本文使用关键点(左上角点、右下角点、中心点)估计的方法实现目标检测任务, 即同时关注目标边界的坐标和目标内部坐标, 减少错误候选框的生成.
1.3.1 关键点预测
使用中心点池化模块、左上角点中心点池化模块和右下角点中心点池化模块分别对最后输出的特征图进行水平方向和垂直方向的最大池化操作, 将两个方向上的最大值进行相加, 得到最后每类关键点的热图.
图4为关键点池化模块, (b)为左上角点池化模块(右下角点与其相似, 在Conv3× 3后使用向右、向下的池化方法).每类的热图均为H× W× C, 其中, H× W为热图的尺寸, C为类别构成的通道数, 使用二值掩膜表示每个关键点的位置表示哪一类别, 因此每个关键点仅能表示一个类别.
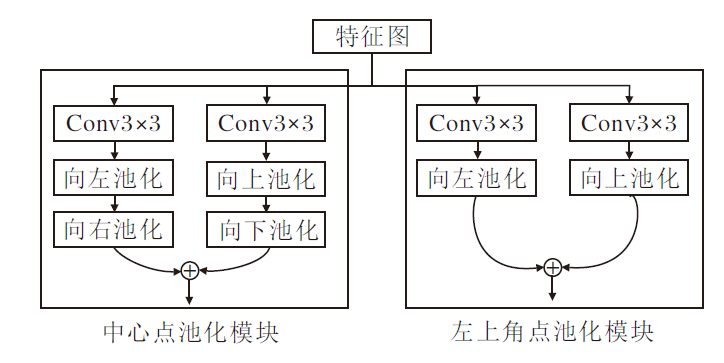 | 图4 关键点池化模块Fig.4 Keypoint pooling module |
1.3.2 角点分组
为了形成最终的目标候选框, 需要对所有左上角点和右下角点配对, 属于同一目标的一对角点可生成一个候选框.为每个角点都设置1个嵌入式(Embedding)向量, 如果一对角点的嵌入式向量相差足够小, 可认为这两个角点属于同一目标.嵌入式向量通过Lpull和Lpush两个损失函数进行学习, 使用CornerNet[22]的角点分组:
其中, N为输入图像中目标的数量, etk、ebk分别为第k个目标实际坐标的左上角点和右下角点的嵌入式向量.嵌入式向量通过Lpull习得同一目标下一对角点的嵌入式向量更近, 使用Lpush惩罚不同目标的一对角点的嵌入式向量, 使嵌入式向量最终学到上述规则.
1.3.3 损失函数
Ldet表示基于focal loss的预测关键点的损失函数[25]:
Ldet=
其中, pcij表示热图中关键点(i, j)被判定为类别为c的得分, ycij表示真实框的坐标.
通过平滑L1范式(smooth L1 Loss)[3]将热图上的关键点坐标映射回真实目标所在的图像中.热图上的点(⌊
ok=[
其中n为下采样因子.估计的关键点坐标与真实坐标的偏移量为
Loff=
整个网络的损失函数由Ldet、
L=Ldet+
本次实验使用静态道路元素数据集BDD100K[26], 数据集共标注近10万幅实际驾驶的图像, 包含的目标类别有Bike、Bus、Car、Motor、Person、Rider、Traffic light、Traffic sign、Train、Truck, 训练集共69 863幅图像, 校验集共10 000幅图像.
实验使用BDD100K官方对静态图像检测的评估标准, 使用平均精度(Average Precision, AP)和平均召回率(Average Recall, AR)作为检测算法的评价指标.AP包括mAPIoU=0.5, 0.05, 0.95, 即平均精度均值(Mean Average Precision, mAP), 表示计算堆叠率分别为0.5、0.05、0.95时的平均精度; APIoU=0.5, 即AP50, 表示计算堆叠率为0.5时的平均精度; APIoU=0.75, 即AP75, 表示计算堆叠率为0.75时的平均精度; A
实验在NVIDIA GTX 1080Ti GPU的服务器上进行, 基于tensorflow2.0对算法进行开发.为了增加算法的鲁棒性, 本文参照视网膜网络(Retina Network, RetinaNet)[28]图像预处理方法, 对图像和关键点进行随机缩放、旋转、裁切等操作.在训练模型时, 实验使用冲量(Momentum)为0.9、权重衰减率为0.000 1的随机梯度下降算法(Stochastic Gradient Descent, SGD)[29].算法接收的输入图像分辨率为896× 896, 实验共进行300次迭代的训练, 每次迭代训练70 000幅经过预处理的图像, 批尺寸(Batch Size)为8, 在第232次迭代时达到最优效果.在训练初始阶段, 学习率从0线性增长到0.16, 之后使用余弦衰减规则进行下降.算法使用swish激活函数[30], 衰减率为0.999 8.
为了验证本文算法的有效性, 对比如下算法:EfficientDet-D3[1]、SSD[5]、RefineDet[6]、YOLOv3[13]、Gaussian YOLOv3[31]、多尺度深度卷积神经网络(Multi-scale Deep Convolutional Neural Network, MS-CNN)[32]、尺度不敏感的卷积神经网络(Scale-Insensitive Convolutional Neural Network, SINet)[33]、综合特征增强卷积神经网络(Comprehensive Fea-ture Enhancement Convolutional Neural Network, CFENet)[34]、感受野块网络(Receptive Field Block Net, RFBNet)[35].
表1为各算法检测性能对比, 所有算法均使用官方源码, 去除所有针对响应速度(如TensorRT)的优化方法.校验集为BDD100K提供的10 000幅图像.相比其它算法, 本文算法在mAP值和检测速度上优势明显:mAP值最优, 达到29.1%.在检测速度上, 相比RFBNet、YOLOv3、EfficientDet-D3, 本文算法也能达到实时检测, 高于其它6种算法.
| 表1 各算法在BDD100K数据集上的检测性能对比 Table 1 Comparison of detection performance of different algorithms on BDD100K dataset |
为了分析本文算法对每类道路元素的检测能力, 表2为本文算法对不同类别道路元素的平均精度.其中, 算法后的数字表示该算法接受的输入图像的分辨率, 如CFENet-800为CFENet接受800× 800的输入图像.本文算法尤其在小目标(如Traffic light, Traffic sign)上的AP值具有较大的提升, 对Traffic light, Traffic sign的AP值分别提升至15.69%和35.45%.
| 表2 在BDD100K数据集上针对每类道路元素各算法的AP值对比 Table 2 AP value comparison of different algorithms on BDD100K dataset for each road element % |
此外, 受CenterNet[25]启发, 表3给出不同分类回归网络在BDD100K数据集上的平均精度对比.由表可知关键点池化模块的重要性, 对小目标AP值的提升效果明显, 如APS和ARS都具有较大幅度的提升(APS提升近5%, ARS提升近2%), 表明使用关键点定位目标方法的有效性.
| 表3 不同分类回归网络在BDD100K数据集上的AP值对比 Table 3 AP value comparison on BDD100K for different classification and regression networks |
图5为本文算法分别在白天、夜间的检测效果, 其中(b)为使用角点坐标画出矩形框检测后的图像, 同时对角点和中心点的坐标进行可视化, (c)为依照关键点的关注点绘制的热图.由图可看到, 本文算法通过关键点估计的方式, 可检测一定条件下的物体, 并通过热图可看出, 关键点较准确地定位目标物体.
 | 图5 关键点标注和热图可视化Fig.5 Visualization of keypoint labelling and heatmap |
实验使用类激活映射(Class Activation Maps, CAM)[36]在P3、P4、P6层分别取4个通道的特征进行可视化, 如图6所示.由图可知, 在浅层(P3)仍保留较多特征信息, 但噪音也较多, 而在深层(P6)噪音几乎都被去除, 一些小目标的特征信息同样被去除.因此在提取特征后使用特征融合, 同时保留深浅层特征信息, 对提高检测精度十分重要.
 | 图6 P3、P4、P6层的特征映射图可视化Fig.6 Visualization of feature map of label P3, P4 and P6 |
本文提出基于关键点估计的实时道路元素检测算法.以EfficientNet-B3为特征提取网络, 改进BiFPN作为特征融合网络, 利用关键点代替锚框实现分类与回归任务, 在保证检测速度的同时, 提高检测精度.本文使用基于关键点估计的方法避免对锚框大小和纵横比的设定, 同时通过相关实验验证关键点估计方法对远距离小目标检测的有效性.在公共数据集BDD100K上的实验表明, 本文算法可在真实的交通场景中检测车辆、行人、骑行者、交通信号等元素.今后将提高算法在雨雪天气下的检测精度, 进一步提高本文算法的检测性能, 更好地服务于视频监控、辅助驾驶等场景中对道路元素检测的需求.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|