{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于 l2,0范数稀疏性和模糊相似性的图优化无监督组特征选择方法
[孟田田1  , 周水生
, 周水生1 , 田昕润1 ]
, 周水生, 田昕润]
|
|



作者简介:

孟田田,硕士研究生,主要研究方向为机器学习、最优化理论与算法.E-mail:mengtiatian7@163.com.

田昕润,硕士研究生,主要研究方向为最优化计算理论与算法、模式识别及应用.E⁃mail:xrtian_1@stu.xidian.edu.cn.
基于图的无监督特征选择方法大多选择投影矩阵的 l2,1范数稀疏正则化代替非凸的 l2,0范数约束,然而 l2,1范数正则化方法根据得分高低逐个选择特征,未考虑特征的相关性.因此,文中提出基于 l2,0范数稀疏性和模糊相似性的图优化无监督组特征选择方法,同时进行图学习和特征选择.在图学习中,学习具有精确连通分量的相似性矩阵.在特征选择过程中,约束投影矩阵的非零行个数,实现组特征选择.为了解决非凸的 l2,0范数约束,引入元素为0或1的特征选择向量,将 l2,0范数约束问题转化为0 -1整数规划问题,并将离散的0 -1整数约束转化为2个连续约束进行求解.最后,引入模糊相似性因子,拓展文中方法,学习更精确的图结构.在真实数据集上的实验表明文中方法的有效性.
About Author:
MENG Tiantian, master student. Her research interests include machine learning and optimization theory and algorithm.
TIAN Xinrun, master student. Her research interests include optimization theory and algorithm, and pattern recognition and application.
Most graph-based unsupervised feature selection methods choose l2,1-norm sparse regularization of the projection matrix instead of non-convex l2,0-norm constraint. However, the l2,1-norm regularization method selects features one by one according to the scores, without considering the correlation of features. Therefore, an unsupervised group feature selection method for graph optimization based on l2,0-norm sparsity and fuzzy similarity is proposed, and it simultaneously performs graph learning and feature selection. In graph learning, the similarity matrix with exact connected components is learned. In the process of feature selection, the number of non-zero rows of projection matrix is constrained to realize group feature selection. To solve the non-convex l2,0-norm constraint, the feature selection vector with elements of 0 or 1 is introduced to transform the l2,0-norm constraint problem into 0-1 integer programming problem, and the discrete 0-1 integer constraint is transformed into two continuous constraints to solve the problem. Finally, fuzzy similarity factor is introduced to extend the method and learn more accurate graph structure. Experiments on real datasets show the effectiveness of the proposed method.
近年来, 随着信息技术的高速发展, 大量的数据出现在实际生活中, 增长速度迅猛.大规模的数据为机器学习[1]、图像处理[2]、模式识别[3]等领域提供丰富的信息.然而, 高维数据不可避免地包含冗余信息, 这可能导致机器学习算法过拟合, 甚至产生“ 维数灾难” .如何处理这些大规模数据也成为实际应用中的一大挑战.为了避免维数灾难, 挖掘数据中的有效信息, 降维作为数据预处理的一种重要手段[4], 受到学者们越来越多的关注.
降维主要有两种方式: 特征选择[5, 6]和特征提取[7, 8].特征提取是对原始特征空间进行映射或变换, 得到原始特征线性组合或非线性组合生成的一组特征.与特征提取不同, 特征选择是在原始特征空间中进行, 通过某种评价策略, 从原始特征集上选择最具有代表性的特征子集.因此, 相比特征提取, 特征选择保留数据的原始物理意义, 具有更强的可解释性.
根据数据标签的使用情况, 特征选择可分为3类:监督特征选择[9, 10]、半监督特征选择[11]和无监督特征选择[12].在实际生活中, 数据标签的获取成本很高, 因此无监督特征选择具有重要的研究意义和研究价值.
根据评价策略的不同, 特征选择也可分为:过滤式特征选择[13, 14]、包裹式特征选择[15]和嵌入式特征选择[16, 17].过滤式特征选择先对原始特征进行“ 过滤” , 再将过滤后的特征用于后续的学习任务.包裹式特征选择把最终使用的学习器的性能作为特征子集的评价标准, 由于计算成本较高, 不适用于大规模数据集.嵌入式特征选择结合过滤式特征选择与包裹式特征选择的优点, 将特征选择过程嵌入模型构建中, 使选择的特征可提高算法的性能.
由于局部结构在流形学习中具有良好性能, 可获取数据的分布流形信息, 选择更好地保持数据流形结构的特征, 因此流形学习越来越多地引用至嵌入式无监督特征选择方法.Cai等[18]提出MCFS(Multi-cluster Feature Selection), 通过谱分析获取局部流形结构, 再利用l1范数稀疏约束选择特征.Yang等[19]提出UDFS(Unsupervised Discriminative Feature Selection), 将判别分析和投影矩阵的结构稀疏l2, 1范数最小化融合到一个联合框架, 进行无监督特征选择.
此外, 由于谱分析理论可提供丰富的流形结构信息, 并且数据结构通常以图的形式捕获, 因此基于图的特征选择方法吸引学者们的关注.Shang等[20]在子空间学习的特征选择框架的基础上, 引入图正则化的思想, 在特征空间上构造特征映射, 保留特征流形上的几何结构信息.Nie等[21]提出SOGFS(Structured Optimal Graph Feature Selection), 将相似性矩阵构造和特征选择过程构建到同一框架中, 同时进行局部结构学习和特征选择.Li 等[22]提出GURM(Generalized Uncorrelated Regression Model), 加入基于最大熵原理的图正则化项.Zhang等[23]提出EGCFS(Unsupervised Feature Selection via Adap-tive Graph Learning and Constraint), 通过自适应图学习方法, 将相似矩阵的构造嵌入优化过程中, 将类间散点矩阵最大化的思想和自适应图结构集成到一个统一的框架中.
由于稀疏性是真实世界数据的固有属性, 因此稀疏学习是基于图的无监督特征选择的常用方法之一.许多特征选择方法应用正则化项实现稀疏学习, 如l1范数、l2, 0范数、l2, 1范数等.在特征选择任务中, 矩阵的l2, 0范数可约束矩阵的非零行个数, 恰好为选择特征的个数, 因此显然是特征选择的最佳选择.由于l2, 0范数的非凸性, 优化问题是个NP难题.在现有的特征选择研究中, 大部分考虑矩阵的l2, 1范数实现稀疏性.通过l2, 1范数正则化进行特征选择, 需要对所有特征评分、排序, 逐个选择评分最高的特征, 未考虑特征之间的相关性.由于l2, 0范数约束正则化参数为选择特征的个数, 在学习过程中动态选择一组最好的特征, 并且不需要花费时间进行正则化参数的调节.因此, 学者们针对求解l2, 0范数约束的特征选择问题进行研究.Cai等[24]引入松弛变量, 通过增广拉格朗日函数进行优化.Du等[25]提出启发式更新过程, 在每次迭代中贪婪搜索最优解.Nie等[26]采用与文献[27]类似的方法, 通过投影矩阵的满秩分解, 将l2, 0约束问题转换为矩阵迹的优化问题进行求解.
尽管上述方法都是对l2, 0范数特征选择问题进行求解, 但在实际优化过程中, 仍需要通过某种方式排序选择特征, 这意味着这些方法依然是l2, 1范数的变体, 没有从根本上解决l2, 1范数正则化存在的问题.为此, 本文提出解决l2, 0范数组稀疏的特征选择方法, 即基于l2, 0范数稀疏性和模糊相似性的图优化无监督组特征选择方法(Unsupervised Group Feature Selection Method for Graph Optimization Based on l2, 0-norm Sparsity and Fuzzy Similarity, F-SUGFS).引入0-1特征选择向量, 将l2, 0范数约束转换为特征选择向量的0-1整数约束, 并利用l2-box将离散的0-1整数约束转化为2个连续约束, 通过交替方向乘子法(Alternating Direction Method of Mul- tipliers, ADMM)进行求解, 动态选择一组最优的特征, 实现组特征选择.最后, 引入模糊相似因子, 进一步扩展方法.在多个真实数据集上的实验验证本文方法的有效性.
对于矩阵X∈ Rd× n, XT表示矩阵的转置, tr(X)表示矩阵的迹, rank(X)表示矩阵的秩.X的l2, 0范数定义为
‖ X‖ 2.0=
其中a=0时‖ a‖ 0=0, 否则‖ a‖ 0=1.X的l2, 1范数定义为
‖ X‖ 2.1=
对于向量r∈ Rd× 1, r的l2范数定义为
‖ r‖ 2=(
diag(r)表示对角矩阵, 对角元素为向量r的元素.1d表示d× 1维列向量, 元素全为1.
相似性矩阵的构造和约束是基于图的方法的关键.给定数据矩阵X∈ Rd× n, 考虑概率近邻[28], 即对于数据xi, 所有数据点{x1, x2, …, xn}都有Sij的概率与xi成为邻居.通常越小的距离‖ xi-xj
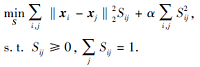 |
定理1[28] 拉普拉斯矩阵LS的特征值0的重数等于具有相似性矩阵S的图中连通分量的个数.
在将数据划分为c簇的聚类任务中, 理想的邻居分配是相似图的连通成分恰好为聚类数c.根据定理1, 约束拉普拉斯矩阵LS的秩
rank(LS)=n-c,
其中
LS=D-
度矩阵D为对角矩阵, 对角线元素
Dii=
令σ 1, σ 2, …, σ c为拉普拉斯矩阵最小的c个特征值, 则rank(LS)=n-c等价于
根据文献[29]:
具有c个连通分量的相似图构造如下:
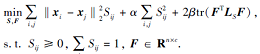
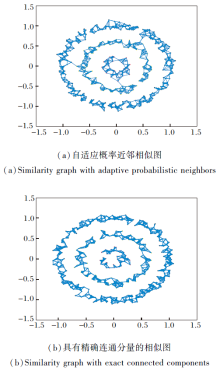
如图1所示, 使用一个聚类数为3的数据集显示自适应概率近邻相似图和具有精确联通分量的相似图之间的差异.若Sij> 0, 连接数据点xi和它的近邻xj.由(a)构造的相似图互相连通, 只有1个连通分量, 由(b)构造的相似图互不连通, 有3个连通分量, 恰好为该数据集的聚类数, 因此具有精确连通分量的相似性矩阵可学习准确的数据结构信息.
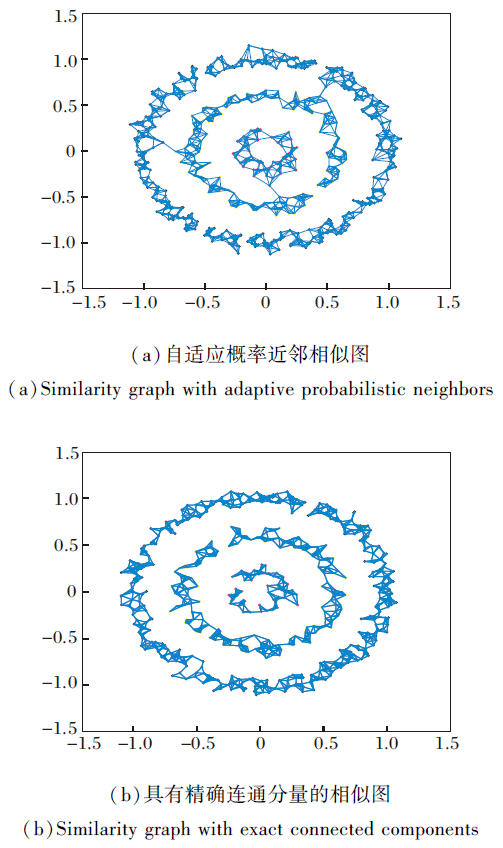 | 图1 两种相似图的区别Fig.1 Difference between two kinds of similarity graph |
给定数据矩阵
X=[x1, x2, …, xn]∈ Rd× n,
xi∈ Rd× 1为第i个样本, d为原始特征维数.X还可表示为
X=[f1, f2, …, fd]T,
fi∈ Rn× 1为第i个特征, n为样本点的个数.无监督特征选择的目标为在不利用标签信息的情况下, 从原始数据中选择最具有代表性的k个特征子集, k为选择特征的个数, k≪d.
根据流形学习理论, 高维数据中的信息可由低维流形表示.投影矩阵
W=[w1, w2, …, wd]T∈ Rd× m,
将数据点投影到低维空间, 即
WTX=
对于特征选择任务, W的第i行wi衡量第i个特征的重要性.当
‖ wi‖ ≠ 0
时, 选择第i个特征fi, 当
‖ wi‖ =0
时, 舍弃第i个特征fi.若选择k个特征, 则理想情况为W恰好有k个非零行, 即
‖ W‖ 2, 0=k,
因此选择精确个数的特征选择任务即为求解
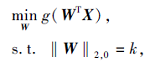 |
其中, g(· )的目标是学习一个投影矩阵W, 与原始数据矩阵X以最佳线性组合近似低维流形, 从而选择更好地保持数据流行结构的特征.
由于非凸非光滑性, 难以求解l2, 0范数优化问题, 因此大部分研究使用W的l2, 1正则化项代替W的l2, 0范数约束, 即
基于l2, 1范数正则化模型求解的投影矩阵W不同于l2, 0范数约束直接选择W的非零行对应的特征, 而是通过‖ wi‖ 2的大小衡量特征的重要性, 排序选择最大的‖ wi‖ 2对应的特征, 未考虑特征的相关性, 单个选择最优的特征.此外, 由于l2, 1范数正则化问题中的正则化参数λ 无明确的含义, 需要花费时间对其进行调优, 而l2, 0范数约束的参数k具有明确意义, 即选择特征的数量, 因此不需要进行参数的调节.
由于l2, 0范数约束的上述优势, 学者们现已提出一些解决l2, 0范数约束模型[24, 25, 26, 27].实际上, 模型仍类似l2, 1范数, 通过某种排序选择特征, 而没有实现组特征选择.而本文提出将问题(2)转化为0-1整数约束, 直接选择得分为1对应特征的方法, 在优化过程中动态选择一组最优的特征.
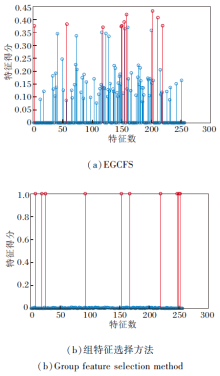
在真实数据集MSRA25上利用l2, 0范数和l2, 1范数进行特征选择的区别如图2所示.2种方法均在数据集上选择10个特征.横坐标表示数据集的256个特征, 纵坐标表示2种不同特征选择方法对应的特征得分.图2(a)为基于l2, 1范数的EGCFS[23], 将求解的投影矩阵W的‖ wi‖ 2大小作为特征评分, 需要对分数进行排序, 选择得分前10的特征.然而, 从(a)中可观察到, 大多数分数非常相近, 因此根据得分大小单个选择的特征可能不是一组最佳的特征子集.图2(b)为本文提出的组特征选择方法.引入元素为0或1的特征选择向量, 并且约束元素为1的个数为选择特征的个数, 可通过直接选择得分为1的特征得到一组特征子集, 实现组特征选择.
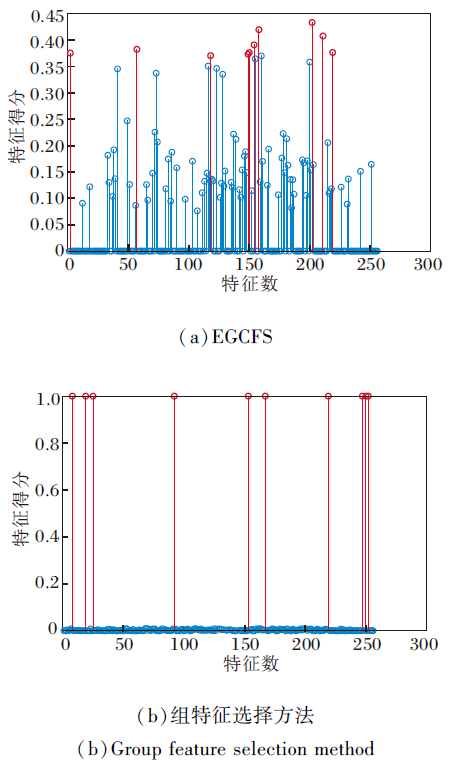 | 图2 两种特征选择方法在MSRA25数据集上选择10个特征的区别Fig.2 Difference of two feature selection strategies selecting 10 features on MSRA25 dataset |
传统的基于图的无监督特征选择方法包括两个阶段:构造相似性矩阵和通过稀疏正则化进行特征选择.仅从原始数据矩阵中构造相似性矩阵, 在后续特征选择任务中保持不变, 那么由于原始数据通常包含噪声和冗余信息, 导致学习的相似性矩阵次优.本文提出基于l2, 0范数稀疏性的无监督组特征选择方法(Unsupervised Group Feature Selection Method for Graph Optimization Based on l2, 0-norm Sparsity, SUGFS), 将相似性矩阵学习与特征选择统一到同一框架, 同时学习具有精确连通分量的相似性矩阵S和具有l2, 0范数约束的投影矩阵W.图学习可为特征选择提供精确的数据结构信息, 而特征选择过程又可为图学习去除冗余信息, 具体公式描述如下:
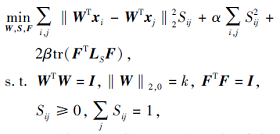 |
其中k为选择特征的个数, α 、 β 为正则化参数, 投影矩阵W∈ Rd× m, d为原始特征维数, m为投影维数.
为了精确选择k个特征, 约束W的非零行个数为k, 从而选择W的非零行
替代约束
‖ W‖ 2, 0=k,
直接选择k个特征.将式(3)中WT替换为WTdiag(r), 得
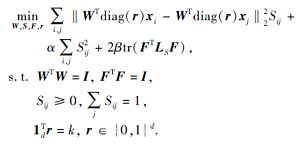 |
这样, 通过特征选择向量r∈ {0, 1}d, 可实现组特征选择, 同时选择一组最优的特征而不是逐个选择特征.
此外, 受FCM(Fuzzy C-means)在K-means聚类的基础上引入模糊因子以提高聚类精度的启发, 本文引入模糊相似因子ρ (ρ > 1), 进一步扩展模型(4), 提出基于l2, 0范数稀疏性和模糊相似性的图优化无监督组特征选择方法(F-SUGFS), 具体公式描述如下:
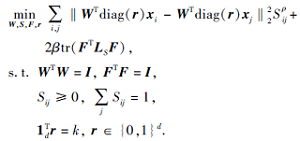 |
为了求解SUGFS, 将目标函数(4)分解为4个子问题, 交替求解4个变量W, S, F, r.
2.2.1 固定W, S, F, 求解r
优化变量r∈ {0, 1}d为一个0-1整数约束, 不易求解.本文利用lp-box[30]中p=2的情况, 称为l2-box, 求解r的0-1整数规划问题, 将离散的0-1整数约束转化为2个连续的约束.具体方法如下.
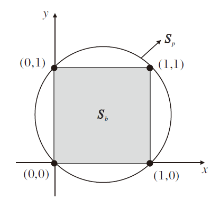
命题1 l2-box 二元集r∈ {0, 1}d等价于一个“ 盒子” Sb与一个d-1维球体Sp的交集:
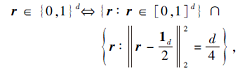
其中
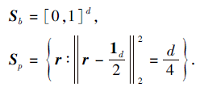
l2-box在二维情况下的几何解释如图3所示.当d=2, r为二维向量(x, y)时, r的0-1约束为r∈ {0, 1}d, 即
x∈ {0, 1}, y∈ {0, 1}.
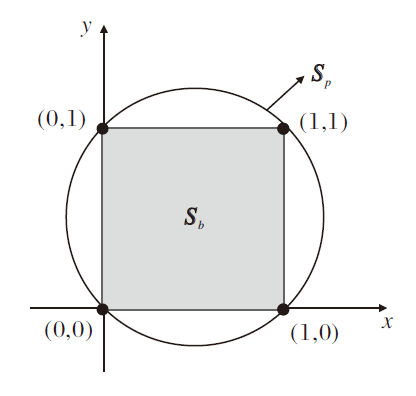 | 图3 l2-box在二维空间的几何解释Fig.3 Geometrical explanation of l2-box in two-dimensional space |
根据命题1,
Sb={x∈ [0, 1], y∈ [0, 1]}
为一个实心正方形,
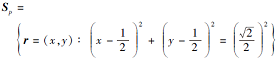
为半径为
根据命题1, 固定W, S, F, 模型(4)变为
s.t.
其中,
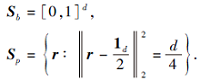
定义增广拉格朗日函数:
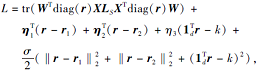
其中, η 1∈ Rd, η 2∈ Rd, η 3∈ R, 为3个等式约束的拉格朗日乘子, σ > 0为惩罚参数.
为了求解模型(4), 利用ADMM迭代更新变量r, r1, r2和拉格朗日乘子η 1, η 2, η 3.
1)更新变量r, r1, r2:
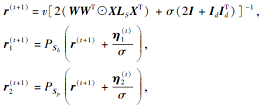 |
其中,
v=σ (
2)更新拉格朗日乘子η 1, η 2, η 3:
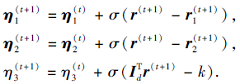
2.2.2 固定S, r, F, 求解W
当S, r, F固定时, 模型(4)变为
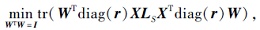 |
W∈ Rd× m的最优解为A的最小的m个特征值对应的特征向量, 其中
A=diag(r)XLSXTdiag(r).
2.2.3 固定W, S, r, 求解F
当W, S, r固定时, F的最优解为
F∈ Rn× c的最优解为LS的最小的c个特征值对应的特征向量.
2.2.4 固定W, r, F, 求解S
当W, r, F固定时, 模型(4)变为
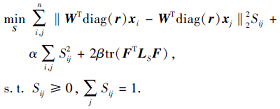 |
可验证
2tr(FTLSF)=
其中fi为F∈ Rn× c的第i行.
将式(10)代入式(9), 可得
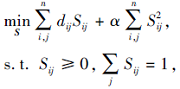 |
其中
dij=‖ WTdiag(r)xi-WTdiag(r)xj
β ‖ fi-fj
相似性矩阵S的第i行Si表示第i个数据与其它数据点的相似性, 因此可独立求解每个Si:
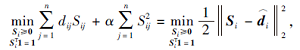 |
其中
单纯性约束的Si可利用文献[31]求解:
其中,
ui=
的根.
相似性矩阵S表示数据间的相似性, 距离越近的数据具有越高的相似性.因此在实际应用中, 希望学习一个稀疏的Si, 使每个数据xi只与距离xi最近的l个数据点相似, 相似度大于0, 与较远的数据点相似度为0.这样可获得良好的性能, 提高效率.
假设数据点xi与其余数据点的距离由小到大为
di, 1, di, 2, … , di, l, di, l+1, … , di, n,
因为与xi距离最近的数据为xi本身, di, 1=0, 所以xi的l个近邻为di, 2, di, 3, …, di, l+1对应的数据.为了使S具有稀疏性, 每个Si仅有固定的l个非零元素, 在实际求解过程中, 利用式(13)求解di, 2, … , di, r, di, r+1对应位置的Si, 2, Si, 3, …, Si, r+1, 其余元素为0.
在SUGFS的基础上, 引入模糊相似因子ρ > 1, 进一步拓展为F-SUGFS, SUGFS表示为ρ =1的特殊情况, F-SUGFS变量W, r, F的求解与SUGFS类似.下面仅给出相似性矩阵S的求解.
当变量W, r, F固定时, 模型(5)转化为
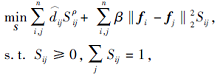 |
其中
式(14)的增广拉格朗日函数定义为
L=
对Sij求偏导等于0, 得
Sij=
其中
Qij=
综上所述, F-SUGFS步骤如算法1所示.
算法1 F-SUGFS
输入 数据矩阵X∈ Rd× n, 选择特征个数k,
最近邻个数l, 投影矩阵维数m, 聚类数c
输出 特征选择向量r
初始化 求解式(1), 初始化相似性矩阵S, 拉普拉
斯矩阵
LS=D-
WTW=I的投影矩阵W, 求解式(11), 初
始化F.
循环直至收敛.
step 1 利用ADMM求解r.
step 2 求解式(7), 更新W, 为A的最小m个特征值对应的特征向量.
step 3 求解式(8), 更新F, 为LS的最小c个特征值对应的特征向量.
step 4 求解相似性矩阵S.当ρ =1时求解式(13); 当ρ > 1时求解式(15).
step 5 更新拉普拉斯矩阵LS.
算法1交替求解4个变量W, S, F, r, 并且在每次迭代中单调减小式(4)中的目标函数值, 具体分析如下.
使用g(Wt, St, Ft, rt)表示t次迭代时的目标函数(4), 则有
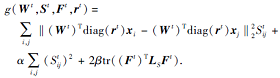
2.2.1节中利用l2-box ADMM更新0-1向量r, 根据文献[30]可得lp-box ADMM生成的变量序列的收敛性, 即
g(Wt, St, Ft, rt)≥ g(Wt, St, Ft, rt+1).
其次, 根据2.2.2节和2.2.3节, Wt+1和Ft+1为目标函数第t次迭代时的最优解:
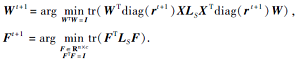
因此有
g(Wt, St, Ft, rt)≥ g(Wt+1, St, Ft+1, rt+1).
最后根据式(12)和式(13), 得
g(Wt, St, Ft, rt)≥ g(Wt+1, St+1, Ft+1, rt+1).
同理可证F-SUGFS的收敛性.
根据算法1的步骤, 分析每步的时间复杂度.
step 1中通过ADMM过程求解r, 这个过程的主要步骤为计算式(6), 需要计算d× d矩阵的逆, 时间复杂度为O(d3), 假设step 1需要t1次迭代, 因此step 1总共耗时O(t1d3).考虑LS的稀疏性, step 2和step 3的时间复杂度为O(n2l).step 4中需要独立求解S的每行, 时间复杂度为O(n2m+ndm).假设算法1需要迭代t2次, 算法1的整体时间复杂度为
O(n2mt2+d3t1t2).
为了说明F-SUGFS与其它无监督特征选择方法在计算复杂度上的差异, 5种无监督特征选择方法的计算复杂度如下.LS(Laplacian Score)[14]为O(n2d), MCFS为O(n2d+ck3+nck2), UDFS为O(n2c+d3), SOGFS为O(n2m+d3), EGCFS为O(n2m+d3).
由对比结果可看出, 过滤式的特征选择方法LS具有较低的计算复杂度.相比其余4种嵌入式特征选择, MCFS计算复杂度较低.由于基于图的特征选择方法大多需要特征分解, 因此算法1的时间复杂度与基于图的特征选择算法SOGFS和EGCFS的时间复杂度相似.
实验条件为Windows 10系统, 8 GB内存, Intel(R) Core(TM) i7-4790 CPU @3.60 GHz, MatlabR2018b.
本文实验在8个真实数据集上进行, 包括人脸数据集(MSRA25, Yale, COIL20)、生物数据集(Colon, Prostate_GE, GLIOMA, Lung)、语音字母识别数据集ISOLET、面部表情数据集JAFFE.数据集具体信息如表1所示.
| 表1 实验数据集 Table 1 Experimental datasets |
为了验证本文方法性能, 对比如下无监督特征选择方法.
1)Baseline.基线方法, 不进行特征选择, 使用原始数据进行K-means聚类任务.
2)LS[14].经典的过滤式特征选择算法, 基本思想是根据特征的局部保持能力对特征进行评估, 选择得分最高的前K个特征作为最终选择的特征子集.
3)MCFS[18].通过具有l1范数正则化的回归模型衡量特征的重要性, 最近邻个数设置为5.
4)UDFS[19].正则化参数取值范围为
{10-2, 10-1, 1, 10, 102, 103}.
5)SOGFS[21].同时进行局部结构学习和l2, 1范数正则化的特征选择.正则化参数取值范围为
{10-2, 10-1, 1, 10, 102, 103},
特征降维维数m设置在[
6)EGCFS[23].利用嵌入的图学习和约束选择不相关但有区别的特征.正则化参数α 、γ 取值范围为
{10-2, 10-1, 1, 10, 102, 103}.
7)SUGFS.特征降维维数m设置在[
8)F-SUGFS.本文设置参数ρ =2, 与SUGFS进行对比.
为了评估所有无监督特征选择方法的性能, 将选择的特征用于基于K-means的聚类任务.为了避免K-means随机初始化的影响, 运行10次K-means聚类取平均结果.在评估每种方法的性能时, 使用2个经典的聚类算法评估指标:准确率(Accurary, ACC)及归一化互信息(Normalized Mutual Informa-tion, NMI).ACC和NMI值越大说明方法性能越优.
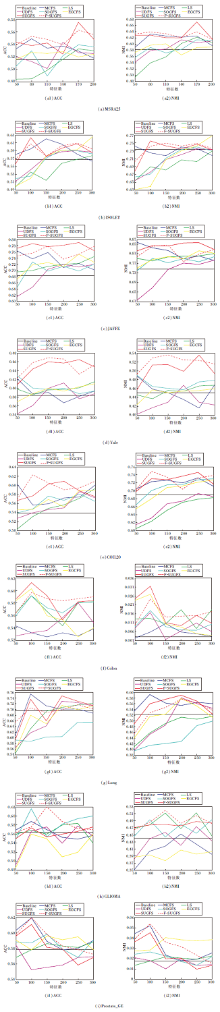
图4为8种无监督特征选择方法在9个数据集上选择特征个数与ACC和NMI的关系.在MSRA25数据集上选择50~200个特征, 间隔30.其余数据集上选择50~300个特征, 间隔50.
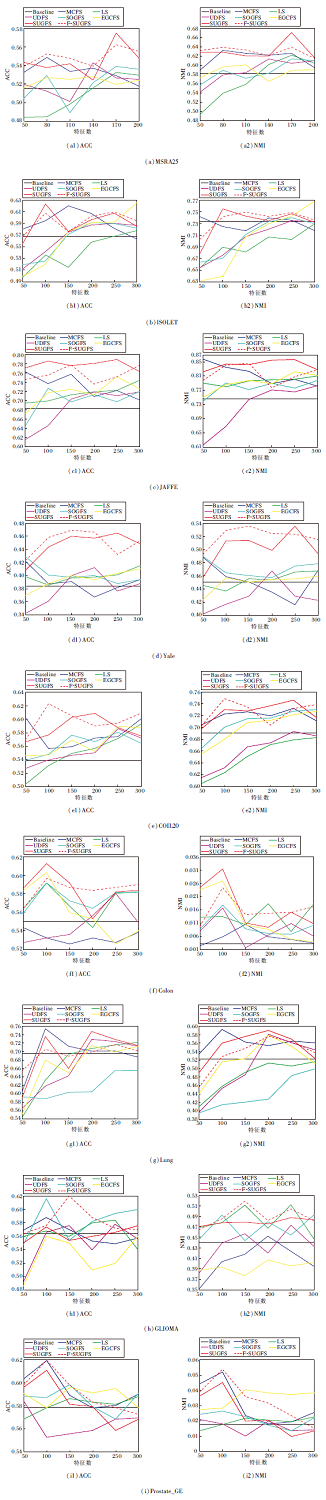 | 图4 各方法在9个数据集上选择不同特征数时的实验结果Fig.4 Experimental results of different methods with different feature numbers on 9 datasets |
由图4可看出, 大部分特征选择方法仅选择少量特征进行聚类的结果便优于Baseline, 表明特征选择的必要性和有效性.特征选择可去除冗余、不相关特征及噪声, 选择具有代表性的特征, 提高聚类精度.
通过实验可看出, 并不是选择越多特征聚类效果越优.一般情况下, 聚类精度会随选择特征个数的增多呈现先增大后减小的趋势.因为随着选择特征个数的增多, 可能因此冗余特征或噪声被选择, 从而影响实验结果.
由图4也可直观看出, 在大部分数据集上, 本文方法在选择较少的特征时就取得比其他方法更高的聚类精度和归一化互信息.在面部表情数据集JAFFE和人脸数据集Yale上, SUGFS和F-SUGFS效果均较显著.
由图4还可观察到, 除了ISOLET、Lung数据集, 本文方法在其余7个数据集上无论选择多少特征, 均超过Baseline.相比其它嵌入式特征选择方法, 过滤式特征选择方法LS在多个数据集上性能较差, 这是因为过滤式特征选择未考虑针对后续学习器以选择特征子集.
表2和表3为各方法在9个数据集上的最佳聚类结果(ACC和NMI), 其中黑体数字为最佳值, 斜体数字为次优值.由表可看出, 本文方法在7个数据集上都取得最佳聚类结果, F-SUGFS取得和SUGFS同样好的结果, 并且在高维数据集GLIOMA与Prostate_GE上SUGFS的性能均有所提高.
| 表2 各方法在9个数据集上的最高ACC值对比 Table 2 Optimal ACC comparison of different methods on 9 datasets % |
| 表3 各方法在9个数据集上的最高NMI值对比 Table 3 Optimal NMI comparison of different methods on 9 datasets % |
表4和表5为各方法在9个数据集上均选择100个特征的聚类结果, 表中黑体数字表示最优值, 斜体数字表示次优值.表6给出本文方法与5种特征选择方法的运行时间对比.
| 表4 各方法在9个数据集上选择100个特征的ACC值 Table 4 ACC of different methods with 100 selected features on 9 datasets % |
| 表5 各方法在9个数据集上选择100个特征的的NMI值 Table 5 NMI of different methods with 100 selected features on 9 datasets % |
| 表6 各方法在9个数据集上的运行时间对比 Table 6 Running time comparison of different methods on 9 datasets s |
由表4和表5可看出, 本文方法选择特定个数的特征依然获得较优结果, 体现本文方法的稳定性.
对比SOGFS, 本文的l2, 0范数约束在不同数据集上均取得显著优势, 表明l2-box求解的0-1约束特征选择向量的有效性.对比Baseline, 本文方法明显提高Baseline的聚类精度, 在Yale数据集上提升最快, ACC和NMI值均提高20%左右, 在COIL20数据集上提升约15%, 在其余数据集上平均提升约8%.
由表6可知, 与2.5节复杂度分析一致, 过滤式特征选择方法LS的运行时间最短, 但从图4的实验结果来看, LS选择的特征聚类效果较差.本文方法与基于图的无监督特征选择方法SOGFS和EGCFS具有相近的运行时间, 随着数据集维数的增大, 运行时间也变长, 但从表1和表2的聚类效果来看, 本文方法具有较优性能.因此, 本文方法是一种相对高效的无监督特征选择方法.
本文提出基于l2, 0范数稀疏性的图优化无监督组特征选择方法(SUGFS), 利用l2, 0范数约束, 可同时选择一组最优的特征子集.为了求解非凸的l2, 0范数约束, 引入元素为0-1的特征选择向量, 将投影矩阵的l2, 0范数约束转化为向量的0-1整数规划问题, 进而利用l2-box ADMM进行求解.同时引入模糊相似性因子, 可根据不同数据集进行调节, 适用于不同数据集, 性能较优.通过实验验证本文方法的有效性.本文方法在大部分数据集上聚类效果都得到明显提升, 但当数据集维数较大时, 效率会有所下降.因此, 如何加速本文方法是今后研究方向之一.
本文责任编委 高 阳
Recommended by Associate Editor GAO Yang
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|