

{kind=link}
{kind=link}
{kind=link}
{kind=link}
定位与通信受限的网联协同感知算法
[毛瑞清1  , 贾宇宽
, 贾宇宽1 , 孙宇璇1, 2 , 周盛1 , 牛志升1 ]
, 贾宇宽, 孙宇璇, 周盛, 牛志升]
|
|



作者简介: 
毛瑞清,博士研究生,主要研究方向为协同感知、车联网、面向任务的通信.E-mail:mrq20@mails.tsinghua.edu.cn. 
贾宇宽,博士研究生,主要研究方向为协同感知、车联网、面向任务的通信.E-mail:jyk20@mails.tsinghua.edu.cn. 
孙宇璇,博士,副教授,主要研究方向为边缘计算、边缘智能、面向任务的通信.E-mail:yxsun@bjtu.edu.cn. 
牛志升,博士,教授,主要研究方向为排队论、流量工程、移动互联网、无线网络资源管理、绿色通信与网络.E-mail:niuzhs@tsinghua.edu.cn.
随着车联网通信技术的不断发展,协同感知的网联自动驾驶成为未来智慧交通系统中重要的组成部分,可有效解决传统单车智能在感知和计算能力上的固有局限.然而,现有的协同感知算法大多依赖准确的定位信息进行多视角融合,往往忽略通信带宽与通信时延的约束.因此,文中提出面向定位与通信受限条件下的特征层级协同感知算法,在不依赖准确位置与位姿信息的情况下实现不同视角信息的匹配,同时对通信时延具有一定的鲁棒性,能根据信道状态动态调整通信数据量.文中算法结合传统两阶段感知范式与深度度量学习,通过传输区域特征图进行跨视角信息匹配,降低定位误差和通信时延带来的影响.同时,通过车联网通信传输的区域特征图数量可以实时在线调整通信数据量,满足不同信道条件的约束.在协同感知数据集上的实验表明,文中算法在各场景下均表现出显著的协作增益,在一定通信时延下感知精度不显著衰减,可有效降低所需传输的数据量.
About Author:
MAO Ruiqing, Ph.D. candidate. His research interests include cooperative perception, vehicular networks and task-oriented communications.
JIA Yukuan, Ph.D. candidate. His research interests include cooperative perception, vehicular networks and task-oriented communications.
SUN Yuxuan, Ph.D., associate professor. Her research interests include edge computing, edge intelligence and task-oriented communications.
NIU Zhisheng, Ph.D., professor. His research interests include queuing theory, traffic engineering, mobile internet, radio resource management of wire-less networks, and green communication and networks.
With the continuous development of vehicle-to-everything network, cooperative perception enabled connected autonomous driving becomes an important component in future intelligent transportation systems. It effectively addresses inherent limitations of traditional stand-alone intelligence in perception and computing capabilities. However, most existing cooperative perception algorithms rely on accurate positioning information for data fusion, ignoring constraints of communication bandwidth and commu-nication delay. In this paper, a feature-level cooperative perception algorithm for localization and communication-constrained conditions is proposed. The matching of different perspective information is achieved without relying on accurate positions and poses, while the robustness of the proposed algorithm to communication delay is maintained and the amount of communication data is dynamically adjusted according to the channel state. The traditional two-stage perception paradigm is combined with deep metric learning, utilizing regional feature maps for cross-perspective information matching to overcome the impact of localization errors and communication delays. Moreover, the number of regional feature maps transmitted through V2X communication can be dynamically adjusted in real-time to adapt to different channel conditions, and thus the amount of communication data is changed. Experimental results show that the proposed algorithm exhibits significant cooperative gains in various scenarios, maintains perception accuracy under certain communication delays, and effectively reduces the required amount of transmitted data.
近年来, 传统的单车自动驾驶在安全性和可靠性方面日益受到挑战, 因此, 学者们提出利用同质[1, 2]或异质[3, 4]的多传感器信息融合以增强单车感知的精度, 但仍无法从根本上解决单一视角下盲区和远距感知的固有限制.
基于车联网(Vehicle-to-Everything, V2X)通信[5]的网联自动驾驶作为一项新兴的自动驾驶技术, 在十字路口通行、匝道汇入等复杂交通场景中显现出独特优势.每个道路参与方(包括车辆、路侧单元等)均可在本地采集传感器数据, 并通过无线车联网系统分享给邻近的终端, 经由多视角感知信息融合算法, 最终实现目标检测等任务.在这一过程中, 处于本车视野盲区内的物体可通过其它参与方的感知信息得以补充, 从而增强检测的总体精度[6].这一过程即为协同感知技术.
协同感知技术按照其共享并融合数据的位置不同分为3个层级:原始数据层级(前融合)、特征数据层级(中融合)、目标数据层级(后融合).在原始数据层级融合框架[7]中, 各终端直接共享传感器捕获的图像/点云等信息.该方案尽可能多地保留各视角的信息, 但所需传输的数据量较大, 对带宽极为有限的无线车联网通信而言是较大的负担, 往往会造成较高的延迟.与之对应, 在目标数据层级融合框架[8]中, 各终端在本地运行目标检测算法, 将得到的感知结果(包括目标标签、位置、朝向角等)进行共享.这种方案所需的通信数据量极低, 但会损失较多的原始感知信息, 仅能提供各终端能独立检测的物体信息.在典型的目标检测框架中, 特征信息往往连接原始数据与检测器.因此, 特征数据层级融合框架[9, 10]利用特征提取算法对原始数据进行压缩, 在保留检测所需信息的同时降低待传输数据量, 使协同感知技术能在有限的无线车联网通信条件下得以最大化感知增益.
网联自动驾驶中的协同感知技术面临两大根本性难题:1)无线通信系统中存在的带宽资源受限和随机延时问题; 2)车辆高移动性导致的位置与位姿信息不准确问题.为了解决这两大难题, 建立一种能适应时变无线信道条件, 同时对时空坐标对齐鲁棒的融合算法框架至关重要.近年来, 部分工作着眼于过滤协同感知过程中冗余背景数据, 以此降低传输开销, 然而这些工作并未根据信道状态显式调整通信的数据量.与此同时, 鸟瞰图视角(Bird's-Eye View, BEV)感知在单车多传感器与多车协同感知[2, 11, 12, 13]方面都展现出优良性能, 然而BEV感知技术和传统融合技术相同, 仍严重依赖准确的位置与位姿信息, 以实现透视图变换和多视角对齐[7, 9, 14, 15].
本文提出面向定位与通信受限条件下的特征层级协同感知算法, 在不依赖准确位置与位姿信息的情况下实现不同视角信息的匹配, 同时对通信时延具有一定的鲁棒性, 能根据信道状态动态调整通信数据量.考虑到目前激光雷达成本依旧高昂, 并且对无人驾驶车辆的重量和风阻具有显著的负面影响[16, 17], 本文着眼于纯视觉图像信息的融合感知实现, 从而无需点云提供的准确深度信息.在这一过程中, 核心难点在于当存在较大视差时, 如何将某一视角下的特定物体与另一视角下的物体进行匹配, 并克服有限带宽、随机时延和非准确位置位姿信息的影响.为了最大程度降低所需传输的数据量, 本文算法仅传输区域特征图, 用于刻画待检测的前景物体信息, 并消除不存在物体的背景区域信息.与此同时, 给出通信数据量与感知精度的折衷关系, 从而使与之对应的通信流量控制算法设计成为可能.此外, 算法利用深度度量学习进行跨视角信息匹配, 不依赖于全局位置与位姿信息, 进而不受制于传统协同感知算法对超高精度定位系统的要求, 使算法在网联自动驾驶场景, 尤其是隧道和高层密集型地区中能得到更广泛的应用.同时, 由于不依赖准确的时空位置关系, 同样可以容忍较大程度的时延不确定性.
目标检测是自动驾驶中至关重要的一项基本任务.一般而言, 根据算法是否在目标类别判定与检测框回归前显式提取存在前景物体的区域, 当前的目标检测框架可分为两阶段检测器和一阶段检测器.R-CNN(Region-Based Convolutional Neural Network)系列算法[18]是两阶段检测器的开创性工作, 在目标检测任务上具有重要意义.与此同时, 诸如SSD(Sin-gle Shot MultiBox Detector)[19]和YOLO(You Only Look Once)[20]的一阶段检测器着眼于降低算法复杂度, 提升算法执行效率, 并在工业应用上取得一定成功.
近年来, 以CenterNet[21]和CornerNet[22]为代表的一类算法, 不依赖于检测框提取的检测范式, 直接从原始感知信息中提取物体的关键点, 简化检测流程.随着Transformer结构的发展, DETR(Detection Transformer)系列检测算法[23]利用编解码器结构, 绕开传统卷积神经网络检测器依赖的非极大值抑制流程, 表现出较强的端到端检测性能.而Wang等[24]提出Anchor DETR, 进一步将传统卷积神经检测器中的检测框与Transformer结构结合, 产生的Query信息具有更强的可解释性.
协同感知技术是网联自动驾驶的重要组成部分.由于激光雷达产生的点云天然具有良好的空间深度信息, 基于点云的多视角信息融合框架成为协同感知技术中的一个重要分支.Chen等[7]首先提出Cooper(Cooperative Perception), 直接在三维点云基础上实现重叠和融合.Rawashdeh等[25]和Xiao等[26]分别使用深度神经网络增强共享协作信息.Nassar等[14, 15]提取周围物体, 通过重识别方法进行融合.由于V2X通信资源受限, V2VNet[9]、When2-com[27]和DiscoNet(Distilled Collaboration Network)[28]分别给出不同的技术路径, 压缩共享的特征数据.Hu等[10]提出Where2comm, 基于空间网格化的BEV特征图对传输信息进行筛选和处理, 在空间域上实现数据压缩.然而, 上述算法均未显式考虑非理性的信道条件.Xu等[29]提出V2X-ViT(V2X Vision Trans-former), 利用视觉Transformer架构对抗通信中的噪声干扰.目前绝大多数的协同感知工作都严重依赖准确的位置与位姿关系, 融合性能受到严重限制.
本文提出面向定位与通信受限条件下的特征层级协同感知算法, 旨在从特征层级融合不同视角下具有较大视差的感知数据(具体示意图如图1所示), 并对抗实际环境中的定位与通信的非理想性, 这一融合框架又称为中融合.
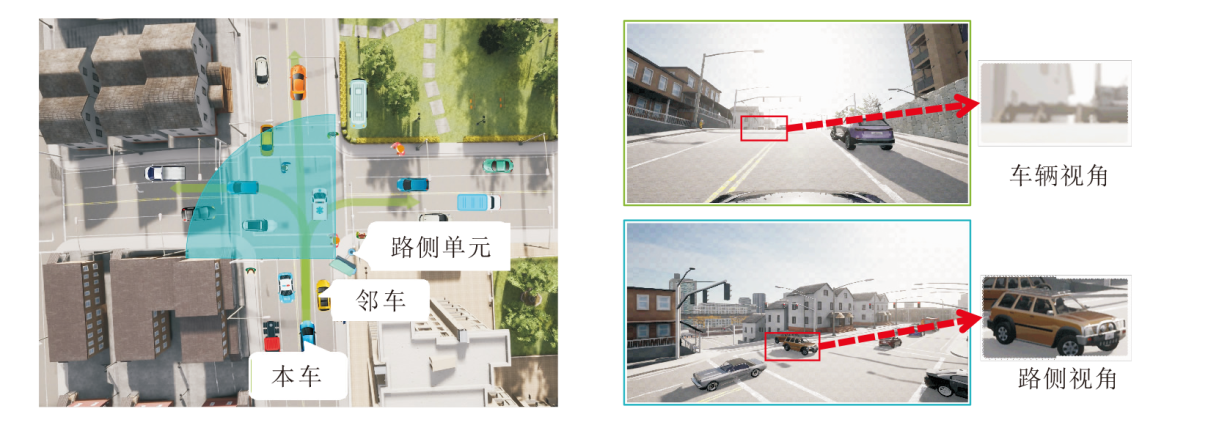 | 图1 协同感知场景中不同视角示意图Fig.1 Different perspectives in collaborative perception |
本文算法由三个阶段组成.第一阶段是区域特征图生成, 由各个协作方在本地独立运行计算.通过V2X通信交互协作信息后, 在第二阶段采用基于深度度量学习的多视角特征数据融合方法, 汇聚和处理来自不同协作源的特征层级信息.第三阶段是最终检测器, 对融合后的特征信息进行判别和检测输出.
具体而言, 本文算法对来自不同终端、不同视角的区域特征图进行相关性学习和分析, 并将不同视角特征级融合过程建模为一个二分图匹配问题.通过这种三阶段感知架构, 基于深度度量学习的特征数据融合模块可与任意前沿两阶段检测器结合, 从而具有相当程度的通用性和迭代能力.本文算法框图如图2所示.
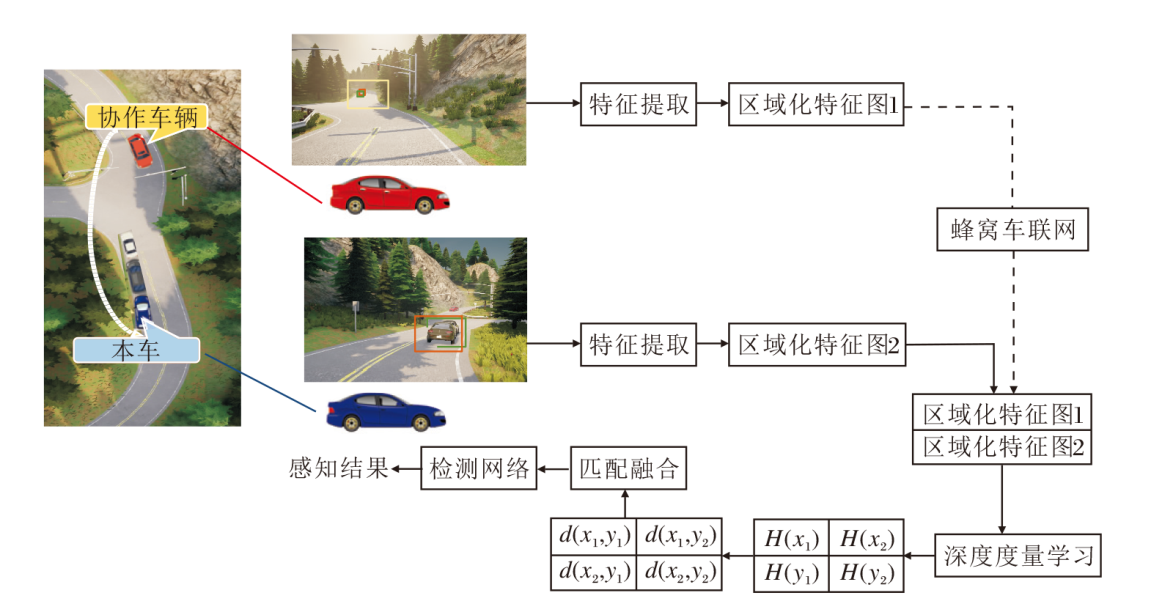 | 图2 本文算法框图Fig.2 Architecture of the proposed algorithm |
本文算法重点关注网联自动驾驶的典型应用场景, 如十字路口通行、高速匝道汇入等.在这些场景中, 车辆常受到周围邻近车辆和建筑物的遮挡, 受限于严重的视野盲区问题.假定所有协作参与方都配备有网联智能功能, 即具有一定程度的计算和V2X通信能力.在此基础上, 各终端可独立实现区域特征图的生成, 并获取单视角感知结果(即跳过第二阶段).而在协同感知场景下, 协作终端可通过V2X通信系统与邻近终端交换本地的区域特征图, 在不干扰单车感知流程的基础上实现补盲和增强.注意到算法流程中并不依赖地理位置、相机位姿、点云的深度信息或高清地图, 因此算法更具有经济性和实用性.
本文采用的基础检测框架是典型的两阶段检测器Faster R-CNN[18].事实上, 本文的融合算法可兼容所有两阶段检测器, 包括一些不依赖检测框的检测算法[30].
两阶段检测器在选取潜在前景物体区域后生成区域特征图, 提取仅包含前景物体的特征.该过程可去除无需检测的背景区域, 大幅减少特征图传输所需的数据量.在网联自动驾驶中, 高可靠低延时的通信要求限制可传输数据量的大小.相比直接传输原始数据(即原始数据层级融合), 通过V2X网络传输区域特征图更高效.同时, 相比仅传输最终检测结果(即目标数据层级融合), 通过V2X网络传输区域特征图保留尽可能多的语义信息, 提升最终感知性能.
如图2所示, 区域特征图提取阶段的输入是来自两个不同视角的一对图像, 一个来自本车, 另一个是邻近的协作终端(车辆或路侧单元).每幅图像都被送入骨干网络以提取全局特征, 同时辅助以特征金字塔技术[31], 增强多尺度目标的感知性能. 然后, 算法将全局特征送入区域候选网络(Region Proposal Network, RPN)[18], 生成存在潜在前景物体的区域.同时, 每个候选框都会被赋予一个分数, 作为真实前景对象的置信度, 再利用非极大值抑制算法, 过滤前N个候选框作为最终输出.利用这些候选框, 在全局特征图上框选最终的区域特征图数据.由于区域具有不同的尺寸大小, 因此需要采用感兴趣区域(Region of Interest, ROI)对齐技术[32], 将不同大小的候选框映射为统一规模的区域特征图.
综上所述, 区域特征图提取阶段的最终输出是来自两个终端的一对区域特征图, 每个区域特征图的维度为N× W× H× C, 其中, N表示RPN网络输出的候选框数量, C表示骨干网络输出的特征维度, W和H分别表示ROI对齐过程后每个区域的统一宽度和高度.
在这一过程中, 原始图像是由不同终端上的传感器采集得到, 因此区域特征提取可在各终端上并行完成, 这意味着整个区域特征图提取阶段可分为两条独立的通道.此外, 由于实际系统中无线车联网通信信道具有时变特性, 每次协作所能传输的最大数据量是不固定的.基于区域化特征图提取的方案可动态选取置信度最高的Top-N个区域进行传输, 从而实现对受限通信条件的自适应调节.
协同感知需要在较大视差下不同视角图像中匹配同一对象, 这与典型的双目视觉识别任务不同[1], 是一个具有挑战性的问题.此外, 本文希望能仅依赖特征图信息完成对齐和融合任务, 而不依赖准确的深度信息和位置位姿信息, 这无疑加大任务的难度.
在该任务中, 需要为每个潜在前景物体找到与之匹配的区域特征图, 即从感知到相同前景物体的其它终端找到匹配的候选区域.由于不同视角不同相机的光照条件和位姿状态可能有很大差异(尤其是路侧单元), 同一型号不同车辆产生的特征图可能非常相似, 而同一车辆不同角度的特征图反而可能具有显著差异.这种类内差异性和类间相似性与车辆重识别问题具有一定的相似之处, 是融合算法设计面临的主要挑战之一.
为了解决该挑战, 本文引入深度度量学习方法, 进行多视图特征融合.该方法近期已应用于车辆重识别问题[33, 34]并取得成功.通过深度度量学习, 将多视角特征融合问题建模为一个二分图匹配问题, 并通过基于阈值的贪心算法进行简化求解.
深度度量学习的基本思想是通过学习度量函数表征不同样本之间的相似性[35, 36].一般而言, 由度量学习得到的度量函数会将原始数据投影到一个可度量的特征空间(通常为欧几里得空间).因此, 传统的距离度量标准(如欧氏距离或余弦相似度等)可直接在该特征空间中执行, 使不同样本之间相似度的量化成为可能.在区域特征图提取阶段中, 从原始图像生成的区域特征图对应不同的潜在前景区域.记本车相机生成的区域特征图
$S=\left\{x_{i}\right\}_{i=1}^{N}, $
其中, xi表示本车感知中第i个区域的区域特征图, 尺寸为C× W× H.通过V2X通信得到的其它终端生成的区域特征图
$T=\left\{y_{j}\right\}_{j=1}^{N}, $
其中, yj表示其它终端中第j个区域的区域特征图, 尺寸为C× W× H.
本文的深度度量学习网络为一个使用ReLU激活函数的两层全连接结构, 并在第1层后加入Dropout机制[37]以减少过拟合, 具体地,
$\begin{array}{l} H\left(x_{i}\right)=W_{2} \max \left(W_{1} x_{i}+b_{1}, 0\right)+b_{2}, \\ H\left(y_{j}\right)=W_{2} \max \left(W_{1} y_{j}+b_{1}, 0\right)+b_{2}, \end{array}$
其中
$ \begin{array}{l} d\left(x_{i}, y_{j}\right)=\left\|H\left(x_{i}\right)-H\left(y_{j}\right)\right\|_{2}, \\ i=1, 2, \cdots, N, j=1, 2, \cdots, N, \end{array}$
从而构建两个视角之间的相似度矩阵:
$ \boldsymbol{D}=\left[\begin{array}{cccc} d\left(x_{1}, y_{1}\right) & d\left(x_{1}, y_{2}\right) & \cdots & d\left(x_{1}, y_{N}\right) \\ d\left(x_{2}, y_{1}\right) & d\left(x_{2}, y_{2}\right) & \cdots & d\left(x_{2}, y_{N}\right) \\ \vdots & \vdots & & \vdots \\ d\left(x_{N}, y_{1}\right) & d\left(x_{N}, y_{2}\right) & \cdots & d\left(x_{N}, y_{N}\right) \end{array}\right]$
通过两个终端提取的区域特征图集合S、T, 以及得到的相似度矩阵D, 可构建图
G=(S, T; E),
其中, 每个节点表示一幅区域特征图, E表示节点之间边(即相似度)的集合:
$ e_{i j}=d\left(n_{i}, n_{j}\right), n_{i} \in S \cup T, n_{j} \in S \cup T .$
显然, 当节点间距离越小, 这一对区域特征图包含相同目标的可能性就越大.因此多视角特征融合任务可表示为一个二分图匹配问题. Kuhn-Munkres(KM)算法是一种在多项式时间内解决二分图最佳匹配问题的方法.但KM算法的复杂度为
本文对特征图之间的相似度设置阈值τ , 从而仅对相似度超过阈值的特征图进行匹配, 避免错误匹配的影响. 基于该阈值, 本文进一步提出一种贪心策略方法, 用于匹配计算. 对于本车视角中每幅区域特征图
除了传统两阶段识别算法中存在的分类损失和检测框回归损失之外, 本文算法最具挑战性的部分是如何定义特征匹配过程中的损失函数.由于本文将其建模为深度度量学习后的聚类分析问题, 三元组损失函数[38]成为首选.对于每个本车视角下的区域特征图
算法1 三元组损失函数设计
输入
输出
IF
$ y_{n, i}=\arg \max _{y_{j} \in T} d\left(x_{i}, y_{j}\right) $
IF该前景物体存在于T中THEN
选择对应的
ELSE
$ y_{p, i}=x_{i} $
END
ELSE
随机选择一个背景区域特征图作为
$y_{n, i}=\arg \min _{y_{j} \in T} d\left(x_{i}, y_{j}\right)$
END
在算法中, 根据
$ L=\frac{1}{N} \sum_{i=1}^{N} \max \left(d\left(x_{i}, y_{p, i}\right)-d\left(x_{i}, y_{n, i}\right)+\alpha, 0\right) $
受Cipolla等[39]的工作启发, 不同任务的损失函数之间可通过待学习的不确定性参数进行加权求和, 从而更好地平衡整体端到端学习任务.
由于不依赖地理位置和姿态信息, 融合方法无法刻画目标物体之间的相对位置关系.为了解决此问题, 通过点云或基于图像的深度估计等方式, 可保留区域化特征图的深度信息, 得到单视角下潜在目标的相对三维位置关系.进一步地, 如果能充分利用不同视角下物体的空间结构关系, 可更精确地进行匹配和对准, 提高最终的检测性能.例如, 当场景中存在诸如路标、路灯等标志性物体时, 场景中物体的空间结构会相对稳定, 可利用该锚点大幅降低匹配的不确定性.
在实验中, 本文使用Faster R-CNN[18]作为基本架构.由于来自不同视角图像的特征图生成是相互独立的, 本文在第一阶段中构建两个参数不共享的独立骨干网络与RPN.对于每个通道, 一个带有特征金字塔的预训练ResNet-101[40]作为骨干网络, 并将输出的全局特征图输入到典型RPN和ROI对齐过程中, 在每个单独图像上生成区域特征图.其中, 每个区域特征图的特征尺寸为256, 空间尺度为7× 7.对于深度度量学习模块, 构建一个两层全连接网络, 隐藏层尺度为256, 最终输出维度为32.换言之, 每个区域特征图都映射为统一的32维欧几里得空间.
最新开源的DOLPHINS数据集[41]具有多个网联自动驾驶相关的驾驶场景, 可同时提供车端和路端的多视角信息, 是少有的多场景、多视角、大数据量的数据集.因此, 本文选取该数据集上的两个典型场景进行训练和测试, 并采用目标检测任务评估算法.初始学习率设置为 0.001, 训练平台和测试平台为4块RTX 3090显卡组成的服务器.评价指标选择AP(Average Precision).
首先对比本文算法和单车感知, 两者在不同情况下的AP值如表1所示.由表可见, 本文算法可从其它协作终端提供的特征信息中有效提取相关信息, 相比单车感知, AP值更高.
| 表1 本文算法与单车感知的性能对比 Table 1 Performance comparison between the proposed algorithm and stand-alone perception % |
本文算法效果示意图如图3所示.由图可见, 本文算法对困难目标均实现不同程度的检测精度提升.对于那些本车视野中几乎不可见的物体(如(a)中未检测到的红色车辆), 由于不同的环境位置关系导致的遮挡关系不同, 可能被路侧单元感知(如(b)), 因此本文算法可通过特征级融合汇聚这些信息并加以识别((c)中检出红色车辆).
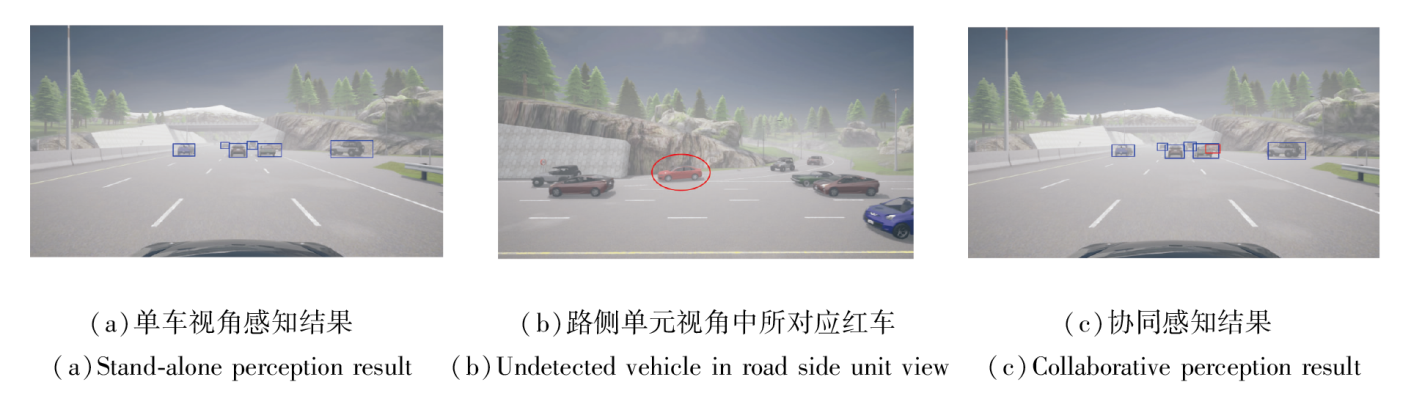 | 图3 本文算法效果示意图Fig.3 Perception results of the proposed algorithm |
这种情形对于自动驾驶的安全性和可靠性至关重要, 如在坡道上的前方车辆往往难以检出, 此时很难预测和判别变道等操作.如果能利用协同感知提前感知, 可充分保证驾驶的安全性, 提升交通通行效率.
然而, 协同感知的增益在不同场景下有所不同.从表1中可发现, 其增益与合作机会的多少密切相关.当本车检测到大量在协作终端中可见的部分遮挡物体时, 特征级融合可大幅提升检测精度, 如高速匝道汇入场景.
另一方面, 如果两个视角之间的相关性不足, 协作终端无法提供本车待检测物体的信息, 性能增益会很小, 如十字路口场景所示.
在消融实验中, 本文删除基于深度度量学习的特征匹配模块, 直接在特征维度上叠加来自不同视角的区域特征图.有无特征匹配模块的消融实验结果如表2所示.由表可见, 删除特征匹配模块后, 协同感知的性能急剧下降.这一结果表明同一物体的区域特征图之间必须进行正确匹配, 以避免错误匹配带来的噪声干扰.
| 表2 有无特征匹配模块的消融实验结果 Table 2 Ablation experiment results with and without feature-matching module % |
为了探究本文算法在各种通信延迟下的鲁棒性, 根据DOLPHINS数据集上数据的采集率, 将来自协作终端的图像分别延迟1~2帧, 即0.5~1.0 s, 本文算法在不同时延下的AP值如表3所示.由表可见, 随着通信时延的增加, 本文算法的感知精度损失非常小.这是由于本文算法匹配过程中仅使用区域特征图之间的内在相似性, 因此鲁棒性不依赖于不同视角的时空坐标对齐.当前景物体的可见度未发生很大变化时, 基于深度度量学习的匹配方案就可从协作方图像中捕获信息.进一步考虑, 如果某物体在数秒内被协作方感知, 但当前时刻恰好进入其视野盲区内, 那么这种带有时延的融合反而会带来一定程度的增益.这表明历史陈旧信息对于协同感知而言并非没有意义的, 合理利用历史信息可带来一定的性能提升.
| 表3 本文算法在不同时延下的AP值 Table 3 AP values of the proposed algorithm under different communication latencies % |
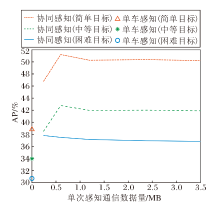
相比原始数据层级融合, 基于区域特征图的特征层级融合可大幅减少所需传输的数据量, 而相比目标数据层级融合, 基于区域特征图的特征层级融合可保留尽可能丰富的语义信息.更重要的是, 由于前景物体的数量通常小于候选区域的数量, 因此当网络训练较良好时, 可根据信道质量调整共享区域特征图的数量, 选择置信度最高的区域特征图优先传输.由于通过V2X通信共享的总数据量与区域特征图的数量成正比, 在实验中通过改变候选区域特征图的数量以刻画感知精度与数据量大小之间的关系, 结果如图4所示.假定传输的特征图均使用INT8编码, 在保持相同平均精度的情况下, 可大幅降低所需传输的总数据量.特别地, 当单次感知通信数据量为600 kB时, 感知精度反而达到最优.进一步分析表明, 当传输区域特征图的数量减少时, 由背景区域特征图不匹配引起的噪声也会随之减少, 同时前景物体区域特征图在良好训练的网络中可保留完整, 会在一定的区域特征图数量下达到最优效果.此外, 在实际系统实现中, 每个区域特征图均可进一步压缩为256维(视具体场景与性能要求决定)的特征向量, 这意味着最终的通信需求可降低到kB量级, 相比原始图像MB量级的数据量而言是巨大的提升.
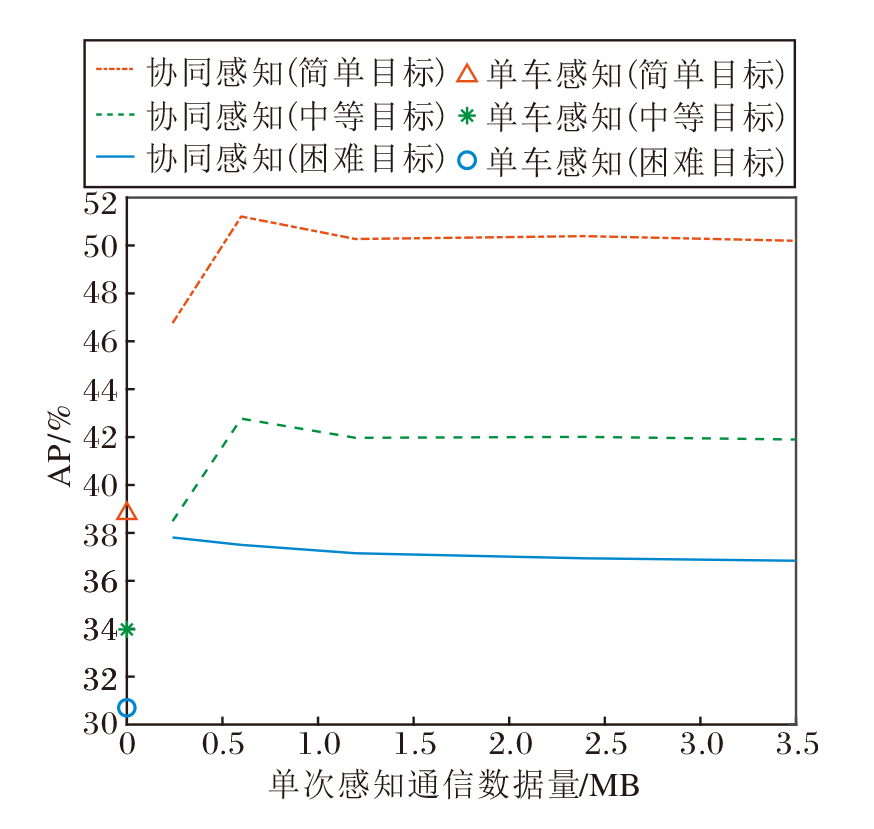 | 图4 感知精度与传输数据量的关系Fig.4 Relationship between perception performance and the communication payload |
本文提出面向定位与通信受限条件下的特征层级协同感知算法, 将深度度量学习方法融入典型的两阶段检测器, 并将特征层面融合过程建模为二分图匹配.实验表明, 本文算法充分利用协作方提供的视角信息, 提升感知性能.消融实验进一步表明, 本文的基于深度度量学习的特征匹配方法对于大视差条件下的感知信息融合至关重要.此外, 本文算法与所有两阶段检测器兼容, 无需地理位置、位姿、点云和高精度地图, 使算法的实际部署更经济和便捷.此外, 本文算法还考虑非理想通信条件与车联网终端的高移动性, 保障不同通信延迟下的鲁棒性.显式刻画的感知精度与V2X通信数据量之间的关系也为面向协同感知的通信流量控制协议设计提供思路.
今后可从两个研究方向上进行进一步探索:1)当前算法仅探究一个协作方的情形, 当存在多个不同视角的协作方时, 如何更高效地利用多来源的数据是值得探究的问题; 2)利用已知固定物体作为锚点, 可重建待检测物体之间的相对位置关系, 从而增强融合的准确性和鲁棒性.
本文责任编委 程翔
Recommended by Associate Editor CHENG Xiang
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|