

{kind=link}
{kind=link}
{kind=link}
{kind=link}
驾驶场景下基于场景图嵌入融合光流特征的风险识别方法
[肖尧1  , 杨一箭
, 杨一箭1 , 苟超1
, 杨一箭, 苟超]
|
|



作者简介:

肖 尧,博士,副教授,主要研究方向为多模态混合交通智能体动力学、无人机运动学控制与运行仿真.E-mail:xiaoyao9@mail.sysu.edu.cn.

杨一箭,硕士研究生,主要研究方向为计算机视觉、机器学习等.E-mail:yangyj226@mail2.sysu.edu.cn.
多模态交通参与者的时空交织与行为互动复杂且难以精准识别,增加驾驶风险识别的难度.为此,文中构建虚拟交通场景图数据集CARLA_242,用于碰撞风险评估,数据集涵盖7类交通参与者及16种场景图关系.同时提出基于场景图嵌入融合光流特征的风险识别方法,包含如下三个核心模块.空间建模模块采用多关系图卷积网络联合编码节点特征与关系信息,再通过图池化与读出操作,生成场景图嵌入;光流提取模块对视频序列进行光流估计,提取表征动态运动的光流特征;时空建模模块采用Temporal Transformer Encoder,对场景图嵌入与光流特征的融合表示进行时序建模,实现驾驶风险识别.在3个场景图数据集上的实验表明文中方法性能较优,实验结果验证场景图与光流特征多模态融合在驾驶风险识别中的有效性.
About Author:
XIAO Yao, Ph.D., associate professor. His research interests include multimodal mixed traffic intelligent agent dynamics and UAV kinematic control and operational simulation.
YANG Yijian, Master student. His research interests include computer vision and machine learning.
The spatiotemporal and behavioral interactions of multimodal traffic participants are complex and difficult to recognize accurately. Therefore, the difficulty of driving risk identification is increased. To address this issue, a virtual traffic scene graph dataset, CARLA_242, is constructed for collision risk assessment. The dataset contains seven types of traffic participants and sixteen types of scene graph relations. A risk identification method via fusion of scene graph embeddings and optical flow features is proposed. The method consists of three core modules. In the spatial modeling module, node features and relation information are first jointly encoded by a multi-relational graph convolutional network and then exploited to obtain scene graph embeddings through graph pooling and readout operations. In the optical flow extraction module, optical flow is estimated from video sequences, and optical flow features representing dynamic motion are extracted. In the spatiotemporal modeling module, the fused representations of scene graph embeddings and optical flow features are processed by a temporal transformer encoder for temporal modeling to achieve driving risk identification. Experiments demonstrate the superior performance of the proposed method on three scene graph datasets. The results validate the effectiveness of multimodal fusion of scene graph and optical flow features for driving risk identification.
驾驶员对场景风险的错误评估往往会导致交通事故的发生, 自动驾驶系统能有效降低交通事故发生率, 因此利用自动驾驶系统进行风险判断具有重要研究价值.然而, 在多模态交通参与者交通系统中, 机动车、非机动车与行人在共享空间内的时空交织与行为互动呈现出高度的复杂性, 这对自动驾驶系统识别潜在冲突与防控风险提出更高的要求.应对这一复杂性, 需要依赖高质量的数据支撑, 但现有视频数据集普遍缺乏准确的时空参数, 从而制约风险评估深度学习模型的构建效能与可信度.此外, 仅对交通环境中物理实体进行感知与识别已远远不够, 未来自动驾驶系统亟需具备更高层次的语义理解能力, 能对场景中各类交通行为进行认知与推理.针对上述情况, 目前已经催生多个研究方向的交叉融合与深入探索, 如风险感知[1]、驾驶行为理解[2, 3]、行人行为预测[4]、场景生成[5, 6]、驾驶员行为分析[7]、同步定位与地图构建[8]等.
在自动驾驶安全研究中, 朱增乐等[9]提出基于Transformer的多模态融合目标检测语义通信模型.苏卫星等[10]提出考虑实时环境风险场的自动驾驶局部路径动态规划算法.Yurtsever等[11]提出结合CNN-LSTM(Convolutional Neural Network-Long Short-Term Memory)的危险行为识别方法.然而, 在复杂动态交通环境中, 上述方法仍在高层语义建模与行为模式解析方面存在局限.
作为理解视觉场景的有力工具, 场景图为风险评估提供新的思路[12, 13].Yu等[1]使用场景图作为神经网络学习的中间表示, 结合MR-GCN(Multi-rela-tional Graph Convolutional Network)和LSTM-attn提取时空特征, 进行自车主观风险评估.Liu等[14]对行人过街场景进行场景图建模, 采用基于Trans- former架构的时空序列模型, 评估和预测行人碰撞风险.
在基于视觉信息的风险评估模型中, BEV(Bird's View)因其直观且容易融合的特性被广泛采用.BEV能将车辆周围感知信息映射为二维地图表示, 但透视图到BEV的投影会引入几何误差[15].为了获取更准确的训练数据, 模拟器生成的数据集逐渐成为主流[16].CARLA(Car Learning to Act-An In- side Out)[17]作为开源仿真平台, 可提供真实地图、多种天气与光照条件以及多传感器模拟, 并支持车辆、行人和环境的精细控制, 用于风险评估和算法训练.通过CARLA可构建行人横穿、车辆侧碰、追尾等高风险场景[18], 并采集高精度、多传感器同步数据.
在此基础上, 本文构建CARLA_242场景图数据集, 在构建方式与数据精度上与现有的现实场景图数据集(如 114-crossing数据集)存在显著差异.在实际场景中, 通常依赖图像投影或基于BEV的估计方法获得交通参与者的空间位置和运动信息, 因此不可避免地受到视觉检测误差和投影计算偏差的影响, 而CARLA_242场景图数据集直接基于CARLA模拟器生成, 能从底层仿真环境中提取交通参与者的精确坐标、速度及其它运动学参数, 避免中间推算环节带来的不确定性.因此, 相比基于真实图像构建的场景图数据集, CARLA_242数据集在位置与运动信息的准确性和一致性方面具有显著优势, 为后续的建模与风险识别提供更可靠的实验基础.
本文还构建M_356混合数据集, 为后续交通场景图数据集的研究提供良好的“ 虚拟-虚拟现实混合” 基线数据集.
同时, 本文提出基于场景图嵌入融合光流特征的风险识别方法(Risk Identification in Driving Sce-narios via Fusion of Scene Graph Embeddings and Optical Flow Feature, RIvSGOF), 采用图卷积网络(Graph Convolutional Network, GCN)、CNN与Trans-former架构, 融合光流特征与场景图嵌入, 捕捉动态运动信息与场景交互信息.实验表明, 增加更细致描述的关系能提升本文方法处理场景图数据的准确性, 采用光流特征融合场景图嵌入的方式能提升方法对驾驶场景风险判断的准确性.
在视觉任务上, 场景图早先被视为一种语义图像检索框架[12], 采用< 主语, 谓语, 宾语> 的结构, 描述场景构成关系, 该结构数据被认为可提高模型针对场景理解和人机交互任务的处理能力.近年来, 场景图开始被用于自动驾驶领域的场景理解任务, 如道路车辆驾驶行为分类[2]、行人行为预测[19]、行人意图预测[4]、碰撞风险评估[1]、行人碰撞预测[20]等.
通常此类运用于自动驾驶场景任务中的场景图被称为交通场景图, 相关研究也逐步聚焦于其构建方式与表达能力的提升.Zhang等[21]利用流量场景的细粒度实例级注释, 设计自下而上的表示范式.Zipfl等[22]使用独立于道路的几何图形和道路拓扑, 构建场景图.Malawade等[23]使用交通实体间的欧氏几何关系构建交通场景图, 并开源相应生成工具.目前研究普遍采用交通场景图作为中间特征表示, 进而利用图神经网络挖掘复杂交通场景中的结构化关系与动态交互.
针对更具体的自动驾驶场景理解任务, 场景图也有更细化的研究.Mylavarapu等[2]将场景图构建成单目相机视角下车辆与车道标线的关系图.Song等[19]针对行人之间及行人与信号灯的交互, 构建交通感知场景图, 挖掘行人的动态约束.
视频与多模态场景图生成的研究目前现也取得显著进展.Nguyen等[24]提出HyperGLM, 将实体场景图与过程图融合为统一超图, 并结合多模态大语言模型, 实现复杂视频关系的多任务建模.Im等[25]提出EGTR(Extracting Graph from Transformer), 使用Detection Transformer多头自注意力中的关系信息, 并引入关系平滑与连通性预测, 提升单阶段场景图生成效率.Chen等[26]提出DIFFVSGG, 基于潜变量扩散模型, 实现在线场景图生成与持续时序推理.Wu等[27]提出USG(Universal Scene Graph), 系跨模态端到端生成方法, 通过对象关联与文本对比学习, 增强语义表达与泛化能力.
碰撞风险评估(Crash Risk Assessment)在自动驾驶系统中起着核心性、基础性且决定性的作用.通常会使用是否发生碰撞代表是否存在风险[28].传统的风险评估采用统计学的方法.Fu等[29]使用动态贝叶斯网络评估风险状态.Katrakazas等[30]结合动态贝叶斯网络和交互感知运动模型预测碰撞风险.Wu等[31]提出基于轨迹数据的风险评估方法, 通过风险场理论的风险排斥指标预测两辆车之间发生碰撞的风险大小.
除了传统方法之外, 基于深度学习的方法开始逐渐应用在自动驾驶系统风险评估领域.唐伟文等[32]提出融合时序知识图谱的双层次多视角时空图神经网络模型.Yurtsever等[11]提出基于单目视觉的深度学习风险评估框架, 通过语义分割与时序CNN-LSTM, 分类危险变道行为, 判断风险或安全.Schoonbeek等[33]提出RiskNet, 使用CNN对单帧驾驶序列进行分类判断.Karim等[34]提出AM-Net(Attention-Guided Multistream Feature Fusion Net-work), 使用两个门控循环单元(Gated Recurrent Unit, GRU)融合注意力机制模块, 从连续视频帧中提取对象边界框和光流特征, 进行风险判断.Yu等[1]使用场景图作为交通场景的中间表示, 判断驾驶场景是否存在风险, 但是该研究只针对于一些方位关系和距离关系进行场景图构建, 忽略在驾驶场景下其它交通主体与自我车辆之间的动态交互关系.
近年来, 出现了基于Vision Transformer架构的研究.Liu等[35]提出边特征增强的交通场景图碰撞风险评估模型, 融合视觉节点特征与图边信息, 并采用层次化节点更新.苟超等[36]提出基于平行视觉的风险增强感知方法, 融合关系图注意力网络和Transformer编码器模块, 对场景图序列数据进行时空建模.
光流估计(Optical Flow Estimation)作为计算图像序列中像素级运动信息的基本计算机视觉任务, 目标是在连续帧之间估计场景中各像素的二维位移向量场.光流反映图像亮度模式在时间维度上的变化, 常用于建模动态场景中的显式运动信息.
传统光流方法基于亮度恒常性假设, 通常通过线性近似和迭代求解实现稠密或稀疏光流估计.由于对亮度变化进行一阶泰勒展开, 这类方法隐含小幅运动的假设, 因此在驾驶场景下的车载视觉条件中, 可能无法发挥最优效果.
近年来, 随着大规模合成数据和端到端学习框架被提出, 基于CNN和Transformer的光流估计方法成为主流.Teed等[37]提出RAFT(Recurrent All-Pairs Field Transforms), 基于所有像素对间的全局相关性匹配与递归优化, 显著提升精度与鲁棒性.Jiang等[38]提出GMA(Global Motion Aggregation), 引入注意力机制, 聚合全局运动信息, 改善遮挡区域中的光流估计, 并且不会损害非遮挡区域的性能.Huang等[39]提出FlowFormer, 直接将 Transformer 架构引入光流估计, 通过 Attention 模块进行时空对齐与特征融合.Morimitsu等[40]提出RPKNet (Recurrent Par-tial Kernel Network), 引入部分核卷积与可分离大内核等结构, 在显著降低参数与计算量的同时实现无微调的泛化性能.Yuan等[41]提出UnSAMFlow, 将SAM(Segment Anything Model)的物体层级信息引入无监督光流估计, 并结合语义增强、单应性平滑约束与掩码特征聚合, 有效提升遮挡与运动边界处的估计质量.Luo等[42]提出FlowDiffuser(Advancing Opti- cal Flow Estimation with Diffusion Models), 将光流估计重构为条件流生成问题, 提出新的范式转变.Dong等[43]提出MemFlow, 设计记忆读写模块, 聚合历史运动信息, 并结合分辨率自适应缩放, 实现高效的实时光流估计与预测.
本文将驾驶场景中的风险评估问题形式化为一个有监督二分类问题.所有驾驶序列的集合被划分为两个联合穷尽且互斥的子集:风险驾驶集和安全驾驶集.将长度为T的场景图序列及对应视频序列帧
$\begin{aligned} X= & (S, I)= \left(\left\{S_{1}, S_{2}, \cdots, S_{T}\right\}, \left\{i m g_{1}, i m g_{2}, \cdots, i m g_{T}\right\}\right) \end{aligned}$
作为训练模型的输入, 其中场景图序列S由真实图像序列或模拟器生成的交通参与者参数通过场景图提取模块生成.场景图构建过程不属于本文方法的训练范畴.模型输出结果为序列的二分类风险标签y∈ {0, 1}, 其中, 0表示安全, 1表示风险.
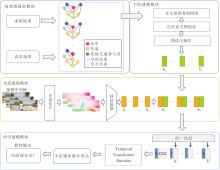
本文提出基于场景图嵌入融合光流特征的风险识别方法(RIvSGOF), 整体架构如图1所示.
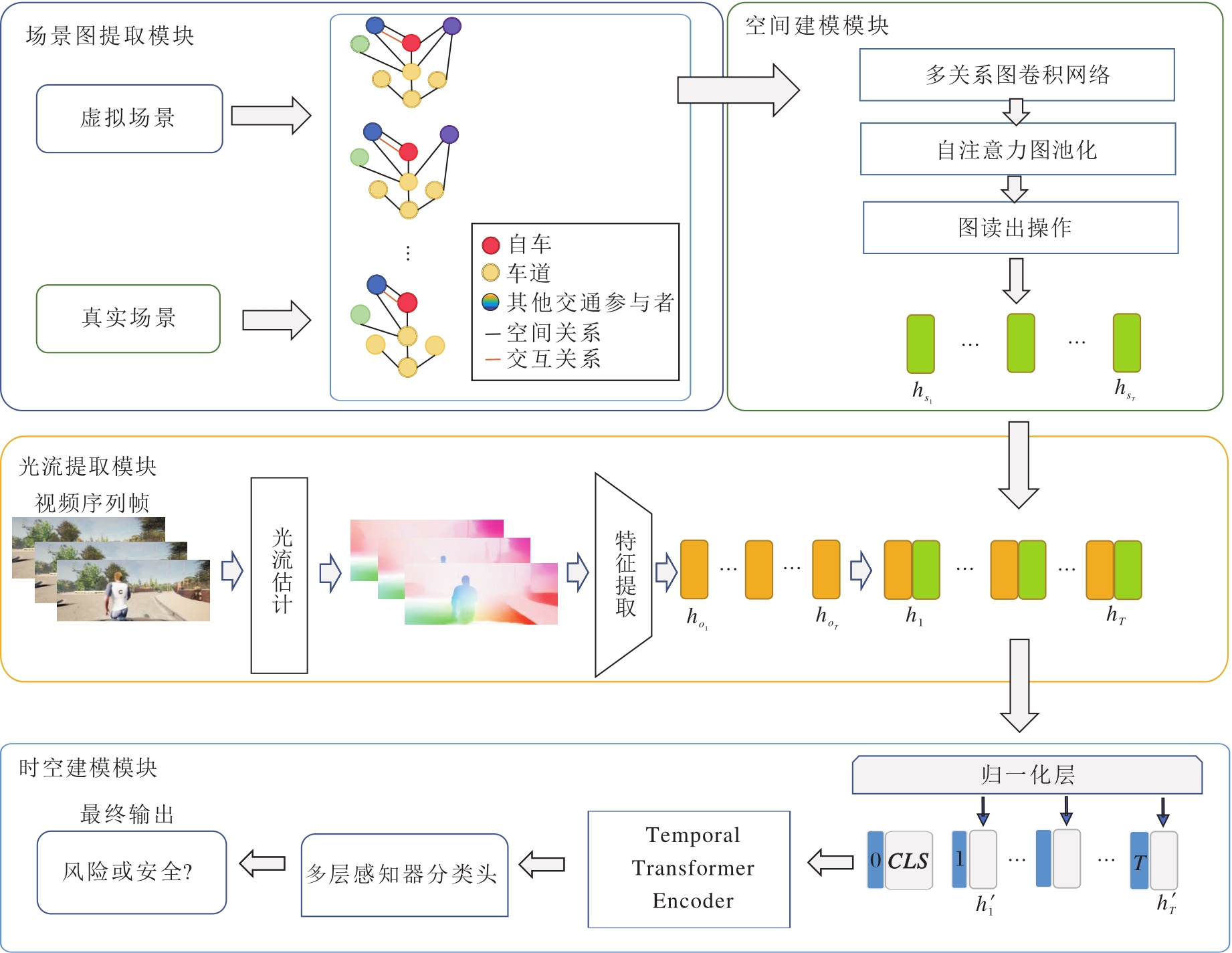 | 图1 RIvSGOF框架图Fig.1 Framework of RIvSGOF |
RIvSGOF主要由如下4个模块组成:场景图提取模块、空间建模模块、光流提取模块、时空建模模块.首先通过场景图提取模块对驾驶场景中的交通参与者及其关系进行建模, 获得结构化的场景表示.再在空间建模模块中对场景图的空间关系及交互关系进行编码, 捕捉不同实体之间的交互特征.然后, 借助光流提取模块获取视频序列中的时序运动信息, 为后续融合提供动态光流表征, 将场景图特征与光流特征进行多模态融合.最后, 在时空建模模块中, 通过时空模型实现对驾驶场景风险的识别.
在场景图提取模块中, 基于开源项目ROAD-SCENE2VEC[23]进行扩展, 增加对本文新定义关系类型的支持, 通过读取CARLA模拟器生成的对应驾驶场景序列中的交通实体参数进行场景图构建.在空间建模模块中, 依次使用多关系图卷积网络、图池化操作和图读出操作产出场景图嵌入.在光流提取模块中, 对场景图对应视频图像序列进行光流估计, 得到光流图后, 再通过预设的特征提取器提取光流特征向量, 与场景图特征进行融合.在时空建模模块中, 使用Temporal Transformer Encoder(后文简记为TTE)[14]进行复合嵌入的动态时序关系捕捉, 最终输出风险预测.
受天气和摄像机视角影响, 单目相机的物体检测及BEV投影可能不稳定[15], 潜在影响模型训练的可信度.本文直接使用CARLA模拟器提供的交通参与者参数(位置、速度、航向角等)作为场景图构建的输入, 基于开源工具ROADSCENE2VEC[23]自动生成场景图, 而非人工标注.
本文设计规则基于参与者的空间距离和速度差异判定关系类别, 实现批量、高效、可扩展的场景图生成.这种方法避免视觉识别的不确定性, 使研究重点集中在基于场景图结构的风险预测效果上, 而非端到端的图像检测与关系抽取.
对于一个驾驶场景序列帧中每帧对应的场景图St={Nt, Et}, 场景图的节点集合
Nt={o1, t, o2, t…, on, t},
表示驾驶场景中出现的n个交通参与者, 交通参与者限定为自车视野范围内的轿车、行人、自行车、面包车、货车及摩托车.构建场景图时, 若目标出现在自车视野中且与自车距离小于25 m, 即被判定为会与自车构成关系的交通参与者.将CARLA模拟器车载摄像头在时刻t检测的对象定义为oi, t, 并使用对应的世界坐标、速度和类型(汽车、摩托车、行人、车道等), 构建节点属性.邻接矩阵Et表示St的边, Et中的每个值表示相应节点间边的类型(如near、getting close to、isIn等).
ROADSCENE2VEC工具中的交通场景图是标准的三车道形式, 生成的场景图默认从Root Road抽象节点出发, 并默认通过isIn关系连接Left Lane、Middle Lane、Right Lane节点.
本文构建的关系分为两种:1)空间关系, 针对交通参与者与自车之间的空间描述; 2)交互关系, 针对交通参与者与自车之间的交互描述.详细的关系类型如表1所示.
| 表1 场景图关系 Table 1 Scene graph relation |
根据交通参与者的世界坐标及自车的世界坐标计算两者的欧氏距离, 再通过欧氏距离和航向角计算各交通目标与自车的距离及方位夹角, 添加距离关系及方位关系.在空间关系的提取上, 参考ROAD-SCENE2VEC中原生的距离关系, 同时还考虑交通参与者的自身空间体积, 也就是给予一个更保守的碰撞箱.在空间的方位关系上, 针对CARLA左手坐标系下的航向角进行规则修改, 保留inDFrontOf, inSFrontOf, atDRearOf, atSRearOf, toLeftOf, toRight-Of这些关系.其中, 如inDFrontOf与inSFrontOf中的“ D、S” 分别表示前方(Direct)与侧方(Side), 类似关系同理.near_coll表示接近碰撞.其余关系含义如英文所示.
本文设置getting close to, getting away from, passing by, passed by表示交通参与者与自车的4种交互关系, 其中passing by, passed by是针对行人与自车的关系, getting close to, getting away from无节点类型的限制.
与114-crossing数据集[14]不同的是, 本文的getting close to, getting away from关系不是通过每个交通实体的相对位置坐标计算自车与交通参与者之间的距离, 再对比相邻帧之间的交通参与者与自车之间的距离变化, 而是通过CARLA模拟器提供的速度参数进行矢量计算, 得到两者之间是彼此靠近或远离.passing by与passed by设定如下:先确定行人位置是否在自车的视野中且距离在10 m以内, 同时行人相对自车行进方向是否有一定的横向速度分量, 若上述条件都符合, 则同时加入passing by和passed by两个交互关系, 其中passing by的节点指向为从行人指向自车, passed by的节点指向为从自车指向行人.
有无行人的可视化场景图示例如图2所示, 在图中, 绿色边框中的关系为所有参与者都有的交互关系, 红色边框中的关系为针对行人的交互关系.
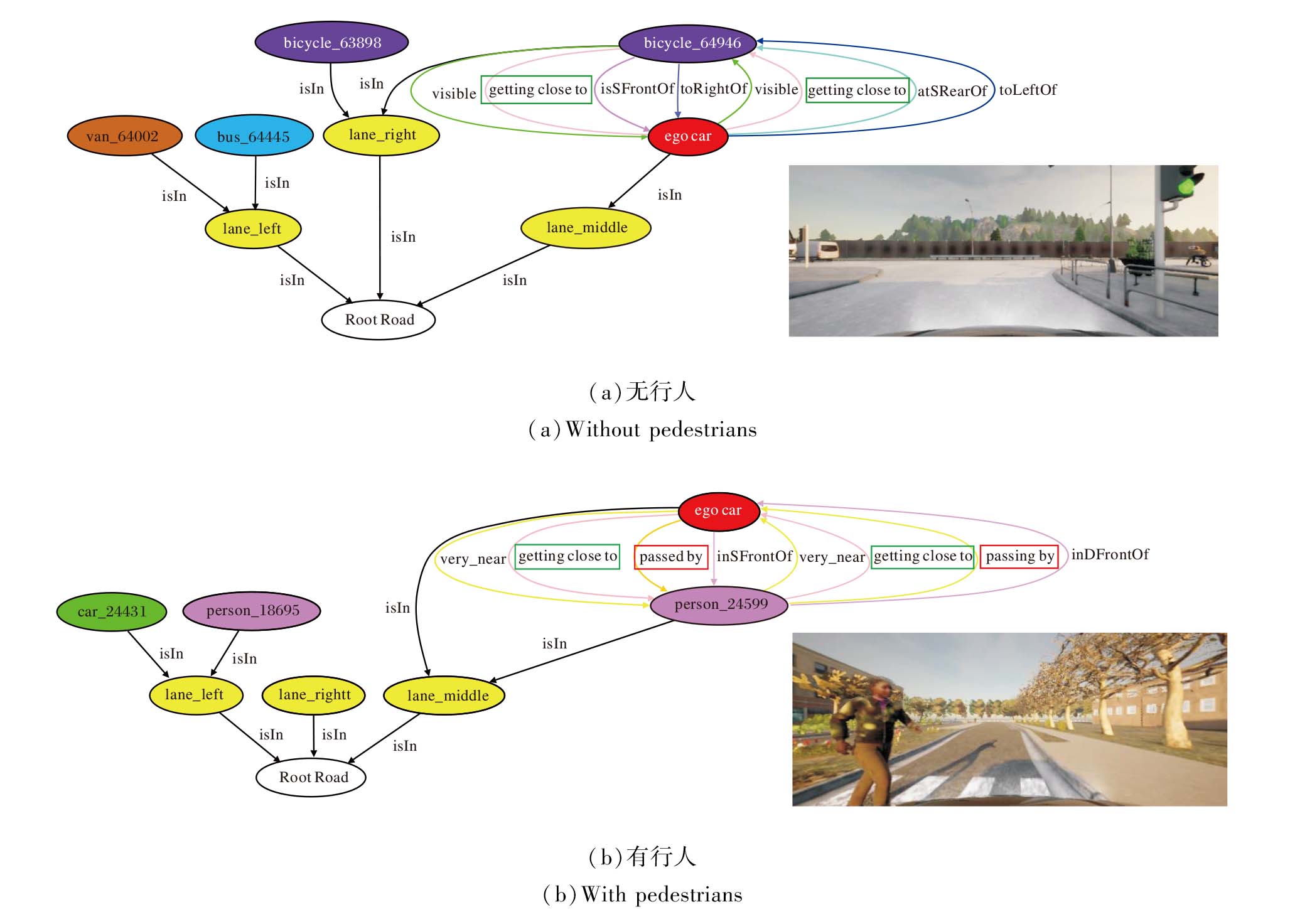 | 图2 有无行人的交互场景图Fig.2 Interaction scene graph with and without pedestrians |
在空间建模模块中, 采用MR-GCN[1]作为图卷积层.图卷积的运算基于邻接关系的局部聚合, 不要求输入图具有统一的节点数量或边数量.在输入空间建模模块之前, 需要处理场景图的节点作为初始特征, 节点特征由节点类型的独热向量(One-Hot)与入度、出度嵌入相加得到, 入度和出度分别表示指向或发出的边数.本文设定节点种类数(独热向量维度)为12, 通过对应独热向量中的非零元素反映节点的入度和出度, 与独热向量保持相同维度.不同边类型分配独立的权重矩阵, 特征输入维度是由节点特征维度决定, 个数由边类型总数决定, 本文预设边类型总数为12或16.
首先根据输入节点特征和边类型, 启动图卷积操作.再依据每条边的关系类型选取对应的可学习变换矩阵, 对邻居节点特征进行线性变换.然后, 按照目标节点聚合线性变换结果, 并对不同关系类型的邻居信息进行归一化处理.返回聚合结果后, 图卷积层还会将节点自身特征通过自连接矩阵进行变换, 最终经过激活, 输出第l+1层的节点嵌入表征:
$\begin{array}{l} \boldsymbol{h}_{o_{i, t}}^{(l+1)}= ReL U\left(\left(\sum_{r \in R} \frac{1}{\left|N_{i}^{r}\right|} \sum_{j \in N_{i}^{r}} \boldsymbol{W}_{r}^{(l)} \boldsymbol{h}_{o_{j, t}}^{(l)}\right)+\boldsymbol{W}_{\text {root }}^{(l)} \boldsymbol{h}_{o_{i, t}}^{(l)}\right), \end{array}$
其中,
每层经过MR-GCN卷积层的嵌入后, 拼接成
定义第t帧的所有节点嵌入
如果将卷积处理后的图特征维度都传入之后的学习模块, 可能会导致神经网络的学习速度降低, 泛化性减弱, 故一般采用池化操作减小特征维度.本文采用SAGPool[44]作为池化层, 为后续任务保留主要节点信息, 删除不相关的节点聚合.然后获得节点的自注意力分数:
s=FastRGCNConv(H
它反映各个节点的重要性, 其中, FastRGCNConv(Fast Relational Graph Convolutional Network Con-volution)表示针对多关系图的高效卷积层, 可在保持关系建模能力的同时降低计算和参数复杂度.
预设一个超参数池化比率k∈ (0, 1), 确定节点嵌入池化程度.对于每个时刻的场景图, 取自注意力分数最高的前k比率的节点嵌入进行保留, 即
H
其中, topk(s)表示对于s中从大到小排序的前k比率的节点进行保留操作, ☉表示对应元素之间点乘, 即逐元素相乘.
为了将图中所有节点的特征表示整合为一个统一的图级表示, 进行图读出操作.在特征维度上对所有节点的最终嵌入执行聚合操作, 从而捕捉图的全局语义信息.在RIvSGOF中, 选择求和作为图读出操作(Add Pooling, ADDPOOL), 即得到每个场景图的最终图嵌入:
对于每帧场景图重复这一操作, 获得整个场景图的向量化表征:
HS=[
光流估计是计算图像序列中每个像素在不同时间点之间运动的一种方法, 通常表现为一个二维向量场, 描述图像中每个像素在两个视频序列帧之间的移动方向和速度.由于物体的整体移动具有一致性, 所以在画面中可呈现出类似于全景分割的效果, 同时又在驾驶场景中展示目标相对自车运动趋势的信息.
本文使用的光流估计模块为RAFT[37], 使用预训练权重raft-things.获取光流图之后采用的特征提取模块为PyTorch中预训练好的ResNet50[45], 从之后的特征融合考虑, 最后一层输出层的输出维度设为64维而不是原来的1 000维.
生成的光流图
OFt=RAFT(imgt, imgt+1),
其中imgt表示对应的视频帧.集合
$\begin{array}{l} \boldsymbol{H}_{o}=\left\{\boldsymbol{h}_{o_{1}}, \boldsymbol{h}_{o_{2}}, \cdots, \boldsymbol{h}_{o_{T}}\right\}, \\ \boldsymbol{h}_{o_{t}}=ResNet\left(\boldsymbol{O F}_{t}\right), \end{array} $
表示一个场景图序列经过特征提取后得到的光流特征.
光流特征提取器结构如图3所示.
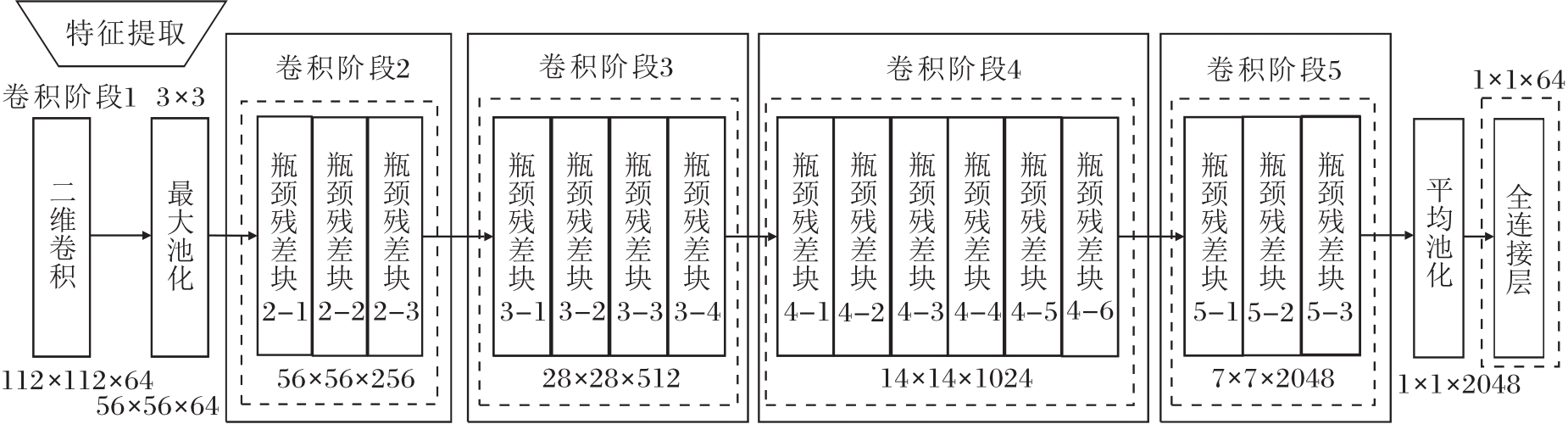 | 图3 光流特征提取器结构图Fig.3 Architecture of optical flow feature extractor |
TTE[14]是一种Transformer结构的解码器, 本文时空建模模块采用TTE, 并使用图卷积神经网络学习获取的图级嵌入序列HS={
本文在此基础上, 提出光流特征与场景图嵌入结合的方式, 构建包含有两者特征信息的表征:
ht=[
定义所有序列的表征集合H={h1, h2, …, hT}, 该表征可视为以场景图嵌入为标签信息的光流特征.
输入这种复合嵌入后, 首先对其进行归一化, 得到
H'={h'1, h'2, …, h'T}.
然后, TTE为H'增加分类标记(CLS), CLS表示一个定义形状为(1, 1, d)的张量, 其中, d表示嵌入维度, 从标准正态分布中随机采样生成.此分类标记会在之后进行一系列分类操作, 进行学习更新.由于典型的Transformer架构自身没有顺序感知能力, 所以需要通过位置嵌入提供时间序列信息[14].因此, TTE会向已拼接分类标记的表征添加时序位置嵌入, 最终得到输入:
x0=[hcls; h'1; h'2; …; h'T]+hpos,
其中, hcls表示分类标记, h'i∈ Rd表示经过归一化处理后的表征, hpos∈ R(T+1)× d表示时序位置嵌入表征.拼接方式见图1中时空建模模块.
x0随后被输入L 层的Transformer单元中, 经过归一化(Layer Normalization, LN)后输入多头自注意力(Multi-headed Self-Attention, MSA)、前馈神经网络(Feedforward Network, FF)模块处理, 得到
$\begin{array}{l} \boldsymbol{x}_{l}=F F\left(LayerNorm\left(\boldsymbol{x}_{l}^{\prime}\right)\right)+\boldsymbol{x}_{l}^{\prime}, \\ \boldsymbol{x}_{l}^{\prime}=M S A\left(LayerNorm\left(\boldsymbol{x}_{l-1}\right)\right)+\boldsymbol{x}_{l-1} \cdot \end{array}$
随后多层感知器分类头进行归一化处理, 再对原始的logits进行softmax操作, 得到概率分布, 取对数, 输出对数概率:
其中, xL表示第L层(最后一层)Transformer层的类别标记向量, LN(·)表示归一化操作.
对碰撞类别取指数, 得到风险概率, 最终通过取概率最大值获得二值预测y∈ {0, 1}.
模型的训练使用交叉熵损失计算预测损失:
L=CrossEntropyLoss(Y,
其中, Y表示真实标签,
在公开交通风险评估数据集 Riskbench[18]上, 基于交通参与者目标边界框编号与车载摄像头出现目标对应这一基本要求, 筛选数据, 得到CARLA_242数据集.
RiskBench数据集是一个专为自动驾驶系统中风险场景评估与建模而设计的综合性基准数据集, 共6 916个场景序列, 场景类型包括以下4种.1)交互式:对动态风险做出让行.2)碰撞:碰撞场景.3)障碍物:与静态元素交互.4)非交互式:正常驾驶.
本次构建的CARLA_242数据集是针对Risk-bench中的碰撞与非互动两类进行筛选, 其中, Riskbench中的碰撞类标记为风险驾驶场景, 非互动类标记为安全驾驶场景.
CARLA_242数据集共有242个驾驶场景序列, 包含20 768帧驾驶场景, 平均每个场景序列约86帧.CARLA_242数据集为完全由CARLA模拟器构建的虚拟数据集, 包含7类交通参与者(小汽车、自行车、行人、面包车、公交车、卡车、摩托车), 并且含有自车与汽车、自行车、行人、面包车、摩托车等的交互.在CARLA_242场景图数据集上, 根据有无交互关系又分为CARLA_242_r16数据集(有交互关系)和CARLA_242_r12数据集(无交互关系).
在真实数据集方面, 采用114-crossing数据集[14]进行训练对比.114-crossing数据集筛选于CAP-DATA[46]、JAAD[47]数据集, 并依据有无交互关系分为IESG数据集(有交互关系)和Non-IESG数据集(无交互关系).CAP-DATA数据集是一个基于DADA-2000数据集[48]扩展的大规模事故基准数据集.JAAD数据集是一个行人-人行横道行为基准数据集.114-crossing数据集共有114个视频序列, 共计19 960帧, 平均每个视频图像序列包含175帧图像.
基于IESG和CARLA_242_r16以及Non-IESG和CARLA_242_r12这两对数据集, 构建M_356混合数据集, 分为M_356_r16数据集(有交互关系)和M_356_r12数据集(无交互关系), 即M_356数据集既包含CARLA模拟器生成的虚拟场景数据集又包含真实行人过街场景数据集.
数据集具体信息如表2所示.
| 表2 实验数据集 Table 2 Experimental datasets |
RIvSGOF包含3个核心组件:基于图卷积网络的空间建模模块、基于Transformer的时空建模模块、光流提取模块.对于空间建模模块, 图卷积网络层数设为3, 维度设为64, 中间图池化层中的池化比率设为0.5.对于时空建模模块, TTE中Transformer层的维度设为114, 包含50维对应场景图特征, MLP(Multi-Layer Perceptron)维度设为200, 注意力头(Attention Heads)数量设为8.对于光流提取模块, 采用预训练的残差网络, 并将最后输出层维度设为64.所有数据集上的学习率设为0.000 01.模型训练使用Adam(Adaptive Moment Estimation)优化器, 批大小设为16, 权重衰减率设为0.000 5.针对CARLA_242、M_356这类包含CARLA仿真数据集信息的数据集, 训练迭代轮次设为51, 而对于IESG这类纯粹现实数据集, 迭代轮次同步为150[14].
使用配置NVIDIA GeForce RTX 3060的台式机训练模型, 并选择准确率(Accuracy, Acc)、曲线下面积(Area Under the Curve, AUC)、F1得分(F1)对比方法性能.
MR-GCN按最优参数设置[1], GCN层数设为2, 维度设为100, MRGIN(Multi-relational Graph Inter-action Network)设置与MR-GCN相同.IESG数据集上对比数据来自其对应文献[14, 49].
选择如下对比方法:MR-GCN+LSTM-attn[1]、MR-GCN+LSTM-last[1]、MR-GCN+mean[1]、TTE[14]、MRGIN[23]、DAE(Dynamic Attention Enhancement)[49].TTE为基线方法, DAE在IESG数据集上达到最优性能[49].
采用五折交叉验证进行实验对比.将每个数据集划分为五个等份, 其中四份用于模型训练, 剩余一份用于测试, 循环进行, 最终对各轮结果取平均, 以此全面评估分类性能.
在CARLA_242_r16、IESG、M_356_r16场景图数据集上进行五折交叉验证, 定量结果如表3所示, 表中黑体数字表示最优值.由表可见, 相比基线方法TTE, RIvSGOF在3个场景图数据集上都取得显著的性能提升.在CARLA_242_r16数据集上, Acc值提升约2%, AUC值提升约3%, F1值提升约1.8%.在M_356_r16数据集上, Acc值提升约5.2%, AUC值提升约5.6%, F1值提升约7.9%.在IESG数据集上, Acc值提升约3.8%, AUC值提升约1.0%, F1值提升约4.2%.
| 表3 各方法在3个数据集上的指标值对比 Table 3 Comparison of metric values among different methods on 3 datasets |
为了评估针对TTE提出的改进效果及数据集关系增强的影响, 设计如下消融实验.在CARLA_242、114-crossing、M_356场景图数据集上进行测试, 训练设置与对比实验一致, 114-crossing数据集上TTE数据来自其对应文献[14].针对有无光流特征介入、有无交互关系, 分别采用五折交叉验证进行实验验证, 结果如表4和表5所示.
| 表4 有无光流特征下的消融实验结果 Table 4 Ablation experiment results with and without optical flow features |
| 表5 有无交互关系消融实验结果 Table 5 Ablation experiment results with and without interaction relations |
由表4可见, 相比无光流特征的TTE, RIvSGOF的指标值更高, 表明融合场景图特征与光流特征可提升性能.由表5可见, 引入交互关系对提高方法性能具有显著影响.总之, 对于光流特征的介入及更丰富的交互关系的加入而言, 两者效果的叠加使方法性能达到最优.
下面对比不同维度光流特征与场景图特征融合的效果, 在CARLA_242_r16数据集上进行五折交叉验证, 结果如表6所示, 表中黑体数字表示最优值.由表可见, 选择32维光流特征时方法表现一般.应用128维光流特征时的性能差于选择64维光流特征时的性能, 说明过高维度可能引入冗余信息并影响泛化性, 光流维度比例过大, 可能导致光流特征在融合过程中占据主导, 削弱场景结构信息的作用.当光流特征维度增至64时, 方法性能达到最优, 表明适度扩展光流特征有助于更充分表征动态信息.本文场景图特征拼接维度为50, 64维光流特征与其维度相近, 能在特征融合时保持良好的平衡, 使动态信息与场景结构信息互补, 提升方法的表达能力.128维光流特征与50维场景图特征的差距过大, 可能导致动态特征在融合过程中占据主导, 削弱场景结构信息的作用.因此64维光流特征与场景图特征维度较匹配.
| 表6 光流特征维度改变对方法性能的影响 Table 6 Effect of different optical flow feature dimensions on method performance |
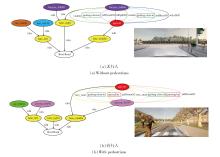
案例1与案例2均为自车转弯过程中与行人侧后方发生碰撞的驾驶场景, 不同之处在于案例1中自车右转前存在短暂停车行为, 而案例2中自车左转且行人在过街前曾停下.案例分析中关键帧光流图与场景图如图4所示.
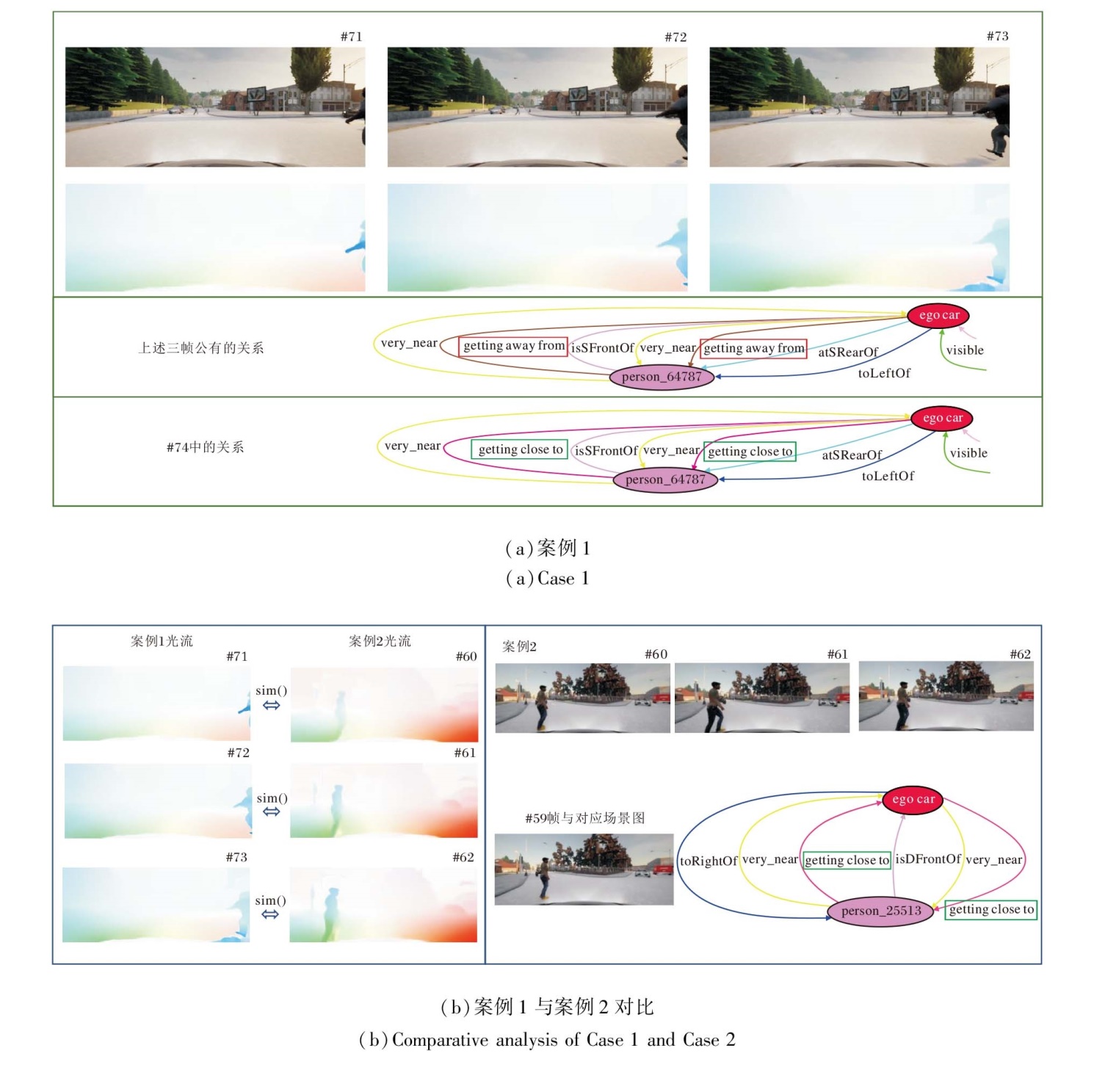 | 图4 案例分析Fig.4 Case analysis |
在案例1中, 自车第50帧至第70帧前在路口停车, 随后才右转, 此时目标出现, 由于自车停止而目标行动, 故目标在其出现后的几帧内先表现为“ 远离” 的关系, 随后自车启动, 关系转变为“ 接近” .
这一关系的阶段性变化可能导致基于场景图特征的方法判断存在一定的不确定性, 最终输出概率为[0.540, 0.460], 即倾向于判断为安全, 判断错误但概率差异较小.加入光流特征后, 概率为[0.234, 0.766], 即倾向于判断为风险, 能更明确地识别风险.进一步地, 将案例1与案例2中自车开始转弯后的对应帧光流特征进行余弦相似度计算, 结果为0.762、0.800、0.855, 即在两个案例中的车辆执行转弯动作的最初几帧中, 光流特征具有较高且逐步上升的相似性.这说明在场景图关系存在差异时, 光流仍能捕捉跨案例的相似运动模式, 为方法提供额外判别信息.
相比之下, 案例2中目标始终保持“ 接近” 关系, TTE已能较好识别风险(输出概率为[0.112, 0.888], 判断为风险), 而RIvSGOF融合光流特征后, 预测置信度进一步提升(输出概率为[0.075, 0.925], 判断为风险).由此可见, 在此案例中光流特征不仅在场景图关系存在变化时增强风险识别能力, 也在关系稳定时提高预测确定性, 从而从整体上增强方法的可靠性.
目前在具有多模态交通参与者的驾驶场景中存在难以精确获取各个交通参与者准确交通参数的问题, 因此, 本文通过筛选与处理Riskbench数据集, 设计CARLA_242这一完全由模拟器生成的虚拟场景图数据集, 并采用与现实场景图数据集融合的形式构建M_356混合数据集, 获得更具有泛化性的训练数据集, 为之后针对多模态交通参与者交通风险评估, 尤其是多模态交通参与者交通场景图关系研究提供较丰富的基准数据集.
本文同时提出驾驶场景下基于场景图嵌入融合光流特征的风险识别方法(RIvSGOF), 结合富含运动信息的光流图与富含交互信息的场景图, 通过Transformer架构进行学习评估, 在CARLA_242、M_356数据集上获得较优性能, 并通过光流消融实验证实场景图嵌入融合光流特征的有效性, 即多模态数据融合可有效帮助Transformer架构判断评估驾驶场景是否存在风险.未来工作考虑将更多类型的多模态信息(如激光雷达数据或驾驶员行为数据)与场景图嵌入进行融合, 以便进一步提升风险识别的精度与鲁棒性.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|