



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于双重并行任务的无人机小目标两阶段检测方法
[杨艺1, 2  , 朱江睿
, 朱江睿1, 2 , 王科平1, 2 , 张高鹏3 , 钱伟1, 2 , 王田4 ]
, 朱江睿, 王科平, 张高鹏, 钱伟, 王田]
|
|



作者简介:

杨 艺,博士,副教授,主要研究方向为深度学习、强化学习、智能控制等.E-mail:yangyi@hpu.edu.cn.

朱江睿,硕士研究生,主要研究方向为图像识别、目标检测、深度学习.E-mail:zhujiangrui@home.hpu.edu.cn.

张高鹏,博士,副教授,主要研究方向信号处理,航天器成像、目标感知等.E-mail:zhanggaopeng@opt.ac.cn.

钱 伟,博士,教授,主要研究方向为时滞系统、随机系统、网络控制系统等.E-mail:qwei@hpu.edu.cn.

王 田,博士,教授,主要研究方向为人工智能、计算机视觉、模式识别.E-mail:wangtian@buaa.edu.cn.
目标在图像中的尺寸过小是无人机目标检测面临的主要挑战之一,特别是当无人机飞行高度较高且成像分辨率较低时,小目标特征极易在深度神经网络的深层特征中弥散.为此,文中提出基于双重并行任务的无人机小目标两阶段检测方法,并行任务包含小目标检测任务与超分辨率重建任务.在超分辨率重建任务分支中,构建空间先验模块和窗口注意力引导模块.小目标检测任务分支以Swin Transformer为基础,并且分别由空间先验模块和窗口注意力引导模块进行浅层特征的空间信息和深层特征的注意力的超分辨率重建.两阶段检测方法分为训练阶段和推理阶段.在训练阶段,超分辨率重建任务分支均以高分辨率特征为标签,从而增强小目标检测任务分支对细节特征的提取能力.在推理阶段,仅保留小目标检测任务分支,可提升方法的推理速度,降低资源开销.在公共数据集VisDrone和自制无人机数据集JZ-UAV上的实验表明,文中方法识别精度较高.
About Author:
YANG Yi, Ph.D., associate professor. His research interests include deep learning, reinforcement learning, and intelligent control.
ZHU Jiangrui, Master student. His research interests include image recognition, object detection, and deep learning.
ZHANG Gaopeng, Ph.D., associate professor. His research interests include signal processing, spacecraft imaging, and target perception.
QIAN Wei, Ph.D., professor. His research interests include time-delay systems, stochastic systems, and networked control systems.
WANG Tian, Ph.D., professor. His research interests include artificial intelligence, computer vision, and pattern recognition.
The excessively small size of targets in images is a major challenge for drone-based object detection. Particularly when drones operate at high altitudes with low imaging resolution, features of small targets are prone to dissipation within the deep layers of deep neural networks. To address this issue, a method of dual-branch two-stage detection for small objects in unmanned aerial vehicle(DB-TS) is proposed. The parallel tasks consist of a small object detection task and a super-resolution reconstruction task. In the super-resolution reconstruction branch, a spatial prior module(SPM) and a window attention module(WAM) are constructed. The small object detection branch is built upon the Swin Transformer backbone. The spatial information from shallow features and the attention guidance from deep features are reconstructed via super-resolution methods of SPM and WAM, respectively. The two-stage detection framework consists of a training phase and an inference phase. During the training phase, the fine-grained detail extraction capability of the small object detection branch is strengthened by using the high-resolution features as ground truth in the super-resolution reconstruction branch. During the inference phase, inference speed is significantly improved and computational resource consumption is reduced by retaining only the small object detection branch.Experiments on VisDrone and JZ-UAV datasets demonstrate that the proposed method achieves higher recognition accuracy compared to baseline models and exhibits superior performance among compared state-of-the-art methods.
随着科技的进步和发展, 无人机(Unmanned Aerial Vehicle, UAV)的应用越发广泛, 不仅在工程上能进行道路监测、安全监控、线路巡检, 还在军事上完成对敌人的精准打击等任务.在我国2025年“ 九三” 阅兵当中, 各种侦查、制空、打击型无人机纷纷亮相, 表明无人机在当代甚至是未来战争中的重要地位.此外, 无人机在民用方面的应用也十分广泛.2025年国庆长假期间, 福州市“ 福智巡” 低空无人机平台在高速公路疏堵中成功实现快速响应与违法行为识别, 显著提升交通管理效率.与此同时, 电力行业正全面推进无人机智能巡检系统, 已覆盖全国主要输电网络, 实现对线路缺陷的自动化精准识别.
无人机在目标检测领域被广泛应用[1].特别是近年来, 随着芯片制程技术的快速发展, 在无人机环境下直接部署CNN、Transformer等架构的目标检测模型得以实现, 并已形成成熟的产品.然而, 如何在有限的运算资源上提升模型的检测精度, 仍是无人机环境下小目标检测任务的主要挑战之一.
计算机视觉是无人机执行监测、跟踪、识别等任务[2]的主要信息来源.因此, 视觉目标检测的精度是无人机执行任务成败的关键.然而, 无人机执行任务时, 机器视觉中目标尺度随飞行高度的变化而变化.当飞行高度变化较大时, 机器视觉中的目标将呈现为大目标和小目标两种极端情况, 这为目标检测带来巨大挑战.另一方面, 为了保障目标检测的实时性, 无人机图像的分辨率通常不能设置太高.当无人机飞行高度过高且图像分辨率不足时, 目标的成像像素较少, 极易出现误检、漏检等现象.
为了解决上述问题, 学者们提出多尺度融合[3]、上下文信息结合[4]、区域建议[5]、超分辨率[6]等方法.其中, 超分辨率能恢复图像细节以提供更多小目标特征, 因此在检测领域受到广泛关注和研究.
根据神经网络结构的不同, 基于超分辨率的方法可以分为级联式、端到端式、多任务学习式等.其中, 多任务学习框架分为目标重建分支和目标检测分支.在训练阶段, 通过目标重建分支引导网络获取重建小目标纹理所需的细节特征, 进而在目标检测网络中完成小目标的定位和分类.在测试阶段, 舍弃目标重建分支, 降低推理成本的同时确保小目标检测的精度.
多任务学习框架的超分辨率重建分为特征重建方法和图像重建方法.特征重建方法通常采用高分辨率特征引导低分辨率特征进行重建[7].由于高分辨率特征小目标细节并未丢失, 因此可引导低分辨率特征小目标信息的保留.在图像重建方法中, 重建分支和检测分支共享相同的特征提取网络.重建分支将深层特征恢复为高分辨率图像, 并利用损失函数监督特征提取网络, 从而保留重建小目标所需的细节特征[8].
多任务学习框架的重建大多是针对特征图的全局重建, 这种方法虽然能改善检测任务的整体性能, 但对小目标检测的性能提升依然有限.基于多任务学习框架的方法可从如下两个方面改进:重建特定的权重分布、结合网络特性.因此, 设计引导权重分布以深度协同超分辨率与检测任务的多任务学习框架, 是提升小目标检测精度的关键步骤之一.Swin Transformer[9]拥有独特的移位窗口注意力机制, 在捕捉长距离依赖关系的同时能获取局部细节特征.窗口注意力机制将整幅图像划分为相同大小的窗口并在内部进行注意力计算, 较小的窗口更适用于捕捉像素不足的小目标特征.因此, 在多任务学习框架中适合被用作目标重建和目标检测的主干网络.
然而, 在低分辨率图像中, 基于Swin Trans-former的小目标检测面临两个核心问题.1)浅层网络的Patch Embedding存在下采样过程, 快速压缩分辨率的同时也导致小目标位置信息在空间上更易丢失.2)微弱的小目标特征难以在深层网络中的局部窗口被激活, 导致注意力分布无法聚焦于微弱、已弥散的小目标特征.
因此, 本文提出基于双重并行任务的无人机小目标两阶段检测方法(Dual-Branch Two-Stage Detec-tion for Small Objects in UAV Images, DB-TS), 通过重建分支与检测分支协同训练机制, 将高分辨率特征作为监督信号, 引导主干网络在训练过程调整优化方向.基于Swin Transformer的注意力机制, 设计窗口注意力引导模块(Window Attention Module, WAM), 并集成在深层网络中.WAM对齐高低分辨率网络的窗口注意力分数, 引导注意力聚焦深层网络中被噪声淹没的小目标特征, 增强小目标特征响应的同时可有效抑制背景干扰.为了解决在浅层网络特征提取阶段小目标的空间细节丢失问题, 设计空间先验模块(Spatial Prior Module, SPM), 在浅层网络的特征图上进行空间域对齐, 利用高分辨率特征图的空间位置先验进行引导, 显著提升方法对浅层特征小目标区域的细节保留能力.各数据集上的实验表明, DB-TS识别精度较高.
在神经网络深度学习算法代替传统的手工提取特征的方法之后, 目标检测技术已逐渐发展成熟.小目标检测一直是目标检测中较难的任务之一, 并受到计算机视觉领域研究者的广泛关注, 衍生出各种各样的解决方法.
随着卷积神经网络(Convolutional Neural Net- work, CNN)[10]在人工智能各领域取得显著进展, 该技术也逐渐应用于目标检测领域.
在早期FPN(Feature Pyramid Network)[11]未普及之前, 典型的如YOLO(You Only Look Once)[12]和最初的Faster R-CNN[13]等, 通常只将主干网络输出的单层或最后一层级特征图提供给检测器, 导致检测尺寸过于单一, 并且深层特征图虽然具有丰富的语义信息, 但分辨率较低, 常使检测器难以精准定位小目标特征, 检测性能较差.Liu等[14]提出SSD(Single Shot Multibox Detector), 设计多尺度预测机制, 缓解上述问题.尽管这一设计显著提升对多尺度目标的适应性, 但多级特征图之间是独立进行预测的, 缺乏有效的跨尺度特征融合.
为了解决不同层级特征无法交互的问题, Lin等[11]提出FPN, 通过自上而下路径与横向连接, 将深层的强语义特征与浅层的高分辨率特征有机融合, 利用不同层级的特征图交互实现多尺度检测.该网络显著增强用于检测小目标的浅层特征的语义表达能力, 从而有效改善小目标的检测性能.
随着ViT(Vision Transformer)[15]将Transformer架构[16] 引入计算机视觉领域, 其强大的长距离依赖建模能力展现出与CNN相当的性能.然而, ViT由于固有的计算复杂度及对图像进行均匀分块的处理方式, 在小目标检测任务中难以有效捕捉精细的局部特征, 限制自身在此类任务中的直接应用.为了克服ViT的局限性, Liu等[9]提出Swin Transformer, 引入分层金字塔结构和移位窗口自注意力机制, 在降低计算量的同时保留全局上下文信息.这种设计能像CNN一样生成多尺度特征图, 兼容FPN等经典架构, 最终在包括小目标检测在内的多种视觉任务中实现精度的显著提升.
随着研究的深入, 越来越多的小目标检测方法被提出.Shermeyer等[17]通过超分辨率技术生成多分辨率图像, 用于网络训练, 提升遥感图像的检测性能.Cao等[18]提出 GCNet(Global Context Network), 设计全局上下文建模模块, 增强小目标的语义感知能力.Tan等[19]提出BIFPN(Bi-directional Feature Py-ramid Network), 引入加权双向连接, 用于处理小目标信息.与此同时, Zhang等[20]基于Faster R-CNN, 提出Dynamic R-CNN, 在区域建议机制中调整自适应回归损失, 并采用分阶段感知的目标检测策略.
超分辨率方法作为一种直接有效的技术路径, 核心思想并非是复杂的特征交互, 而是通过直接恢复图像的高频细节与提升分辨率, 从根本上增加小目标的特征丰富度.
低分辨率图像上的小目标检测的核心挑战在于有限像素承载的特征信息过少.超分辨率技术通过恢复图像的低频结构并增强高频细节, 为这一难题提供极具潜力的解决思路.
超分辨率技术的早期研究集中于基于插值的图像重建方法, 如双线性与双三次插值.Dong等[21]提出SRCNN(Super-Resolution Convolutional Neural Net-work), 标志着该领域进入深度学习时代, 通过端到端学习实现从低分辨率输入到高分辨率输出的非线性映射.此后, ESRGAN(Enhanced Super-Resolution Generative Adversarial Networks)[22]、RCAN(Residual Channel Attention Network)[23]等强大的架构被开发出来, 有效提升重建图像的真实感与清晰度, 尤其是生成对抗网络(Generative Adversarial Network, GA-N)[24]的兴起显著推动这一进程.Li等[25]提出Per-ceptual GAN(Perceptual Generative Adversarial Net-work), 首次证实基于GAN的超分辨率方法生成的丰富纹理与细节能直接赋能下游目标检测器, 提升性能.
为了解决小目标检测精度较低的问题, 越来越多的学者开始将超分辨率重建思路和目标检测方法结合, 进一步提升小目标的检测精度.此类方法主要分为3类:基于级联策略的结合目标检测方法、基于端到端训练的结合目标检测方法和基于多任务结构的结合目标检测方法, 相应归类如表1所示.
| 表1 超分辨率重建结合目标检测方法归类 Table 1 Taxonomy of methods combining super-resolution reconstruction and object detection |
1)基于级联策略的结合目标检测方法.传统研究方案通常采用级联式设计, 将预训练的超分辨率模块直接串联于检测网络的输入端, 或嵌入主干网络内部及后端.该类方法通过提升输入图像或中间特征图的分辨率, 在一定程度上保留更多的图像细节[26].然而, 由于其中的超分辨率组件多为独立训练, 且优化目标通常面向人类视觉感知质量, 而非检测任务本身, 因此恢复的特征可能缺乏对目标识别至关重要的语义上下文信息, 导致检测性能提升有限.
2)基于端到端训练的结合目标检测方法.Haris等[27]率先提出端到端的联合训练方法, 将超分辨率模块作为预处理组件嵌入检测网络中, 并引入面向任务的损失函数以实现协同优化.随后出现的联合训练框架, 如SRODNet[28]及ESRTMDet(End-to-End Superresolution Enhanced Real-Time Rotated Object Detector)[29], 设计专用的超分辨率架构, 展示良好的效果.尽管上述方法实现检测与超分辨率任务的协同优化, 但训练过程的计算开销较大, 耗时显著.
3)基于多任务结构的结合目标检测方法.近年来, 越来越多的研究采用多任务并行策略以融合超分辨率技术[30], 在训练过程中构建并行的超分辨率引导分支, 而非采用串行的级联结构, 这样在利用重建损失提升小目标检测精度的同时不增加额外的推理成本.Zhang等[31]提出 SuperYOLO, 融合多模态数据并引入辅助的超分辨率学习, 提升小目标检测性能.Chen等[7]提出DRENet(Degraded Reconstruc-tion Enhancement Network), 在低分辨率图像训练过程中, 通过RCAN重建中间特征图以匹配原始空间维度, 并利用真实高分辨率图像提供特征级监督, 防止小目标特征的丢失.
与此同时, 高分辨率特征引导方法也受到广泛关注.Noh等[8]利用GAN生成逼真的高分辨率图像, 作为低分辨率特征优化的监督信号.Zhang等[32]基于YOLOv8s6[33]架构, 构建高分辨率引导分支, 指导主干网络学习, 并通过GAN实现对抗性特征对齐, 完成从高分辨率到低分辨率的特征蒸馏.
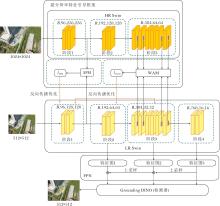
本文提出基于双重并行任务的无人机小目标两阶段检测方法(DB-TS), 结构如图1所示.DB-TS包括特征提取主干Swin Transformer、超分辨率特征引导框架(Super-Resolution Feature Guided Framework, SR)、颈部网络FPN及Grounding DINO[34]检测器.
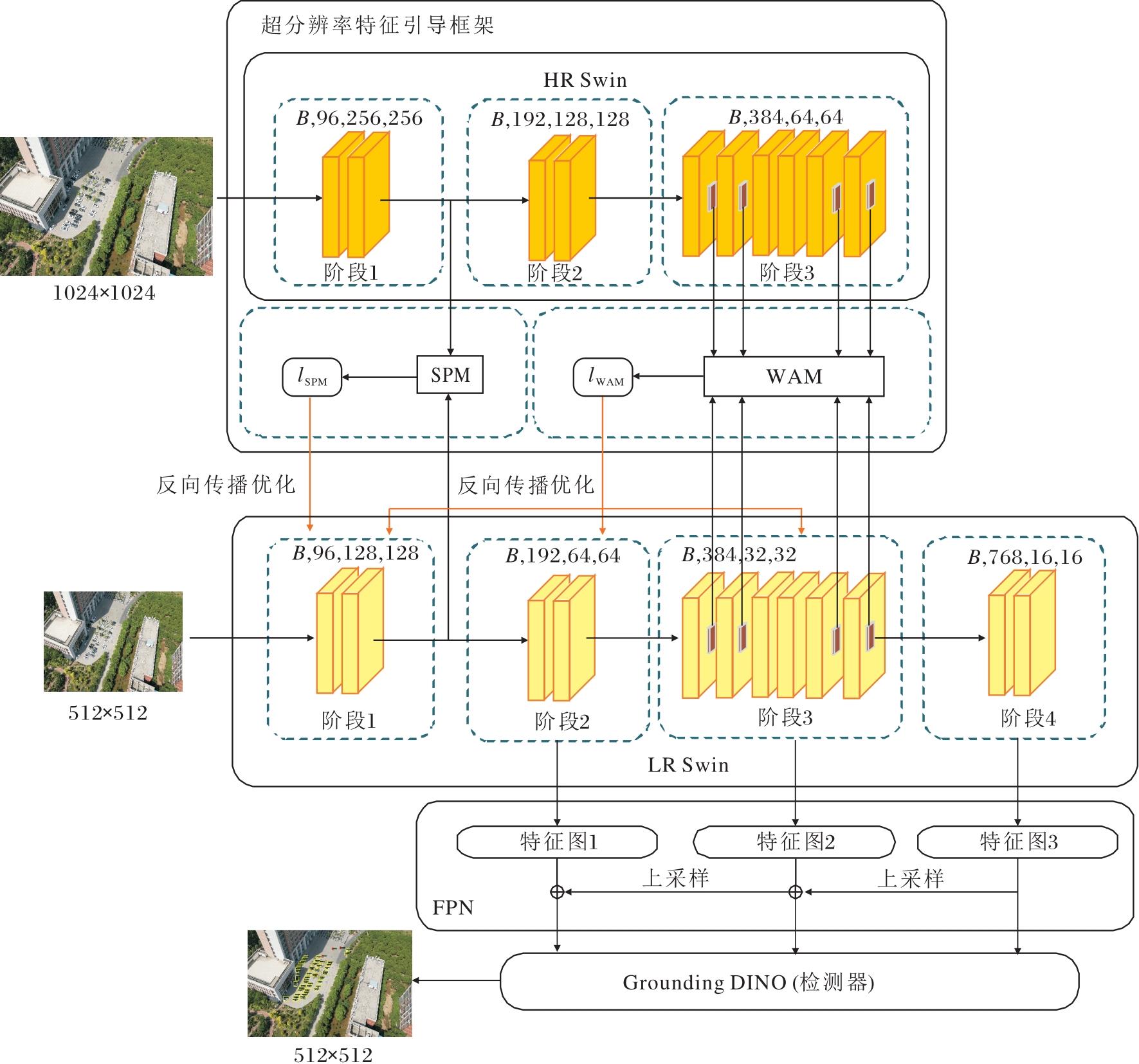 | 图1 DB-TS架构图Fig.1 Overall architecture of DB-TS |
基础主干网络Swin Transformer(在图中和后文表示为LR Swin)由512× 512图像进行训练和测试, 该网络输出的特征图被送入颈部网络FPN进行特征融合, 再输入检测器进行预测.由于本文重点关注方法的精度提升, 因此检测器部分采用参数量较大的开放集目标检测模型Grounding DINO以获取较高的检测精度.在训练过程中, Grounding DINO使用标注提供的类别作为简单提示词.超分辨率特征引导框架包含一个由高分辨率图像预训练的Swin Transformer并行分支(在图中和后文表示为HR Swin).HR Swin的结构和LR Swin完全相同, 并且在训练时权重保持一致, 目的是提供高分辨率特征作为超分辨率重建的标签, 进而通过小目标信息丰富的高分辨率特征约束LR Swin尽可能关注低分辨率图像中的小目标特征.空间先验模块(SPM)和窗口注意力引导模块(WAM)是超分辨率方法衍生的两个模块.SPM利用高分辨率特征的浅层空间信息作为先验知识, 约束网络在训练过程中尽可能向着目标区域进行拟合.WAM在注意力计算过程中对齐两个网络生成的注意力分数, 引导注意力机制关注更多的小目标特征.
小目标在无人机图像中成像像素较少, 且重要特征容易在下采样中丢失, 这种现象在低分辨率图像中更明显.由于高分辨率图像能提供更多的小目标细节特征, 可以较好地避免上述问题, 因此采用超分辨率方法进行上采样, 获取高分辨率特征是常见思路.但是常规的超分辨率方法在图像输入之前或在中间某一阶段进行上采样放大, 会造成网络的计算负担加重、计算时间变长.
相比在网络内部使用超分辨率方法进行上采样的思路, 近些年逐渐衍生出一种构建超分辨率重建分支的方法, 这种方法通过构建额外的重建分支, 对网络某一个部分或层级的训练进行约束, 使用一种多任务的指导思想增强网络对特定信息的关注程度, 使用辅助任务增强主要任务需要的目标特征.
DB-TS也是借用这种思想, 在图1中的LR Swin的上部, 构建一个使用高分辨率图像预训练的Swin Transformer网络分支, 如图1中HR Swin.构建HR Swin的主要目的是提供重建任务的标签, 因此HR Swin在训练过程保持权重锁定, 不参与反向传播.在HR Swin的基础上构建WAM和SPM, 重建LR Swin中的低分辨率特征, 并始终采用HR Swin提供的高分辨率特征作为重建标签.由于重建任务恢复细节信息需要LR Swin尽可能保留小目标特征, 因此通过重建任务对齐低分辨率特征和高分辨率特征, 是引导LR Swin保留小目标特征的关键.
在超分辨率重建模型的选择上, 本文选择RCAN[23]作为上采样的超分辨率网络, 该网络独特的通道注意力特性使其在处理维度较高的特征时更有优势.在WAM中RCAN的残差块和残差组数量都设为1, SPM中RCAN的残差块和残差组数量都设为2.在重建损失的选择上, 本文选择对异常值较敏感的MSE损失函数, 更容易感知低分辨率特征图上小目标特征的丢失.
本文在探究超分辨率框架下的指导方法时, 注意到Swin Transformer的窗口注意力是相对ViT的改进, 本身就具有独特的优势以捕捉小目标特征, 并且窗口注意力机制在高分辨率图像上表现较优.凭借这一特点, 本文提出窗口注意力引导模块(WAM), 核心思想是利用HR Swin提供的更精确的窗口注意力图, 引导LR Swin的注意力分布, 聚焦于小目标的关键局部特征.
在Swin Transformer的自注意力计算中, Q和K分别表示自注意力的查询矩阵和键矩阵, 目的是为了在网络的迭代过程中指导网络逐渐向目标特征的方向进行拟合.计算产生的注意力分数则是Q和K乘积的结果, 相比直接使用Q和K作为超分辨率方法进行指导, 注意力分数能直接表达关注的特征区域和维度, 直接进行特征表达.注意力计算前的张量X∈ RB× H× W× C(B表示批次大小, H表示高度, W表示宽度, C表示通道数).通过Swin Transformer的window_partition模块进行维度变化, 即
$ \boldsymbol{X}_{1}=\text { window_partition }(\boldsymbol{X}) \in \mathbf{R}^{N \times W_{s} \times W_{s} \times C}, $
其中, N=B×
$ \boldsymbol{a} \boldsymbol{t t n}=\boldsymbol{Q} \boldsymbol{K}^{\mathrm{T}} \in \mathbf{R}^{N \times W_{s} \times W_{s} \times C} .$
通过维度变化可得到适合超分辨率模块上采样的形状, 变换后attn'∈
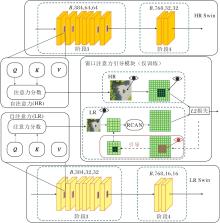
WAM结构如图2所示.首先获取LR Swin计算窗口注意力时由Q和K相乘得到的注意力分数, 在7× 7的窗口上使用RCAN进行上采样, 上采样后注意力分数为attnSR∈
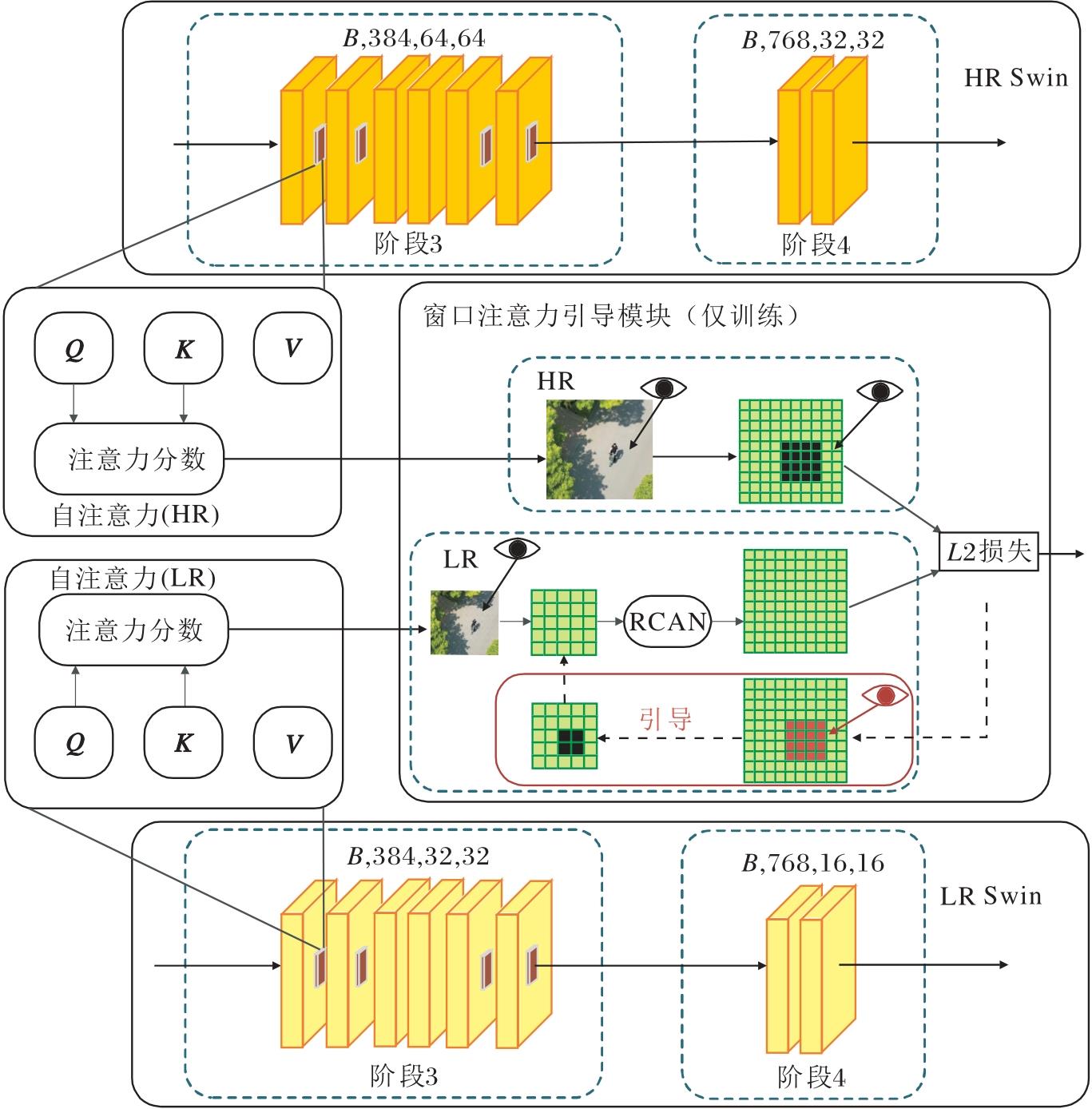 | 图2 WAM结构图Fig.2 Structure of WAM |
在WAM对LR Swin的重建层级选择上, 将LR Swin第3阶段的注意力计算作为重点, 因为这个阶段在网络中占比最大, 并且在这个阶段图像分辨率已下采样到第一阶段分辨率的1/4, 信息迭代过程中非常容易丢失细节.另一方面, 第3阶段的特征已具有较高的通道维度信息, 更能发挥RCAN的通道注意力特性.由于Swin Transformer本身具有移位窗口注意力机制的特点, 所以Swin Transformer的每个阶段通常都包含至少两次注意力计算, 一次是常规窗口注意力, 一次是移位窗口注意力.由于这两次自注意力计算必须是连续的, 因此本文在进行超分辨率重建时通常会使用连续的两个层级的特征进行重建.如图2所示, 重建层级选择第3阶段的4处层级, 分别是第3阶段的前两个层级和最后两个层级.在层级内部计算注意力时获取该层级产生的注意力分数, 用于超分辨率方法重建.每个层级的注意力分数使用同一个WAM对齐并单独计算损失.
在训练过程中, WAM使用高分辨率注意力分数对Swin Transformer窗口注意力中每个窗口的权重分布进行引导.该方法的核心在于注意力分数直接决定网络中特征聚合的方向.小目标微弱的特性信息容易被背景淹没, 很难被注意力机制关注.引导LR Swin的注意力分数向重建标签对齐, 实质上是引导网络在训练过程中, 为小目标区域分配更多的权重响应, 增强网络对小目标特征的学习能力.
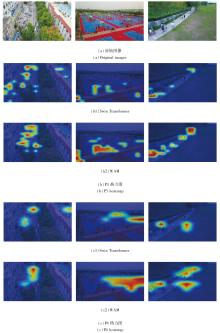
为了说明WAM对无人机图像在深层网络聚焦小目标并抑制干扰的作用, 本文将主干网络的第3个层级输出的特征图(P3)和第4个层级输出的特征图(P4)进行热力图绘制, 包括Swin Transformer生成的特征图及添加窗口注意力模块(WAM)生成的特征图, 具体如图3所示, 其中特征图的权重获取来自消融实验.由于P3和P4是网络最后两个层级的特征图绘制的热力图, 且WAM影响的输出层级也是第3层级和第4层级, 因此P3和P4可有效反映WAM的作用.
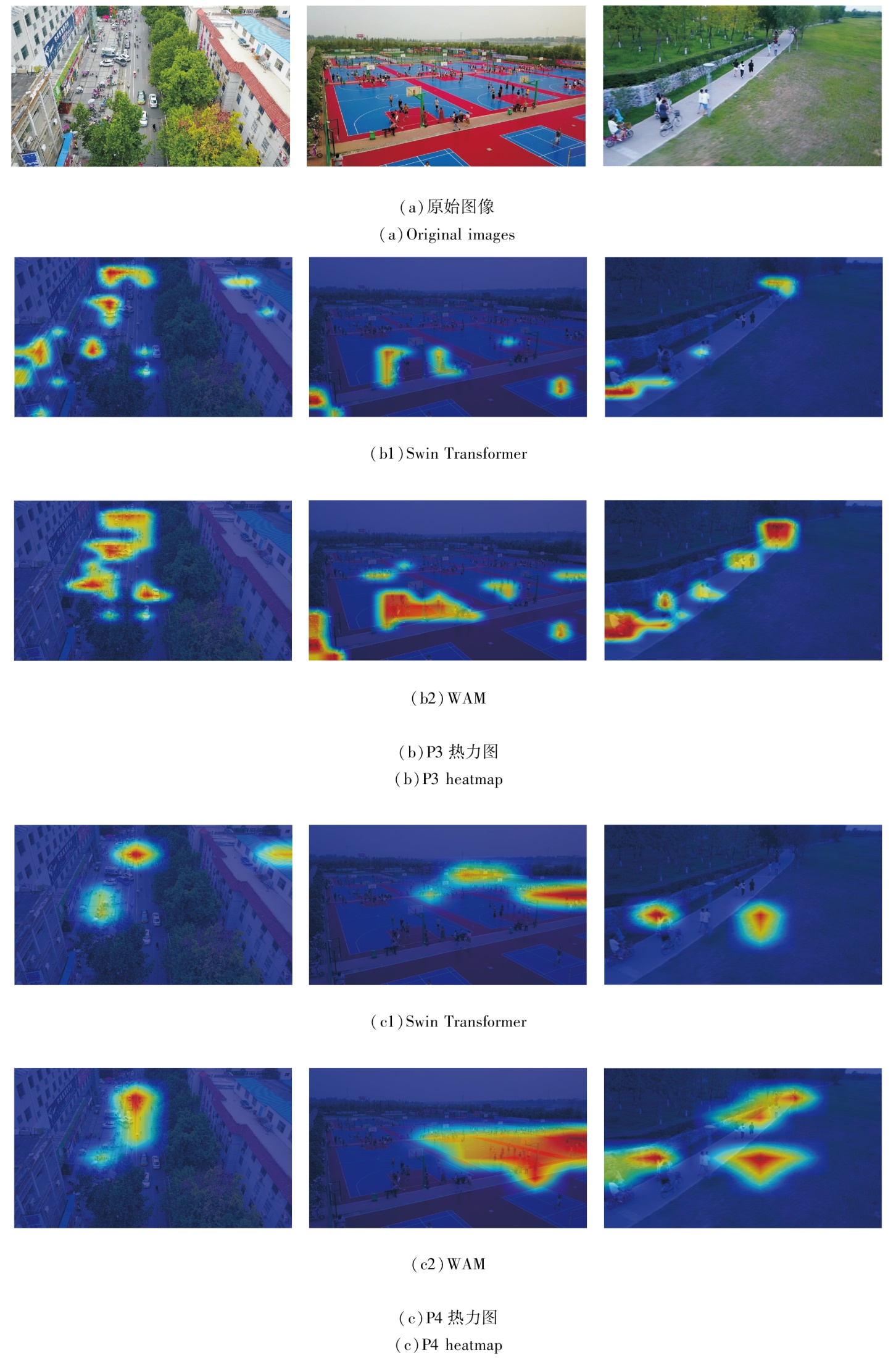 | 图3 Swin Transformer和WAM生成的特征热力图Fig.3 Feature heatmaps generated by Swin Transformer and WAM |
在第1幅图像的P3热力图中, 相比Swin Trans- former, WAM抑制左下方在房屋上的背景信息的响应, 将更多的权重分配在中间部分的汽车和行人区域, 由此可说明WAM抑制干扰的能力.在第2幅图像和第3幅图像的P3热力图中, 能看出一些在Swin Transformer中被忽略的目标在WAM的作用下被发掘.在所有P4热力图中可明显看出, WAM聚焦目标的能力比Swin Transformer在目标区域的响应更高, 位置更准确.因此, WAM能在Swin Transformer的基础上有效聚焦目标并抑制干扰.
相比直接在各个层级输出的特征图上进行重建, WAM通过超分辨率方法在窗口注意力上进行重建, 聚焦于窗口注意力机制本身, 使得LR Swin可更准确地感知小目标的局部细节特征, 从而显著提升小目标检测分支在复杂场景中捕捉小目标细节特征的能力.
小目标的特征丢失通常发生在网络的下采样中, 而Swin Transformer中第1个层级输出的特征图还并未经历过多的下采样, 相比其它层级的特征图, 分辨率通常较高.此时特征图中还保留大量小目标特征, 但是相比高分辨率特征图, 低分辨率特征图中的小目标特征仍较小, 网络无法较好地分辨哪些特征属于小目标而不属于背景噪声, 而高分辨率特征图凭借丰富的细节信息, 已能在一定程度上大致区分小目标特征和背景特征.
另一方面, 相比深层特征图, 浅层特征图并没有较高的通道维度, 此时特征信息的重心依然体现在空间位置上.
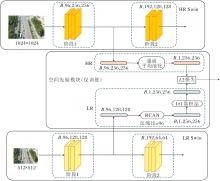
因此, 本文构建空间先验模块(SPM), 结构如图4所示.在SPM中, 高分辨率特征在浅层特征图可向低分辨率特征提供空间上的先验信息, 帮助LR Swin提前对目标所在区域聚焦注意力, 进而在后续注意力计算中更快地向着小目标特征进行拟合.
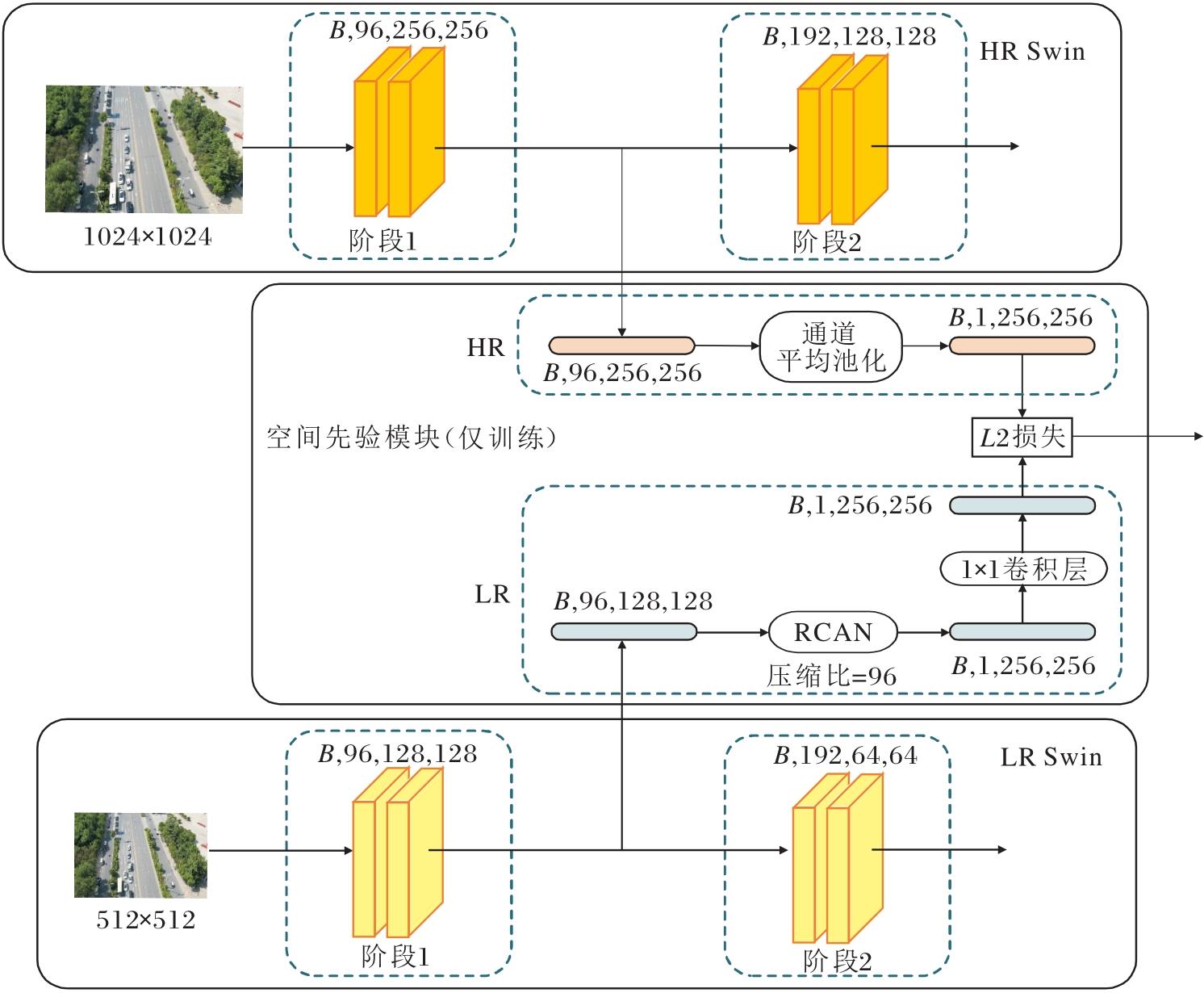 | 图4 SPM结构图Fig.4 Structure of SPM |
在SPM中, 首先获取HR Swin和LR Swin在第1个层级输出并且还未下采样的特征图.HR Swin和LR Swin产生的特征图分别表示为FHR和FLR.通过平均计算将高分辨率特征图中通道维度C变为1, 变换后的特征图为:
$ \boldsymbol{F}_{\mathrm{HRM}}=\frac{1}{C} \sum_{c=1}^{C} \boldsymbol{F}_{\mathrm{HR}} .$ (1)
在低分辨率特征图送入RCAN上采样的过程中, RCAN内部的通道注意力模块压缩比设为96.为了利用通道注意力机制, 在上采样过程中, 将通道注意力的维度C压缩为1, 在降低计算量的同时, 简化RCAN内部通道级特征校准的影响.处理后的低分辨率特征图为:
$ \boldsymbol{F}_{\mathrm{SR}}=\operatorname{Conv}_{1 \times 1}\left(\operatorname{RCAN}_{r d=96}\left(\boldsymbol{F}_{\mathrm{LR}}\right)\right), $ (2)
其中, RCANrd=96(· )表示上采样操作, Conv1× 1(· )表示1× 1卷积.然后把两种特征图送入L2损失函数, 使高分辨率特征图在训练时从空间上为LR Swin提供先验信息并抑制背景噪声的影响, 引导LR Swin的输出在空间布局上与高分辨率特征相似, 这样不仅加快收敛速度, 而且进一步提升检测精度.
为了说明SPM对无人机图像小目标在浅层网络保留小目标细节的作用, 将主干网络第2个层级输出特征图(P2)和第3个层级输出特征图(P3)进行热力图绘制, 包括Swin Transformer生成的特征图及在空间先验模块(SPM)作用下的特征图, 具体如图5所示.生成特征图的权重同样来自消融实验.另外, 由于DB-TS的第1个层级特征图并未作为输出特征图, 因此未用于制作热力图.
 | 图5 Swin Transformer和SPM生成的特征热力图Fig.5 Feature heatmaps generated by Swin Transformer and SPM |
由图5第1幅图像的P2特征图可看出, 相比Swin Transformer, SPM作用下的特征图在道路等背景区域响应大幅减少, 因此SPM具有一定的背景抑制能力.
由第2幅的P2特征图可看出, SPM作用下的特征图在上半图像两侧行人密集区域, 即小目标较多的区域响应更强.
第3幅的P2特征图也是如此.在中间层P3特征图上可明显看出, SPM在Swin Transformer的基础上进一步增强目标区域的响应, 且第3幅图像的P3特征图重新为右侧汽车提供权重分配.因此, SPM可在浅层更有效保留小目标细节, 获取更高的检测精度.
本文使用的损失函数包含检测器损失lDET和重建损失.重建损失由两个损失函数构成:由WAM产生的窗口注意力对齐损失lWAM, 由SPM产生的空间对齐损失lSPM.
对于窗口注意力对齐损失lWAM, 首先获取LR Swin和HR Swin分支分别产生的注意力分数attnLR和attnHR, 再将LR Swin的注意力分数在7× 7窗口使用RCAN进行上采样, 此时RCAN内部的通道注意力压缩比为12, 低分辨率特征通过维度转化和高分辨率特征保持一致, 上采样后的注意力分数为:
attn″SR=RCANrd=12(attnLR).
然后将两个注意力分数使用MSE损失进行计算.相比L1损失来说, 使用MSE损失可使得超分辨率方法对于异常值更敏感, 而由于一些异常值经常属于小目标特征丢失的部分, 因此使用MSE损失更符合本文的任务要求.
由于本文使用Swin Transformer第3个阶段中4个层级产生的注意力分数进行计算, 因此使用attnSR(N)和attnLR(N)分别表示不同层级注意力分数, 其中N∈ [1, 6], 则WAM产生的损失为:
lWAM=lWAM(1)+lWAM(2)+lWAM(5)+lWAM(6),
其中,
$ \begin{array}{l} l_{\operatorname{WAM}(N)}=l_{\mathrm{MSE}}\left(\boldsymbol{a t t n}_{S R(N)}, \boldsymbol{a t t n}_{\operatorname{HR}(N)}\right), \\ N=1, 2, 5, 6 . \end{array}$
空间特征对齐损失lSPM根据Swin Transformer第1个阶段产生的特征图进行损失计算, 由式(1)和式(2)可得
lSPM=lMSE(FHRM, FSR).
由此可得总损失函数:
l=lDET+lWAM+lSPM.
由于大多数无人机数据集是在混合高度下拍摄的, 并且很少有无人机数据集对每幅图像进行具体高度的划分, 从而无法在指定高度下进行图像验证, 例如验证方法在高空图像上的测试效果.
为了测试DB-TS对小目标检测的优化程度以及验证网络对不同高度下无人机图像的检测效果, 自制一个共计11 646幅无人机图像的数据集JZ-UAV.使用无人机型号是DJI Mini 3 Pro, 获取的所有图像都是1 920× 1 080.拍摄背景包含学校、道路、街区等大多数城市背景, 目标包含两类:行人和汽车.对每幅图像拍摄的高度进行分类, 高度分别是30 m, 50 m, 70 m, 90 m, 100 m, 并且70 m以上飞行高度的图像居多, 高空图像中每幅图像包含较多的小目标, 目标像素比例较少, 从而能严格验证方法对小目标检测的鲁棒性.数据集按7∶ 1∶ 2的比例划分训练集、测试集、验证集.为了严格测试在全高度图像下训练的模型的检测能力, 测试集筛选为只保留高空图像, 即只包含在90 m和100 m高度下拍摄的图像, 以此进行更贴合任务需求的实验设计.
为了进一步评估DB-TS的泛化能力, 还在公开的VisDrone数据集[35]上进行测试.该数据集由天津大学机器学习与数据挖掘实验室的AISKYEYE团队开发, 是一个面向无人机平台的大规模小目标检测数据集, 共包含10 209幅图像, 涵盖10类, 如行人、人群、自行车、汽车等, 图像分辨率多样, 包括1 920× 1 080、1 360× 765、960× 540等.由于未公开测试集的真实标注, 本文所有在VisDrone数据集上的实验结果均基于验证集得出.
本文选择如下评价指标:参数量、衡量实时性能的帧率、平均精度均值(Mean Average Precision, mAP)、IoU阈值大于0.5时的mAP50、IoU阈值大于0.75时的mAP75、评估尺寸小于32× 32的目标精度mAPS, 评估尺寸介于32× 32至96× 96之间的目标精度mAPM.
实验数据均来自实验室自行配置的一台包含Intel i7-12700处理器、32 GB内存及NVIDIA Ge-Force RTX 4090GPU的服务器.实验操作平台系统为Ubuntu 18.04, 深度学习模型基于PyTorch框架搭建.为了保证所有方法代码来源的统一, 所有代码及预训练方法权重均来自于开源工具箱MMDetec-tion.它是一个由开放视觉算法平台OpenMMLab团队开发和维护的开源目标检测工具箱, 收录各种较先进的视觉模型, 本文所用的模型以及组合均来自MMDetecion提供的配置, 包括每种组合模型的预训练权重也都来自这个工具箱.本文使用的模型组合Swin-Grounding DINO来自这个工具箱的官方配置.YOLOv8[33]的代码来源于这个平台提供的MMYOLO工具箱, 它专门用于YOLO的运行.
在训练过程中, 所有方法都保持统一的数据增强模式, 即只有50%的概率翻转作为增强策略.归一化操作采用均值[123.675, 116.28, 103.53]和标准差[58.395, 57.12, 57.375].在测试和训练中, 图像统一裁剪为512× 512, 保证不会因为使用不同的增强策略导致对比过程的不公平.
但是, YOLOv8的训练保留YOLO系列经典的Mosaic方法, 这是因为考虑到Mosaic数据增强是YOLO系列算法的原生组成部分, 为了保证训练方法完整性并与原文献实现保持一致, 在YOLOv8中保留该增强策略.
在训练DB-TS需要的高分辨率特征网络时, 采用和Swin Transformer相同的增强策略, 但图像裁剪为1 024× 1 024, 使用和低分辨率网络相同的预训练权重.在训练完成后取最佳权重作为超分辨率方法中的预训练权重, 并且在低分辨率网络训练时, 整个高分辨率网络分支全程保持权重锁定状态.在测试阶段依然只使用512× 512图像进行测试, 完全舍弃超分辨率方法.
为了确保训练过程的一致性, 大多数实验均采用相同的超参数配置.优化器选用解耦权重衰减的 AdamW(Adaptive Moment Estimation with Decoupled Weight Decay), 初始学习率设为1e-4, 权重衰减系数设为0.05.批量大小统一设为1.验证指标显示, 大多数方法在第20个训练轮次之前即已出现过拟合迹象, 因此训练过程限制为20个训练轮次, 并从中选取在验证集上性能最优的检查点用于后续的对比评估.
ConvNeXt V2[36]和YOLOv8收敛较慢, 训练轮数设置为50.YOLOv8使用MMYOLO为YOLO系列提供的基础配置:初始学习率设为0.01, 权重衰减设为0.000 5, 优化器为SGD(Stochastic Gradient Descent).
为了验证DB-TS内部每个模块对Swin Trans-former的影响, 在保留高分辨率特征网络的前提下, 把每个模块单独加在Swin Transformer上, 在公共无人机数据集VisDrone上进行消融实验.具体消融实验结果如表2所示, 表中黑体数字表示最优值.
| 表2 各模块在VisDrone数据集上的消融实验结果 Table 2 Ablation experiment results of different modules on VisDrone dataset |
由表2可看出, SPM单独作用在Swin Trans-former时, mAP值提升至25.5%, mAPS值提升至16.1%.WAM单独作用在Swin Transformer时能取得25.6%的mAP和15.7%的mAPS, 在mAPM值上也达到最高值(36.8%), 这说明WAM可有效增强网络对于小目标和中等目标的关注.SPM和WAM叠加后, 能取得25.8%的mAP和16.2%的mAPS.此外, 舍弃超分辨率特征引导框架(SR)后, 推理速度和参数量发生变化, 精度提升与保留SR一致.由此可看出DB-TS中每个模块都能有效提升小目标检测能力, 并在推理阶段舍弃SR后仍保持性能提升.
为了分析DB-TS内部特征, 在VisDrone数据集上进行可视化实验.由于WAM的特征上采样为分辨率极低的高维图像, 可视化结果更难以理解, 因此, 选择SPM中处理的浅层特征图, 对通道维度进行平均池化后再执行可视化, 具体如图6所示.从图可看出, LR特征图通过超分辨率方法进行重建后, 图像细节几乎能和HR特征图保持一致, 由此说明特征级重建指导是容易实现且有效的.
 | 图6 特征图重建过程的可视化结果Fig.6 Visualization results of feature map reconstruction process |
为了验证不同的超分辨率方法对SPM和WAM的影响, 在VisDrone数据集上进行实验.实验中引入双线性插值法(Bilinear Interpolation, BI), 替换SPM和WAM中的RCAN.
不同上采样组合的消融实验结果如表3所示, 表中黑体数字表示最优值.由表可见, 全部采用BI进行上采样时, 检测精度相对较低, 同时WAM(BI)+SPM(RCAN)的性能优于WAM(RCAN)+SPM(BI)的性能, 这表明BI在对浅层特征放大时带来的噪声更小, 且后者组合的帧率最快.检测精度总体较高的方法仍是两个模块均采用RCAN的组合, 虽然这个组合参数量较大且速度略慢, 但考虑到本文的并行框架不增加推理阶段的成本, 可以在训练阶段全部采用RCAN上采样.
| 表3 不同上采样组合的消融实验结果 Table 3 Ablation experiment results of different upsampling combinations |
下面针对WAM和SPM的损失权重对训练的影响进行消融实验, 分别使用0.5、1.0、1.5的倍率组合对WAM和SPM的损失权重进行测试, 结果如表4所示, 表中黑体数字表示最优值.由表可见, 1倍lWAM和1.5倍lSPM的组合, 精度最低, 因此单独增大lWAM不利于方法训练.另一方面, 虽然在1.5倍lWAM和1.5倍lSPM组合下, mAPM值达到最优, 但1倍lWAM和1倍lSPM在其它各项指标上均为最高值.本文最终的目的是小目标检测精度mAPS达到最高值, 因此, 实验部分选择1倍lWAM和1倍lSPM作为最佳组合.
| 表4 不同权重组合损失函数的消融实验结果 Table 4 Ablation experiment results of loss functions with different weight combinations % |
为了评估改进后的Swin Transformer(DB-TS(without SR))的性能, 分别在VisDrone数据集和自制数据集进行对比实验.主干网络选择ResNet-50、Swin Transformer[9]、ConvNeXt V2-B[36]、ConvNeXt-T[37]、CSPNeXt[38]、CSP-DarkNet[39].检测器选择Faster R-CNN[13]、Dynamic R-CNN[22]、YOLOv8-m[33]、Groun-ding DINO[34]、DINO(DETR with Improved Denoising Anchorboxes)[40]、RTMDet-S[41]、DiffusionDet[42].
各方法在VisDrone验证集上的性能对比如表5所示, 在JZ-UAV验证集上的性能对比如表6所示, 验证集包含所有高度拍摄的图像.各方法在JZ-UAV测试集上的性能对比如表7所示, 测试集只包含90 m和100 m高度拍摄的图像.表5~表7中黑体数字表示最优值在检测器的选择上, Swin Transformer和DB-TS(without SR)未选择常规的Faster R-CNN等检测器, 而是选择具有开放词汇检测能力的Grounding DINO.Grounding DINO能根据文本描述在图像中检测对应的物体, 甚至包括在训练数据中未出现的类别, 这使它区别于传统的仅能识别固定类别集合的检测方法.但是在训练过程中, 仍和其它方法一样使用标注提供的类别作为简单提示词, 目的就是为了验证DB-TS(without SR)对这种较先进的开放词汇检测器在传统任务上是否也能有进一步的性能提升.本文在训练过程中只使用最后三个层级的特征图送入Grounding DINO进行检测, 一方面是为了减轻计算压力, 另一方面是为了和MMDetection官方提供的Swin-Grounding DINO检测组合的基础配置保持一致.
| 表5 各方法在VisDrone验证集上的性能对比 Table 5 Performance comparison of different methods on VisDrone test set |
| 表6 各方法在JZ-UAV验证集上的性能对比 Table 6 Performance comparison of different methods on JZ-UAV test set |
| 表7 各方法在JZ-UAV测试集(只包含高空图像)上的性能对比 Table 7 Performance comparison of different methods on JZ-UAV test set(only containing high-altitude images) |
由表5可看出, DB-TS(without SR)在各项精度指标上均达到较高值, 并且在小目标检测上极具优势.由于本文的研究目标是以小目标的检测精度为主, 因此选择的模型为Swin-Grounding DINO这一参数量较大但性能较高的组合, 这也导致在对比实验中该方法的参数量也是所有方法中最大的.由于本文提供的超分辨率方法并未参与测试当中, 仅用于训练, 可直接在测试阶段去除且不影响检测精度, 因此DB-TS(without SR)以测试参数为准, 和原模型并无区别.
由表6可看出, 在包含低空到高空所有高度图像的情况下, DB-TS(without SR)的mAP值提升仅为0.1%, 效果并不明显.因此, 为了更契合研究小目标检测的主题, 在JZ-UAV测试集上只保留90 m至100 m的高空图像进行验证.由表7可看出, 在小目标居多的高空图像测试集上, DB-TS(without SR)的mAP值达到21.1%, 相比Swin Transformer提升0.7%.
为了进一步说明DB-TS的有效性, 在VisDrone、JZ-UAV数据集上进行可视化分析, 使用如下对比方法:Swin Transformer[9]、YOLOv8[33]、ConvNext V2[36]、DINO[40]、Diffusiondet[42].具体可视化结果如图7和图8所示.各方法可视化原始图像中黄色方框区域内的手动放大图像, 椭圆框内是DB-TS识别出而其它方法并未识别出的目标.
 | 图7 各方法在JZ-UAV数据集上可视化结果Fig.7 Visualization results of different methods on JZ-UAV dataset |
 | 图8 各方法在VisDrone数据集上可视化结果Fig.8 Visualization results of different methods on VisDrone dataset |
由图7第1幅图像可明显看出, 右下角被树林遮挡的汽车, 除了DB-TS之外的其它方法均未检测出.第2幅图像和第4幅图像中大多数汽车类别被黄色检测框标注, 但用于标注更小行人目标的红色检测框只在DB-TS中包含.第3幅图像和第5幅图像中汽车位于原图像右上角, 属于较小目标, 但除了DB-TS之外成功检测到全部目标的方法很少.第6幅图像同样是包含被树林遮挡的汽车, DB-TS几乎完整检测, Swin Transformer和YOLOv8也能检测出大部分, DINO、DiffusionDet、ConvNeXt V2则遗漏较多.
在图8中, 在第1幅图像上DINO和DB-TS均能检测出大部分蓝框标注的汽车, 且DB-TS在中间区域检测出的目标更多.在第2幅图像中心区域的红色标注框的行人中, DB-TS标注较多.对于第3幅图像中位于右下角的紫色标注框内的自行车, 除了DINO检测到少部分, 其余方法均未检测出, 而DB-TS检测数量较多.对于第5幅图像中右下角房子内的摩托车, DINO虽然定位数量较多, 但几乎全是错误分类, 其余方法检测较少, DB-TS的检测较全面.
由图7和图8的可视化分析可得, DB-TS应对图像中小目标的检测能力更优, 如像素占比较小的行人、自行车等.由此有效说明DB-TS对于无人机图像小目标的检测性能, 但是从图像中也能发现另一些局限性问题.例如:由图7第5幅图像可看出, 仍存在一些汽车未能被DB-TS检测.在第6幅图像上, 一些存在于树林中被遮挡的汽车未被DB-TS检测.在图8第1幅图像和第2幅图像上, 一些密集的行人和汽车也未能被DB-TS检测.这表明DB-TS在一些被严重遮挡和过于密集的小目标上仍存在一定的局限性.
为了更方便区分DB-TS可视化结果, 在其它方法的可视化结果中使用黄圈和红圈手动标记相对DB-TS来说未被检测的目标.从JZ-UAV数据集的可视化结果也可看出, 无人机高空图像中小目标居多, DB-TS检测的目标数量多于对比方法.
选择Swin Transformer[9]、Faster R-CNN[13]、RT- MDet-s[18]、Dynamic R-CNN[20]、YOLOv8-m[33]、Con-VeXt V2-B[36]、ConVeXt-T[37]、DINO[40]、Diffusion-Det[42]作为对比方法, 各方法在VisDrone、JZ-UAV(高空图像)数据集上针对每个类别的mAP50指标如表8所示, 表中黑体数字表示最优值.
| 表8 各方法在不同目标类别上的mAP50对比 Table 8 mAP50 of 10 methods on different target categories % |
由表8可见, Faster R-CNN、Dynamic R-CNN等在JZ-UAV高空测试集上对行人的检测精度只有0.1%, 这是因为在高空中, 行人在整个图像当中像素占比非常少, 这些方法使用的基本都是Faster R-CNN等较早的检测器, 这些检测器对极小目标的检测性能有限, 并且本文实验中未使用任何形式的数据增强, 导致这些方法的行人检测精度较低.DB-TS不只是单一地对某个目标产生指标提升, 而是在大多数无人机图像的常见类别上均有一定的效果提升.
本文针对无人机小目标检测任务中因目标尺寸较小、分辨率较低而导致的特征丢失与弥散问题, 提出基于双重并行任务的无人机小目标两阶段检测方法(DB-TS).基于Swin Transformer, 构建超分辨率重建分支, 使用高分辨率特征作为标签, 重建检测分支的特征, 通过重建任务引导注意力机制聚焦小目标特征, 提升方法在无人机图像上的小目标检测精度.在公共数据集VisDrone和自制无人机数据集JZ-UAV上的实验表明, 在重建分支的引导下, 检测分支能捕捉无人机图像中背景复杂且尺寸极小的目标, 如高空图像中行人检测, 并且对其它常见类别的检测精度均有提升.
在可视化检测结果中, DB-TS依然无法检测一些被严重遮挡或过于密集的小目标.因此在未来的工作中, 将研究如何使DB-TS向着改善严重遮挡或过于密集小目标检测的方向改进, 并将改进的主干网络与性能更强的检测器进行适配, 使方法能在无人机图像上获取更高的小目标检测精度.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|