

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于协同语义与几何增强的可供性学习网络
[杨泽存1  , 赵纪元
, 赵纪元1 , 赵雨晨1 , 李忠豪1 , 卓鹏涛1 ]
, 赵纪元, 赵雨晨, 李忠豪, 卓鹏涛]
|
|



作者简介:

杨泽存,硕士研究生,主要研究方向为开放词汇检测、智能感知.E-mail:18253140199@163.com.

赵雨晨,硕士研究生,主要研究方向为模式识别.E-mail:2358797739@qq.com.

李忠豪,硕士研究生,主要研究方向为人工智能.E-mail:827918162@qq.com.

卓鹏涛,硕士研究生,主要研究方向为智能控制.E-mail:1461156908@qq.com.
开放词汇3D可供性检测作为连接高层语义理解与底层机器人操作的关键纽带,旨在赋予具身智能体在非结构化环境中响应自然语言指令并精准定位物体功能区域的能力.然而,现有方法多依赖冻结的预训练视觉-语言模型进行浅层特征匹配,面临文本指令语义歧义性与特征空间几何-语义错位的双重挑战,导致模型泛化性不足.为此,文中提出基于协同语义与几何增强的可供性学习网络(Synergistic Semantic and Geometric Enhancement Based Affordance Learning Network, SSGE-Net).首先,构建物理感知语义增强模块,生成包含几何约束、功能描述及交互逻辑的结构化三元组,实现语义致密化,弥补指令信息的缺失.然后,设计多尺度几何感知细化模块,利用局部动态图卷积与全局自注意力机制捕获互补的拓扑细节,增强几何特征的判别力.最后,提出基于Transformer解码器的深度跨模态对齐模块,利用交叉注意力,根据文本指令动态重构点云特征,实现语义引导下的精准锚定.在3D AffordanceNet数据集上的广泛实验表明,SSGE-Net在全视图任务及部分视图任务上性能均有一定提升,验证其在复杂视点及长尾类别场景中的优越性与鲁棒性.
About Author:
YANG Zecun, Master student. His research interests include open-vocabulary detection and intelligent perception.
ZHAO Yuchen, Master student. His research interests include pattern recognition.
LI Zhonghao, Master student. His research interests include artificial intelligence.
ZHUO Pengtao, Master student. His research interests include intelligent control.
Open vocabulary 3D affordance detection is regarded as a critical link connecting high-level semantic understanding and low-level robotic manipulation to precisely localize object functional regions in unstructured environments. However, existing methods mostly rely on frozen pre-trained vision-language models for shallow feature matching. The generalization ability of these models is insufficient due to the dual challenges of semantic ambiguity in text instructions and geometry-semantic misalignment in feature space. To address these issues, a synergistic semantic and geometric enhancement based affordance learning network(SSGE-Net) is proposed in this paper. First, a physics-aware semantic enhancement module is constructed to generate structured triplets of geometric constraints, functional descriptions and interaction logic. Semantic densification is achieved with these triplets. Thus, the lack of instruction information is compensated for. Second, a multi-scale geometry refinement mechanism is designed. Complementary topological details are captured by utilizing local dynamic graph convolution and global self-attention mechanisms to enhance feature discriminability. Finally, a deep cross-modal alignment mechanism based on Transformer decoders is proposed. Point cloud features are dynamically reconstructed by cross-attention under semantic guidance to achieve precise anchoring. Extensive experiments on 3D AffordanceNet dataset demonstrate that SSGE-Net achieves consistent performance improvements under both full-view and partial-view settings. These results validate its superiority and robustness in complex viewpoints and long-tail category scenarios.
具身智能的核心目标在于赋予机器人在真实世界中理解与交互的能力[1], 作为连接底层视觉感知与高层操作意图的桥梁, 开放词汇3D可供性检测旨在预测支持特定动作的功能区域, 服务于机器人动作规划与人机协作.早期的可供性检测主要基于闭集设定[2], 通常采用PointNet++[3]等架构从点云中提取几何特征.此类全监督范式受限于固定标签体系, 难以泛化至非结构化环境中的开放长尾类别和复杂的自然语言指令, 限制其在真实世界中的应用潜力.
近年来, 随着深度学习向开放词汇范式的不断演进[4, 5], 利用预训练视觉-语言模型解决零样本识别问题已成为主流趋势之一[6].CLIP(Contrastive Language-Image Pretraining)[7]等基础模型通过大规模对比学习建立强大的跨模态语义对齐能力.在此基础上, Nguyen等[8]提出OpenAD(Open-Vocabu-lary Affordance Detection), 率先将CLIP文本嵌入引入三维点云, 建立首个开放词汇3D可供性检测基准, 初步实现零样本推理.PointVLA[9]等方法进一步探索视觉-语言模型在三维操作任务中的应用, 试图缩小通用模型与具体任务间的领域差异.
尽管上述工作拓展模型的感知边界, 但在处理精细化交互任务时仍面临语义歧义性与几何-语义错位的双重挑战.首先, 物理交互往往隐含复杂的常识约束, 仅凭简短的类别名称缺乏对形状及物理属性的显式描述, 导致模型难以区分依赖常识的精细意图[10].其次, 由于CLIP等模型主要基于2D图像预训练, 缺乏对3D拓扑结构的感知[11], 直接进行浅层特征匹配常导致高层语义指令无法精准锚定具体的几何功能区域.
针对上述局限, 本文提出基于协同语义与几何增强的可供性学习网络(Synergistic Semantic and Geometric Enhancement Based Affordance Learning Network, SSGE-Net).区别于传统范式依赖的浅层匹配, SSGE-Net模拟人类认知中视觉感知与语言理解的交互机制, 构建语义-几何双流深度协同架构.首先, 针对性地解决开放词汇3D可供性检测中存在的语义歧义与语义-几何错位难题, 为精细化物理交互确立新范式.然后, 在核心机制上, 构建物理感知语义增强模块(Physics-Aware Semantic Enhance-ment, PASE), 同时设计多尺度几何感知细化模块(Multi-scale Geometry-Aware Refinement Module, MG-AR), 配合深度跨模态对齐模块(Deep Cross-Modal Alignment, DCMA), 提升网络在复杂几何环境下的感知粒度.实验表明, SSGE-Net在3D AffordanceNet数据集[12]的全视图任务与部分视图任务上的mIoU(Mean Intersection over Union)值分别达到33.88%和32.74%, 鲁棒性与泛化性较优.
早期的可供性检测多受限于全监督框架下的大规模的标注数据.为了缓解这一约束, 研究重心逐渐向零样本学习迁移.Cheraghian等[13, 14]率先提出基于映射的直推式策略, 试图在特征空间中建立视觉数据与未见类别语义向量的联系.Michele等[15]提出3DGenZ, 转向生成式范式, 合成未见类别的虚拟特征, 补全训练分布.此类方法本质上仍属于数据驱动的特征迁移, 缺乏外部通用知识库的支撑, 导致模型在处理非典型物体或长尾物体时, 难以构建具备较强泛化能力的语义-几何映射关系.
视觉-语言模型的引入从根本上改变特征对齐的方式.与早期零样本学习方法不同, van Vo等[16]直接利用CLIP的预训练空间, 通过特征蒸馏和注意力机制将点云特征对齐至文本嵌入.部分工作如Robotic-CLIP[17]进一步尝试引入时序动作数据进行微调, 以适应动态任务.此外, 开放词汇理念也扩展至场景级表示学习中, Liao等[18]提出OV-NeRF, 利用预训练的视觉-语言模型增强神经辐射场的语义分割与理解能力.尽管上述方法利用视觉-语言模型的广义语义, 但核心缺陷在于特征编码的静态性, 视觉特征的提取过程独立于文本指令.由于采用“ 先提取、后匹配” 的解耦架构, 模型无法根据特定语言指令动态调整几何特征的激活区域, 造成特征表达与具体意图的脱节.
为了突破静态特征的局限, 近期工作开始探索几何与语义的深层协同.Shao等[19]提出GREAT(Geometry-Intention Collaborative Inference), 尝试通过端到端的协同模块融合结构线索与意图, Lu等[20]提出GEAL, 借助2D基础模型的先验知识, 增强3D定位能力.
本文提出基于协同语义与几何增强的可供性学习网络(SSGE-Net), 整体架构如图1所示.
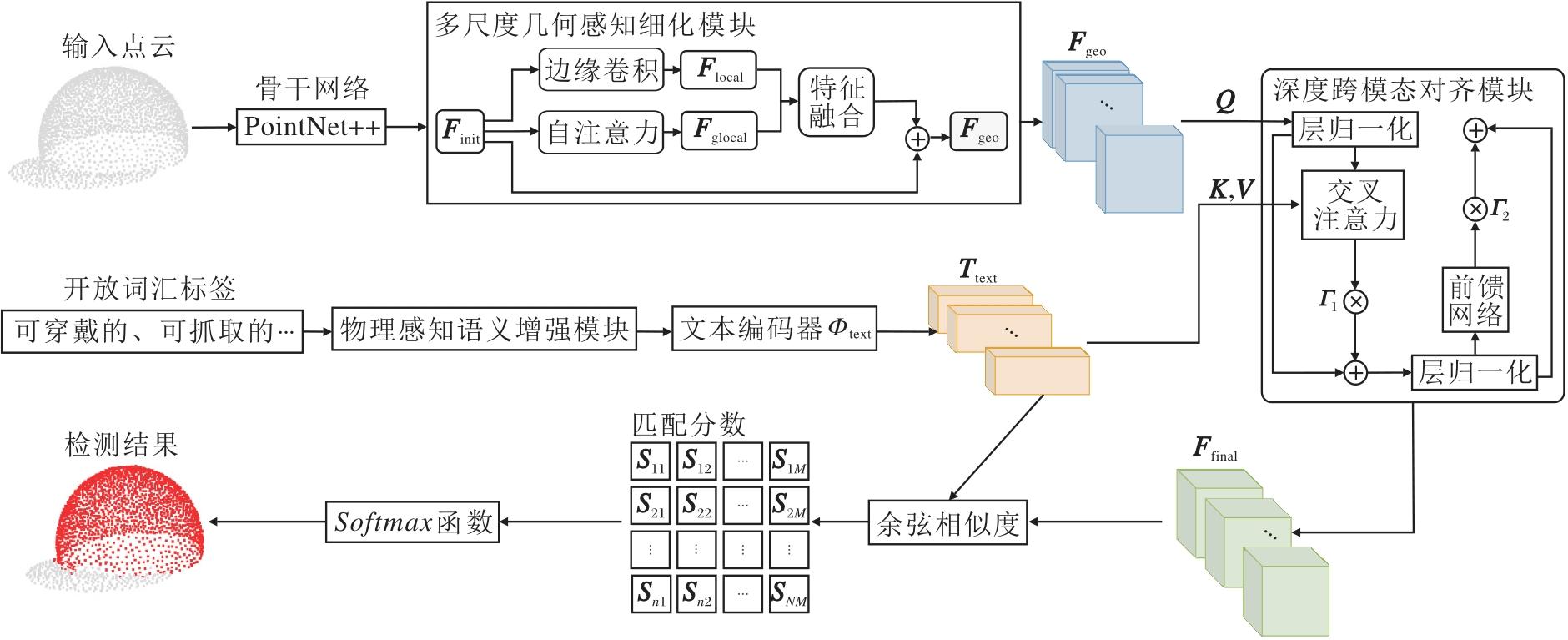 | 图1 SSGE-Net 整体架构Fig.1 SSGE-Net architecture |
给定包含 N个点的无序输入点云P∈ RN× 3, 其中, N表示点数, 3表示点的三维笛卡尔坐标(x, y, z), 以及一组由自然语言描述构成的开放词汇可供性标签集合C={c1, c2, ···, cM}, 其中, ck表示第k个类别的文本指令, M表示类别总数.SSGE-Net的目标是学习一个映射函数, 为点云中的每个点pi预测对应的可供性语义类别yi∈ C.
现有开放词汇感知范式受限于文本指令固有的语义歧义性与信息瓶颈.传统方法多采用如“ a point cloud of {class}” 的刚性人工模板生成文本嵌入, 粗粒度的类别标签仅承载语言符号信息, 丢失与机器人操作密切相关的底层物理属性.例如:标签“ grasp” 在语言学上是一个简单的动词, 但在几何空间中隐含“ 需具备适合人手或夹爪握持的细长、环状或边缘拓扑结构” 这一关键物理先验.由于缺乏对这些几何约束的显式描述, 视觉特征难以在复杂的3D空间中实现与语义意图的精准锚定, 导致几何特征与语义表征之间的错位.
本文提出物理感知语义增强模块(PASE), 旨在利用大语言模型(Large Language Model, LLM)的广义知识库实现语义致密化.区别于直接使用原始标签的传统策略, 将语义扩展过程形式化为结构化的三元组生成任务, 即构建映射函数, 选用GPT-4生成包含Tgeo、功能性描述Tfunc及交互逻辑Tint的致密语义集合.具体而言:Tgeo显式定义支持特定动作的局部拓扑特征, 消除形状歧义; Tfunc阐述部件的物理用途与因果关系, 增强语义解释性; Tint刻画机器人与物体的接触模式, 提供操作先验.例如:针对“ grasp” 类别, 模型不再将其视为孤立单词, 而是基于该规则将其重构为“ 一个呈半圆环状的细长结构(几何), 用于被人手稳固握持(交互), 以便于提升或移动物体(功能)” 的详尽定义.
将生成的物理增强描述输入参数冻结的CLIP文本编码器Φ text.对于第m个类别, 通过
tm=Φ text(P(
计算语义向量, 构建包含M个类别、维度为D的物理感知特征空间:
Ttext=[t1, t2, ···, tM]∈ RM× D,
其中P(· )表示提示符模板的拼接与处理操作.此设计利用冻结参数保留CLIP的通用对齐能力, 避免灾难性遗忘.相比原始稀疏空间, 构建的Ttext具有更高的类间可分性与几何指向性, 显著增强网络在复杂场景中的推理鲁棒性.
为了从无序点云中提取具有较高判别力的视觉表征, 选取PointNet++[3]作为骨干网络, 获取初始点云特征Finit.标准骨干网络主要依赖逐层下采样与最大池化操作, 这种处理方式虽然扩大感受野, 却不可避免地导致高频几何细节的丢失.在可供性检测任务中, 关键的功能区域, 如刀刃的锋利边缘、杯把的弯曲连接处, 往往依赖于精细的局部拓扑结构, 骨干网络容易模糊这些对于分割边界至关重要的几何线索.针对此局限, 本文提出多尺度几何感知细化模块(MGAR).设计并行的“ 局部-全局” 双分支架构, 分别利用动态图卷积与自注意力机制捕获互补的几何上下文, 并通过自适应融合策略实现特征增强.
局部几何分支旨在显式建模点云的微细局部拓扑.区别于PointNet++仅聚合独立点特征的方式, 引入动态图卷积EdgeConv算子, 捕获点与点之间的相对几何关系.
对于特征空间中的每个中心点pi, 利用k-近邻动态构建局部邻域图 N(i), 并聚合邻域内的边缘特征, 计算公式如下:
$\boldsymbol{f}_{\text {local }}^{(i)}=\max _{j \in N(i)} M L P\left(\left(\boldsymbol{f}_{\text {init }}^{(j)}-\boldsymbol{f}_{\text {init }}^{(i)}\right) \oplus \boldsymbol{f}_{\text {init }}^{(i)}\right), $
其中, $\oplus$表示特征拼接操作, MLP(· )表示多层感知机(Multilayer Perception),
为了弥补局部算子感受野受限的缺陷, 本文并行构建全局语义分支, 利用自注意力机制捕获长程依赖.该分支将整个点云视为一个全连接图, 计算点与点之间的语义相关性, 聚合全局形状上下文, 由此得到全局特征:
$\boldsymbol{F}_{\text {global }}={Softmax}\left(\frac{\boldsymbol{Q}_{s} \boldsymbol{K}_{s}^{\mathrm{T}}}{\sqrt{D}}\right) \boldsymbol{V}_{s}, $
其中, Qs、Ks、Vs表示初始特征Finit经由线性投影生成的查询(Query)、键(Key)和值(Value)矩阵, D表示缩放因子.该机制使每个点都能感知物体的整体拓扑结构, 有效缓解因局部几何相似性导致的语义歧义问题.
为了整合上述互补的几何线索, 设计一个包含融合MLP与残差连接的聚合模块.局部特征Flocal与全局特征Fglobal首先在通道维度进行拼接, 经由MLP映射至原始维度后, 与输入特征Finit进行残差相加, 得到最终的细化几何特征:
$\boldsymbol{F}_{\text {geo }}=\boldsymbol{F}_{\text {init }}+ { FusionMLP }\left(\boldsymbol{F}_{\text {local }} \oplus \boldsymbol{F}_{\text {global }}\right), $
其中FusionMLP(· )表示特征融合多层感知机.
该残差设计不仅促进梯度的有效反向传播, 也保证网络在增强细粒度与全局上下文的同时, 不会丢失原始骨干网络提取的基础几何信息.
现有方法多采用浅层的余弦相似度进行特征匹配, 缺乏模态间的深度交互.为此, 本文设计基于Transformer解码器架构的深度跨模态对齐模块(DCMA), 旨在根据文本语义动态重构点云特征.这里的“ 动态” 主要体现在特征更新的条件性.不同于参数固定的静态特征提取, DCMA利用交叉注意力机制, 根据输入的具体文本指令实时生成注意力权重, 视觉特征能自适应地聚合与当前语义最相关的几何信息, 实现以文本为条件的特征重构与对齐.
将细化几何特征Fgeo映射为查询向量, 将物理增强后的文本特征Ftext映射为键向量和值向量.为了增强非线性表达能力, 引入可学习的线性投影矩阵WQ, WK, WV, 则
$\begin{array}{l} \boldsymbol{Q}=L N\left(\boldsymbol{F}_{\mathrm{geo}}\right) \boldsymbol{W}_{Q}, \\ \boldsymbol{K}=\boldsymbol{F}_{\mathrm{text}} \boldsymbol{W}_{K}, \quad \boldsymbol{V}=\boldsymbol{F}_{\mathrm{text}} \boldsymbol{W}_{V}, \end{array}$
其中LN(· )表示层归一化.
利用多头注意力机制捕获几何与语义的关联.为了保证训练稳定性并缓解深层网络的特征退化问题, 在残差连接中引入层缩放机制, 使用可学习的对角矩阵Γ 1、Γ 2进行自适应调节.为了获得第一阶段的对齐特征$\widehat{\boldsymbol{F}}$, 首先计算标准的多头注意力图:
${Attn}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})={Softmax}\left(\frac{\boldsymbol{Q} \boldsymbol{K}^{\mathrm{T}}}{\sqrt{d_{k}}}\right) \boldsymbol{V} . $
再应用层缩放与残差连接, 获得对齐特征:
$\widehat{\boldsymbol{F}}=\boldsymbol{F}_{\mathrm{geo}}+\boldsymbol{\Gamma}_{1} \odot {Dropout}({Attn}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})), $
其中Dropout(· )表示随机失活.
然后, $\widehat{F}$进入前馈神经网络, 进行进一步的通道交互, 得到最终的深度对齐特征:
$\boldsymbol{F}_{\text {final }}=\widehat{\boldsymbol{F}}+\boldsymbol{\Gamma}_{2} \odot { Dropout }(F F N(L N(\widehat{\boldsymbol{F}}))), $
其中FFN(· )表示前馈部位网络.
此机制实现几何区域在语义指引下的精确锚定.
在推理阶段, 计算对齐后的点云特征Ffinal 与物理感知文本特征Ftext之间的余弦相似度矩阵S.对于第i个点和第m个可供性类别, 匹配分数为:
$S_{i, c}=\frac{\boldsymbol{F}_{\text {final }}^{(i)} \cdot\left(\boldsymbol{F}_{\text {text }}^{(m)}\right)^{\mathrm{T}}}{\left\|\boldsymbol{F}_{\text {final }}^{(i)}\right\|\left\|\boldsymbol{F}_{\text {text }}^{(m)}\right\|} . $
最后, 利用带有温度系数τ 的Softmax函数生成点级可供性预测概率分布Y∈ RN× M, 其中
$y_{i, m}=\frac{\exp \left(\frac{S_{i, m}}{\tau}\right)}{\sum_{k=1}^{M} \exp \left(\frac{S_{i, k}}{\tau}\right)} . $
概率分布Y直接用于计算损失函数并确定最终的语义类别.
3D可供性检测任务中功能区域的稀疏性导致正负样本极度不平衡, 单纯的交叉熵损失容易被背景类主导.因此采用混合损失函数策略, 联合使用Focal Loss与Dice Loss进行协同优化.总损失函数表示为:
$L_{\text {total }}=L_{\text {focal }}+L_{\text {dice }} . $
其中:Lfocal动态调整样本权重, 迫使模型关注那些难以分类的样本, 缓解类别不平衡问题; Ldice直接优化预测区域与真实标签之间的集合重叠度, 增强对细粒度功能区域的分割完整性.在实验中, 为了均衡像素级分类精度与区域级几何一致性的重要性, 未引入额外的超参数, 而是直接将两者的权重均设为1.
为了全面评估SSGE-Net的性能, 在3D Affor-danceNet数据集[12]上进行实验.该数据集包含23个物体语义类别的22 949个三维形状, 覆盖18种典型的可供性动作类别和1个背景类别.
遵循现有的标准实验协议, 在如下2种任务上进行评估.1)全视图任务, 使用完整的点云数据作为输入, 旨在评估模型在理想感知条件下的语义-几何理解能力.2)部分视图任务, 模拟真实机器人视点受限的情况, 通过部分遮挡的点云数据测试模型的泛化能力.
选取mIoU作为核心评价指标, 该指标通过计算所有类别预测区域与真实区域交集与并集的比值, 能同时惩罚漏检与误检, 相比单纯的准确率, 更公平地反映模型在细粒度功能区域上的分割质量.其次, 鉴于可供性数据集通常存在显著的类别不平衡现象, 辅以平均类别准确率(Mean Accuracy, mAcc)作为关键补充.该指标本质上是各类别召回率的算术平均值, 意味着无论类别样本多少, 其在评估中的权重均等, 从而有效检验模型在面对样本稀少的长尾类别时是否具备鲁棒的泛化性.最后, 使用总体准确率(Accuracy, Acc), 衡量模型在全局范围内的点级预测稳定性, 该指标直观反映整个测试集上被正确分类的点数占总点数的比例.
SSGE-Net 基于PyTorch 2.4.1深度学习框架构建, 开发语言采用 Python 3.8, 并配置CUDA 11.8计算环境.所有实验均在单张NVIDIA GeForce RTX 3090 GPU上完成推理与训练.在超参数配置方面, 训练总轮数设为200, 批尺寸大小设为16.
为了验证SSGE-Net的有效性, 选取5种具有代表性的前沿方法进行对比:首个开放词汇可供性检测方法(OpenAD[8])、点云零样本学习(文献[13]方法)、引入直推式设定的点云直推式零样本学习(文献[14]方法)、基于生成式范式的3D生成式零样本学习(3DGenZ[15])、利用文本-点云相关性蒸馏的方法(文献[16]方法).
3.2.1 定量评估
各方法在全视图任务与部分视图任务上的性能对比如表1所示.由表可见, SSGE-Net在核心指标上具有显著优势, 并在不同任务上展现卓越的泛化能力.
| 表1 各方法在两类任务上的指标值对比 Table 1 Comparison of metric values achieved by different methods on two tasks % |
在全视图任务上, SSGE-Net语义理解能力显著提升.相比当前先进的文献[16]方法, SSGE-Net的mIoU值提升11.55%, 并最终达到33.88%, 相比OpenAD更是实现19.51%的性能飞跃.这种优势直接归因于物理感知语义增强模块(PASE)的引入, 有效修正传统范式中模糊的浅层特征匹配, 使网络能精准解析依赖常识推理的复杂交互意图.
在部分视图任务上, SSGE-Net展现极强的几何鲁棒性与推理韧性, 即便面临严重的视点遮挡与点云缺失情况, 依然保持32.74%的mIoU值, 这一数值远超OpenAD在全视图任务上的14.37%.更具说服力的是, 当观测条件从全视图退化为部分视图时, OpenAD与文献[16]方法的相对性能衰减幅度分别为13.0%与8.3%, 而SSGE-Net仅下降3.4%.这一极低的性能损耗有力证实多尺度几何感知细化模块(MGAR)在捕捉局部拓扑结构方面的有效性, 网络即使在几何信息严重残缺的情况下, 仍能凭借局部微观特征与全局上下文的协同推理, 准确重建完整的功能区域.
3.2.2 可视化结果
OpenAD和SSGE-Net在全视图任务上的典型可视化结果如图2所示.
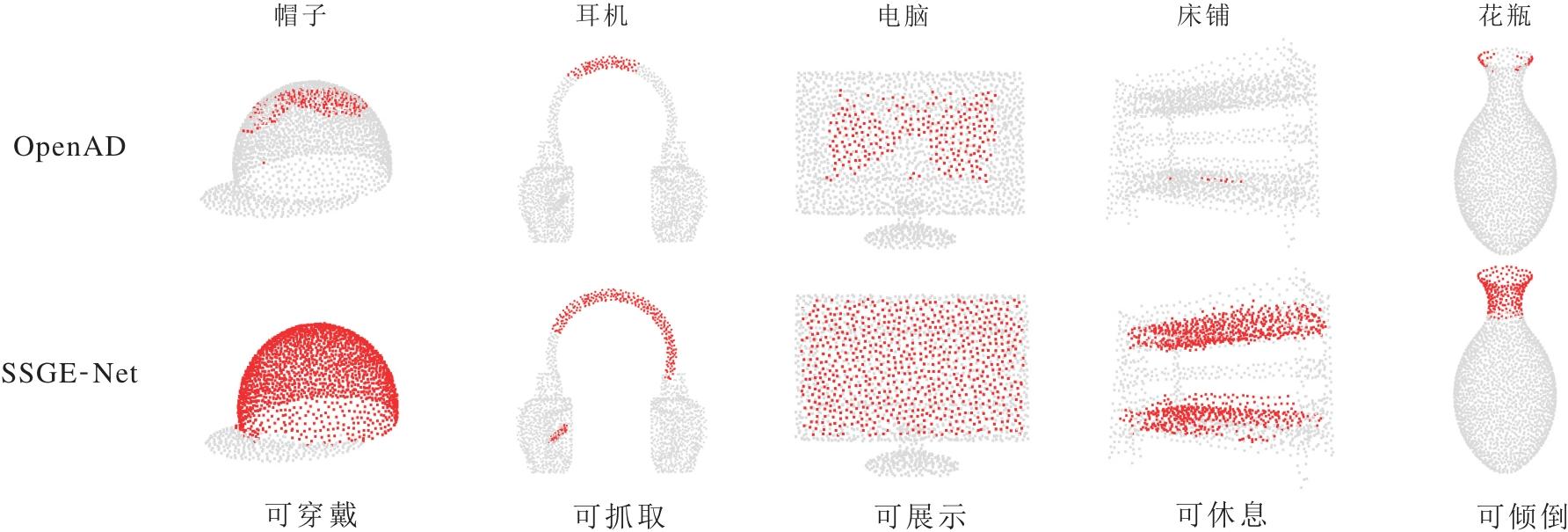 | 图2 OpenAD和SSGE-Net在全视图任务上单标签可视化结果对比Fig.2 Comparison of single label visualization results between OpenAD and SSGE-Net on full-view task |
由图2可见, 在几何信息完整时, SSGE-Net 表现出较优的语义-几何一致性与预测完整性.
针对帽子、电脑与床铺等具有大尺度连续表面的物体, OpenAD的预测结果呈现明显的稀疏性与破碎感, 大量核心功能区域, 如电脑屏幕中心、床铺床垫区域, 未被有效激活, 并且伴随显著的背景噪声漂移.相比之下, SSGE-Net 凭借深度跨模态对齐模块(DCMA), 不仅实现对“ 可穿戴” 、“ 可展示” 及“ 可休息” 语义区域的致密覆盖, 成功填补OpenAD的预测空洞, 而且精准滤除非功能区域的离群噪声, 使分割边界高度贴合物体的物理轮廓.
在处理耳机与花瓶等具有细长拓扑或曲率变化的物体时, OpenAD难以维持几何结构的连通性, 导致耳机头梁与花瓶瓶口的预测出现断裂.MGAR帮助SSGE-Net在局部微观拓扑进行捕捉, 成功保持“ 可抓取” 与“ 可倾倒” 区域的几何连续性.生成的预测掩码边缘锐利、线条流畅, 充分验证双重增强策略在处理细粒度几何特征时的优越性.
在几何信息缺失的部分视图任务上, SSGE-Net和OpenAD典型可视化结果如图3所示.由图可见, SSGE-Net在部分视图任务上的抗干扰鲁棒性较强, 这也是具身智能体在非结构化环境中作业的关键能力之一.
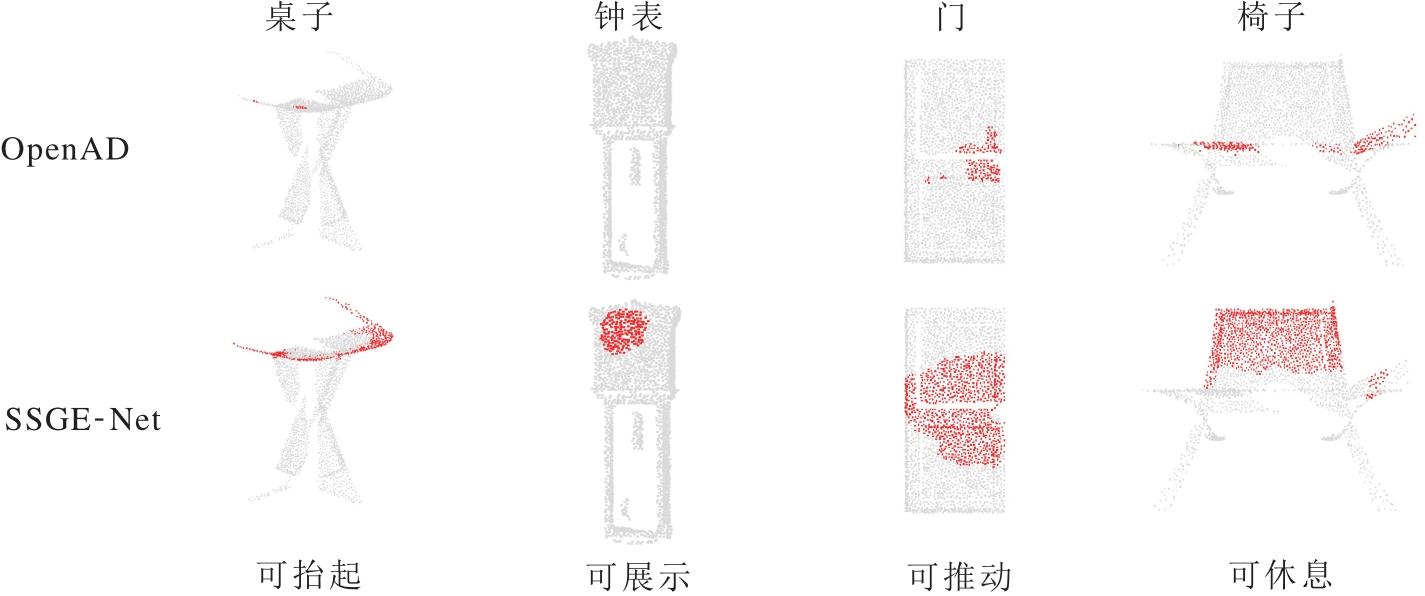 | 图3 OpenAD和SSGE-Net在部分视图任务上单标签可视化结果对比Fig.3 Comparison of single label visualization results between OpenAD and SSGE-Net on partial view task |
在处理门与椅子等存在显著遮挡的物体时, OpenAD暴露出对局部几何特征的过度依赖.由于缺乏对物体整体拓扑结构的建模能力, 预测区域往往随几何截断而中断, 导致门板推力区及椅背休息区预测呈现不连续的状态.SSGE-Net并未局限于残缺的局部观测数据, 而是利用PASE成功实现“ 语义补全” , 推断被遮挡部分的潜在功能逻辑, 准确重建残缺门板的完整可推动区域及椅子背部的连续可休息区域.
在处理钟表与桌子等点云稀疏的物体时, OpenAD因关键几何特征点缺失而在钟表物体上几乎完全失效, 出现漏检.SSGE-Net却保持对表盘显示区域的高响应度, 并清晰勾勒桌子边缘的可抬起区域.这有力证实SSGE-Net并非进行简单的浅层模板匹配, 而是真正学习物体几何结构与功能语义之间深层的映射关系, 能在几何信息严重退化时实现鲁棒的零样本推理.
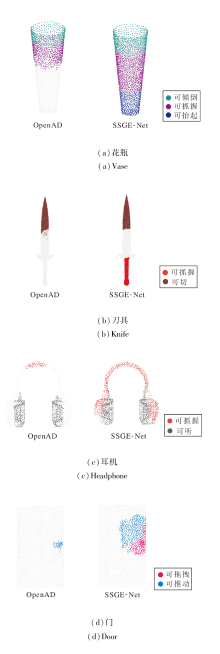
3.2.3 多标签共现与细粒度分析
为了深入探究SSGE-Net在复杂交互场景中的推理边界, 选取花瓶、耳机、刀具及门这四类具有显著物理属性差异的物体进行可视化对比, 结果如图4所示.由图可见, SSGE-Net 在解决语义推理完备性与功能部件几何解耦这两大核心挑战上, 展现出优于OpenAD的显著优势.
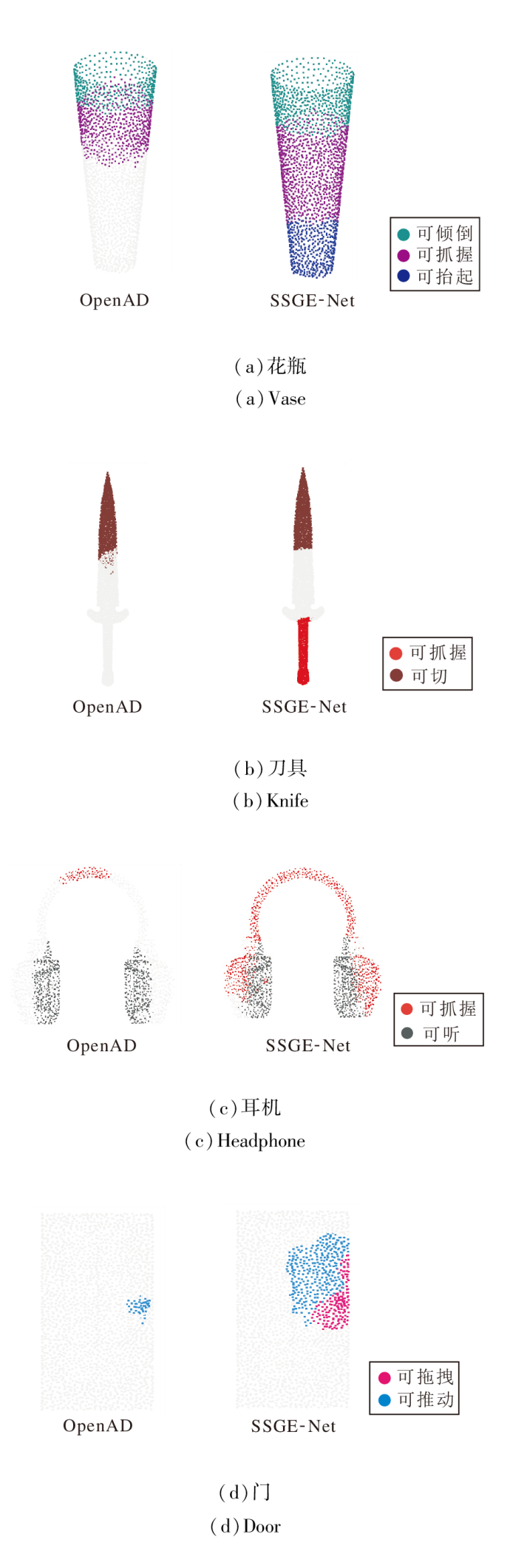 | 图4 一物多标签的可供性检测结果对比Fig.4 Comparison of multiple-label affordance detection results for one object |
在多义性语义的完备召回方面, SSGE-Net突破浅层视觉特征匹配的逻辑盲区.对比结果显示, OpenAD出现明显的语义遗漏现象, 仅能识别物体表面的部分显式特征, 忽略隐含的物理交互属性.例如:在刀具图像中仅识别刀刃的“ 可切” 属性, 却完全遗漏红色的“ 可抓握” 手柄区域.SSGE-Net凭借设计的PASE, 利用LLM的常识推理能力补全从物体形态到潜在功能的逻辑链条, 实现对“ 可抓握” 与“ 可抬起” 等多重标签的全面召回, 彻底消除传统方法的语义盲区.
在功能部件的几何解耦方面, SSGE-Net细粒度分区与边界收敛能力更优.OpenAD 的预测结果在这些物体上均表现出严重的语义弥散现象, 即功能标签错误跨越物理边界, 不同功能区域相互粘连, 无法精确分割瓶口与瓶身.SSGE-Net得益于MGAR对局部拓扑结构的敏锐捕捉, 精准实现严格的功能分区:将花瓶自上而下清晰划分为“ 可倾倒” 、“ 可抓握” 与“ 可抬起” 三个独立且边界锐利的几何区域.同样, 在门的图像中, SSGE-Net也清晰界定大面积的“ 可推” 区域与边缘的“ 可拖拽” 区域.这种像素级的语义隔离能力使网络在处理细粒度几何结构时, 能有效抑制相邻功能区域的特征干扰, 实现鲁棒的精细化推理.
下面分析SSGE-Net各核心组件在全视图任务与部分视图任务上的性能贡献及计算资源消耗, 结果如表2所示.由表可见, SSGE-Net通过双重增强策略实现性能的全面提升, 全视图任务与部分视图任务上的mIoU值分别达到33.88%与32.74%.
| 表2 各模块的消融实验结果 Table 2 Ablation experiment results of each module |
PASE在性能改善中发挥主导作用, 仅引入该模块, 全视图任务上的mIoU值从19.92%提至29.29%.值得注意的是, 该模块并未引入额外的参数量与推理开销, 这种“ 零推理成本” 的特性有力验证在文本编码阶段注入显式物理先验以消除语义歧义的高效性.
MGAR与DCMA有效增强网络对局部拓扑细节的捕捉能力.尽管MGAR因引入动态图卷积导致浮点计算量增至27.63 G, DCMA使参数量增至4.94 M, 但得益于GPU的并行计算优势, 二者带来的推理延迟增量极为有限, 分别约为12 ms与3 ms.单独引入这两个模块时, mIoU值均实现超过5%的增长, 呈现“ mAcc 平稳而 mIoU 显著提升” 的趋势, 表明网络正从粗糙分割策略向高精度的边界拟合转变.
各模块在联合使用时展现出显著的协同增益效应.SSGE-Net以仅14.4 ms的时间成本增加, 换取mIoU值的大幅提升(13.96%), 验证该架构在精度与效率权衡上的优越性.更重要的是, SSGE-Net在部分视图任务上的mAcc值达到50.23%, 超过全视图任务上的49.38%.这一结果进一步证实SSGE-Net 在几何缺失的极端场景中, 不再单纯依赖外观特征匹配, 而是成功利用内嵌的物理逻辑进行有效的特征补全, 从而确立其在非结构化环境中的鲁棒性优势.
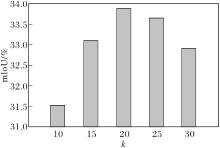
MGAR中局部几何分支的近邻数k决定拓扑特征聚合的感受野范围, 是影响网络细粒度感知能力的关键超参数.定义k=10, 15, ···, 30, 其对SSGE-Net性能的影响如图5所示.
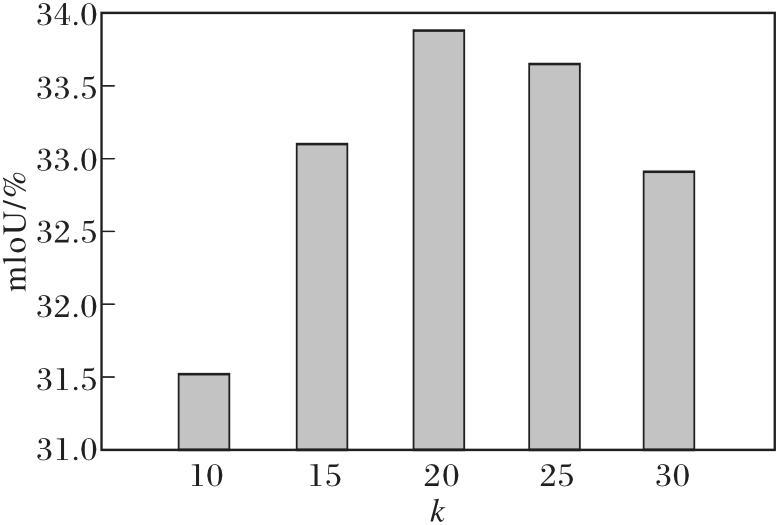 | 图5 k对SSGE-Net性能的影响Fig.5 Effect of k on SSGE-Net performance |
由图5可见, 全视图任务上mIoU值随k值增加呈现先升后降的趋势, 在k=20处达到峰值33.88%.实验表明, 过小的k值导致感受野受限, 难以捕捉微细边缘; 过大的k值(k> 20)引入非相关几何噪声, 导致特征过平滑并模糊功能边界.综合考虑特征判别力与噪声抑制, 本文选取k=20作为最优参数.
为了验证2.2节PASE中三元组规则的必要性, 设计如下3种不同粒度的语义策略进行对比.1)简洁型:仅描述物体类别名称.2)通用型:使用通用字典定义, 缺乏特定物理约束.3)物理感知型:引入几何、功能与交互逻辑的结构化描述.
3种语义策略的mIoU值对比如表3所示.由表可见, 相比简洁型中mIoU值达到28.11%, 通用型虽然通过增加文本信息量将全视图任务上mIoU值提升至30.65%, 但仍受限于缺乏显式的几何指向性.PASE进一步将全视图任务与部分视图任务上的mIoU值分别提升至33.88%与32.74%, 实现5.77%和5.21%的显著增益.这一结果有力证实跨模态对齐效率的提升并非单纯源于文本长度的增加, 而是在于显式注入与 3D 几何特征高度匹配的拓扑结构与交互逻辑先验.
| 表3 不同语义扩展策略的性能对比 Table 3 Performance comparison of different semantic extension strategies % |
为了验证SSGE-Net在机器人端侧的部署潜力, 在NVIDIA RTX 3090平台上进行定量评估, OpenAD和SSGE-Net的计算效率与资源消耗对比如表4所示.由表可见, SSGE-Net的参数量为7.04 M, 浮点计算量为31.93 G, 在现代边缘计算设备算力范围内仍属轻量级范畴.
| 表4 OpenAD和SSGE-Net的计算效率与资源消耗对比 Table 4 Comparison of computational efficiency and resource consumption between OpenAD and SSGE-Net |
在关键的推理效率方面, SSGE-Net单帧耗时为146.0 ms.相比OpenAD, 用约15 ms的时间增量换取19.51%的 mIoU 性能提升.该推理速度可满足机器人静态抓取任务对200 ms 响应窗口的实时性要求, 由此证实SSGE-Net在精度与效率权衡上的优越性及其实际部署的可行性.
本文针对具身智能感知中开放词汇3D可供性检测面临的语义歧义性与几何-语义错位问题, 提出基于协同语义与几何增强的可供性学习网络(SSGE-Net).为了突破传统浅层特征匹配范式的局限, 构建双流增强机制.在语义端引入物理感知语义增强模块(PASE), 利用常识推理将抽象的语言指令“ 致密化” 为显式的几何约束.在几何端, 设计多尺度几何感知细化模块(MGAR), 配合基于Trans-former的深度跨模态对齐模块(DCMA), 使视觉特征在语义线索的指引下进行动态重构.
在3D AffordanceNet数据集上的广泛实验验证SSGE-Net的有效性, 不仅在全视图任务上获得33.88%的mIoU值, 更在模拟真实机器人视线受阻的部分视图任务上展现出优越的鲁棒性, mIoU值依然保持在32.74%.消融实验进一步揭示, SSGE-Net不再单纯依赖表层的外观匹配, 而是成功学习物体功能与几何结构之间深层的映射关系, 从而在长尾类别与几何信息严重退化的非结构化场景中具备卓越的零样本推理能力.
未来的工作将致力于弥合从仿真感知到实体操作的领域鸿沟, 聚焦如下两个方向.1)探索轻量化模型蒸馏技术, 满足机器人端侧实时推理的需求; 2)将SSGE-Net拓展至动态时空场景, 结合时序动作逻辑, 构建具备通用操作能力的具身智能体.
本文责任编委 兰旭光
Recommended by Associate Editor LAN Xuguang
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|