
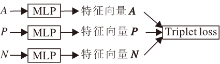
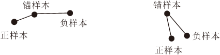


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于度量学习的回环检测描述子提升算法
[韩彬1  , 罗伦
, 罗伦1 , 刘雄伟1 , 沈会良1 ]
, 罗伦, 刘雄伟, 沈会良]
|
|



作者简介:

韩 彬,硕士研究生,主要研究方向为激光SLAM、机器学习.E-mail:binhan_0902@foxmail.com. 
罗 伦,博士研究生,主要研究方向为激光SLAM、激光点云数据处理.E-mail:luolun@zju.edu.cn. 
刘雄伟,硕士研究生,主要研究方向为图像处理、机器学习.E-mail:liuxw11@zju.edu.cn.
回环检测是同步定位与地图构建系统的组成模块,目前大多数回环检测算法从数据帧提取特征描述子,通过描述子之间的欧氏距离搜索回环,未对提取的特征描述子进行特征增强.针对上述问题,文中提出基于度量学习的回环检测描述子提升算法.设计轻量级算法模块,对生成的描述子进行特征空间变换,增强描述子的区分能力,有效提升回环检测性能.通过位姿和描述子结合的方式成组制作三元组数据集,解决标签模糊的问题.提出扩充数据集的思路,解决回环样本显著不足的问题.基于三元组损失函数改造损失函数,适配回环检测场景,训练用于特征空间变换的神经网络模块.在KITTI、NCLT数据集上的测试表明,文中算法具有较强的泛化能力.
About Author:
HAN Bin, master student. His research interests include lidar SLAM and machine learning.
LUO Lun, Ph. D. candidate. His research interests include lidar SLAM and lidar point cloud processing.
LIU Xiongwei, master student. His research interests include image processing and machine learning.
Loop detection is an important part of simultaneous localization and mapping (SLAM). In most of the loop detection algorithms, feature descriptors are extracted from data frames, and loops are searched through the Euclidean distance between the descriptors. However, feature enhancement is not conducted on the extracted feature descriptors. In this paper, an algorithm of feature descriptor enhancement for loop detection based on metric learning is proposed. A lightweight algorithm module is designed to transform the feature space of the descriptors to enhance the distinguishing ability of the descriptors and improve the loop detection performance effectively. Pose and descriptors are combined to establish a triple dataset and thus the problem of fuzzy labels is solved. An idea of expanding the dataset is proposed to solve the problem of significantly insufficient loop samples. Based on triplet loss, the proposed loss function is adapted to the loop detection scene, and it is utilized to train a neural network module for feature space transformation. Experiments on KITTI and NCLT datasets show that the generalization ability of the proposed algorithm is strong.
本文责任编委 李贻斌
Recommended by Associate Editor LI Yibin
回环检测作为同步定位与地图构建(Simulta-neous Localization and Mapping, SLAM)中关键问题之一, 主要用于识别机器人是否曾到达过当前位置, 在降低累积误差、提高地图一致性方面具有重要作用.目前, 回环检测算法主要分为基于视觉的回环检测算法和基于激光雷达的回环检测算法.由于激光雷达精度相对受光照、视角影响更小, 基于激光雷达的回环检测算法通常具有更高的鲁棒性.
基于激光雷达的回环检测算法可大致分为基于机器学习的回环检测算法和基于手工特征的回环检测算法.基于机器学习的的回环检测算法中的典型算法, 如基于3D点云分割的回环检测(Segment Based Loop-Closure for 3D Point Clouds, SegMatch)[1], 对点云进行分割聚类, 使用最近邻搜索对分割的点云进行检索, 再利用基于随机森林的分类器进行分段点云匹配.基于点云检索的场景识别网络 (Deep Point Cloud Based Retrieval for Large-Scale Place Recognition, PointNetVLAD)[2] 和大尺度场景描述网络(Large-Scale Place Description Network, LPD-Net)[3]利用点云网络(PointNet)[4]提取点云特征, 再使用聚合局部特征编码网络(Vector of Locally Aggregated Des-criptors Network, NetVLAD)[5]为输入点云生成全局描述子矢量.基于手工特征的回环检测算法常见思路是人工设计不破坏点云结构信息的特征描述子, 将每帧三维点云数据压缩成一个特征向量, 再通过特征描述子之间的欧氏距离进行回环搜索.主流的描述子有多视点投影的全局描述子(Multiview 2D Projection, M2DP)[6], 定向直方图标签描述子(Signature of Histograms of Orientations, SHOT)[7], 视点特征直方图描述子(Viewpoint Feature Histogram, VFH)[8], 形状集成描述子(Ensemble of Shape Func-tions, ESF)[9], Scan Context描述子[10], Iris描述子[11]等.
He等[6]提出 M2DP, 将一帧三维点云数据投影到平面上, 再利用奇异值分解(Singular Value Decomposition, SVD)提取奇异向量, 拼接成192维特征描述子, 具有较好的鲁棒性.Tombari等[7]设计SHOT描述子, 在特征点处建立局部坐标系, 结合邻域点的空间位置信息和几何特征统计信息描述特征点.Rusu等[8]提出VFH, 先找到视角方向, 确定旋转一致性, 再利用点云法向量和视角之间的夹角制作直方图, 从而制成描述子.Kim等[10]提出Scan Context描述子, 在构建时效率较高, 只提取每个点云区域内最有代表性的一个点, 可运用在实时SLAM系统中.上述描述子算法在应用时较简单, 只对每帧雷达数据提取特征描述子, 再直接利用常见的距离度量函数(欧氏距离、余弦距离等)进行回环搜索.但是, 由于内部有区分度不高或混淆性较强的特征存在, 因此算法性能受到影响.
度量学习针对某特定任务学习一个距离度量函数, 使该度量函数能帮助基于特征距离的算法取得更优性能.深度度量学习是度量学习的一种, 常应用于人脸识别、行人重识别、图像检索等领域, 目标是学习一个从原始特征空间到区分度更强的特征空间的映射, 在这个区分度更强的空间中, 同类样本之间的距离(欧氏距离、余弦距离等)缩小, 异类样本之间的距离拉大.在深度度量学习中, 常见的损失函数是三元组损失函数(Triplet Loss)[12], 用于学习一个区分度更好的特征空间.
Shrivastava等[13]针对Triplet Loss, 提出在线挖掘难样本的方法, 可使Triplet Loss训练效率更高、效果更优.在行人重识别的应用场景中, Hermans等[14]发现难样本挖掘三元组损失函数(Batch Hard Triplet Loss)比难样本挖掘的方式更稳定、效果更优.Xuan等[15]提出可视化分析的方法, 对训练过程进行建模分析, 了解不同难度样本对训练的影响.在上述场景中, 样本标签都是明确的, 因此非同类即为负样本对, 同类即为正样本对, 很好区分.而在本文处理的回环检测中, 样本标签不明确, 因此数据集的制作及难样本的挖掘存在困难.此外, 在回环检测场景中, 回环样本的数目显著不足, 需要设计方法补充.常规的Triplet loss对样本的利用不够充分, 也需要进一步提升.整体算法在应用时需要简单高效, 这对网络设计也提出要求.
为了解决上述问题, 本文将度量学习引入回环检测场景中, 提出基于度量学习的回环检测描述子提升算法.在生成传统描述子后, 设计网络对描述子进行特征变换, 基于Triplet Loss的思想改造损失函数, 训练网络, 增强描述子算法的区分度.由于回环检测场景中不存在完全相同的两帧数据, 为单帧数据分配类别标签存在困难, 而两帧数据是否互为回环帧可通过两帧之间的位姿关系明确, 因此利用两帧之间的位姿关系判断是否互为回环, 从而对两帧之间的关系构造标签.若两帧互为回环帧, 将两帧当作正样本对, 否则当作负样本对, 以此避免单帧分配标签困难的问题.同时, 扩充回环样本, 解决数量显著不足的问题, 并针对回环检测场景改造Triplet Loss用于训练, 学习相对更好的特征空间.在使用常见的距离度量函数搜索回环前, 先对描述子进行特征空间的变换, 提升描述子的性能.本文以M2PD描述子[6]、Scan Context描述子[10]为例对算法进行测试, 结果表明本文算法能有效提升回环检测能力.
本文旨在回环搜索前加入一个特征空间映射模块, 将描述子映射到一个查询帧与回环帧之间的距离相对变小、查询帧与非回环帧之间距离相对变大的特征空间.通过这种空间映射, 放大特征描述子中区分回环效果较优的部分, 剔除不相关或冗余部分及会混淆判断的部分, 完成对特征的重构, 提升特征描述子的效果.
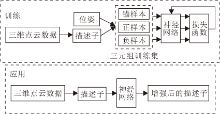
由此, 本文提出回环检测描述子提升算法, 算法流程如图1所示.在训练阶段, 将三维点云数据利用特征描述子算法转化为描述子, 并与位姿结合, 通过位姿关系选取正负样本对, 制作三元组形式的数据集.基于相似度分析, 采取利用邻近样本扩充正样本的方式, 解决回环样本显著不足导致的训练集较小的问题.扩充训练集后, 输入网络中, 基于Triplet Loss改造的损失函数进行训练.在应用阶段, 将三维点云数据转化为特征描述子, 通过训练得到的网络模块进行增强, 提升各描述子算法的效果.
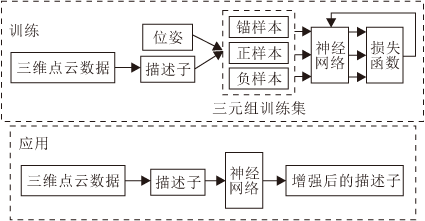 | 图1 本文算法流程图Fig.1 Flowchart of the proposed algorithm |
本文使用多层感知器(Multi-layer Perceptron, MLP)对特征进行空间映射, MLP计算量较小, 容易训练, 能够满足实时性要求较高、训练数据不充足的回环检测场景的要求.MLP结构如图2所示, 包括3个隐藏层.本文利用非线性函数增强网络对特征的学习能力, 并加入批归一化(Batch Normalization), 抑制过拟合, 加速收敛.
 | 图2 MLP结构图Fig.2 Structure of MLP |
深度度量学习主要用于学习一个较好的特征空间, 在此空间中, 相似样本的特征距离相对较小, 不相似样本之间的特征距离较大, 从而对数据进行区分.
本文使用基于Triplet Loss改造的针对回环检测场景设计的损失函数.如图3所示, 本文选择某一个锚样本(Anchor)A , 与它标签相同的样本P作为正样本(Positive), 与它标签不同的样本N作为负样本(Negative).以3个样本的形式制作成一个三元组, 分别输入同个网络(本文采用MLP)中, 得到3个特征向量, 计算Triplet Loss:
L=max(dA-P-dA-N+α , 0), (1)
再使用反向传播算法更新原本的模型, 其中, dA-P为选定样本A与正样本P之间的距离, dA-N为选定样本A与负样本N之间的距离.使用这个损失函数训练的目的是让负样本对之间的距离大于正样本对之间的距离.
 | 图3 度量学习示意图Fig.3 Sketch map of metric learning |
定义样本数量为k, 由于本文使用三元组数据集, 需要挑选3个样本组成三元组, 因此样本空间的量级会达到k3.若不进行针对性优化, 算法的收敛速度很慢, 容易陷入局部最优.而如果采用批量(Batch)输入的方式训练, 收敛较快, 但图4所示的两种容易学习的三元组(dA-P< dA-N)会拉低平均损失函数值, 使训练不充分, 对数据的拟合不足.
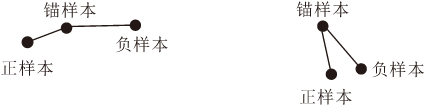 | 图4 两种简单三元组形式Fig.4 Two kinds of simple triplet |
在现实场景中回环样本通常不多, 并且三元组内的样本重复度较高.所以为了更充分地利用数据集, 受Hermans等[14]的启发, 本文提出适配回环检测这种有成组标签的Batch Hard Triplet Loss:
L=
其中, N=1, 2, …, n, n为三元组批量的大小, i为批量内的一个三元组序号,
这种做法的优势在于, 一次训练只取批量中最难的一个三元组, 忽略那些损失函数值为0、对训练没有贡献的简单三元组, 使损失函数值不会过早收敛到0附近, 从而使训练更充分.相比利用所有数据进行训练的方式, 效率更高.
相比先挖掘全部困难样本, 再用这些困难样本批量输入训练, 本文提出的这种方式更稳定, 因为以损失函数的形式进行样本挖掘, 只是选取一个批量中的最难样本, 这样样本在整个数据集中只能算是较难的, 而如果对训练集进行难样本挖掘的处理, 相当于使用整个数据集中难的样本进行训练, 会使训练难度加大, 造成收敛困难, 并且对数据集的利用率降低, 对数据的拟合程度差于本文提出的损失函数.
为了增强损失函数的稳定性和效果, 本文提出进一步提高数据利用率的方法.将简单三元组分成图4所示的两种, 两者的选定样本都离正样本较近、离负样本较远, 在式(2)中损失函数值为0.但是如果从正样本的角度上看, 以正样本作为锚样本, 则此时图4右图的损失函数值不为0.这部分样本是完全可以被利用起来的, 为此将损失函数改写为
L=
其中, N=1, 2, …, n,
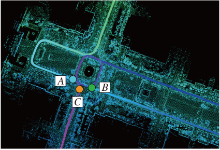
在回环检测场景中, 为单帧数据分配类别标签存在困难, 此类问题在路口处较常见.如图5所示, A、C是经过该路口时留下的两帧数据, B是再一次回到该路口时的一帧数据.{A, B}、{B, C}为两组回环, 若为A、B分配同一标签, B与C也应是同样标签, 从这个角度讲, A、B、C标签相同.而实际上, 回环帧是指机器人再一次到达历史轨迹附近检测到的历史帧, 因此A、C之间不存在回环关系.在图像分类场景中, A、B同类, B、C同类, 则A、B、C必然同类.然而回环检测场景下单帧数据分类不明确, 与图像分类问题具有明显区别.
 | 图5 轨迹示意图Fig.5 Sketch map of trajectory |
如上所述, 无法为单帧数据分配标签.而两帧之间是否互为回环可通过位姿关系明确判断, 因此, 本文选择对两帧之间的关系构造标签.若两帧互为回环帧, 将两帧当作正样本对, 否则当作负样本对, 以此避免单帧分配标签困难的问题.
由于训练时只能以成对、成组的形式输入, 因此本文采用Triplet Loss进行成组数据的训练.此类数据集制作通常是选取一个样本A, 一个与A同类的正样本P, 组成正样本对{A, P}, 再选取一个其它类别的样本N, 组成负样本对{A, N}.{A, P, N}记为一个三元组.通过训练使负样本对之间的距离大于正样本对之间的距离.
在回环检测场景中, 类比通常做法, 本文选取三元组的方式如图6所示, 通过位姿和相似度搜索的方式制作三元组.以查询帧作为锚样本, 将查询帧与其对应的回环帧(距离小于距离阈值且相似度大于正样本阈值)组成正样本对, 将查询帧与距离够远且相似度大于负样本阈值的帧组成负样本对, 从而建立三元组.
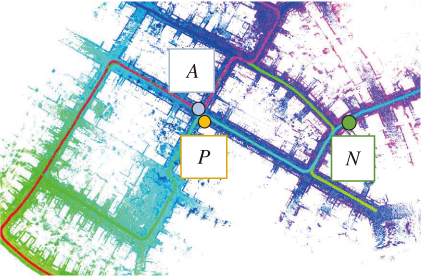 | 图6 挑选三元组示意图Fig.6 Sketch map of picking triples |
若仅以查询帧对应的回环帧制作三元组, 用于制作正样本的数据显著不足, 极大程度上限制整个数据集的大小.从回环检测的本质上说, 回环检测算法依赖查询帧与回环帧描述子之间的相似性, 而这种相似性源自查询帧与回环帧在点云结构上的相似性.从理论上看, 相邻帧之间由于距离较近, 扫描到的点云大致类似, 应该也具有类似查询帧与回环帧的关系.因此, 本文提出把查询帧的相邻帧作为正样本, 这样可大量扩充数据集, 减轻样本不平衡对算法造成的影响.
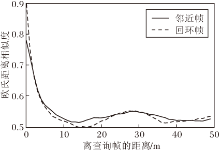
以M2DP描述子为例, 在KITTI数据集[16]上, 本文对查询帧与回环帧、查询帧与相邻帧之间的关系进行统计分析.定义总帧数为N, 统计查询帧i与帧数在[i-200, i-1]∪ [i+1, i+200]范围内相邻帧的关系, 以两帧之间距离为横坐标, 两帧之间的欧氏距离相似度为纵坐标, 绘制图7中实线所示结果.统计查询帧i和帧数在[0, i-200]∪ [i+200, N]范围内帧的关系, 如图7中的虚线所示, 此时由于去除相邻帧, 横坐标较小的就是回环帧, 因此可利用图中虚线观察查询帧与回环帧之间的关系.
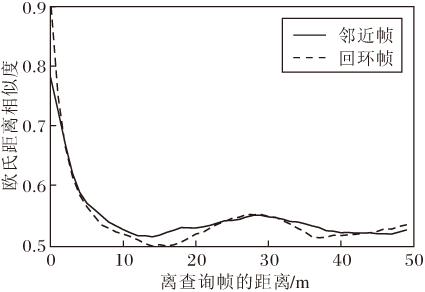 | 图7 查询帧和回环帧、邻近帧的相似度关系Fig.7 Similarity relationship between queried frames and loop frames, adjacent frames, respectively |
由图7可发现, 距离较近的帧, 与查询帧的相似度会显著高于其它帧.无论是回环帧还是相邻帧, 在相似度的分布上是类似的, 都与两帧之间的距离有关.距离达到某个阈值后, 点云特征的区分性不够, 随着距离的增加, 相似度降低到0.5~0.55附近.因此可利用相邻帧中相似度高于某个阈值的帧(即距离小于距离阈值且相似度大于相似度阈值的帧)补充回环样本, 以KITTI07序列为例, 若只用回环部分作为正样本, 可制作正样本对1 467对.而如果加入邻近数据补充回环样本, 总共可制作出正样本对31 740对, 极大程度上扩充数据量.
本文使用M2DP描述子[6]和Scan Context描述子[10]测试算法的有效性.M2DP描述子将三维点云数据投影到平面上, 再利用SVD提取奇异向量, 拼接成192维特征描述子.Scan Context描述子将点云以激光雷达为中心进行环形分区, 并将环形区域切割成固定数量的点云区域, 提取每个点云区域内最有代表性的一个点, 拼成一幅维度为Nr×Ns图像.在回环搜索时, 提取每行的L0范数, 制作成一个Nr维的特征向量.
所有的训练、测试都在电脑(Intel i5 8500处理器, 16 GB内存)上进行.
本文选取的测试数据集为KITTI[16]、NCLT数据集[17].KITTI数据集是目前国际上通用的计算机视觉算法评测数据集, 包含针对市区、乡村等场景采集的激光雷达数据, 本文使用其中的00、02、05、06、07序列.这几个序列存在回环, 并且KITTI数据集提供与激光雷达数据一一对应的位姿真值.位姿真值来源于采集过程中的RTK-GPS、IMU等传感器信息.
NCLT数据集是密歇根大学对校园环境进行多次采集得到的数据集, 序列名与采集日期对应.本文使用20120115、20120204、20120820、20121028、20121116这些具有回环的序列.参考NCLT数据集[17], 本文使用其中较准确的相邻帧间隔8 m左右的位姿真值及其对应的激光雷达数据.位姿真值来源于RTK-GPS等传感器信息, 并进行位姿图优化的处理.
本文从每帧点云数据中提取对应的特征描述子, 利用特征描述子之间的特征欧氏距离作为回环的判断指标.如果查询帧与搜索的特征距离最近的回环帧之间的特征距离小于特征阈值, 且实际距离小于5 m, 认为找到正确的回环检测.
为了避免邻近数据被误认为是回环帧, 在KITTI数据集上, 筛除查询帧相邻200帧的数据, 即对某个查询帧i来说, 回环帧的搜索范围为[0, i-200].在NCLT数据集上, 由于该数据集提供较精准的相邻帧间隔8 m的位姿真值, 而本文使用的回环检测距离阈值是5 m, 不存在邻近数据被误认为回环帧的情况, 所以采用的搜索范围为[0, i-1].
本文使用精确率-召回率曲线(Precision-Recall, P-R)、F1值( F1 Score)指标评估算法性能.
本节测试采用的训练集均为KITTI数据集上00序列, 采用的测试集是KITTI数据集上02、05、06、07序列.M2DP描述子的提取按照默认参数, 每帧数据对应一个192维描述子.对比算法Point-NetVLAD采用作者在github上的代码.为了保证公平, 在KITTI00序列上进行微调训练.
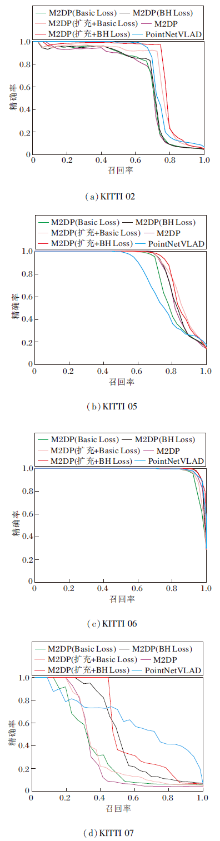
M2DP描述子、使用基础版本的Triplet Loss(简称为Basic Loss)训练后的M2DP描述子、使用本文提出的Batch Hard Triplet Loss(简称为BH Loss)训练后的M2DP描述子、PointNetVLAD在测试集上的P-R曲线如图8所示.
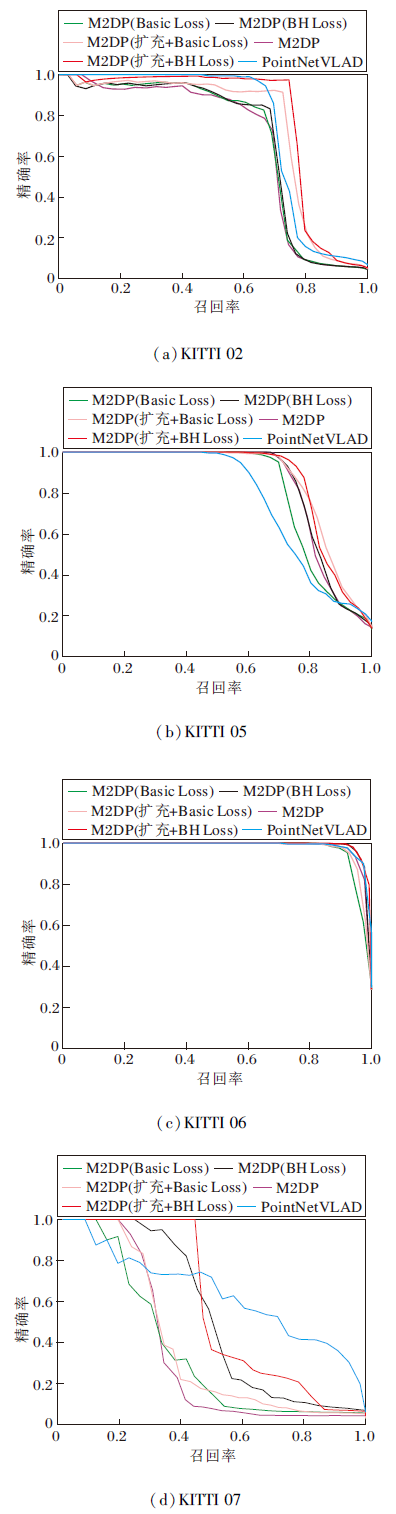 | 图8 M2DP描述子在KITTI数据集上的Top1 P-R曲线Fig.8 Top1 precision-recall curves of M2DP descriptor on KITTI dataset |
由图8可知, 在数据扩充前, BH Loss效果明显优于Basic Loss.Basic Loss无法超过M2DP描述子的效果, 而BH Loss能较好地达到或超过M2DP描述子的效果, 这表明BH Loss能更充分利用样本, 数据拟合效果更优.在数据扩充后, BH Loss效果依旧优于Basic Loss.在利用邻近数据补充回环样本后, 无论是使用BH Loss训练还是使用Basic Loss训练, 相比扩充前, 效果都有明显提升, 说明数据集较小会限制算法效果.虽然在数据集扩充后, Basic Loss在部分场景(如KITTI 05序列)中可接近BH Loss的水平, 但是综合来看, BH Loss明显优于Basic Loss.考虑到数据集较小的问题在回环检测场景中普遍存在, 因此BH Loss优势明显.基于深度学习的描述子算法PointNetVLAD在KITTI00序列上微调后, 测试效果优于训练前的M2DP.经过BH Loss增强后, M2DP在P-R曲线及F1值上超越PointNetVLAD, 说明本文算法具有一定优势.注意到PointNetVLAD使用更多的训练数据, 相比之下, 本文算法训练简单, 效果更优.
扩充前后各算法Top1结果的F1值如表1和表2所示, 表中黑体数字表示最优结果.在训练前, M2DP描述子的性能在部分序列上不如Point-NetVLAD, 尤其是在KITTI 07序列上, 差距较大.通过BH Loss增强后, 在这些序列上效果都有提升, F1值都超过PointNetVLAD, 由此验证本文算法的有效性.
| 表1 扩充前M2DP描述子Top1结果的F1值 Table 1 Top1 F1 score of M2DP descriptor before data augmentation |
| 表2 扩充后M2DP描述子Top1结果的F1值 Table 2 Top1 F1 score of M2DP descriptor after data augmentation |
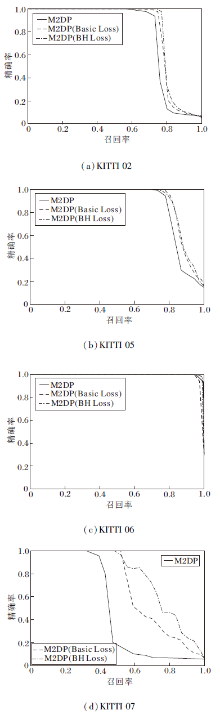
由于Top1的结果只能观察到回环帧与查询帧的特征距离是否最小, 为了观察训练前后查询帧与对应回环帧的距离是否普遍被拉近, 绘制数据扩充后Top10 P-R曲线, 如图9所示.
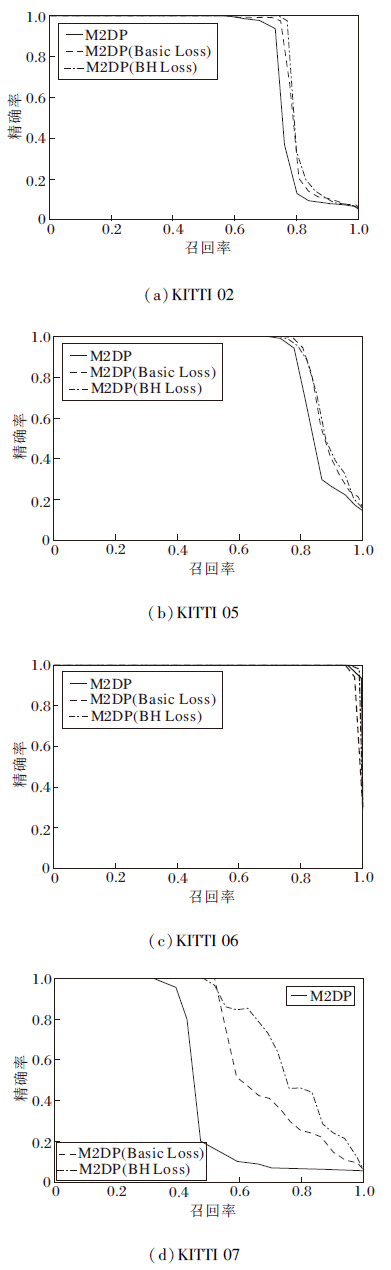 | 图9 M2DP描述子在KITTI数据集上的Top10 P-R曲线Fig.9 Top10 precision-recall curves of M2DP descriptor on KITTI dataset |
Top10结果的F1值如表3所示, 表中黑体数字表示最优结果.在M2DP描述子效果较差的场景下, 如KITTI07序列, BH Loss能有效拉近查询帧与对应回环帧的距离, Top10的准确度有很大的提升, 明显优于Basic Loss.在M2DP描述子效果较优的场景下, 如在02、05、06序列上, BH Loss也能起作用.由于Top10问题比Top1更简单, 因此本文算法与Basic Loss在简单场景下差距不大, 但总体而言, 本文的BH Loss优于Basic Loss.
| 表3 扩充后的M2DP描述子Top10结果的F1值 Table 3 Top10 F1 scores of M2DP descriptor after data augmentation |
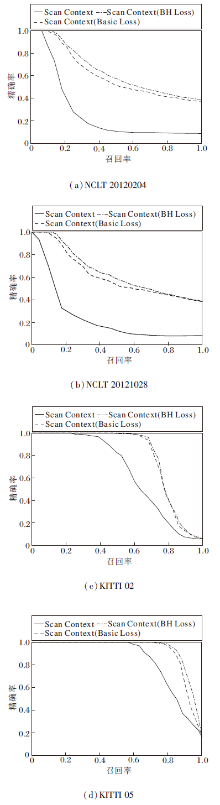
本文采用与2.3节完全相同的训练、测试方式, 对Scan Context描述子进行测试.Scan Context描述子的提取基本按照默认参数, 为了避免改变网络结构, 将Scan Context描述子维度从区分度较低的20维提升至192维, 改变后与M2DP描述子维度保持一致.评估时未用KITTI 数据集上00序列训练, 采用KITTI、NCLT数据集测试.
各算法的Top10 P-R曲线如图10所示, 观察图10(c)、(d)可发现, BH Loss在Scan Context描述子上依然有效, 可明显提升描述子的性能, 效果优于Basic Loss, 这得益于本文算法能更充分利用数据集, 挖掘样本之间的关系信息, 增强描述子的区分度.观察图10(a)、(b)可发现, BH Loss虽然是在KITTI数据集上完成训练, 但是在NCLT数据集上测试也取得明显效果.
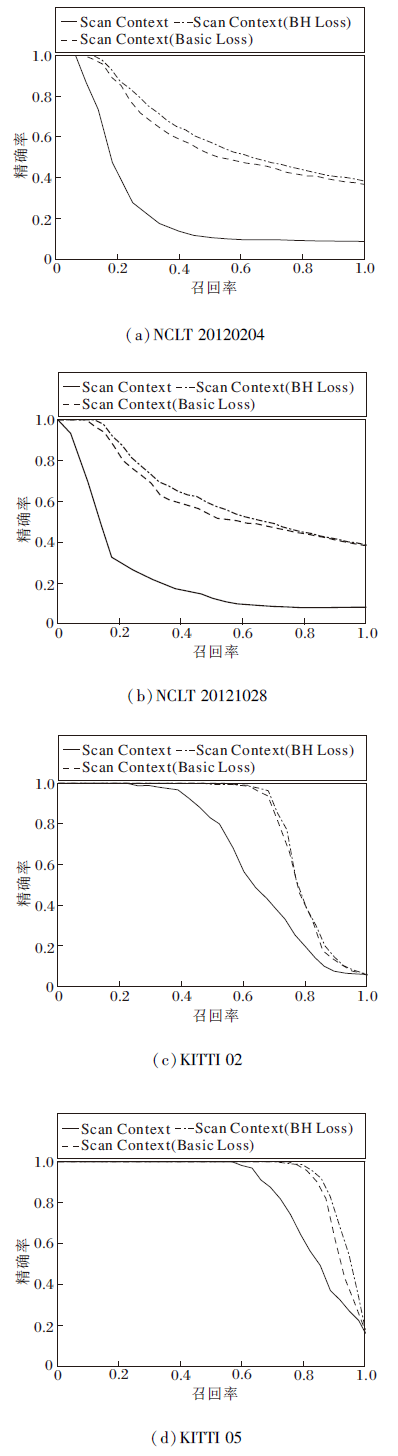 | 图10 Scan Context描述子的Top10 P-R曲线Fig.10 Top10 precision-recall curves of Scan Context descriptor |
各算法在NCLT数据集上Top10结果的F1值如表4所示.
| 表4 Scan Context描述子结果的Top10 F1值 Table 4 Top10 F1 scores of Scan Context descriptor |
由表4可知, 本文算法具有一定的泛化能力, 有跨越数据集使用的潜力.在原本效果较差的NCLT数据集上的提升比KITTI数据集更明显.
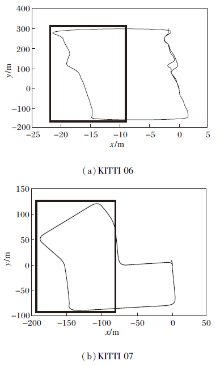
为了验证本文算法可使用无回环的数据进行训练, 并提升算法回环检测的性能这一特性, 本文将KITTI数据集上06、07序列进行切分, 取无回环的第200帧到第800帧用于训练, 剩余数据用于测试.数据划分情况如图11所示, 图中粗线框部分为训练数据, 其余为测试数据.
 | 图11 数据集划分情况Fig.11 Dataset division |
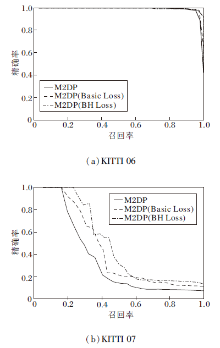
测试结果如图12所示, 训练后的M2DP效果有所提升, 使用BH Loss训练提升更大, 这得益于BH Loss在训练中能充分挖掘训练集的信息, 且使用的网络结构较为简单.
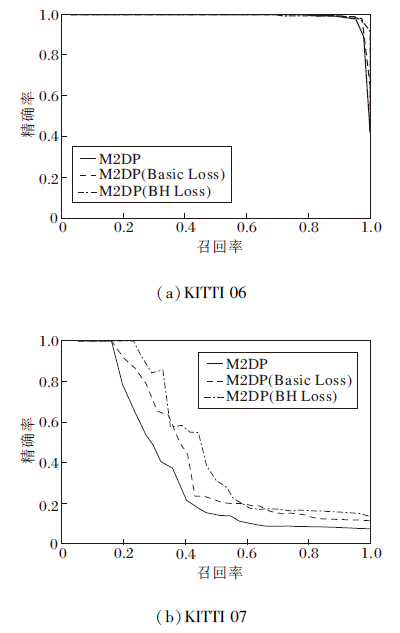 | 图12 序列片段测试结果Fig.12 Sequence fragment test results |
无回环数据的F1值如表5所示, 两个序列上的描述子效果均有提升, 在原效果较差的KITTI 07序列上提升明显, 验证BH Loss可利用不存在回环的数据提升回环检测的效果.由于正负样本的判断只是通过两个距离阈值, 对位姿精度要求不高, 因此在实际应用时, 可利用里程计模块计算位姿和对应帧的数据制作训练集, 方便快捷.
| 表5 无回环数据的F1值 Table 5 F1 score without loop |
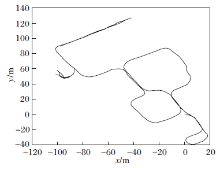
真实数据集采集自浙江大学玉泉校区的校园, 使用的激光雷达型号为Velodyne VLP-32C.位姿通过LOAM(Lidar Odometry and Mapping in Real-Time)[18]及位姿图优化获得, 绘制的行驶轨迹如图13所示, 由于其中大部分回环为逆向回环, 挑战性较大.本文选用具有旋转不变性的Scan Context描述子进行测试, 采用与2.4节完全相同的训练方式在KITTI数据集00序列上训练模型, 然后在真实数据集上进行测试.
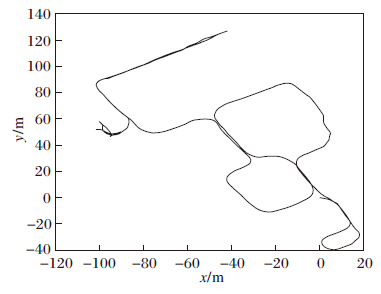 | 图13 真实数据集轨迹图Fig.13 Trajectory of real dataset |
真实数据集上的测试结果如图14所示, 在真实场景下, Scan Context描述子的Top1 P-R曲线较差, 训练后有较大的提升.这一结果进一步验证本文算法具有跨数据集使用的潜力.
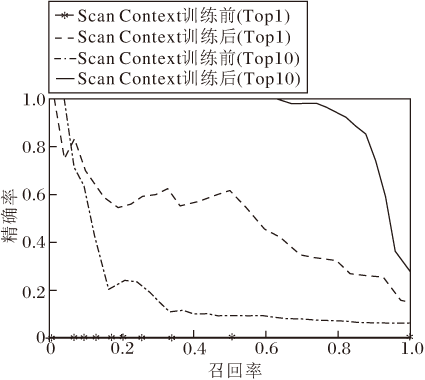 | 图14 真实数据集上的测试结果Fig.14 Testing results on real dataset |
真实数据集上的F1值如下所示:Scan Context训练前Top1结果为0.007, Top10结果为0.239, Scan Context训练后Top1结果为0.552, Top10结果为0.870.Top1结果的F1值提升0.545, Top10结果的F1值提升0.631, 说明在KITTI数据集00序列训练后, 真实场景下的数据集也起到明显效果, 体现本文算法的应用价值.
本文提出基于度量学习的回环检测描述子提升算法.制作三元组数据集应对标签不明确的问题, 提出利用邻近数据补充回环数据量的方法, 解决回环数据太少的问题.针对回环检测数据集数据量较小、训练较难的问题, 基于Triplet Loss改造适配的损失函数, 通过训练网络, 将描述子映射到一个区分度更高的空间.整体算法简单易用, 提升效果明显.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|