











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
动态环境下基于延迟语义的RGB-D SLAM算法
[王浩1  , 周申超
, 周申超1 , 方宝富1 ]
, 周申超, 方宝富]
|
|



作者简介:
王 浩,博士,教授,主要研究方向为分布式智能系统、机器人.E-mail:jsjxwangh@hfut.edu.cn.
周申超,硕士研究生,主要研究方向为视觉SLAM.E-mail:1103944960@qq.com.
目前,将分割网络与SLAM(Simultaneous Localization and Mapping)结合已成为解决视觉SLAM不能应用于动态环境的主流方案之一,但是SLAM系统受到分割网络处理速度的限制,无法保证实时运行.为此,文中提出基于延迟语义的RGB-D SLAM算法.首先,并行运行跟踪线程与分割线程,为了得到最新的延迟语义信息,采取跨帧分割的策略处理图像,跟踪线程根据延迟语义信息实时生成当前帧的语义信息.然后,结合成功跟踪计数(STC)与极线约束,筛选当前帧动态点的集合,并确定环境中先验动态物体的真实运动状态.若确定该物体在移动,继续将物体区域细分为矩形网格,以网格为最小单位剔除动态特征点.最后,利用静态特征点追踪相机位姿并构建环境地图.在TUM RGB-D动态场景数据集及真实场景上的实验表明文中算法在大部分数据集上表现较优,由此验证算法的有效性.
About Author:
WANG Hao, Ph.D., professor. His research interests include distributed intelligent systems and robots.
ZHOU Shenchao, master student. His research interests include visual SLAM.
Visual simultaneous localization and mapping(SLAM) cannot be applied to dynamic environment. The mainstream solution is to combine segmentation network and SLAM. However, real-time operation of SLAM systems is not guaranteed due to the processing speed constraints of segmentation network. Therefore, a RGB-D SLAM algorithm based on delayed semantic information in dynamic environment is proposed. Firstly, tracking and segmentation threads run in parallel. To obtain the latest delayed semantic information, a cross-frame segmentation strategy is employed for image processing, and real-time semantic information for the current frame is generated by the tracking thread according to the delaysemantic information. Then, the dynamic point set of the current frame is selected and the real motion state of the prior dynamic object in the environment is determined by combining successful tracking count and epipolar constraints. When the object is determined as moving, the object area is further subdivided into rectangular grids, and dynamic feature points are removed with the grid as the minimum unit. Finally, the camera pose is tracked by static feature points and an environment map is constructed. Experiments on TUM RGB-D dynamic scene dataset and real scenes show that the proposed algorithm performs well and its effectiveness is verified.
同时定位与地图构建(Simultaneous Localization and Mapping, SLAM)[1]技术是指机器人从未知的环境出发, 利用自身携带传感器获取的信息完成自身定位并建立环境地图, 它是机器人导航的核心技术, 近年来得到相关领域学者的广泛关注.相比以激光雷达作为传感器, 相机的成本更低且能获取更丰富的场景信息.因此, 在SLAM研究领域, 以相机为传感器的视觉SLAM[2]已成为一个热门研究话题.
ORB-SLAM[3]是视觉SLAM的经典算法之一, 在纯静态的环境中表现优秀, 但当相机视野中出现动态物体时, 动态物体上的特征点将被用于相机位姿估计, 导致估计的位姿与真实位姿存在较大偏差.然而, 在现实世界中往往存在大量的动态物体, 这使得传统的视觉SLAM不能真正部署在现实世界中.如何解决动态物体对SLAM系统造成的影响成为当下亟待解决难题之一.
随着计算机硬件与深度学习技术的发展, 将深度学习技术与SLAM系统结合现已成为解决传统SLAM在动态环境下出现问题的有效方法[4, 5].此解决方案通过神经网络识别环境中的物体, 将识别结果作为系统的先验信息, 可显著提高系统对周围环境中静态物体和动态物体的认知和区分能力.但是目前结合语义分割网络或实例分割网络的SLAM 系统仍存在一些问题, 如SLAM跟踪线程必须等待分割网络的处理结果才能进行相机位姿估计和环境地图建立.然而, 图像分割是一个耗时任务.例如, Mask R-CNN[6]、Deep-Lab[7]处理一帧图像耗时超过100 ms, 而SegNet[8]等轻量级网络虽然速度较快, 但仍达不到实时性的要求, SLAM系统受限于图像分割网络处理速度而无法保证实时性.此外, 大多数系统将环境中的先验动态物体都视为刚性物体, 整体检测物体的动静状态, 而忽略非刚性先验动态物体(如人类)在运动过程中仍有许多区域保持静止, 这些区域的特征点可用于相机追踪并提供更精确的位姿估计.
目前视觉SLAM主要分为特征点法[3]、半直接法[9, 10]、直接法[11].Klein等[12]提出PTAM(Parallel Tracking and Mapping), 设计的Tracking、Mapping双线程的架构, 大幅减少SLAM的处理时间.Mur-Artal等[4]提出ORB-SLAM2, 包含跟踪、建图、重定位、闭环检测四个模块, 适用于单目相机、双目相机和RGB-D相机, 且只需要CPU支持就能实时运行.Campos等[5]提出ORB-SLAM3, 在ORB-SLAM2的基础上增加IMU(Inertial Measurement Unit)和Atlas[13], 提高SLAM系统在中大型环形环境的鲁棒性.Engel等[14]提出LSD-SLAM(Large-Scale Direct Monocular SLAM), 不需要提取特征点和计算描述子, 而是直接追踪整幅图像的所有像素.
传统视觉SLAM都建立在周围环境是静态这个强假设上, 并不适用于真实世界的动态环境.为了克服这一缺陷, Sun等[15]根据自运动补偿图像差异检测动态物体运动, 然后使用粒子滤波器和最大后验(Maximum a Posteriori, MAP)估计器, 精确确定前景, 剔除动态区域.Zhang等[16]提出FlowFusion, 使用密集的光流残差检测场景中的动态区域, 通过相机位姿将前一帧偏移, 得到一幅全静态假设的光流图, 再和经过PWC Net[17]的真正光流图对比, 找出动态区域.Dai等[18]提出DSLAM(Dynamic SLAM), 基于点相关的方法区分静态点和动态点, 通过Delaunay三角剖分, 将地图点初始化为图结构, 并利用静态点和动态点的相对位置关系分割图, 最后保留静态区域, 用于位姿估计.艾青林等[19]提出基于网络分割与双地图耦合的RGB-D SLAM, 使用网格分割代替像素级分割, 通过双向光流法找出动态特征点, 再结合几何连通性与深度聚类进行逐帧动态区域分割, 避免动态特征点参与位姿估计.
上述算法都是在几何学的基础上处理图像, 在一定程度上可减少动态物体对SLAM的影响, 处理速度较快, 对硬件要求相对较低.然而, 算法也存在一些局限性.首先, 精度不够高, 估计的轨迹跟真实轨迹仍存在较大误差; 其次, SLAM系统缺乏环境的语义信息, 无法建立环境的语义地图.
随着深度学习技术快速发展, 将图像分割、目标检测与视觉SLAM结合已成为解决SLAM适用于动态场景的方法.Bescos等[20]提出 DynaSLAM, 利用 Mask R-CNN对图像进行实例分割, 并通过多视图几何法检测非先验动态对象.Yu 等[21]提出DS-SLAM, 使用SegNet进行语义分割, 并结合语义信息与运动一致性, 提高位姿估计精度, 生成包含语义信息的八叉树地图.Zhong等[22]提出Detect-SLAM, 将特征点属于动态物体的概率称为移动概率, 特征点区分为四种状态:高置信度静态、低置信度静态、高置信度动态和低置信度动态.Detect-SLAM只对关键帧使用SSD(Single Shot Multibox Detector)[23]目标检测, 并在跟踪线程中逐帧传播移动概率.Fang等[24]利用Mask R-CNN描述关键点周围的语义信息, 并与知识图谱一起构建语义信息描述符, 精确检测动态对象.
但上述方法仍存在一些问题, SLAM系统在跟踪每帧时依赖于图像分割对当前帧的处理结果, 之后才能进行后续帧的跟踪.然而, 图像分割是一个耗时的任务, 故SLAM系统受限于图像分割的处理速度, 无法保证实时性.此外, 在SLAM系统获取环境中先验动态物体的语义信息后, 未精细判断物体上的动态区域, 而是直接剔除整个先验动态物体.
针对上述问题, 本文提出基于延迟语义的RGB-D SLAM算法(RGB-D SLAM Algorithm Based on De-layed Semantic Information in Dynamic Environment, DSV-SLAM).跟踪线程无需等待当前帧的分割结果, 而是结合当前帧深度图与延迟语义信息, 通过网格聚类的方法实时生成语义信息.为了使跟踪线程尽可能地获取最新的延迟语义信息, 采用跨帧分割的策略, 而不是对所有的图像帧逐帧分割.当跟踪线程获取先验动态物体的语义信息后, 并非直接剔除, 而是判断其真实的运动状态.如果它们是静止状态, 保留物体上的特征点用于位姿估计; 如果它们在运动, 则更精细地划分动态物体区域, 并仅剔除移动区域.DSV-SLAM解决SLAM应用于动态环境的问题, 提升相机位姿估计的精度, 并且系统不受图像分割网络的影响而能保持实时性.
算法
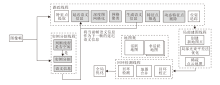
本文基于ORB-SLAM3进行重构, 提出基于延迟语义的RGB-D SLAM算法(DSV-SLAM).算法框架如图1所示, 图中用灰色标记的模块是本文新增模块.
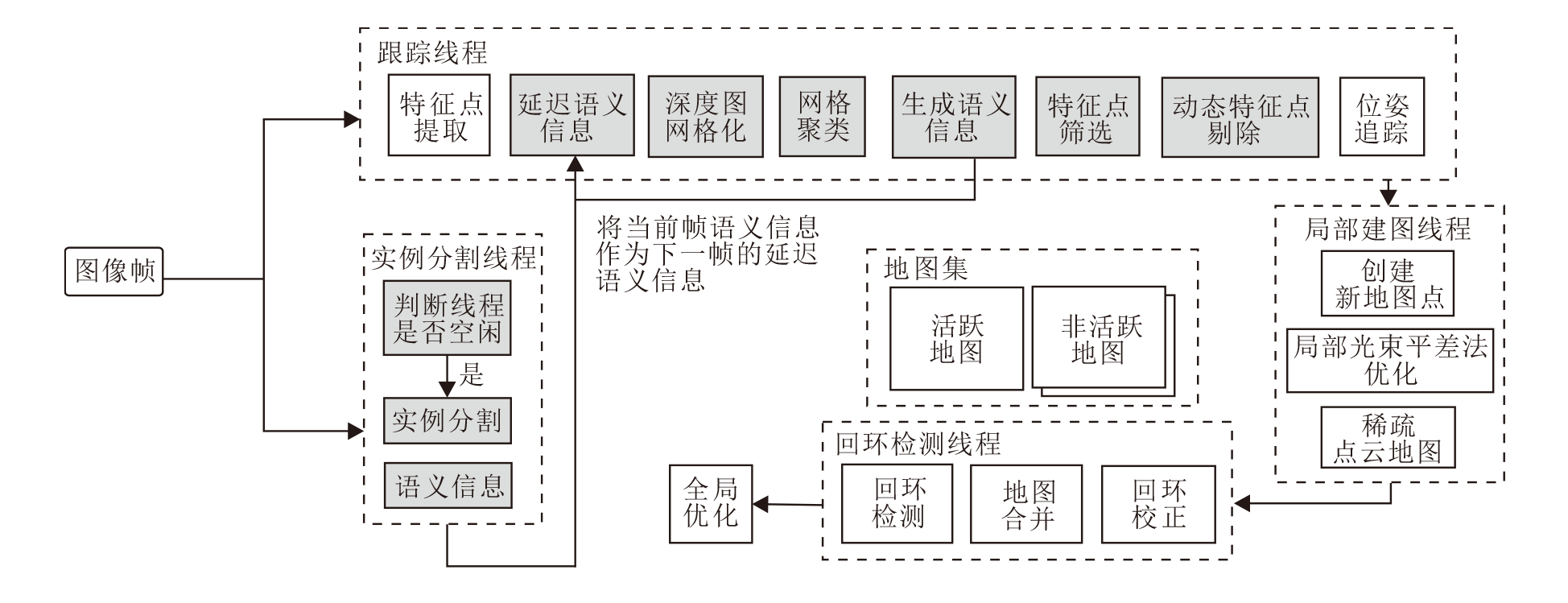 | 图1 DSV-SLAM框架图Fig.1 Structure of DSV-SLAM |
DSV-SLAM包含四个线程:跟踪线程、实例分割线程、局部建图线程、回环检测线程.为了使SLAM的跟踪线程与图像分割线程松耦合, 算法未采用串行的处理模式, 而是让跟踪线程与分割线程并行处理图像帧.本文系统与机器人操作系统(Robot Ope-rating System, ROS)集成, 将ORB-SLAM3与图像分割线程分别当作ROS的两个单独节点运行, 图像信息通过ROS服务通信的方式在两个节点间通信, 跟踪线程与分割线程通过进程互斥量保证整个系统有效地并行运行.
当SLAM节点读取一组连续RGB-D图像后会同时通过ROS间的通信传递给图像分割节点进行处理, 分割节点会根据是否完成上一次分割任务, 而决定是否处理当前帧.同时, 若分割节点完成对图像的分割, 则通过ROS间的通信传递给SLAM节点进行后续处理.由于两个线程并行运行, 并且分割线程的处理速度慢于跟踪线程, 分割线程返回的语义信息相对于当前帧来说是滞后的语义信息, 本文将它定义为延迟语义信息, 利用深度图网络生成当前帧语义信息.为了减少由于处理速度不一致带来的信息差, 分割线程采用跨帧分割的策略, 即线程不会对图像进行逐帧分割, 而是根据是否完成对上一次图像的分割任务确定是否对当前图像进行分割, 以确保跟踪线程能接收到最新的语义信息.
为了兼顾图像分割的速度与精度, 本文采用SOLOv2[25]轻量级模型分割图像.当跟踪线程跟踪当前帧时, 若分割线程未完成上一次分割任务, 则结合前一帧的语义信息和当前帧的深度图生成语义信息; 否则, 根据延迟语义信息和当前帧的深度图生成语义信息.在得到先验动态物体的语义信息后, 精细判断物体各部位的运动状态, 筛选并剔除动态特征点, 利用静态特征点估计相机位姿和建立静态环境地图.
本文使用的SOLOv2是实例分割网络, 能区分场景中相同类别的不同实例, 如区分场景中不同的人, 这样就能知道每个先验动态物体在环境中的深度信息与位置信息.令Fn表示第n帧的RGB图像, Sn表示语义分割对第n帧分割结果, S'n表示DSV-SLAM生成的第n帧语义信息, Dn表示第n帧深度图像.
跟踪线程获取延迟语义信息后, 不能直接去除当前帧的动态物体.但是, 图像帧在时间和空间上是连续的, 在极短的时间内, 在连续的几个图像帧中, 同一物体在空间中的位置与深度都不会发生剧烈的变化.如图2所示, 图中黄色边缘内区域表示先验动态物体延迟语义信息.
 | 图2 当前帧深度图与延迟语义信息的差异Fig.2 Difference of current frame depth image and delayed semantic information |
当跟踪线程对第n帧RGB图像Fn进行跟踪时, 实例分割线程返回第k(k < n)帧Fk的实例分割结果:
${{S}_{k}}=\{(S_{k, id}^{i}, S_{k, mask}^{i})|i\ge 0\}$,
其中,
$d_{k}^{i}=\frac{1}{N}\overset{N}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, {{v}_{i}}$,
其中, N表示Dk落在掩膜区域
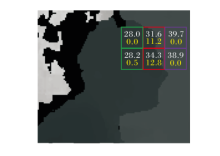
首先, 将图像Fn的深度图Dn划分为w× w的矩形网格.若网格的平均深度值相近并且在几何上相邻, 这些网格很可能属于同一物体.网格的标准差大小反映像素点所处网格的差异程度.标准差越大, 表明该网格内的像素点越不可能属于同一物体, 往往位于物体边缘.标准差越小, 说明该网格内的像素点越可能属于同一物体, 通常位于物体内部.如图3所示, 白色数字表示深度平均值, 黄色数字表示标准差, 绿色边框的网格属于一类物体.紫色边框的网格属于另一类物体, 它们都位于物体内部.红色边框网格位于两类物体相交的边缘.
 | 图3 网格的平均值与标准差Fig.3 Mean and standard deviation of mesh |
深度图Dn第h个网格的平均深度值:
$m_{n}^{h}=\frac{1}{N}\overset{N}{\mathop{\underset{j=1}{\mathop \sum }\, }}\, {{v}_{j}}$,
其中, N表示网格内所有像素的个数, vj表示网格区域内每个像素点对应的深度值.第h个网格的标准差:
$std_{n}^{h}=\sqrt[]{\frac{1}{N-1}\overset{N}{\mathop{\underset{j=1}{\mathop \sum }\, }}\, {{({{v}_{j}}-m_{n}^{i})}^{2}}}$.
传统方法是基于深度图中聚类中心与各点深度值的差异进行聚类, 本文与此不同, 是对深度图进行网格划分, 计算每个网格内深度值的均值与标准差, 用于聚类.这种方法可显著减少计算量, 提高处理速度.
将第k帧的先验动态物体i的掩膜
${{d}_{f}}=\text{ }\!\!|\!\!\text{ }m_{n}^{h}-d_{k}^{i}\text{ }\!\!|\!\!\text{ }$.
当网格h满足条件1), 即差值df和网格标准差都小于等于阈值θ b, 将其加入集合V.
遍历集合V, 找出满足条件1)且不在集合V中所有内部网格, 也加入集合V.再找出与集合V中元素邻接的边缘网格, 加入集合V.邻接的边缘网格应满足条件2), 即网格标准差大于阈值θ b, 并且网格内部像素点的深度值与
网格聚类示意图如图4所示, 绿色边缘的网格表示内部网格, 红色边缘的网格表示边缘网格.
 | 图4 网格聚类示意图Fig.4 Illustration of grid clustering |
根据集合V中的所有网格生成先验动态物体在当前帧的语义信息.遍历集合V中的网格, 如果该网格是内部网格, 将该网格内的所有像素点提取为掩膜, 否则, 对边缘网格h中像素点深度值在[
 | 图5 当前帧语义信息Fig.5 Semantic information of current frame |
在得到当前帧语义信息后, 若直接将先验动态物体掩膜内的特征点标记为动态特征点并剔除, 当这些动态特征点占总特征点的比例较大时, 会导致跟踪线程的特征点数量过少, 从而使视觉SLAM系统的跟踪失败.所以, 本文筛选先验动态物体掩膜内的特征点, 判断其真实的运动状态.
首先, 定义地图点的成功跟踪计数(Successful Tracking Count, STC).STC表示自地图点被创建后, 被后续帧成功跟踪次数的累加和.当关键帧的特征点被创建为地图点加入局部地图后, 若该地图点为一个静态的地图点, 那么该点在后续帧的局部地图跟踪过程中应能被多次跟踪.反之, 若该点创建后很少被跟踪成功, 则认为该点是一个可疑的动态点.选取离当前帧的参考关键帧最近的5个关键帧生成的地图点, 统计自该地图点Pi被创建到当前帧的STC, STC的更新公式如下:
STC(Pi)=STC(Pi)+1.
计算STC(pi)与STC(avg)的比值dstc.若dstc> θ stc, 并且该特征点位于先验动态物体上, 认为特征点pi为可疑动态特征点, 加入动态特征点集合Vd.
根据极线约束进一步验证Vd的特征点.若P为空间中一个地图点, 直线lk-1, lk为极线:
${{l}_{k}}={{F}_{k}}_{-1, k}\times {{x}_{k}}_{-1}={{[\begin{array}{* {35}{l}} {{X}_{k}} & {{Y}_{k}} & {{Z}_{k}} \\ \end{array}]}^{T}}$,
其中xk-1为特征点pk-1的归一化像素坐标.
pk、 pk-1为P在图像帧中对应的特征点.在理想情况下, pk应位于极线lk上, 但在实际情况中, 由于噪声的存在, pk偏离极线lk, pk到lk的距离为:
$d=\frac{{{x}^{\text{T}}}_{k}\ {{F}\ _{k-1,k}}\ \ \ {\ \ \ {x}\ _{k-1}}\ \ \ \ }{\ \ \ \sqrt[]{\left| {{X}_{K}} \right|{^{2}}+\left| {{Y}_{K}} \right|{^{2}}}\ \ \ \ }$,
其中, xk表示特征点pk的归一化像素坐标.Fk-1, k表示Fk-1变换到Fk的基础矩阵, 它的计算不会使用可疑动态特征点集合Vd中的点, 而是通过Fk-1与Fk的静态匹配特征点对通过随机采样一致性(Random Sample Consensus, RANSAC)计算得出.
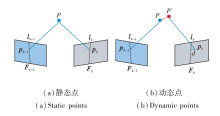
若地图点未移动, d应小于阈值θ s.若地图点发生移动, 如图6所示.
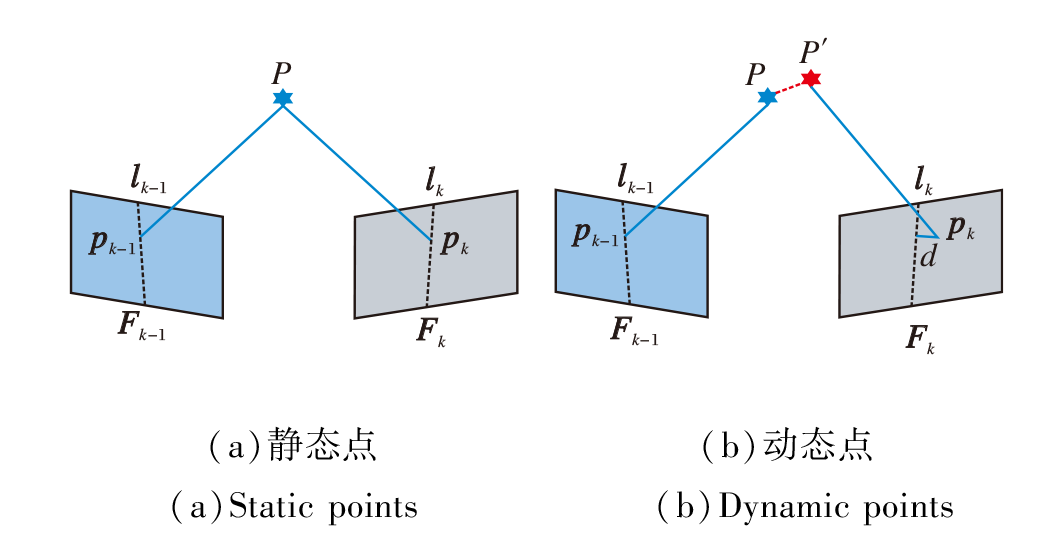 | 图6 极线约束示意图Fig.6 Epipolar constraints |
图6中P移动到P'位置, 此时与P'对应的特征点pk到lk的距离d大于阈值θ s, 该点不满足极限约束, 为动态特征点.θ s阈值过大与过小都会导致位姿精度的下降.图7为不同θ s阈值在walking_xyz图像序列下绝对轨迹均方根误差(Root Mean Square Error, RMSE)的误差值.遍历Vd的特征点, 根据极限约束对所有特征点进行验证筛选.
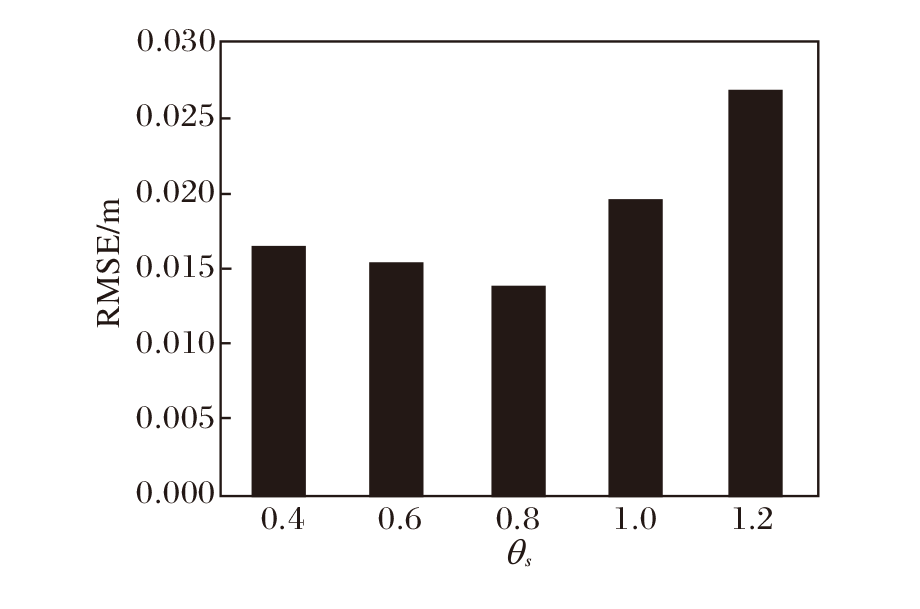 | 图7 θ s不同时绝对轨迹RMSE值对比Fig.7 Comparison of absolute trajectory RMSE with different values of θ s |
动态特征点筛选结果如图8所示, 红点为动态特征点, 绿点为静态特征点.(a)为经过STC筛选的特征点, (b)为极线约束进一步验证得到的特征点分类结果.
 | 图8 动态特征点筛选结果Fig.8 Screening results of dynamic feature point |
为了准确剔除当前帧中的动态特征点, 需要精细判断先验动态物体各区域的运动状态.与将先验动态物体视为刚体整体判定运动状态不同, 本文认为运动物体(如人)在运动中仍有许多区域保持静止, 而且在一定区域内特征点有相同的运动趋势.所以, 本文将结合动态特征点集合Vd、当前帧语义信息S'n和与之对应的网格集合V剔除动态特征点.首先遍历特征点集合
本文在TUM RGB-D数据集、真实场景中的医院环境、家居环境中测试算法.选取TUM数据集中fr3动态场景数据集的fr3/walking_* 序列和fr3/sitting_* 序列作为实验数据集.fr3/walking_* 序列为高动态数据集, 场景中有2个人在桌前来回走动, 而fr3/sitting_* 序列的动态程度较低, 2个人坐在桌前交谈, 运动幅度较小.真实场景中都选取有人活动的动态场景进行测试.为了消除偶然误差, 提高实验结果的准确性, 本文对每个测试数据集序列运行10次, 并将所有结果取平均值作为最终的实验结果.
实验运行环境为64位Ubuntu 18.04系统, Inter i5-12400F CPU、NVIDIA GeForce GTX3070、16 GB运行内存.
参数的设置经过在公共数据集与真实环境共10个序列上的验证调优得到, 具体数值如下:θ b=3, θ stc=1.2, θ s=0.8, θ obj=1.5, θ grid=2, w=25.
DSV-SLAM在fr3/walking_* 序列上的运行结果如图9所示, (a)是未使用DSV-SLAM前的结果, 因为使用延迟语义信息, 先验动态物体(黄色区域)掩膜未能准确标识环境中移动的人.(b)为结合当前帧深度图与延迟语义信息网格聚类后的结果, 绿色网格区域为人所在区域.(c)为DSV-SLAM得到的最终结果, 精确标识人的位置, 用于后续动态特征点的剔除.在(a)中, 由于相机快速移动, 导致图像右侧的人消失在当前帧的视野中, 而延迟语义信息显示他还在相机视野中, DSV-SLAM可准确判别这种边界情况, 如(c)右侧并未错误生成掩膜, 由此验证DSV-SLAM的鲁棒性.
 | 图9 DSV-SLAM在fr3/walking_* 序列上的生成图像Fig.9 Images generated by DSV-SLAM on fr3/walking_* sequence |
DSV-SLAM在医院场景(左图)和真实家居(右图)的生成图像如图10所示.
 | 图10 DSV-SLAM在真实场景中的生成图像Fig.10 Images generated by DSV-SLAM in real-world scene |
由图10可见, 在真实动态场景下, DSV-SLAM依然表现较优.
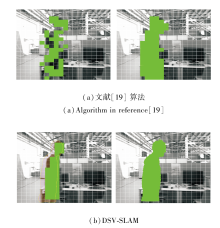
此外, 本文还与文献[19]算法进行对比.文献[19]算法通过双向补偿光流法找出图像中可疑的动态区块, 通过几何连通性处理孤立区块与被包围区块, 再通过K-means++聚类进行优化, 得到结果图.DSV-SLAM使用延迟语义信息作为参照, 得到初始动态网格区域, 然后, 采用计算与其相邻网格平均深度值差值的方法进行聚类, 最后, 结合深度图对每个网格进行掩膜提取, 得到最终图像.
2种算法网络聚类分割结果如图11所示.
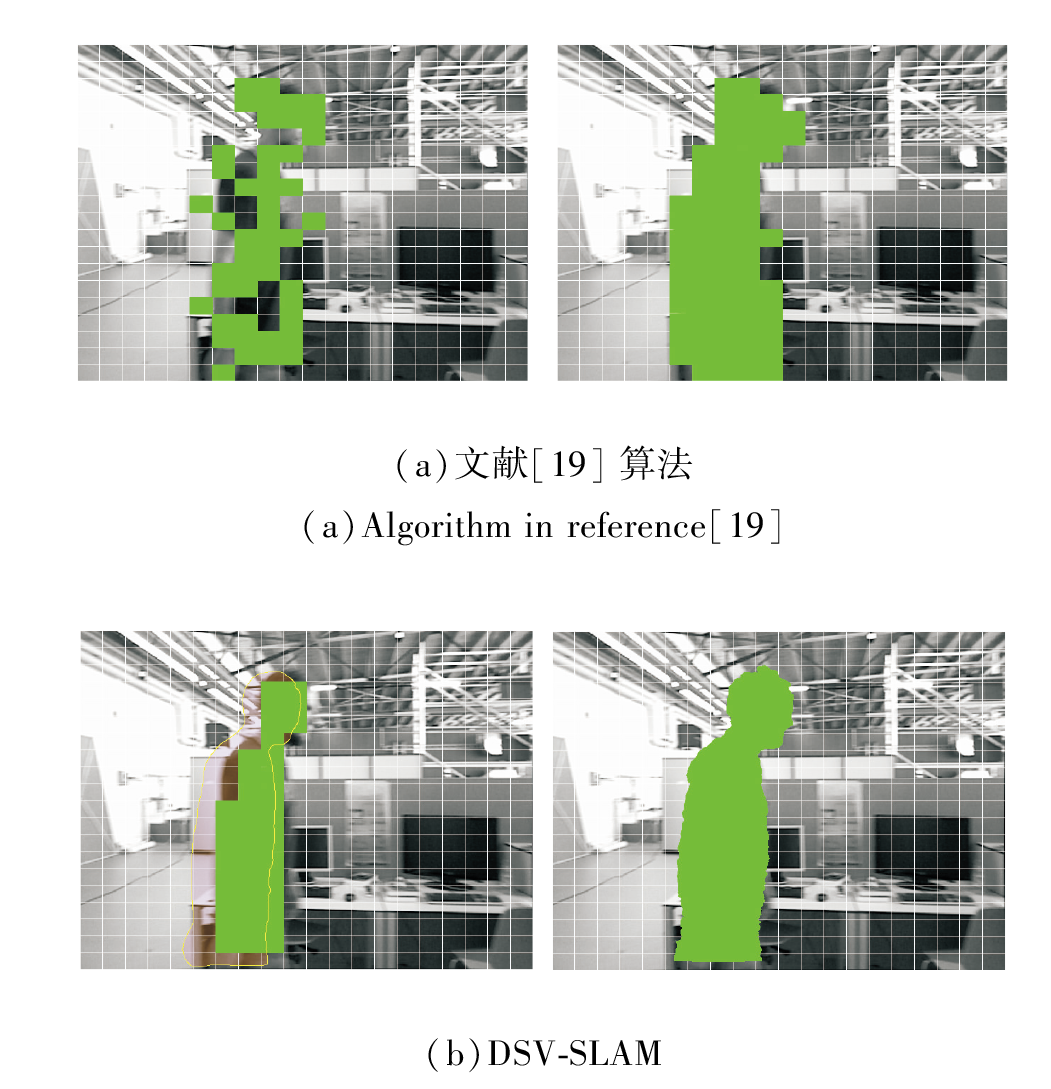 | 图11 两种算法网格聚类分割结果对比Fig.11 Segmentation result comparison of 2 grid clustering algorithms |
由图11可见, DSV-SLAM的聚类速度快于K- means++聚类, 不需要迭代选择K个聚类中心, 对比(a)、(b)可看出, DSV-SLAM能得到更精细的先验动态物体掩膜信息.
为了检测DSV-SLAM筛选和剔除动态特征点的有效性, 在TUM数据集与真实场景数据集上各选择两个序列进行动态特征点判断和剔除实验, 结果如图12和图13所示, 红点表示动态特征点, 绿点表示静态特征点, 只有静态特征点才能被用于位姿估计.
 | 图12 DSV-SLAM在TUM数据集上动态特征点筛选与剔除 结果Fig.12 Dynamic feature points screening and removal by DSV-SLAM on TUM dataset |
 | 图13 DSV-SLAM在真实场景动态特征点筛选与剔除结果Fig.13 Dynamic feature points screening and removal of DSV-SLAM in real-world scene |
在图12(a)中, 坐在凳子上的人处于静止状态, 所以他身上的特征点都被识别为静态特征点, 而他右边站立的人处于运动状态, DSV-SLAM准确识别他身上的动态特征点区域和静态特征点区域.(b)为对(a)中动态点剔除后的结果.
在图13(a)中, DSV-SLAM不仅识别属于人身上的动态特征点, 而且还识别人手上书本上的动态特征点, 展现DSV-SLAM对场景中的被动移动物体检测能力.同时, DSV-SLAM也准确将(a)静止坐在病床上的人识别为静态物体, 保留人身上的静态特征点用于位姿跟踪, (b)为对(a)中动态点剔除的结果.实验结果表明, DSV-SLAM能准确判别先验动态物体真实的运动状态.若物体在运动, 能分区域剔除物体上动态特征点, 保留静态特征点用于追踪相机位姿.
此外, 大部分语义SLAM系统都将先验动态物体当做整体以剔除动态特征点, 如DS-SLAM[21]、Fang等[26]提出的动态特征点剔除算法, 而DSV-SLAM对动态物体进一步细分为网格区域以判断运动状态.本文选取DS-SLAM进行动态特征点筛选和剔除.实验选取的图像帧为环境中出现大量光滑地板的弱纹理场景, 该场景下环境中能提取到的特征点数量较少, 而DS-SLAM通过运动一致性和先验动态物体的语义信息检测动态特征点.
DS-SLAM和DSV-SLAM筛选和剔除动态特征点的结果如图14所示.
 | 图14 两种算法动态特征点筛选和剔除结果Fig.14 Dynamic feature points screening and removal of 2 algorithms |
由图14(a)可看出, 动态特征点的数量占比接近总数量的一半.再将动态物体上的特征点全部剔除, 当动态特征点的数量占比较大时可能会因静态特征点数量不足导致跟踪失败.DSV-SLAM不整体剔除动态物体的特征点, 而是使用网格进一步细分动态物体, 从而判断每个网格区域的运动状态, 由(b)可看出, DSV-SLAM保留动态物体一部分静态特征点用于后续的跟踪匹配, 提高系统的鲁棒性.
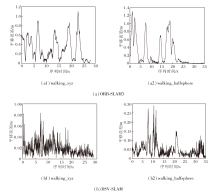
对比真实位姿轨迹与估计位姿轨迹可以定量评估SLAM的性能, 评估指标为绝对轨迹误差(Abso-lute Trajectory Error, ATE)和相对位姿误差(Rela-tive Pose Error, RPE).在TUM RGB-D数据集上选择walking_xyz、walking_halfsphere序列, ORB-SLAM3和DSV-SLAM的ATE对比如图15所示, 红色线段表示真实轨迹与估计轨迹的绝对误差, 红色线段越短表示误差越小, 算法精度越高.
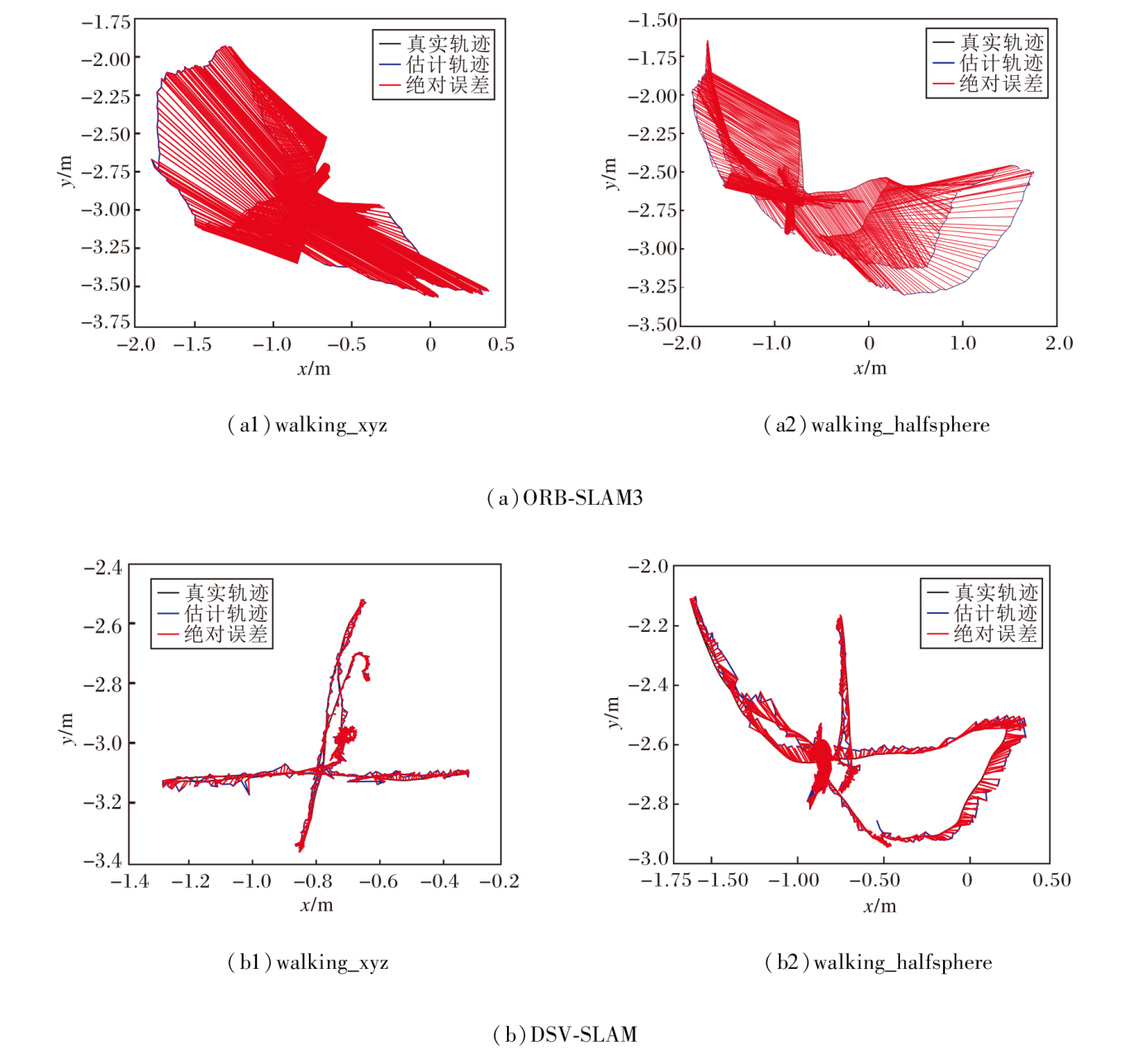 | 图15 两种算法在2个序列上的ATE对比Fig.15 ATE comparison of 2 algorithms on 2 sequences |
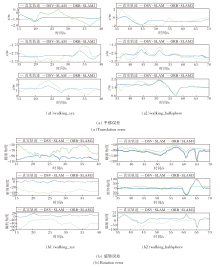
ORB-SLAM3与DSV-SLAM在walking_xyz、walking_halfsphere序列上的RPE对比如图16所示, 图中y轴表示估计位姿与真实位姿在某一时刻的平移误差.
 | 图16 两种算法在2个序列上的相对位姿误差对比Fig.16 RPE comparison of 2 algorithms on 2 sequences |
从图16可清晰看出, DSV-SLAM的精度远高于ORB-SLAM3.
DSV-SLAM和ORB-SLAM3在fr3数据集的5个序列上的ATE与RPE对比如表1和表2所示, 同时计算DSV-SLAM比ORB-SLAM3性能提升的百分比.
| 表1 两种算法在5个序列上的ATE对比 Table 1 ATE comparison of 2 algorithms on 5 sequences |
| 表2 两种算法在5个序列上的RPE对比 Table 2 RPE comparison of 2 algorithms on 5 sequences |
由表1和表2可以看出, 在fr3/walking_* 高动态序列上, 相比ORBSLAM3, DSV-SLAM的性能大幅提升, 这是因为在高动态环境中运动物体运动幅度较大, 场景中动态特征点数量占比较高, 能有效剔除这些动态特征点.而在sitting_xyz低动态序列上, DSV-SLAM提升并不明显, 因为在低动态的环境中, 动态物体只有小幅运动, 场景中动态特征点的数量极少, 这种情况下ORB-SLAM3根据RANSAC就能剔除这些外点, 并达到较优的跟踪效果.
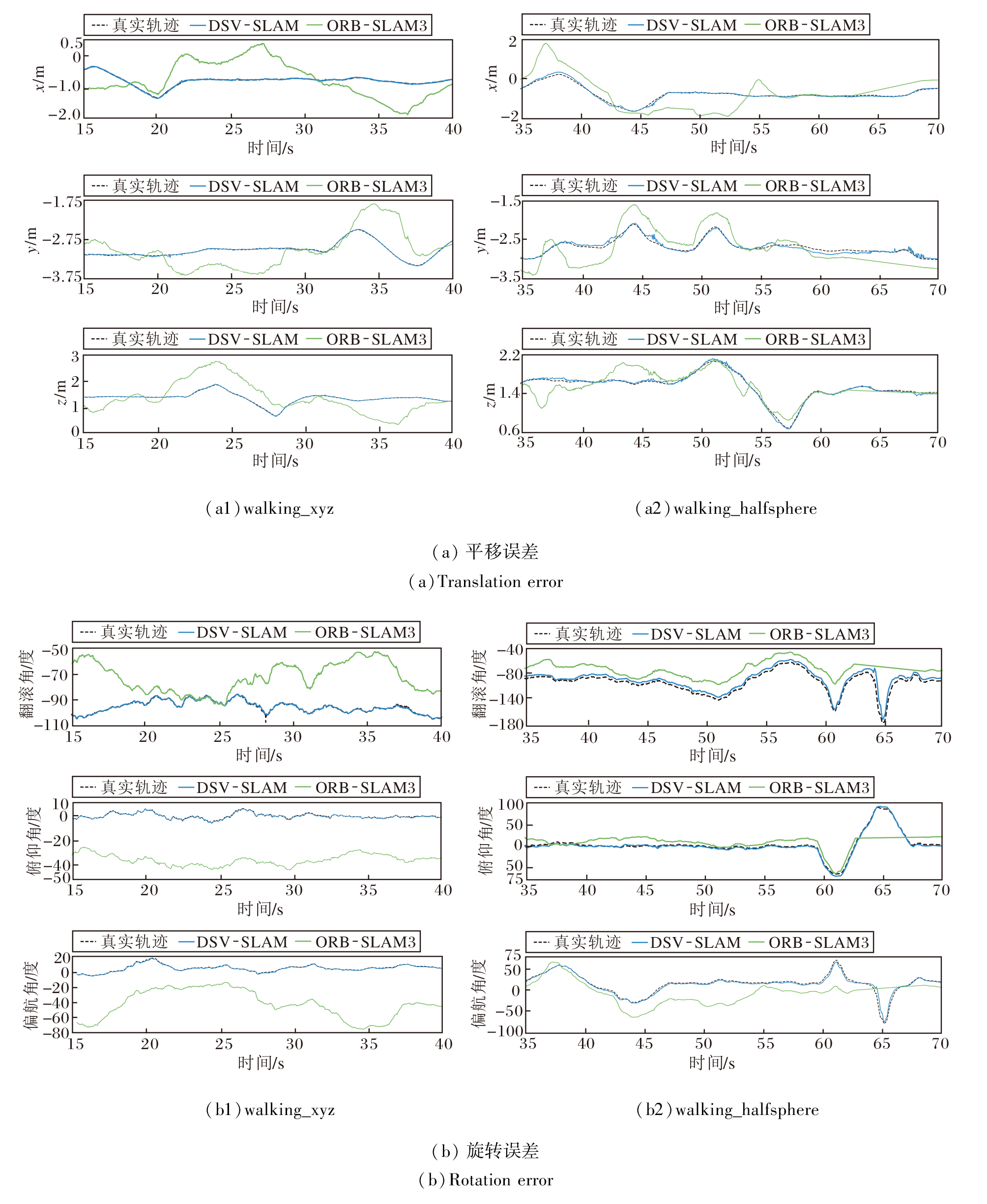
在walking_xyz、walking_halfsphere序列上, 对比DSV-SLAM和ORB-SLAM3估计的相机运动轨迹与相机真实轨迹, 如图17所示.图中蓝线表示ORB-SLAM3估计的相机运动轨迹, 绿线表示DSV-SLAM估计的相机运动轨迹.
 | 图17 DSV-SLAM、ORB-SLAM3与真实轨迹对比图Fig.17 Comparison of real trajectories and trajectories generated by DSV-SLAM and ORB-SLAM3 |
由图17可以看出, 在相同尺度下, DSV-SLAM获得的相机运动轨迹与真实轨迹基本一致, 而 ORB-SLAM3由于受动态物体的影响, 轨迹出现较大偏差.
除了与ORB-SLAM3对比, 本文还选择近年来处理动态场景较优秀SLAM:DynaSLAM[20]、DS-SLAM[21]、RS-SLAM[27]、SG-SLAM[28]、DPF-SLAM(Dy-namic Probability Fusion SLAM)[29].各算法的ATE对比如表3所示.原文献若提供开源代码, 给出使用开源代码在本文实验环境中的运行结果; 否则, 直接引用原文献中的数据, 并且使用* 标明.表中黑体数字表示精度最高, 斜体数字表示精度次高.由表可以看出, 这些面向动态场景的视觉SLAM在不同的场景序列中各有优势.DynaSLAM在高动态序列上表现良好, 但在sitting_xyz低动态序列表现不佳, 这是因为DynaSLAM并未考虑环境中人真实的运动状态, 而是将人都视为动态物体剔除, 当人身上的特征点数目过多时, 可能导致用于位姿估计的特征点太少而算法失效.DS-SLAM在高动态序列的表现差于DynaSLAM, 是因为DS-SLAM使用轻量级语义分割网络SegNet, 处理速度快于DynaSLAM使用的实例网络Mask R-CNN, 但精度不高, 在高动态场景下容易出现漏分割现象, 导致位姿估计精度下降.RS-SLAM有两个序列精度次高, 是因为它使用贝叶斯更新, 让分割结果更精确, 并且检测环境中被动移动物体的运动状态, 提高位姿估计的精度.DSV-SLAM在高低动态环境中都表现良好, 因为DSV-SLAM能准确判断先验动态物体的真实运动状态, 最大程度地保留环境中的静态特征点用于相机位姿估计, 从而提升算法精度, 保证系统的鲁棒性.
| 表3 各算法在5个序列上的ATE对比 Table 3 ATE comparison of different algorithms on 5 sequences |
为了体现DSV-SLAM的实时性, 统计语义分割模块和跟踪模块处理一帧图像的耗时, 并计算整个SLAM系统处理一帧图像的平均耗时.选择ORB-SLAM3[5]、DynaSLAM[20]、DS-SLAM[21]、RS-SLAM[27]、PSPNet-SLAM(Pyramid Scene Parsing Network SL- AM)[30]进行对比实验, 运行时间如表4所示.
| 表4 各算法主要模块的运行时间对比 Table 4 Running time comparison of main modules of different algorithms ms |
对于开源SLAM使用在本文实验环境中各个模块真实的运行时间, 没有源代码的SLAM用* 标明, 并根据原文献给的数据近似计算.由表4可得, DynaSLAM、RS-SLAM等由于语义网络分割非常耗时, 整个系统处理每帧的时间都超过150 ms.而DSV-SLAM将语义线程与跟踪线程并行执行, 系统的执行速度不受语义分割网络的影响, 系统处理1帧大约为28 ms, 大幅减少时间开销, 保证系统的实时性.
实验使用搭载Kinect V2相机的机器人, 在真实的实验室场景下验证DSV-SLAM的有效性, 结果如图18所示.(a)为原始特征点提取结果, (b)为DSV-SLAM结合延迟语义信息生成的当前帧语义分割结果, (c)为动态特征点的筛选结果, (d)为剔除动态特征点的结果, 算法在机器人上的运行帧率为35.82 毫秒/帧.DSV-SLAM在真实场景中能保证实时性的同时, 获得环境中动态物体的语义信息, 提升SLAM系统在高动态环境下的定位精度, 因此在真实场景中具有普适性与鲁棒性.
 | 图18 DSV-SLAM在实体机器人真实场景中的结果Fig.18 Experimental results of DSV-SLAM on physical robots in real scene |
为了使SLAM在动态环境中有更好的精度和鲁棒性, SLAM系统需要语义网络为其提供对周围环境的感知能力, 从而辨别环境中出现的动态物体.然而, 目前大部分SLAM与语义网络结合的系统都采用串行模型, SLAM系统对当前图像帧的跟踪过程中非常依赖语义网络对图像帧的分割结果, 导致整个SLAM系统的实时性无法保证.因此, 本文提出基于延迟语义的RGB-D SLAM算法(DSV-SLAM), 在ORB-SLAM3基础上增加实例分割线程, 并与跟踪线程并行运行, 跟踪线程不会因为等待当前帧的语义信息而堵塞, 而是实时生成当前帧的语义信息.在得到当前帧的先验动态物体语义信息后, 并不会直接将物体上的特征点视为动态点直接剔除, 而是判断物体真实的运动状态.如果确定该物体在运动, 继续将物体区域细分为网格, 以网格为最小单位剔除动态特征点.在TUM RGB-D公共数据集、真实医院场景和真实家庭环境上的实验表明, 相比ORB-SLAM3, DSV-SLAM在动态环境中性能大幅提升, 相比其它处理动态场景的先进SLAM仍保持较高的定位精度, 并且整个系统能保持实时运行.今后将尝试构建对象级语义地图, 利用构建的地图实现机器人导航.
本文责任编委 李贻斌
Recommended by Associate Editor LI Yibin
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|