




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于鸟瞰图的空间-通道注意力多传感器融合
[吉宇哲1  , 陈奕洁
, 陈奕洁2 , 杨柳青1, 2 , 郑心湖2 ]
, 陈奕洁, 杨柳青, 郑心湖]
|
|


作者简介: 
吉宇哲,博士研究生,主要研究方向为多模态融合感知、多车协同感知.E-mail:yji755@connect.hkust-gz.edu.cn. 
陈奕洁,硕士研究生,主要研究方向为多智能体协同感知、车路协同系统.E-mail:ychen324@connect.hkust-gz.edu.cn. 
杨柳青,博士,教授,主要研究方向为无线通信网络、多智能体系统、通讯感知一体化等.E-mail:lqyang@ust.hk. 
郑心湖,博士,助理教授,主要研究方向为多模态感知、多智能体协同感知、网联智能.E-mail:xinhuzheng@ust.hk.
基于鸟瞰图(Bird's-Eye View, BEV)的目标感知算法现正成为研究热点,但少有针对BEV的多传感器融合.因此,文中提出基于空间-通道注意力的多传感器融合模块,对不同模态的特征数据增加局部注意力机制,能有效修正多传感器之间的空间误差.利用转置注意力操作,充分融合图像和点云数据,消解不同模态语义信息之间的异质性,使融合的BEV特征在不引入空间偏差的同时,有效结合多传感器各自的独特信息,实现更全面准确的感知.在nuScenes数据集上的实验以及大量的消融实验表明,文中融合模块能有效提升目标检测算法的精度,可视化结果展现融合后的特征具有更完整、准确的特征信息,可明显提升对远处物体的检测.
About Author:
JI Yuzhe, Ph.D, candidate. His research interests include multimodal fusion perception and multi-vehicle cooperative perception.
CHEN Yijie, master student. His research interests include multi-agent cooperative perception and vehicle-road cooperative systems.
YANG Liuqing, Ph.D., professor. Her research interests include wireless communication networks, multi-agent systems and integrated communication and sensing.
ZHENG Xinhu, Ph.D., assistant profe-ssor. His research interests include multi-modal perception, multi-agent cooperative perception and networked intelligence.
Object perception based on bird's-eye view(BEV) is one of hot issues, but studies on multi-sensor fusion for BEV are still insufficient. Therefore, a multi-sensor fusion module based on spatial-channel attention is proposed. Spatial errors between multiple sensors can be effectively corrected by adding local attention mechanisms to features of different modalities. By using transpose attention operations, the image and point cloud data are fully integrated to resolve the heterogeneity between different modal semantics. Consequently, the fused BEV features achieves more comprehensive and accurate perception by effectively combining the unique information of each sensor without introducing spatial misalignment. Experiment on nuScenes dataset and extensive ablation experiments show that the proposed fusion module effectively improves the accuracy of object detection. Visualization results demonstrate that the fused features can capture more complete and accurate information, especially in distant objects detection.
如何实现对环境的周密感知, 一直是自动驾驶领域的重要研究内容, 也是自动驾驶算法落地的重要安全保障之一.当前, 依靠单一种类传感器实现的感知由于不同传感器的固有属性, 无法保证在不断变化的驾驶环境中稳定获取高质量感知结果.例如:LiDAR(Light Detection and Ranging Sensors)得到的点云数据具有较准确的位置及深度信息, 但是缺乏纹理信息, 稠密不均, 较远处的点较稀疏, 有效感知的范围受限.与之相比, 单目相机得到的图像具有颜色、纹理信息和较远的感知范围, 但是遮挡的问题较严重, 而且图像由于投影的特性, 自然缺少深度及位置信息, 难以独立得到精确的3D物体检测及分割结果.
现阶段无人驾驶车辆往往配备有诸如单目相机、LiDAR、毫米波雷达及GPS等不同的传感器.同时深度学习网络在计算机视觉领域高速发展[1], 能通过大量训练, 通过各种传感器数据学习复杂、高质量的特征表示.因此, 较复杂的多传感器融合技术被认为是获得精度更高、鲁棒性更强的感知结果的重要手段之一[2].
多传感器融合根据融合阶段以及数据表示, 可分为输入融合、特征融合和结果融合[3].由于结果融合的算法框架简单、灵活, 能充分利用成熟的单模态算法得到检测结果, 可满足任何新的传感器的添加[4], 只需融合各个不同模态得到的检测结果, 同时重新计算感知输出置信度[5], 就可得到融合后的多模态检测结果.当前, 基于结果融合的相关研究最成熟.然而, 结果融合算法的特征粒度较粗, 无法充分利用各模态数据细粒度的输入信息及特征信息, 最终效果受到限制[6].结果融合的效果对融合算法的选择高度敏感, 融合算法选择不当反而会引入更多的假阳性或过滤原本正确的单模态结果.同时, 结果融合算法需要根据各传感器的特征手动设计, 难以自动匹配各传感器得到的检测结果, 从而影响结果融合的最终效果.
近年的研究热点转向能充分利用各传感器输入信息的输入融合上.输入融合能让各模态的细粒度数据在后续层进行更深度的交互和融合.当前自动驾驶相关的多传感器输入融合的关键是将多个模态的输入信息投影到同个空间中, 主要的实现思路有两种.
1)利用已知传感器的内参和外参, 将某一传感器, 如单目相机的像素点投射到对应的三维LiDAR点云上, 从而赋予LiDAR点云更多的颜色和纹理信息.再对増广后的LiDAR点云采用已有的LiDAR学习网络进行训练, 得到最终结果[7].除去对像素点的投影, 还有后续的研究将图像进行语义或实例分割后的结果投射到3D点上[8].这种方法的优势是算法实现较简单, 只需要利用已有的点云处理模型而不需要单独设计网络模块.但是由于点云和图像存在稠密程度的差异, 将稠密的图像投射到稀疏的点云上时, 会损失图像稠密有序的性质, 并且逐像素的投射过程不具有鲁棒性, 容易受到外参变化的影响, 从而引入更多的噪音及错误信息.
2)将图像数据转化为伪激光雷达点云(Pseudo-LiDAR)[9], 伪激光雷达点云通常比真正的LiDAR点云更稠密, 可从一定程度上缓解LiDAR点云的稀疏性.但是由于图像特征天然缺少深度信息, 得到的伪点云的深度估计不准确, 会导致长尾问题的出现[10].同时处理稠密的点云会进一步加大对内存和计算时长的消耗.这类算法通常难以满足自动驾驶实时推理的要求, 也难以在现实环境中部署.
特征融合则兼具输入融合和结果融合的优点.经过深度神经网络学习提取到的特征既能保留输入信息中绝大多数的有益信息, 便于后续对融合特征的继续学习, 又能过滤噪音, 避免因投影不准对特征图注入大量噪音的问题.同时特征往往是经过下采样后的结果, 所以相比输入融合, 特征融合需要更少的内存消耗, 更快得到实时推理结果[11].
从对输入融合的分析中可看出, 多传感器融合的关键是将不同的传感器数据转换到相同的特征空间中, 输入融合通常采用更准确但处理复杂度过高的3D空间, 导致推理时长的大幅提升.近年来, 基于鸟瞰图(Bird's-Eye View, BEV)的单目相机算法[12, 13, 14]及激光点云算法[15, 16, 17]的突破, 提供一个具有丰富语义信息且处理较简单的特征空间, 即BEV空间.作为一种伪图像特征, BEV特征能被常规的2D卷积[18]高效处理, 并且在BEV特征空间中, 能通过池化及上采样, 轻松实现不同传感器特征之间维度的对齐, 使新传感器数据的加入变得简单, 具有较强的拓展性.最重要的是, BEV空间提供可解释性更强的环境表征, 能实现对方向、速度和检测目标等关键属性的轻松编码, 而融合得到的BEV特征可轻松应用于多种不同的下游任务, 如目标检测、地图分割等.
但是目前基于BEV的多传感器融合框架的研究仍处于初期探索阶段, Liu等[19]提出BEVFusion, 加速图像特征体素化的实现, 但其只使用简单的拼接和卷积对多传感器特征进行融合, 未有效融合图像特征.Borse等[20]提出X-Align(Cross-Modal, Cross-View Alignment Strategy), 首先对多传感器的BEV特征应用卷积进行融合, 再通过通道注意力修正卷积结果.但是该工作的融合模块只考虑通道之间的注意力, 未显式修正空间上的不对齐, 从而相比拼接和卷积的融合方式, 取得的提升有限.上述方法关注点主要在语义分割上, 未将其应用于3D目标检测任务中.
本文致力于提升多传感器在BEV特征空间的融合效果, 提出基于空间-通道注意力的多传感器融合模块.本文融合模块分为3个子模块.1)提出多窗口跨模态的局部注意力子模块(Multi-window Cross-Modal Local Attention Module, MW-CLAM), 采用不同的注意力窗口大小, 修正图像BEV特征中不同幅度的空间误差.2)分裂注意力子模块(Split Attention Module, SAM), 应用分裂注意力操作, 在不引入较多额外参数和计算的前提下, 对修正后的图像BEV特征进行进一步的学习与整合, 高效提升整合后图像BEV特征的质量.3)转置注意力子模块(Transpose Attention Module, TAM), 运用转置注意力操作, 在通道维度上深度融合图像及点云特征, 修正不同模态之间的语义异质性.实验表明, 本文融合模块能有效修正图像特征存在的空间误差, 缓解不同传感器数据在融合中的语义异质性, 提升融合后BEV特征质量以及在下游任务(目标检测)中的最终检测效果.
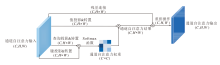
本文提出基于空间-通道注意力的多传感器融合模块, 整体架构如图1所示.模块分为两个分支:LiDAR点云的处理分支和多视角图像处理分支.激光雷达点云处理分支对激光雷达点云进行体素化后采用SECOND(Sparsely Embedded Convolutional Detection)[16]作为点云数据处理的骨架网络, 对点云特征进行3D稀疏卷积.多视角图像处理分支采用预训练的Swin Transformer[21]充分提取图像特征, 将提取的图像特征采用LSS(Lift, Splat, Shoot)[12]的处理方式, 投射到3D空间中, 估计每种深度的概率, 将深度的概率矩阵与图像的特征矩阵进行外积操作, 得到对应的3D点特征.再对图像生成的3D点进行体素化, 得到图像分支的BEV特征.最后, 通过本文融合模块, 融合图像和激光点云特征, 融合后的特征通过FPN(Feature Pyramid Network)[22]后输入TransFusion[23]检测头, 得到目标检测的结果.本文融合模块不需要传统目标检测方法所需的非最大值抑制(Non-Maximum Suppression, NMS)后处理过程, 能高效、精准地生成目标检测结果.
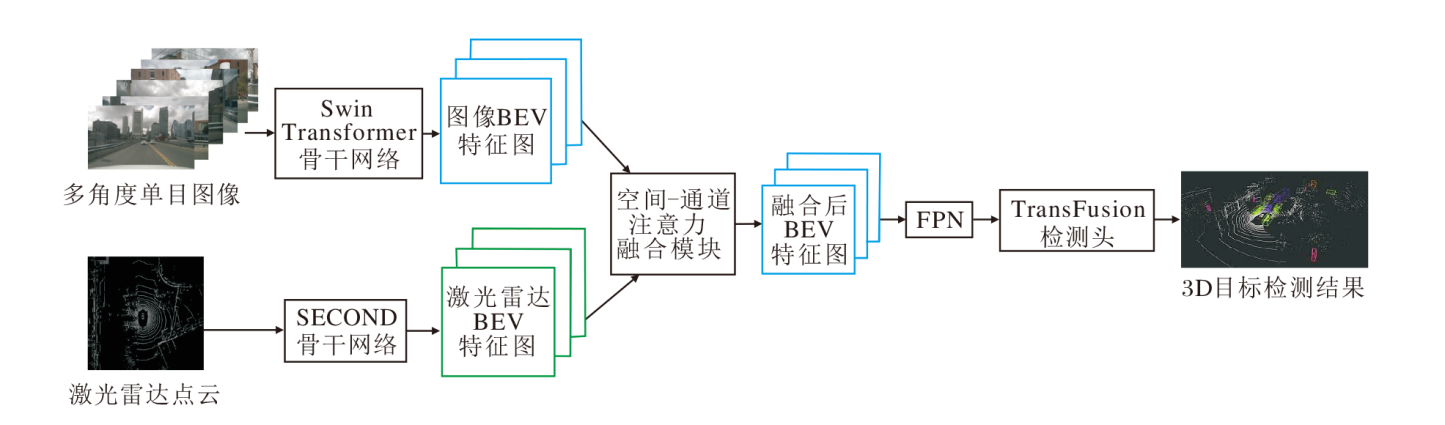 | 图1 本文融合模块流程图Fig.1 Flow chart of the proposed fusion module |
本文提出的空间-通道注意力的多传感器融合模块结构图如图2所示.融合模块包含3个子模块.
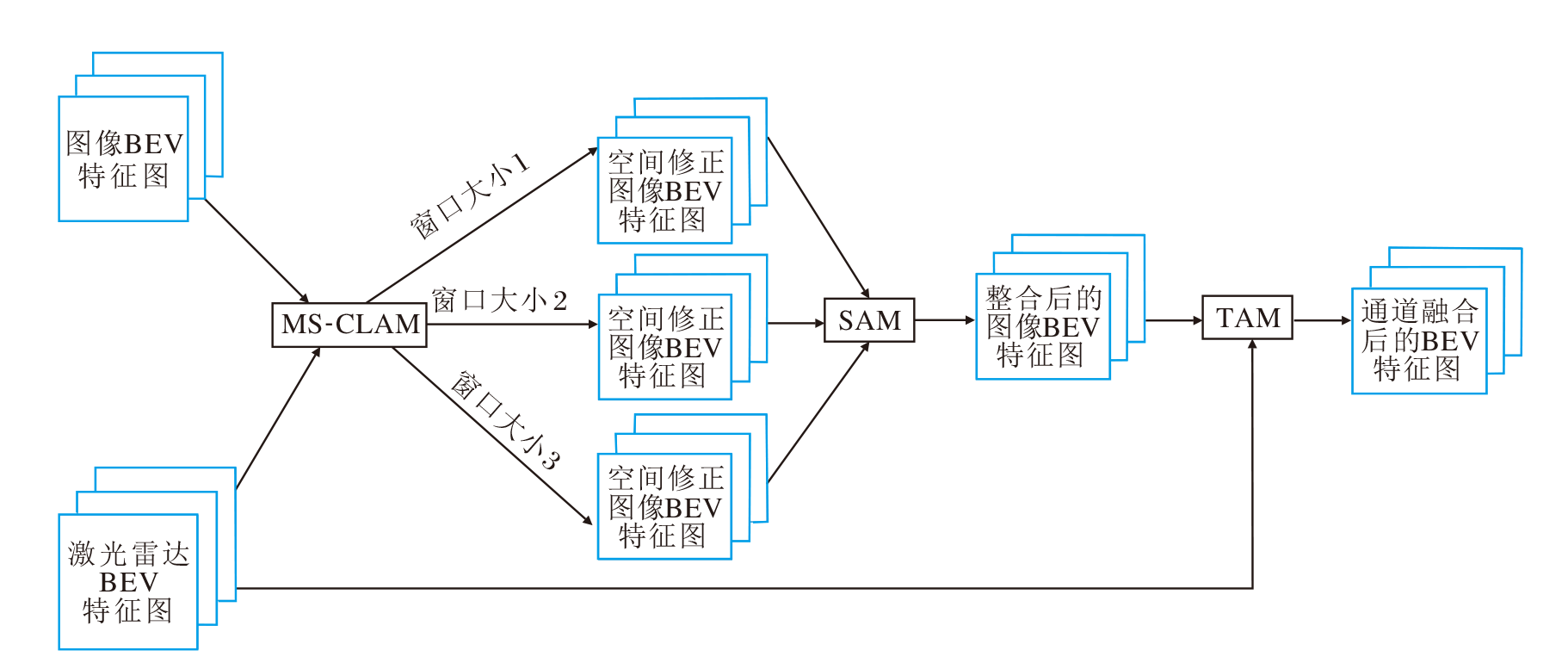 | 图2 本文融合模块结构图Fig.2 Structure of the proposed fusion module |
1)多窗口跨模态的局部注意力子模块(MW-CLAM), 利用激光点云的BEV特征, 对图像BEV特征进行空间修正.
2)分裂注意力子模块(SAM), 对MW-CLAM得到的多个修正后的图像BEV结果进行高效整合.
3)转置注意力子模块(TAM), 对激光点云BEV特征和修正后的图像BEV特征进行通道维度的深入融合.
在对图像特征进行LSS[12]后的体素化过程中, 可通过控制体素化的粒度, 让激光点云和图像的BEV特征具有相同的空间分辨率RH× W, 其中, H、V分别表示BEV特征的高度和宽度.
注意力操作的第1步是对特征进行投影, 从而得到键、值及查询特征.在Transformer以及其大多数在自然语言处理领域的变体中, 都是采用线性层对特征进行投影.而在本文提出的多窗口跨模态的局部注意力子模块(MV-CLAM)中, 由于特征是在BEV空间中, 具有天然的空间语义, 所以采用卷积的方式对特征进行投影.采用卷积能在不引入位置编码的情况下自然保持空间信息且拥有较好的计算性能.具体操作步骤如下.
首先, 定义如下:Clidar表示待融合的激光雷达分支BEV特征的通道数, Cweight表示注意力操作中投影的键和查询通道数, Ccamera表示待融合的单目相机分支BEV特征的通道数, Cvalue表示注意力操作中投影的值的通道数.对于激光点云的BEV特征
$ \boldsymbol{F}^{\text {lidar }} \in \mathbf{R}^{H \times W \times C^{\text {lidar }}}, $
通过卷积核
$ \boldsymbol{X}^{\text {query }} \in \mathbf{R}^{1 \times 1 \times C^{\text {lidar }} \times C^{\text {weight }}}$
进行1× 1卷积投影, 得到激光点云查询特征
$ \boldsymbol{Q}^{\text {lidar }} \in \mathbf{R}^{H \times W \times C^{\text {weight }}}$
同时对于图像特征
$ \boldsymbol{F}^{\text {camera }} \in \mathbf{R}^{H \times W \times C^{\text {camera }}}, $
通过卷积核
$ \boldsymbol{X}^{\text {key }} \in \mathbf{R}^{1 \times 1 \times C^{\text {camera }} \times C^{\text {weight }}}、 \boldsymbol{X}^{\text {value }} \in \mathbf{R}^{1 \times 1 \times C^{\text {camera }} \times C^{\text {value }}}$
分别进行1× 1的卷积投影, 分别得到键
$ \boldsymbol{K}^{\text {camera }} \in \mathbf{R}^{H \times W \times C^{\text {weight }}}$
和值
$ \boldsymbol{V}^{\text {camera }} \in \mathbf{R}^{H \times W \times C^{\text {value }}} .$
在局部窗口注意力操作中, 对于激光点云的每个空间位置(i, j)的查询特征
通过对激光点云的每个查询特征进行上述操作, 最终得到修正后的图像BEV特征
$ \boldsymbol{F}^{\text {camera' }} \in \mathbf{R}^{H \times W \times C^{\text {value }}}$
具体的局部窗口注意力操作如下:
$ \begin{array}{l} a=\max \left(i-\left\lfloor\frac{k H}{2}\right\rfloor, 0\right), \\ b=\min \left(i+\left\lfloor\frac{k H}{2}\right\rfloor, H\right), \\ c=\max \left(j-\left\lfloor\frac{k W}{2}\right\rfloor, 0\right), \\ d=\min \left(j+\left\lfloor\frac{k W}{2}\right\rfloor, W\right), \end{array}$
$ \text { window_ij }=\{[x, y, :] \mid a \leqslant x \leqslant b, c \leqslant y \leqslant d\} \text {, }$
$ \boldsymbol{F}_{[i, j, :]}^{\text {camera' }}=\operatorname{softmax}\left(\boldsymbol{Q}_{[i, j, :]}^{\text {lidar }} * \boldsymbol{K}_{\text {window_ij }}^{\text {camera }}\right) * \boldsymbol{V}_{\text {window_ij }}^{\text {camera }}, $
其中, i∈ {1, 2, …, H}, j∈ {1, 2, …, W}, * 表示卷积操作.
激光点云的特征通常拥有更精准的语义以及空间特征信息, 通过该信息投影得到的查询也具有极强的辨别能力, 能有效指导对局部的图像特征进行重组, 从而在保留图像语义特征的情况下, 让图像特征在空间上变得更精准有效.
单窗口跨模态局部注意力融合框图如图3所示, 在MW-CLAM中, 采用多个不同窗口大小的跨模态局部注意力操作, 整合不同感知域的图像特征, 消除图像特征不同幅度的位置偏移.这个想法受到GoogLeNet[24]这种Inception模型[25]的启发.不同于传统的卷积层实现, 在Inception模型中通常会同时设计多个路径特征学习模块, 避免对彼此模块之间学习的干涉, 从而独立学习不同侧面的特征, 最终结合独立学习的特征, 得到全局特征.
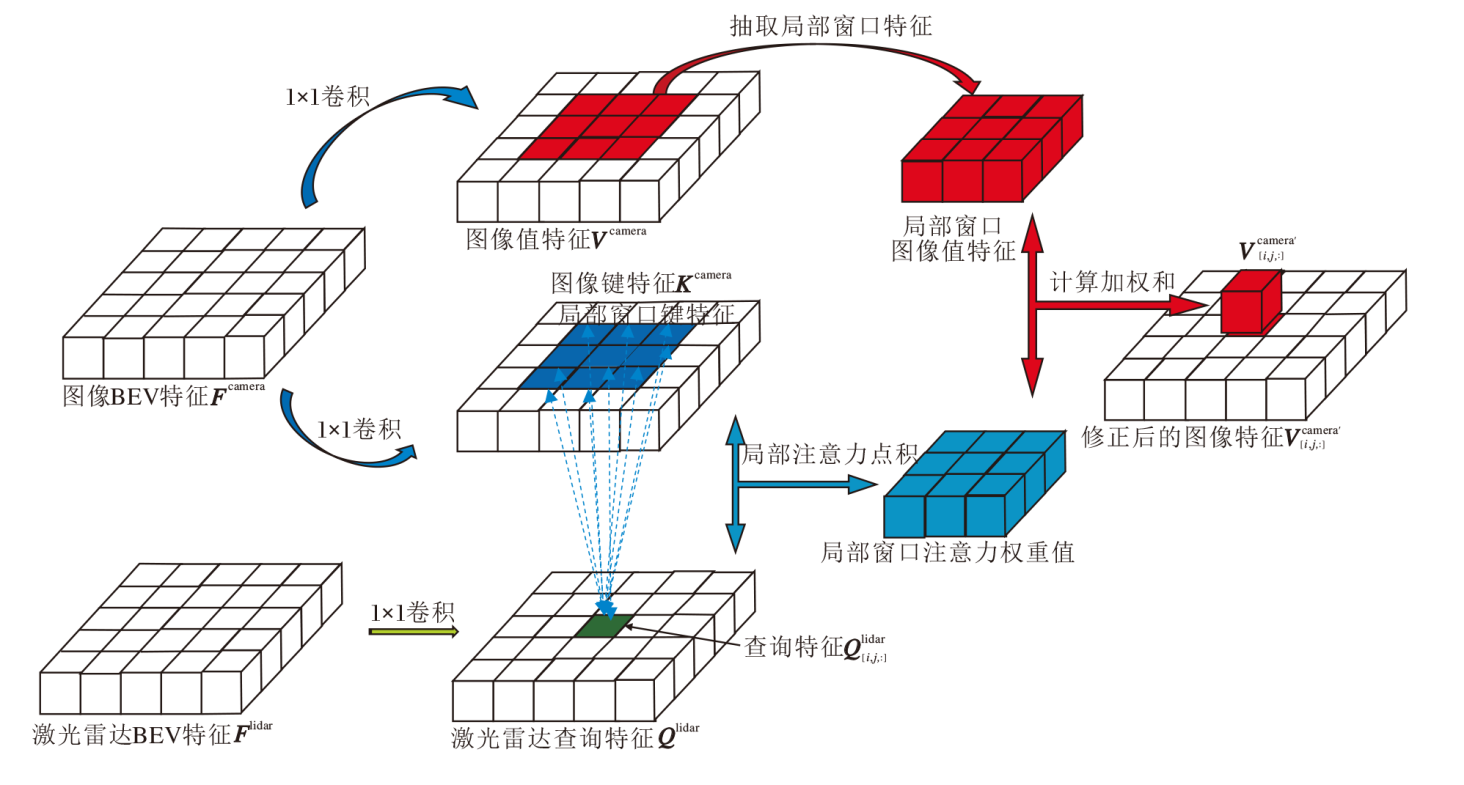 | 图3 单窗口跨模态局部注意力融合操作框图Fig.3 Single window cross-modal local attention fusion operation |
采用分裂注意力操作[26], 整合不同窗口大小学到的图像BEV特征.虽然采用拼接再卷积的方法, 对通道维度进行下采样, 在理论上可行且符合直觉, 但是通过后续的消融实验证实, 这种方式在速度和效果上并非最优.首先, 由于拼接后的特征维度取值很大, 所以再进行卷积时会引入过多的额外参数.其次, 拼接后的特征存在大量冗余信息, 可能导致冗余信息主导最终学习的特征, 丢弃通过不同窗口大小学习的独特特征.
分裂注意力[26]是通道维度注意力的一种实现, 相比拼接再卷积, 只会引入很少的额外参数, 却能有效利用通道维度的注意力, 同时有效合并任意数量的输入.具体操作过程如下.
通过MW-CLAM得到的R个结果:
$ \boldsymbol{F}_{r}^{\text {camera' }} \in \mathbf{R}^{H \times W \times C^{\text {value }}}, r=1, 2, \cdots, R, $
每个结果拥有相同维度.首先对R个结果进行逐元素的相加, 得到全局组合特征:
$ \boldsymbol{F}^{\text {camera_combine }}=\sum_{r=1}^{R} \boldsymbol{F}_{r}^{\text {camera' }} \in \mathbf{R}^{H \times W \times C^{\text {value }}} .$
对全局组合特征Fcamera_combine在空间维度(H, W)上进行全局平均池化, 得到维度为Cvalue的池化结果S, 包含维度相关的全局语义统计信息, 即
$ \boldsymbol{S}_{[:, :, c]}=\frac{1}{H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W} \boldsymbol{F}_{c}^{\text {camera } \_ \text {combine }}, $
其中, [∶ , ∶ , c]表示向量切片操作, 提取第c通道上所有空间特征值, c=1, 2, …, Cvalue.
通过全连接层, 批标准化层 (Batch Normaliza-tion, BN)以及ReLU激活层对全局语义统计信息S进行进一步的映射学习, 得到学习结果:
$ \boldsymbol{S}^{\text {hidden }}=\operatorname{ReLU}(B N(\text { Dense }(\boldsymbol{S}))) \in \mathbf{R}^{c^{\text {hidden }}}, $
其中, Chidden表示通过全连接层后中间结果的输出维度, Dense(· )表示全连接层操作.
对于Shidden, 通过R个不同的全连接层, 得到R个逐通道的软权重:
$ \boldsymbol{S}_{r}^{\text {weight }}=\text { Dense }_{r}\left(\boldsymbol{S}^{\text {hidden }}\right) \in \mathbf{R}^{\text {Cvalue }}, r=1, 2, \cdots, R \text {, }$
再逐通道对每组的软权重应用softmax, 将其标准化为概率分布, 得到对应每组输入
$ \boldsymbol{W}_{r}(c)=\frac{\exp \left(\boldsymbol{S}_{r}^{\text {weight }}(c)\right)}{\sum_{j=1}^{R} \exp \left(\boldsymbol{S}_{j}^{\text {weight }}(c)\right)}, c=1, 2, \cdots, C^{\text {value }} .$
将Wr作用在
$ \boldsymbol{F}^{\text {camera_split }}=\sum_{r=1}^{R} \boldsymbol{W}_{r} * \boldsymbol{F}_{r}^{\text {camera' }} \in \mathbf{R}^{H \times W \times C^{\text {value }}} .$
分裂注意力子模块(SAM)流程图如图4所示.
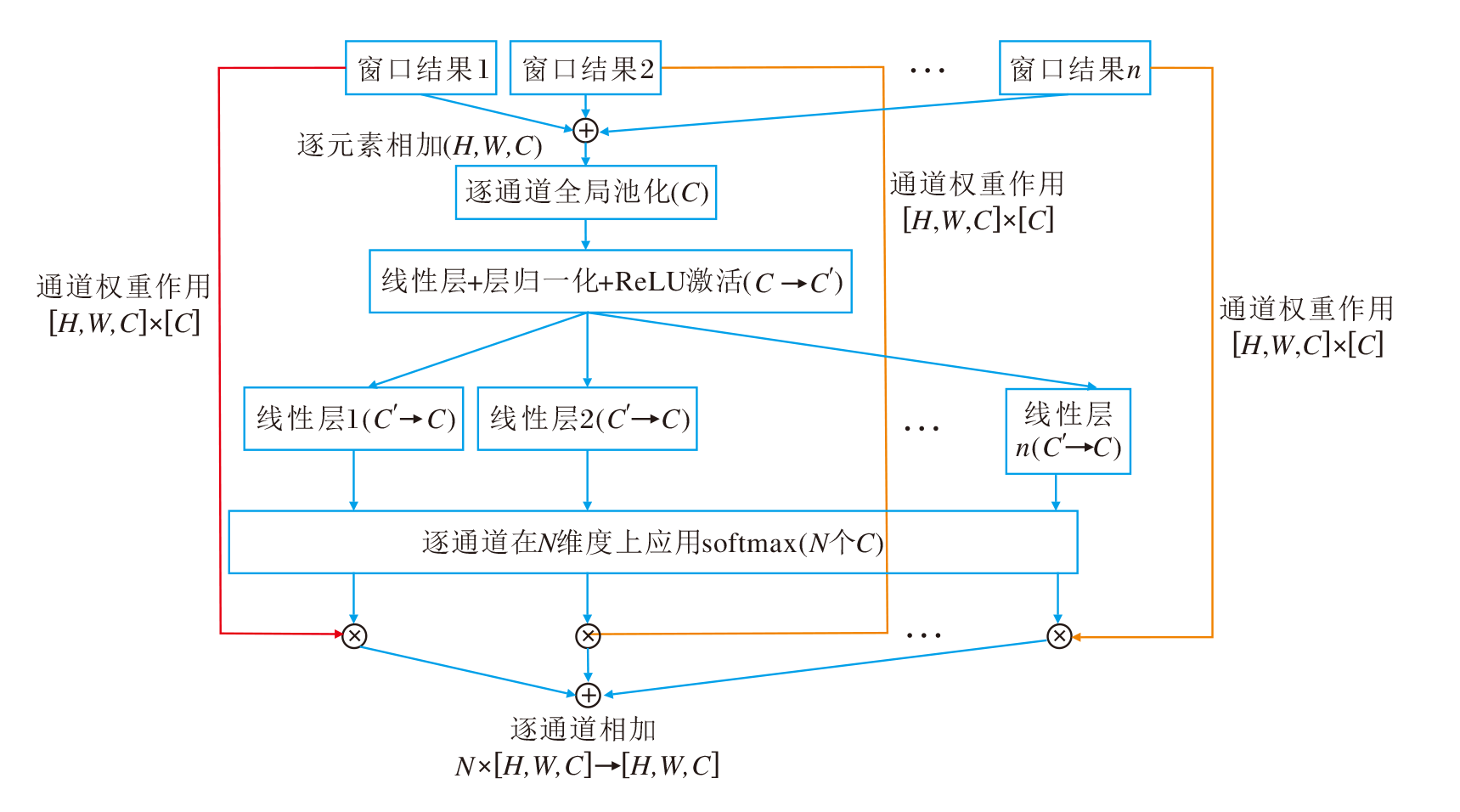 | 图4 SAM流程图Fig.4 Flow chart of SAM |
在经过SAM整合不同窗口大小自注意力的图像特征后, 得到修正后的图像特征, 以及未经过处理的激光雷达点云特征.虽然在MW-CLAM中采用激光雷达点云特征作为查询, 让图像特征能通过激光雷达查询特征进行修正和重组, 但是两种特征在语义上还存在异质性.在计算机视觉中, 通道特征往往表示不同的语义信息, 如RGB图像中不同的通道标识不同的颜色信息.而在经过深度网络学习后的每个特征通道可能会表示不同的复杂语义信息, 如边的信息甚至更复杂的纹理信息.为了填补不同传感器特征之间语义信息之间的差异, 采用转置注意力操作[27], 对语义信息进一步进行整合.
在进行转置之前先将激光雷达点云特征
$ \boldsymbol{F}^{\text {lidar }} \in \mathbf{R}^{H \times W \times C_{\text {lidar }}}$
和SAM输出的图像特征
$ \boldsymbol{F}^{\text {camera_split }} \in \mathbf{R}^{H \times W \times C^{\text {value }}}, $
沿通道维度进行拼接, 得到拼接结果:
$\boldsymbol{F}^{\text {concate }}=\boldsymbol{F}^{\text {camera_split }} \| \boldsymbol{F}^{\text {lidar }} \in \mathbf{R}^{H\times W \times (C^{lidar}+C^{value})}$
再通过卷积核
$\boldsymbol{W}^{\text {conv }} \in \mathbf{R}^{1 \times 1 \times\left(C^{\text {value }}+C^{\text {lidar })} \times C^{\text {fusion }}\right.}$
进行1× 1卷积操作, 得到融合特征:
$\boldsymbol{F}^{\text {fusion }}=\boldsymbol{W}^{\text {conv }} * \boldsymbol{F}^{\text {concate }} \in \mathbf{R}^{H \times W \times C^{\text {cusion }}}, $
其中Cfusion表示融合模块的最终输出通道数.因为Ffusion的通道维度与Fconcate接近, 所以这步卷积操作对通道维度没有进行过多的下采样, 能较容易地保留多传感器特征的全部有益信息.
下面通过转置注意力的操作, 让每个通道都能参考全局的语义信息修正该通道的特征.转置注意力子模块(TAM)的操作与传统的注意力机制相似, 首先, 通过3个线性层WQ、Wk、Wv分别对Ffusion进行投影, 得到查询Q、键K和值V:
$\begin{array}{c} \boldsymbol{Q}=\boldsymbol{W}^{Q} \boldsymbol{F}^{\text {fusion }}, \\ \boldsymbol{K}=\boldsymbol{W}^{K} \boldsymbol{F}^{\text {fusion }}, \\ \boldsymbol{V}=\boldsymbol{W}^{V} \boldsymbol{F}^{\text {fusion }} . \end{array}$
分别对键和值应用L2正则化, 让训练更稳定.与传统注意力机制的差别在于, TAM应用点积计算协方差注意力值时, 不是对Q和KT进行点积, 而是先将其分别进行转置后应用点积, 从而生成
$\boldsymbol{F}^{\text {final }}=\boldsymbol{V} * \operatorname{softmax}\left(\boldsymbol{Q}^{T} * \boldsymbol{K}\right)+\boldsymbol{F}^{\text {fusion }}$
因为转置注意力认为通道之间是无序的, 所以没有位置编码参与计算.TAM流程图如图5所示.
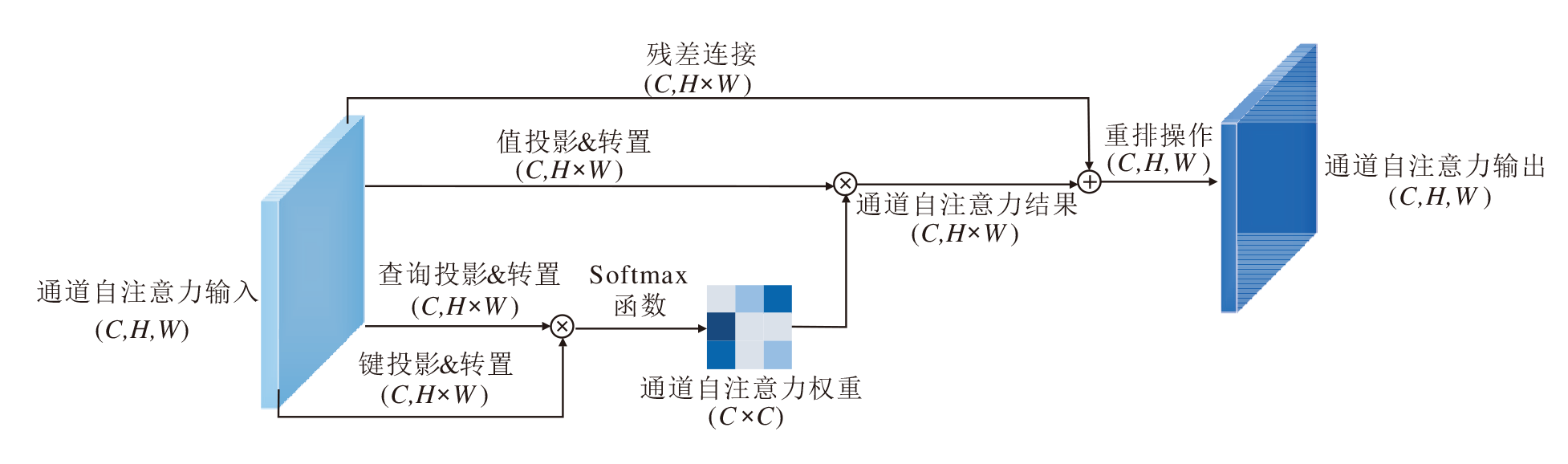 | 图5 TAM块流程图Fig.5 Flowchart of TAM |
为了验证本文融合模块能有效提升多传感器融合的效果, 在nuScenes数据集[28]上进行实验, 使用官方划分的训练集以及验证集.nuScenes数据集拥有6个单目相机, 这些相机时间对齐、视角不同, 环绕车身360° 的视角, 无视觉死角.同时, 一个32线的激光雷达负责捕捉完整的周围环境信息.数据集包含约1 000个场景和40 000个相机激光雷达对齐的关键帧.相比KITTI数据集[29], nuScences数据集有超7倍物体标注, 适用于更有效的深度目标检测网络的训练及测试.
选择3D目标检测中常用的检测指标— — 平均准确率(Mean Average Precision, mAP)计算不同召回率下获得的准确率的平均值外, 还统计nuScences检测得分(nuScenes Detection Score, NDS), 综合衡量检测精度、分类精度、偏向角精度以及对物体速度的估计精度等指标.
实验选用PyTorch 1.12.1以及mmdetection3d 1.2.0作为深度学习框架, 并在NVIDIA GTX A40上进行训练.
网络中的基本超参数设置如下.激光雷达体素化的分辨率在X轴和Y轴上都是0.075 m, Z轴上为0.2 m.处理时, 保留在X轴和Y轴上前后54 m、Z轴上3 m以内的点.输入融合模块的图像BEV特征的通道数Clidar为256, 激光点云特征的通道数Ccamera为80.最终融合后的BEV特征通道数Cfusion为256.数据增强方式与BEVFusion保持一致.对激光点云中的所有点进行整体随机的缩放、旋转及平移, 并打乱点的顺序, 防止采样偏差.对于图像采用旋转翻转等操作.为了保持图像和点云的空间匹配, 通过矩阵的形式记录所用的数据增强, 并应用在另一个模态的数据中.
训练中使用AdamW(Adam with Decoupled Weight Decay)[30]优化器, 学习率设置为0.000 2, 并采用余弦退火(Cosine Annealing)策略调整学习率和动量.
对本文融合模块进行有效性验证, 由于当前对于多传感器数据在BEV上与融合模块相关的研究较少, 所以选择激光雷达单模块、通道平均融合、BEVFusion[19]、X-Align[20]进行对比实验.4种模块的骨架网络相同.在对比实验中, MW-CLAM中窗口大小(kHs× kWs)为3× 3, 5× 5, 11× 11.
各模块在nuScences数据集上的指标值对比如表1所示.由表可见, 相比激光雷达单模态, 通道平均融合的效果最差, 只提升1.09%的mAP和0.15%的NDS.BEVFusion也只实现1.14%的mAP和0.38%的NDS的提升, 说明卷积因其有限的空间融合度, 无法有效解决特征的空间不对齐问题.在X-Align中, 相比BEVFusion, 基于通道注意力的融合效果在mAP和NDS上分别提升0.66%和0.25%.说明相比每个通道平均权重, 在通道层面的注意力能有效综合全局信息, 带来更有效的信息利用.相比X-Align, 本文融合模块在mAP和NDS上又分别提升0.85%和0.46%.表明本文融合模块能有效解决空间上的不对齐问题, 修正图像BEV特征的空间误差, 并联合通道注意力, 使图像BEV特征提供更多的有益信息, 进而增强多传感器融合的效果.
| 表1 各模块在nuScenes数据集上的指标值对比 Table 1 Index comparison of different modules on nuScenes dataset |
为了验证本文融合模块中各子模块的有效性, 设置如下消融实验.分别将MW-CLAM、SAM、TAM加入融合模块中, 没有SAM时, 采用1× 1卷积融合MW-CLAM得到的多窗口结果, 消融实验结果如表2所示.由表可见, 3个子模块都具有一定的有效性, MW-CLAM在精度提升方面贡献最多.
| 表2 子模块消融实验结果 Table 2 Ablation experiment results of submodules |
在给定模块输入通道数和输出通道数后, SAM和TAM都不会引入可调的超参数, 而MW-CLAM会引入窗口数量及每个窗口大小这两个超参数.所以在消融实验中, 首先通过单窗口局部注意力的效果验证窗口大小的影响, 再通过实验表现较好的窗口大小组合, 形成多窗口的局部注意力组合, 探究窗口数量及窗口组合对于模块性能的影响.
改变MW-CLAM中窗口大小后所得消融实验结果如表3所示.由表可观察到, 当窗口大小在5× 5到11× 11之间时, 指标值对于窗口大小的取值并不敏感, 均优于BEVFusion的性能.特别地, 在窗口大小为11× 11时指标值达到最优.这说明局部注意力能赋予两个模态之间更大的空间融合度, 更有效地通过激光点云特征指导图像特征的的重组以及空间误差的修正.然而, 在窗口大小远大于11× 11, 如21× 21或41× 41时, mAP值反而下降, 这印证绝大多数空间误差不会过大.所以过大的窗口甚至全局的空间注意力反而会引入过多的噪音, 增加训练难度, 导致性能下降.
| 表3 MW-CLAM中窗口大小不同时的消融实验结果 Table 3 Ablation experiment results of MW-CLAM with different window sizes |
多个窗口组合的消融实验结果如表4所示, 为了排除SAM和TAM对消融实验的干扰, 实验中没有引入SAM和TAM, 而是通过卷积对多窗口得到的结果进行融合.
| 表4 不同窗口大小组合的消融实验结果 Table 4 Ablation experiment results with different window size combinations |
从表4可看出, 当没有SAM时, 多窗口局部注意力不总是优于单窗口的, 可能是由于卷积难以有效提取多窗口得到的综合信息.因此, 需要一种更强大的计算机制, 如SAM, 高效整合多窗口的综合信息.当窗口组合选择合适时, 如[3× 3, 5× 5, 11× 11]和[5× 5, 11× 11, 21× 21], 即使没有SAM, 多窗口局部注意力效果也优于表3中所有单窗口的效果, 由此验证多窗口局部注意力的潜力和必要性.同时, 窗口数量为3时的指标值要整体强于窗口数量为2时, 说明多个大小分布不一的窗口能有效提取不同的信息进行互补, 从而弥补不同幅度的空间偏差.
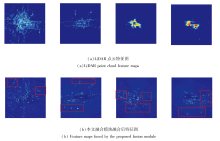
首先对比经过本文融合模块和BEVFusion融合后的特征图, 具体如图6和图7所示.由图6可观察到, 通过BEVFusion融合后的特征图与单激光雷达模态的特征图区别并不显著.这意味着在融合过程中, 可能由于图像特征的较低质量以及较多的噪音, 在学习的过程中图像特征被大量丢弃.如图7所示, 经过本文融合模块后, 图像的特征图能对融合后的特征图具有更多的影响.相比仅使用激光雷达模态的特征图, 最终融合的特征图呈现出新的信息增益, 特别在远距离区域中, 这有助于补偿激光雷达在远处由于数据稀疏性导致的信息丢失.而在近处, BEV-Fusion融合后的特征图继承激光雷达点云特征在较近距离激活程度较高的特点, 保留路面及其它背景物体反射点, 给定位近处感兴趣的物体带来困难.本文融合模块融合后的特征图起到一种接近非最大值抑制的作用, 借助图像的纹理信息抑制激光雷达中无关点的特征表达, 使物体定位更准确, 提供更精准的位置信息.
 | 图6 BEVFusion融合前后特征图对比Fig.6 Comparison of feature maps before and after BEVFusion |
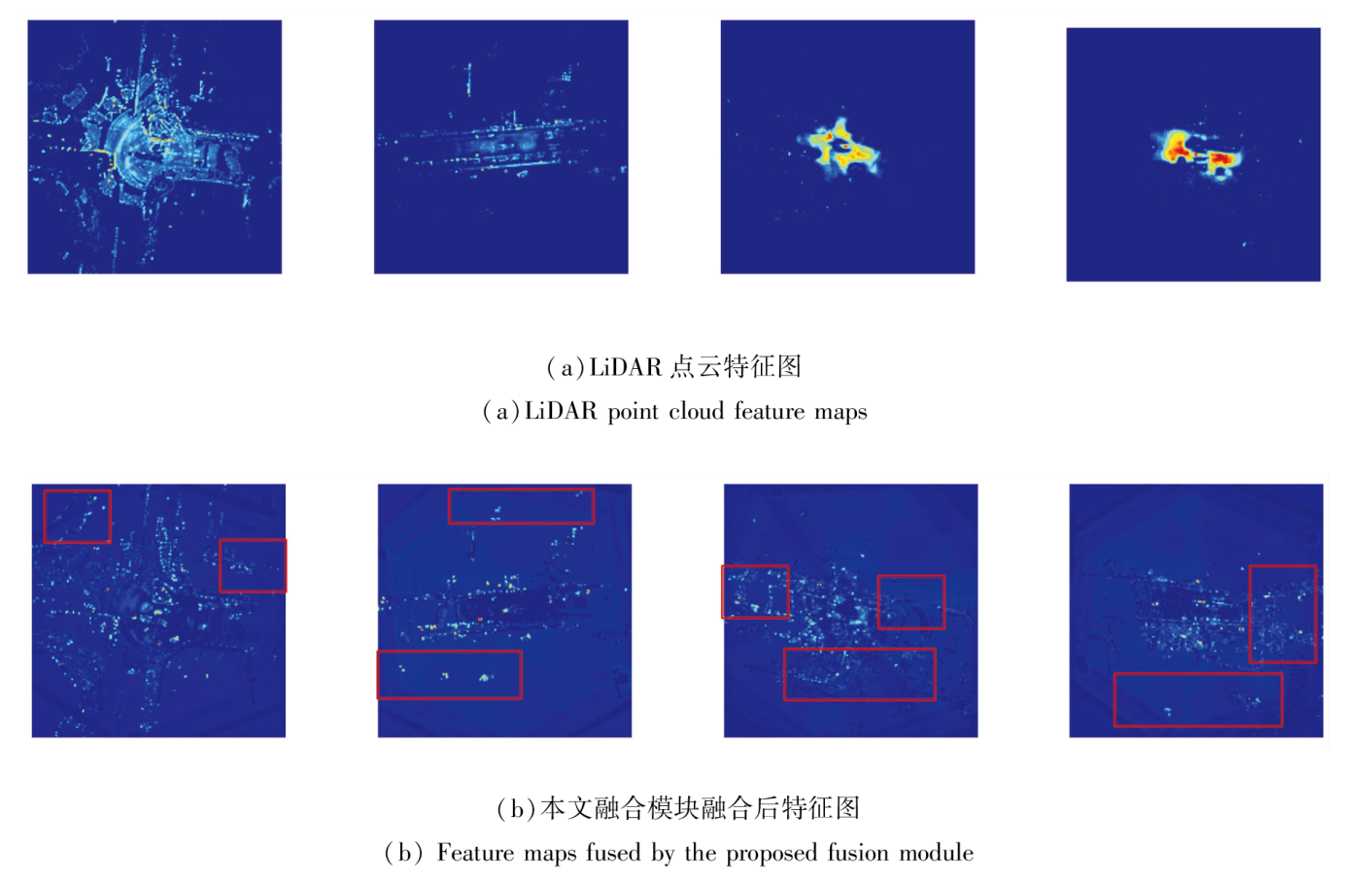 | 图7 本文融合模块融合前后特征图对比Fig.7 Comparison of feature maps before and after the fusion by the proposed fusion module |
对比BEVFusion与本文融合模块融合后的目标检测结果, 结果如图8所示.由图可更直观地观察到两者在效果上的差异.在前两个场景中, 本文融合模块能成功检测到较远距离的物体, 如第1个场景中间远处的车辆和第2个场景中的远处公交车.在这些较远位置, 由于激光雷达点的稀疏性, 即使是公交车这样的较大物体的检测也变得尤为困难.BEV-Fusion无法有效利用图像信息, 所以出现漏检现象, 而本文融合模块却能有效利用图像的纹理信息, 避免此类漏检问题.在第3个场景的中远位置处, BEV- Fusion错误地将两辆车的部分形状连接, 造成对物体的错检.而本文融合模块通过对纹理信息的识别和判断, 正确地将其评判为两辆车, 避免错检和漏检的发生.
 | 图8 两种模块检测结果可视化对比Fig.8 Visualization comparison of detection results between 2 modules |
从目标检测的可视化结果可看出, 本文融合模块能在激光雷达较稀疏的中远距离区域, 更有效地利用图像的纹理信息, 得到更准确的检测结果, 避免错检和漏检.
本文提出空间-通道注意力的多传感器融合模块, 并应用在3D目标检测任务中.考虑到不同传感器数据之间存在的各种空间误差和不对齐问题, 设计多窗口跨模态的局部注意力子模块(MW-CLAM), 旨在修正多传感器特征间的空间误差.同时, 考虑到多传感器特征之间存在的语义信息异质性, 通过分裂及转置注意力操作, 在通道维度上进行注意力操作, 有效弥补多传感器特征之间的语义信息差距.实验表明, 本文融合模块可有效提升3D目标检测的精度.
本文融合模块在设计上的不足之处主要是MW-CLAM中有较多的超参数, 如窗口大小和窗口组合, 增加搜索最佳超参数和训练调优的难度.此外, 2D图像分支取得的质量较差的BEV特征也限制多传感器融合最终检测精度的进一步提升.
今后可探索空间注意力模块的简化工作, 使训练调优更简便, 并提升训练效果的稳定性与鲁棒性.同时, 鉴于BEV多传感器融合框架具有较高的可拓展性, 可考虑替换更高精度的2D图像处理分支, 进一步深化多传感器融合操作, 提升多传感器融合的精度.
本文责任编委 陈仕韬
Recommended by Associate Editor CHENG Shitao
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|