
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
自动驾驶安全挑战:行为决策与运动规划
[关鑫1  , 史佳敏
, 史佳敏1 , 陈仕韬1 , 刘剑毅1 , 郑南宁1 ]
, 史佳敏, 陈仕韬, 刘剑毅, 郑南宁]
|
|



作者简介:

关 鑫,硕士研究生,主要研究方向为自动驾驶车辆的运动规划.E-mail:xinguan@stu.xjtu.edu.cn.

史佳敏,博士研究生,主要研究方向为基于强化学习的无人驾驶研究.E-mail:3120105180@stu.xjtu.edu.cn.

陈仕韬,博士,助教,主要研究方向为无人驾驶.E-mail:chenshitao@xjtu.edu.cn.

郑南宁,博士,教授,主要研究方向为计算机视觉、模式识别.E-mail:nnzheng@mail.xjtu.edu.cn.
在自动驾驶技术发展中,安全性一直作为首要因素被业界重视.行为决策与运动规划系统作为该技术的关键环节,对智慧属性具有更高要求,需要不断地随着环境变化做出当前的最优策略与行为,确保车辆行驶过程中的安全.文中分别对行为决策和运动规划系统进行深层次阐述,首先,介绍行为决策中基于规则的决策算法、基于监督学习的决策算法、基于强化学习的决策算法的算法理论及其在实车中的应用.然后,介绍运动规划中基于采样的规划算法、基于图搜索的规划算法、基于数值优化的规划算法和基于交互性的规划算法,并对算法的设计展开讨论,从安全角度分析行为决策和运动规划,对比各类方法的优缺点.最后,展望自动驾驶领域未来的安全研究方向及挑战.
About Author:
GUAN Xin, master student. His research interests include motion planning for autonomous vehicles.
SHI Jiamin, Ph.D. candidate. Her research interests include autonomous driving based on reinforcement learning.
CHEN Shitao, Ph.D, assistant lecturer. His research interests include autonomous dri-ving.
ZHENG Nanning, Ph.D.,professor. His research interests include computer vision and pattern recognition.
In the development of autonomous driving technology, safety is always regarded as a top priority. The behavior decision-making and motion planning systems, as key components of the technology, possess higher requirements for intelligence. They need continuously make optimal strategies and behaviors according to the changing environment to ensure the safety of vehicle driving. The behavior decision-making and motion planning systems are expounded. Firstly, the theory and applications of rule-based decision algorithms, supervised learning-based decision algorithms, and reinforcement learning-based decision algorithms are introduced. Then, sampling-based planning algorithms, graph search-based planning algorithms, numerical optimization-based planning algorithms and interaction-based planning algorithms in motion planning are discussed and their designs are discussed. Behavior decision-making and motion planning are analyzed from the perspective of safety, and the advantages and disadvantages of various methods are compared. Finally, future research directions and challenges for safety in the field of autonomous driving are predicted.
随着人工智能的发展, 自动驾驶技术逐渐走入人们的生活, 为日常出行带来极大便利.经过数十年的发展, 自动驾驶技术取得长足进步, 其中安全性始终是该项技术中需要考虑的首要因素[1].完整的自动驾驶(Autonomous Driving)系统包括感知定位、决策规划、控制执行三个主要系统.各个系统均存在着不同方面的安全挑战.受到传感器盲区和恶劣天气等的影响, 环境感知算法会出现障碍物误检、漏检等情况.行为决策规划算法在未知场景下可能会做出错误或高风险的判断, 出现避让障碍物不及时导致碰撞的情况.导航控制算法在线控失灵的情况下无法正常控制车辆按照预期的轨迹行驶.决策规划系统作为整个无人驾驶系统中的重要环节, 对自动驾驶车辆的安全性起到关键性作用.
行为决策算法的目标是通过车辆与环境之间的自主交互和学习, 制定安全的行驶策略.传统的自动驾驶车辆安全约束算法大多需要基于定制化程序解决特定任务, 缺乏面向不同驾驶任务的固定范式, 因此无法对自动驾驶车辆策略进行预编程.此外, 传统的决策算法主要用来处理静态交通环境的规划问题, 无法很好地应对复杂的动态交通场景.
当前以模仿学习(Imitation Learning)[2]和强化学习(Reinforcement Learning)[3]为代表的学习类算法已逐渐成为研究的热点.模仿学习可以从人类专家的决策数据中学习安全可靠的驾驶策略.强化学习通过“ 试错” , 最大化自动驾驶车辆与交通环境交互过程中的回报, 避免错误的决策.强化学习算法能够对未知场景具有更好的泛化性, 在行为决策领域具有广阔前景.
运动规划算法旨在基于当前的决策生成起点到终点的可行驶轨迹, 包含随机采样、网格图搜索、数值优化等主流算法.采样算法在空间中进行可达点的连接, 并通过碰撞检测保证行驶安全.图搜索中的占用栅格类算法倾向于贴近障碍物生成行驶轨迹, 很少被直接用于自动驾驶.相比之下, 单元连通图类的图搜索算法往往能生成更加安全的轨迹.数值优化算法通过特定的安全空间约束严格保证轨迹的无碰撞性.
本文分别对行为决策和运动规划系统进行深层次阐述, 首先, 介绍行为决策中基于规则的决策算法、基于监督学习的决策算法、基于强化学习的决策算法的理论及其在实车中的应用.然后, 介绍运动规划中基于采样的规划算法、基于图搜索的规划算法、基于数值优化的规划算法和基于交互性的规划算法, 并展开讨论算法的设计, 从安全角度对行为决策和运动规划进行介绍分析, 对比各类方法的优缺点.最后, 展望自动驾驶领域未来的安全研究方向及挑战.
自动驾驶系统可分为感知定位、决策规划、导航控制等技术环节, 具体如图1所示.
 | 图1 自动驾驶系统组成部分Fig.1 Composition of autonomous driving system |
感知定位系统接收激光雷达、相机、全球定位系统(Global Positioning System, GPS)、惯性测量单元(Inertial Measurement Unit, IMU)等传感器的数据信息, 对周边环境进行语义解析, 提供车辆当前的位置、速度等状态信息, 模拟人类的视觉系统.决策规划系统根据感知定位算法的输出结果做出最优决策, 并进行运动规划, 将生成的满足车辆动力学约束、安全、可行驶的轨迹发送给控制系统, 模拟人类“ 大脑” .最终导航控制系统进行纵向速度控制与横向角度控制, 输出命令到线控层, 完成对车辆的驱动.
1.2.1 感知定位系统隐患分析
环境感知算法通过多种传感器对车辆周围的环境信息进行全方位的探测, 并负责解析和理解周围环境, 为规划模块提供感知结果, 生成安全可行的路径.然而, 在复杂的交通场景下, 感知的结果具有不确定性, 甚至是错误的, 这将严重影响决策规划算法.例如, 车道线识别、障碍物的检测与跟踪等结果出现偏差时, 决策规划算法给出的“ 安全” 路径将是不安全的.目前在此方面已有许多研究工作.
车道检测算法在车道保持和车道偏离控制等系统中都发挥着关键作用, 确保此类辅助驾驶功能的安全运行.文献[4]~文献[6]中利用多传感器数据和深度神经网络, 实现3D空间中的车道检测.Song等[7]提出车道检测和分类策略, 使用立体视觉提供车辆的横向定位信息, 并对前方可能的碰撞发出警告.
为了避免可能发生的事故, 自动驾驶系统需要检测和跟踪道路上的其它车辆, 这项任务需要估计周围车辆的形状、相对速度、尺寸和三维位置等信息.Tayara等[8]使用卷积回归进行车辆检测和计数.Chen等[9]利用深度卷积神经网络(Deep Convolutional Neural Networks)进行目标位置预测, 提出3D对象检测的框架.类似地, Rajaram等[10]利用Faster R-CNN、RefineNet和预设兴趣框进行车辆检测和定位.上述工作使自动驾驶车辆能够检测道路上的其它车辆, 从而提高自动驾驶的安全水平.
相比其它物体, 人类安全的重要性更高.因此, 学者们提出一系列算法, 专门用于检测和跟踪行人以避免碰撞.Ouyang等[11]提出深度特征提取、处理变形和遮挡及行人检测分类的联合框架, 提高自动驾驶的安全性.Cai等[12]提出CompACT(Complexity Aware Cascade Training), 将级联与卷积神经网络集成, 以更快的速度实现准确的行人检测.类似地, Wang等[13]提出PCN(Part and Context Network), 处理身体部位语义、上下文信息以及复杂的遮挡, 得到高度准确的定位结果, 提高自动驾驶的安全性.
1.2.2 决策规划系统隐患分析
决策规划系统是自动驾驶的核心, 具有承上启下的作用, 在接收感知定位系统的输出信息后完成行为决策, 并为控制模块提供一条满足动力学约束、驾驶安全性和舒适性的轨迹.此外, 局部避障要求自动驾驶技术必须具备较高实时性.经典的规划算法主要通过约束车辆与障碍物之间的距离或表征障碍物形状以保证安全空间, 或者对目标进行优化控制以保证生成安全可靠的轨迹.此外, 决策规划系统还应具备对其它模块的故障进行补救的能力.例如, 面对前方“ 鬼探头” 的情况(指行人从路边停靠车辆前方突然出现), 依靠紧急制动等基于规则的方案仍存在一定的安全风险.在复杂的动态场景中, 自动驾驶车辆需要对前方的可能隐患做出预测, 提前规划更为安全可靠、避免潜在风险的轨迹.综上所述, 决策规划算法需要对单模块的安全风险及多模块的集成风险具有一定的预防性判断.
1.2.3 导航控制系统隐患分析
在自动驾驶系统中, 控制模块不仅要在纵向上保持速度的平滑性, 限制极端的加减速情况, 还需要在横向上进行轨迹跟踪, 使得自动驾驶车辆沿着期望参考轨迹行驶.此外, 原先由人为控制的油门、刹车板等机械器件也交由电子元件进行控制, 更要求它的控制精确度以及车辆实时可控性, 这都对底层线控单元提出更高的要求, 因此这对整个系统的安全性也需要更严格的要求.
线控制动是安全限制的最后一道防线, 在自动驾驶中至关重要, 特别是在紧急情况下, 发挥着至关重要的作用.Zhu等[14]提出FPC(Fusion Predictive Control), 解决线控制动系统在多次紧急制动过程中的动态响应, 有效提升制动效果.
线控转向技术使车辆安全跟随参考轨迹行驶.Erlien等[15]提出使用两个安全驾驶包络线进行避障和稳定性控制的共享控制框架.一个包络线由车辆操纵极限确定, 另一个包络线由车道边界和障碍物施加的空间限制确定.当驾驶员命令轨迹处于两个包络线之外时, 模型预测控制器就会进行干预, 主要任务是确保车辆在先前定义的安全驾驶范围内安全行驶.以这种方式, 控制器与驾驶员共享控制, 同时避免障碍并防止失控.
行为决策算法制定安全的行驶策略供下层模块使用并生成安全可行轨迹.在复杂和高度动态化的交通环境中, 自动驾驶车辆需要考虑交通规则、周围交通参与者和道路状况以做出安全可靠的决策.针对这种高复杂度的动态环境, 部分可观测马尔可夫决策过程(Partially Observable Markov Decision Pro-cess, POMDP)提供一个理想、严格的模型处理交互性和不确定性, 因此适合自动驾驶的决策.研究人员对其建模进行求解, 求解算法主要包括基于规则的决策算法、基于监督学习的决策算法和基于强化学习的决策算法.
基于启发式的决策算法是指利用固定的规则和条件做出决策.在自动驾驶应用场景城市挑战赛中, Junior[16]和Odin[17]在狭窄范围的理想场景内可以较好地描述类人的规划过程, 但由于实际的交通场景存在较高的动态性和不确定性, 很难创建覆盖所有交通场景的安全规则库, 不适用于城市驾驶等复杂场景.Jian等[18]应用有限状态机描述不同的车辆行为, 并获得预期的结果, 但这种方法不能较好地考虑交通参与者之间的交互.在熵风险度量下, Wang等[19, 20]研究博弈论框架中风险感知代理的交互, 性能明显优于不考虑交互性的算法.
POMPD是一个强大的数学模型, 可捕捉未知环境变化的不确定性, 因此也是解决交互性问题的最佳模型之一.Bai等[21]将POMDP用于预先路径的速度规划, 提高算法的及时性, 并在复杂、动态的环境中实现有效的自动驾驶.然而, 自动驾驶的决策必须推理大规模状态空间和长期未来交通场景, 这就分别加剧维度诅咒和历史诅咒问题.Cunningham等[22]选择一组闭环行为中的一个行为, 前向预测并模拟捕获这些代理动作之间的复杂交互.Galceran等[23]从潜在策略分布进行采样, 模拟预测并执行具有最大预期奖励值的策略, 将时间消耗限制在实时水平.
基于启发式的决策算法由一组明确的规则和条件作为前提, 因此决策过程透明、可预测, 容易扩展其功能和适应性, 从而满足不同的应用场景和需求.另外, 精心设计和测试的决策过程可以被高度优化, 因此基于规则启发式的决策算法准确性和可靠性较高.
尽管POMPD提供一种系统化的方法以合并未知的不确定性, 但当扩展到现实世界的大型问题时, 无法很好地进行计算.为了优化该问题, Zhang等[24]丰富语义层行为的多样性, 利用特定领域的专家知识指导车辆运动, 可在复杂的驾驶环境中实时生成长期的横向行为和纵向行为.基于最优化理论的安全决策模型[25, 26]考虑车辆动力学模型, 在线连续优化, 生成更加舒适安全的可行驶轨迹.针对与其它移动车辆的安全高效交互问题, Dai等[27]结合启发式搜索算法和二次优化算法, 为自动驾驶车辆生成安全、平滑的速度分布.实验表示在与其它动态车辆的交互中, 自动驾驶车辆的规划速度能够适应不断变化的环境.
基于规则的决策算法通过调整和修改规则以达到特定的决策目的, 对系统达到精确控制, 使其具备一定可控性.不足之处在于:缺乏灵活性, 只能处理已经预定义好的情况, 难以处理异常情况; 增加规则在某种程度上会增加复杂性, 维护成本相对较高; 这些规则往往无法自我学习和优化, 需要手动进行调整和修改等.总之, 基于规则的决策算法在某些场景下可以取得较优效果, 但在应对复杂和不确定的情况时可能存在一些限制.因此, 将基于规则的决策算法与其它决策算法结合, 可以提高系统的性能和鲁棒性.
随着人工智能和机器学习的快速发展, 模仿学习针对已有专家数据对智能体进行训练, 能够使其具备更多的智慧属性, 应对基于规则的传统算法在行为决策层的巨大挑战.
人类驾驶的演示数据容易被大规模收集, 模仿学习使用收集到的数据训练模型, 该模型可以通过感知输入直接生成控制车辆运动的命令.Bojarski等[28]提出的经过人类驾驶示范训练的深度网络已经逐渐学会道路保持和避让障碍物, 然而, 这些系统具有特性限制.例如, 训练道路保持和避让障碍物的网络无法引导车辆在即将到来的十字路口提前转弯.Codevilla等[29]以高级命令输入为条件, 集成相机感知信息模仿学习, 训练时不仅给出感知输入和控制信号, 而且给出专家意图的表示, 使模拟学习能够在复杂的城市环境中应用.Wang等[30]提出构建鲁棒的自主车辆控制器技术, 使用变分近似训练的概率变量模型, 使车辆在行驶过程中更加安全.但是, 由于自动驾驶控制的本质是一个顺序决策问题, 需要大量数据, 因此方法有很大的复合误差.Zeng等[31]结合端到端驱动和传统工程方案, 将原始激光雷达数据和高清地图作为输入, 提出神经运动规划器, 用于学习在复杂的城市场景中的自主驾驶.
综上所述, 基于监督学习的自动驾驶决策算法利用历史数据训练模型, 能够自动做出决策.在训练数据足够丰富时, 可以获得很高的准确性.随着不断收集和整理的数据量的增加, 可以不断优化和扩展该模型, 使其逐渐适应更广泛的场景和情况.然而, 基于监督学习的算法需要大量的标注数据以训练模型, 数据的质量和数量对模型性能有重要影响, 对数据的依赖性太强.如果模型过于复杂或训练数据不够多样化, 容易导致模型过拟合, 对新数据的泛化能力较差.相反, 当模型面对没有见过的情况时, 决策能力也会受到影响.
随着强化学习的兴起, 智能体的自主学习能力能够较好地应对不同路况而做出最适合的安全决策, 并具备强大的智能性和普适性.本节主要介绍强化学习的基本理论, 包括强化学习的基本要素、约束马尔科夫决策过程(Constrained Markov Decision Pro-cess, CMDP)等, 进一步分类自动驾驶领域中的安全强化学习算法, 探讨安全强化学习在行为决策中的理论困境和当前热点.
2.3.1 基础理论
传统强化学习本身的设计没有过多考虑安全性问题, 因此学者们引入安全强化学习(Safe Reinfor-cement Learning)[32]的概念.安全强化学习定义为:智能体在部署或者学习过程中, 考虑其本身和周围环境的损坏指标、安全状态的概率以及在与环境交互中得到的损失反馈等不等式约束, 最大化目标函数, 求解满足安全约束的最优策略.
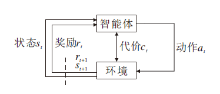
安全强化学习一般通过CMDP建模, 使用七元组 (s, a, p, r, c, d, γ)表示, 即状态、动作、状态转移概率、奖励、代价、代价阈值和折扣因子[33].CMDP结构如图2所示.
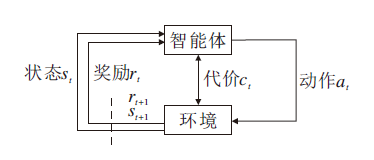 | 图2 CMDP结构图Fig.2 Structure of CMDP |
CMDP是对智能体施加额外约束的马尔科夫决策过程(Markov Decision Process, MDP), 目标是使智能体不仅通过长远奖励得到最优策略, 同时确保环境状态的一些指标符合约束.例如在交通管理中, 在满足车辆平均延迟和特定路段的车辆通行类型的限制下, 智能体最大化车流量.CMDP的建模公式为
$\begin{aligned} & \max _{\pi \in P(S)} V(\pi)=E_\pi\left[\sum_{t=0}^{+\infty} \gamma^t r\left(s_t, a_t\right)\right], \\ & \text { s.t. } J_{C_i}(\pi)=E_\pi\left[\sum_{t=0}^{+\infty} \gamma^t c_i\left(s_t, a_t\right)\right] \leqslant d_i, \end{aligned} i=1, 2, …, m.$
$\begin{aligned} & \Pi_C=\left\{\pi \in \Pi: \forall i, J_{C_i}(\pi) \leqslant d_i\right\}, \end{aligned}$
最优策略为
$\begin{aligned}& \pi^* =\arg \max _{\pi \in \Pi} J(\pi) . \end{aligned}$
CMDP通过最优化满足安全下的奖励目标函数, 可较好地平衡奖励和安全约束, 因此, 安全强化学习适用于自动驾驶系统, 在保证一定安全性的同时, 可求解特定驾驶任务中的最优策略.
2.3.2 安全强化学习算法分类
本节对安全强化学习算法进行分类:1)优化准则转换, 通过在目标函数中加入约束条件, 梯度更新时采用不同的优化准则.2)通过风险指标引导探索过程.3)引入外界因素, 在学习不安全动作时进行修正.
2.3.2.1 优化准则转换
优化准则转换基本流程是在目标函数中加入拉格朗日对偶方法处理的约束条件, 梯度更新时采用不同的优化准则.Lagrange Multipliers Method(LMM)将约束项作为惩罚项直接代入策略迭代, 即
$\begin{aligned}& \max _{\pi \in P(S)} V^{\prime}(\pi)=V(\pi)-\sum_{i=1}^N \lambda_i\left(J_{C_i}(\pi)-c_i\right), \\ & \lambda_i \geqslant 0 . \end{aligned}$
在策略优化过程中, 给予违反约束的策略一个正λ i惩罚.λ i不仅和约束的量级有关, 而且不同的选择会导致优化结果的不同, 所以需要很强的经验选取λ i.优化准则转换主要分为约束策略优化(Constrained Policy Optimization, CPO)[34]和奖励约束策略优化(Reward CPO, RCPO)[35].
约束策略优化(CPO)通过局部策略搜索和信任区域扩张的方法将单步策略更新限定在不违反约束的增长方向上.最大的创新在于引入环境约束:
$\begin{aligned}& \max _{\pi \in P(S)} V(\pi)=E_\pi\left[\sum_{i=0}^{\infty} \gamma^t r\left(s_t, a_t\right)\right], \\ & \text { s. t. } J_{C_i}(\pi)+\frac{1}{1-\gamma} E_\pi\left[\sum_{t=0}^{\infty} \gamma^t c_i\left(s_t, a_t\right)\right] \leqslant d_i, \\ & \quad i=1, 2, \cdots, m, D_{\mathrm{KL}}\left(\pi, \pi_K\right) \leqslant \delta .\end{aligned}$
由于近似误差会导致实际解不符合要求, 因此按照约束梯度进行下降, 直到进入局部信任域.设
ci=
CPO具体步骤如下.
算法1 CPO
输入 初始化策略π0
输出 安全策略π *
for k = 0, 1, …, do
采样若干采样轨迹序列D={τ}~π k=π(θ k)
根据轨迹序列D采样估计量$\hat{g}, \hat{b}, \hat{H}, \hat{i}$
if 近似CPO是可行的 then
闭式解
约束策略:
θ * =θ k+
else
信任约束策略:
θ * =θ k-
end if
通过回溯线搜索获得θ k+1, 以强制满足约束的样本估计
end for
Cui等[36]采用CPO, 在信任区域优化策略, 选取直道和复杂几何道路等多个测试场, 验证算法在自动驾驶中良好的安全性.在动态复杂的城市交通环境中, Xu等[37]提出并行约束策略优化, 引入安全规则作为安全强化学习智能体的先验知识, 保证策略在学习过程中的安全性, 提高收敛速度.同时, 增加信任区域约束, 允许较大的更新步长.
奖励约束策略优化(RCPO)通过代替惩罚信号引导策略向满足约束的方向优化, 是多时间尺度约束策略优化方法.最大的创新是利用拉格朗日松弛法改写目标函数, 符合渐进满足约束:
在较快的时间尺度上, 通过上式求解找到θ, 而在较慢的时间尺度上, 增加λ, 直到满足约束.
RCPO具体步骤如下.
算法2 RCPO
输入 惩罚c, 约束C, 阈值α, 学习率η1(k)
输出 安全策略π *
初始化 执行者参数θ=θ0, 评价者参数v=v0, 拉格朗日乘数法λ
for k = 0, 1, …, do
初始化状态s0~μ
for t = 0, 1, …, do
采样动作at~π, 观察下一个状态st+1, 奖励rt和惩罚ct
评价者更新:
$v_{k+1} \rightarrow v_k-\eta_3(k)\left[\frac{\partial\left(\widehat{R}_t-\widehat{V}\left(\lambda, s_t, v_k\right)\right)^2}{\partial v_k}\right]$
执行者更新:
$\theta_{k+1} \rightarrow \Gamma_\theta\left[\theta_k+\eta_2(k) \nabla_\theta \widehat{V}(\lambda, s)\right]$
拉格朗日乘法系数更新:
λ k+1→ Γ λ [λ k+η1(k)
end for
end for
相比CPO, RCPO不同的是利用随机估计中多尺度更新的思想, 使用不同的速率更新对偶变量.代珊珊等[38]提出基于动作约束的软行动者-评论家算法(Constrained Soft Actor-Critic, CSAC), 首先对环境奖赏进行合理限制.为了使乘客感到舒适, 应尽量保持无人车动作转角平缓, 防止产生抖动, 因此在奖赏函数中加入惩罚项, 使自动驾驶车辆横向控制尽量安全平滑.另外, CSAC标记智能体的错误动作, 当目前状态选择动作后使无人车偏离轨道或发生碰撞时, 标记该动作为约束动作.在之后的训练中通过合理约束更好地指导无人车选择新动作.实验表明, CSAC能够有效降低危险动作的概率, 提高自动驾驶过程中的稳定性, 同时加快模型的训练速度.
2.3.2.2 探索过程的修正
在强化学习中, 智能体通过试错的方式, 选择最高奖励的行为以优化策略.大多数探索环境的方法都是基于启发式的, 依赖于从环境采样中收集的演示数据, 或者随机地进行探索.这些探索方法虽然高效地勘探状态空间, 但大多数都对某些行为的风险有所忽略.
为此学者们在强化学习中修改探索过程以保证智能体在信任域中探索, 修改方式主要有两种:1)基于先验知识修改探索过程; 2)使用基于熵度量和预期回报的加权和, 有效评估探索过程中的风险程度, 引导智能体探索环境.
在早期阶段强化学习算法是在没有先验知识的情况下, 采用ε -greedy随机探索策略开始学习, 这种策略会导致智能体经过大范围探索状态和动作空间, 从环境中学习到足够的知识及获取丰富的信息, 才能优化策略.然而对于风险区域和不相关区域, 随机探索策略也要花大量的时间探索状态和动作空间, 甚至可能使智能体在风险区域内发现某种捷径, 对智能体或环境造成不可修复的损害.
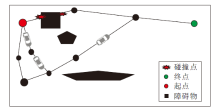
基于先验知识的方法最初被用于引导强化学习的探索方向, 缩短训练时间.根据它们的设计方式, 已证明适合处理风险领域的问题.智能体根据收集的专家经验或者基于安全规则的先验信息初始化智能体状态, 具体探索过程如图3所示.在智能体状态初始化之后, 系统可以根据初始训练阶段预测的值切换到玻尔兹曼机或完全贪婪策略的探索.通过这种方式, 初始化的智能体在早期探索阶段中, 接触安全可信任区域的概率较高, 能够缩短训练时间, 有效降低智能体因错误动作而造成损伤的几率.
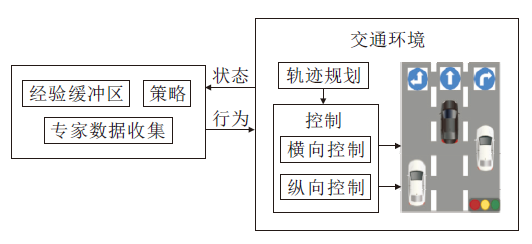 | 图3 基于先验知识修改探索过程Fig.3 Modification of exploration process based on prior knowledge |
Wu等[39]提出专家演示辅助安全强化学习策略迭代方法, 采用基于值迭代的Double Dueling DQN(D3QN)作为决策模型, 用于收集专家驾驶员通过驾驶模拟器执行驾驶任务生成的优质轨迹数据.然后将专家驾驶数据集视为安全演示的数据发送到D3QN的策略训练缓冲区.通过安全演示的帮助, D3QN策略的安全性、效率和渐近性得到有效提高.该策略通过车道变换场景进行检验, 并引导自动驾驶车辆在高速道路上做出高级行为决策.
专家演示数据和基于规则的决策模型可以为代理提供初始知识, 但这并不足以防止后续勘探中的危险情况.
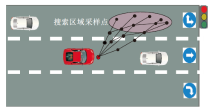
另一种探索过程是使用某种形式的风险度量进行的, 如图4这种基于熵度量和预期回报的加权和的时间差异度量.
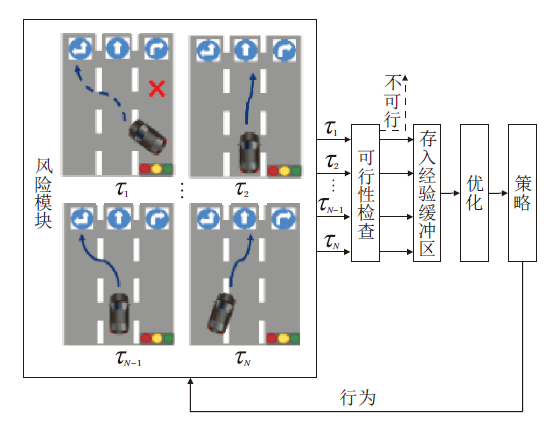 | 图4 基于风险估量修改探索过程Fig.4 Modification of exploration process based on risk assessment |
Zhang等[40]提出BLF-SRL(Barrier Lyapunov Function-Based Safe Reinforcement Learning Algori-thm).在学习过程中, 将BLF约束嵌入到优化反演控制方法, 将状态变量约束在设计的安全区域内.Lu等[41]使用基于策略优先级的层次结构, 将每个策略划分为具有不同选择优先级的子策略, 从而缩小动作空间.通过智能体迁移学习初始化策略, 加速对最优策略的初始探索.子策略分布的制定基于评估风险值的安全准则, 如果因为网络安全问题而导致学习失败, 可以避免产生危险子策略.Mo等[42]结合强化学习和蒙特卡罗树搜索算法(Monte Carlo Tree Search, MCTS), 提出两个安全强化学习框架, 即风险状态估计模块和安全策略搜索模块, 减少不安全的行为.具体过程是一旦风险状态估计模块根据当前状态信息和智能体执行的动作计算出未来状态的风险, 基于MCTS的安全策略搜索模块将被激活, 通过为风险操作添加额外奖励以确保更安全的勘探.在实际应用中, 这样的策略大幅加强自动驾驶车辆的安全行为概率.
2.3.2.3 基于直接干预动作的方法
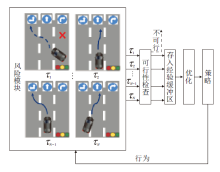
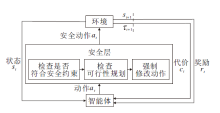
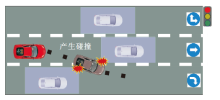
基于先验知识和基于风险估量的修改探索过程都可以有效保证智能体在安全领域勘探环境的同时, 尽量避免做出错误决定, 陷入致命状态.但是, 有时候可能存在系统错误, 导致智能体未必能做出正确的决策.学者们提出安全监视器, 及时纠正智能体做出的错误决策, 具体如图5所示.
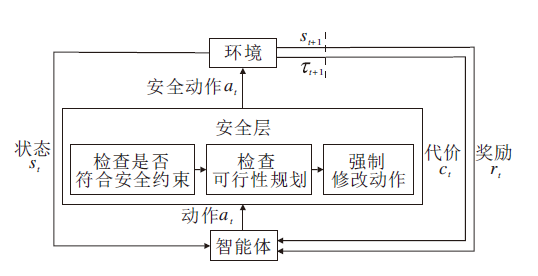 | 图5 直接干预动作Fig.5 Hierarchical Behavior and Motion Planning |
Yang等[43]提出描述系统行为的不确定性建模语言, 将其设计转化为概率时间自动机网络并结合安全强化学习, 构造SCFM(Safe Control with Formal Methods).在学习过程之前对状态空间进行探索, 构建一个服从概率计算树逻辑描述的约束的状态集, 使用基于规则的监视器监视系统, 判断所要执行的动作是否安全, 并纠正不安全的行为.
Krasowski等[44]在强化学习中加入安全层, 在执行高级决策之前验证它们的安全性, 并将决策模型运用到城市驾驶的十字路口场景中, 提出的安全层基于安全约束的制动集合处理变道和过十字路口的行为, 在安全集合中选择高效动作, 保证乘客安全.作者在包含城市驾驶场景的inD数据集上的大量实验表明, 安全代理不会引起碰撞, 相比不安全基线代理, 安全层的变道可得到更优的性能.该研究论证强化学习在实际车辆行车过程中的可行性, 在模型中增添安全层大幅提高行车安全性.
2.3.3 安全强化学习在自动驾驶中的应用
现实中, 安全强化学习应用在自动驾驶领域主要有如下优势:解决效率问题, 解决安全问题, 解决无模型静态规划问题.
强化学习端到端决策模型通过“ 试错” 的方式, 自主地从环境中学习决策生成策略, 减少感知和规则的手工需求.Kang等[45]使用基于动态规划和强化学习的有效数据驱动方法完成车道保持任务, 定义垂直于前车的虚拟前车, 构造误差系统, 通过数值模拟验证性能优于传统的决策优化算法.Cai等[46]提出DQ-GAT, 实现可扩展和主动的自动驾驶, 其中基于图形注意力的网络用于隐式建模交互, 深度Q学习用于无监督方式的网络端到端训练, 通过轨迹数据集的定性研究结果表明, 学习策略可以以实时速度转移到实际应用中, 在可见场景和不可见场景中更好地权衡安全性和效率.Jaritz等[47]只使用来自前视摄像头的RGB图像, 训练A3C(Asynchronous Advantage Actor-Critic)框架, 用于学习赛车游戏中的控制端输出.对弯道、山路等真实图像序列的开环测试表明, 该方法具有一定的自适应能力.
当交互式车辆很多时, 端到端学习方法不能确保结果的安全性, 为了解决这一问题, Li等[48]提出H-CtRL(High-Level Reinforcement Learning Algori-thm), 使用真实世界的数据集再现交通场景, 在各种现实模拟场景中证实其有效性, 在安全性和效率方面都具有令人满意的性能.
自动驾驶车辆在施加额外的约束后, 通过试错的方式探索交通环境, 使智能体不仅要通过长远奖励得到最优策略, 还要确保环境状态的一些指标符合约束.Ma等[49]提出CAP(Conservative and Adap-tive Penalty), 捕获模型的不确定性和自适应性, 平衡回报和成本目标, 解释潜在的建模错误.Mirchevska等[50]结合强化学习与安全验证, 确保智能体在任何时候都只选择安全的操作.实验证实自动驾驶车辆可在具有任意车道数量的模拟高速公路上执行合理的车道变化, 并且优于基于规则的决策方法, 可以较好地适应复杂场景, 并且不需要大量的人工标注数据以训练模型.Krasowski等[51]使用安全层扩展强化学习解决缺乏安全保障的问题, 该安全层将动作空间限制在安全动作的子空间中, 并在换道场景中进行验证.
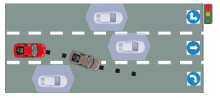
针对长视野问题, Wang等[52]使用强化学习解决长视野驾驶任务的HBMP(Hierarchical Behavior and Motion Planning)问题, 并且成功地应用于现实世界, 验证了泛化能力.Wang等[53]提出基于强化学习的协商感知运动规划框架, 自适应地实时动态修改运动规划器的预测视界长度, 并且采用RL(Rein-forcement Learning)调整驾驶风格, 最终在真实世界窄车道导航场景中进行测试, 结果显示该方案具备良好的通用性.Kamenev等[54]提出PredictionNet, 预测所有周围交通代理的运动以及自我车辆的运动, 并使用强化学习扩展DNN(Deep Neural Network), 可以更好地处理罕见或不安全的事件, 成功控制数百公里的真实车辆.
尽管强化学习类方法发展十分迅猛, 但其仍有不足之处.首先, 端到端决策模型主要是使用单个网络充当传统自动驾驶系统中的多个模块, 输出连续性的低维控制命令, 如方向盘转角和油门、踏板等, 其状态空间的庞大性和动作空间的连续性, 往往需要更多的优秀动作序列以训练模型, 大幅降低学习速率.此外, 使用单个网络充当整个自动驾驶系统, 较难捕捉作为中间规划者的行为决策, 很有可能使网络学会有限的战术决策, 如路径跟踪.
其次, 强化学习一般使用交通环境和周围交通参与者信息构成的向量作为输入, 尽量避开高维视觉输入, 但不以视觉为输入的自动驾驶车辆缺乏实际意义, 难以真正的自动驾驶.而且, 智能体需要不断尝试和反馈, 训练时间较长, 需要大量的计算资源和时间.同时, 学习过程不可解释, 无法直观理解模型的决策过程.另外, 不同的初始策略可能导致不同的学习结果.因此安全强化学习还有很大的提升空间.
自动驾驶技术的行为决策面临如下多种挑战.
1)不确定性.自动驾驶系统需要处理各种不确定性, 如环境感知不确定性、传感器误差、行为模型不准确等.这些不确定性可能导致行为决策出现偏差或错误, 因此自动驾驶系统需要能够有效处理这些不确定性.
2)多模态决策.在不同的交通场景中, 自动驾驶系统可能需要识别当前的交通场景, 并根据当前场景选择最优的行为决策, 如超车、变道等.这也意味着自动驾驶系统需要支持多模态决策.
3)道德决策.在某些情况下, 自动驾驶系统可能需要作出道德决策, 如在紧急情况下选择撞击哪个障碍物或避免哪个障碍物.这些道德决策需要考虑伦理、法律和社会因素, 这对自动驾驶系统的行为决策提出额外的挑战.
4)人机交互.自动驾驶技术需要和人类驾驶员、行人等进行交互.自动驾驶系统的行为决策需要考虑人类驾驶员和行人的行为, 确保他们的安全和舒适感.因此, 自动驾驶系统需要与人类驾驶员和行人进行有效交互, 传达自己的行为意图和接受其他人的行为信号.
针对上述挑战, 基于规则的方法显然不具备应对更加智能的决策, 而学习类方法相对较优, 但从安全的角度上看, 目前学习类方法相对于基于规则的方法仍有差距.
运动规划算法基于当前策略、环境信息及自身车辆的位姿信息进行规划, 输出一条满足安全性、平滑性的轨迹.本文围绕经典规划算法的分类, 包括基于采样的规划算法、基于图搜索的规划算法、基于数值优化的规划算法[55], 另外也介绍其它环境交互性算法, 如Bug算法、矢量直方图等.最后总结运动规划在自动驾驶技术中的挑战.
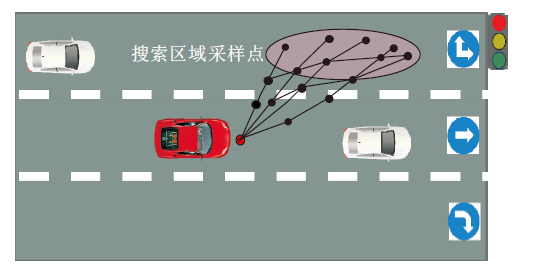
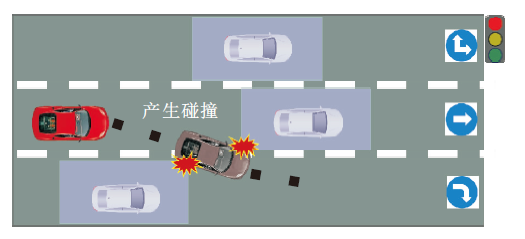
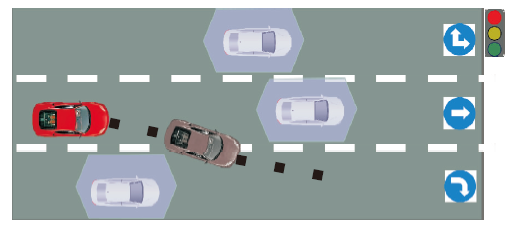
基于采样的规划算法在空间中进行状态或速度点采样, 并通过碰撞检测算法去除有碰撞风险的采样点.
Kavraki等[56]提出PRM(Probabilistic Roadmap Method), 首先使用随机采样的方式在环境中建立完整的无向图, 将连续空间离散化, 再通过碰撞检测剔除危险碰撞点, 完成路径规划.然而, 在搜索过程中PRM会产生大量的碰撞检测, 浪费资源.PRM示意图如图6所示.
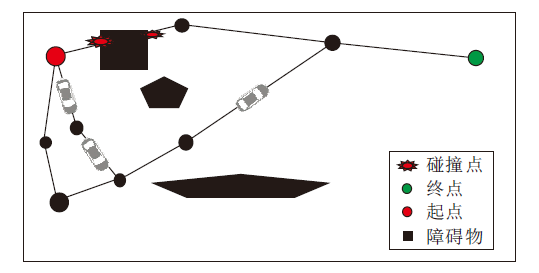 | 图6 PRM示意图Fig.6 Sketch map of PRM |
Fox等[57]结合可见图采样方法与PRM, 减少PRM中大量碰撞检测的代价.在此方法中, 采样点的数量会对最终的路径产生较大的影响, 并且由于某些限制, 无法保证避开所有的动态障碍物, 在特殊场景, 如狭窄通道中, 可能会出现找不到解的情况.针对这种窄通道问题, Hsu等[58]提出AHS(Adap-tive Hybrid Sampling), 测试发现, AHS在窄通道中能够安全通行, 具有良好性能.
Lavalle等[59]提出RRT(Rapid-Exploration Ran-dom Tree), 从特定的初始状态出发建立局部路线图, 在构型空间中不断延伸树型数据结构, 具体示意图如图7所示.它与PRM不同之处在于同时进行搜索与建图, 并保证概率完备性.
 | 图7 RRT示意图Fig.7 Sketch map of RRT |
经典RRT只完成空间维度下的采样搜索, Hesse等[60]在RRT中增加时间维度.Ma等[61]将A* 算法的思想应用于RRT, 首先获得车辆的粗略避障, 再通过应用三次样条插值方法优化粗糙路径, 解决实际车辆安全超车任务.上述算法仅针对当前时刻进行避障, 缺乏对未来时间的考虑.因此, Alesiani等[62]提出LGRT(Local Growing Rapid Tree), 在潜在驱动区域内局部生长随机探索树, 提供未来运动的预测范围, 从而在高度复杂的环境中提供实时运动规划.Smit等[63]基于道路布局信息, 向搜索树添加初始探索分支, 并重复先前的解决方案以改进Stable-Sparse-RRT, 检查多边形之间边界是否重叠(由多边形表示障碍物车辆以及主车), 若重叠即视为碰撞.从而提高总体规划性能.
DWA(Dynamic Window Approach)在速度空间中搜索适当的纵向速度和旋转速度指令, 通过速度采样信息扩展至状态信息, 判断是否会发生碰撞[64, 65, 66, 67].经典的DWA在局部避障中表现良好, 但容易陷入局部极小值, 而且在愈加复杂的现实环境中, 无法预测环境中其它障碍物的运动.为了解决这一问题, Missura等[64]提出Dynamic Collision Model, 能通过考虑其它对象的运动预测潜在的碰撞行为, 可显著减少动态环境中与非完整车辆的碰撞次数.
基于采样的路径规划算法考虑多种约束条件, 如车速、交通规则等, 生成符合实际的路径, 普适性较强, 可以根据场景的不同生成不同的候选路径, 并选择最优的路径.然而, 采样精度和数量对生成路径的质量有很大的影响, 在复杂的交通场景中可能无法生成符合实际的路径, 或者需要大量的计算资源以生成路径.
基于图搜索的规划算法先使用几何结构将空间进行分解, 再将障碍物检测信息覆盖在网格上, 根据车辆与障碍物的碰撞性进行探索.从图的结构来看, 可分为占用栅格图和拓扑连通图等.占用栅格图类算法会生成贴近障碍物行驶的轨迹, 导致车辆行驶过程中危险系数较高, 在自动驾驶系统中应用较少.因此本节着重介绍连通图类的搜索算法.
3.2.1 障碍物的表征算法
如何表示障碍物在图搜索类算法中起着关键作用, 用于保证自动驾驶车辆最大安全限度的通行.Kuan等[68]将障碍物使用凸多边形表示, 首先将凹障碍物体分解为相互连接的凸障碍物体, 获得统一的障碍表示, 方便后续处理.Liu等[69]将车辆自身和周围的交通工具都建模为矩形, 可更准确地表示交通工具的形状, 具体如图8所示.
 | 图8 障碍物表示为矩形Fig.8 Obstacles represented as rectangles |
Nilsson等[70]提出Low-Complexity Trajectory Planning Algorithm, 使用三角形表示障碍物, 具体如图9所示.此算法考虑由自动驾驶车辆纵向和横向运动定义的各种形状的安全临界区域.相比矩形区域, 三角形区域自由空间明显增大.
 | 图9 障碍物表示为三角形Fig.9 Obstacles represented as triangles |
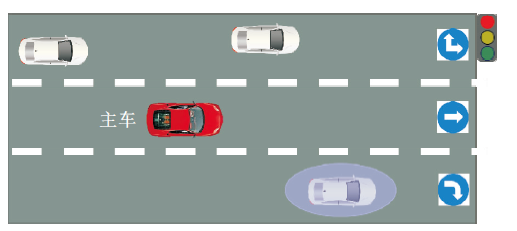
Claussmann等[71]将障碍物视作椭圆形, 包括两个关键距离, 前者越大保证被控车辆在行驶方向上前进距离更远, 后者越大, 被控车辆选择的轨迹就越安全, 具体如图10所示.
 | 图10 障碍物表示为椭圆形Fig.10 Obstacles represented as ovals |
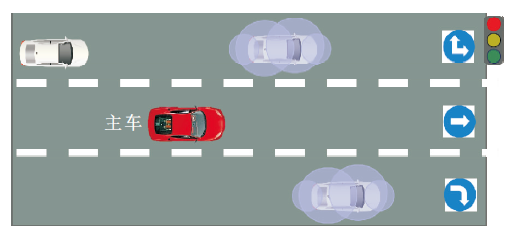
Mouhagir等[72]将障碍物标注为圆形, 为了保证安全距离, 在占用网格中对横向和纵向扩展, 使障碍物表示每边扩展 0.5 m, 具体如图11所示.
 | 图11 障碍物表示为圆形Fig.11 Obstacles represented as circles |
Hubmann等[73]将交通灯和动态代理渲染为纵向和时域中的障碍物, 并应用基于搜索的方法获得通用驾驶策略.Ajanovic等[74]扩展障碍物表示, 并将禁止变道实线作为障碍物, 约束驾驶安全性.
3.2.2 占用栅格图搜索算法
在占用栅格图搜索类算法中, 先将周围环境用网格分解, 根据实际情况判断该网格是否被占据, 常用0和1填充每个栅格.在车辆探索的过程中, 若当前栅格被障碍物占据, 此方向的路径延伸将被终止.Li等[75]在城市道路中使用Dijkstra's Algorithm进行规划.A* 算法是在Dijkstra的基础上发展而来, 在成本函数中增加目标权重, 可以实现快速的路径搜索.
由于A* 算法存在内存消耗、实时性、动态适应性等问题, 学者们又相继进行改进, 提出IDA* (Itera-tive Deepening A* )[76]、D* Algorithm (Dynamic A* )[77]、Hybrid
3.2.3 拓扑连通图搜索算法
拓扑连通图不同于占用栅格图的单一网格分解, 而是生成一堆不规则的区域.它的分解策略有两种:基于自由空间区域的单元分解和基于障碍物形状的空间分解.
3.2.3.1 基于自由空间区域的单元分解
位形空间的自由空间被分解为若干区域, 每个区域是一个单元.使用节点表示每个单元, 边模拟单元间的邻接关系, 最终形成一幅连通图.在这个连通图中寻找包含起点和终点的路径, 最终根据生成路径的单元序列生成单元内部的路径.连通图一般为凸多边形, 因此在连通图中任何两点都可以在不与多边形边界相交的情况下用直线段绘制形成可规划的安全区域[80].
Tehrani等[81]提出General Behavior and Motion Model, 单元的大小依赖主车辆和其它车辆的相对速度.Yu等[82]在网格中利用车道语义信息, 对信息进行编码, 在全局坐标系下估计姿态, 构建车道分布的横向位置不确定度垂直于车道方向, 计算横向高斯分布的标准差以保证安全性.Moras等[83]提出Occupancy Grid Framework, 采用可信度方法对传感器信息进行建模, 并与世界固定地图进行全局融合.Song等[84]为了使避障更稳定, 鼓励主车适当地改变车道, 并同时生成包括道路边界和障碍物车辆在内的道路环境图.
基于可视性图静态分解, Choi等[85]根据速度障碍分析构建动态安全区域, 最小化预期碰撞时间和当前速度对障碍物的安全性表示成本, 进行实时避障, 返回导致碰撞的自我车辆的所有速度集合[86], 表示之外的速度保证在障碍物速度预测正确的假设下不会发生碰撞, 然后使用连通图[68]或基于空间约束的优化方法求解通道和区域通道.Bender等[87]使用同伦方法构建可规划空间, 从路径速度分解中枚举可能的机动变量.Altché 等[88]提出四个无碰撞单元划分, 将时空的无碰撞部分划分为凸子区域, 分解计算最佳无碰撞轨迹的NP-hard问题, 但计算耗时过长.Speidel等[89]提出一种分支策略以及适用于交互式城市场景的可接受启发式算法, 提高轨迹质量和效率, 并限制速度和加速度, 保持和前方车辆的位置关系以保证安全.在此方法中, 车辆无需考虑在每个单元中的具体位置, 这严格保证车辆行进过程中的安全性, 因为所处的任意区域都是自由空间.该方案接收其它所有车辆的预测轨迹, 对行动策略进行评估, 环境车辆增多时容易影响计算效率.
3.2.3.2 基于障碍物形状的空间分解
基于障碍物的几何形状对位形空间进行分解, 自由空间的连通性通过曲线连接表示, 随后在该连通图中寻找连接起点和终点的路径.
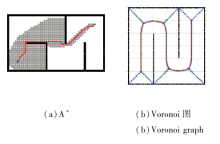
Aurenhammer等[90]扩展多边形障碍物的表示, 分解生成一个非规则网格, 并将其解释为与每个障碍物等距.为了增加障碍物和自我车辆之间的距离, 在移动机器人技术中开发加权[91]和不确定Voronoi图[92].Voronoi图提取障碍物之间的中间点, 最大化车辆和障碍物之间的距离.A* 与Voronoi图之间的对比如图12所示.
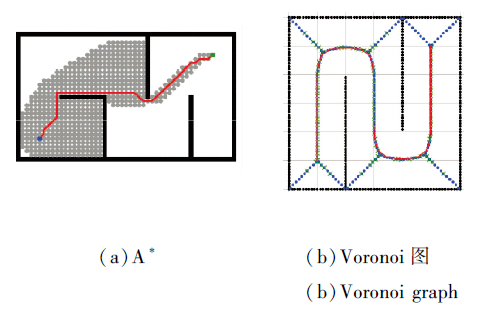 | 图12 A* 与Voronoi图对比Fig.12 A* vs. Voronoi graph |
此外, 等距离并不一定保证安全.为了应对这些问题, 当障碍物更近时, 近似方法会分成更细的单元, 以获得更精确的占用网格.
基于图搜索的规划算法构建道路网络图、搜索最优路径, 可以处理复杂的交通场景和实时变化的情况, 并保证生成的路径是最优路径, 从而提高路径规划的效率.
但是, 基于图搜索的规划算法可能会导致生成的路径不是全局最优路径, 在构建道路网络图和搜索最优路径中需要大量的计算资源和时间.另外, 该算法对道路网络图的建立要求较高, 需要准确的地图数据和道路信息, 否则可能会导致生成的路径不符合实际情况.
运动规划的优化问题主要有带约束的优化和无约束优化两种.其中数值优化通常表示为在一组约束条件下状态变量序列中成本函数的最小化, 这些方法旨在最小化或最大化受不同约束变量影响的函数, 通常将和障碍物的距离约束严格纳入目标函数中进行考虑.本节主要针对优化问题中的安全保证, 分别对其约束条件以及目标函数中的安全约束进行分析.
3.3.1 凸优化区域中的安全分析
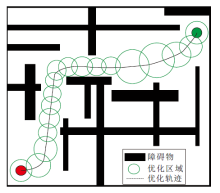
在图搜索类算法中, 如果对障碍物不做膨胀, 那么生成的自由空间区域依然无法避免规划生成的轨迹和障碍物的触碰风险, 因此换一个角度考虑, 将对障碍物的形状描述转换为对自由空间的形状描述, 在自由空间内进行轨迹优化.在文献[93]中这种类似“ 气泡” 的圆形区域约束不对整个自由空间进行计算, 只根据环境和车辆模型建立自由空间的局部子集, 节省大量的计算代价.在此基础上考虑时间维度, 形成一段空间区域(即凸自由空间), 可广泛应用于轨迹生成.
Zhu等[94]提出CES(Convex Elastic Smoothing), 沿着参考轨迹放置一系列圆形气泡, 识别前向空间中无碰撞的区域, 将这样的一个区域认为是一个无碰撞的“ 管” (如图13所示), 在该管内拉伸参考轨迹, 并且优化沿拉伸轨迹的速度分布也可以看作是一个凸优化问题.Erlien等[95]不仅考虑空间信息, 还考虑车辆动力学以构建管状凸区域.然而, 这两项工作都在静态环境中生成安全区域, 无法处理动态障碍.
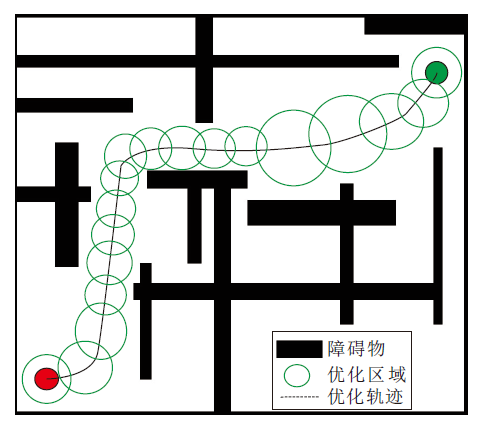 | 图13 凸管状区域Fig.13 Convex tubular area |
为了应对动态障碍物, Park等[96]使用线性安全区域构造碰撞避免约束, 使可行的约束集始终包含初始轨迹, 并利用这些约束将轨迹生成问题重新表述为凸优化问题.Liu等[97]在参考轨迹周围找到一个凸可行集, 并利用该凸可行集加速非凸优化.然而, 避免碰撞是他们的主要关注点, 因此没有考虑语义元素.Li等[98]建立语义级决策树, 对长期机动序列进行采样, 并根据周围环境计算每个机动序列的安全走廊, 再采用穷举搜索算法同步生成安全走廊内的侧向轨迹, 在生成的轨迹候选中, 选择代价最小的一个作为搜索结果.
受到上述区域生成方法的激励, Ding等[99]进一步将空间区域扩展到时空域以应对动态障碍, 提出轨迹优化公式, 保证输出轨迹的安全性和可行性.Toumich等[100]首先生成一条只避开静态障碍物的全局路径, 然后在其周围生成一条安全通道, 扩展安全通道的概念, 使其包含时间维度, 以便考虑其它车辆的未来位置, 但大规模的碰撞避免约束加剧维度诅咒问题.Cen等[101]简单地沿着引导路线构建一条通道, 使车辆的操纵与障碍物安全分离.上述算法在预测不确定性和相互作用不确定性的限制上还有所不足.Zhu等[102]明确考虑每个机器人与障碍物之间的碰撞概率, 并建立机会约束非线性模型, 预测控制问题, 建立碰撞概率近似的紧界, 有效解决不确定性问题.
3.3.2 目标函数设计中的安全考虑
在根据运动学约束计算轨迹时, 建立目标函数需要先以明确定义的数学形式对自我车辆和环境约束进行建模, 对于一些硬约束也可将其添加到目标函数中, 转变成软约束以优化.
在实际的车辆测试过程中, 对于二次凸优化问题, 二次规划优化算法(Quadratic Programming, QP)是常见的解决方法.QP的使用涉及对原始问题的凸近似解的迭代搜索, 如对距离偏移、速度、加速度等进行顺序二次规划优化.
Miller等[103]使用混合整数二次规划形式化描述变道和超车问题, 对障碍物的考虑如下:
$\begin{aligned} \sigma_{\mathrm{safe}}^a= & -\frac{\left(v_{\mathrm{obj}}-\left|a_{\max , \mathrm{obj}}\right| \delta_{\mathrm{brake}}-v_{\mathrm{ego}}\right)^2}{2\left(\left|a_{\max , \mathrm{obj}}\right|-\left|a_{\max , \mathrm{ego}}\right|\right)}-v_{\mathrm{obj}} \delta_{\text {brake }}+ \\ & \frac{1}{2}\left|a_{\max , \mathrm{obj}}\right| \delta_{\text {brake }}^2+v_{\mathrm{ego}} \delta_{\text {brake }}, \end{aligned}$
$\sigma_{\mathrm{safe}}^b=-\frac{v_{\mathrm{obj}}^2}{2\left|a_{\max , \mathrm{obj}}\right|}+\frac{v_{\mathrm{ego}}^2}{2\left|a_{\max , \mathrm{eg} o}\right|}+v_{\mathrm{ego}} \delta_{\mathrm{brake}}.$
弹性带算法[93]将环境建模为弹簧-质量系统, 考虑N个离散节点, 在障碍物节点上施加势能, 实现障碍物的远离.文献[65]将弹性带应用于车辆跟随, 引导车辆路径的变形.Keller等[104]开发一个与时间相关的弹性带框架, 具有用于车道变换的时间航路点.
为了在复杂的城市环境中保持车辆和其它车辆的安全, 自动化车辆必须以更高的速度和加速度处理动态情况.特别地, 可能需要采取突然和极端的行动, 避免与其它车辆或物体发生碰撞.在这种紧急情况下, 自动车辆的规划算法必须能够具备一定预测能力以避免碰撞.
模型预测控制(Model Predictive Control, MPC)将未来时刻的情况纳入当前时刻进行考虑.模型预测控制器解决一个优化问题, 根据车辆运动学约束以及周围环境进行建模, 在更长的时间范围内找到预测运动解, 但只应用第一个动作序列, 并在下一个时间步重复, 将障碍物离自车的距离作为MPC中的一种约束以保证自我车辆在纵向和横向上的安全[105, 106, 107].
Brown等[108]通过单轨动力学模型建模, 捕捉车辆旋转对潜在碰撞的影响, 使控制器能够推理旋转车辆纵向位置和横向位置, 并且通过对车辆的新颖表示进行避障, 惩罚所有车辆和障碍物圆圈对之间的距离.MPC的主要优点是重新规划能力及预测性, 但对于非凸和高复杂度问题, 计算代价仍然太大.
基于数值优化的规划算法通过优化目标函数生成最优路径, 可以同时优化多个目标, 如最短路径、最小加速度、最小曲率等, 生成符合实际的路径.经优化后可以生成全局最优路径, 适应多种复杂的交通场景.
然而, 基于数值优化的规划算法需要预设目标函数, 准确量化路径规划的目标, 否则可能会生成不符合实际的路径.另外, 此算法对初始路径的依赖度较高, 需要准确的初始路径, 否则可能会导致优化过程失败.
交互性算法更多为应用在局部规划中的一些算法, 根据从传感器中获得的实时测量信息及时调整路径, 避免发生碰撞, 主要包括BUG Algorithm、人工势场法、矢量场直方图法(Vector Field Histo- gram, VFH).
Bug Algorithm基本思想是车辆朝着目标前进, 当路径上出现障碍时, 让机器人绕着障碍物的轮廓移动, 绕离它后继续驶向目标[109, 110, 111].该算法符合人类的环境探索思维, 在未知环境下往往能取得不错的效果.
人工势场法将期望的速度方向看作是吸引力, 道路边界和障碍物等看作是障碍物, 主要优点是能够对场景表示的动态演变起直接反应[112, 113].Wolf等[114]调整车道、道路、障碍物和期望速度上的一组四个人工势, 用于模拟描述公路功能, 但有可能陷入局部极小值.为了克服这个问题, 一个简单的解决方案是添加一个启发式算法, 以随机路径退出最小值[115].这倾向于随后消除局部极小值.然而, 如文献[114]所述, 在城市道路规划场景中, 局部最小值可能是必要的, 它保证自我车辆的安全, 避免不确定的车道变化.
考虑到真实世界情景的不确定性, VFH作为一种经典的运动规划算法[116, 117], 广泛应用于处理移动机器人的轨迹规划问题.然而, 传统的VFH由于车辆的非完整约束, 很少应用于自动驾驶汽车, 特别是在城市环境中.
针对这一问题, Qu等[118]提出同时考虑车辆运动学和动力学约束的有约束VFH算法.首先为VFH开发一个新的活动区域, 保证该区域内的所有状态对车辆都是可访问的, 再改进成本函数, 引导搜索偏向于车辆的可行运动方向.
基于交互性避障的路径规划算法可以适应多种复杂的交通场景, 并根据实时环境信息, 动态调整路径, 避免碰撞和其它危险情况, 从而生成符合实际的路径.其缺陷是对传感器的要求较高, 另外可能会存在路径不连续问题, 需要对其增加优化模块, 保证轨迹可行驶性.
运动规划由机器人领域发展至今, 规划算法已相对成熟, 各算法具体性能对比如表1所示.表中√ 表示性能较优, × 表示性能较差, -表示性能处于两者之间.
| 表1 运动规划算法的性能对比 Table 1 Performance comparison of motion planning algorithms |
运动规划尽管在自动驾驶技术中发挥重要作用, 但仍面临如下挑战.
1)数据处理.交通参与者很多, 动态障碍物的大小、速度等各不相同, 自动驾驶车辆实时获取并处理大量的传感器数据, 包括雷达、激光雷达、相机等多种类型的传感器数据, 并将其进行处理和整合, 对这些不确定的物体建模, 从而实现精确的运动规划.
2)鲁棒性.在自动驾驶技术中, 车辆需要应对多样化的交通场景, 如不同的路况、天气、路线等, 这使得运动规划需要具备一定的灵活性和适应性.自动驾驶车辆必须能够应对各种意外情况和异常情况, 如突然出现的障碍物、道路损坏等.
3)实时性和安全性保障.自动驾驶技术需要保障安全性, 特别是在高速公路等高速行驶场景, 需要对道路情况做出正确的反应, 并及时避免碰撞或危险情况.
4)实际可行性.自动驾驶技术需要考虑实际可行性, 包括成本、可靠性、兼容性等方面, 这也是运动规划需要考虑的因素之一.
在工程化应用中, 由于不同的人会有不一样的感受和主观想法, 舒适性等指标非常难以量化.在车路协同概念的快速发展中, 当前车辆的规划行为也不仅仅依靠自身, 更需要利用所处道路范围内的大量环境信息.
总之, 运动规划在自动驾驶技术中的挑战是多方面的, 需要综合考虑各种因素, 并不断优化和改进, 实现更安全、高效、可靠的自动驾驶技术.
指标能够从量和质的角度去分析评判算法优劣性, 对于衡量一种算法的好坏十分重要.自动驾驶技术中常见的安全性指标如下.
1)碰撞检测.用于检测自动驾驶车辆是否与周围环境中的障碍物碰撞, 包括静态障碍物和动态障碍物.基于动态环境下的不确定性, 在决策中也会将碰撞风险作为指标进行考量.具体碰撞检测距离定义为:
dc=abs(St-St, k),
其中, St为t时刻主车位置, St, k为t时刻第k个障碍物的位置.
2)最小安全距离.车辆与周围障碍物之间的最小安全距离通常表示为一个固定距离或一个相对于障碍物大小的比例.针对上述碰撞检测距离dc, 若大于最小安全距离, 不符合安全约束.
3)速度限制.车辆的运动速度不能超过某个安全限制, 以确保它们在运动过程中可以及时避让障碍物或停下来, 此参数间接限制最小安全距离.另外, 速度也被分解为横向速度和纵向速度逐一考虑, 即
V=
4)安全转弯.车辆在转弯时需要满足一定的安全条件, 避免碰撞或失控, 满足曲率和车辆速度的平衡关系.
5)稳定性.车辆在运动过程中需要保持稳定, 避免翻车或失控.一般使用车辆侧向加速度、车辆滚动角度等指标量化自动驾驶系统的车辆稳定性.
自动驾驶技术是一种革命性的技术, 正在逐步改变人们的出行方式和城市交通格局.它的核心问题之一是如何实现精确、高效的运动规划, 保证车辆的安全性、可靠性和舒适性.决策规划作为该技术的核心环节, 不仅要解决其本身的安全隐患, 更要兼顾其它模块隐患.
目前, 自动驾驶技术已经取得很大进展, 但是仍然面临着一些挑战.本文主要阐述自动驾驶中决策和规划模块的算法, 并针对其进行一系列安全分析.随着自动驾驶技术的成熟及其产业化进程的迅速推进, 决策规划系统的作用愈加重要.
未来, 随着自动驾驶技术的不断发展和完善, 应用场景和范围也将越来越广泛, 包括城市公共交通、物流配送、出租车服务等方面.同时, 自动驾驶技术将和其它智能化技术结合, 如5G通信技术、人工智能等, 进一步提高自动驾驶技术的性能和应用效果.当然, 自动驾驶技术对复杂环境的识别和处理, 对多样化交通场景的适应能力、数据处理和计算能力的提高, 与人类驾驶员共享道路的协同能力等方面也需要得到更大的关注.因此, 未来的自动驾驶技术研究需要继续深入, 不断探索和创新, 实现更加智能化、安全、可靠、高效的自动驾驶技术.
今后将继续研究一种在众多环境因素中通过语义分析并和环境大量交互后得出的规划方案, 使之对自动驾驶车辆本身和周边的车辆达到一个良性的互动, 满足道路交通上的安全自动驾驶.总之, 未来的自动驾驶技术安全框架应该是整体协作集成框架.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
|
| [80] |
|
| [81] |
|
| [82] |
|
| [83] |
|
| [84] |
|
| [85] |
|
| [86] |
|
| [87] |
|
| [88] |
|
| [89] |
|
| [90] |
|
| [91] |
|
| [92] |
|
| [93] |
|
| [94] |
|
| [95] |
|
| [96] |
|
| [97] |
|
| [98] |
|
| [99] |
|
| [100] |
|
| [101] |
|
| [102] |
|
| [103] |
|
| [104] |
|
| [105] |
|
| [106] |
|
| [107] |
|
| [108] |
|
| [109] |
|
| [110] |
|
| [111] |
|
| [112] |
|
| [113] |
|
| [114] |
|
| [115] |
|
| [116] |
|
| [117] |
|
| [118] |
|