


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
连续环境中基于语义拓扑图的视觉语言导航推理
[谢子龙1  , 许明
, 许明1 ]
, 许明]
|
|



作者简介: 
谢子龙,硕士研究生,主要研究方向为具身智能、机器人导航.E-mail:zilong6037@gmail.com.
针对现有视觉语言导航方法在连续环境中推理能力不足的问题,提出基于语义拓扑图的视觉语言导航推理模型.首先,通过场景理解辅助任务识别导航环境中的区域和物体,构建空间邻近知识库.然后,智能体在导航过程中与环境实时交互,收集位置信息,编码视觉特征,并预测区域和物体的语义标签,逐步生成语义拓扑图.在此基础上,提出辅助推理定位策略,利用自注意力机制,从导航指令中提取物体信息和区域信息,并结合空间邻近知识库和语义拓扑图,对物体和区域进行推理定位,以辅助导航决策,确保智能体的导航轨迹与指令对齐.最后,在公开数据集R2R-CE和RxR-CE上的实验表明,文中模型的导航成功率较高.
About Author:
XIE Zilong, Master student. His research interests include embodied intelligence and robot navigation.
To address the issue of inadequate reasoning ability of existing vision-language navigation methods in continuous environments, a method for semantic topological maps-based reasoning for vision-and-language navigation in continuous environments is proposed. First, regions and objects in the navigation environment are identified through scene understanding auxiliary tasks, and a knowledge base of spatial proximity is constructed. Second, the agent interacts with the environment in real time during the navigation process, collecting location information, encoding visual features and predicting semantic labels of regions and objects. Thereby a semantic topological map is gradually generated. On this basis, an auxiliary reasoning localization strategy is designed. A self-attention mechanism is employed to extract object and region information from navigation instructions, and the spatial proximity knowledge base is combined with semantic topological map to infer and localize objects and regions. The above assists navigation decisions and ensures that the agent navigation trajectory aligns with the instructions. Experimental results on public datasets R2R-CE and RxR-CE demonstrate the proposed method achieves a higher navigation success rate.
视觉语言导航(Vision-and-Language Navigation, VLN)[1]旨在使智能体理解人类指令, 识别视觉观察, 并在未知环境中实现精确导航.早期研究[2, 3, 4, 5]使用循环神经网络构建智能体, 例如:Fried等[3]提出Speaker-Follower Models, 利用LSTM(Long Short-Term Memory)建模视觉观察和动作序列, 但其在学习长期依赖关系方面效率较低, 限制导航历史信息的有效传播.因此, 学者们提出基于Transformer架构的智能体[6, 7, 8], 通过注意力机制更好地模拟导航动作之间的长期依赖关系.Chen等[9]提出DUET(Dual-Scale Graph Transformer), 进一步引入拓扑图, 实现高效导航.一些研究[10, 11, 12]则引入导航知识, 增强智能体的泛化能力.例如:Li等[11]提出KERM(Know-ledge Enhanced Reasoning Model), 从知识库中提取知识, 更好地理解视觉信息.Xu等[12]提出HSPR(Hierarchical Spatial Proximity Reasoning), 通过辅助任务构建关于导航环境的邻近知识库, 协助智能体进行导航决策和物体定位.
然而, 这些工作都集中在离散环境的VLN设置上, 将导航环境离散为一个无向图, 即假设智能体已知当前位置的邻接节点集, 并忽略地形或障碍物对导航的影响.为了反映更真实的场景, Krantz等[13]引入VLN-CE(Vision-and-Language Navigation in Con-tinuous Environments), 将Matterport3D[14] 中预定义的离散无向图迁移至连续的Habitat[15]空间上, 智能体可通过一系列低级控制(如左转15° 或向前移动0.25 m)自由导航到任何无障碍点, 而不是在固定节点之间转移, 从而使导航任务更贴近实际, 但也更具有挑战性.
目前针对VLN-CE任务的研究还较少, 一些已发表文献[13, 16, 17]通过实验验证VLN-CE智能体的导航性能远低于VLN智能体.在VLN-CE早期的研究中, Krantz等[13]通过跨模态注意力模型直接预测低级控制动作, 但在真实机器人上可能导致频繁的停止、启动和转弯动作, 增加硬件要求.因此, Krantz等[17]提出WPN(Waypoint Prediction Network), 每步都预测一个基于语言指令的航路点作为子目标, 再通过一组低级控制到达子目标.Raychaudhuri等[18]提出LAW(Language-Aligned Waypoint), 通过有监督的训练, 更好地对齐智能体导航路径与语言指令.Hong等[19]引入高准确性的航路点预测器, 估计连续空间中的可导航位置, 并在每个时间步构建以智能体为中心的局部导航图.
近期研究[20, 21, 22]聚焦于构建一个由航路点预测模块、高级规划模块和低级控制模块组成的完整导航系统.Krantz等[20]率先构建这样的模块化导航系统, 使大多数 VLN 智能体都可以在VLN-CE中运行.Wang等[21]运用ERG(Environment Representa-tion Graph), 在语义层面上表达环境, 加强语言指令与环境间的关联性, 并提出跨模态注意力导航框架, 结合ERG与定制损失函数, 进一步提升导航的精确性和效率.An等[22]构建目前最先进的VLN-CE智能体— — ETPNav(Evolving Topological Planning for Vision-Language Navigation), 将导航过程分解为高级规划和低级控制两个层面, 利用基于Transformer的跨模态规划器, 根据拓扑图和指令生成详细的导航计划, 最后通过避障控制器精准执行该计划.但上述方法都未考虑除视觉和语言模态信息之外的空间相关性线索的显式使用, 未对其充分挖掘和利用.
为了解决上述智能体在挖掘空间相关性线索和推理能力方面存在的不足, 本文提出基于语义拓扑图的视觉语言导航推理模型(Semantic Topological Maps-Based Reasoning Model for Vision-and-Language Navigation, STRM).首先, 通过场景理解辅助任务识别导航环境中的区域, 并挖掘区域间、物体间的空间邻近关系.在导航过程中, 智能体利用航路点预测器构建语义拓扑图, 整合节点位置、视觉特征及所属区域和包含物体的特征.然后, 采用辅助推理定位策略, 根据语言指令对拓扑图中的节点进行推理定位, 规划子目标并通过子目标控制器完成.在R2R-CE、RxR-CE数据集上的实验表明, STRM的导航成功率较高, 验证其在复杂连续环境中导航的有效性.
VLN-CE基于原始VLN任务中使用的 Room-to-Room数据集[1].VLN 让智能体在预定义无向图上导航, 图中节点包含来自Matterport3D数据集[14]的全景图.而VLN-CE则在3D 模拟器Habitat[15]中实例化VLN且摒弃预定义无向图的设定, 将 VLN任务迁移到更真实的连续空间中进行.
按照全景VLN-CE设置, 在每个时间步t, 智能体会收到由12个RGB图像
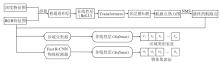
本文提出基于语义拓扑图的视觉语言导航推理模型(STRM), 整体框架如图1所示.
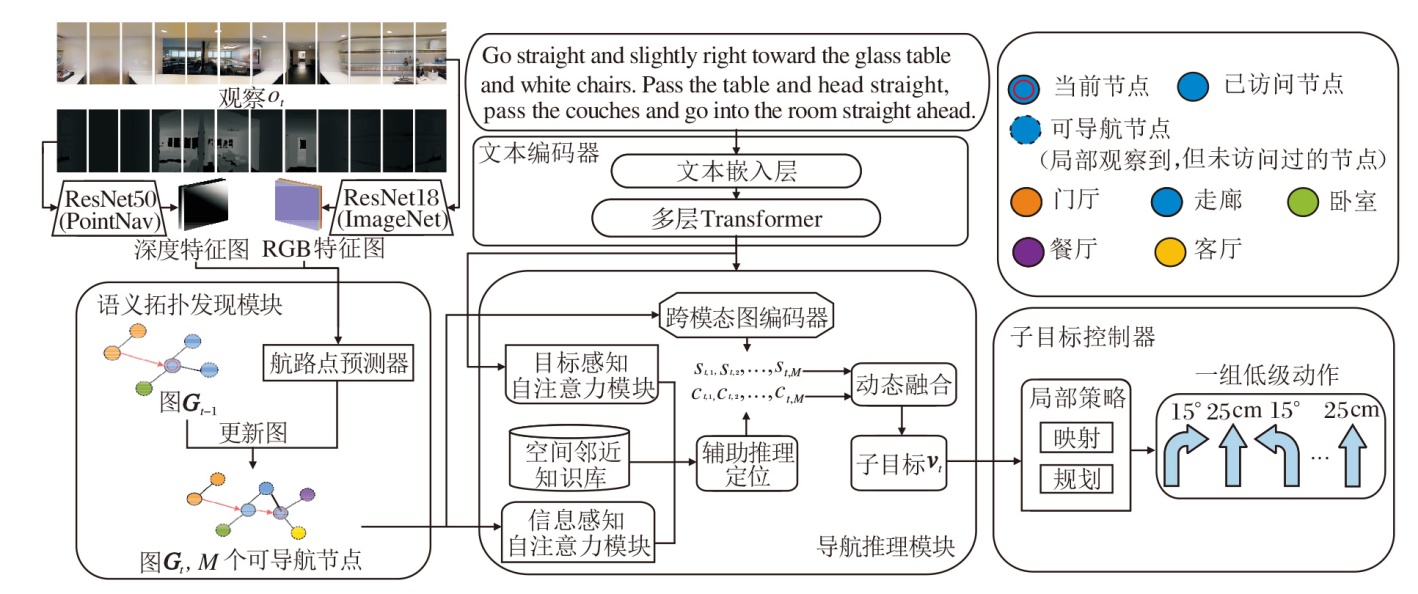 | 图1 STMR整体框架图Fig.1 Overall structure of STMR |
STRM主要由4个核心模块组成:文本编码器、语义拓扑发现模块、导航推理模块、子目标控制器.文本编码器编码导航指令.语义拓扑发现模块利用航路点预测器预测当前节点周围的航路点和其所属区域类型, 并逐步更新语义拓扑图.导航推理模块根据指令中提到的物体或区域, 利用预先构建的空间邻近知识库和辅助推理定位策略, 在语义拓扑图上对可导航节点所属区域及包含物体进行推理定位, 确定具体的子目标节点.子目标控制器通过局部策略预测一组低级控制动作, 使智能体精准到达子目标.
为了构建空间邻近知识库, 帮助智能体在未知场景中推理和决策, 本文借鉴场景理解辅助任务[12], 在离散导航环境中挖掘不同区域和物体之间的邻接关系, 示例如图2所示.该辅助任务首先利用导航场景的区域类型标签将每个场景分割成不同区域, 一个场景如果存在多个类型相同的区域, 且彼此间并不连通, 则需进一步分割成多个独立区域, 确保后续连通次数的精确计数.
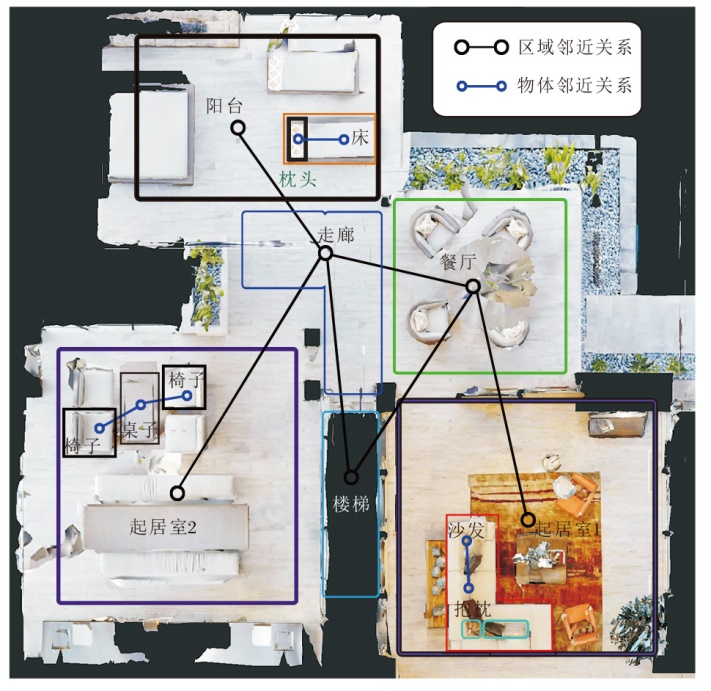 | 图2 在某一场景中邻近关系的挖掘Fig.2 Mining proximity relationships in a specific scene |
连通性的判断基于如下原则:对于任意两个不同的区域A、B, 如果A中存在一个节点, 它的邻接节点集为C, 且C∩ B≠ Ø , 则认定A、B是连通的.
接着统计分割后区域间的连通次数.对于物体间的邻近关系判断, 认定在同一子视图
对邻近计数矩阵进行简单归一化得到的邻近概率矩阵并不准确, 因为忽略邻近计数矩阵中数值的极端化特点.为了解决这一问题, 本文采用特定的归一化函数, 更精确地计算邻近概率矩阵:
Qi, j=
其中, ai表示C中第i行去除两个最大值和最小值后计数的平均值, mi表示在此基础上C中第i行的最大值加上ai.
文本嵌入层通过添加每个单词对应的位置嵌入和与文本类型嵌入对导航指令的嵌入表示进行增强:
再将这些增强的单词嵌入输入一个多层Transformer模型[23]中, 每个单词嵌入会与所有其它单词嵌入进行自注意力操作, 确保模型在确定每个单词的最终表示时, 能充分考虑句子中所有单词的上下文信息, 即
$\hat{\boldsymbol{w}}_{i}=\text { Transformer }_{f}\left(\boldsymbol{w}_{i}^{e}\right), f=1, 2, \cdots, F, $
其中F表示Transformer的层数.通过这个过程, 模型能为每个单词生成一个上下文表示.
智能体在导航过程中会逐步将走过的轨迹及其周围的环境抽象化为一个语义拓扑图, 在时间步t表示为Gt={Vt, Et}, Vt表示K个节点的集合, Et表示连接边.语义拓扑图中节点分为当前节点、已访问节点及可导航节点, 不同的颜色表示不同的区域类型, 其中, 可导航节点是仅从已访问节点局部观察到但尚未实际访问过的节点.
采用在ImageNet数据集[24]上预训练的ResNet-18[25], 在PointNav数据集[26]上预训练的ResNet50, 分别对RGB图像和深度图像两种模态数据进行编码, 提取特征图.然后, 航路点预测器利用这些特征图, 对以智能体为中心的空间关系进行建模, 识别障碍物的位置, 理解当前的场景结构, 预测周围的可通行位置(即航路点).该预测器是在文献[19]的基础上进行的改进, 具体结构如图3所示.
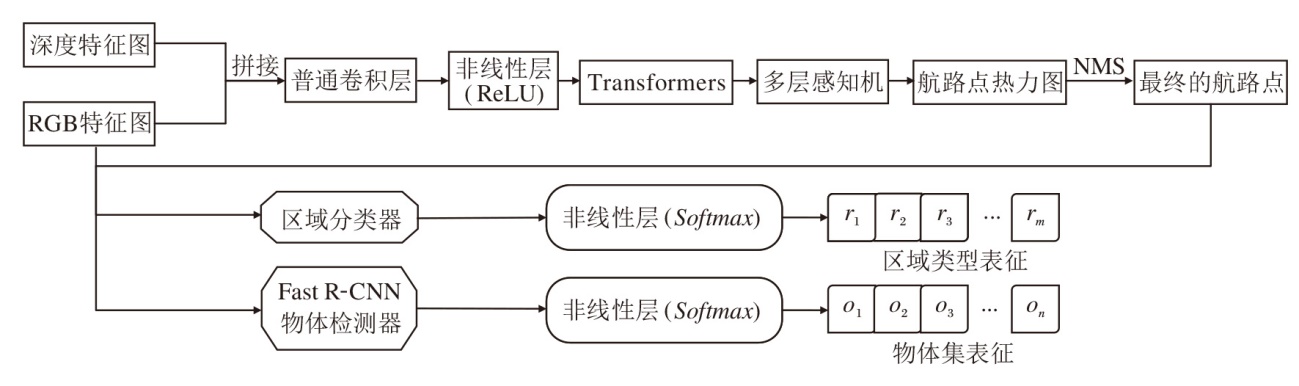 | 图3 航路点预测器结构图Fig.3 Structure of waypoint predictor |
通过拼接RGB和深度特征图, 并经过ReLU激活函数的非线性变换后, 特征图送入一个两层Transformer模型中, 每层具有12个自注意力头, 以建模不同视图之间的空间关系.然后, 通过多层感知机预测映射到3D空间中的航路点概率热力图, 执行非极大值抑制(Non-Maximum Suppression, NMS), 得到最终的航路点.
为了赋予节点丰富的语义信息, 本文在航路点预测器中集成预训练好的区域分类器[12]和Fast R-CNN物体检测器[27], 用于预测节点所属的区域类型及检测其中包含的物体.在获取预测的航路点后, 结合前一时刻的语义拓扑图Gt-1, 利用这些航路点与图中现有节点的空间关系更新语义拓扑图.此过程利用航路点定位函数
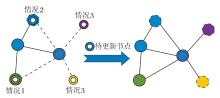
FL将航路点的位置作为输入, 计算其与图中所有节点的欧几里德距离.如果最小距离小于阈值γ , 则FL返回相应节点作为待更新节点.具体更新过程如图4所示.
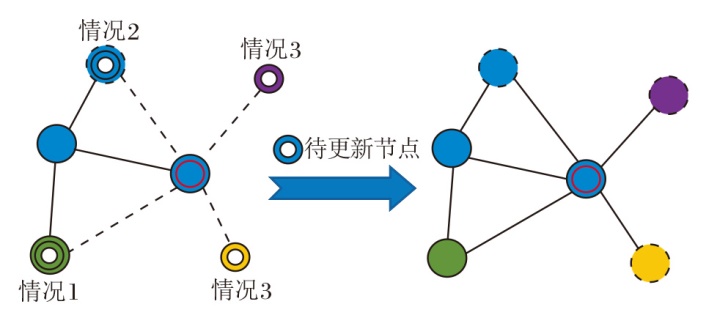 | 图4 语义拓扑图更新过程Fig.4 Update process of semantic topological map |
对于这些待更新节点, 可分为3种情况.1)若待更新节点与图中已访问节点重合, 删除此待更新节点, 并在当前节点与这个已访问节点之间添加一条边, 反映两者之间的连接关系.2)若待更新节点与图中已存在的可导航节点重合, 将该节点的位置和视觉表示信息累加到相应的可导航节点上.可导航节点的位置和视觉表示会更新为其累积的平均值, 语义表示保持不变.3)若待更新节点与图中任何节点均不重合, 视为新的可导航节点.
构建好空间邻近知识库和语义拓扑图后, 智能体需要利用这些知识在图上的可导航节点中确定一个子目标节点.智能体通过跨模态图编码器[9]和辅助推理定位策略实现这一过程.跨模态图编码器建模所有节点和指令之间的关系, 并编码环境布局, 预测各节点的视觉得分.辅助推理策略利用空间邻近知识库和可导航节点中的区域和物体表征进行推理, 确定其所属区域及包含物体的定位置信度.最后通过动态融合, 得到最终得分, 选择得分最高的节点为子目标.
2.4.1 跨模态图编码器
跨模态图编码器融合节点编码与指令嵌入表示, 实现不同模态间的深度交互.这一编码器由多层图感知跨模态Transformer构成, Transformer每层都集成交叉注意力与自注意力机制, 确保节点编码与文本指令嵌入表示之间的关联得到精准建模.该编码器还引入GASA(Graph-Aware Self-Attention), 将图的拓扑结构纳入考量, 确保近距离、更相关的节点得到应有的重视, 具体计算公式如下:
$\operatorname{GASA}(\boldsymbol{X})=\operatorname{softmax}\left(\frac{\boldsymbol{X} \boldsymbol{W}_{q}\left(\boldsymbol{X} \boldsymbol{W}_{k}\right)^{\mathrm{T}}}{\sqrt{d}}+\boldsymbol{E} \boldsymbol{W}_{e}+\boldsymbol{b}_{e}\right) .$
其中:X表示一个包含图中所有节点编码的堆栈; E表示空间矩阵, 元素表示任意两节点间的最短距离, 基于图中的边Et计算得出这些距离; We、be表示两个可学习的参数.
编码器堆叠N层, 最终输出各节点的视觉-文本关联嵌入表示$\hat{v}_{t, i}$.将$\hat{v}_{t, i}$输入多层感知机中, 得到各个节点的视觉得分:
$s_{t, i}=M L P\left(\hat{\boldsymbol{v}}_{t, i}\right), $
其中, st, 0表示停止动作的得分, MLP(· )表示多层感知机.智能体一般不需要重新回到已访问节点, 因此将遮蔽已访问节点的得分, 只输出可导航节点的得分.
2.4.2 辅助推理定位策略
辅助推理定位策略利用空间邻近知识库, 结合导航指令中提及的物体或区域, 对导航过程中出现的物体或区域进行推理定位, 从而确保指令与轨迹的精确对齐.
首先, 通过两个自注意力模块对指令和语义拓扑图上的可导航节点进行信息提取.目标感知自注意力模块将指令嵌入
$\boldsymbol{P}_{I_{t}}^{o}=\operatorname{softmax}\left(F C\left(\sum_{i} \boldsymbol{\alpha}_{t, i} \hat{\boldsymbol{w}}_{i}\right)\right), $
其中
α t, i=softmax(
Wo∈
如果指令中还提及将要经过的区域, 则同时提取区域类型表示:
$\boldsymbol{P}_{I_{t}}^{r}=\operatorname{softmax}\left(F C\left(\sum_{i} \boldsymbol{\beta}_{t, i} \hat{\boldsymbol{w}}_{i}\right)\right), $
其中,
$\boldsymbol{\beta}_{t, i}=\operatorname{softmax}\left(\hat{\boldsymbol{w}}_{i} \boldsymbol{W}_{r} \boldsymbol{h}_{t-1}^{\mathrm{T}}\right), $
Wr∈
同理, 信息感知自注意力模块将可导航节点的嵌入表示
其中Qo、Qr分别表示从辅助任务得到的物体邻近概率矩阵和区域邻近概率矩阵.
2.4.3 动态融合
在得到可导航节点的视觉得分和定位置信度后, 通过动态融合得出最终的子目标决策得分.在每个时间步, 将停止动作的嵌入表示$\hat{v}_{t, 0}$输入两层前馈网络中, 预测一个用于融合的标量:
$\sigma_{t}=\operatorname{sigmoid}\left(F F N\left(\hat{\boldsymbol{v}}_{t, 0}\right)\right), $
其中FFN(· )表示两层前馈网络.最终得分
ft, i=σ tst, i+(1-σ t)ct, i.
通过σ t可自适应调整视觉得分和定位置信度对子目标决策所占权重大小.
子目标控制器旨在通过预测一组低级动作引导智能体到达指定的子目标.首先, 控制器会在语义拓扑图上执行Dikjstra算法, 规划到达子目标的最短路径Bt={bn
此外, 子目标控制器还集成“ Tryout” 的启发式避障机制[22], 用于在导航过程中检测并处理潜在的死锁情况.该机制采用试错法, 一旦检测到死锁, 即智能体被障碍物阻挡而无法前进时, 引导智能体旋转至预定义的航向角并尝试继续前行.通过这种方式, 智能体能有效避免与障碍物的碰撞, 提高导航的灵活性和成功率.
为了提高智能体在导航任务中的泛化能力, 采用自监督预训练方法.首先从Matterport3D模拟器中导出离散的预定义图, 将Habitat模拟器中渲染的RGB-D图像与这些预定义图对齐以进行特征映射.预训练过程通过两种任务来执行:MLM(Masked Language Modeling)[29]和SAP(Single-Step Action Prediction)[8].MLM任务通过恢复遮蔽词汇优化文本编码器, 能更好地理解导航指令.而在SAP任务中, 专家演示路径随机分成几部分, 并为每部分构建相应的语义拓扑图.该任务的目标是预测每个局部语义拓扑图的下一个子目标节点, 即教师动作, 以此提升导航推理模块对子目标选择的准确性.损失函数如下:
其中, wi表示屏蔽词的标签, LM表示屏蔽后的指令, P表示专家演示路径,
通过PID(Pseudo Interactive Demonstrator)[9]进一步微调模型, 损失函数LPID与预训练中LSAP的结构相同, 但
在导航过程中, 智能体不断重复更新拓扑图、选择子目标、到达子目标的过程, 直到选择停止动作.若智能体执行的操作步骤超过预设定的最大步数, 会被强制终止.智能体停止时与目标位置的距离必须小于指定阈值, 才被视为导航成功.
VLN-CE中的R2R-CE、RxR-CE数据集都是基于连续环境设计的, 旨在评估视觉语言导航智能体的性能.R2R-CE数据集源自原始的Room-to-Room数据集[1], 经过转换以适应连续环境场景, 包含5 611个最短路径轨迹, 每个轨迹都对应大约3条英文指令.这些轨迹被划分为训练集、验证集和测试集.平均路径长度为9.89 m, 每条指令平均由32个单词组成.测试集表示为Test-Unseen, 验证集进一步细分为Val-Seen和Val-Unseen, Seen表示包含新路径和指令但导航场景是训练集中见过的, Unseen表示包含全新的路径、指令和导航场景.
RxR-CE数据集从Room-across-Room数据集[30]转换而来, 提供更多指令且更具挑战性.与R2R-CE数据集具有相同的导航场景, 指令覆盖英语、印地语和泰卢固语等多种语言.每条指令平均有120个单词, 比R2R-CE数据集上的指令更长.RxR-CE数据集上的注释路径长度也远超过R2R-CE数据集, 达到15.23 m.在RxR-CE数据集上, 智能体底盘半径较大(0.18 m)且被禁止沿着障碍物滑动, 导致其更容易与障碍物发生碰撞.
智能体性能评价指标包括:1)轨迹长度(Tra-jectory Length, TL).平均路径长度(单位m).2)导航误差(Navigation Error, NE).智能体最终位置与目标之间的平均距离(单位m).3)成功率(Success Rate, SR).导航误差小于3 m的轨迹所占比例.4)Oracle成功率(Oracle Success Rate, OSR).到达或经过目标位置的轨迹所占比例.5)以路径长度加权的成功率(Success Weighted by Path Length, SPL).受到轨迹长度惩罚的成功率.6)归一化动态时间归整(Normalized Dynamic Time Wrapping, ND-TW).标注的最短路径与导航轨迹之间的平均相似度.7)以成功率加权的动态时间归整(NDTW Penalized by SR, SDTW).受到成功率惩罚的NDTW.
除轨迹长度和导航误差外, 所有指标值均越高越好.
实验平台为一台装有4块NVIDIA RTX 3090 GPU的Linux服务器, 为Ubuntu 18.04操作系统.实验环境配置为Cuda 11.0, Python 3.8.5和Pytorch 1.7.1.
超参数设置如下:Nr=31, No=1 600, 特征通道维度Dw=Dh=768, 航路点定位函数中的阈值γ =0.25, 文本编码器和跨模态图编码器中的Transformer层数分别为9和4, 其它参数与文献[31]相同.
在预训练过程中, 使用4个NVIDIA RTX 3090 GPU, 并将批量大小设置为 16, 进行10万次迭代以预训练模型, 学习率设置为5e-5.拓扑图在此过程中是构建好的, 即从Matterport3D模拟器导出的离散预定义图.然后在下游任务中, 对性能最佳的预训练模型进行微调, 批量大小为 8, 在 1个 NVIDIA RTX 3090 GPU 上进行2万次迭代, 设置学习率为1e-5.这时拓扑图是未知的, 需要智能体在Habitat模拟器中与环境实时交互, 并逐步构建拓扑图.对于R2R-CE、RxR-CE数据集, 根据Val-Unseen验证集上最高SPL指标选择最佳的训练批次.
为了验证STRM在导航任务中的有效性, 选择与如下一些经典VLN-CE模型进行对比.
1)Seq2Seq(Sequence-to-Sequence)[13].赋予智能体跨模态注意力和空间视觉推理能力, 提升其在复杂环境中的导航与交互性能.
2)SASRA(Semantically-Aware Spatio-Temporal Reasoning Agent)[16].专注于对齐自上而下的局部语义信息与导航指令, 增强智能体对环境的感知与理解能力.
3)WPN[17].智能体根据其隐藏状态及环境特征智能选择航路点, 实现精准导航.
4)LAW[18].引入衡量智能体在导航过程中完成子指令的指标, 有效指导智能体学习策略的制定与优化.
5)CWP-CMA(Candidate Waypoints Predictor and Cross-Modal Matching Agent)[19].为智能体提供候选航路点预测器, 以实现连续环境离散化, 并为智能体提供候选航路点.引入一种增强的跨模态匹配方法, 智能体能更精准地选择候选方向, 提升导航的准确性和效率.
6)CWP-RecBERT(Candidate Waypoints Predictor and Recurrent Bidirectional Encoder Representations from Transformers)[19].为智能体提供候选航路点预测器, 以实现连续环境离散化. 引入循环的VLN BERT模型, 能同时解决导航和指代表达(Referring Expression)任务.
7)Sim2Sim(Simulation-to-Simulation)[20].将智能体从VLN的离散环境迁移到VLN-CE的连续环境中, 并减小两者间的导航性能差距.
8)Graph-CMA(Cross-Modal Attention with Gra-ph)[21].结合语义信息和GCN学习对象间关系, 融入对象标签的嵌入表示, 并通过跨模式注意力导航框架实现精准导航.
9)ETPNav[22].结合高级拓扑规划和低级控制器执行VLN-CE任务, 通过拓扑测绘构建地图, 跨模态规划器制定导航计划, 低级控制器精细执行导航计划.
各模型在R2R-CE、RxR-CE数据集上的性能对比如表1和表2所示, 表中黑体数字表示最优值.
| 表1 各方法在R2R-CE数据集上的指标值对比 Table 1 Metric value comparison of different methods on R2R-CE dataset |
| 表2 各方法在RxR-CE数据集上的指标值对比 Table 2 Metric value comparison of different methods on RxR-CE dataset |
由表1可知, 相比ETPNav, STRM在Val-Unseen验证集上至少提高2%的SR, 2%的SPL.STRM同时也具有良好的泛化能力, 相比ETPNav, 在Test-Unseen测试集上至少提高1%的SR, 1%的SPL.由表2也可看出, STRM性能最优.这些结果表明STRM能在复杂的连续环境中借助邻近空间知识, 通过空间感知和逻辑推理, 更精确地指引行进路径, 显著提升导航的准确性和效率.
为了验证STRM中核心模块的有效性, 在R2R-CE数据集的Val-Unseen验证集上进行一系列的消融实验, 结果如表3所示, 表中黑体数字表示最优值.在跨模态编码器基础上结合辅助推理定位策略, SR和SPL分别提升9.08%和3.73%, 说明该策略在导航中发挥一定作用.通过动态融合方法整合两者, SR和SPL进一步提升0.86%和1.51%, 验证该融合方法的有效性.
| 表3 在Val-Unseen验证集上的消融实验结果 Table 3 Ablation experiment results on Val-Unseen |
在空间邻近知识库上的消融实验结果如表4所示, 表中黑体数字表示最优值.由表可见, 未使用空间邻近知识库的模型表现较差, 原因是此时辅助推理定位策略未能发挥作用.另外可看出, 在仅利用区域邻近知识时, 智能体导航轨迹更接近最短路径; 仅使用物体邻近知识时, 虽然导航成功率略微提升, 但SPL却有所降低.将两者结合后, 模型达到最佳性能, 表明区域邻近知识在粗粒度规划中发挥关键作用, 确保整体导航方向不偏离目标区域, 而物体邻近知识则有助于实现细粒度物体定位, 确保准确找到指令中的指定物体.
| 表4 在空间邻近知识库上的消融实验结果 Table 4 Ablation experiment results on spatial proximity knowledge base |
此外, 评估区域类型预测的准确率, STRM的Top-5 准确率达到84.76%, 而未经过预训练的CKR(Cross-Modality Knowledge Reasoning)[10]Top-5 准确率仅为53.3%, 这一结果证明预训练技术能显著提高模型的泛化能力.
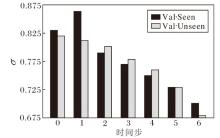
本节深入探讨动态融合中用于权衡视觉得分与定位置信度的权重平衡因子σ 的作用.在智能体的导航过程中, 这一权重的动态调整体现其对环境信息的灵活运用能力.σ 随时间步的变化情况如图5所示.由图可见, 智能体在导航初期主要依赖于视觉得分, 而随着导航的深入进行, 对定位置信度的权重逐渐增加.
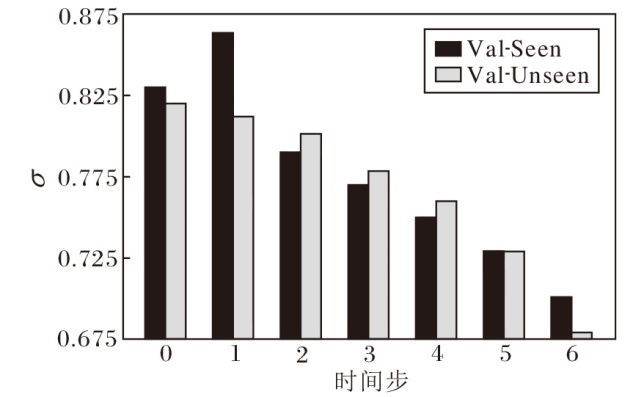 | 图5 权重平衡因子σ 随时间步的变化情况Fig.5 Change of weight balance factor σ with time step |
具体来说, 从Val-Unseen验证集上可看出, 视觉得分的平均权重因子在导航开始时为0.82, 在中期降至0.73, 最终在接近目标时降为0.68.这一变化表明, 在导航的初期阶段, 智能体可能并不需要急于定位特定的物体或区域, 因此更多地依赖于视觉得分规划路径.然而, 随着导航的推进, 智能体需要更精确地探索环境, 此时物体或区域的定位置信度便成为更重要的参考因素.
利用辅助任务构建的部分物体邻近知识可视化结果如图6所示.由图观察发现, 构建的物体邻近关系符合日常认知.例如:餐桌与椅子配套, 衣柜与镜子通常相伴, 而地毯与杯子则鲜有相邻的情况.
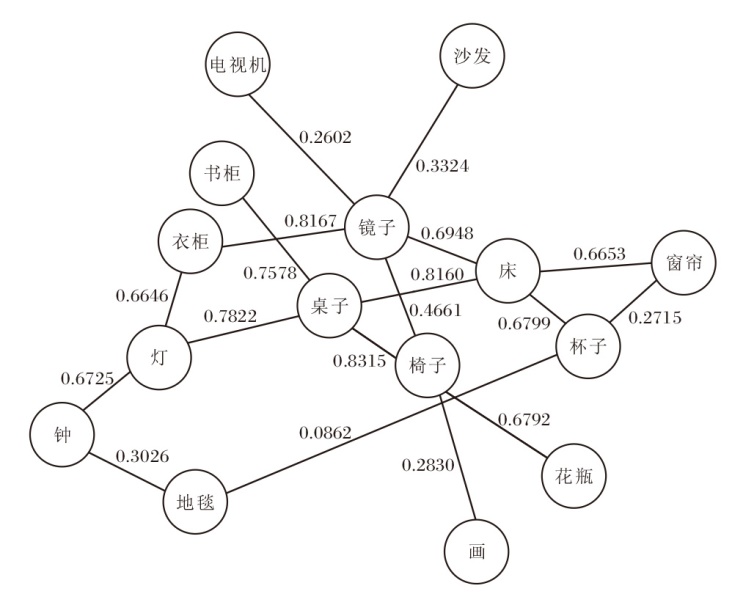 | 图6 物体邻近知识可视化Fig.6 Visualization of object proximity knowledge |
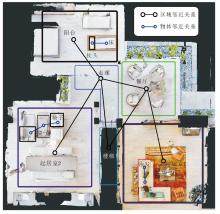
STRM在R2R-CE数据集上进行推理导航的过程如图7所示.智能体进入卧室后左转寻找洗手台, 尽管可能无法识别洗手台, 但通过空间邻近知识库, 识别与洗手台相邻的物体, 精确推断其位置.在经过洗手台后, 智能体需前往淋浴室.通过识别厕所和洗手间等相关区域, 智能体再次利用空间邻近知识库, 推理定位淋浴室的位置.
 | 图7 STRM推理导航示例Fig.7 Example of STRM reasoning navigation |
本文提出基于语义拓扑图的视觉语言导航推理模型(STRM).构建空间邻近知识库和语义拓扑图, 结合辅助推理定位策略, 实现导航轨迹与指令的高度对齐, 有效提升导航精度.在R2R-CE、RxR-CE数据集上验证STRM的有效性.然而, 面对复杂环境时, STRM在障碍物处理方面仍存在不足, 会发生碰撞或卡住的现象.今后将考虑引入更高级的避障策略, 提高模型在复杂环境中的灵活性和鲁棒性.
本文责任编委 李贻斌
Recommended by Associate Editor LI Yibin
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|