

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于卷积神经网络的三维目标检测研究综述
[王亚东1  , 田永林
, 田永林2, 3 , 李国强1 , 王坤峰1 , 李大字1 ]
, 田永林, 李国强, 王坤峰, 李大字]
|
|



作者简介:

王亚东,博士研究生,主要研究方向为计算机视觉、深度学习.E-mail:2019200756@buct.edu.cn.

田永林,博士研究生,主要研究方向为计算机视觉、智能交通系统.E-mail:tyldyx@mail.ustc.edu.cn.

李国强,硕士研究生,主要研究方向为计算机视觉、深度学习.E-mail:2018210413@buct.edu.cn.

李大字,博士,教授,主要研究方向为模式识别、强化学习.E-mail:lidz@buct.edu.cn.
深度学习尤其卷积神经网络为精确目标检测提供可能,推动三维目标检测在自动驾驶、机器人等领域发挥重要作用.文中综述基于卷积神经网络的三维目标检测研究进展.首先总结三维目标检测的应用价值、基本流程及存在的挑战.再介绍卷积神经网络基本原理、典型的二维目标检测网络结构、常用的开源数据集及点云表示形式等相关基础知识.然后介绍卷积神经网络在三维目标检测中的应用进展,根据不同数据模态及方法共性对方法进行梳理.最后对当前三维目标检测研究存在的问题进行论述,对未来的研究发展趋势进行展望.
About Author:
WANG Yadong, Ph.D. candidate. His research interests include computer vision and deep learning.
TIAN Yonglin, Ph.D. candidate. His research interests include computer vision and intelligent transportation systems.
LI Guoqiang, master student. His research interests include computer vision and deep learning.
LI Dazi, Ph.D., professor. Her research interests include pattern recognition and reinforcement learning.
Three-dimensional(3D) object detection plays a critical role in the fields of autonomous driving and robotics, since deep learning methods can offer possible solutions for accurate object detection, especially convolutional neural networks. The research progresses of convolutional neural network-based 3D object detection are reviewed comprehensively. Firstly, the practical value, basic procedures and challenges of 3D object detection are summarized. Next, the preliminary knowledge of convolutional neural networks, typical 2D object detection network structures, some widely-used open source datasets and point cloud representations is introduced. Then, progresses on the application of convolutional neural networks in 3D object detection are presented, and the methods are sorted out and analyzed according to different data modalities and method commonalities. Finally, issues in the existing research of 3D object detection are discussed, and future research trends are prospected.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
三维目标检测[1, 2, 3]是一种基于图像几何和统计特征的三维分析方法, 包括定位和分类两个任务, 要求从传感数据中获取特定目标的三维包围框, 包括目标类别、中心位置、尺寸、方向等信息.
近年来, 随着深度学习技术的发展, 基于卷积神经网络(Convolutional Neural Network, CNN)的三维目标检测方法达到较高的准确性和实时性要求, 逐渐应用于自动驾驶、机器人等领域.
一些自动驾驶技术企业对其产品进行测试.谷歌Waymo公司已经在美国10多个州测试无人驾驶汽车.百度Apollo在2020年投入55辆测试车.从2020年至今, 由于新冠肺炎疫情的影响, 京东、阿里等公司的无人配送车陆续投入测试运行.自动驾驶汽车的感知模块将原始传感数据转化为高层语义信息, 如动态目标(车辆、行人等)的位置和尺寸、交通标志类型、可行驶区域等.其中, 目标检测处于自动驾驶感知模块的核心, 如果不能及时准确地检测目标, 将导致交通事故[4].
近年来, 一些公司开发智能机器人替代人类完成特定任务, 如巡检机器人、医疗机器人等.无论自动驾驶还是机器人导航, 都离不开环境感知, 尤其离不开目标检测.相比二维目标检测, 三维目标检测考虑目标的深度信息, 属于立体检测, 更符合实际应用需求, 但是也因为要估计三维信息, 检测难度远高于二维目标检测.
现有的三维目标检测方法可大致分为单阶段方法和两阶段方法.单阶段方法的计算速度较快, 不需要细化就可直接估计目标的包围框.两阶段方法首先从场景中提取感兴趣区域(Region of Interest, ROI)或候选框(Region Proposal)作为候选目标, 再通过分类得分和位置回归对这些候选目标进行分类和细化[5].
单阶段方法可直接生成检测框[6, 7, 8].目前主要有两种方式:1)首先生成二维检测框, 再结合深度信息进行三维框回归; 2)端到端直接生成三维检测框.
一般而言, 基于图像的检测方法中两种方式使用都较广泛, 而基于点云的检测方法一般使用端到端的方式.无论哪种方式, 检测流程都是先提取特征, 再根据特征进行尺寸、方向、位置等变量的回归预测.为了提高精度, 一些方法会对结果进一步细化.
两阶段方法首先生成可能包含目标的候选框, 再根据候选框进行特征提取, 实现区域分类和位置回归[9, 10, 11].具体流程一般分为如下3部分.
1)候选框生成.传统的检测方法通常提前设置多个固定尺寸的候选框, 对输入图像进行顺序搜索, 计算量十分庞大.如果只是在输入图像中搜寻特定类型目标的可能区域, 会大幅减少计算量, 这种搜索策略即候选框生成.传统的候选框生成策略主要包括3种基于滑动窗的候选框生成[12, 13]、基于投票机制的候选框生成[14]和基于图像分割的候选框生成[15].
2)特征表示.三维目标检测离不开特征提取, 而特征的表示方式直接影响检测精度, 决定设计网络的检测性能.在目前的两阶段特征表示中:基于图像的方法一般采用特征金字塔网络, 将候选框映射为特征向量, 得到它的特征表示; 基于点云的检测方法一般将其投影为鸟瞰图或表示为体素形式, 从而将其转化为结构规则的数据.
3)区域分类.将特征向量作为输入以预测候选区域所属的目标类别.三维目标检测方法除实现分类以外, 还需要实现目标位置、三维检测框尺寸、方向等变量的回归预测.目前常用的分类方法有logistic回归、softmax函数等.
一般来说, 通过候选框生成和细化, 两阶段方法能获得更高的检测精度, 但是需要更高的训练成本和更多的推理时间.相比之下, 单阶段方法的计算速度更快, 更容易优化, 但是其检测精度通常低于两阶段方法.
目前三维目标检测研究已渐成体系, 但是仍存在各种问题, 如训练数据场景单一、适应点云特性较差、图像依赖性较弱、点云和图像数据增广的维度难以统一等, 性能指标尚未达到最优, 是一个充满挑战的研究领域.
为了帮助研究人员系统地了解三维目标检测知识, 本文梳理三维目标检测的发展脉络, 探讨该领域存在的问题及发展趋势.本文综述CNN在三维目标检测中的应用进展.首先从CNN、传感器、三维目标检测流程等基本概念着手介绍, 并总结常用的开源数据集, 为综述三维目标检测的研究现状提供丰富的背景知识.然后重点介绍CNN在三维目标检测中的应用进展, 根据传感数据模态, 将现有方法分为基于图像的检测方法、基于点云的检测方法及基于图像和点云融合的检测方法.针对每类方法, 按照单阶段和两阶段处理方式, 并根据共性分类进行阐述分析.最后, 分析现有方法存在的问题和局限性, 指出潜在的解决思路和未来发展趋势.
卷积神经网络(CNN) 最初是受到生物视觉系统的神经机制启发, 针对二维识别设计的一种生物物理模型, 在平移情况下具有不变性, 在缩放和倾斜情况下也具有一定的不变性, 具有局部连接、权值共享的特点.
CNN的前身是神经认知机模型[16], 利用神经认知机的思想, LeCun等[17]提出CNN的现代雏形— — LeNet.Krizhevsky 等[18]提出AlexNet网络, 实现准确的图像分类.Simonya等[19]提出VGG16网络结构.
虽然CNN在图像分类方面取得突出的成绩, 分类准确率甚至超过人类, 但在目标检测领域仍处于发展阶段.针对二维目标检测, Girshick等[20]提出区域卷积网络(Region-CNN, R-CNN), 提取大约2 000个候选区域, 大幅提升检测精度.但是R-CNN对每个候选区域需要单独计算卷积特征, 计算量巨大.更严重的是, 传统CNN的输入图像需要固定尺寸, 导致输入CNN的信息丢失.
为了解决上述R-CNN出现的诸多问题, He等[21]提出空间金字塔池化网络(Spatial Pyramid Pooling Networks, SPPnet), 解决图像变形导致的信息丢失问题, 并且采用空间金字塔池化替换全连接层之前的最后一个池化层, 使输入不再拘泥于固定尺寸.但在整个过程中, 区域提议需要的计算量仍然很大.
为了提高R-CNN网络的检测速度, Girshick[22]又提出Fast R-CNN网络, 使用ROI提取特征, 同时加入候选框映射功能, 使网络能反向传播, 解决网络训练问题, 但Fast R-CNN的候选框提取过程仍十分耗时.为了进一步提升检测速度, Ren等[23]提出Faster R-CNN, 核心是引入区域建议网络(Region Proposal Network, RPN).RPN与检测网络共享全图像卷积特征, 实现几乎零损耗的区域建议, 在低分辨率的特征图上提取候选框, 大幅减少计算量.考虑到Faster R-CNN提取的特征不足, 王浩等[24]提出基于多层上下文信息的目标检测算法, 不同倍数扩大候选框, 提取上下文信息, 提升Faster R-CNN的特征表达能力.张绳昱等[25]在Faster R-CNN的基础上引入有效感受野的样本匹配算法, 在增强浅层特征表达能力的同时减少锚框匹配的计算量.
不同于上述两阶段方法, 单阶段方法取消候选区域, 直接提取特征生成检测结果.Liu等[26]提出SSD(Single Shot Multi-box Detector), 采用多尺度思想, 通过6个不同尺度的特征图共同预测, 较好地适应目标的尺度变化.但SSD缺乏特征的全局表达能力, 因此储珺等[27]将全局注意力机制引入SSD, 有效衡量多尺度不同通道的特征权重, 丰富特征全局信息.Redmon等[28]提出YOLO(You Only Look Once), 将目标检测作为回归问题进行求解, 通过全连接层直接预测置信度及目标位置, 有利于从全局信息检测目标.
针对单阶段方法正负样本比例失衡的问题, Lin等[29]提出Focal Loss, 通过分类概率构建权重系数, 抑制容易检测样本的权重, 对困难样本实现有效挖掘.为了避免生成锚框并进行后处理带来的计算资源消耗问题, Zhou等[30]提出CenterNet, 寻找目标边界框的中心点, 并以中心点为基准回归目标的位置等信息, 取消锚框的限制.
同样, 针对三维目标检测, 学者们也已提出很多基础网络结构, 并发展出很多性能优越的检测网络.Beltrá n等[31]提出BirdNet, 将点云投影为鸟瞰图 (Bird's Eye View, BEV)后再进行处理.Qi等[32]提出PointNet, 直接对点云进行处理.Shi等[33]提出PV-RCNN(Point-Voxel Region CNN)网络, 融合体素和点云的优势, 实现高精度检测.Limaye等[34]受到点柱(PointPillars)[35]的启发, 基于SSD[26], 提出SS3D(Single Shot 3D Object Detector), 将目标检测维度扩展到三维.Yang等[36]提出3DSSD(Point-Based 3D Single Stage Object Detector), 是一种轻量级的基于点云的单阶段目标检测网络, 较好地实现精度和速度的平衡.
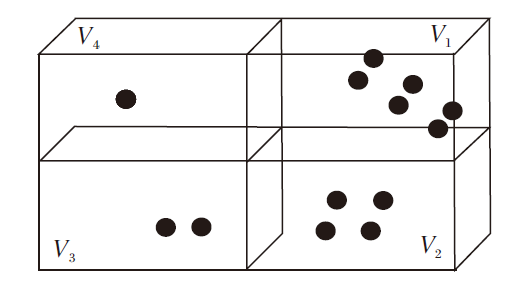
三维目标检测常用数据模态为图像和点云, 图像可直接作为CNN的输入, 由于点云的稀疏性和不规则性, 二维检测中研究成熟的CNN不能直接用于处理点云, 并且点云的表示形式直接影响模型的性能.因此, 本节介绍点云数据的表示形式.目前, 常用的表示方式主要有3种:点表示形式、体素表示形式、图表示形式.
1.2.1 点表示形式
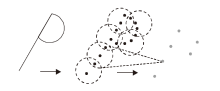
点云是指获取物体表面每个采样点的空间坐标形成的点的集合.用于三维目标检测的点云通常由激光雷达扫描得来, 包含点的三维坐标、强度等信息, 数据表示形式[32]如图1所示.点表示形式直接对点云进行处理, 即采用最原始的点作为输入, 这种表示形式通常基于PointNet网络[32], 骨架网由点编码层和点解码层构成, 编码层下采样提取语义信息, 解码层将采集的语义信息传递给未采样的点, 使其具备特征信息, 从而保证全部的点都包含特征信息.最后基于这些点得到候选框.典型方法如F-PointNet(Frustum-PointNet)[37]、Point RCNN[38]等.
点表示方法因为使用最原始的点云数据, 保留最丰富细致的信息, 在所有方法中输入信息损失最小.但是, 点表示方法需要处理的数据量较大, 运行速度较慢, 并且一般使用多层感知器, 感知能力较差.
1.2.2 体素表示形式
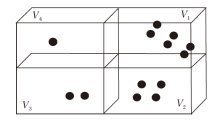
体素是体积元素的简称, 是数字数据在三维空间分割上的最小单位, 类似于二维空间的最小单位像素, 数据表示形式[39]如图2所示.体素表示形式将点云转化为规则的体素形式, 对点云进行处理.点云体素化首先需要设置参数, 包括体素大小及每个体素可容纳的点云数量.然后依次根据坐标得到每点在体素的索引, 并根据索引判断此体素种类是否已达到设置的最大值.若达到, 丢弃此点; 未达到, 保留.最后提取体素特征, 进行回归预测.基于体素的典型方法包括:VoxelNet(Voxel Network)[2]、Voxel-FPN(Voxel-Feature Pyramid Network)[40]等.
基于体素的方法不仅性能较优, 计算速度也较可观, 尤其是稀疏卷积的发展, 促进体素方法的应用. 但是, 基于体素的方法受设置参数的影响, 不可避免地丢失一部分点云信息.
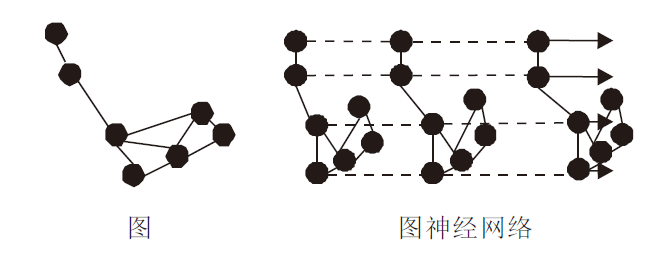
1.2.3 图表示形式
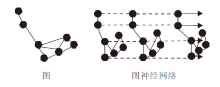
Shi等[41]提出图表示形式, 如图3所示.核心在于构建图神经网络, 再通过图卷积进行特征提取.图神经网络的计算费时, 对于应用是一个严重限制.但是图表示方法能较好地适应点云的不规则性, 并且可得到更多局部信息, 因此是一种有发展潜力的点云数据表示形式.
除上述3种表示形式以外, 还有将点云投影为二维鸟瞰图、点云与体素混合等方式.与点云不同, 图像的表示形式较单一.图像和点云作为两种常见的数据模态, 各有优缺点:图像可提供丰富的纹理, 但缺乏深度信息, 对光照要求较高; 点云可提供深度信息但较稀疏:两者的具体差异如表1所示.大体上, 基于点云的三维检测方法精度高于基于图像的三维检测方法.在造价方面, 激光雷达(LiDAR)价格远高于摄像机, 这是研究基于图像的三维检测方法的一个重要原因.学者们关注图像和点云融合方法, 以期达到更好的检测效果.
| 表1 图像和点云的差异性 Table 1 Comparison of the difference between image and point cloud |
将深度学习技术应用于三维目标检测, 训练模型离不开大规模的公共数据集.本节介绍三维目标检测常用数据集, 包含图像数量、适用场景、检测框数量等方面.本节提到的各数据集的对比如表2所示.
| 表2 常用数据集情况对比 Table 2 Comparison of common datasets |
1.3.1 室外数据集
1)KITTI数据集[42].自动驾驶领域著名的基准数据集之一, 传感器配置包括一个广角摄像机和一个激光雷达.数据集包含城市驾驶场景中的汽车、行人、骑车人等目标的二维/三维标注, 适用于多种视觉任务, 如立体视觉、光流、三维目标检测、三维跟踪等, 共计7 481幅训练图像和7 518幅测试图像.根据物体的遮挡和截断程度, 将检测分为容易、中等、困难级别.KITTI数据集被广泛使用, 但该数据集只包含交通场景, 并且只针对训练集进行真值标注.
2)ApolloScape数据集[43].百度公司发布的大规模交通场景数据集, 包括摄像机图像和雷达扫描点云.收集中国10余个城市各种照明条件下的交通场景, 包含非常复杂的交通流, 混杂车辆、骑车人和行人.相比KITTI数据集, ApolloScape数据集具备更高的点云密度.
3)Waymo数据集[44].Waymo公司发布的自动驾驶数据集.数据采集范围较广, 包含场景较多.在白天、夜晚、黎明、黄昏、雨天、晴天等各种驾驶条件下进行数据采集.共有798个训练序列, 约有158 361个LiDAR样本; 有202个验证序列, 约有40 077个LiDAR样本.不同于只标注90° 范围的KITTI数据集, Waymo数据集标注完整的360° 周边范围.
4)KAIST数据集[45].考虑到大部分数据集的采集场景过于单一, Choi等提出KAIST多光谱数据集.数据集提供以粗略的时间段(白天和晚上)和精细的时间段(日出、早晨、下午、日落、夜晚和黎明)捕捉世界的不同视角.为了自主系统的全天候感知, 开发一个多传感器平台, 支持使用对齐的RGB/热摄像机、RGB立体声、三维LiDAR和惯性传感器.针对行人、自行车和汽车, 分别标注52 826、5 205和250 882个包围框.
5)nuScenes数据集[46].nuTonomy公司发布的交通场景数据集, 由1 000个场景组成, 每个场景长度为20 s, 带有23个类别和8个属性的3D包围框.nuScenes数据集有100倍于KITTI数据集的图像和7倍于KITTI数据集的标注, 是多模态数据集, 包含夜间和雨天的数据.
6)Cityscapes数据集[47].原本是图像分割领域应用广泛的数据集之一.考虑到目前三维目标检测领域的纯图像数据集(不包含深度图)稀少, 为了进一步推动基于图像的三维目标检测研究, 在城市景观三维模型的基础上进行三维标注, 命名为Cityscapes 3D.数据集使用立体相机采集, 包含8种类别, 共5 000幅图像, 其中2 975幅用于训练, 500幅用于验证, 1 525幅用于测试.
1.3.2 室内数据集
1)NYU-Depth V2数据集[48].由1 449对密集标注的RGB图像和深度图像组成, 图像是由Microsoft Kinect捕捉到的.数据集包含464个场景, 26个场景类型, 将逐像素稠密标注合并到40个室内目标类, 其中, 训练集包括795幅图像, 测试集包括654幅图像.后来又对该数据集进行改进, 适用于三维目标检测任务.
2)B3DO数据集[49].在目标和姿态方面具有显著的多样性, 包含从75个场景拍摄的849幅图像, 50个目标类.数据集以2D包围框的形式提供基本的目标标注.后来通过添加所有目标的3D中心点的标注扩展数据集.
3)SUN3D数据集[50].包含大型的RGB-D室内场景视频, 其中包含摄像机姿态、目标标注和配准到全局坐标系的点云, 这些点云由RGB-D结构和运动重构而成.数据集提供8个标注序列, 共捕获415个序列, 分布在41个不同建筑的254个不同空间.
4)SUN RGB-D数据集[51].包含10 335幅室内场景的RGB-D图像, 包括146 617个二维包围框、58 657个三维包围框, 具有精确的物体方向及三维房间布局和场景类别.整个数据集包含47个场景类别、800个目标类别, 每幅图像中平均标注14.2个目标.数据集包含5 285幅训练图像和5 050幅测试图像, 支持多个视觉任务, 包括3D目标检测、场景分类、语义分割、目标定位、房间布局估计和场景理解.
5)ScanNet数据集[52].不同于大多数RGB-D数据集仅涵盖小范围的场景视图, ScanNet数据集包含1 513个室内场景、2.5 M个视图, 其中深度图像采集分辨率为640× 480, RGB图像分辨率为1 296× 968.对场景进行三维重建及密集的语义分割标注, 可用于三维目标分类、语义分割、CAD建模等任务.ScanNet数据集的采集使用带深度相机的简易设备, 并且提供接口以方便新用户使用.
基于图像和点云的三维目标检测的度量指标是统一的, 包括精度 (Precision)、平均精度(Average Precision, AP)、召回率(Recall)等.
定义TP表示正样本被正确识别为正样本, FP表示负样本被错误识别为正样本, FN表示正样本被错误识别为负样本.精度是指所有被识别为正样本的样本(包括TP和FP)中正样本所占的比率:
Precision=
召回率是指测试集中所有正样本中被正确识别为正样本的比例:
Recall=
精度和召回率的取值处于[0, 1]内, 受到超参数(如交并比阈值)的影响, 呈曲线形式变化.一般来说, 召回率越高, 精度越低.平均精度记录精度与召回率曲线下方的面积, 是衡量目标检测性能的依据, 数据集中所有目标的平均精度命名为mAP(mean AP), 下文所有方法对比中准确度度量指标均采用mAP.
根据传感数据的模态, 可将三维目标检测方法大致分为基于图像的检测方法、基于点云的检测方法、基于图像和点云融合的检测方法.本节根据不同数据模态介绍一些典型方法, 梳理方法脉络, 并分析三维目标检测方法的优缺点.
基于图像的三维目标检测是指仅使用图像数据模态, 通过图像固有几何属性估计深度信息, 从而实现三维检测的方法, 其中图像数据模态包括单目图像、双目图像及深度图.
由于图像缺乏深度信息, 基于图像的三维目标检测方法一般通过几何约束、多框拟合、实例分割等方式得到检测结果.
2.1.1 单阶段方法
通常, 基于图像的单阶段方法先生成二维检测框, 再利用真实世界先验知识 (即真实目标尺寸) 或通过几何约束得到准确的三维包围框.Li等[1]提出GS3D(3D Guidance and Using the Surface Fea-ture for Refinement), 结合驾驶场景的先验知识, 从2D包围框和可见表面提取特征, 并融合为判别能力较强的结构信息, 消除特征的模糊性.几何约束的方法一般是利用图像目标的二维几何特征, 通过投影迭代优化或坐标变换映射到三维空间.Liu等[53]对候选框和目标之间的拟合度进行确定性评分, 使用严格的约束获得三维位置.
上述方法首先生成二维检测框, 但某种程度上二维检测网络是冗余的, 在三维检测中引入不可忽略的噪声.Liu等[54]提出SMOKE(Single Stage Monocular 3D Object Detection via Keypoint Esti-mation), 通过关键点估计和三维变量回归, 预测每个目标的三维包围框.方法不需要复杂的预处理和细化阶段, 提升检测速度.
上述方法均使用单目图像, 对于深度估计不够有效, Luo等[55]基于深度图, 提出3D-SSD(3D-Single Shot Multibox Detector), 采用分层特征融合策略, 通过2个VGG-16, 结合RGB-D图像的外观特征和几何特征, 并通过多尺度获得更丰富的语义信息, 尽可能捕获小目标的细节.
不同于上述有监督学习方法, Beker等[56]提出基于二维实例分割与形状先验的自监督学习方法, 通过实例化每个目标并进行可微渲染以预测目标的三维信息.自监督学习能在保证检测精度的前提下减少标注工作量, 是未来研究的热点.
2.1.2 两阶段方法
Chen等[57]提出3DOP(3D Object Proposals), 在网络结构上扩展Fast R-CNN, 在最后一层卷积层增加一个上下文分支和方向回归损失以联合学习目标的位置和方向.在3DOP的基础上, Chen等[58]提出Mono3D(Monocular 3D), 利用上下文、语义、手工设计的形状特征和位置先验, 将每个候选框投射到图像中, 对其进行评分.
基于3DOP的工作对于深度的估计不够准确, 为了得到更精确的深度信息, 有学者将关注点放在视差方向.Li等[59]提出Stereo R-CNN, 充分利用立体图像中的语义几何信息进行检测, 对比左右两幅图像的视差, 得到深度信息.迟旭然等[60]使用金字塔网络, 将Stereo R-CNN左右两条支路压缩为单条支路, 增加全连接分支区分前景和背景, 增强关键点的检测能力, 在保证精度的同时将检测速度提高1.73倍.Bao等[61]提出MonoFENet(Monocular 3D Object Detection with Feature Enhancement Network), 使用PointFE(Point Cloud Feature Enhancement) 网络处理点云, 结合图像信息, 进行2D框和3D框回归.该方法仅使用单目图像即取得良好的三维检测性能.
除了通过提升深度估计准确性以改善三维检测性能以外, 还有学者关注目标形状本身, 结合实例分割, 进一步细化目标姿态以实现精确检测.Kundu等[62]提出3D-RCNN, 以ResNet-50-C4[63]为骨架网络, 首先通过ROI提取特征, 再通过全连接层进行形状和姿态的回归, 最后通过实例分割, 恢复图像中所有目标实例的三维形状和姿态.
Wang等[64]提出伪雷达(PseudoLiDAR), 他认为造成图像和点云差异的主要原因是表示形式, 因此提出将图像点云化, 将基于图像的深度图转化为伪LiDAR表示以模仿LiDAR信号.由于深度估计的准确性直接影响伪雷达方法的性能, Guizilini等[65]提出自监督学习目标的密集外观和几何信息, 提高单目图像深度估计的准确性.Sun等[66]提出Disp R-CNN(Disparity R-CNN)网络结构, 综合考虑视差估计和伪雷达两种图像处理方式, 预测感兴趣目标像素的视差, 再将实例视差图转换为实例点云, 输入三维检测器进行三维包围框回归.
伪LiDAR方法的提出为缩小图像和点云之间检测精度的差距提供了可能性, 为基于图像的检测方法、基于图像和点云融合的检测方法提供新的思路.
2.1.3 分析总结
基于图像的三维检测方法已得到广泛研究, 图像丰富的纹理信息及相对低廉的设备价格决定它在目标检测领域的重要性.但是图像对光线和天气条件敏感, 限制其实际应用, 而且图像在卷积处理后, 远距离目标会发生一定的变形[67] .另外, 图像缺乏深度信息, 导致三维检测不准确, 尤其对于远距离目标和被遮挡目标.因此, 以可得到视差估计的双目图像作为输入的检测精度往往高于单目图像.
选取OFT-Net(Orthographic Feature Transform Network)[8]、SS3D[34]、SMOKE[54]、Stereo R-CNN[59]、MonoFENet[61]、StereoFENet(Stereo 3D Object Detec-tion with Feature Enhancement Network)[61]、Disp R-CNN[63]、PseudoLiDAR[64], 在KITTI数据集上, 各方法的车辆检测性能对比如表3所示, 表中黑体数字表示最快的运行时间, 斜体数字表示利用伪雷达思想的方法.
| 表3 基于图像的三维目标检测方法在车辆检测上的性能对比 Table 3 Performance comparison of image-based 3D object detection methods for vehicle detection |
由表3可看出, 基于双目图像的方法检测精度高于基于单目图像的方法, 说明准确的深度信息能提高检测精度.值得注意的是, 基于伪雷达思想的方法精度远高于其它方法, 表明图像转换为点表示形式的有效性.
基于点云的三维目标检测方法可采用网格或原始点云的数据表示.
基于网格的方法将不规则的点云转换为规则的网格表示, 如3D体素或2D鸟瞰图, 通过学习网格特征进行三维目标检测.
基于原始点云的方法直接从原始点云中提取特征并进行三维检测.本节介绍一些典型的单阶段方法和两阶段方法.
2.2.1 单阶段方法
为了方便处理不规则的点云数据, 很多方法采用体素化分割点云, 从而将其转换为规则形式.Al Hakim[68]基于YOLO[28]提出3D YOLO, 首先将输入点云划分为3D体素网格, 再基于3DNet(3D Network)学习目标的形状描述, 输出带类别分数的三维包围框.
点云体素化的一个难点是体素大小的设置.较小的体素可提供更高的检测精度, 较大的体素可提高推理速度.为了平衡体素大小, Ye等[69]提出HVNet(Hybrid Voxel Network), 混合体素特征提取, 连接不同尺度的特征点, 提升检测精度.
将点云转换为常规的三维体素网格或图像, 会丢失点云数据蕴含的信息.为了直接处理点云, Qi等[32]提出PointNet网络, 提出空间变换网络解决旋转问题及应用最大池化解决无序性问题.但是PointNet未捕获由度量空间点引起的局部结构, 限制识别细粒度模式的能力和对复杂场景的泛化能力.因此, Qi等[70]进一步提出PointNet++, 以分层方式处理在度量空间中采样的一组点.
为了解决三维物体质心难以确定的问题, Qi等[71]提出基于深度霍夫投票的VoteNet, 给定一个三维场景的点云, 通过VoteNet网络投票得到目标中心, 再对投票进行分组和聚合, 预测目标的3D包围框和语义类.
直接处理点云会导致大量的计算, 但点云体素化又会丢失点云信息, Noh等[72]混合体素与点云, 提出HVPR(Hybrid Voxel-Point Representation), 分别提取点的特征和体素特征, 并根据相关性进行匹配, 在体素框内形成包含聚合特征的伪点, 更好地表达目标的三维结构.
除了上述常用的点云处理方法以外, 还有一些新颖的方法也适应点云的特性.针对点云的稀疏性, Meyer等[73]提出LaserNet.利用LiDAR的距离图(Range Image)构建密集的输入图像, 采用深层聚合网络有效提取和组合多尺度特征, 并通过全卷积网络预测三维包围框的顶点分布, 生成每个目标的预测.但LaserNet利用概率分布预测包围框, 需要有足够多的数据样本训练, 才能得到精确的检测结果.为了适应点云的不规则性, Shi等[41]提出Point-GNN(Point-Graph Neural Network), 将固定半径内的点聚合为图的顶点, 使用邻居点的相对坐标作为输入计算两个顶点间的边特征, 实现边缘特征提取, 通过全连接层整合特征, 进行分类回归.图神经网络为点云的处理提供新的思路, 取得的效果也较优, 是一个值得关注的研究方向.
近年来, 一些研究人员关注无锚框(Anchor-Free)检测方法.Chen等[74]提出OSH(Object as Hotspots), 将目标表示为点团的集合, 将这些点团视为hotspot, 直接从单个hotspot进行预测, 并通过聚合这些hotspot预测获得最终结果.Yang等[36]提出3DSSD, 融合欧氏空间最远点采样及基于特征距离的采样策略, 排除大量的背景点, 同时通过无锚框回归预测三维框并设计三维中心分配策略, 将较高的分类分数分配给靠近实例中心的候选点, 得到更精确的定位预测.刘斌平等[75]提出基于网格的无锚框方法, 使用目标中心所在的网格进行目标检测框及类别的预测, 此方法的体素化过程通过对点进行均值计算替换常用的特征编码操作, 提升处理速度.
2.2.2 两阶段方法
借鉴图像处理的思想, Beltrá n等[31]提出Bird-Net, 将点云投影为鸟瞰图处理, 再利用Faster R-CNN处理鸟瞰图, 得到位置、朝向、类别等2D信息, 最后对高度进行计算, 完成三维检测.考虑到BirdNet对高度的处理不够精确, Barrera等[76]提出BirdNet+, 提取定义目标包围框的所有参数, 包括高度和仰角, 避免进一步的后处理.
将点云投影为鸟瞰图, 不可避免地会丢失点云包含的高度信息.为了在点云规则化的过程中保留高度信息, Zhou等[2]提出VoxelNet, 将稀疏的点云数据转化为稠密的体素张量, 进行随机抽样, 使用3D卷积, 得到全局特征张量, 整合特征进行位置、尺寸和方向的回归.Lehner等[77]基于VoxelNet构建候选框生成网络和局部细化网络, 通过补丁细化提高三维检测精度.Zhou等[39]融合鸟瞰图和透视图, 通过映射函数的方式提出动态体素方法.
相比传统体素方法, 动态体素不需要预先设置固定大小的体素化张量, 也不需要设置体素网格中点的上限, 有效降低信息损失, 克服体素信息丢失、远距离目标检测精度较低的问题.
与单阶段的点云处理类似, 学者们也使用两阶段方法直接处理点云数据, 更好地保留原始点云信息.Shi等[38]基于R-CNN提出Point RCNN, 直接处理三维点云, 利用三维框生成地面真实分割掩码, 分割前景点, 同时从分割后的点生成少量的候选包围框.该策略避免在整个三维空间中使用大量的三维锚框, 节省计算量.Yang等[78]提出STD(Sparse-to-Dense 3D Object Detector), 考虑到三维物体可以是任意方向的, 引入基于点的球形锚点, 而不是传统的长方体, 在不丢失定位信息的情况下, 准确生成目标候选框.然后利用PointsPool(Points Pooling)层压缩表示候选框, 减少推理时间.第二阶段减少后处理中的错误删除, 进一步提高性能.
2.2.3 分析总结
总之, 基于网格的方法不可避免丢失将点云体素化包含的信息.例如, 基于体素的方法通过K× T× F将点云体素化, 其中, K为最大体素数, T为每个体素中的最多点云数, F为点的特征.由于K、T的限制, 会造成信息丢失, 将同一物体的点云进行切割, 尤其远处的点云稀疏及小目标的点云特征不足, 容易受到这种切割方式的影响, 降低三维检测精度.直接对点云进行处理, 可更充分地利用点云信息, 但是会造成重复计算, 带来巨大的计算量.
考虑到体素与点表示形式各有优缺点, Shi等[33]提出PV-RCNN, 通过体素到关键点场景编码和关键点到网格特征抽象策略, 首先将点云体素化并通过最远点采样进行关键点的提取, 通过体素抽象模块将体素编码成关键点的特征, 最后将关键点转化为网格对目标候选框进行细化.由于结合体素和点云的优点, PV-RCNN取到良好的三维检测性能.
选取VoxelNet[2]、PV-RCNN[33]、3DSSD[36]、Point RCNN[38]、Point-GNN[41]、STD[78]、SA-SSD(Structure Aware Single Stage 3D Object Detection)[79]、3D IOU-Net(3D Intersection-over-Union Network)[80]、RangeRCNN[81], 在KITTI数据集上, 各方法的车辆检测性能对比如表4所示, 表中黑体数字表示最高的检测精度.
| 表4 基于点云的三维目标检测方法在车辆检测上的性能对比 Table 4 Performance comparison of point cloud-based 3D object detection methods for vehicle detection |
由表4可看出, 单阶段方法检测速度更快, 而两阶段方法精度更高, 但双方之间的差距逐渐变小, 检测方法正沿着速度与精度平衡的方向发展.PV-RCNN的检测精度也证实点云与网格两种数据表示形式各有优点, 点云与网格的合理混合表示形式是一个值得关注的方向.
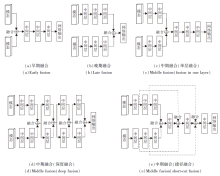
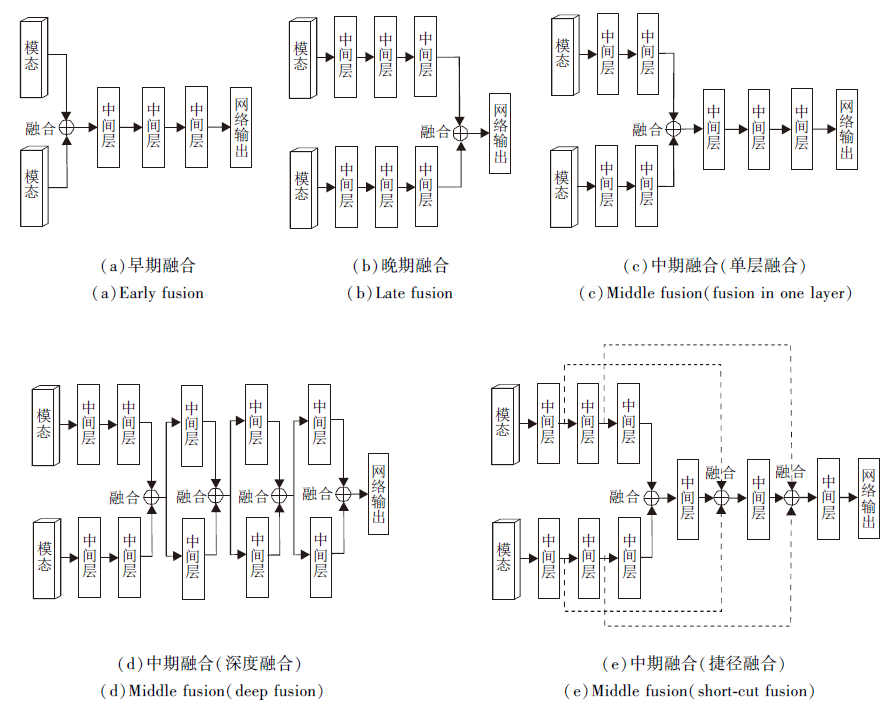
不同类型的传感器各有优劣, 单一传感器无法实现精确高效的检测[82].为此, 将具有互补特性的多种传感器融合以增强感知能力, 成为新兴的研究主题[83].目前, 三维目标检测领域常用的融合数据有图像和点云, 融合方法有加法或平均数、级联、集合、专家混合等, 融合时机可分为早期、中期和晚期融合[84], 具体如图4所示.早期融合主要融合原始或预处理的传感器数据, 可充分利用数据的原始信息, 对计算量要求较低, 但因为它联合处理多个数据模态, 不够灵活, 若输入数据扩充, 需要重新训练网络结构.晚期融合结合不同数据模态网络结构的决策输出, 具有较高的灵活性和模块化, 当引入新的感知模态时, 只需要单独训练结构而不影响其它网络, 但计算成本较高, 会丢失很多中间特征.中期融合是早期融合和晚期融合的折衷, 在中间层融合特征, 使网络能学习不同特征表示, 难点在于如何寻找合适的特征融合时机.
2.3.1 单阶段方法
为了提升检测速度, Sindagi等[85]基于VoxelNet结构, 提出MVX-Net(Multimodal Voxel Network), 使用混合融合策略, 包括早期融合, 即点云投影到图像, 及中期特征融合.
为了融合RGB图像和点云数据信息, 首先利用二维检测网络提取特征, MVX-Net网络在ImageNet[86]上进行预训练, 然后对2D目标检测任务进行微调, 编码语义信息, 作为先验知识, 帮助推断目标的存在.
针对点云, 通过VoxelNet提取特征, 融合图像特征和点云特征, 得到最终的检测结果.MVX-Net受到传统体素化方法的影响, 不可避免地会丢失信息, 可考虑通过映射函数进行体素化, 解除对点数的限制, 更充分地利用点云信息.
Meyer等[87]扩展LaserNet, 采用早期融合策略, 提出图像和点云融合的三维目标检测方法.三维数据表示采用LiDAR的自然距离视图, 将LiDAR点与图像的像素关联, 并将三维点映射到二维图像上, 这种映射被用于将信息从摄像机图像转换到LiDAR图像.然后融合CNN提取的特征, 结合LiDAR点云和图像的特征并传递到LaserNet, 得到检测结果.
2.3.2 两阶段方法
不同于单阶段融合方法, 两阶段多采用中期融合和晚期融合策略, 以中期融合为主.
基于2D目标候选框, Xu等[88]提出PointFusion, 是典型的晚期融合结构之一.PointFusion首先生成2D检测框, 将点投影到图像平面以选择相应的点, 最后基于ResNet[63]和PointNet, 结合图像和点云特征, 估计三维目标.因为PointFusion将点云和图像分开处理, 使点云信息得以最大限度地保留, 但其依赖于稠密点云, 当点云较稀疏时, 效果较差.Yoo等[89]提出3D-CVF(3D Cross-View Spatial Feature Fusion)网络, 保证在不丢失信息的情况下合并两个异构的功能映射.3D-CVF使用跨视角空间特征融合策略结合摄像机和LiDAR的特征.王刚等[90]使用特征金字塔分别处理点云俯视图及图像, 融合二者的候选区域, 选取得分最高的K个候选区域, 指导点云与图像的特征池化, 并使用ROI Align池化操作提升小目标的检测精度.
中期融合由于能深度融合多模态特征而被广泛使用.Chen等[91]提出MV3D(Multi-view 3D), 基于点云俯视图生成3D的目标候选框, 通过ROI池化将图像和点云鸟瞰图、前视图特征整合到同一维度进行融合.但是MV3D特征图下采样会导致小目标实例空间信息丢失, Ku等[3]提出AVOD(Aggregate View Object Detection), 通过自编码结构在最终特征图上采样到原始大小, 解决问题.周晓蕾[92]设计3D GIOU损失函数替换AVOD的损失函数, 训练时根据检测框与真实框的匹配程度优化损失函数, 进一步提升检测精度.Liang等[93]提出多传感器深度连续融合网络(Deep Continuous Fusion for Multi-sensors, MMF), 将图像特征投影到BEV图进行回归, 并且通过元素求和组合成BEV, 解决BEV和图像特征融合问题.Tian等[94]提出多模态局部特征的自适应和方位感知融合网络, 从图像、鸟瞰图和点云聚合局部特征, 实现高精度检测.
还有一种融合策略是使用图像信息辅助点云生成三维候选框, 这种融合策略一般以点云信息为主, 图像信息只用于提供目标位置或轮廓, 划定目标区域并反馈到点云数据对应区域, 帮助点云更好地实现回归任务.Qi等[37]提出F-PointNet, 从2D图像区域获得3D视锥, 再基于分割的目标点云得到位置, 并通过PointNet网络平移对齐点, 利用RGB-D映射和Frustum融合特征, 形成三维检测结果.基于VoteNet, 结合图像信息, Qi等[95]提出ImVoteNet(Image Vote Network), 使用深度霍夫投票, 通过图像表决推动点云中的三维目标检测, 利用梯度混合融合二维检测和三维检测.黄漫等[96]基于深度补全克服点云的稀疏性, 并根据二维实例分割结果指导点云实例分割, 精确化目标的点云表示, 提升检测性能.
2.3.3 分析小结
目前, 学者们已提出很多图像和点云融合的方法, 多模态融合将是未来的研究热点, 数据优势互补对于三维目标检测意义重大, 但是研究仍不成熟, 还没有非常好的融合策略能够兼顾各数据模态的优点, 以及在有效保留原始信息的同时实现深层次融合.
大部分融合方法将点云处理为规则形式与图像特征融合, 不可避免地会丢失点云的三维信息, 另外很多融合方法不能充分利用图像信息.如何尽可能充分利用图像与点云信息, 并且平衡不同模态的数据质量, 仍值得进一步研究.
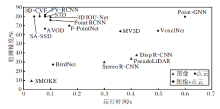
基于不同数据模态、不同阶段的三维目标检测方法在性能上差距较大, 一些典型的三维目标检测方法在KITTI数据集上的性能对比如图5、图6所示.
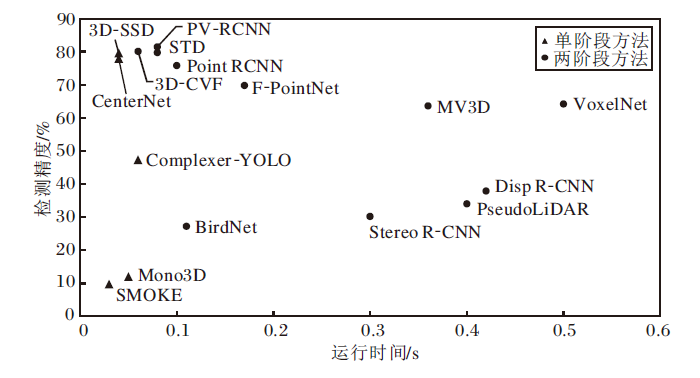 | 图5 KITTI数据集上的单阶段、两阶段典型方法对比Fig.5 Comparison of typical single-stage and two-stage methods on KITTI dataset |
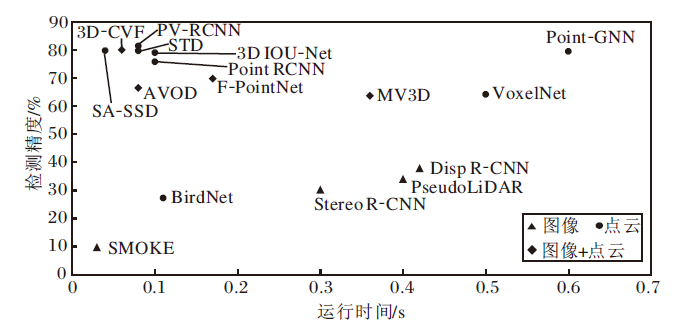 | 图6 KITTI数据集上的不同数据模态典型方法对比Fig.6 Comparison of typical methods for different data modes on KITTI dataset |
由图5和图6可见, 单阶段的三维目标检测方法运行速度较快, 能较好地满足实时性要求, 但是检测精度通常不如两阶段的检测方法.尽管最新的单阶段方法取得较高的检测精度, 但在测试数据集的排行榜上仍然以两阶段方法为主.但是, 由于两阶段方法需要候选框生成操作, 运行速度通常较慢.从最新的结果来看, 兼顾准确性与实时性成为三维目标检测的发展趋势.
选取如下数据模态典型方法:YOLO3D[7]、F-PointNet[37]、3D-SSD[55]、VoteNet[71]、LSS(Latent Su-pport Surfaces)[81]、PointFusion[88]、Deep Context[97]、COG(Clouds of Oriented Gradients)[6].在SUN RGB-D数据集上, 各方法的床检测性能对比如表5所示.
| 表5 不同数据模态方法在床检测上的性能对比 Table 5 Performance comparison of different modal methods for bed detection |
由表5可知, 一些融合图像和点云的检测方法的精度低于单独基于点云的检测方法, 这与融合利用图像信息的方式有很大关系, 信息融合不当可能会干扰点云信息的利用.因此, 融合时合理处理数据十分重要. 另外, 基于图像的方法精度最低, 反映深度信息对于三维目标检测的重要性.如何在保证精度的情况下实现实时检测, 在提升精度的情况下兼顾速度, 以及充分利用点云和图像数据的各自优势, 成为三维目标检测研究的关注重点.
不同数据模态的三维检测方法整体对比如表6所示, 表中概括各种数据模态的优缺点.
| 表6 不同数据模态方法的优缺点对比 Table 6 Comparison of different modal methods |
1)存在域偏移问题, 应用于未知场景效果较差.三维目标检测优异的结果通常依赖于大规模的基准测试, 如KITTI、SUN RGB-D数据集.目前的CNN直接应用于未知的新场景时, 存在域偏移和数据集偏见现象[98], 对未知场景的适应性较差.为了克服域偏移问题, Zheng等[99]提出由粗到细的跨域检测方法, 核心思想是通过注意力机制强调前景重要性.该方法考虑到实际应用存在很多未知场景, 通过注意力机制或实例分割等方式强调前景重要性, 进而提高跨域检测的准确性, 是一种值得借鉴的思路.
2)特征融合困难, 不能充分利用点云信息.图像和点云的融合存在困难.首先, 图像通过投影到图像平面记录真实世界, 而点云保留三维几何形状.此外, 点云是不规则、无序的, 而图像是规则、有序的.这必然导致图像和点云处理方式的巨大差异.将点云转化为体素、鸟瞰图等规则形式, 不可避免地会丢失点云蕴含的三维信息.如何处理不规则的稀疏点云是三维目标检测的一项重要挑战.考虑到已有工作[64]证明伪LiDAR表示形式的可行性, 可将图像关键特征点云化, 与点云融合时可直接处理点云, 而不需要转化为规则形式, 最大限度地保留点云蕴含的三维信息, 这种处理方法为图像和点云融合提供一种新思路.
3)对图像的依赖性较弱, 工程应用困难.考虑到点云携带深度信息, 目前的融合方法更多依赖于点云, 但是LiDAR设备造价昂贵, 过于依赖LiDAR, 不利于实际工程应用.因此更多地依赖视觉传感器实现精确的目标检测是一个有意义的研究方向.例如, 研究以视觉传感器为主、低线束LiDAR为辅的三维目标检测.
4)速度与精度难以兼顾.单阶段的三维目标检测方法运行速度较快, 满足实时性要求, 但精度一般不如两阶段的检测方法.由于候选框生成和细化步骤的存在, 两阶段方法往往能取得更高的检测精度, 但是导致更多的推理时间和更复杂的训练成本.因此, 如何在保证精度的情况下实现实时检测, 或在提升精度的情况下兼顾速度, 仍是一项挑战.一个重要的研究方向是改进单阶段检测方法, 通过增加辅助模块[79], 在训练时发挥辅助模块作用, 提升模型精度, 而实际检测时忽略辅助模块, 提升速度.另一个思路是通过关键点抽样、投票机制等方式在保证核心信息不丢失的情况下, 降低处理量, 实现速度与精度兼得.
5)数据集质量仍有待提高.目前已有很多开源数据集, 但是数据缺乏多样性.例如, 现有数据集大多为光照条件良好或天气良好的场景, 而真实世界中却存在各种极端天气, 如雨、雪、雾等.为了更贴近实际情况, 构建更具多样性的数据集是一项必须的工作.另外, 如果数据标注出现错误或偏差, 对模型训练也会造成影响[29].使用包括多样性驾驶环境、数据标签和传感器的大型多模态数据集可显著提高深度神经网络在动态环境下的精度和鲁棒性.然而, 由于成本、硬件甚至时间限制, 获取真实世界数据并精确标注是一项困难的任务[100].克服这些限制的一种方法是数据增广.最近的一项研究[101]表明, 在KITTI数据集上, 目标检测性能提升的有效方法是扩充训练数据, 而不是改进网络结构.Li等[102]开发仿真系统, 生成多样化的虚拟驾驶场景.Pfeuffer等[103]、Kim等[104]通过在KITTI数据集上添加人工空白区域、光照变化、遮挡、随机噪声等增广训练数据集.
1)无锚框检测.现有的三维目标检测大多使用预先定义好的锚框, 这些锚框需要很多超参数, 如数量、尺寸比等, 而且基于锚框的方法一般需要非最大抑制以抑制重叠的高置信度检测包围框, 因此带来额外的计算负担.最近, 一些研究者开始关注无锚框(Anchor-Free)方法, 通过定义关键点或中心区域预测目标位置与尺寸, 消除锚框超参数的设置, 具有较优性能, 在泛化性能方面更具潜力, 是未来研究的热点之一.
2)弱监督或自监督检测.精确的三维目标检测需要大规模的标注数据, 费时费力.弱监督三维目标检测[105]仅需要一组弱标注的场景数据和一些精确标注的目标, 即可实现接近于监督学习的检测性能.自监督学习可通过形状先验、同类对比等方式从无标注数据中挖掘信息.研究如何在弱监督或自监督学习下达到良好的检测性能, 可降低数据标注成本, 推动三维目标检测的进一步发展.
3)适应点云特性.如何处理不规则、稀疏的点云是三维目标检测的一项关键挑战.图表示形式能较好地适应点云的不规则性, 得到更多局部信息, 目前已有的成果也验证其检测的准确性, 未来会是一种较好用的点表示形式.而针对点云的稀疏性, 合理使用密集的距离图是一个值得关注的方向, 最近已有学者开始基于距离图处理点云, 通过转换为鸟瞰图克服距离图遮挡严重的问题[106].针对点云的密度变化, 可关注动态卷积方式来适应特征变化[107].
4)多模态融合.多模态融合可利用图像、点云数据优势, 弥补二者不足, 之前的工作大多采用将点云规则化的融合方式, 点云处理方式不当, 导致检测效果与点云相比无太大优势, 甚至弱于仅基于点云的方法, 但是伪雷达表示的提出为图像和点云融合提供一种新的思路.研究的深入也使融合机制日渐成熟, 在保证充分利用图像与点云数据优势的同时实现深度融合, 未来多模态融合的检测精度一定会有明显的提升.
深度学习是人工智能的核心技术, 而三维目标检测是计算机视觉领域的重要研究主题, 具有巨大的应用价值.本文综述CNN在三维目标检测中的应用进展:全面介绍三维目标检测相关知识, 重点介绍CNN在三维目标检测中的应用进展, 根据单阶段和两阶段处理方式, 对典型的三维目标检测模型进行总结, 对存在的问题和挑战进行分析, 并且对未来的研究发展方向进行展望.
在今后研究中, 对深度神经网络结构还需要进行更多的创新, 进一步提高三维目标检测方法的速度、精度和鲁棒性.需要指出的是, 无锚框检测是一个值得关注的研究方向.另外, 图像和点云融合可弥补两种模态数据的不足, 有利于获得更好的检测结果.特别地, 充分利用图像和点云信息, 实现多模态数据的深度融合, 是三维目标检测需要持续努力的研究方向.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
|
| [80] |
|
| [81] |
|
| [82] |
|
| [83] |
|
| [84] |
|
| [85] |
|
| [86] |
|
| [87] |
|
| [88] |
|
| [89] |
|
| [90] |
|
| [91] |
|
| [92] |
|
| [93] |
|
| [94] |
|
| [95] |
|
| [96] |
|
| [97] |
|
| [98] |
|
| [99] |
|
| [100] |
|
| [101] |
|
| [102] |
|
| [103] |
|
| [104] |
|
| [105] |
|
| [106] |
|
| [107] |
|